
無制限のデータレイクと
分析ジョブサービスで簡単にビッグデータ分析を
実現
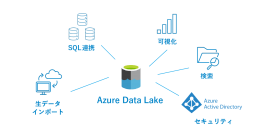
Azure Data Lake は、データ格納領域の「Azure Data Lake Store」と分析ツール「Azure Data Lake Analytics」、
管理機能「Azure HDInsight」から構成されます。
そのためさまざまな種類のデータを格納し、複数のプラットフォームと言語で処理/分析を簡単に実行できます。
複雑性は排除されているのでデータを保存/分析する方法に悩むことなく、
大規模なデータセットの処理やペタバイト規模のファイルと数十億個のオブジェクトを保管/分析することが可能です。
Azure Data Lakeの特長
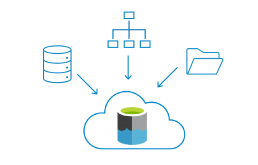
01.ペタバイト規模のファイルを無制限に保管できる
ペタバイトを超えるファイルを数十億個も保存することができます。
使用するストレージのスペックを増やしたり減らしたりする際の
コードの書き直しなども不要なので、
ビッグデータを管理する際の煩雑さはありません。
構造化データ、半構造化データ、または非構造化データ、
あらゆる範囲のデータを保管できます。

02.ビッグデータへの
コスト効率が高い
ストレージはAzureBlob Storageの上に構築されているため、
ストレージ容量とトランザクションコストが低くなります。
また、ジョブ単位課金モデルを選択でき、ライセンス契約などは不要なので
余分な費用を抑えることができます。
他のクラウドストレージサービスとは異なり、
データを分析する前にデータを移動または変換する必要はありません。

03.ハイブリッドクラウド環境をサポート
Azure HDInsightコンポーネントを使用して、既存オンプレミスの
ビッグデータインフラストラクチャをクラウド(Azure)に拡張し、
高度な分析機能を活用できるようになります。
様々なサービスとワンクリック展開でシームレスな統合を可能にします。
Azure Data Lakeの
3つのコンポーネント
Azure Data Lake は、ストレージ、分析サービス、およびクラスター管理機能を提供する3つのコンポーネントで構成されています。
Azure Data Lake Store

無制限ストレージ
Azure Data Lake Analytics
分析
Azure HDInsight

クラスター管理
Azure Data Lake Store
- データのサイズに制限はなく、大規模な並列分析を実行できる
- ディレクトリやサブディレクトリを介してファイルを整理および操作できるため、管理が簡単
- Azure ActiveDirectoryを介した役割ベースのアクセス制御とシングルサインオン機能を提供
- Hadoop分散ファイルシステム(HDFS)を使用してデータを管理およびアクセス可能
Azure Data Lake Analytics
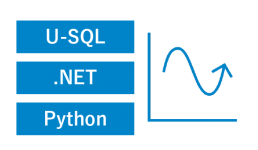
- ペタバイト規模の超並列データ変換処理プログラムを
U-SQL、R、Python、.NETで処理/開発および実行可能 - 処理能力をジョブごと割り当てることでパフォーマンス向上
- データ処理はオンデマンドで瞬時に拡大・縮小することができる
Azure HDInsight
- Hadoop、Spark、Hive、LLAP、Kafka、Storm、Rなどのオープンソースフレームワークを使用可能
- 既存のオンプレミスのビッグデータをAzureに拡張し、クラウドの高度な分析機能を活用できる
- Azure Virtual Network、暗号化、およびAzure ActiveDirectoryとの統合しセキュリティ強化
- AzureMonitorログと統合して、すべてのクラスターを監視できる
活用例
Azureベースの
データドリブンシステムで
DX/業務改革を促進
お客様の課題
- IoT などのセンサーデータをはじめ多種多様なデータを蓄積するDWH をクラウドに構築して拡張性を担保したい。
- さまざまな部門を巻き込んでDX に取り組みたい。
Azure Data Lake導入後
- 検索速度やDB の互換性、夜間のデータ伝送処理にかかる時間などが改善。
- Office365 などビジネス部門で利用できるアプリやサービスとの親和性が高く、業務改革にも取り組めた。
Azure Data Lake 導入価格
データ量により価格は変動しますが、以下ご参考ください。
| Azure(月額) | ¥159,590~ |
|---|---|
| 構築作業 | ¥3,000,000~ |
| 保守(月額) | ¥200,000 |
| メンテナンス(月額)*オプション | ¥200,000 |
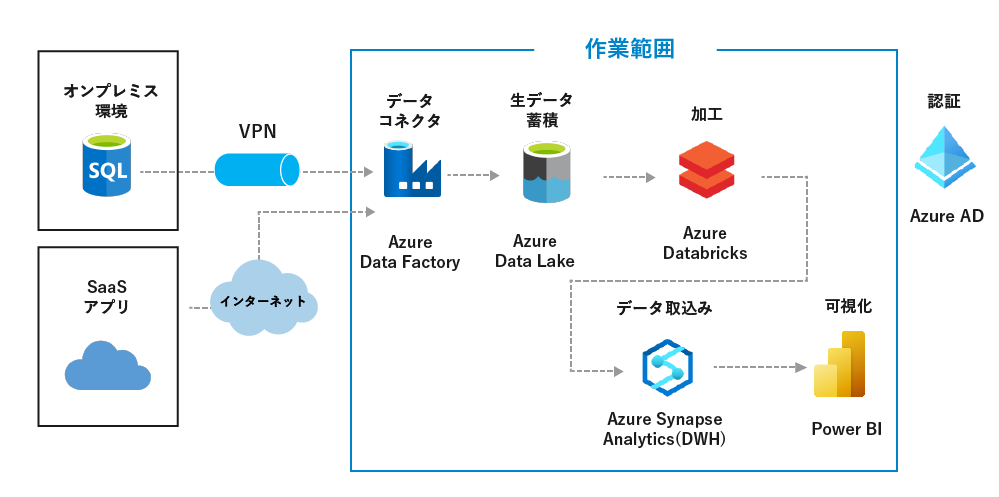
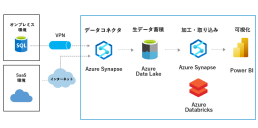
- オンプレミス/SaaSアプリに散乱する企業データをAzure Data Factoryを活用し、Azure Data Lakeの大容量ストレージに収集・蓄積します。
- 収集・加工したデータはPower BIで可視化します。
- Azure Data Factoryを補完するために、CDateを活用すれば、収集できるデータはさらに広がります。