Data+AI Summit 2024 Day1 (6/11)
powered by 日商エレクトロニクス

こんにちは、日商エレクトロニクスのデータサイエンティスト、トゥアンです。
本記事では、6月11日に開催されたData + AI Summit Day1の各セッションの前半部分を随時更新しながらまとめていきます
Data+AI Summit 2024の公式サイトはコチラ >
Data+AI Summit 2024のDay2のまとめはコチラ >
Data+AI Summit 2024 キーノート1のまとめはコチラ >
●こんな方におススメ
- Data + AI SUMMIT 2024 基調講演の内容を日本語でサクッと把握したい方
- GenAIやLLMの最新技術をキャッチアップしたい方
1. DBRXの紹介
DBRXは、DatabricksのMosaic研究チームによって作成されたオープンな汎用LLMです。DBRXは、さまざまな標準ベンチマークにおいて、新たなLLMの最先端を打ち立てました。GPT-3.5を凌駕し、Gemini 1.0 Proとも競合する性能を持っています。
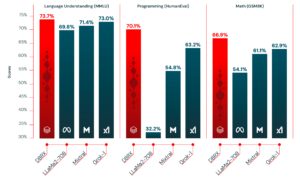
この新たな最先端のパフォーマンスを実現するために、Mosaic チームはLLMのトレーニング方法を共有しました。以下に詳細を示します。¹
- DBRXはMixture of Experts (MoE) アーキテクチャを採用しており、同じ計算量でより高い品質を実現しています。
- DBRXはContinued Trainingと呼ばれる手法を使用しています。この手法は、GPT-4のPretrainに基づき、サイズ、データ、およびデータドメインをスケールアップしてモデルが継続的に学習し続けるようにするものです。
- DBXRは、より広範なドメインを持ち、高品質のデータセットでトレーニングされました。
その手法を実現するために、Mosaicチームは以下のようなリソースを活用しました。
- LiLacAI によるデータ探索・キュレーション。
- Notebook と Apache Spark によるデータクリーニング・前処理。
- Unity Catalog によるデータ保存とガバナンス。
- Mosaic Multi-Cloud Training (MCT) によるモデル学習。
- MLflow と Lakeview によるトラッキング。
- モデル API と AI Playground による推論と評価。
2. RAGの使用における課題
しかし、RAGの手法にはまだ解決すべき課題が残っています。
- 正確さを測定し評価することが難しい。
- 十分なフィードバックを収集することが難しい。
- 正確さを改善し、幻覚を減らすことが難しい。
RAGの 正確さを向上させるために:
- 高品質なメトリクスを定義する。
- 評価指標を客観的に測定する(人間のフィードバックなど)。
3.LlamaParseの紹介
LLMモデルを用いたRAGアプリケーションを構築する際、多様なデータ形式を効果的に解析することが重要です。ドキュメントには、表、グラフ、画像などの複雑な要素が含まれることが多く、確実な抽出方法が必要です。LlamaParseは、このプロセスを効率化するオープンソースツールであり、LLMプロンプトを強化するための情報の効率的な活用を可能にします。
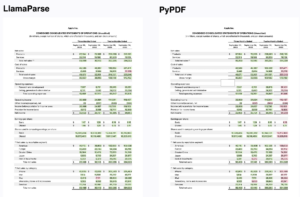
LlamaParseが提供するもの:
- 複数のベクターでのインデックス化
- チャンクにメタデータを追加。
- 同じテキストに複数のベクターを持つ。
- Docstoreの提供
- ソースドキュメントを保存。
- キャッシュ/インクリメンタル同期。
- Chatstoreの提供:
- ユーザーごとの会話履歴を保存。
- ナレッジグラフの提供:
- 取得を改善するためのナレッジグラフ。
4. Databricks Asset Bundlesの紹介
Databricks Asset Bundlesは、データおよびAIプロジェクトにおいて、ソース管理、コードレビュー、テスト、CI/CDなどのソフトウェアエンジニアリングのベストプラクティスを採用を促進するためのツールです。
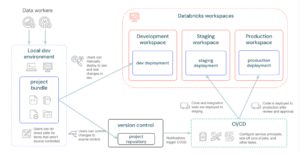
YAMLファイルで定義されたバンドルは、ジョブ、パイプライン、ノートブックなどのDatabricksリソースを一元管理し、プロジェクトの構造、テスト、デプロイ方法を定義します。
バンドルは、必要なクラウドインフラ、ソースコード、Databricksリソース設定、テスト、メタデータなどを含み、単一のユニットとしてデプロイされます。 チーム開発、MLパイプライン管理、組織標準設定、コンプライアンス遵守などに最適なソリューションです。 Databricks CLIを使用して、YAMLファイルで定義されたバンドルを検証、デプロイ、実行できます。
この記事を書いた人
この投稿者の最新の記事
- 2025年6月13日ブログ【Azure Databricks】Databricks Data + AI Summit Day 3:基調講演ハイライトまとめ
- 2025年6月12日ブログ【Azure Databricks】Databricks Data + AI Summit Day 2:基調講演ハイライトまとめ
- 2025年6月11日ブログ【Azure Databricks】Databricks Data + AI Summit Day 1:Databricksとパートナー企業からの最新アップデート
- 2025年3月7日ブログ【Azure Databricks】LLMとDatabricksで企業のデータ活用を加速する方法