目次
1.はじめに
皆さんこんにちは。
今回は、Azure Databricksのメダリオンアーキテクチャの考え方とどうやってブロンズ、シルバー、ゴールドを使い分けているかについて説明していきます。
2.概要
メダリオン アーキテクチャはデータを論理的に整理するために用いられるデータ設計を意味します。データがアーキテクチャの 3 つのレイヤー(ブロンズ → シルバー → ゴールドのテーブル)を流れる際に、データの構造と品質を段階的に向上させることでデータの分析や処理をより効率的に行うこうができます。
3.前提要件
サブスクリプション
・既存のサブスクリプションで共同作成者ロールが必要。
・Azure Data Factory、Databricks、Storage accountのリソースが作成されたこと。
・新規ファイルが作成される時にパイプライン実行用のトリガーがブロンズ コンテナーで設定されたこと。
Databricks ワークスペース
・コンピューティングの作成・起動・終了可能の権限を持っているアカウントが必要。
・カタログでデータ編集可能の権限を持っているアカウントが必要。
・Databricks Account Consoleの管理者ロールが必要。
4.メダリオンアーキテクチャ
4-1.メダリオンアーキテクチャとは
メダリオンアーキテクチャとは、レイクハウスのデータを論理的に整理するために用いられるデータ設計を意味します。データは3 つのレイヤー(ブロンズ → シルバー → ゴールドのテーブル)を流れる際に、データの構造と品質を向上させることを目的としています。メダリオンアーキテクチャは、「マルチホップ」アーキテクチャとも呼ばれます。
Data Lakehouseにも弱点があり、特に多種類のデータ(非構造データ、半構造データ、構造データ)を保存するためデータ管理が難しくなります。
メダリオンアーキテクチャを使用して、この課題を解決できます。
今回は、メダリオン アーキテクチャについて説明していきます。また、実際にメダリオン アーキテクチャを使用するサンプルも紹介していきます。
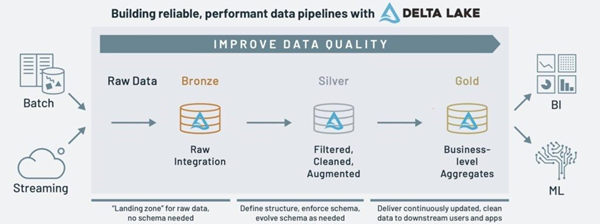
4-2.メダリオンアーキテクチャのレイヤにつて
- ブロンズレイヤー
ブロンズレイヤーでは、外部ソースシステムからのあらゆるデータを格納します。ブロンズレイヤーのデータの特徴が次の通りです。
-
- 再利用できるという目的で、ブロンズレイヤーのデータの情報はソースデータと同じ情報を持っています。
- データを簡単に検索・取得するために、データソースと時間などの特徴に応じて区別されます。
- シルバーレイヤー
ブロンズレイヤーのデータを結合、マージ、フィルタリング、クレンジング(適度なレベル)し、あらゆる主要なビジネスエンティティなどの汎用データを提供します。シルバーレイヤーのデータの特徴が次の通りです。
-
- 重複データが削除されます。
- 不要な情報が削除されます。
- 既存マスターデータテーブルと連携するために、リンクフィールドが追加されます。
- データのロールバックができるように、バージョン管理します。
- インデックスを作成します。
データをクエリすることはできますが、データがそれほど多くなく複雑でない場合は、3NF(第3正規形)やData Vaultなどのデータモデリングの手法を使用する必要はありません。
- ゴールドレイヤー
ゴールドレイヤーは業務ロジックに最適化されたデータを提供します。結合が少ない非正規化や、読み取りが最適化されたデータやビューを提供します。ゴールドレイヤーのデータの特徴が次の通りです。
-
- レポート作成に最適化されています。
- データはバージョン管理されます。
- 業務ロジックに応じてデータの構築が最適化されています。
4-3.メダリオンアーキテクチャの利点と弱点
利点
- 各レイヤーでデータを変換するためのロジックが明確に定義されているため、デバッグと改修が容易になります。
- 各レイヤーでデータ品質が改善されるので、再分析実行の時間もかかりません。
- ゴールドレイヤーのデータが特定の目的のために使用されるので、再分析実行が必要である場合もあります。生データから再実行が不要であることから、時間をかなり節約できます。
- データが複数のレイヤーに分割されるので、ユーザーの権限割り当てを管理やすいです。ユーザーグループが、利用目的に応じてレイヤーのみにアクセスできます。
弱点
- 多くのストレージ容量が必要:複数のレイヤーに分割されるので、データ量も増えてきます。
- 影響範囲の把握:データの変更が発生した際の影響範囲をつかみにいです。(Databricksのデータリネージ機能を活用することで影響範囲を把握可能です)
5.メダリオンアーキテクチャの事例
5-1.概要
ADFでパイプラインを使用する場合、コンテナーで新規ファイルが作成されるたびにパイプライン実行用のトリガーを設定する必要があります。パイプライン実行用のクラスターが、トリガーからの起動信号があると有効になり、データの処理が終了すると無効になります。
Delta Live Tables を使用して実行する場合、トリガーの設定が不要であり、パイプラインがコンテナーからストリーミングデータ処理を実行できます。ただし、パイプライン実行用のクラスターが、データストリーミングのために、継続的に有効になる必要があります。
今回の例では、ファイル受信を想定しているためADFを使用します。パイプラインの実行手順は次の図の通りです。各ノートブックが、レイヤーでデータのフィルターを実行します。
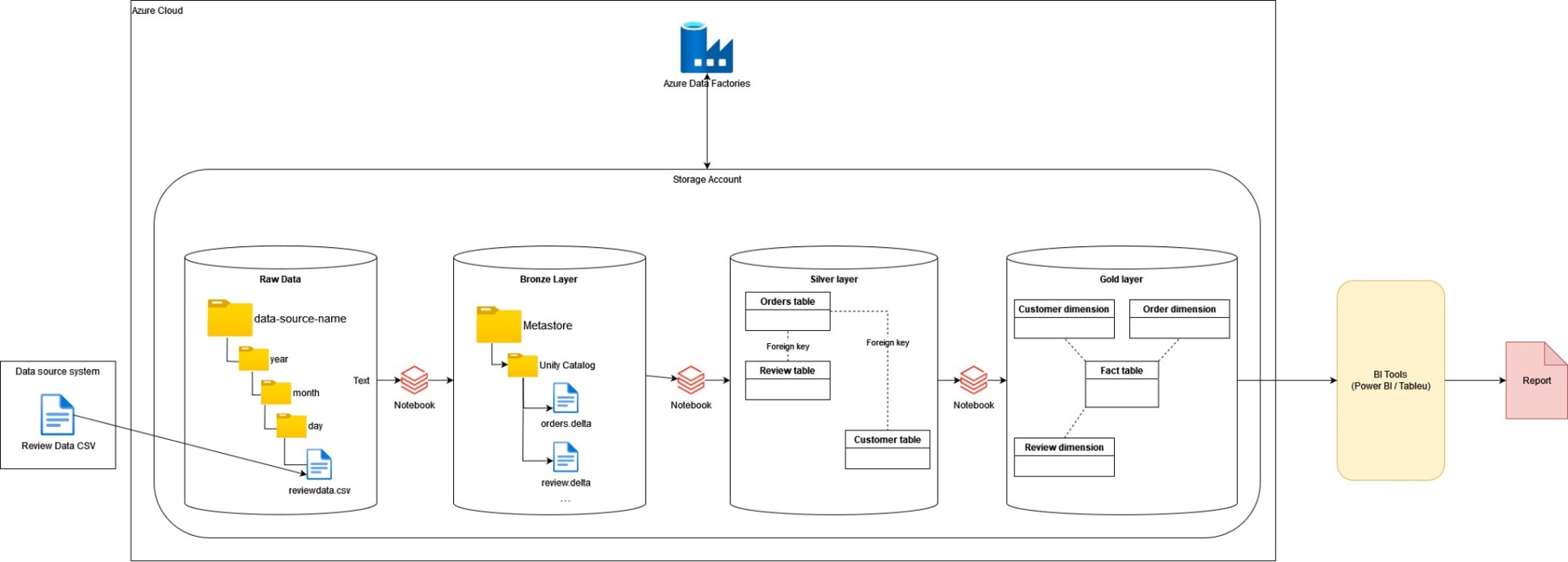
国別格付けが総収益に比例しているか確認するためのデータ加工する際、各レイヤーでどういった処理を行う必要があるか説明いたします。
生データ⇒ブロンズレイヤー
- AZCopyを使用し、外部データソースからデータをストレージアカウントに保存します
- ストレージアカウントからデータを読み込み、Delta形式のテーブルとして保存します
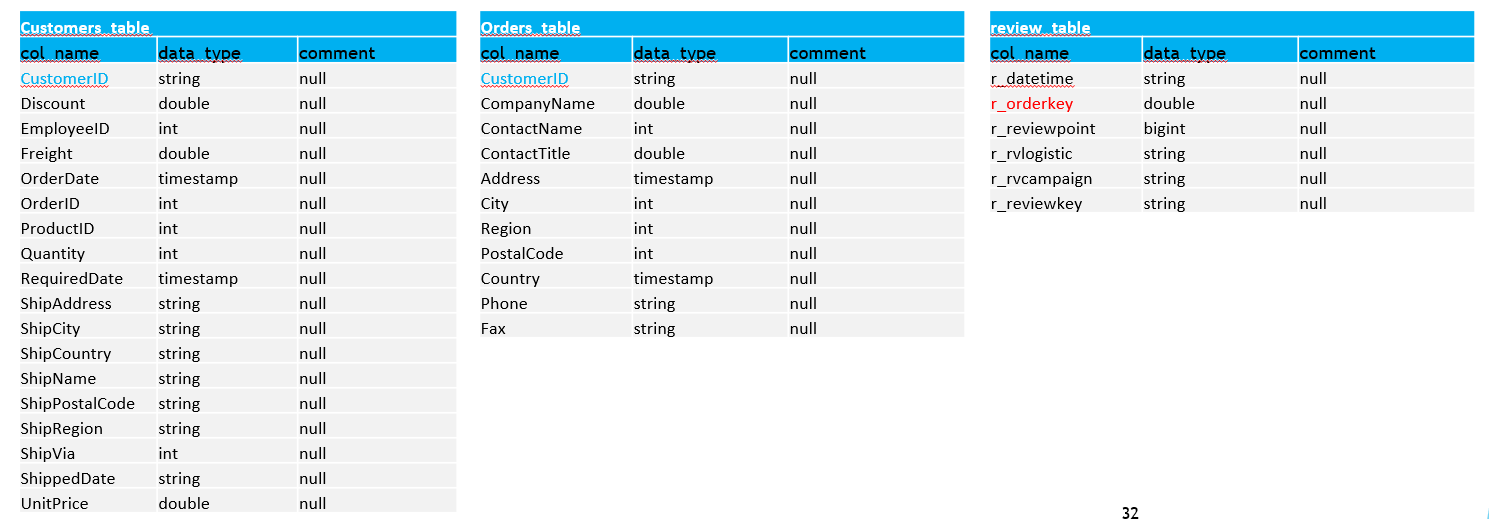
ブロンズレイヤー⇒シルバーレイヤー
- 列名を変更を実施します(スペースを下線で置き換える、列名を短縮する等)
- 以下のデータを代入、変換します
- r_orderkey:全ての NULL データを「1」に代入します
- r_reviewpoint:データ型を Long (整数) に変更します
- review_idを作成します: review_idが「timestamp」+「r_orderkey」で構成され、主キーとして設定します
- シルバーレイヤーの orders_table と review_table を更新します
シルバーレイヤー⇒ゴールドレイヤー
- 国別の平均格付けを抽出します
- 国別の総収益を抽出します
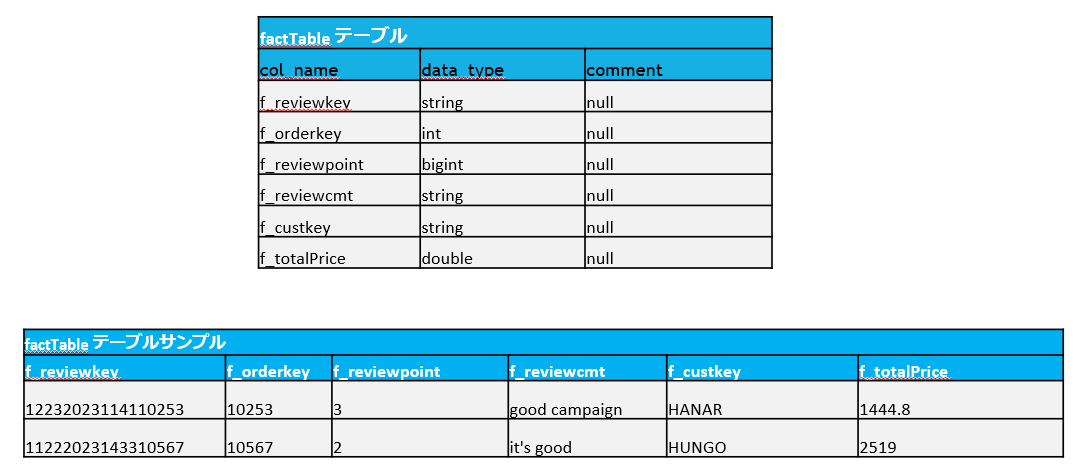
- スター スキーマ データモデリングに従い、Dimensions と Facts のテーブルを作成しレポートを提供します
- Fact:(f_reviewpoint)格付けおよび、(f_totalPrice)総収益に関する情報
- Dimension:国別情報 (customer_dimension テーブル内) があり、「[CustomerID] = [f_custkey]」キーを使用して [fact] テーブルに連携されます
5-2.パイプラインの作成
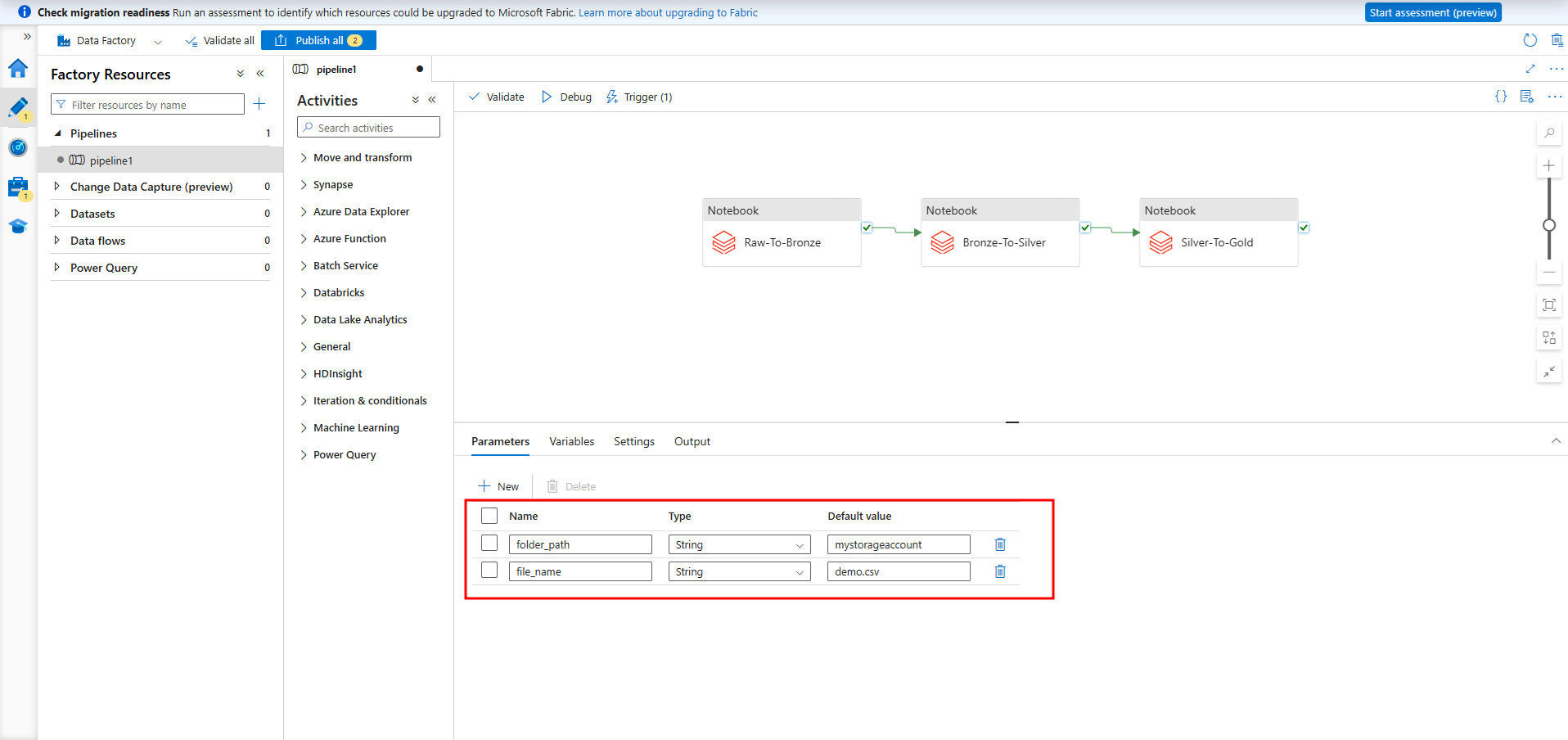
① 今回の例では、ストリーミングデータではないので、Azure Data Factoryを使用してパイプラインを実行します。Databricksへ「new job cluster」新規ジョブクラスターで接続するように設定するので、パイプラインがトリガーされると新規クラスターが起動されます。Databricks ワークスペースからアクセス トークンを取得します。
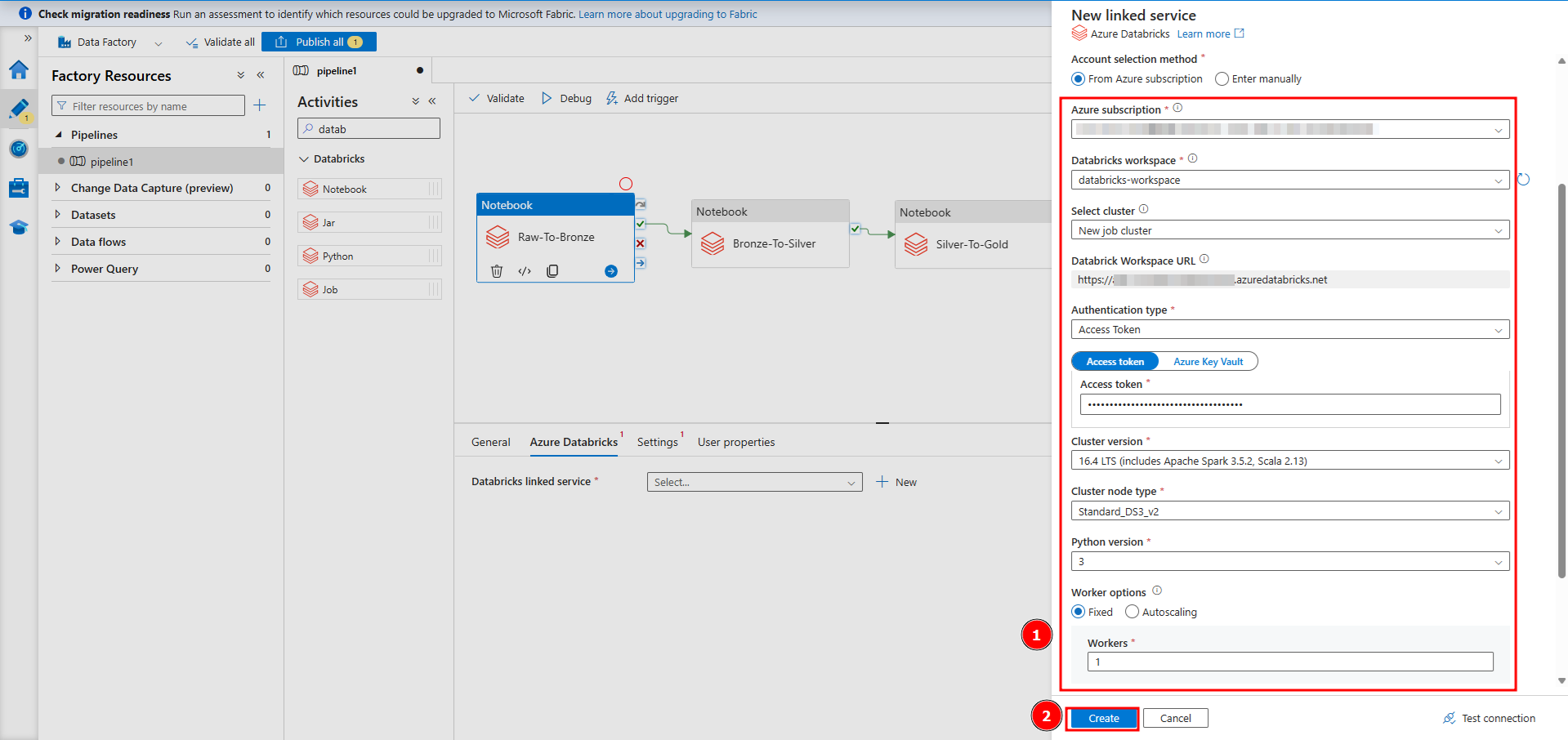
パイプラインが以下の3つノートブックを実行します。
- 生データからブロンズレイヤーまでデータ変換用のノートブック
- ブロンズレイヤーからシルバーレイヤーまでデータ変換用のノートブック
- シルバーレイヤーからゴールドレイヤーまでデータ変換用のノートブック
② 生データからブロンズレイヤーまでデータ変換用のノートブックを使用して、Blob ストレージへファイルアップロードのトリガーを設定します。
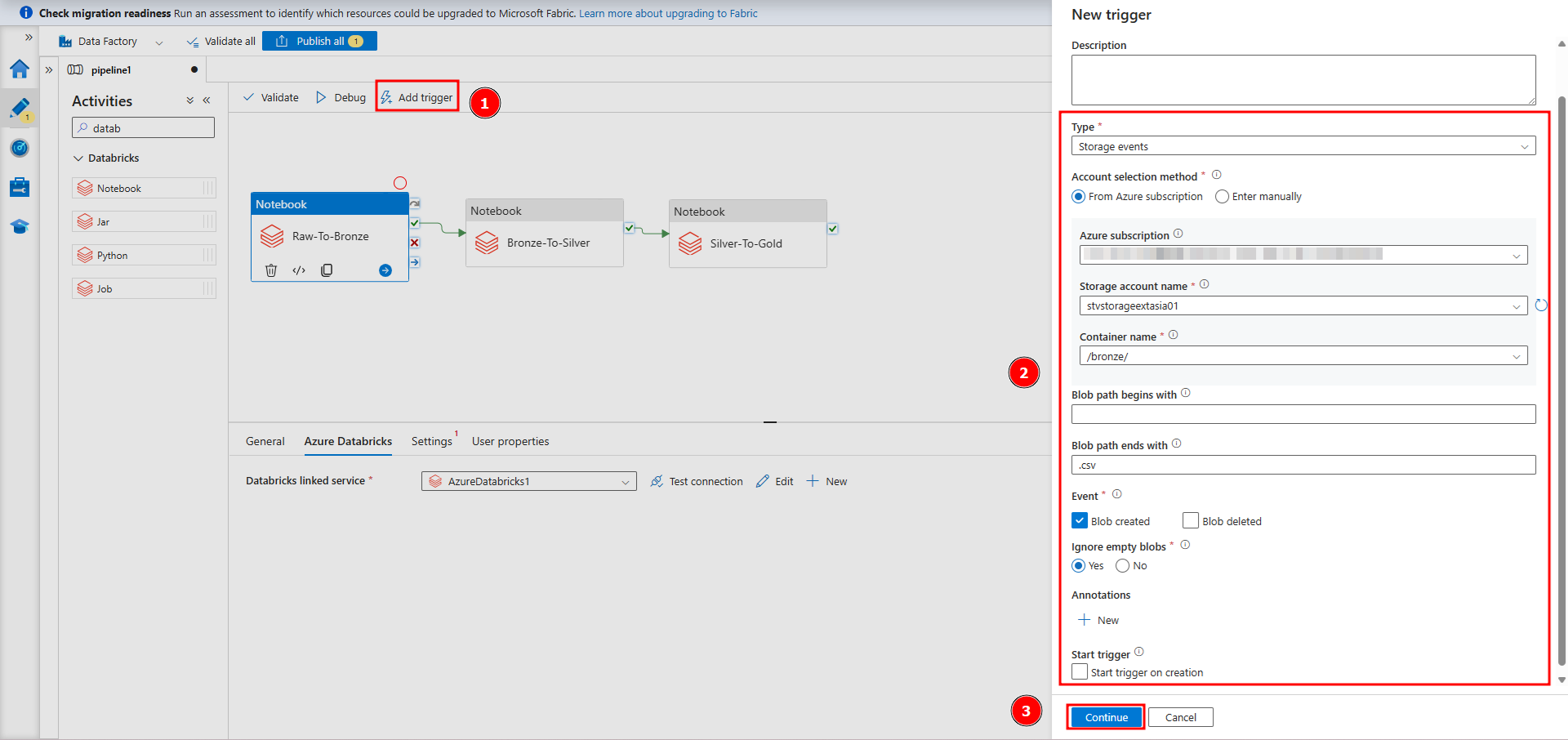
③ ストレージアカウントへのアップロードした新規ファイルのパスをノートブックが取得できるようにトリガーまたはパイプラインのパラメーターを設定します。
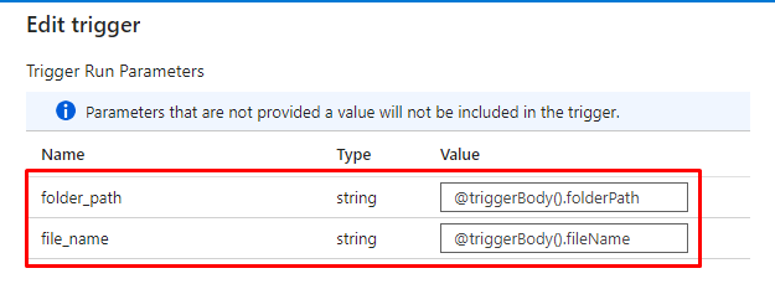
④ 1番目のアクティビティへファイルパスが以下の設定通りに渡されます。
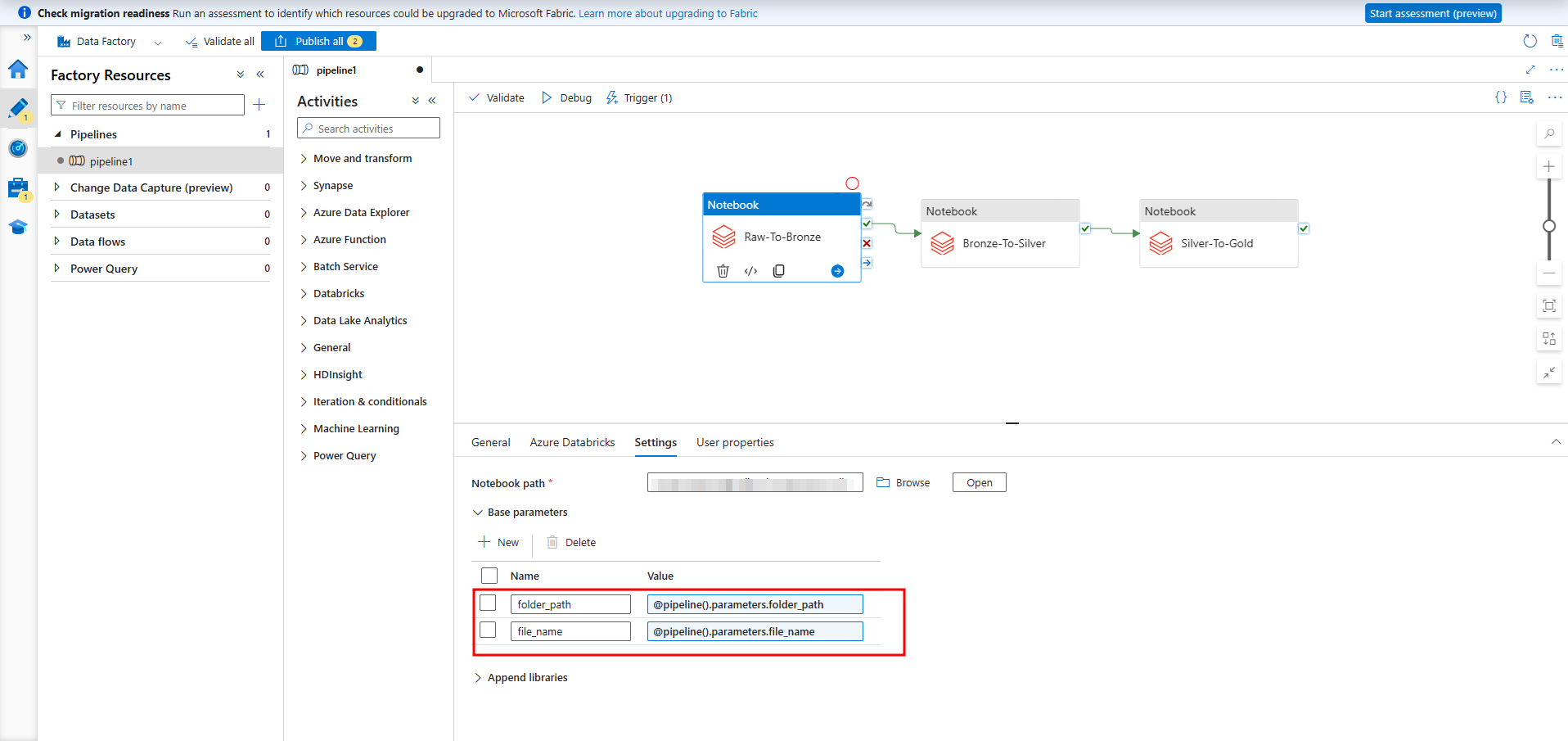
5-3.データの起動
① 新規データがシステムへアップロードされた時の ETL プロセスを示すために、各レイヤーで必要なデータを作成します。
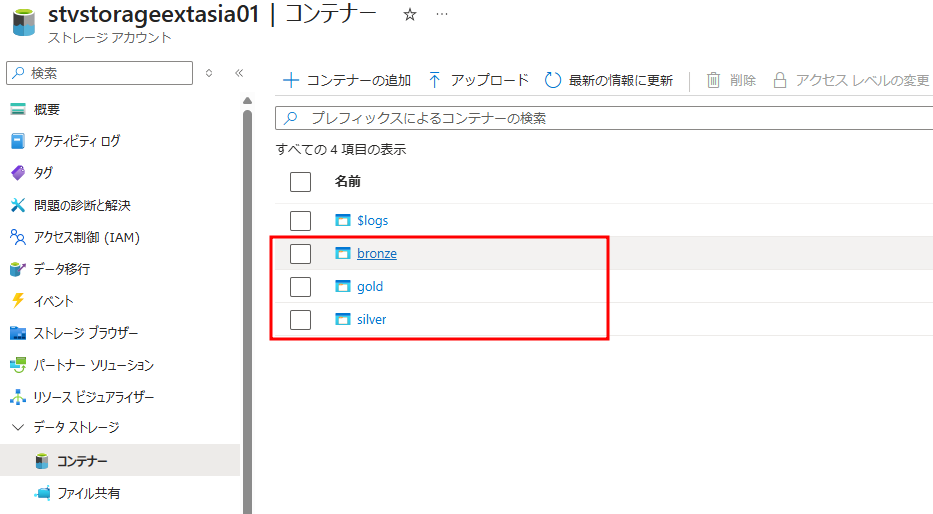
② 作成されたコンテナに対応するシルバーレイヤーとゴールドレイヤーのスキーマを含む外部の場所を作成します。
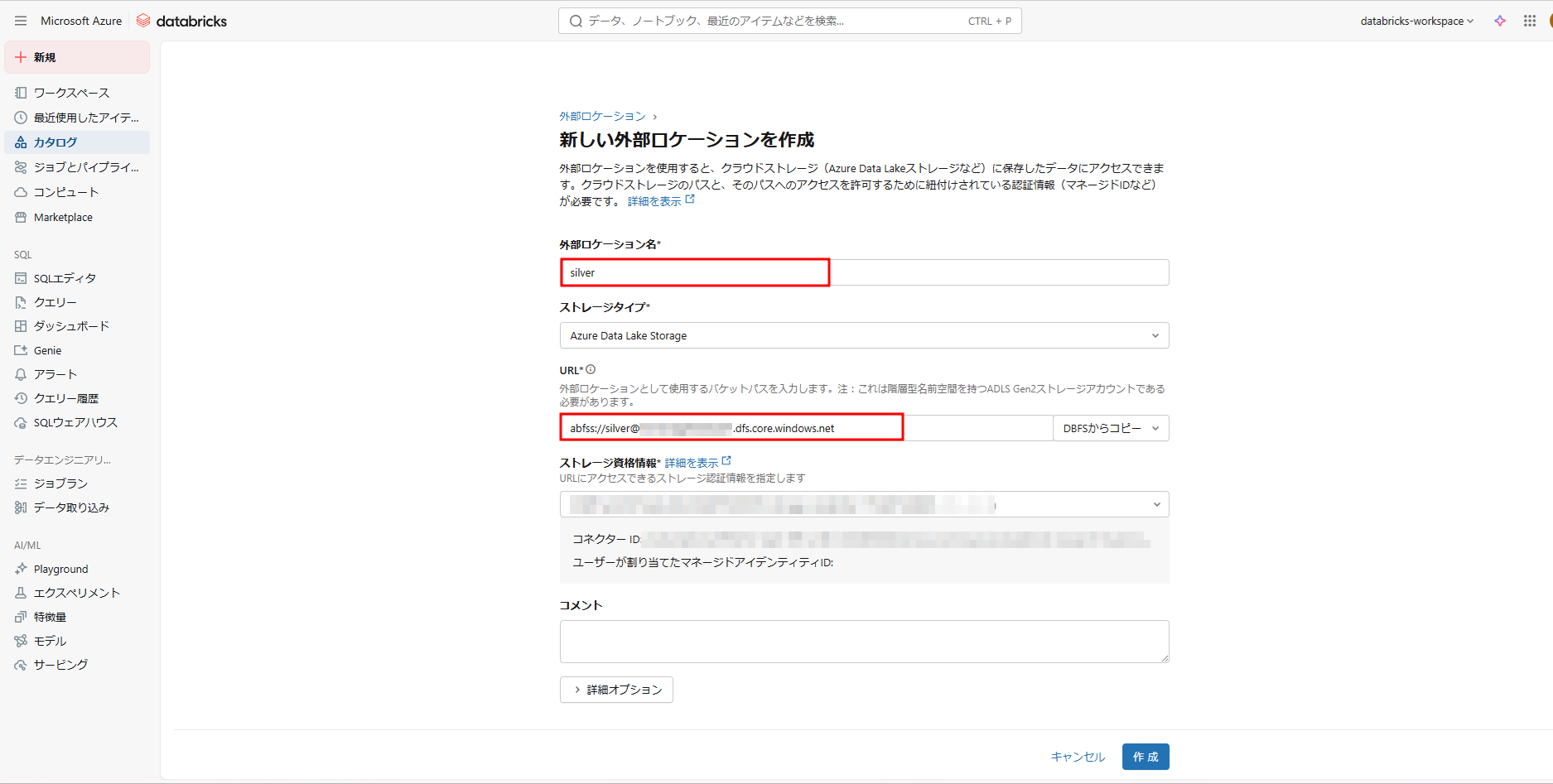
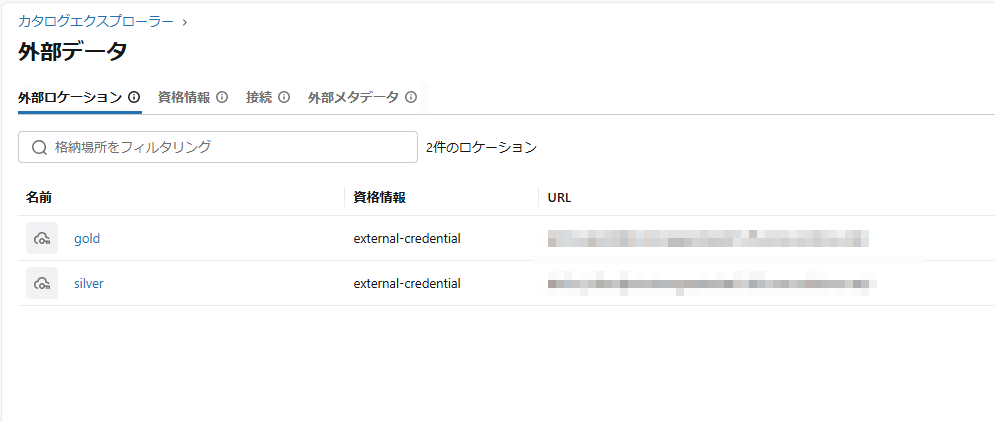
③ シルバーレイヤーとゴールドレイヤーのデータを格納するシルバーとゴールドのスキーマを作成します。
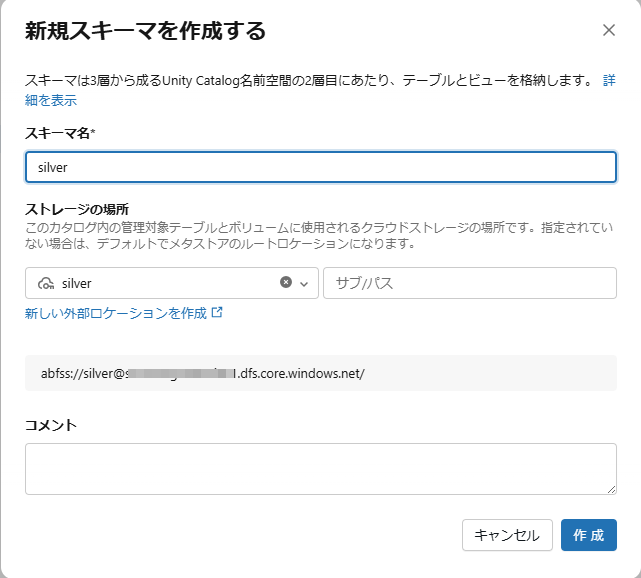
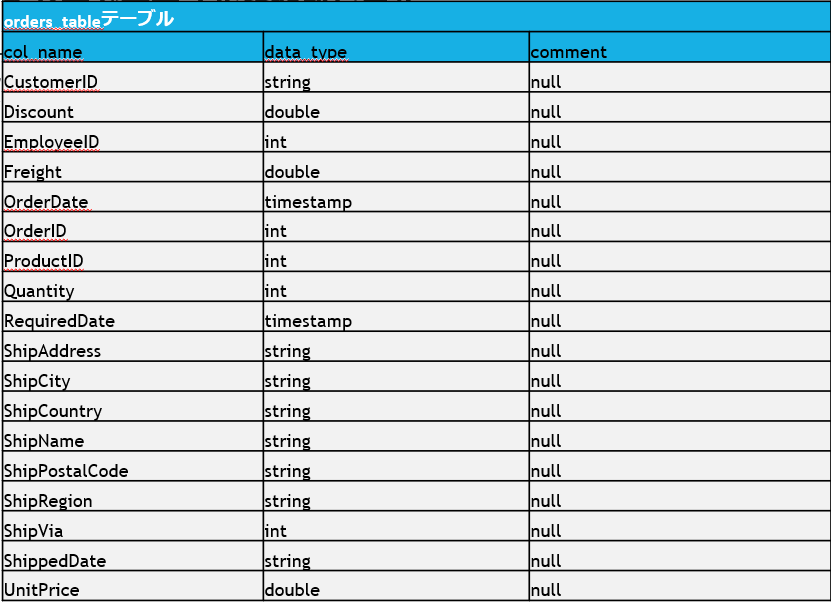
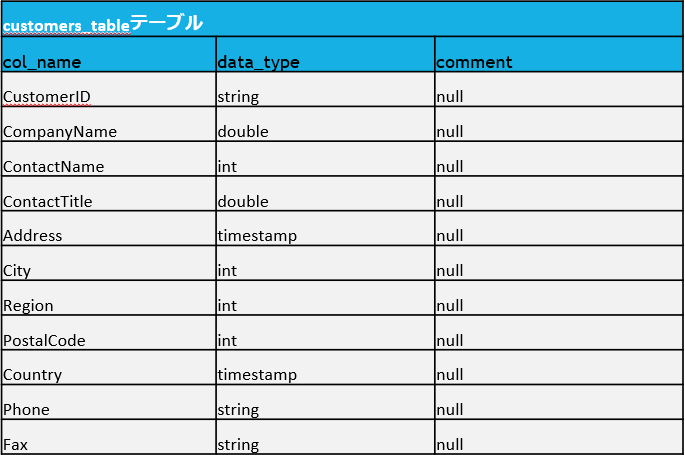
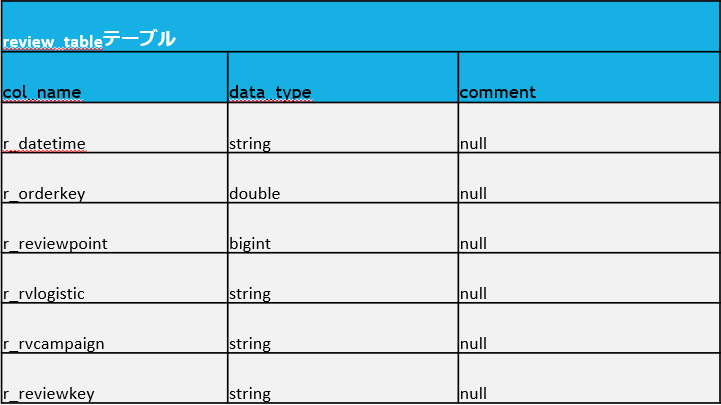
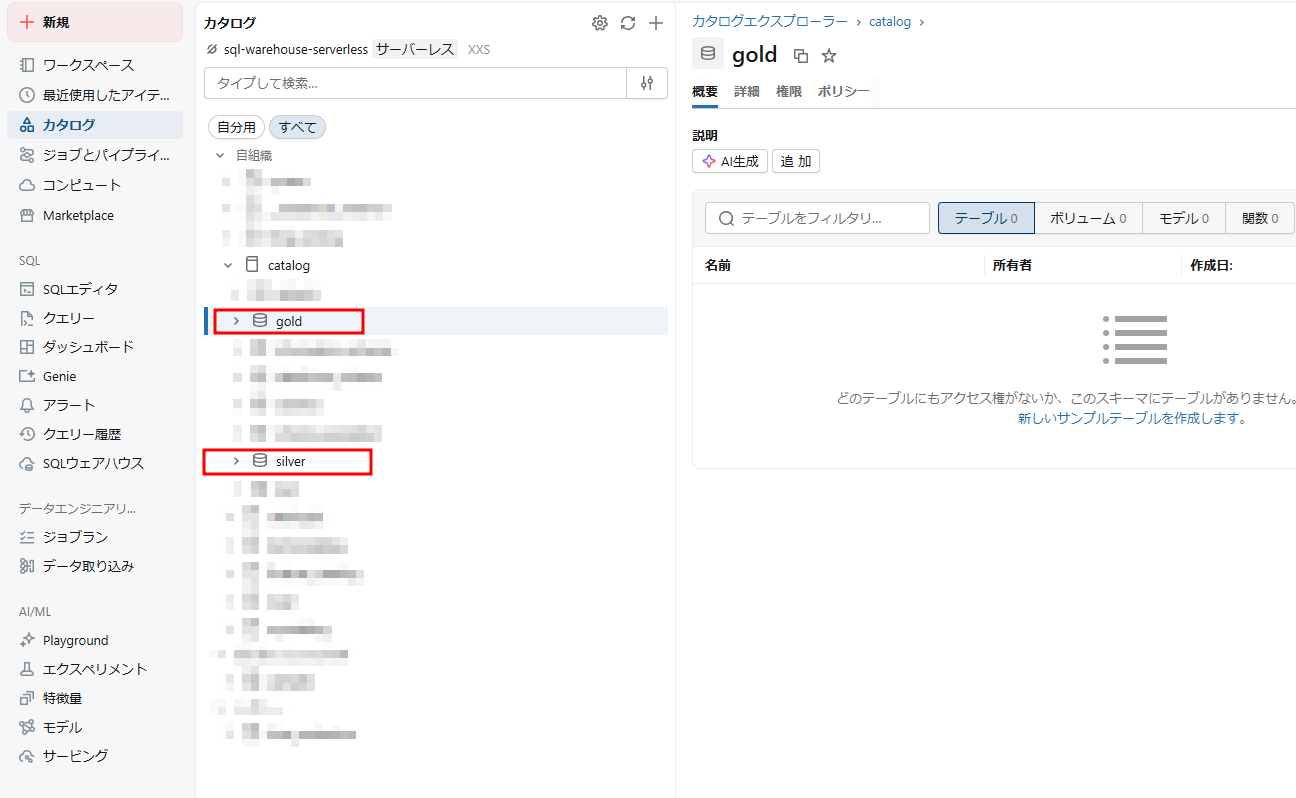 シルバーレイヤーでテーブルを作成します。
シルバーレイヤーでテーブルを作成します。
このテーブルが、ブロンズから生データを主キー・外部キー追加などの業務的なデータに変換するように使用されます。



ゴールドレイヤーでテーブルを作成します。
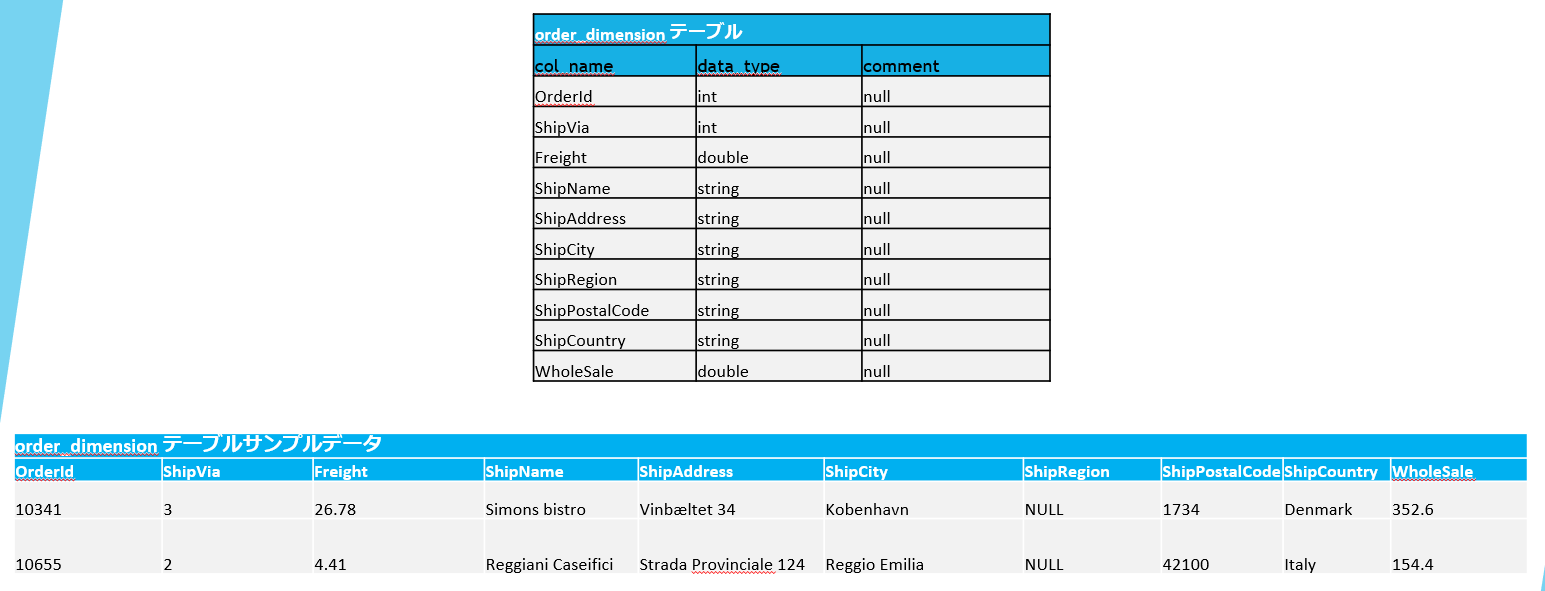
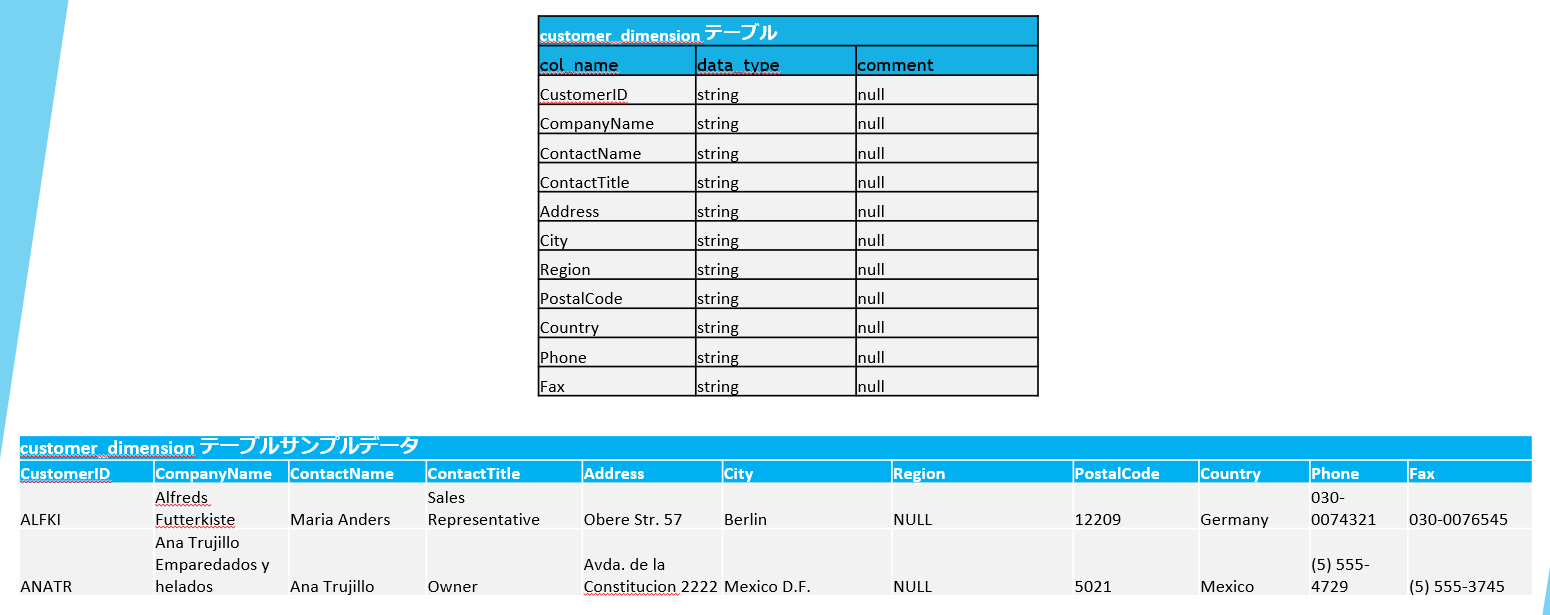
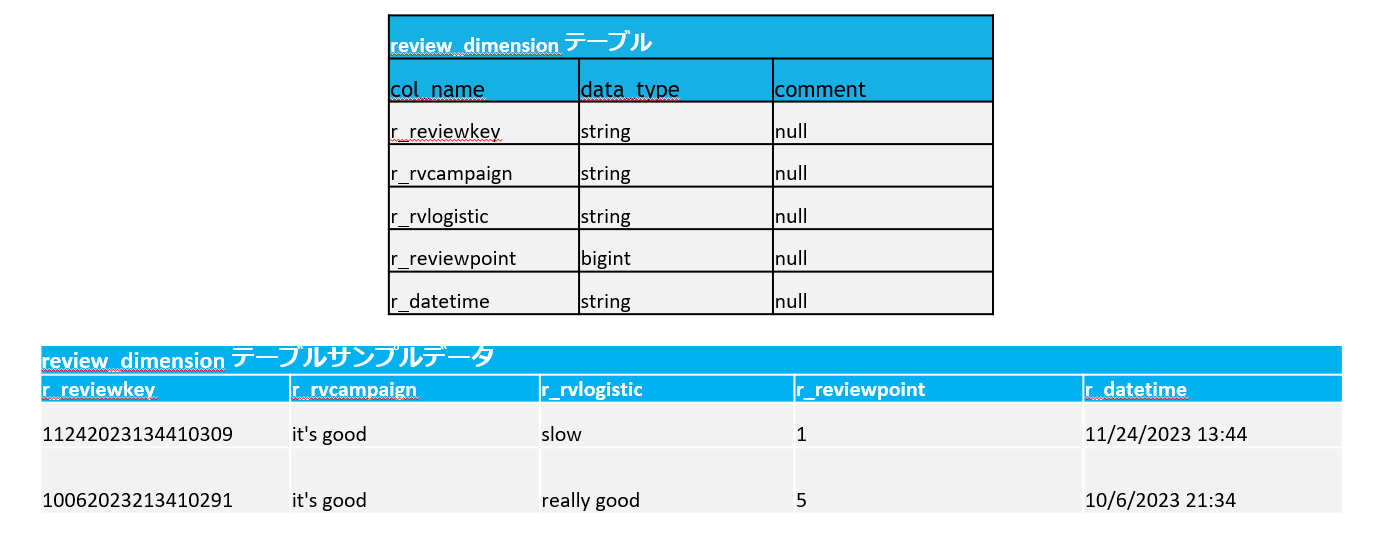
5-4.ブロンズレイヤーの処理
ググールでダウンロードされたCSVファイルが、次の形式に従います。

CSVファイルがフォルダパス <データソース名/年/月/日>に保存します。
以下のazcopyコマンドを使用して、ストレージアカウントへこのCSVファイルをアップロードします。
※ 文法
azcopy copy “local-file-path” “https://<storage-account-name>.blob.core.windows.net/<bronze-container-name>/<file-path>?<sas-token>”
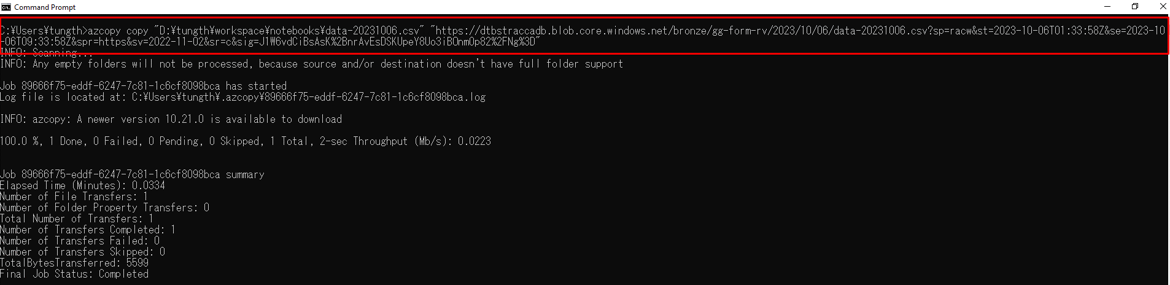
CSVファイルがアップロードされると、パイプラインがファイルパスというノートブックの入力値でトリガーされます。
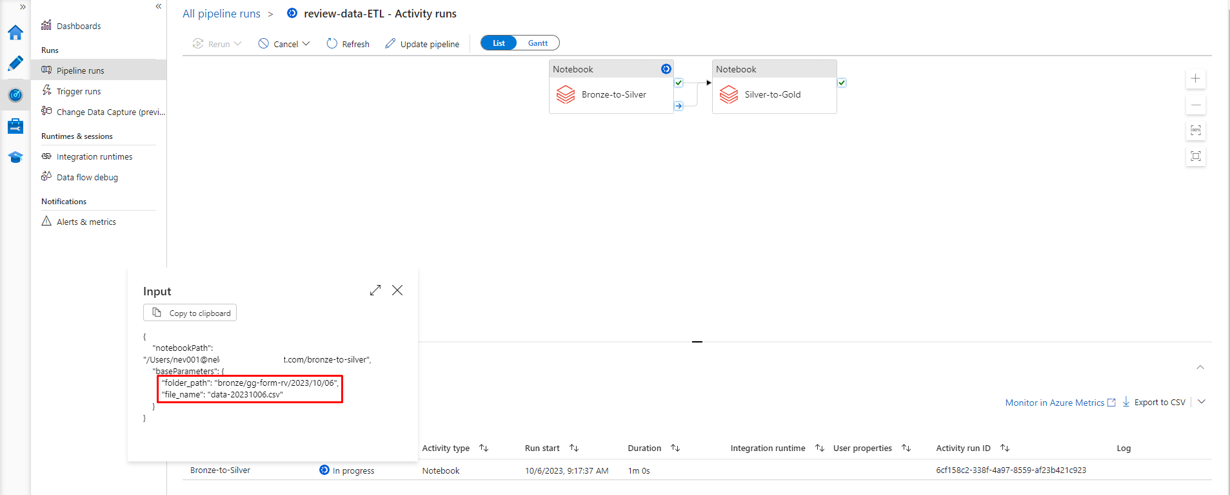
5-5.シルバーレイヤーの処理
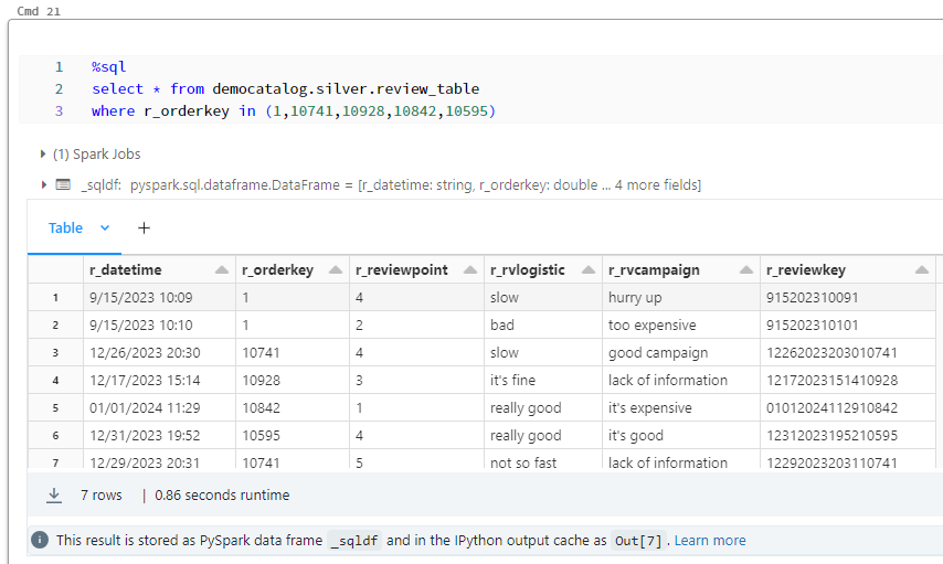
シルバーレイヤーのデータに対して、review_table のレコードが一意になるように、orderIDの欠落情報および、r_orderkeyを追加します。
シルバーレイヤーのテーブルは、他のテーブルとの関係を確立できます。
ブロンズレイヤーからシルバーレイヤーまでデータ変換用のノートブック
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
import pandas as pd import io import pyspark.sql import math # パイプラインのパラメータを読み込む dbutils.widgets.text("folder_path", "","") dbutils.widgets.text("file_name", "","") folder_path = dbutils.widgets.get("folder_path") file_name = dbutils.widgets.get("file_name") # ファイルパスを作成する container_name = 'bronze' storage_account_name = 'dtbstraccadb' file_path = folder_path + '/' + file_name file_path = file_path.replace("bronze/","") print(file_path) stracc_key = "QeWiWu3DLu08FRXhxXMwAlkMAj8Rz/UJxUb5YoStnoZCJC5dzHfREItmenODQOEow0FiunHcvX/f+ASt2AJX4A==" spark.conf.set("fs.azure.account.key." + storage_account_name + ".dfs.core.windows.net", stracc_key) url = "abfss://" + container_name + "@" + storage_account_name + ".dfs.core.windows.net/" + file_path print(url) df = spark.read.option("header", True).option("inferSchema", True).csv(url) pandasDF = df.toPandas() pandasDF = pandasDF.rename(columns={"Timestamp": "r_datetime", "Fill in your receipt id": "r_orderkey", "How satisfied were you with the event?": "r_reviewpoint", "Additional feedback on logistics": "r_rvlogistic", "Any overall feedback for the campaign?": "r_rvcampaign"}) no_orderkey = 1 new_columns = [] for index, row in pandasDF.iterrows(): # orderkeyがNULL または orders_tableにorderkeyが既存しない 場合は orderkey = 1 if (math.isnan(row['r_orderkey'])): row['r_orderkey'] = no_orderkey pandasDF.at[index, 'r_orderkey'] = no_orderkey result = spark.sql("SELECT * FROM democatalog.demoschema.orders_table WHERE OrderID = " + str(row['r_orderkey'])) if(len(result.head(1))== 0): print(row['r_orderkey']) row['r_orderkey'] = no_orderkey pandasDF.at[index, 'r_orderkey'] = no_orderkey create_time_str = row['r_datetime'].replace("/","") create_time_str = create_time_str.replace(":","") create_time_str = create_time_str.replace(" ","") review_id = str(create_time_str) + str(int(row['r_orderkey'])) new_columns.append(str(review_id)) pandasDF = pandasDF.drop(['_c0'], axis=1) pandasDF['r_reviewkey'] = new_columns spark_df = spark.createDataFrame(pandasDF) spark_df = spark_df.withColumn("r_reviewpoint", spark_df["r_reviewpoint"].cast("Long")) # review_tableにデータを保存する spark_df.write.mode("overwrite").saveAsTable("democatalog.silver.review_table") |
ADFでパイプラインの実行状況が確認できます。
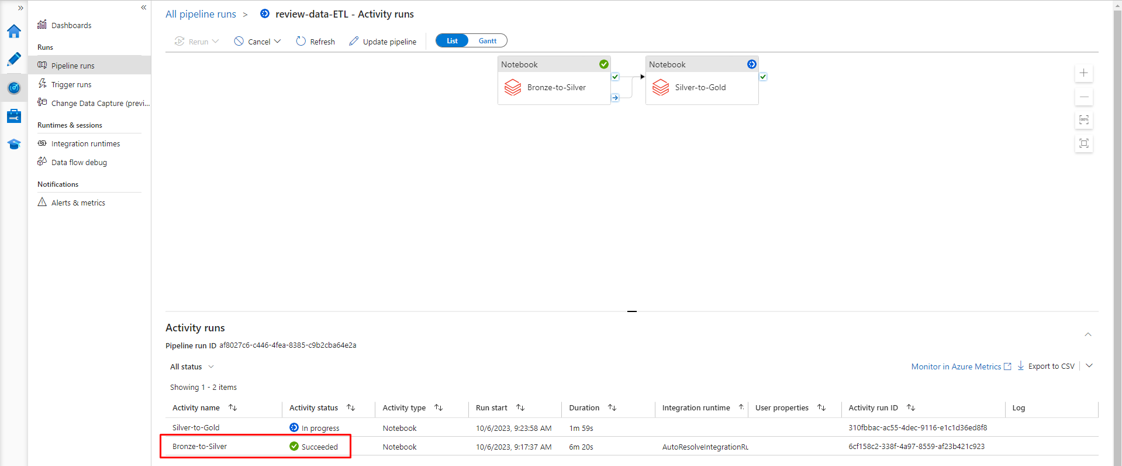
ブロンズレイヤーからデータがシルバーレイヤーに変換されました。review_table のレコードが一意になるように、欠落情報および、r_orderkeyが追加されました。
最初の「番号」カラムが削除されます。

シルバーレイヤーのデータ
5-6.ゴールドレイヤーの処理
ゴールドレイヤーのデータは、分析しやすいようにキンバル スター スキーマ形式に設定されます。 スター スキーマの構造は、分析のロジックによって異なります。
この例では、国別の総収益と国別の平均スコアを表示したいため、次のようにスター スキーマを整理します。
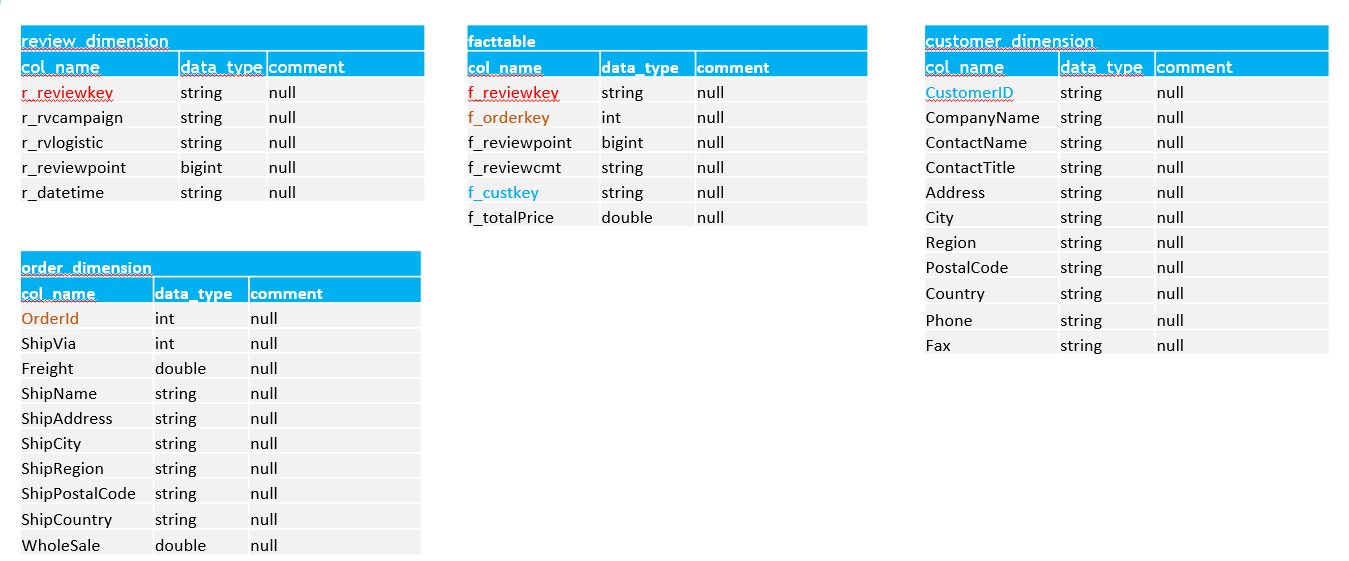
パイプラインを使用して、データがゴールドレイヤーに正常に取り込まれました。
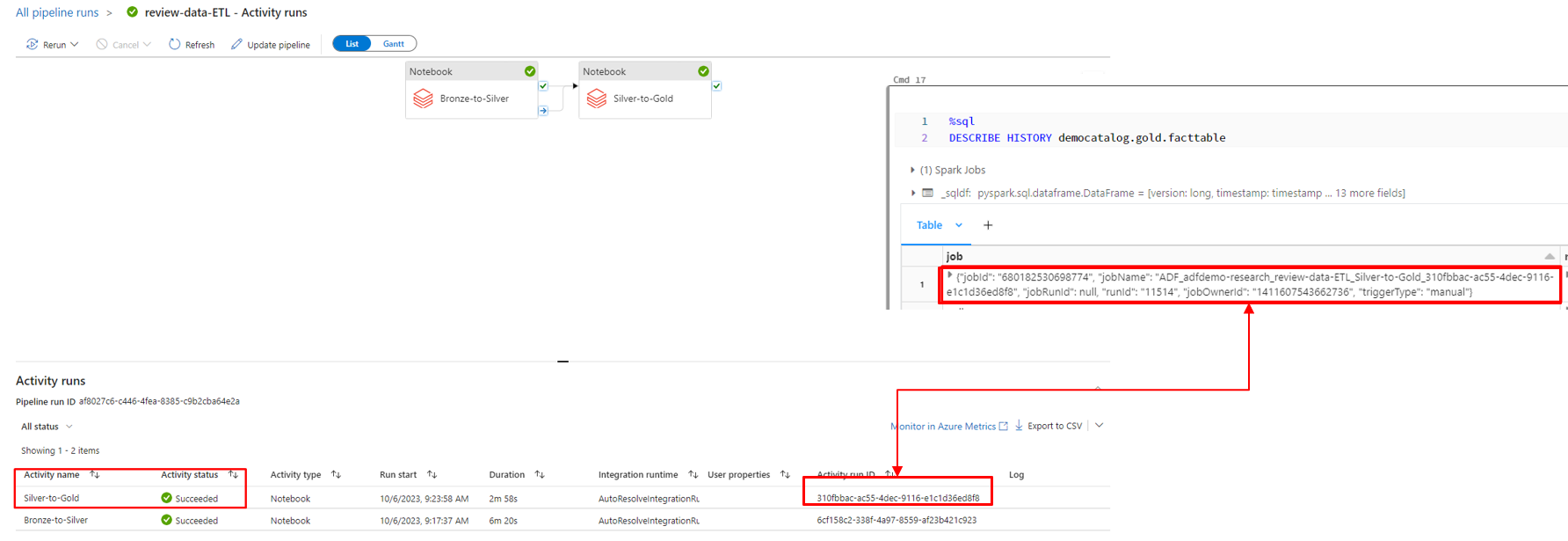
データをシルバーレイヤーからゴールドレイヤーに取込みの流れは以下の通りです。
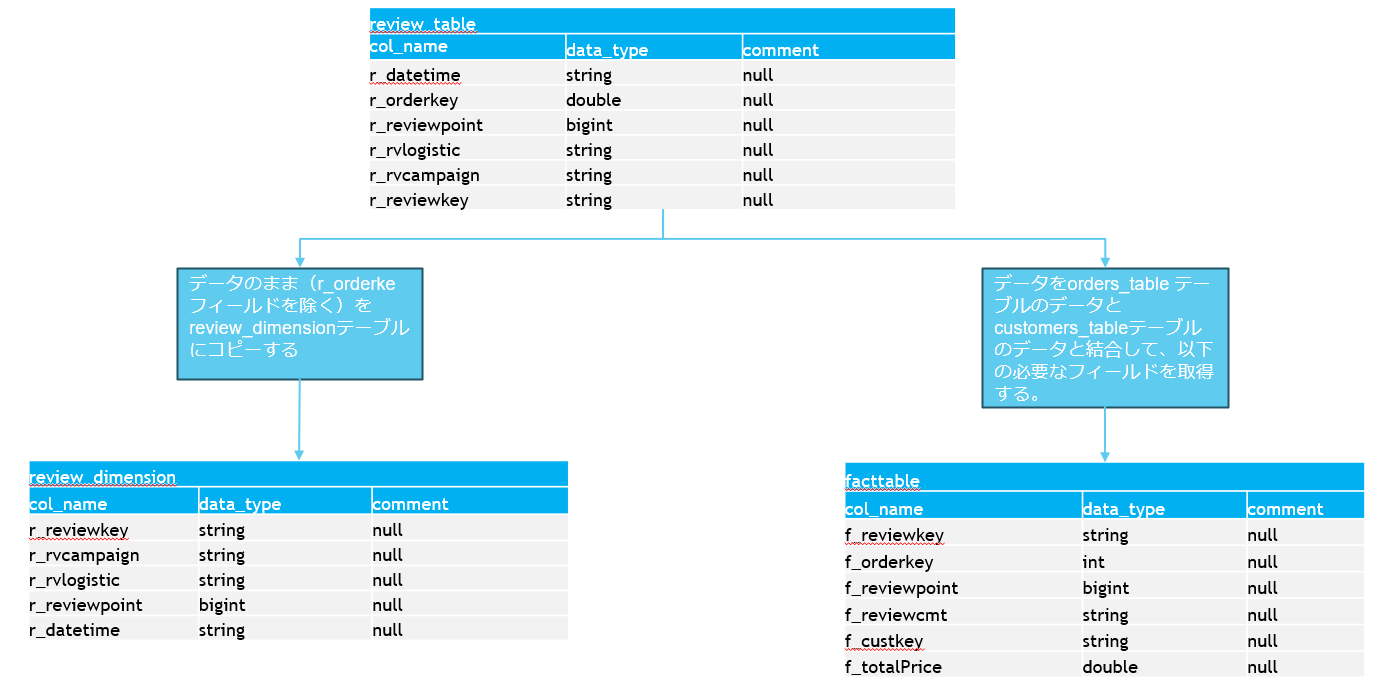
データをシルバーレイヤーからゴールドレイヤーに取込みのノートブックは以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
%md ### Insert new data to gold layer: review dimension %sql CREATE TABLE IF NOT EXISTS democatalog.gold.review_dimension as select r_reviewkey, r_rvcampaign, r_rvlogistic, r_reviewpoint, r_datetime FROM democatalog.silver.review_table %md ### Insert new data to gold layer: fact table %sql Insert into democatalog.gold.factTable select distinct f_reviewkey, f_orderkey, f_reviewpoint, f_reviewcmt, f_custkey, order_dimension.WholeSale as f_totalPrice from (select r_reviewkey as f_reviewkey, OrderId as f_orderkey, r_reviewpoint as f_reviewpoint, r_rvcampaign as f_reviewcmt, CustomerID as f_custkey from democatalog.silver.review_table inner join democatalog.silver.orders_table on review_table.r_orderkey = orders_table.OrderID) inner join democatalog.gold.order_dimension on f_orderkey = OrderId |
5-7.レポート作成
Power BI や tableauなどの色々なツールを使用して、レポートを出力できます。但し、今回の例では、Databricksを使用してレポートを作成できます。
以下のクエリを使用して、国別の総収益と国別平均スコアを表示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
%sql select r_reviewkey, r_reviewpoint, f_custkey,ShipCountry, WholeSale, OrderId from democatalog.gold.review_dimension Inner join (select * from democatalog.gold.order_dimension inner join democatalog.gold.factTable on OrderId = f_orderkey) On f_reviewkey = r_reviewkey |
クエリの実行結果は以下の通りです。
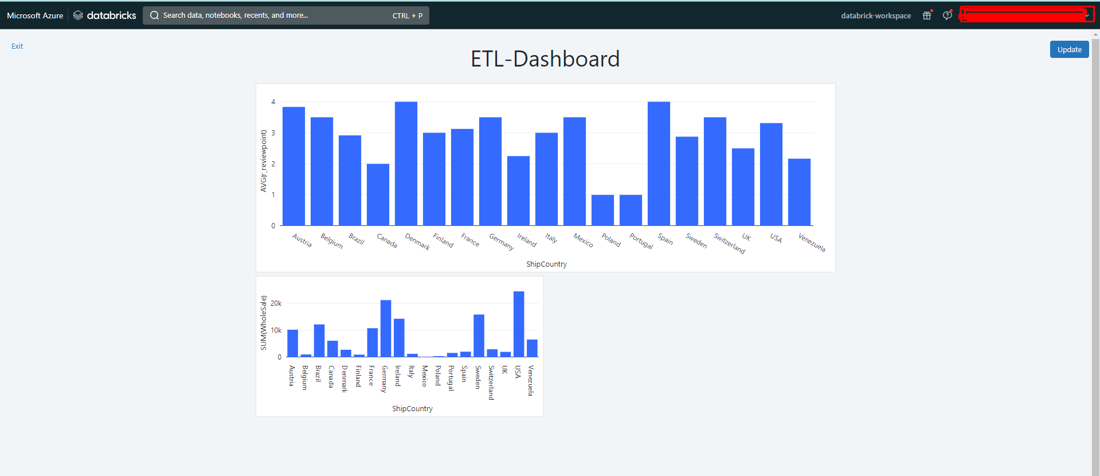
5-8.エラー処理
上記のデータの取込パイプラインを使用すると、エラーデータやロジックエラーが発生する場合にDatabricksで再実行しやすいです。
シルバーレイヤーとゴールドレイヤーのデータを前のバージョンにロールバックします。Time Travelを使用して、Delta Tableでロールバックできます。
ブロンズのデータがソースデータと同じで、変更されないので、データをロールバックした後、パイプラインのみを再実行します。
6.まとめ
Azure Databricksのメダリオンアーキテクチャの利用目的、および機能についてについて説明しました。
メダリオンアーキテクチャの利点は以下の通りです。
各レイヤーでデータフィルタリングのロジックが明確に定義され、デバッグや修正が簡単になります。
各レイヤーでデータ品質が改善されるので、再分析実行の時間もかかりません。
ゴールドレイヤーのデータが特定の目的のために使用されるので、再分析実行が必要である場合もあります。生データから再実行が不要であることから、時間をかなり節約できます。
データが複数のレイヤーに分割されるので、ユーザーの権限割り当てを管理やすいです。ユーザーグループが、利用目的に応じてレイヤーのみにアクセスできます。
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
・Azure Databricks連載シリーズはこちら