1. はじめに
皆さんこんにちは。
今回からMicrosoft Fabricについての連載ブログを始めていきます。
全5回を予定しています。第4回ではSynapse Data Engineering ユーザー向け Fabric チュートリアル_第(1回)について説明いたします。
第1回:Microsoft Fabric 概要と試用版の作成方法
第2回:Power BI ユーザー向け Fabric チュートリアル
第3回:Data Factory ユーザー向け Fabric チュートリアル
第4回:Synapse Data Engineering ユーザー向け Fabric チュートリアル_第1回 (今回)
第5回:Synapse Data Engineering ユーザー向け Fabric チュートリアル_第2回
前回のブログで、Microsoft Fabric の Industry Solutions の使用方法について説明しました。
今回は、Microsoft Fabric の Synapse Data Engineering の使用方法を「第1回」、「第2回」という2パートに分けて、簡単に説明していきます。
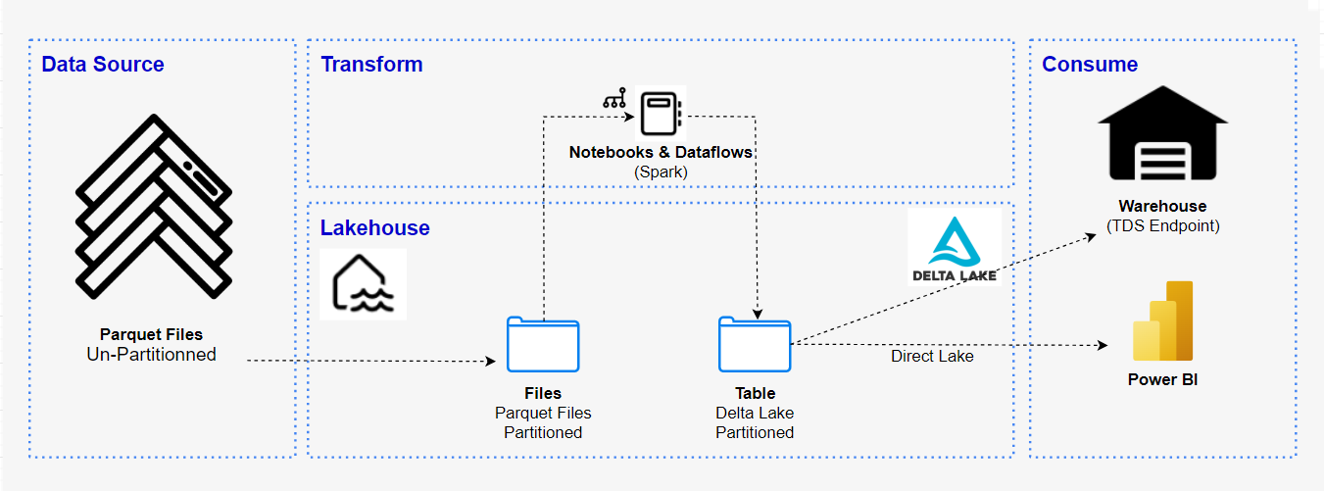
データ ソースからレイクハウスへのデータ取込など、次のステップに必要なデータの準備は、第1回で説明されています。目的は、ユーザーがデータ ソースからレイクハウスにデータを取込む方法を理解できるようにすることです。
第2回は、レイクハウスへ取込んだデータを使用し、データ変換を行い、レポートを作成します。目的は、レイクハウスでデータを処理した後、レポートを作成する際に MS Fabric で Synapse Data Engineering を使用する方法をユーザーが理解できるようにすることです。
この例では、MS Fabricのデータエンジニアリングを使用して、データの取得からデータの消費までのプロセスを完了します。詳細としては、様々なデータソースからデータを収集し、レイクハウスに読み込み、ノートブックに変換し、最後にレイクハウスからレポートを作成します。
Fabricの柔軟性を利用して、レイクハウスまたはデータウェアハウスアーキテクチャを実装できる場合がある、またはそれらを組み合わせてシンプルな実装で両方の利点を最大限に活用できる場合もあります。このチュートリアルでは、小売店を例として、そのレイクハウスを最初から最後まで構築します。
2. 前提要件
実施する際の前提条件は以下の通りです。
・開始する前に、組織に対して Fabric を有効にする必要があります。
・まだサインアップしていない場合は、無料試用版にサインアップしてください。
・Wide World Importers (WWI) sample database をダウンロードして使用する必要があります。
3. データエンジニアリングとは
データエンジニアリングは、様々なソースやフォーマットでの生データを収集して分析できるようにするシステムを設計および構築するプロセスです。
MS Fabric のデータエンジニアリングは、インフラストラクチャとシステムを設計、構築、維持管理する際に、組織が大量のデータを収集、保存、処理、分析できるようにします。
4. レイクハウスへのデータインジェスト
4-1.Fabric ワークスペースの作成
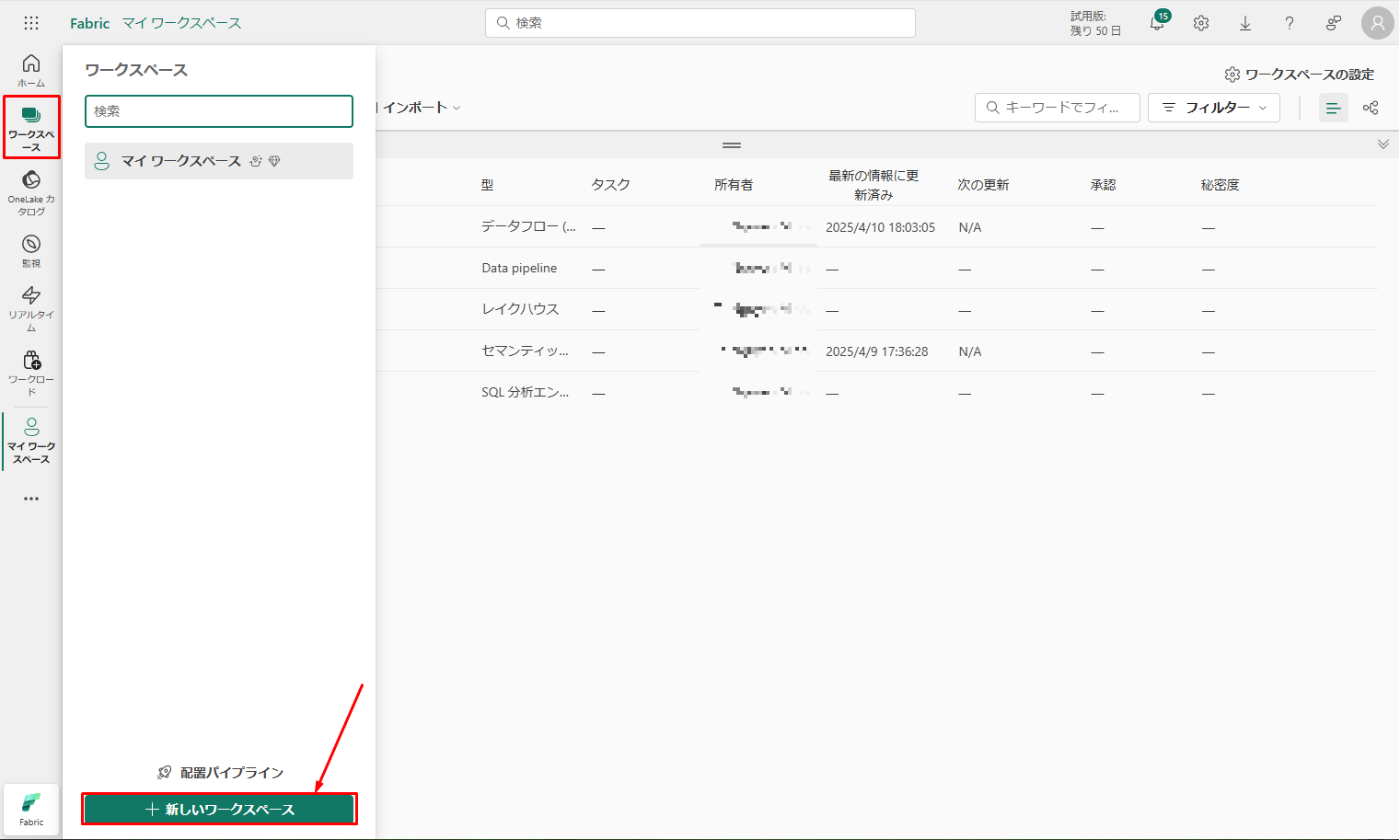
ワークスペースを作成します。
①「ワークスペース」と「新しいワークスペース」を選択します。
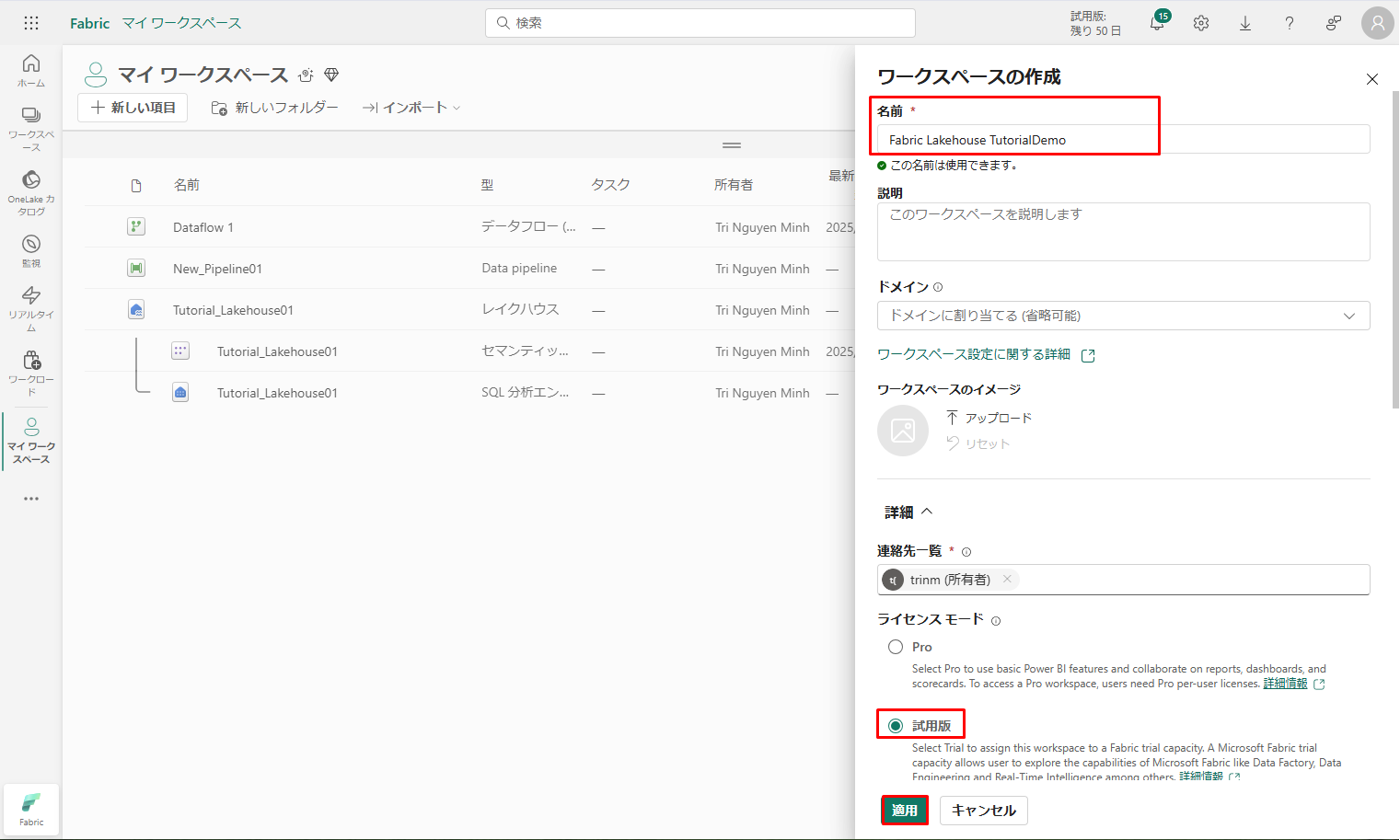
 「ワークスペースの作成」フォームに次の詳細を入力します。
「ワークスペースの作成」フォームに次の詳細を入力します。
①「名前]:名前を一意にする追加の文字を入力します。
②「説明]:ワークスペースの説明 (省略可能) を入力します。
③ 詳細:「ライセンス モード」で「試用版」の容量を選択します。
④「適用」をクリックしてワークスペースを作成します。
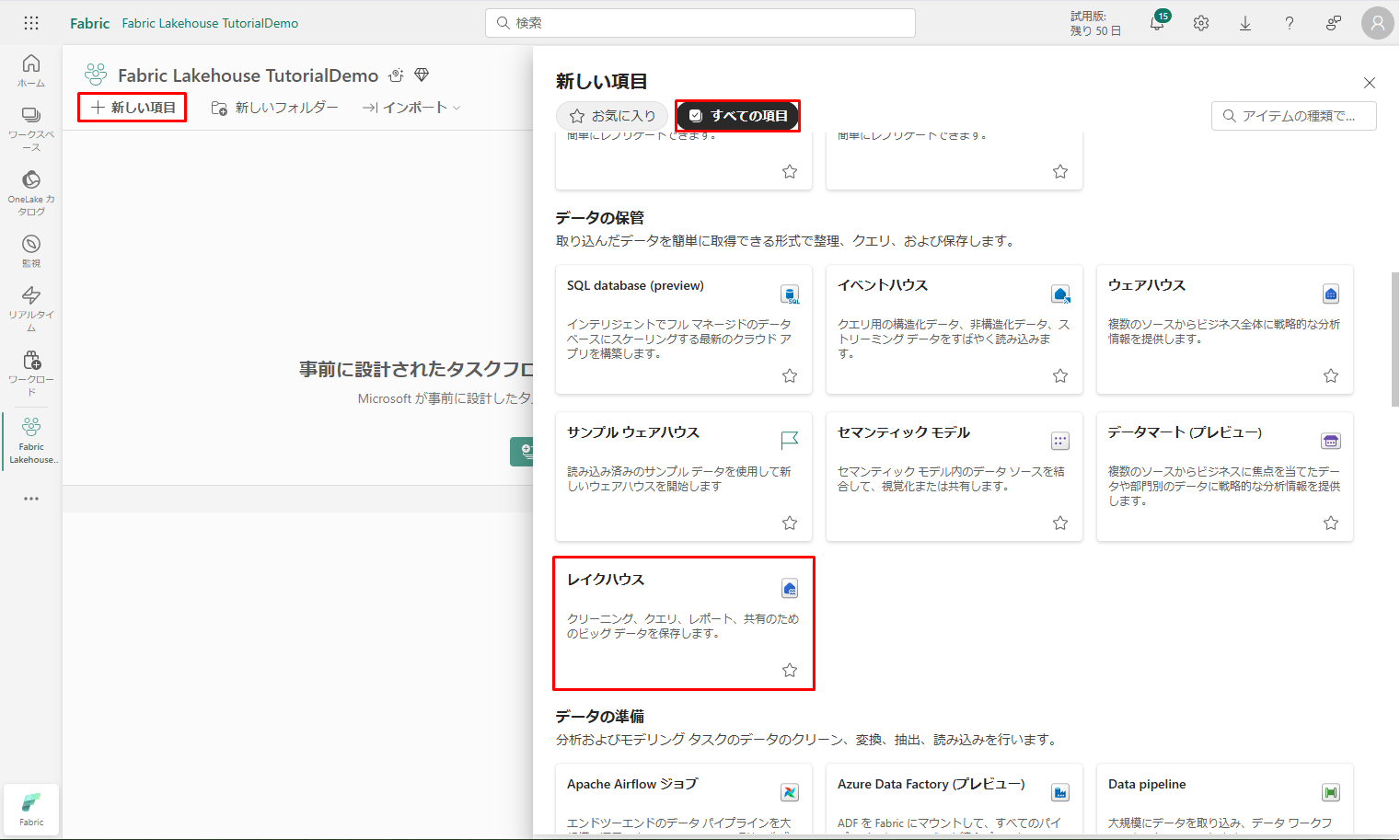
 4-2.レイクハウスの作成
4-2.レイクハウスの作成
レイクハウスを作成します。
① ワークスペースが正常に作成されたら、「新しい項目」をクリックし、「データの保管」タブで「レイクハウス」を選択し、新しいレイクハウスを作成します。
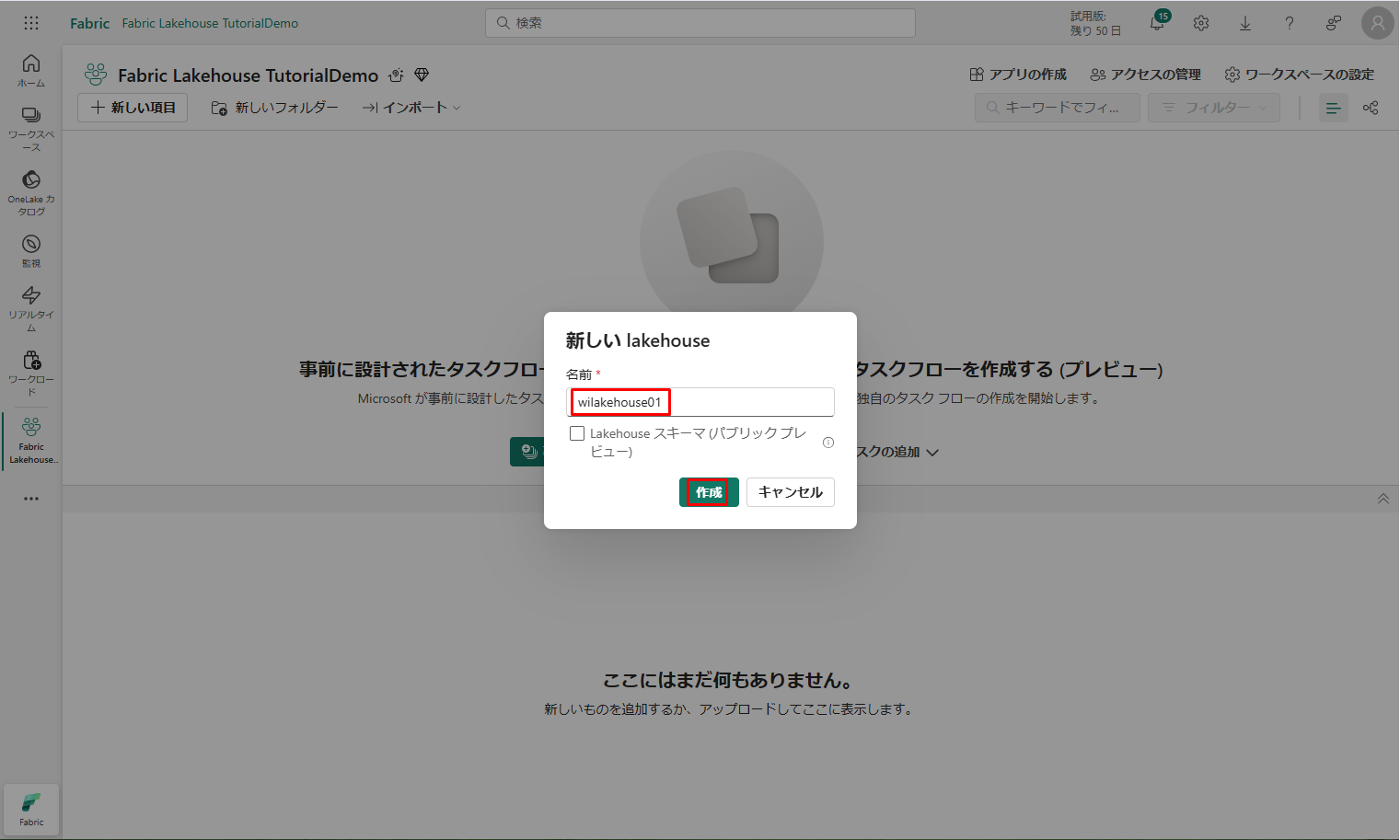
③「新しい lakehouse」ダイアログ ボックスの「名前」フィールドに「wilakehouse01」と入力します。
④「作成」を クリックして、新しいレイクハウスを作成して開きます。
 4-3.サンプル データの取り込み
4-3.サンプル データの取り込み
サンプル データを取り込みます。
① Fabric samples repo から dimension_customer.csv ファイルをダウンロードします。
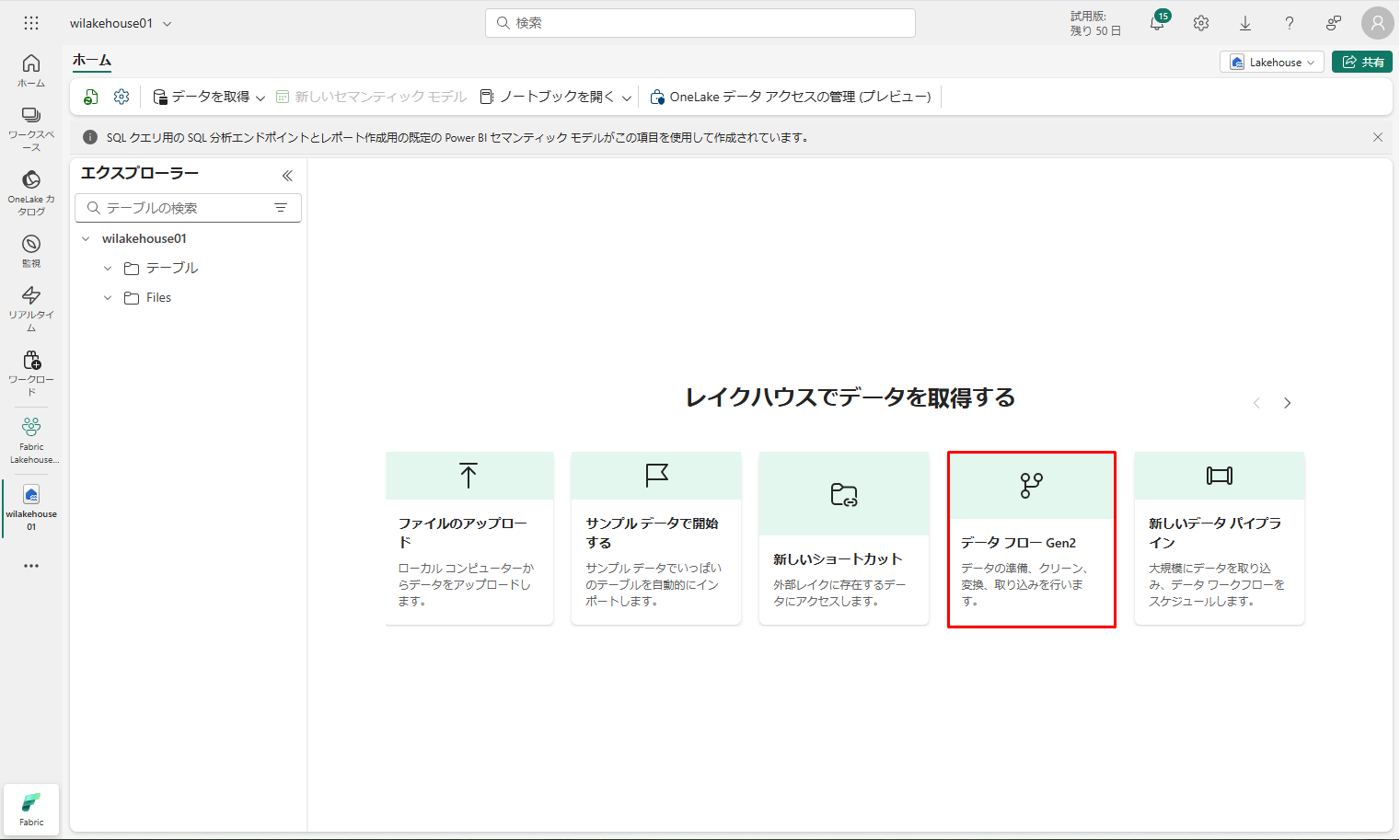
② レイクハウスにデータを読み込むオプションは、Lakehouseエクスプローラーに表示されます。「データ フロー Gen2」を選択します。
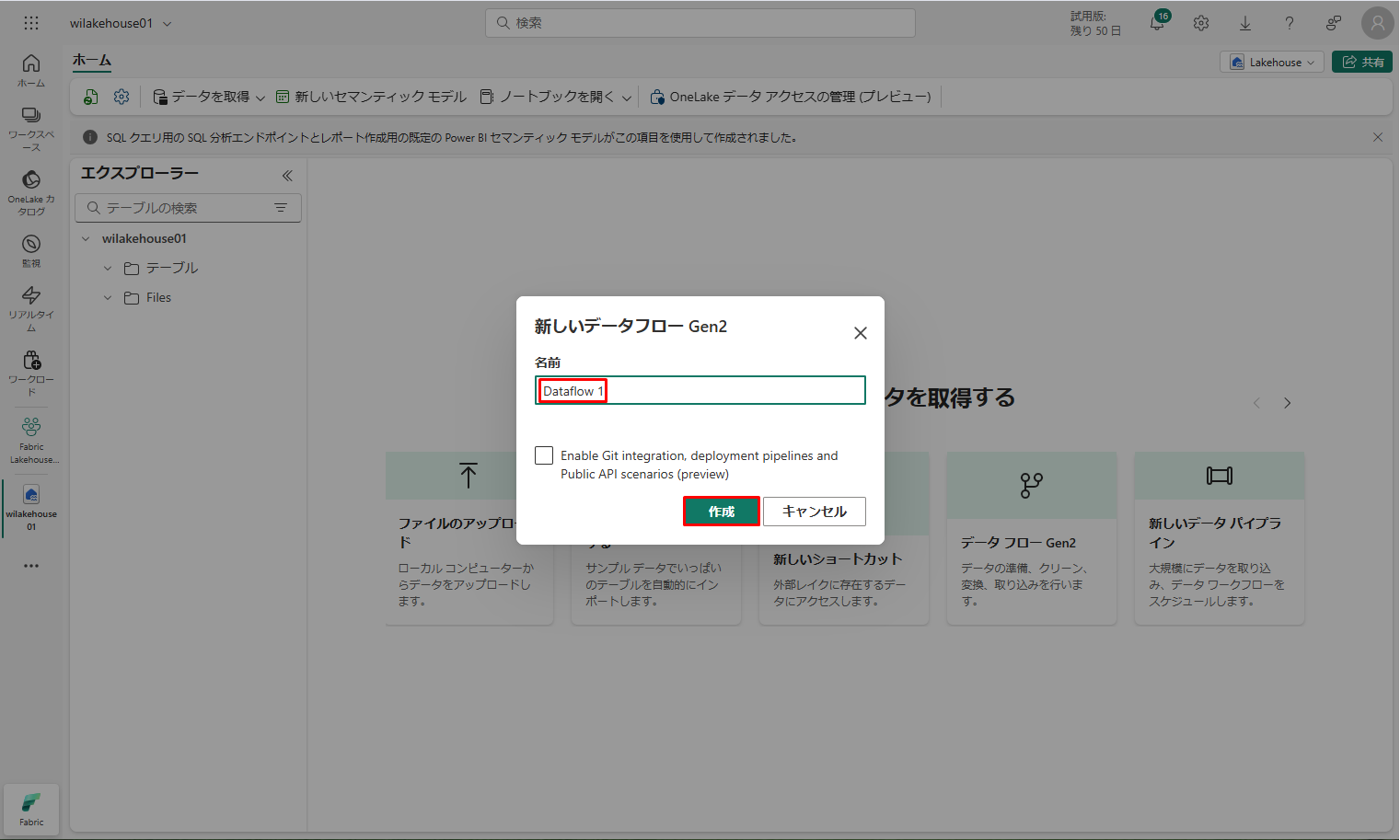
「新しいデータフロー Gen2」ダイアログ ボックスの「名前」フィールドに「Dataflow 1」と入力します。
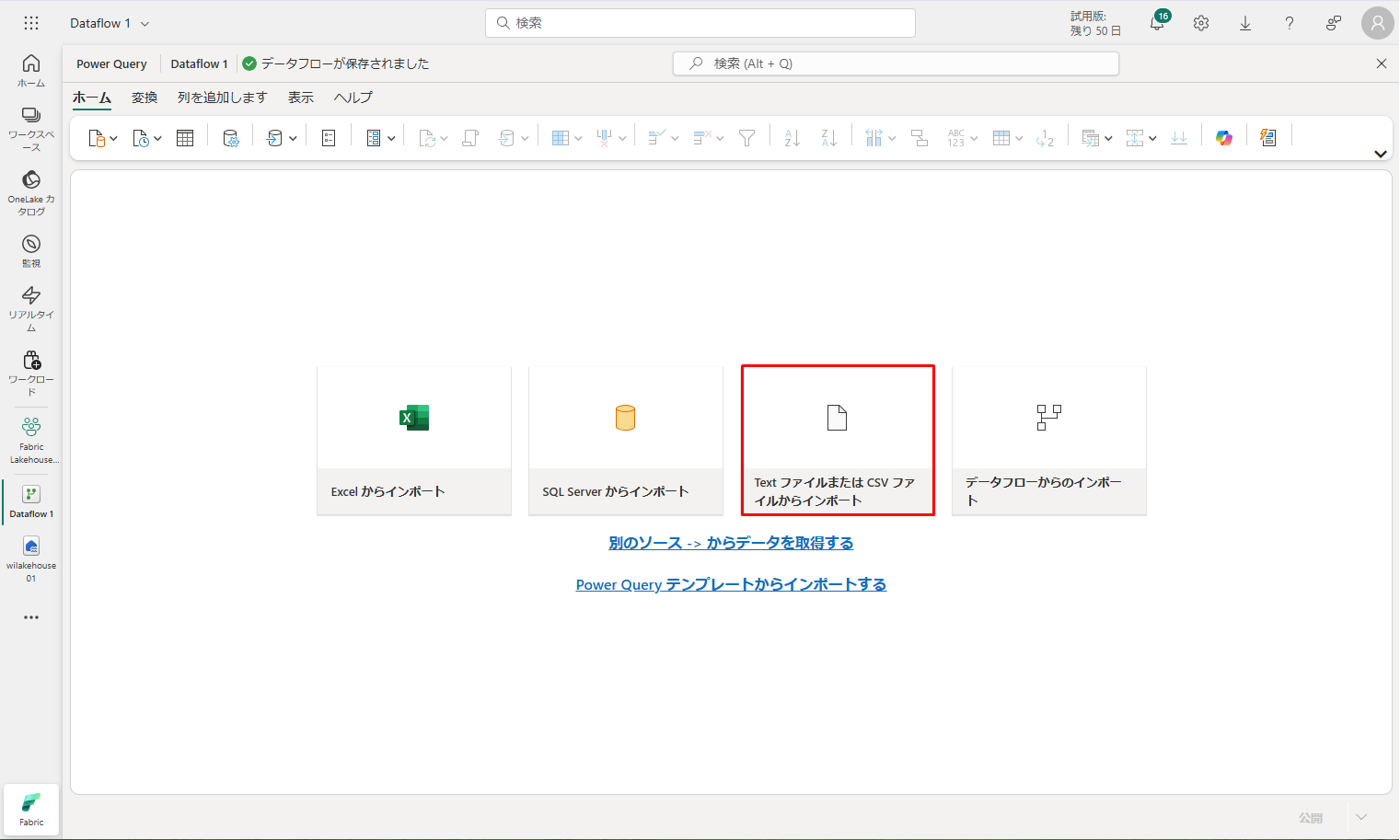
 ③ 新しいデータフローウィンドウで、「Text ファイルまたは CSV ファイルからインポート」を選択します。
③ 新しいデータフローウィンドウで、「Text ファイルまたは CSV ファイルからインポート」を選択します。
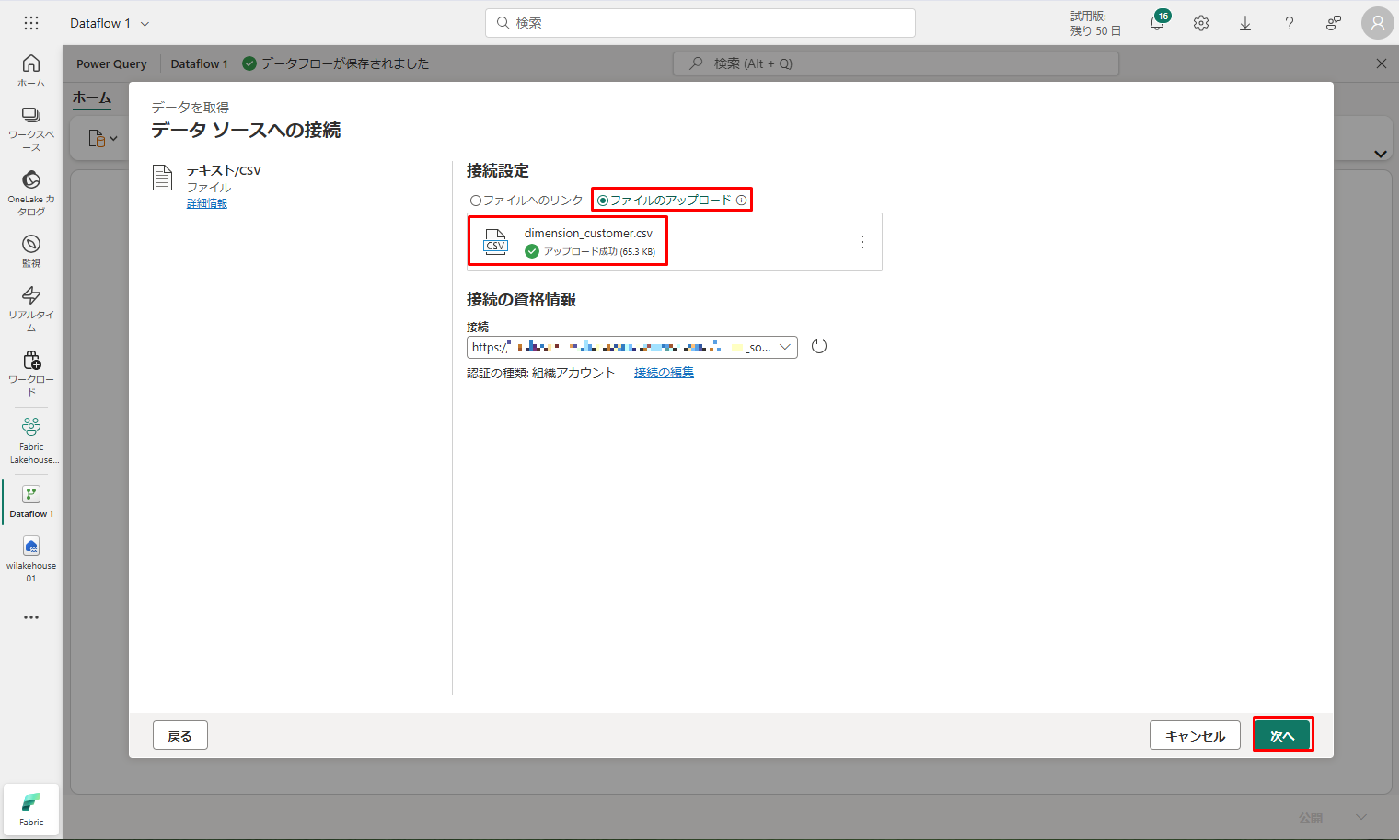
 ④「データ ソースへの接続」ウィンドウで、「ファイルのアップロード」ラジオ ボタンを選択します。
④「データ ソースへの接続」ウィンドウで、「ファイルのアップロード」ラジオ ボタンを選択します。
⑤ 前の手順でダウンロードした dimension_customer.csv ファイルをドラッグ アンド ドロップします。ファイルがアップロードされたら、「次へ」をクリックします。
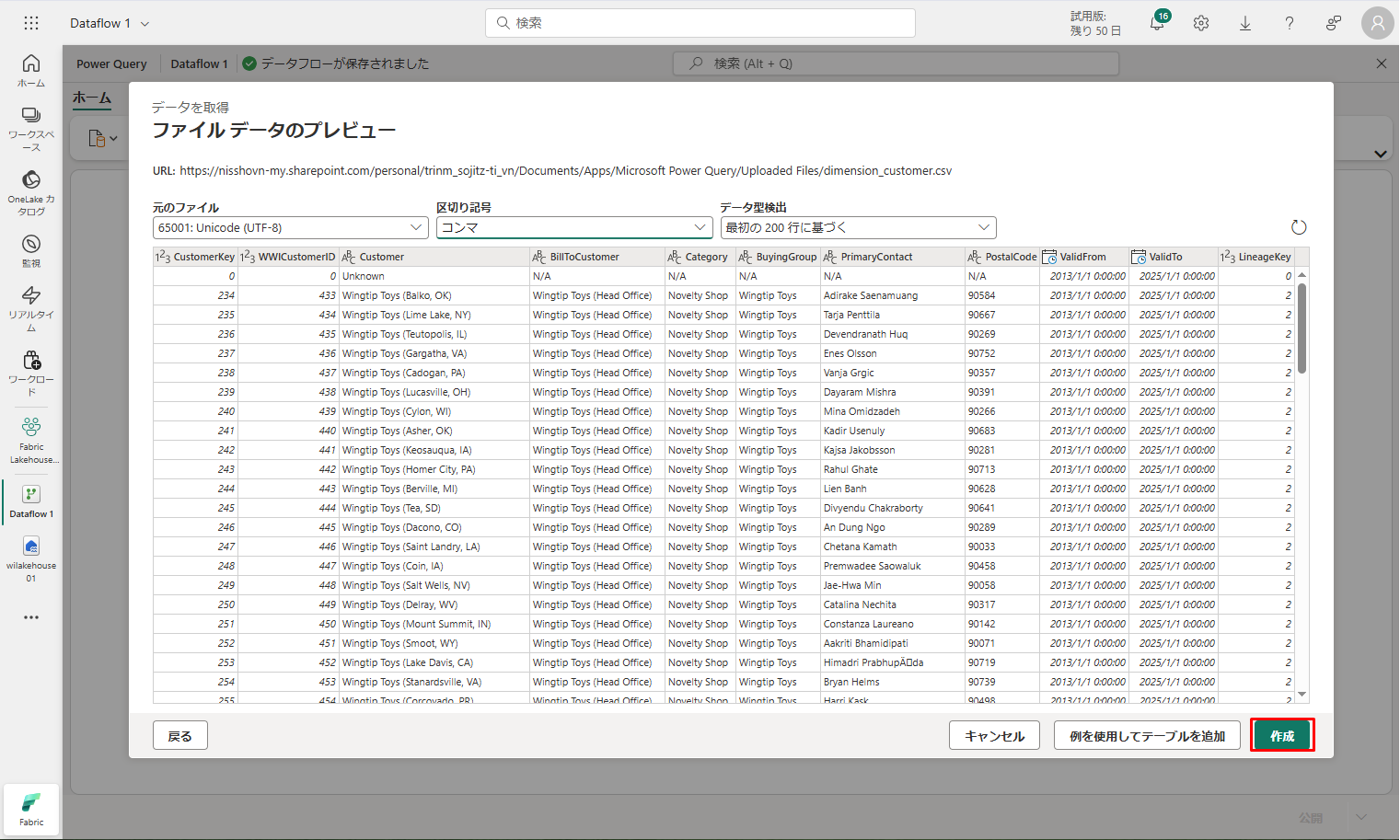
 ⑥「ファイル データのプレビュー」ページのデータをプレビューし、「作成」を選択して続行し、データフロー キャンバスに戻ります。
⑥「ファイル データのプレビュー」ページのデータをプレビューし、「作成」を選択して続行し、データフロー キャンバスに戻ります。
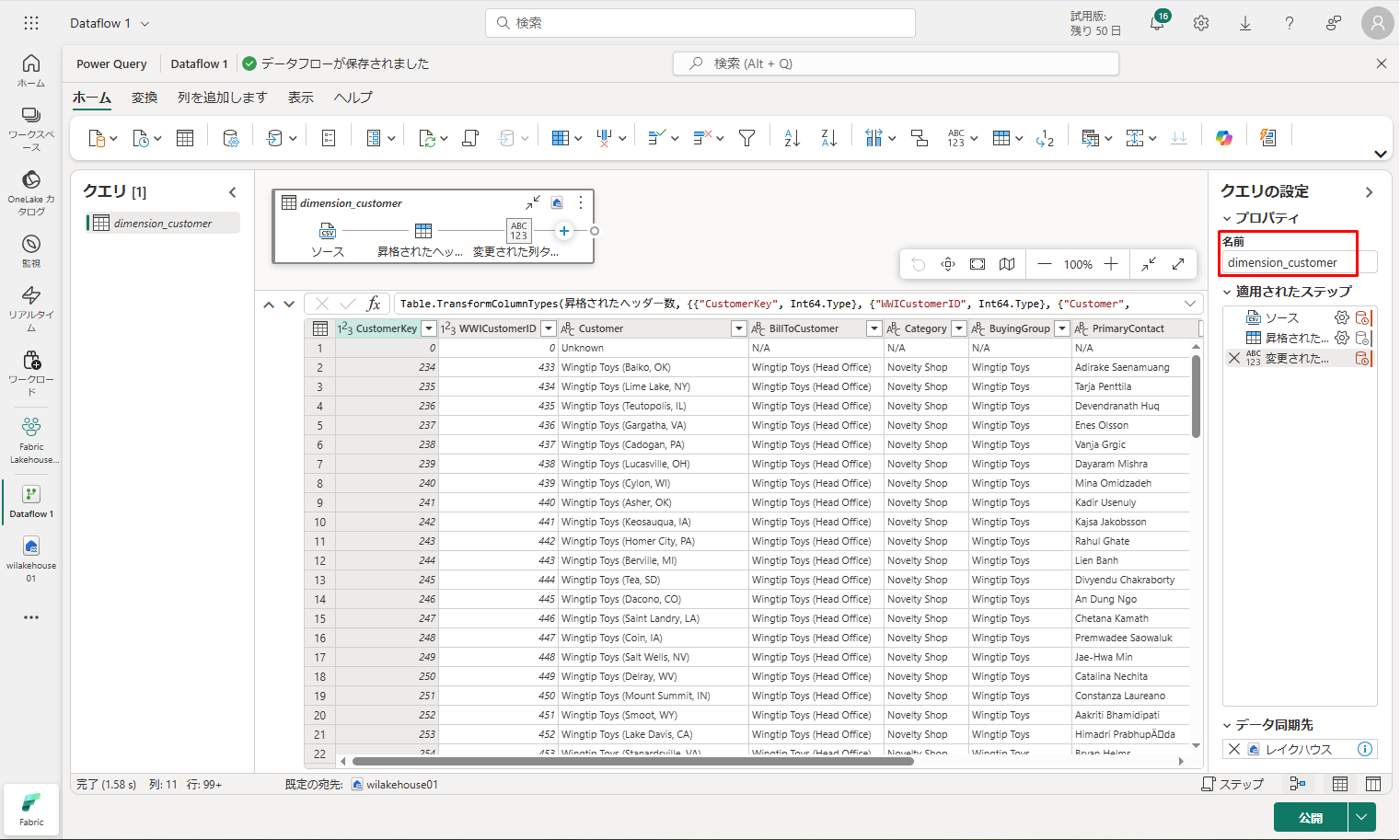
 ⑦「クエリの設定」ウィンドウで、「名前」フィールドを dimension_customer に更新します。
⑦「クエリの設定」ウィンドウで、「名前」フィールドを dimension_customer に更新します。
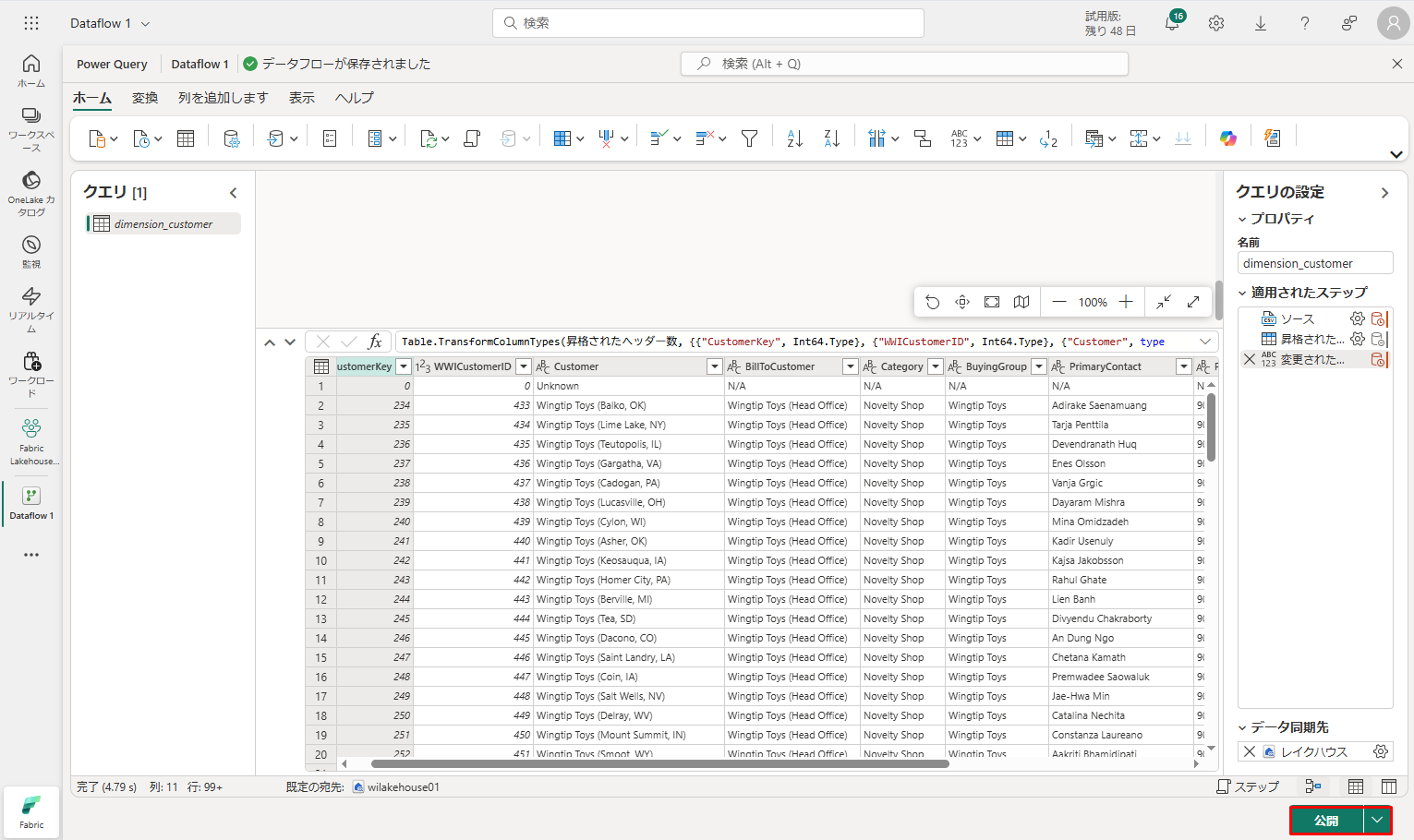
⑧ 次は、画面の右下にある「公開」をクリックします。
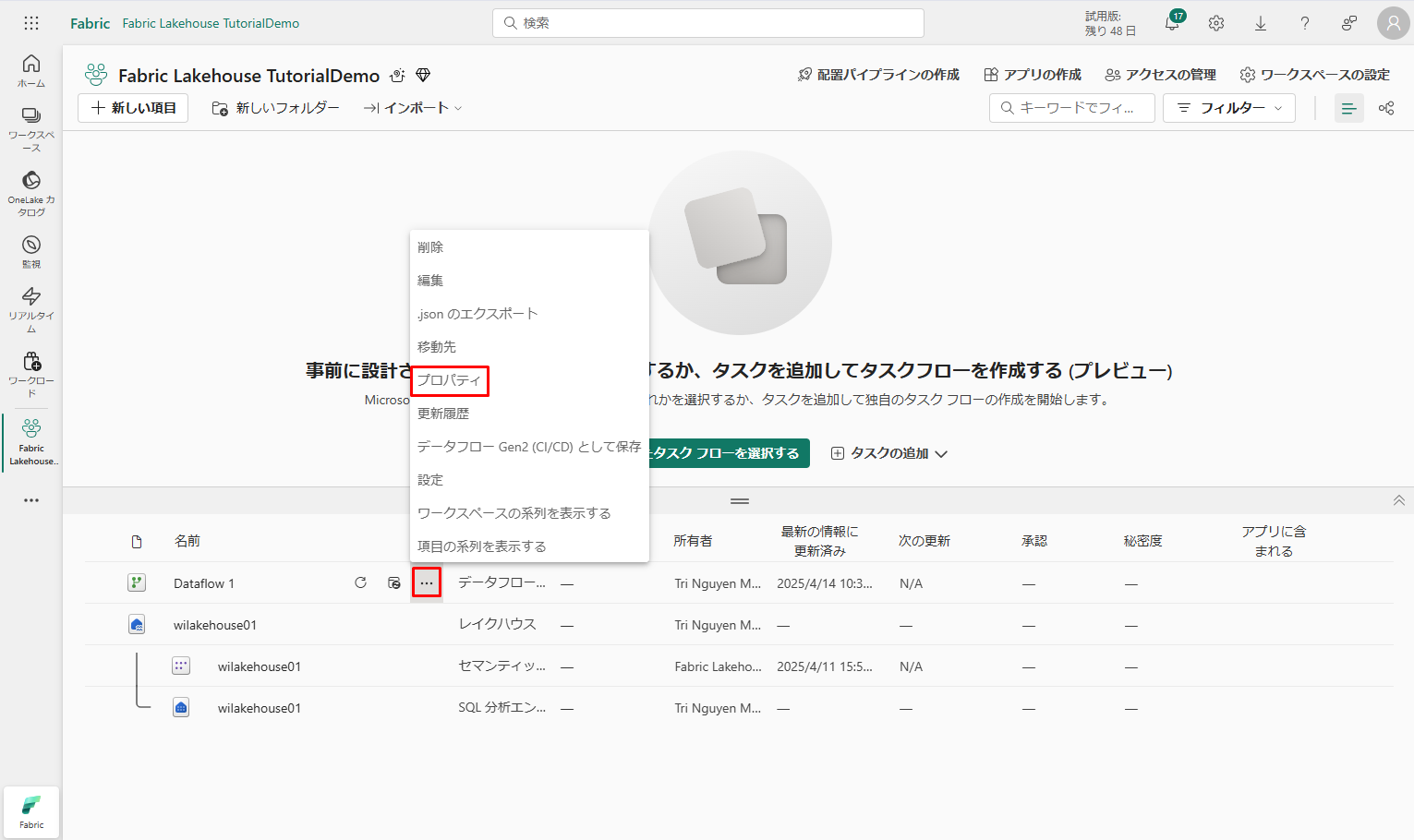
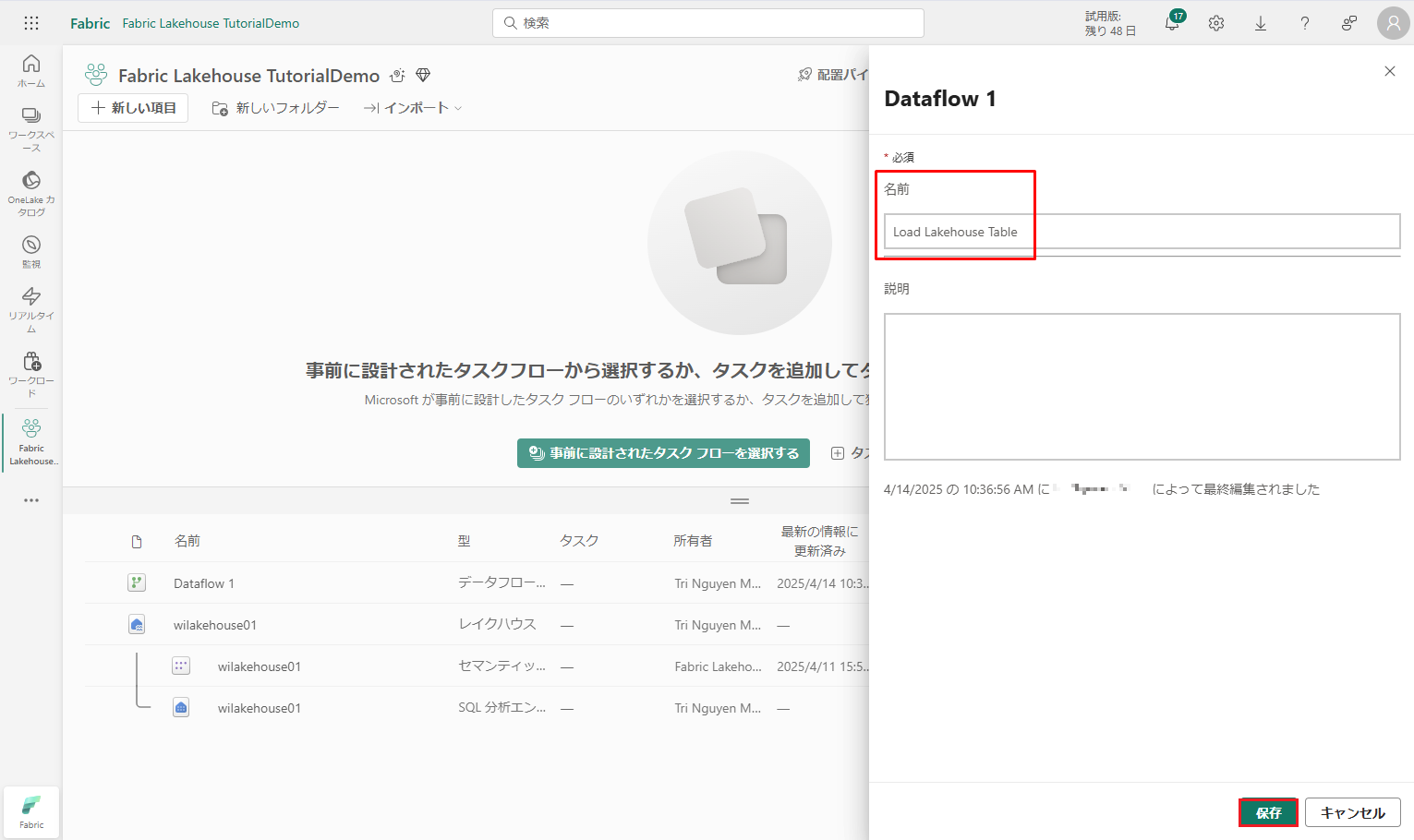
 ⑨ 公開が完了したら、「…」→「プロパティ」を選択します。データフローの名前を Load Lakehouse Table に変更し、「保存」をクリックします。
⑨ 公開が完了したら、「…」→「プロパティ」を選択します。データフローの名前を Load Lakehouse Table に変更し、「保存」をクリックします。
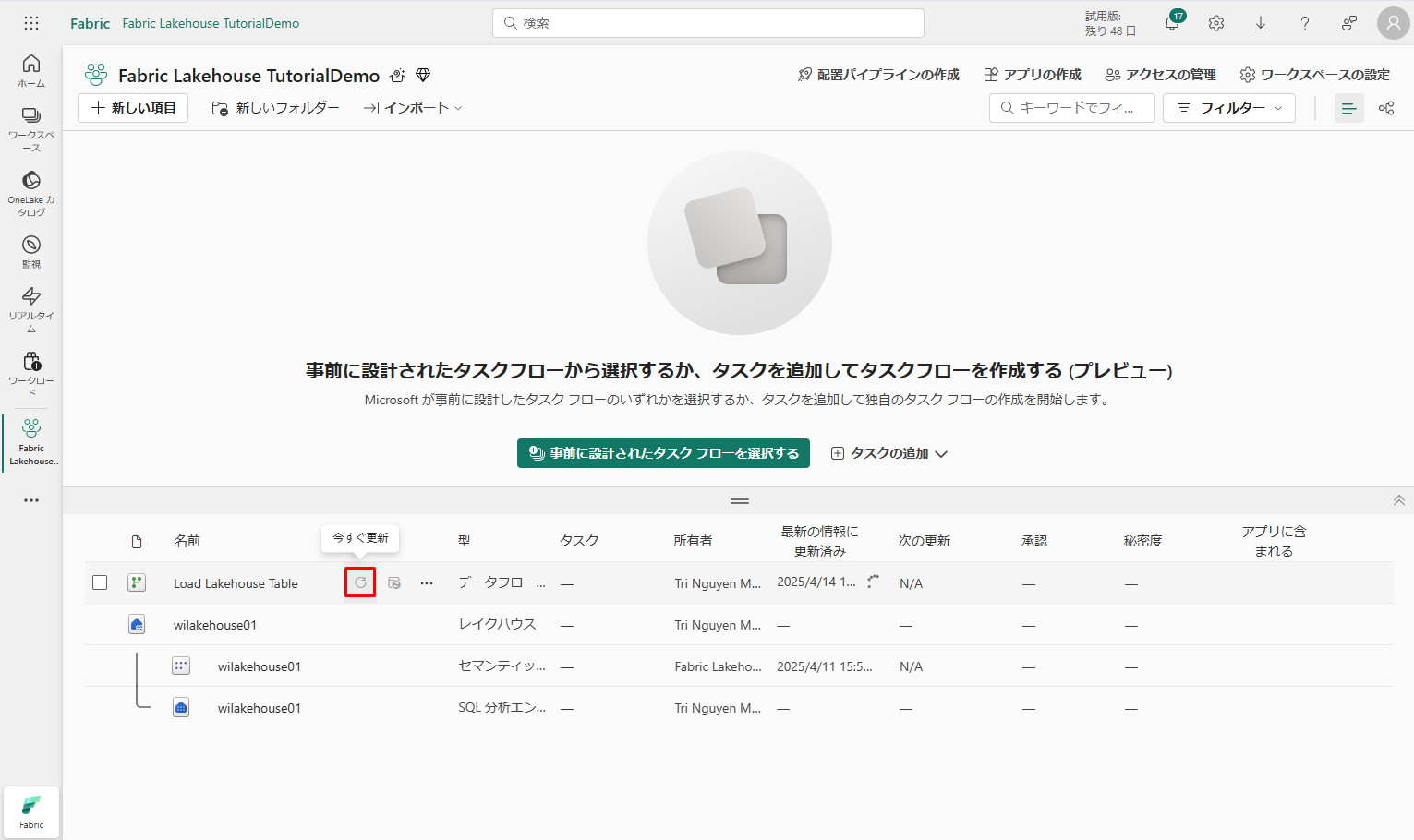
 ⑩ データ フロー名の横にある「今すぐ更新」オプションを選択して、データフローを更新します。
⑩ データ フロー名の横にある「今すぐ更新」オプションを選択して、データフローを更新します。
⑪ データフローを実行し、ソース ファイルからレイクハウス テーブルにデータを移動します。
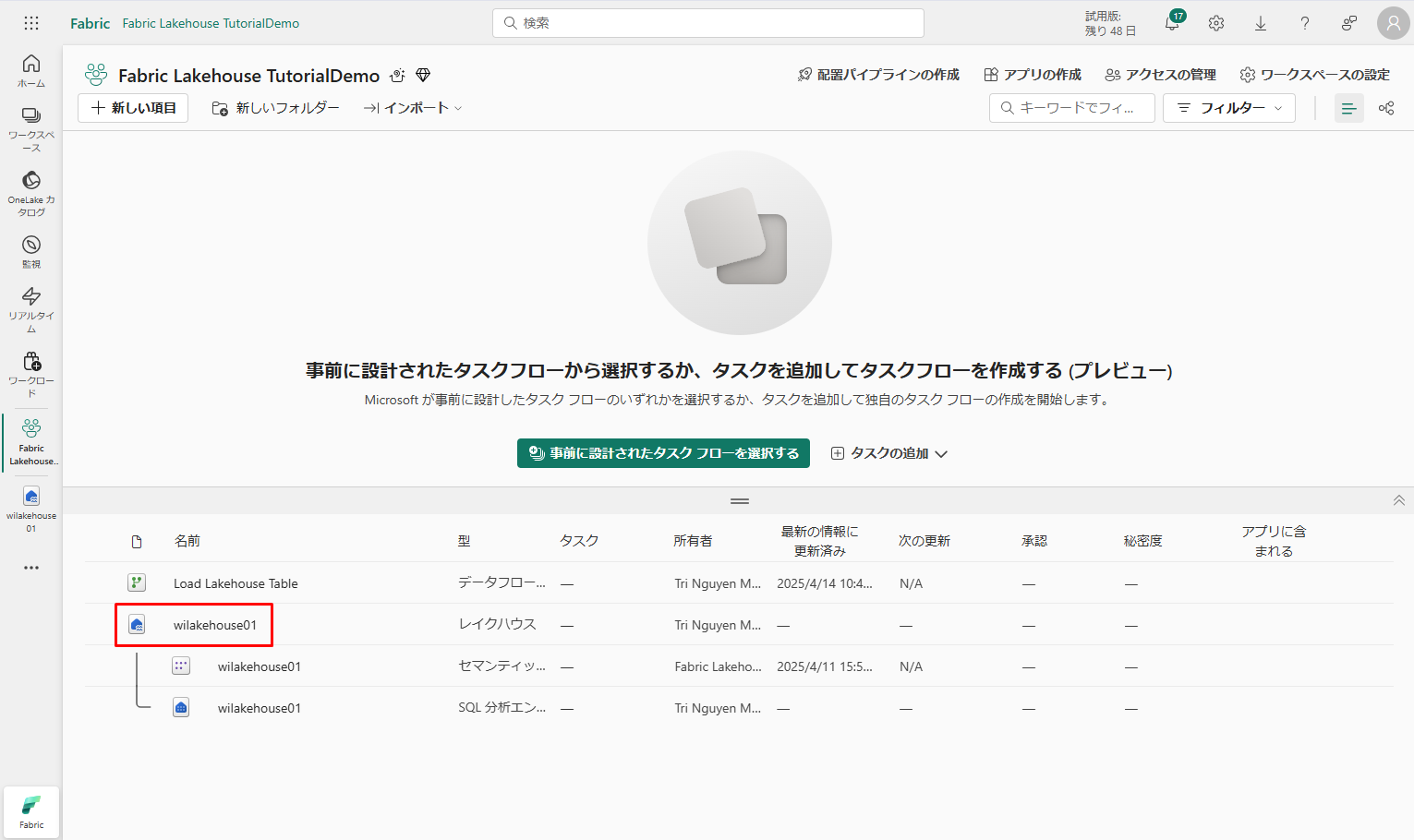
 ⑫ データフローが更新されたら、左側のナビゲーション パネルで新しいレイクハウスを選択して 、dimension_customer デルタ テーブルを表示します。
⑫ データフローが更新されたら、左側のナビゲーション パネルで新しいレイクハウスを選択して 、dimension_customer デルタ テーブルを表示します。
 テーブルを選択してデータをプレビューします。
テーブルを選択してデータをプレビューします。
レイクハウスの SQL 分析エンドポイントを使用して、データに対して SQL ステートメントでクエリを実行できます。
① 画面の右上にある「Lakehouse」ドロップダウン メニューから「SQL 分析エンドポイント」を選択します。
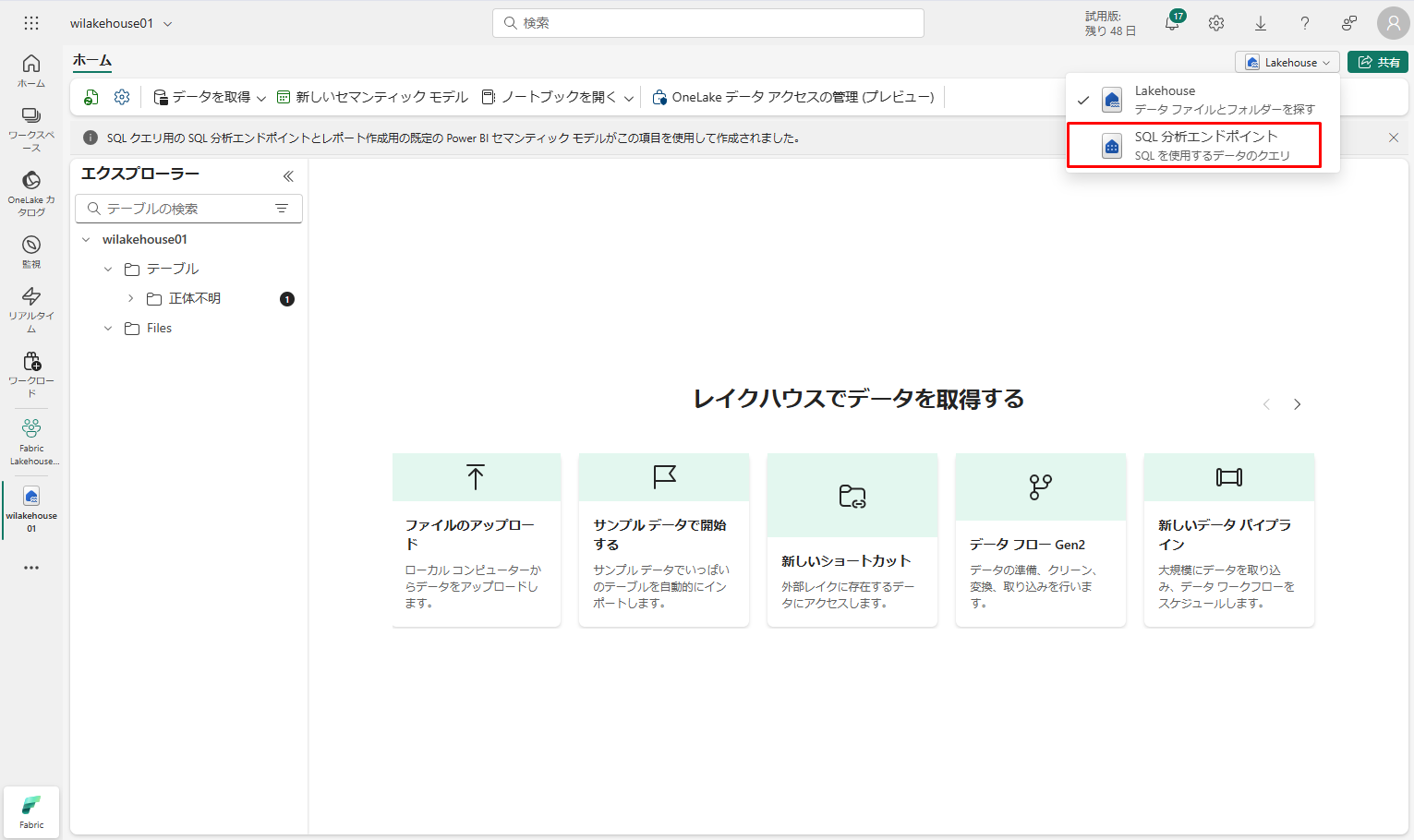 ② そのデータをプレビューするには、dimension_customer テーブルを選択するか、「新規 SQL クエリ」を選択して SQL ステートメントを作成します。
② そのデータをプレビューするには、dimension_customer テーブルを選択するか、「新規 SQL クエリ」を選択して SQL ステートメントを作成します。
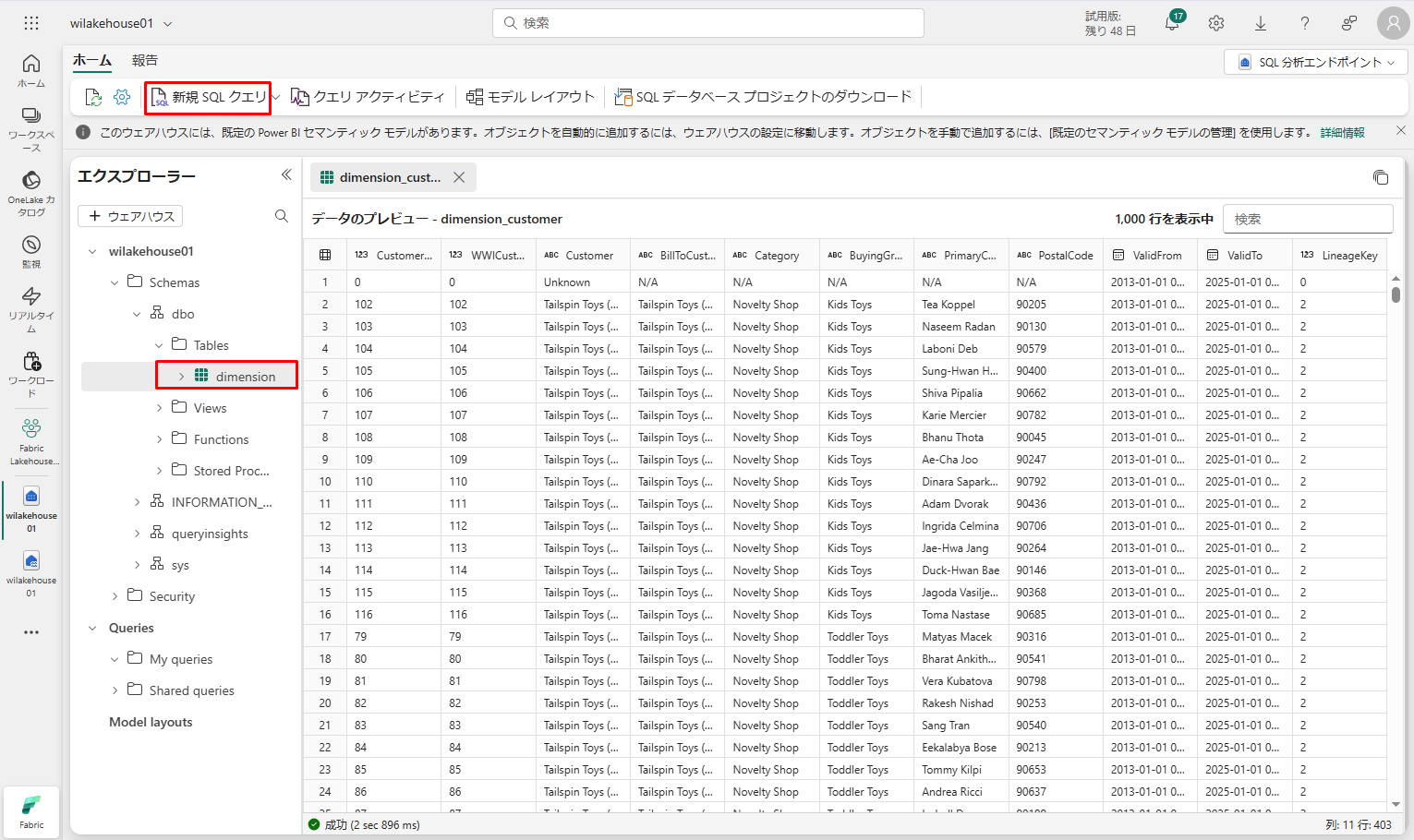 次のサンプル クエリでは、Dimension_customer テーブルの BuyingGroup 列を使用して行数を集計します。
次のサンプル クエリでは、Dimension_customer テーブルの BuyingGroup 列を使用して行数を集計します。
※ 文法
|
1 2 3 4 5 6 7 8 9 |
<span style="background-color: #ffffff;">SELECT column_name(s) FROM table_name WHERE condition GROUP BY column_name(s);</span> |
※例
|
1 2 3 4 5 6 7 |
<span style="background-color: #ffffff;">SELECT BuyingGroup, Count(*) AS Total FROM dimension_customer GROUP BY BuyingGroup</span> |
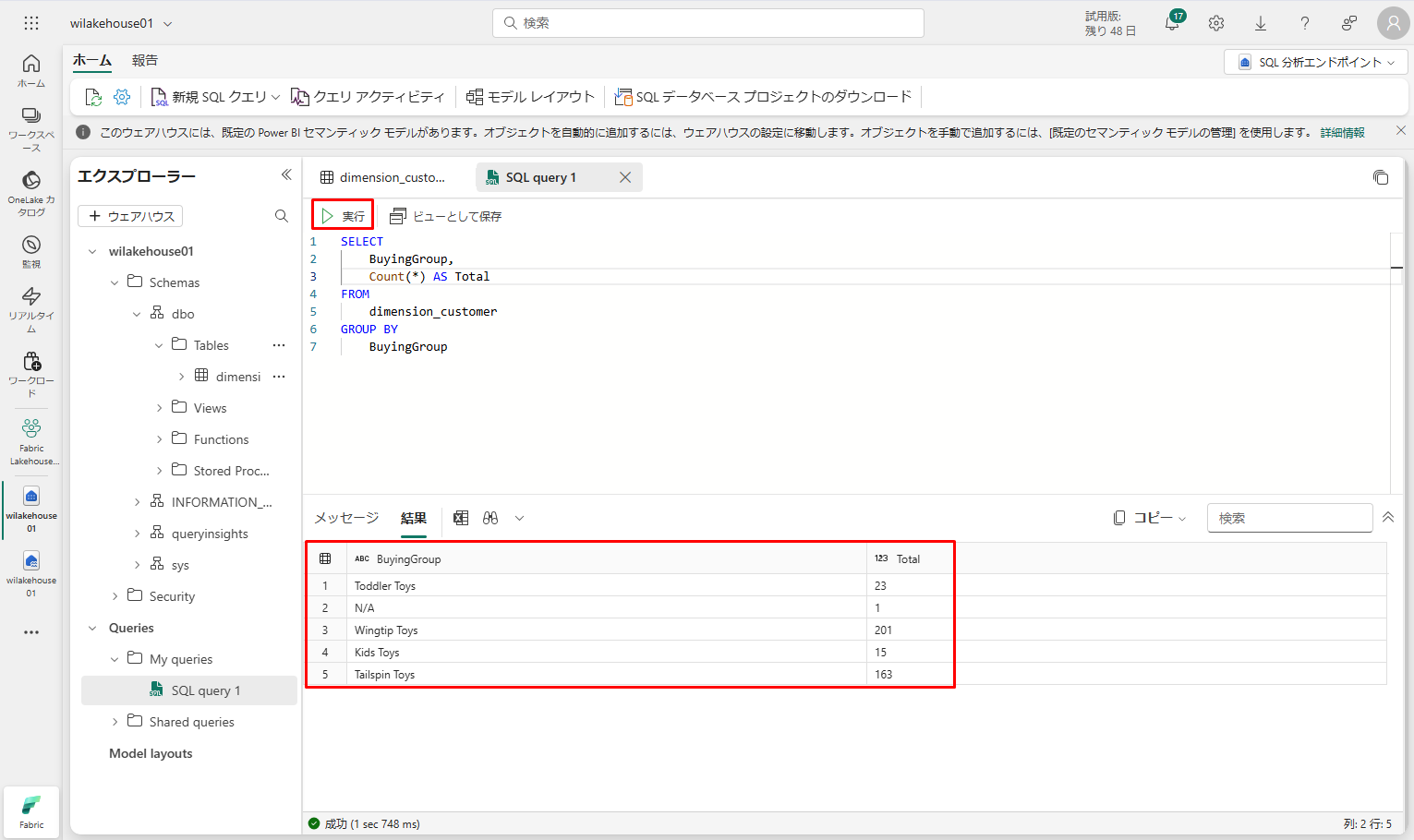
SQL クエリ ファイルは、後で参照できるように自動的に保存されます。
スクリプトを実行するには、スクリプト ファイルの上部にある「実行」アイコンをクリックします。
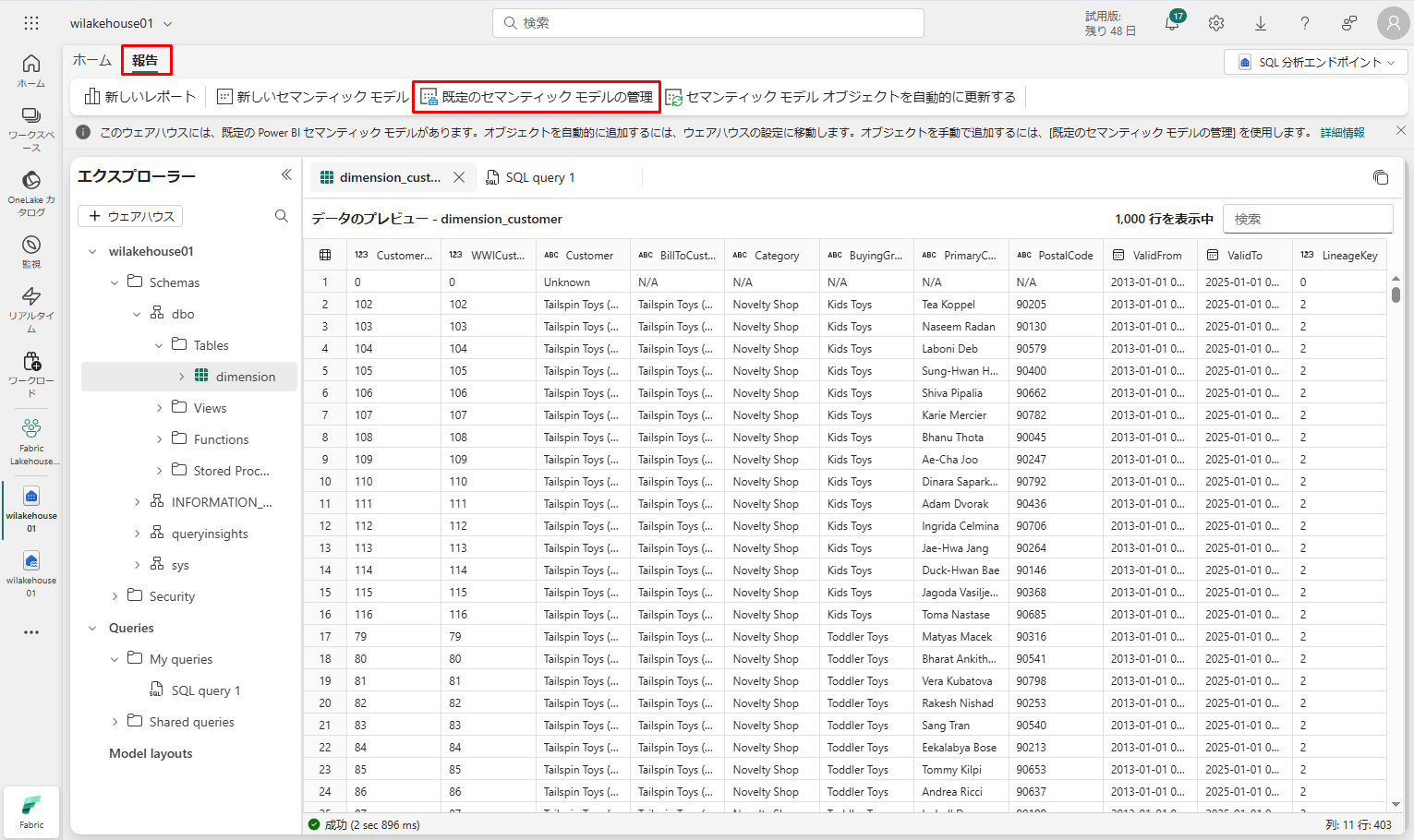
 テーブルの既定のセマンティックモデルを作成するには、次の手順に従います。
テーブルの既定のセマンティックモデルを作成するには、次の手順に従います。
① wilakehouse01 SQL 分析エンドポイントをクリックします。
②「報告」タブ →「既定のセマンティックモデルの管理」を選択します。
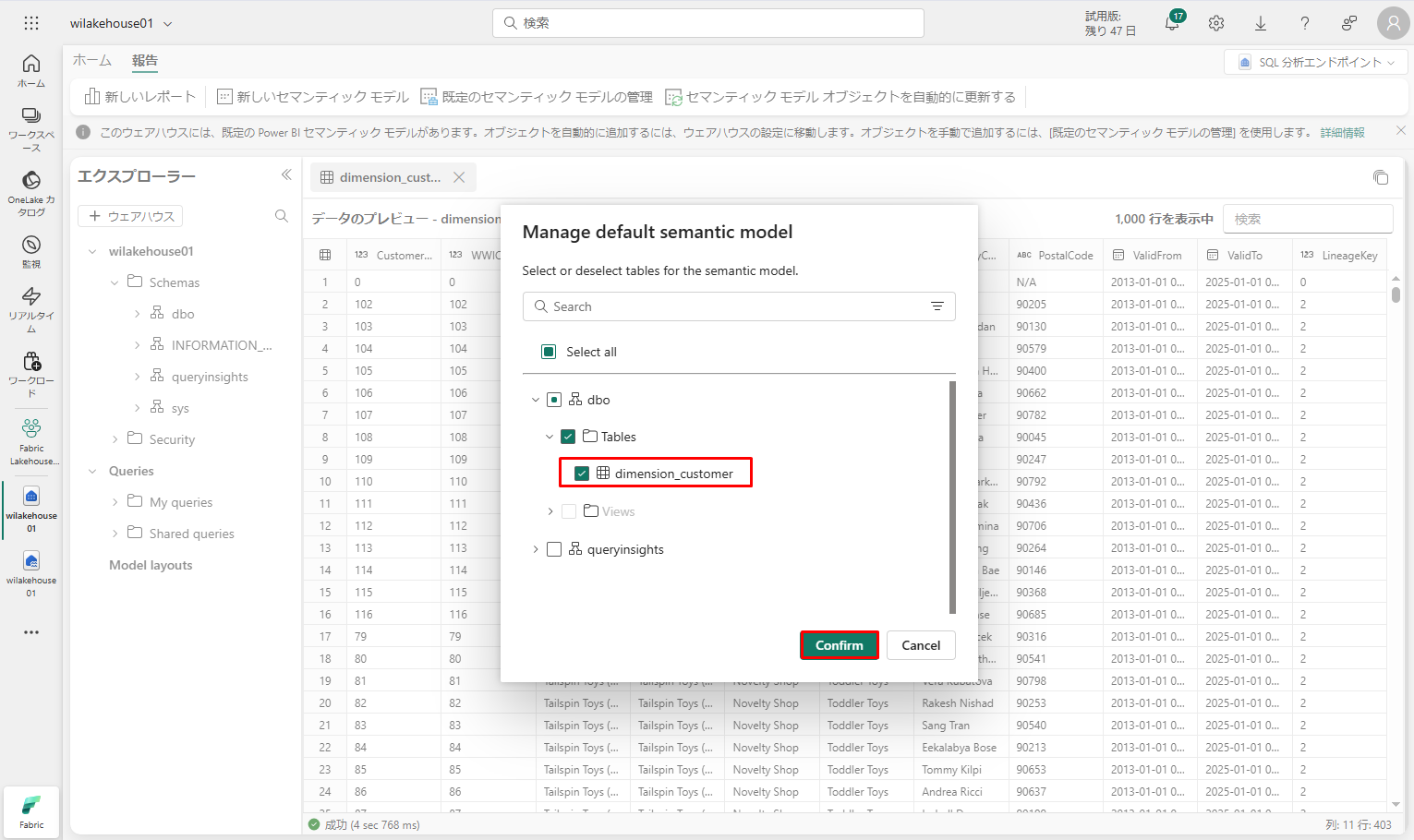
 ③「既定のセマンティックモデルの管理」(Manage default semantic model) ダイアログ ボックスで dimension_customer テーブルを選択します。
③「既定のセマンティックモデルの管理」(Manage default semantic model) ダイアログ ボックスで dimension_customer テーブルを選択します。
④「確認」(Confirm) をクリックします。
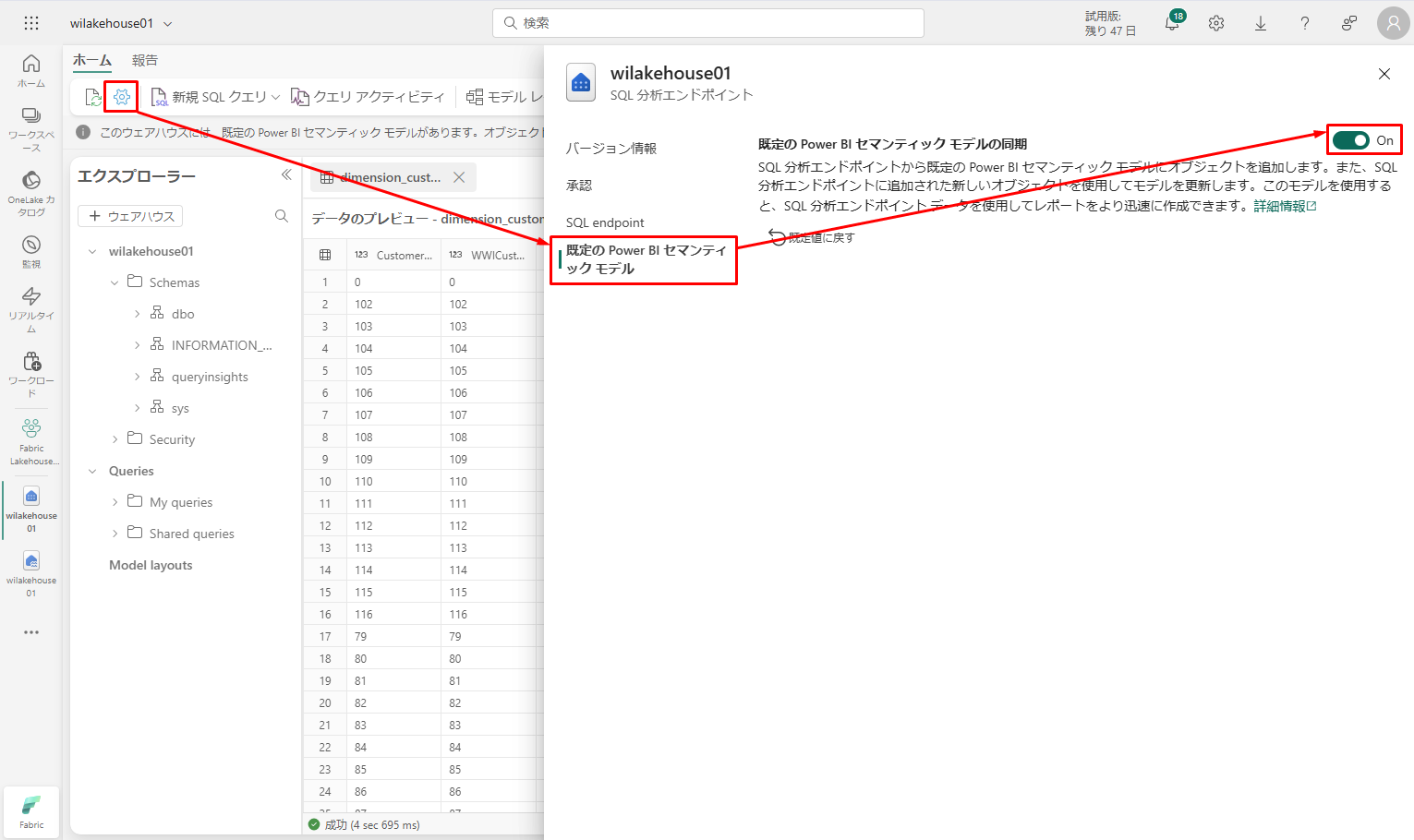
セマンティックモデル内のテーブルが常に同期されていることを確認するには、SQL分析エンドポイントビューに切り替えて、レイクハウスの設定ペインを開きます。「既定のPower BIセマンティックモデル」を選択し、「既定のPower BIセマンティックモデルを同期」をオンにします。
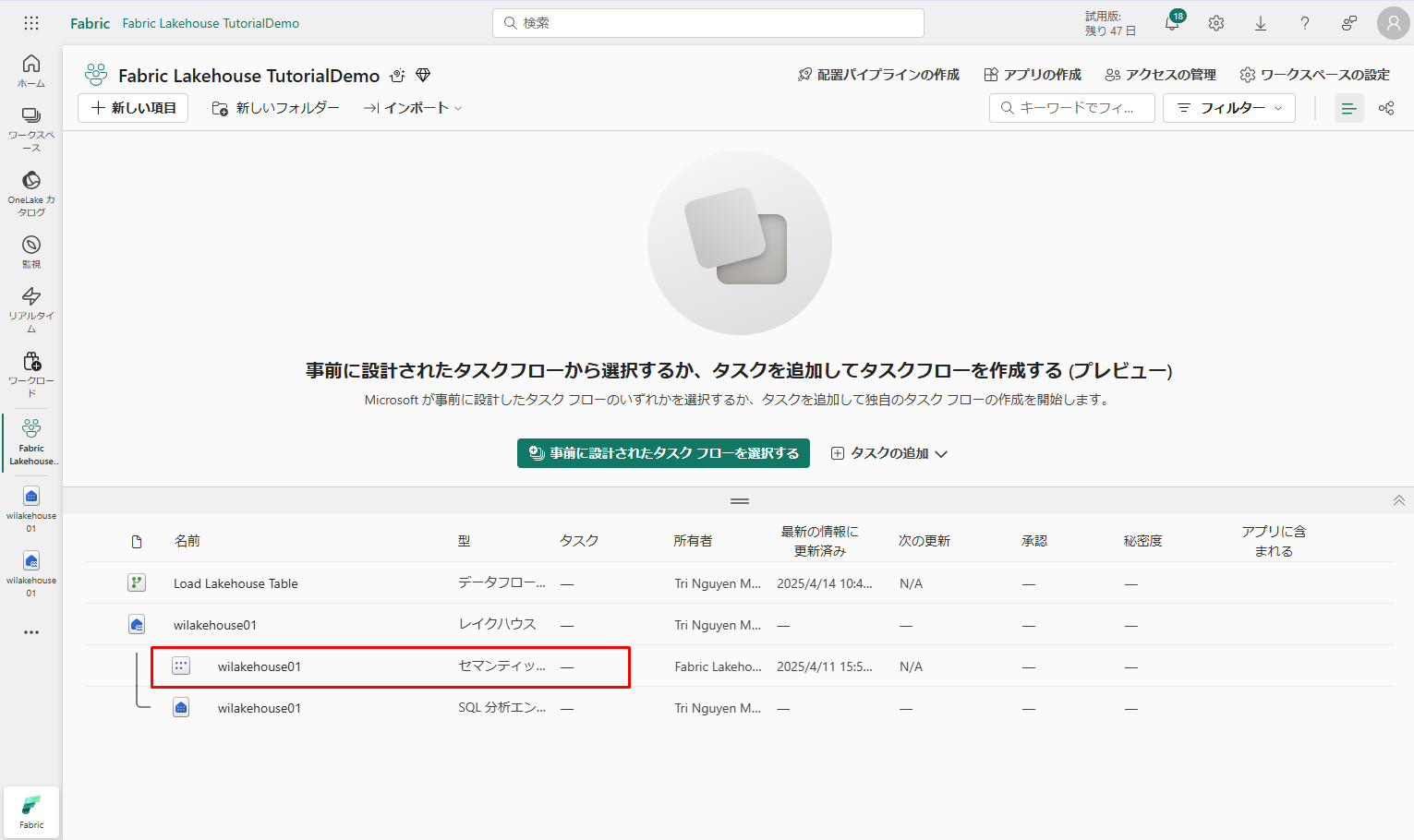
 既定のセマンティックモデルを作成した後、レポートが作成できます。
既定のセマンティックモデルを作成した後、レポートが作成できます。
ワークスペースのアイテム ビューに移動し、 wilakehouse01 セマンティック モデル (デフォルト) を選択します。
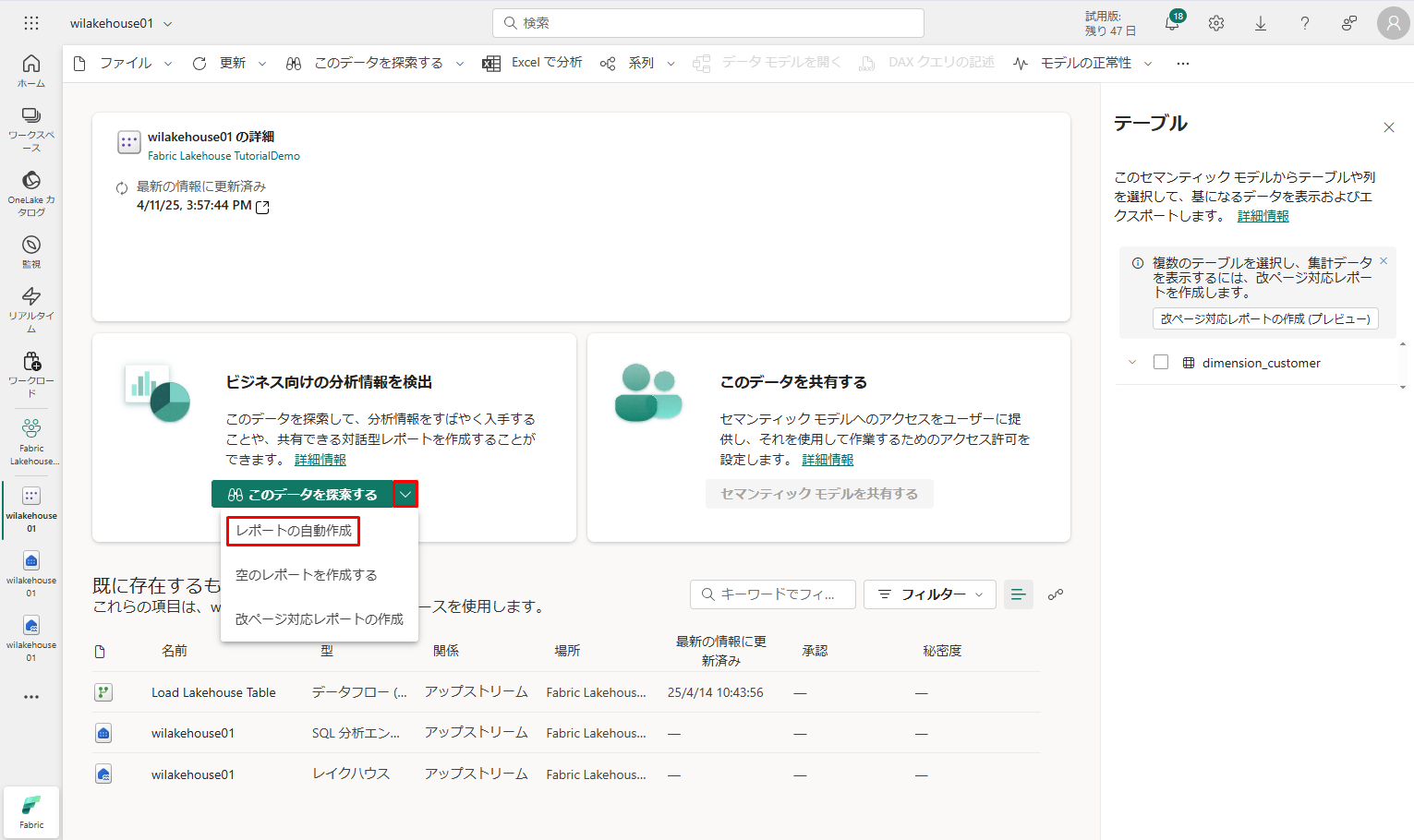
 セマンティック モデル ペインから、すべてのテーブルを表示できます。
セマンティック モデル ペインから、すべてのテーブルを表示できます。
最初からレポートを作成したり、ページ分割されたレポートを作成したり、データに基づいて Power BI でレポートを自動的に作成したりすることもできます。
このチュートリアルでは、「このデータを探索する」の下で、「レポートの自動作成」を選択します。
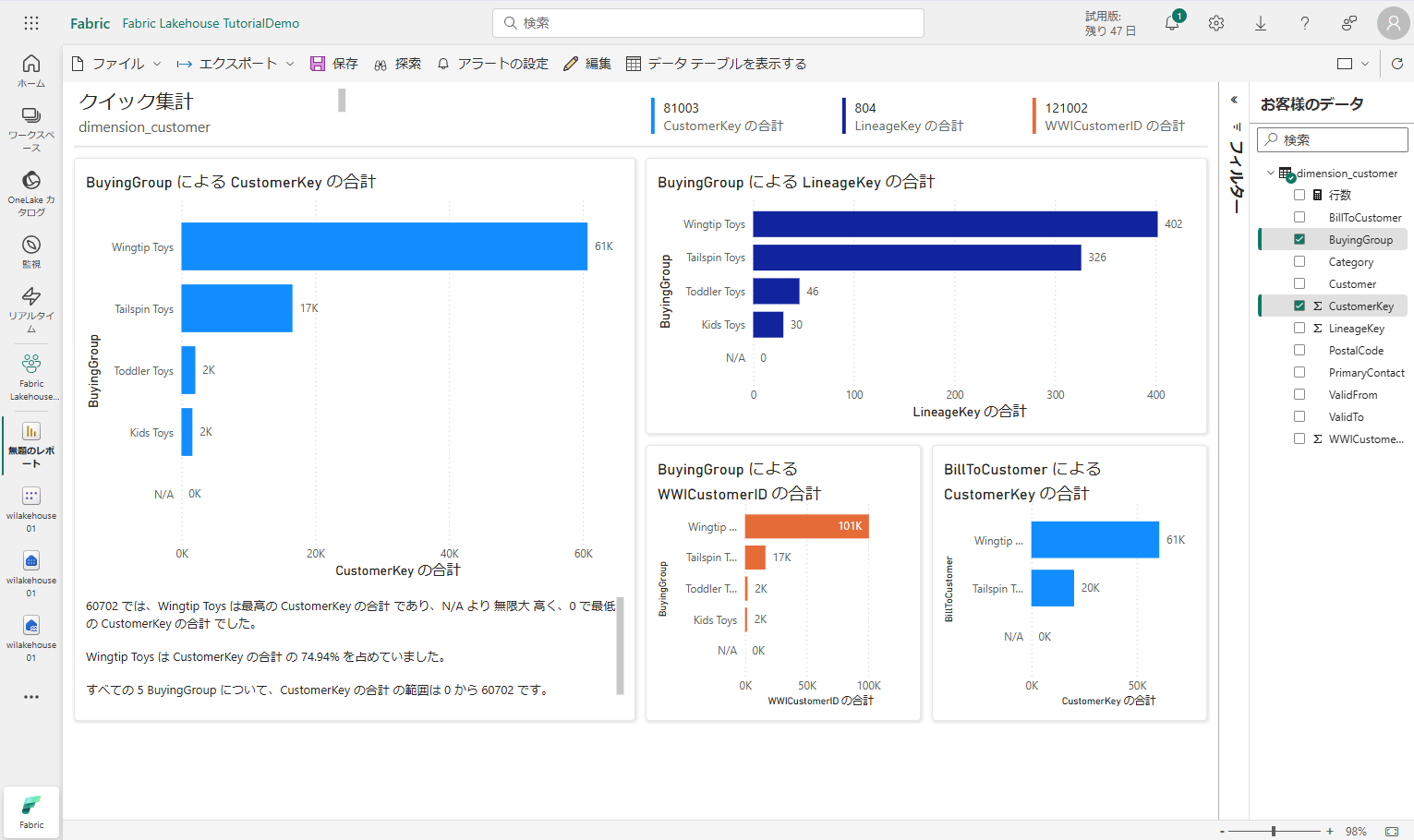
 ディメンションテーブルはメジャーを持たないため、Power BI では行数のメジャーが作成され、異なる列に集計され、次の図に示すように別のチャートが作成されます。
ディメンションテーブルはメジャーを持たないため、Power BI では行数のメジャーが作成され、異なる列に集計され、次の図に示すように別のチャートが作成されます。
上部のリボンから「保存」を選択して、このレポートを後で参照できます。
 4-4.データの取り込み
4-4.データの取り込み
データの取り込み
次は、現在のワークスペースに移動し、「新しい項目」をクリックして、データ パイプラインを選択します
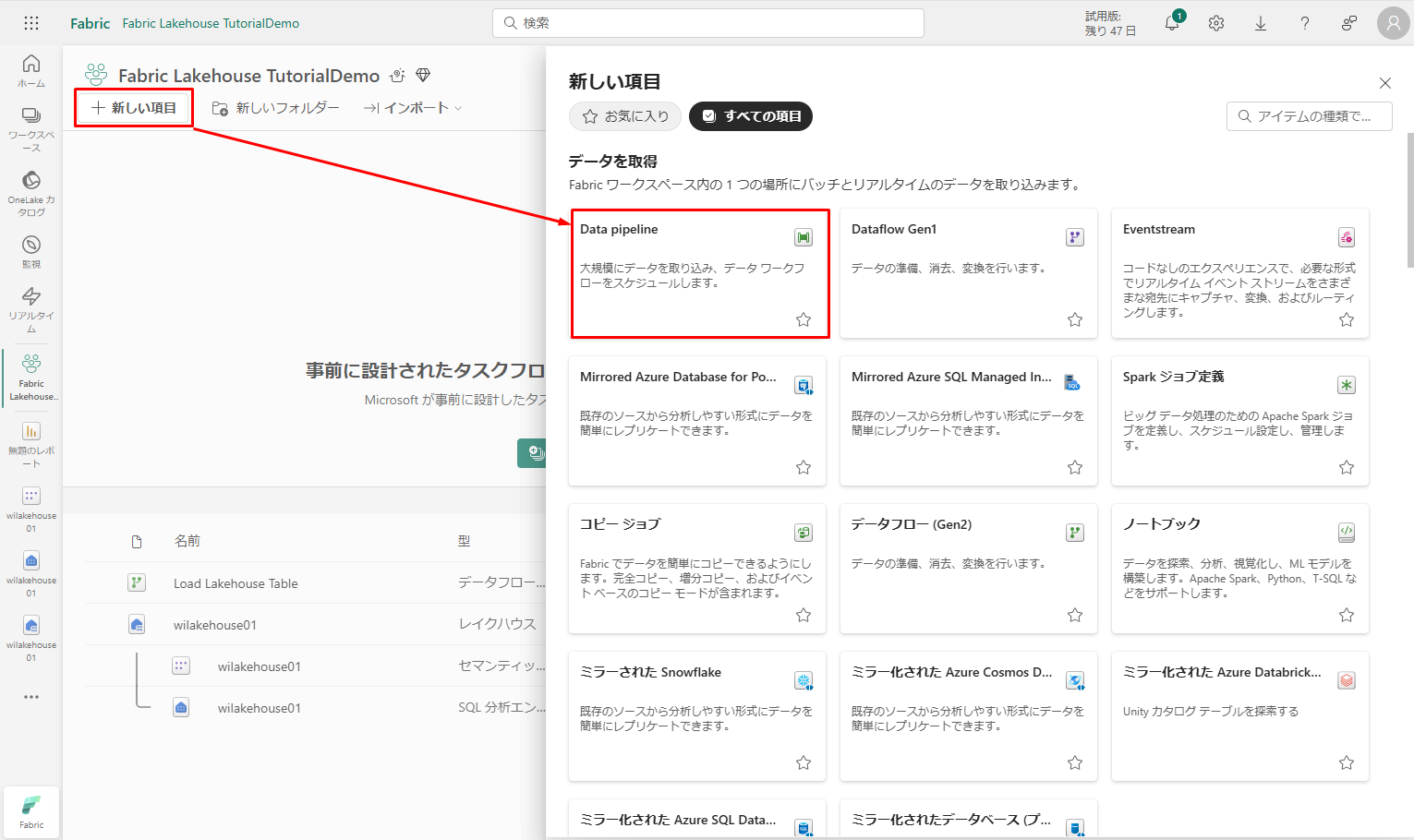 ②「新しいパイプライン」ダイアログ ボックスで、「IngestDataFromSourceToLakehouse」という名前を指定し、「作成」をクリックします。
②「新しいパイプライン」ダイアログ ボックスで、「IngestDataFromSourceToLakehouse」という名前を指定し、「作成」をクリックします。
新しいデータ ファクトリ パイプラインが作成され、開かれます。
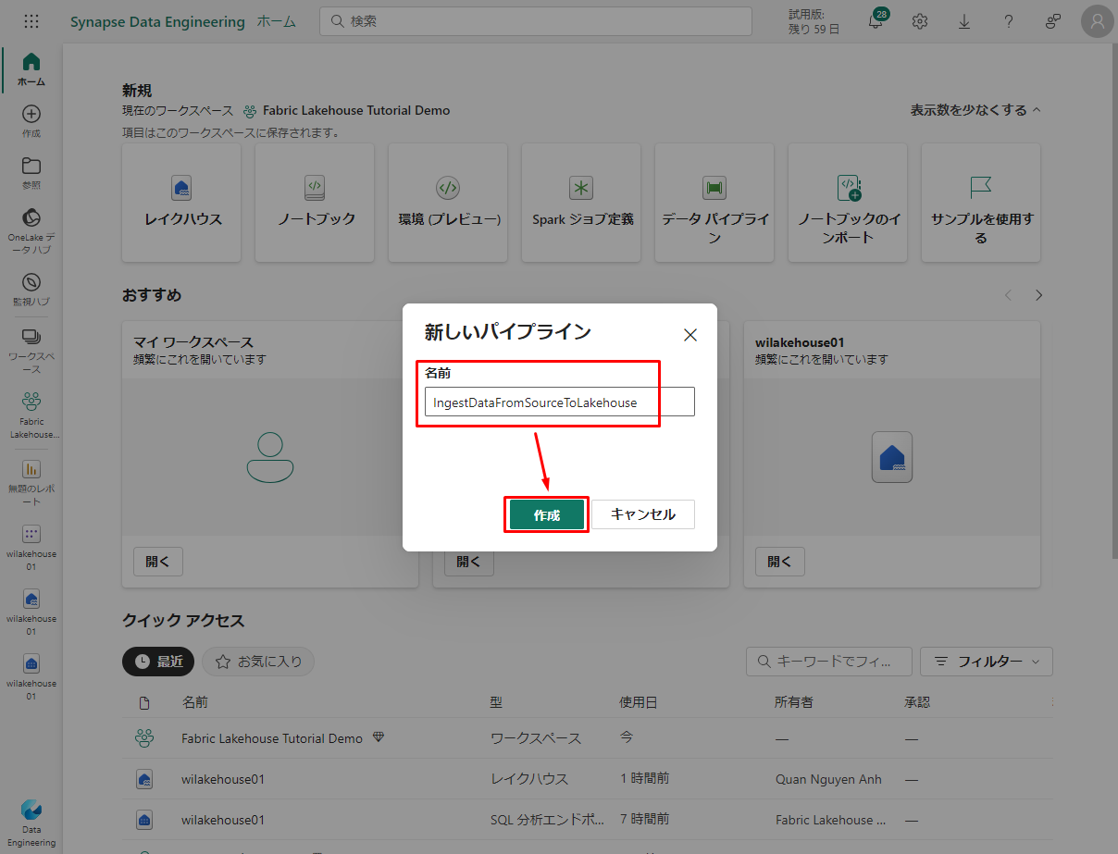
③ 新しく作成したデータ ファクトリ パイプラインで、「パイプライン アクティビティ」をクリックして、パイプラインにアクティビティを追加します。「データのコピー」を選択します。
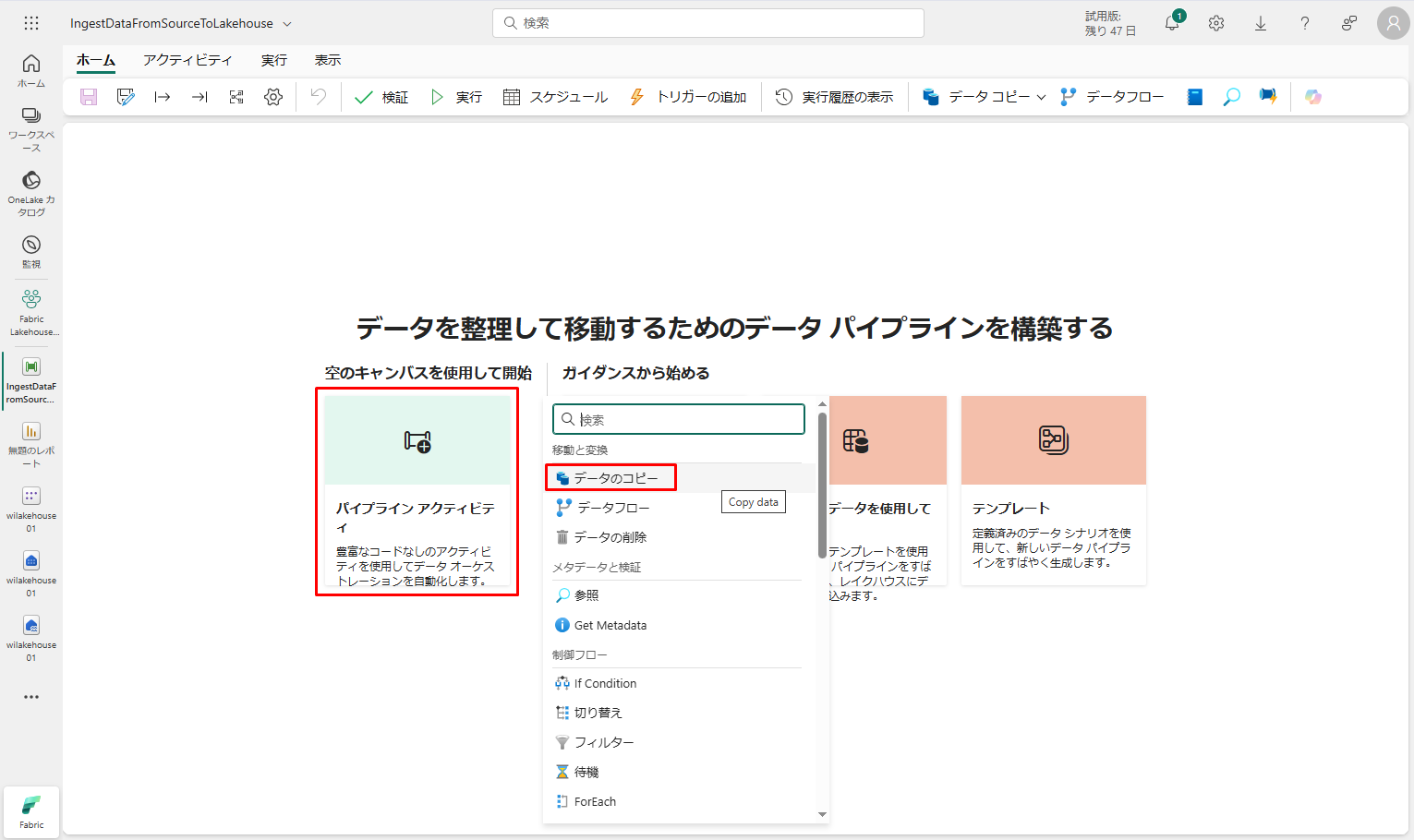 ④ プロパティ ペインの「全般」タブで、データのコピー アクティビティ名を「Data Copy to Lakehouse」に指定します。
④ プロパティ ペインの「全般」タブで、データのコピー アクティビティ名を「Data Copy to Lakehouse」に指定します。
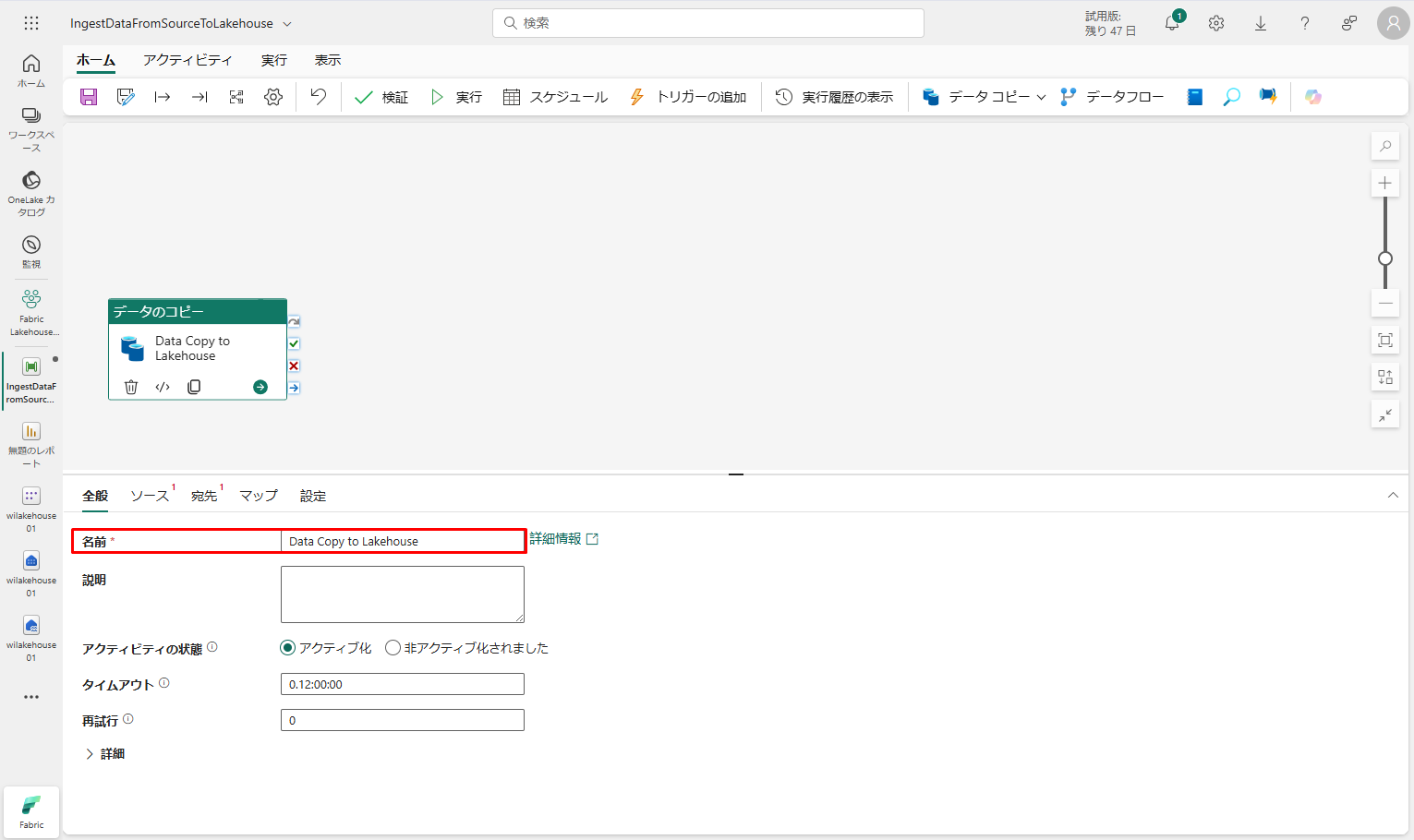 ⑤「ソース」タブに移動し、。次に、「詳細」をクリックして、データ ソースとの新規接続を作成します。
⑤「ソース」タブに移動し、。次に、「詳細」をクリックして、データ ソースとの新規接続を作成します。
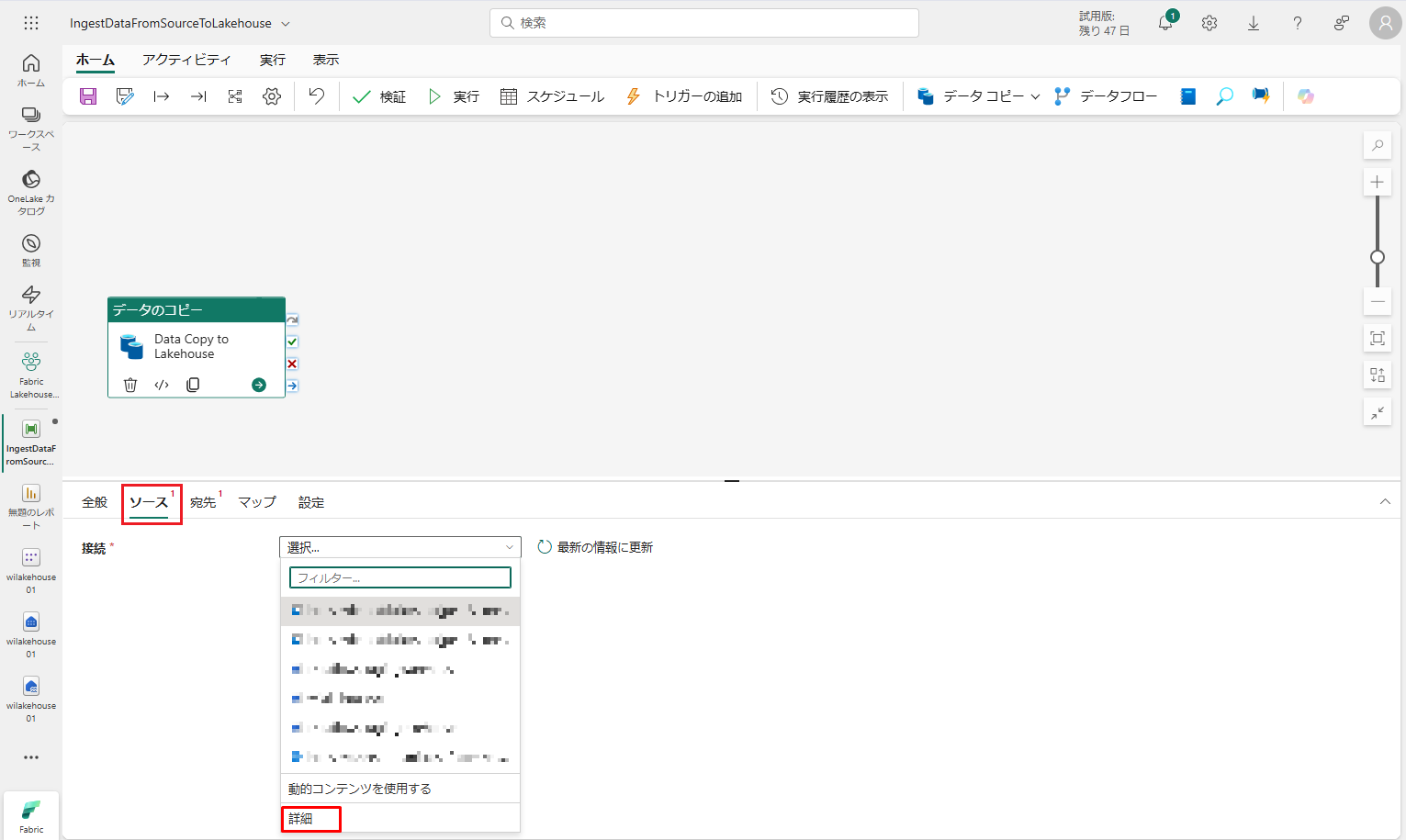 このチュートリアルに従って、すべてのサンプルデータが Azure Blob ストレージ のパブリック コンテナーに既に保存されました。このコンテナーに接続して、データをコピーします。
このチュートリアルに従って、すべてのサンプルデータが Azure Blob ストレージ のパブリック コンテナーに既に保存されました。このコンテナーに接続して、データをコピーします。
このリンク 「Wide World Importers (WWI) sample database」 からダウンロードしたファイルを BLOB ストレージにアップロードしてください。
①「データを取得」ウィザードで、「Azure BLOB ストレージ」をクリックします。
②「データのソースの接続」ウィザードの次の画面で、必要な情報を入力します。次は、「接続」をクリックすると、データ ソースへの接続を作成できます。
アカウント名または URI : https://<storage account name>.blob.core.windows.net/<container name>
例: https://demodtbrickstaccjpe.blob.core.windows.net/sampledata
認証の種類: 接続を認証するには、アクセス キー、サービス プリンシパル、または SAS を使用できます。
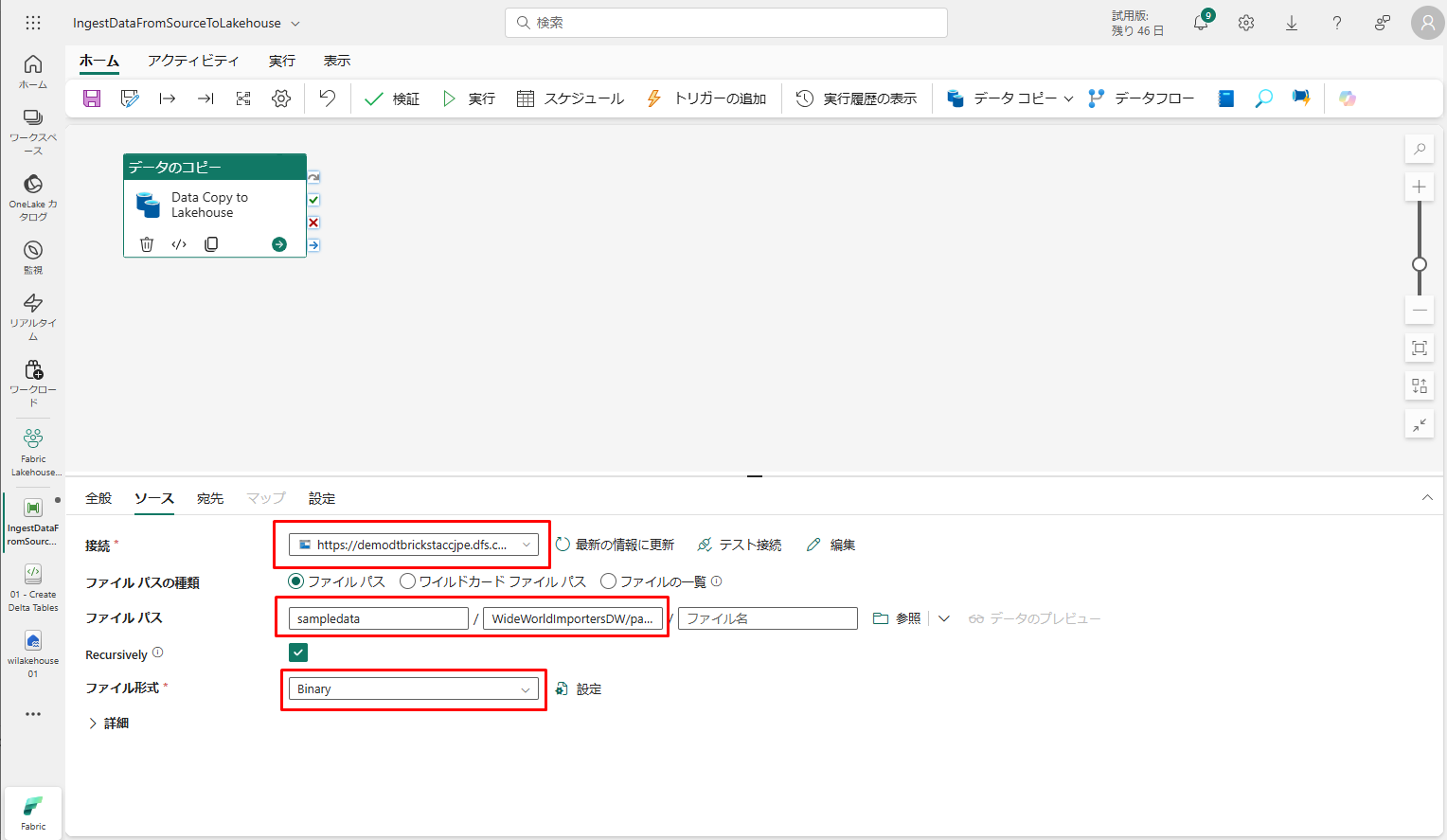
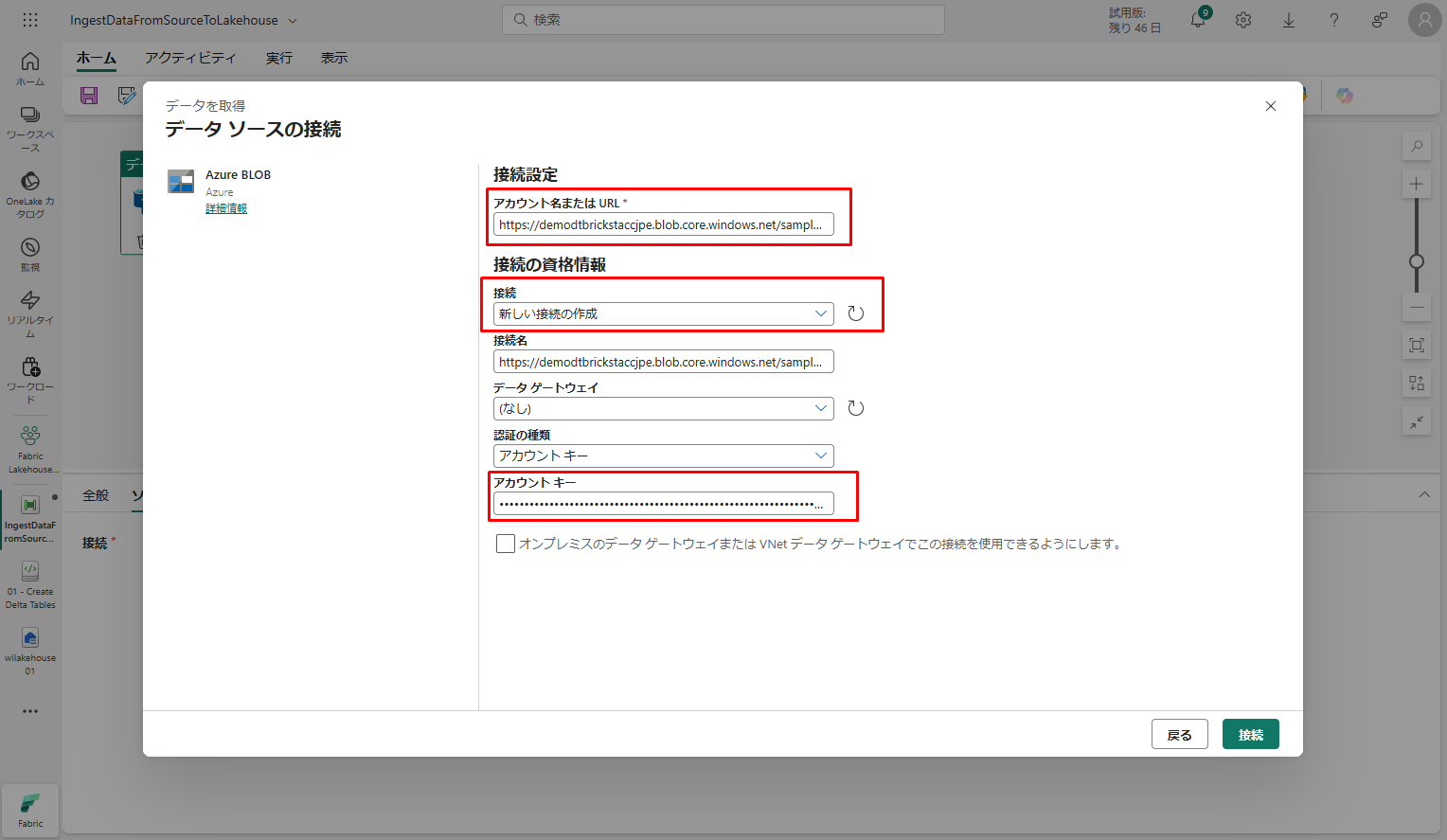 ③ 新しい接続が作成された後、データのコピー アクティビティの「ソース」タブに戻ると、新しい接続が既定で選択されます。接続先の設定を開始する前に、次のプロパティを指定します。
③ 新しい接続が作成された後、データのコピー アクティビティの「ソース」タブに戻ると、新しい接続が既定で選択されます。接続先の設定を開始する前に、次のプロパティを指定します。
- ファイル パスの種類 : ファイル パス
- ファイル パス
- コンテナー名 (最初のテキスト ボックス): sampledata
- ディレクトリ名(2 番目のテキスト ボックス): WideWorldImportersDW/parquet
- Recursively: オン
- ファイル形式 : バイナリ
 ④ 選択したデータのコピー アクティビティの「宛先」タブで、次のプロパティを指定します。
④ 選択したデータのコピー アクティビティの「宛先」タブで、次のプロパティを指定します。
- : wilakehouse01
- ルート フォルダー : ファイル
- ファイル パス
- ディレクトリ名 (最初のテキスト ボックス) : wwi-raw-data
- ファイル形式 : バイナリ
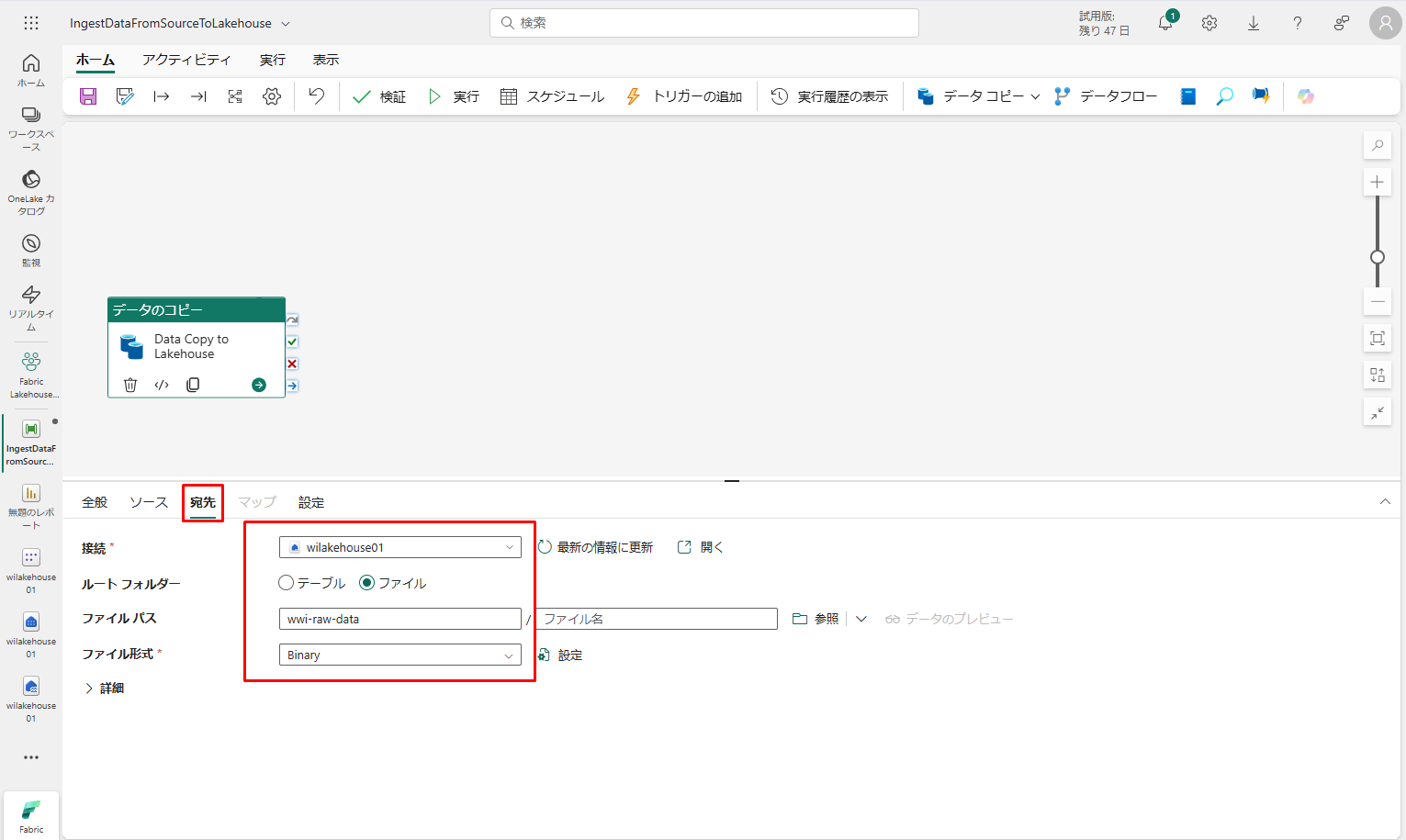 ⑤ データのコピー アクティビティが構成完了しました。 上部のリボンの「保存」ボタンを選択すると、変更内容が保存されます。「実行」をクリックして、パイプラインとそのアクティビティが実行されます。
⑤ データのコピー アクティビティが構成完了しました。 上部のリボンの「保存」ボタンを選択すると、変更内容が保存されます。「実行」をクリックして、パイプラインとそのアクティビティが実行されます。
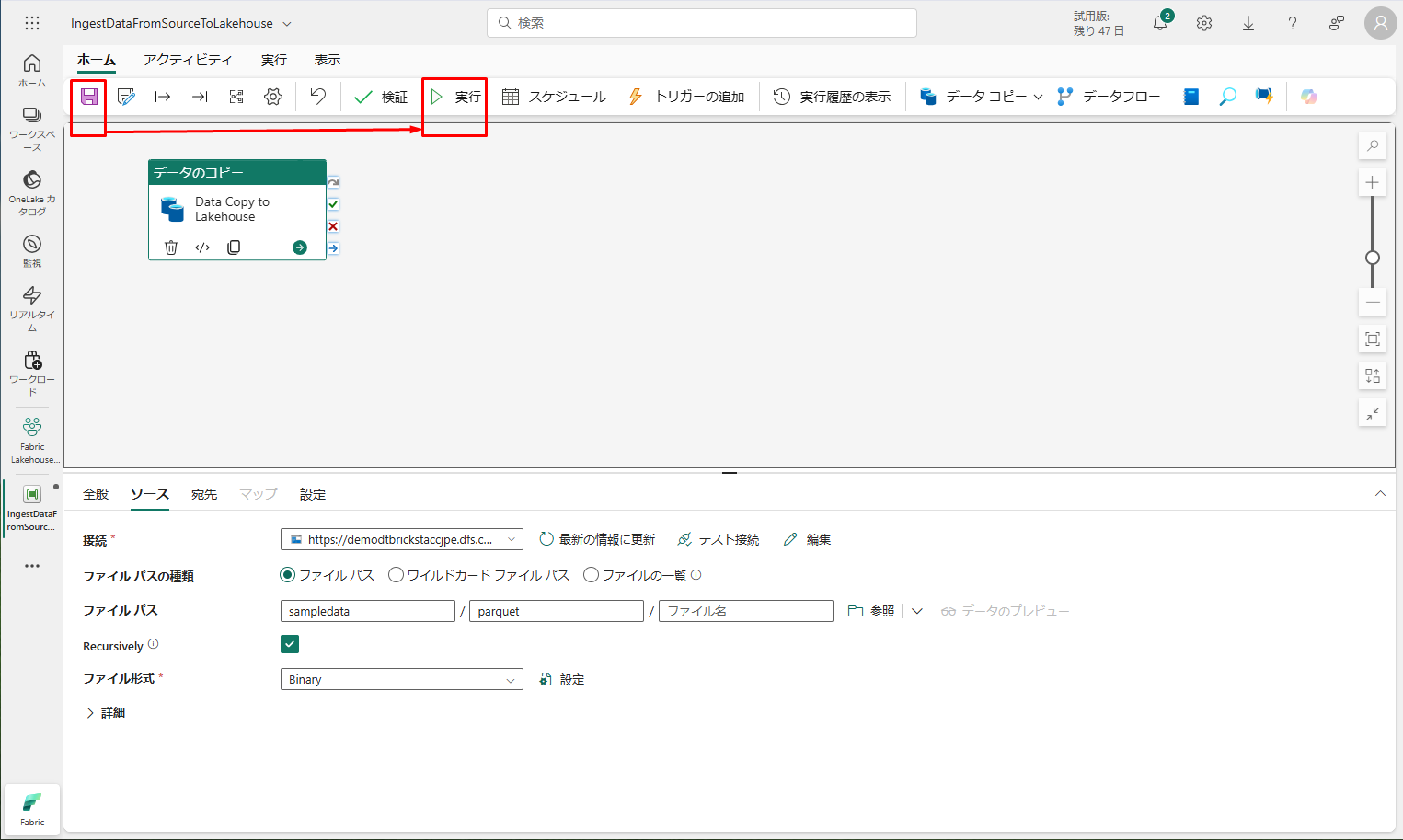
「保存および実行」をクリックします
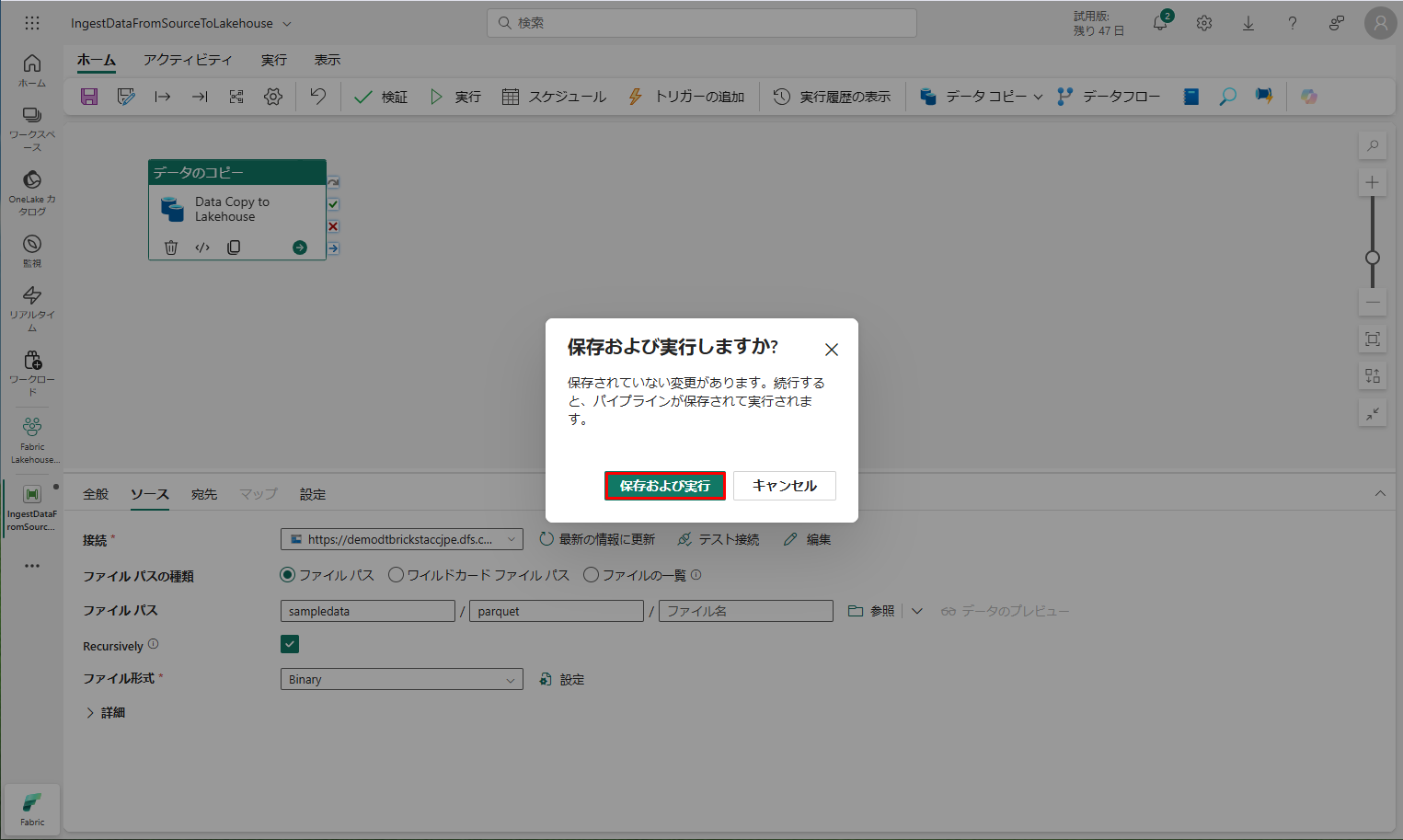 「出力」タブで、パイプラインとそのアクティビティの実行を監視できます。
「出力」タブで、パイプラインとそのアクティビティの実行を監視できます。
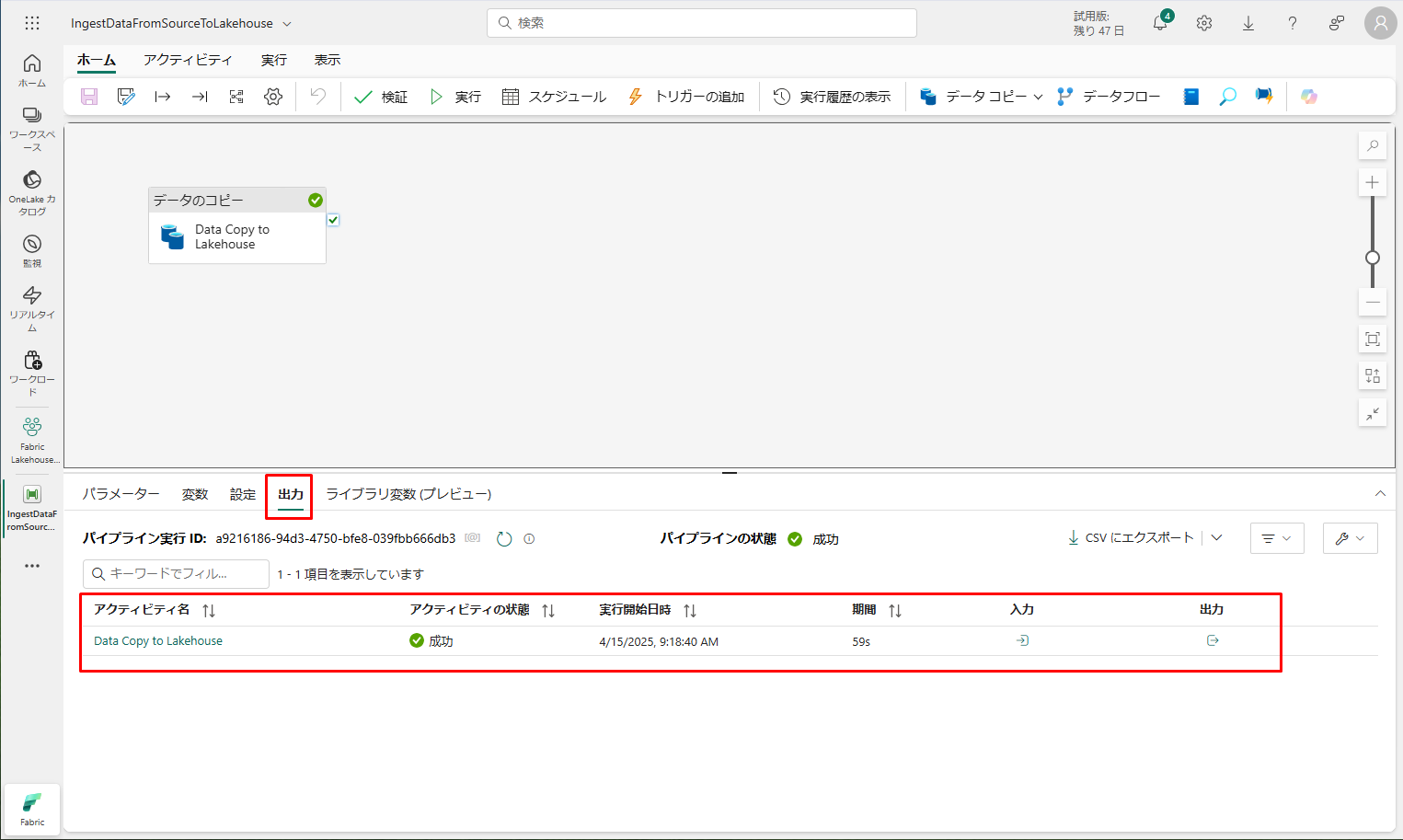 データがコピーされたら、ワークスペースのアイテム ビューに移動し、新しいレイクハウス (wilakehouse01) を選択して、レイクハウス エクスプローラーを起動します。
データがコピーされたら、ワークスペースのアイテム ビューに移動し、新しいレイクハウス (wilakehouse01) を選択して、レイクハウス エクスプローラーを起動します。
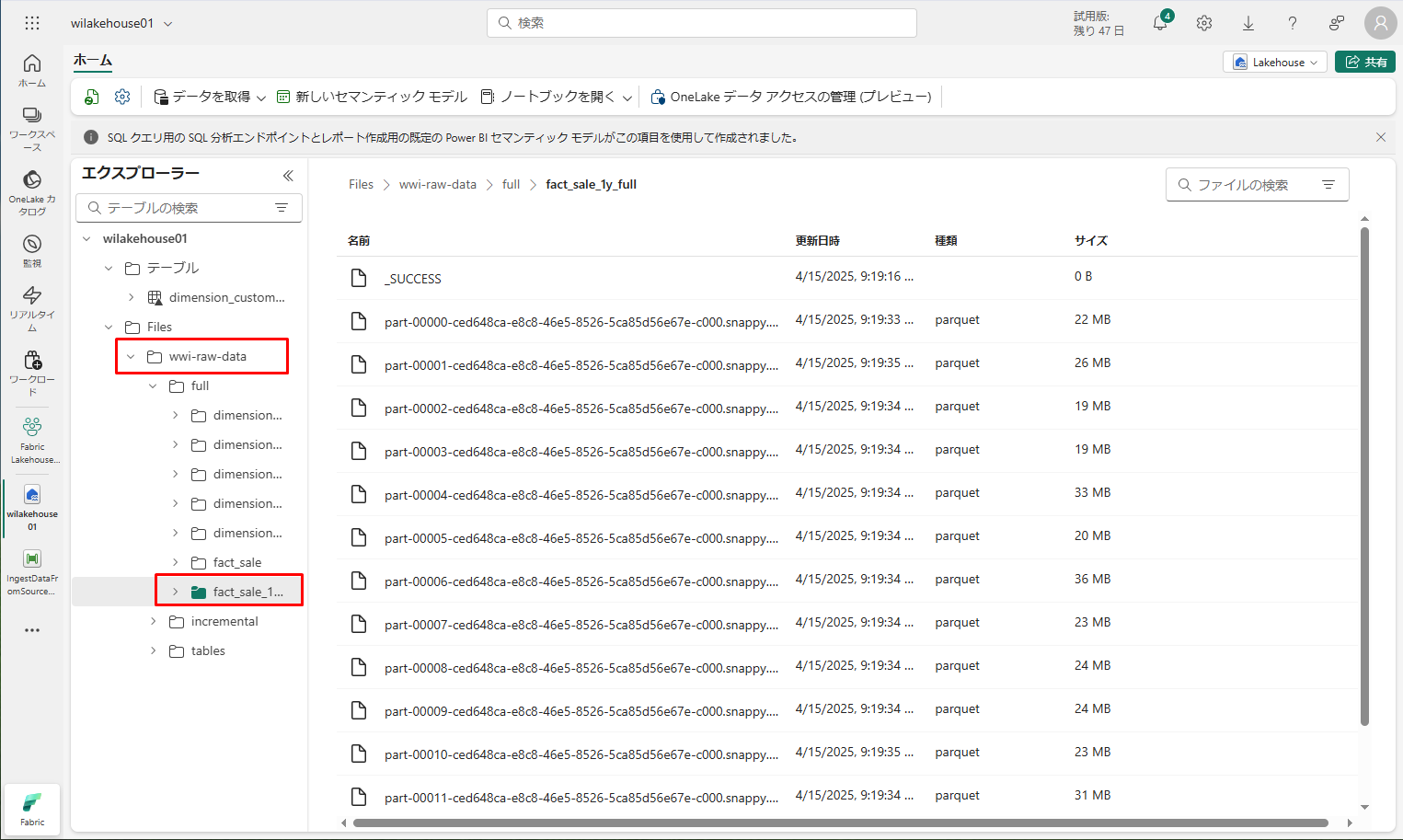
 エクスプローラーのビューで、新しいフォルダー「wwi-raw-data」が作成され、そこにすべてのテーブルのデータがコピーされていることを確認できます。
エクスプローラーのビューで、新しいフォルダー「wwi-raw-data」が作成され、そこにすべてのテーブルのデータがコピーされていることを確認できます。
 5. まとめ
5. まとめ
Microsoft Fabric のSynapse Data Engineering の使用方法の第1回について説明しました。レイクハウスへ取込んだデータの使用、データ変換、およびレポートの作成方法は第2回をご参照ください。業務のご参考になれば幸いです。
第1回:Microsoft Fabric 概要と試用版の作成方法
第2回:Power BI ユーザー向け Fabric チュートリアル
第3回:Data Factory ユーザー向け Fabric チュートリアル
第4回:Synapse Data Engineering ユーザー向け Fabric チュートリアル_第1回 (今回)
第5回:Synapse Data Engineering ユーザー向け Fabric チュートリアル_第2回