目次
1. はじめに
今回は、Auto Loader の スキーマ推論と進化の機能について説明します。
第1回: Auto Loader の概要、Quick Start 方法をしてみる
第2回:【Azure Databricks】Auto Loader と Lakeflow 宣言パイプラインを組み合わせて使用してみる
第3回: Auto Loader の スキーマ推論と進化の機能について説明する(今回)
スキーマ推論と進化の機能がどのように設定され、動作するかを説明いたします。
背景:
前のシリーズで紹介されたように、Auto Loader は入力データに新しいファイルがあると自動的に検出して処理します。スキーマが変更された場合やスキーマ情報を定義せずにテーブルを作成した場合の動作について説明していませんでした。
目的:
Auto Loader のスキーマ推論と進化を使用して、スキーマの変更を自動的に処理できます。これにより、さまざまな形式のデータ変更に柔軟かつ効率的に対応できるようになります。
2. Auto Loader のスキーマ推論と進化とは
Auto Loader のスキーマ推論は、クラウドストレージに追加された新しいファイルを自動的に検出し、 データスキーマを明示的に宣言せずにテーブルを初期化する機能です。スキーマ推論により、データスキーマの宣言を自動化することができます。
Auto Loader のスキーマ進化は、新しい列が導入された場合にテーブルのスキーマを進化させる機能です。 データのスキーマが変更されると、スキーマの進化は既存のテーブルを自動的に検出し、データの損失なしに進化させます。
スキーマ推論と展開に対しては、以下の形式がサポートされています。
| ファイル形式 | サポートされているバージョン |
| JSON | すべてのバージョン |
| CSV | すべてのバージョン |
| XML | Databricks Runtime 14.3 以降 |
| Avro | Databricks Runtime 10.4 以降 |
| Parquet | Databricks Runtime 11.3 以降 |
| ORC | サポートされていません |
| Text | 該当なし (固定スキーマ) |
| Binaryfile | 該当なし (固定スキーマ) |
3. スキーマ推論と進化の設定
前回のブログでは、Auto Loader を使用して [2020_Yellow_Taxi_Trip_Data] データセットをストレージアカウントからロードしました。今回は、そのデータデットを再利用してスキーマ推論と進化の機能を説明します。
① 最初、Databricks ワークスペースでノートブックを作成します。
ワークスペースの画面で、「新規」を選択して、「ノートブック」をクリックします。
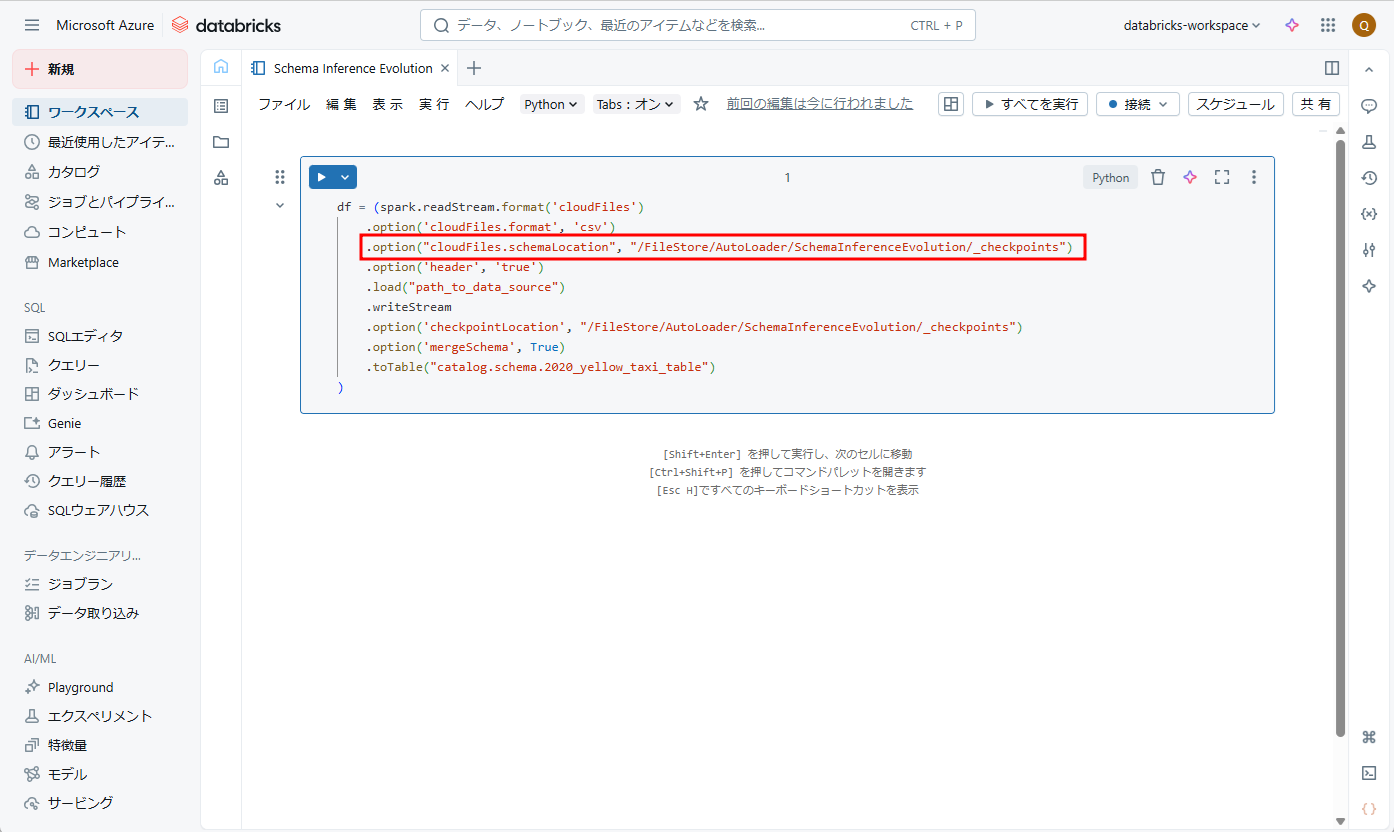
 ② オプション [cloudFiles.schemaLocation] にターゲット ディレクトリを指定すると、スキーマの推論と進化が可能になります。
② オプション [cloudFiles.schemaLocation] にターゲット ディレクトリを指定すると、スキーマの推論と進化が可能になります。
この例では、ターゲットディレクトリは [/FileStore/AutoLoader/SchemaInfrenceEvolution/_checkpoints] です。
[path_to_data_source] の値をデータソースのURLに変更します。
|
1 2 3 4 5 6 7 8 9 10 |
df = (spark.readStream.format('cloudFiles') .option('cloudFiles.format', 'csv') .option("cloudFiles.schemaLocation", "/FileStore/AutoLoader/SchemaInferenceEvolution/_checkpoints") .option('header', 'true') .load("path_to_data_source") .writeStream .option('checkpointLocation', "/FileStore/AutoLoader/SchemaInferenceEvolution/_checkpoints") .option('mergeSchema', True) .toTable("catalog.schema.2020_yellow_taxi_table") ) |
 注意:
注意:
- [checkpointLocation] に指定したのと同じディレクトリを使用することを選択できます。
- Lakeflow 宣言パイプラインを使用する場合、Azure Databricks はスキーマの場所とその他のチェックポイント情報を自動的に管理します。
- ターゲット テーブルに複数のソースデータの場所が読み込まれている場合、各自動ローダー ンジェストワークロードには個別のストリーミングチェックポイントが必要です。
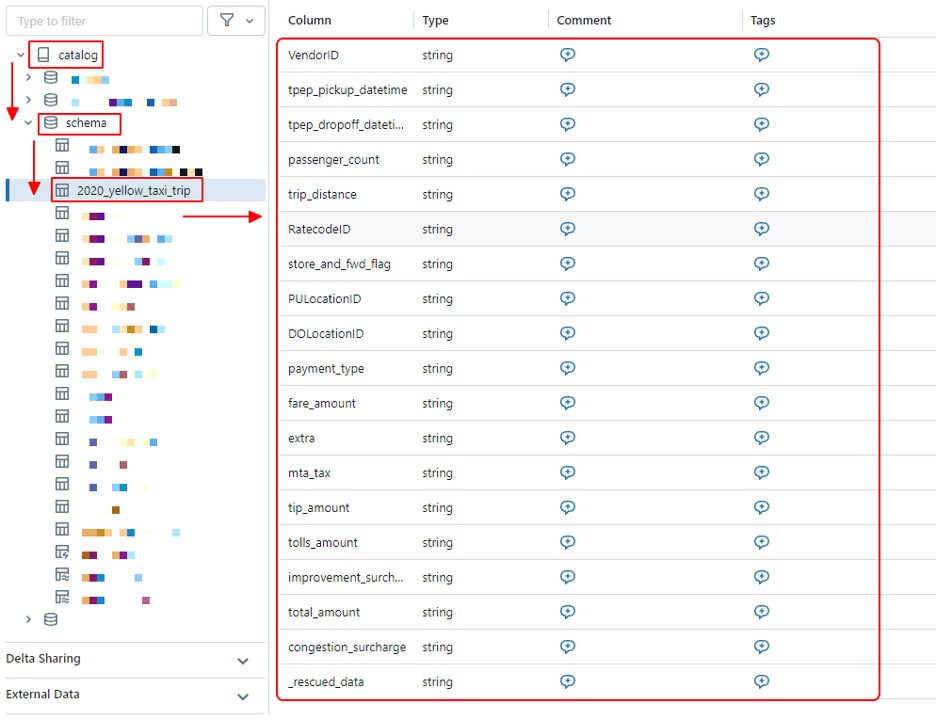
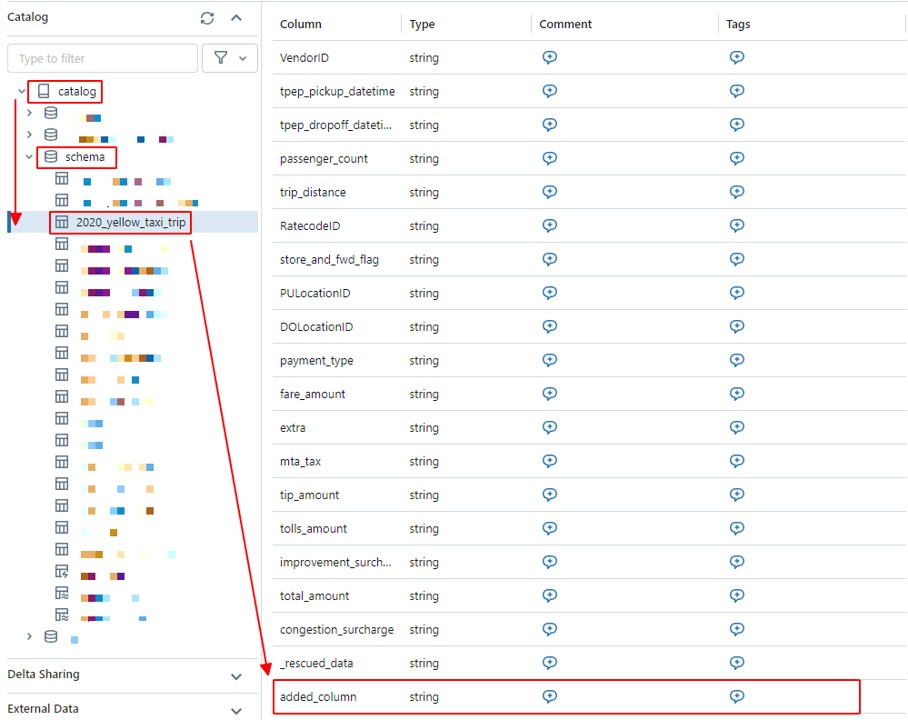
スキーマ推論と進化が有効になると、「catalog.schema.dev_schema_table」テーブルのスキーマは、19列を含む推論されたスキーマになります。そのうち、最初の18列はCSVデータから読み込まれたスキーマであり、1列「rescued_data」は Auto Loader によって自動的に作成されます。
③ 次に、ストレージアカウント内の元のファイルと同じディレクトリにCSVファイルを追加してみましょう。
ファイル [2020_Yellow_Taxi_Trip_Data_Add_Column] には、元のファイルにはない「added_column」という列が追加されています。
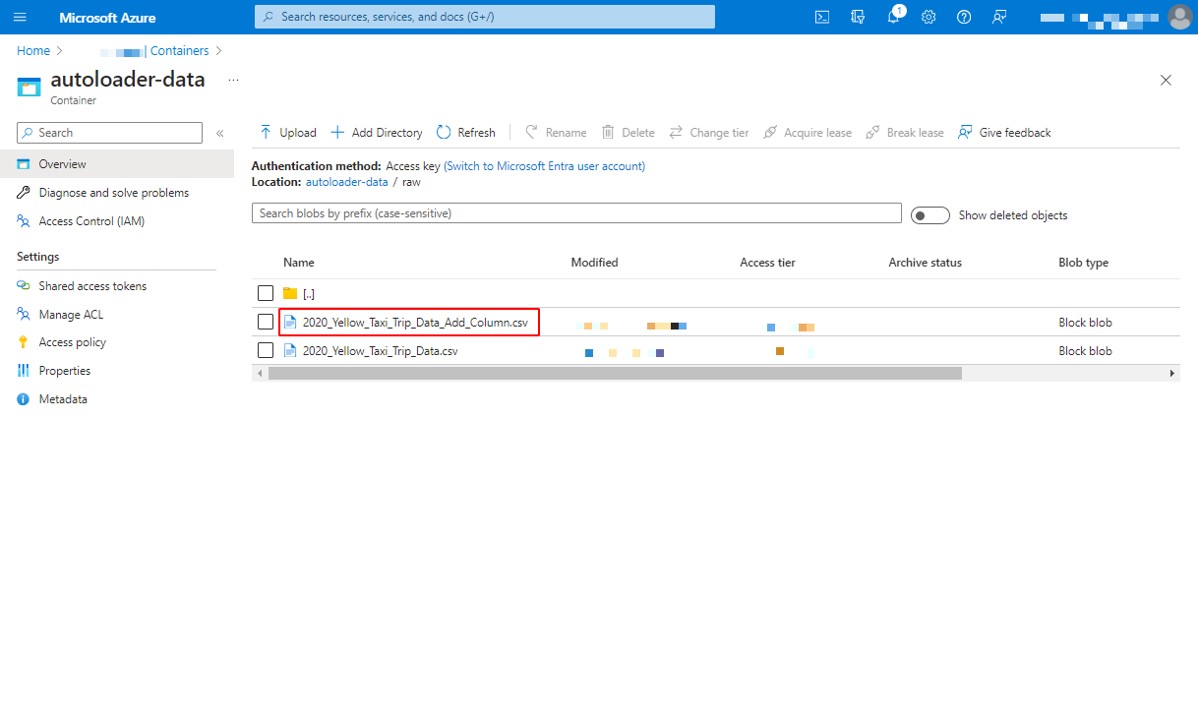
新しいファイルが追加されると、Auto Loader が検出し、スキーマ進化が「added_column」という新しい列を検知しました。その後、ストリームは UnknownFieldException で停止します。
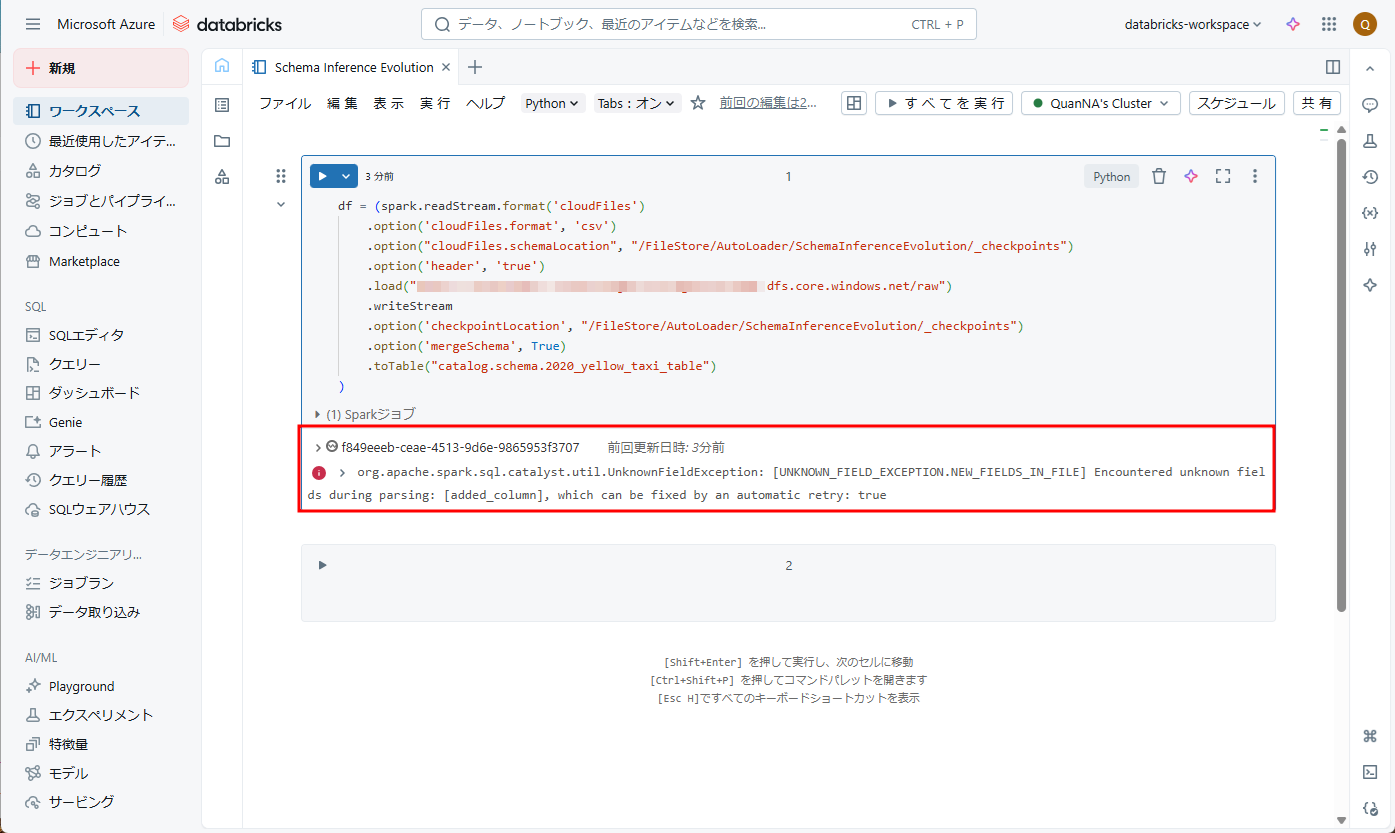 ストリームの処理が停止する前に、Auto Loader は最新データに対してスキーマ推論を実行し、指定されたオプション [schemaLocation] にスキーマを更新します。そして、「added_column」という列がスキーマの最後に追加されます。
ストリームの処理が停止する前に、Auto Loader は最新データに対してスキーマ推論を実行し、指定されたオプション [schemaLocation] にスキーマを更新します。そして、「added_column」という列がスキーマの最後に追加されます。
4つのモードを使用してスキーマ推論の処理フローを制御できます。その詳細については、スキーマの進化のしくみのセッションで具体的に説明します。
④ 次に、Auto Loader が [schemaLocation] で新しいスキーマを読み込み、現在のスキーマに新しいスキーマをマージするために、ストリームを再起動する必要があります。
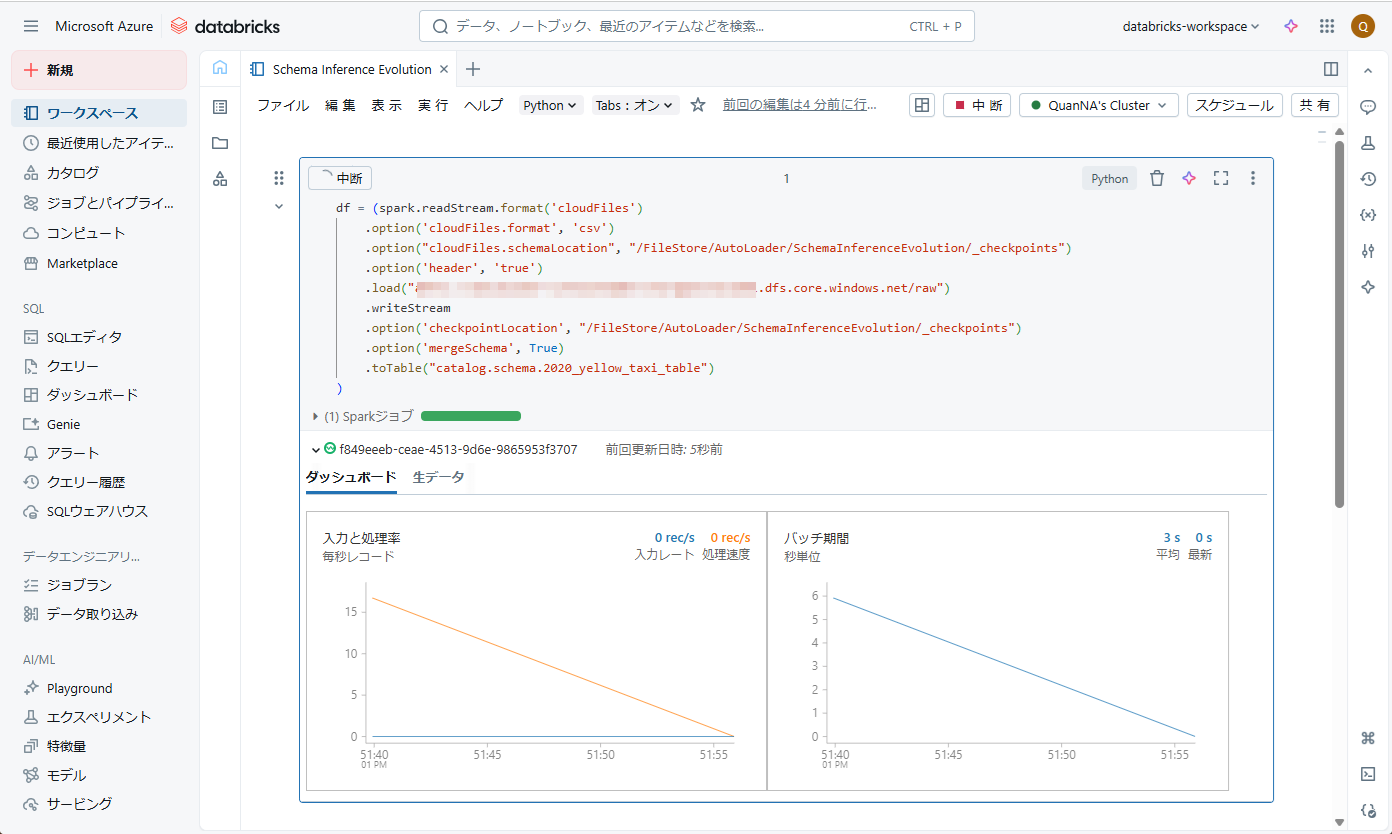 ストリームを再起動した後で、「added_column」という列がスキーマの最後に追加されます。
ストリームを再起動した後で、「added_column」という列がスキーマの最後に追加されます。
4. スキーマ推論のしくみ
Auto Loader では、初めてデータを読み込んだときにスキーマを推論するために、検出された最初の 50GB と 1000ファイルのうち、先に上限を超えた方をサンプリングします。Auto Loader は、入力データに対するスキーマの変更を時間の経過に合わせて追跡するために、構成済みの [cloudFiles.schemaLocation] にある 「_schemas」という ディレクトリにスキーマ情報を格納します。
使用するサンプルのサイズを変更するには、次の SQL 構成を設定します。
- サイズの変更
|
1 |
spark.databricks.cloudFiles.schemaInference.sampleSize.numBytes |
- ファイルの数の変更
|
1 |
spark.databricks.cloudFiles.schemaInference.sampleSize.numFiles |
既定では、スキーマ推論では、型の不一致によるスキーマの進化の問題を回避します。 データ型 (JSON および CSV) をエンコードしない形式の場合、自動ローダーはすべての列 (JSON ファイル内の入れ子になったフィールドを含む) を文字列として推論します。型指定されたスキーマ (Parquet および Avro) を含む形式の場合、Auto Loader はファイルのサブセットをサンプリングし、個々のファイルのスキーマをマージします。
この動作の概要を次の表に示します。
| ファイル形式 | 既定の推論されたデータ型 |
| JSON | String |
| CSV | String |
| XML | String |
| Avro | Avro スキーマでエンコードされた型 |
| Parquet | Parquet スキーマでエンコードされた型 |
5. スキーマ進化のしくみ
Auto Loader では、データを処理する際に新しい列の追加を検出します。 Auto Loader で新しい列が検出されると、ストリームが UnknownFieldException で停止します。ストリームからこのエラーがスローされる前に、Auto Loader によって、データの最新のマイクロバッチに対してスキーマ推論が実行され、新しい列をスキーマの末尾にマージすることによって、スキーマの場所が最新のスキーマで更新されます。存の列のデータ型は変更されません。
Databricks では、このようなスキーマの変更後に自動的に再起動するように、ワークフローを使用して Auto Loader ストリームを構成することをお勧めします。
Auto Loader は、 [cloudFiles.schemaEvolutionMode] オプションの値を変更することによって、スキーマの進化をサポートする4つのモードを提供しています。
| モード | 新しい列を読み取るときの動作 |
| addNewColumns (既定値) | ストリームが失敗します。 新しい列がスキーマに追加されます。 既存の列ではデータ型は展開されません。 |
| rescue | スキーマは進化せず、スキーマの変更によりストリームが失敗することはありません。 すべての新しい列が、復旧されたデータ列に記録されます。 |
| failOnNewColumns | ストリームが失敗します。 提供されたスキーマが更新されるか、問題のあるデータ ファイルが削除されない限り、ストリームは再起動しません。 |
| none | スキーマは進化せず、新しい列は無視されます。また、[rescuedDataColumn] オプションが設定されない限り、データは復旧されません。 スキーマの変更によりストリームが失敗することはありません。 |
6. Auto Loader 使用時のパーティションの動作
データが Hive 形式のパーティション分割でレイアウトされている場合、Auto Loader はデータの基になるディレクトリ構造からパーティション列の推論を試みます。 基になるディレクトリ構造に競合する Hive パーティションが含まれている場合、または Hive 形式のパーティション分割が含まれていない場合、パーティション列は無視されます。
Hive パーティショニング形式のディレクトリ構造の例:
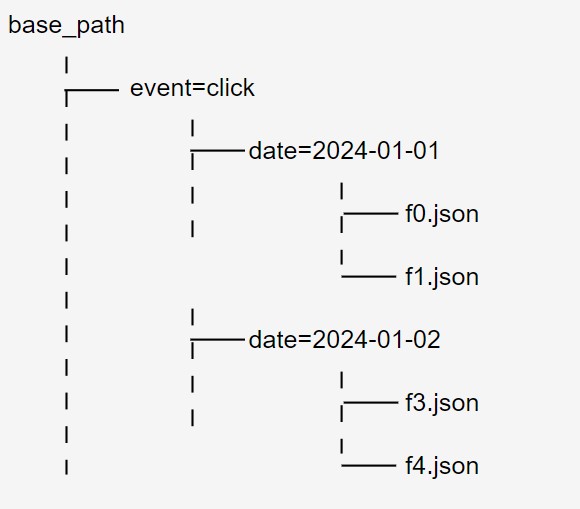
例えば、ファイルのパスが base_path/event=click/date=2024–01-01/f0.json である場合、date と event がパーティション列として推論されます。
バイナリ ファイル形式 (binaryFile) と text ファイル形式では、データ スキーマが固定されていますが、パーティション列の推論がサポートされています。 Databricks では、これらのファイル形式に対して [cloudFiles.schemaLocation] 設定をお勧めします。 これにより、潜在的なエラーや情報の損失が回避され、Auto Loader が開始されるたびにパーティション列が推論されるのを防ぐことができます。
スキーマの展開では、パーティション列は考慮されません。
base_path/event=click/date=2021-04-01/f0.json のような初期ディレクトリ構造があり、base_path/event=click/date=2021-04-01/hour=01/f1.json として新しいファイルの受信を開始した場合、Auto Loader は hour 列を無視します。 新しいパーティション列の情報を取得するには、[cloudFiles.partitionColumns] オプション を event,date,hour に設定します。
注意: [cloudFiles.partitionColumns] オプションは、列名のコンマ区切り一覧を取得します。 ディレクトリ構造に key=value ペアとして存在する列のみが解析されます。
7. 復旧されたデータ列とは
Auto Loader によってスキーマが推論されると、復旧されたデータ列が _rescued_data としてスキーマに自動的に追加されます。[rescuedDataColumn] オプション を設定することにより、列の名前を変更することも、スキーマを提供する場合に列を含めることができます。
復旧されたデータ列を使用すると、スキーマと一致しない列が削除される変わりに、復旧されます。 復旧されたデータ列には、次の理由で解析されないデータが含まれています。
- スキーマに列がない
- 型が一致しない
- 大文字と小文字が一致しない
8. スキーマヒントを使用してスキーマ推論をオーバーライドする
特定のデータ型に列を定義したり、より一般的なデータ型を選択したい場合、スキーマヒントを使用してオーバーライドすることができます。データセット [2020_Yellow_Taxi_Trip_Data] の例に戻りましょう。
スキーマの情報を表示するため、以下の SQL コマンドを使用します。
|
1 |
DESCRIBE TABLE catalog.schema.2020_yellow_taxi_table |
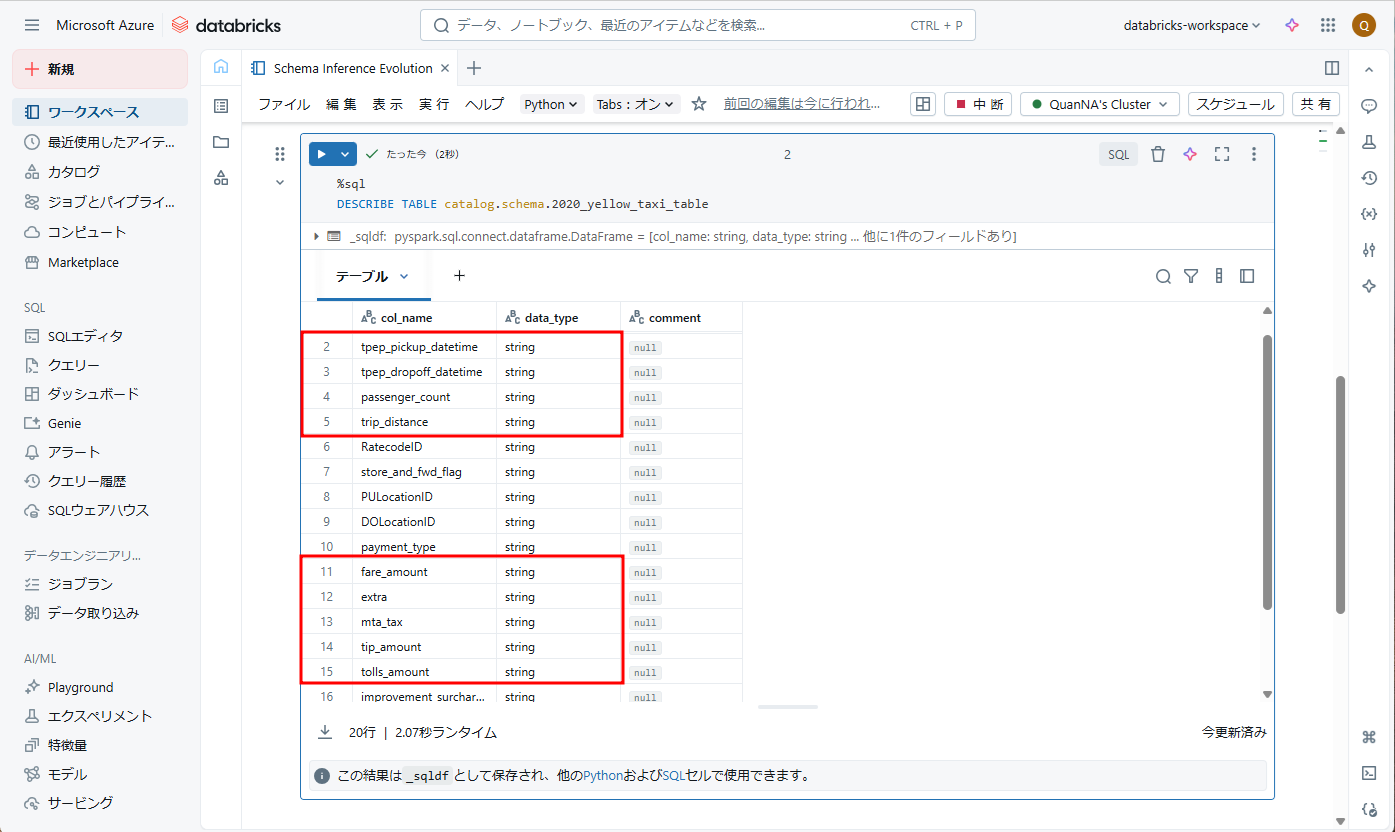 例えば、「tpep_pickup_datetime」、「tpep_dropoff_datetime」の2つの列は DATE 型であり、「passenger_count」の列のデータ型は INT であり、その他の列のデータ型(「trip_distance」、「fare_amount」、「extra」、「mta_tax」、「tip_amount」、「tolls_amount」、「total_amount]」など)は、スキーマの推論時には STRING ではなく FLOATであるとします。スキーマヒントを使用して、列のデータ型をオーバーライドできます。
例えば、「tpep_pickup_datetime」、「tpep_dropoff_datetime」の2つの列は DATE 型であり、「passenger_count」の列のデータ型は INT であり、その他の列のデータ型(「trip_distance」、「fare_amount」、「extra」、「mta_tax」、「tip_amount」、「tolls_amount」、「total_amount]」など)は、スキーマの推論時には STRING ではなく FLOATであるとします。スキーマヒントを使用して、列のデータ型をオーバーライドできます。
スキーマヒントは、Auto Loader にスキーマが提供されない場合のみに、使用できます。
[cloudFiles.inferColumnTypes] オプションがオン又はオフであっても、スキーマヒントを使用できます。
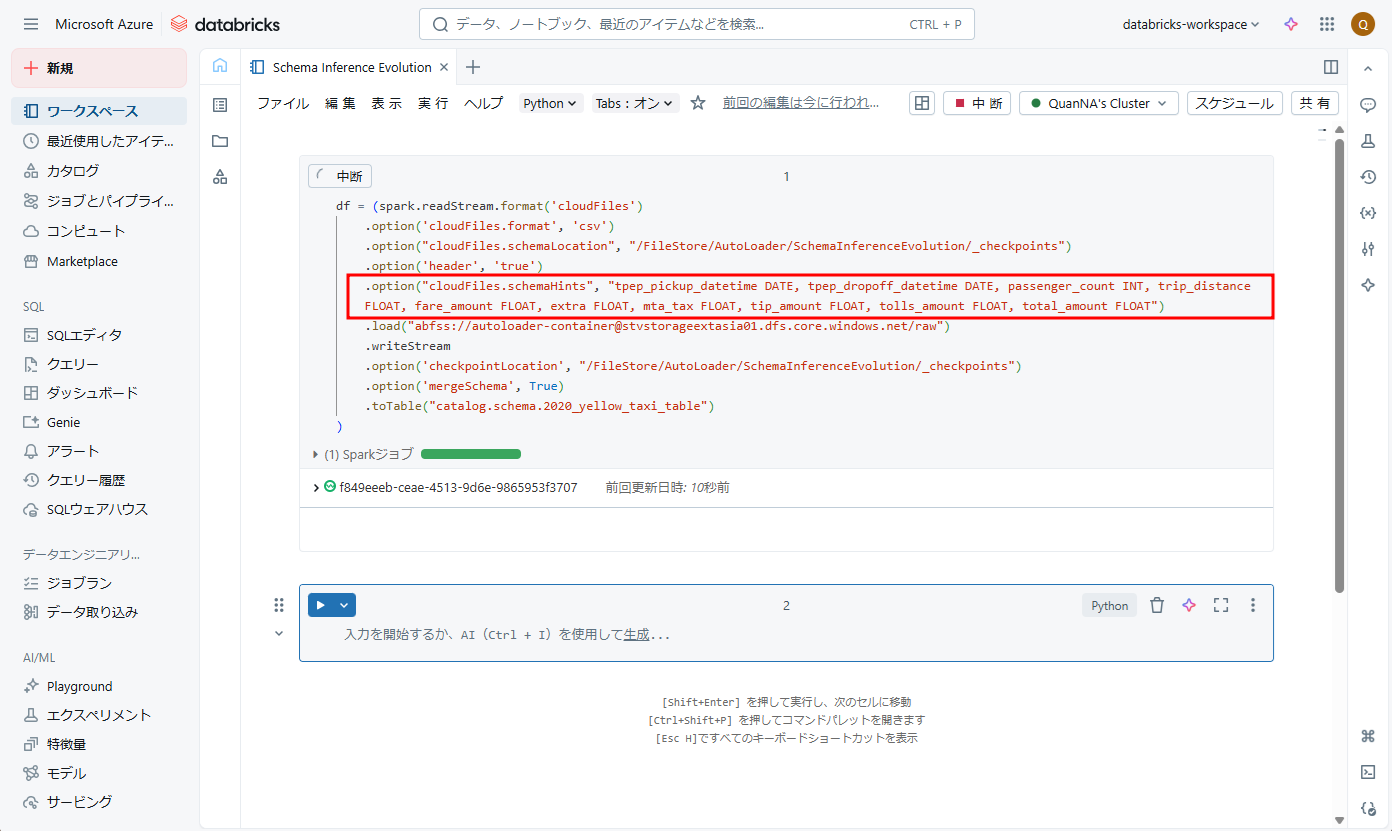
|
1 2 |
.option("cloudFiles.schemaHints", "tpep_pickup_datetime DATE, tpep_dropoff_datetime DATE, passenger_count INT, trip_distance FLOAT, fare_amount FLOAT, extra FLOAT, mta_tax FLOAT, tip_amount FLOAT, tolls_amount FLOAT, total_amount FLOAT") |
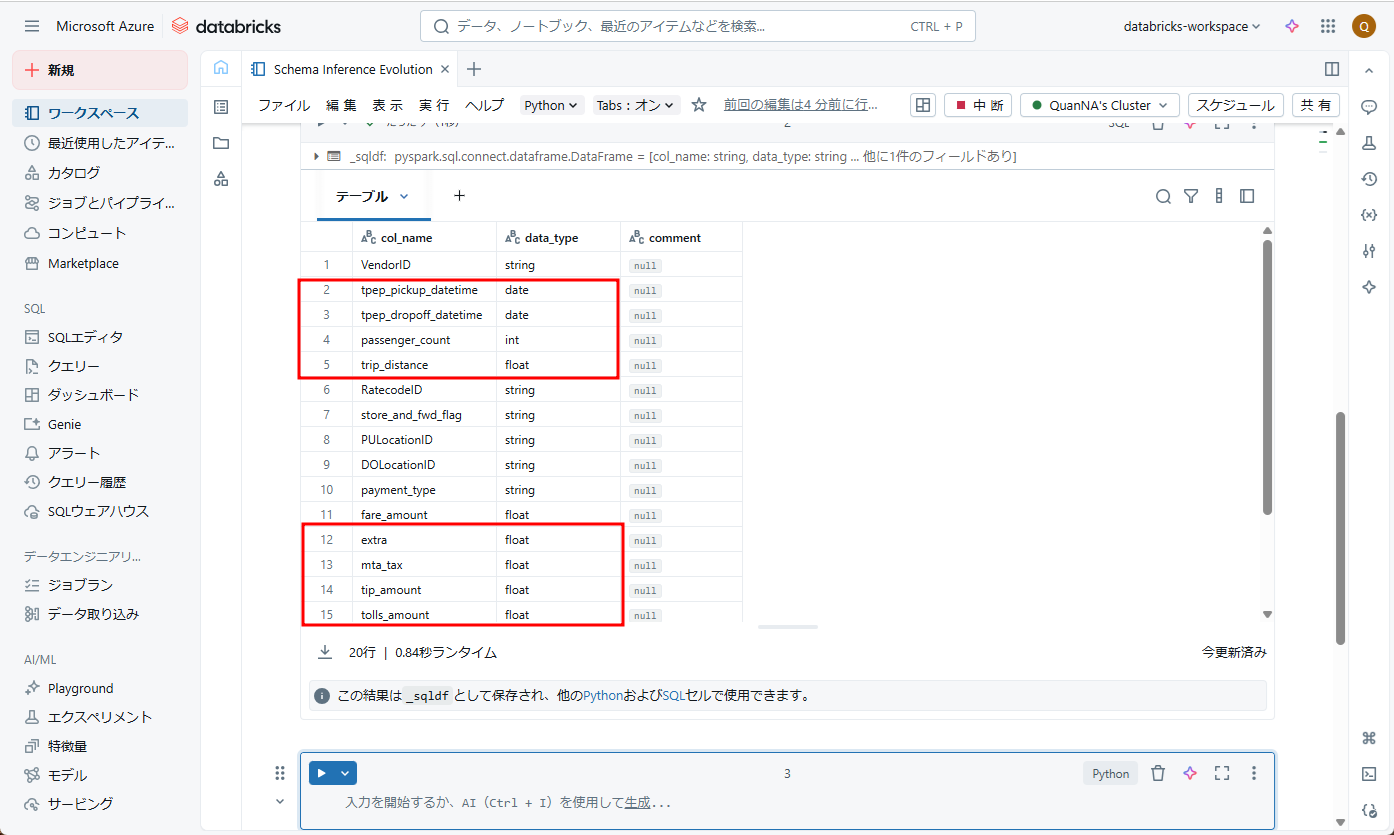
 スキーマヒントを使用してオーバーライドするスキーマ
スキーマヒントを使用してオーバーライドするスキーマ
9. 大文字と小文字が区別される動作を変更する
大文字小文字の区別を有効にしない限り、abc、Abc、ABC の各列は、スキーマ推論の目的で、同じ列と見なされます。大文字または小文字の選択は任意であり、サンプリングされたデータによって異なります。スキーマヒントを使用すれば、文字種 (大文字または小文字) を強制的に指定できます。
例えば、Auto Loaderが大文字と小文字を区別せずにデータを読み取り、列名を事前に指定する場合、スキーマヒントを使用して列名を「VendorID」に強制することができます。[readerCaseSensitive] オプションをfalseに設定すると、列名が「vendorid」のデータは「VendorID」列として扱われます。
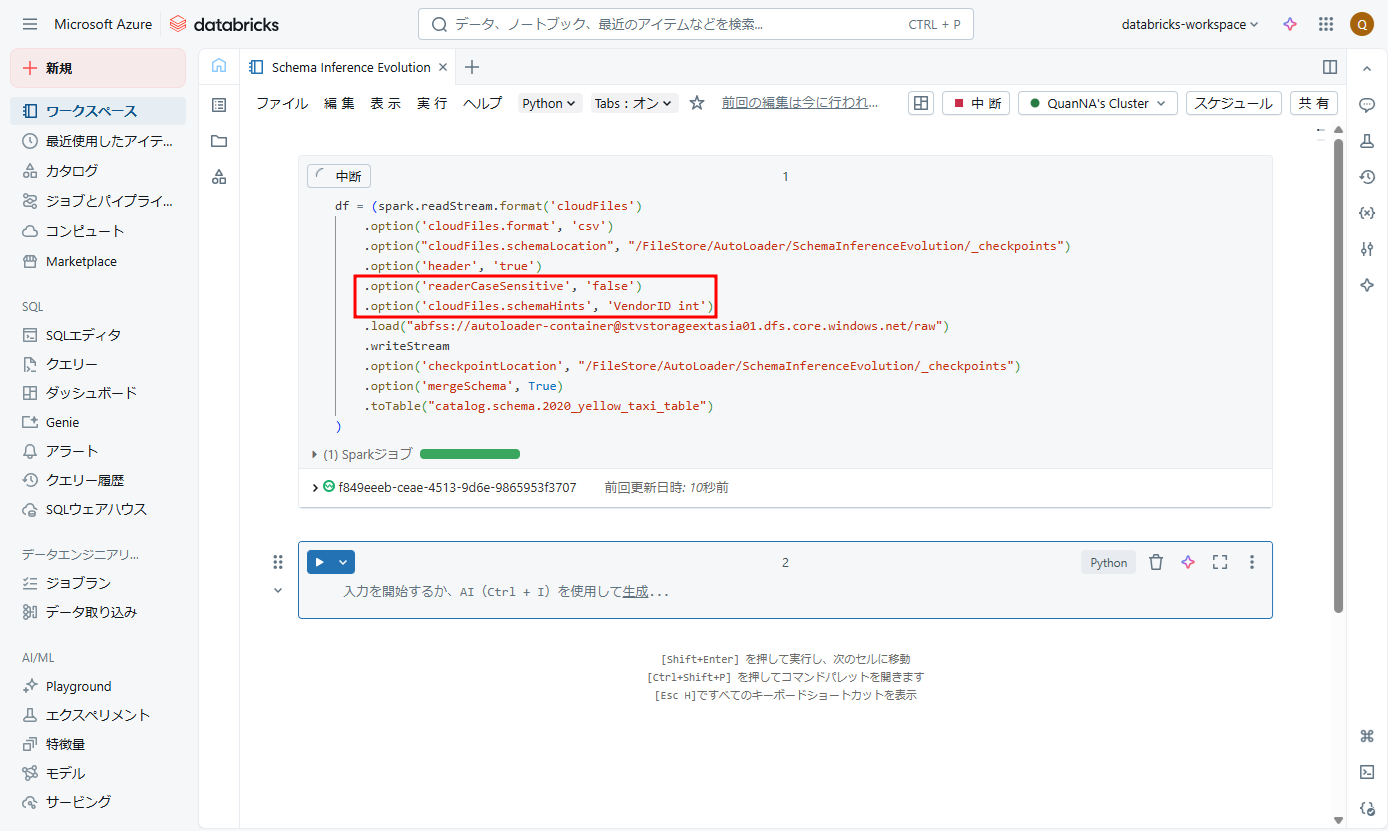
スキーマヒントを使用すると、最初の列の名前を「VendorID」に強制することができます。
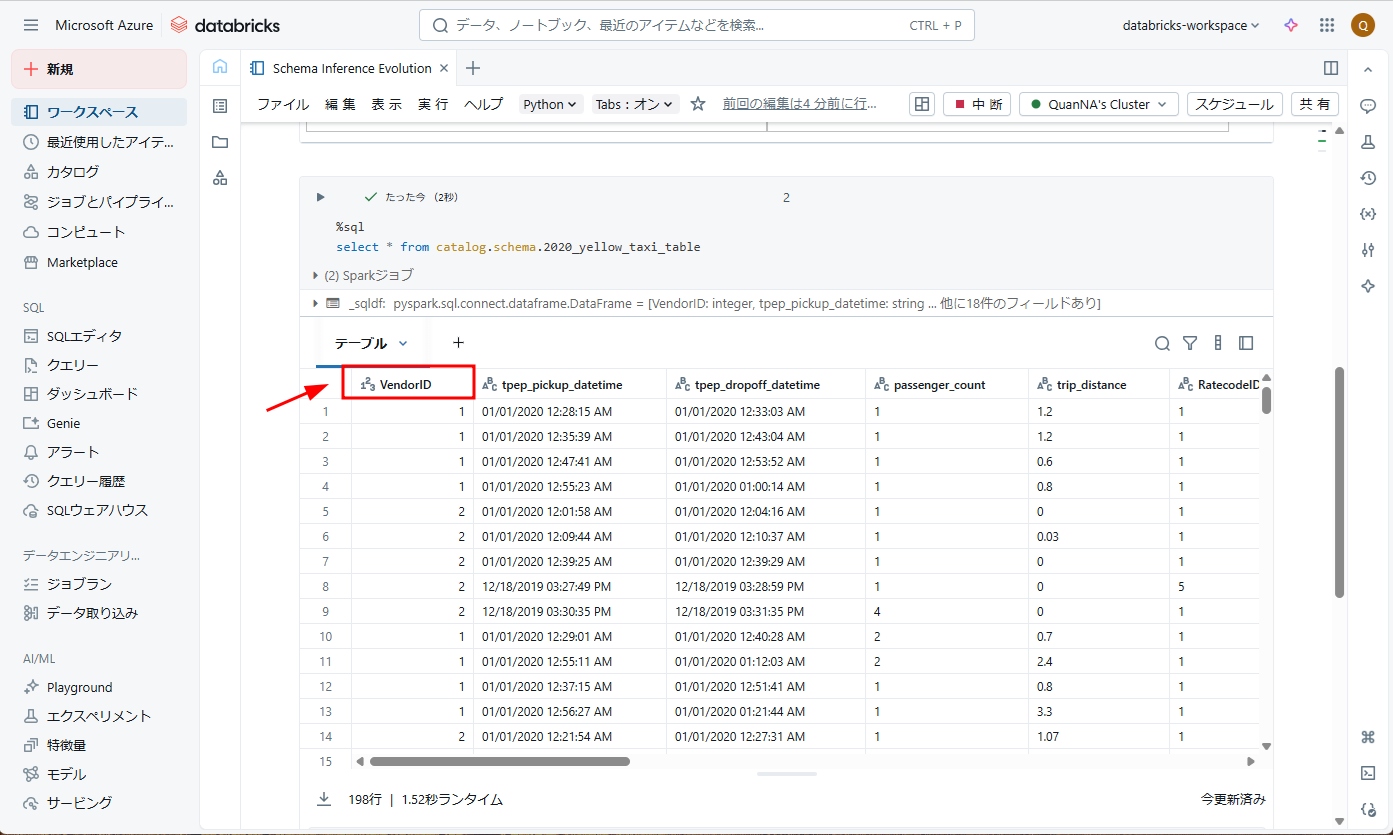 [2020_Yellow_Taxi_Trip_Case_Sensitive_Data]ファイルを追加します。このファイルで列名が「VendorID」ではなく「vendorid」になります。
[2020_Yellow_Taxi_Trip_Case_Sensitive_Data]ファイルを追加します。このファイルで列名が「VendorID」ではなく「vendorid」になります。
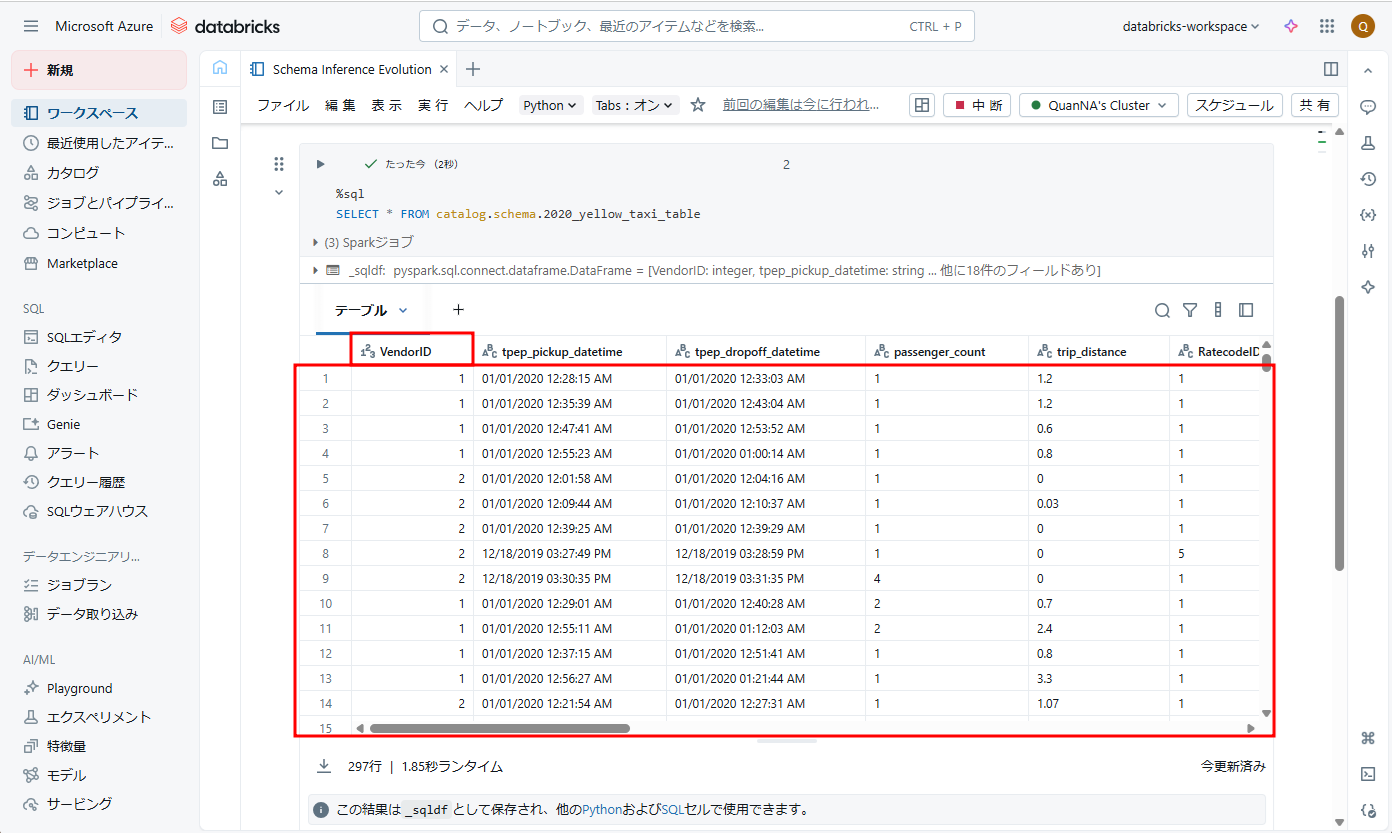
[Dashboard] タブで、AutoLoader が新しいファイルを検出し、進化を実行していることが表示されます。
選択とスキーマの推論が行われると、Auto Loader は、大文字または小文字の選択に関係なく、スキーマと一致するデータを考慮します。
したがって、新しい「vendorid」のデータは、大文字と小文字を区別しないように [readerCaseSensitive] オプションを false に設定しているため、ターゲットテーブルの「VendorID」列に追加されます
10. まとめ
今回は、Auto Loader のスキーマ推論と進化の機能について説明しました。スキーマ推論t進化は難しい内容かもしれませんが
利用することで、インターフェース開発にかかる工数の削減につながります。
第1回: Auto Loaderの概要、Quick Start方法をしてみる
第2回:【Azure Databricks】Auto Loader と Lakeflow 宣言パイプラインを組み合わせて使用してみる
第3回: Auto Loader のスキーマ推論と進化の機能について説明する (今回)
今回の記事が少しでも皆さんの新しい知識や業務のご参考になれば幸いです。日商エレクトロニクスでは、Azure Databricks の環境構築パッケージを用意しています。Azure Databricks や Azure活用、マイクロソフト製品の活用についてご相談事がありましたら
是非お問い合わせください!
Azure Databricks 連載記事のまとめはこちら