目次
1. はじめに
皆さんこんにちは。
今回は、Apache Airflow を使用して Azure Databricks ジョブを調整する方法について説明していきます。
※ 背景
データ処理パイプラインを開発・展開する際、タスク間の複雑な依存関係を管理することが要求されます。Databricks はビッグデータ処理に優れたツールですが、Airflow のような強力なワークフロー管理ツールを提供していないため、 Databricks 上のタスク間の依存関係を管理し、最適化することは困難です。一方、Airflow は柔軟で強力なワークフロー管理ツールであり、データ処理フローを効果的に定義、管理、自動化することができます。
※ 目的
Airflow と Databricks の利点を組み合わせることで、データ処理フローを最適化することができます。
Databricks ジョブは、Airflow によって管理できます。(起動、スケジューリング、監視、正しい順序)
2. 前提条件
- Databricks ワークスペースが必要です。
- Apache Airflowバージョン3.1.3 はインストールされていました。
3. Airflow の概要
3.1 Airflow とは
Airflow は複雑なワークフローのタスクを計画、調整、監視するためのプラットフォームです。
Airflow はワークフローの状態を追跡するための Web インターフェースを提供します。
3.2 Airflow の DAG とタスクとは
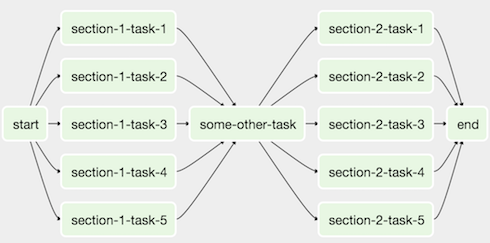
Airflow でワークフローは、DAG の形で表現され、特定の作業を実行するタスクを含み、実行の順序が整理されています。
DAGとは「Directed Acyclic Graph」の略で「依存関係にあるタスクをどの順番で実行するか」を示すものです。
DAGは、タスクで構成されています。タスクは、Python 関数、Bash スクリプトなど、様々な形態で用意できるものです。
3.3 Airflow のアーキテクチャ
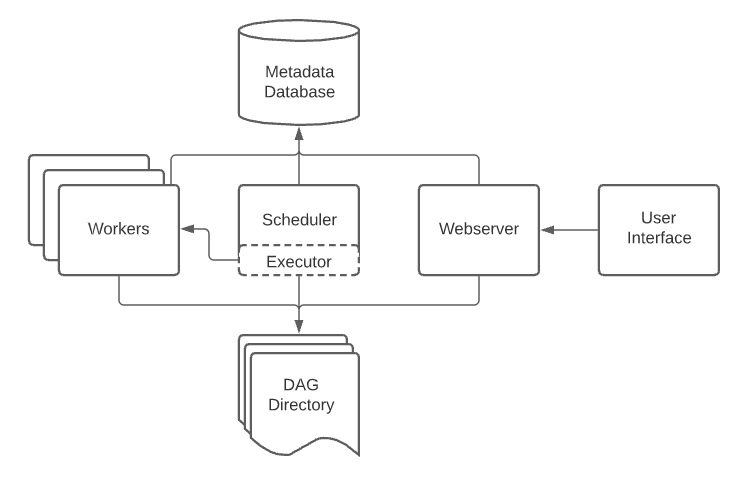
Airflow は、以上の必須コンポーネントが構成されています。
- スケジューラー: ワークフローとタスクの状態を監視し、タスクをエグゼキューターに送って実行する。 エグゼキューターはスケジューラーの構成属性であり、ワーカーを管理し、実行中のタスクを処理します。
- ウェブサーバー: ワークフロー/タスクの管理、実行、デバッグをしやすくする UI
- ワーカー:スケジューラーから指示されたタスクを実行します。
- DAG ディレクトリ: ユーザーが定義したワークフローの初期化コードを含むディレクトリ です。
- メタデータデータベース: スケジューラー、ワーカー、ウェブサーバーの状態を保存します。
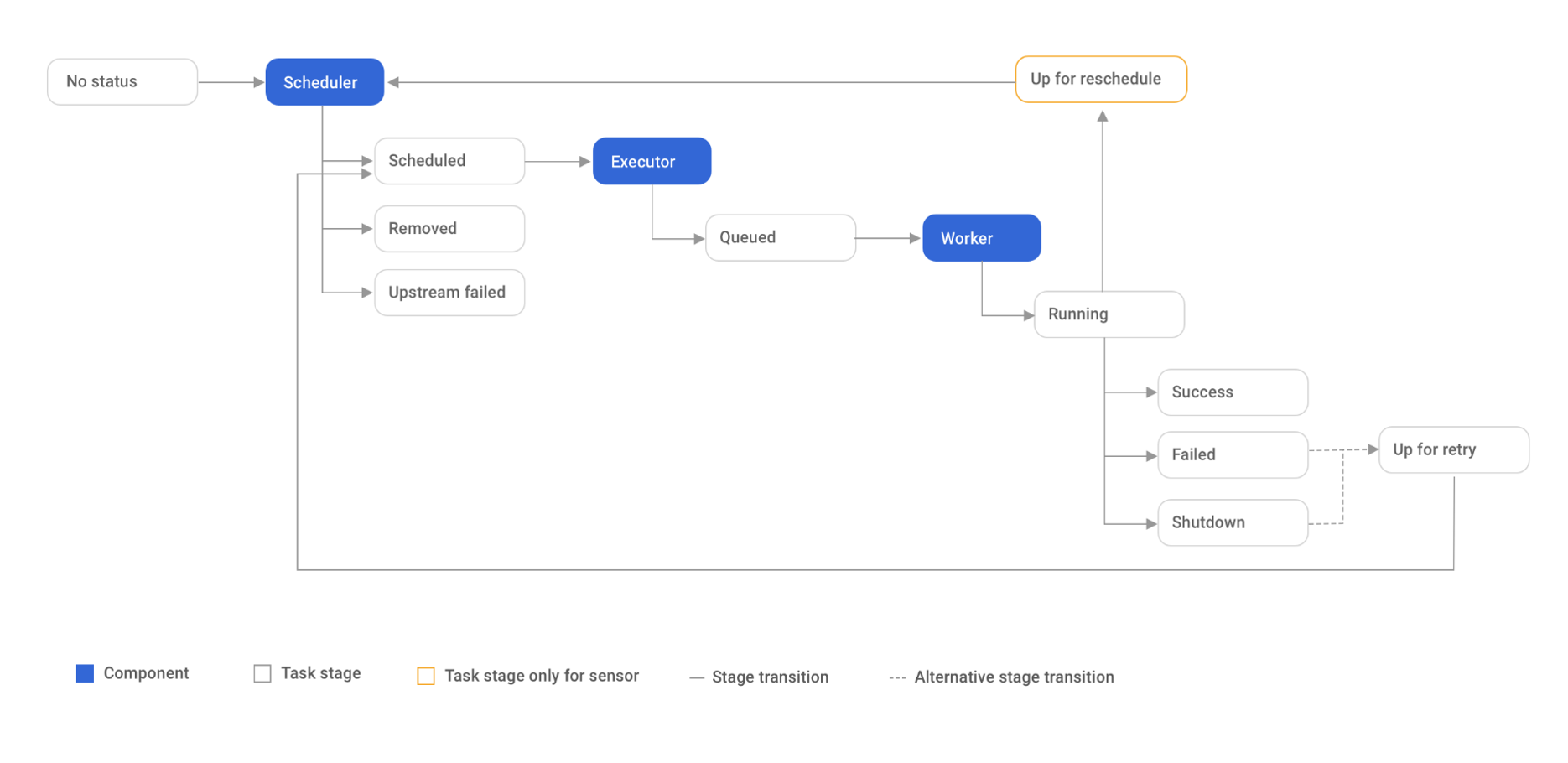
3.4 Airflow のタスク実行フロー
まず、スケジューラは、まだ実行されていないまたは再実行する必要があるタスクを取得して処理します。エグゼキューターはその後、タスクを適切なワーカーに送信します。次はタスクの実行状態(成功、失敗、シャットダウン)やその他の情報を保持するために、タスクインスタンスが作成されます。タスクの実行状態が失敗またはシャットダウンであり、リトライモードが設定されている場合、再実行されます。
4. Airflow と Databricks を組み合わせて使用する方法
ユースケース: ある企業は、株式市場の状況を調査するために、株価データを収集し、各株式の毎月の最高始値を見つける必要があります。さらに、企業は、これらの結果を将来の用途に保存するよう要求しています。
課題: データ処理では、複数のジョブが相互に依存しているため、ジョブのスケジュールと管理が困難になっています。
解決策: Airflow を使用してスケジューリングし、Databricks を使用してデータの収集と処理を行うためのワークフローを構築します。
ワークフローの主なタスクは次のとおりです。

- Load data: 証券コードの株価データを URL から抽出します。
- Clean data: 始値、銘柄コード、取引量、日付などの必要な列のみを取り出して、抽出されたデータのクリーニングします。
- Transform data: クリーニングされたデータに対して、月次の最高始値を計算するために、処理と計算を行います。
4.1 Databricks ワークスペースにノートブックの作成
最初に、3つのノートブックを作成して、述べられた3つのタスクを実行します。
① Databricks ワークスペースのポータル画面から、「New」 → 「Notebook」をクリックします。
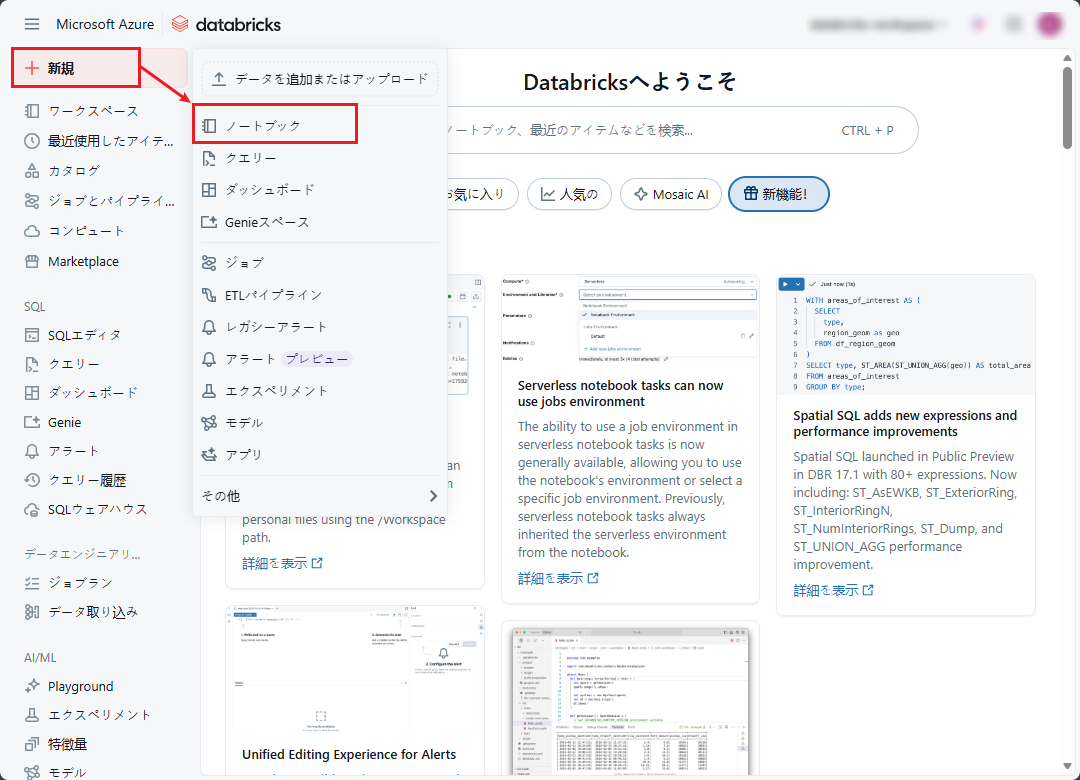
② ノートブック名を「Load Data」に変更し、言語を Python に設定します。
以下のコードをセルに追加します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import pandas as pd # ティッカーリスト TickerList = ["AAPL", "CVX", "FOX"] dataframes = {} # 各ティッカーのデータを取得する for ticker in TickerList: # CSVデータの読み込む dataframes[ticker] = pd.read_csv( f"https://raw.githubusercontent.com/astronautyates/datasourcedb/main/{ticker}_data.csv", on_bad_lines='skip', nrows=100 ) # DataFrame を bronze テーブルとして保存する table_path = f"catalog.schema.bronze_{ticker}_data" spark_df = spark.createDataFrame(dataframes[ticker]) spark_df.write.mode("overwrite").saveAsTable(table_path) |
このノートブックの目的は、株式のデータをURLから収集し、そのデータをブロンズレイヤーに対応する「catalog.schema.bronze_{ticker}_data」に保存することです。
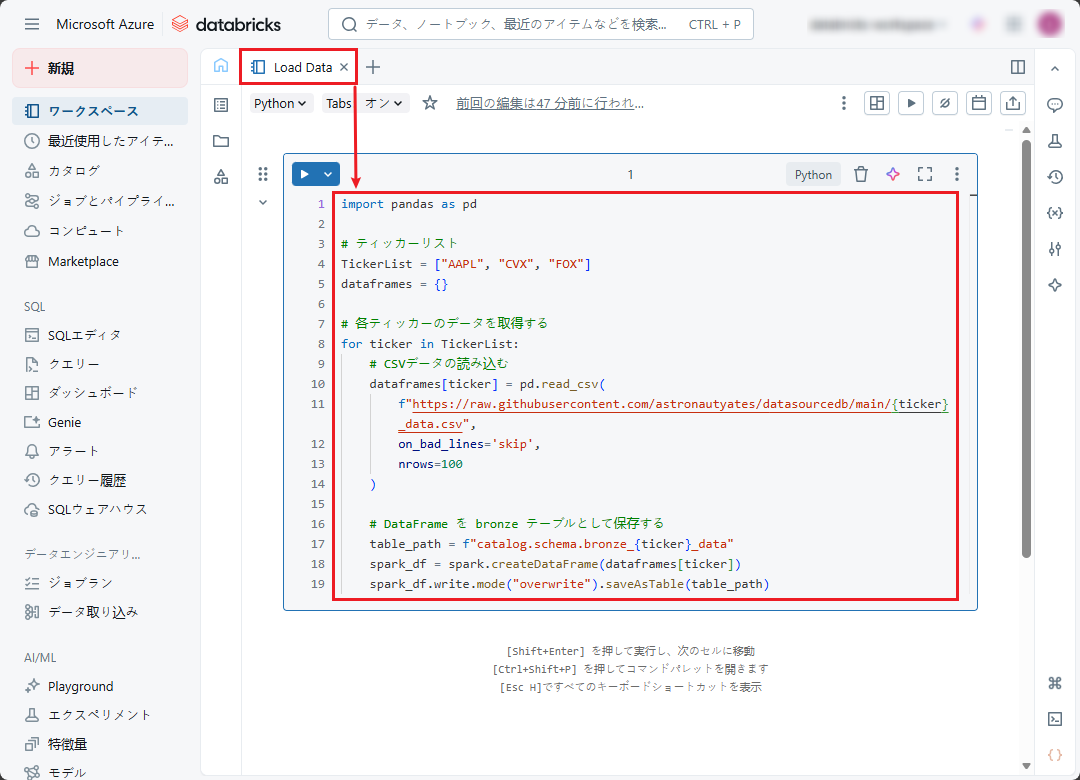
③ 「Clean Data」ノートブックを作成します。
以下のコードをセルに追加します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# ティッカーリスト TickerList = ["AAPL", "CVX", "FOX"] # 各ティッカーのデータをクリーンアップして保存する for ticker in TickerList: bronze_table_path = f"catalog.schema.bronze_{ticker}_data" silver_table_path = f"catalog.schema.silver_{ticker}_data" # データを Spark DataFrame に読み込む dirty_df = spark.read.table(bronze_table_path) # 必要な列を選択する cleaned_df = dirty_df.select("date", "open", "volume", "Name") # DataFrame を silver テーブルとして保存する cleaned_df.write.mode("overwrite").saveAsTable(silver_table_path) |
このノートブックの目的は、抽出されたデータをクリーニングすることです。必要な列のみを保持することです。このデータはシルバーテーブルに保存されます。
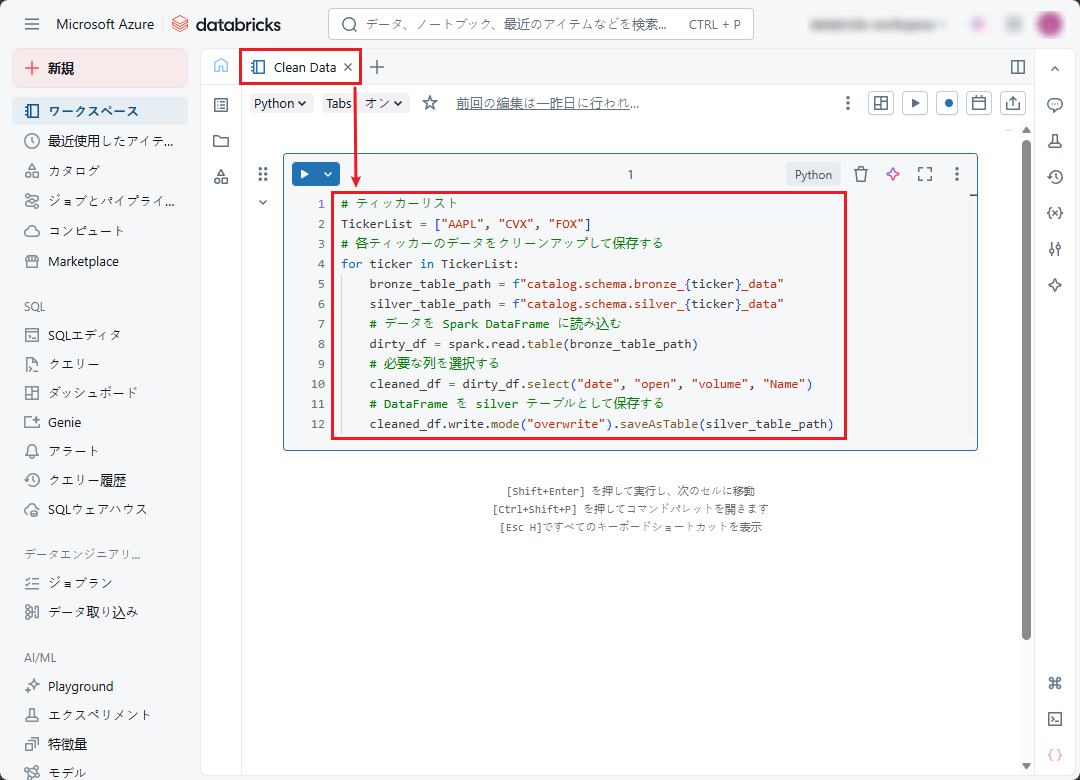
④ 「Transform Data」ノートブックを作成します
以下のコードをセルに追加します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
from pyspark.sql.functions import col, year, month, max # ティッカーリスト TickerList = ["AAPL", "CVX", "FOX"] # クリーンなデータを読み込む for ticker in TickerList: table_path = f"catalog.schema.silver_{ticker}_data" clean_df = spark.table(table_path) # 'date'列を日付型に変換 clean_df = clean_df.withColumn('date', clean_df['date'].cast('date')) # 各月の最大の始値を持つ行を選択 max_open_df = clean_df.groupBy( year('date').alias('year'), month('date').alias('month') ).agg(max('open').alias('max_open')) # 'date'列をTimestampタイプに変換 max_open_df = max_open_df.withColumn('date', max_open_df['year'].cast('timestamp')) # クリーンなデータと最大の始値の行を結合 transformed_df = clean_df.join( max_open_df, (year(clean_df['date']) == max_open_df['year']) & (month(clean_df['date']) == max_open_df['month']) & (clean_df['open'] == max_open_df['max_open']) ).select( clean_df['date'], clean_df['Name'], clean_df['open'], clean_df['volume'] ) # DataFrameをgoldテーブルとして保存する table_path = f"catalog.schema.gold_{ticker}_data" transformed_df.write.mode("overwrite").saveAsTable(table_path) |
このノートブックの目的は、各月の最高始値を特定するために、クリーニングされたデータを処理し、計算することですの計算を実行することです。データはゴールドレイヤーに保存されます。
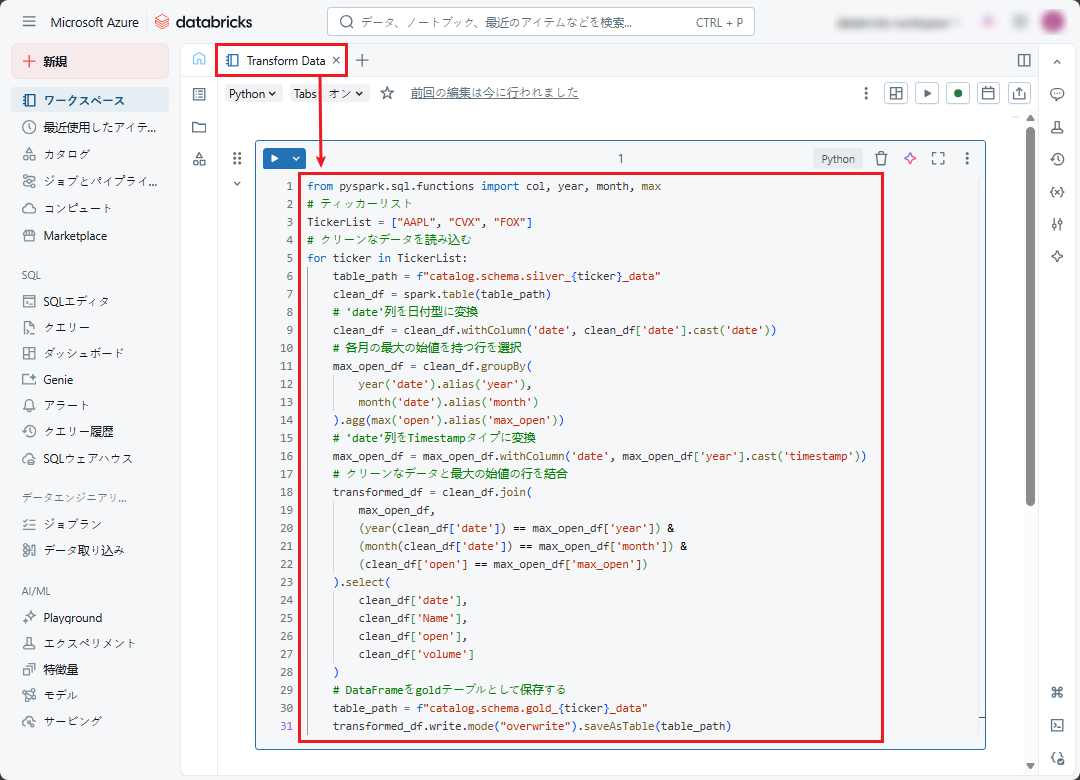
4.2 Databricks ワークスペースにジョブの作成
3つのデータ処理用ノートブックが作成されたので、対応する3つのジョブを作成します。
① ノートブックを実行するジョブを作成するため、Databricks のポータル画面から「ジョブとパイプライン」→「作成」 をクリックします→「ジョブ」をクリックしてください。
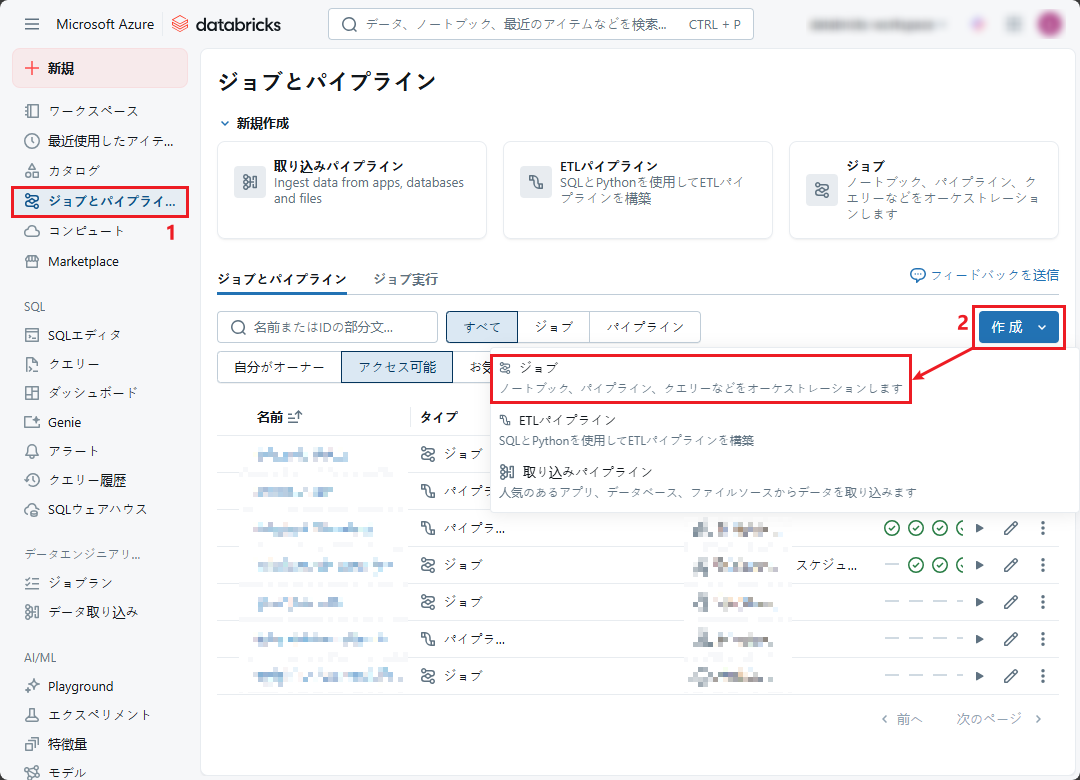
② ジョブ名を「Load Data Job」に変更し、必要な情報を入力します
- 「タスク名」: タスク名 (例: load_data)
- 「種類」: タスクのタイプ(例: ノートブック)
- 「ソース」: タスクのソース (例: ワークスペース)
- 「パス」: ノートブックのパス
- その他のフィールドはデフォルトのままにします
ジョブに関する詳細情報は、こちらを参照してください。
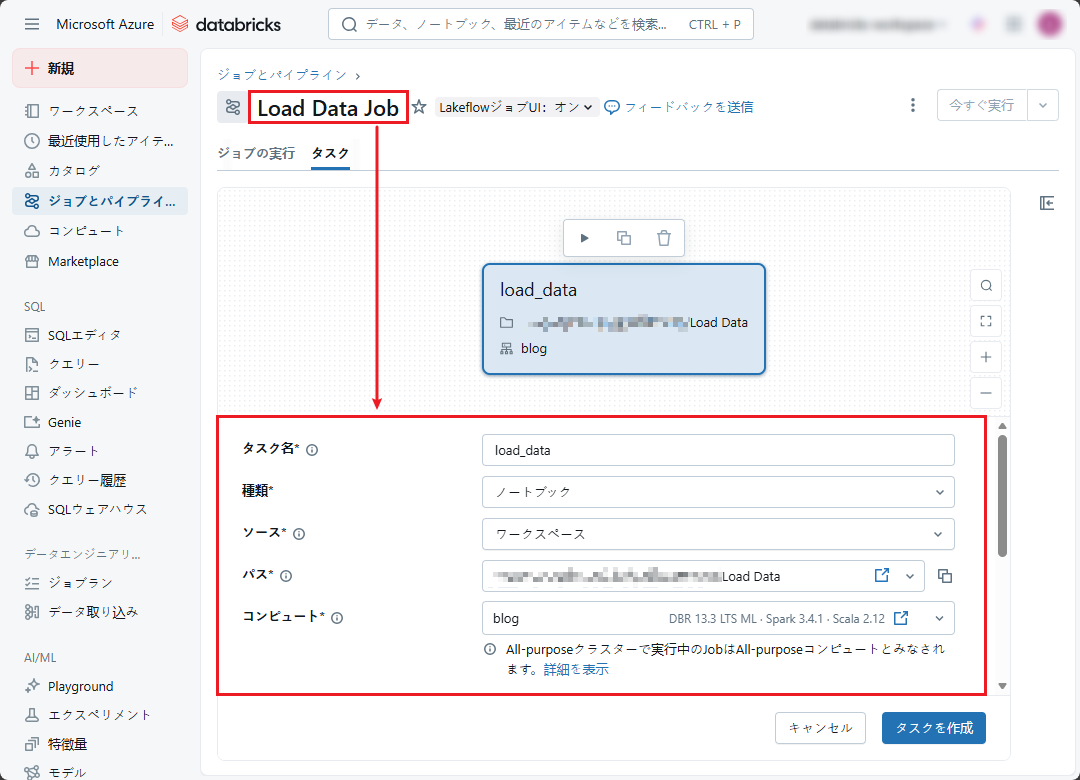
③「Clean Data Job」という2番目のジョブを作成して、「Clean Data」ノートブックを実行します。
注意: 「Clean Data」ノートブックへのパスを選択することが必要です。
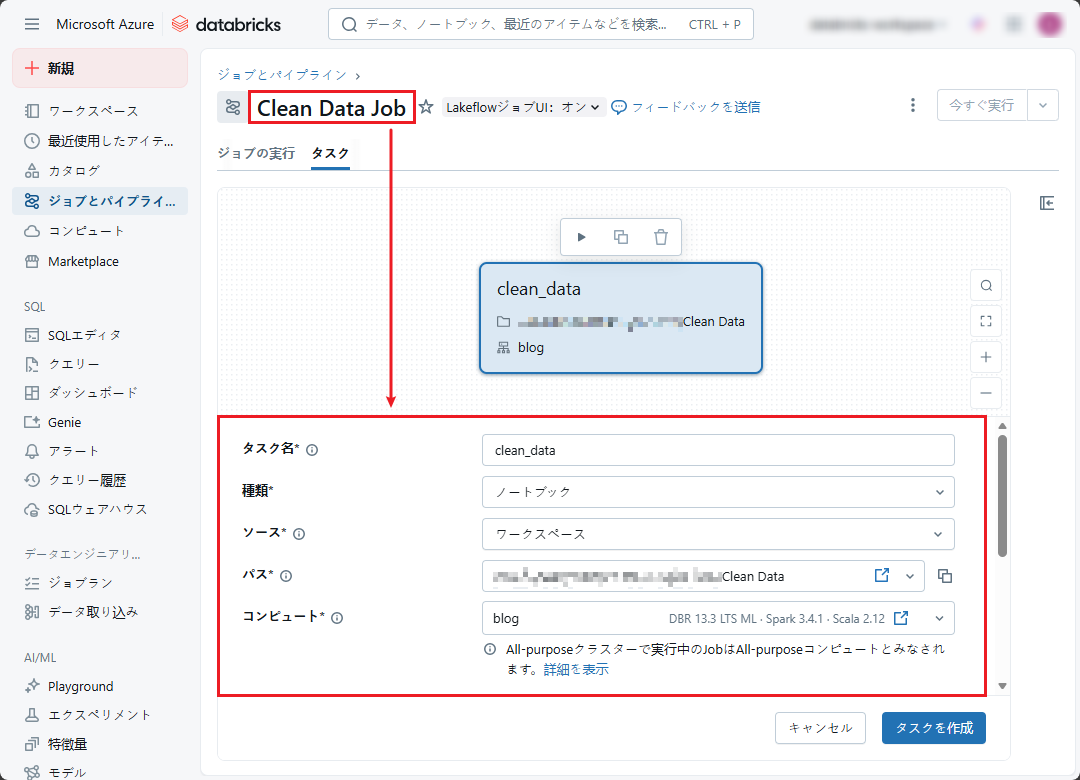
④「Transform Data Job」という3番目のジョブを作成して、「Transform Data」ノートブックを実行します。
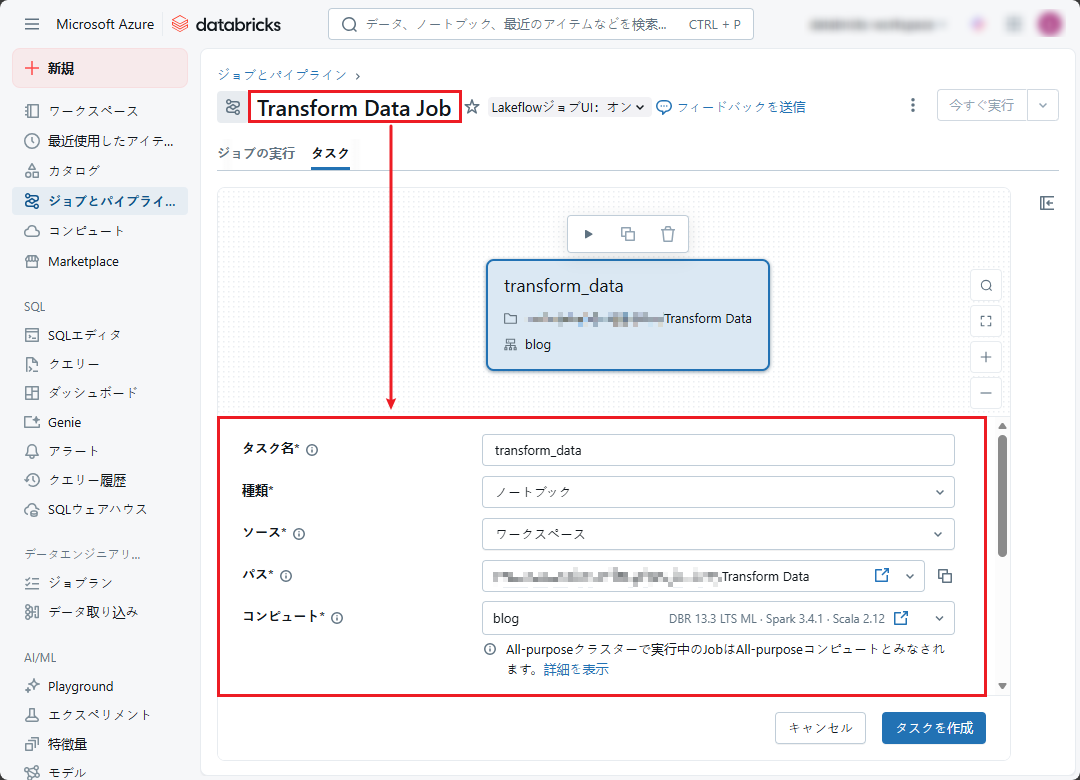
注意: 「Transform Data」ノートブックへのパスを選択することが必要です。
最後に、3つのジョブが作成されました。
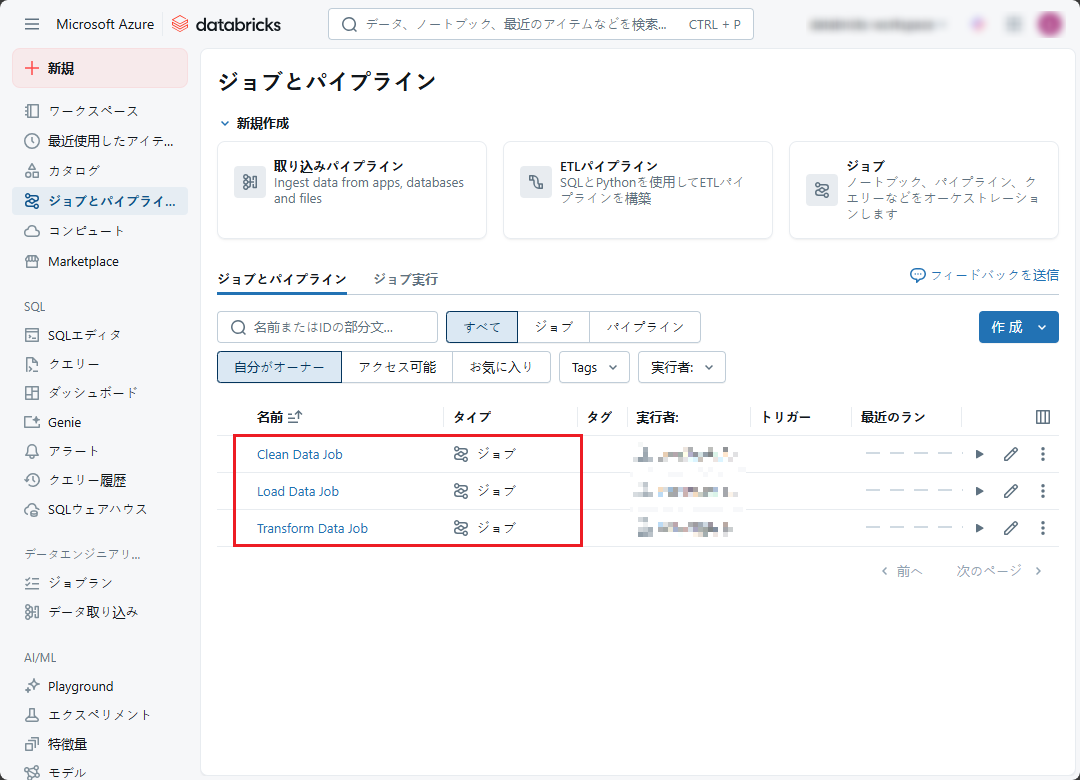
次に、Airflowを使用してこれらの3つのジョブを実行する方法を紹介します。
4.3 Airflow に Azure Databricks 接続の設定
Airflow が Databricks のジョブをトリガーできるように、接続を作成する必要があります。
① Airflow UI で、メニューから「Admin」→「Connections」をクリックします→「Add Connection」をクリックしてください。
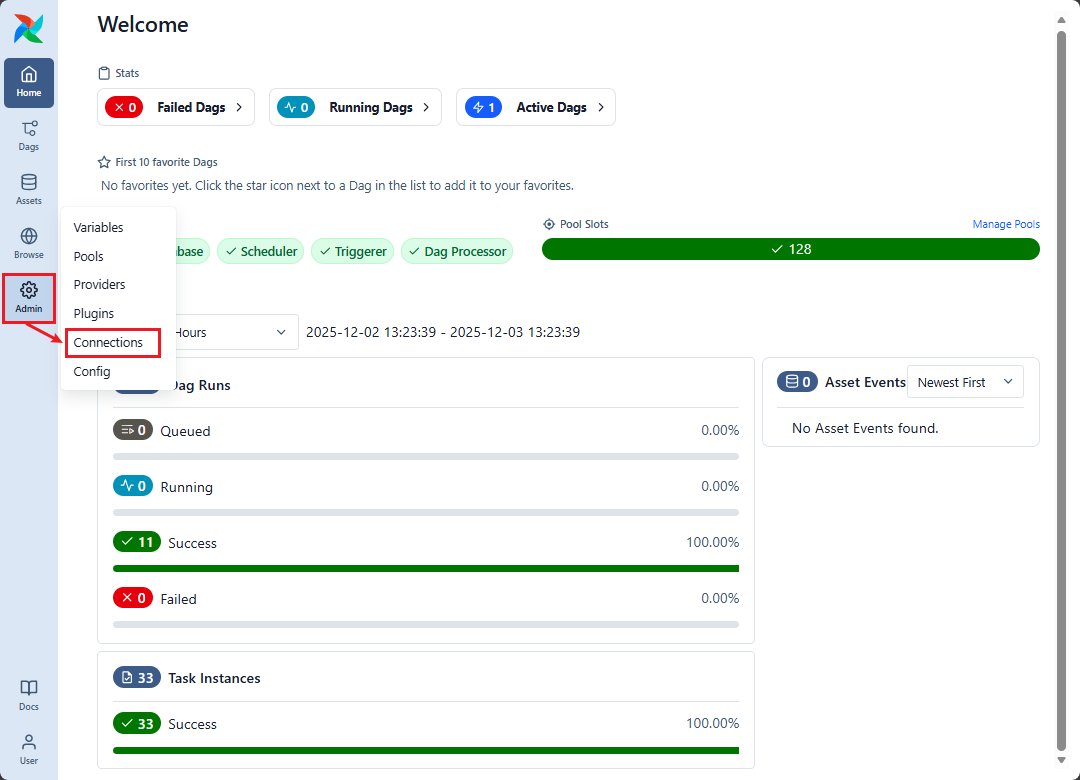
②「Add Connection」 画面で、以下の接続情報を設定します。
- 「Connection Id」: 接続の名前を入力します
- 「Connection Type」: Databricks を選択します。
- 「Host」: 接続する Databricks ワークスペースアドレを入力します。
- 「Password」: Databricks の個人用アクセス トークンを入力します。
「Save」ボタンをクリックします。
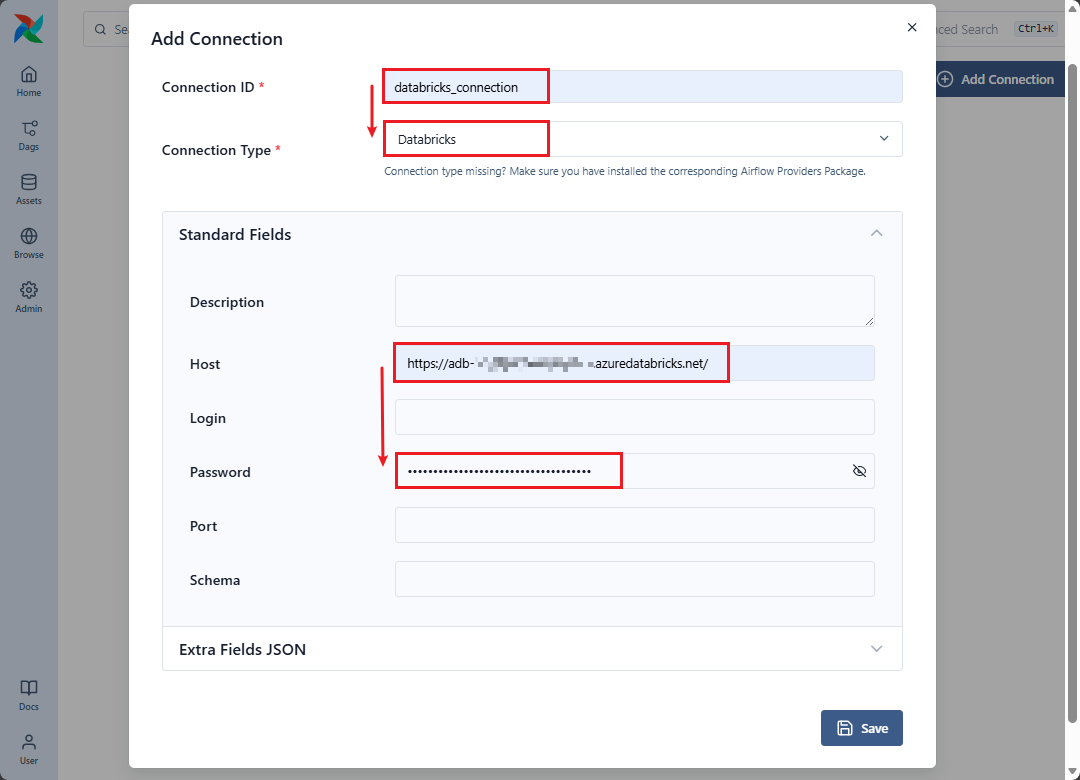
これで、Databricks ワークスペースへの接続が作成されました。
4.4 Azure Databricks ジョブをトリガーする DAG の作成
Python ファイルを作成して、3つのタスクを含む DAG を初期化し、各タスクがジョブをトリガーするようにします。
ジョブ間の依存関係を宣言する必要があります: load_data >> clean_data >> transform_data
以下の情報を変更します。
- 「start_date」: DAG の実行を開始する日付
- 「databricks_conn_id」: 事前に設定された接続 ID
- 「job_id」: Databricks ワークスペースのジョブの詳細に対応する値
- 「schedule」: スケジュールの設定
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from airflow import DAG from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator from datetime import datetime #DAGを作成する with DAG('monthly_highest_stock_price_dag', start_date = datetime(yyyy, mm, dd), schedule = '@monthly' ) as dag: #タスクを作成する load_data = DatabricksRunNowOperator( task_id = 'run_load_data_job', databricks_conn_id = 'databricks_connection', job_id = 'job_id' ) clean_data = DatabricksRunNowOperator( task_id = 'run_clean_data_job', databricks_conn_id = 'databricks_connection', job_id = 'job_id' ) transform_data = DatabricksRunNowOperator( task_id = 'run_transform_data_job', databricks_conn_id = 'databricks_connection', job_id = 'job_id' ) load_data >> clean_data >> transform_data |
注意:ファイルを airflow/dags ディレクトリに保存します。
Airflow の「DAGs」ページにて、「monthly_highest_stock_price_dag」という作成した DAG が表示されます。
Airflow UI の monthly_highest_stock_price_dag 画面で, 「Trigger」をクリックします。
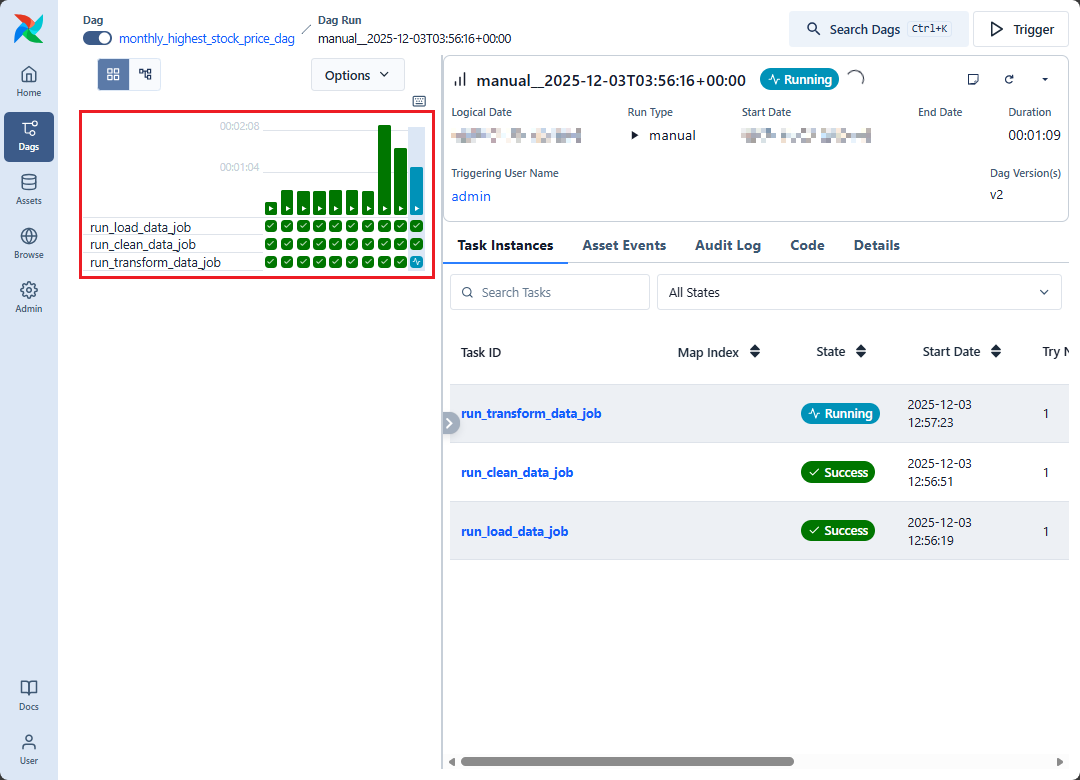
「Graph」タブをクリックして、実行中のタスクの状態や依存関係を追跡します。
「Grid」タブでは、DAG の実行履歴や状態を表示することができます。
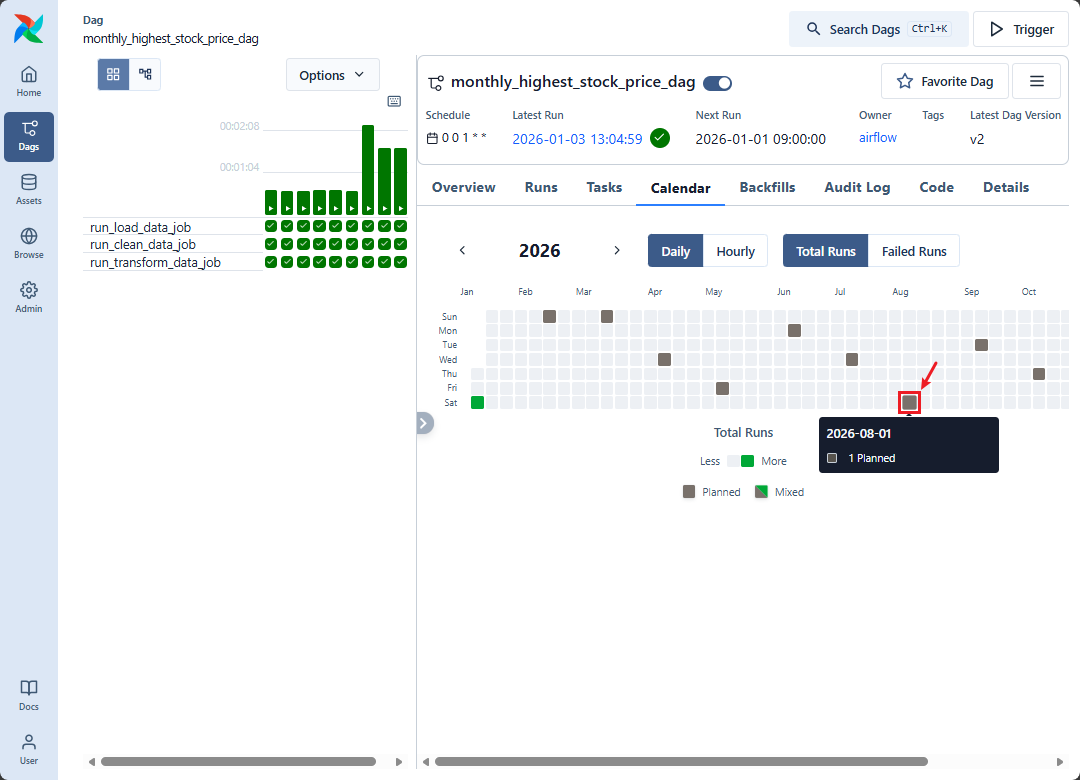
「Calendar」タブでは、DAG のスケジュールされた実行時間が表示されます。
5. Airflow を Azure Databricks で使用するメリット
統合ジョブ管理システムを提供します。
- Airflow は、コネクション管理にて複数の異なるシステムで構成されたワークフローを構築できるようになります。
依存関係のコンポーネントを柔軟に使用できます。
- Airflow はタスク間で柔軟に定義されたサポート関数を呼び出すことができます。
さまざまなタスクを整理し、複雑な要件に対応できます。
- タスクの依存関係を柔軟に整理し、ブランチのロジックを自由にカスタマイズできます。
6.まとめ
この記事では、Airflow の基本的な知識を紹介し、Azure Databricks ジョブを管理するための Airflow の使用方法を説明しました。これにより、Airflow を Azure Databricks で使用する利点を示しました。
今回の記事が少しでも Databricks を知るきっかけや、業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricks の環境構築パッケージを用意しています。
Azure Databricks や Azure 活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
Azure Databricks 連載記事のまとめはこちら
![]() お問い合わせはこちら
お問い合わせはこちら