目次
1.はじめに
本連載では機械学習における代表的な4パターンをAzureのプラットフォームサービスであるAzure Machine Learning Studioを用い、身近な課題を解決することを目指します。
第一回ではAzure Learning Studioの基本的な機能を用いて、平均気温・湿度、降雨量、日照時間といった過去の気象条件から、夏秋ナスの生育予測を行う学習モデル構築を模索します。
2.機械学習4パターン
以下の表は機械学習の典型的な4パターンについて現時点での筆者の理解をまとめたものです。
本連載を通じて作成される実験結果から得られた知識をもとに、内容をアップデートしていくつもりです。
| パターン | 説明 | 応用例 |
| 回帰(Regression) | 過去の教師データをもとに、入力データから値を予測する。
例:
|
|
| 分類(Classification) | 2項分類 例:
|
|
| 多クラス分類: 教師データをもとに、もっとも近いカテゴリへ結論付ける。 たとえば、記事の分類では教師データを品詞分解したものを単語の登場回数、結びつきなどからスコア化し各カテゴリに分類する。 |
|
|
| クラスタリング(Clustering) | 教師データのない状態で、データの集合に何らかの特徴・データ構造を見出す。 |
|
| 異常値検出(Anomaly Detection) | 普段の振る舞いと異なる状況を検出する。 |
|
表 2-1. 機械学習の代表的な4パターン
3.教師データの品質
教師データありの機械学習では専門家の協力のもと、関連性の高いデータを準備することが重要となりそうです。回帰問題における土地の価格予測に関していえば、土地の”面積”、”駅からの距離”、”公示地価”、”接道幅”といった要素だけで地価を予測しようと考えてもうまくいかないでしょう。その地域の”人気度”や、”類似の物件数”、”形”や、”ハザードマップ”なども地価に関連性があるためです。ほかにも様々な要素が絡んできそうですが、不動産アナリストや業者でもなければそこまで考えが及ばないばかりか、仮に知っていたとしてもデータそのものが手に入らないといったことも多いでしょう。
連載第一回では夏秋ナスの収穫量を予測するため、気象庁から入手可能気象なデータが夏秋ナスの収穫量に関連性があるものと仮定しました。同時に、”品種”・”栽培技法”や土壌に与える”肥料の組成・量”といったパラメータも夏秋ナスの収穫量に関連がありそうですが、当該データは今回入手できなかったためパラメータには採用しませんでした。農業関係の専門家でもなければこの手のデータの入手は難しいためです。
そこで、連載第一回では気象データをもとに夏秋ナスの収穫量を予測することを目的とし、精度に問題があれば教師データの見直を行う方向ですすめることにします。
| パラメータ | 採用 | 理由 |
| 累積の降雨量 | 〇 | ナスは植物であり、水が必須なため。 |
| 年平均気温 | 〇 | やや温暖な気候が必要と推測したため。 |
| 年平均湿度 | 〇 | 低すぎると枯れてしまい、高すぎても病気になりやすいと考えたため。 |
| 累積の日照時間 | 〇 | 植物が光合成を行うために不可欠なため。 |
| 栽培技法 | × | 今回入手できなかったため。 |
| 肥料の組成 | × | 今回入手できなかったため用。 |
| 肥料の量 | × | 今回入手できなかったため。 |
表 3-1. 夏秋ナスの収穫量予測に関わるパラメータと採用・不採用の理由
4.教師データとサンプルデータ
4.1 データソース
今回利用するデータは気象庁と農林水産省および政府統計の総合窓口(e-Stat)から引用させてもらいました。
これらは、出典を明示すれば自由に利用可能とあります。
4.2 気象庁
2018年9月4日現在、1725地点のデータを一年ごとないしは日ごとの単位で入手可能でした。
一年ごとの気象データのURLの例は以下の通りで、URLのパラメータのうち、prec_noが県(地方)を、block_noは観測地点のIDとなっています。なお、年平均は各地点のみの提供で、各都道県の年平均データは入手できませんでした。(筆者調べ) 各都道府県のすべての観測地点の平均をとれば、各都道府県の年平均気象データとなりますが、今回は各都道県における県庁所在地の年平均を気象データとしてマップすることにしました。
過去の年間平均気象データURL例:
東京都/東京の年間平均気象データ
出典:気象庁-過去の気象データ検索
4.3 農林水産省
農林水産省-作況調査からは、リンク先となる”政府統計の総合窓口(e-Stat)”を通じて、累年の夏秋なすの収穫量データを含むエクセルファイルをダウンロードする形となります。一部はWebAPIも利用可能です。
出典:農林水産省-作況調査(野菜)
出典:政府統計の総合窓口(e-Stat)
4.4 データセット
回帰問題におけるデータセットとは、Azure Machine Learningが教師データ(サンプルも含む)として利用する一連のデータのことです。2018年9月現在、Azure Machine Learning Studioのフリープランでは以下のファイル形式に対応しています。
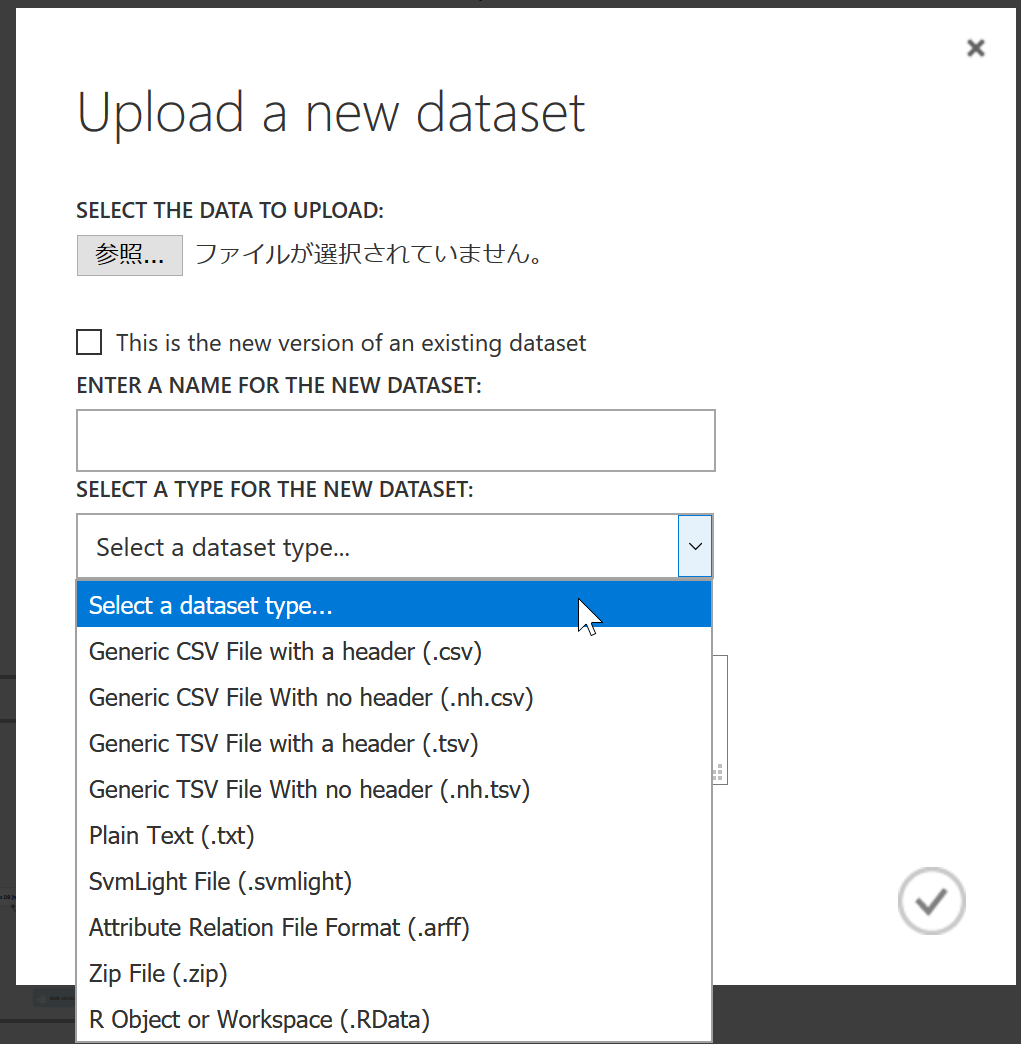
図 4-1. データセットとして利用可能なファイルタイプ
また、今回利用するフリープランでは、以下のリレーショナルデータベースやNoSQLのデータをソースとしてインポートすることも可能です。運用中のアプリケーションや、IoTで生成されるデータを解析するようなケースではこちらを利用することが多くなるでしょう。

図 4-2. データソースとして利用可能なデータベースの種類
4.5 データの加工
今回は気象庁と農林水産省という2つのソースより得られるデータを統合する必要があったため、”県ID”と”年度”をキーとし、任意の列をキーとし、データを時系列で比較的容易に統合できるAzure SQL上にテーブルを作成することにしました。最終的なデータ件数は47都道府県各43年分、合計2116件となりました。なお、県IDは筆者がデータ統合のために各県に独自に付与したものでありこれといった決まりはありません。
ちなみに、ハイブリッドクラウドの環境において、データセットのソースとしてAzure SQLではなくオンプレミスのMicrosoft SQL Serverを利用したい場合は、Azure Machine Learning Studioの有料プランが必要となります。
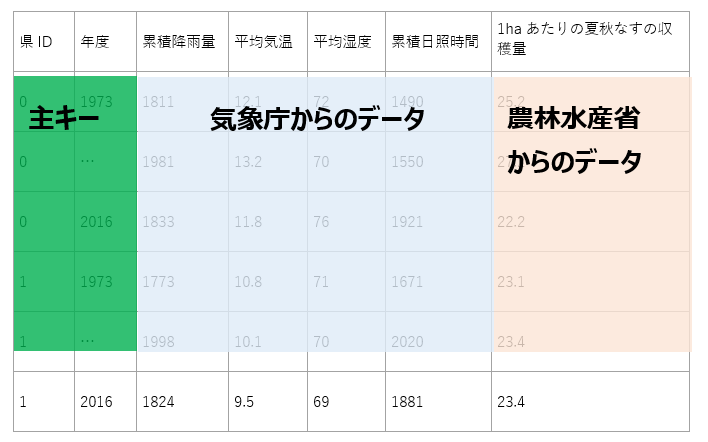
…合計2,116件
表 4-1. 教師・Azure SQLに作成したテーブルのイメージ
5.Azure Machine Learning Studio
5.1 実験(Experiment)の作成
Azure Machine Learning Studioではフローチャートでデータの流れを定義し、実験を形にしていきます。今回作成した実験)の全体像は以下のとおりです。
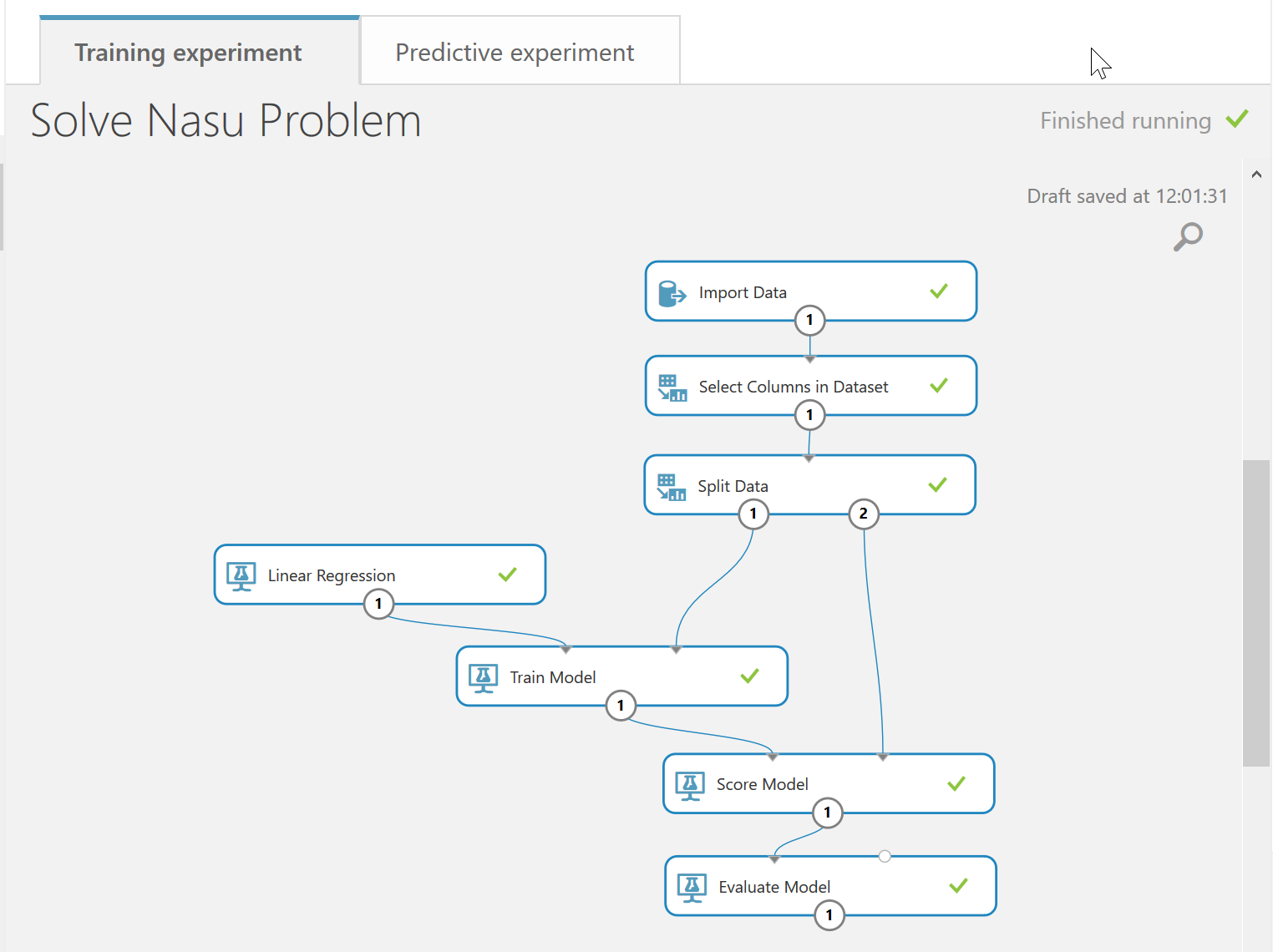
図 5-1. 夏秋ナスの収穫量予測のフロー
5.2 Import Data
このモジュールではソースとなるデータベースサーバーのIPアドレスおよび資格情報と、教師・サンプルデータをデータベースから取り出すためのSQLクエリを設定しておきます。
ここでは、全カラムを指定し、表 4-1. 教師・Azure SQLに作成したテーブルのイメージのような全2116件のデータを取得させています。
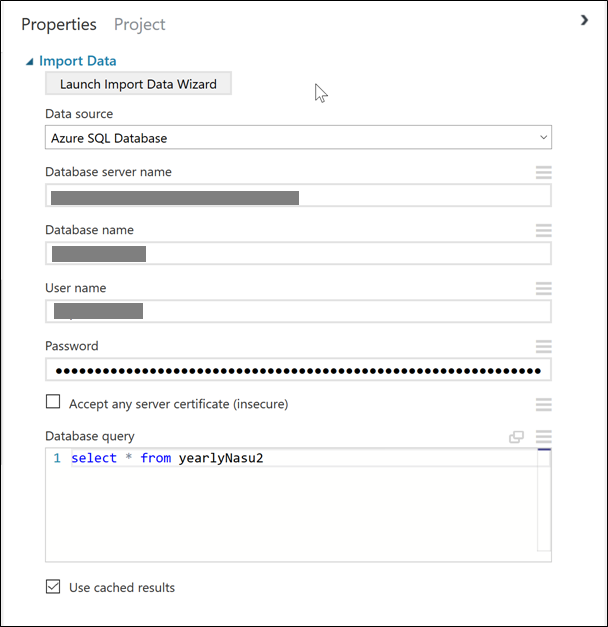
図 5-2. Import Dataモジュール
5.3 Select Columns in Dataset
Azure SQLから取得するデータの中で、評価対象とするカラムを取捨選択するためのモジュールです。 県IDと年度は夏秋ナスの収穫量とは直接関連ないため除外しました。
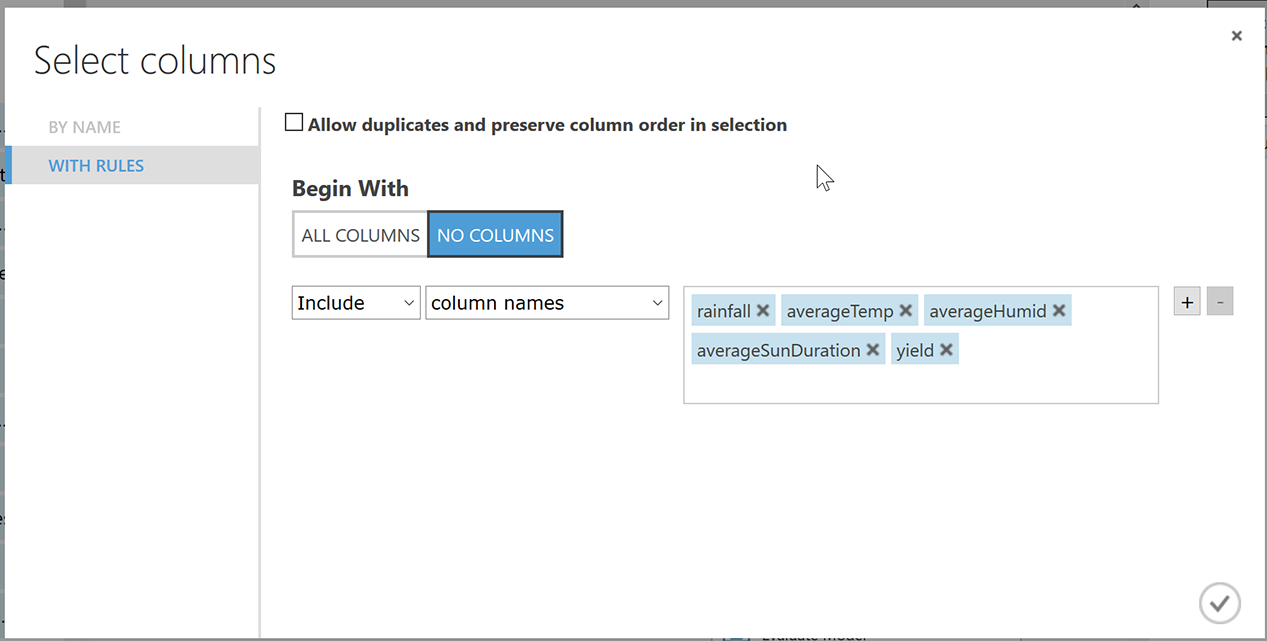
図 5-3. Select Columns in Datasetモジュール
5.4 Split Data
教師データとサンプルデータを分離するためのモジュールです。
“Fraction of rows in the first output dataset”にて教師データとサンプルデータの割合を指定します。サンプルデータは、教師データから生成されたモデルの精度を確認するため学習させずにとっておくデータです。
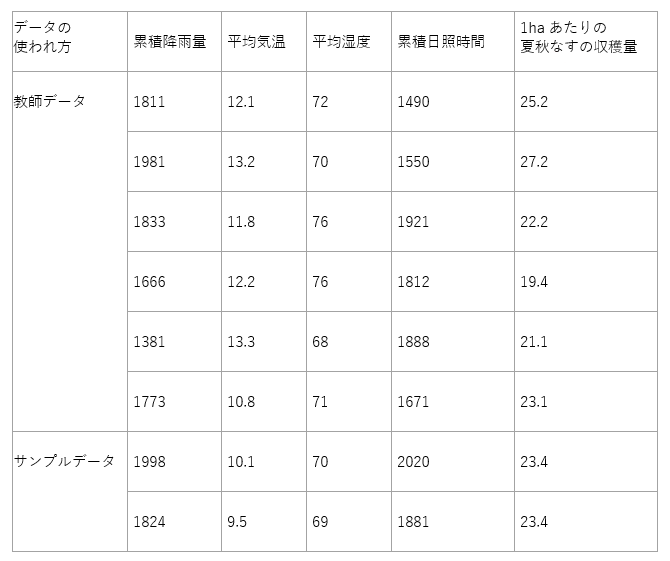
表 5-1. 教師データとサンプルデータのイメージ
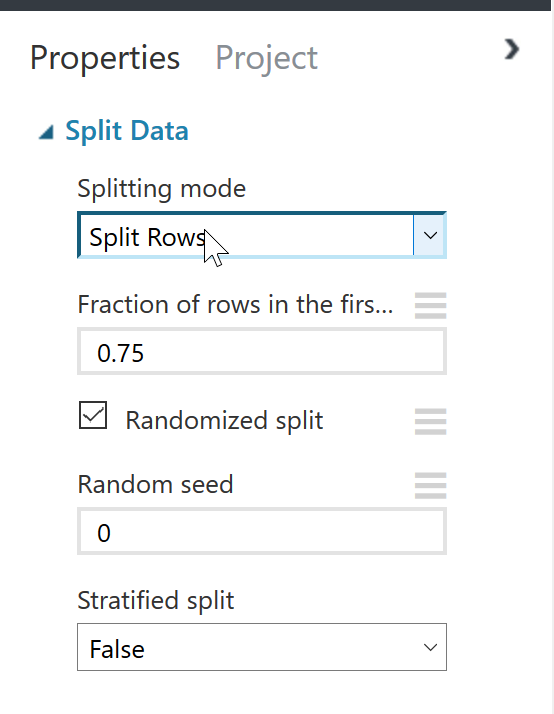
図 5-4. Split Dataモジュール
5.5 Train Modelと学習アルゴリズムの選択
適用する学習アルゴリズムを選択し、Train Modelモジュールと関連付けます。次に、Train Modelモジュールでは予測したい列(目的変数)を選択します。ここでは、気象データより収穫量を予測することが目的であるため”yield”(収穫量)列を選択しました。この状態で実験を実行すると、教師データをもとに収穫量(yield)の誤差が最小化となるような学習モデル(数式)が生成されます。あとで精度を確認して問題があれば学習アルゴリズムを変更すればよいでしょう。
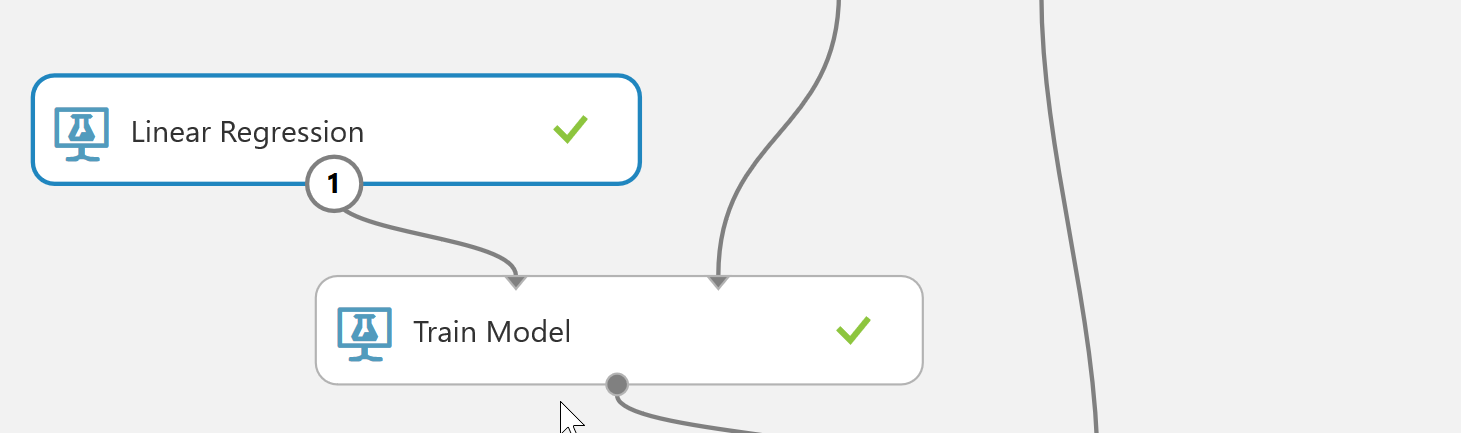
図 5-5. 学習アルゴリズムとTrain Modelの関連付け
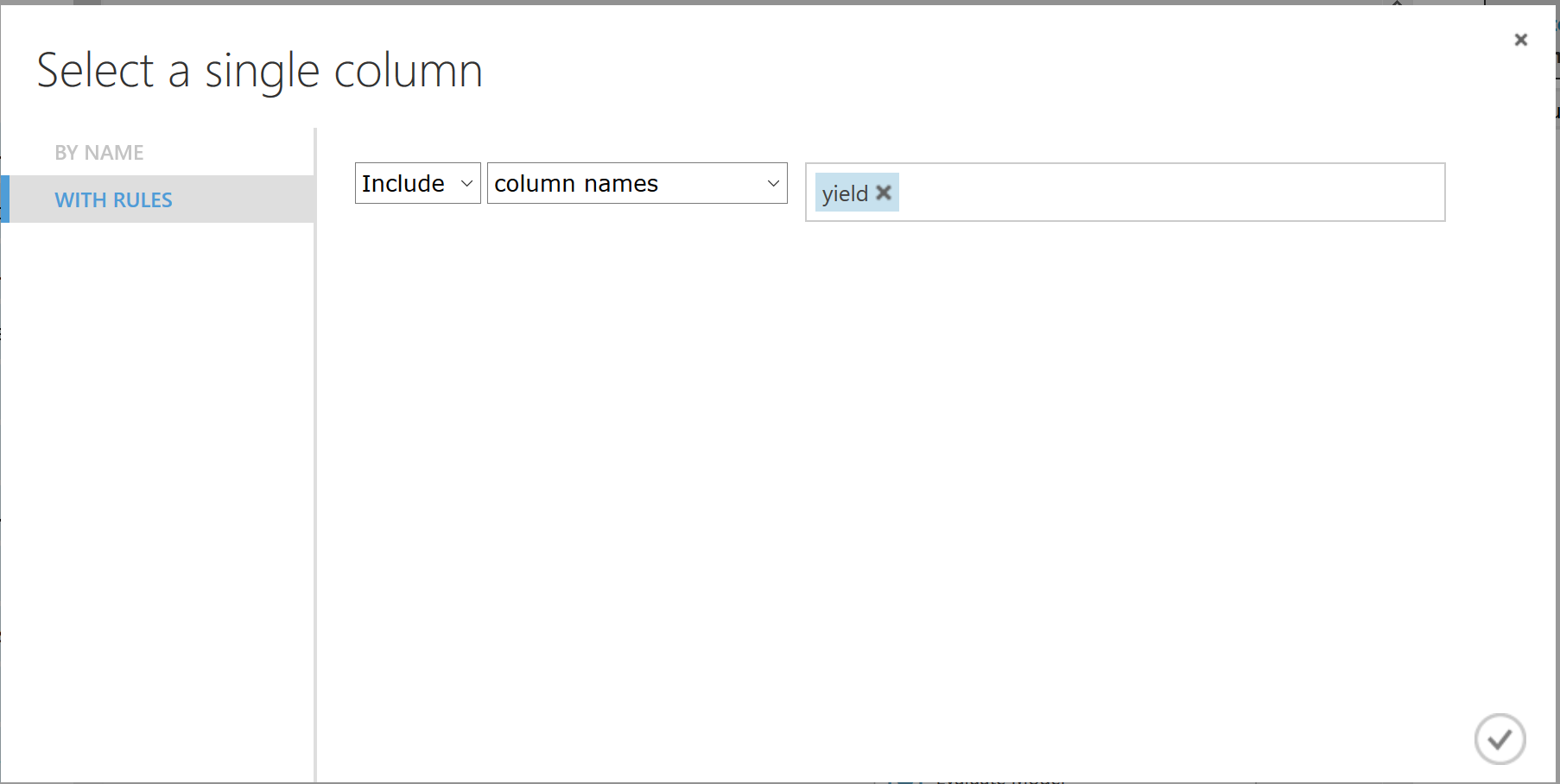
図 5-6. Train Modelモジュール
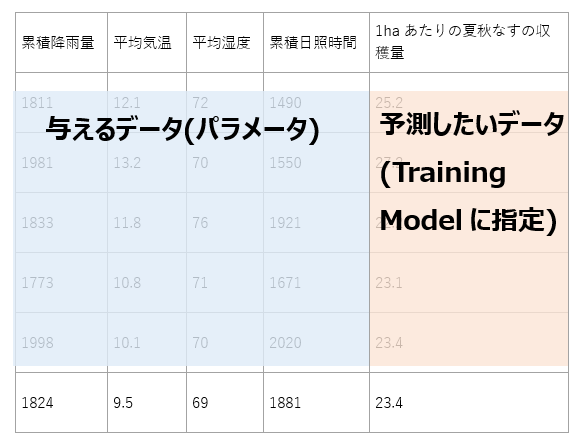
表5-2. Taining Modelモジュールで指定するデータのイメージ
5.6 Score Modelの作成
Score ModelのVisualize(可視化)を選択すると、作成した学習モデル用いてサンプルデータを評価したときの結果を確認できます。平たく言うと、”Scored Labels”列と実際のyield(1haあたりの収穫高)の差が学習アルゴリズムがその気象条件下で見込めると予測した収穫量と実際の収穫量の誤差となるわけです。結果は近いものもあれば遠いものもあり、精度は要改善といったところです。
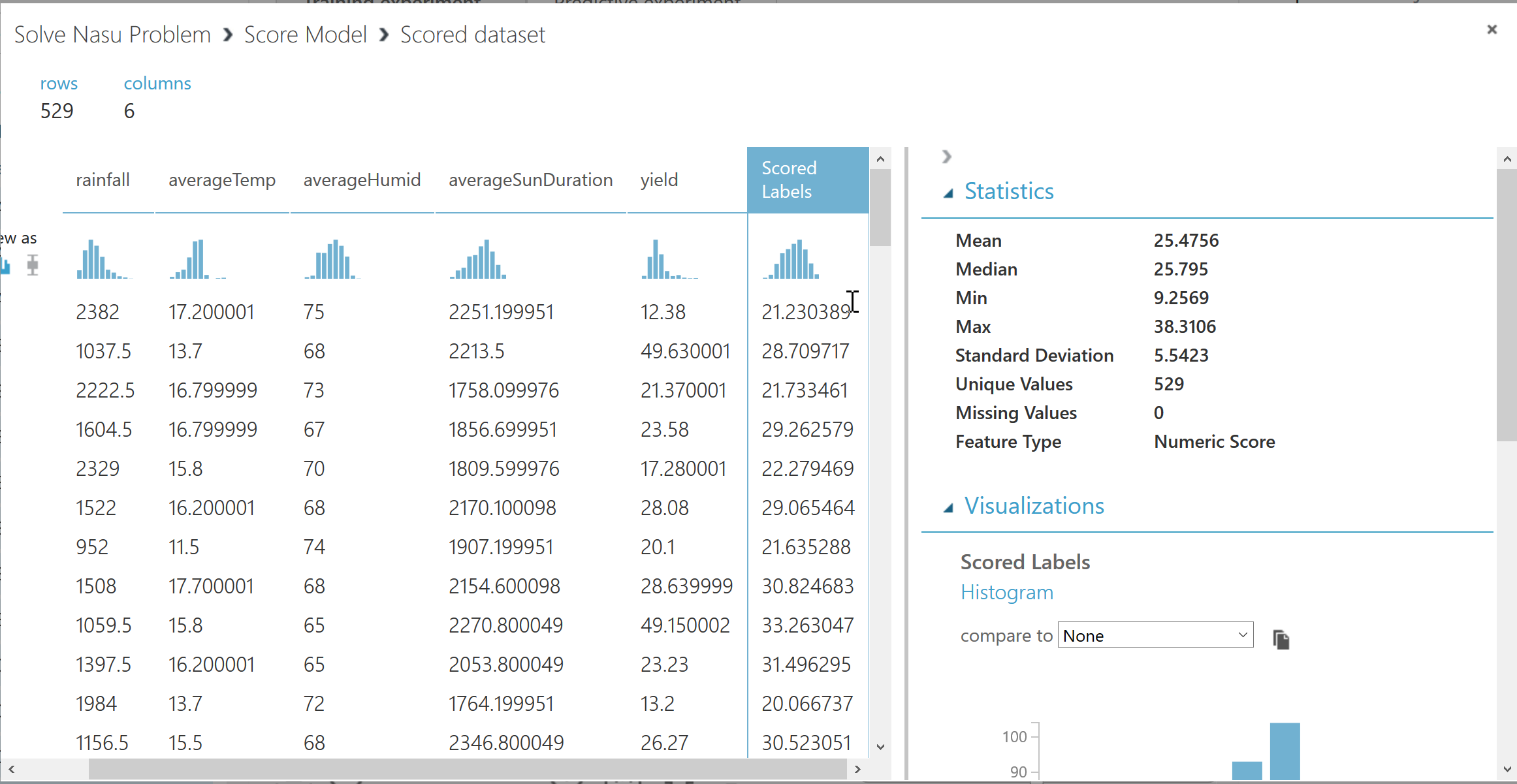
図 5‑7. Scored Labels
5.7 Evaluate Modelの作成
Evalulate Modelは生成された学習モデルの精度を評価します。
5.7.1 学習モデルの評価
Linear Regressionアルゴリズム適用時の学習モデルの評価結果は以下のようになりました。
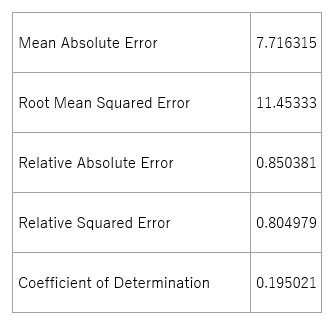
表 5-3. 学習モデルの評価結果(Linear Regression)
マイクロソフト社のチュートリアルによると、”誤差の統計情報は 値が小さいほど予測が実際の値により近い”ことを示しており、Coefficient of Determinationでは、値が 1 (1.0) に近づくほど、予測の精度が高い”とのことです。よって、このモデルの精度はイマイチといわざるを得ないでしょう。
機械学習チュートリアル: Azure Machine Learning Studio で初めてのデータ サイエンス実験を作成する
6.学習モデルの改良
以下方針のもと、前項で作成した学習モデルの精度向上を目指していきます。
- 欠損のあるデータを削除する
- 学習アルゴリズムを変更する
- データセットを見直す
6.1 欠損のあるデータを排除する
Score Modelの結果を眺めていると、yield(収穫量)が0のデータがあることに気づきました。台風や異常気象により夏秋ナスを収穫できなかったか、報告がないなど何らかの理由でソースデータが欠損している可能性がありそうです。収穫量が0のものが教師データとして存在していると、与えられた気象条件下での収穫量が0であると学習されてしまい、精度低下につながります。そこで、SQL文に”where IS NOT NULL”条件を付加して当該データをインポートしないこととしました。これにより、収穫量が記録されていない51件のデータが除外されました。

図 6-1. 変更後のAzure SQLクエリー
Azure Machine Learning Studio存在する”Clear Missing Data”モジュールを使わなかった理由は、該当の行をうまく削除できなかったためです。データをAzure SQLからimportした時点で、NULLデータ(値がない)がゼロに置き換わってしまったためと推測されます。
NULLデータ削除の結果、モデルの精度が若干ではあるものの、以下のように向上しました。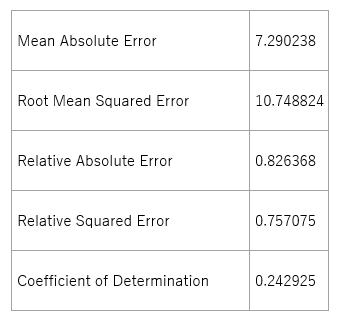
図 6-2. NULLデータ排除後のデータの精度(Linear Regression)
6.2 学習アルゴリズムを変更する
Azure Machine Learning Studioでは、回帰(Regression)アルゴリズムだけでも8種類が存在します。
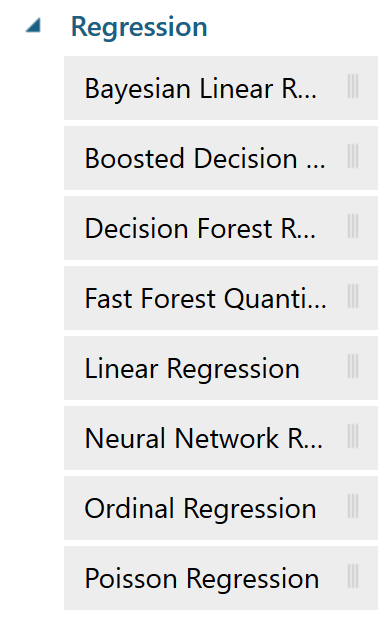
図 6-3. Regressionアルゴリズムの種類
それぞれの学習アルゴリズムはその特徴に応じて使い分ける必要があります。各学習アルゴリズムの説明については、正確を期するためMicrosoft社のWebサイトまたは機械学習の専門書に譲るものとしますが、Azure Machine Learning Studioにおいて”Linear Regression”アルゴリズムを”Neural Network Regression”アルゴリズムに変更するには、それまで使っていたLinear RegressionモジュールとTrain Modelモジュールの接続を削除し、Neural Network RegressionモジュールをTrain Modelモジュールへ接続しなおすだけです。
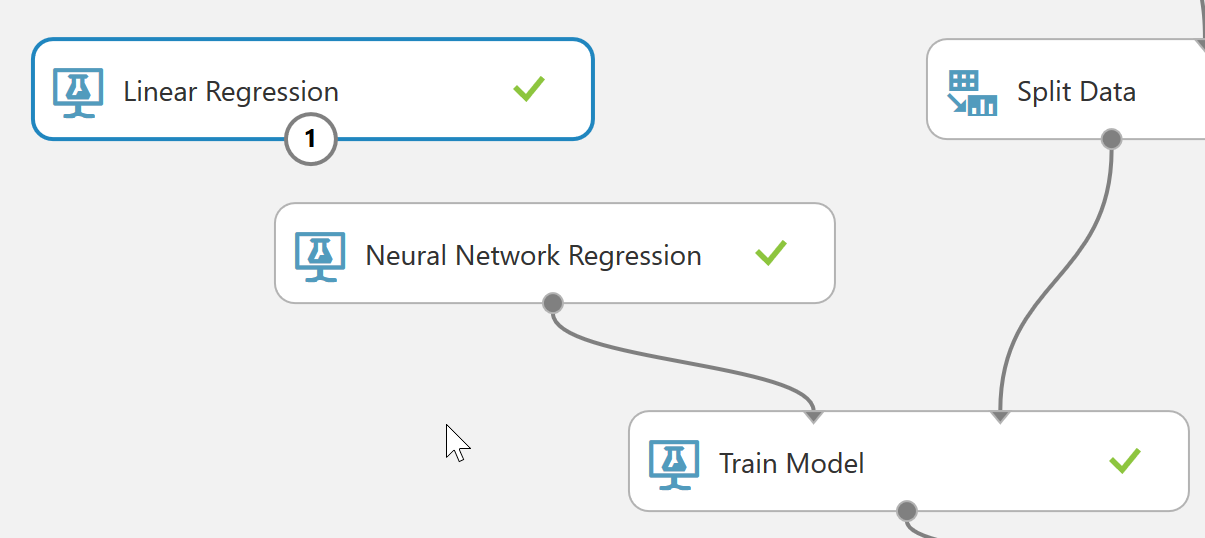
図 6-4. 適用するアルゴリズムの変更
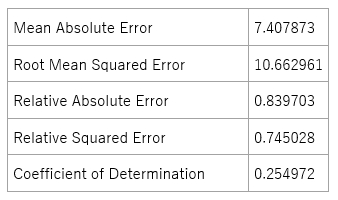
表 6-1 モデルの精度(Neural Network Regression)
同じように非線形学習アルゴリズムである”Boosted Decision Tree”を用いたところ、モデルの精度のやや変化が見られました。
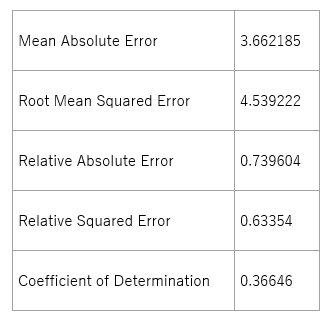
表 6-2. モデルの精度(Boosted Decision Tree)
夏秋ナスの収穫量予測問題では、非線形アルゴリズムであるBoosted Decision Treeが過去の収穫データによりうまくフィットするようです。
6.3 データセットを見直す
夏秋ナスの”品種”、”肥料の組成や量”、”育成技術”をパラメータとして取り入れ、精度の向上を確認できればベストですが、データを入手することができないため今回は見送ることとしました。
しかし、別の観点から収穫量のデータセットに気になるポイントを見つけました。それは、1haあたりの夏秋ナスの2017年の全国平均の収穫量である約23.3t(10aあたり2330kg)を2倍程度も上回るデータの存在です。
表1 平成29年産春野菜、夏秋野菜等の季節品目別作付面積、10a当たり収量、収穫量及び. 出荷量(全国)
たとえば、今回用いた2116件のデータセットのうち、148件は1haあたり50tより多い収穫高があり、30tより多かったデータは526件です。
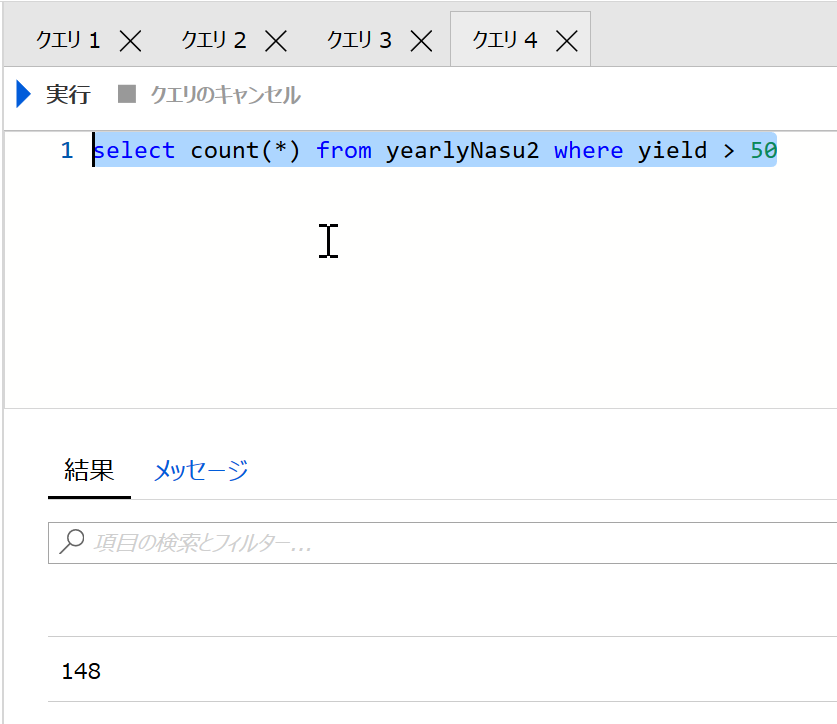
図 6-5. 1haあたり50t以上の収穫量のあるデータの数
農林水産省の統計データからは期間中のナスの栽培回数までは読み取ることはできませんでしたが、なすの収穫において例年No1を誇る高知県をはじめとして、地域によっては一年中ナスの栽培をおこなっているところがあるようです。
一定の期間に同じ土地で複数回の栽培ができる良好な気象条件であるということもできますが、夏秋ナスの収穫量予測において、複数回の栽培は想定していないため、1haあたり30tの収穫量を超えるデータは除外することとしました。実際には1haあたり30tの収穫量があっても、単にその年が豊作であっただけの可能性もありますが、今回は一定期間に2回以上の収穫があったものと仮定して話を進めます。
上記データを除外した結果、Coefficient of Determinationにおいてチューニング前のデータと比較し約38%の精度向上がみられました。Mean Absolute Error,Root Mean Squared Errorも下がっており、精度が向上していることがわかります。
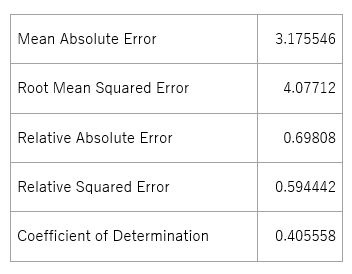
表 6-3. データセットチューニング後のモデルの精度(Boosted Decision Tree)
しかし、評価結果だけではどの程度の精度か感覚的にはわかりづらいでしょうから、Score Modelの結果を載せておきます。Yield列が実際の収穫量で、Scored Labelsが学習結果に基づく予測値です。判断は読者の皆様にお任せしますが、もう少し精度がほしいというのが筆者の率直な感想です。
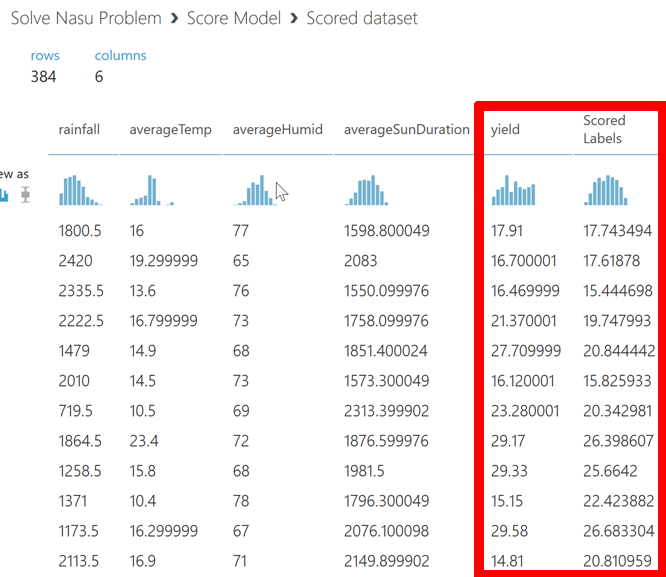
図 6-6. データチューニング後のScore Model
7.Predictive experimentの作成
作成した学習モデルを、AzureのWeb Appとしてデプロイすることができます。すべてテンプレート化され自動化されているため、ユーザーによるWebアプリケーションの作成は不要です。
図 7-1. Webアプリケーションとしてのモデルのデプロイ
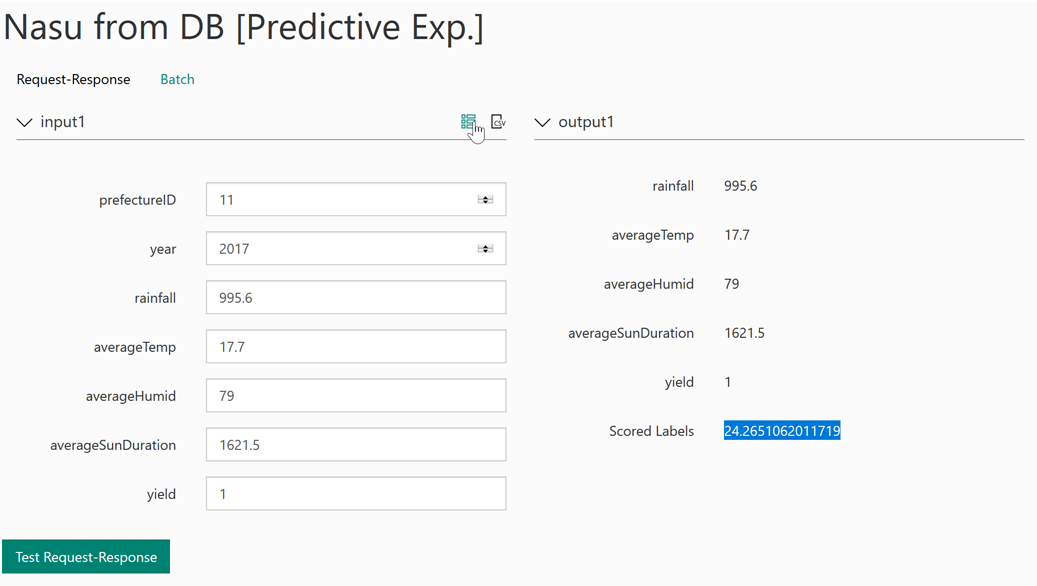
7.1 もしも八丈島でナスを育てたら?
気象庁から得られた八丈島における2017年の気象条件下では、1haあたり約24.3tの夏秋ナスを収穫できるという学習モデルからの予測となりました。これは平均の23.3tよりもやや多い値です。喧噪極まる都会を離れ、八丈島に移住しナスを育て生計をたてることは今回の結果から理論上可能ではありそうですが、学習モデルの精度には不安が残るため、実行に移すには二の足を踏んでしまいます。
8.まとめ
Azure Learning Studioを使った学習モデルの構築は気軽に始められる一方、精度向上のためには教師データとして、的確なデータセットを用意することの重要さがわかりました。
夏秋ナスの育成を予測する第一回で生成した学習モデルは、教師データのチューニングと適切な学習アルゴリズムを選択することで若干の精度向上を果たしたものの、実用には至らぬやや残念な精度を示す結果となってしまいました。最高気温や最低気温といった入手可能なパラメータを可能な限り追加すると、学習モデルの精度をもう少し改善できるかもしれません。
一方で高精度な学習モデルの確立さえできれば、直近の気象データから夏秋ナスの収穫量を最大化するための適切なアクションをアドバイスする仕組みをAzureのMachine Learning StudioとPaaSサービスを用いて低コストで実現できるようになる日もそう遠くなさそうです。たとえば、IoTセンサーを用いて累積の降雨量が少なければ多めに水をやるようアドバイスを表示したり、相対的に気温の低い日が続けばビニールハウスなどでナスを守ることを提案するといった例が考えられます。
最後に、連載第二回では”分類アルゴリズム”を使って、収穫されたナスの画像が出荷基準を満たすものであるかどうかを判定する仕組みを構築する予定です。
(*1)引用:
“The species problem in Iris” Edgar Anderson (1936)
この記事を読んだ方へのオススメコンテンツはこちら
この記事を書いた人

-
こんにちは!双日テックイノベーション(旧:日商エレクトロニクス)では、Microsoft Azure活用に関する有益な情報を皆様にお届けしていきます。Azure移行、データ活用、セキュリティなどに関するお困りごとや、Microsoft Azureに関する疑問点などお気軽にご相談ください。
ブログにしてほしいネタなどのリクエストもお待ちしております。
この投稿者の最新の記事
- 2024年9月12日ブログ2024年版 最新のデータ活用基盤とは?グローバル企業の事例も紹介!
- 2024年7月16日事例Azureデータ活用基盤導入事例:第一フロンティア生命保険株式会社
- 2024年3月27日ブログデータレイクとは? ~DWHとの違い、メリット、活用例などをわかりやすく解説~
- 2024年3月6日ブログデータカタログとは?~機能、導入のメリット、導入方法まで解説~