目次
1. はじめに
皆さんこんにちは。
今回からMicrosoft Fabricについての連載ブログを始めていきます。
全5回を予定しています。第5回ではSynapse Data Engineering ユーザー向け Fabric チュートリアル_第2回について説明いたします。
第1回:Microsoft Fabric 概要と試用版の作成方法
第2回:Power BI ユーザー向け Fabric チュートリアル
第3回:Data Factory ユーザー向け Fabric チュートリアル
第4回:Synapse Data Engineering ユーザー向け Fabric チュートリアル_第1回
第5回:Synapse Data Engineering ユーザー向け Fabric チュートリアル_第2回 (今回)
2. レイクハウスでデータを準備して変換する
➀ 前のチュートリアルで、生データがソースからレイクハウスの「ファイル」セクションに取り込まれました。次に、データを変換し、デルタ テーブルを作成するための準備を行います。
Lakehouse Tutorial Source Code フォルダーからノートブックをダウンロードします。
ワークスペース画面に移動、「インポート」→ 「ノートブック」→「コンピュータ-から」を選択します。
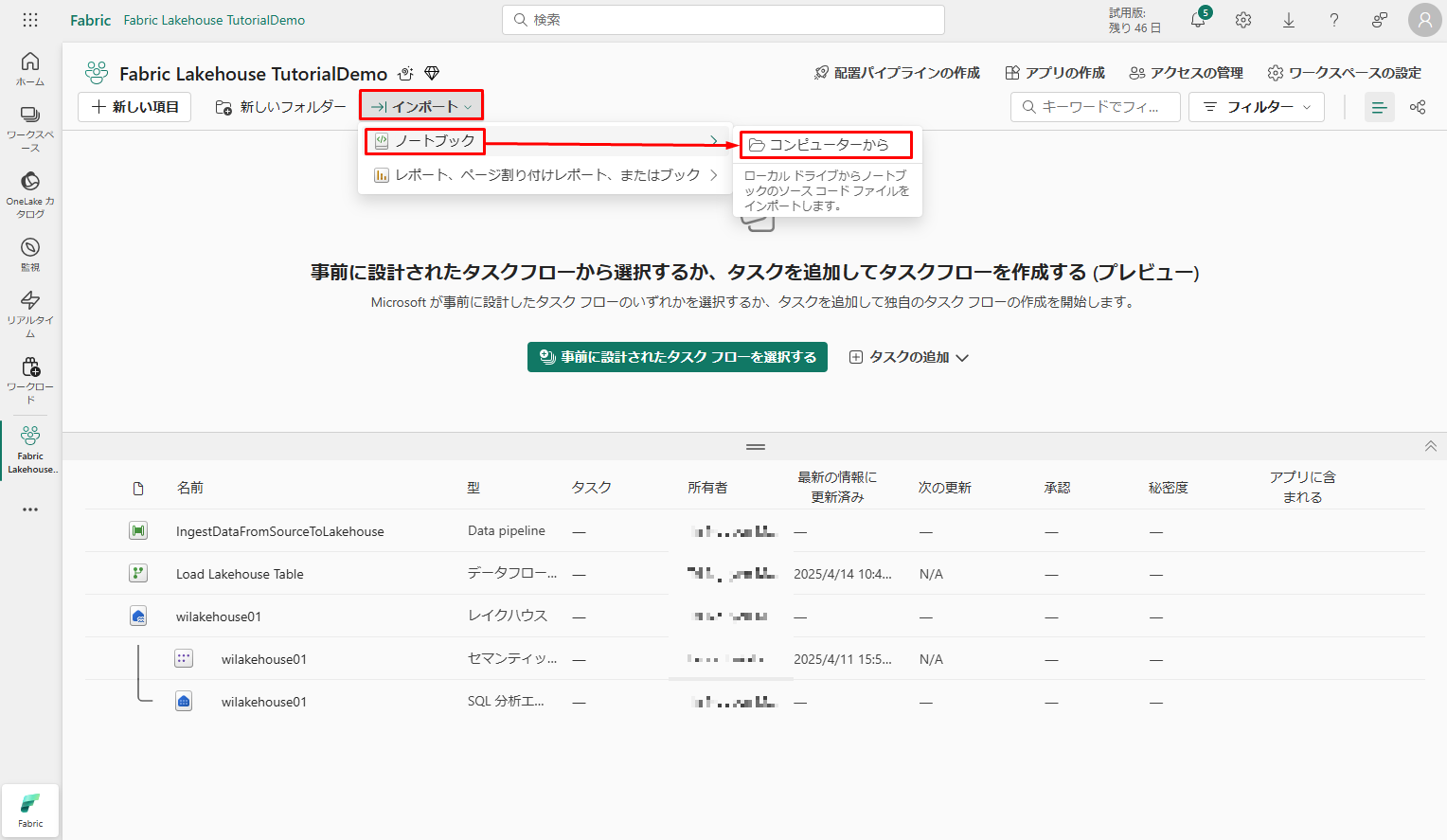
画面の右側に表示される「インポート状態」ウィンドウから「Upload」をクリックします。
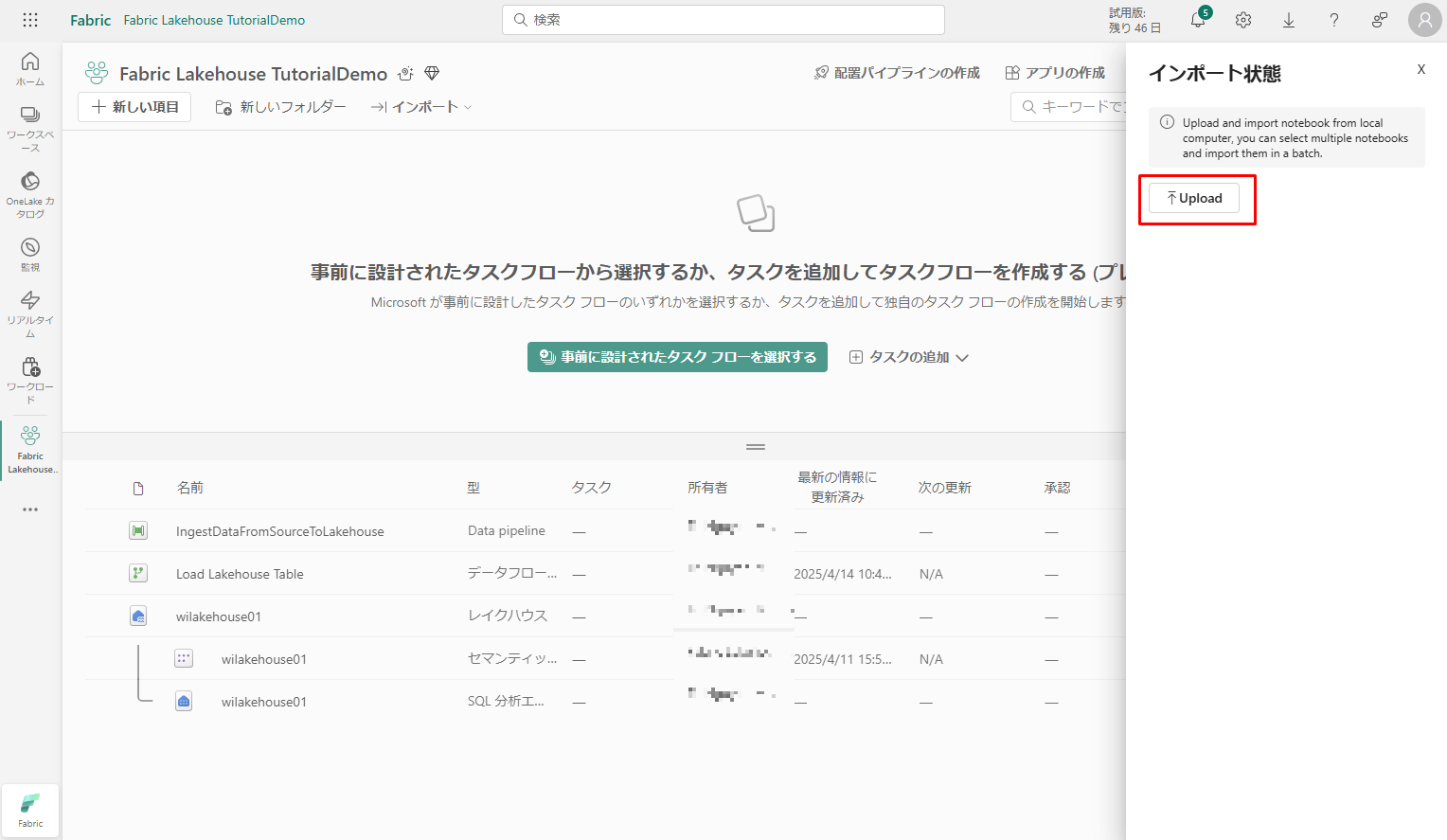
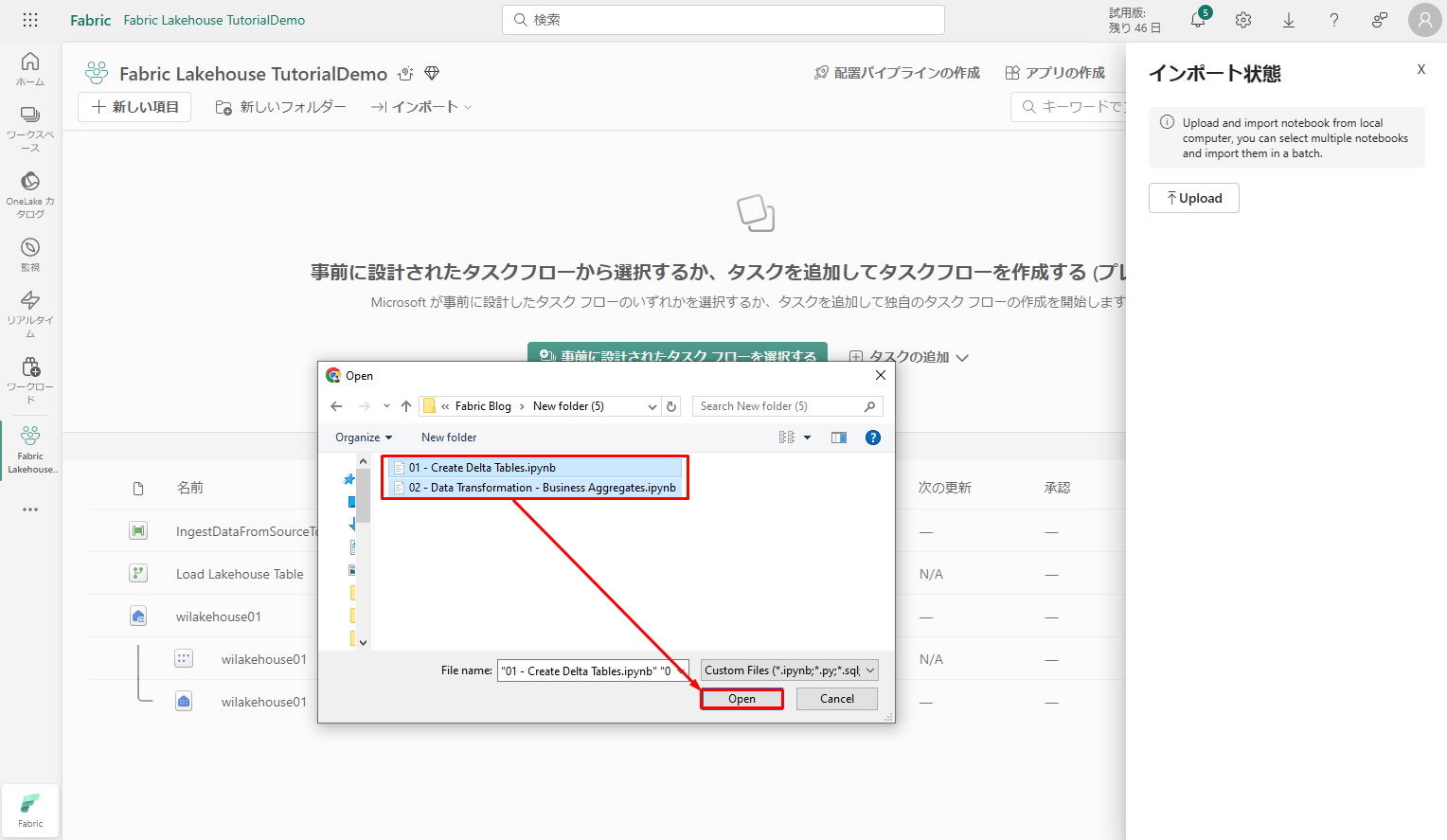
前の手順でダウンロードしたすべてのノートブックを選択します。
「Open」をクリックします。
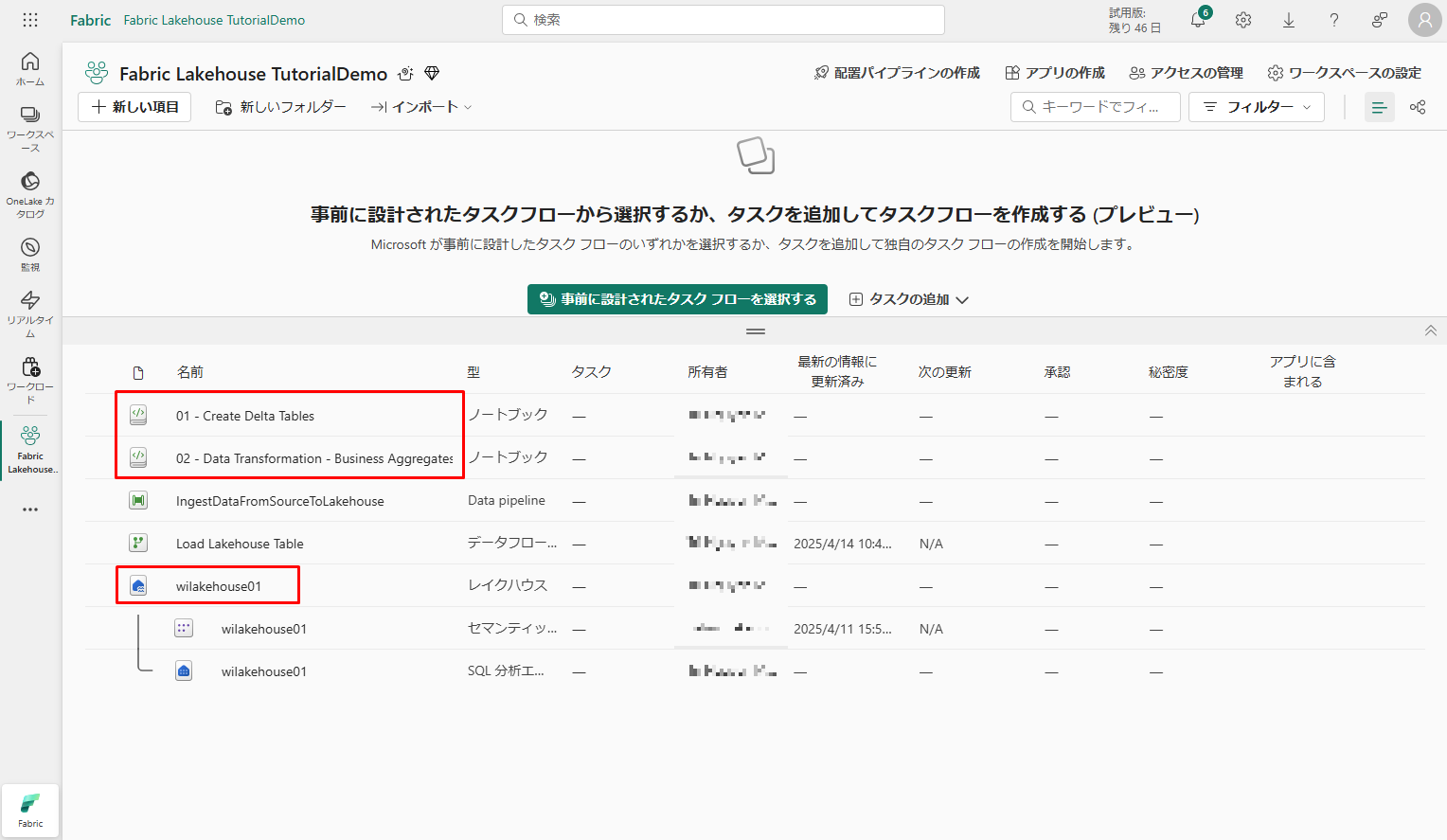
インポートの成功後、ワークスペースのアイテム ビューに移動し、新しくインポートされたノートブックを確認できます。
「wilakehouse01」レイクハウスを選択して開きます。
上部のナビゲーション メニューで「ノートブックを開く」>「既存のノートブック」を選択します。
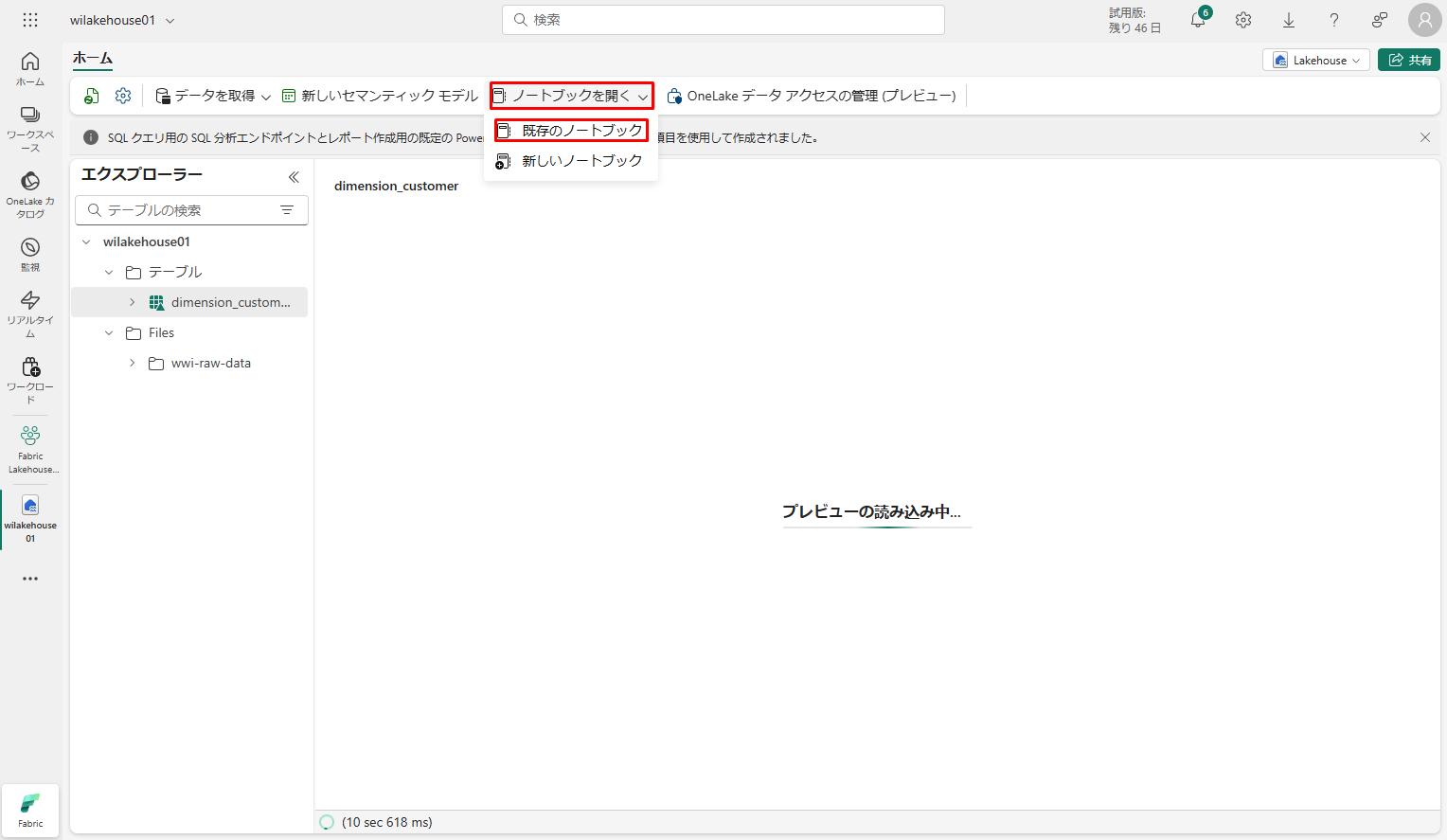
既存のノートブックの一覧から、「01 – Create Delta Tables」>「開く」を選択します。
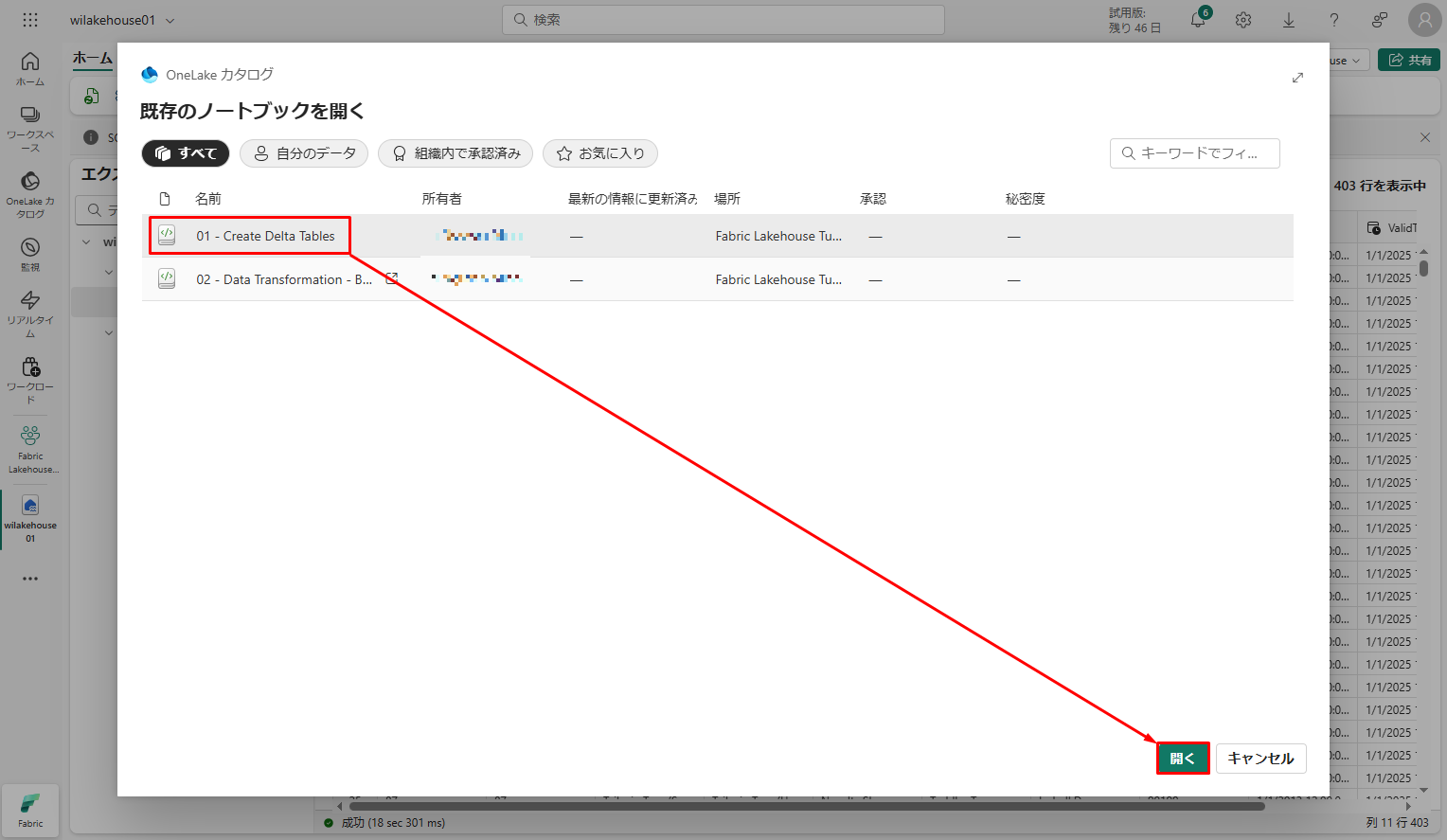
レイクハウス [エクスプローラー] で開いているノートブックにノートブックが開いているレイクハウスに既にリンクされています。
- 上部のリボンで「すべて実行」を選択して、ノートブックを起動し、すべてのセルを順番に実行します。
- または、特定のセルからのコードのみを実行するには、ホバーしたときにセルの左側に表示される「実行」アイコンを選択します。
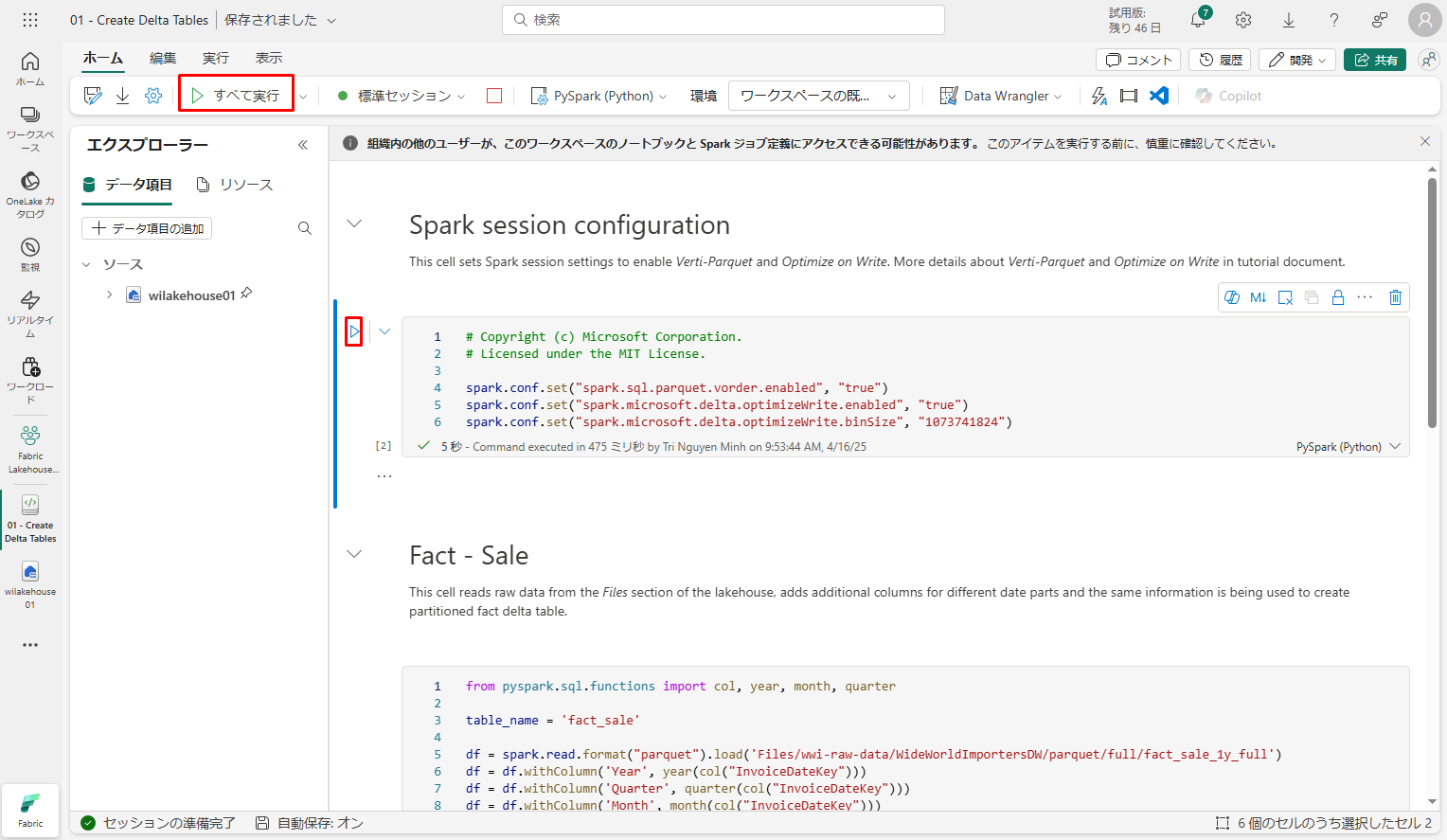
レイクハウスの「テーブル」セクションでデータをデルタ レイク テーブルとして書き込む前に、V オーダーと書き込みの最適化という 2 つのFabric 機能を使用して、データの書き込みを最適化し、読み取りパフォーマンスを向上させます。
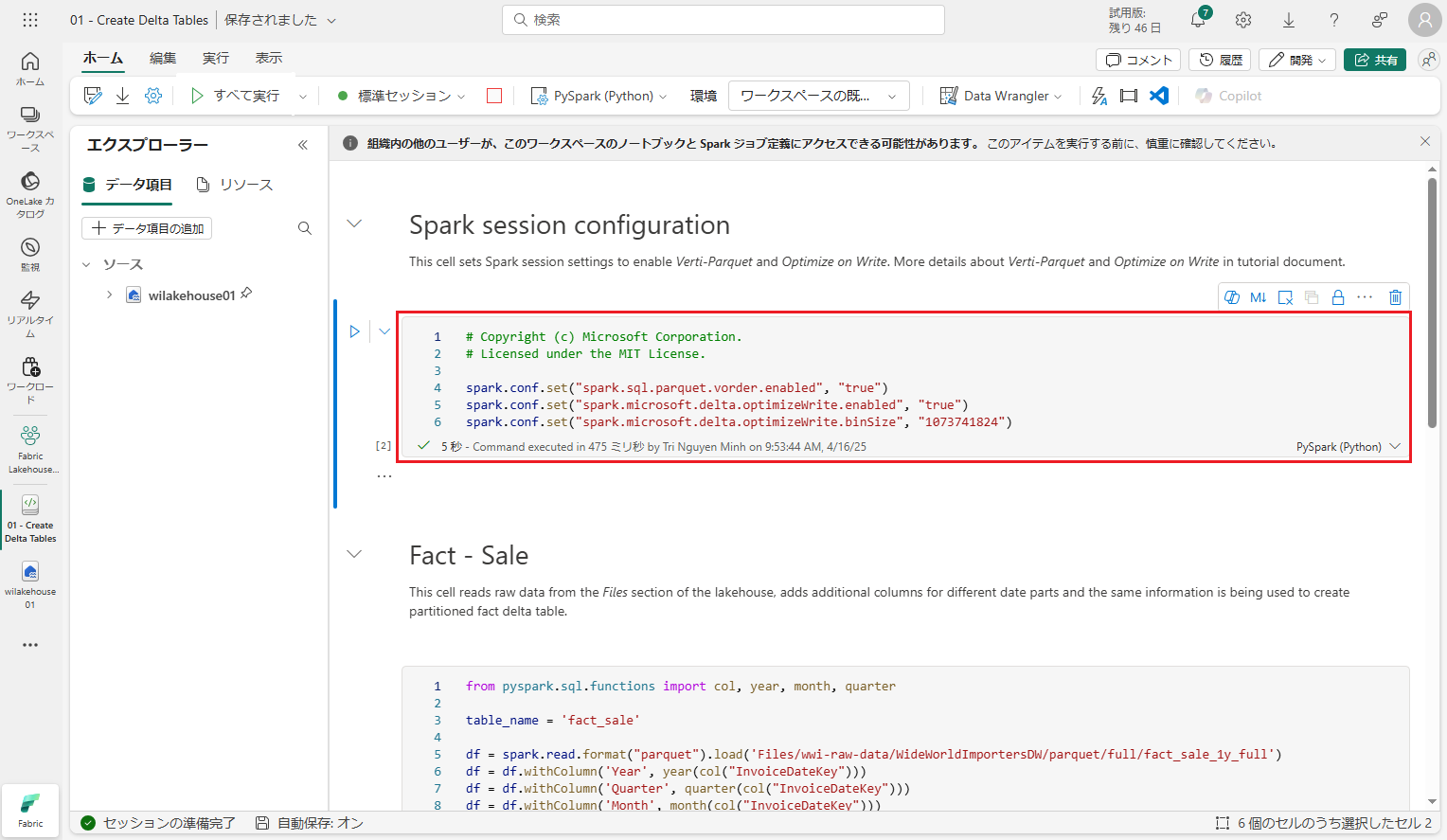
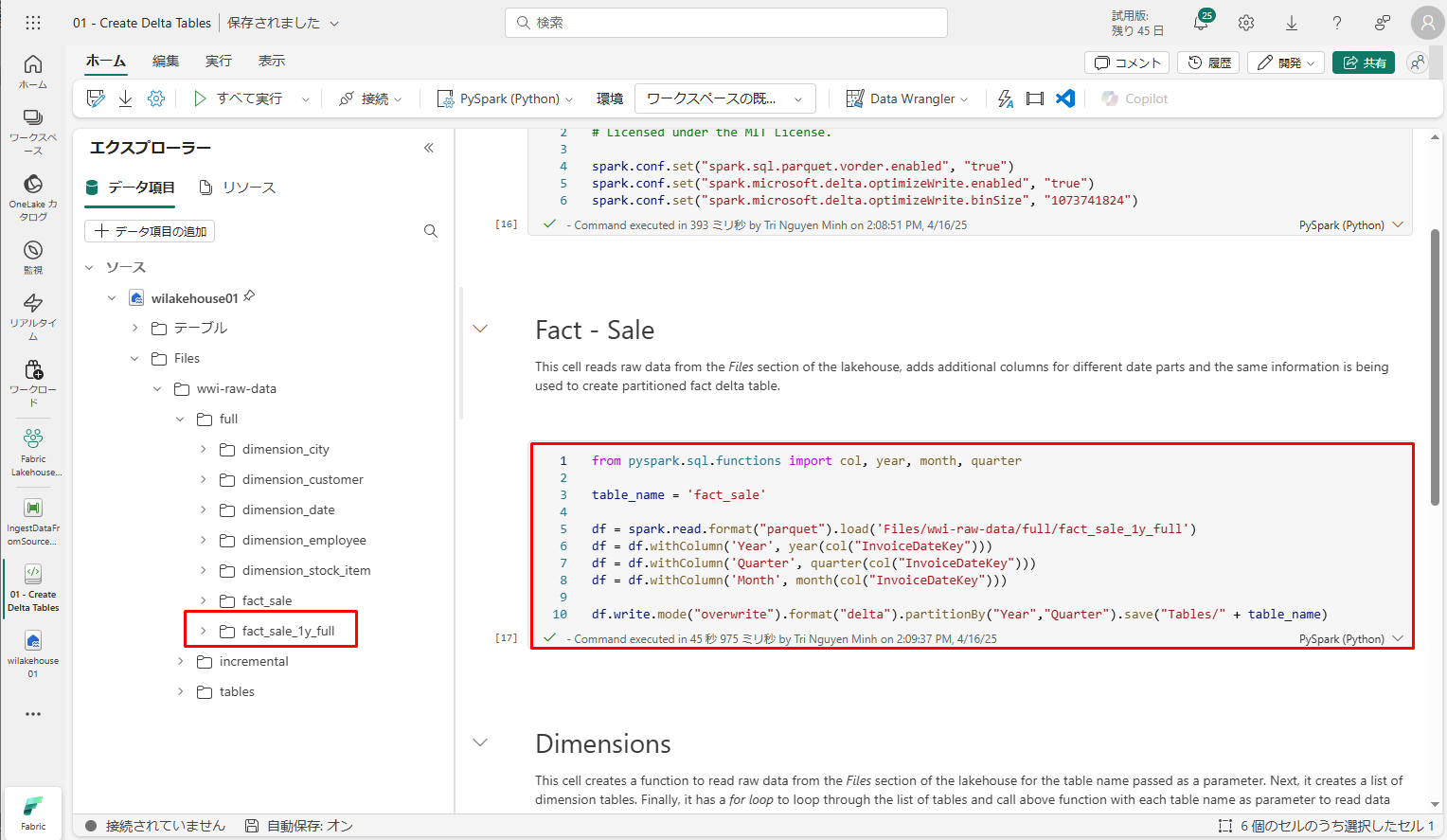
次に、レイクハウスの「ファイル」セクションから生データを読み取ります。このファイルが指定されたパスから Parquet 形式で読み取られます。
- DataFrame df に新しい列を追加して、「InvoiceDateKey」列の日付の「Year 」、「Quarter」、「Month」に関する情報を保存します。
- 最後に、partitionBy Spark API を使用してデータを分割してから、新しく作成されたデータ要素の列 (Year と Quarter) に基づいてデルタ テーブルとして書き込みます。
コード内のファイルパスを実際のパスに変更することを忘れないでください。
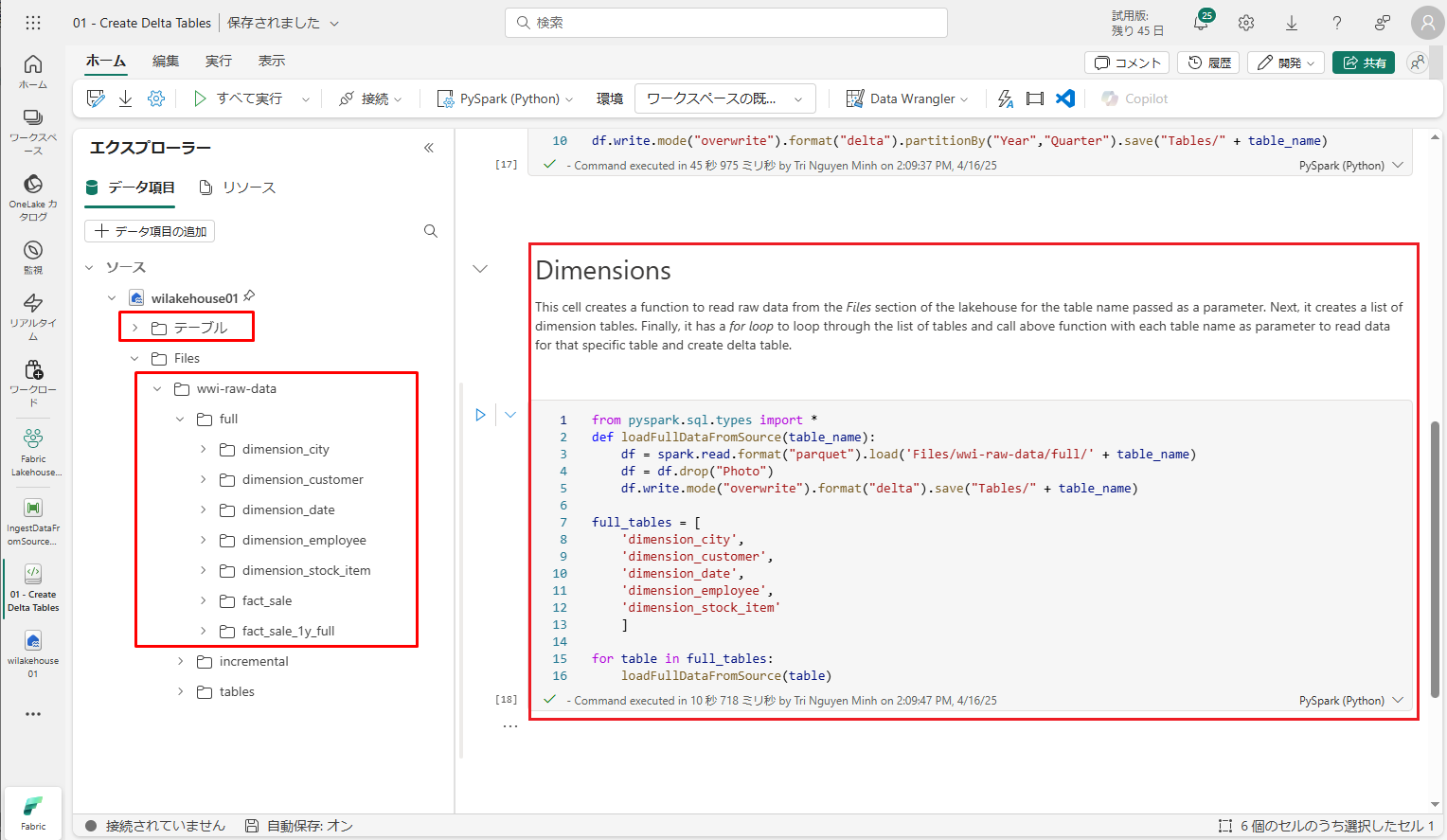
次のセルは、パラメータとして渡されるテーブル名に対して、レイクハウスの「ファイル」セクションから生データを読み取る関数を作成します。
テーブルのリストをループし、入力パラメータから読み取られたテーブル名に対してデルタ テーブルを作成します。
コード内のファイルパスを実際のパスに変更することを忘れないでください。
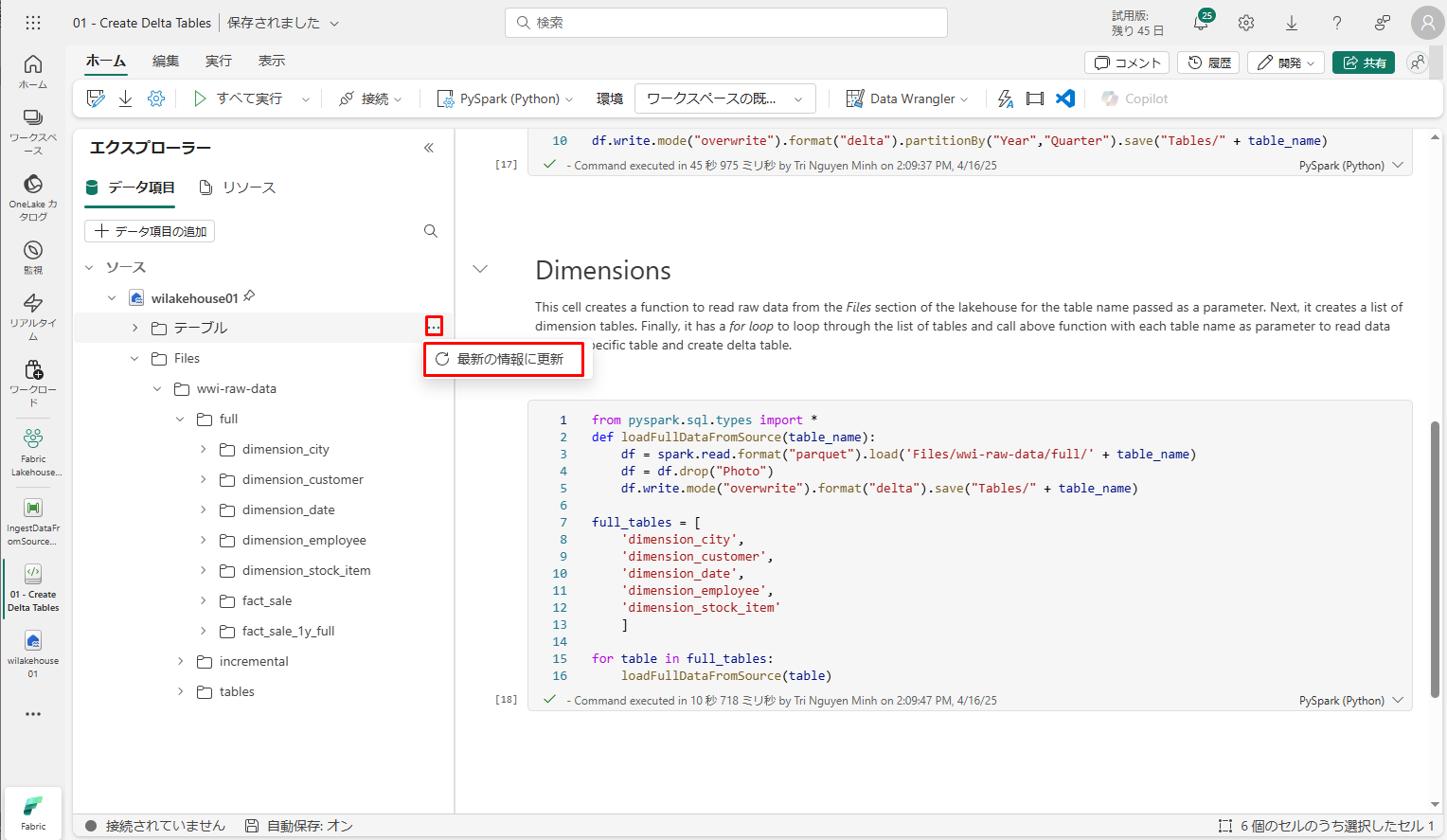
 作成されたテーブルを確認するために、「wilakehouse01」右クリックするか、[…]アイコンをクリックして「最新の情報に更新」を選択します。
作成されたテーブルを確認するために、「wilakehouse01」右クリックするか、[…]アイコンをクリックして「最新の情報に更新」を選択します。
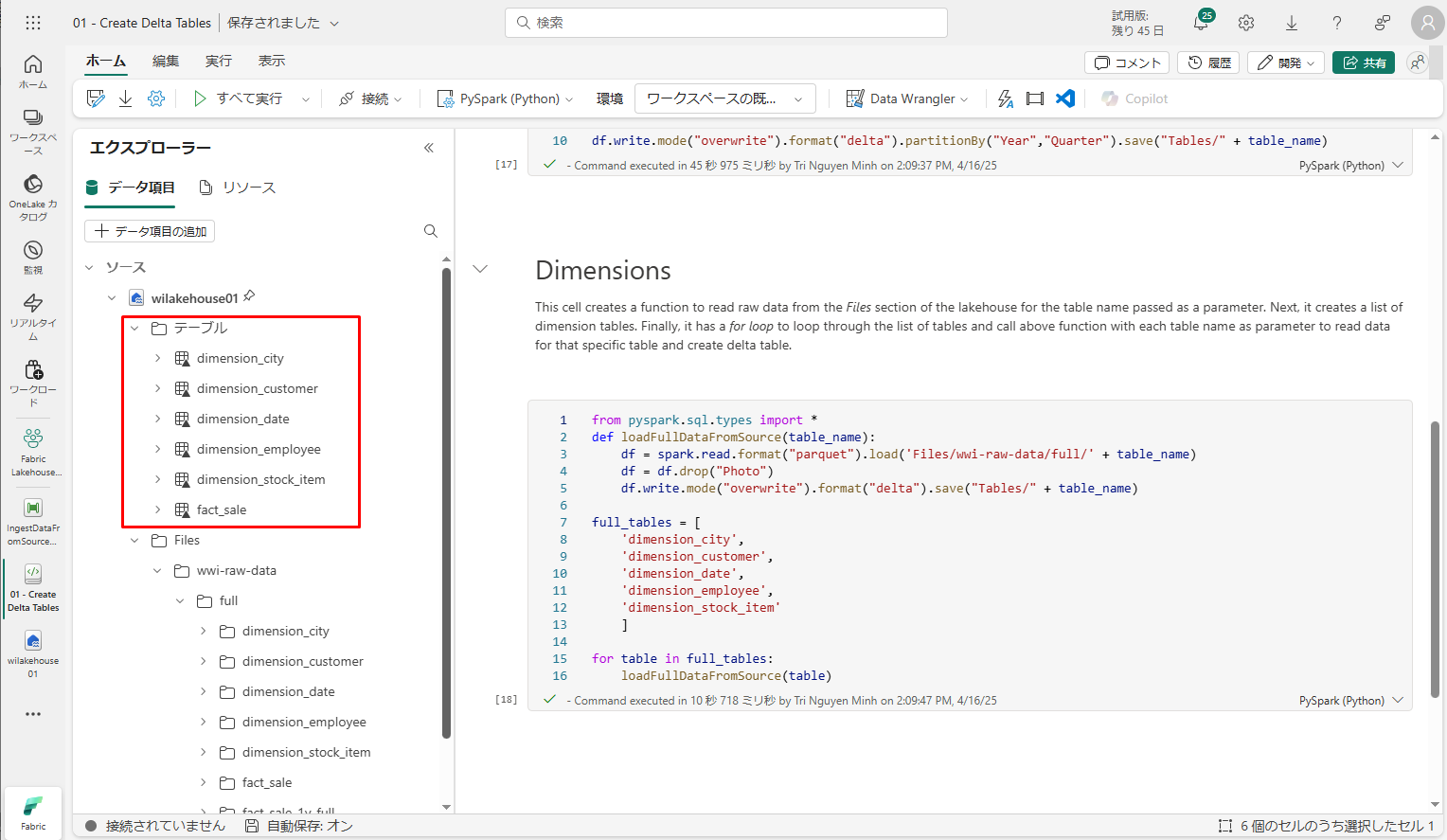
テーブルが表示されます。
テーブルが作成され、[テーブル]タブに表示されていることを確認します。
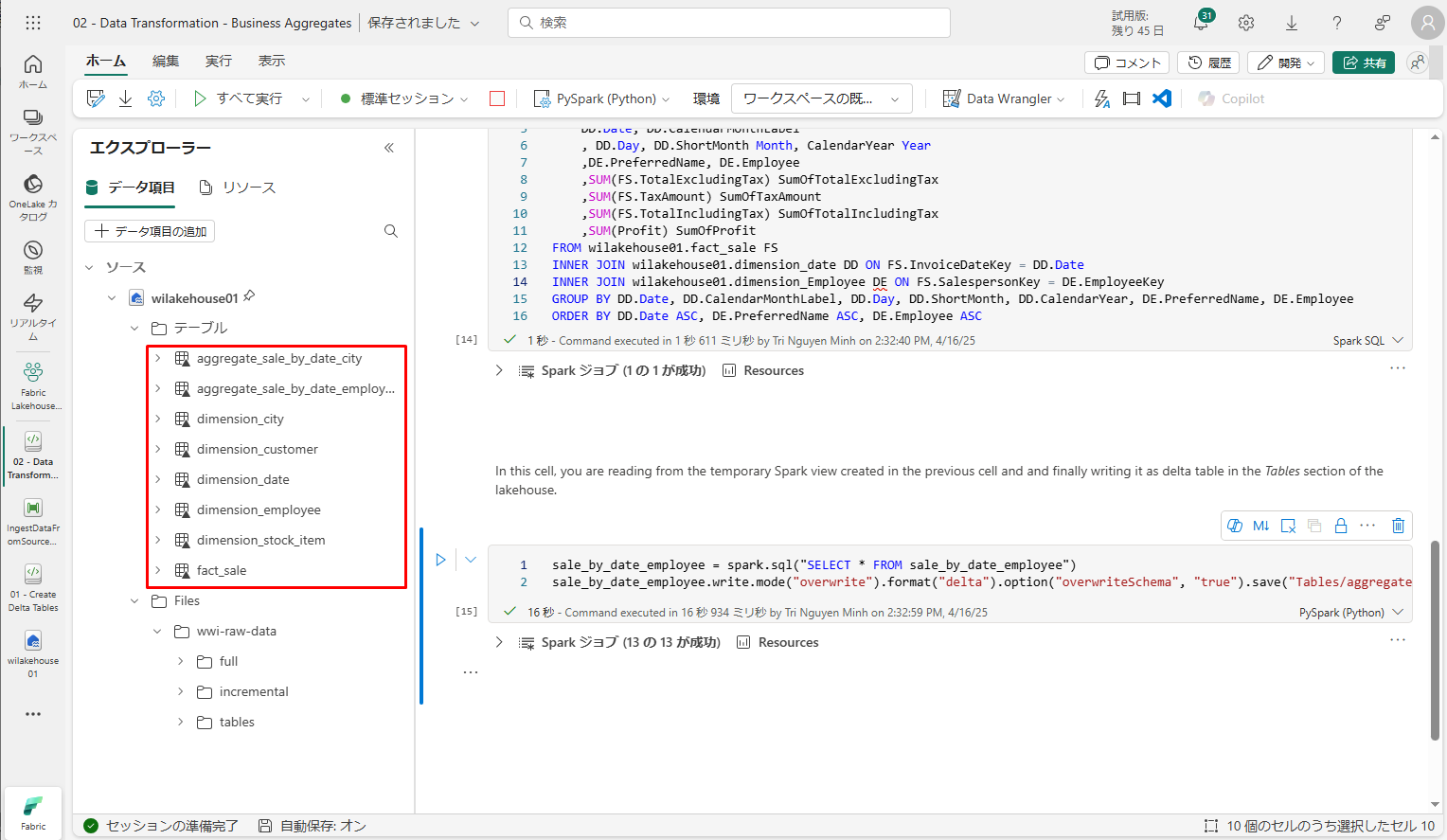
既存のノートブックの一覧から、「02 – Data Transformation -Business」>「開く」を選択します。
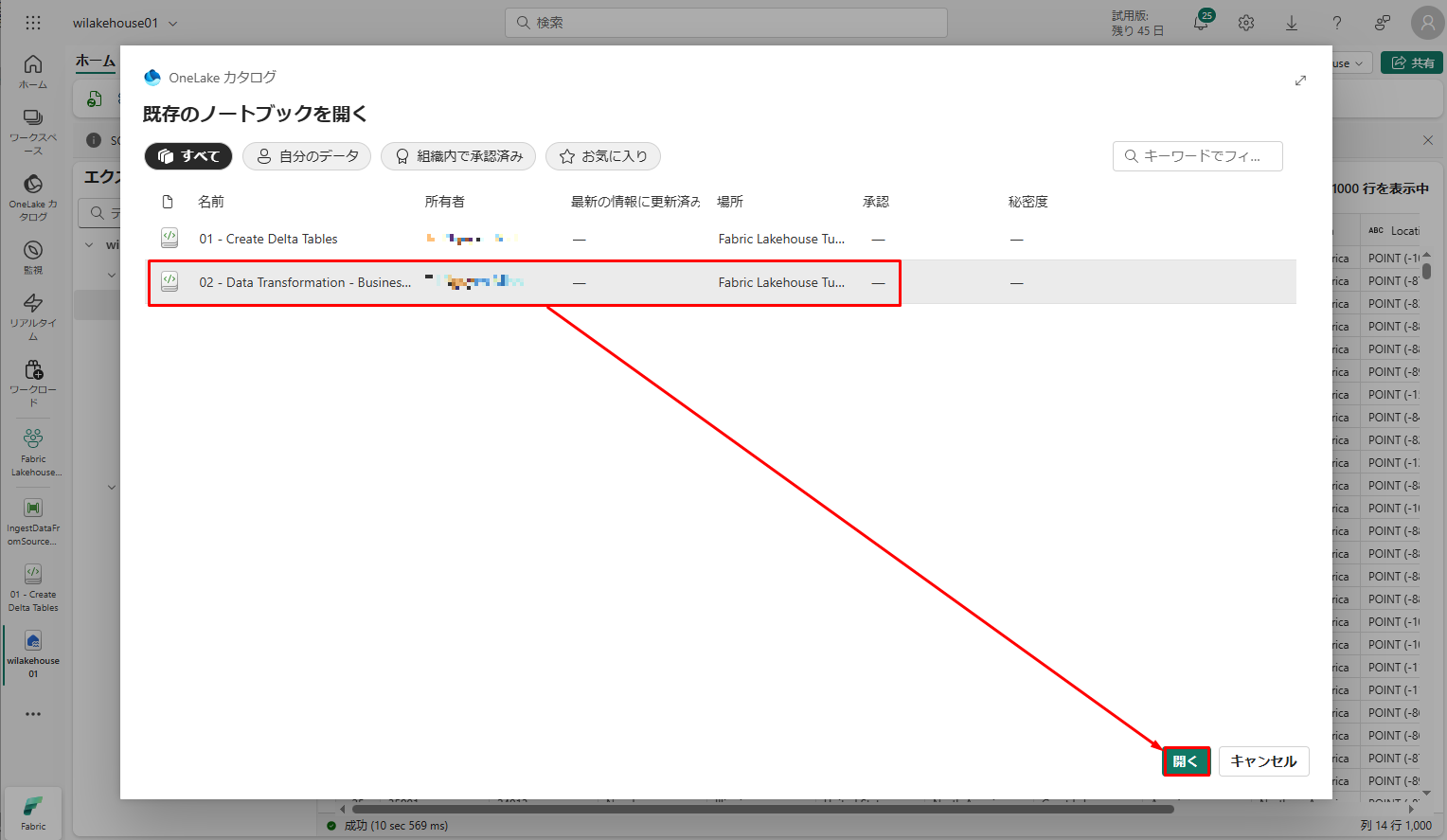
- レイクハウス「エクスプローラー」で開いているノートブックで、ノートブックが開いているレイクハウスに既にリンクされています。
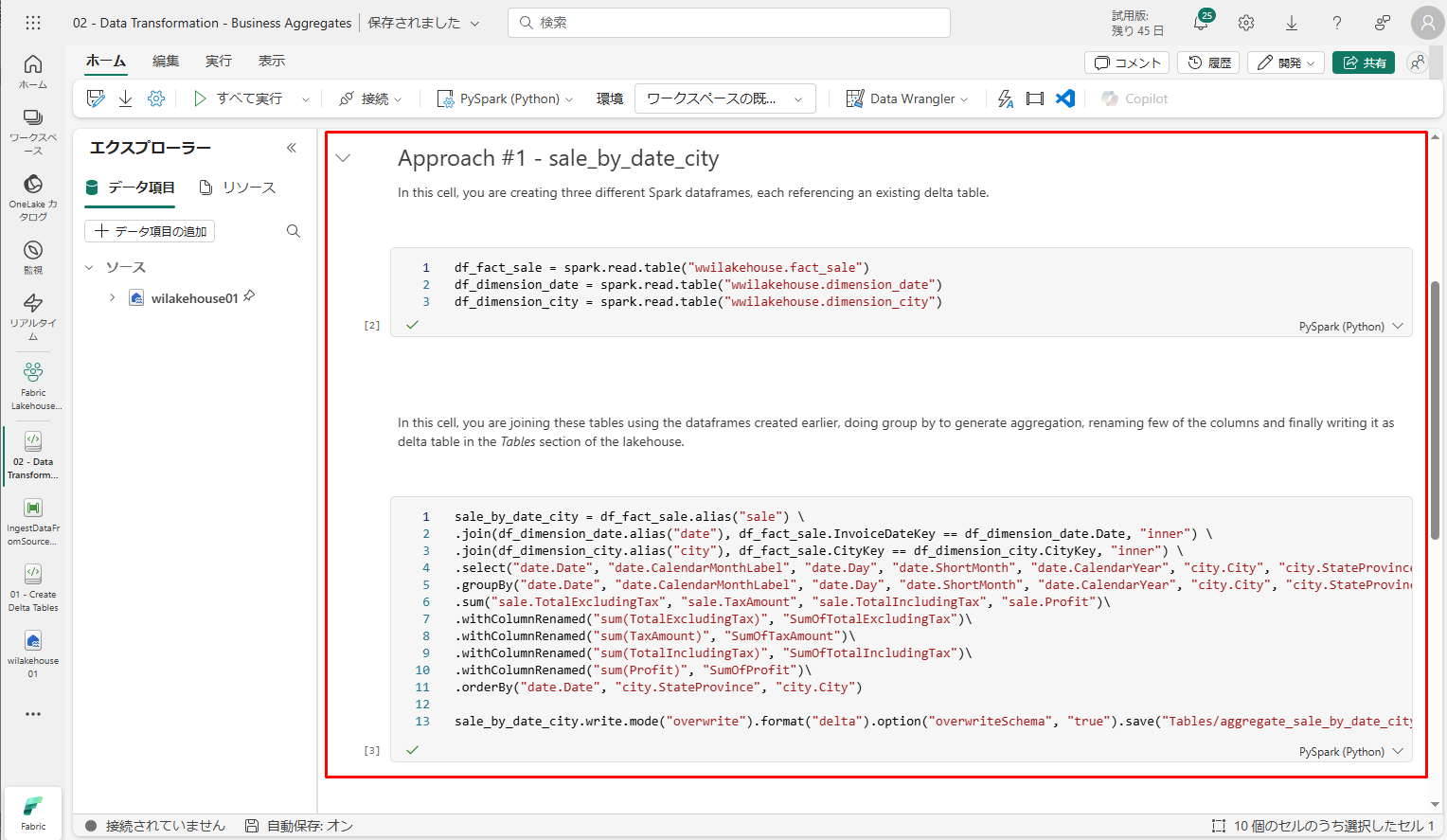
- ビジネス集計を変換、作成する方法は2つがあります。自分に合ったアプローチを選択できる場合があり、またはそれらを組み合わせる場合もあります。
- アプローチ #1 – PySpark を使用して、ビジネス集計を生成するためのデータを結合および集計します。この方法は、Python または PySpark でプログラミングの経験があるユーザーにお勧めです。
例のテーブル名を実際のテーブル名に変更することを忘れないでください。
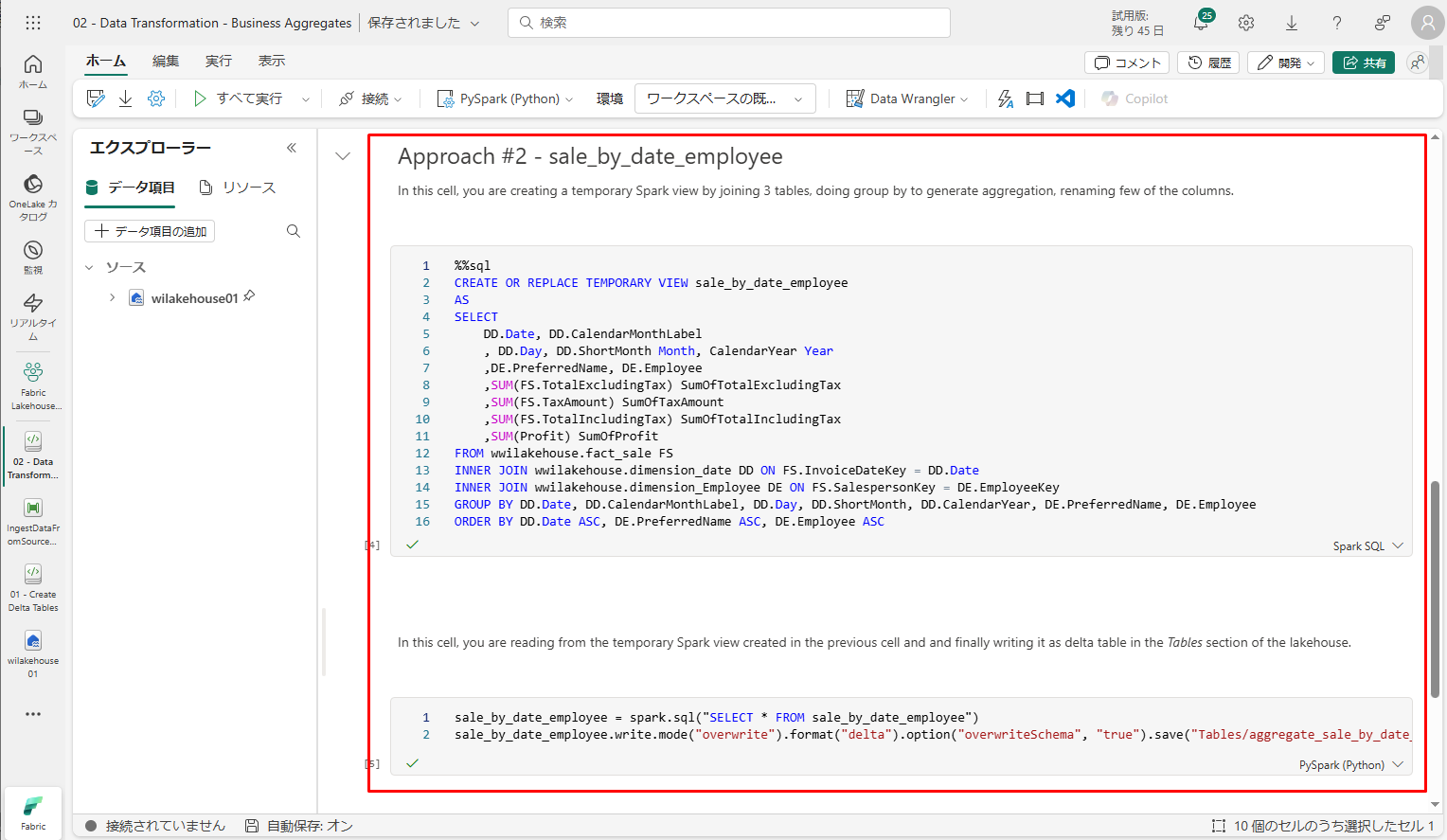
アプローチ #2 – Spark SQL を使用して、ビジネス集計を生成するためのデータを結合および集計します。この方法は、SQL の経験があり、Spark に移行しているユーザーにお勧めです。
例のテーブル名を実際のテーブル名に変更することを忘れないでください。
作成されたテーブルを検証するために、wilakehouse01 レイクハウスを右クリックして「最新の情報に更新」を選択します。
テーブルが表示されます。
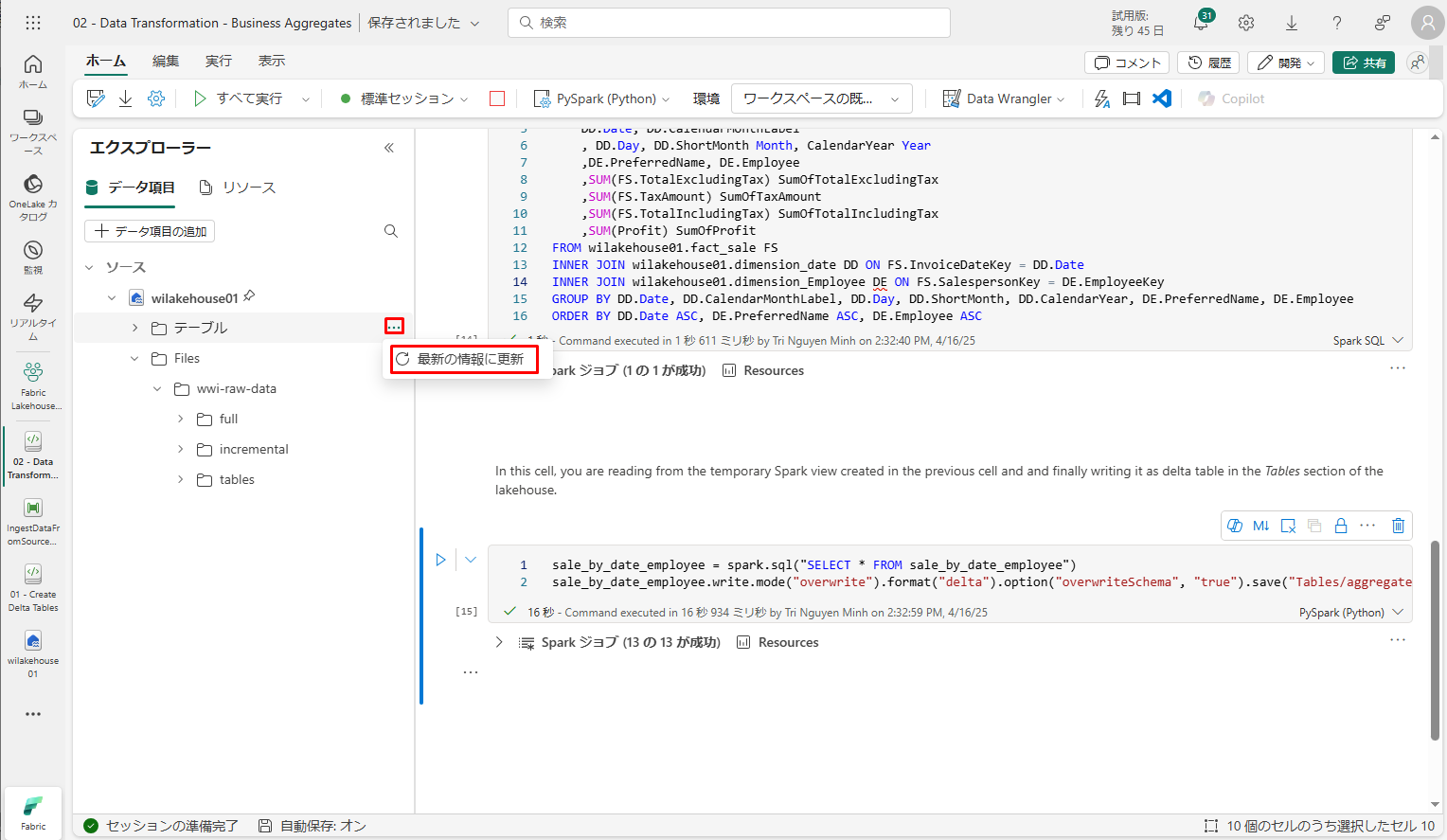
テーブルが作成され、[テーブル]タブに表示されていることを確認します。
3. Microsoft Fabric でのレポートの作成
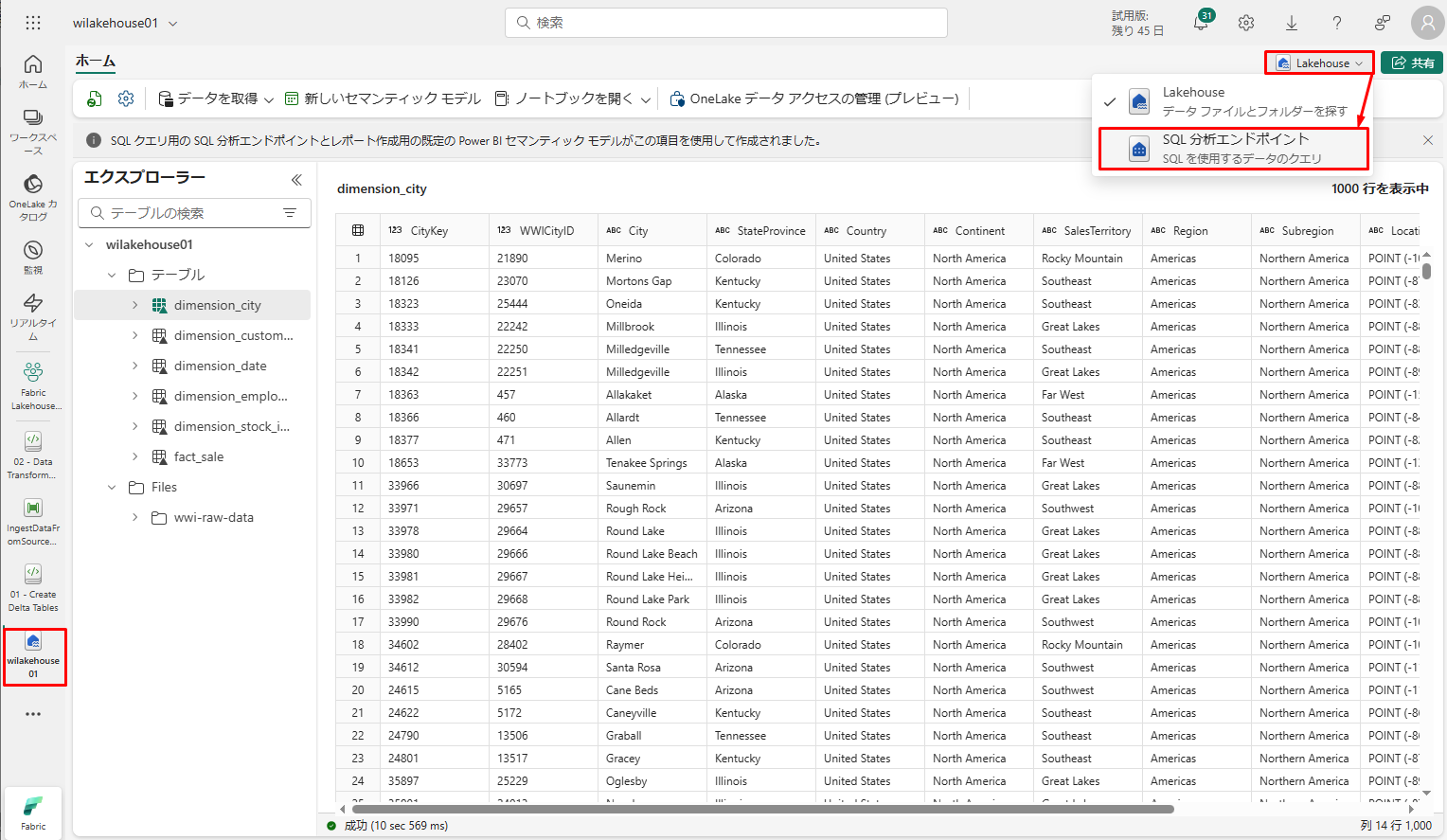
wilakehouse01 レイクハウスで、画面の右上にある「Lakehouse」ドロップダウン メニューから「SQL 分析エンドポイント」を選択します。
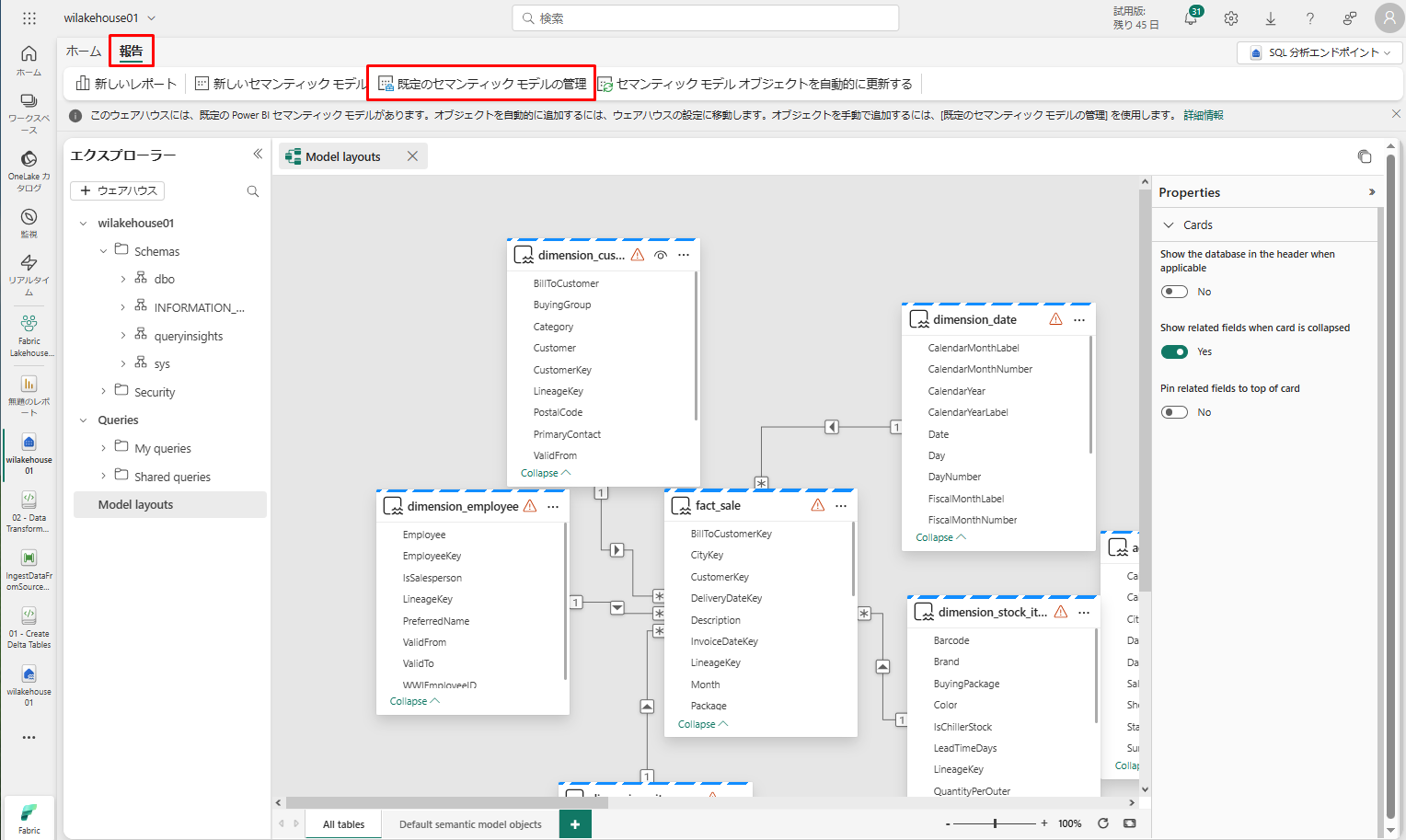
ホームタブで「モデルレイアウト」タブをクリックすると、既定の Power BI セマンティック モデルが表示されます。
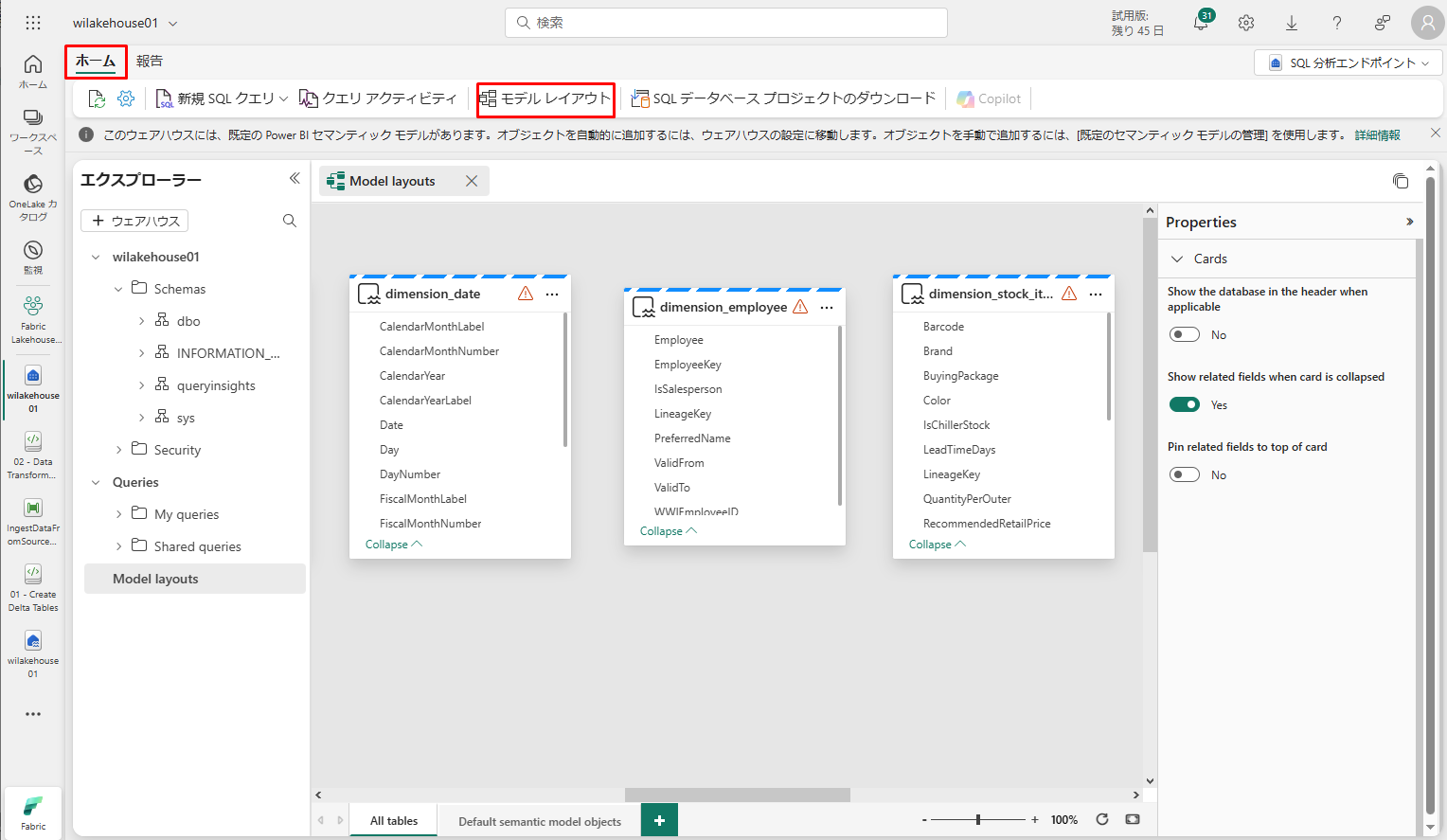
このデータモデルに対して、テーブル間のデータに基づいてレポートや視覚化を作成できるように、テーブル間の関係性を定義する必要があります。
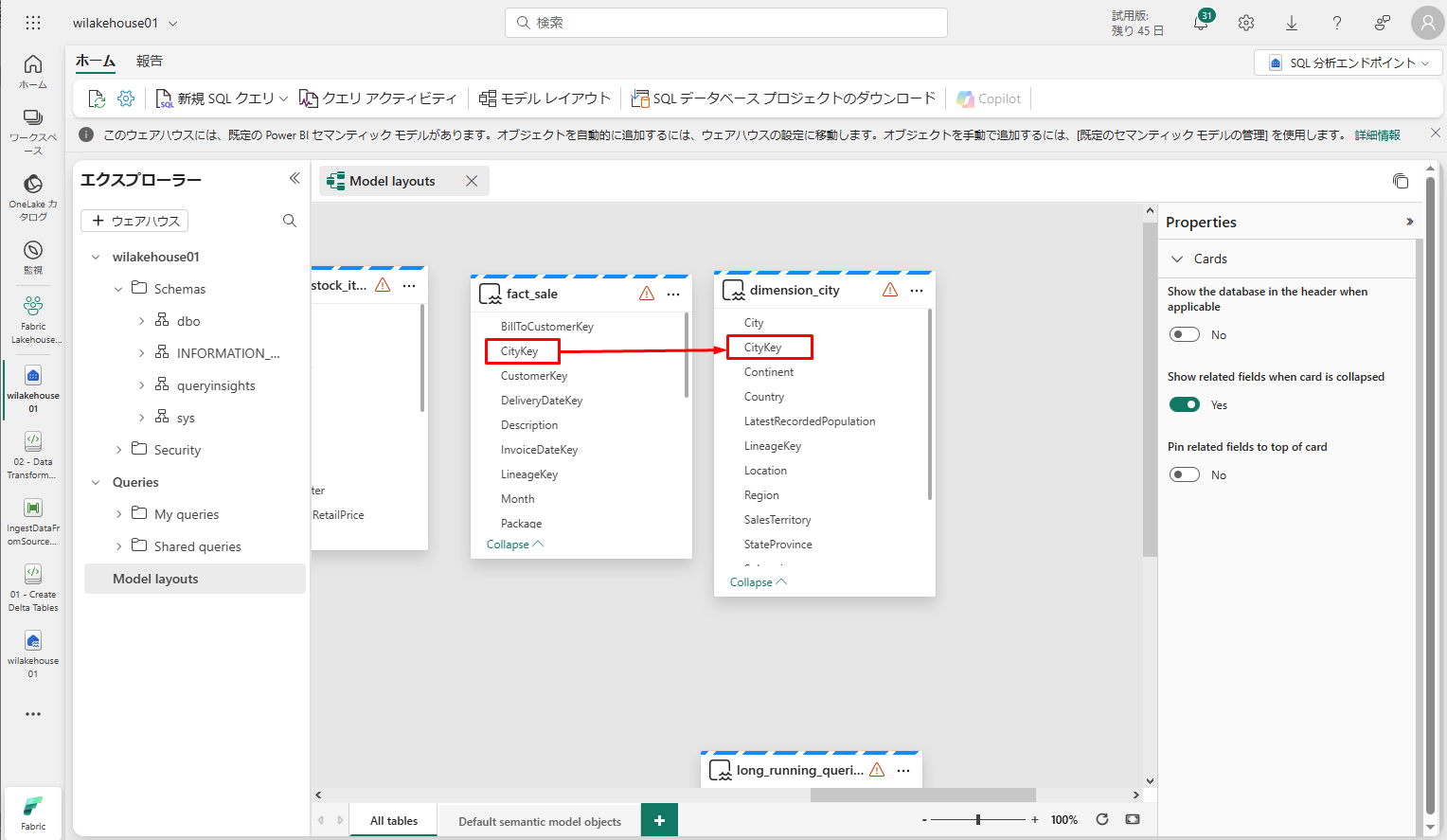
以下のように任意のテーブルのアイコン[…]をクリックしてテーブル間の関係を定義し、関係の管理を選択します。
「Manage relationships」ダイアログボックスが表示されたら、「New relationship」をクリックします。
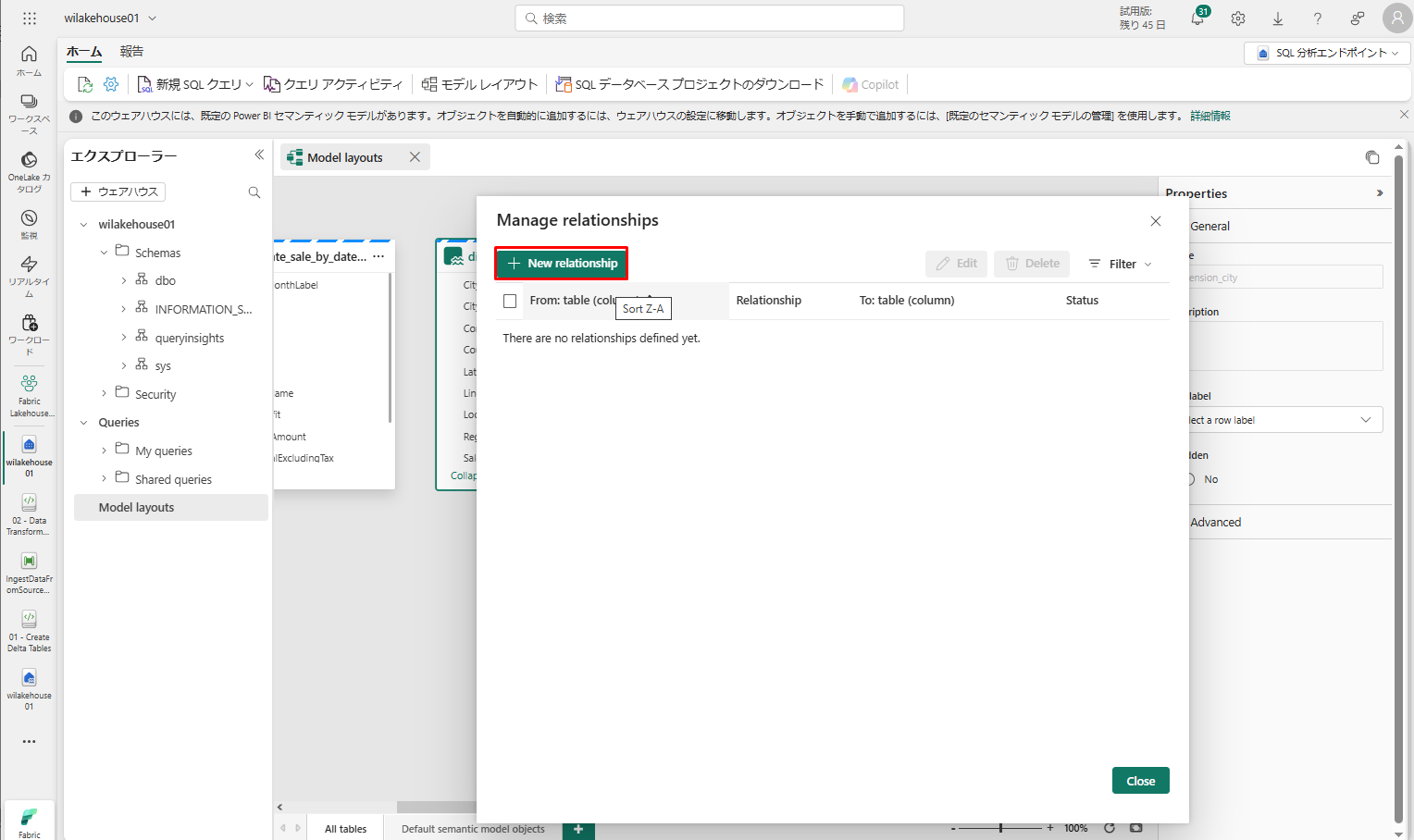
「新しいリレーションシップ」ダイアログ ボックスで:
- テーブル 1 には、fact_sale と CityKey の列が設定されています。
- テーブル 2 には、dimension_city と CityKey の列が設定されています。
- カーディナリティ : 多対一 (*:1)
- クロス フィルターの方向 : 単一
- 「このリレーションシップをアクティブにする」をチェックしたたままにします。
- 「参照整合性を想定」をチェックします。
「OK」をクリックします。
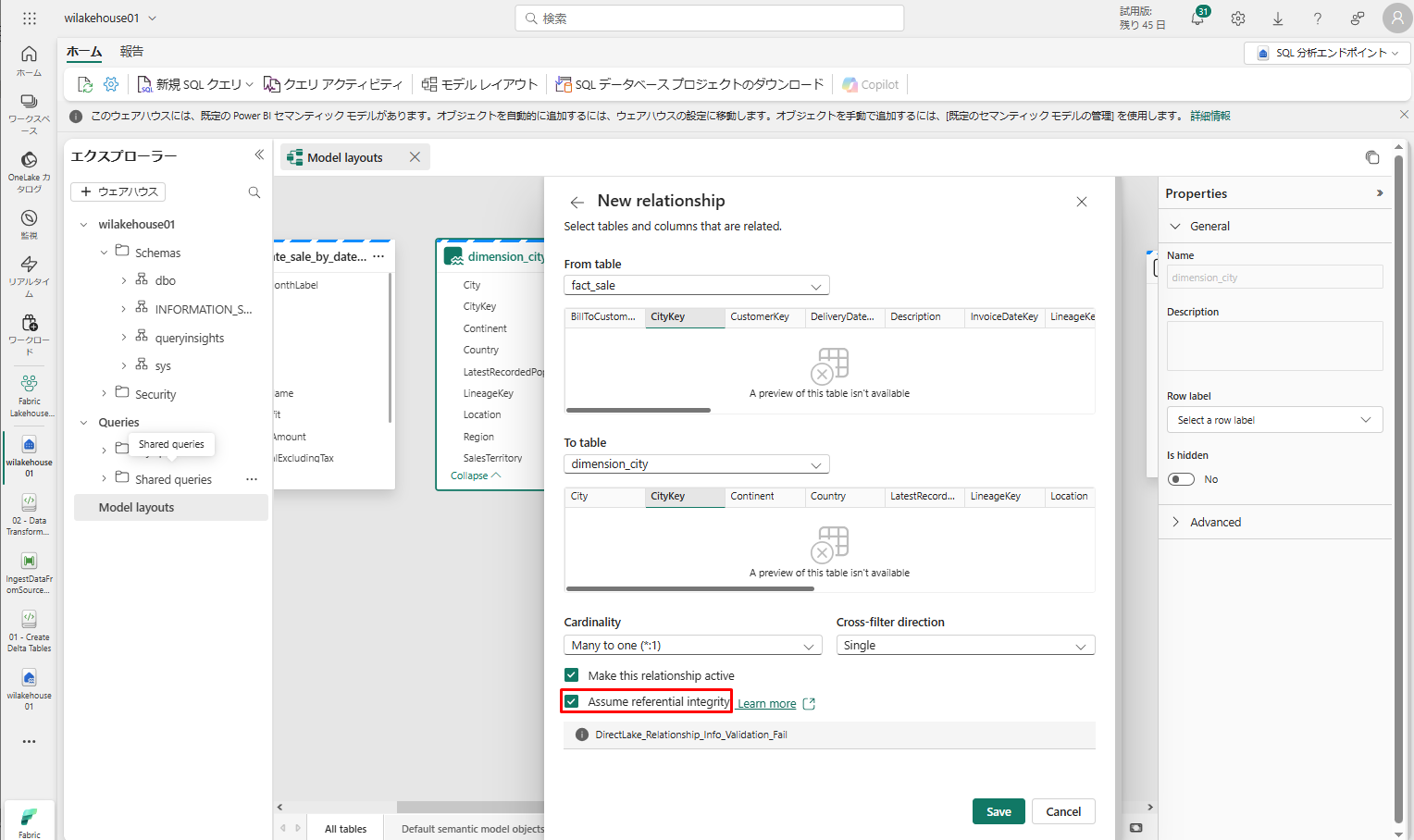
次に、上記のステップと同じ [新しいリレーションシップ] 設定を使用して、これらの新しいリレーションシップを追加します。
- StockItemKey(fact_sale) – StockItemKey(dimension_stock_item)
- Salespersonkey(fact_sale) – EmployeeKey(dimension_employee)
- CustomerKey(fact_sale) – CustomerKey(dimension_customer)
- InvoiceDateKey(fact_sale) – Date(dimension_date)
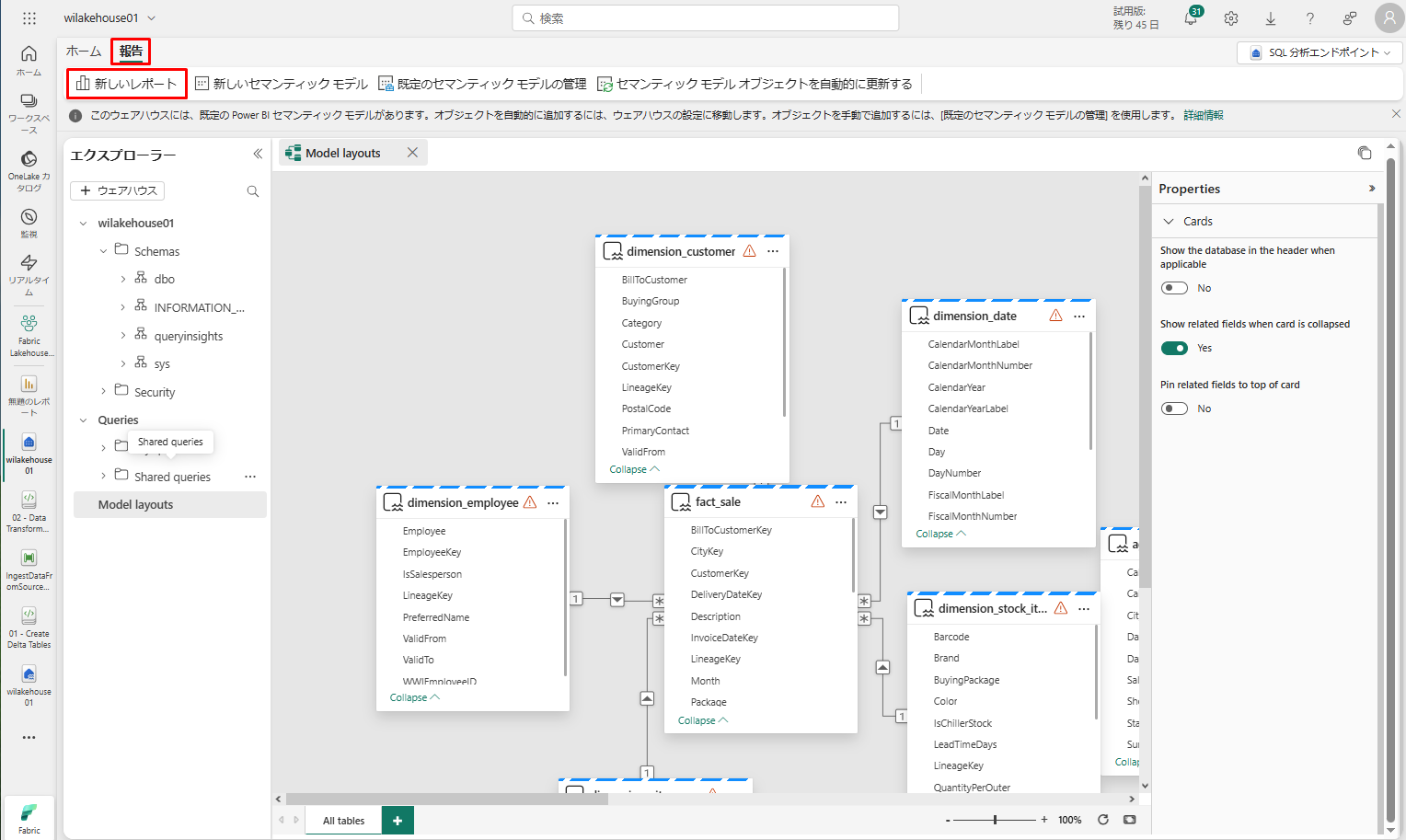
これらの関係を追加すると、次の図に示すように、データ モデルのレポートを作成します。
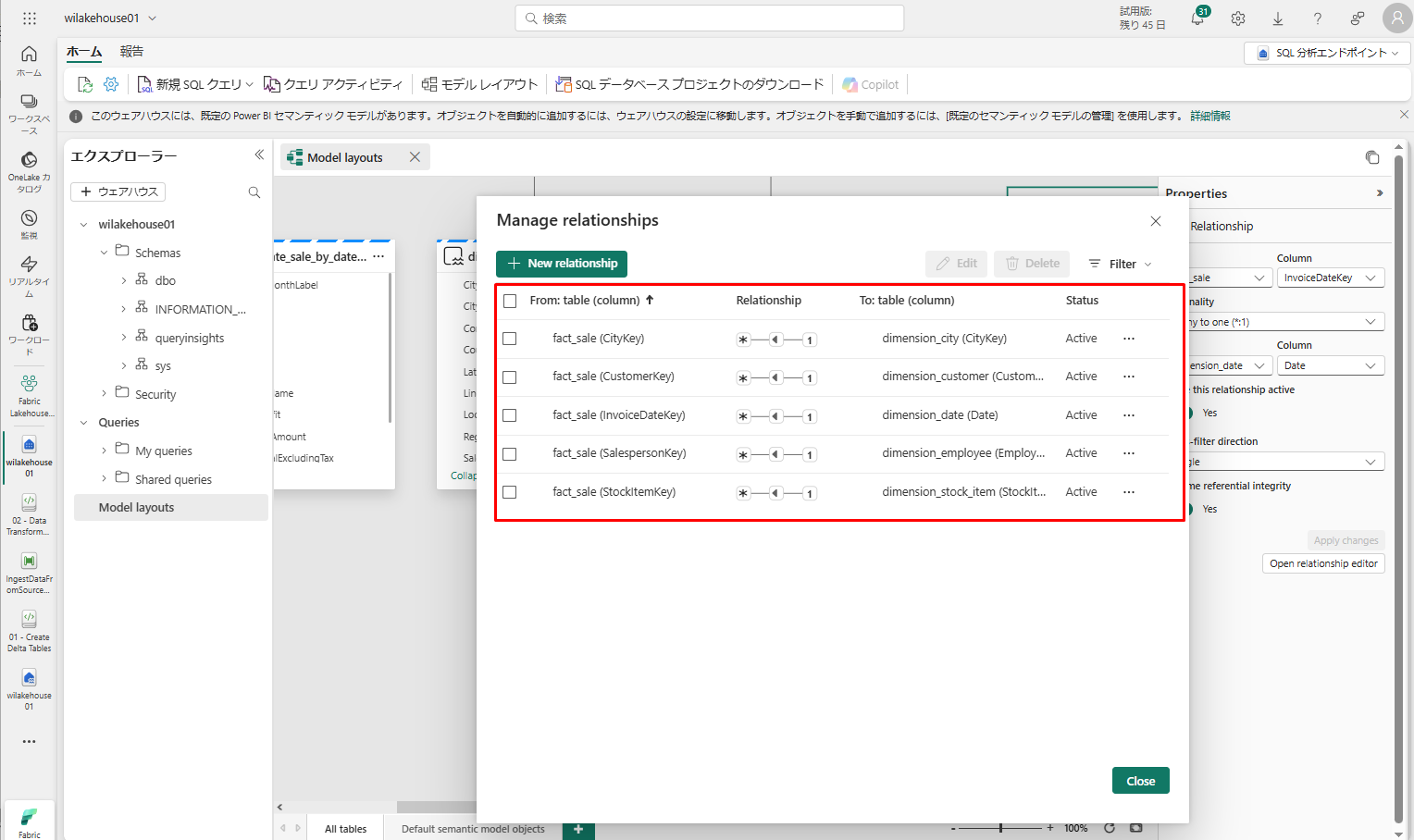
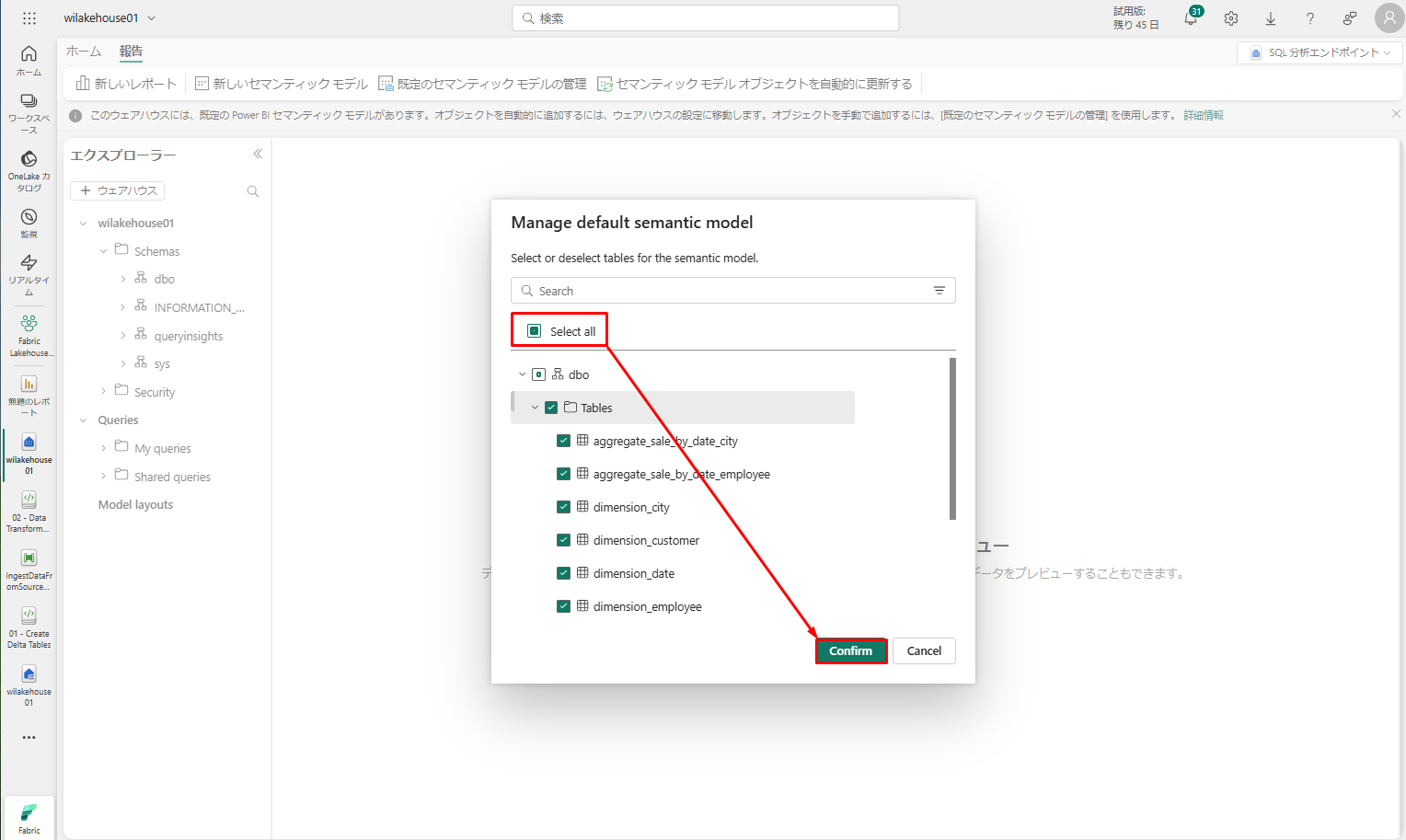
「報告」タブで「既定のセマンティックモデルの管理」を選択します。
「既定のセマンティックモデルの管理」ダイアログ ボックスで 「すべて選択」>「確認」をクリックします。
「新しいレポート」を選択して、Power BI でレポート・ダッシュボードの作成を開始します。
4. タイトルの追加
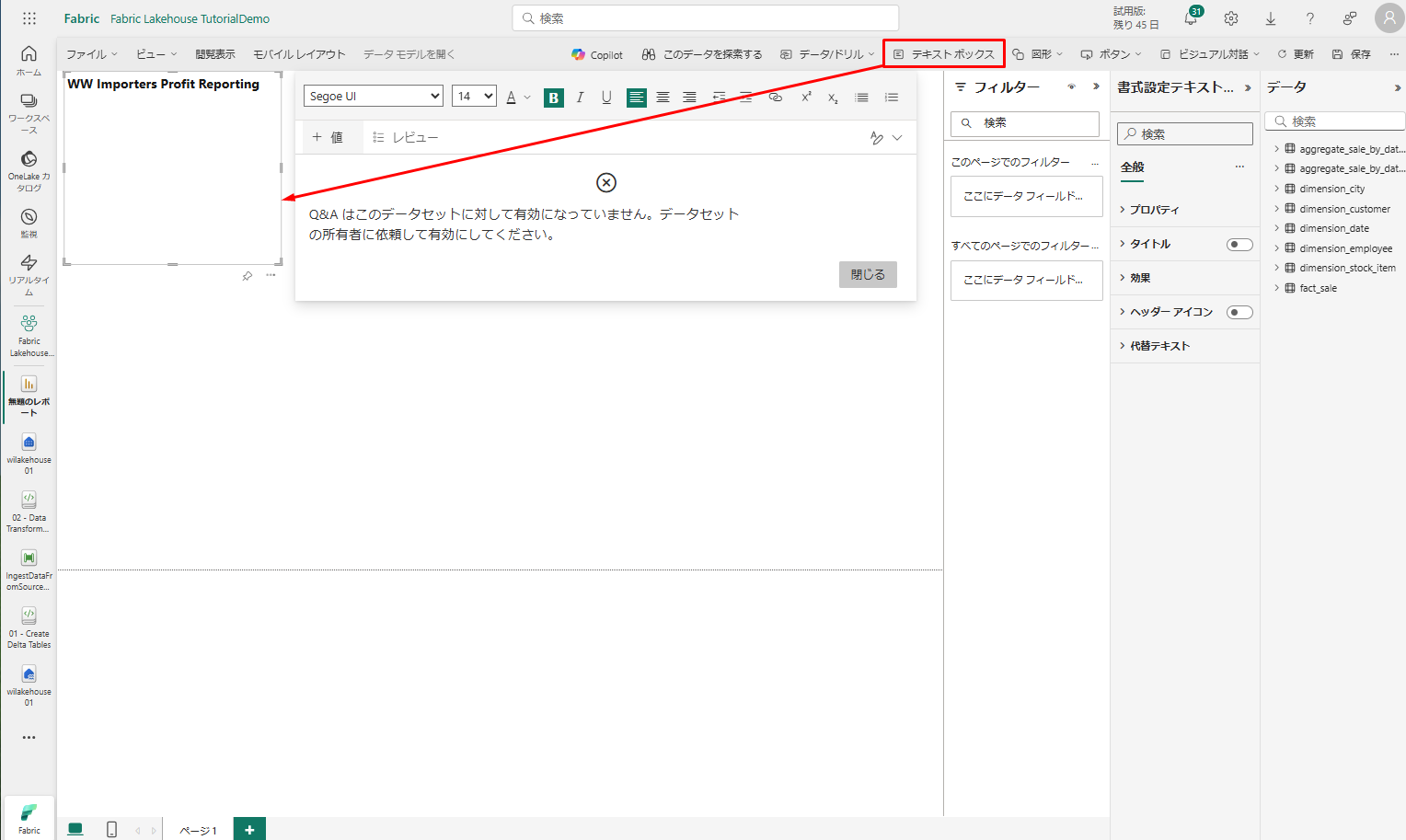
以下の手順で実施して、タイトルを追加します。
- リボンで、「テキスト ボックス」を選択し、「WW Importers Profit Reporting」と入力します。
- レポートページの左上にテキストを強調表示し、サイズを 20 に拡大します。
5. カードの追加
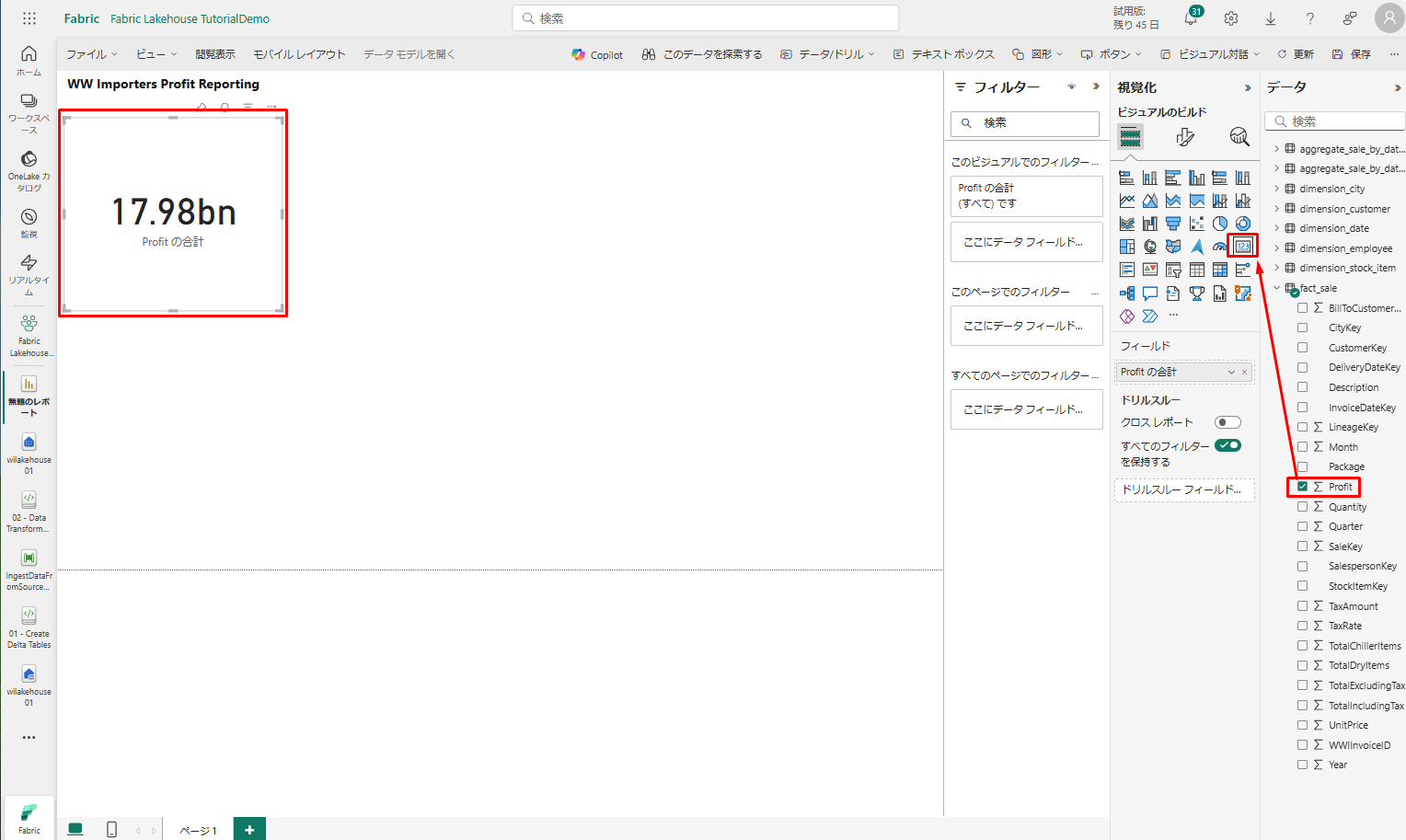
以下の手順で実施して、カードを追加します。
- 「データ」ウィンドウで、「fact_sale」を開き、「Profit」の横にあるボックスをチェックします。 このオプションを選択すると、縦棒グラフを作成し、フィールドを Y 軸に追加します。
- 横棒グラフを選択した後、視覚化ウィンドウでカード ビジュアルを選択します。このオプションを選択すると、ビジュアルがカードに変換されます。
- タイトルの下にカードを移動します。
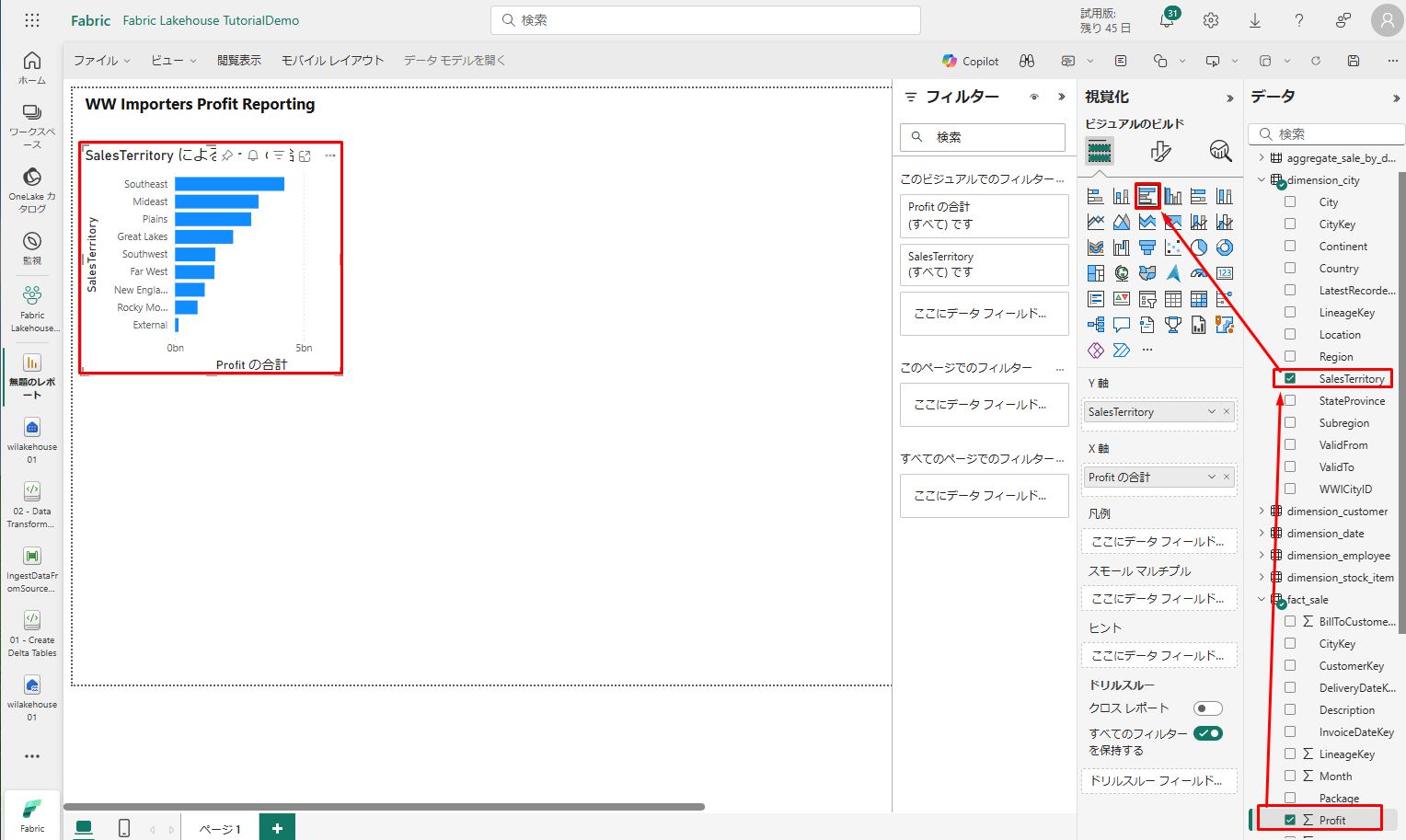
6. 横棒グラフの追加
以下の手順で実施して、横棒グラフを追加します。
- 「データ」ウィンドウで、「fact_sales」>「Profit」ボックスをチェックします。
- 「データ」ウィンドウで、「dimension_city」>「SalesTerritory」ボックスをチェックします。
- 横棒グラフを選択した後、視覚化ウィンドウで「集合横棒グラフ」を表示します。 このオプションを選択すると、縦棒グラフが横棒グラフに変換されます。
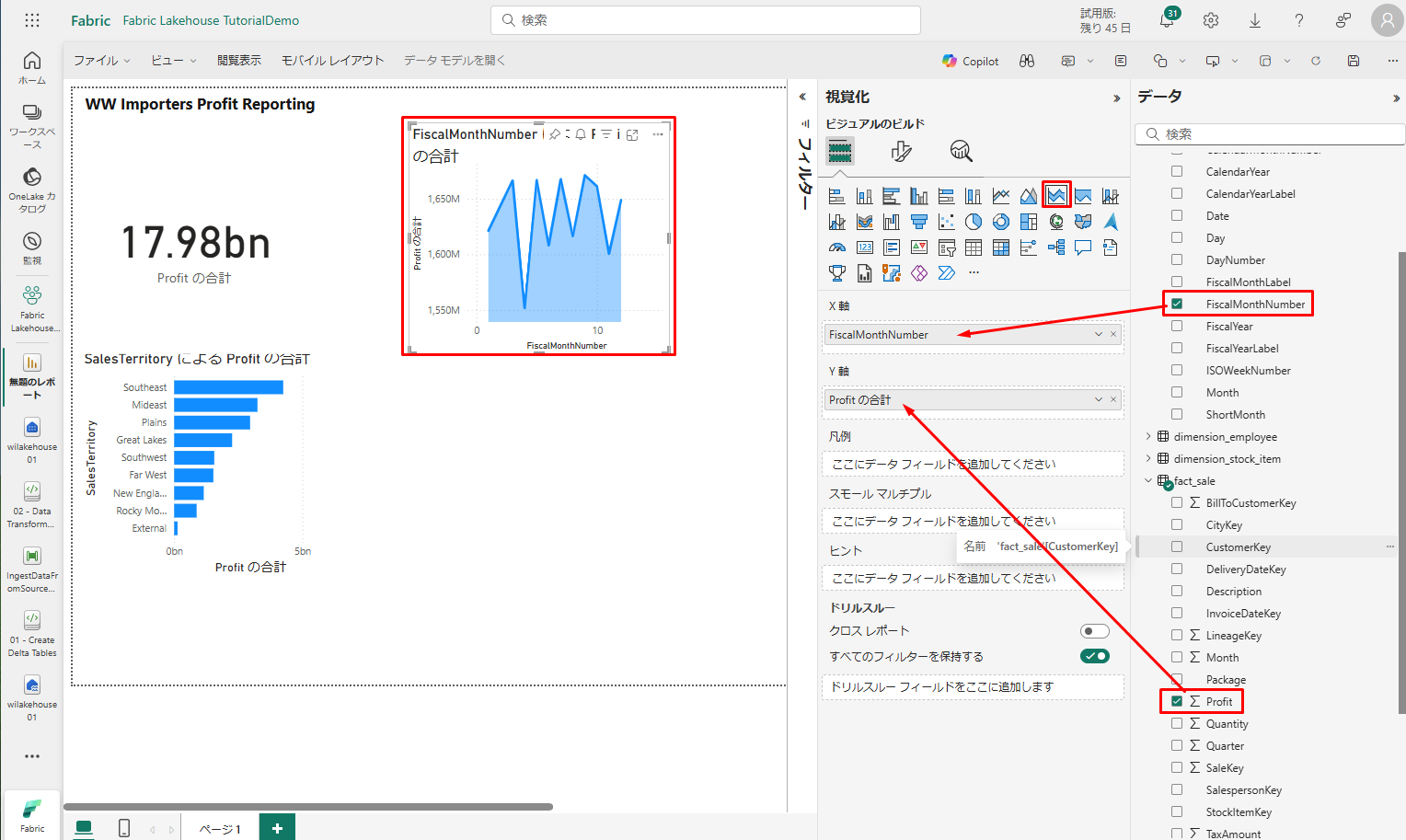
7. 積み上げ面グラフのビジュアルのビルド
積み上げ面グラフのビジュアルのビルドを行います。
- 「視覚化」ウィンドウで、「積み上げ面グラフ」ビジュアルを選択します。
- 前のステップで作成したカード、および横棒グラフビジュアルの右側にある積み上げ面グラフのサイズを変更します。
- 「データ」ウィンドウで、「fact_sales」>「Profit」ボックスをチェックします。「dimension_date」>「FiscalMonthNumber」ボックスをチェックします。
- このオプションを選択すると、会計月次利益を示す塗りつぶし折れ線グラフが作成されます。
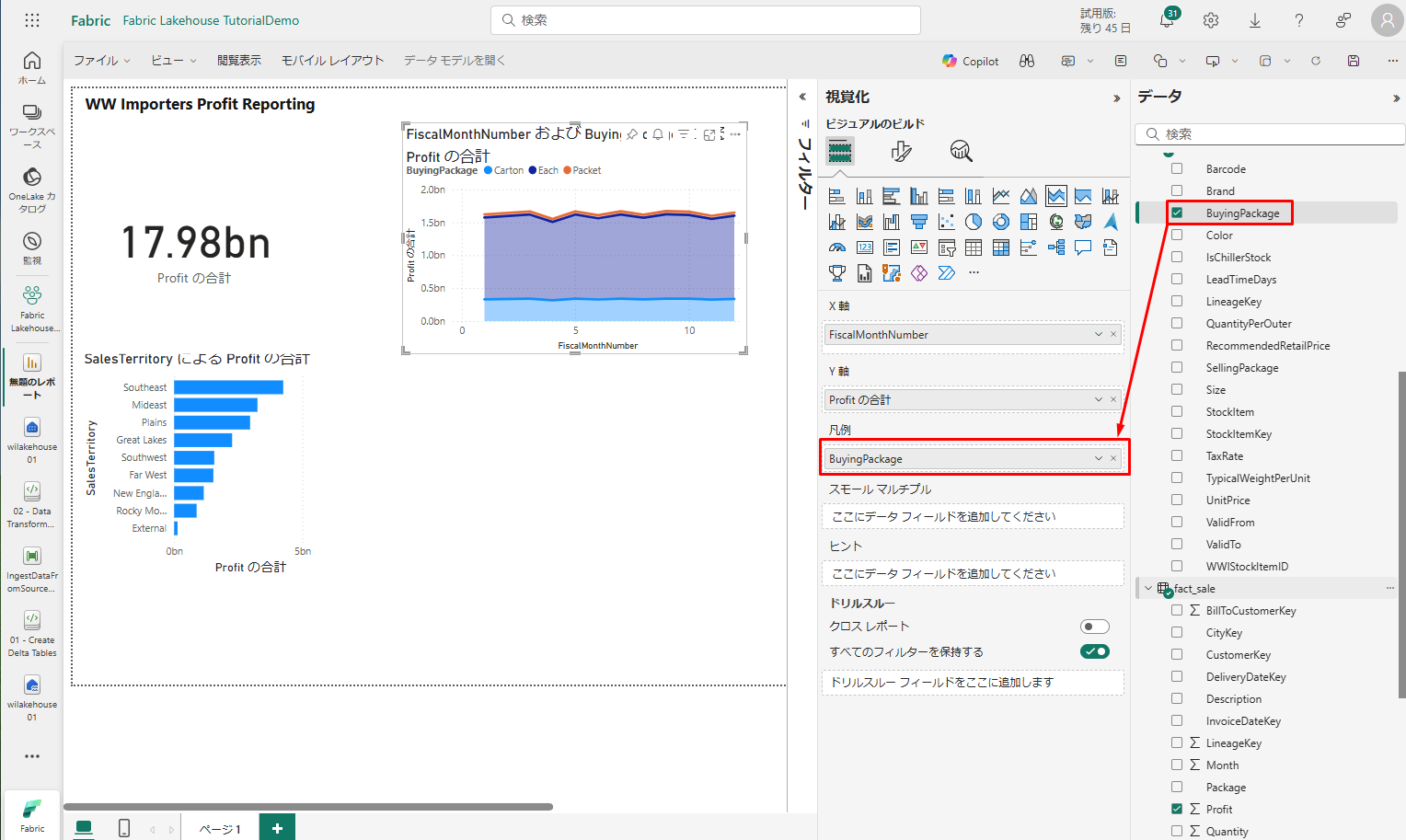
「データ」ウィンドウで、「dimension_stock_item」を展開し、「BuyingPackage」を「凡例」フィールドにドラッグします。
このオプションを選択すると、購入パッケージごとに行が追加されます。
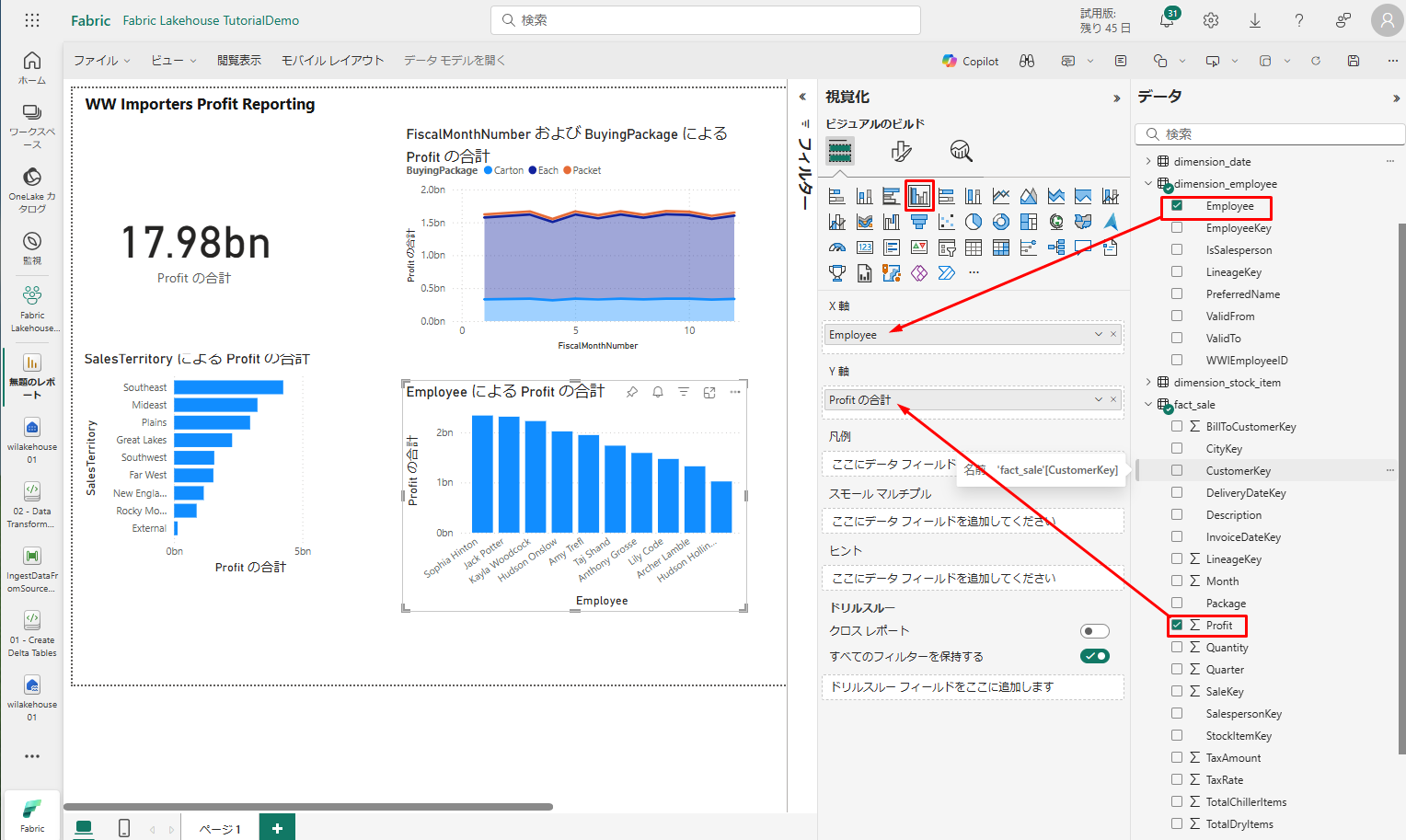
8. 横棒グラフのビルド
横棒グラフのびるど:
- 「視覚化」ウィンドウで、「積み上げ縦棒グラフ」の視覚化を選択します。
- 「データ」ウィンドウで、「fact_sales」を展開し、「Profit」の横にあるボックスをチェックします。 この選択により、フィールドが Y 軸に追加されます。
- 「データ」ウィンドウで、dimension_employee を展開し、「Employee」の横にあるチェックボックスをオンにします。 この選択により、フィールドが X 軸に追加されます。
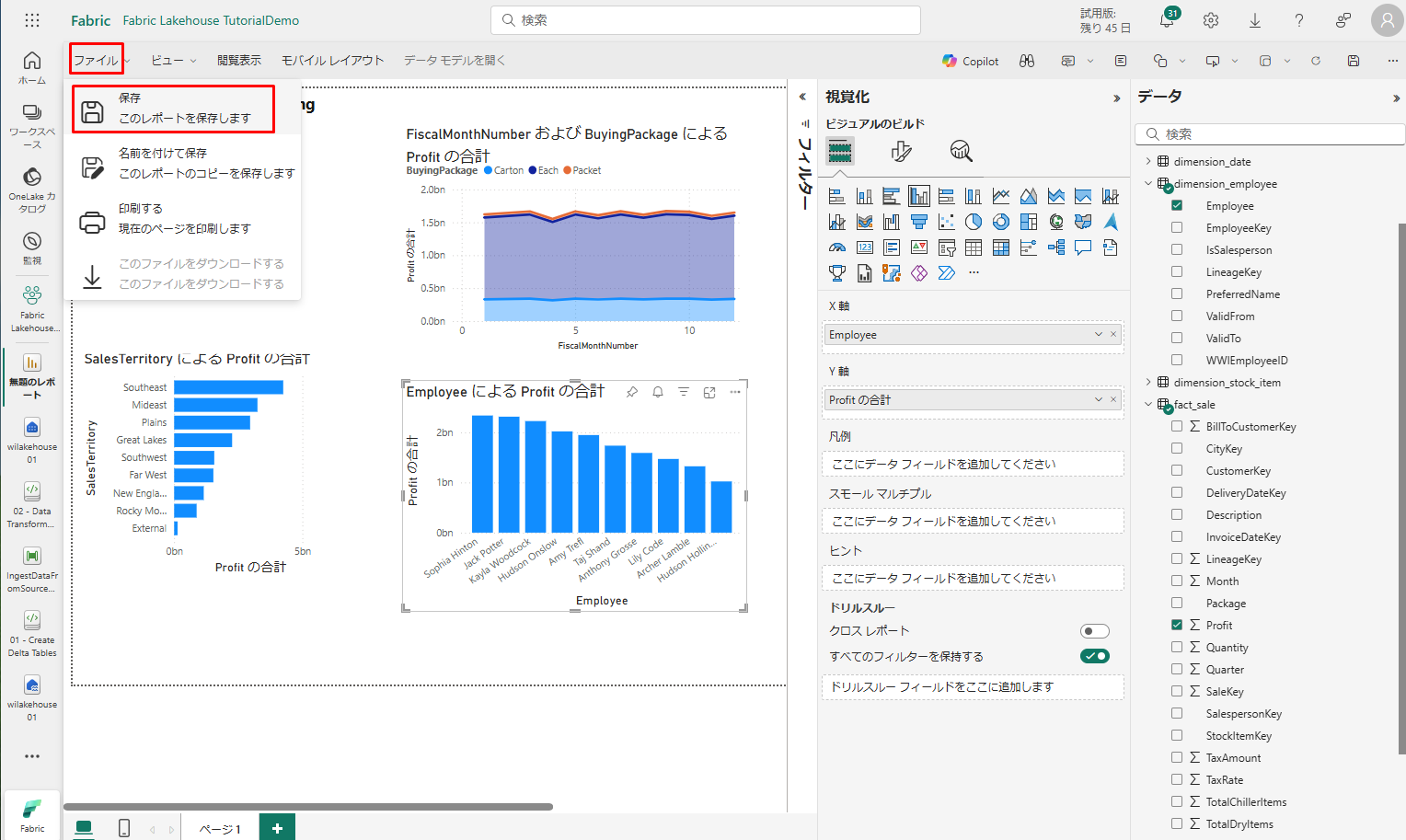
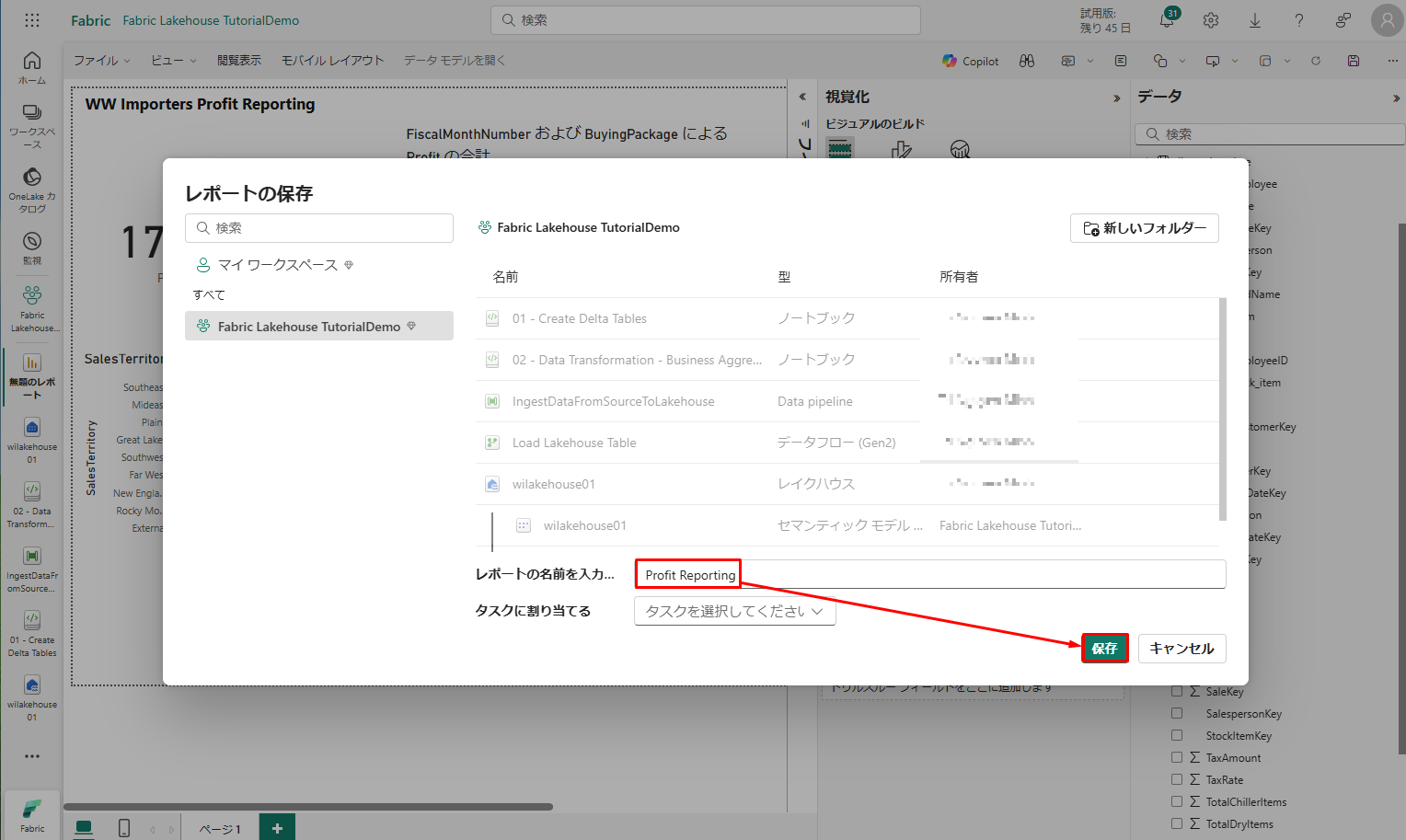
リボンから「ファイル」>「保存」を選択します。
9. まとめ
Microsoft Fabric の Synapse Data Engineering の使用方法の第 2 部 の使用方法をについて実施してみました。 今回の記事が少しでも Microsoft Fabric を知るきっかけや、業務のご参考になれば幸いです。
第1回:Microsoft Fabric 概要と試用版の作成方法
第2回:Power BI ユーザー向け Fabric チュートリアル
第3回:Data Factory ユーザー向け Fabric チュートリアル
第4回:Synapse Data Engineering ユーザー向け Fabric チュートリアル_第1回
第5回:Synapse Data Engineering ユーザー向け Fabric チュートリアル_第2回 (今回)