目次
1. はじめに
皆さんこんにちは。
今回はLakeflow Spark 宣言型パイプラインについて説明していきます。
この連載では、Azure DatabricksのLakeflow Spark 宣言型パイプラインの基本から実行手順について説明しています。
前回、前々回の記事はぜひ下記リンクからご覧ください!
第1回:Lakeflow Spark 宣言型パイプラインの基本を知ろう
第2回:Lakeflow Spark 宣言型のパイプラインを実装してみよう
第3回:Lakeflow Spark 宣言型パイプラインにおけるデータの品質管理とは?(今回)
2.【おさらい】Lakeflow Spark 宣言型パイプラインとは?
Lakeflow Spark 宣言型パイプライン(SDP) は、Azure DatabricksにおけるDelta Live Tables (DLT) Foundationの後継として進化した機能です。
SDPは、バッチ処理とストリーミング処理を単一のフレームワークに統合することで、データパイプラインの構築・管理・実行を容易にします。
SDPは、データ処理ワークフローを自動化し、効率的かつインテリジェントに構成・運用することを可能にします。
詳しくは第1回目の記事をご覧ください。
3.Lakeflow Spark 宣言型パイプラインにおけるデータの品質管理とは?
Lakeflow Spark 宣言型パイプラインの品質管理とは、データパイプラインの出力に対してデータ品質チェックを定義し、実行し、結果を記録する機能です。
データ品質チェックの結果は、イベントログに保存され、ユーザーインタフェースやAPIで確認できます。
SDPの最大の改善点は、Pipeline UI上にData Qualityタブが標準で統合されたことであり、複雑なクエリによるデータ抽出を行うことなく、正常(Passed)および異常(Failed)レコード数を視覚的に確認できる点です。
また、データ品質のエラーが発生した際は事前に定義したエラーポリシーに基づいて対処することができます。
制約条件(Expectations)を活用することで、違反レコードのログ出力、不正データの除外、あるいはデータの整合性を保つためにパイプライン全体を停止するといったデータ制御が可能となります。
4.データ品質管理手順
【準備】Lakeflow Spark 宣言型パイプライン (SDP) を作成しておく
前回の記事を参考に、パイプラインを作成します。
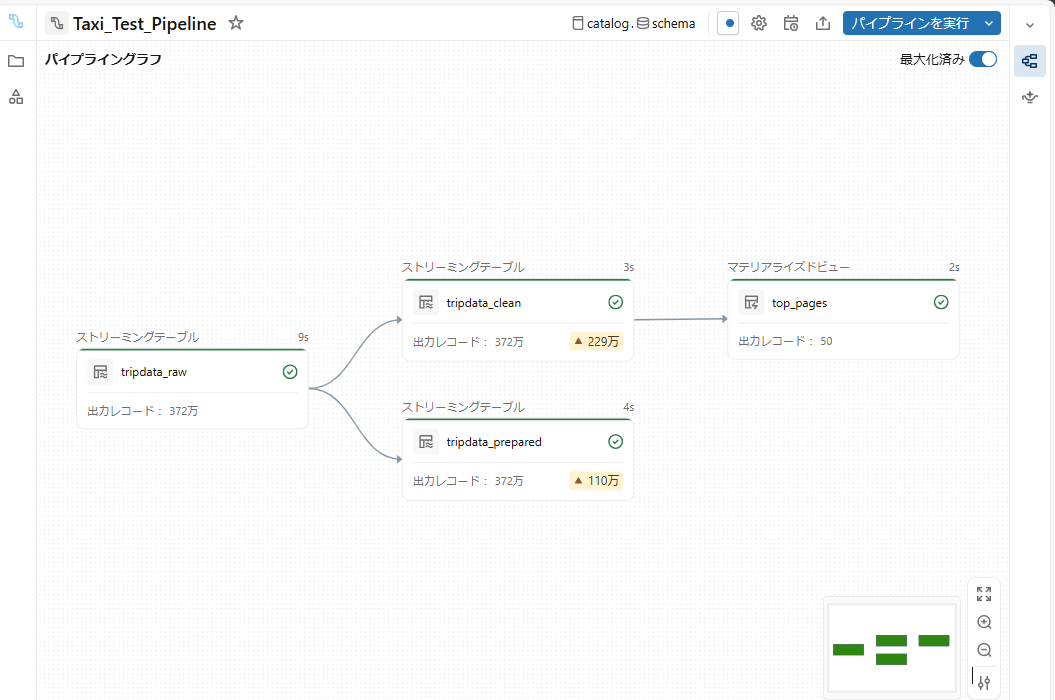
4-1.SDPのUI上でのパイプライン品質の確認
SDPはDelta Live Tablesと比較して大きく改善されており、SDPのユーザーインターフェース上でデータの状態および品質をリアルタイムに確認できる点が特徴です。
Databricks上での確認手順は以下の通りです。
① パイプライン画面にアクセスし、対象のパイプライン(例:Taxi_Test_Pipeline)を選択する。
② DAG図の下部にあるテーブルタブを確認する。この画面では、各テーブルごとにエクスペクテーション列が表示され、データ品質の状態を確認できる。
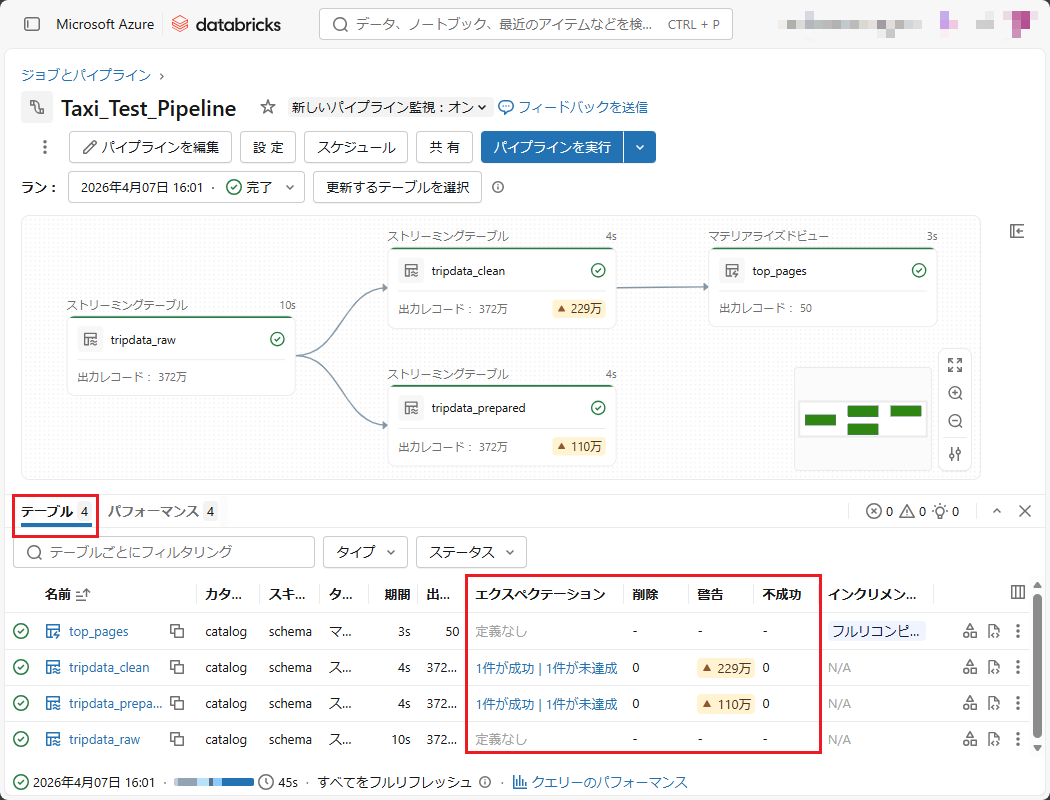
上記の結果から、ログをクエリすることなく、「tripdata_clean」テーブルのデータ品質に関する詳細情報を把握できます。
・エクスペクテーション列: 「1件が成功 | 1件が未達成」と表示されています。これは、第2回で設定した制約(constraint)のうち、1つは完全に満たされ、もう1つは違反データが存在することを示しています。
・警告列: 「229万」と表示されています。これは、約230万件のレコードが設定した条件を満たしていないことを意味します。ただし、第2回では「CONSTRAIN … EXPECT」構文のみを使用し、「ON VIOLATION DROP ROW」や「ON VIOLATION FAIL UPDATE」などの後続オプションを指定していないため、システムは自動的に警告ポリシーとして処理します。その結果、違反レコードは対象のテーブルに書き込まれるが、エラー件数はイベントログに記録されます。
・不成功列および削除列: 上記の「ON VIOLATION …」オプションを設定した場合、これらの列に値が表示され、除外または処理失敗となった不正データの件数を正確に把握できます。
このようなDatabricksのSDPにおける改善により、従来のDelta Live Tablesのように複雑なSQLクエリを記述することなく、どのテーブルでどの程度のエラーが発生しているかを迅速に確認できます。その結果、トラブルシューティングの効率が向上し、Lakehouseにおけるデータの信頼性を高めることが可能となります。
4-2.異常検出によるデータ品質の確認
4.1がパイプラインの健全性を確認する機能であるのに対し、本項ではデータ自体の信頼性を評価します。手順は以下の通りです
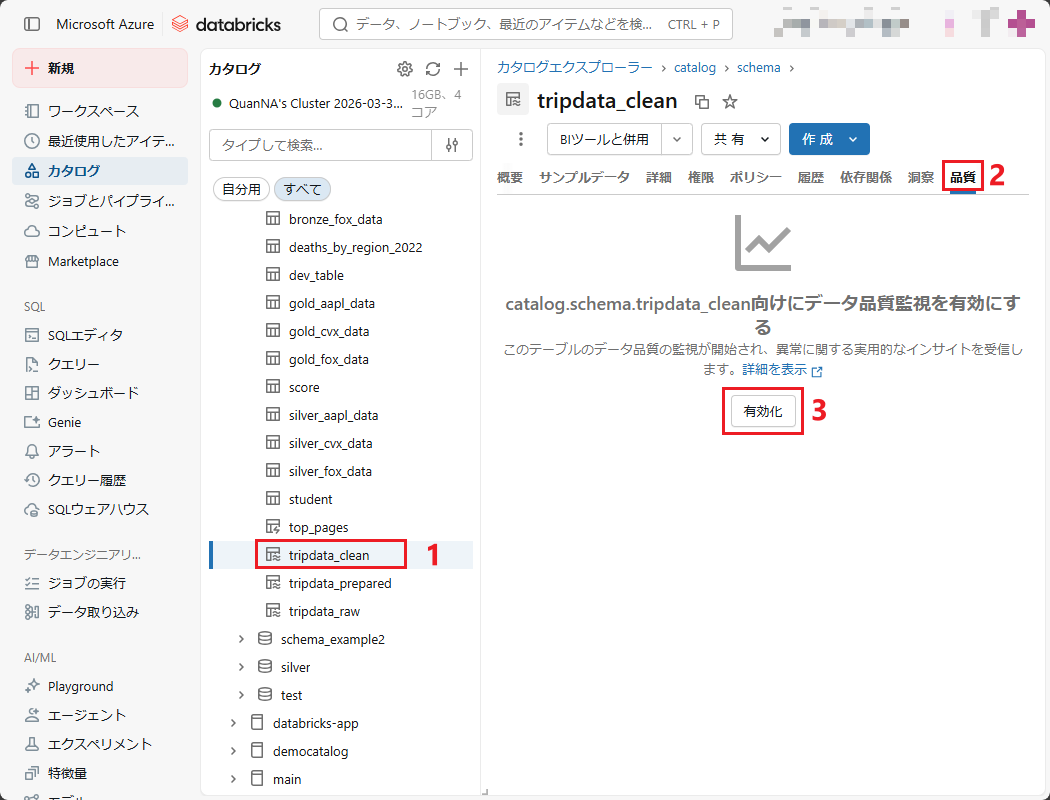
① 左のサイドメニューから「カタログ」にアクセスし、「tripdata_clean」テーブルを検索する。
② 対象のスキーマにて「品質」タブを選択する。
③ 「有効化」を押下する。
④ 「データ品質監視」ポップアップの「異常検出」項目で「スキーマの構成」を選択する。
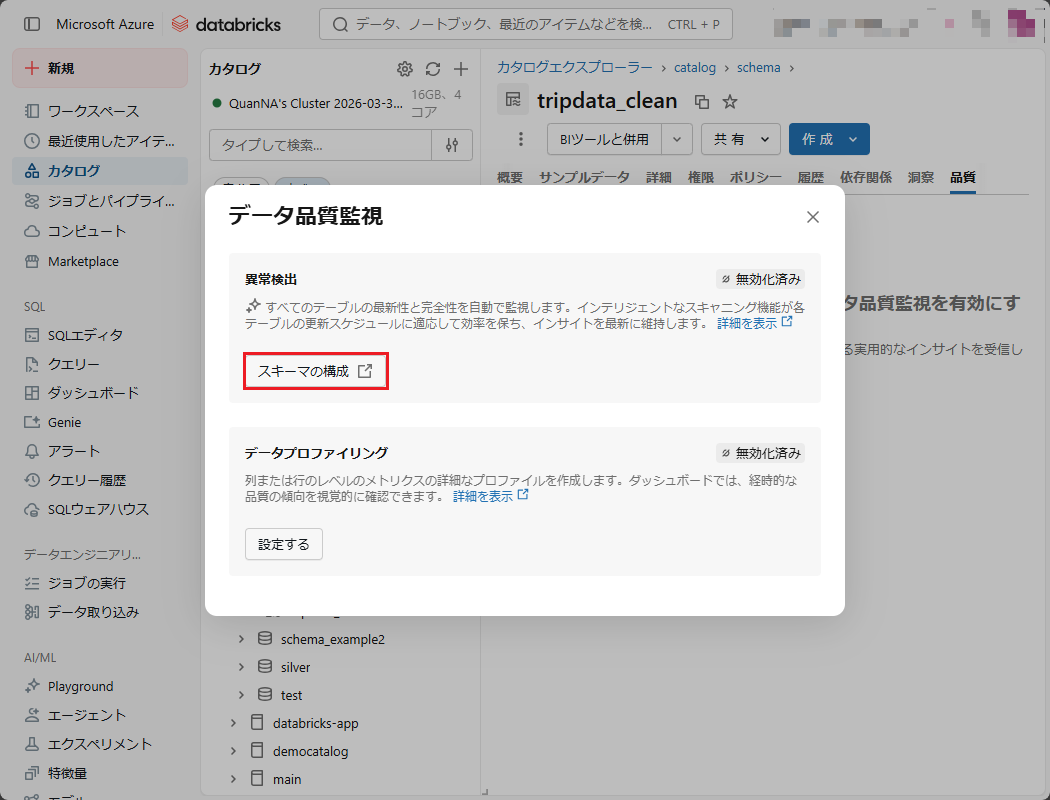
⑤ 「異常検出」のトグルスイッチをオンにし、「保存」ボタンを押下する。
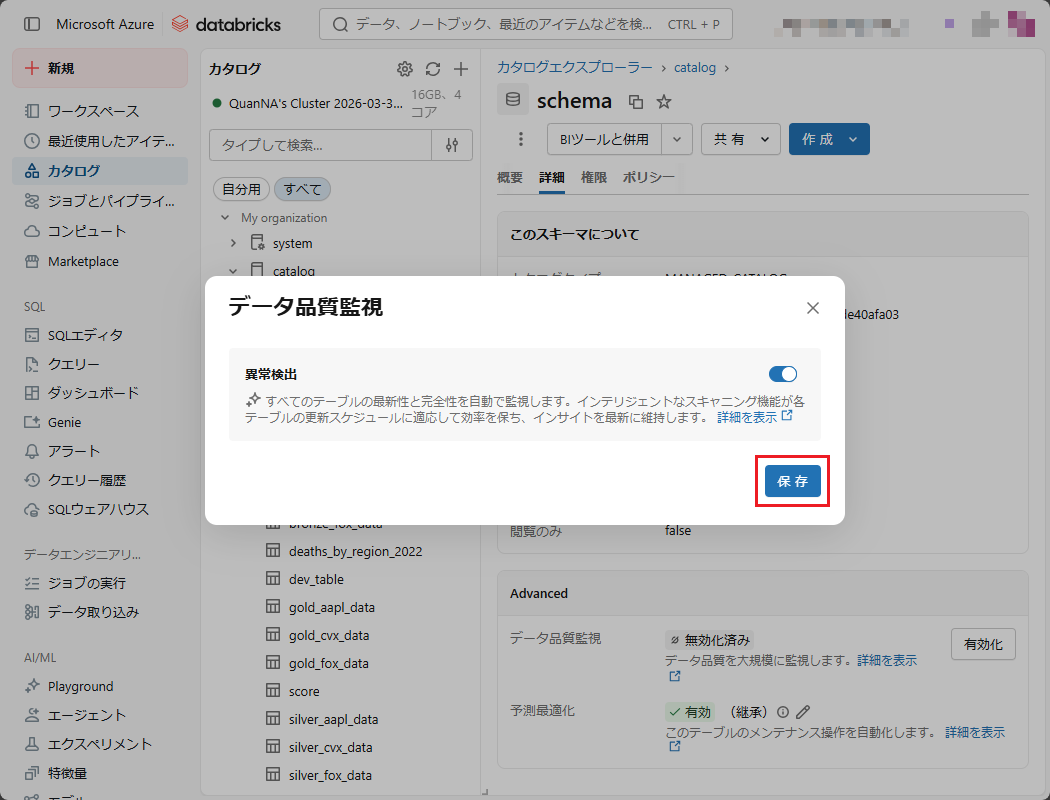
⑥ 続けて、同一ポップアップの「データプロファイリング」項目で「設定する」を押下する。
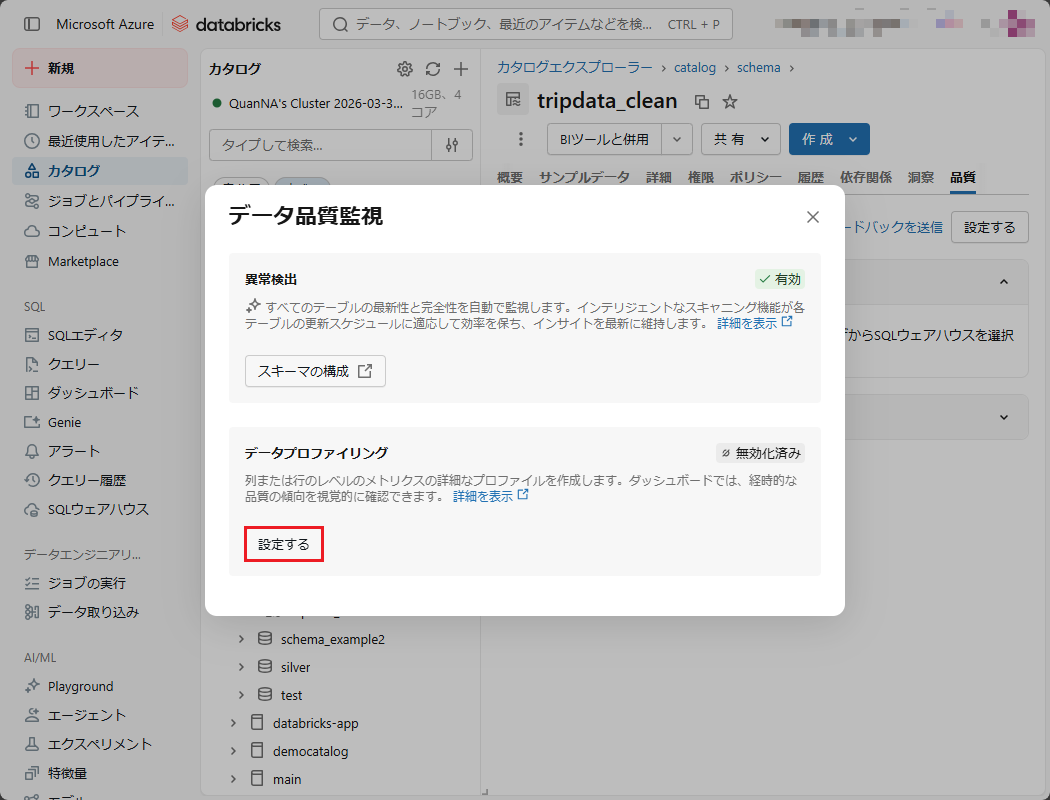
「モニターを作成」ポップアップの「プロファイリング」項目の「プロファイルのタイプ」フィールドにて
- 時系列 : 各期間ごとの指標の変動を追跡するためにタイムスタンプが必要であり、周期的なトレンドの把握に適している。
- スナップショット: 特定時点におけるテーブル全体のデータを対象として分析を行う。
- 推論 : 機械学習モデルにおいて、入力データと出力結果の相関関係を監視する際に利用される。
⑦ 本項(4-3)で利用するため、「プロファイルのタイプ」フィールドの「スナップショット」を選択し、「作成」ボタンを押下する。
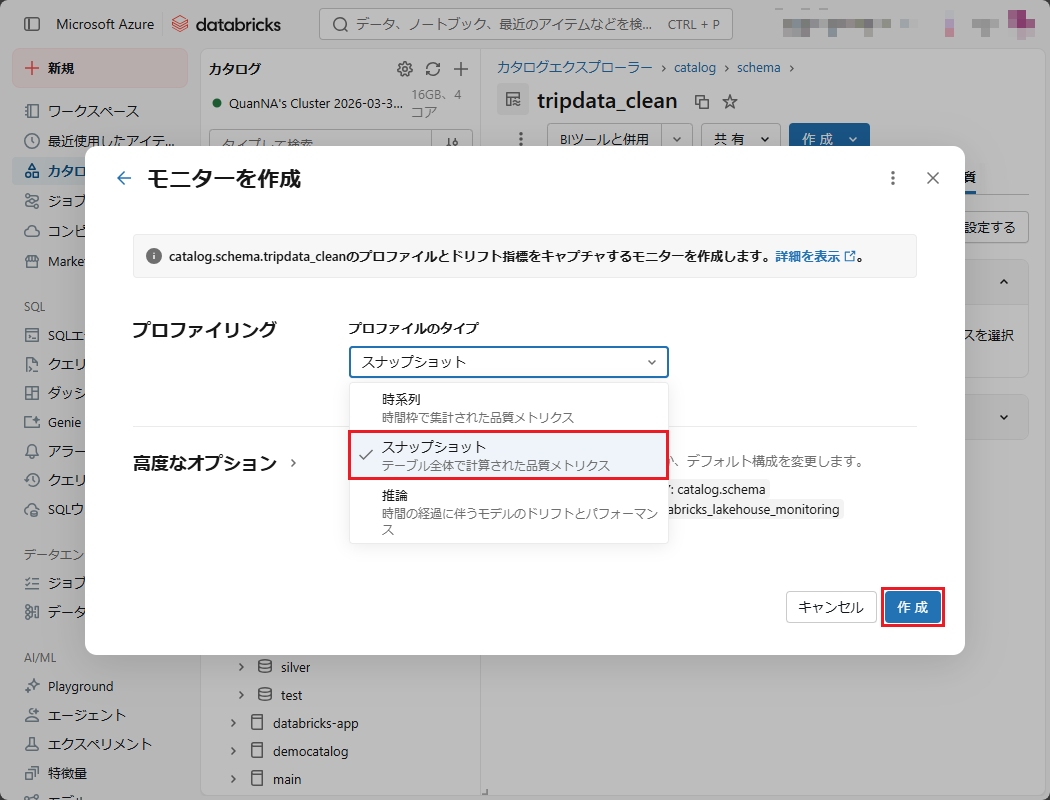
完了後、「品質」タブで結果は以下の通りです。
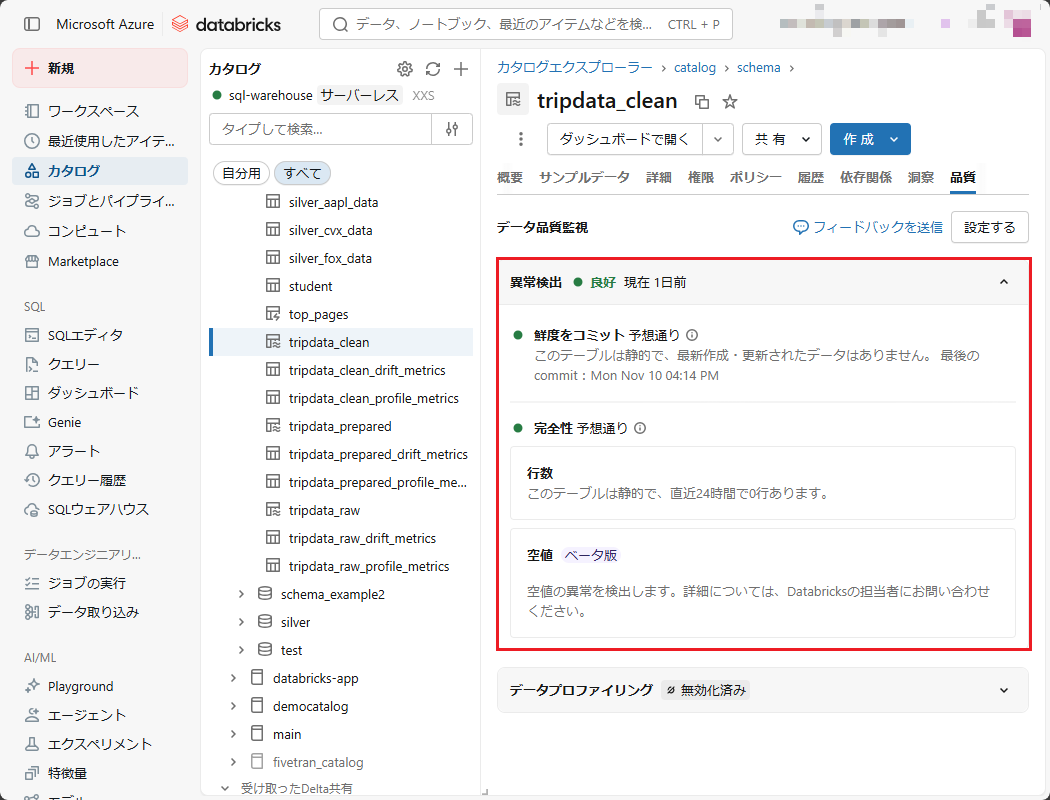
上記の画面から、データ品質について以下の内容を確認できます。
・異常検出: データが安定していることを確認できる。
・鮮度とコミット: 最終レコード更新時刻を監視し、データが常に最新の状態に保たれていることを確認できる。
・完全性: レコード数(Row count)の変動や、各カラムにおけるNULL値の割合を監視することを確認できる。
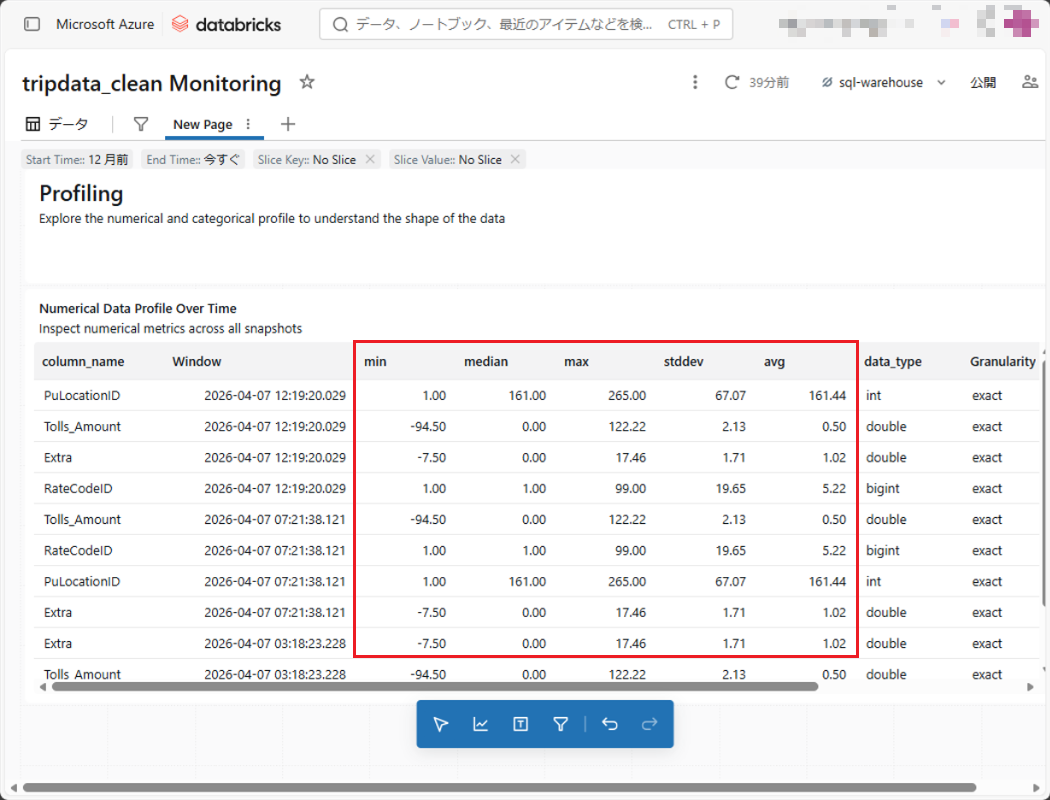
4-3.データプロファイリングによるデータの詳細分析
異常検出がデータ全体の監視を担うのに対し、データプロファイリングは各カラム単位でデータの分布や偏りを詳細に把握するための機能です。
手順は以下の通りです
① 左のサイドメニューから「カタログ」にアクセスし、「tripdata_clean」テーブルを検索する。
② 「品質」タブを選択する。
③ 「データプロファイリング」項目で「ダッシュボードを表示」ボタンを押下する。
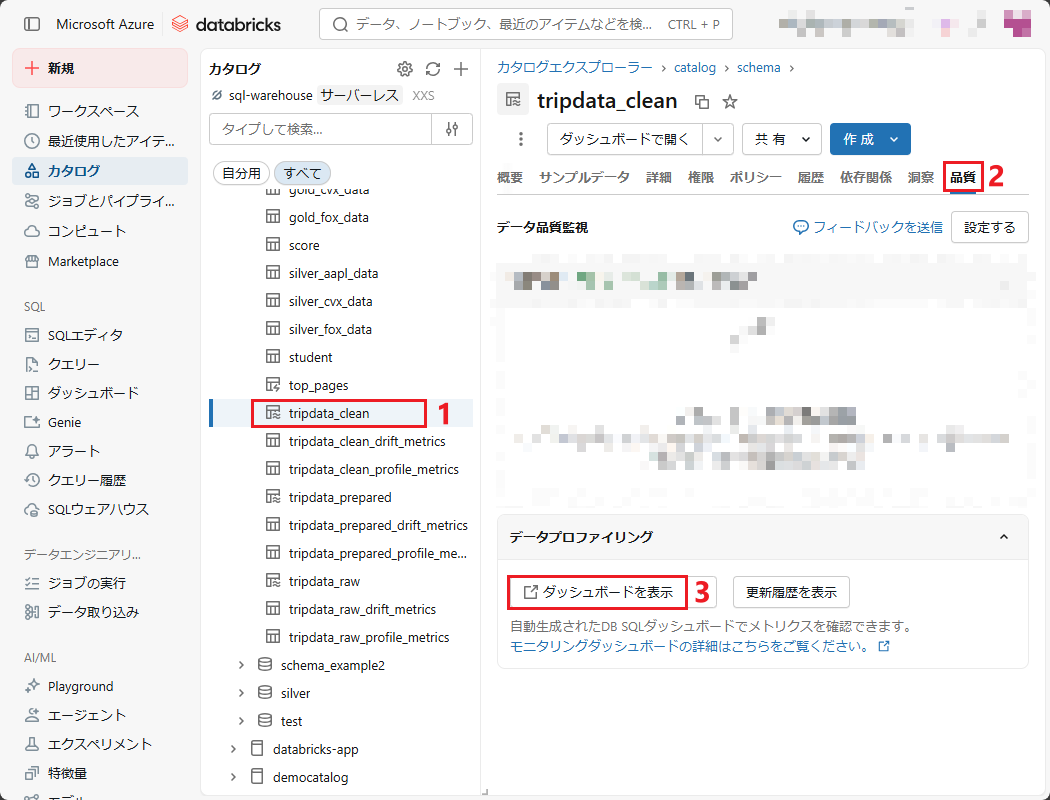
レコード数(Row Count)が3.72Mであることから、スナップショット間におけるデータフローの一貫性が維持されており、データの定量的な完全性が確保されていることが確認できる。
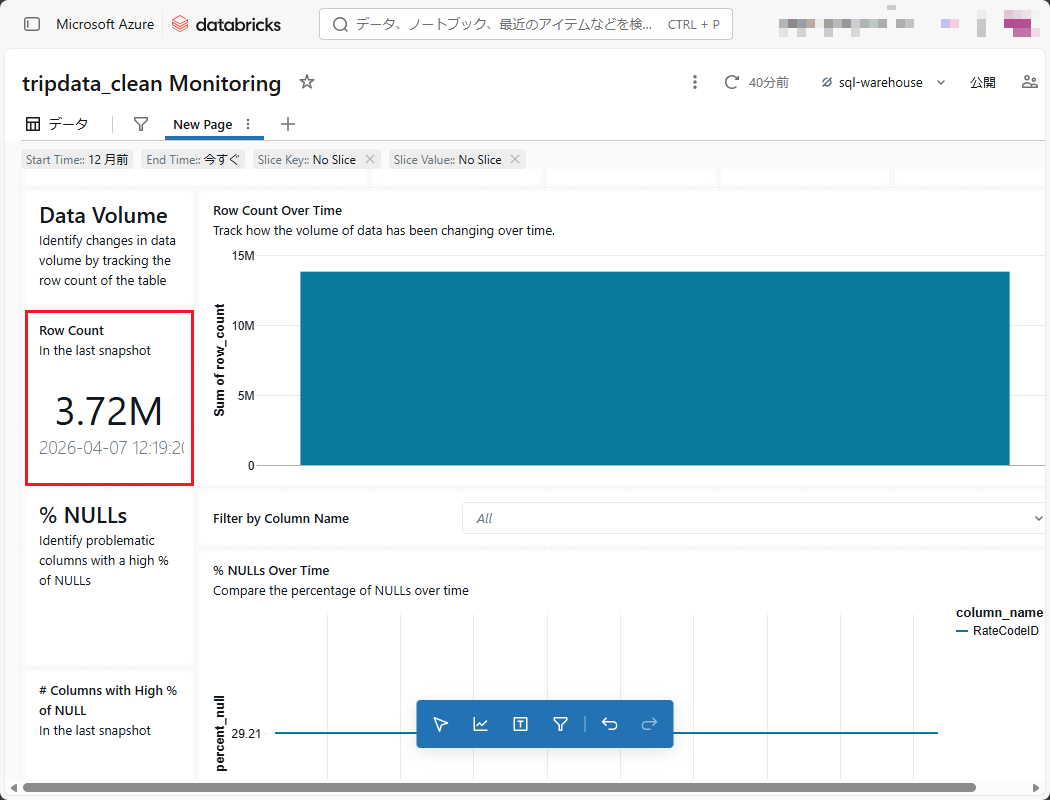
NULL値やゼロ値の割合を自動的に検出することで、データ処理プロセスを最適化するための定量的かつ正確な指標を得ることができる。
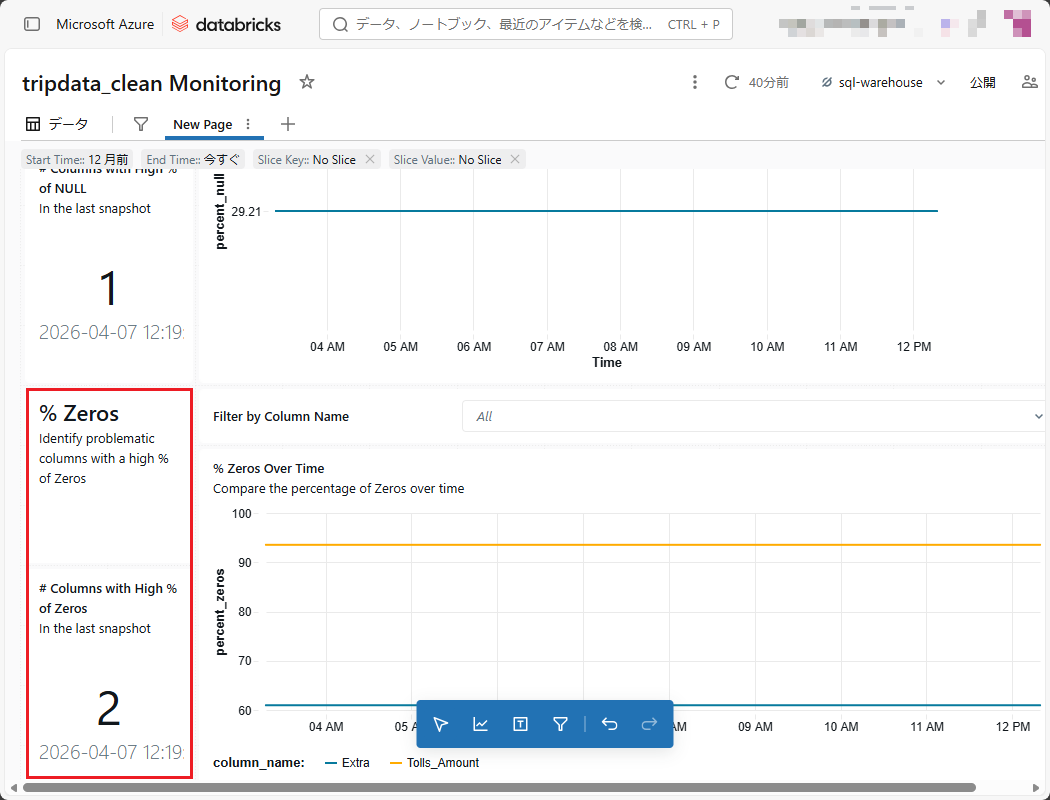
時系列におけるグラフの安定した推移から、本データセットは管理された許容範囲内で安定的に運用されており、データ分布の異常や偏りは確認されていないことが示される。
5. まとめ
本記事ではAzure DatabricksのLakeflow Spark 宣言型パイプラインのデータの品質管理について説明しました。
この連載では、Azure DatabricksのLakeflow Spark 宣言型パイプラインの基本から実行手順について説明しています。
是非合わせてご覧ください。
第1回:Lakeflow Spark 宣言型パイプラインの基本を知ろう
第2回:Lakeflow Spark 宣言型のパイプラインを実装してみよう
第3回:Lakeflow Spark 宣言型パイプラインにおけるデータの品質管理とは?(今回)
今回の記事が少しでも皆さんの新しい知識や業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたら
是非お問い合わせください!
Azure Databricks連載記事のまとめはこちら