目次
1. はじめに
皆さんこんにちは。
今回からMicrosoft Fabricについての連載ブログを始めていきます。
全9回を予定しています。第1回ではFabricの概要と試用版の作成方法について説明いたします。
第1回:Microsoft Fabric 概要と試用版の作成方法
第2回:Power BI ユーザー向け Fabric チュートリアル
第3回:Data Factory ユーザー向け Fabric チュートリアル
第4回:Data Activator ユーザー向け Fabric チュートリアル (進行中)
第5回:Industry Solutions ユーザー向け Fabric チュートリアル (進行中)
第6回:Synapse Data Engineering ユーザー向け Fabric チュートリアル (進行中)
第7回:Synapse Data Science ユーザー向け Fabric チュートリアル (進行中)
第8回:Synapse Data Warehouse ユーザー向け Fabric チュートリアル (進行中)
第9回:Synapse Real-Time Analytics ユーザー向け Fabric チュートリアル (今回)
前回のブログで、Microsoft Fabric の Synapse Data Warehouse の使用方法について説明しました。今回は、実際のシナリオに通して Synapse Real-Time Analytics の使用方法について説明していきます。
Fabricのリアルタイム分析方法について説明したいと思います。
Microsoftから公開されているチュートリアルに沿って構築していきたいと思います。( Real-Time Analytics チュートリアル パート 1 – リソースの作成 – Microsoft Fabric | Microsoft Learn )
2. 前提要件
実施する際の前提条件は以下の通りです。
・開始する前に、組織に対して Fabric を有効にする必要があります。
・まだサインアップしていない場合は、無料試用版にサインアップしてください。
3. FabricのReal Time Analyticsとは
Real-Time Analytics は、ストリーミングと時系列データ向けに最適化されたビッグ データ分析プラットフォームです。高効率なパフォーマンスのクエリ言語とエンジンで、構造化、半構造化、非構造化データを検索できます。Real-Time Analytics は、データの読み込み、データの変換、データの視覚化等、その他のFabric 製品に統合されています。
4. 実際のシナリオからReal Time Analyticsの使用方法
シナリオ:
ニューヨーク イエロー タクシー乗車データと呼ばれるサンプル ストリーミング データに基づいて、データを集計し、インサイトを出し、Power BIでレポートを作成します。
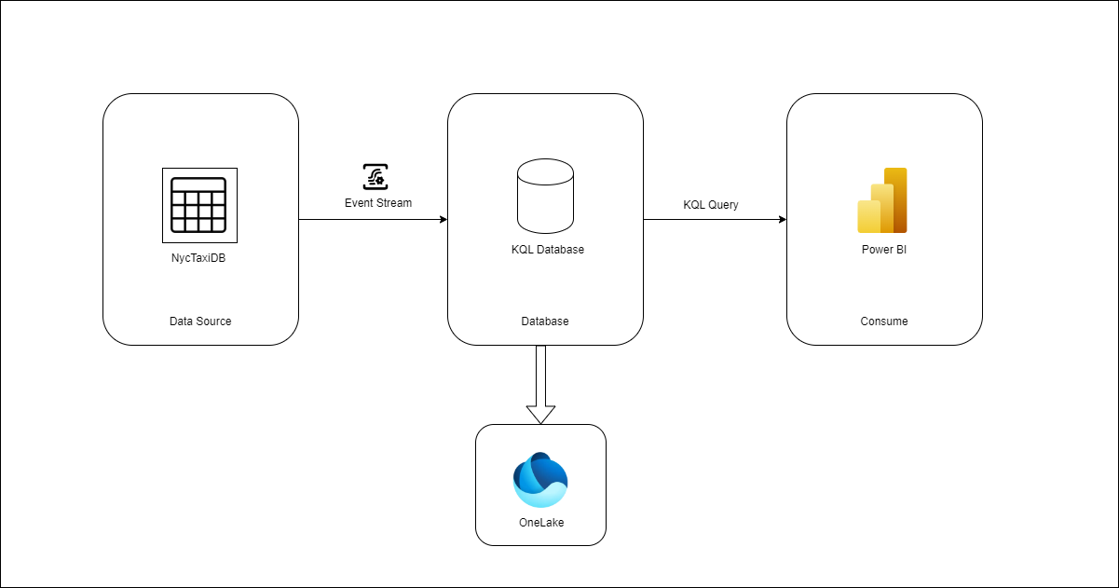
5. KQLデータベースの作成
KQLデータベースの作成
Kusto 照会言語 (KQL)は、構造化データ、半構造化データ、非構造化データに対してクエリを実行するためのシンプルで強力な言語です。
① データベースを作成するワークスペースに遷移します。
② 左下の「リアルタイム分析」![]() を選択します。
を選択します。
③ 左上にある「+ 新規」>「KQL データベース」を選択します。
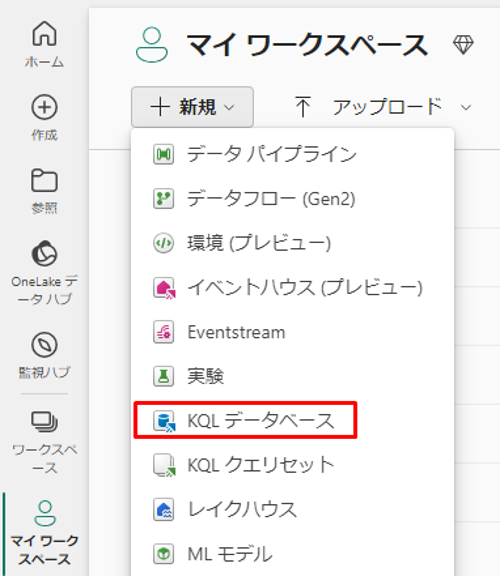
④ データベース名として「NycTaxiDB」と入力します。
⑤「作成」を選択します。
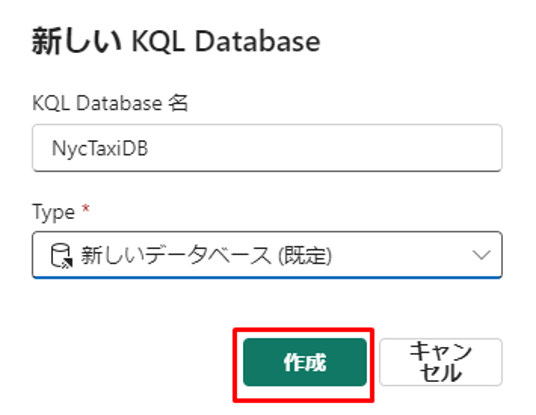
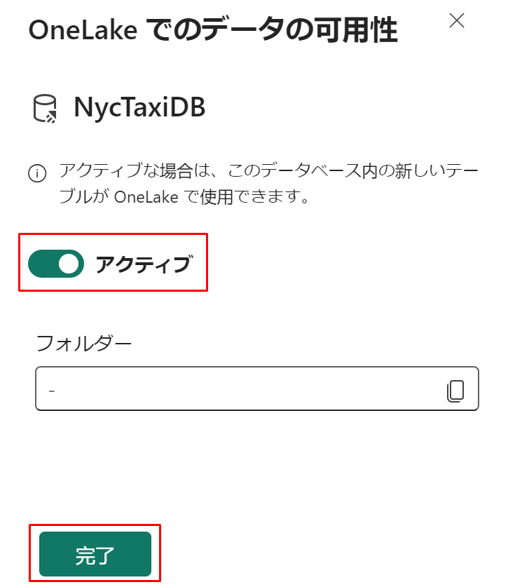
OneLake フォルダーをアクティブにします。
①「データベースの詳細」で、「鉛筆」アイコンを選択します。
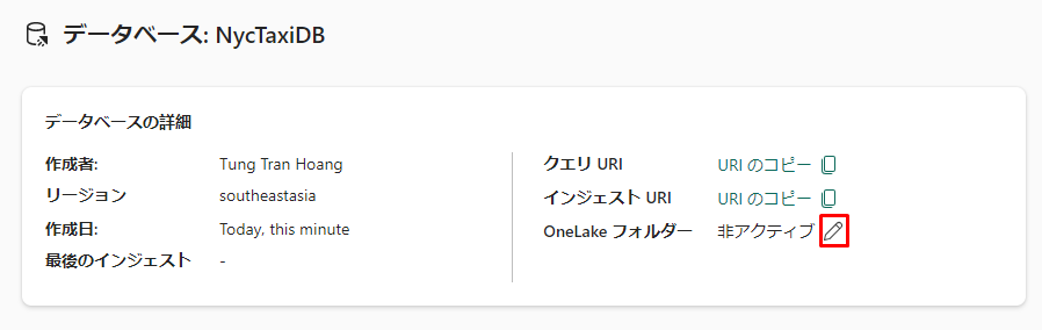
② ボタンを「アクティブ」に切り替え、「完了」を選択します。
6. Eventstream使用し、データの取得
Eventstreamとは
Microsoft Fabric のイベント ストリーム機能はコードなしのエクスペリエンスでリアルタイム イベントをキャプチャ、変換、およびさまざまな宛先にルーティングするための Fabric プラットフォーム内の一元的な場所を提供します。
Eventstream の作成
① Real-Time Analytics のホームページに戻ります。
②「Get Data」>「Eventstream」>「New Eventstream」を選択します。
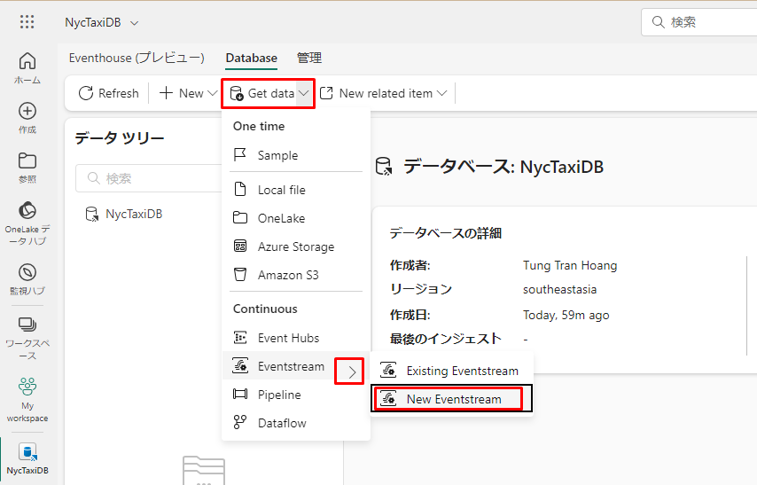
③ Eventstream名として「NyTaxiTripsEventstream」と入力し、「作成」を選択します。Eventstream ランディング ページが表示されます。
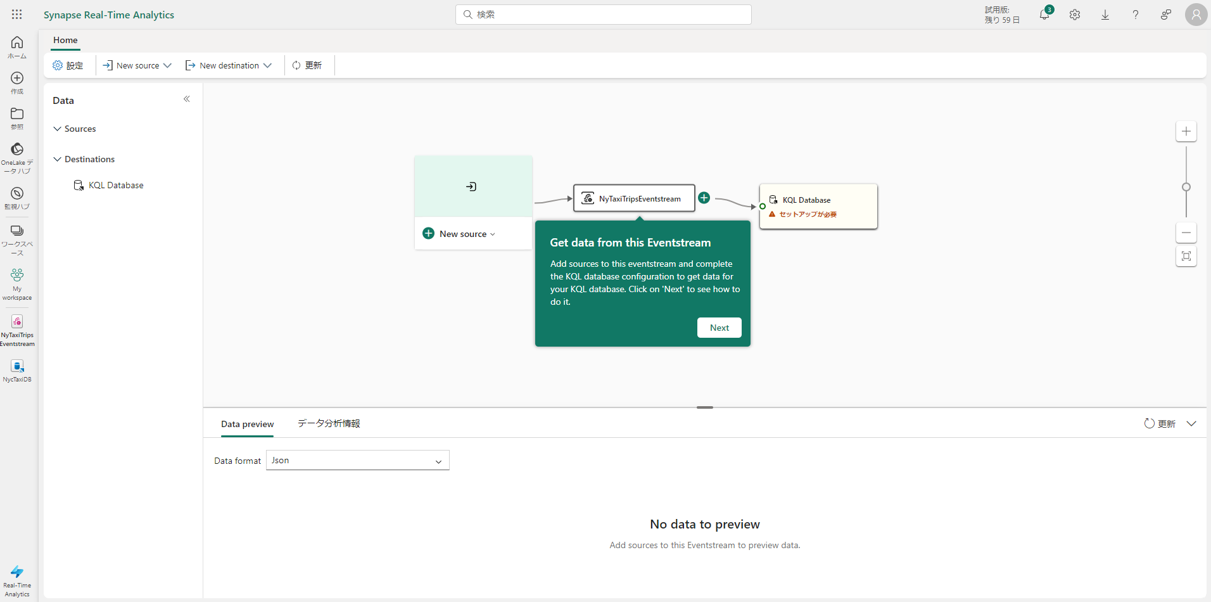
Eventstream から KQL データベースにストリーミングデータの入力
①「New source」>「Sample Data」を選択します。
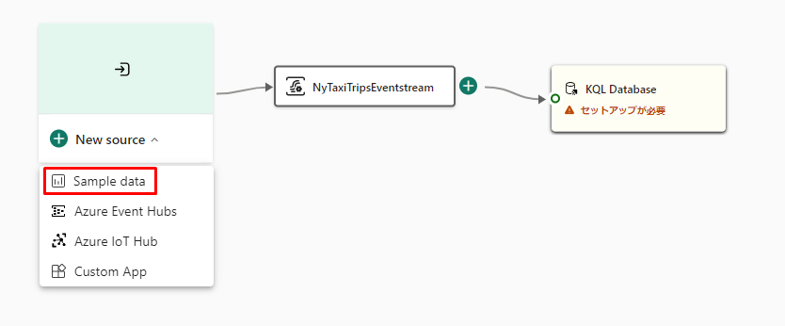
② ソース名として「nytaxitripsdatasource」と入力し、「Sample Data」のドロップダウンから「Yellow Taxi」を選択します。
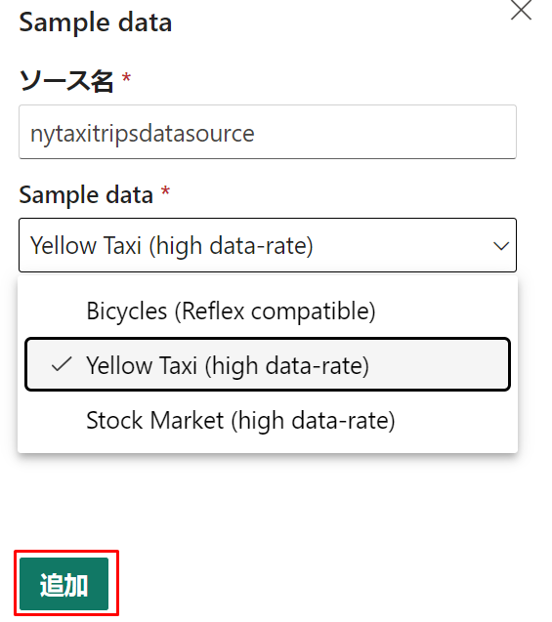
③「 New destination」>「KQL Database」を選択します。

④「Data Ingestion Mode」で、「Direct Ingest」を選択します。
⑤「KQL Database」で、次のようにフィールドに入力します。
・ Destination name : nytaxidatabase
・ Workspace : 現状のワークスペース
・ KQL Database : NycTaxiDB
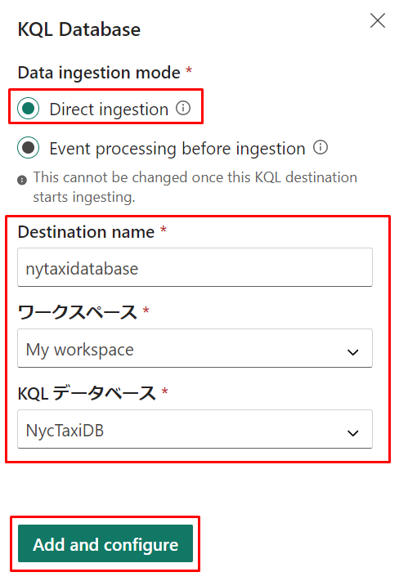
⑥「add configure」を選択し、データ 入力画面が開きます。
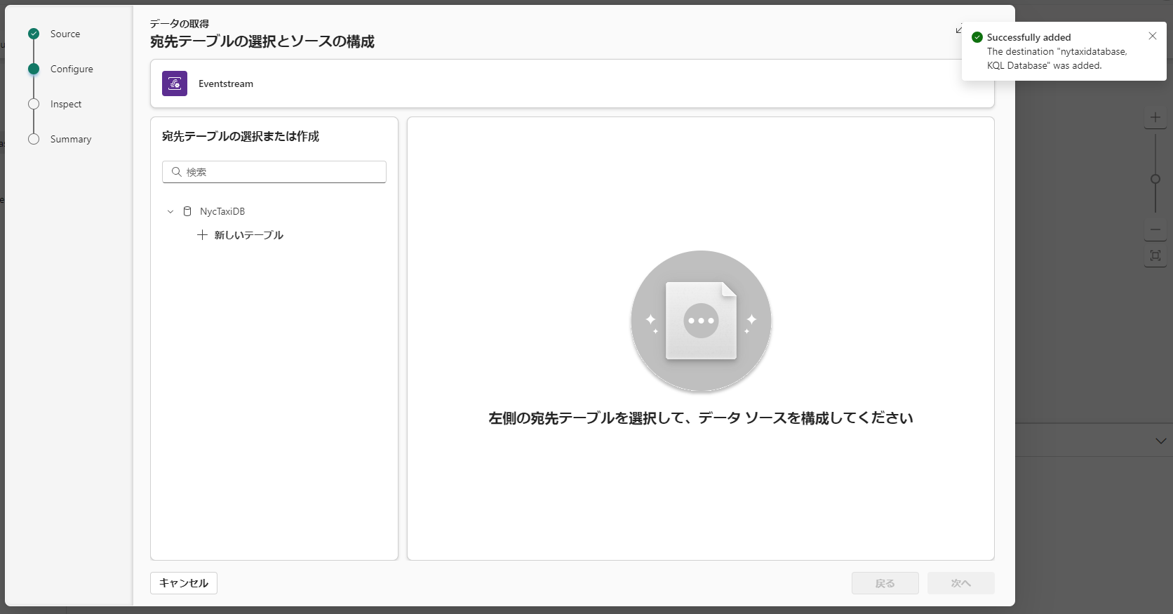
KQL データベースへのデータ読み込みの構成
①「New Table」 を選択し、テーブル名として「nyctaxitrips」と入力します。
② 設定タブでの既定値を確認します。詳細フィルターでの「圧縮」は「None」と選択します。
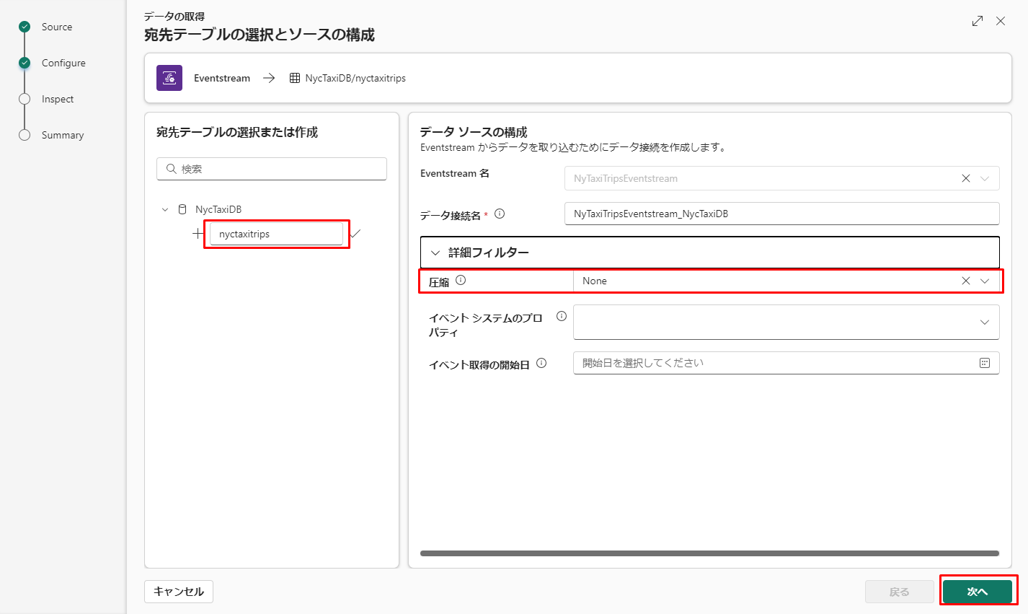
データの定義
「形式」ドロップダウンから「JSON」を選択します。
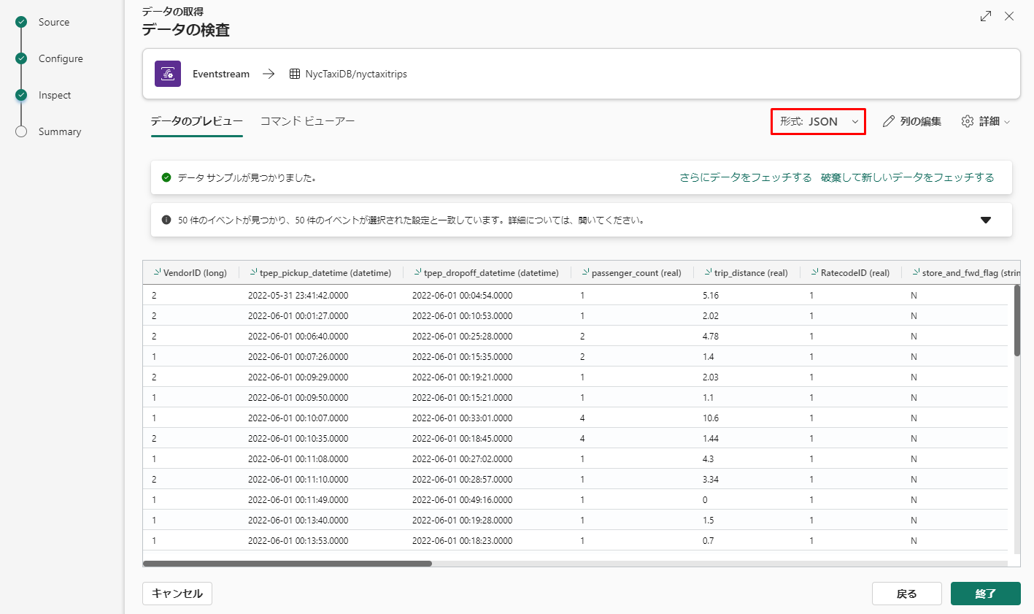
データ型の変更
①「Edit columns」を選択して、次の列のデータ型を変更します。
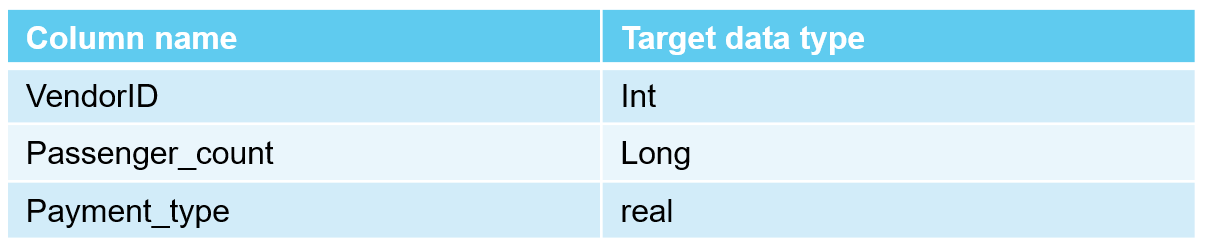
②「適用」を選択して、変更を保存します。
③「完了」を選択します。
7. 履歴 のデータの取得
BLOB ストレージからディメンション データの取得
① GitHub で Fabric サンプルを開き、Locations データをダウンロードします
② ファイルをローカルに保存します。
③ NycTaxiDB の KQL データベースを開きます。
④「Get Data」を選択します。
⑤「ローカル ファイル」 を選択します。
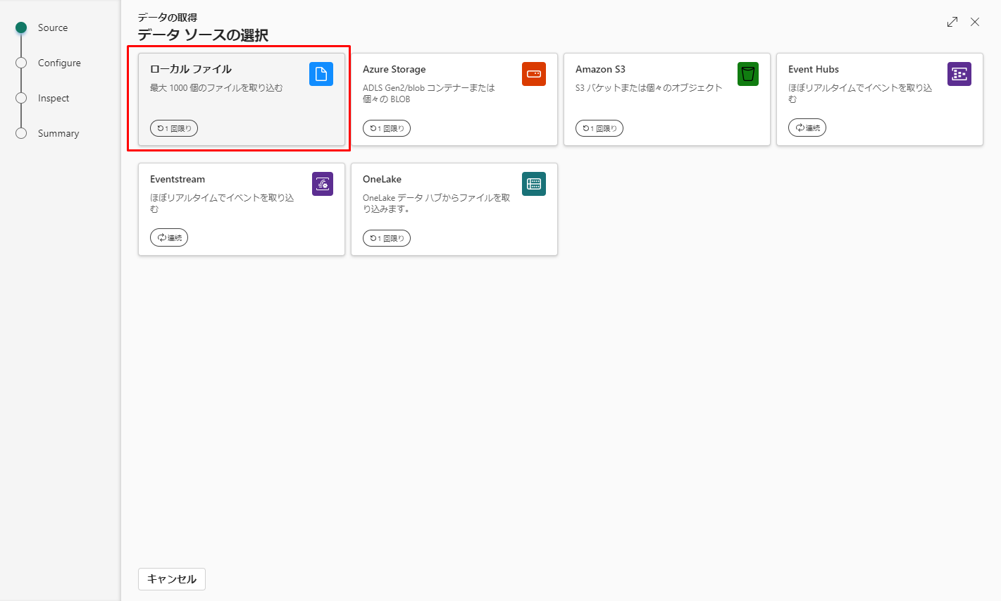
⑥「New Table」を選択し、テーブル名に「Locations」を選択します。
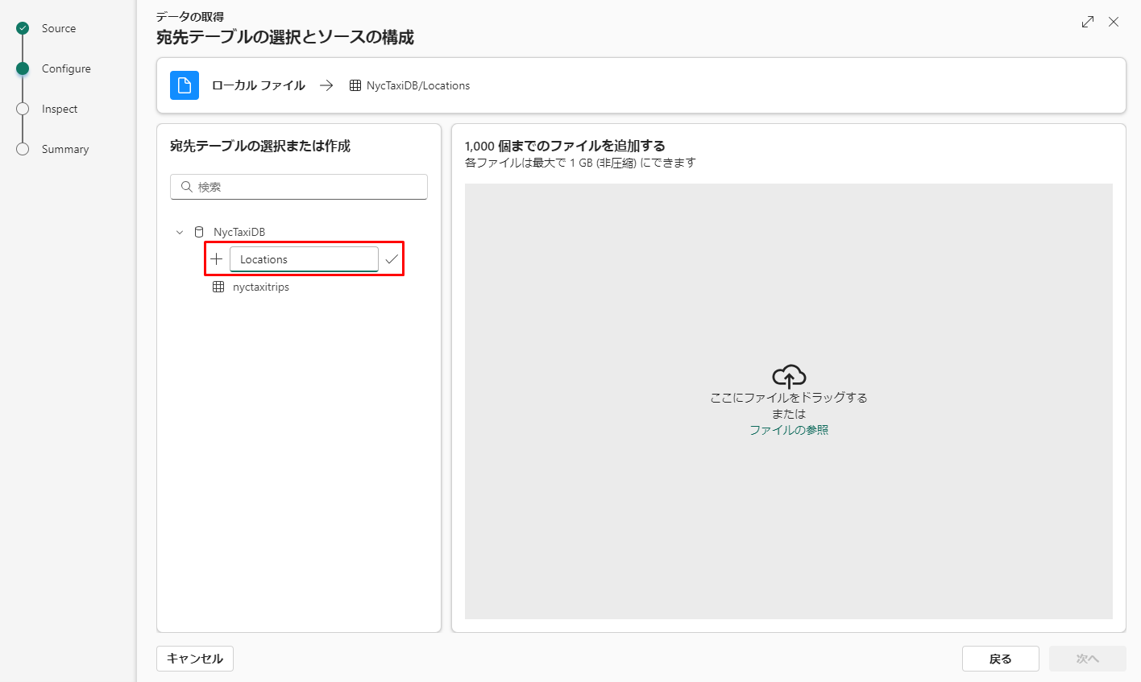
⑦ GithubからダウンロードしたCSVファイルを「Upload file」にドラグ・ドロップします。
⑧「次へ」を選択します。
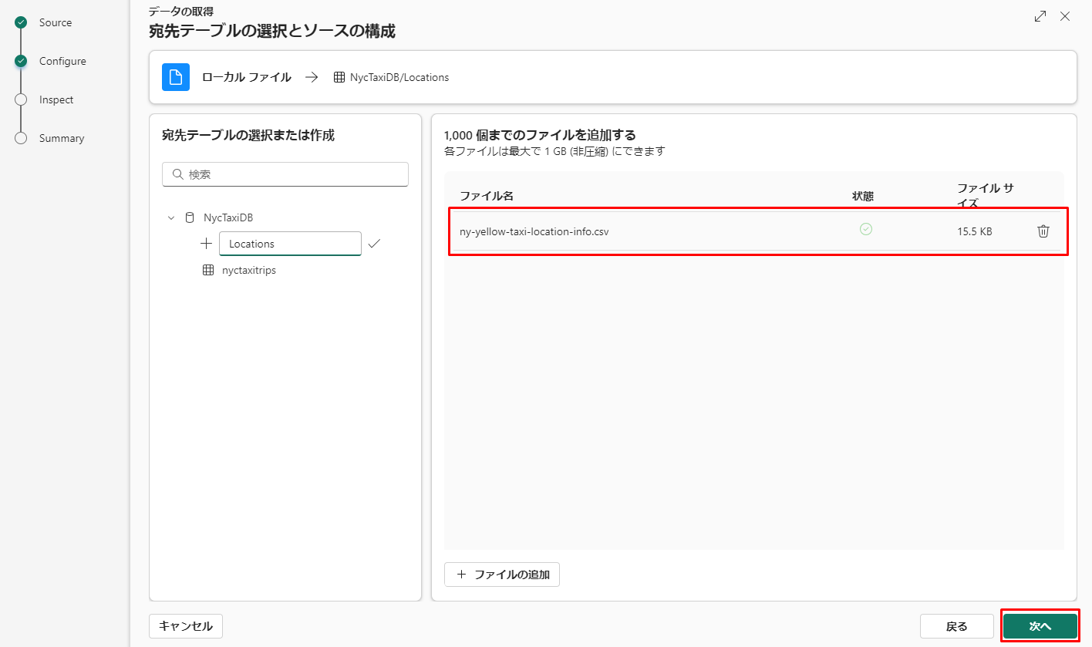
⑨「完了」を選択します。
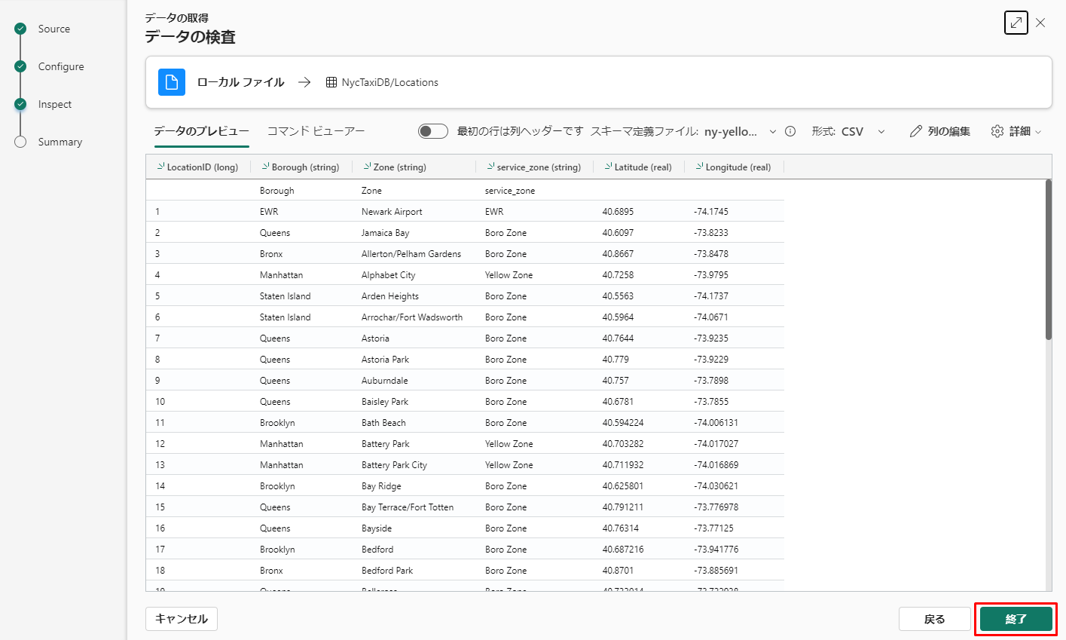
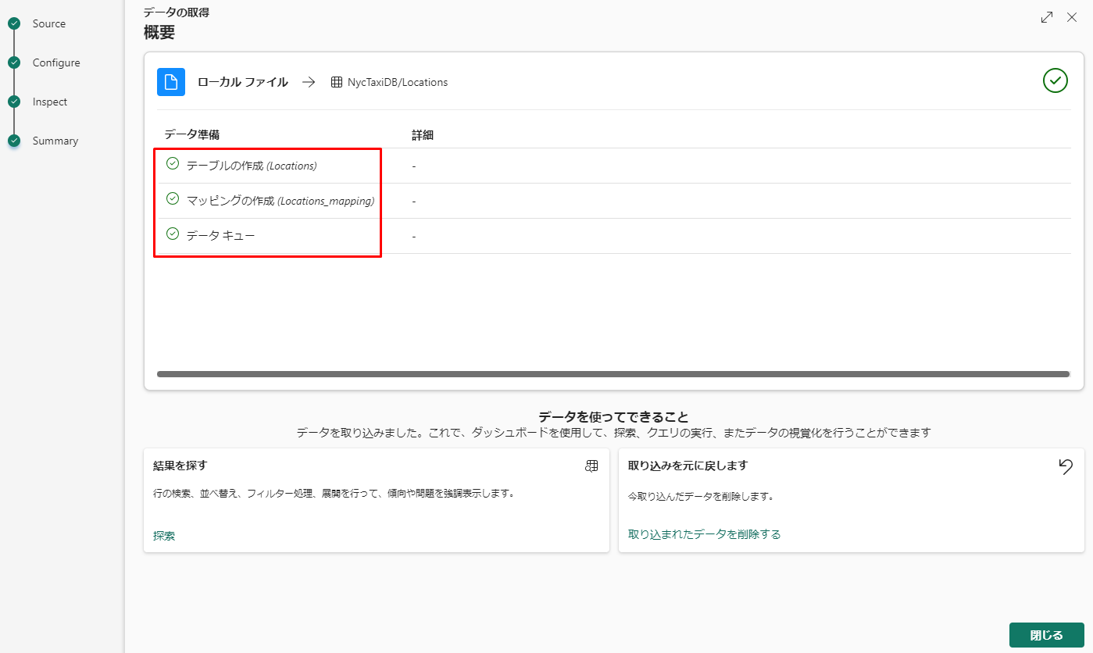
⑩「データ準備」では、3 つの緑色ステップをチェックします。
8. KQLとSQLでデータの使用
KQLでデータを使用する
Kusto Query Language(KQL)は、データを分析して結果を返すための、読み取り専用のクエリです。KQLの要求は、読みやすく、作りやすいデータフロー モデルを利用してプレーンテキストで提示されます。クエリは常に、特定のテーブルまたはデータベースのコンテキストで実行されます。Kusto 照会言語について詳しくは、「Kusto 照会言語 (KQL) の概要」を参照してください。
① KQLデータベース「NycTaxiDB」へ移動する。
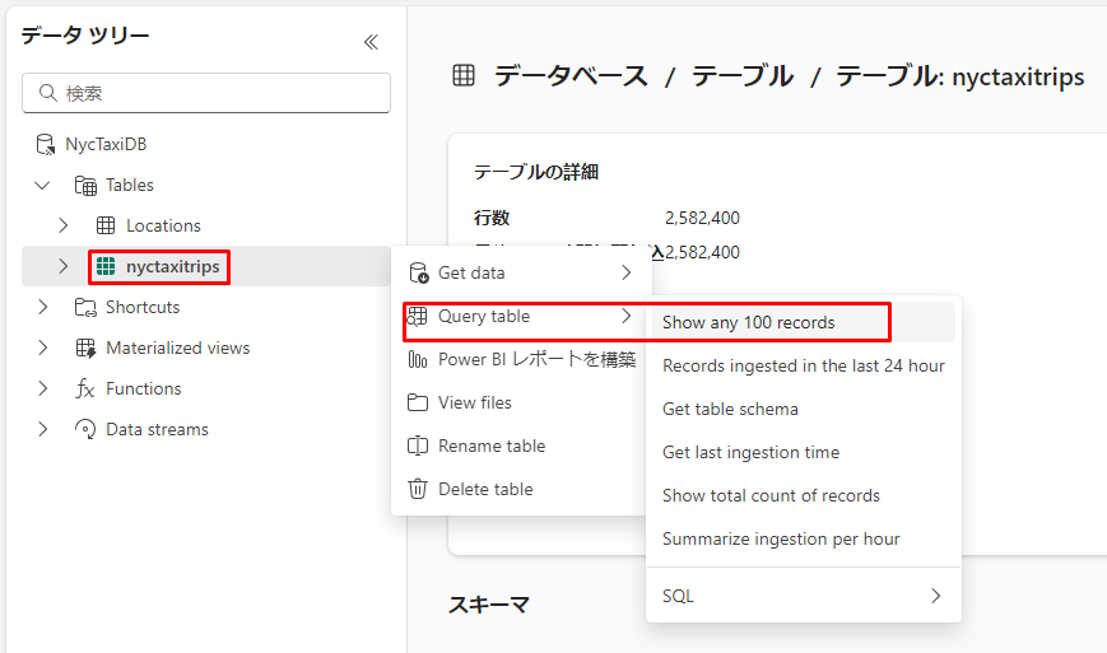
②「エクスプローラー」ウィンドウで、nyctaxitrips テーブルを選択する。 次に、「テーブルの照会」>「任意の 100 件のレコードを表示する」を選択する。
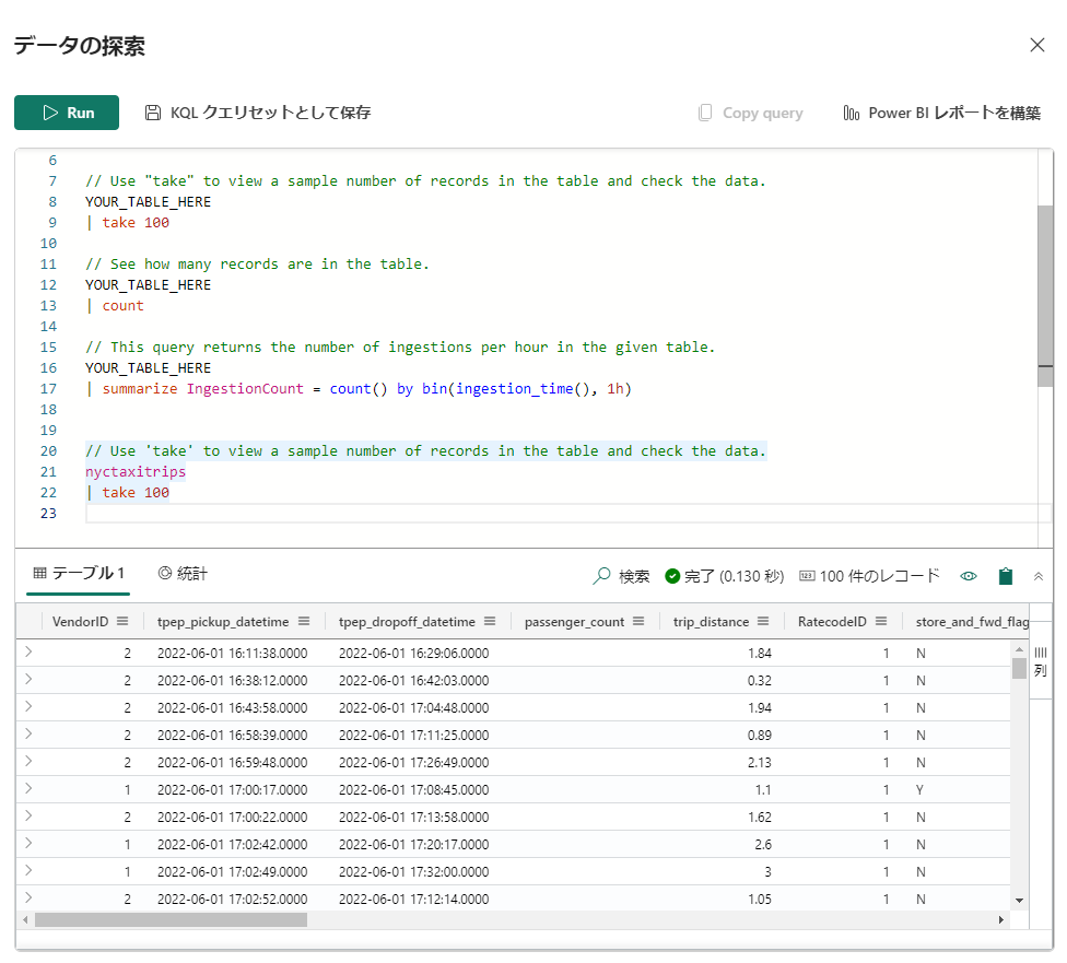
③「Run」ボタンを押して、結果が表示されます。
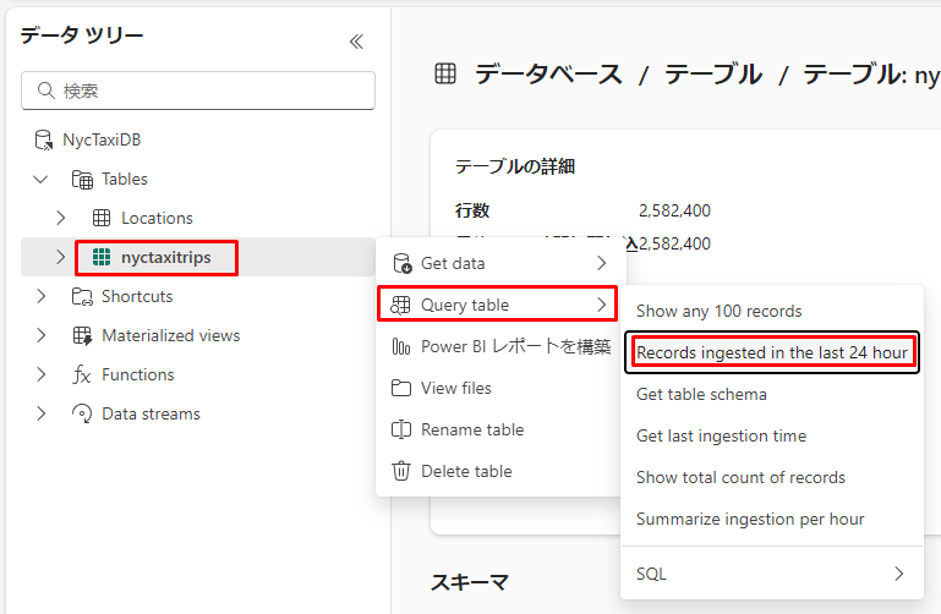
④「エクスプローラー」 ウィンドウで、nyctaxitrips テーブルのその他メニュー「…」を選択します。色々なインサイトが取得できます。
・ 過去24 時間のレコードを表示する
・ テーブルスキーマを取得する
・ 前回に取り込んだ時刻を取得する
・ すべてのレコードを表示する
・ 1時間あたりの処理件数を表示する
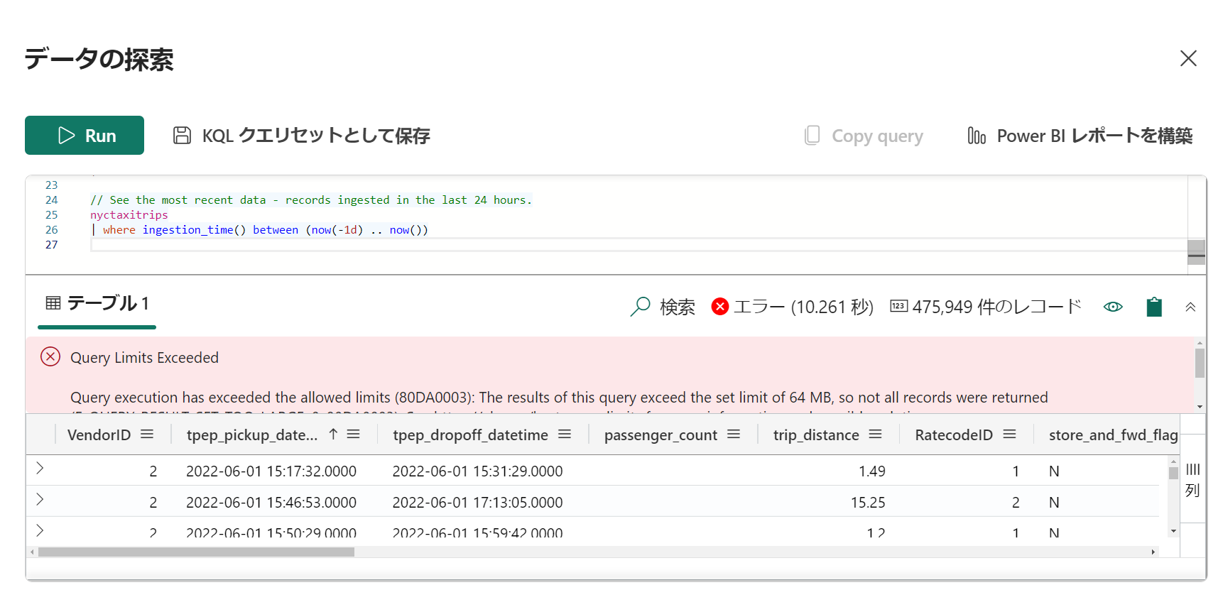
SQLでデータを使用する
Fabricを使用したデータ分析する際、KQLを使用することがMicrosoftから推奨されるが、KQLに対応しない統合ツールに対してReal-Time AnalyticsのSQLでサポートします。
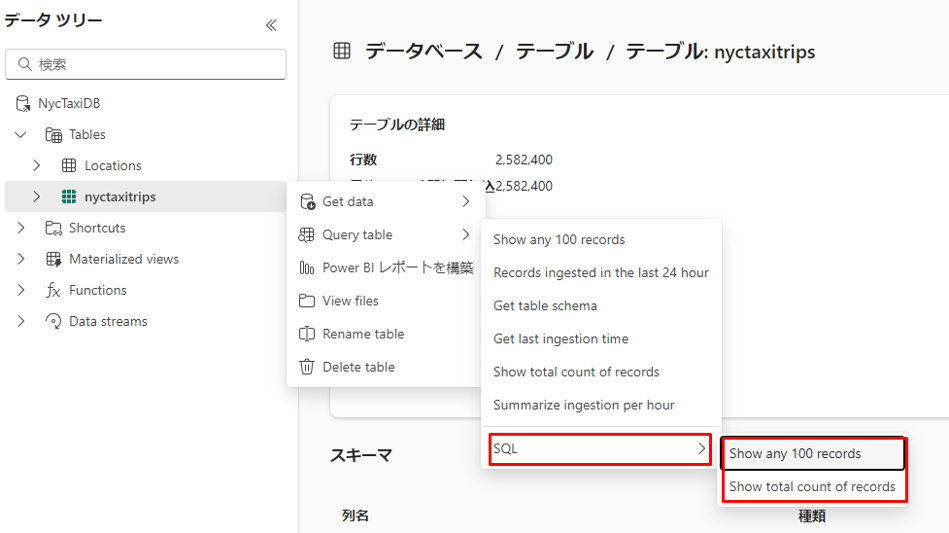
① NycTaxiDB KQLデータベースへ移動する。
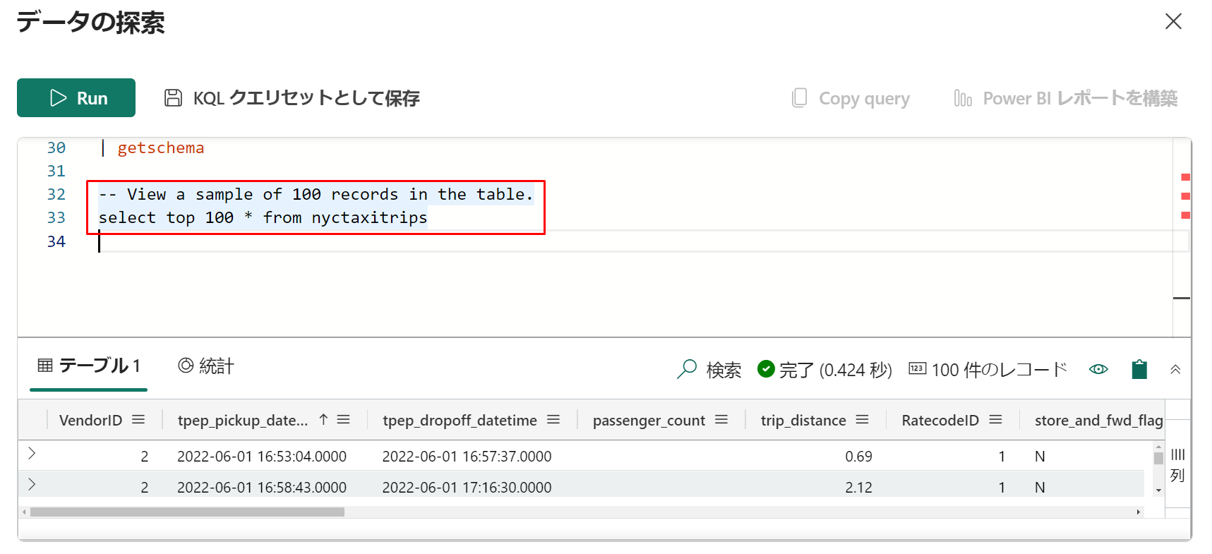
②「エクスプローラー」 ウィンドウで、nyctaxitrips テーブルのその他メニュー「…」を選択します。 「テーブルの照会」 > SQL > 「任意の 100 件のレコードを表示する」を選択する。
9. 高度なKQLクエリの使用
高度なKQLでデータを使用する
次の例でKQLのメリットを紹介します。
KQLクエリ セットを作成します
① NycTaxiDB というKQL データベースへ移動します。
②「エクスプローラー」ウィンドウで「新しい関連アイテム」>「KQL クエリセット」を選択します。
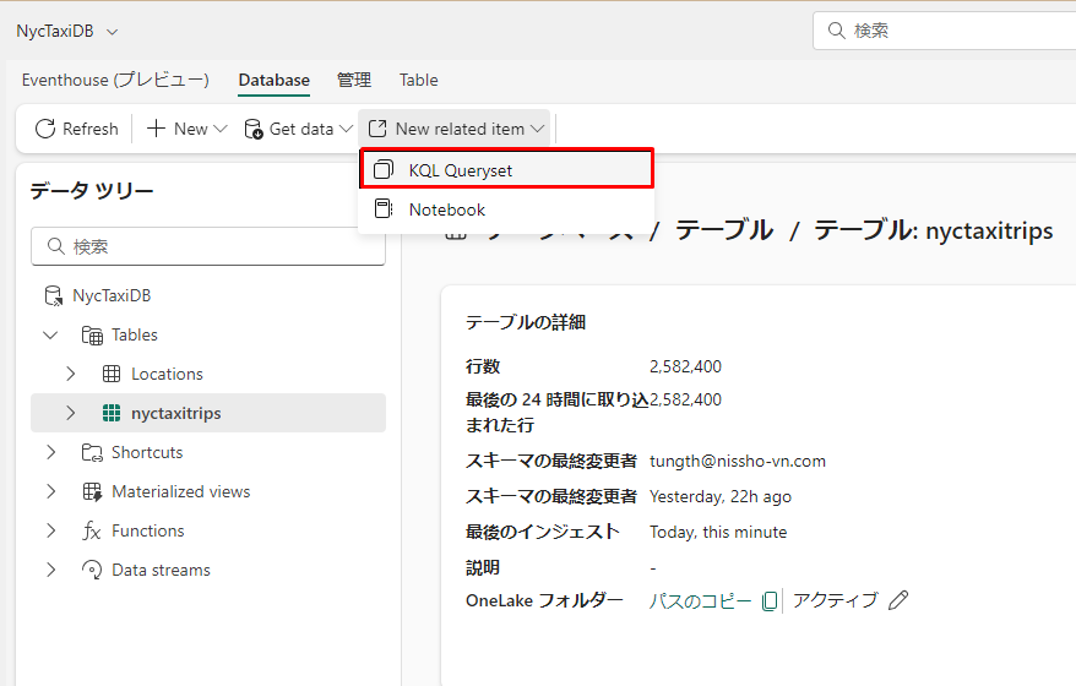
③ KQLクエリセット名をnyctaxiqsとして入力します。
④「作成」を選択します。
⑤ KQLクエリセットの画面が以下のように表示されます。

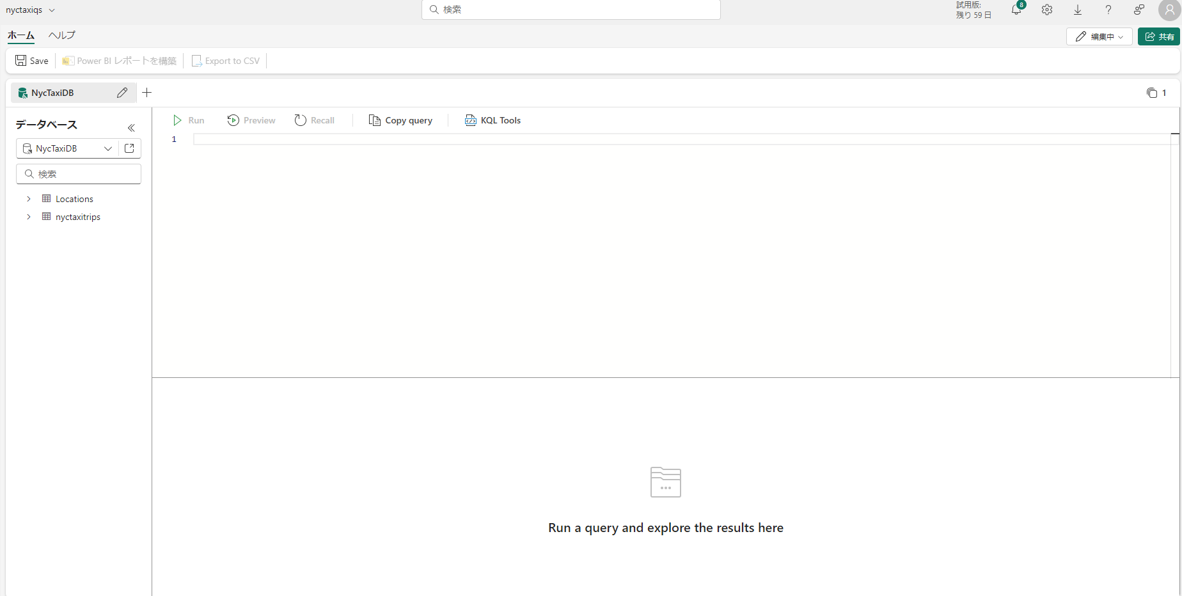
データのクエリ
KQLはクエリから結果を実行して視覚化します。
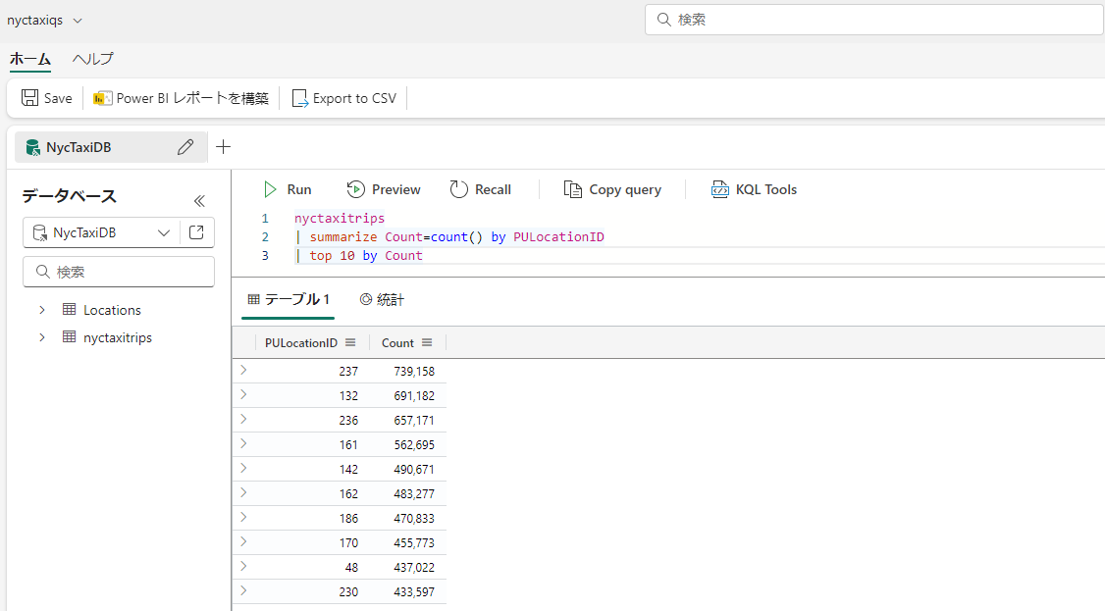
① 次のクエリを実行すると、ニューヨーク市のイエロー タクシーの乗車場所の上位 10 位の結果を返します。
Kusto:
|
1 |
nyctaxitrips | summarize Count=count() by PULocationID | top 10 by Count |
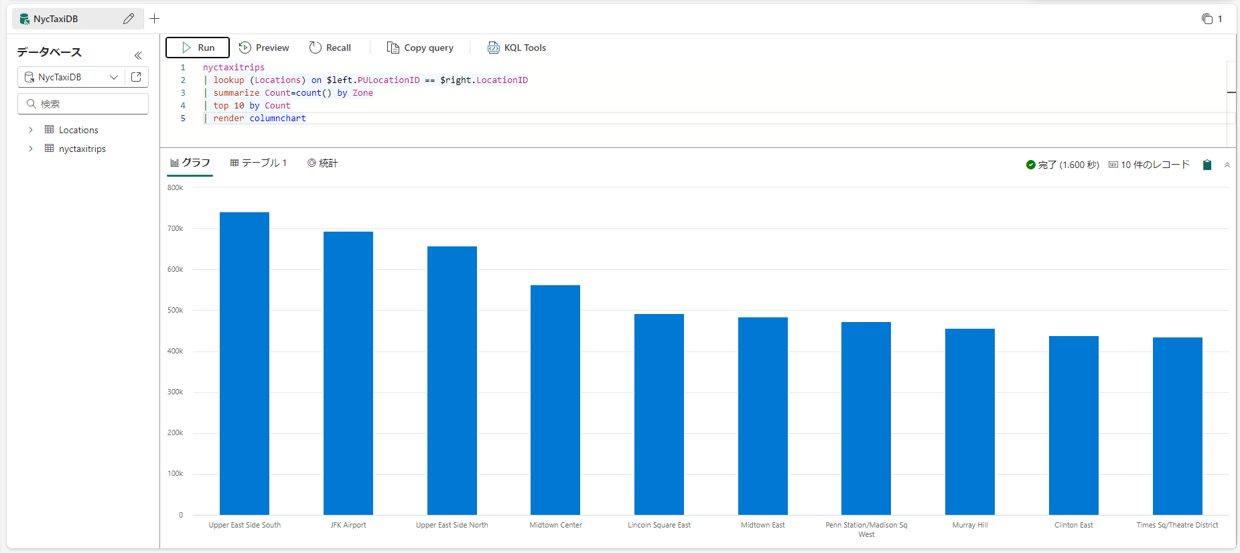
② Yellow Taxis データに基づく名付けのトップ 10 の乗車ポイントを縦棒グラフで表示されます。
Kusto:
|
1 2 3 4 5 6 7 8 9 |
nyctaxitrips | lookup (Locations) on $left.PULocationID == $right.LocationID | summarize Count=count() by Zone | top 10 by Count | render columnchart |
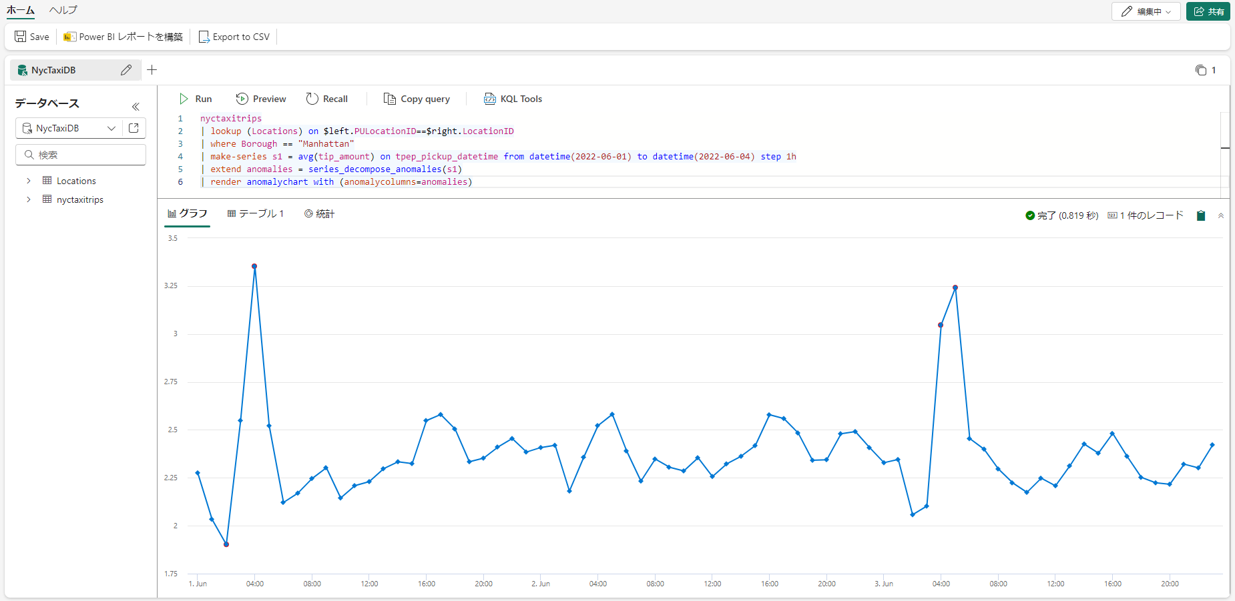
③ KQLは、異常を検知するための機械学習の関数を提供します。
Kusto:
|
1 2 3 4 5 6 7 8 9 10 11 |
nyctaxitrips | lookup (Locations) on $left.PULocationID==$right.LocationID | where Borough == "Manhattan" | make-series s1 = avg(tip_amount) on tpep_pickup_datetime from datetime(2022-06-01) to datetime(2022-06-04) step 1h | extend anomalies = series_decompose_anomalies(s1) | render anomalychart with (anomalycolumns=anomalies) |
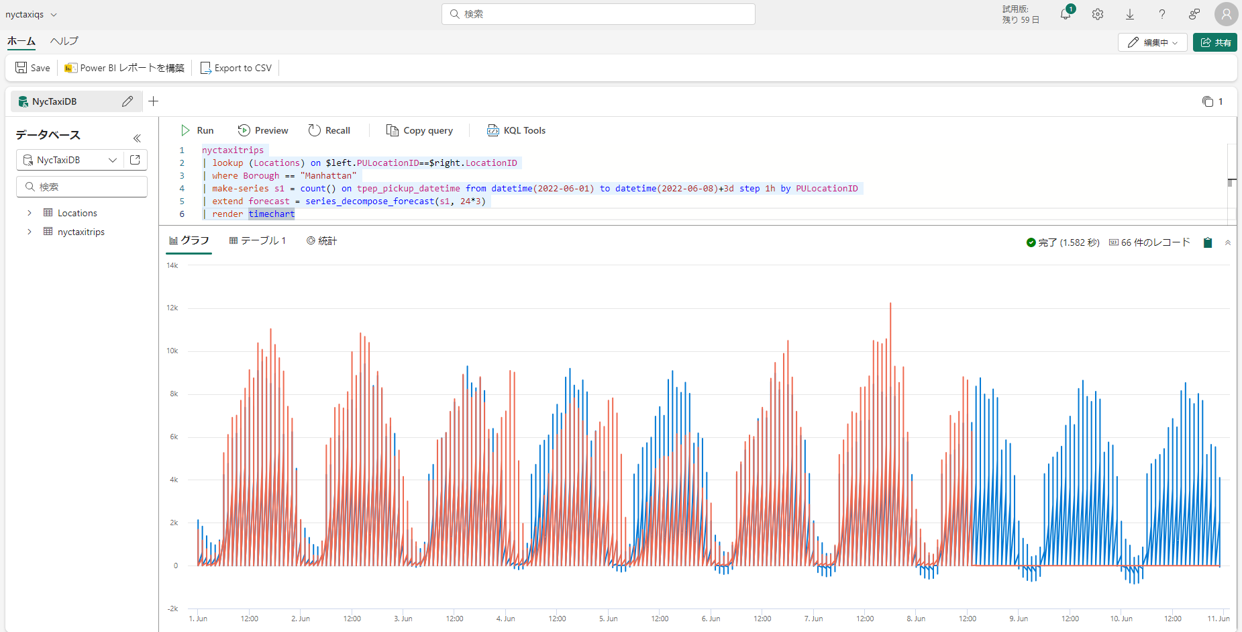
④ series_decompose_forecast 関数で時間ごとに使用の必要なタクシー数を予測します。
Kusto:
|
1 2 3 4 5 6 7 8 9 10 11 |
nyctaxitrips | lookup (Locations) on $left.PULocationID==$right.LocationID | where Borough == "Manhattan" | make-series s1 = count() on tpep_pickup_datetime from datetime(2022-06-01) to datetime(2022-06-08)+3d step 1h by PULocationID | extend forecast = series_decompose_forecast(s1, 24*3) | render timechart |
10. Power BIでレポートの作成
Power BIでレポートを作成する
Power BI レポートは、さまざまな観点を1つのセマンティック モデルに集約することができます。これはマルチパースペクティブ表示ともいえます。
① 次のクエリをコピーしてKQL クエリセットに貼り付けると、このクエリの出力がセマンティック モデルとして使用されます。
Kusto:
|
1 2 3 4 5 6 7 |
nyctaxitrips | where PULocationID == DOLocationID | lookup (Locations) on $left.PULocationID==$right.LocationID | summarize Count=count() by Borough, Zone, Latitude, Longitude |
② クエリ内のどこかにカーソルを置き、「Power BI レポートの構築」を選択します。
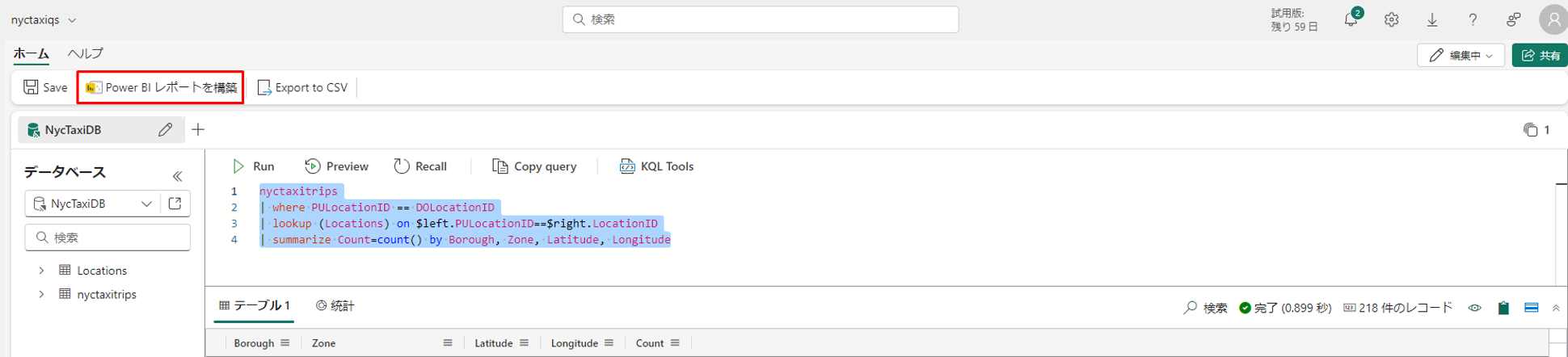
③ Power BI レポート エディターが開き、Kusto Query Resultというクエリの結果が表示されます。
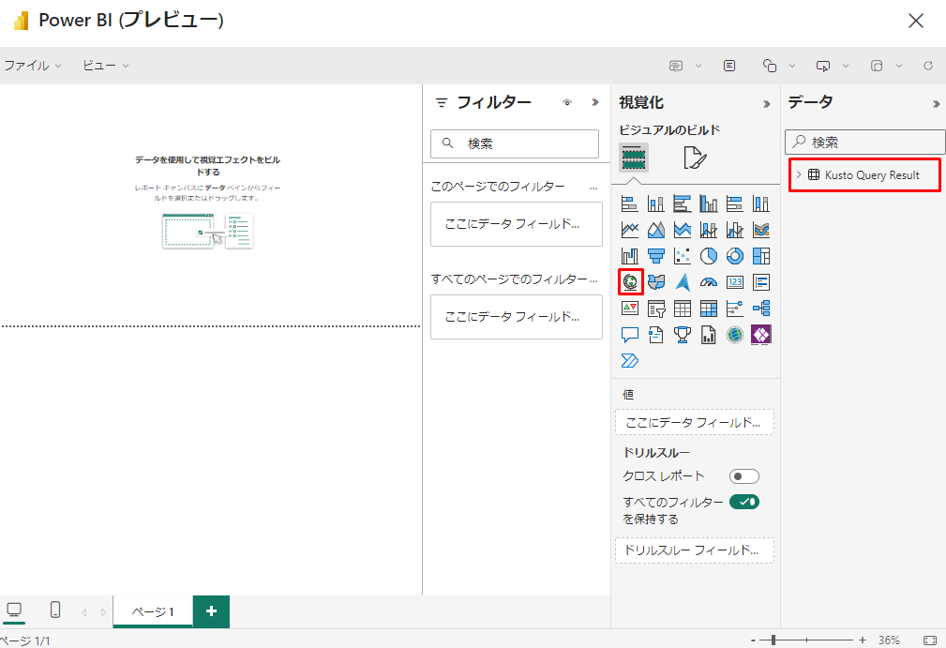
④ レポート エディターで、「Visualizations」(視覚化) >「Map」(マップ) アイコン ![]() を選択します。
を選択します。
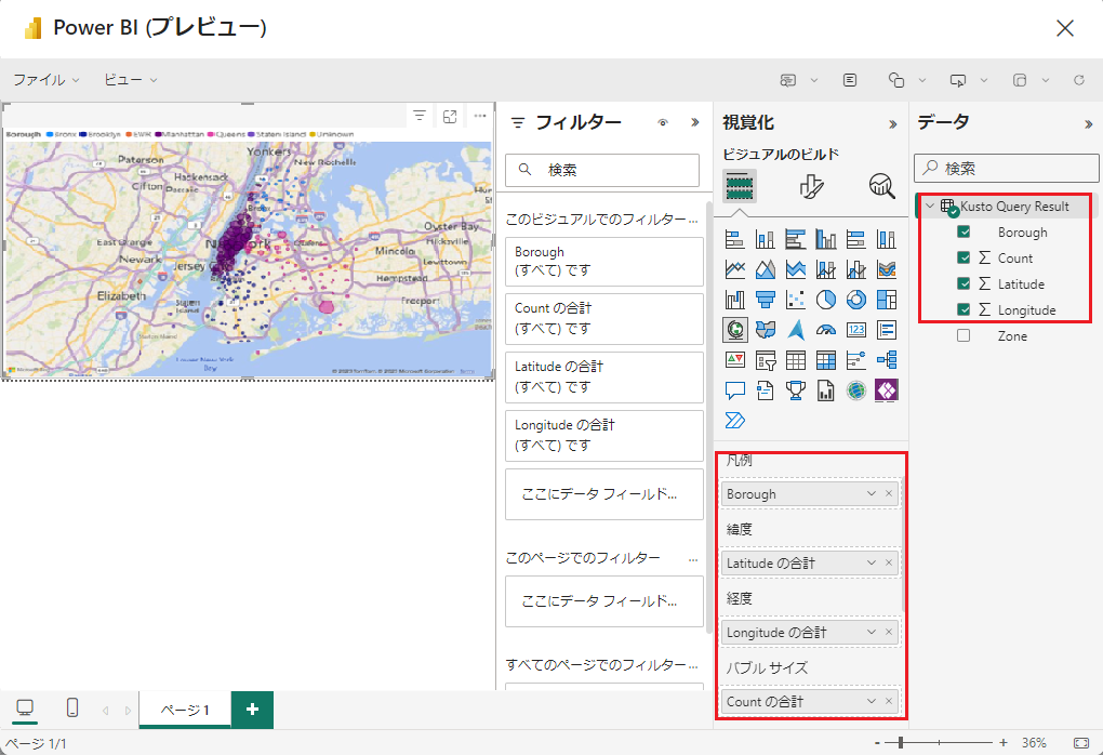
⑤ 次のオプションを選択して、地図に表示させます。
・「Borough」(自治区) >「Legend」(凡例)
・「Latitude」(緯度) >「Latitude」(緯度)
・「Longitude」(経度) >「Longitude」(経度)
・「Count」(数) >「Bubble size」(バブルのサイズ)
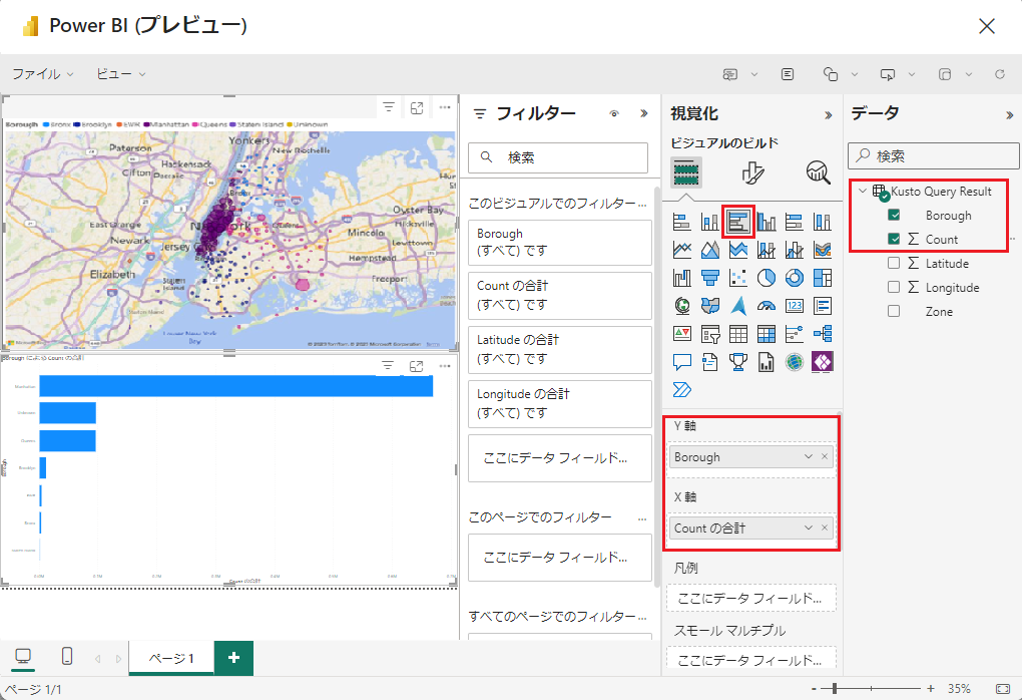
視覚化を追加する
①「Stacked Bar Chart」(積み上げ横棒グラフ) アイコンを選択します。
②「Borough」(自治区) フィールドを Y 軸に、「Count」(数) を X 軸にドラッグします。
11. まとめ
Microsoft Fabric の Synapse Real-Time Analytics の使用方法をについて実施してみました。 今回の記事が少しでも Microsoft Fabric を知るきっかけや、業務のご参考になれば幸いです。
第1回:Microsoft Fabric 概要と試用版の作成方法
第2回:Power BI ユーザー向け Fabric チュートリアル
第3回:Data Factory ユーザー向け Fabric チュートリアル
第4回:Data Activator ユーザー向け Fabric チュートリアル (進行中)
第5回:Industry Solutions ユーザー向け Fabric チュートリアル (進行中)
第6回:Synapse Data Engineering ユーザー向け Fabric チュートリアル (進行中)
第7回:Synapse Data Science ユーザー向け Fabric チュートリアル (進行中)
第8回:Synapse Data Warehouse ユーザー向け Fabric チュートリアル (進行中)
第9回:Synapse Real-Time Analytics ユーザー向け Fabric チュートリアル (今回)
この記事を書いた人
この投稿者の最新の記事
- 2025年3月12日ブログ【Azure Databricks】Databricksのボリュームに保存されたCSVファイルから、カタログのテーブルにデータを取り込む手順書
- 2024年12月2日ブログ【Azure Databricks】Databricks Notebook から MySQL または SQL Server にデータを更新する方法
- 2024年11月6日ブログ【Azure Databricks】Lakehouse フェデレーションと外部カタログについての説明
- 2024年5月15日ブログ【Microsoft Fabric】Synapse Real-Time Analytics ユーザー向け Fabric チュートリアル