目次
1.はじめに
皆さんこんにちは。
今回は、 Talend Big Data Platform を使って、ノーコードでDatabricksジョブを作成する方法について説明します。このジョブは、 parquet 形式のデータをAzure Data Lake Storageに書き込んで、 Azure Databricks からそのデータを読み取ります。
2.前提要件
実施する際の前提条件は下記の通りです。
・Azure Data Lake Storageがあること。
・サービス プリンシパルがあること。
・Talend Big Data Platformのライセンスがあること。
3.サービス プリンシパルをADLSへのアクセス権限を付与する
ADLSからのデータを読み込んで、書き込むには、「ストレージ BLOB データ共同作成者」をサービス プリンシパルに付与する必要があります。
① ADLSのポータル画面で「アクセス制御 (IAM)」をクリックして、「追加」をクリックして「ロールの割り当ての追加」を選択します。
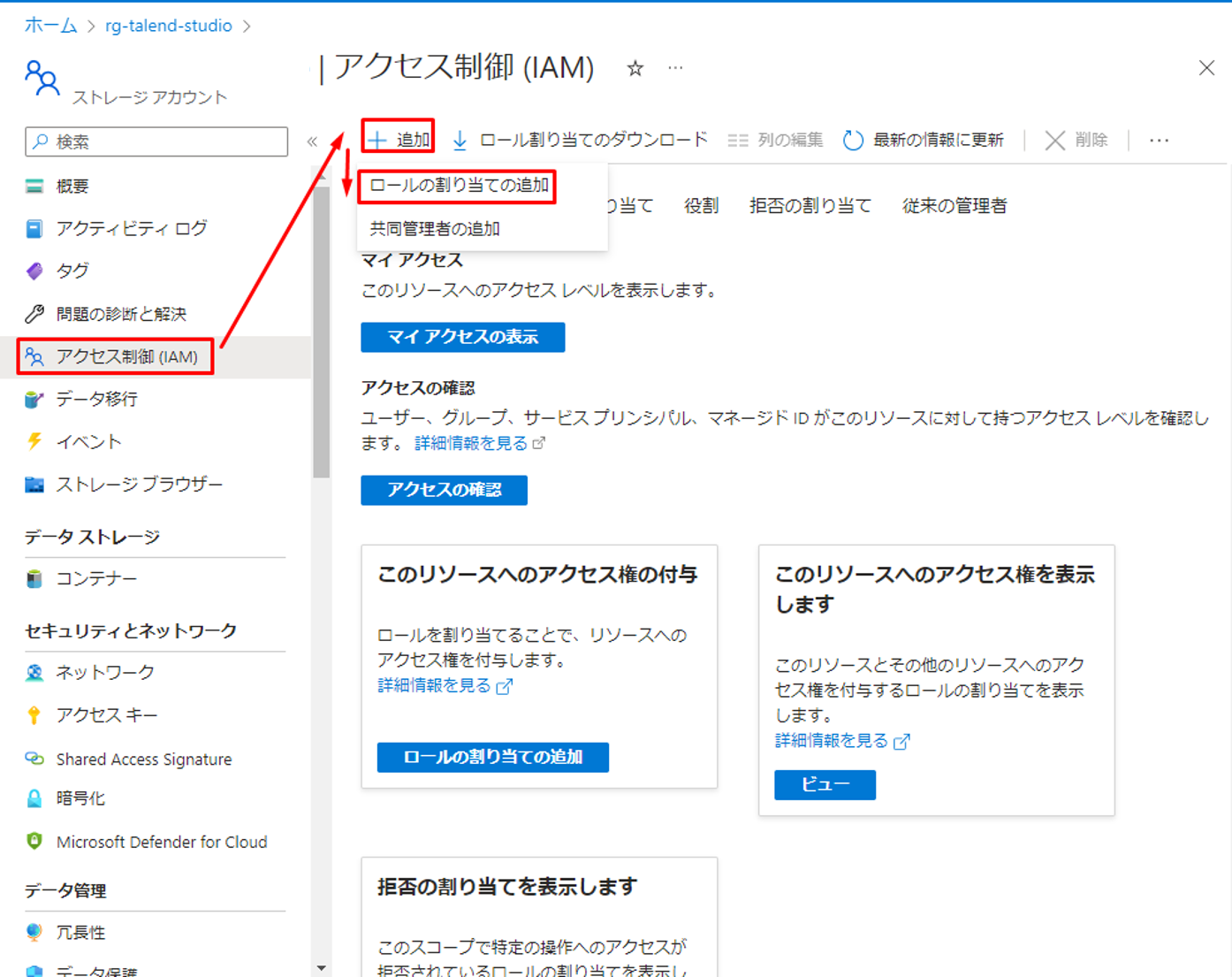
②「ストレージ BLOB データ共同作成者」を選択して、「次へ」をクリックします。
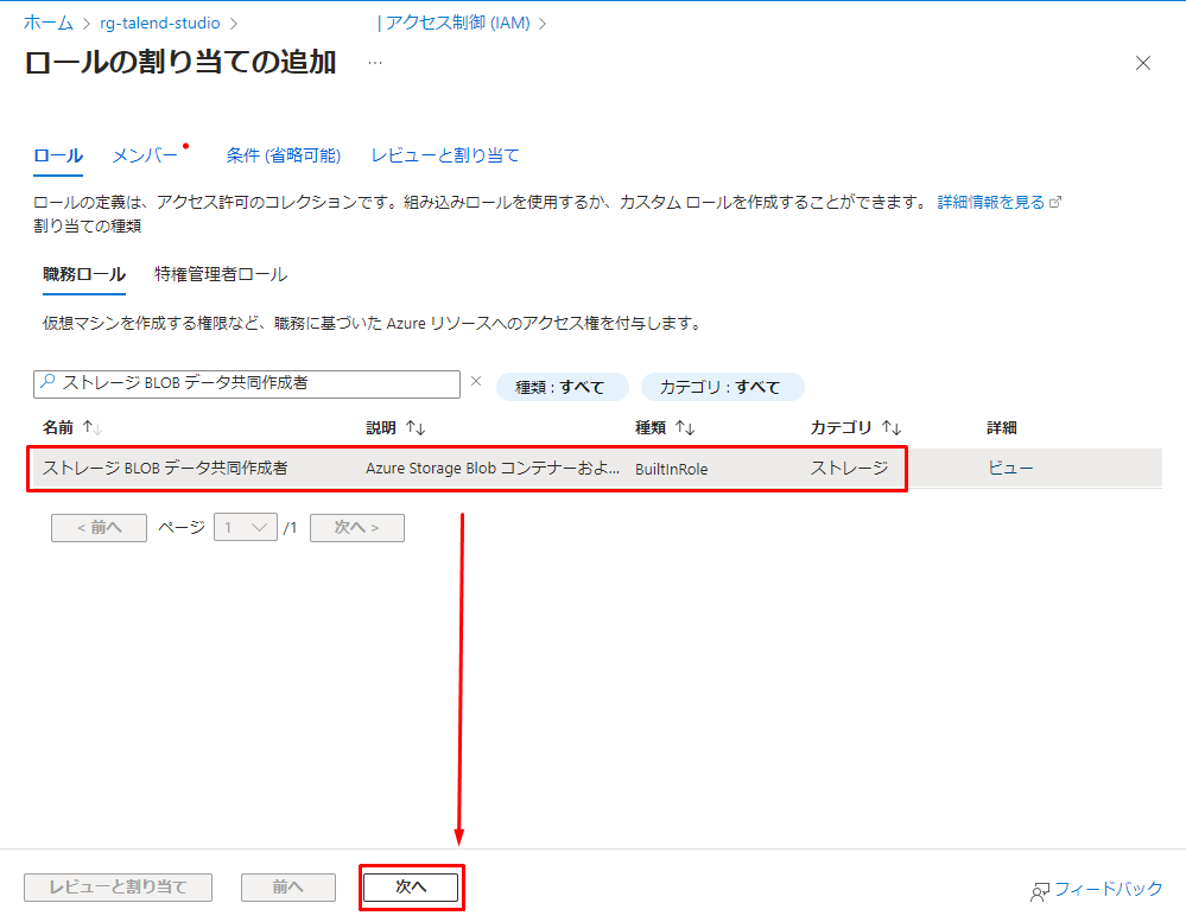
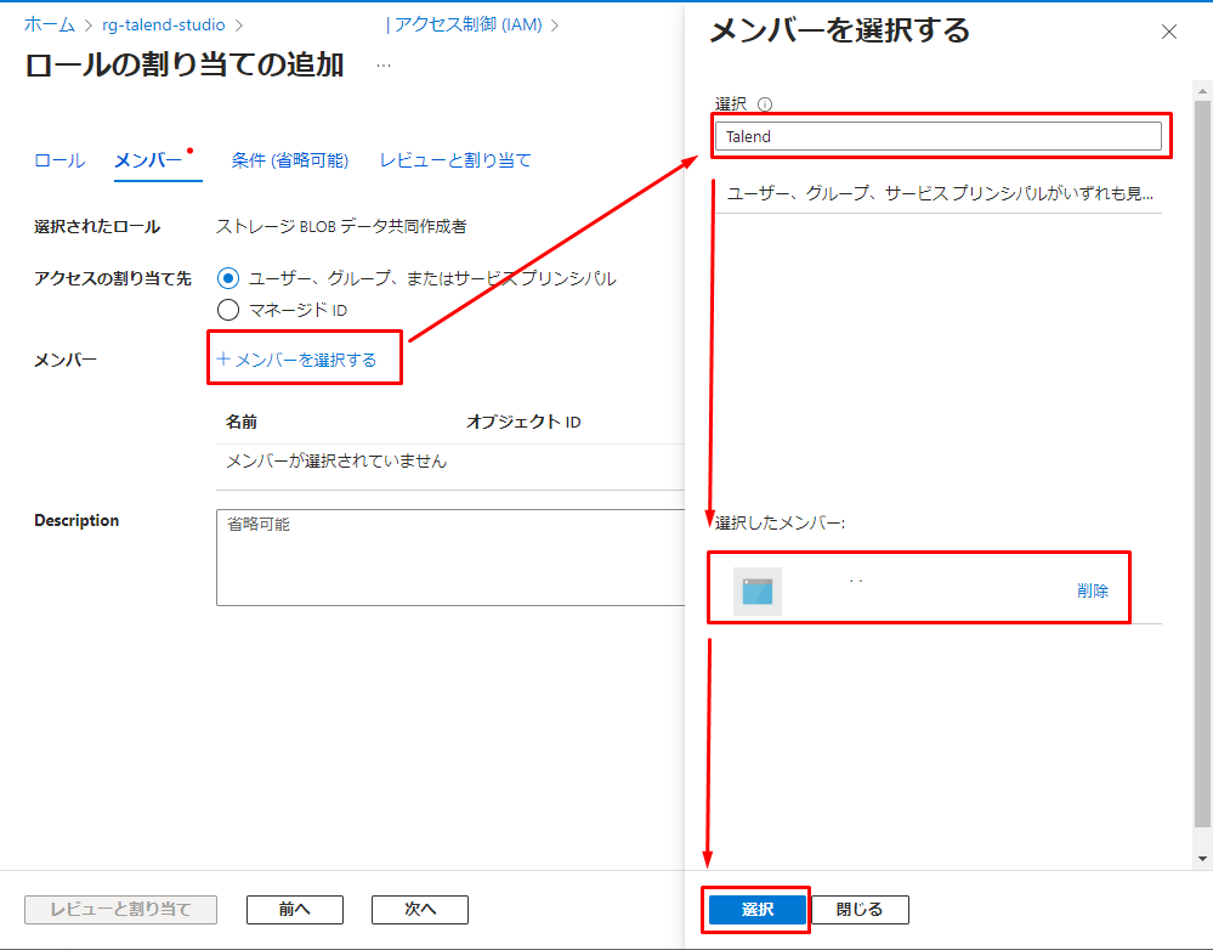
③「メンバー」タブで「メンバーを選択する」をクリックすると、ダイアログが表示されます。
④ 検索して、対象のサービス プリンシパルを選択して、「選択」をクリックします。
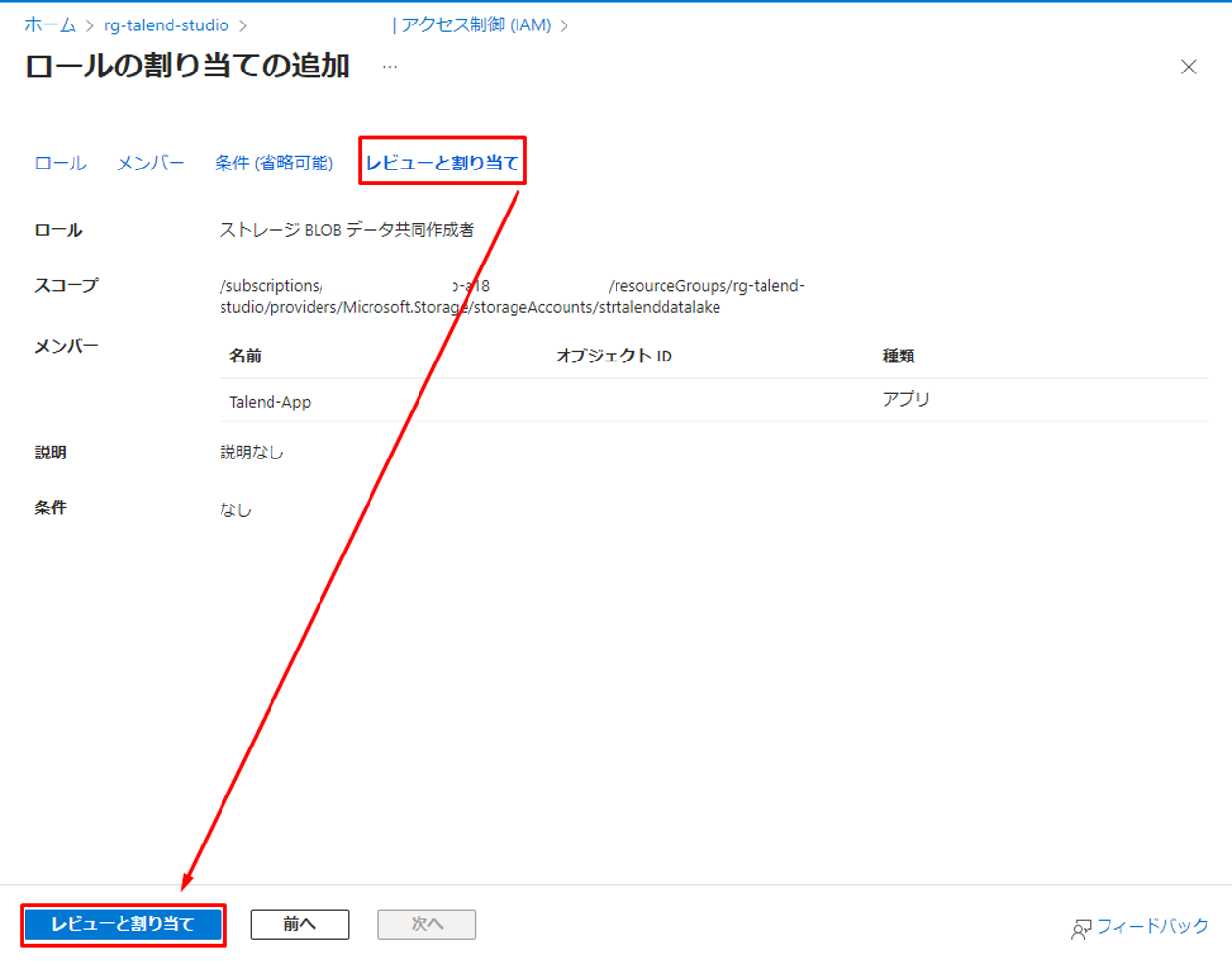
⑤「レビューと割り当て」タブで「レビューと割り当て」をクリックします。
4.クライアントID、ディレクトリIDとシークレットを取得する
Talend ジョブはADLSからのデータを読み込んで、書き込むために、サービス プリンシパルのクライアントID、ディレクトリIDとシークレットが必要です。
① Azureポータルのサイドバーで「Azure Active Directory」をクリックします。
② アプリケーションの一覧が表示されます。ADLSへのアクセス権限が付与されたアプリケーションを選択します。
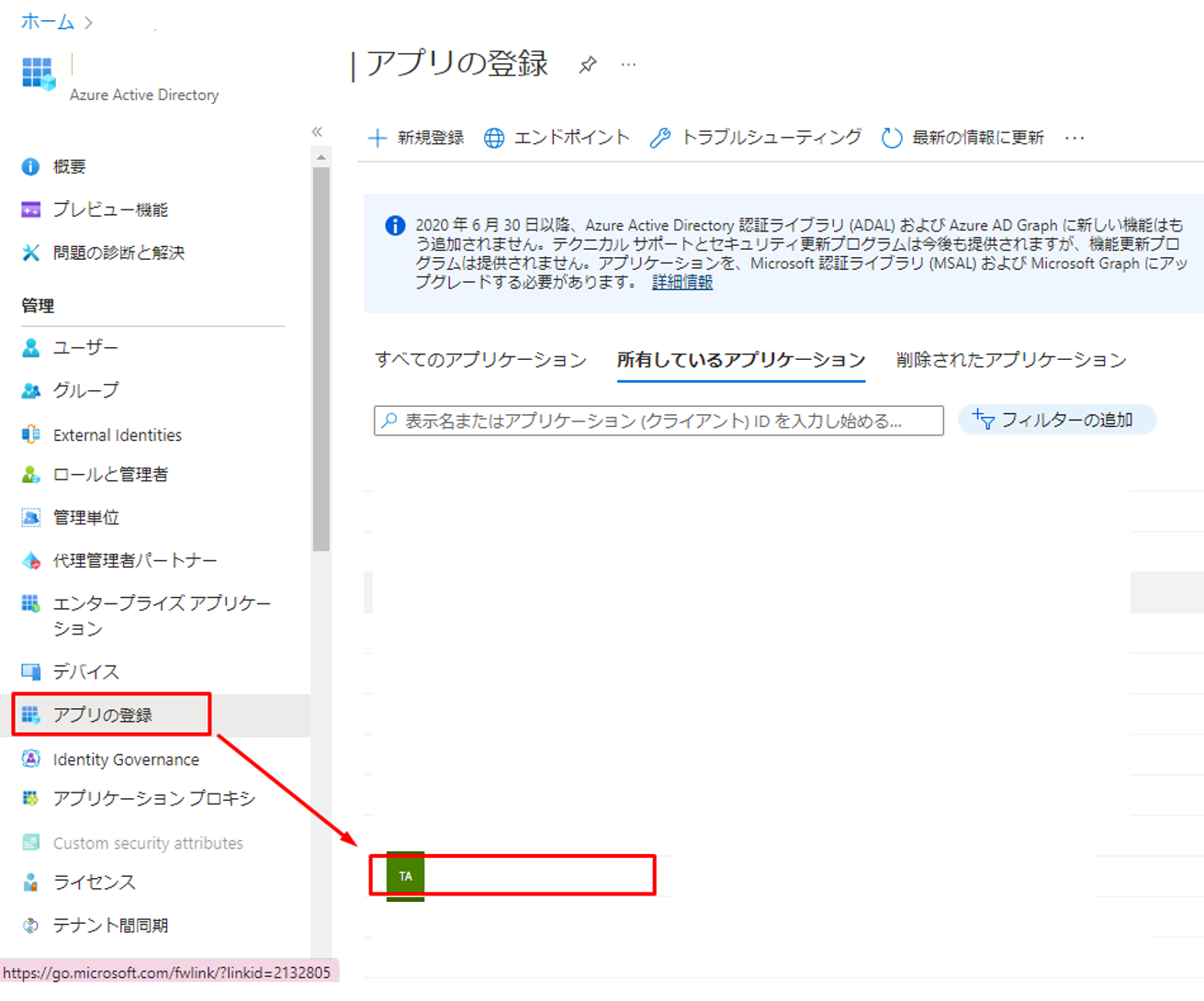
③「概要」画面でアプリケーション(クライアント)IDとディレクトリ(テナント)IDを保存して、次の手順で使用します。
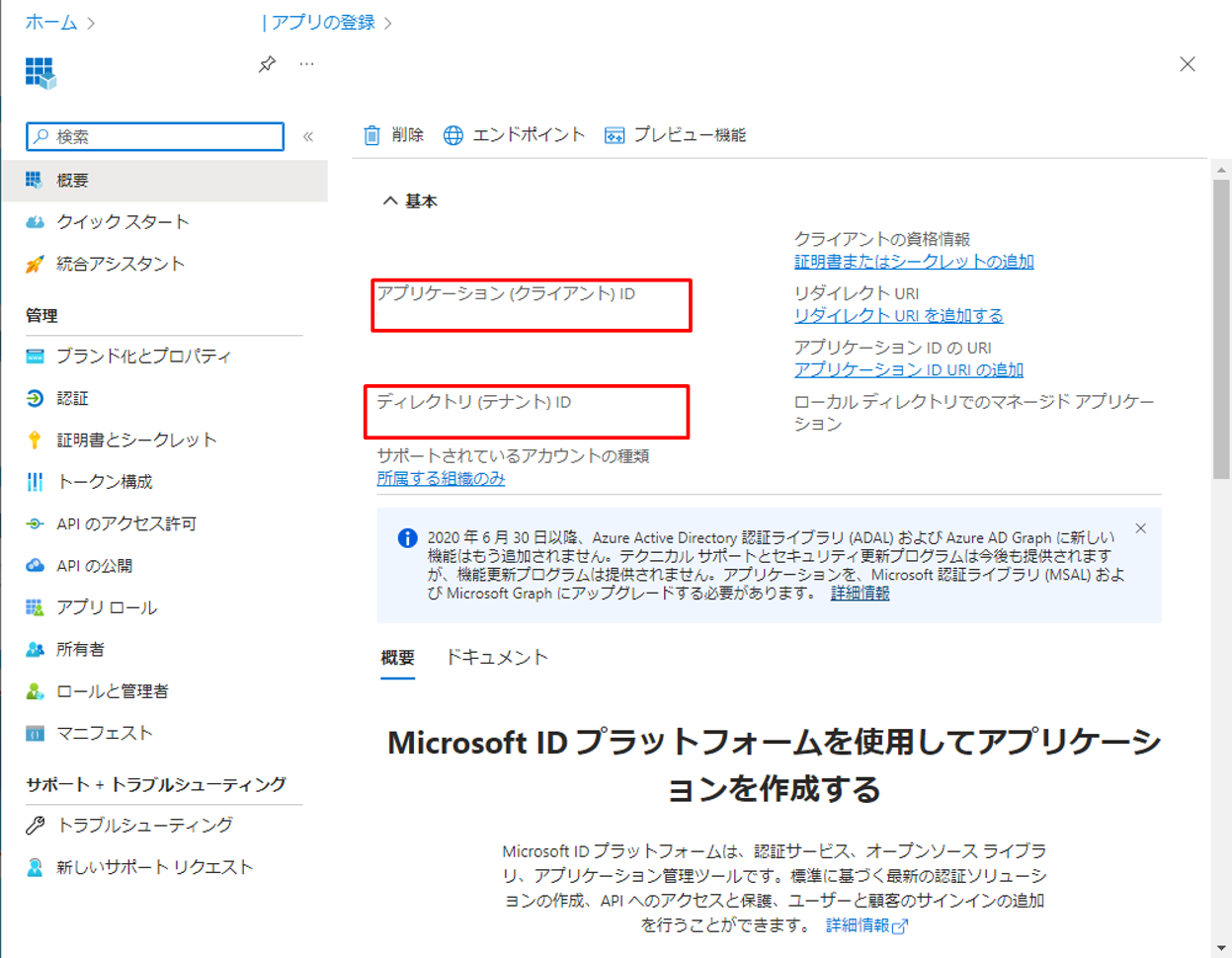
次はシークレットを作成します。
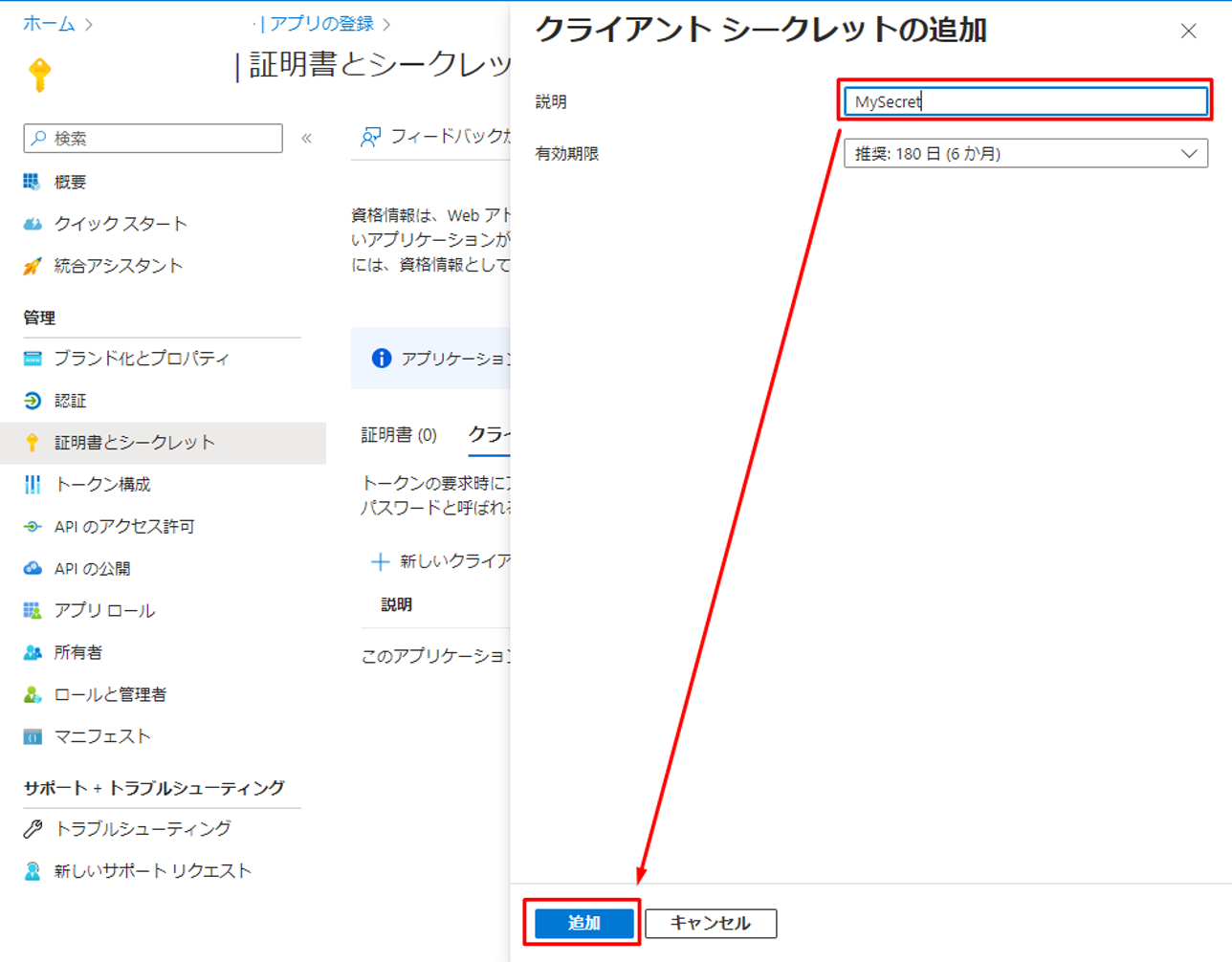
④「証明書とシークレット」をクリックして「新しいクライアントシークレット」をクリックします。
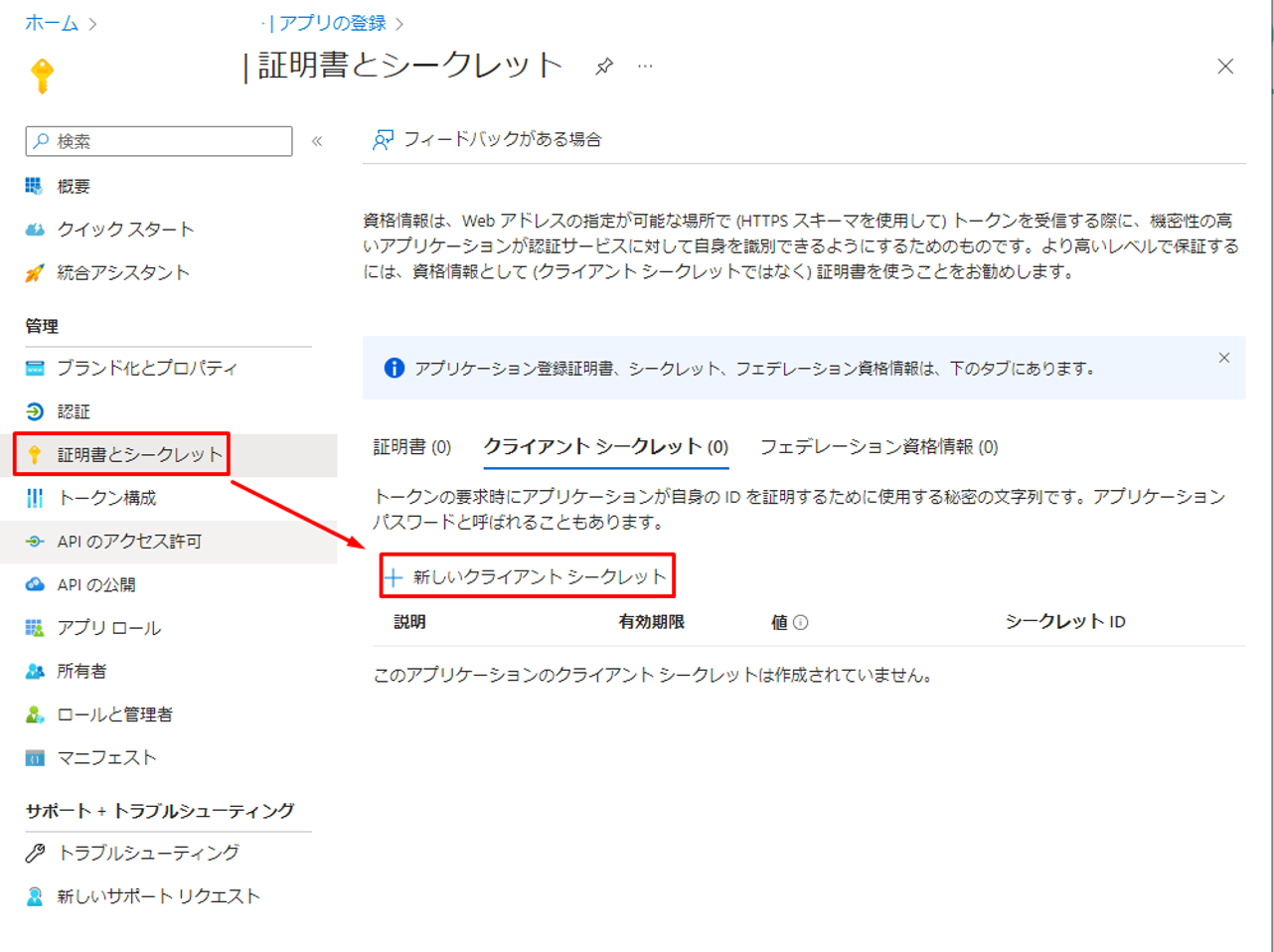
⑤ 表示されているダイアログでシークレット名を入力して、「追加」をクリックします。
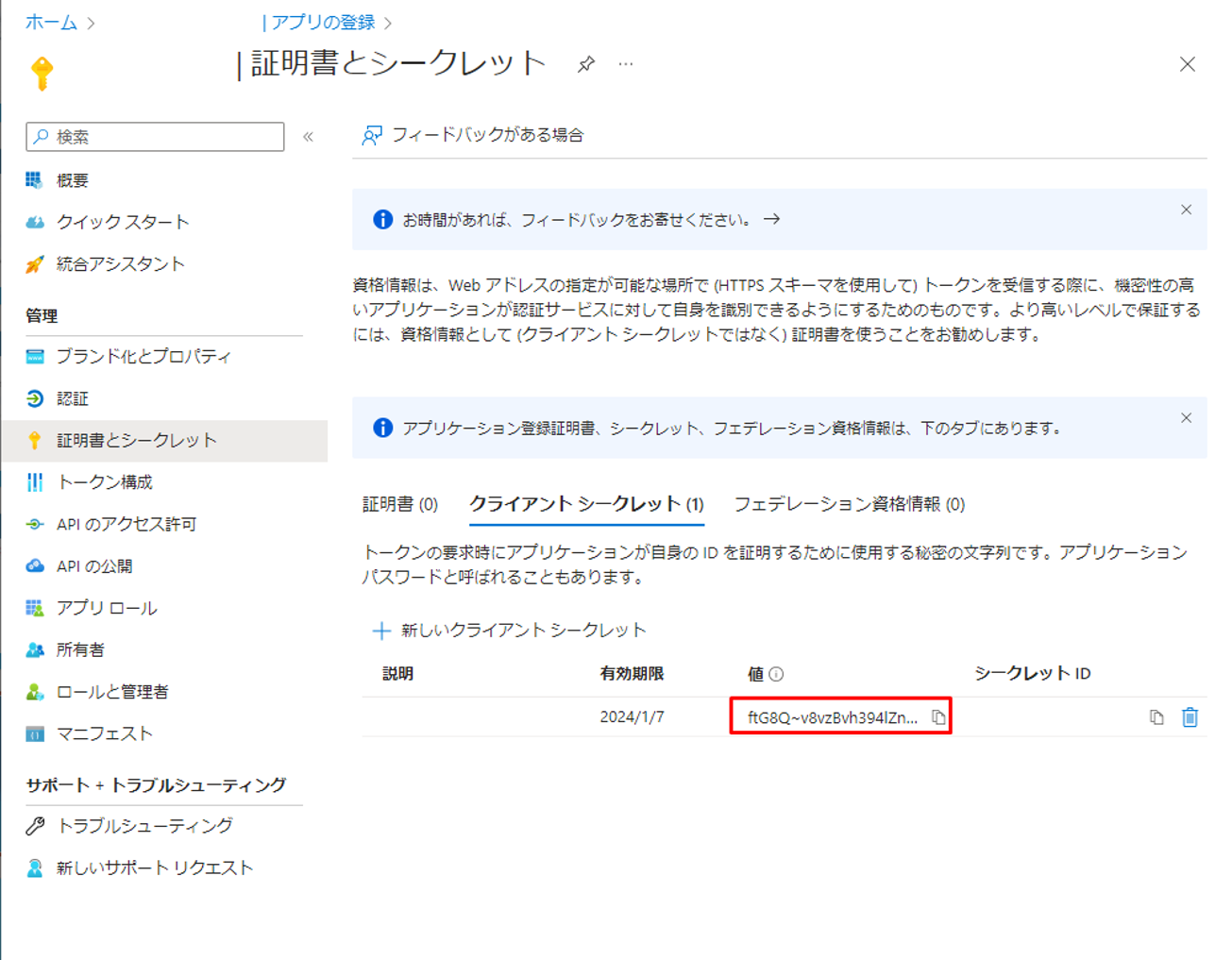
⑥「値」列でシークレットの値をコピーして、保存します。
5.Databricks クラスターを作成して、設定する
クラスターが ADLS にアクセスするには、Spark Configuration(Spark 設定)にいくつかの特定のプロパティを追加する必要があります。
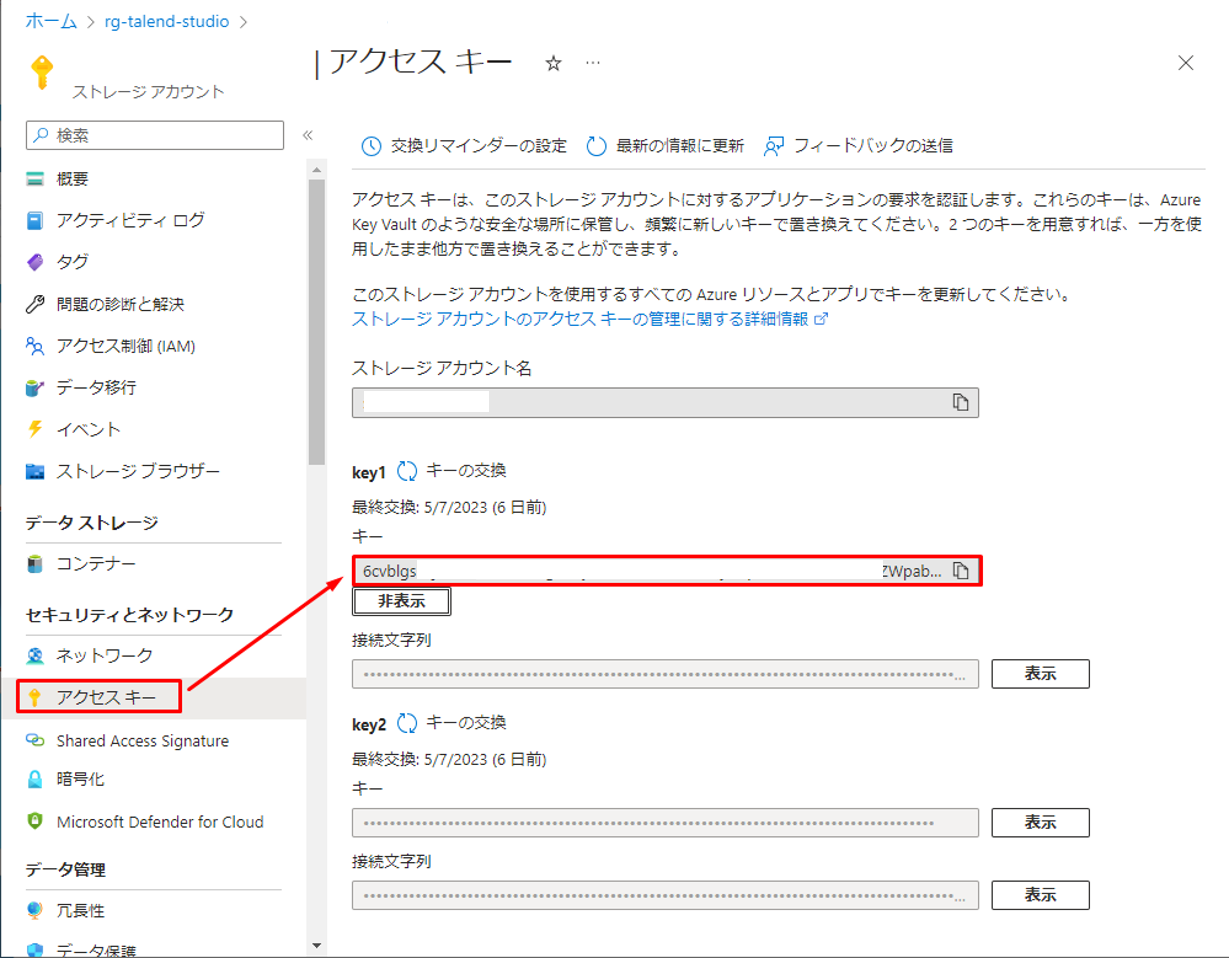
まず、ADLSのアクセスキーが必要です。
① ADLSのポータルで「アクセスキー」をクリックして、「表示」をクリックして希望のキーをコピーします。
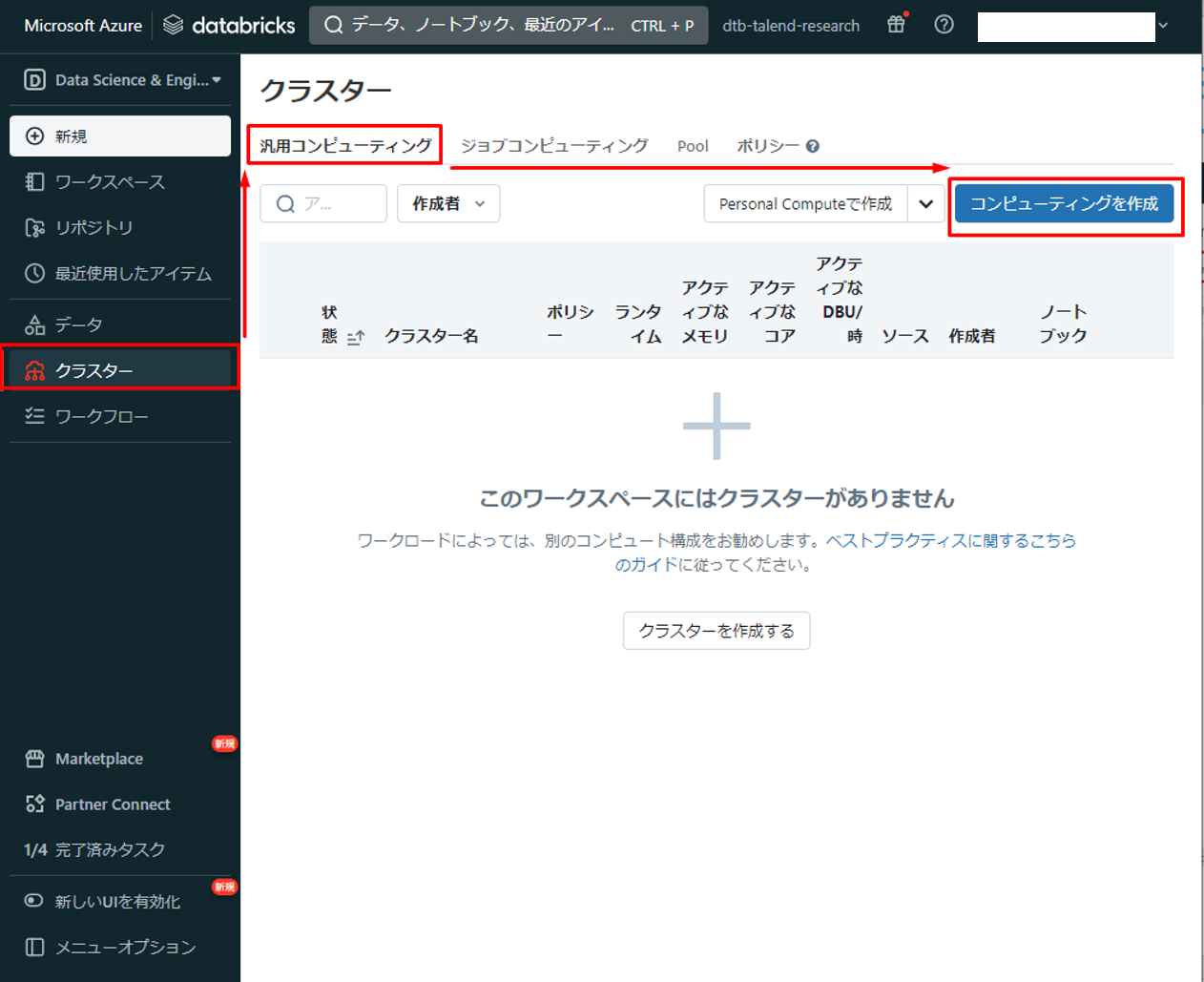
② Azure Databricks画面で「クラスター」を選択して、「汎用コンピューティング」をクリックします。
③「コンピューティングを作成」をクリックします。
④ クラスターに名前を付けて、 「Databricks Runtimeのバージョン」で 「Runtime:7.3 LTS」を選択します。
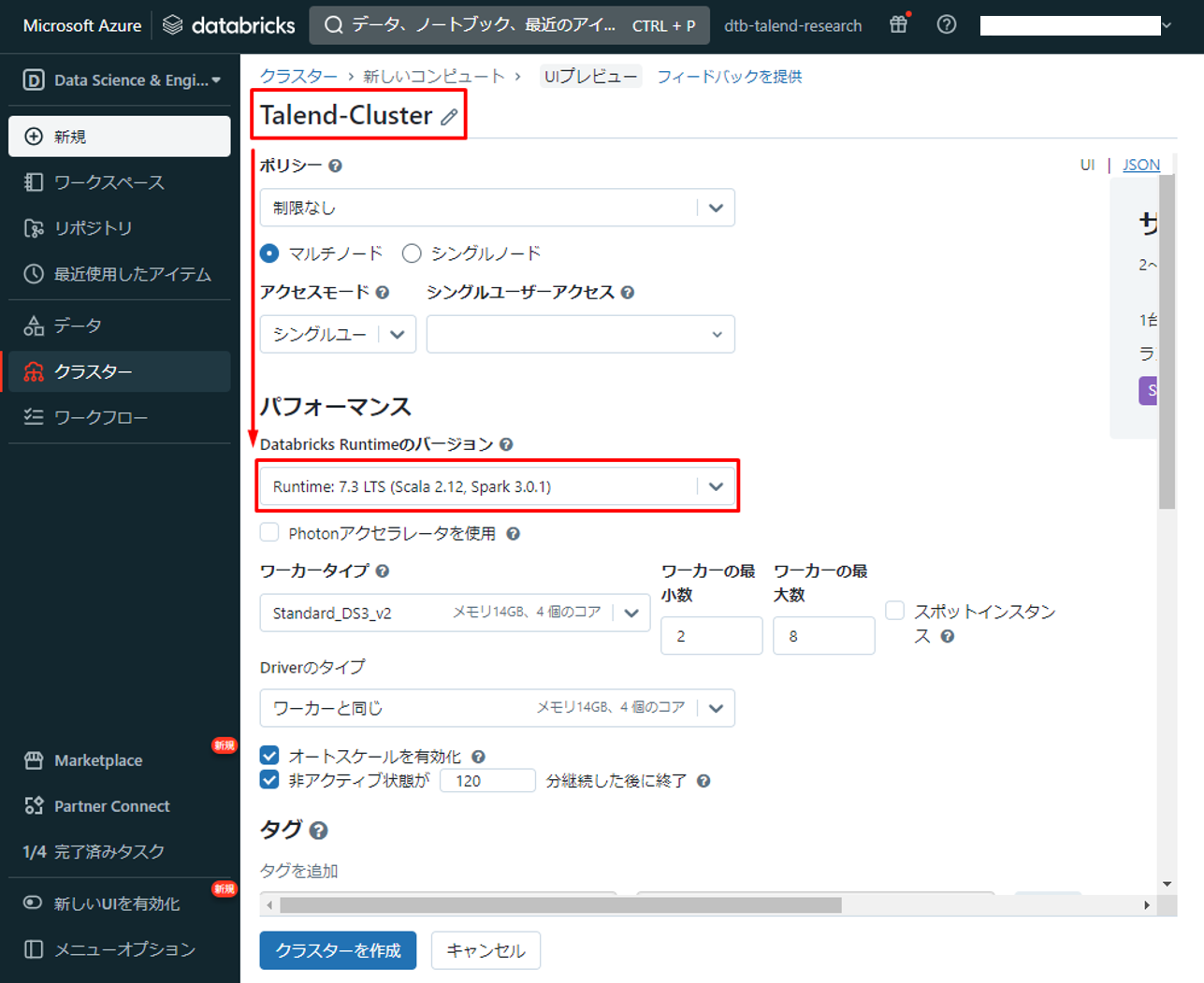
⑤「Spark構成」で以下のパラメーターを入力します。「your-access-key」を保存したADLSのアクセスキーに変更します。
|
1 |
spark.hadoop.fs.azure.account.key.strtalenddatalake.dfs.core.windows.net "your-access-key" spark.hadoop.fs.azure.createRemoteFileSystemDuringInitialization true |
⑥「クラスターを作成」をクリックします。
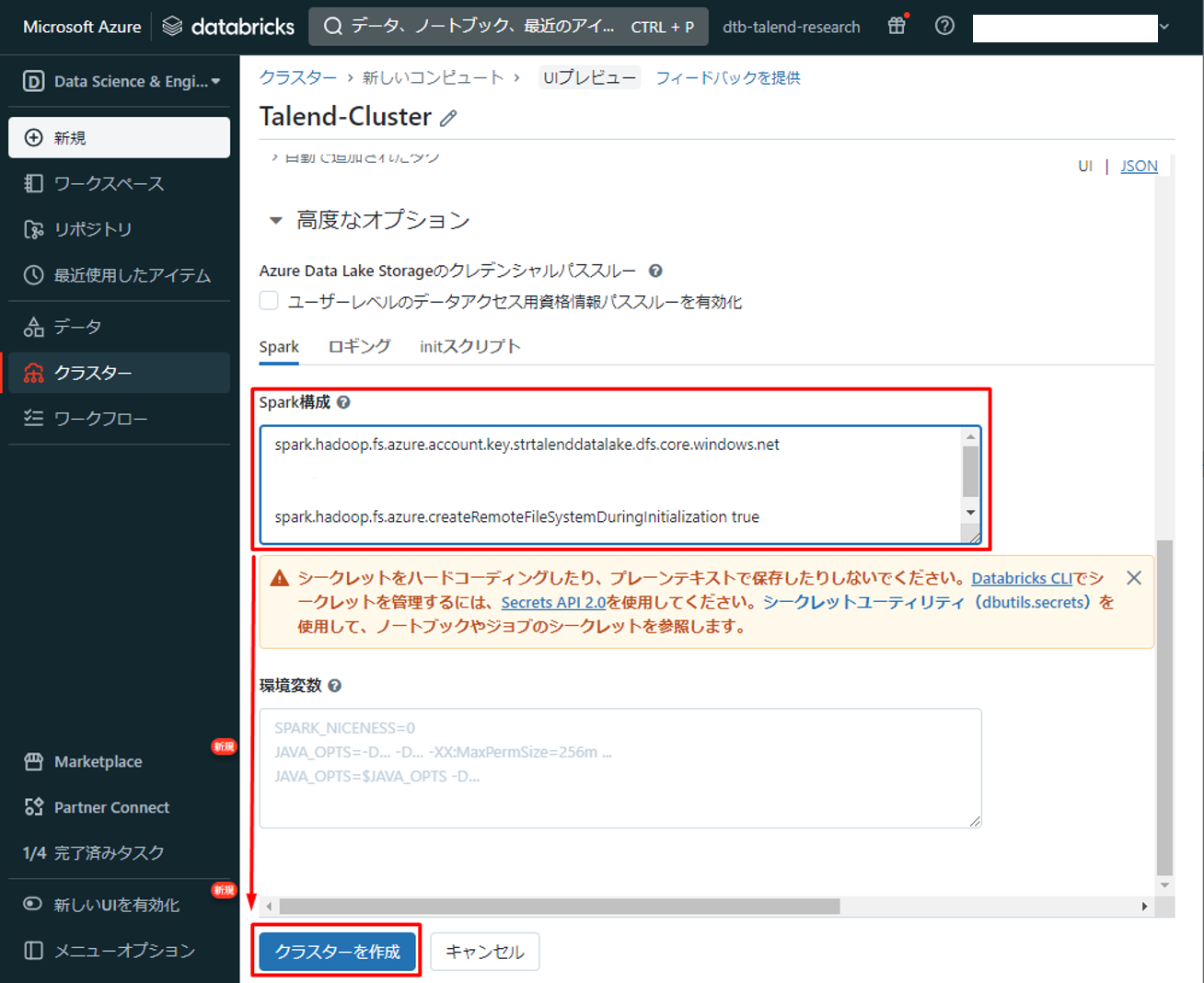
⑦ クラスターを作成した後、「Spark UI」タブで「Environment」クリックして、 「spark.databricks.clusterUsageTags.clusterId」を確認します。
⑧ クラスターIDを保存して、次の手順で使用します。
6.Talend ジョブを作成する
6-1.コンポネントを準備する
Talend Jobを作成するには、 Talend Big Data Platformを開いて、新規プロジェクトを作成します。次は、Big Data Batch Jobを作成します。
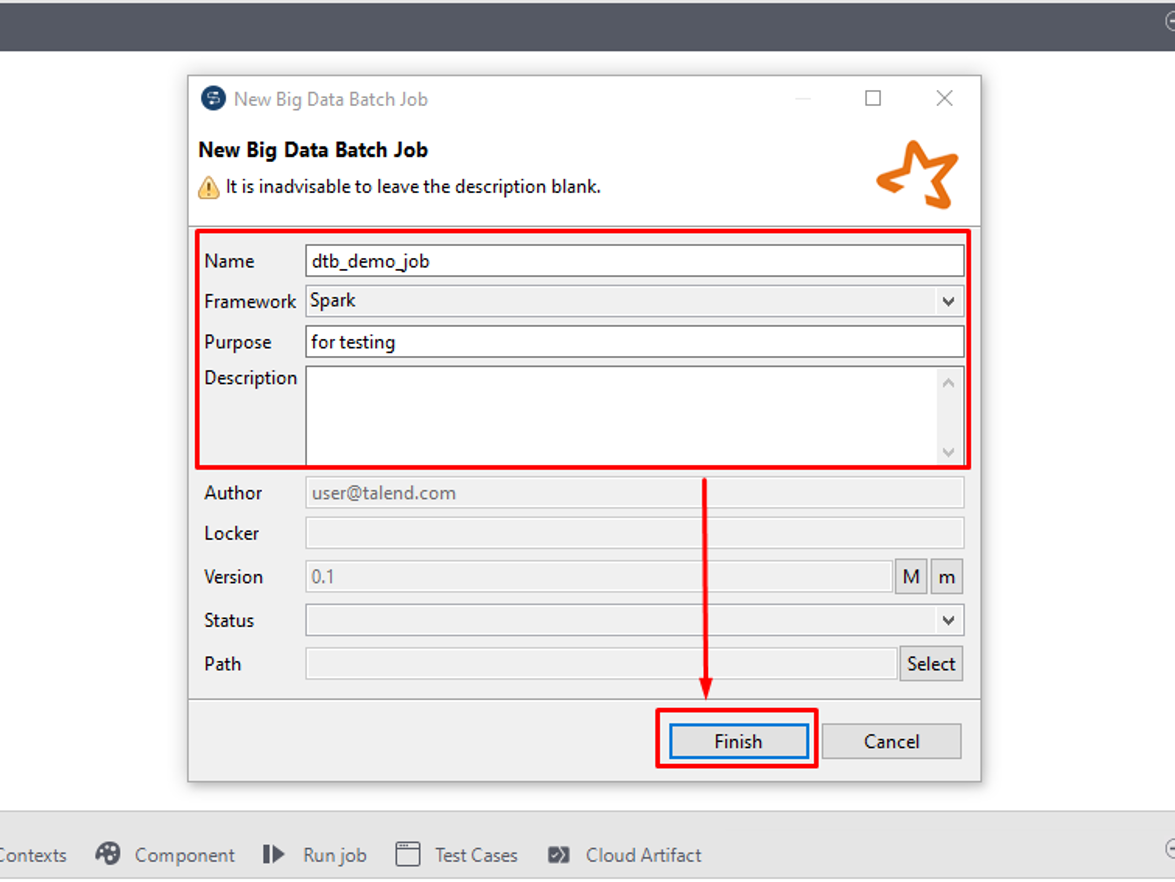
① Big Data Batch Jobを作成するには、「Big Data Batch」をクリックして、「Create Big Data Batch Job」を選択します。
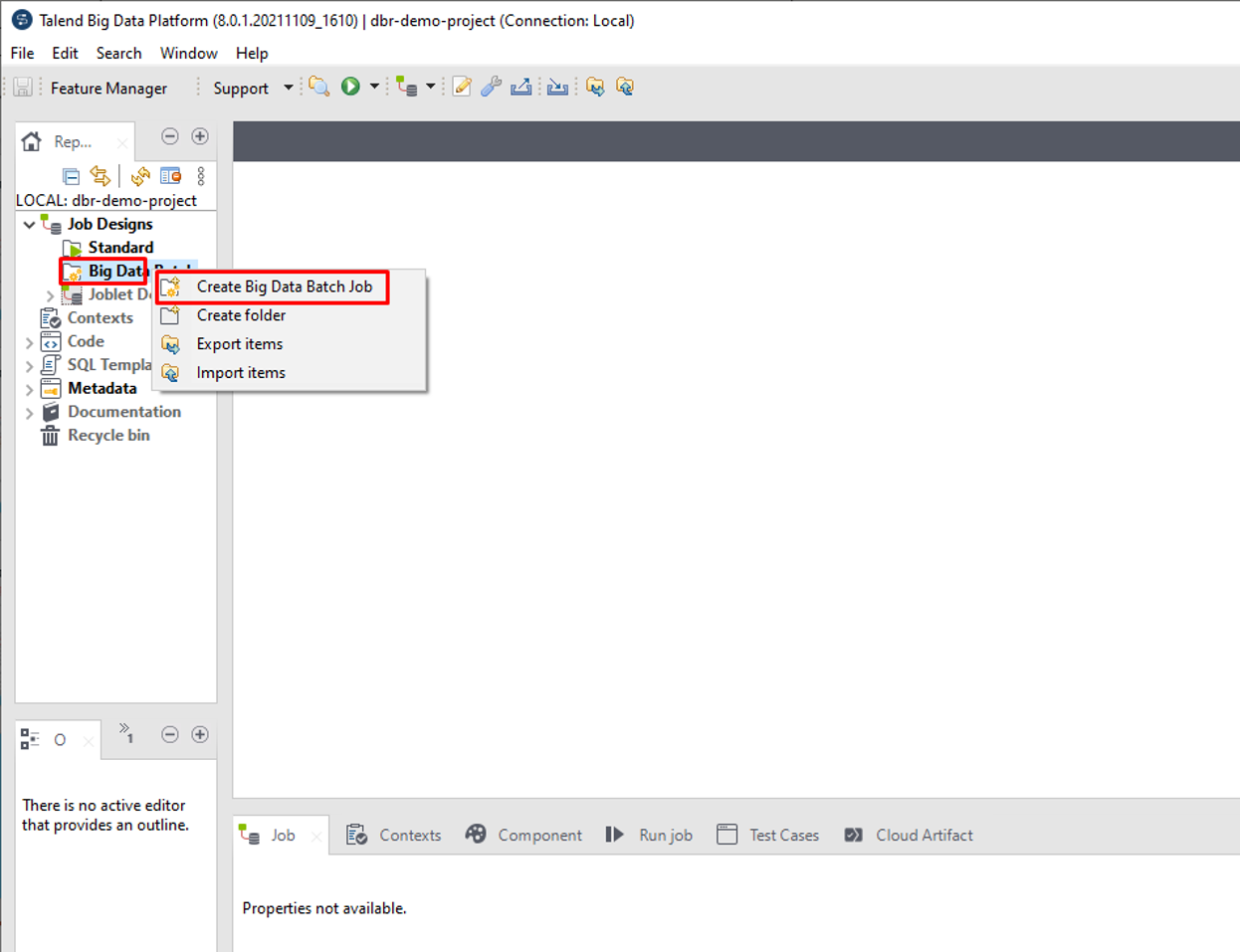
② 表示されているダイアログでジョブ名を入力して、「Finish」をクリックします。
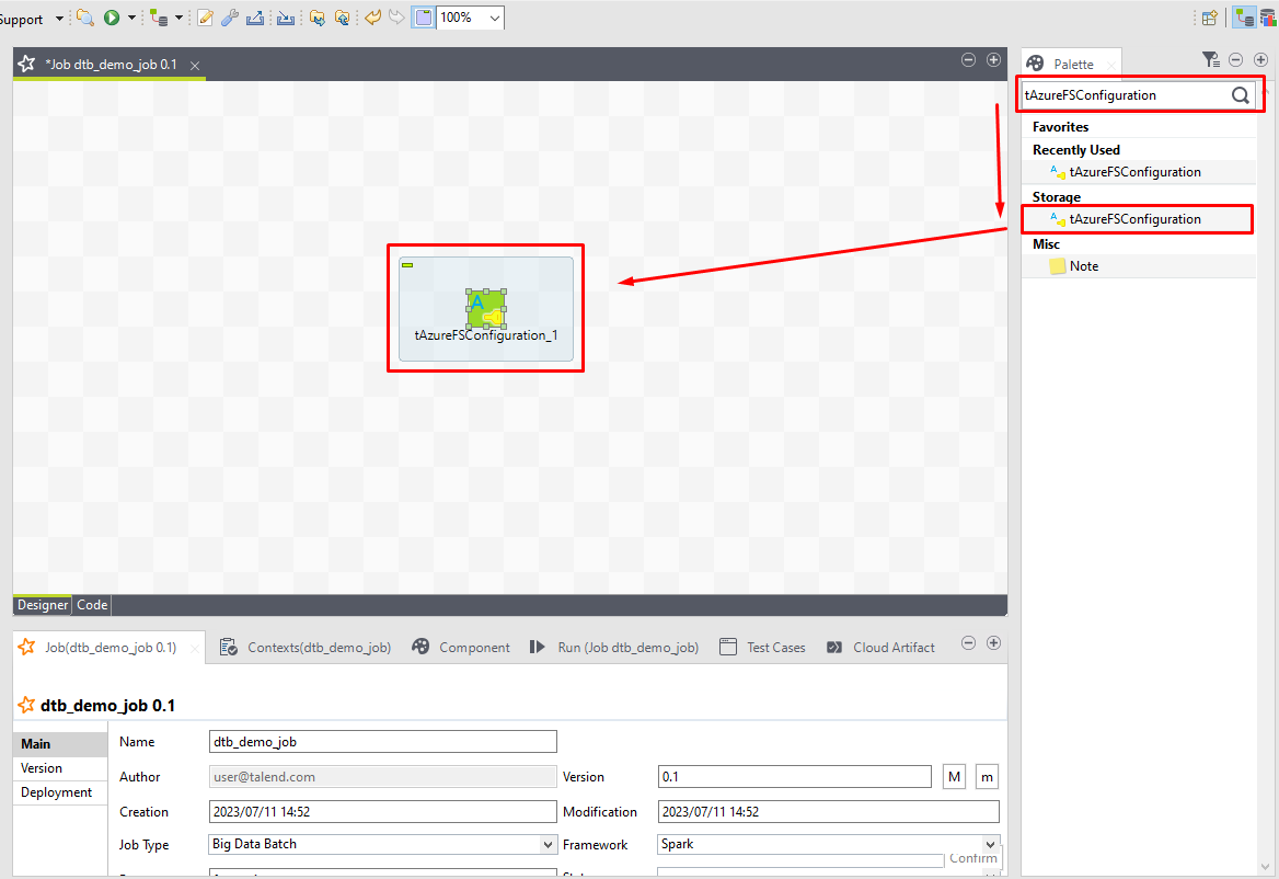
今回のジョブでは、5つのコンポーネントを使用します。
・tAzureFSConfiguration
Storage Account及びDatabricksクラスタへ接続情報を提供します。
・tFileInputParquet
データを準備します。
・tFileOutputParquet
Storage AccountにParquet形式ファイルにレコードを書き込みます。
・tLogRow
Storage AccountからParquet形式のファイルからレコードを抽出します。
・tFixedFlowInput
データ処理を監視する目的で[Run] (実行)コンソールにデータまたは結果を表示します。
コンポーネントの一覧から5つの対象コンポーネントをJob Designer画面にドラッグ アンド ドロップします。
③ 検索欄に「 tAzureFSConfiguration 」と入力して、Job Designer画面にドラッグ アンド ドロップします。
他のコンポーネントに対して、同じ手順で実装します。
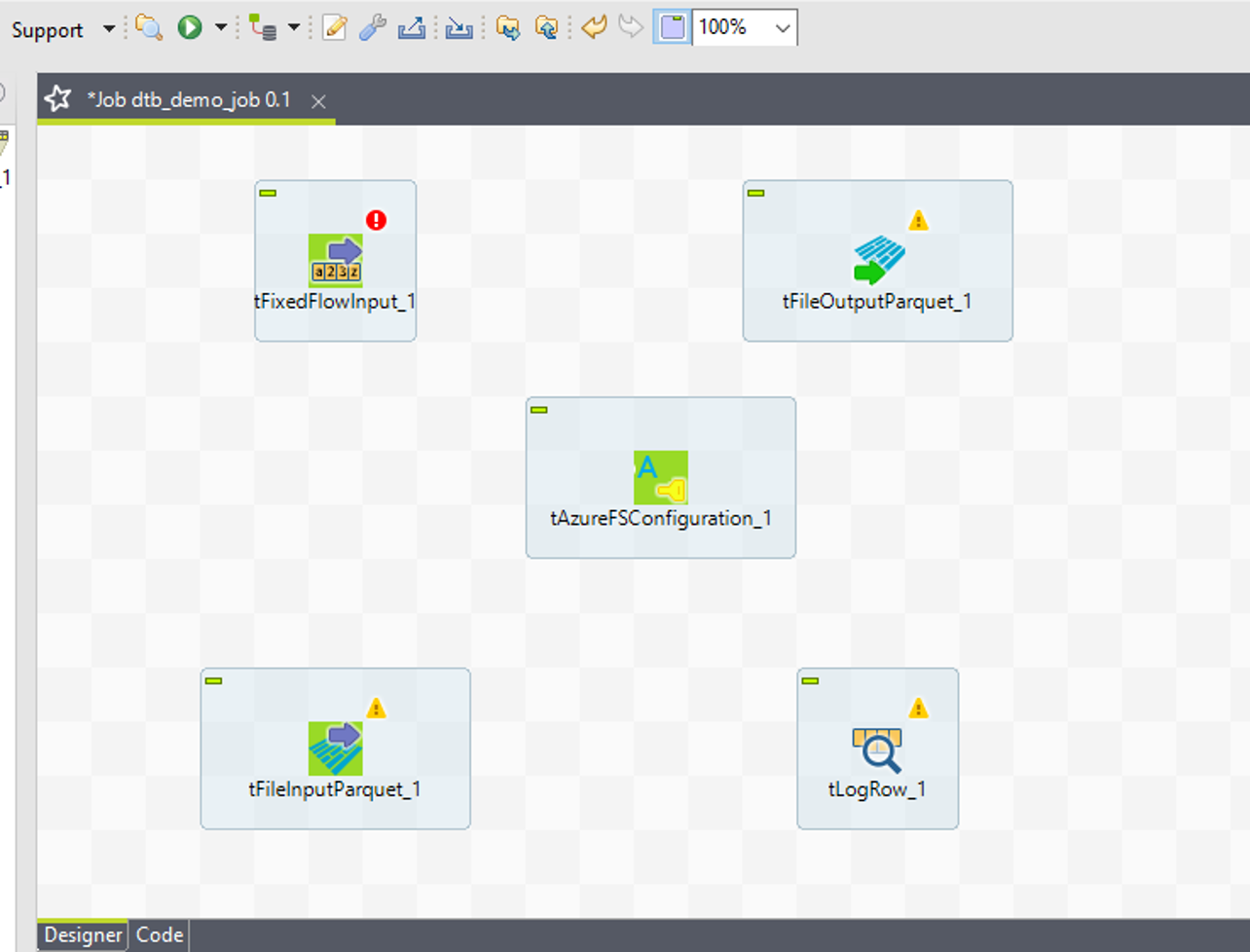
画像の通りに5つのコンポーネントが表示されます。
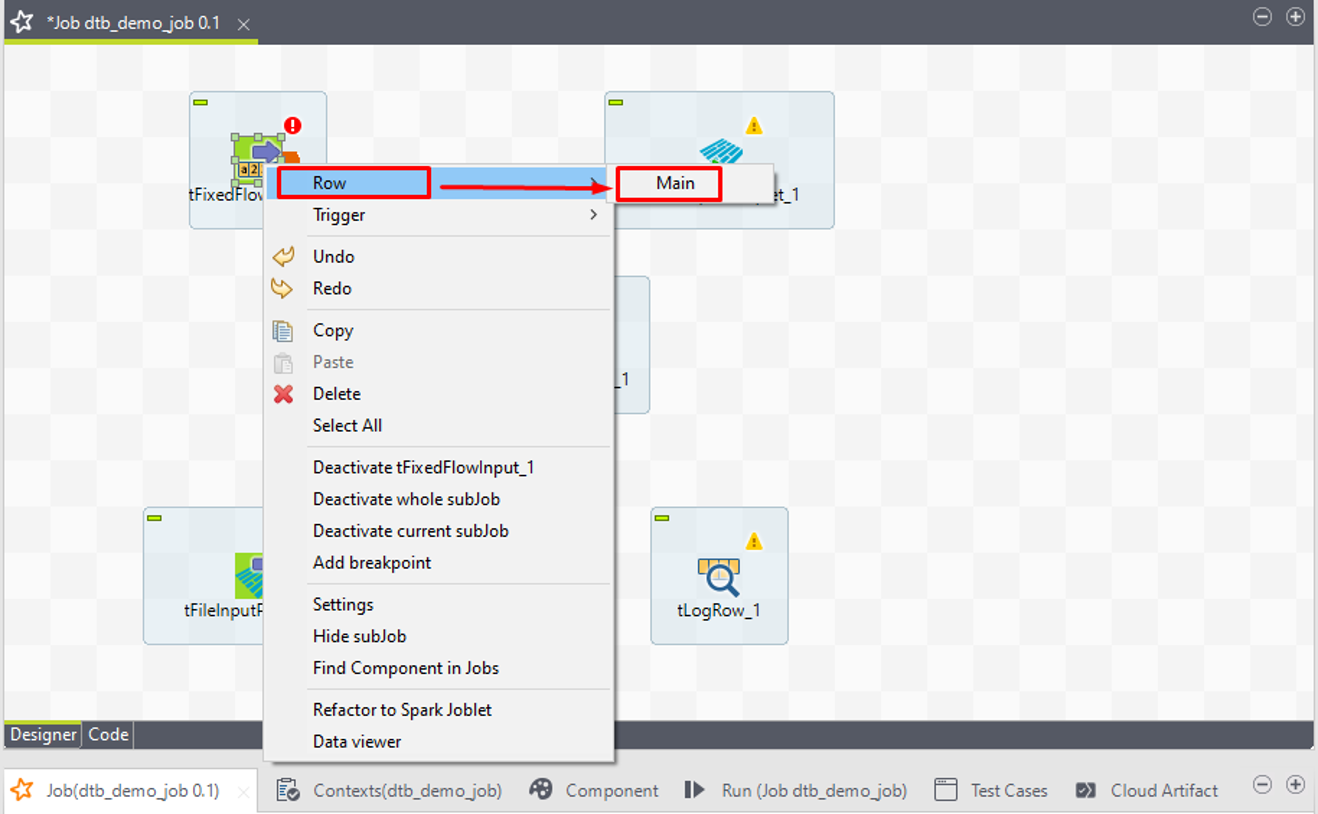
④ tFixedFlowInputを右クリックして、「Row」>「Main」を選択します。
⑤「Row」>「Main」リンクを使って、tFixedFlowInputをtFileOutputParquetに接続します。
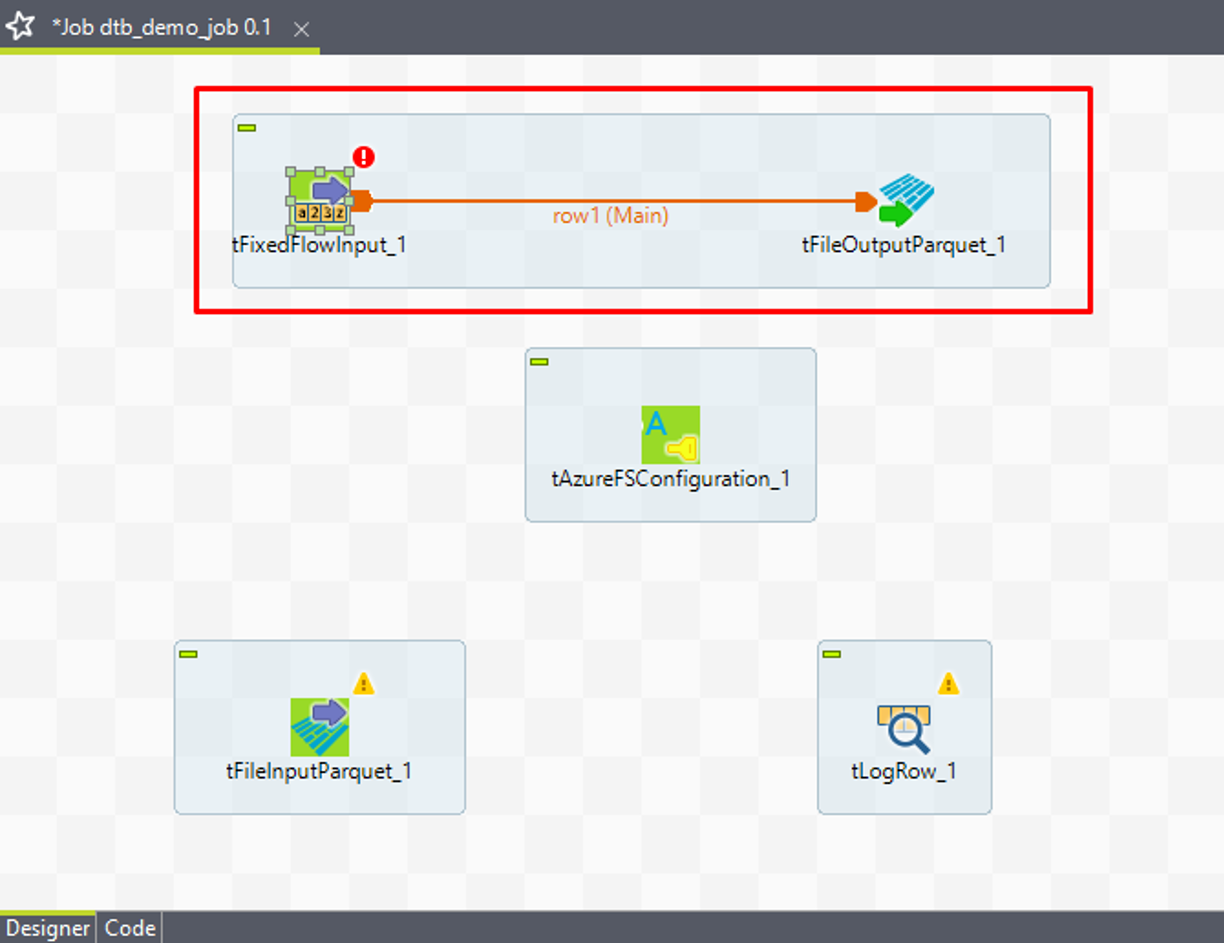
⑥ 同様に、「Row」>「Main」リンクを使って、tFileInputParquetをtLogRowに接続します。
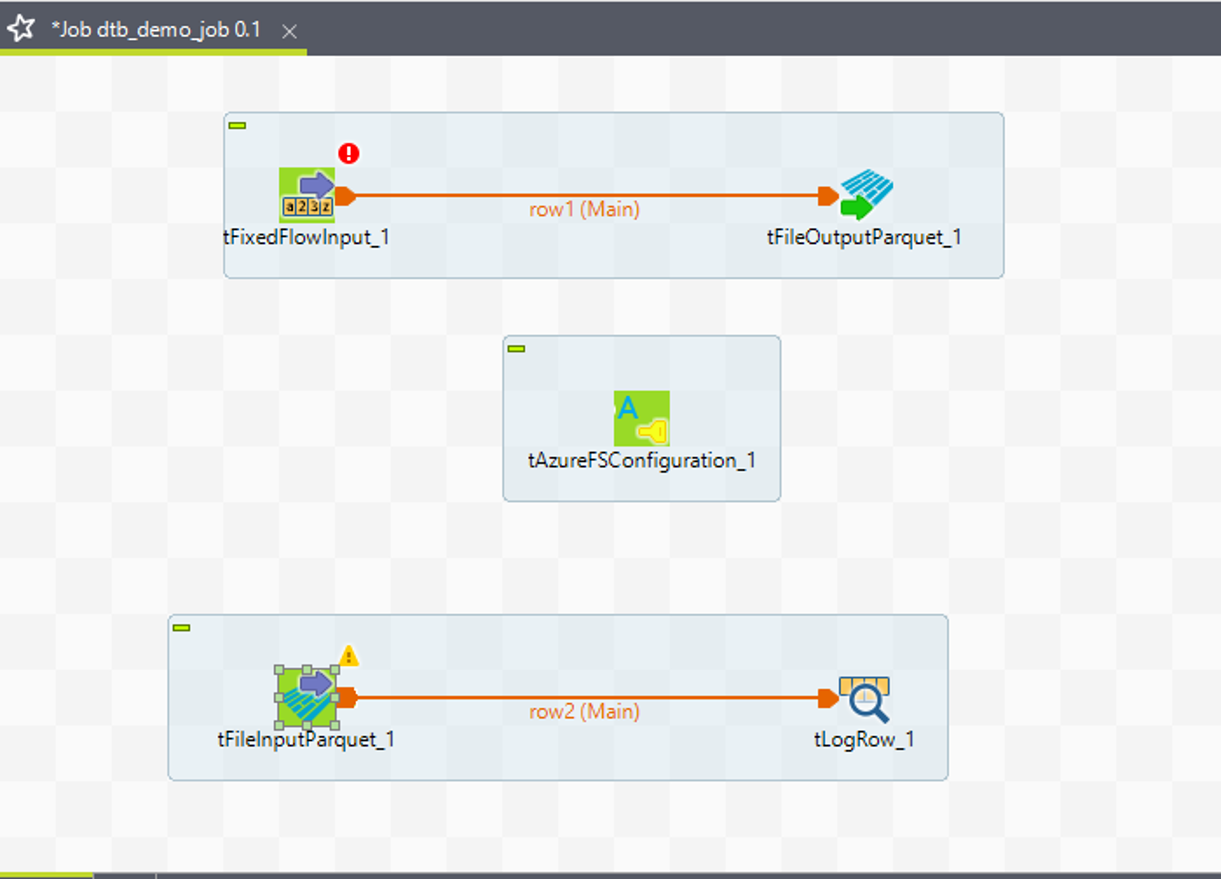
⑦ 次に、「Trigger」>「OnSubjobOk」リンクを使って、tFixedFlowInputをtFileInputParquetに接続します。
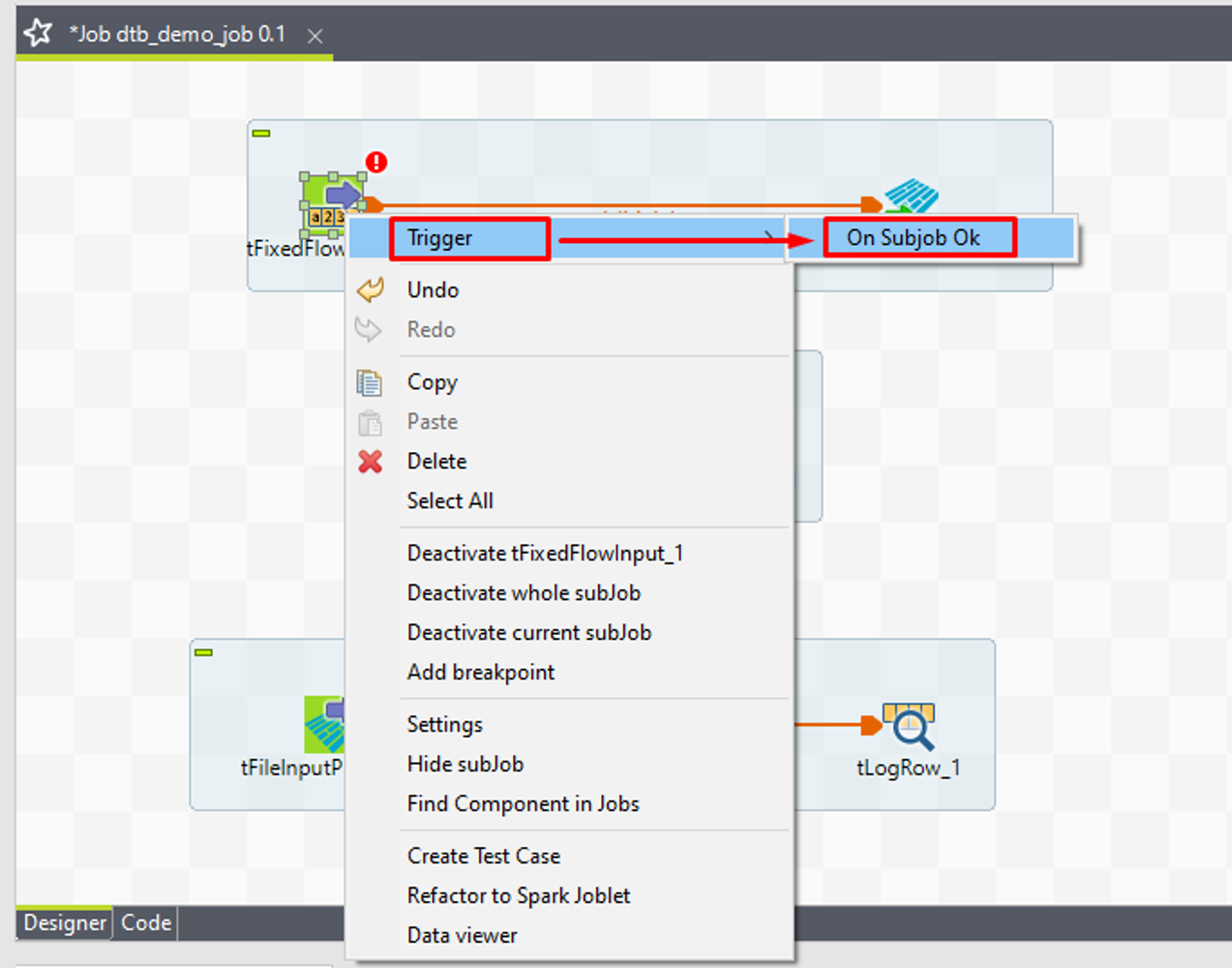
接続結果は画像の通りです。
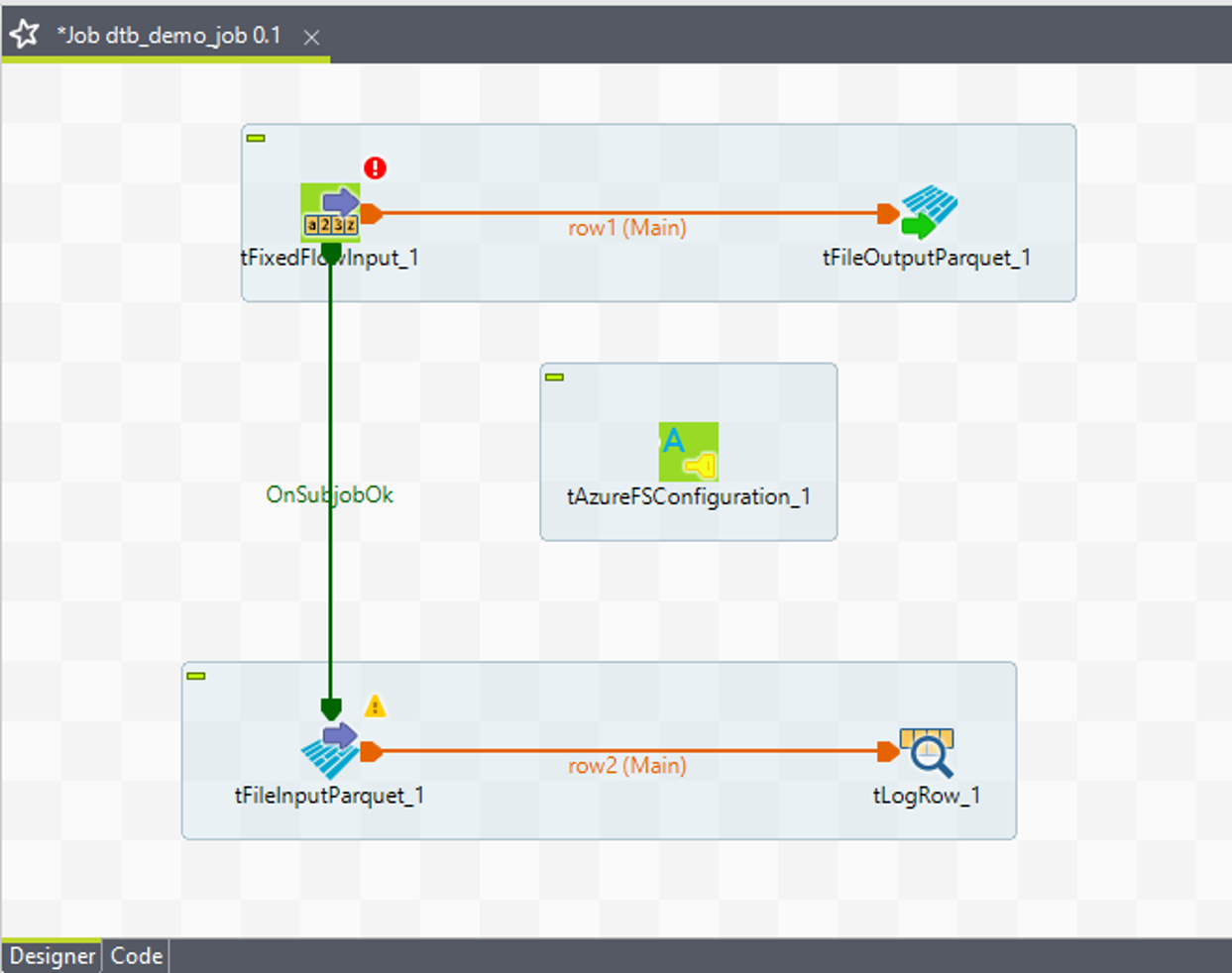
6-2.ADLSへの接続を付与する
① tAzureFSConfigurationを左クリックします。
②「Component」タブの「Basic setting」で、「Azure FileSystem」項目で「Azure Data Lake Storage (Gen2)」を選択して、 「Authentication mode」項目で「Azure Active Directory」を選択します。
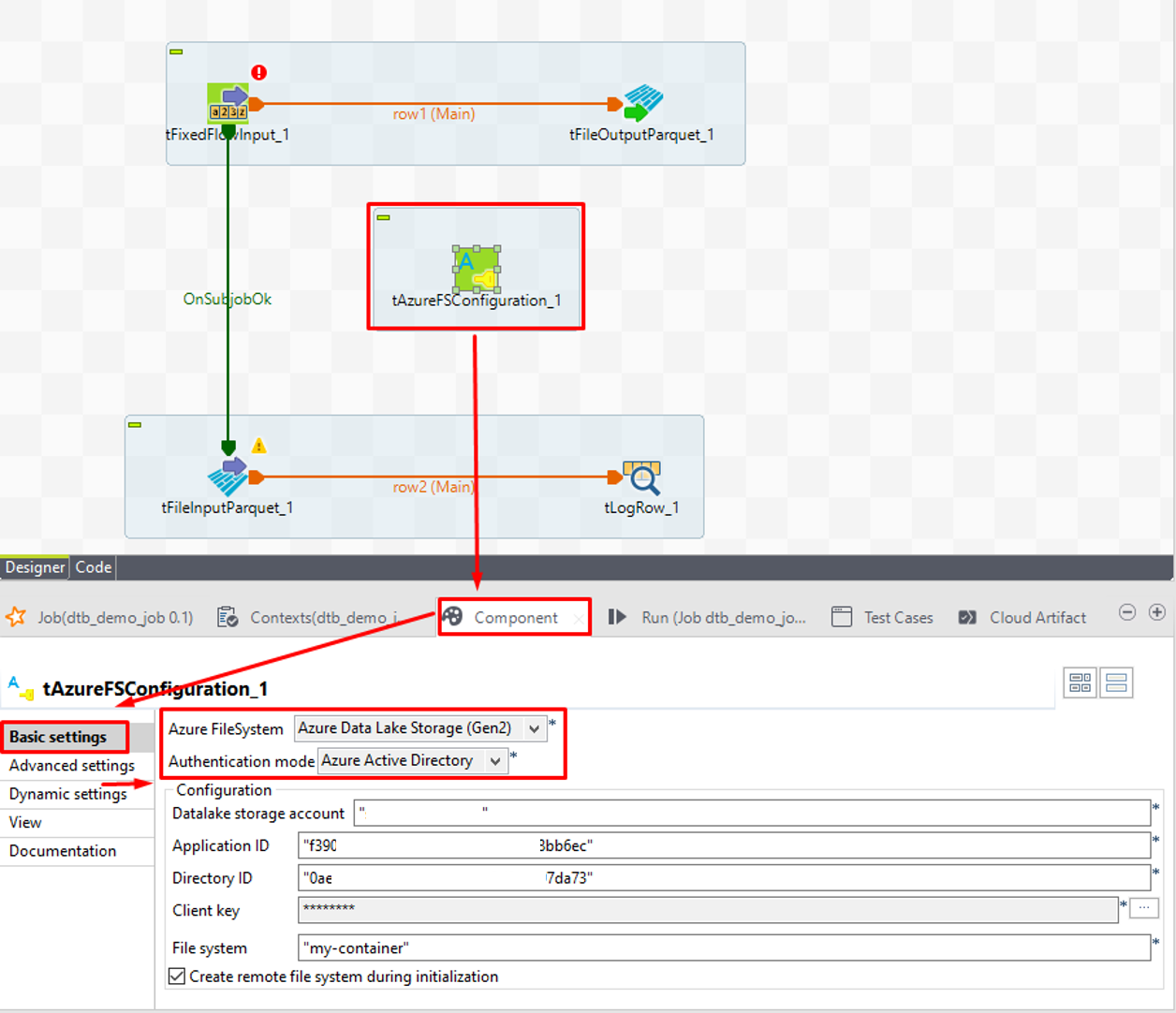
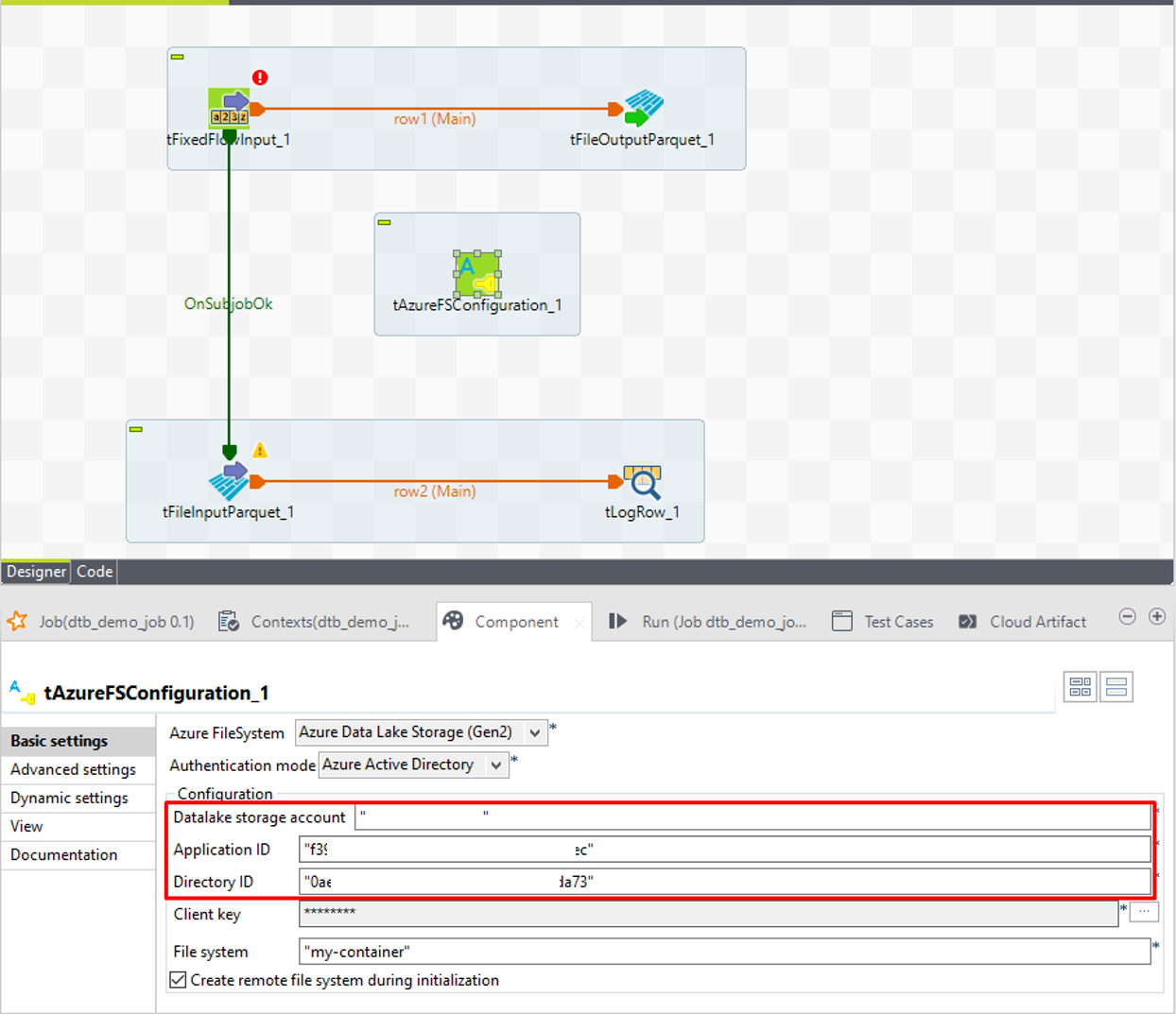
③「Datalake storage account」項目でADLSの名前を入力します。
④「Application ID」項目で保存したアプリケーション(クライアント)IDを入力します。
⑤「Directory ID」項目で保存したディレクトリ(テナント)IDを入力します
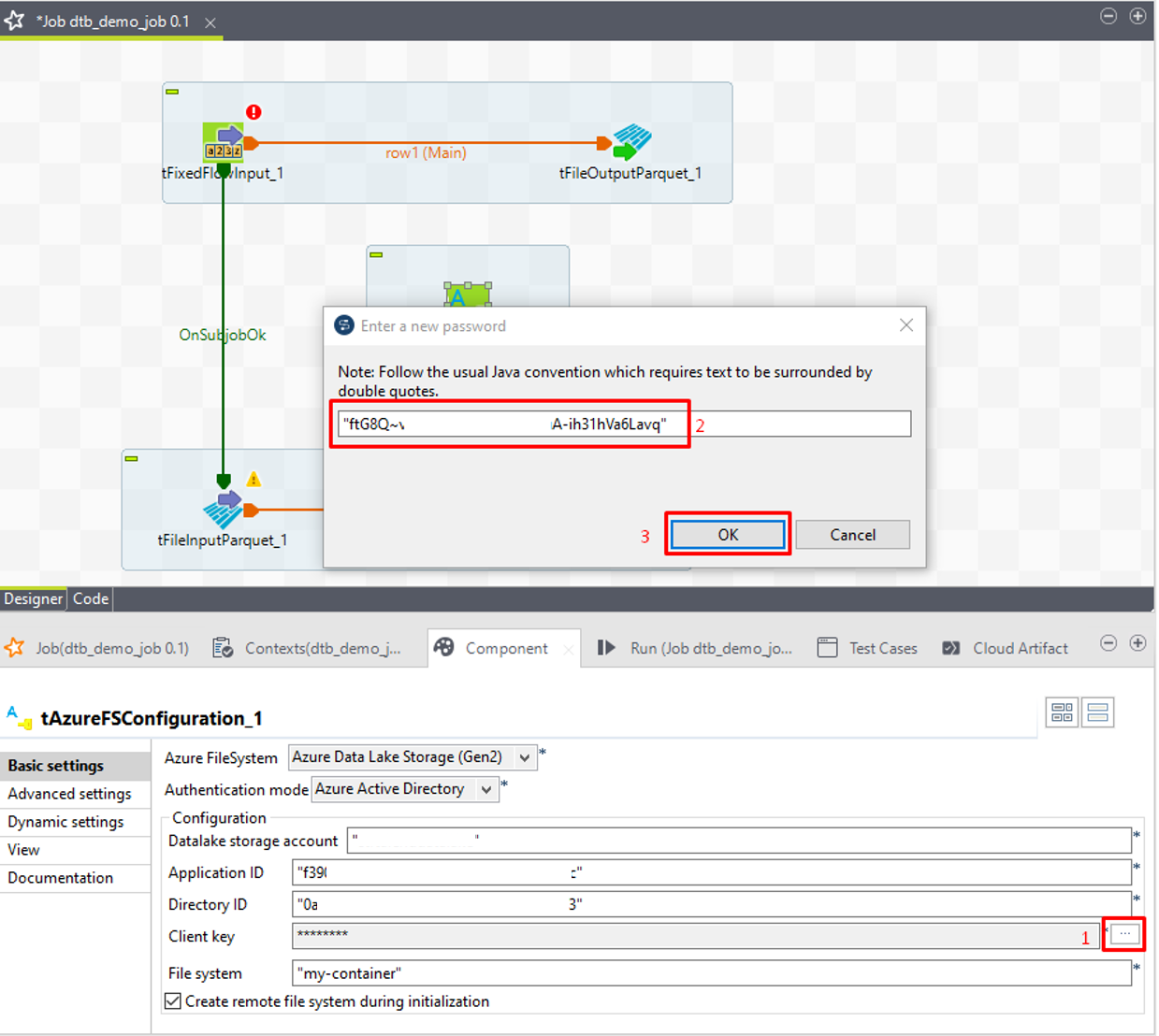
⑥「Client key」項目の3 つの点のアイコンをクリックすると、ダイアログが表示されます。保存したシークレットキーを入力します。
⑦「OK」ボタンをクリックします。
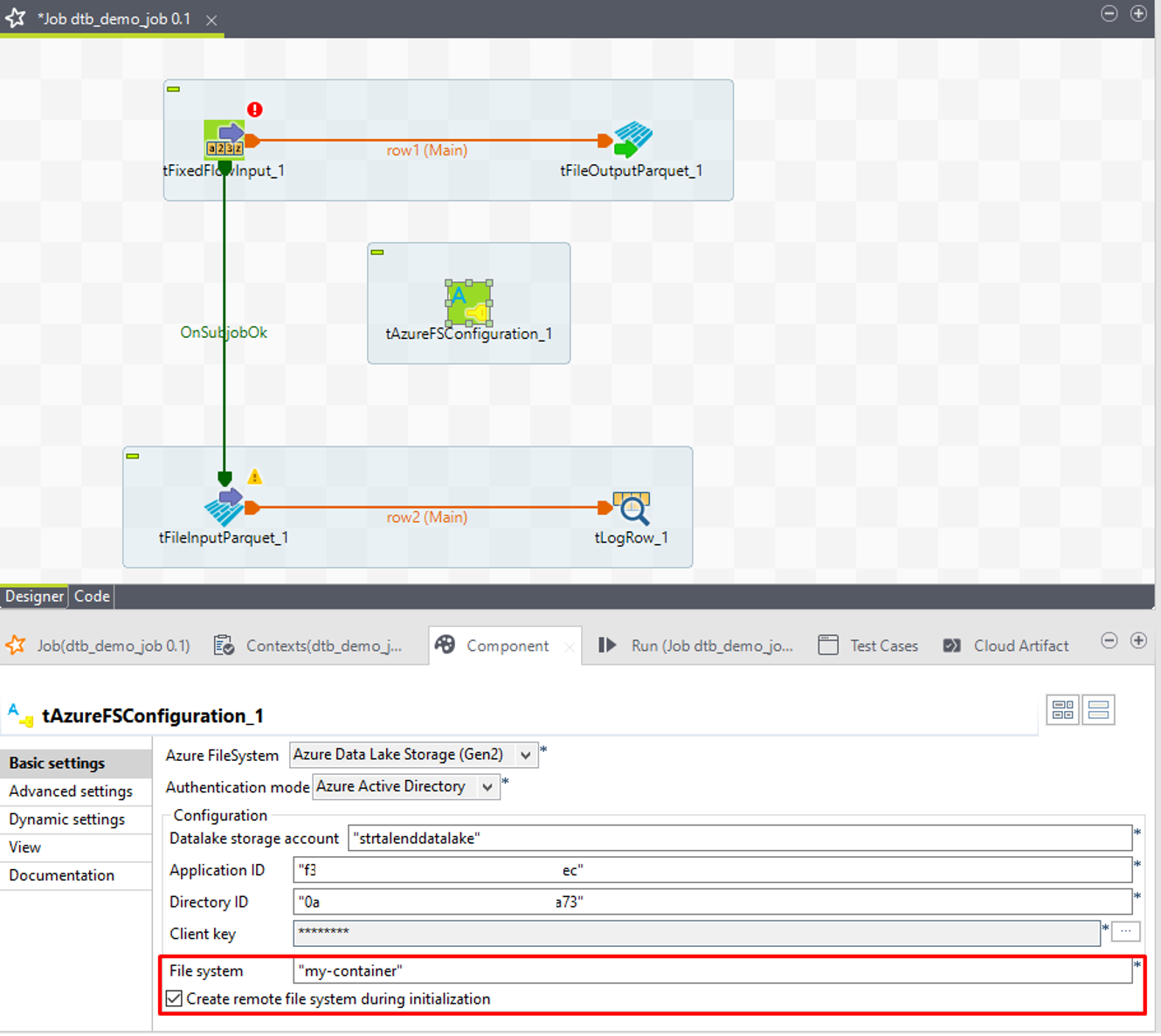
⑧「File system」項目でADLSのコンテナー名を入力します。コンテナーが存在しない場合、「Create remote file system during initialization」オプションをチェックします。
例: “my-container”
6-3.Azure Databricksへの接続を設定する
Azure Databricksへアクセスできるように、以下のパラメーターが必要です。
・エンドポイント
・クラスターID
・トークン
クラスターIDは、前の手順で取得できました。
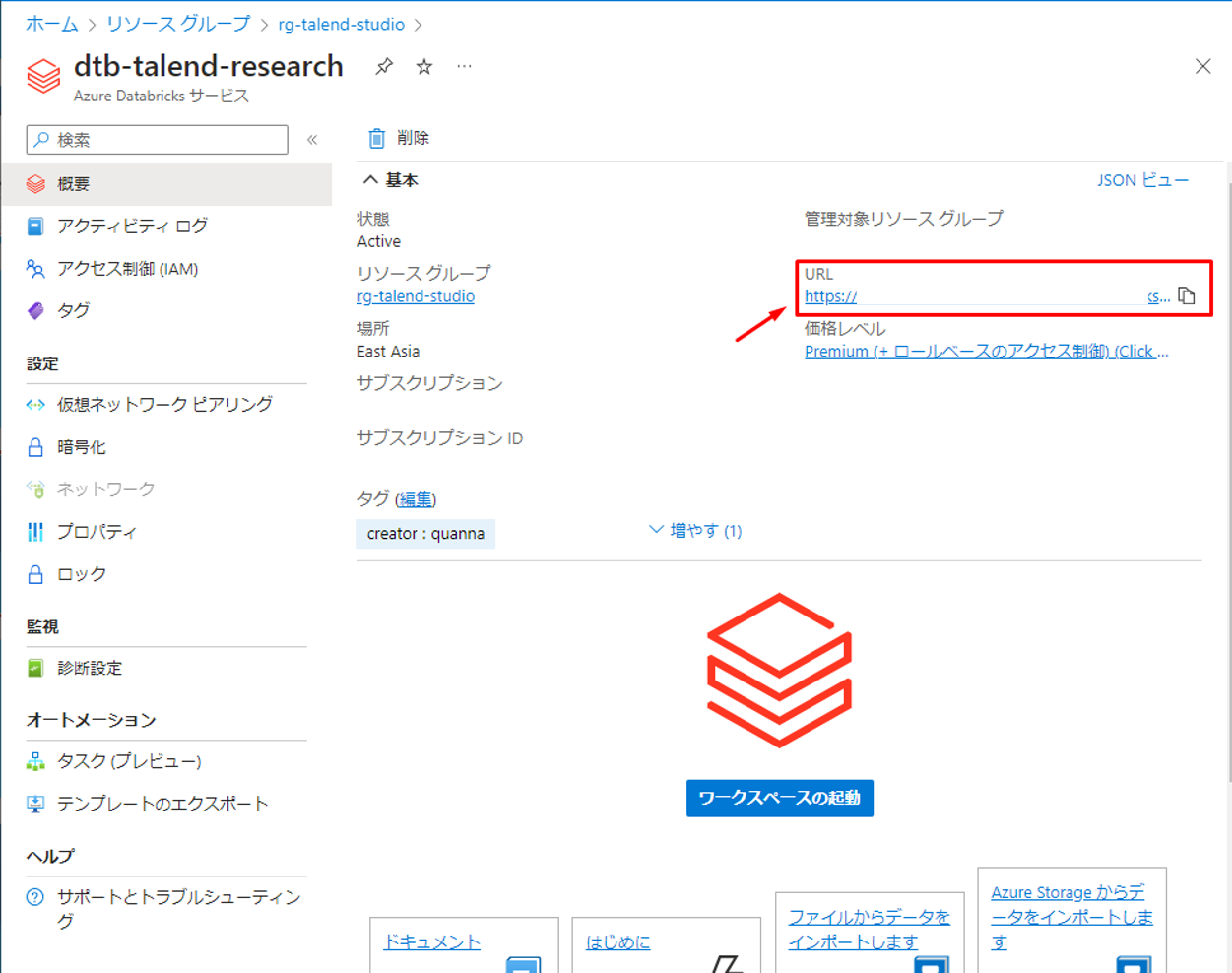
エンドポイントは、 Azure Databricks ポータルで表示されたURLです。
① URLの値をコピーして、次の手順で使用します。
次の手順で実施して、トークンを取得します。
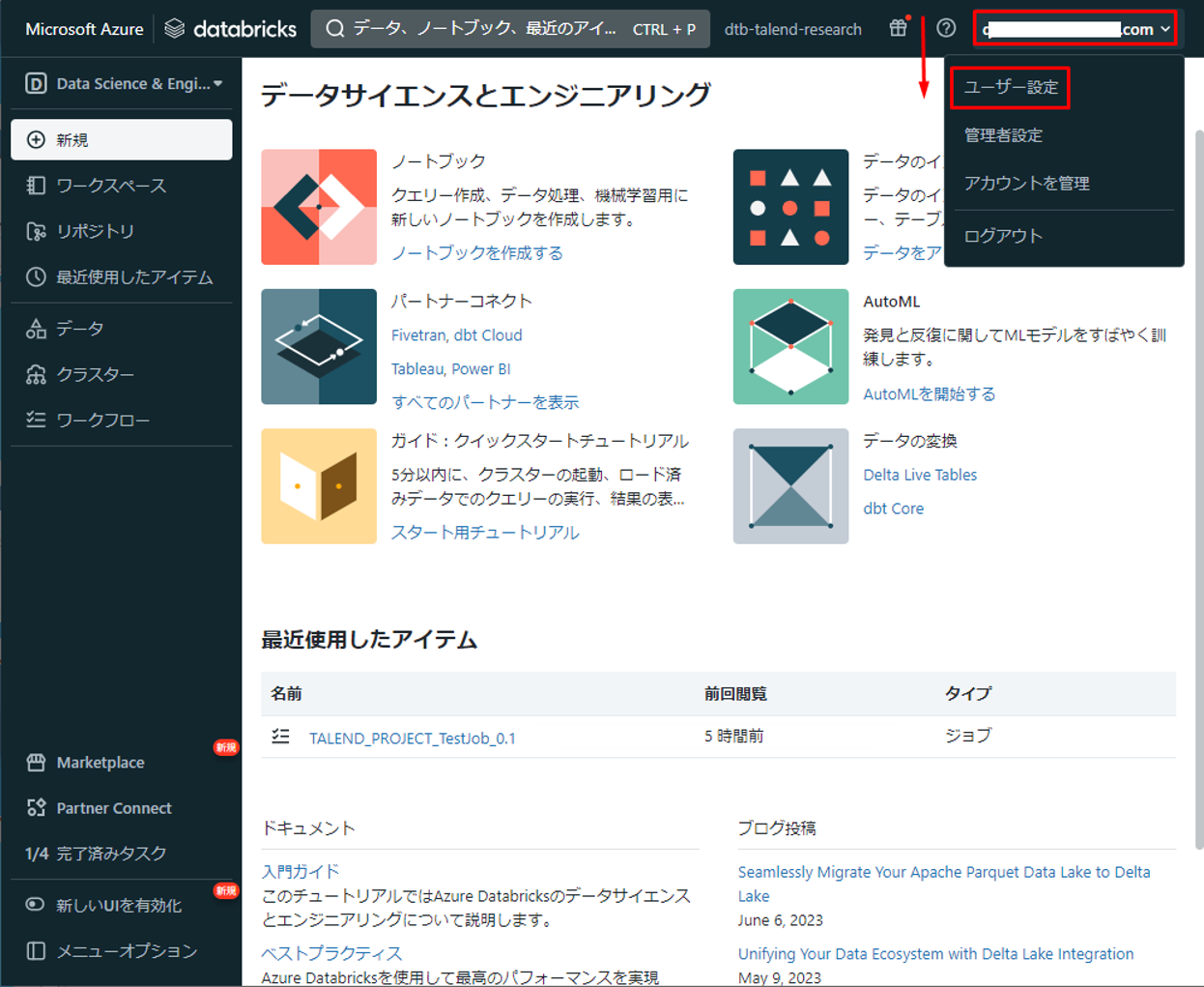
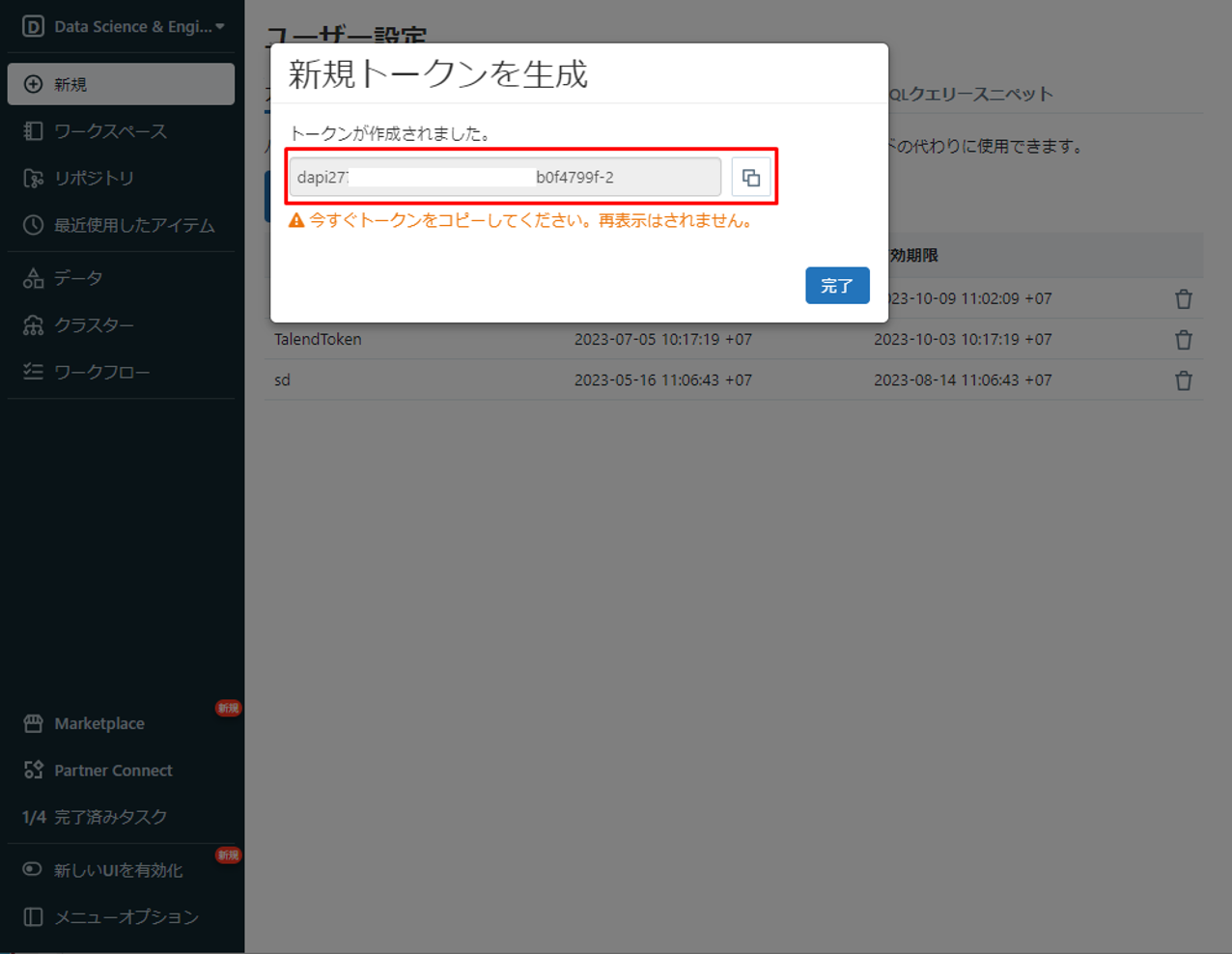
② Databricksのメイン画面でユーザーアカウントをクリックして、「ユーザー設定」を選択します。
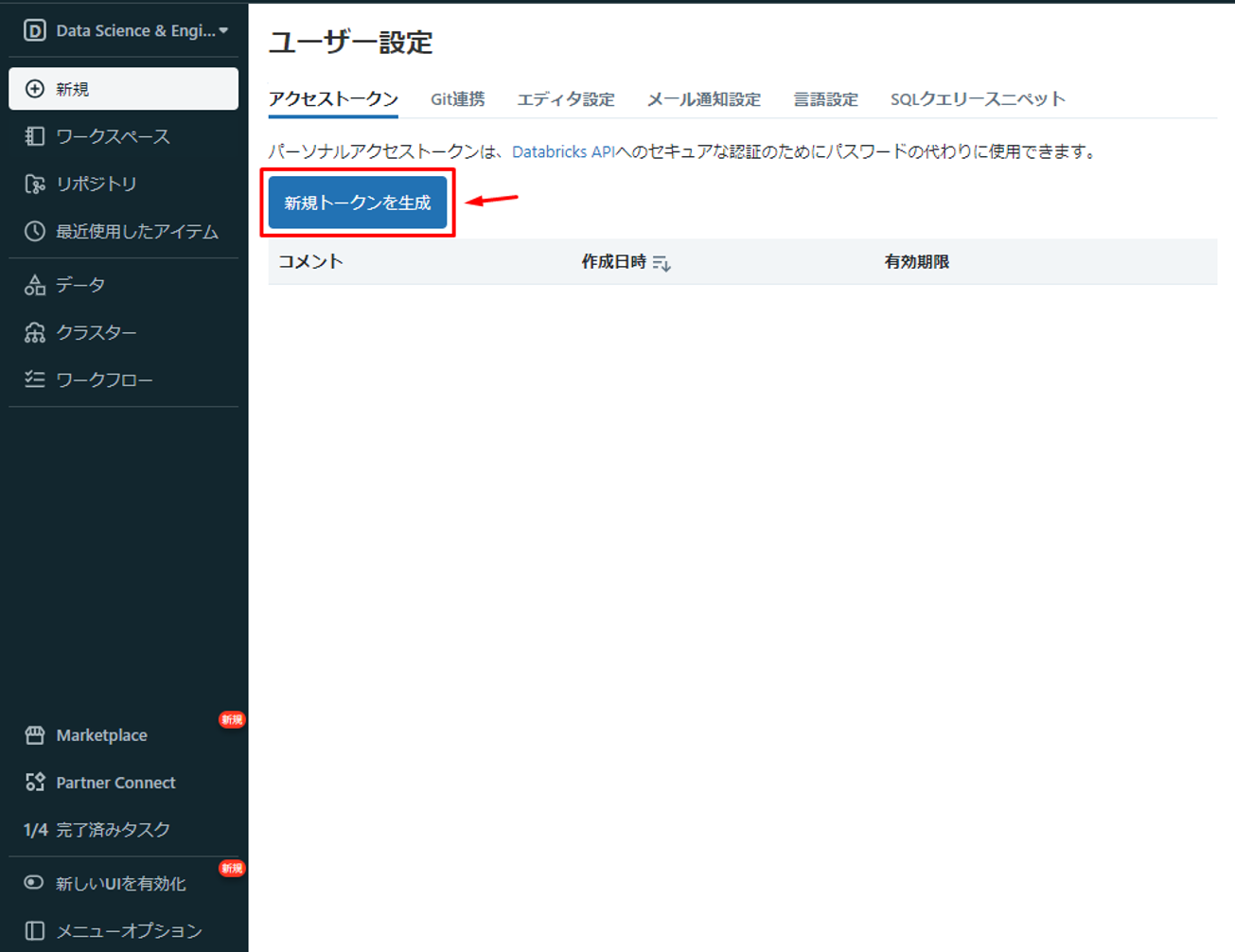
③「新規トークンを生成」をクリックします。
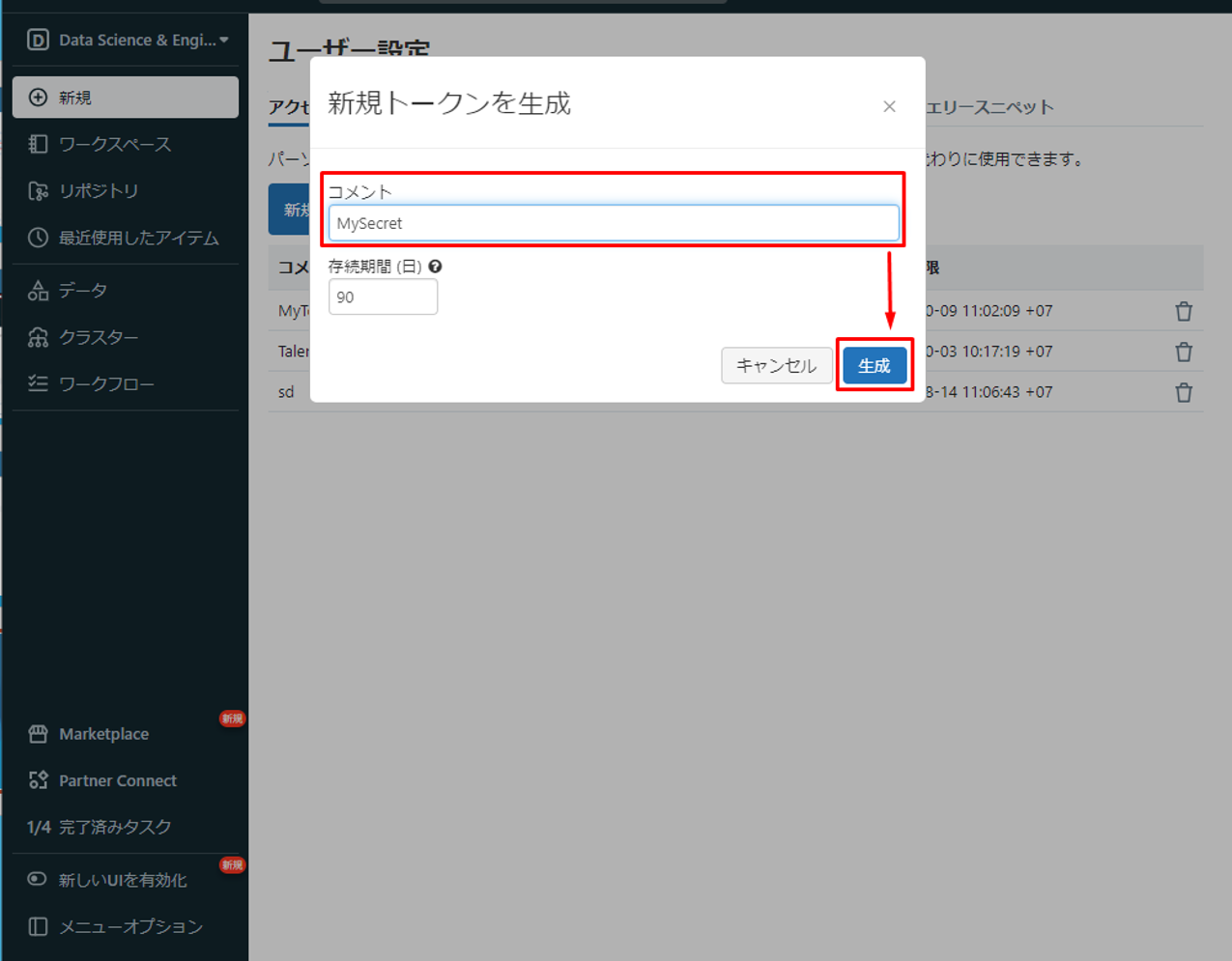
④「コメント」項目で情報を入力して、「生成」をクリックします。
⑤ トークンを保存して、次の手順で使用します。
エンドポイント、クラスターID及び、トークンを取得できました。
次に、Spark Jobsへの接続を設定します。
⑥ Designer画面の「Run」タブで「Spark Configuration」を選択します。
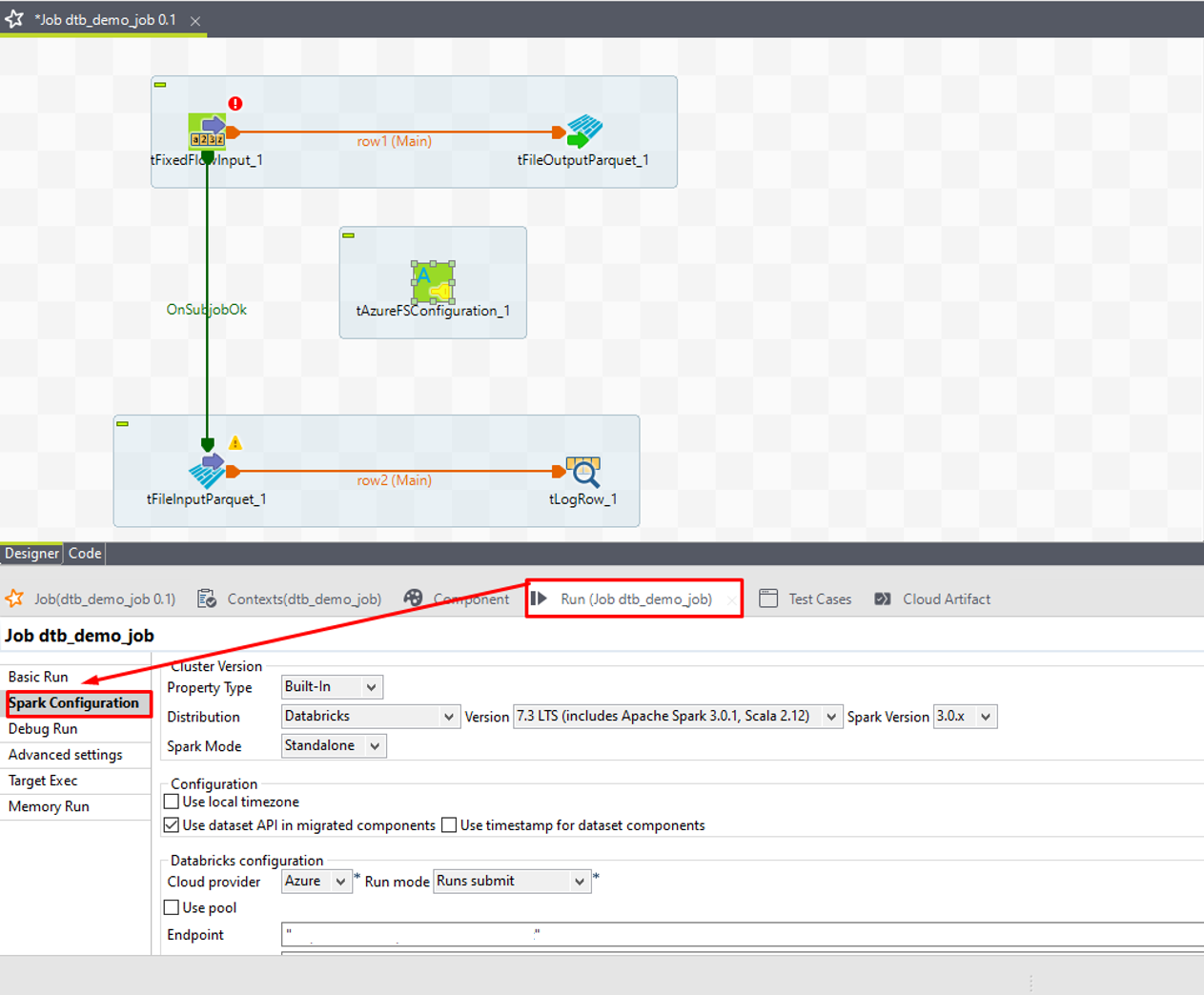
⑦「Cloud provider」項目で「Azure」を選択して、「Run mode」項目で「Create and run now」を選択します。
Run modeは、2つのオプションがあります。
・Create and run now:ジョブはAzure Databricksワークフローで作成されて、直ぐに実行されます。
・Runs submit:Databricksでジョブを作成することなく、1回限りの実行を送信できます。
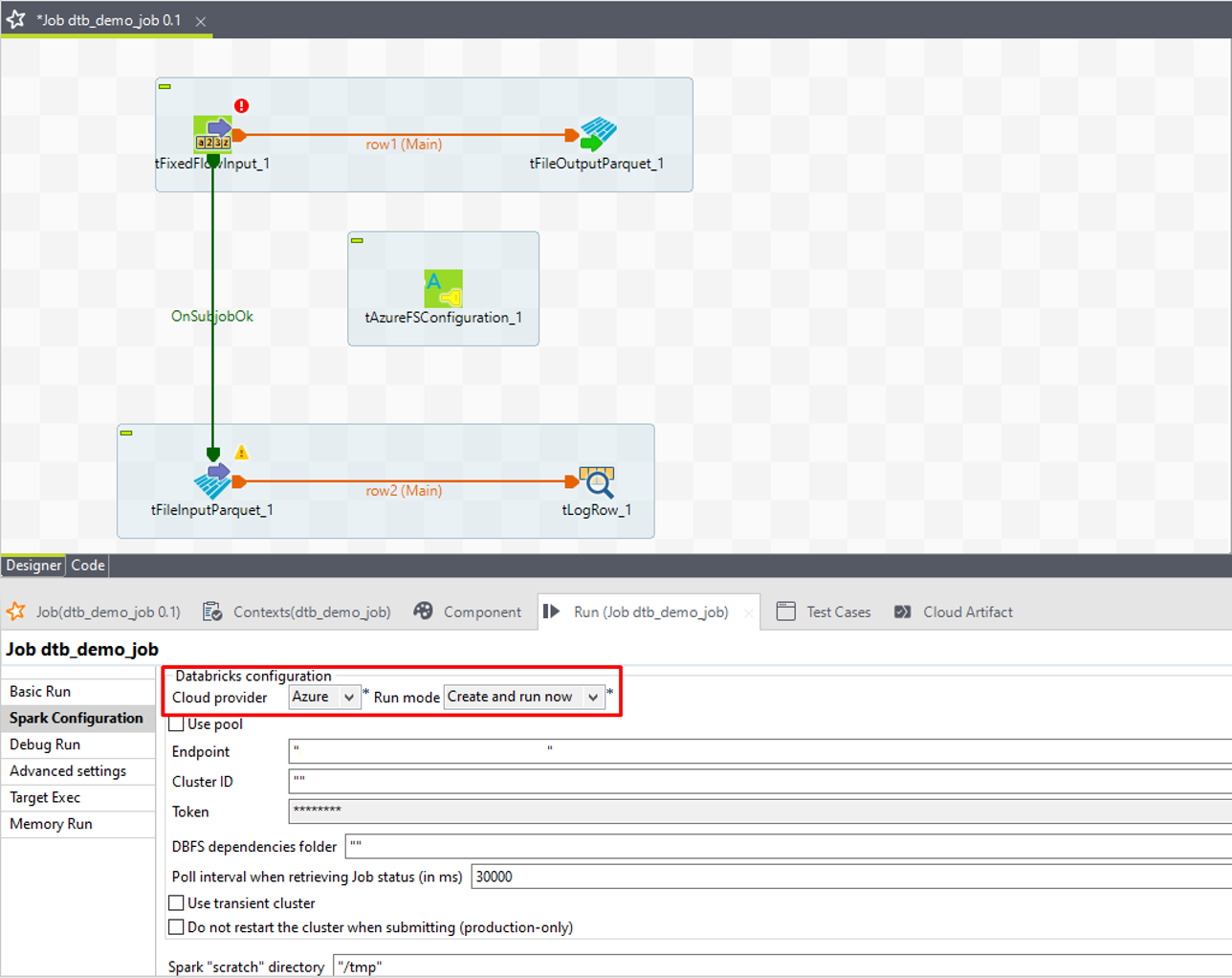
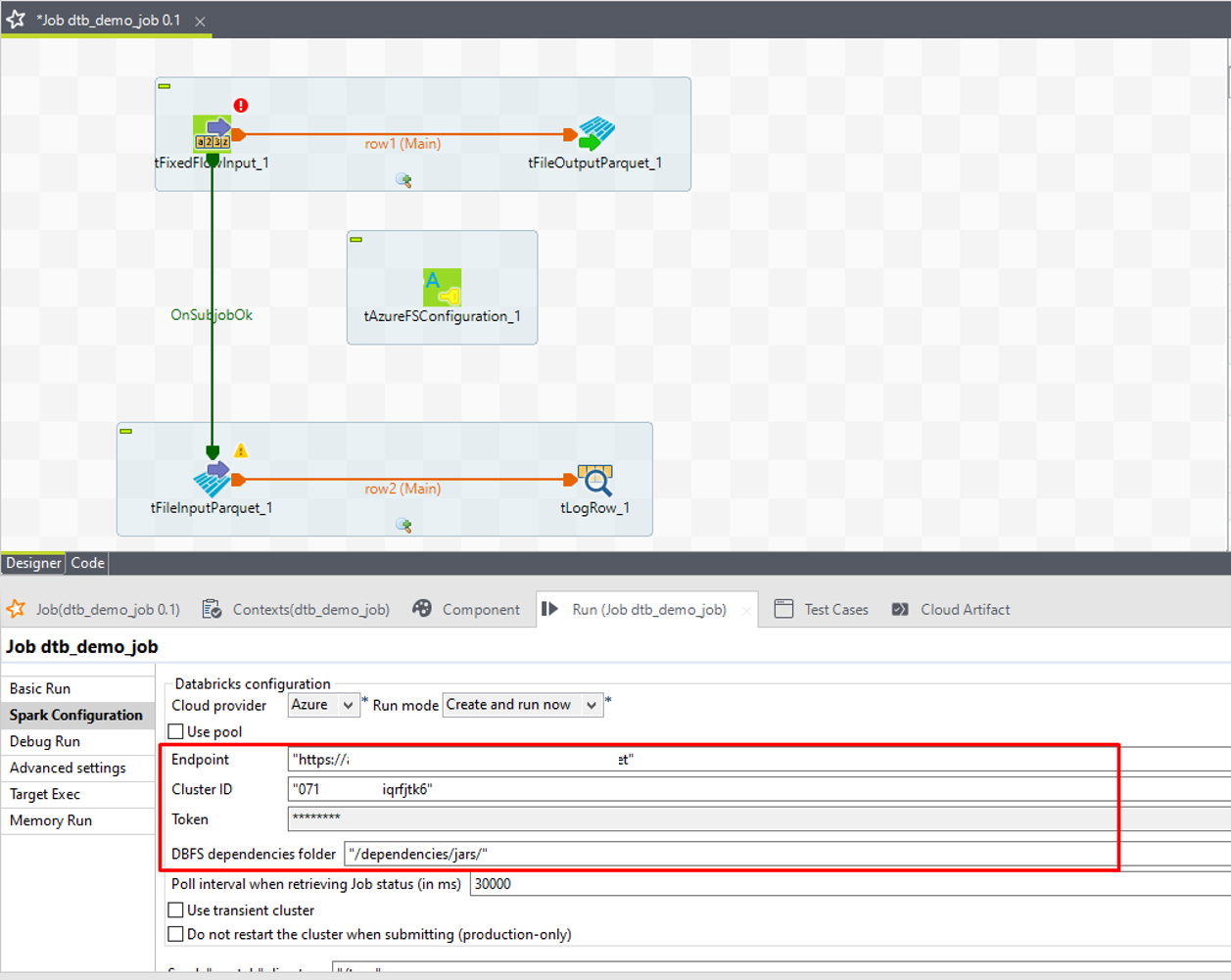
⑧「Endpoint」項目で取得したエンドポイントを入力します。
⑨「Cluster ID」項目で取得したクラスターIDを入力します。
⑩「Token」項目で取得したトークンを入力します。
⑪「DBFS dependencies folder」(DBFS依存項目フォルダー)項目に、Databricksファイルシステムでのジョブ依存項目の保存にランタイムで使用するディレクトリーを入力します。
Azure Databricksへの接続を設定完了しました。
6-4.サンプルデータをADLSに書き込む
① tFixedFlowInput をダブルクリックして、「Component」タブを開きます。「Basic settings」で「Edit Schema」の 3 つの点をクリックします。
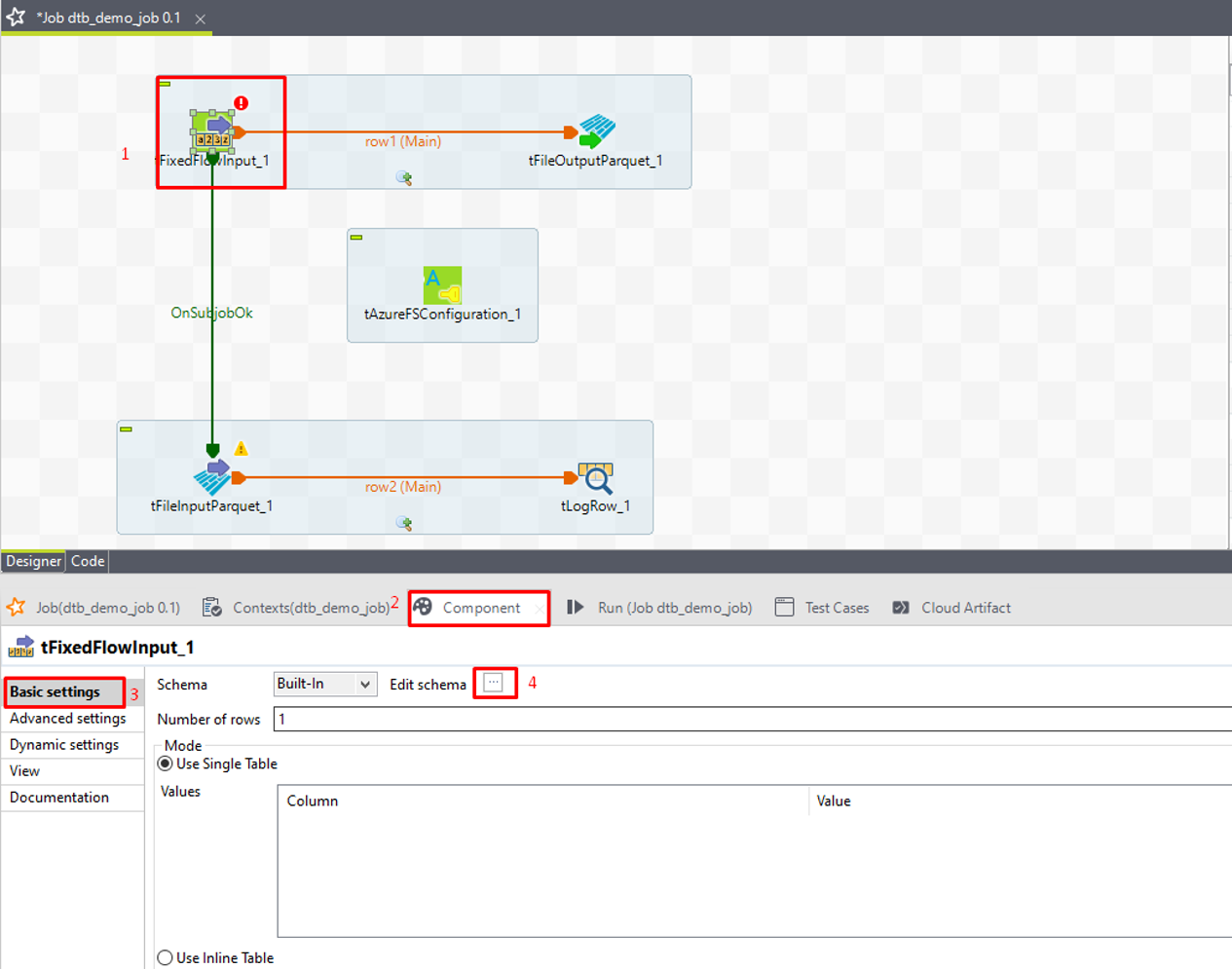
② プラスアイコンをクリックして、スキーマカラムを追加します。
③ 次の画像のように ID 及び名前を追加します。
④「OK」をクリックします。
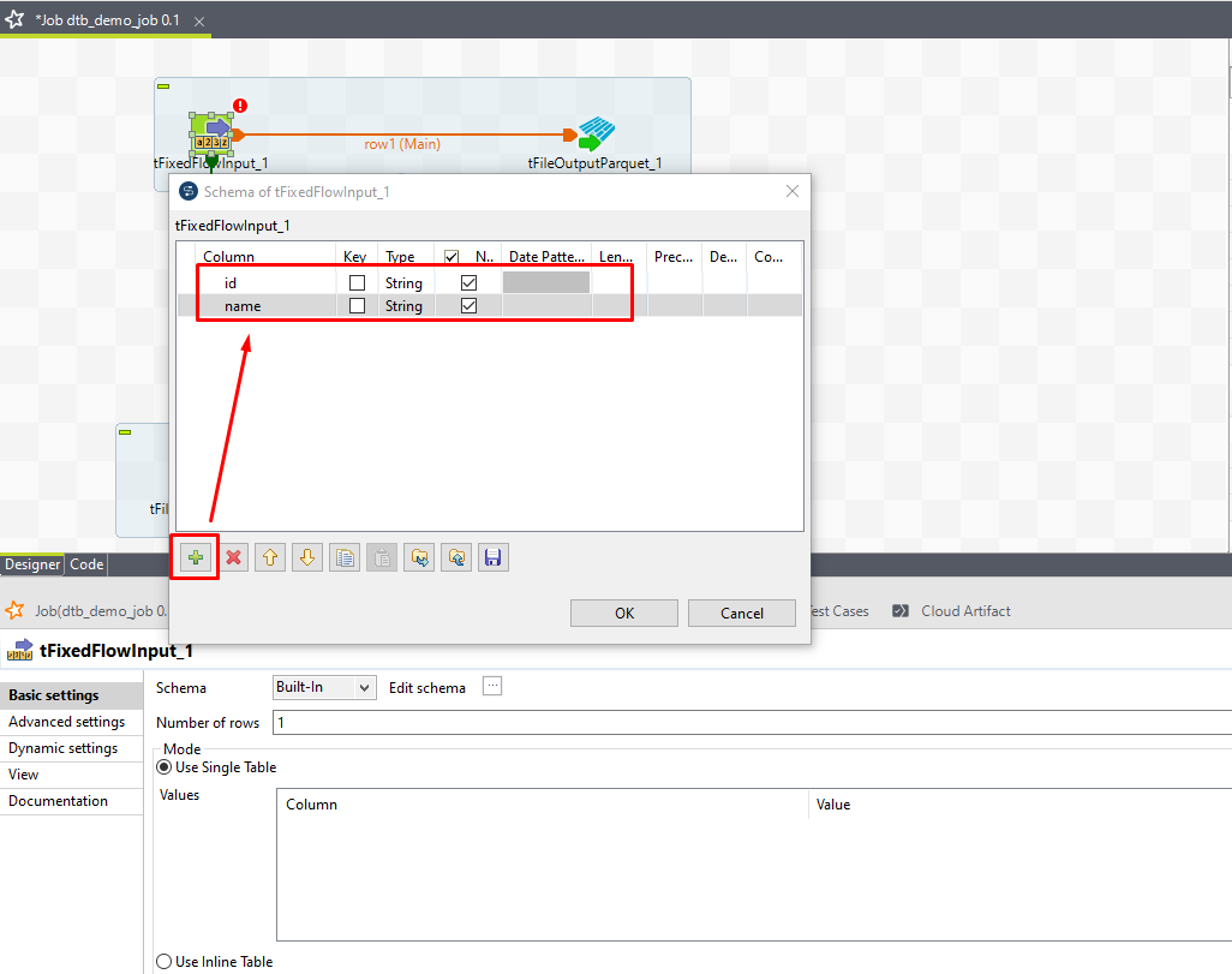
⑤ 確認ダイアログで「Yes」をクリックします。
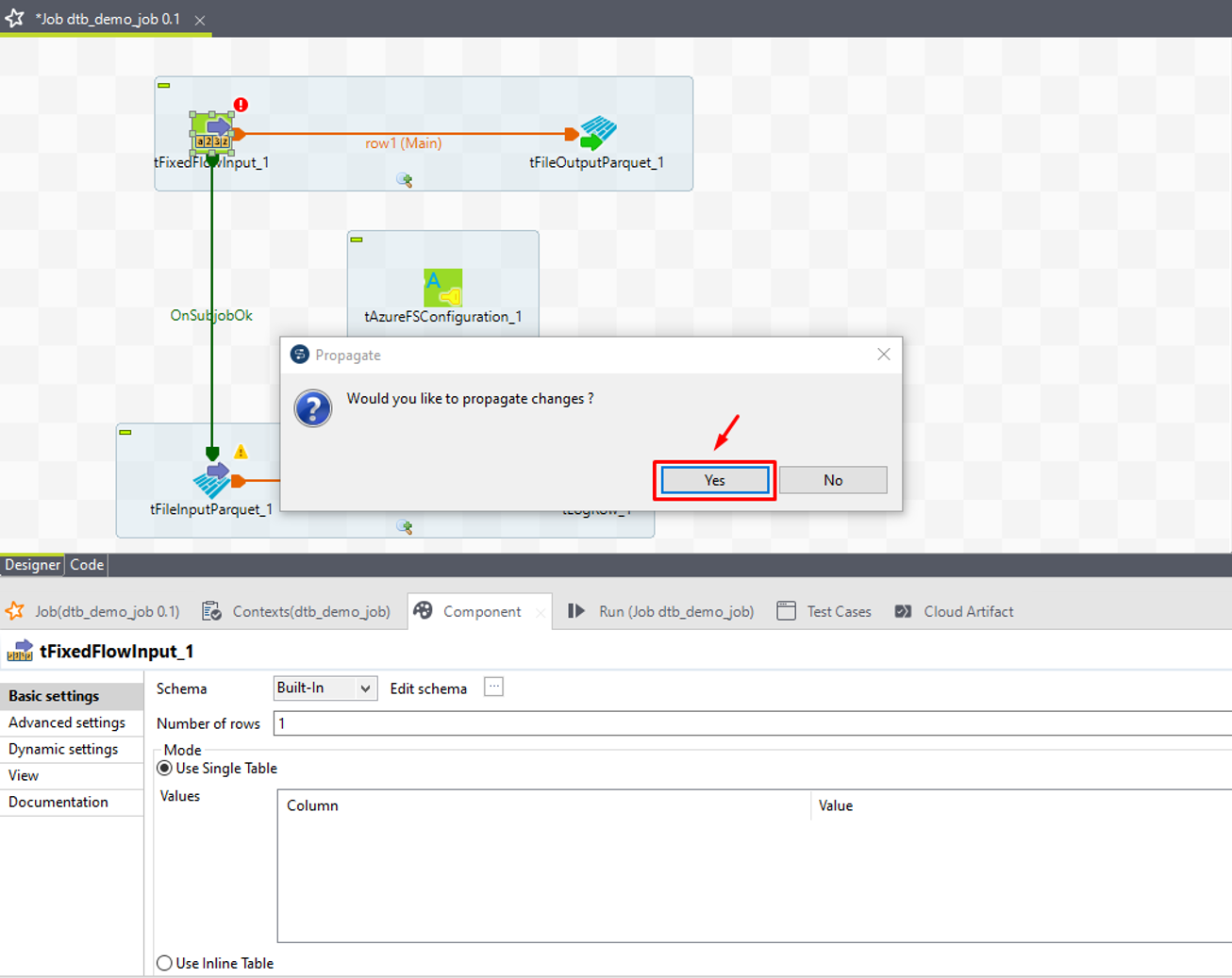
⑥ 次に、「Mode」で「Use Inline Content(delimited file)」を選択します。
⑦ Contentのフィールドにデモデータを入力します。
|
1 2 3 4 5 6 7 |
1;NAQ 2;TTH 3;CQP 4;NTD |
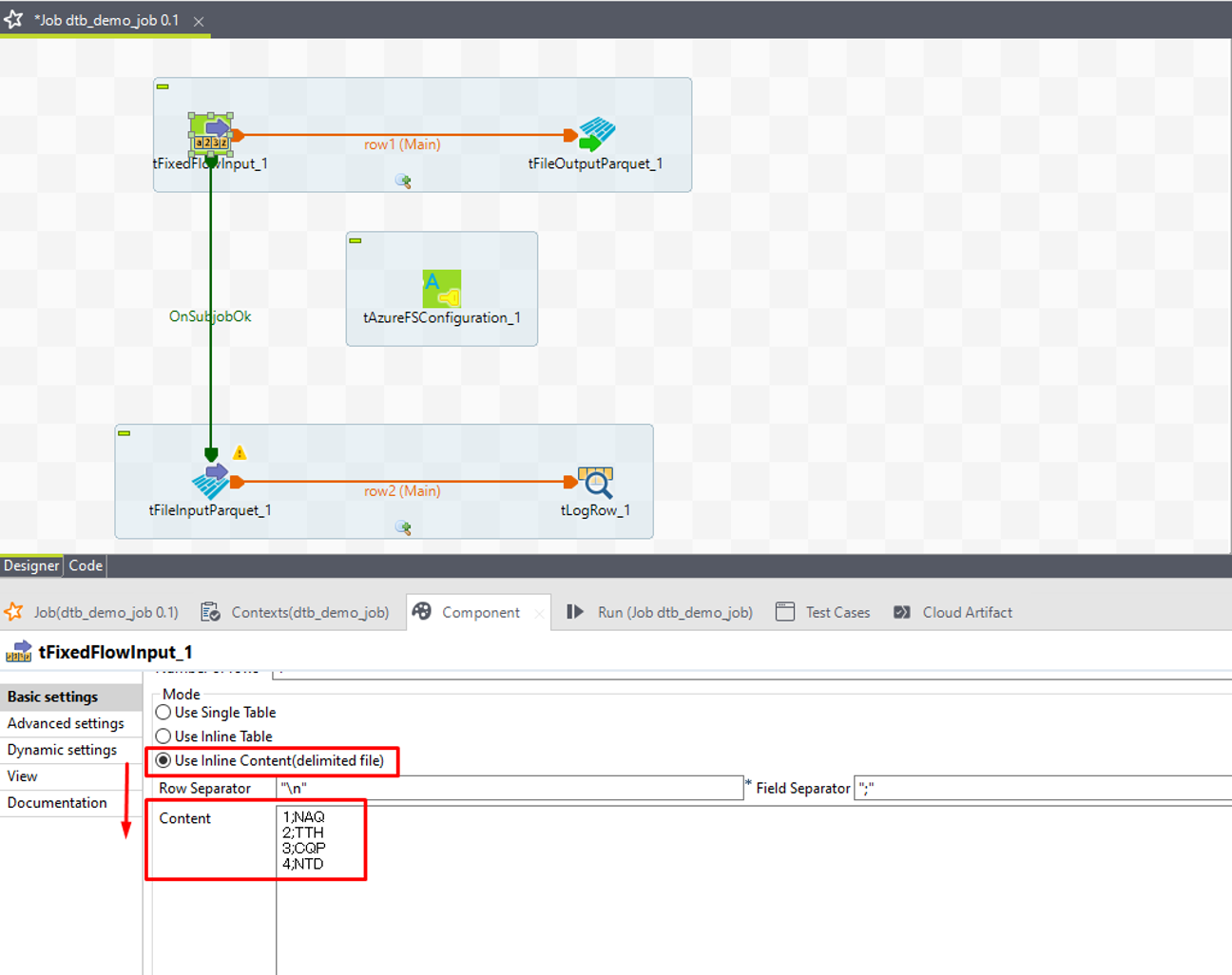
⑧ tFileInputParquetをダブルクリックして[Component] (コンポーネント)ビューを開きます。
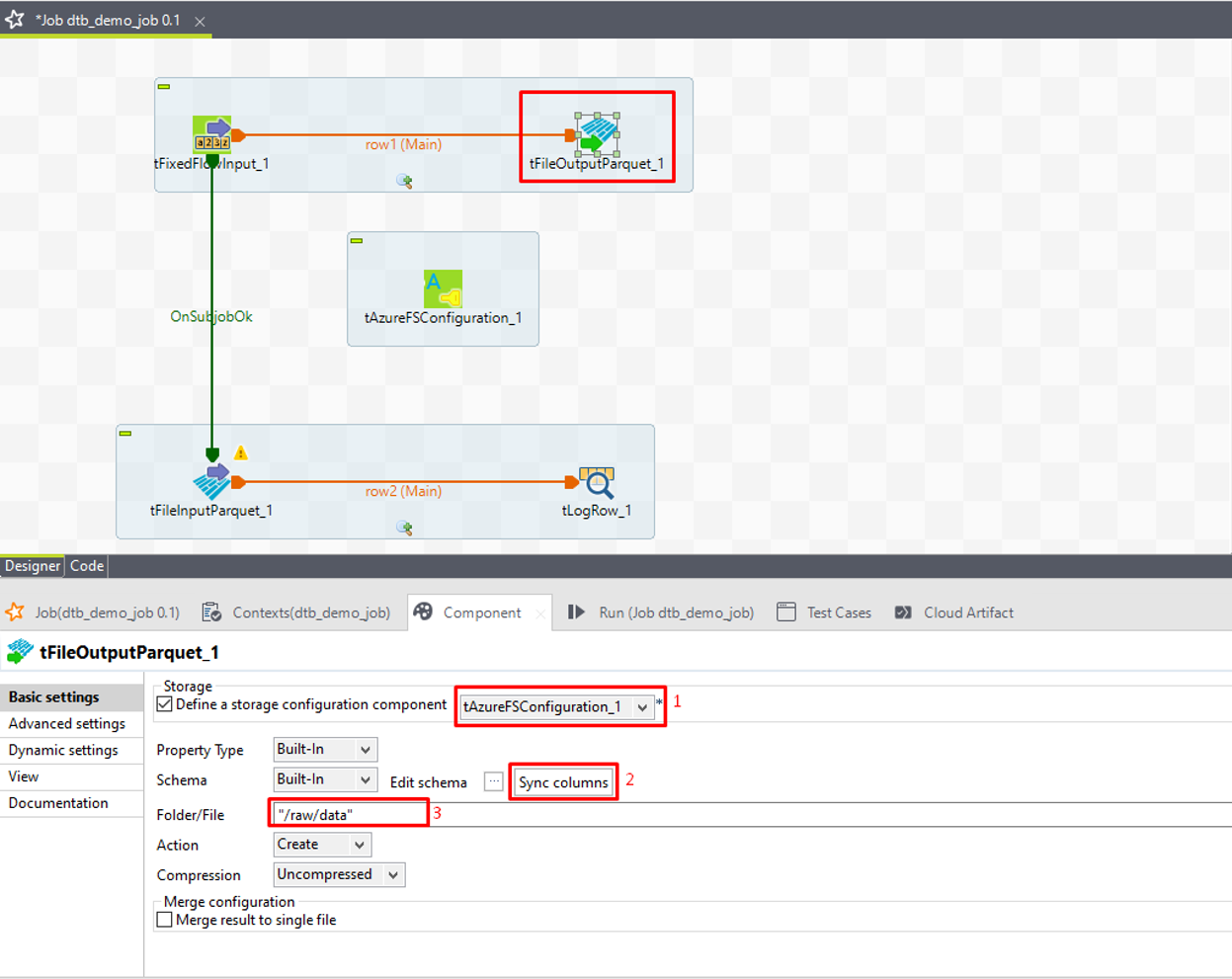
⑨「Define a storage configuration component」チェックボックスをオンにして、前の手順で設定したtAzureFSConfigurationコンポーネントを選択します。
⑩ tFileOutputParquetがtFixedFlowInputと同じスキーマを持つように、「Sync columns」をクリックします。
⑪「Folder/File」項目で、サンプルデータに保管するために使うADLSのフォルダー名を入力します。
例えば:“/raw/data”
⑫「Action」項目で、フォルダーがまだ存在しない場合は「Create」を、フォルダーが既に存在する場合は「Overwrite」を選択します。
6-5.サンプルデータをADLSから読み取る
① tFileInputParquetをダブルクリックして「Component」ビューを開きます。
②「Define a storage configuration component」チェックボックスをオンにして、前の手順で設定したtAzureFSConfigurationコンポーネントを選択します。
③「Basic settings」項目で「Edit Schema」の 3 つの点 のアイコンをクリックします。
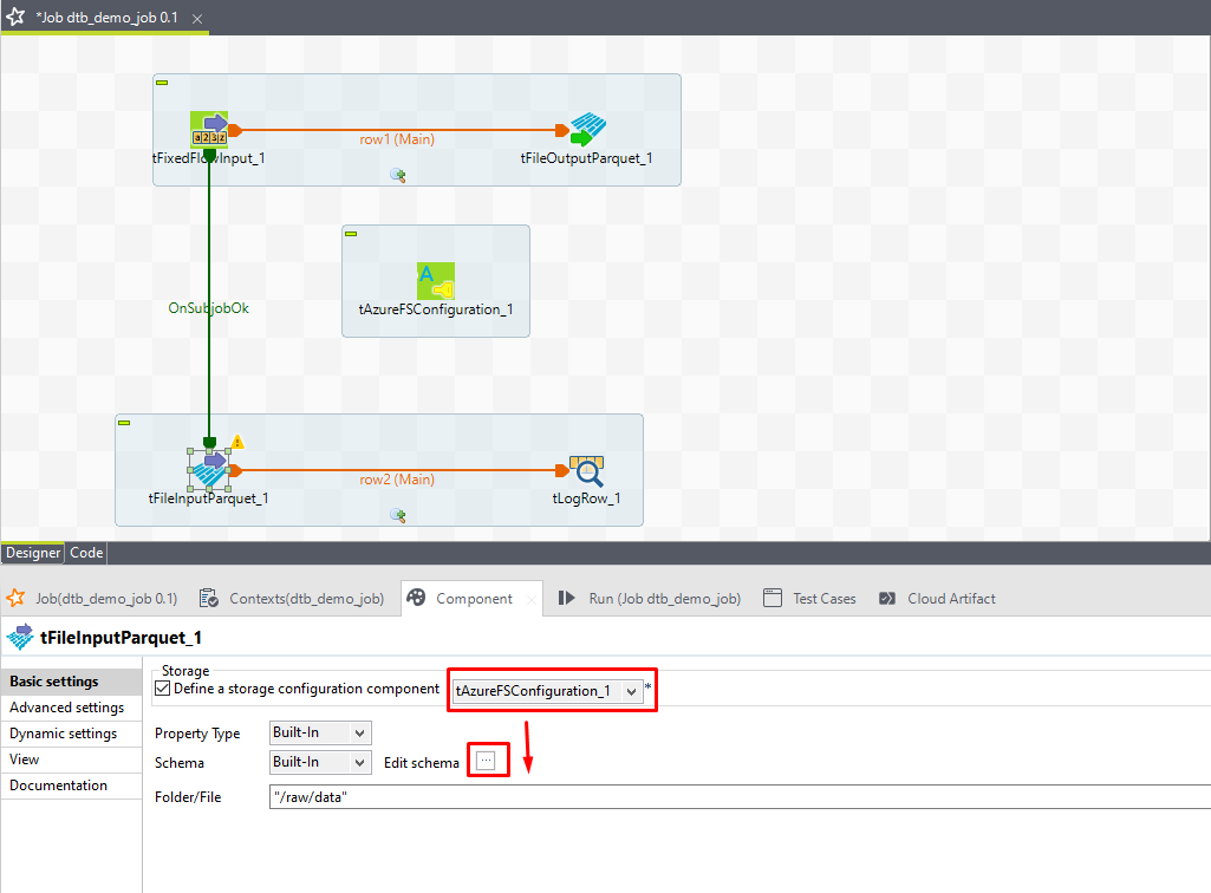
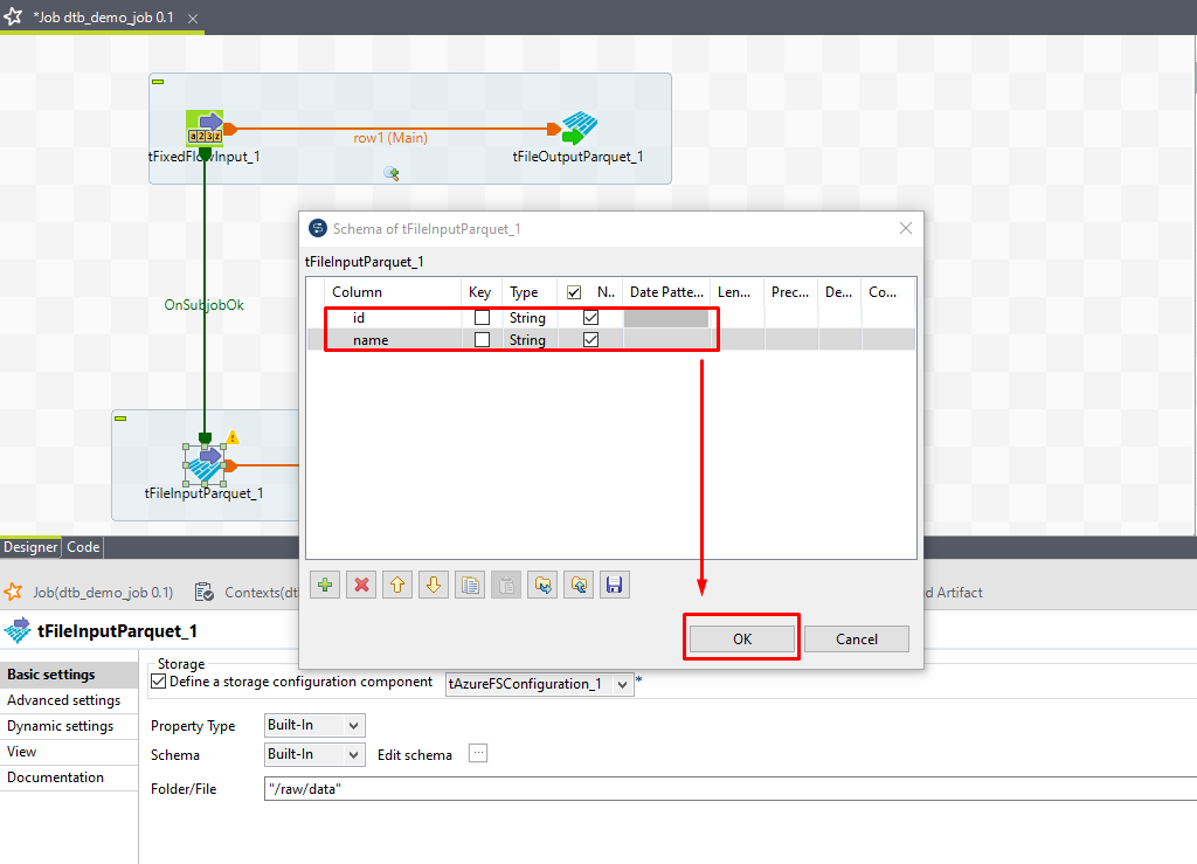
④ プラスアイコンをクリックして、スキーマカラムを追加します。
⑤ 次の画像のように ID 及び名前を追加します。
⑥「OK」をクリックします。
⑦ 確認ダイアログで「Yes」をクリックします。
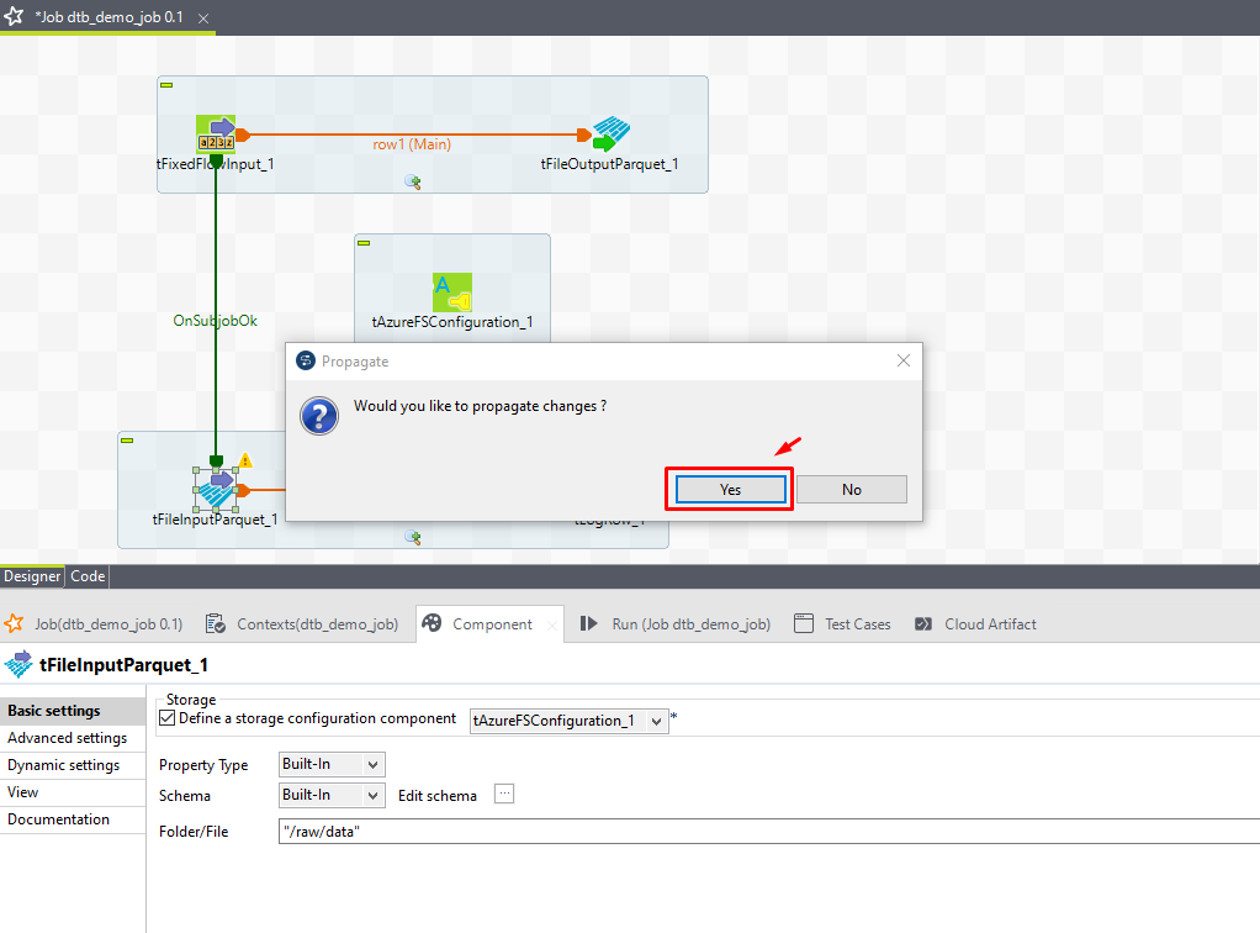
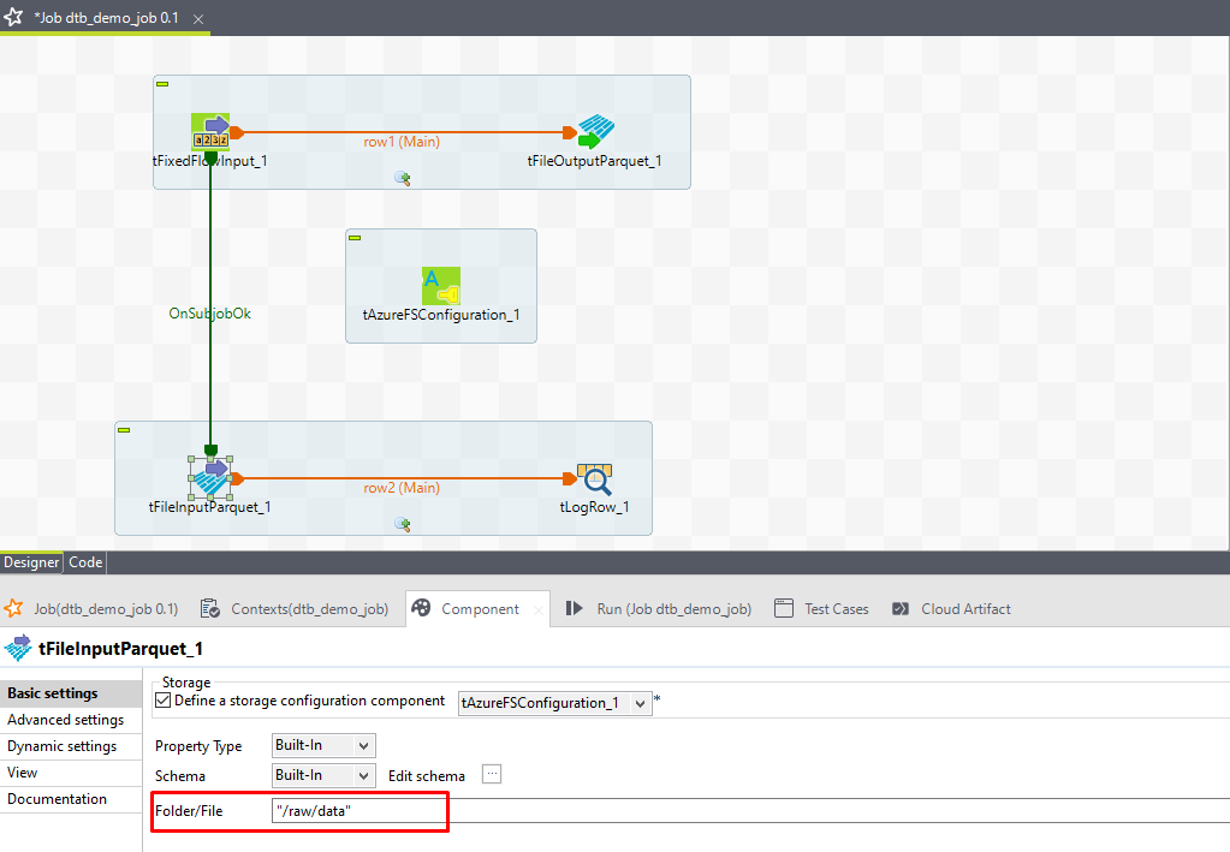
⑧「Folder/File」項目に、データを読み取るフォルダー名を入力します。本書では“/raw/data”です。
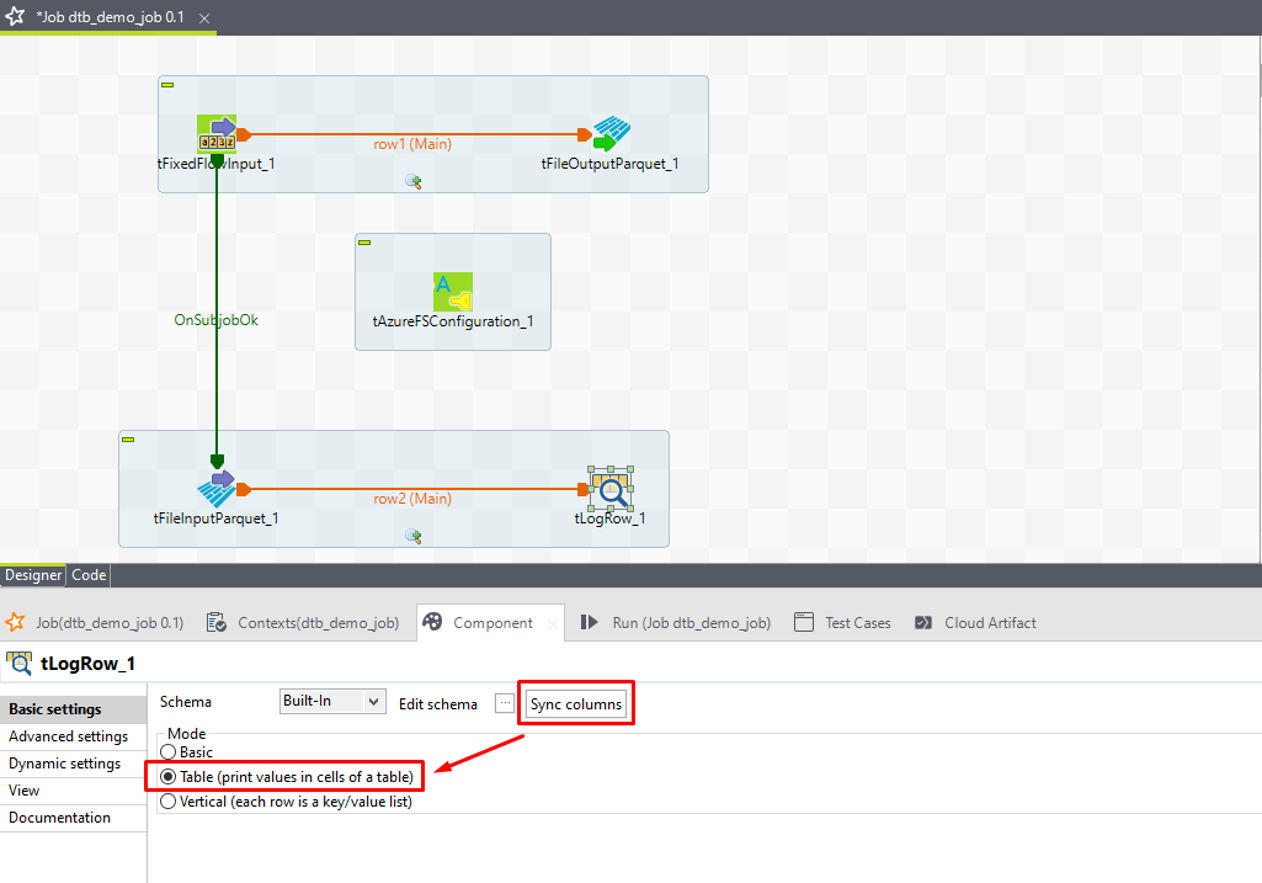
⑨ tLogRowをダブルクリックして「Component」ビューを開き、「Sync columns」をクリックします。
⑩「Mode」項目で「Table」を選択します。
6-6.ジョブを実行する
①「F6」を押してこのジョブを実行します。
完了すると、実行結果を確認します。
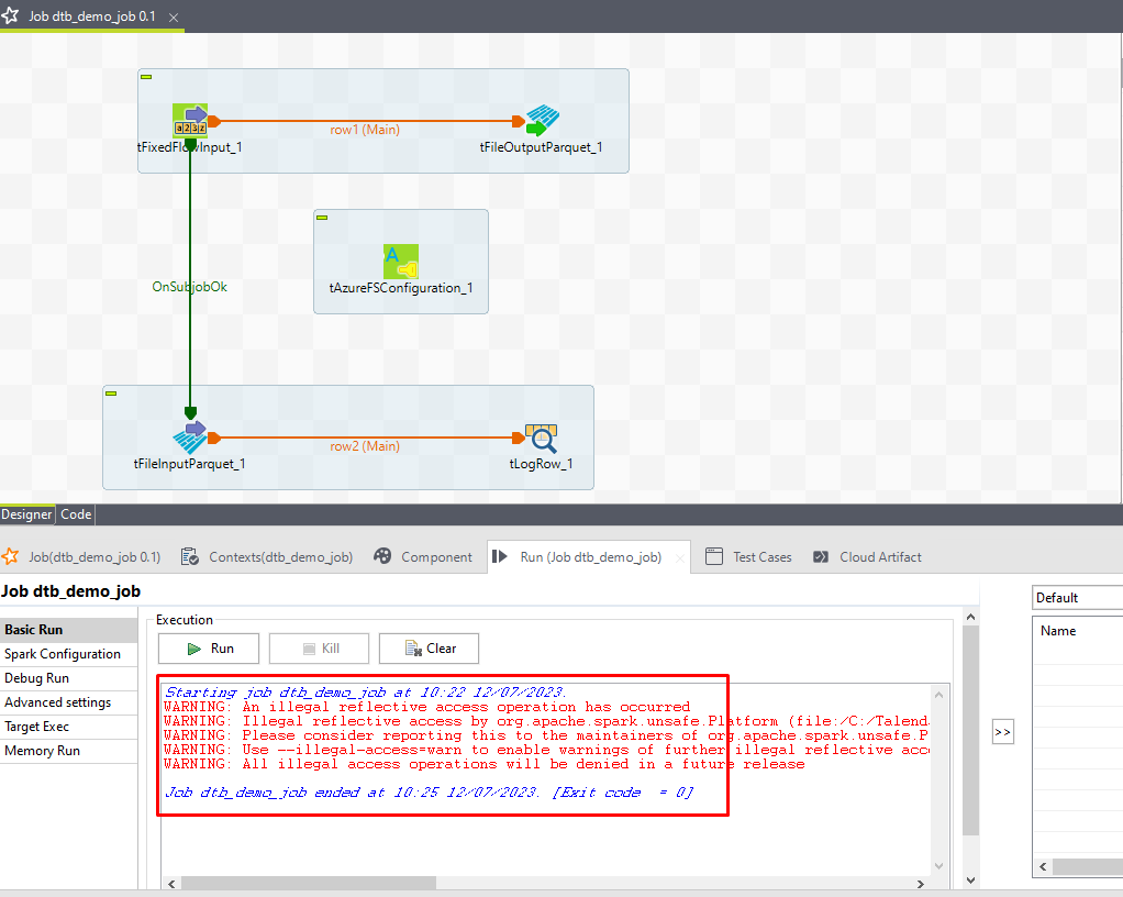
注:ジョブ実行の時に、画像のようなエラーが発生すると次の手順で修正します。
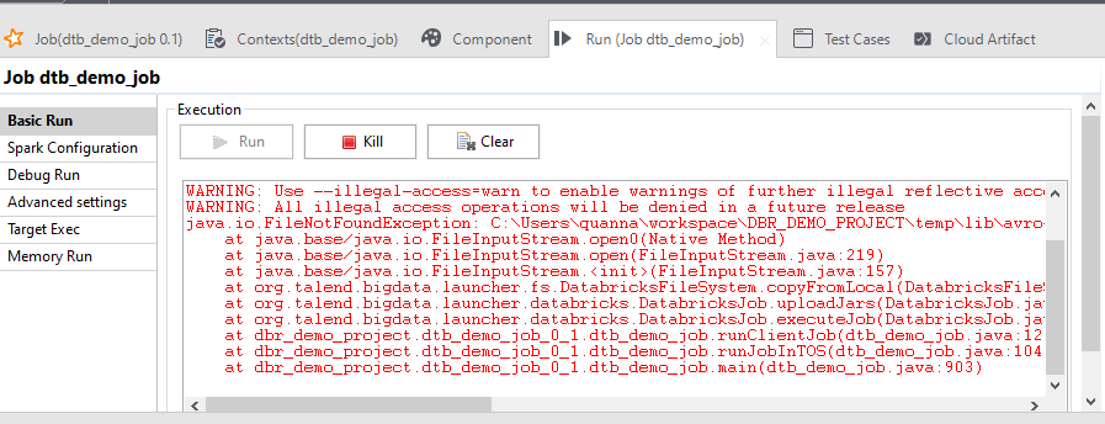
ディレクトリパスでアクセスして、「avro-mapred-1.8.2-hadoop2.jar」ファイルを検索します。
「avro-mapred-1.8.2-hadoop2.jar」ファイル名を「avro-mapred-1.8.2.jar」に変更します。
ジョブを再実行します。
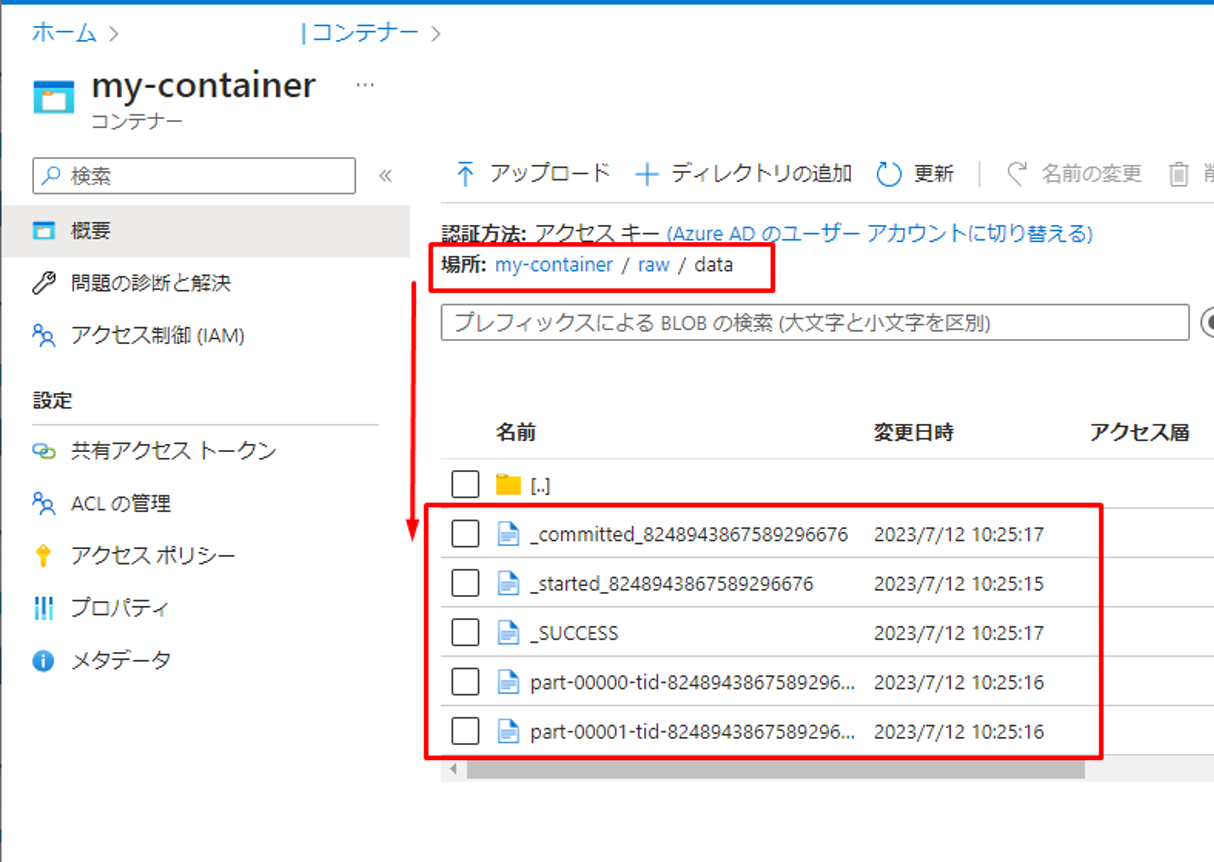
ADLSにアクセスして、「my-container/raw/data」パスでparquet形式のデータを確認できます。
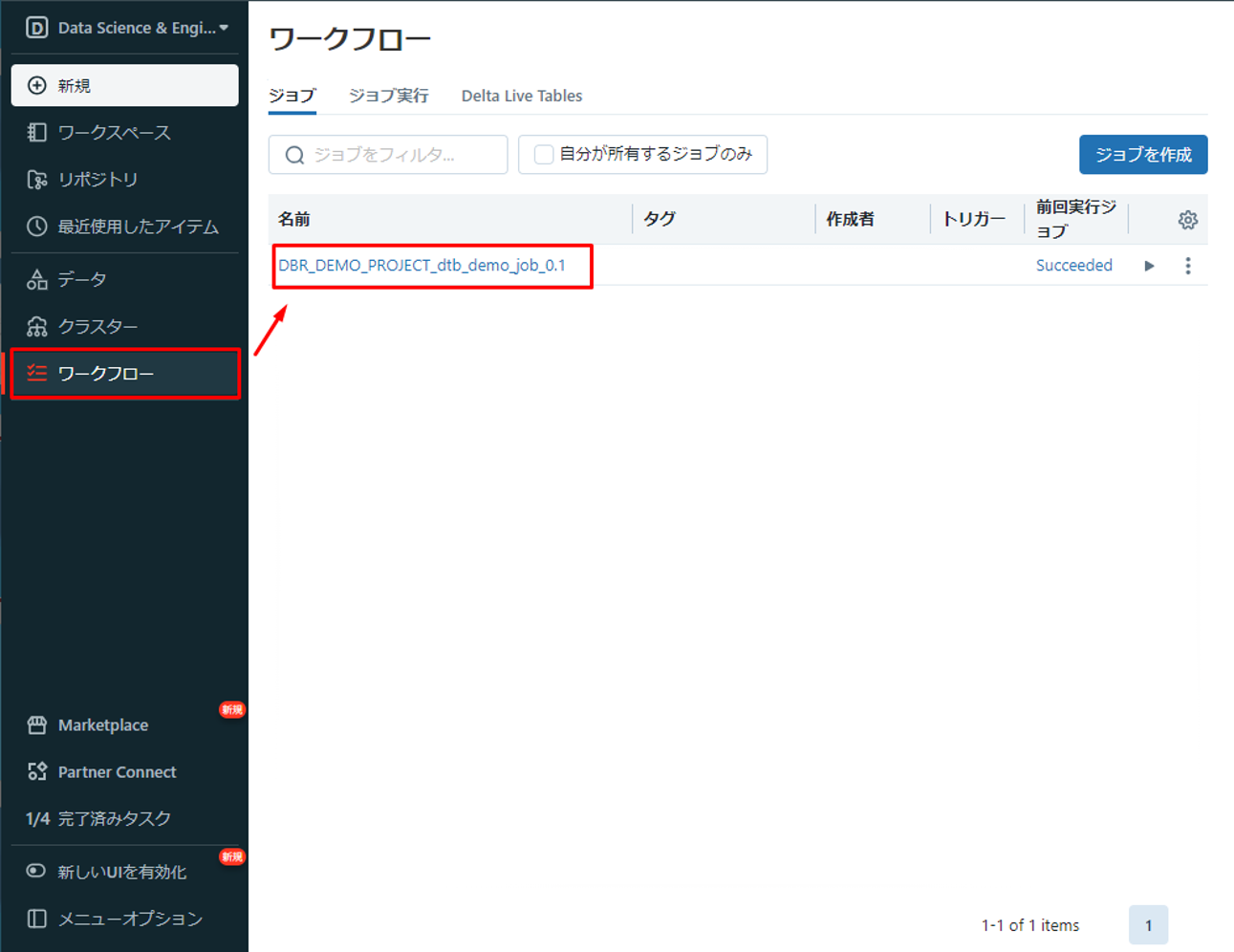
Azure Databricks ワークスペースで「ワークフロー」をクリックして、実行されたジョブを確認できます。
そのジョブをクリックして、結果を確認します。
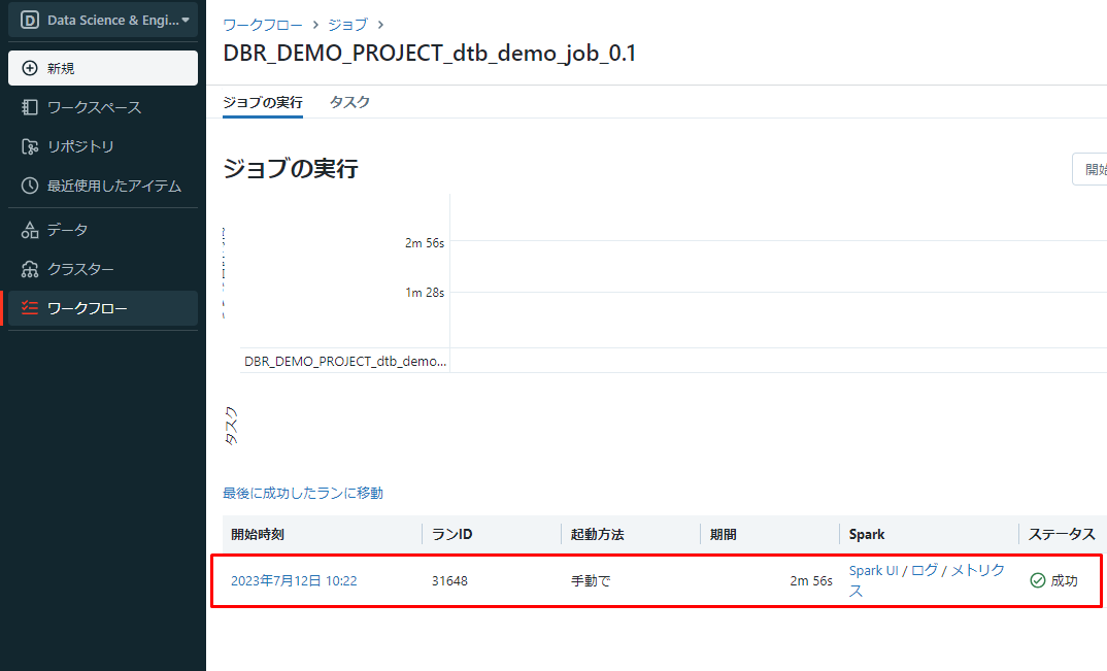
ジョブ実行の履歴が表示されます。
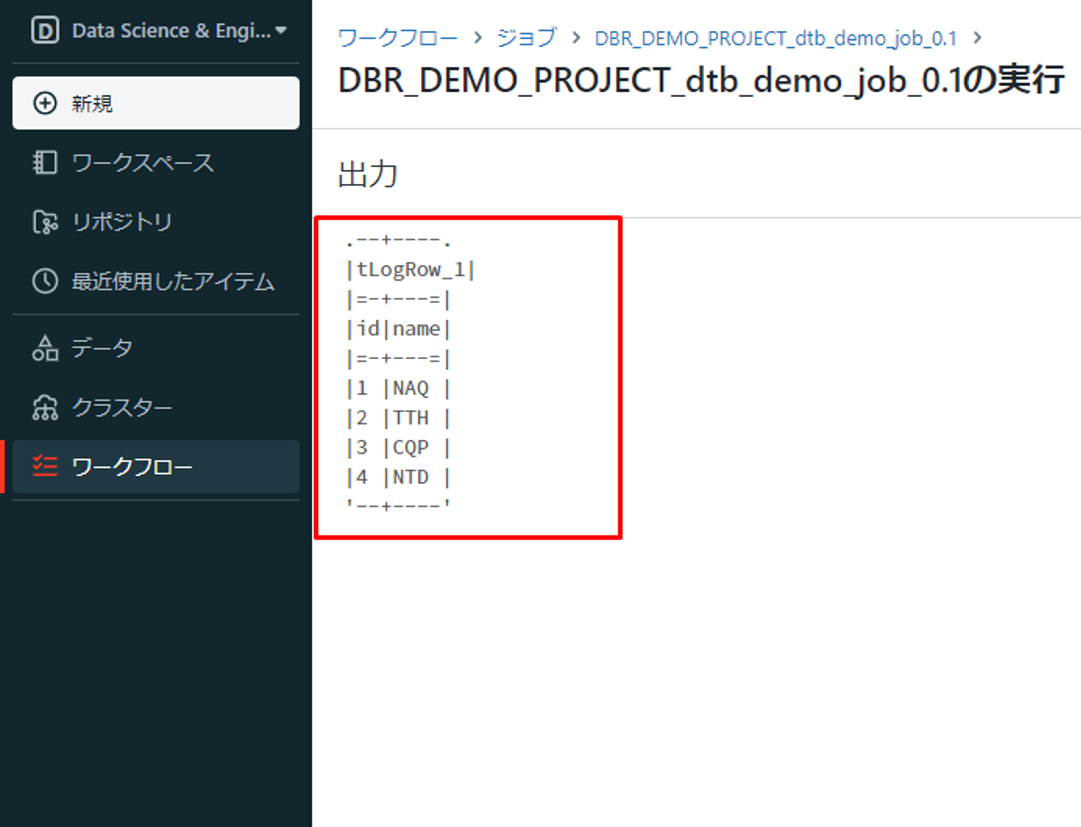
ジョブ実行の履歴をクリックすると、画像に示すように出力結果が表示されます。
Talend Big Data PlatformでDatabricks ジョブを作成できました。
7.ジョブクラスタでジョブを実行する
汎用クラスタを利用して、ジョブを実行しました。
次に、ジョブクラスタを利用してジョブの実行方法について説明していきます。
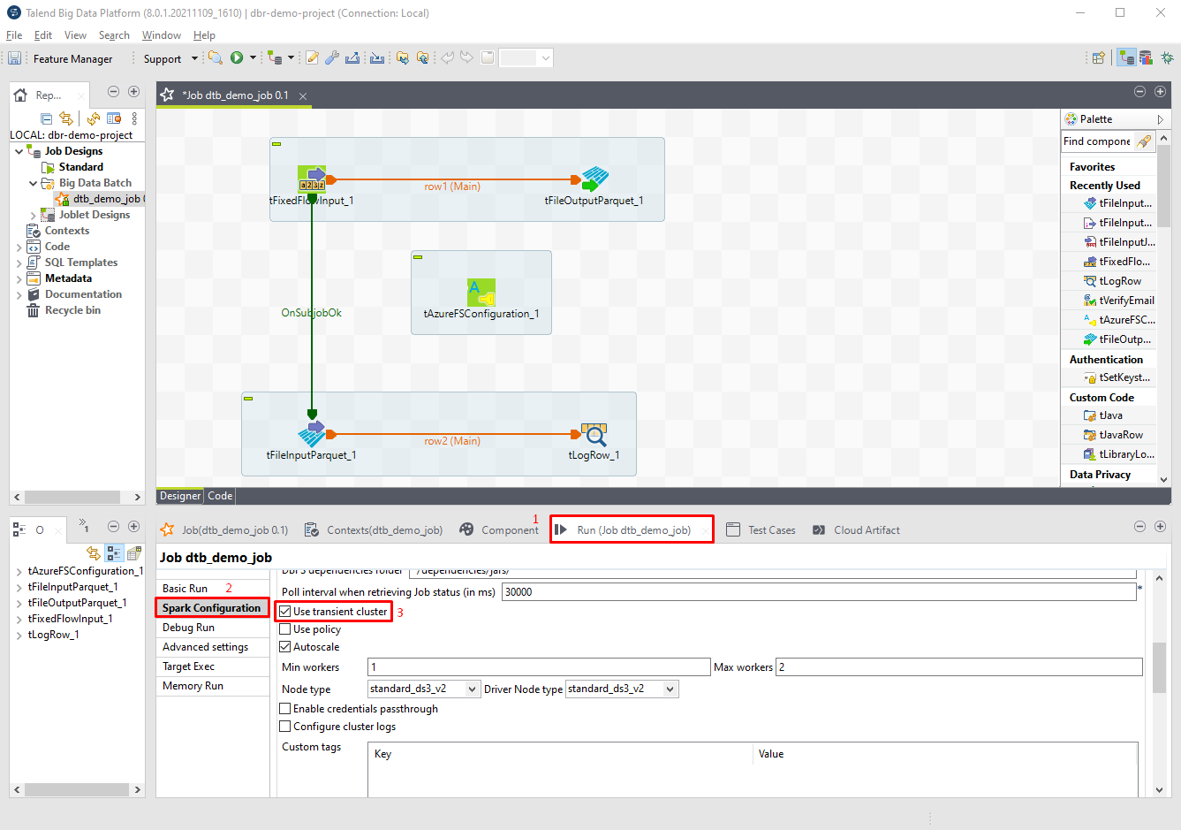
①「Run」タブで、「Spark Configuration」をクリックして、「Use transient cluster」チェックボックスをクリックします。
②「Autoscale」チェックボックスをクリックします。
③「Min workers」項目で「1」を入力します。
④「Max workers」項目で「2」を入力します。
⑤ ジョブクラスタでジョブを実現するにはClusterIDが不要です。
⑥「F6」を押して、ジョブを実行します。
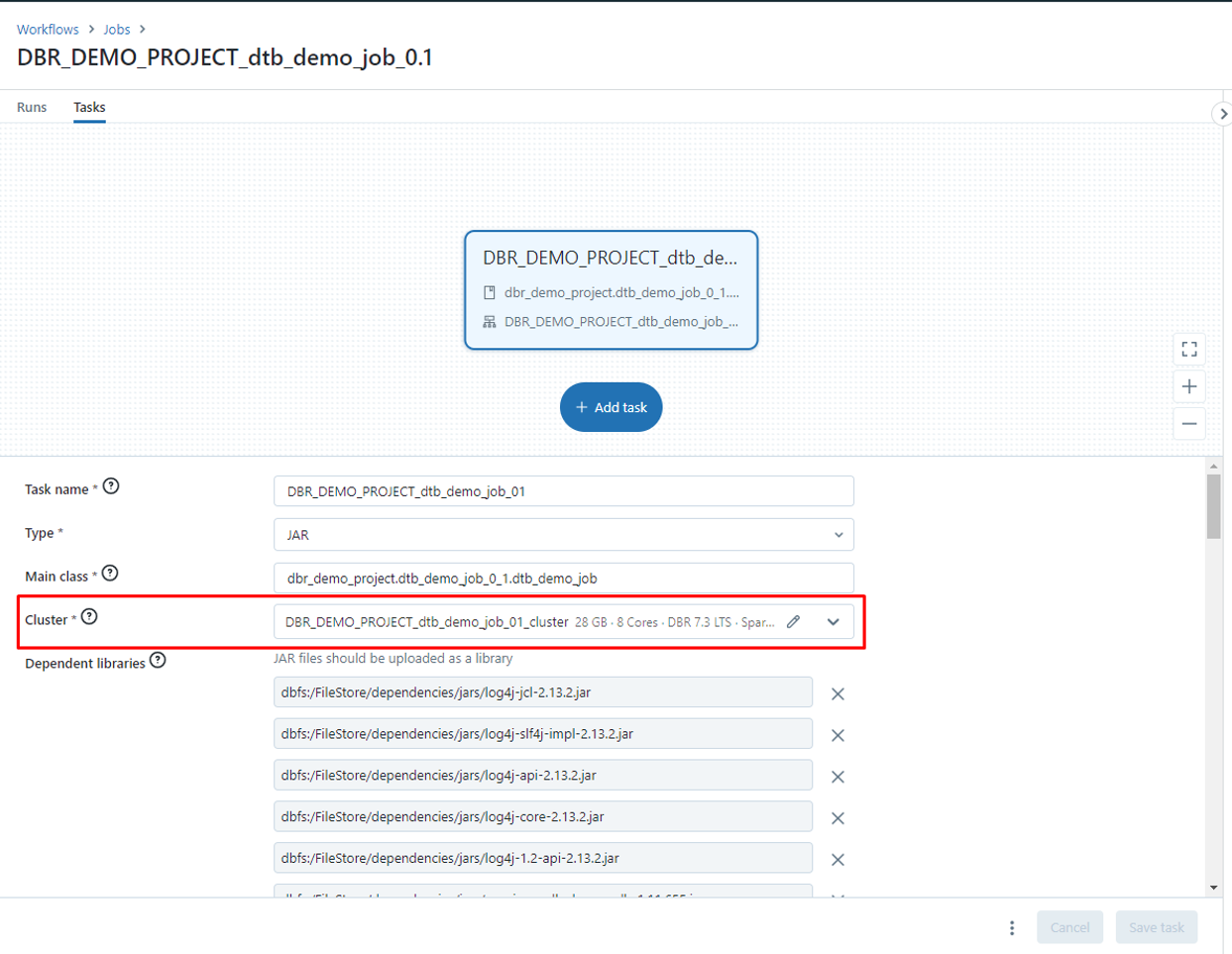
Azure Databricks ワークスペースで「ワークフロー」で新規ジョブが作成されました。
ジョブクラスタでジョブが実行されました。
8.まとめ
Talend Big Data Platform を使って、ノーコードでDatabricksジョブを作成する方法について説明しました。
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
日商エレクトロニクスでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
・Azure Databricks連載シリーズはこちら
Qlik/Talendへのお問い合わせに関しては以下の「Qlik へのお問い合わせ」にてお問合せください!
https://www.qlik.com/ja-jp/try-or-buy/buy-now