Data+AI Summit 2024 Day2 (6/12)
powered by 日商エレクトロニクス

こんにちは、日商エレクトロニクスのデータサイエンティスト、トゥアンです。
本記事では、6月12日に開催されたData + AI Summit Day2の各セッションの前半部分を随時更新しながらまとめていきます。
Data+AI Summit 2024の公式サイトはコチラ >
Data+AI Summit 2024のDay1のまとめはコチラ >
Data+AI Summit 2024 キーノート1のまとめはコチラ >
●こんな方におススメ
- Data + AI SUMMIT 2024 基調講演の内容を日本語でサクッと把握したい方
- GenAIやLLMの最新技術をキャッチアップしたい方
1. Mosaic AIのご紹介: カスタムLLM開発へのゲートウェイ
Mosaic AIは、Databricksの包括的なツールスイートであり、AIとMLのライフサイクル全体を効率化します。予測モデルの構築から最先端のGenAIやLLMまで、Mosaic AIは組織が企業データを安全かつ費用対効果の高い方法で活用できるようにします。
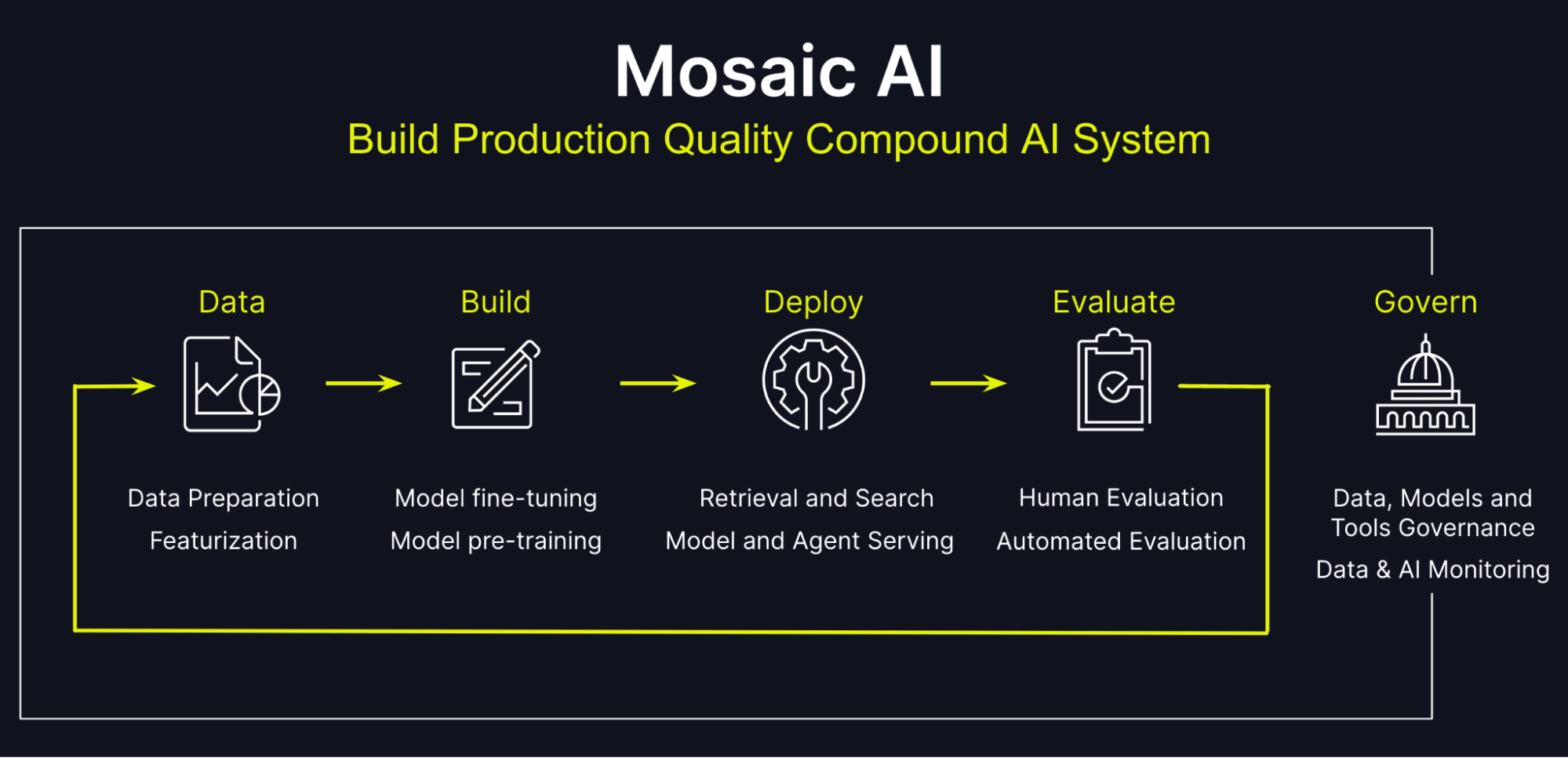
Databricks Mosaic AIプラットフォームは、企業が本番品質のAIシステムを構築するための包括的なソリューションです。 主な機能は以下の通りです。
- Compound AI Systemsの構築と展開:
- Mosaic AI Model Training:モデルのファインチューニングや事前学習をサポート
- Mosaic AI Vector Search:顧客管理キーとハイブリッド検索をサポートしたベクトル検索
- Mosaic AI Agent Framework:RAGアプリケーションの迅速な開発を可能にするフレームワーク
- Mosaic AI Model Serving:エージェントとRAGの提供、Foundation Model APIの一般提供
- Mosaic AI Tool Catalog and Function-Calling:企業全体で共有可能な関数レジストリを作成し、モデルサービングで関数呼び出しをサポート
- AIシステムの評価:
- Mosaic AI Agent Evaluation:自動評価と人間による評価を組み合わせた評価ツール
- MLflow 2.14:LLMやAIシステムを評価するためのモデルに依存しないフレームワーク
- AIシステムの管理:
- Mosaic AI Gateway:モデルの管理、統制、評価、切り替えを容易にする統一インターフェース
- Mosaic AI Guardrails:安全でない応答や個人情報漏洩を防ぐためのフィルタリング
- system.ai Catalog:厳選されたオープンソースモデルのカタログ
これらの機能により、企業は単一のプラットフォームから複合AIシステムを構築し、コラボレーションすることができます。エンタープライズデータを活用することで、一般的なインテリジェンスからデータインテリジェンスへと移行し、より関連性の高い洞察を迅速に得ることができます。
2. Mosaic AI Vector Search
DatabricksのMosaic AI Vector Searchは、Databricks Data Intelligence Platformに統合されたベクターデータベースです。埋め込み(データの意味内容を数学的に表現したもの)の効率的な保存と検索を可能にします。ベクターデータベースは、RAGシステム、レコメンダーシステム、画像/動画認識などのGenAIアプリケーションでよく使用されます。
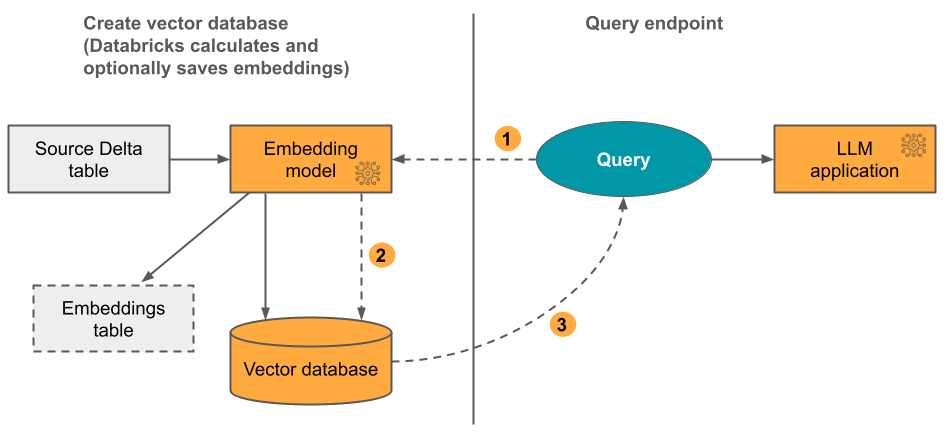
Mosaic AI Vector Searchは、近似最近傍探索にHNSWアルゴリズムを、埋め込みベクトル類似度の測定にL2距離メトリックを使用します。また、ベクトルベースの埋め込み検索と従来のキーワードベースの検索技術を組み合わせた、ハイブリッドキーワード類似度検索もサポートしています。
Databricksでベクトルデータベースを作成するには、埋め込みの提供方法を決定する必要があります。Databricksは3つのオプションをサポートしています。Databricksが埋め込みを計算するためのテキスト形式のデータを含むソースDeltaテーブルの提供、事前に計算された埋め込みを含むDeltaテーブルの提供、またはREST APIを使用して手動でインデックスを更新することです。
Vector Searchを設定するには、ベクトル検索エンドポイントとベクトル検索インデックスを作成する必要があります。Databricksが埋め込みを計算する場合、事前に設定されたFoundation Model APIエンドポイントを使用するか、モデル提供エンドポイントを作成することができます。モデル提供エンドポイントは、REST APIまたはPython SDKを使用してクエリでき、Deltaテーブルの列に基づいてフィルタリングすることができます。
Databricksは、論理的な分離、認証、認可、暗号化などのセキュリティ管理を実施してデータを保護します。認証には、個人アクセストークンまたはサービスプリンシパルトークンを使用できます。使用量とコストの監視は、請求可能な使用量システムテーブルを通して可能です。
3. プロンプトエンジニアリングは終わり?
タスクに最適な魔法のような言葉の組み合わせを見つけ出すのに苦労する必要はありません。評価指標を開発し、モデルに自己最適化させましょう。
— Rick Battle, VMware, “Don’t start a career as an AI Prompt Engineer”
従来のAI開発は、プロンプトエンジニアリングに大きく依存していました。これは、言語モデルから最適なパフォーマンスを引き出すために、適切な言葉を注意深く作成するプロセスです。しかし、このアプローチは時間がかかり、脆弱でした。
- 複雑なシステム: 問題は小さなステップに分割され、それぞれが細かく調整されたプロンプトを必要としました。
- 孤立 vs 統合: 個別にうまく機能するプロンプトも、組み合わせるとうまくいかないことがよくありました。
- 絶え間ない調整: パイプライン、モデル、またはデータに変更があると、プロンプトの書き直しが必要になる可能性がありました。

LMプロンプトと重みをアルゴリズム的に最適化するフレームワーク、DSPyをご紹介します。(明細)

DSPyのパラダイムは、手動のプロンプト作成の必要性を排除します。代わりに、開発者はパフォーマンス指標を定義し、DSPyのAI駆動アルゴリズムが特定のタスクで卓越するようにモデルを最適化します。方法は次のとおりです。
- 分離: DSPyは、プログラムのロジックとモデルのパラメータ(プロンプトと重み)を分離します。
- 最適化: AIを搭載した「オプティマイザー」は、目的の指標に基づいてプロンプトと重みを動的に調整します。
DSPyを使用すると、開発者はもはやプロンプトエンジニアリングの専門家である必要はありません。このフレームワークは、最高の人間が作成したプロンプトよりも優れた結果を生成し、パイプラインやデータの変更にシームレスに適応します。これは、継続的に自己改善するAIシステムへの大きな転換であり、新たなレベルの効率性とパフォーマンスを引き出します。
この記事を書いた人
この投稿者の最新の記事
- 2025年6月13日ブログ【Azure Databricks】Databricks Data + AI Summit Day 3:基調講演ハイライトまとめ
- 2025年6月12日ブログ【Azure Databricks】Databricks Data + AI Summit Day 2:基調講演ハイライトまとめ
- 2025年6月11日ブログ【Azure Databricks】Databricks Data + AI Summit Day 1:Databricksとパートナー企業からの最新アップデート
- 2025年3月7日ブログ【Azure Databricks】LLMとDatabricksで企業のデータ活用を加速する方法