目次
1. はじめに
皆さんこんにちは。
今回はAzure DatabricksのDeltaテーブルのチューニングについて説明していきます。
2.Deltaテーブルとは
Deltaテーブルは、クラウドオブジェクトストレージ上のファイルのディレクトリとして
データを格納し、カタログとスキーマ内のメタストアにテーブルメタデータを登録します。
Delta Lakeは、Azure Databricksで既定のストレージ形式であり、
特に指定がない限りAzure Databricks上のすべてのテーブルはDeltaテーブルです。
3.Deltaテーブルのチューニングとは
Deltaテーブルのチューニングとは、Deltaテーブルのファイルサイズを調整したり、
データを並び替えたりすることでパフォーマンスを向上させることができます。
4.今回紹介するコマンド
【OPTIMIZE】
OPTIMIZEは、小さいファイルを大きいファイルに結合し、
Deltaテーブルを使用する時のクエリ速度を向上させる方法です。
OPTIMIZEは毎日実行することを推奨しています。
ただし、リソースがかかるため、コストもかかります。
[詳細]
・通常、DeltaテーブルでINSERT、UPDATE、DELETE等の操作を実行する際は、
データは複数の場所に保存されるため、クエリの速度は低下します。
ですが、DeltaテーブルでOPTIMIZEを実行すると、Delta Lakeがファイルを最適化し、
小さいファイルは大きいファイルに結合し、同じ場所で保存することができます。
・OPTIMIZE を実行した後、Delta Lake はテーブルの新規バージョンを作成するため、
旧ファイルは削除されることはありません。
※後ほどご説明するVACUUMを実行することで不要なファイルは定期的に削除することができます。
【ZORDER】
ZORDERは、実行するとDelta Lakeが指定された列の値でデータを並べ替え、
クエリの実行時に読み取るデータの負荷を軽減します。
ZORDERを利用する場合、リソースがかかるため、
OPTIMIZEと一緒に使用するのが最適です。
[詳細]
・OPTIMIZEとZORDERは、併用することでDelta Lakeが小さいファイルを大きいファイルに結合し、
同じ場所で保存し、指定された列に従いデータを並び替えることができます。
それによりクエリ速度を向上しますが、実行時間及びリソースがOPTIMIZEよりかかります。
【VACUUM】
VACUUMは実行すると、Deltaテーブルの全ての保存期間切れのデータファイルを削除します。
[詳細]
・ストレージ コストを削減するために、全てのテーブルで VACUUMを実行する必要があります。
・UPDATE、INSERT、DELETEコマンドが実行される頻度によって定期実行期間が異なります。
今回のブログでは、OptimizeTableというデモ用のテーブルを作成し、
作成したテーブルに対してチューニングコマンドを実行していきます。
5.実行方法
5-1.ノートブックを開く
【既存のノートブックを開く】
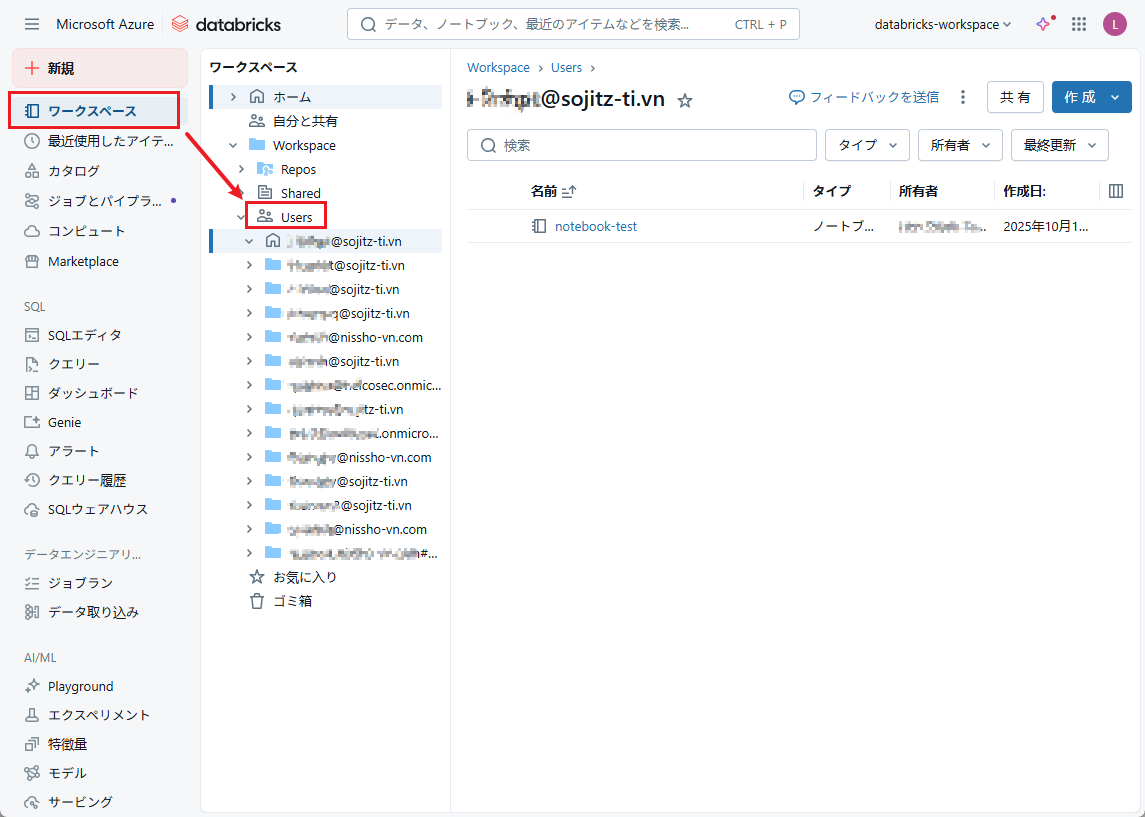
①こちらの手順でワークスペースにアクセスします。
②Azure Databricksポータル画面で、ワークスペース > Users > ユーザー名を選択します。
【新規のノートブックを作成する】
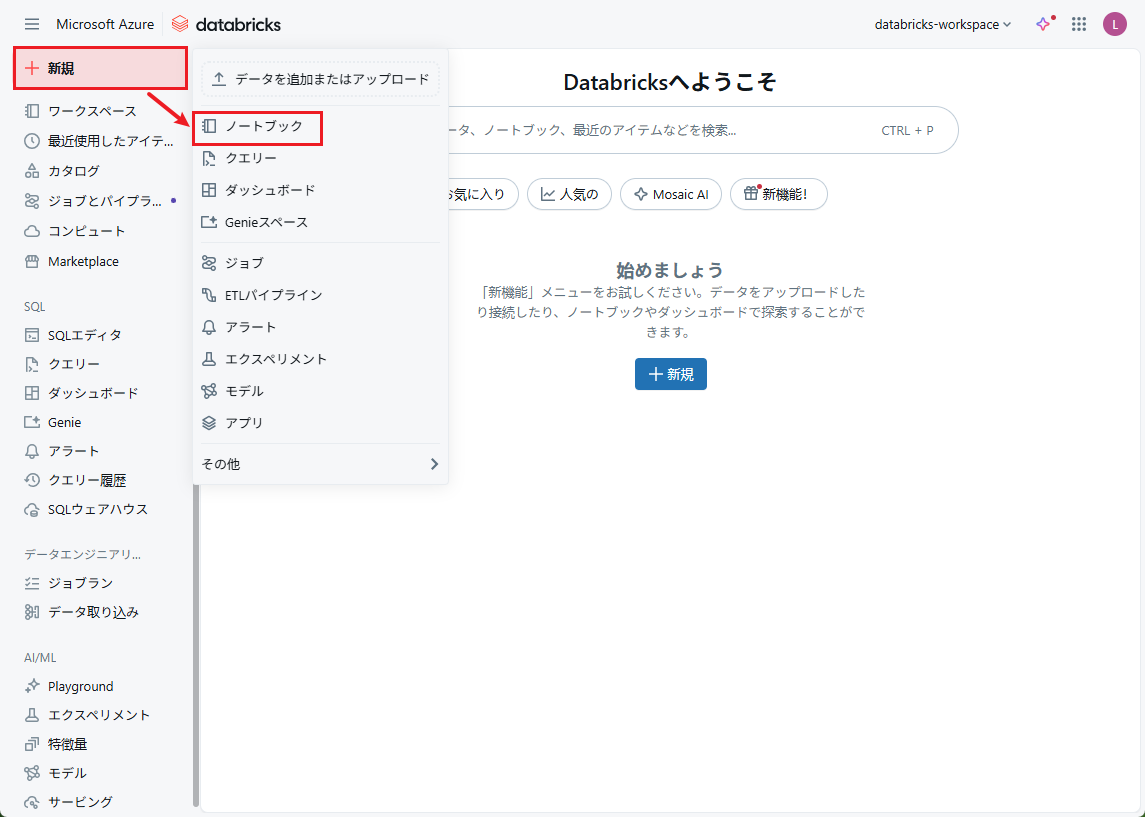
①こちらの手順でワークスペースにアクセスします。
②Azure Databricksポータル画面で、[+新規]>[ノートブック]を選択します。
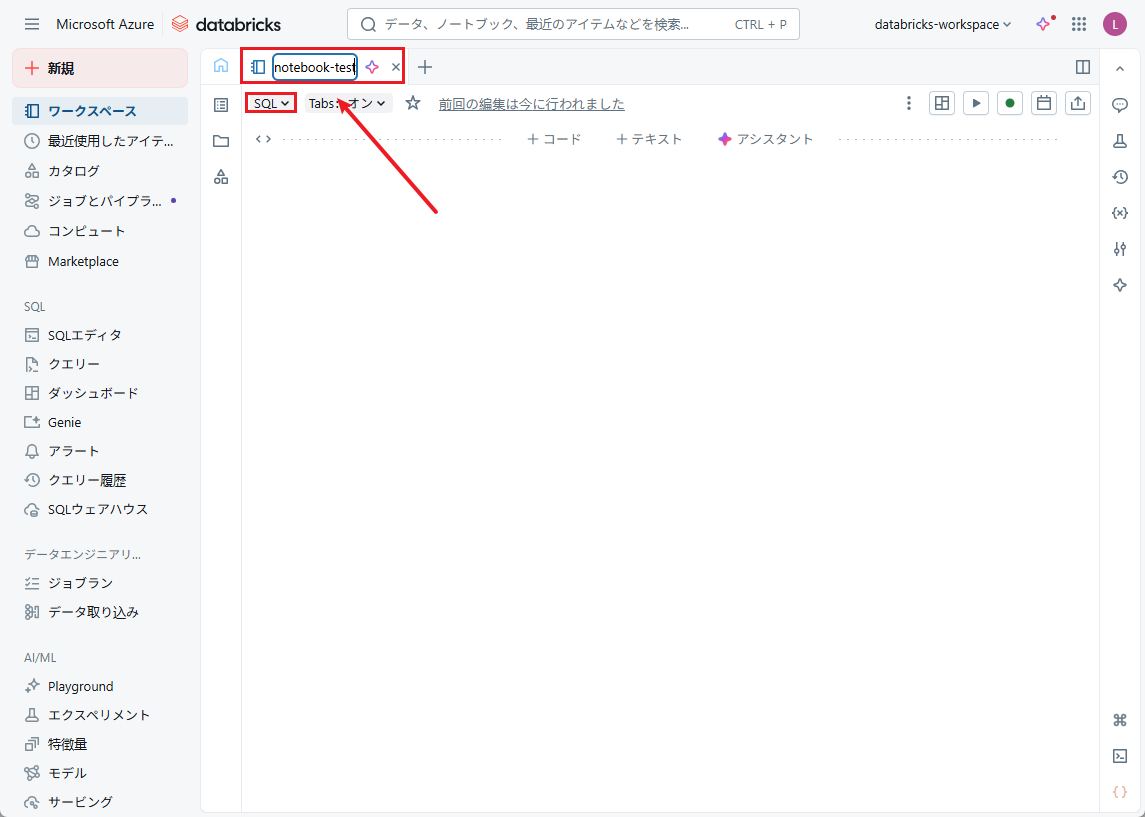
③ツールバーを使って、ノートブックの名前と使用するプログラミング言語を変更できます。
5-2.テーブル作成コマンドを入力し実行する
【文法】
|
1 2 3 4 5 |
CREATE TABLE <カタログ名>.<スキーマ名>.<テーブル名>( [カラム名] [データ型], [カラム名] [データ型] ) PARTITIONED BY ([パーティションキー]); |
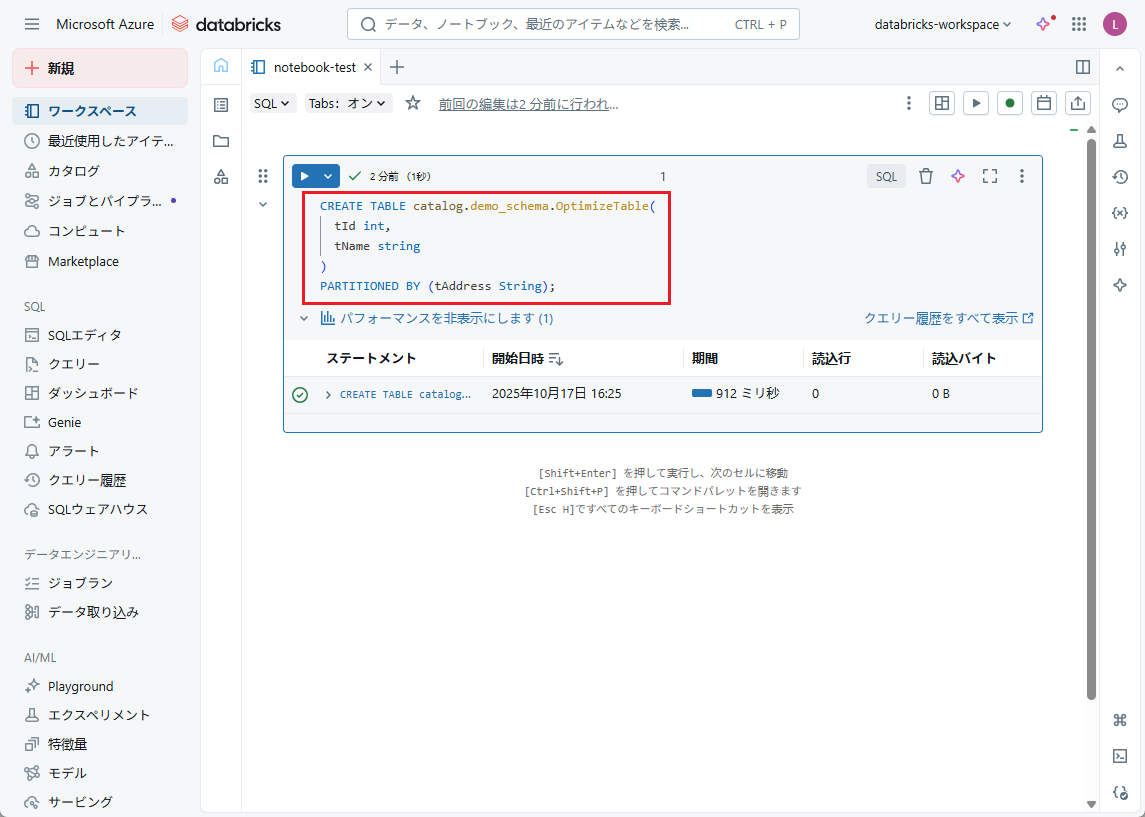
【例】「OptimizeTable」テーブルが作成され、テーブルの「tAddress」に従って場所が分けられます。
|
1 2 3 4 5 |
CREATE TABLE catalog.demo_schema.OptimizeTable( tId int, tName string ) PARTITIONED BY (tAddress String); |
5-3.データ挿入コマンドを入力しRUNを実行する
【文法】
|
1 2 3 4 5 6 7 8 |
%sql INSERT INTO <カタログ名>.<スキーマ名>.<テーブル名> VALUES (1, ' [値]', '[値]'),(2, '[値]', '[値]'),(3, '[値]', '[値]'); INSERT INTO <カタログ名>.<スキーマ名>.<テーブル名> VALUES (4, '[値]', '[値]'),(5, '[値]', '[値]'),(6, '[値]', '[値]'); INSERT INTO <カタログ名>.<スキーマ名>.<テーブル名> VALUES (7, '[値]', '[値]'),(8, '[値]', '[値]'),(9, '[値]', '[値]'); |
【例】作成したテーブルにデータを追加します。
|
1 2 3 4 5 6 |
INSERT INTO catalog.demo_schema.OptimizeTable values (1, 'TableName1', 'Address1'),(2, 'TableName2', 'Address1'),(3, 'TableName3', 'Address1'); INSERT INTO catalog.demo_schema.OptimizeTable values (4, 'TableName4', 'Address2'),(5, 'TableName5', 'Address2'),(6, 'TableName6', 'Address2'); INSERT INTO catalog.demo_schema.OptimizeTable values (7, 'TableName7', 'Address3'),(8, 'TableName8', 'Address3'),(9, 'TableName9', 'Address3'); |
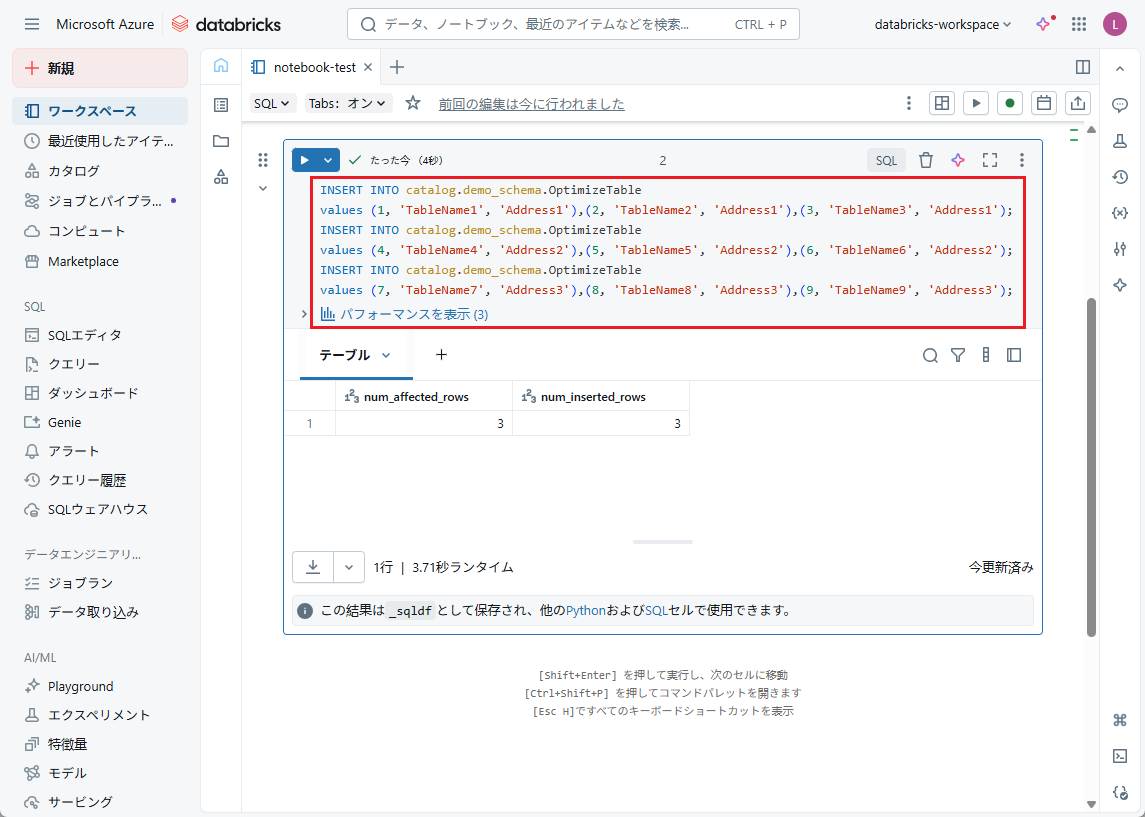
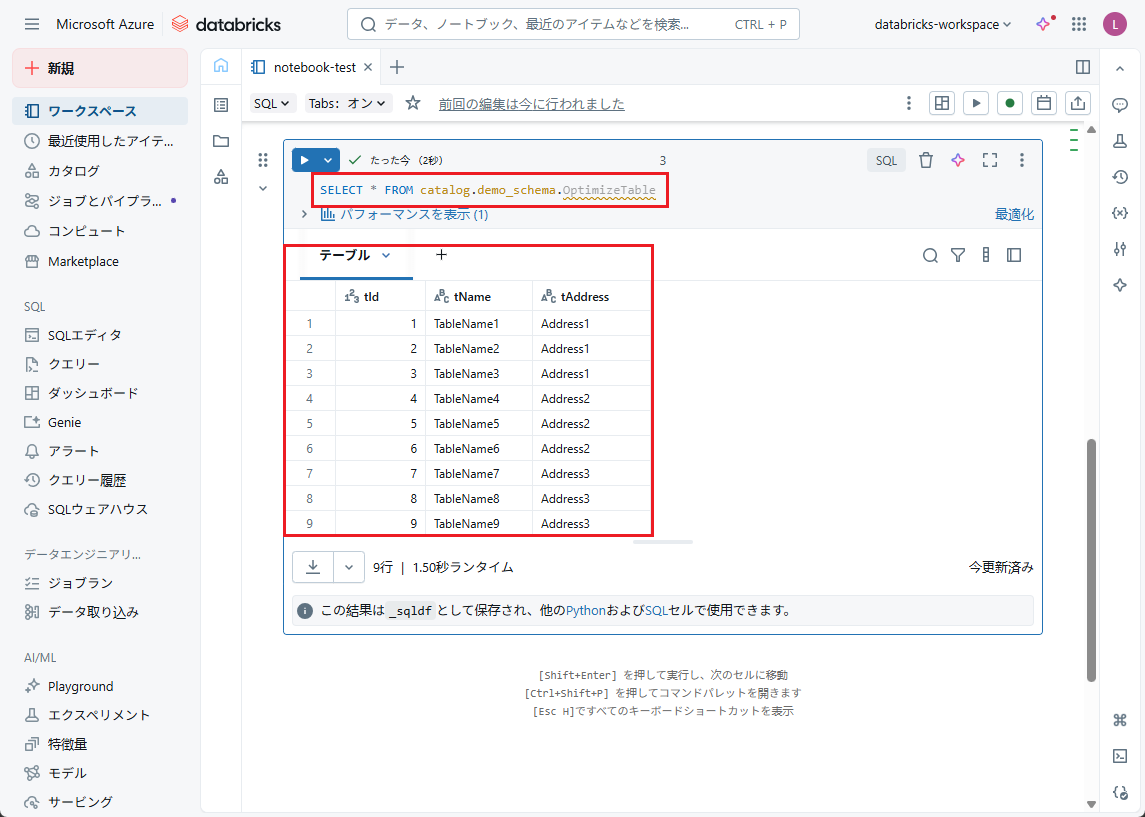
【挿入されたデータを確認する】
以下のコマンドからデータを確認することができます。
|
1 |
SELECT * FROM catalog.demo_schema.OptimizeTable; |
5-4.OPTIMIZEコマンド、ZORDERコマンドを実行する
・テーブル全体にOPTIMIZEコマンドを入力しRUNを実行する
【文法】
|
1 |
OPTIMIZE <カタログ名>.<スキーマ名>.<テーブル名>; |
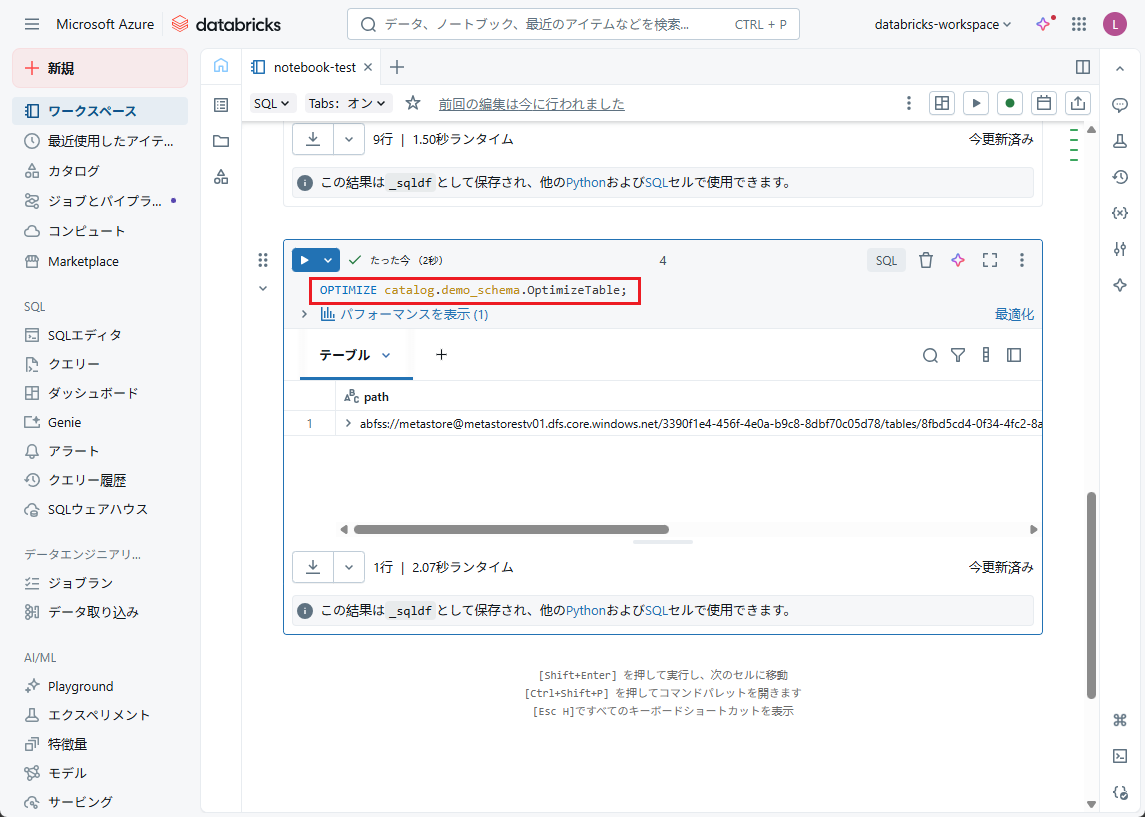
【例】OptimizeTableにOPTIMIZEコマンドを実行します。
|
1 |
OPTIMIZE catalog.demo_schema.OptimizeTable; |
・パーティションのレコードにOPTIMIZEコマンドを入力しRUNを実行する
【文法】
|
1 |
OPTIMIZE <カタログ名>.<スキーマ名>.<テーブル名> WHERE [列名] = '[値]' |
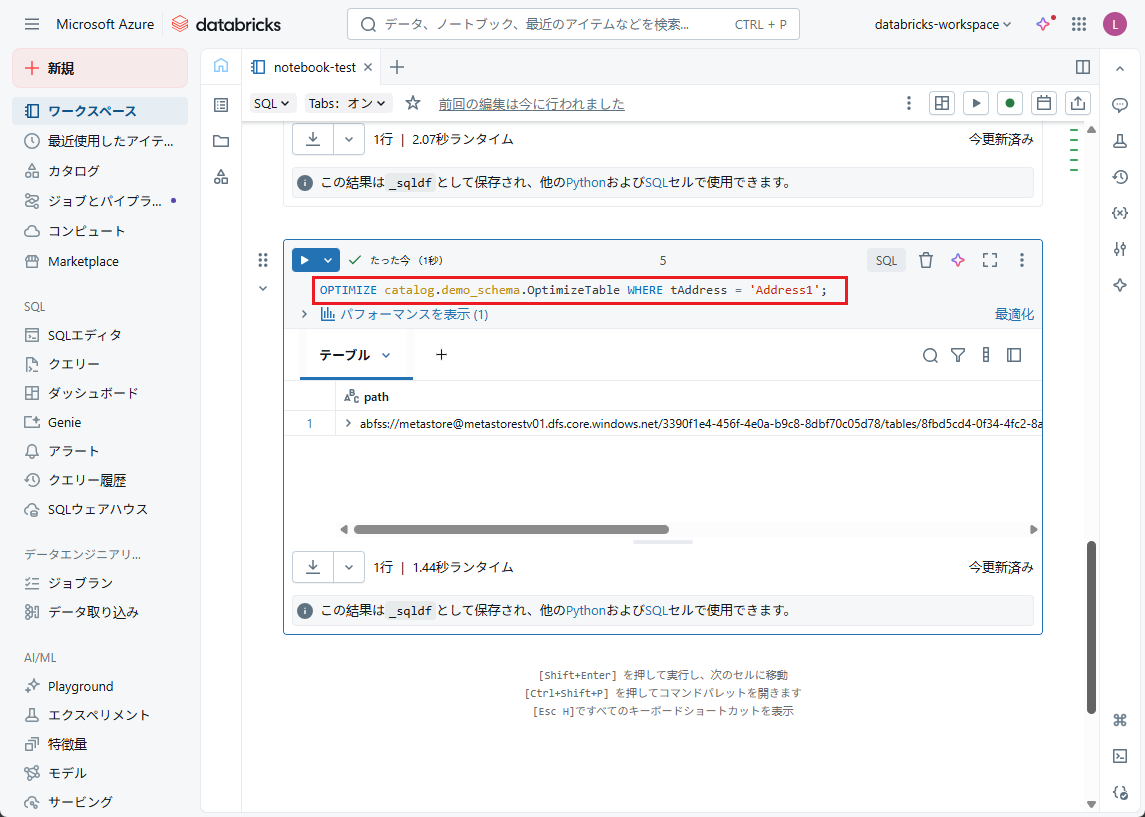
【例】OptimizeTableのtAddress列のAddress1にOPTIMIZEコマンドを実行します。
|
1 |
OPTIMIZE catalog.demo_schema.OptimizeTable WHERE tAddress = 'Address1'; |
・パーティションのレコードにOPTIMIZEコマンドを実行し、
列の値でレコードを並べ替えるためにZORDER を使用する
【文法】
|
1 2 |
OPTIMIZE <カタログ名>.<スキーマ名>.<テーブル名> WHERE [列名1] = '[値]' ZORDER BY ([列名2]) |
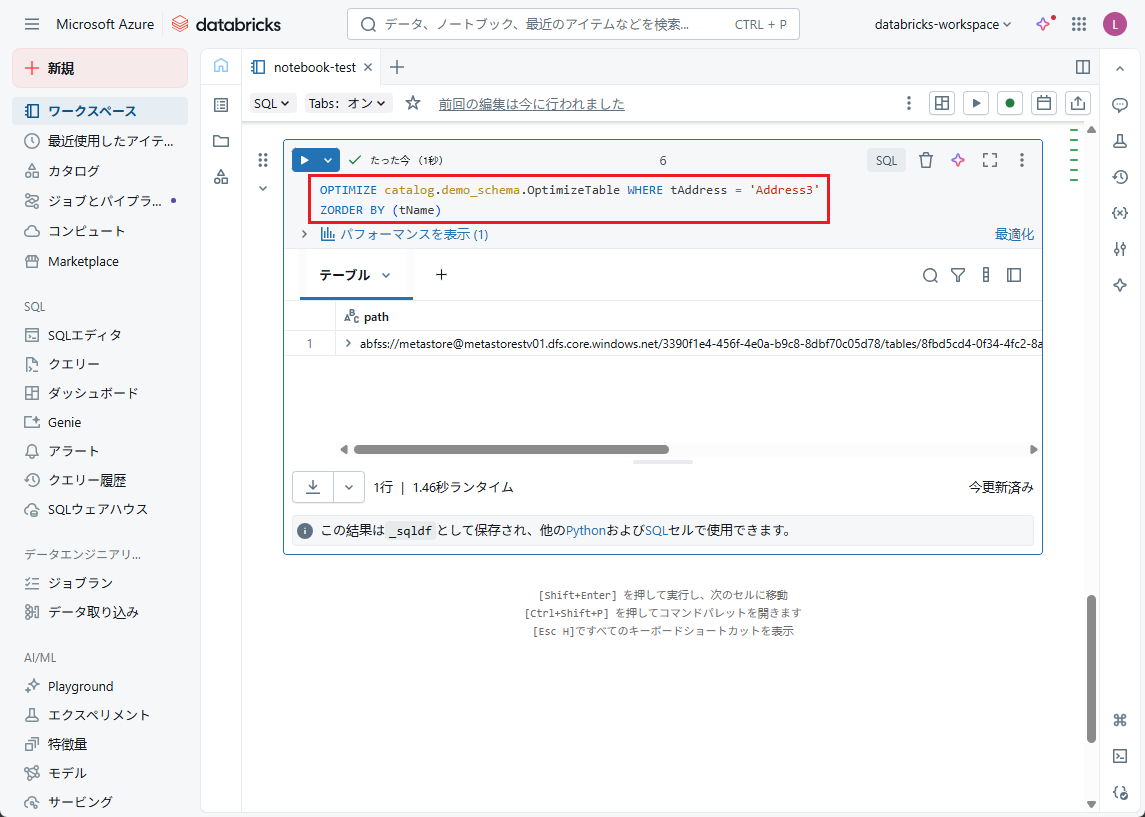
【例】OptimizeTableのtAddress列のAddress1にOPTIMIZEコマンドを実行し、
tNameごとにレコードを並び替えます。
|
1 2 |
OPTIMIZE catalog.demo_schema.OptimizeTable WHERE tAddress = 'Address3' ZORDER BY (tName) |
5-5.VACUUMコマンドを入力しRUNを実行する
最後にVACUUMコマンドの実行方法についてご説明いたします。
【文法】
|
1 |
VACUUM <カタログ名>.<スキーマ名>.<テーブル名> [RETAIN 数 HOURS] DRY RUN |
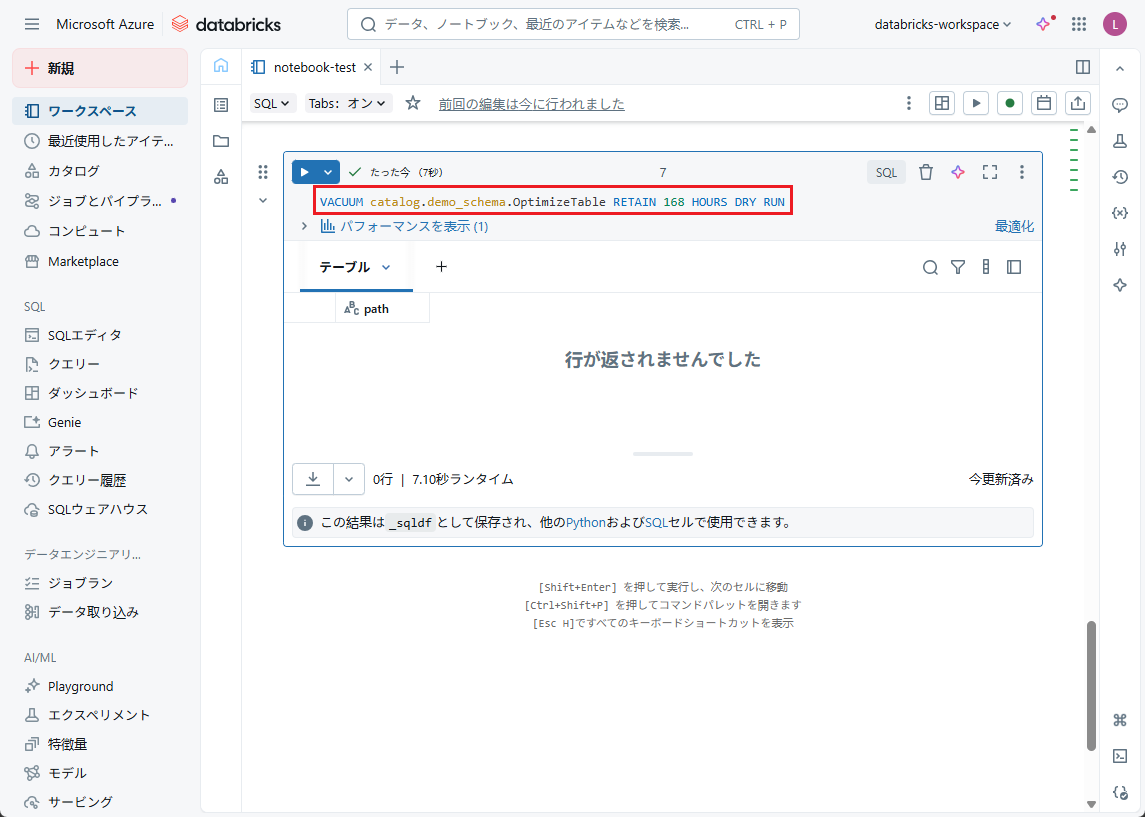
【例】7 日以上経過したデータは削除されます。
|
1 |
VACUUM catalog.demo_schema.OptimizeTable RETAIN 168 HOURS DRY RUN |
6. まとめ
本記事ではAzure DatabricksのDeltaテーブルのチューニングについて説明しました。
ご紹介したコマンドを実行することで、
Deltaテーブルのファイルサイズを調整でき、パフォーマンスを向上させることができます。
今回の記事が少しでも皆さんの新しい知識や業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
Azure Databricks連載記事のまとめはこちら