目次
1. はじめに
皆さんこんにちは。
今回はAzure Databricks Delta Live Tablesのパイプラインの作成について説明していきます。
この連載では、Azure DatabricksのDelta Live Tablesの基本から実行手順について説明しています。
第1回:Delta Live Tablesの基本を知ろう
第2回:Delta Live Tablesのパイプラインを実装してみよう(今回)
第3回:Delta Live Tablesのデータの品質管理とは?
2.【おさらい】Delta Live Tablesパイプラインとは?
Delta Live Tablesパイプラインは、
Delta Live Tablesでデータ処理ワークフローを構成して実行するためのリソースです。
詳しくは前回の記事をご覧ください。
3.パイプラインを作成する
【準備】ノートブックを開く
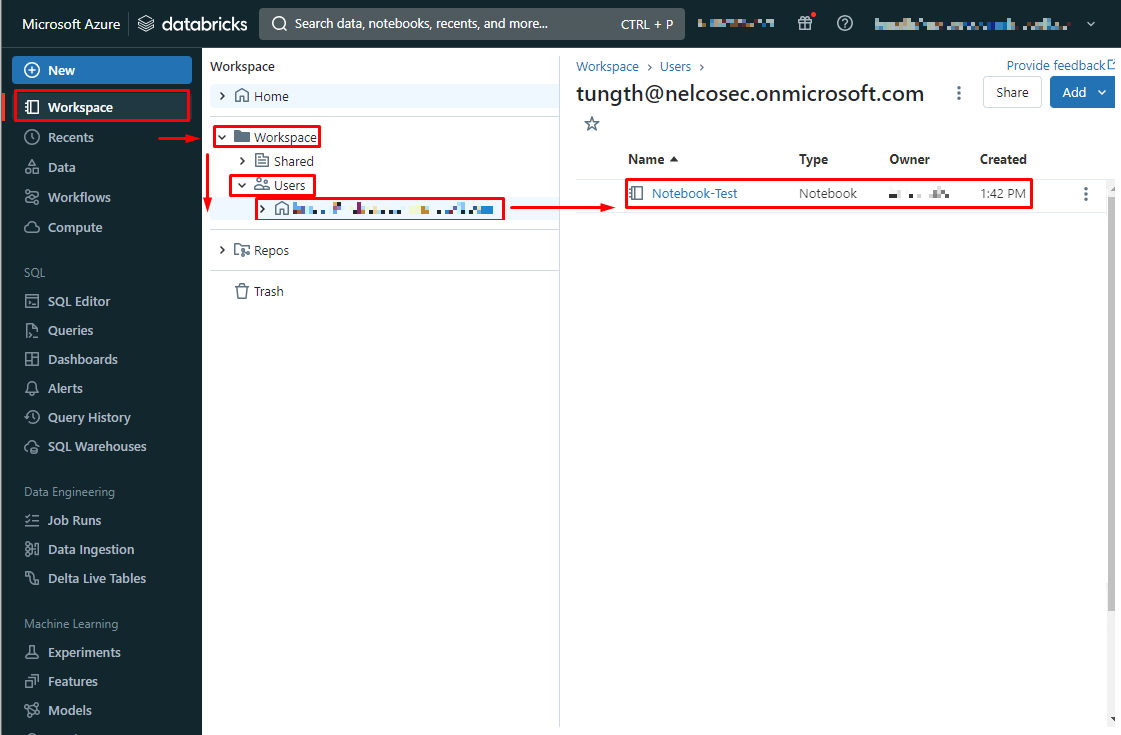
〇既存のノートブックを開く
①こちらの手順でワークスペースにアクセスします。
②Azure Databricksポータル画面で、サイドバーを展開します。
③Workspace > Workspace > Users >自分のユーザー名 > 使用するノートブック を選択します。
 〇新規のノートブックを作成する
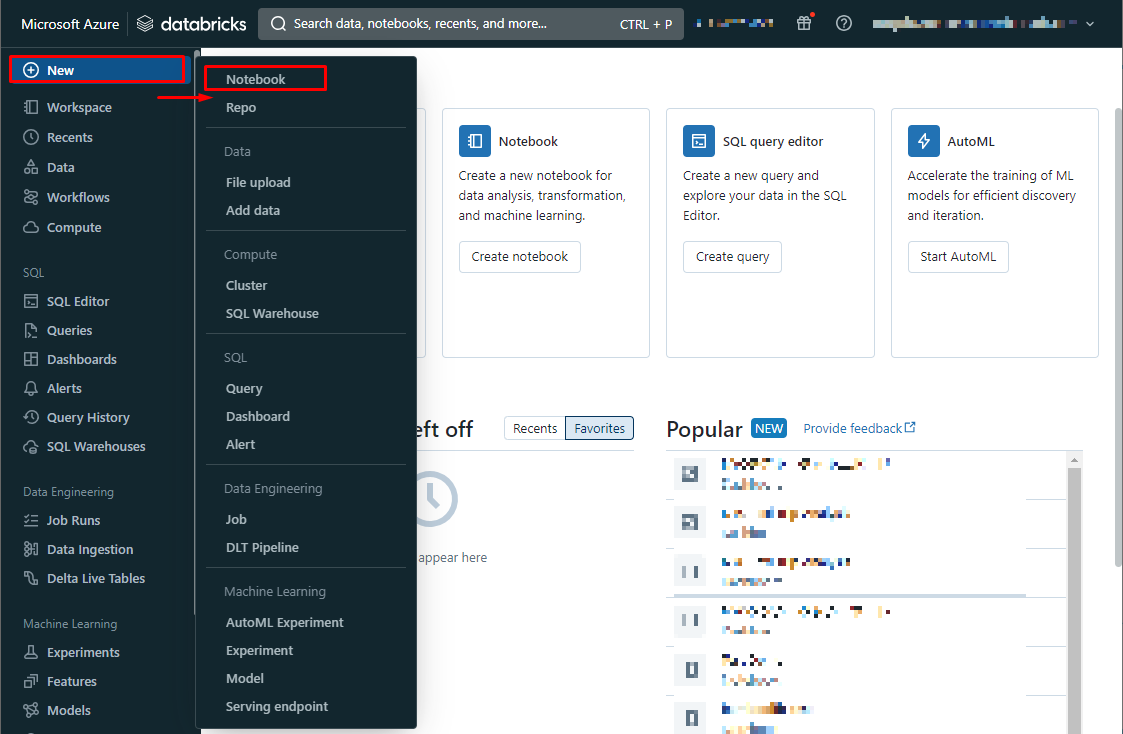
〇新規のノートブックを作成する
①こちらの手順でワークスペースにアクセスします。
②Azure Databricksポータル画面で、サイドバーを展開します。
③+New > Notebook を選択します。
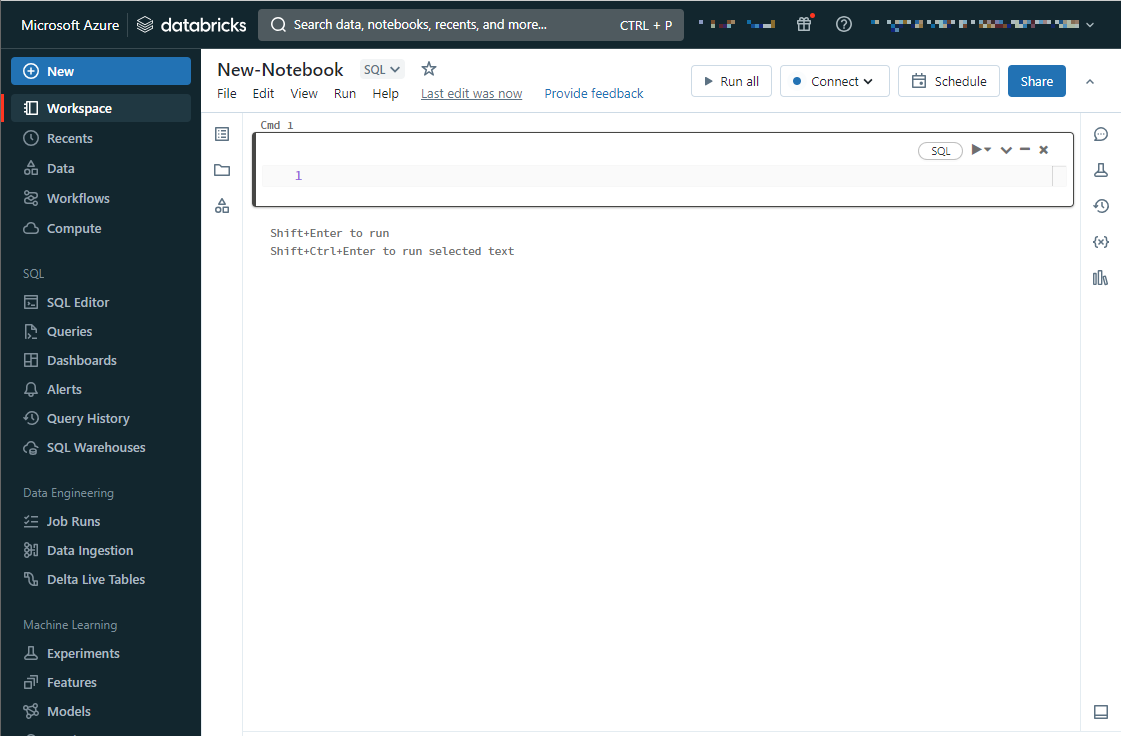
⑤作成したノートブックが開かれます。
3-1.Notebookにコマンドを入力する
【シナリオ】
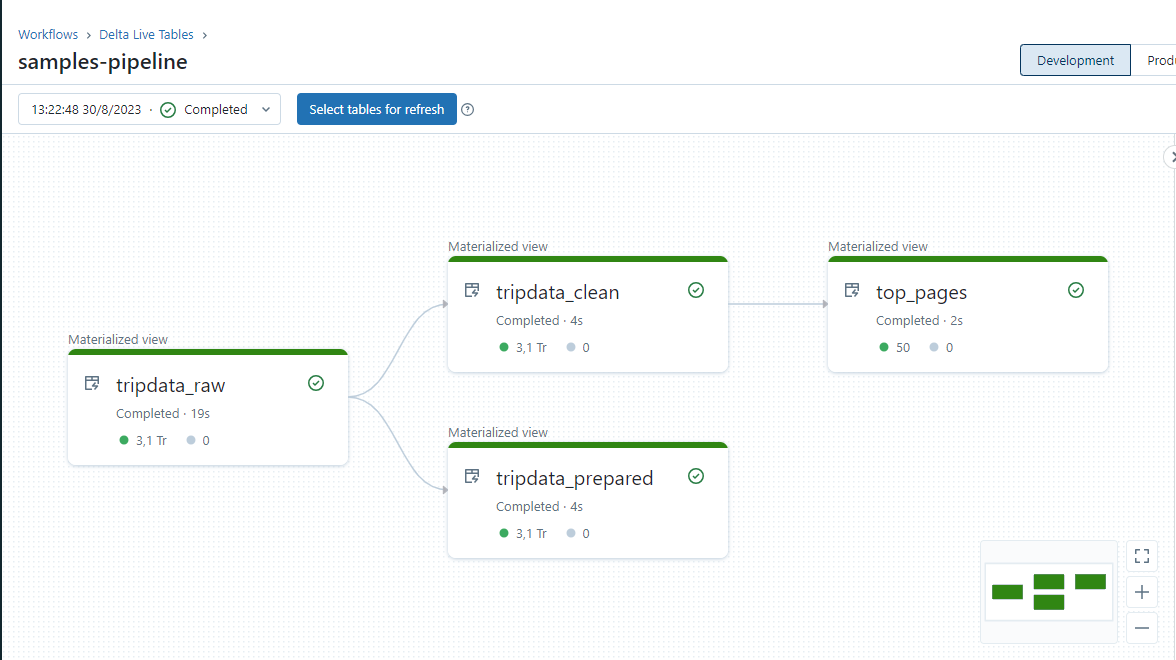
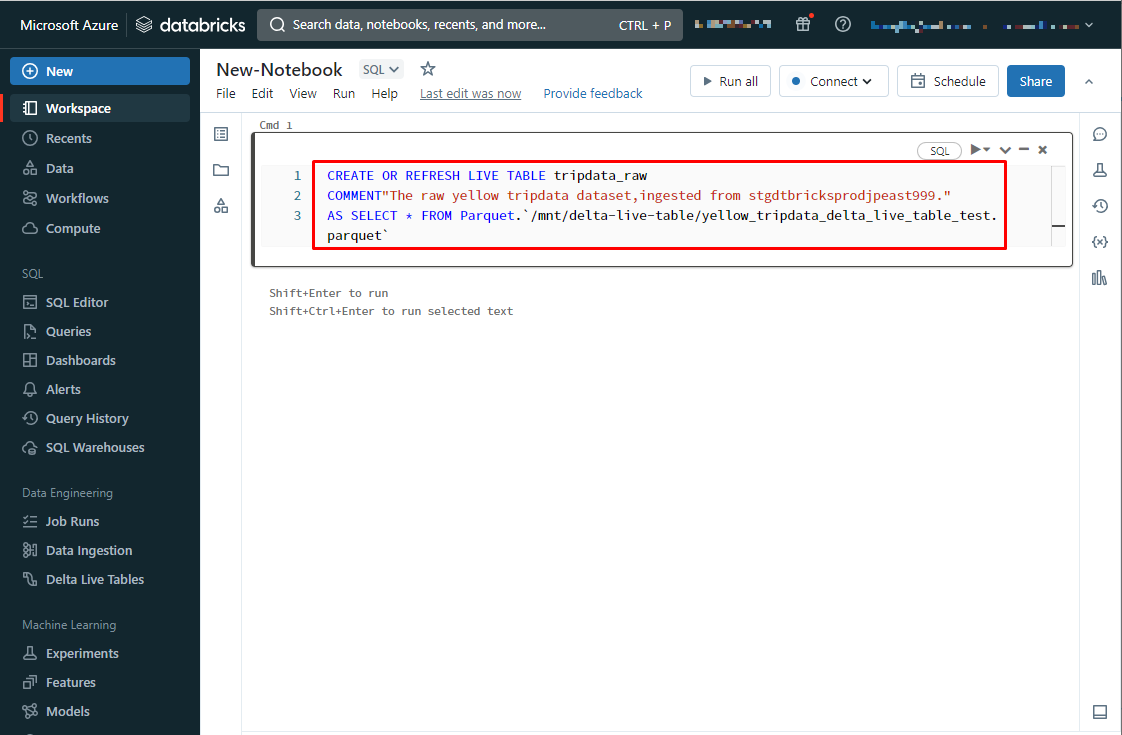
①ストレージからのyellow trip datasetという生データを取り込み 、tripdata_rawというテーブルを作成します。
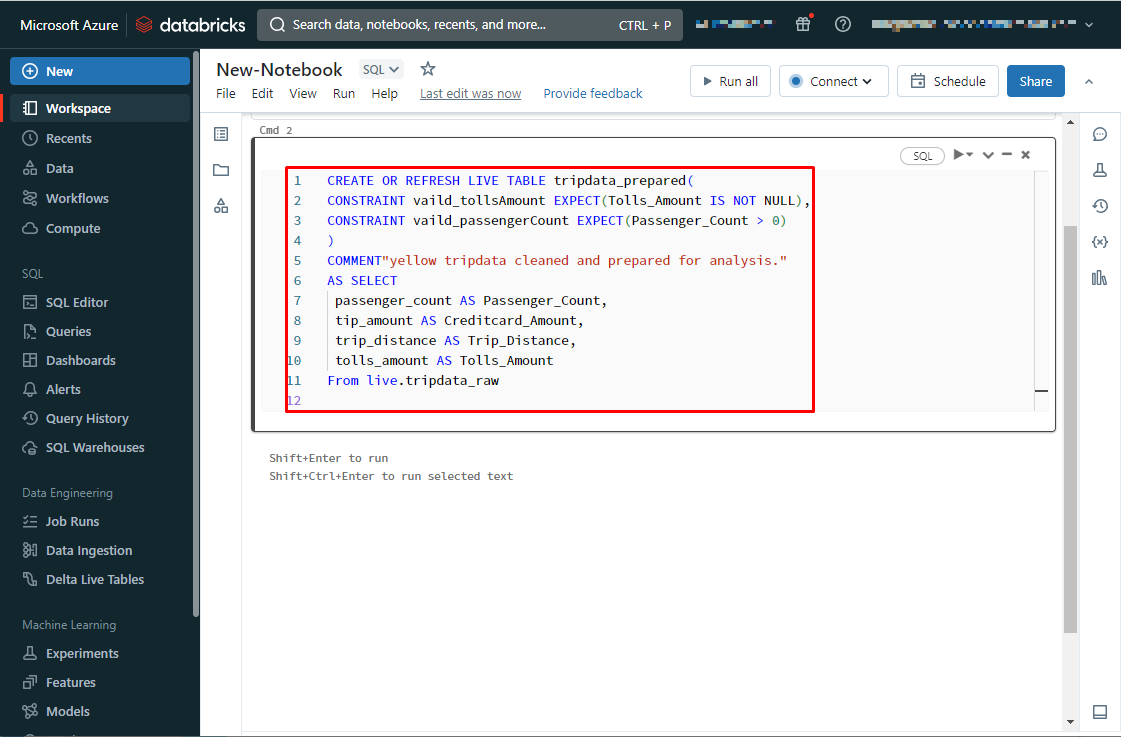
②tripdata_rawテーブルをクレンジングし、 tripdata_preparedテーブルを作成します。
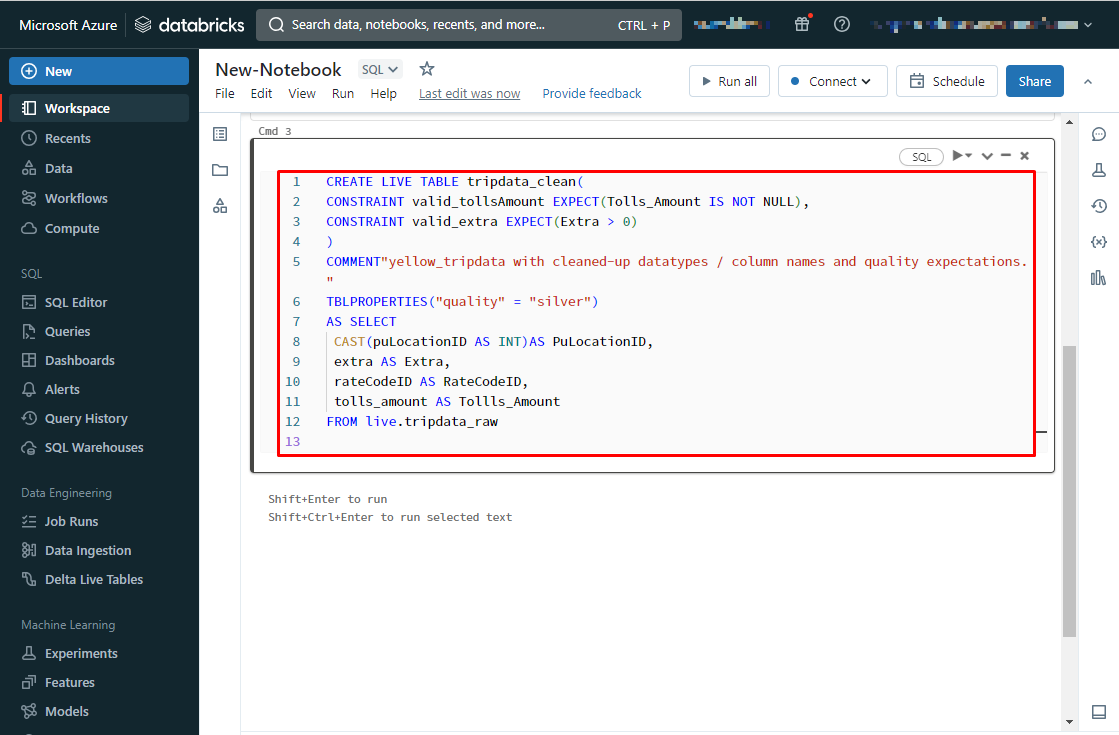
③tripdata_rawテーブルをクレンジングした、tripdata_cleanテーブルを作成し、
データ型/列名と品質の期待値を持つデータに加工します。
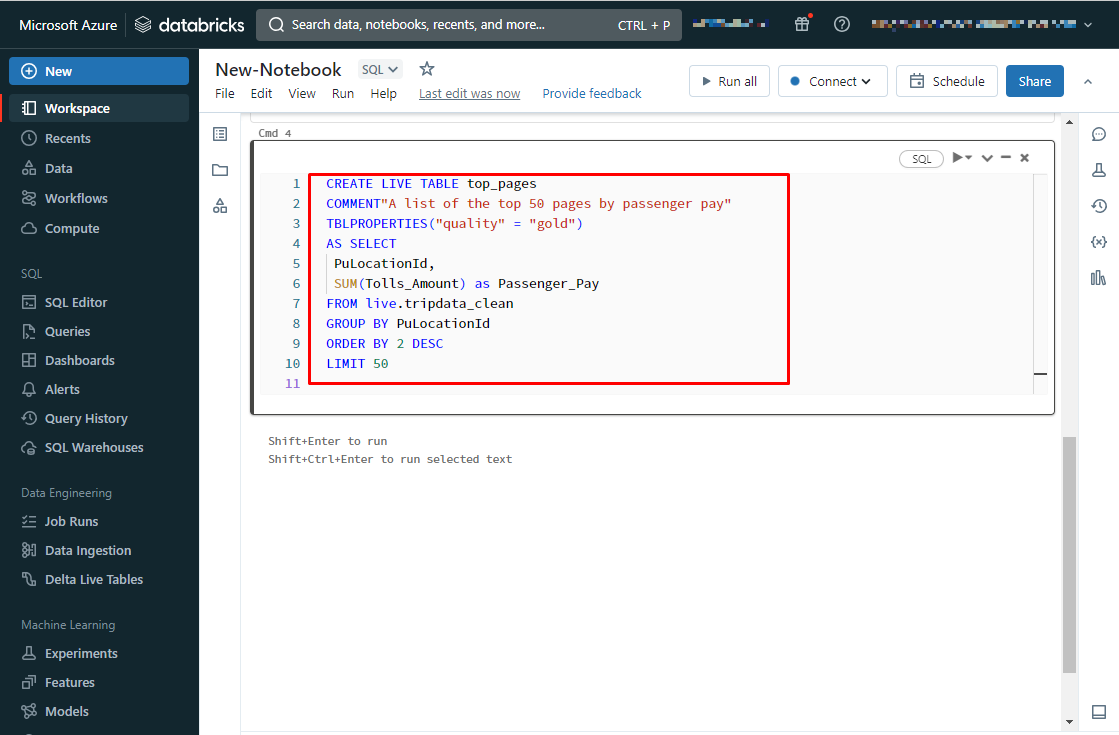
④ピックアップした場所ごとにグループ化し、通行料金の合計額を計算します。
さらに計算結果を降順に並び替え上位50件に絞り込んだtop_pagesテーブルを作成します。
【SQLの詳細】
①ストレージからのyellow trip datasetという生データを取り込み 、tripdata_rawというテーブルを作成します。
|
1 2 3 |
CREATE OR REFRESH LIVE TABLE tripdata_raw COMMENT"The raw yellow tripdata dataset,ingested from stgdtbricksprodjpeast999." AS SELECT * FROM Parquet.`/mnt/delta-live-table/yellow_tripdata_delta_live_table_test.parquet` |
②tripdata_rawテーブルをクレンジングし、 tripdata_preparedテーブルを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE OR REFRESH LIVE TABLE tripdata_prepared( CONSTRAINT vaild_tollsAmount EXPECT(Tolls_Amount IS NOT NULL), CONSTRAINT vaild_passengerCount EXPECT(Passenger_Count > 0) ) COMMENT"yellow tripdata cleaned and prepared for analysis." AS SELECT passenger_count AS Passenger_Count, tip_amount AS Creditcard_Amount, trip_distance AS Trip_Distance, tolls_amount AS Tolls_Amount From live.tripdata_raw |
③tripdata_rawテーブルをクレンジングした、tripdata_cleanテーブルを作成し、
データ型/列名と品質の期待値を持つデータに加工します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE LIVE TABLE tripdata_clean( CONSTRAINT valid_tollsAmount EXPECT(Tolls_Amount IS NOT NULL), CONSTRAINT valid_extra EXPECT(Extra > 0) ) COMMENT"yellow_tripdata with cleaned-up datatypes / column names and quality expectations." TBLPROPERTIES("quality" = "silver") AS SELECT CAST(puLocationID AS INT)AS PuLocationID, extra AS Extra, rateCodeID AS RateCodeID, tolls_amount AS Tolls_Amount FROM live.tripdata_raw |
④ピックアップした場所ごとにグループ化し、通行料金の合計額を計算します。
さらに計算結果を降順に並び替え上位50件に絞り込んだtop_pagesテーブルを作成します。
|
1 2 3 4 5 6 7 8 9 10 |
CREATE LIVE TABLE top_pages COMMENT"A list of the top 50 pages by passenger pay" TBLPROPERTIES("quality" = "gold") AS SELECT PuLocationId, SUM(Tolls_Amount) as Passenger_Pay FROM live.tripdata_clean GROUP BY PuLocationId ORDER BY 2 DESC LIMIT 50 |
3-2.パイプラインを作成する
①Delta Live Tablesをクリックします。
②Delta Live Tables > Create pipeline をクリックします。
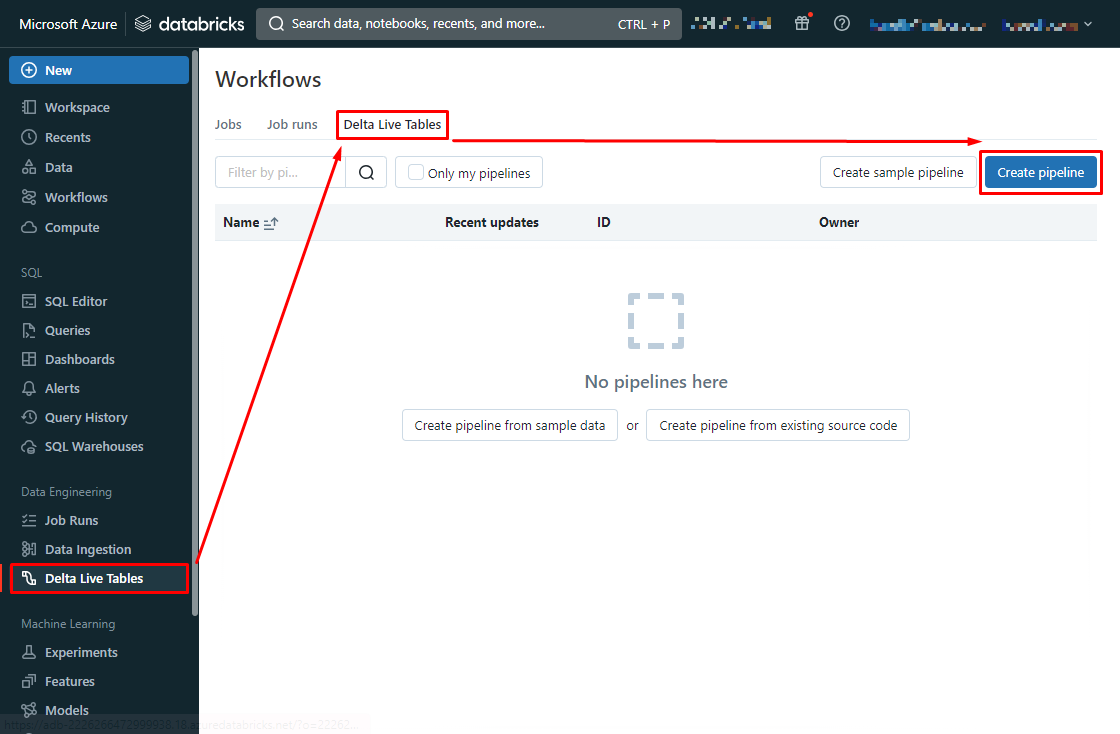
③パイプラインの設定を入力します。
【General】
Pipeline name → 名前を入力
Product edition → Advanced
Pipeline mode → Triggered
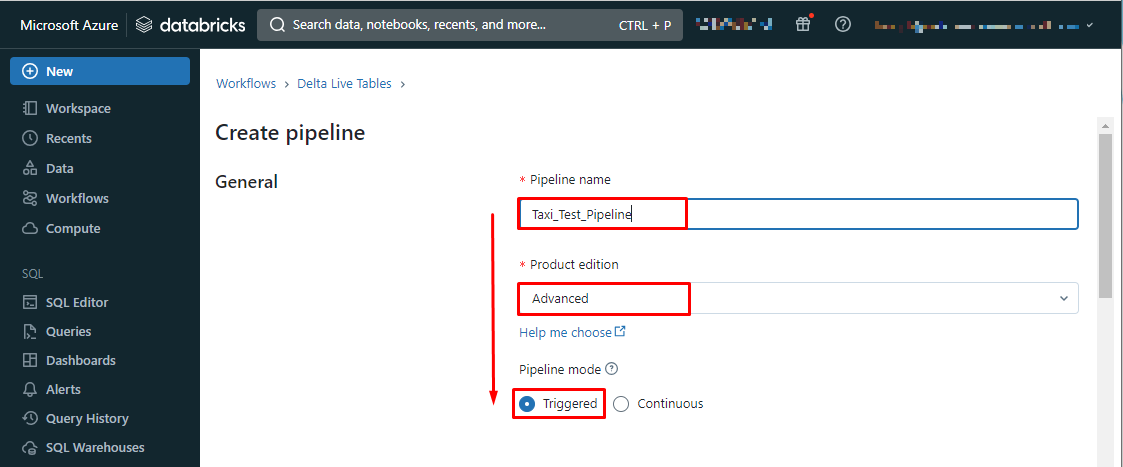
【Source code】
Notebook liblaries → ![]() をクリック > 指定するnotebookを選択しSelectをクリック
をクリック > 指定するnotebookを選択しSelectをクリック
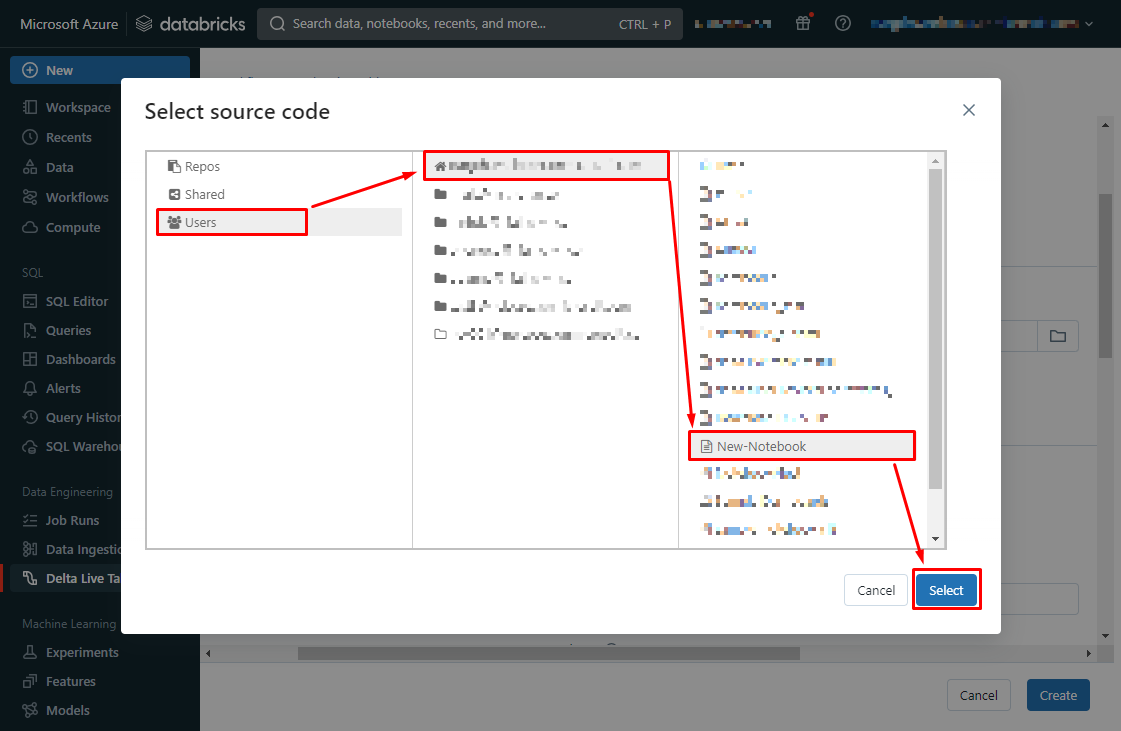
【Destination】
Storage options → Unity Catalog
Catalog →指定するcatalogを選択します。
Target schema →指定するschemaを選択します。
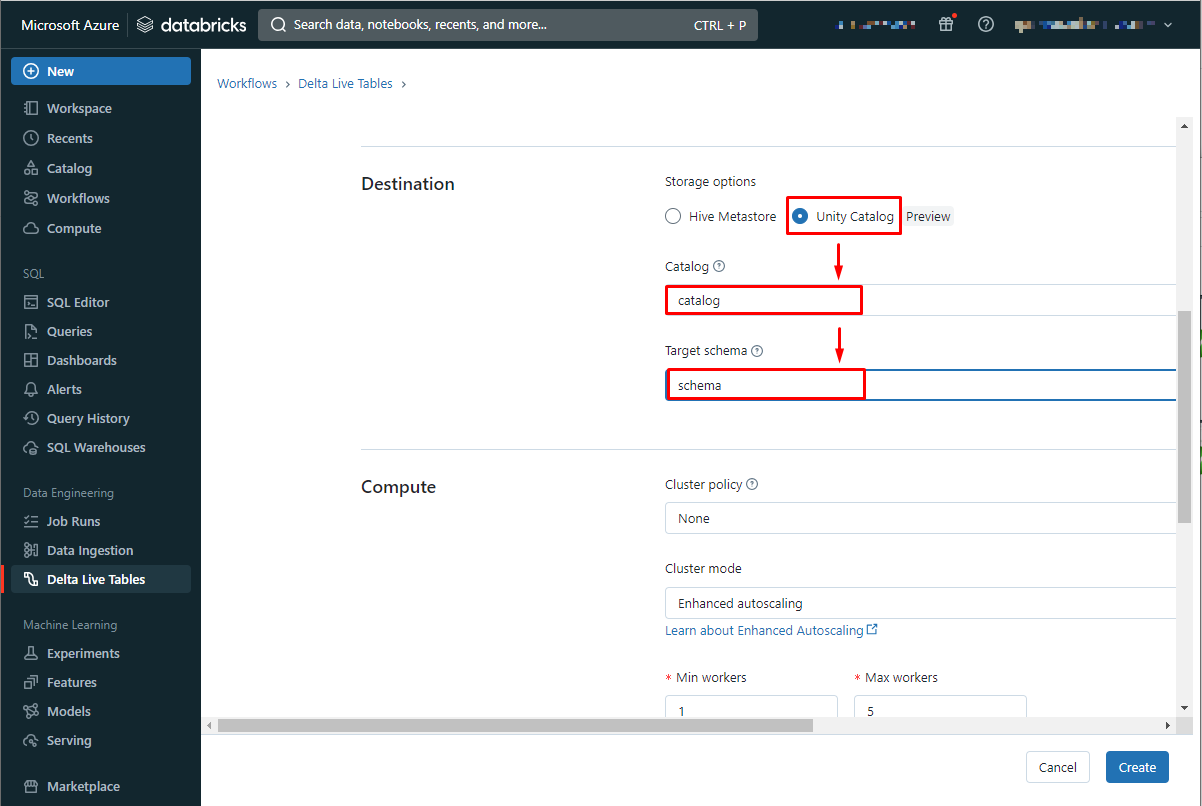
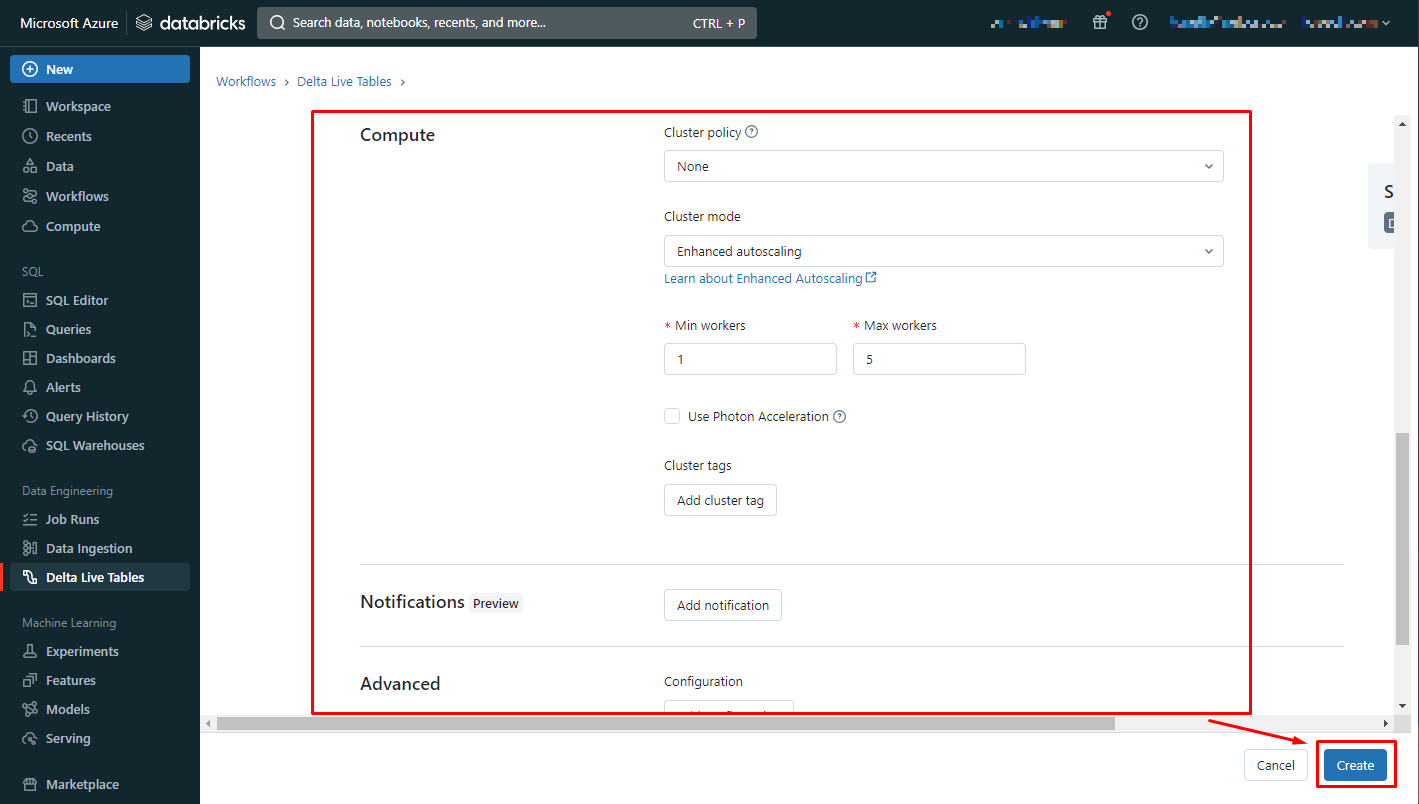
【Compute】【Notifications】【Advanced】
既定値のままCreateをクリックします。
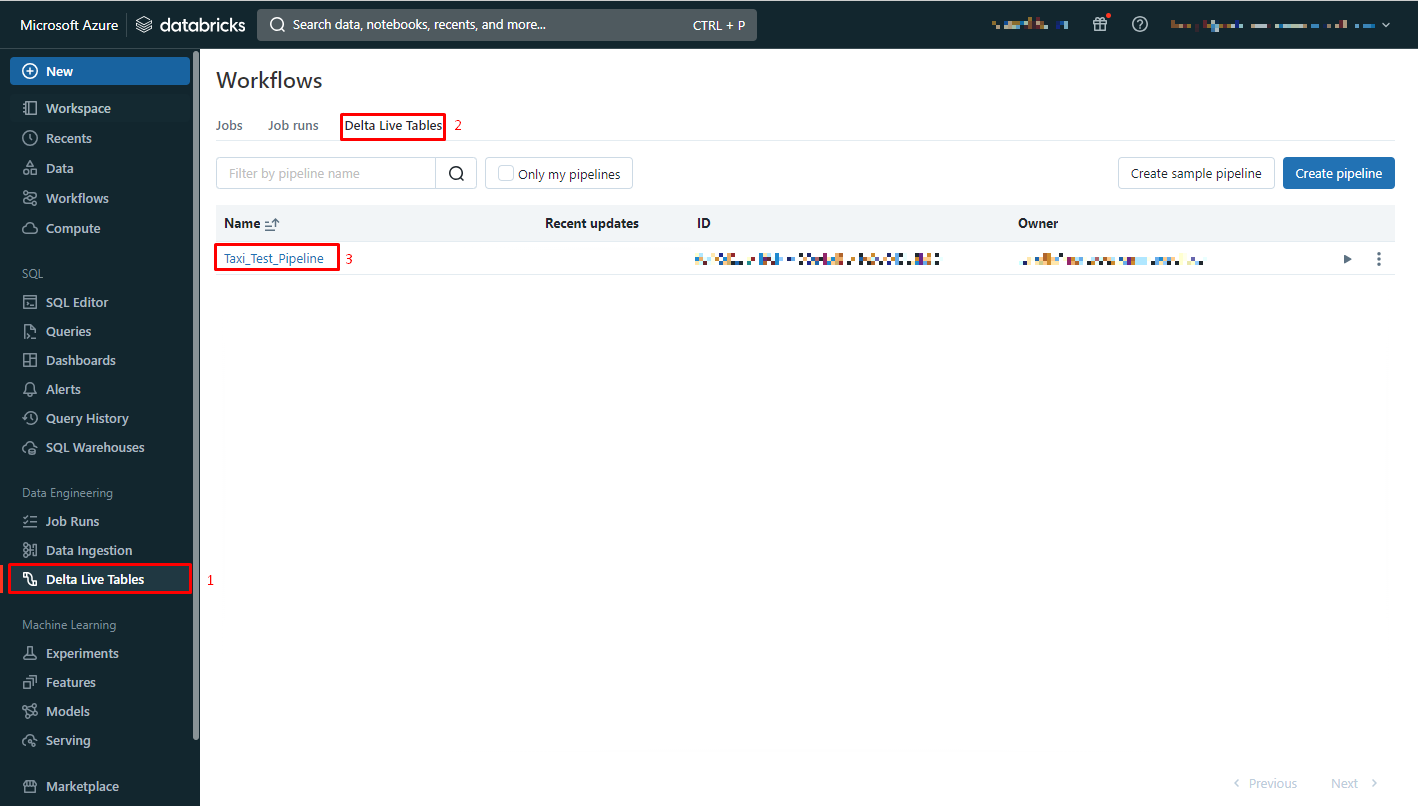
4.パイプラインを実行する
①Delta Live Tables > Delta Live Tables > 作成したパイプラインをクリックします。
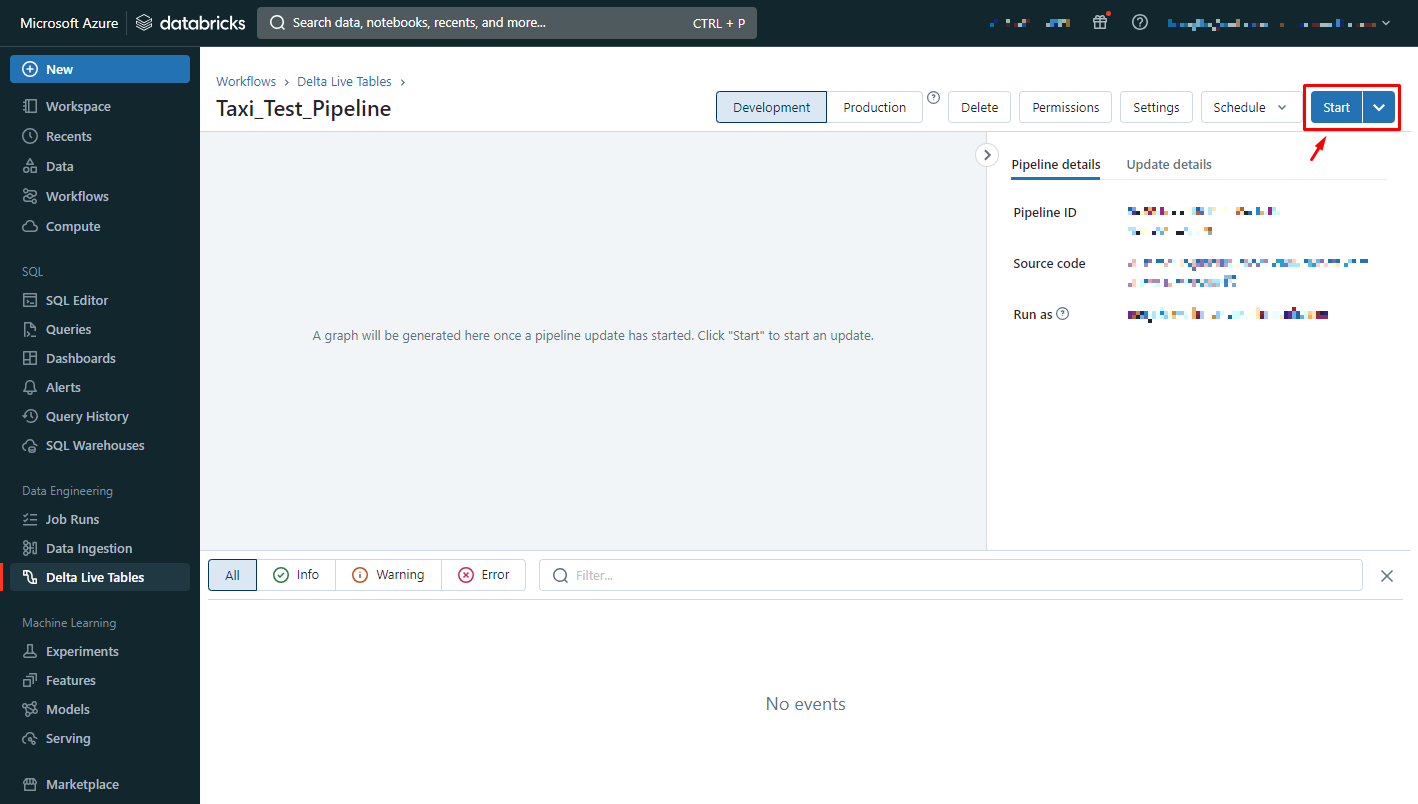
②Startをクリックするとパイプラインが開始されます。
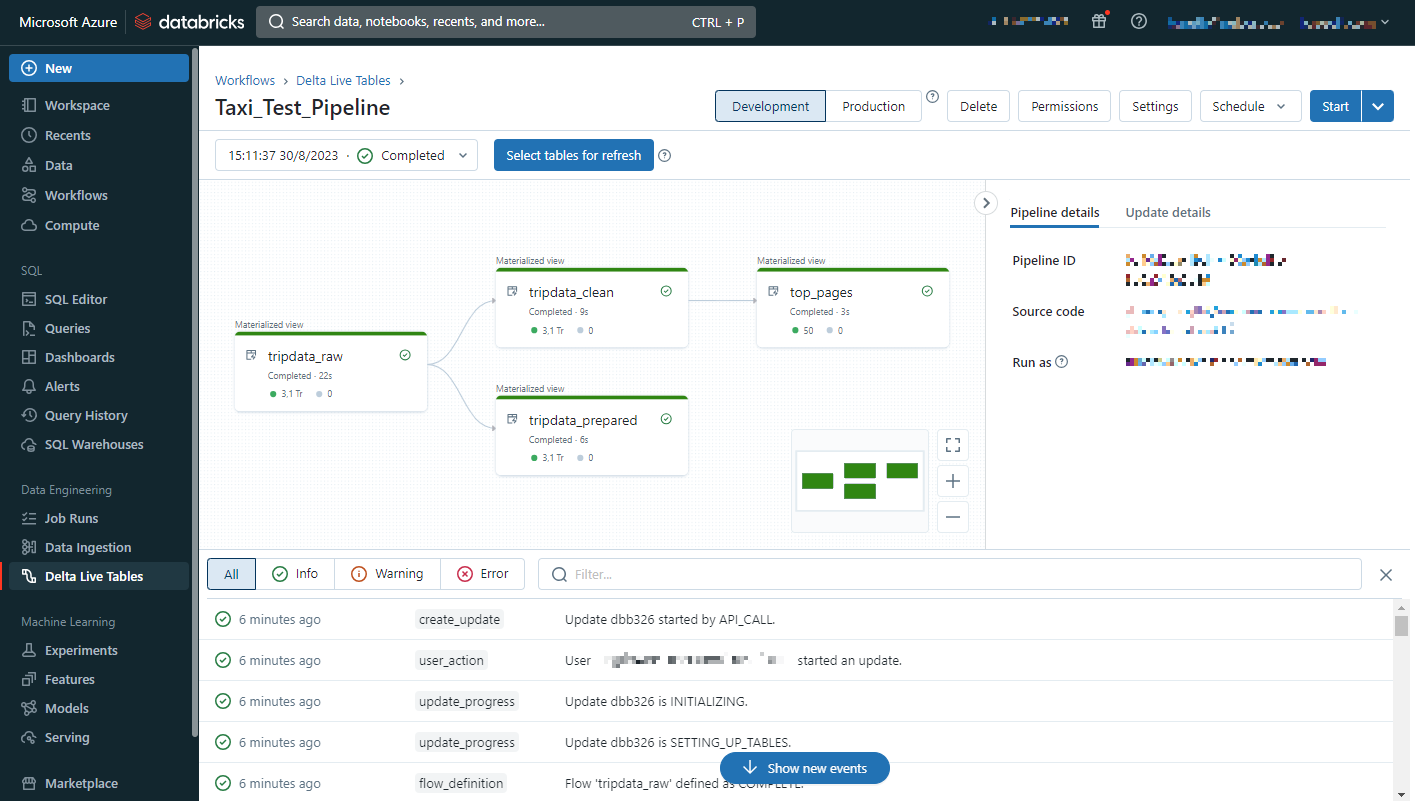
③実行結果が表示されます。
5. まとめ
本記事ではAzure DatabricksのDelta Live Tables パイプライン作成手順について説明しました。
この連載では、Azure DatabricksのDelta Live Tablesの基本から実行手順について説明しています。
是非合わせてご覧ください。
第1回:Delta Live Tablesの基本を知ろう
第2回:Delta Live Tablesのパイプラインを実装してみよう(今回)
第3回:Delta Live Tablesのデータの品質管理とは?
今回の記事が少しでも皆さんの新しい知識や業務のご参考になれば幸いです。
日商エレクトロニクスでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたら
是非お問い合わせください!
Azure Databricks連載記事のまとめはこちら