Data+AI Summit 2024 キーノート1

こんにちは。6月11日よりData + AI Summit2024が開催されていますね。
現地参加しているメンバーから、キーノートの速報をお届けします。
目次
Data + AI Summit2024とは
Data + AI Summit2024は年に1度実施されるDatabricksの年次カンファレンス。
サンフランシスコで開催され、全世界から1.6万人が現地で参加、6万人以上がオンラインで参加。
140か国から参加者が集まり、APACからは700名、日本からは250名が参加しているとのこと。
日本からの参加者は昨年から倍増しているそうで、Databricksの注目の高まりを感じます。

日本からの参加者に向けた特別セッションもあり、それも含めると次のような日程です。
赤字は日本・APACからの参加者向けのプログラム
- 6/11(月) 技術者向けハンズオンやハッカソン
- 6/12(火) ゼネラルセッション、Asia Pacific & Japan Welcome Reception、Data + AI Summit Japan Night
- 6/13(水) キーノート1とゼネラルセッション
- 6/14(木) キーノート2とゼネラルセッション、Japan Closing Session
キーノート速報
本日はData + AI Summitの主要なテーマや方向性が発表される13日のキーノートの内容を速報でお届けします。
Databricksのビジョン
Databricks CEO Ali Ghodsi氏の登場で幕を開けたキーノート。
多くの企業がデータ+AIの企業になりたい、競争力を高めるためにこの5年間データとAIが重要になると言っている。
そのためにはデータとAIの民主化が必要になる。
課題は「AIを本番業務で利用すること」「セキュリティ確保」「断片化するデータスタックの統合」。
インハウスで、フルスタックでData + AIを実行していかないといけない。
Databricksはこの課題にオープンで、包括的なプラットフォームを提供することで応える。

データのレイヤ:Delta Lake UniForm
先日買収をしたTabularのニュースを報告。
TabularはApahce Icebergを立ち上げたメンバーが創業した企業で、Icebergの開発に深く関わっている。
これまでDatabricksのレイクハウスはDelta Lakeの技術で実現してきていたが、Tabularの技術を活用しIcebergにも対応できるようになる。Delta Lake UniFormとして、異なるデータ形式でも参照し両者を相互運用することで、Single Source of Truthの実現に近づけることができる。

ガバナンスのレイヤ:Unity CatalogのOSS化
Unity CatalogのOSS化を発表。もっとも歓声があがっていた。
Unity Catalogではテーブル、ファイルだけではなく、データモデルやダッシュボードなど、あらゆるアセットを統合して管理することが可能。
これまではDatabricks上で利用するものでしたが、今後は他からUnity Catalogを呼び出して使えるようになる。
今後OSSのコミュニティ、ユーザーの支援を受けながら大きく成長していくことが期待される。

データ活用のレイヤ:100% Serverless
レイクハウス上でデータ活用をするレイヤすべてのサーバレス化を発表。AIもDWHもStream処理もETLもあらゆるコンピューティング機能を実際に使った分だけの支払いで利用することが可能。
サーバレス化は7月1日より順次行われるとのこと。日本リージョンでリリースが待ち遠しいですね、

主要アップデート
Ali Ghodsi氏のあとは主要な製品カテゴリのアップデイトの共有がありました。中心的な発表を記載します。
Genarative AI
一般的なAIはインターネットのデータを使ってトレーニングしている。
一方Databricksで作れるのは汎用モデルではなく、自社データをもとにした専用のモデル。
データ自体の理解はもちろん、販売する製品や自社特有のメタデータなども考慮しないと有効なデータ活用にはつながらない。
さらにGen AIを活用は、特定の(モノリシックな)モデルの活用で完結するほど単純ではなく、複数のモデルやコンポーネントを組み合わせた、自社独自のモデルを作っていく必要がある。
その点でDatabricksは自社専用のモデルを包括的に支援するアップデートを追加している。
モデル作成の機能のアップデイト
- Mosaic AI Model Training Fine-tuning (発表)
OSSのモデルのノーコードのファインチューニング機能、ワンクリックで利用可能 - Mosaic AI Model Training
自社データを使ったカスタムLMMをこれまでの10分の1のコストで構築 - Shutterstock ImageAI powerd by Databricks(発表)
Shutterstockが保有する著作権違反などがない画像データをもとにした画像生成モデルを利用可能に(AdobeのFireflyに近いイメージでしょうか)
本番展開の機能のアップデイト
- RAG with Mosic AI Vector Search(GA):自社データの検索性能をあげる機能がGAに
- Mosic AI Tool Catalo(発表)
社内・社外で利用できる社内または社外の共通関数をToolとして作成・共有が可能に
評価機能のアップデイト
- Mosic AI Agent Framework(発表)
Unity Catalogで管理する自社データをもとにAIシステムを構築することが要になる - Mosaic AI Agent Evarluation(発表)
モデルの精度向上のため、アウトプットを評価できる機能 - MLflow 2.14(発表)
モデルのパラメータを追跡する機能を実装
ガバナンスの機能のアップデイト
- Mosaic AI Gateway(発表)
展開したAIサービスを管理する統合AIゲートウェイ
データウェアハウス(DWH)
DatabricksがDWH製品のDatabricks SQLを発表したのは2021年。
該当製品は最も成長がはやく、当時372秒かかっていた処理が2024年には5秒に短縮している。
顧客は何もせずにこれだけの性能改善を得られている。
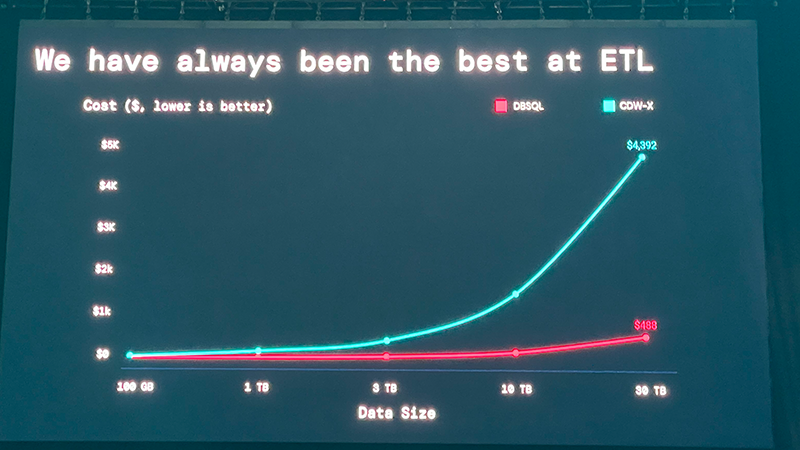
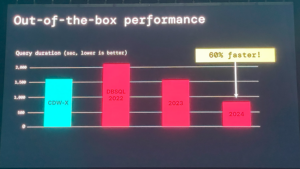
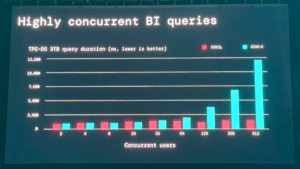
某雪印のCDWHとTPC-DSのベンチマークで比較すると性能差は顕著で30TBのETL処理ならコストは10倍、1TBでも2倍レベルの差がある、何もチューニング市内巣の状態で計算処理は60%高速、BIのユースケースでたとえば512人が同時接続すると10倍の費用差が出てくると発表している。(なかなか露骨で強いライバル心を感じます)
機能アップデイト
- Automatic liquid clustering key selection
自動的にパーティションをチューニングしレイアウトを変更 - Auto Stastics
デルタのカラムの分析を自動化 - Predictive I/O 2.0
データ操作のパフォーマンスを向上させる最適化機能がより高度化/li> - AI Functions
Databricks SQLから直接AIを実行可能に。たとえば顧客からの問い合わせ情報に感情の情報を付与するなどが可能
Databricks AI/BI
これまでのLake ViewがDatabricks AI/BIに名称変更。
これまで以上に、容易にグラフィカルにダッシュボードを作成することが可能。共有や閲覧制限の管理も実施できる。
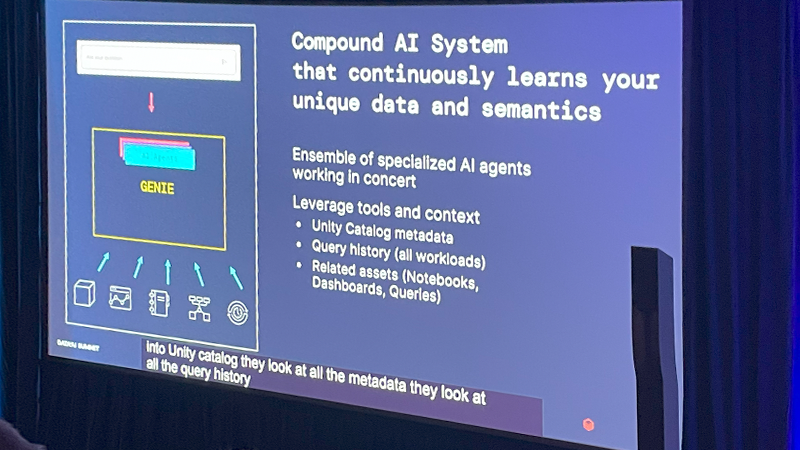
それに加え自然言語で自社データの内容に問い合わせができるGINIEを新たに発表。Unity Catalogと連動しお客様のデータの内容やメタデータを理解したうえで、自然言語の問い合わせに回答をしてくれます。
ダッシュボードでKPIだけでみたあと、その深堀りの分析や別の角度での分析を自然言語で実現するというような使い方が可能になります。(ただし現時点ではDatabricksにログインしないと該当機能は使えない、実際にはもっとも恩恵を受けるのは、Databricksユーザーでない社内の一般ユーザーが共有されたBIをみて~がいうシナリオと考えられるため、もう一段機能改善が期待される)
キーノート速報2に続く
初日のキーノートで発表された内容はここまで。
注目のUnity Catalogや、噂されているデータ取り込みの新規機能の話はまだ出ていません。
明日のキーノート2で発表されるでしょうか。
明発表があれば、次のブログ記事アップデイトを報告します!!
記事を更新しました。こちらをご覧ください!!
※本記事内で利用している画像は一部別セッションのものが含まれます
この記事を書いた人

- 双日テックイノベーション(旧:日商エレクトロニクス)特設サイト「Azure導入支援デスク」サイトマスターです。