目次
1. はじめに
皆さんこんにちは。
今回は外部ロケーションに新しいファイルが追加された際に、Databricks ジョブを自動的に起動する方法について説明していきます。
【背景】
企業環境では、データはバッチアップロード、業務システムからの定期抽出、またはパートナーからのデータレイクへのファイルダンプなど、複数のソースからインジェストされます。一般的な課題として、ダウンストリーム処理が固定スケジュールや運用チームの手動操作(フォルダの確認、ジョブの実行、結果の検証)に依存していることが挙げられます。これにより、データレイテンシの発生、ファイル漏れのリスク増加、レポーティング・AI向けのニアリアルタイム要件への対応が困難になります。
Azure DatabricksはDatabricksジョブ向けのファイル到着トリガーを提供しており、外部ロケーションまたはボリュームに新規ファイルがアップロードされた際にジョブを自動実行できます。これにより、パイプラインはイベント駆動型となり、手動運用を削減し、データが到着次第処理されることが保証されます。
【目的】
本記事では、Azure Databricks上でイベント駆動型パイプラインを構築する方法を解説します。外部ロケーションに新規ファイルが到着すると Databricksジョブが自動起動し、ファイルを読み込んでUnity Catalogに書き込みます。
【目標】
本記事を読了後、読者は以下のことが可能になります:
- チェックポイントを使用した増分(インクリメンタル)方式でCSVを取り込むPythonノートブック を構築する。
- ファイル到着トリガーを使用して新規ファイル到着時に自動実行される Databricksジョブを作成する。
2.前提条件
本手順を実施するにあたり、以下の前提条件が満たされている必要があります:
- Databricks Workspace において Unity Catalog が有効化されていること。
- 外部ロケーションの作成/管理権限を有していること。
- 対象の カタログ・スキーマ に対する CREATE 権限およびテーブルへの書き込み権限を有していること。
- Databricksジョブの作成・実行権限を有していること。
- ランディングゾーンとして利用する Azure Data Lake(ADLS Gen2)が用意されていること。
- サンプルデータをダウンロード済みであること。
3.ファイル到着トリガーとは
ファイル到着トリガーは、Databricksジョブのトリガー機能であり、cronやスケジュールによる実行の代わりに、外部ロケーションまたはボリュームに新規ファイルが追加された際にジョブを自動起動させることができます。
ファイルが到着したタイミングでジョブが実行されるため、データレイクのランディングゾーンにおけるインジェスト処理に非常に適しています。
4.デモ例
【デモサンプルのご紹介】
詳細な設定手順に入る前に、本セクションでは本記事を通して使用するデモサンプルの概要について説明します。
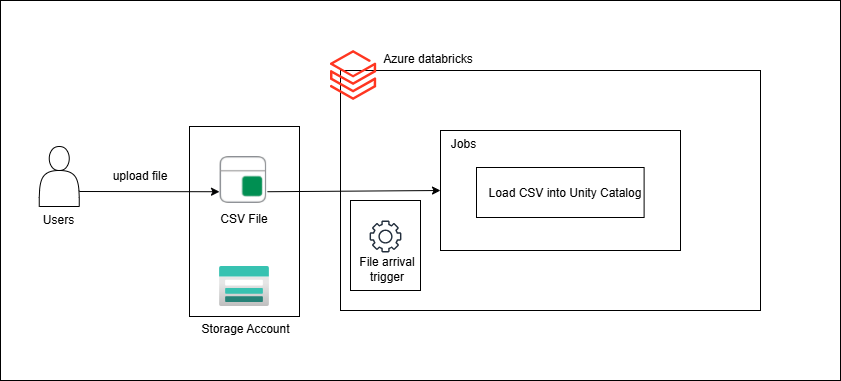
ユースケース
Data Platformチームは、複数のチーム(または外部パートナー)からCSVファイルを受領します。Azure Storage Account内のランディングディレクトリ(例:…/jlpt_vocab/incoming/)に新しいファイルがアップロードされるたびに、そのデータをDeltaテーブルへインジェストし、下流システム(BI/GenAI/RAG/分析)で即時利用可能にする必要があります。
課題
1. Azure Storage Account内の新規ファイルを自動的に検知すること。
2. ジョブを起動し、Unity Catalog 上の Delta テーブルにデータを追加(append)すること。
3. 同一ファイルの重複取り込みを防止すること。
本デモでは、Databricksジョブとファイル到着トリガーを組み合わせて、上記の課題を解決する構成を実装します。
なお、今回使用するサンプルデータには、Kaggleから取得した「JLPT vocabulary by level」を利用します。
フロー:
1. ユーザーが語彙データ(CSV ファイル)を Storage Account にアップロードする
2. Databricksジョブが自動的に起動し、ファイルをロードする
3. データが Unity Catalog 内のテーブルにロードされる
4-1.ランディングゾーン用の外部ロケーションの作成
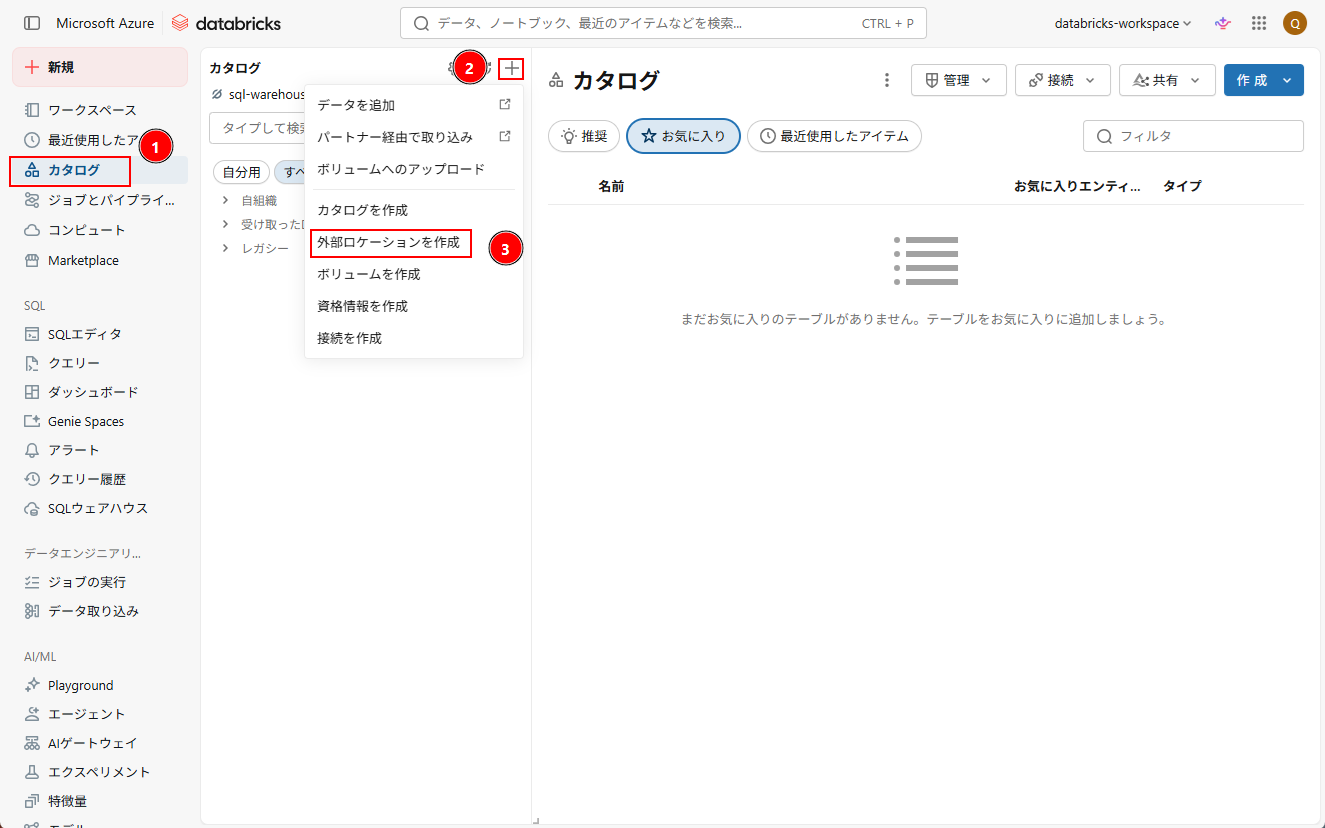
以下は、外部ロケーションを作成する手順です。
1. Databricks Workspace のホーム画面から、「カタログ」→「外部ロケーションを作成」をクリックする。
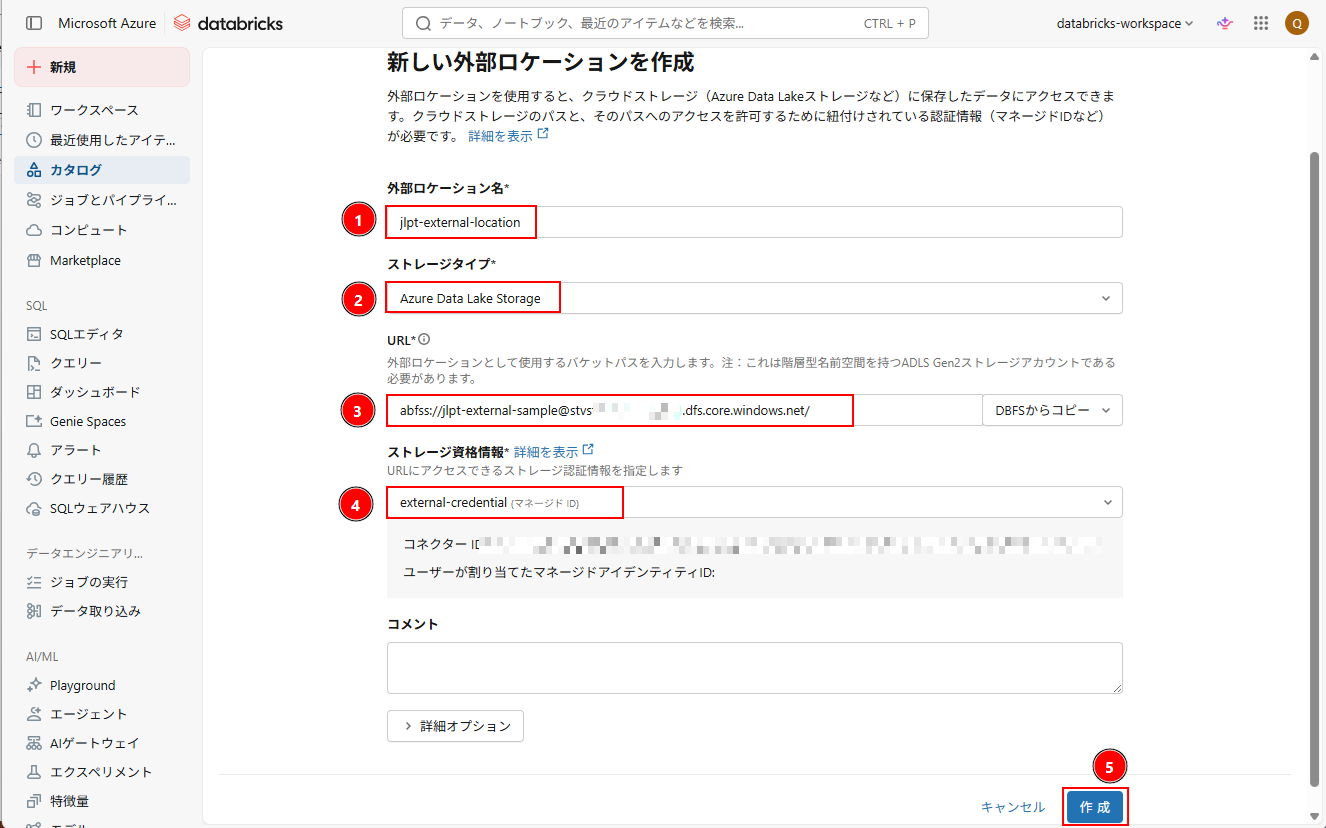
2. 初期設定として、以下の情報を入力する。
- 外部ロケーション名: 名前を入力する。
- ストレージタイプ: 「 Azure Data Lake Storage 」 を選択する。
- URL:
|
1 |
abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/jlpt_vocab/ |
<container_name>: CSV ファイルを格納するフォルダを含むコンテナー名
<storage_account_name>: ストレージ アカウント名
- ストレージ資格情報: ストレージの資格情報を選択する。
3. 設定完了後、「作成」をクリックする。
※ ストレージ アカウントのコンテナー内に「/jlpt_vocab/」のパスが存在していることを確認してください。
※ また、ストレージの資格で利用する Managed Identity には、ストレージ アカウントに対して以下の権限が付与されている必要がある:
- ストレージ BLOB データ共同作成者
- ストレージ キュー データ共同作成者
- ストレージ アカウント共同作成者
さらに、当該ストレージアカウントが属するリソースグループに対して、以下の権限が必要となる。:
- EventGrid EventSubscription 共同作成者
4. 外部ロケーションが正常に作成されたことを確認する。
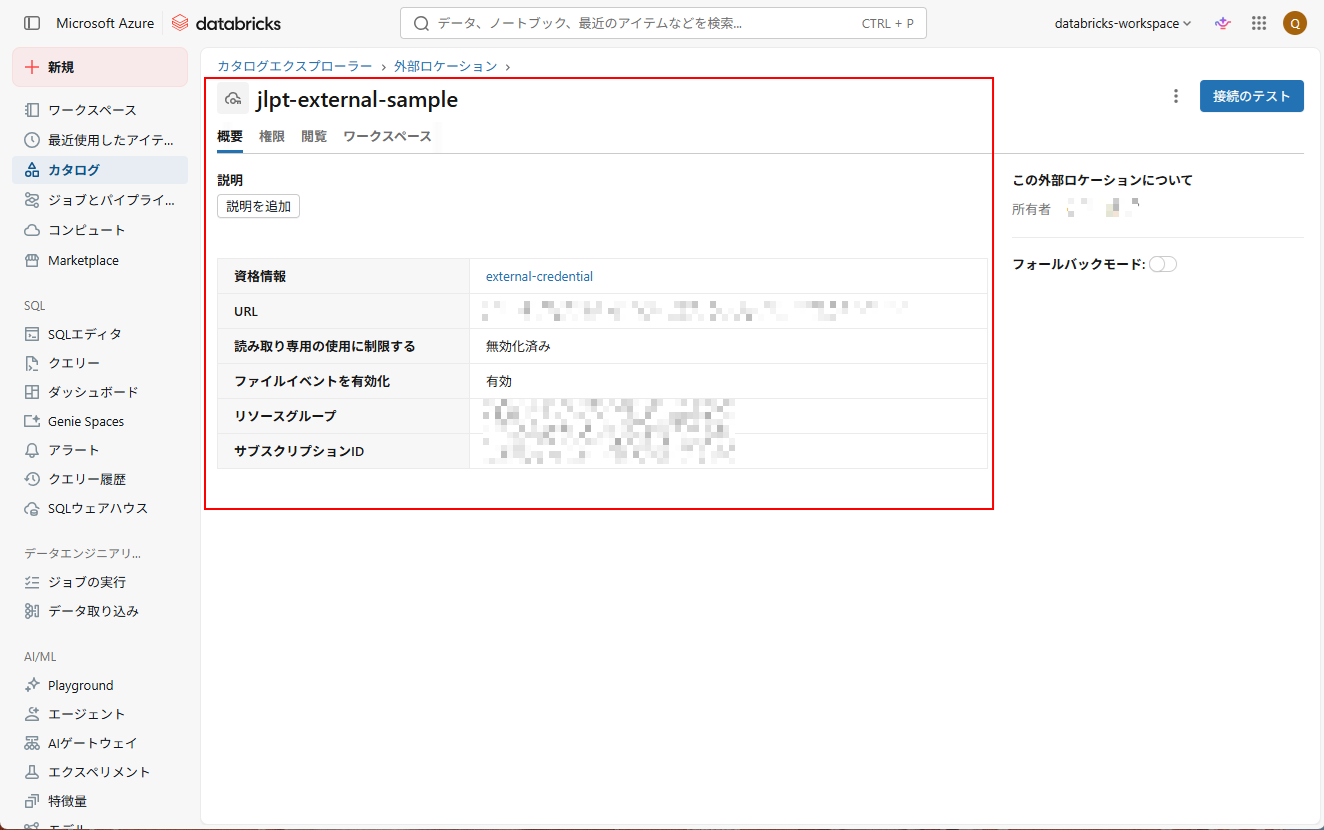
4-2.Unity Catalogでのターゲットテーブル・スキーマの作成
以下はCSVファイルから読み込んだデータを格納するスキーマ・テーブルを作成する手順です。
1. Databricks Workspaceのホーム画面から、「新規」→「ノートブック」をクリックし、ノートブックを作成する。
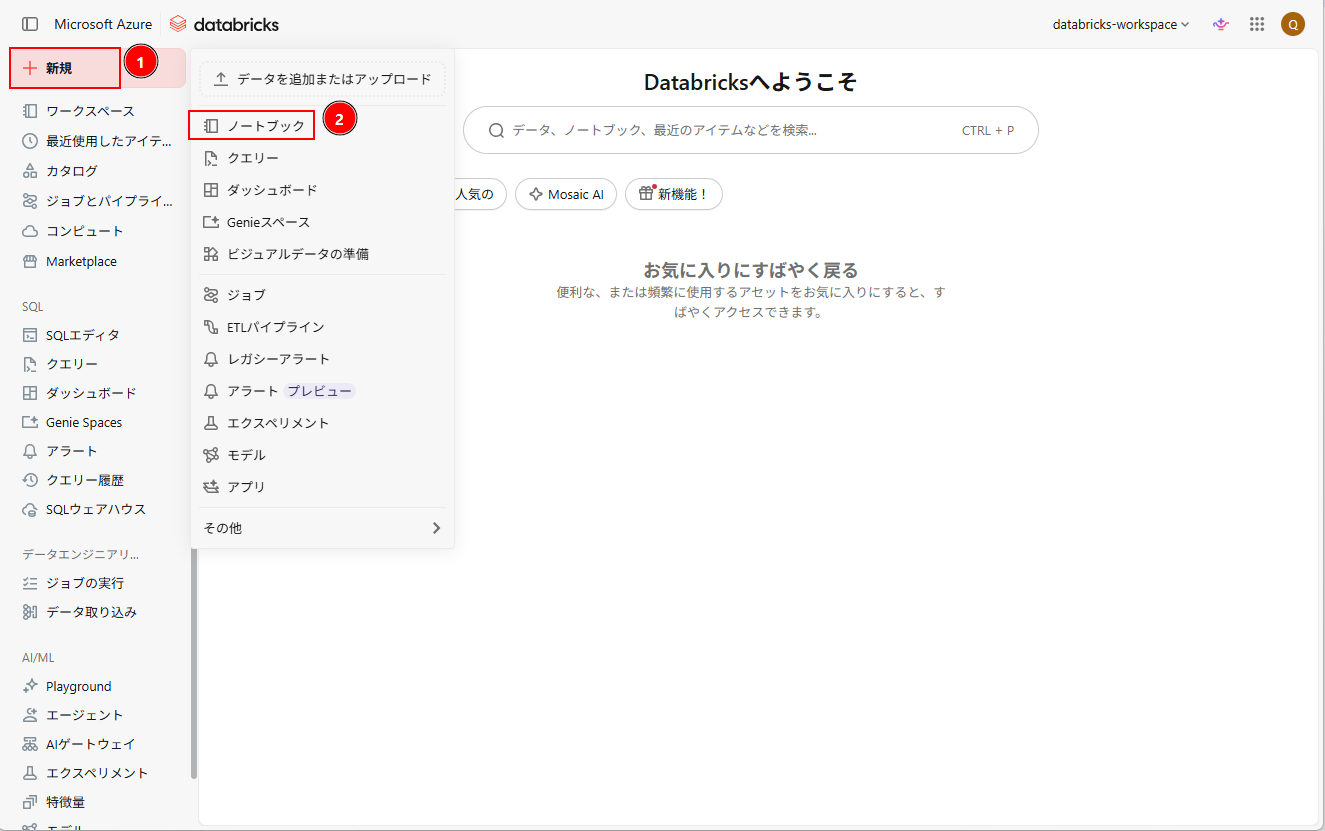
2. ノートブック上で、以下のコマンドを実行し、テーブル・スキーマを作成する。
|
1 2 3 4 5 6 7 8 9 10 |
%sql CREATE DATABASE IF NOT EXISTS blog_catalog; CREATE SCHEMA IF NOT EXISTS blog_catalog.myschema; CREATE TABLE IF NOT EXISTS blog_catalog.myschema.jlpt_vocab( Original STRING, Furigana STRING, English STRING, JLPT_Level STRING ); |
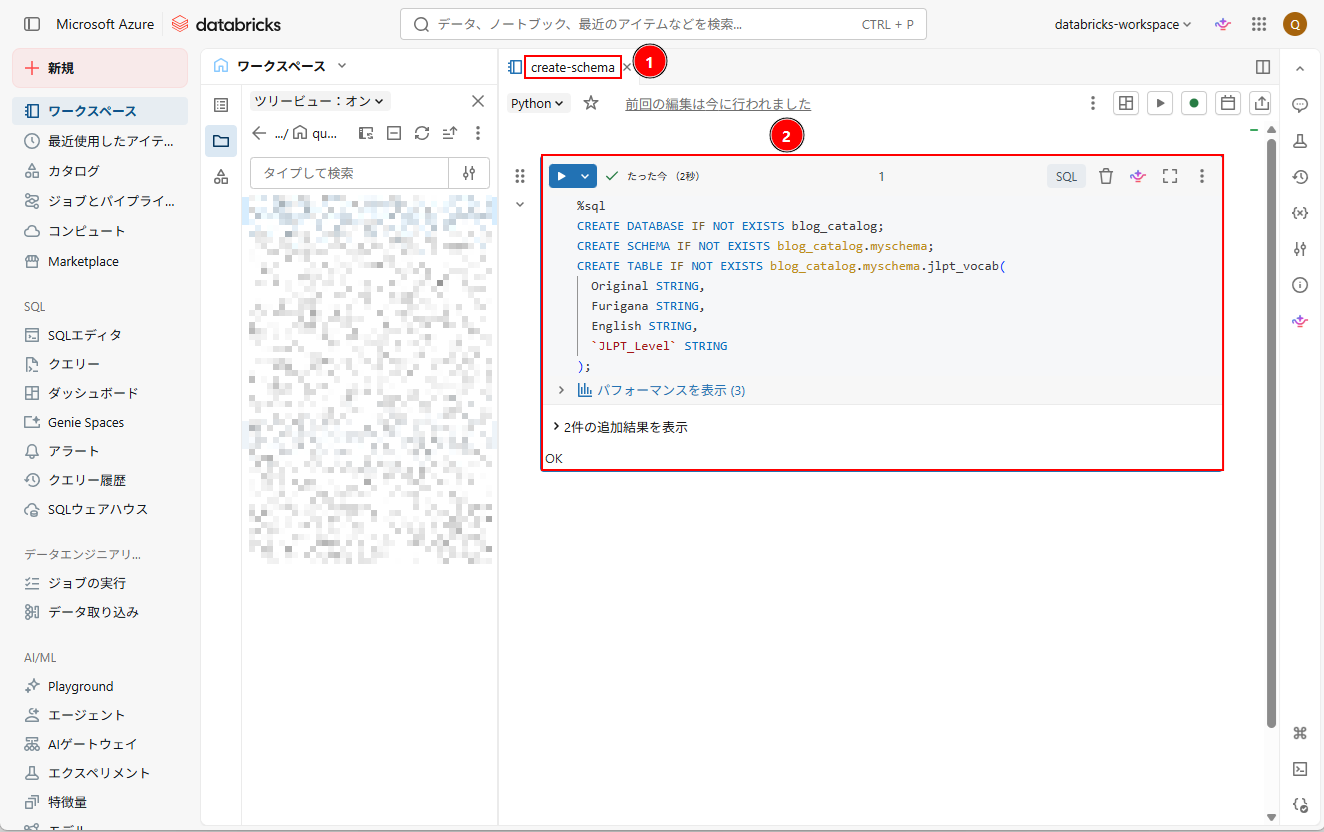
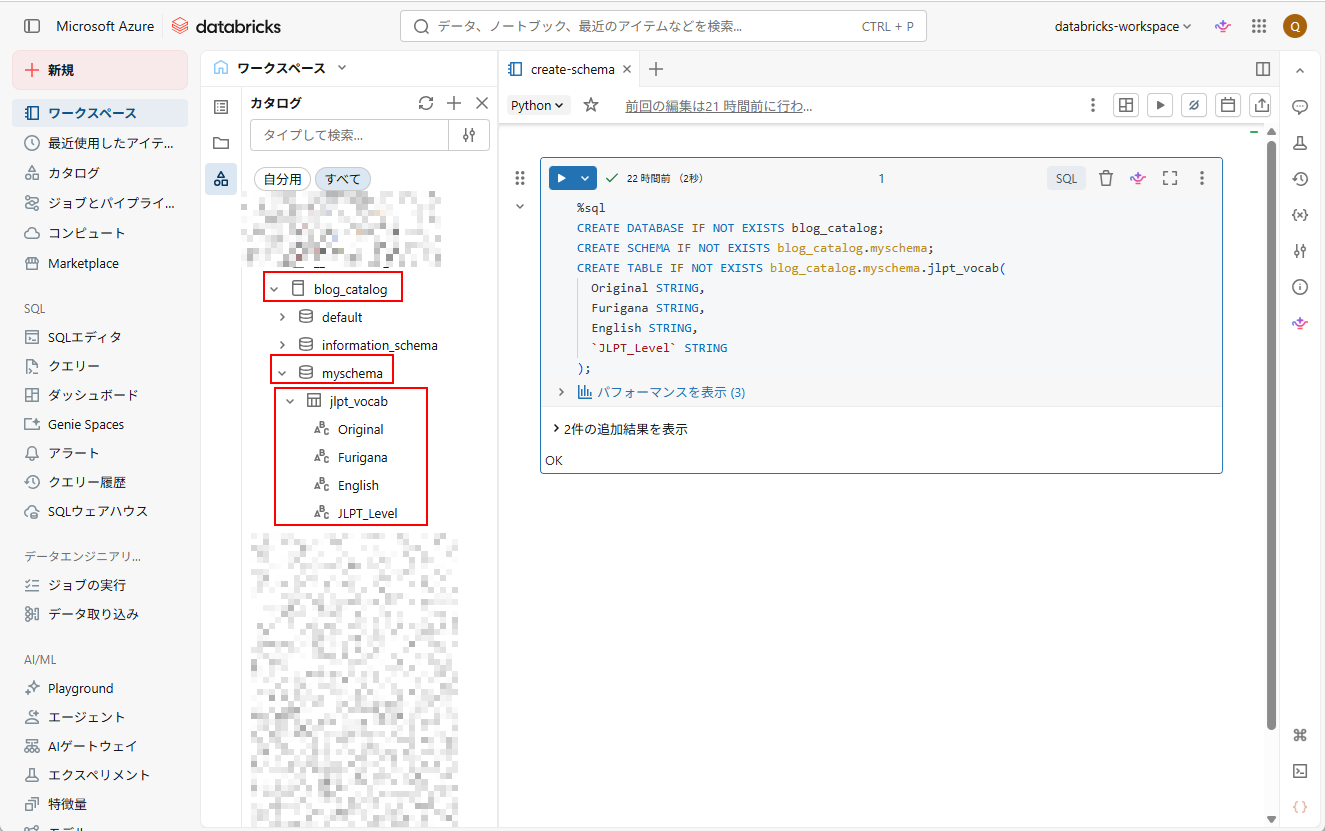
3. 実行後、テーブルが作成されていることを確認できる。
4-3.外部ロケーションへのサンプルファイルのアップロード
以下は外部ロケーションにサンプルCSVファイルをアップロードする手順です。
1. Azure Portal 上の ADLS Gen2 画面から、外部ロケーションとして使用するコンテナーにアクセスします。
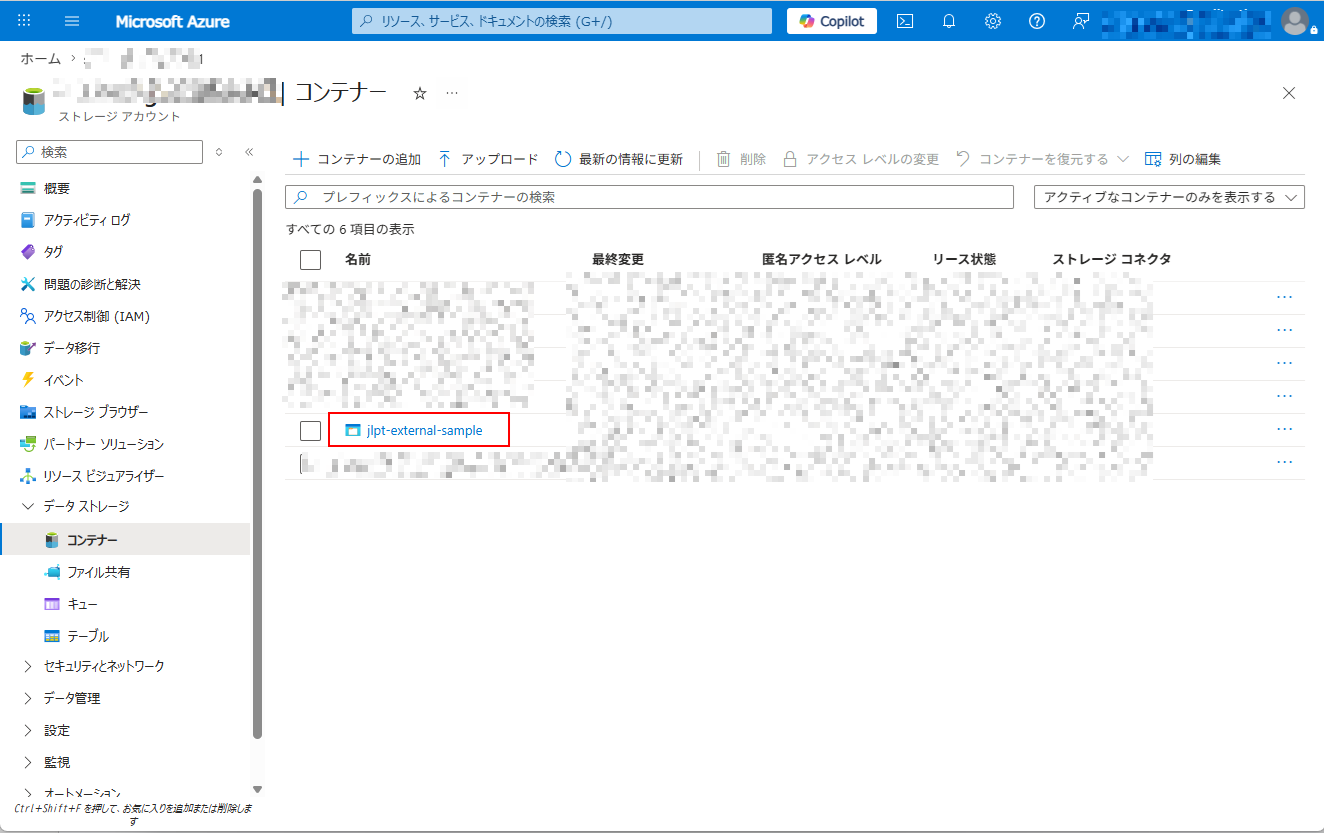
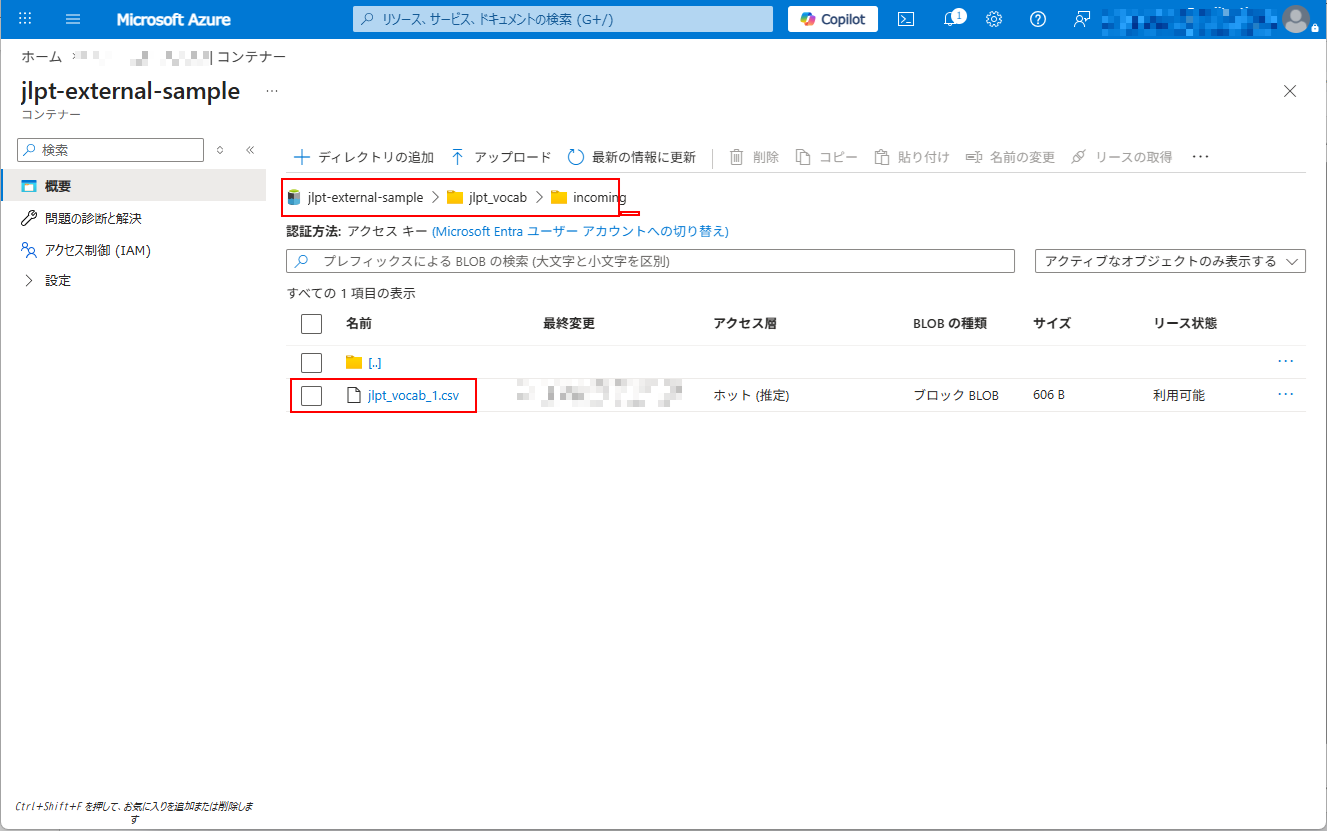
2. 次に、「jlpt_vocab/incoming」フォルダが存在しない場合は作成し、「incoming」フォルダにサンプルファイル「jlpt_vocab_1.csv」をアップロードする。
「jlpt_vocab_1.csv」は、は前提条件のステップでダウンロード済みのファイルです。
4-4.増分取り込み用のPythonノートブックの作成
以下は外部ロケーションからCSVファイルを読み込み、Unity Catalog内のテーブルに取り込むためのノートブックを作成する手順です。
1. Databricks Workspace のホーム画面から、「新規」→「ノートブック」をクリックする。
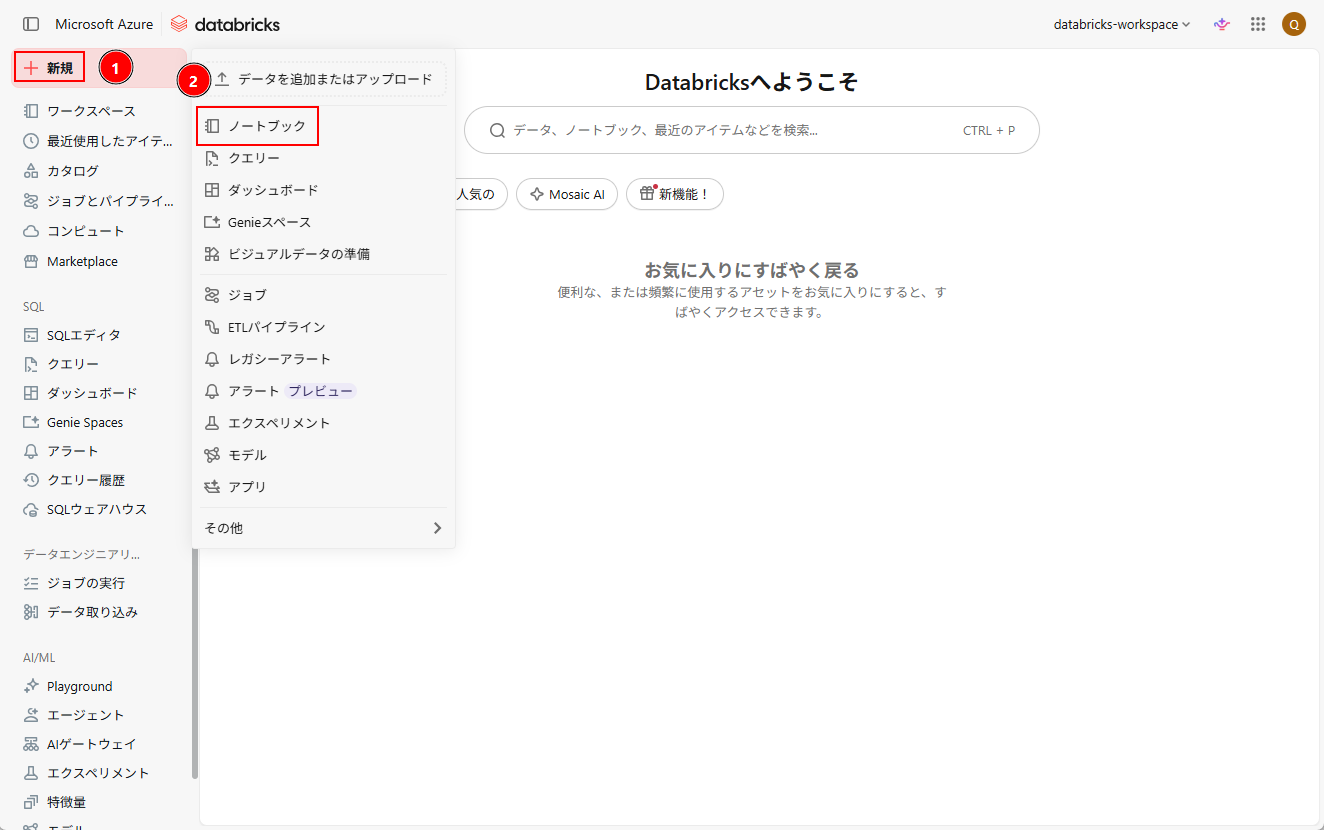
2. ノートブック名を「load-csv」に変更し、以下のコマンドを入力する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Configuration file_location = "abfss://<container_name>@<storage_account>.dfs.core.windows.net/jlpt_vocab/incoming/" # The same URL configured for the file arrival trigger. checkpoint_location = "abfss://<container>@<storage_account>.dfs.core.windows.net/jlpt_vocab/checkpoint_location/" # a separate URL (outside `file_location`) used to store the Auto Loader checkpoint, which enables exactly-once processing. sink_table = "blog_catalog.myschema.jlpt_vocab" # Delta table to write to # Use Auto Loader to discover new files. # Do not modify code below this line streamingQuery = spark.readStream.format("cloudFiles") \ .option("cloudFiles.format", "csv") \ .option("cloudFiles.schemaLocation", checkpoint_location) \ .option("cloudFiles.useManagedFileEvents","true") \ .load(file_location) \ .writeStream \ .option("checkpointLocation", checkpoint_location) \ .trigger(availableNow = True) \ .option("mergeSchema", "true") \ .toTable(sink_table) |
<container>: コンテナー名
<storage_account>: ストレージ アカウント名
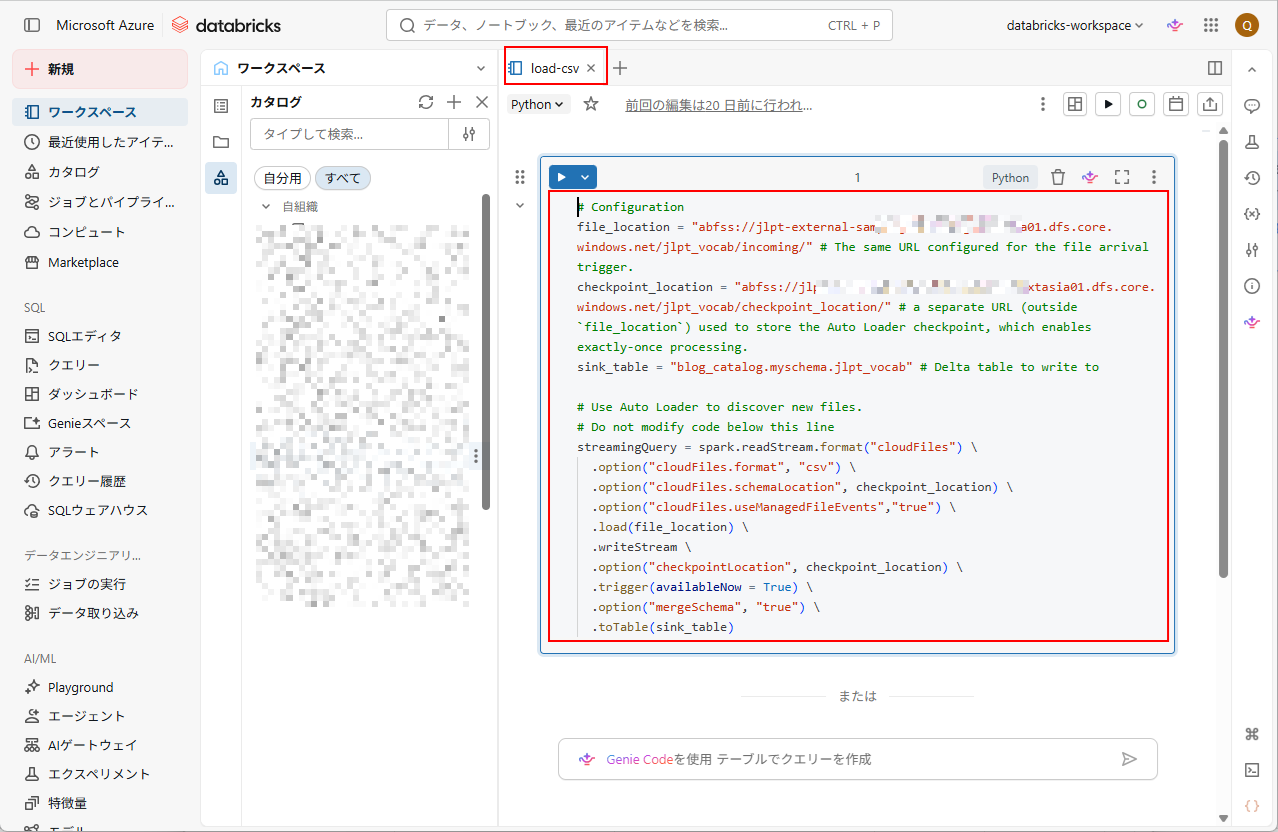
以上で、ノートブックの作成が完了しました。
4-5.ファイル到着トリガーを使用したDatabricksジョブの作成
以下はDatabricksジョブを作成し、ファイル到着トリガーを設定する手順を設定する手順です。
1. Databricks Workspace のホーム画面から、「ジョブとパイプライン」→「作成」→「ジョブ」をクリックする。
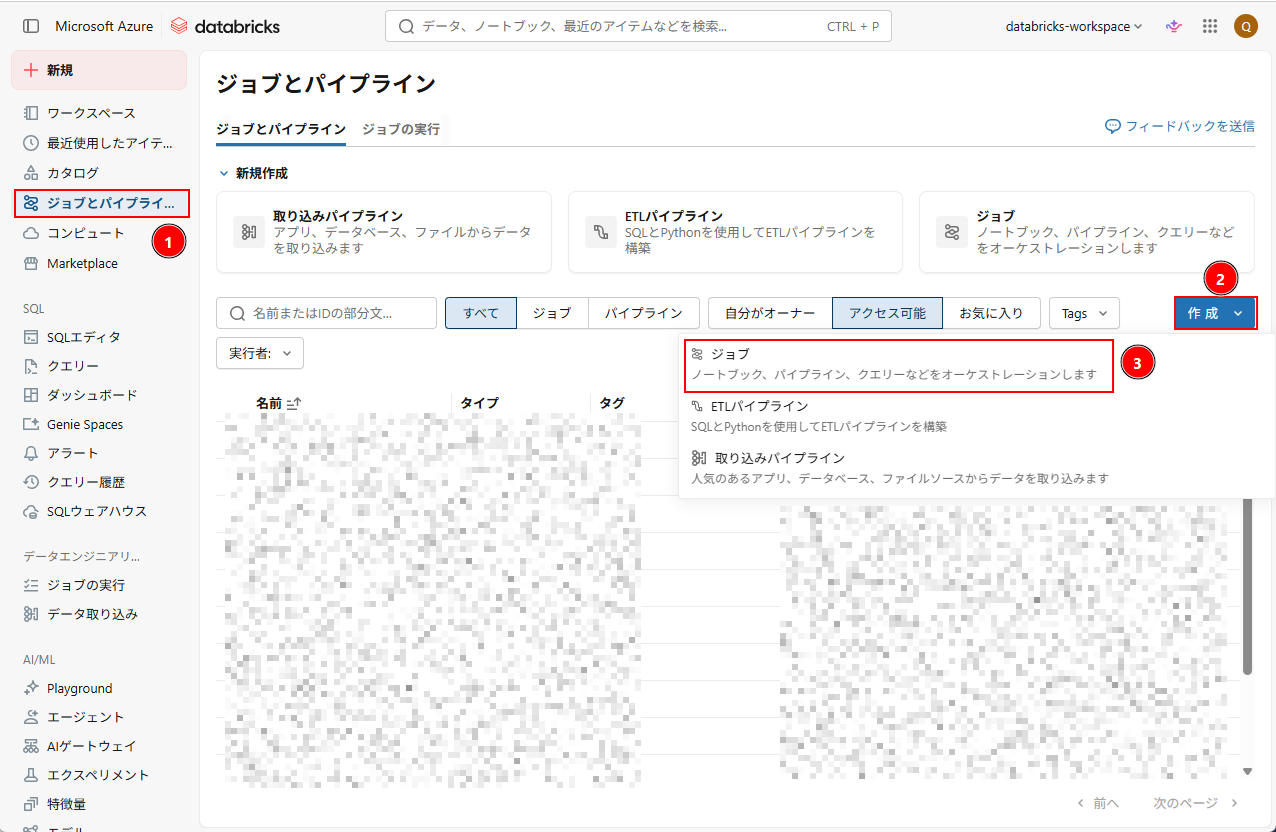
2. ジョブ名を「file-arrival-trigger-demo」に変更し、「ノートブック」をクリックしてタスクを追加する。本タスクでは、先に作成したノートブックを実行する。
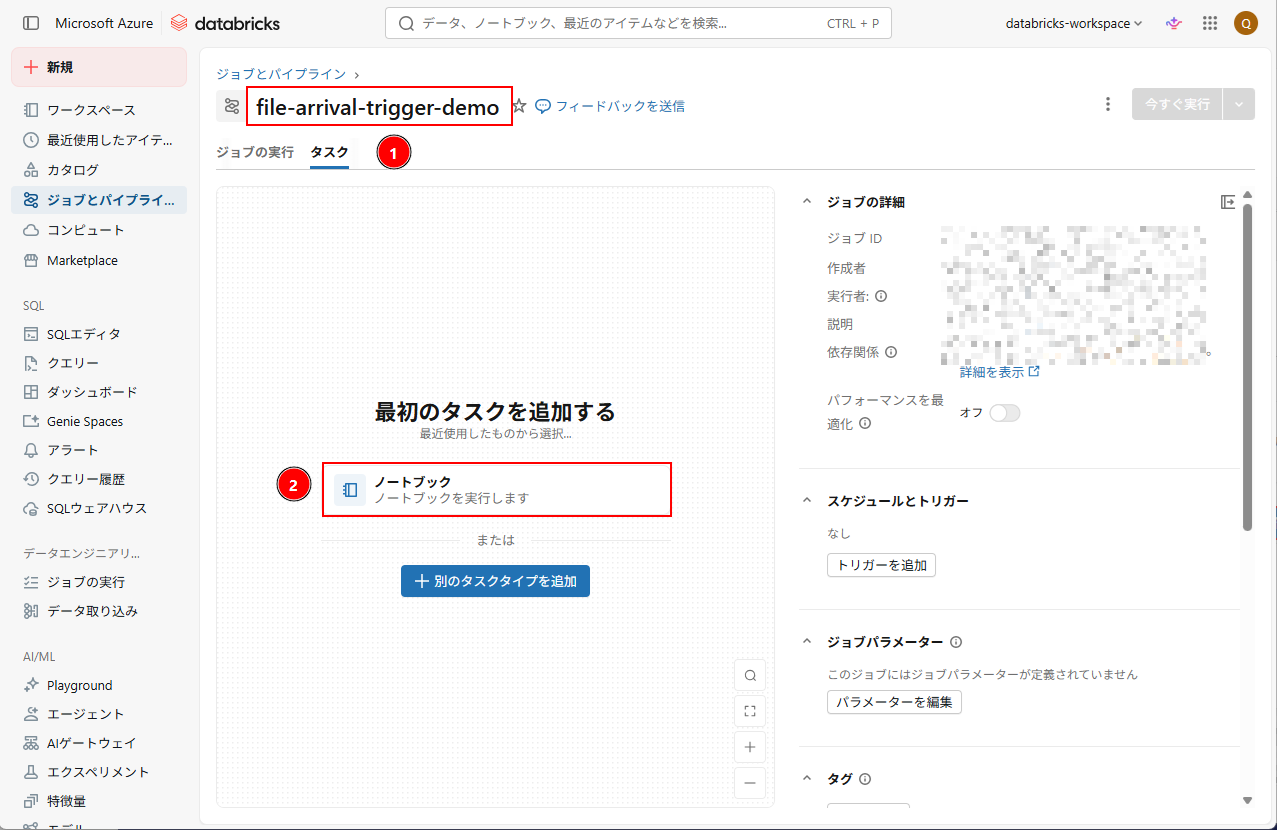
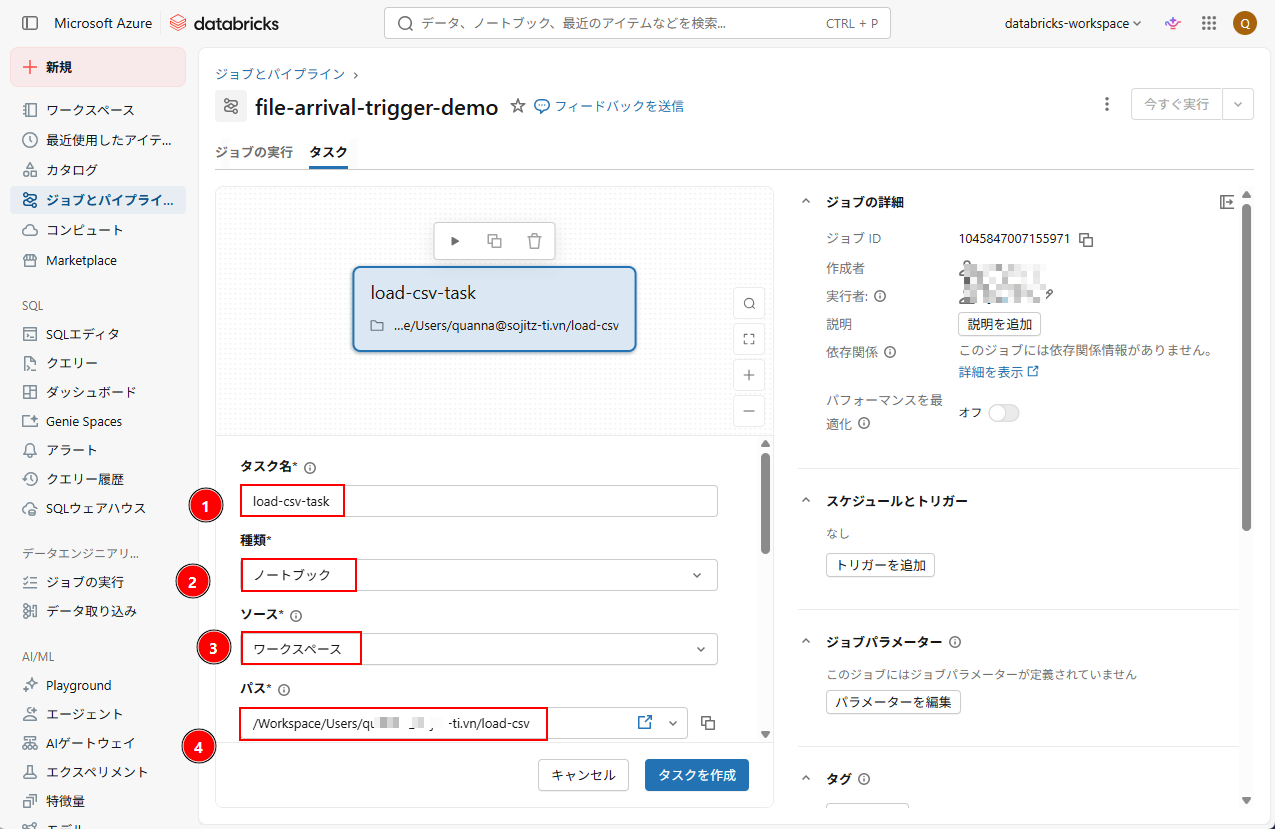
3. タスクの設定として、以下の情報を入力する。
- タスク名:タスク名を設定する(例:「load-csv-task」)
- 種類:ノートブック
- ソース:ワークスペース
- パス:作成済みのノートブックを選択する
4. 以下の情報を入力する。
- コンピュート: サーバーレス
- 環境とライブラリ: デフォルト設定のままとする。
「タスクを作成」をクッリクする。
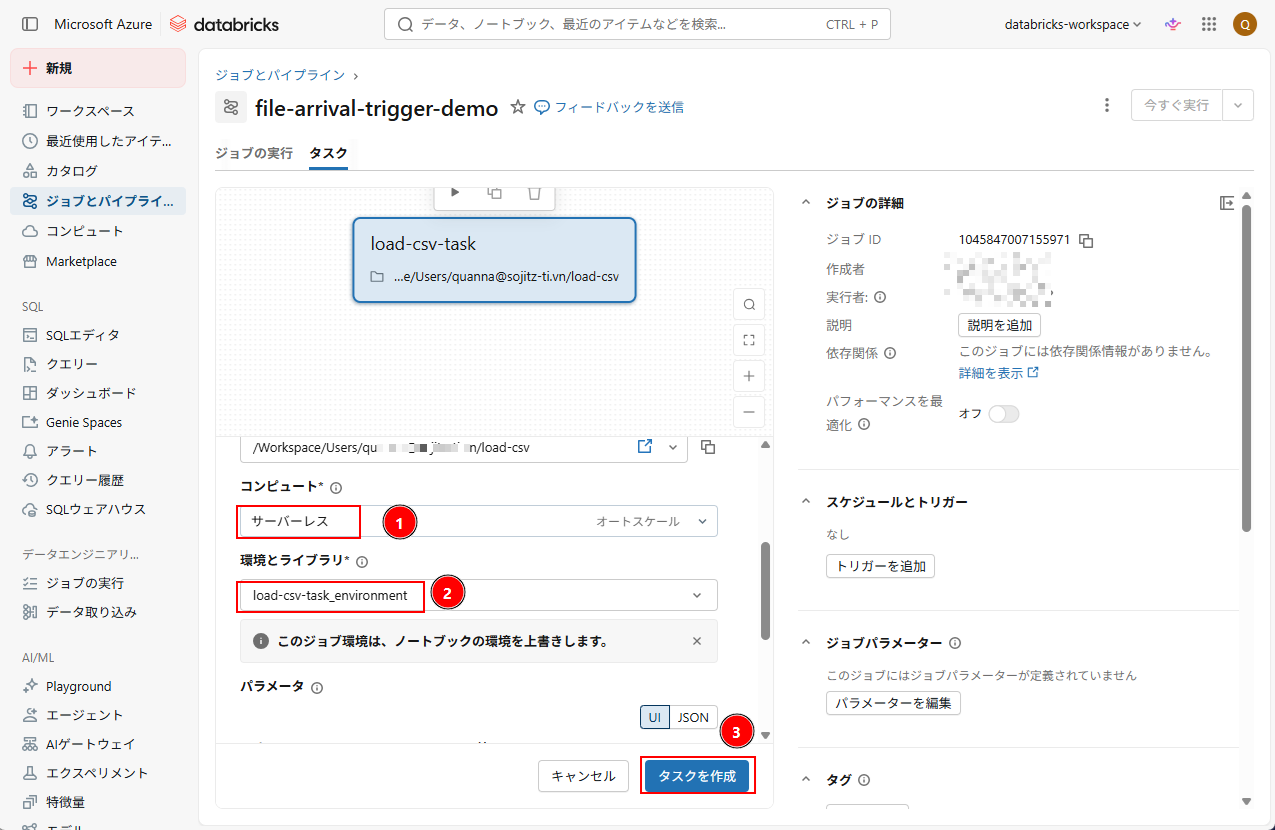
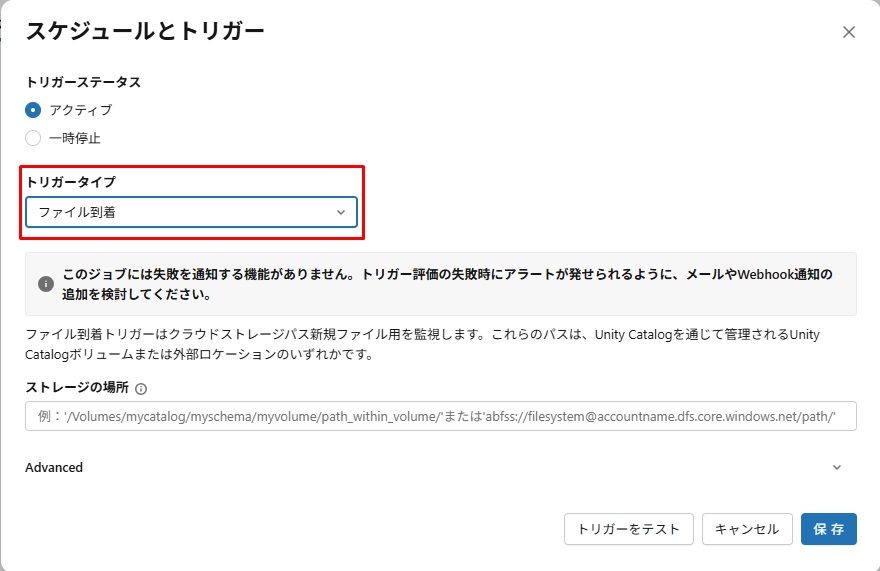
5. タスクの作成後、「トリガーを追加」をクリックし、ジョブのトリガーを設定する。
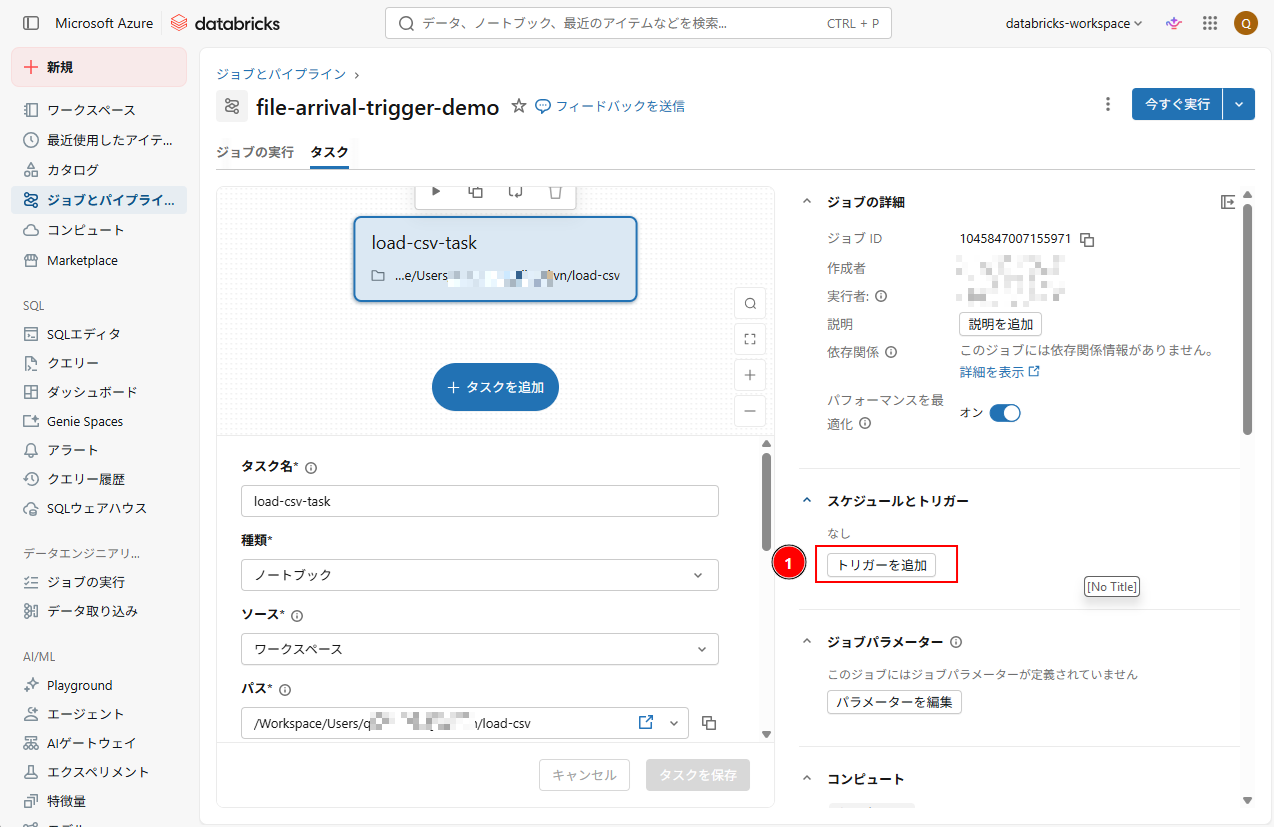
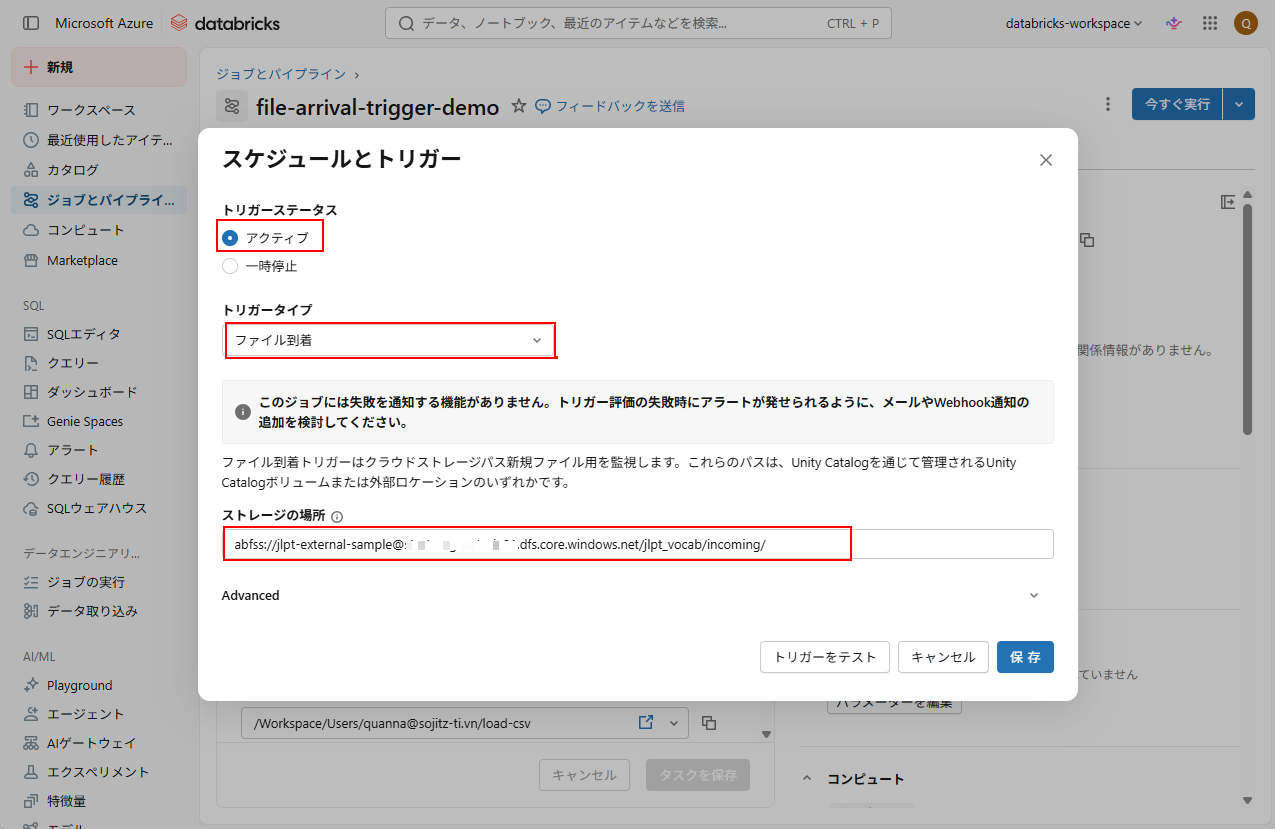
6. トリガーの設定として、以下の内容を入力する。
- トリガーステータス: アクティブ
- トリガータイプ: ファイル到着
- ストレージの場所:
|
1 |
abfss://<container>@<storage_account>.dfs.core.windows.net/jlpt_vocab/incoming/ |
<container>: コンテナー名
<storage_account>: ストレージアカウント名
設定後、「保存」をクリックする。
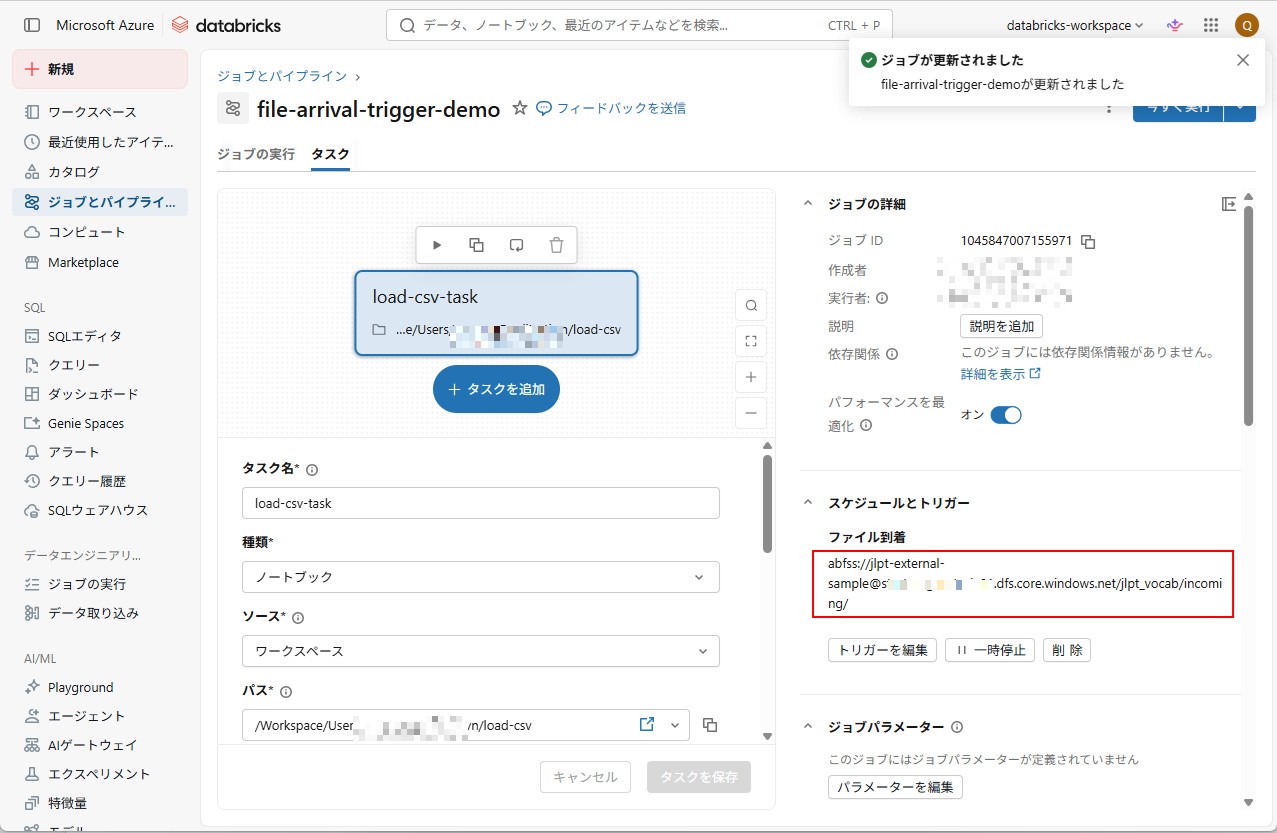
7. トリガーが正常に追加されていることを確認する。 「/jlpt_vocab/incoming/」のパスに新しいファイルが追加されると、本ジョブが自動的に実行される。
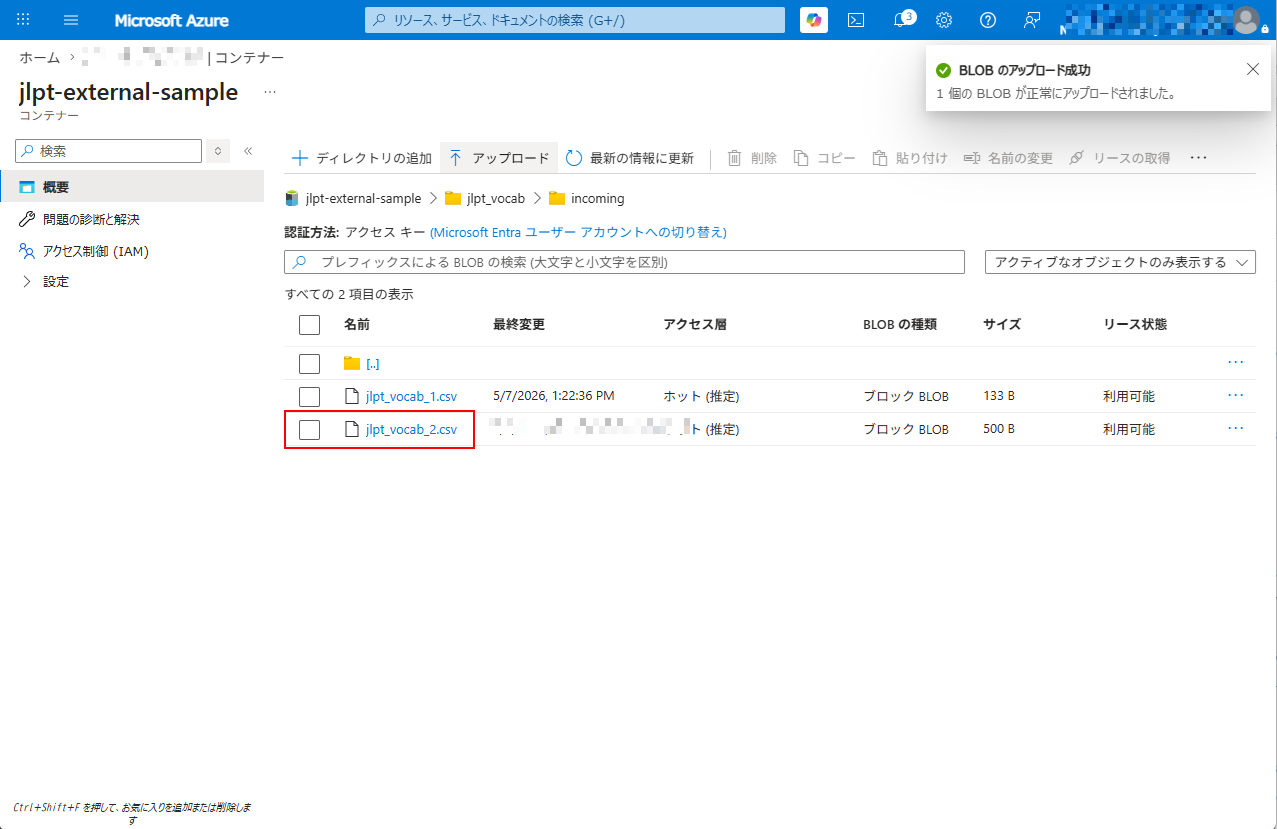
4-6.エンドツーエンドテスト
1. 検証のため、「/jlpt_vocab/incoming/」のパスに「jlpt_vocab_2.csv」ファイルをアップロードします。
2. Databricksジョブが自動的に実行されていることを確認できます。
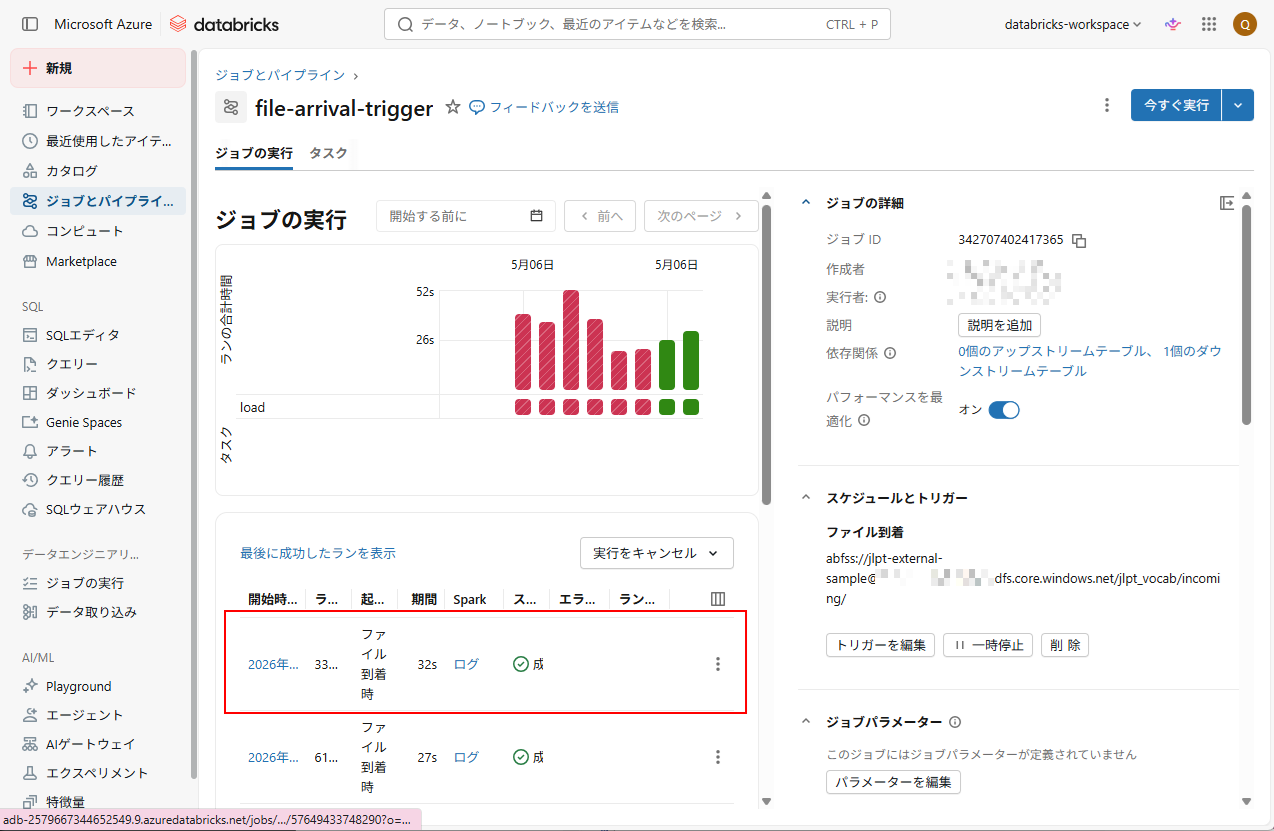
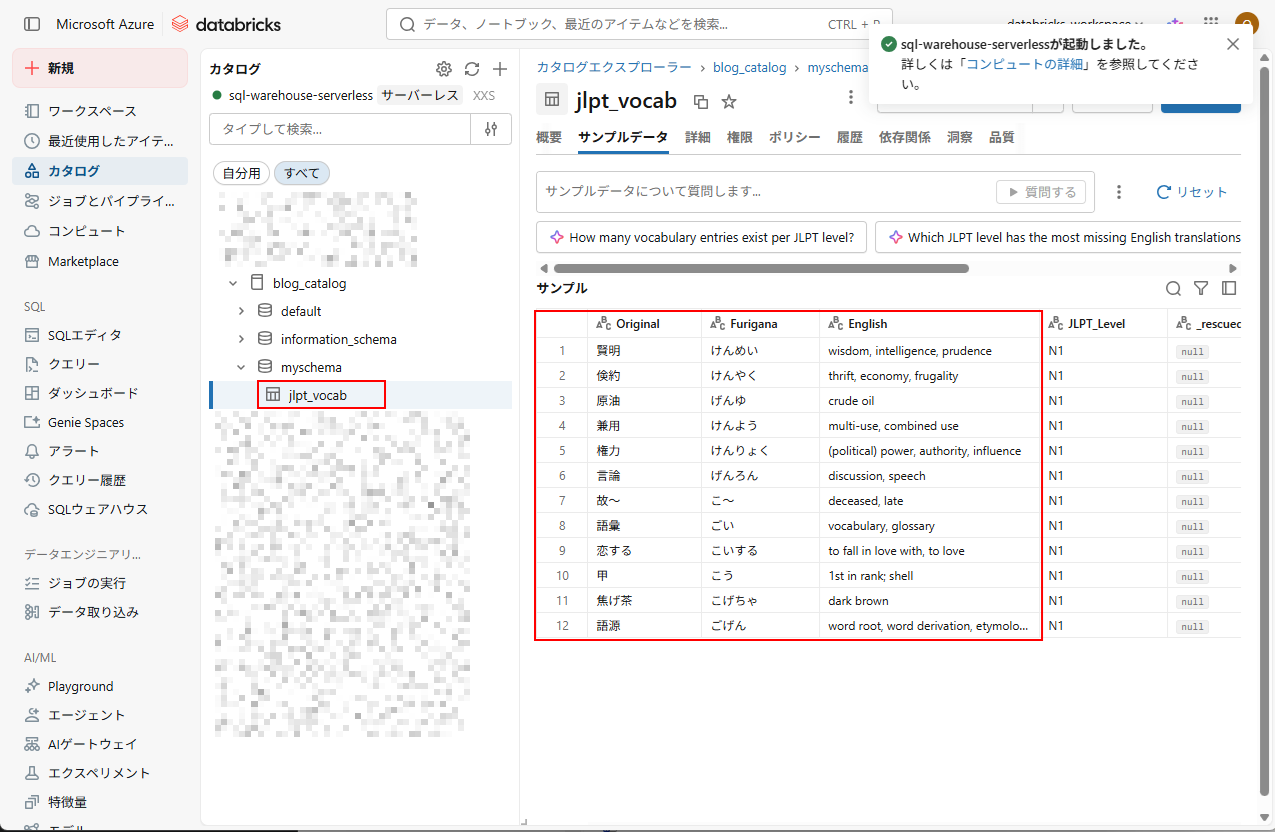
3. データが処理され、Unity Catalog 内のテーブルに格納されていることを確認できます。
5.まとめ
ファイル到着トリガーを活用することで、Azure Databricks上にイベント駆動型のパイプラインを構築できます。外部ロケーションにデータがアップロードされたタイミングで、ジョブが自動的に実行され、データのインジェストおよびDeltaテーブルの更新が行われます。
さらに、Unity Catalog(ガバナンス)とAuto Loader(増分処理+チェックポイント)を組み合わせることで、実践的な運用フレームワークを実現できます。これは、複数のデータソースからインジェストを行い、手動オペレーションを削減したい企業のData Platformにとって、非常に適した構成となります。
今回の記事が少しでも皆さんの新しい知識や業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたら是非お問い合わせください!
Azure Databricks連載記事のまとめはこちら
この記事を読んだ方へのオススメコンテンツはこちら
この記事を書いた人
この投稿者の最新の記事
- 2026年5月28日ブログ【Azure Databricks】外部ロケーションに新しいファイルが追加された際に、Databricks ジョブを自動的に起動する
- 2026年4月8日ブログ【Azure Databricks】Databricks環境におけるDatabricks Appsの設定および利用方法
- 2024年3月7日ブログ【Azure Databricks】Apache Airflow を使用して Azure Databricks ジョブを調整する
- 2024年2月27日ブログ【Azure Databricks】Auto Loader と Lakeflow 宣言パイプラインを組み合わせて使用してみる