目次
1.はじめに
皆さんこんにちは。
今回は、Databricks AutoMLの使用方法について説明していきます。
2.前提要件
実施する際の前提条件は
・操作ユーザーは Azure Databricks ワークスペースにアクセス権限があること。
・操作ユーザーは、ノートブックの作成・実行権限があること。権限が付与されていない場合、管理者に権限を付与してもらう様に依頼してください。
3.Databricks AutoML の概要
Databricks AutoML は、機械学習、および深層学習モデルを自動的に構築するために使用されるツールです。 このツールには次の利点があります。
- データ前処理、特徴エンジニアリング・特徴抽出、ハイパーパラメータ調整、モデル評価など、機械学習・深層学習モデルの構築プロセスにおけるすべてのタスクを、データエンジニアの介入をあまり必要とせずに自動的に処理します。
- モデル選択の時に様々なモデル構造を評価するため、モデル構築においてMLFlow と組み合わせることができます。
- MLFlow レジストリと組み合わせて、トレーニング プロセス全体を管理し、モデルを使用します。
- モデルの使用法を自動的に構築し、モデルのデプロイメントを容易にします。
4.Databricks でクラスターを作成する
Databricks AutoML は、Databricks ML Compute Cluster を使用してモデルのトレーニングを実行します。
Databricks AutoML を使用する前に、コンピューティング クラスターを事前に初期化する必要があります。
① Databricks ワークスペースの左側のサイドバーで「コンピュート」をクリックします。
②「コンピュートを作成」ボタンをクリックします。
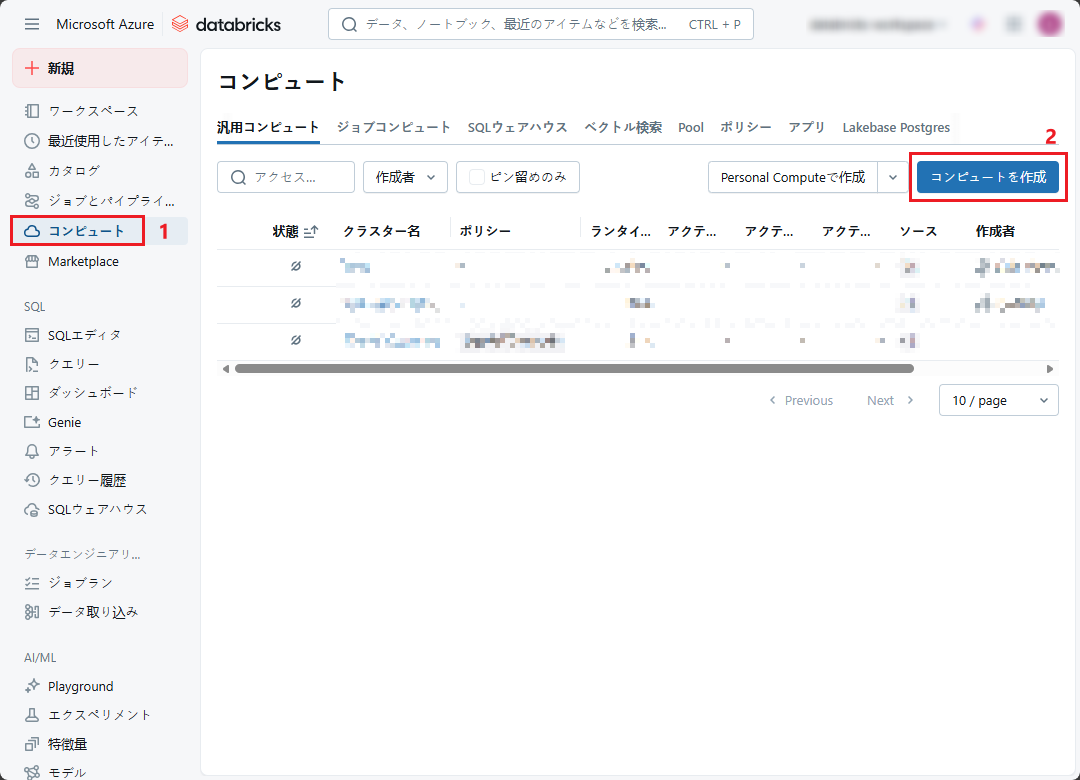
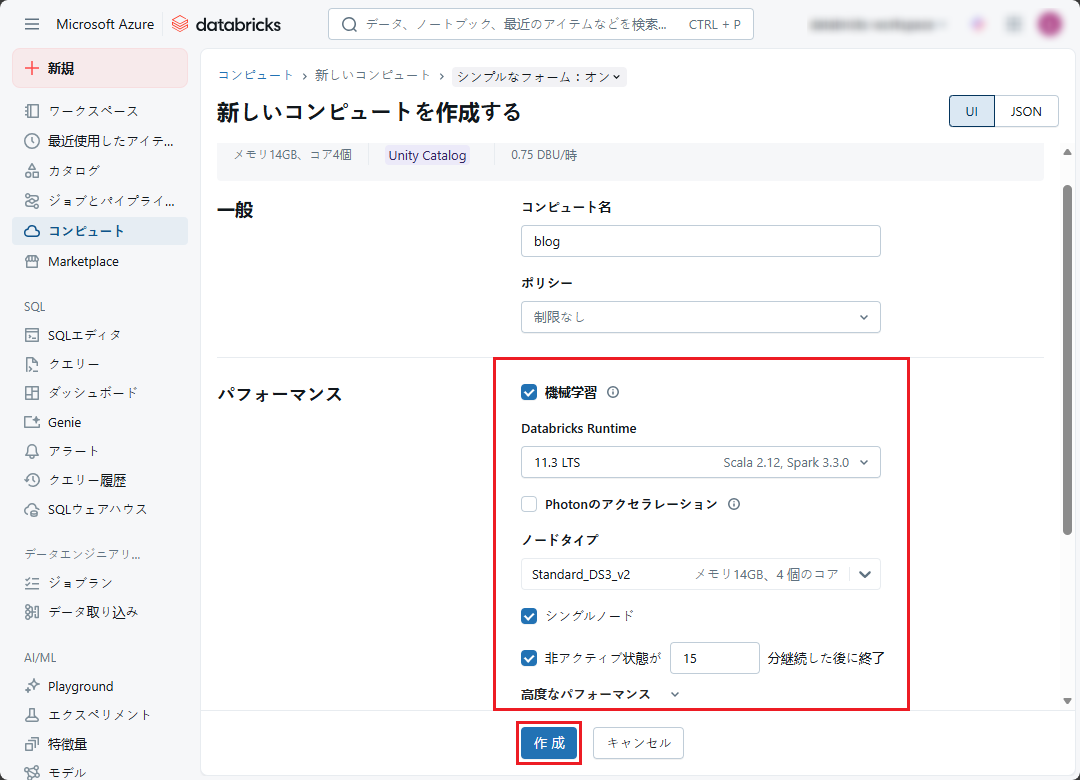
クラスター名: 任意のクラスター名を入力します。
クラスターモード: シングルノード (クラスターはテストのみに使用されます)
ランタイムバージョン: Databricks ランタイム 9.1 ML 以降。クラスター ML (機械学習) を使用する必要があることに注意してください。 ここでは、Scala 2.12 で Runtime 11.3 を使用します。
ノードタイプ: Standard_DS3_v2 (デフォルト)
③ 設定が完了したら「作成」ボタンをクリックします。
5.Databricks AutoML のトレーニング データをインポートする
まず、Databricks AutoML に使用するデータをインポートします。
Databricks AutoML は Spark DataFrame のデータのみを使用できます。 ただし、Spark DataFrame は、次のように様々なソースからデータを受信できます。
- CSV (Unity カタログ・Hive メタストア、および Databricks Delta テーブル経由)
- Pandas DataFrame (Spark Pandas API 経由)
- RDBMS (Spark データベース コネクタ、および JDBC コネクタ経由)
- Parquet (Unity カタログ・Hive メタストア、および Databricks Delta テーブル経由)
- Protobuf (Unity カタログ・Hive メタストア、および Databricks Delta テーブル経由)
- その他
今回のデモでは、データを CSV ファイルとして使用します。
以下のようにデータを作成します。
- データを含む CSV ファイルを Unity カタログにアップロードします。
- Unity カタログは CSV ファイルから Databricks Delta テーブル にデータを自動的に転送します。
- Spark を使用して Databricks Delta テーブルのデータを Unity カタログから Spark DataFrame にロードします。(このプロセスは、ユーザーに表示されずに、AutoML によって自動的に実行されます。)
【データの概要】
- 今回のデモでは、winequality-red データセットを使用して、ワインの品質を予測します。
- 分類問題に変換するために、 Databricks のNotebookを使用して、quality スコアを元に quality カラムをquality ブール に変換しました。
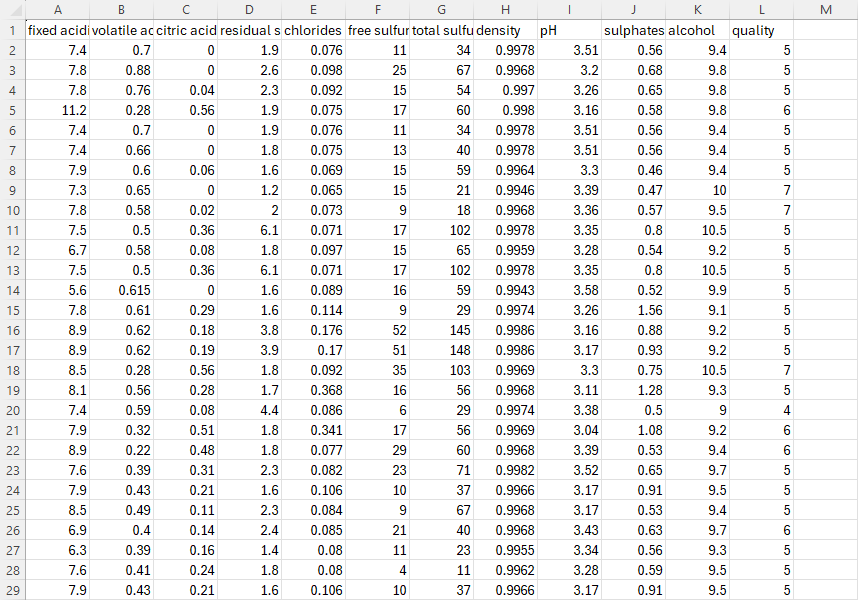
次のように、データを含む CSV ファイルを Unity カタログに Delta テーブルとしてアップロードします。
① Azure Databricks ワークスペースで、「新規」>「データを追加またはアップロード」をクリックします。
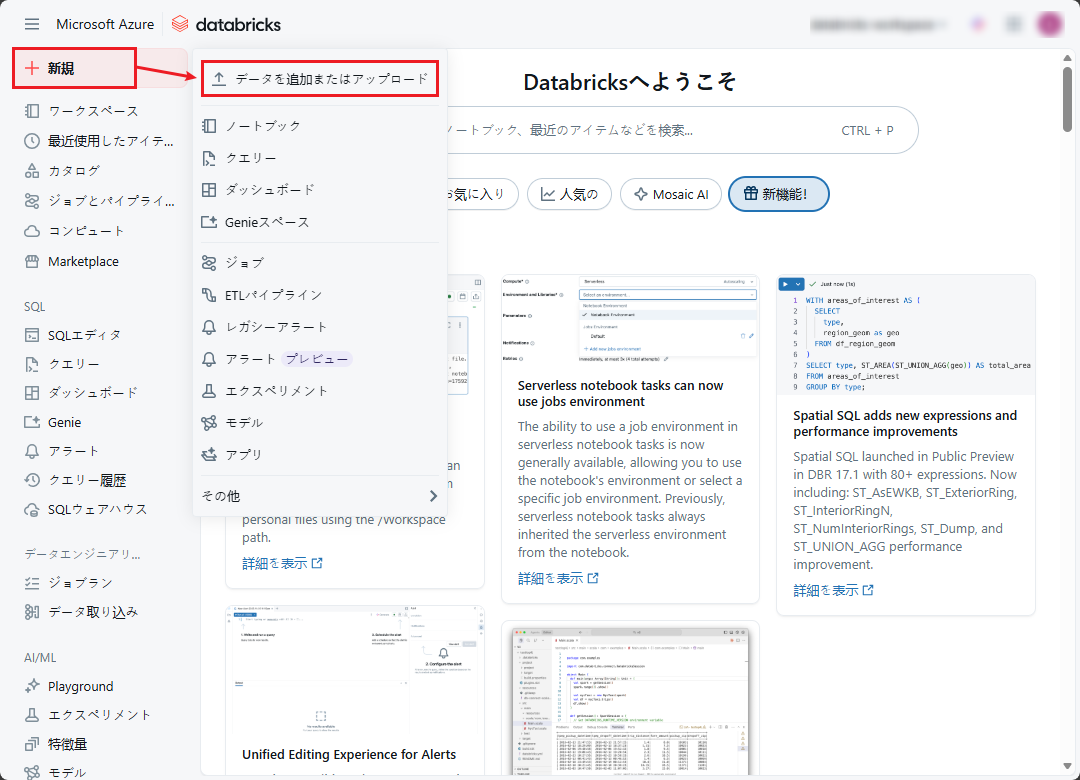
② データを追加ページで、「テーブルを作成または変更」を選択してください。
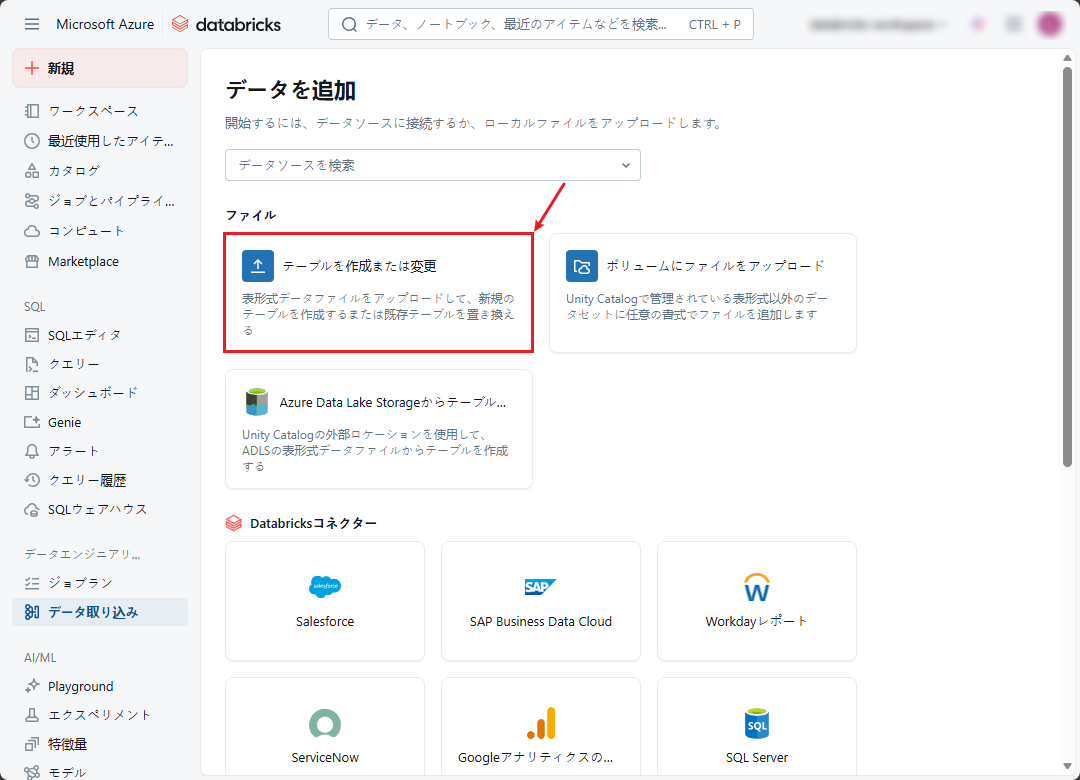
③ ファイルのアップロードウィンドウで、アップロード対象のファイルをボックスにドラッグアンドドロップして、または「参照」をクリックしてアップロード対象のファイルを選択します。
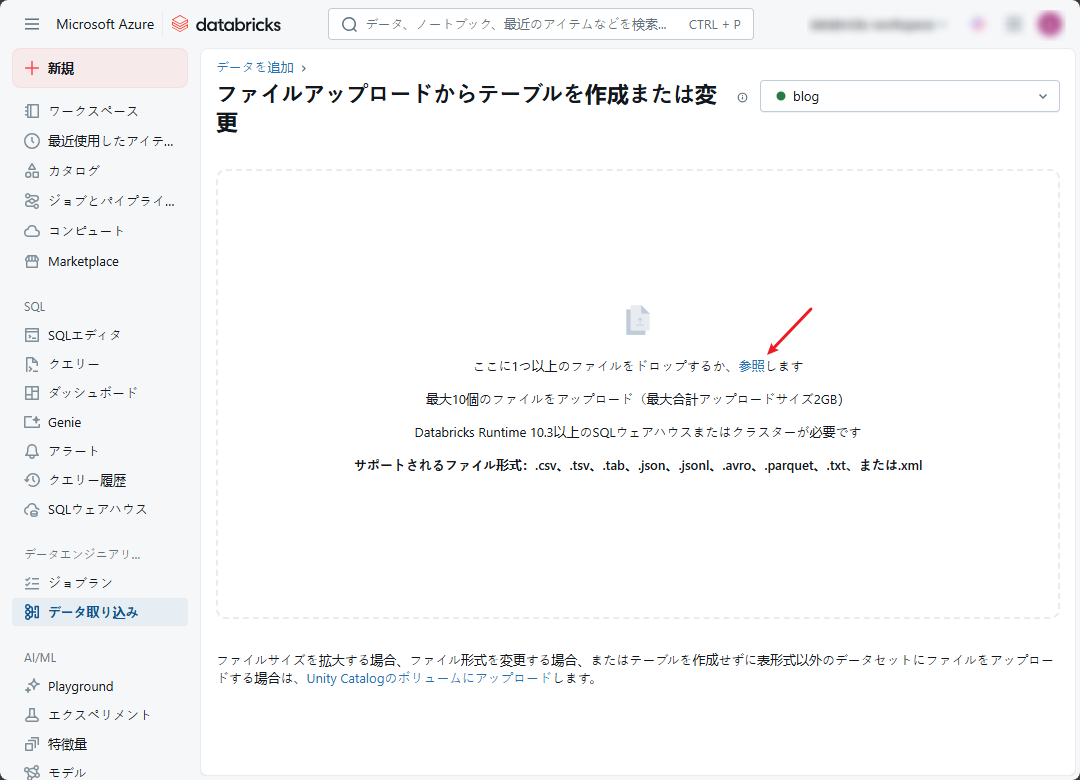
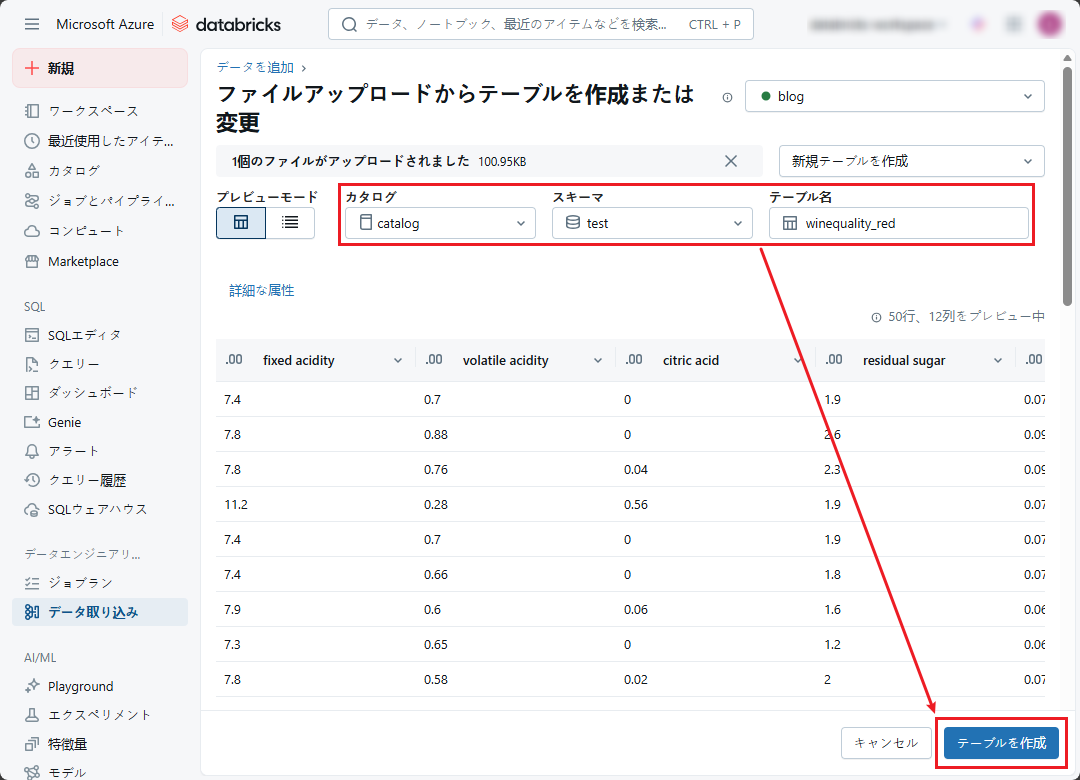
④ 「winequality-red」CSV ファイルを選択します。
⑤ カタログとスキーマを選択し、csv ファイルから作成されたテーブルに名前を設定します。
⑥ 「テーブルを作成」をクリックします。
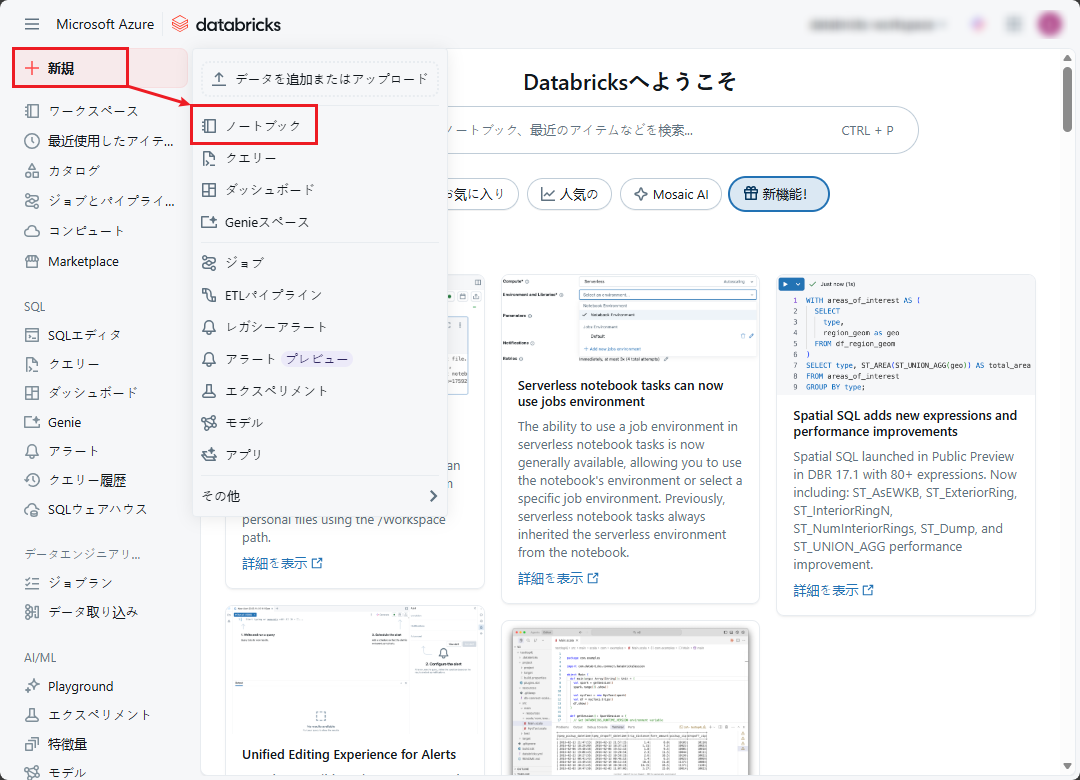
⑦ 新規のNotebook を作成して、quality カラムをデータセット内のquality ブール に変換します。
⑧ Databricksワークスペースの左メニューにマウスをホバーして、「新規」 → 「ノートブック」をクリックします。
⑨ 新規作成したノートブックの画面が表示されます。ノートブックに名前を付け、デフォルトの言語として Python を選択します。
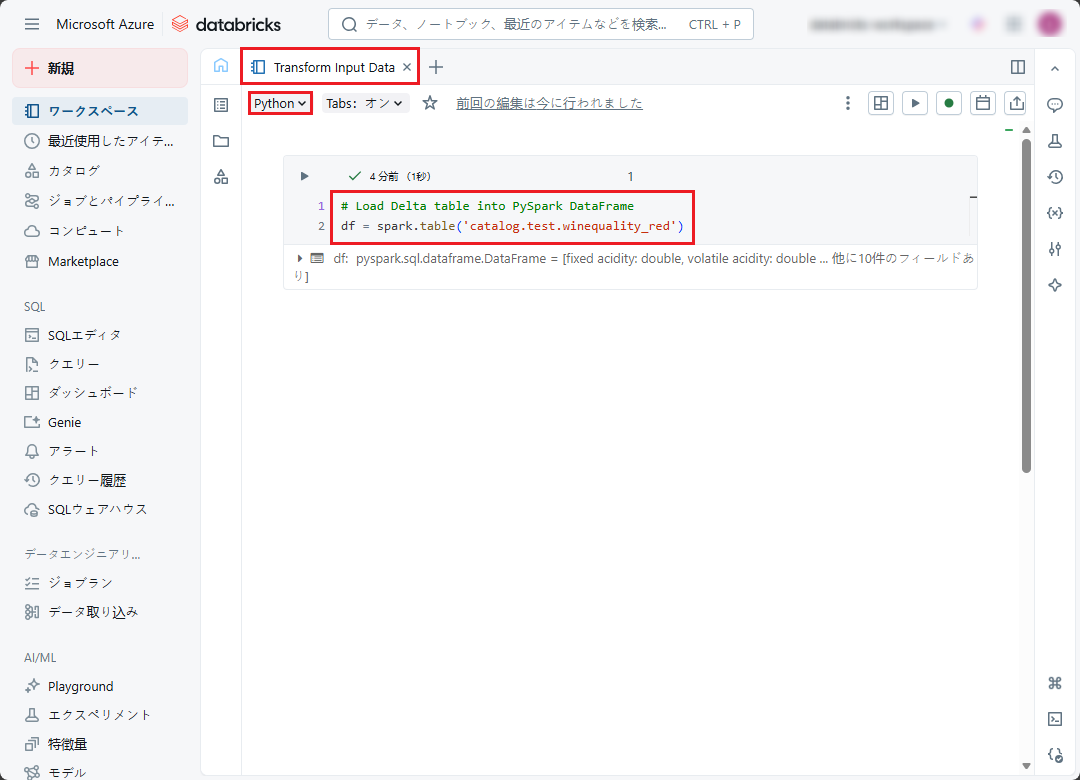
⑩ 以下のコードをノートブックにコピぺして、実行します。
|
1 2 3 |
# Load Delta table into PySpark DataFrame df = spark.table('catalog.test.winequality_red') |
⑪ quality スコアが 7 以上の場合、カラムの値が「Good」となります。それ以外の場合は「Not Good」となります。
以下のコードをノートブックにコピぺして、実行します。
|
1 2 3 4 5 6 7 8 9 |
from pyspark.sql.functions import when # Convert 'quality' column to 'Good' if 'quality' >= 7, otherwise 'Not Good' df_new = df.withColumn('quality', when(df['quality'] >= 7, 'Good').otherwise('Not Good')) # Overwrite the Delta table with the updated DataFrame df_new.write.format("delta").mode("overwrite").option("overwriteSchema", "true").saveAsTable("catalog.test.winequality_red") |
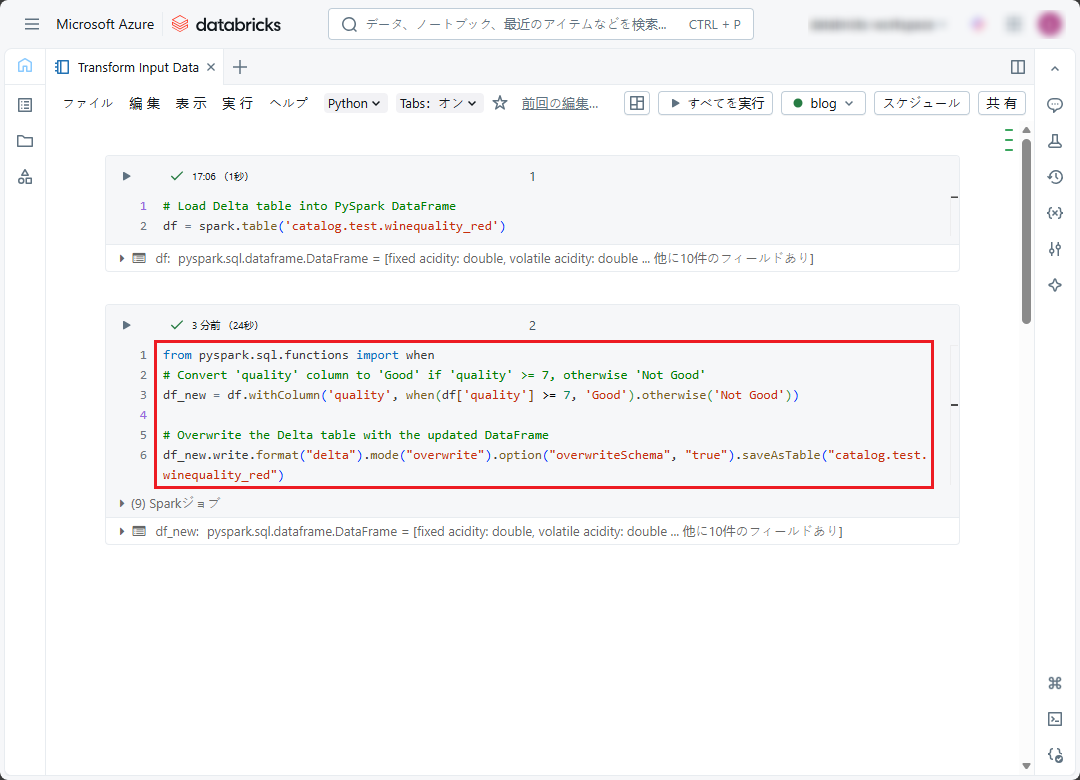
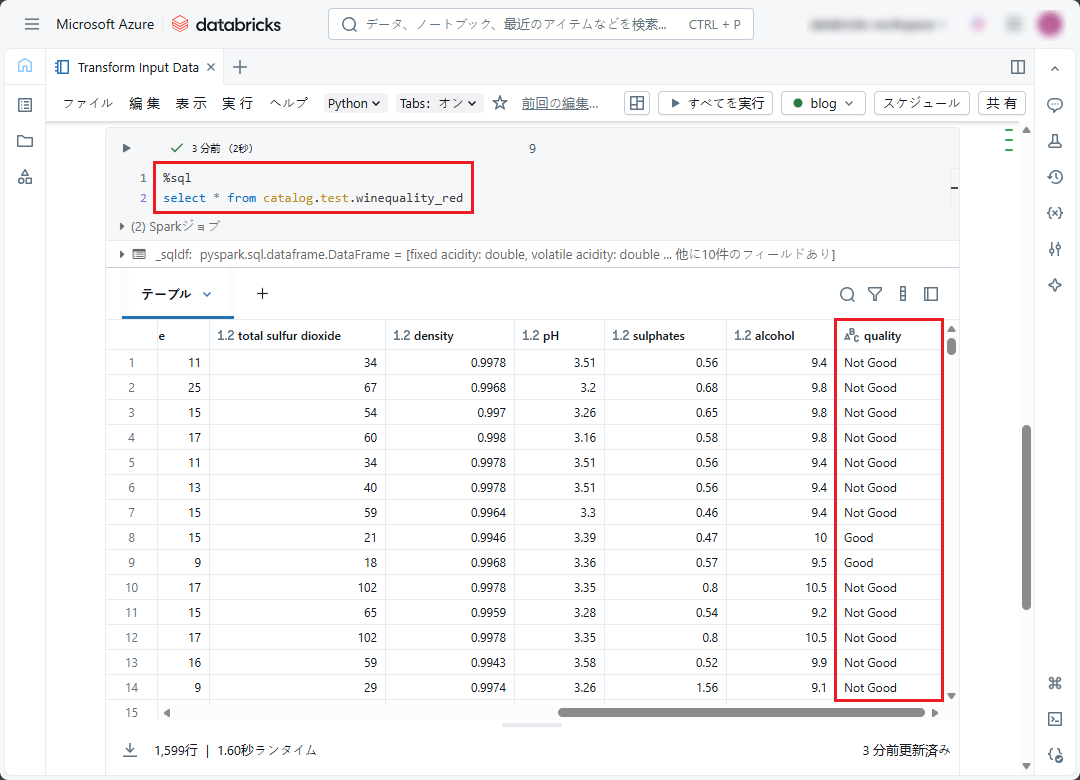
変換後のデータには、ワインの組成指数とそのワインの品質 (Good、Not Good) が含まれます。
6.AutoML でモデルをトレーニングする
【背景】
以下の前提条件でAutoMLを使った機械学習モデルを作成します。
- 目的:ワインの成分に基づいてワインの品質 (Good、Not Good) を予測できる ML モデルを作成します。(Red Wine Quality データセットを使用)
- 機械学習の問題のタイプ:分類問題(Classification)
- 予測ターゲット:quality 列
- 特徴:
- quality 列を除き、データセット内の残りのフィールドはワインの成分に関する情報です。
- ワインの成分に関する全ての情報(全ての残りのフィールド)をトレーニング プロセスに使用します。
- 評価メトリクス:F1-score
- トレーニングフレームワークは以下の通りです。
- XGBoost
- Scikit-learn
- LightGBM
- タイムアウト時間: 5 分
※ AutoMLは評価メトリクスが改善しない場合、トレーニングを中断することがあります
クラスター、及び入力データのテーブルを作成した後、Databricks Machine Learning の AutoML Experimentを作成します。
① Databricks ワークスペースの左側のサイドバーにマウスをホバーして、「エクスペリメント」を選択します。
②「AutoMLエクスペリメントを作成」をクリックします。
③ 定義した背景に従って AutoML を設定します。
- クラスター: 事前に作成されたコンピューティング クラスターを選択します。
- 機械学習の問題のタイプ:分類問題
- 入力学習用データセット: Red Wine Qualityデータセットの作成したデルタ テーブルを使用します。
- 予測ターゲット: quality 列
- エクスペリメント名(Experiment Name): 自動入力またはカスタム名を入力します。
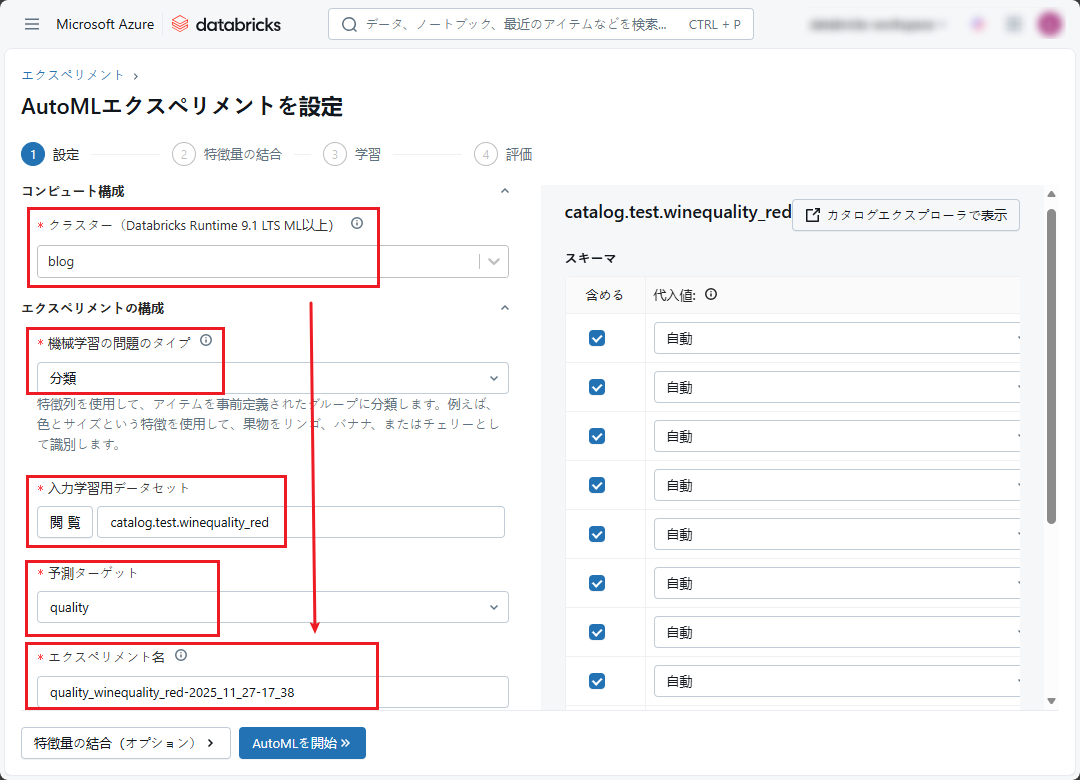
④ 拡張構成(任意):
- タイムアウト: 5分
- トレーニング フレームワーク: lightgbm、sklearn (scikit-learn)、xgboost
⑤ 全ての構成を設定したら、「AutoMLを開始」をクリックして、分類アルゴリズムの様々な反復をトレーニングします。
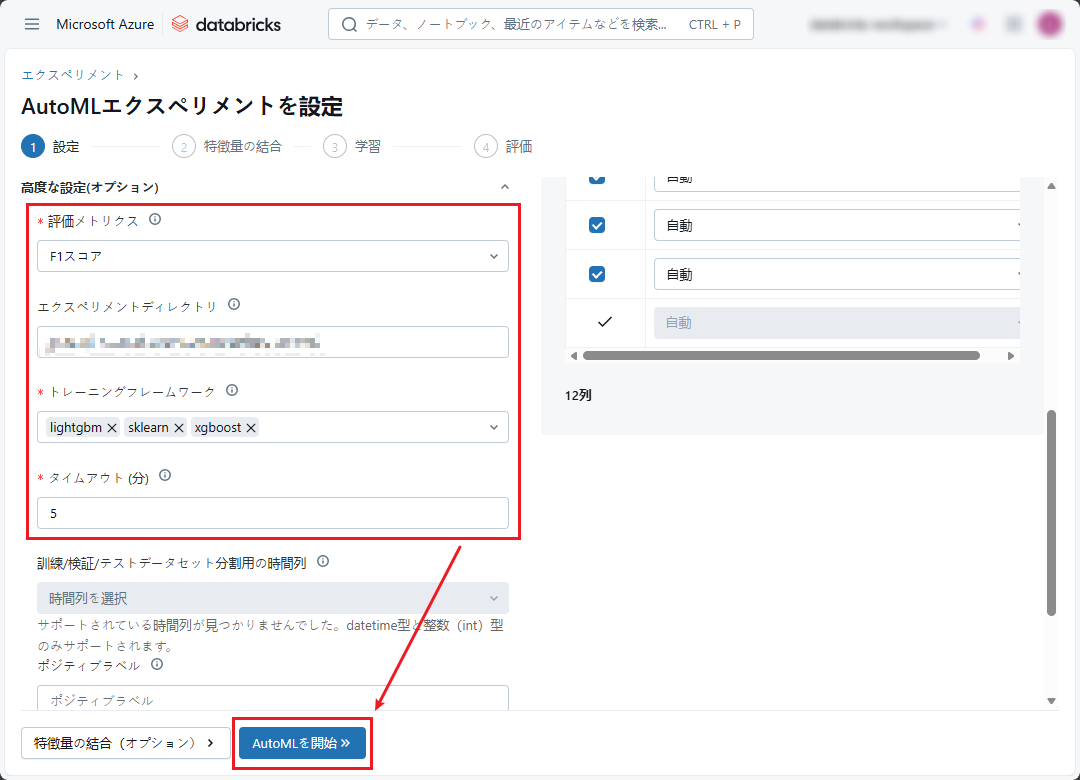
その後、設定したタイムアウト時間に従ってデータセット トレーニングが自動的に実行されます。
「AutoMLを開始」をクリックした後、Databricks AutoML はデータ探索用ノートブック (トレーニング用の使用データを詳しく説明するためのノートブック) を作成します。
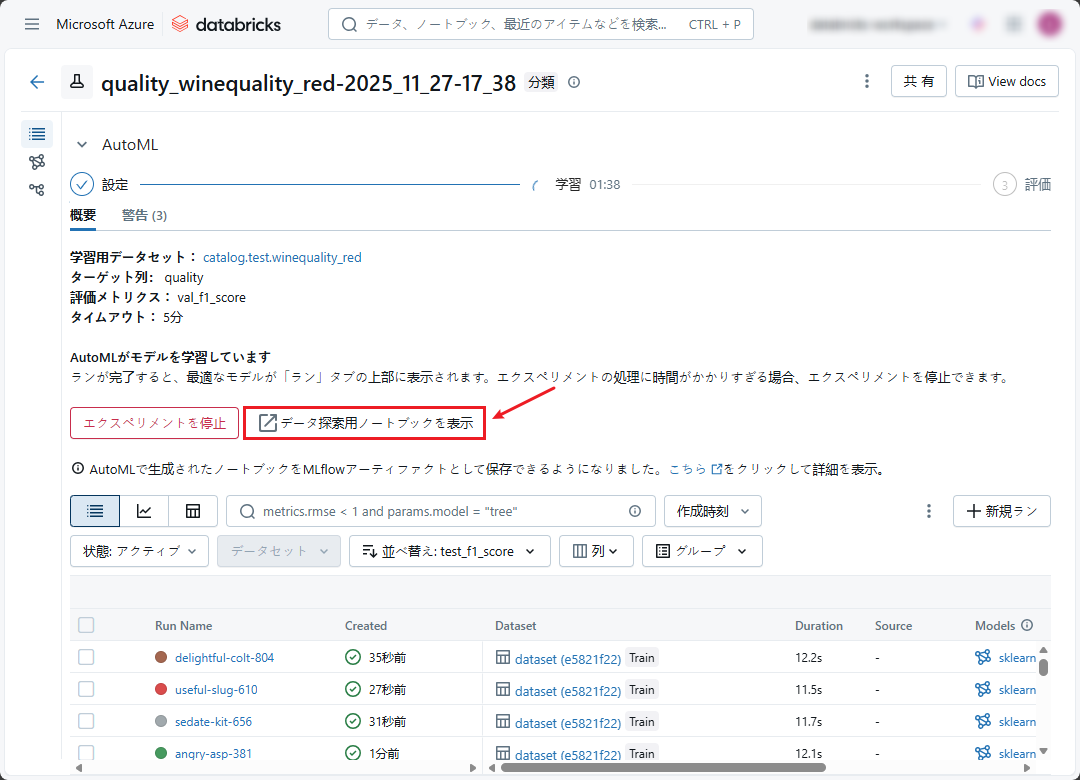
データ探索用ノートブック:AutoML から自動的に生成されるノートブックであり、簡潔でデータを視覚化し、解釈するのを支援することを目的としています。
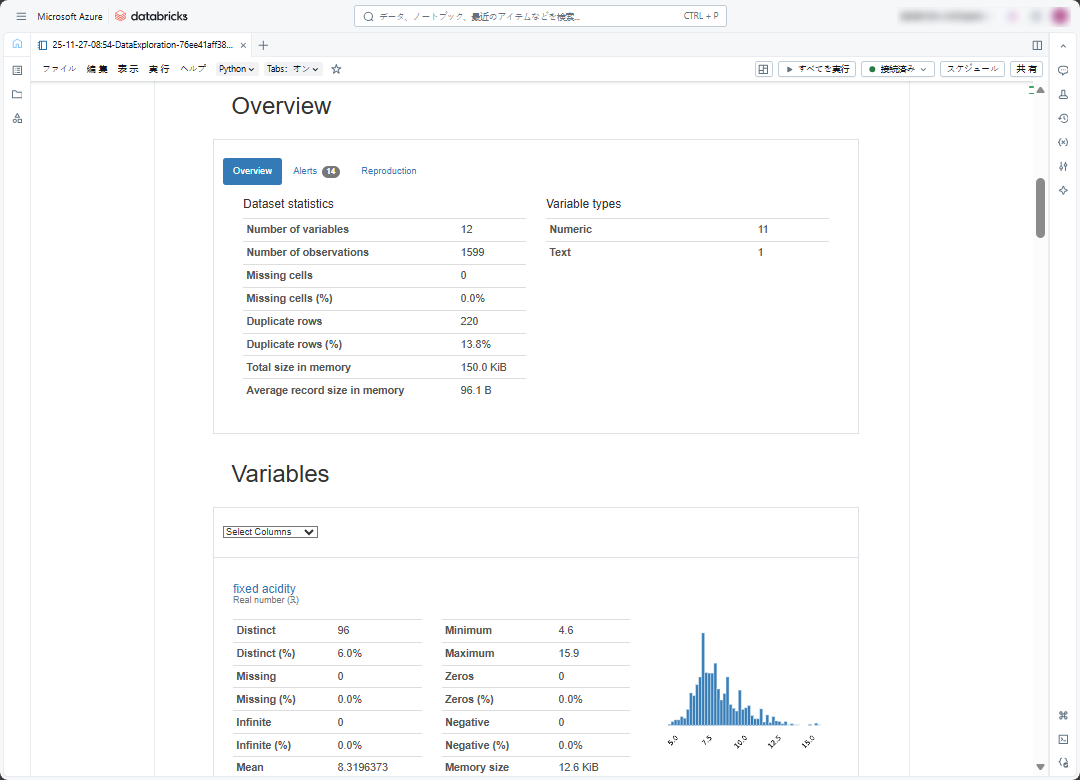
データ探索用ノートブックでは、データを次の通りに説明します。
- 概要:データの概要、変数の数、重複行の数、NULL とゼロの数など。
- 変数:変数内のNULLとゼロの数、変数の最大・最小、異なる値の数、度数分布表、相関関係など、各変数の概要。
- Interations:2 つの任意変数間のデータの干渉を表します。
- Correlations:ヒートマップは、2 つの任意変数間の相関の程度を示します。
- 欠落した値(missing values):変数ごとの欠落した値の数。
- 最初の行・最後の行:最初の10行・最後の 10行。
- 重複行:最も重複された上位 10 行。
AutoML は、複数のライブラリ、アーキテクチャ、ハイパーパラメータのセットなどを使用して多くのモデルを生成します。それに、生成されたモデルの中に最も高い評価指標(f1_score)があるのモデルを検索します(ベスト モデル)。
トレーニング プロセスの後、AutoML は、トレーニングされたモデル、選択した評価指標(f1-score)等のトレーニング結果を表示します。
結果を保存して、複数のAutoML Experiment 間での結果を比較するために、AutoML を MLFlow と組み合わせて実行できます。
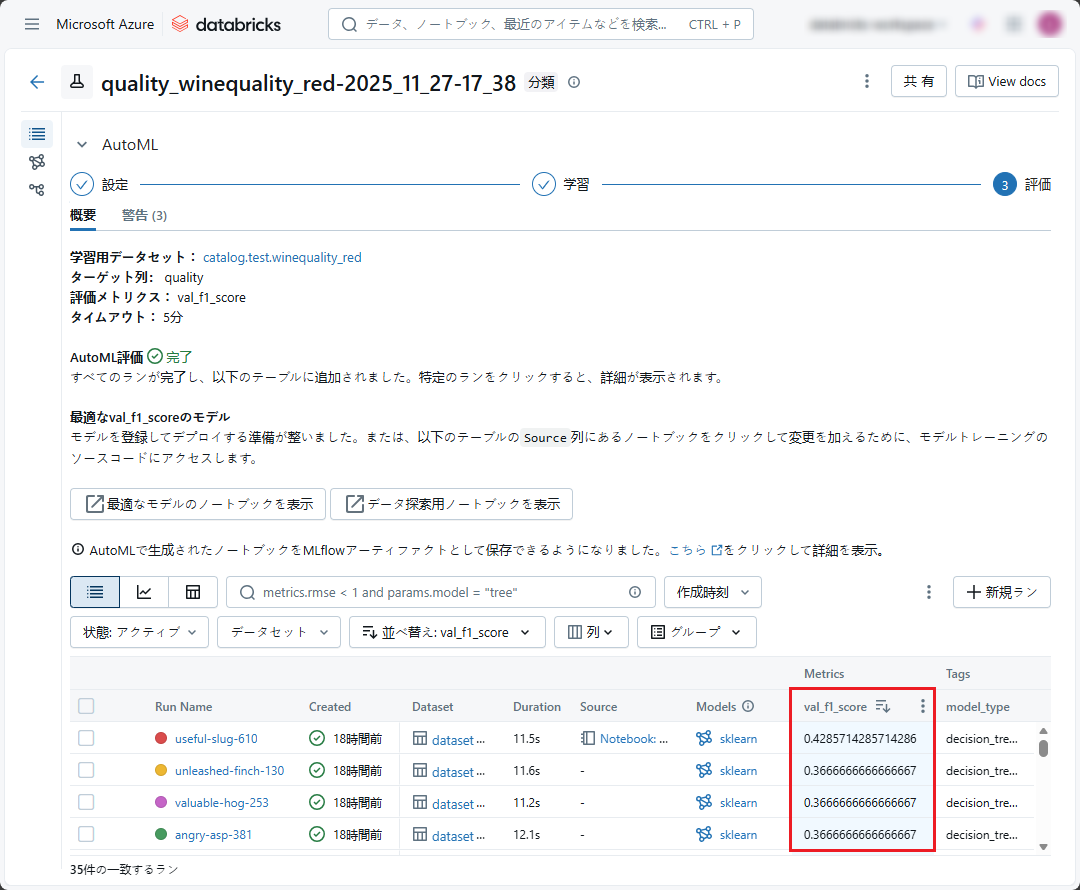
トレーニングが完了した後、Databricks AutoML は最適なモデルに対応するノートブック (最高モデルのノートブック) を生成します。
AutoML エクスペリメントの画面で、「View notebook for best model」をクリックします。
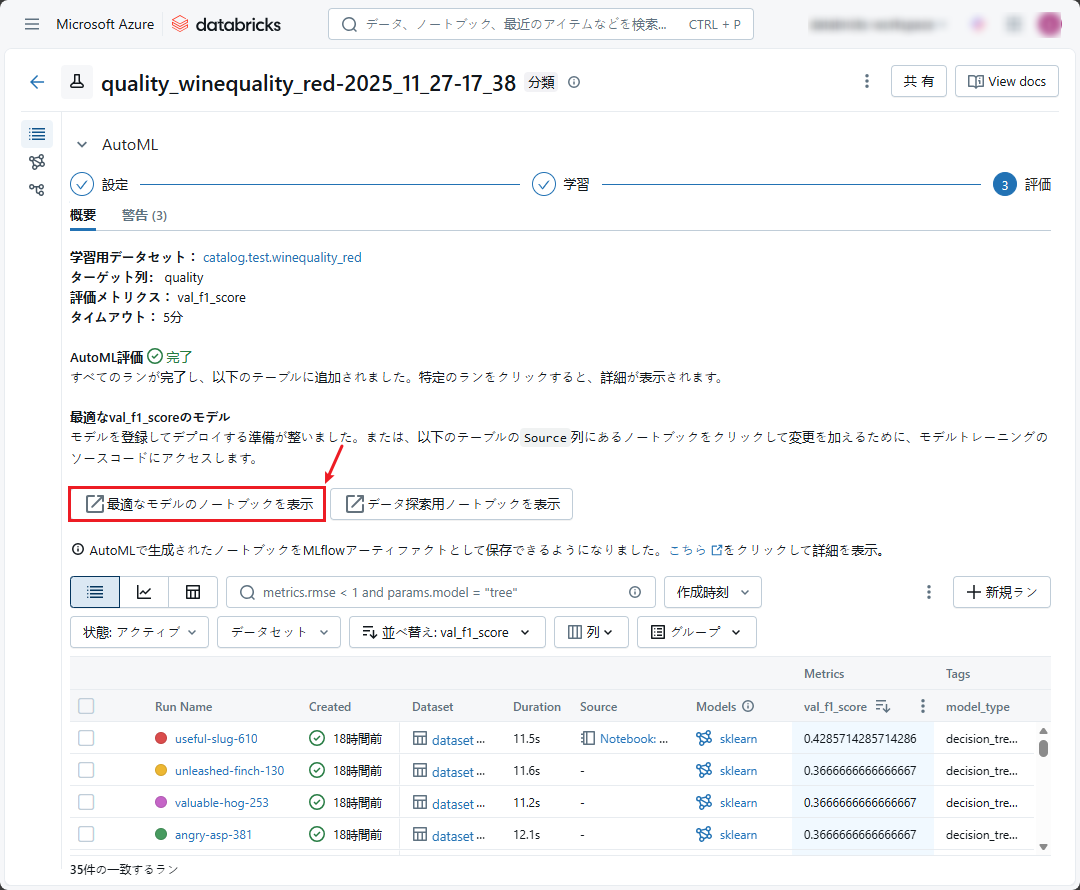
このノートブックは Databricks AutoML から自動的に生成され、モデルのトレーニング方法、最適なモデル品質、モデルの実現方法について説明することを目的としています。
ノートブックには次の情報が含まれます。
- モデル構造:最適なモデルで使用される構造です。 今回の例ではロジスティック回帰です。
- データのロード:トレーニング時に使用するデータをロードする方法、およびフィルター メソッドを使用したトレーニング時に使用する特徴を選択する方法です。(サポートされている列を選択する)
- 前処理:データの前処理(空のデータの埋め込み処理、train-validation-test のデータセット分割操作などを含む)
- トレーニング:ハイパーパラメーターの最適化、wrapper-method の機能選択、モデルのトレーニングなどのプロセスが含まれます。トレーニング プロセスの後、ノートブックには train-validation-test のデータセットに対応する f1-score も表示されます。
- 推論:モデルを使用して新しいデータを予測する方法です。
- また、ノートブックには、confusion matrix、ROC curve、Precision-Recall Tradeoff curveなど、他のモデルの測定結果も表示されます。
7.Databricks AutoML トレーニング結果を評価・改善する
前述の通り、Databricks AutoML は評価指標(f1-score)及び、最も最高評価の高いモデルに対応する最適なモデルのノートブックを表示します。
また、トレーニングされたモデルのノートブック(最適なモデルに加えて)も、モデル リストの「Source」カラムに表示されます。
他の該当モデルのノートブックが、最適なモデルのノートブックの情報および、構成と同じです。
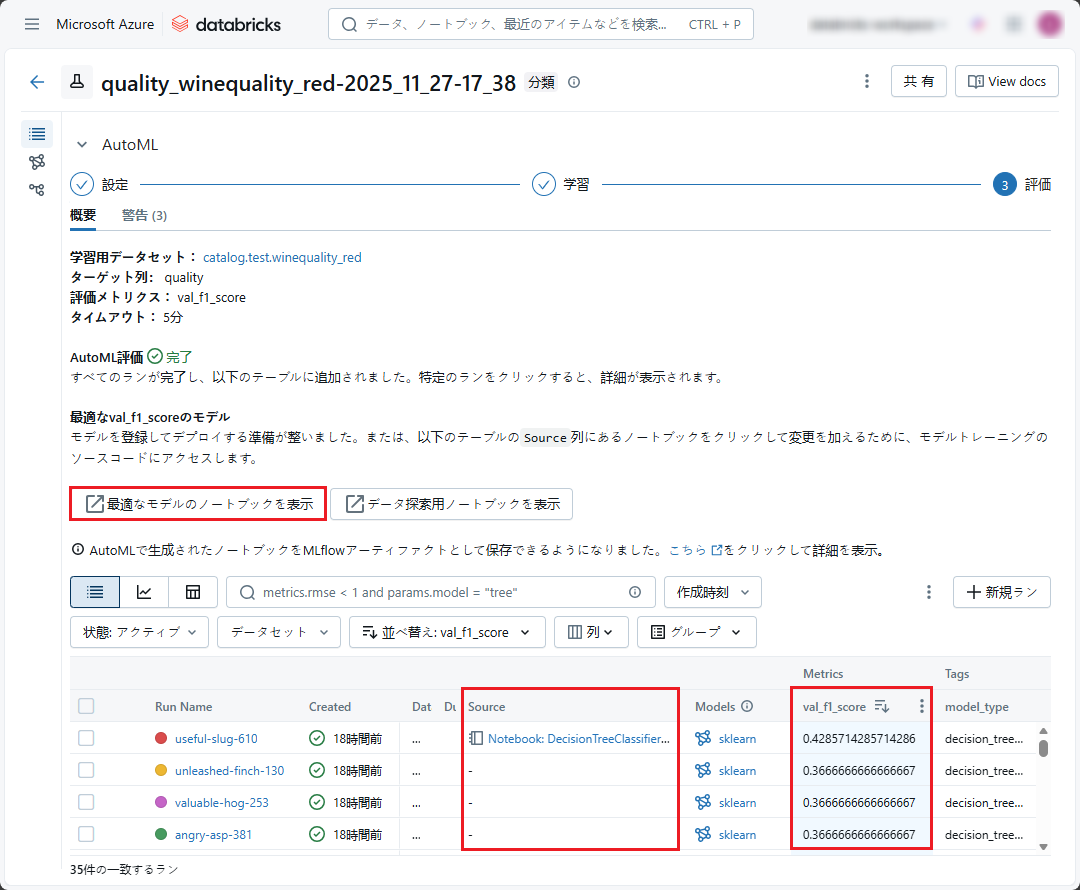
Databricks AutoML は、最も高い f1-score 値に従ってモデルを自動評価し、最適なモデルを提案します。そのため、AutoML でトレーニングされたモデルを評価し、選択する必要はありません。
ただし、多くの場合、AutoML での最適なモデルが、必ずしも良いモデルであるとは限りません。今回のデモでは、最適なモデルの f1-score が 0.429 となります。
- そのため、その最適なモデルを次の通りで再評価する必要があります。
- トレーニング後モデルの改善方法((転移学習、量子化など))があれば、適用した方が良いです。
- モデルの評価指標が低すぎる場合、トレーニング プロセス (アルゴリズムと構造の誤り、貧弱なハイパーパラメーター、エポック不足など) またはデータ (データ不足、不適切な特徴抽出など) に問題があるということです。各課題(モデルの構成、ハイパーパラメーター、データの修正など)を見直し、再度トレーニングする必要があります。
操作性と高速性があるので、f1-score が低いモデルが使用される場合もあります。
- 他のモデル(最適なモデルの以外)をDatabricks AutoMLで使用したい場合、「Source」カラムの「Notebook」をクリックします。(前述の通り)
今回は、AutoMLの使用方法について説明していきますので、この最適なモデルが良いモデルであると想定し、使用します。
8.Databricks AutoML の最適なモデルを使用する
最適なモデルの使用をデモするために、次のように標準的な推論・予測フローを構築します。
- モデルのロード・準備
- データのロード・処理
- 推論・予測:処理済みのデータがロードされ、推論・予測されます。
このフローの手順は、データとモデルの複雑さによって、細かな手順に分けされるか、または複数の処理があります。
Unity CatalogのDelta テーブル から「quality」カラムの値を予測するためのテスト データを使用します。
以下の例では、「winequality-infer」テストデータ をDatabrick に Delta テーブルとしてアップロードします。
データのアップロード方法は、Red Wine Quality データセットのアップロード方法と同じです。(5.項目のご参照)
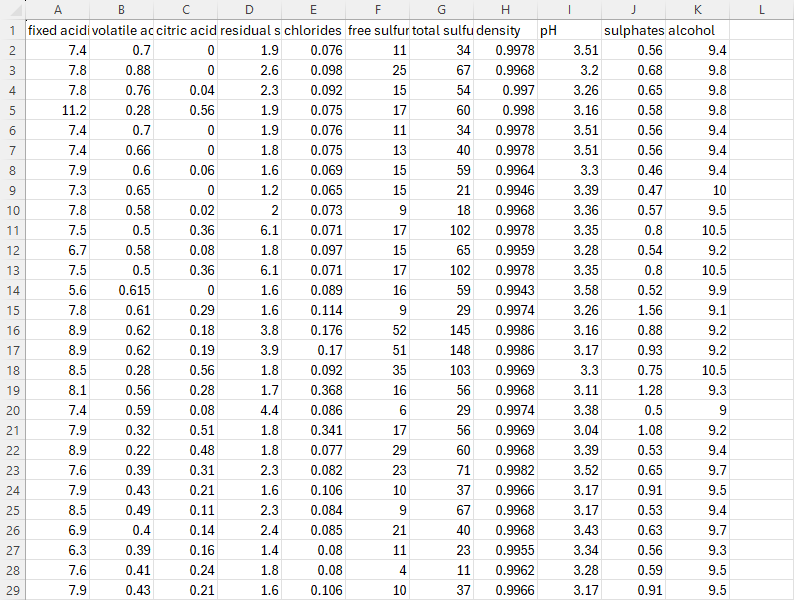
Databricks AutoML からのモデルを推論・予測プロセス向けに使用するために、下記の情報が必要です。
- Model_URI
- 新規ノートブック( model_uri を使用してモデルをロードし、データを処理できるようにするため)
実行後、AutoML Experiment は最適なモデルをMLFlow モデル レジストリにアーティファクトとして記録し、そのモデルに model_uri という一意の識別子パスを割り当てます。
model_uri には次の情報があります。
- runs:これは、MLFlow モデル レジストリ内の全てURI モデルのプレフィックスです。
- { mlflow_run.info.run_id }:これは、モデルがトレーニングされた実行の ID です。
- /model:これは実行時のモデルへのパスです。
Databricks AutoML によって生成された最適なモデルの model_uri は、「 View notebook for best model 」の最後にあります。
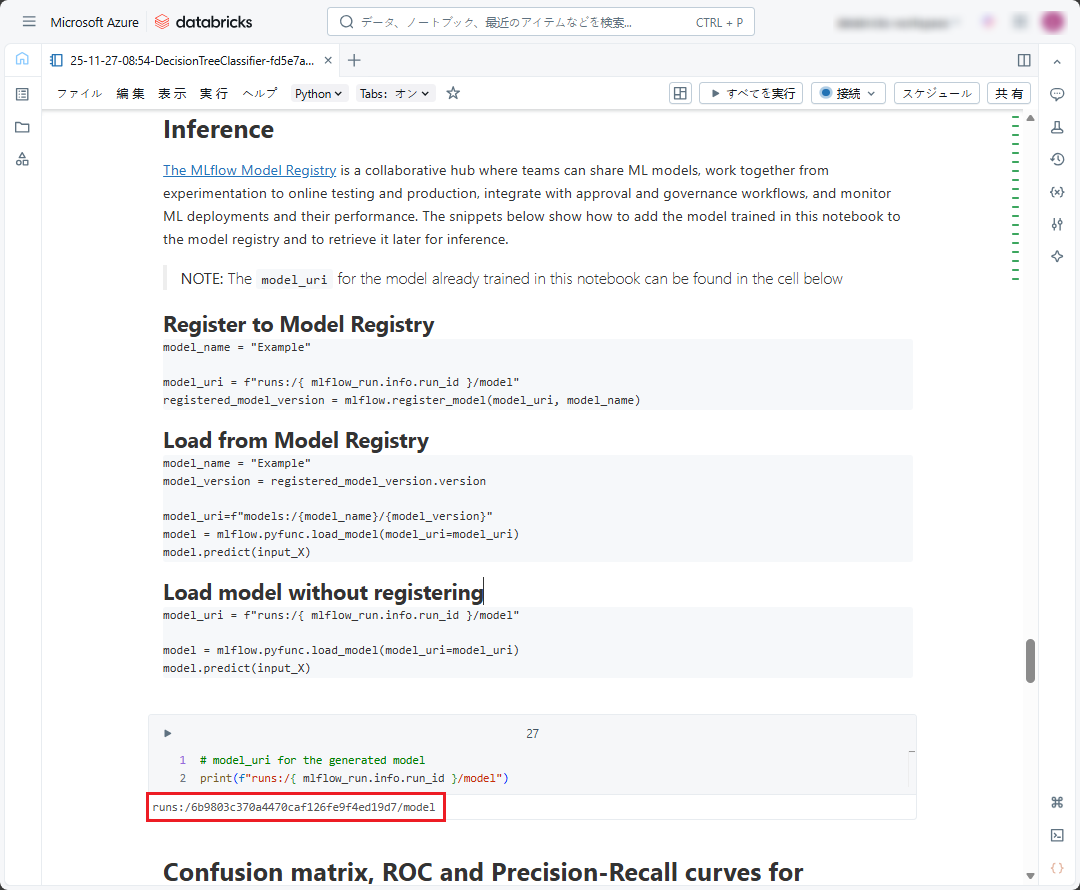
モデルを使用するには、新規のNotebook 作成が必要です。
① Databricksワークスペースの左メニューにマウスをホバーして、「新規」 → 「ノートブック」をクリックします。
② 新規作成したノートブックの画面が表示されます。ノートブックに名前を付け、デフォルトの言語として Python を選択します。
③ 以下のコードをノートブックにコピぺします(8.項目のご参照)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# import the mlflow library import mlflow # This line defines the model_uri variable. The URI is the run ID of the run where the model was trained. model_uri = "runs:/6b9803c370a4470caf126fe9f4ed19d7/model" # This line calls the mlflow.pyfunc.load_model() function and returns the model as a Python object # model now contains the loaded model model = mlflow.pyfunc.load_model(model_uri=model_uri) |
最適なモデルが MLFlow モデル レジストリに記録されたので、mlflow と model_uri を使用して、モデルをロードして実行できます。
最適なモデルは、MLFlow モデル レジストリ (名前付きモデル) に登録することもでき、モデルの状態 (ステージング、本番、アーカイブ)、モデルのバージョン、およびMLflowのモデルサービング等を確認できます。
今回のデモでは、MLFlow モデル レジストリの機能と登録方法については深く説明しません。
④「Shift+Enter」を押して上記のコードを実行します。
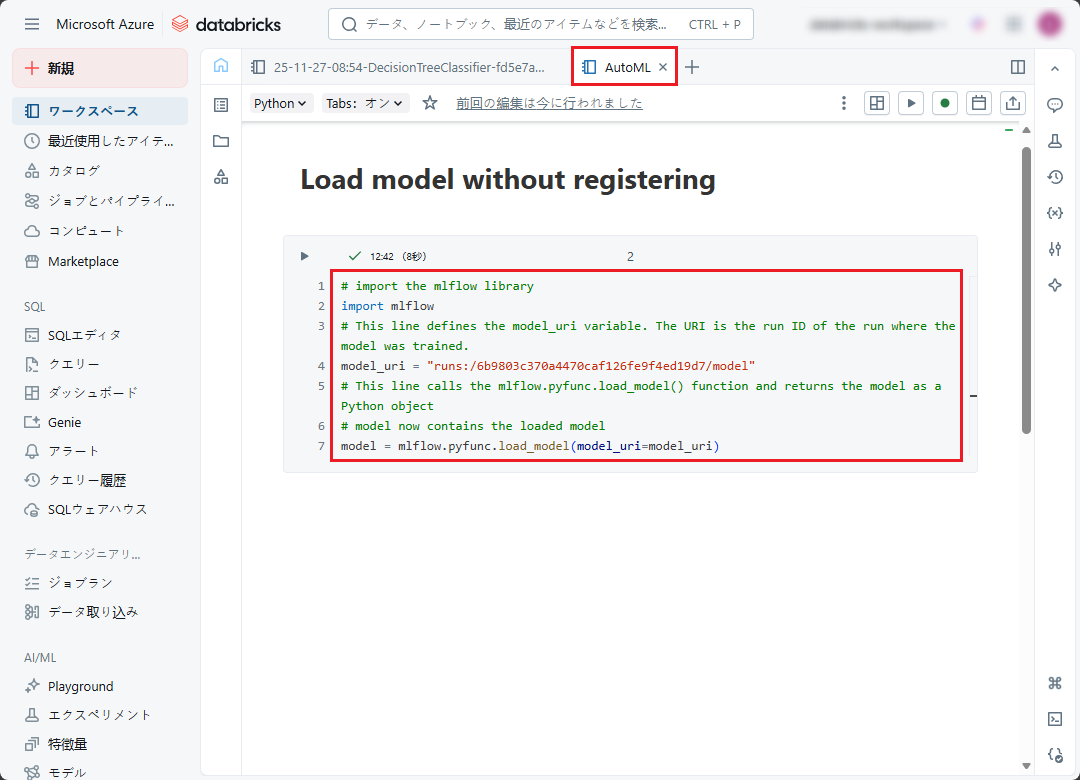
Databricks AutoML でトレーニングされたモデルが、入力データを DataFrame として受信するため、前の手順でアップロードされた Delta テーブルのデータを DataFrame 形式で読み込みます。
推論処理用のデータは、推論の処理前に、トレーニング データの処理方法と同様に処理され、モデルに適う必要があります。
⑤ 以下のコードをノートブックにコピぺし、「Shift+Enter」を押してコードを実行します。
|
1 2 3 4 5 6 7 |
# Read the delta table into a DataFrame df = spark.read.format("delta").table('catalog.test.winequality_infer') # Create a Pandas dataframe from the DataFrame df_pandas = df.toPandas() |
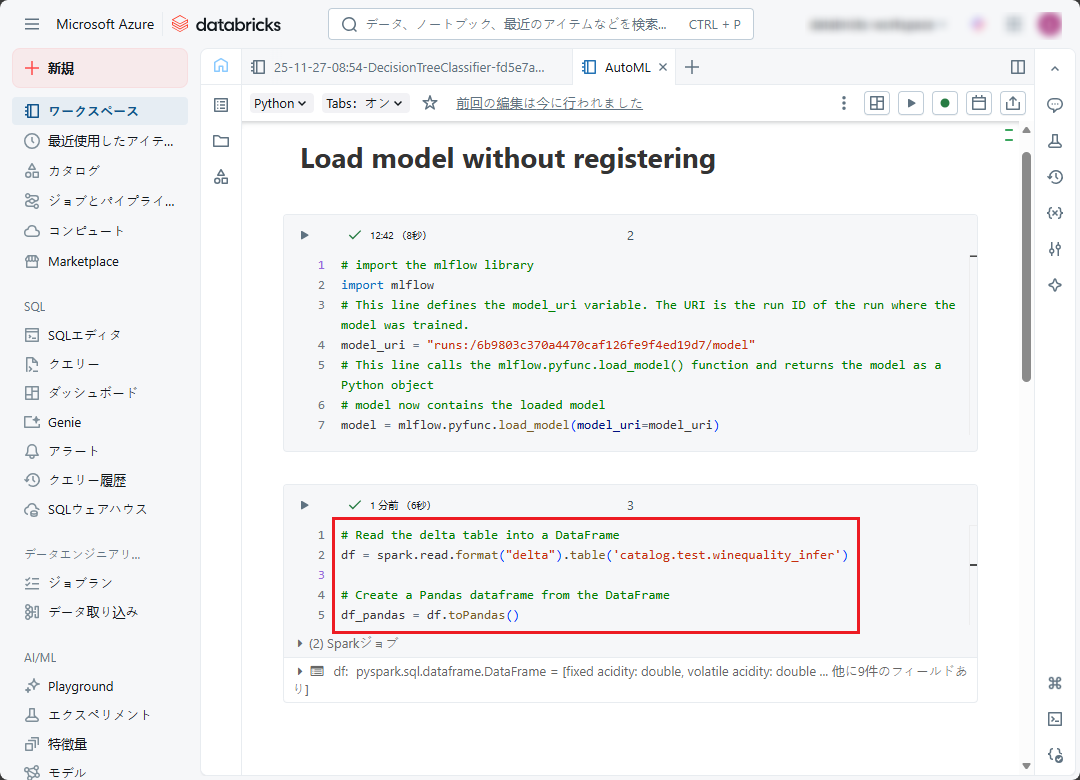
⑥ DataFrame を作成した後、次のコードを実行して INTEGERを FLOAT 64 に型変換します。
|
1 2 3 4 5 |
# converts the columns free sulfur dioxide and total sulfur dioxide to float64 df_pandas["free sulfur dioxide"] = df_pandas["free sulfur dioxide"].astype('float64') df_pandas["total sulfur dioxide"] = df_pandas["total sulfur dioxide"].astype('float64') |
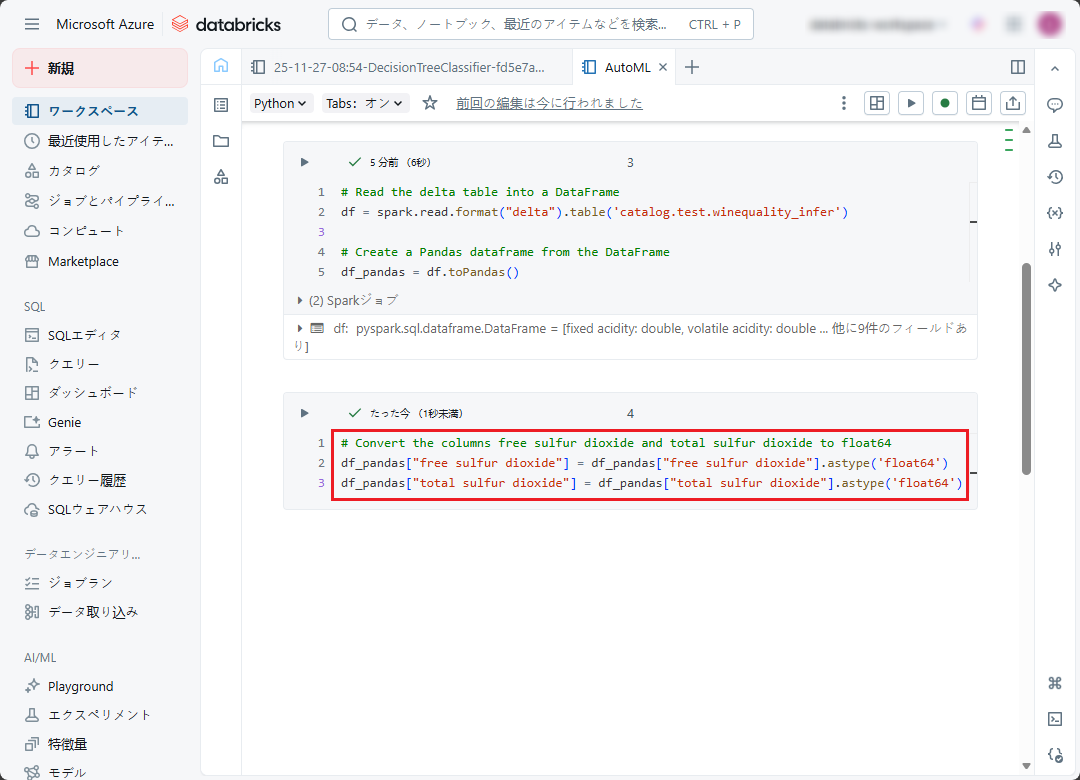
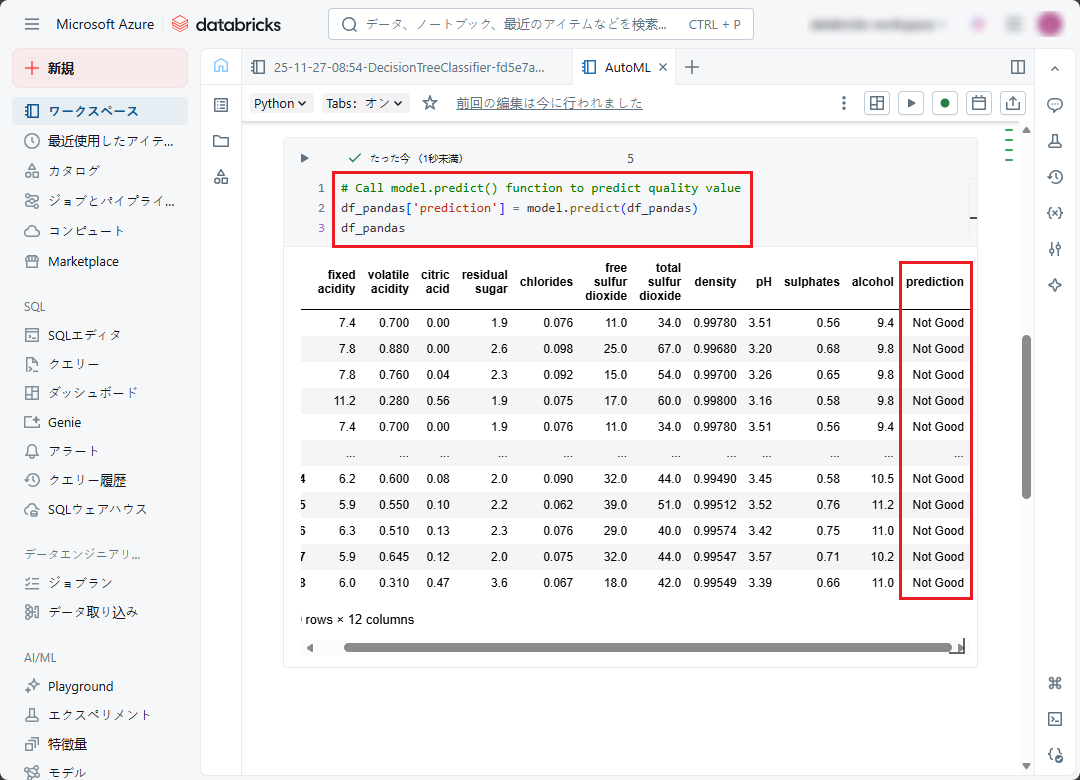
⑦ 推論・予測を実行するには、model.predict(df_pandas) を使用します。(df_pandas が、作成された DataFrame です)
前の手順で作成された DataFrame を呼び出して、予測結果を表示します。「prediction」カラムの値が、該当レコードの「fixed acidity」から「alcohol」カラムまでの値によって決まれます。
|
1 2 3 4 5 |
# calls the model.predict() function to predict quality value for each record of data test df_pandas['prediction'] = model.predict(df_pandas) df_pandas |
9.まとめ
本連載では、
Databricks AutoMLの使用方法について詳細に説明していきます。
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
・Azure Databricks連載シリーズはこちら