1. はじめに
皆さん、こんにちは。
今回は、 Databricksコンテナーサービスの利用方法について説明いたします。
Databricks container servicesはDatabricksクラスターの作成時にDockerイメージを指定できます。利用の目的を次のように示します。
- インストールするシステムライブラリを完全に制御できます。
- Dockerイメージは、絶対に変更されないロックダウンされた環境です。
- Azure DatabricksをDocker CI/CDと統合できます。
※ 注意:
- Databricks Runtime for Machine Learning では、Databricks container services はサポートされていません。
- Databricks container services は、標準アクセス モード (以前の共有アクセス モード) を使用するクラスターではサポートされていません。
2. 前提要件
- Azure Databricksワークスペースが必要です。
- Azure コンテナーレジストリが必要です。
- Azure CLIが必要です。
- Azure アカウントにコンテナーレジストリへの「Container Registry Data Importer and Data Reader」許可が付与されている必要があります。
- デーモンを実行してローカルに Docker をインストールする必要があります。
3. コンテナー サービスを有効にする
① クラスター上でコンテナーを利用するには、ワークスペース管理者はDatabricksコンテナーサービス機能を有効にすることが必要です。 以下のAPIを利用し、その機能を有効にできます。
|
1 2 3 4 5 |
curl -X PATCH -n \ https://<Databrickss-instance>/api/2.0/workspace-conf \ -d '{ "enableDcs": "true" }' |
※ <Databricks-instance> をワークスペース名に変更する。
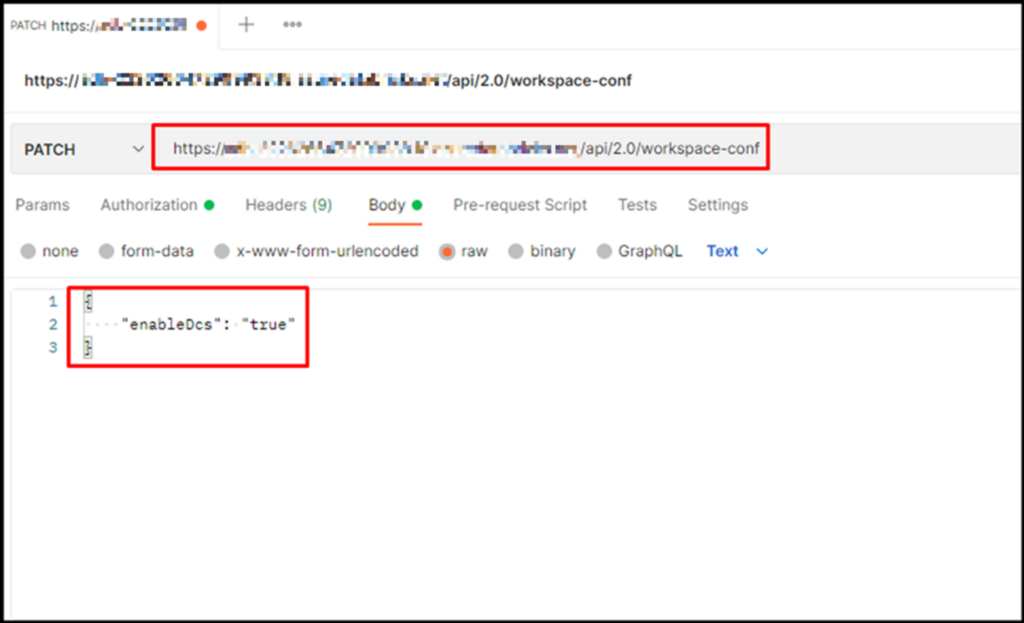
※ 注意: 他のツールを利用してAPIを実施できます。今回は、Postmanツールを利用しています。
4. Docker HubからAzureコンテナーレジストリにベースイメージをインポートする
ベース イメージは、 Docker Hubでホストされています。 今回はAzureコンテナーレジストリを利用するので、Docker HubからAzureコンテナーレジストリにベースイメージをインポートすることが必要です。
Databricksではさまざまなイメージが提供されていますが、今回は「python:16.4-LTS」イメージを使用します。
Docker HubからAzureコンテナーレジストリへ「python:16.4-LTS」イメージをインポートするには、Azureコンテナーレジストリにログインが必要です。
① Azure CLIにログインし、以下のコマンドを実行します。
文法:
|
1 |
az acr login --name <acr-name> |
※ <acr-name>をAzureコンテナーレジストリ名に変更します。
例:
|
1 |
az acr login --name dtbrickscontainerrgt |
② 次に、以下のコマンドを実行します。
文法:
|
1 |
az acr import --name <acr-name> --source docker.io/databricksruntime/<image-name> --image <image-name> |
※ <acr-name>をAzureコンテナーレジストリ名に変更します。
※ <image-name>をイメージ名に変更します。
例:
|
1 |
az acr import --name dtbrickscontainerrgt --source docker.io/databricksruntime/python:16.4-LTS --image python:16.4-lts |
③ Azureコンテナーレジストリへアクセスし、インポート完了を確認します。
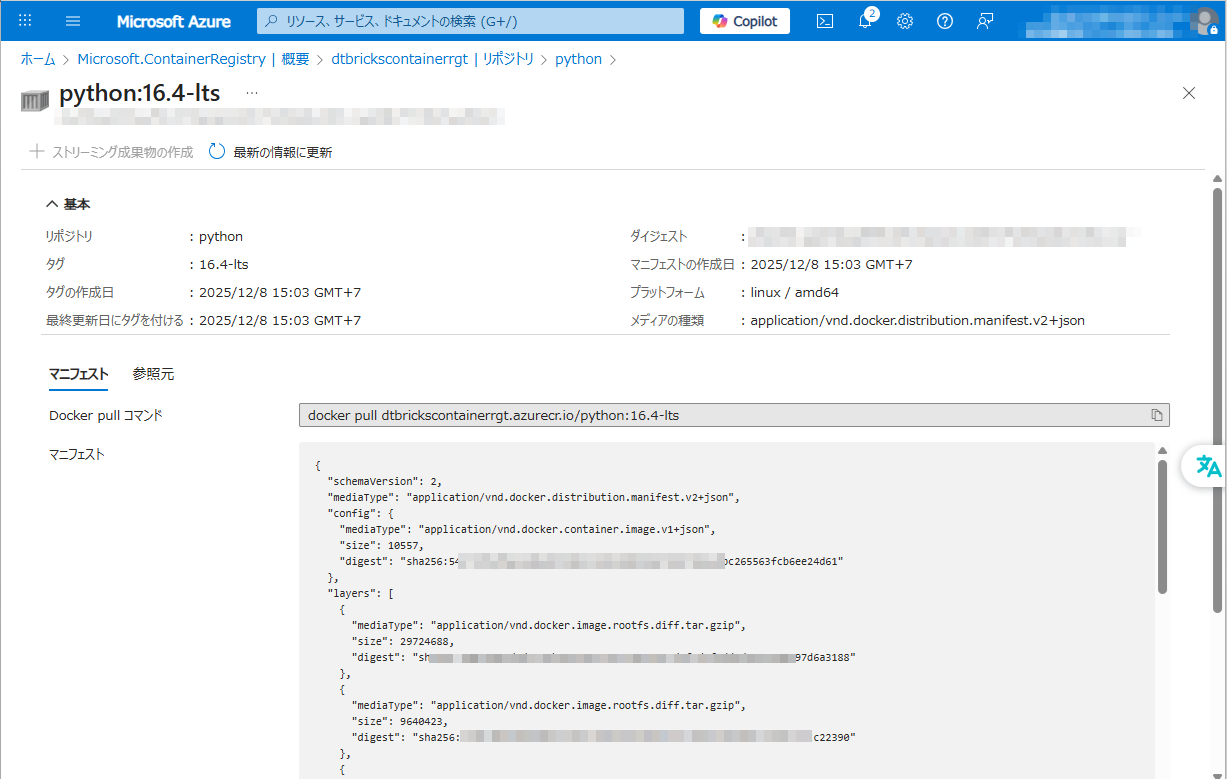
5. ベースを構築する
ベースイメージをインポートした後で、希望のイメージを構築できます。
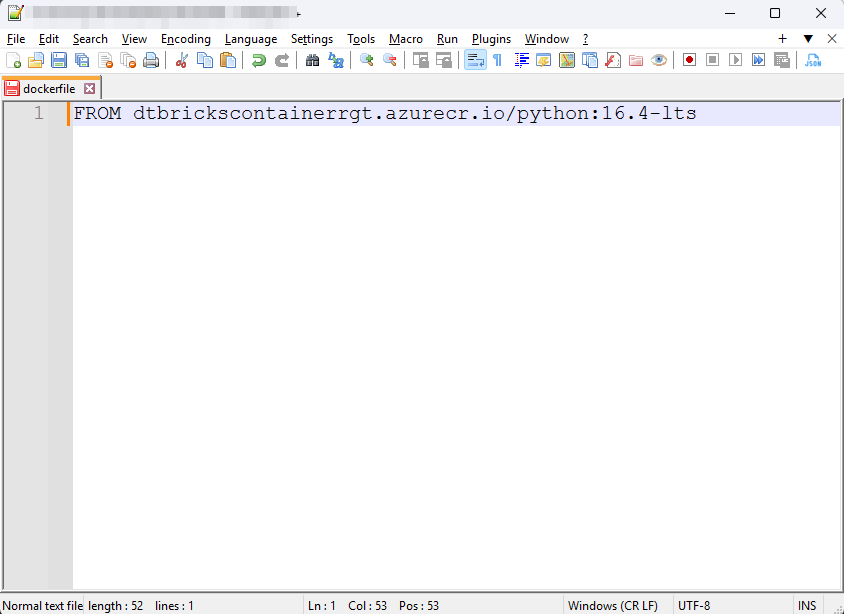
① 「dockerfile」を作成し、以下のコマンドを追加します。
文法:
|
1 |
FROM <acr-name>.azurecr.io/<image-name> |
※ <acr-name>をAzureコンテナーレジストリ名に変更します。
※ <image-name>をインポートされたイメージ名に変更します。
例:
|
1 |
FROM dtbrickscontainerrgt.azurecr.io/python:16.4-lts |
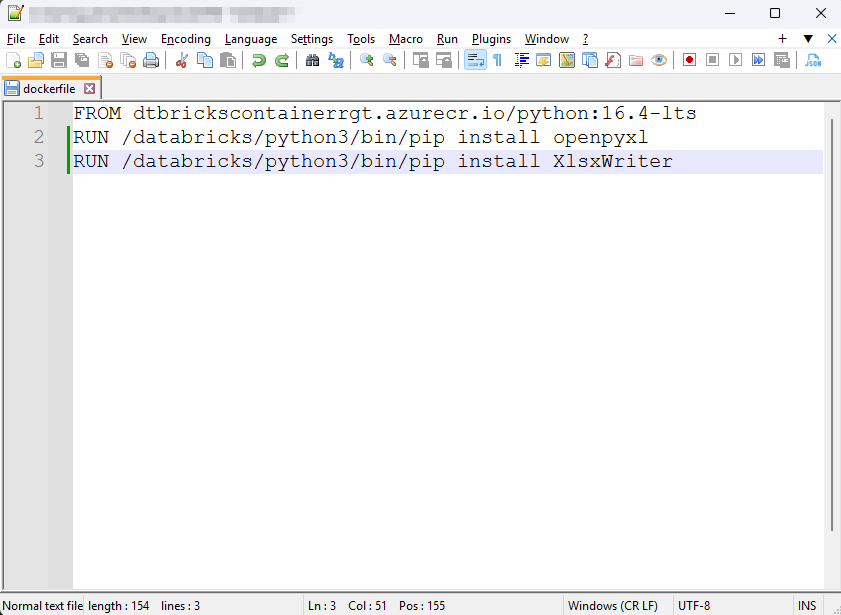
② 「XlsxWriter==3.1.8」や「openpyxl==3.1.2」等の標準で対応しないライブラリを指定するには、以下のコマンドを追加します。
|
1 2 |
RUN /databricks/python3/bin/pip install openpyxl RUN /databricks/python3/bin/pip install XlsxWriter |
③ 「dockerfile」の作成完了後、イメージを構築します。「dockerfile」を含むフォルダーでCommand Promptを開き、以下のコマンドを実行します。
文法:
|
1 |
docker build -t <acr-name>.azurecr.io/<custome_image_name> . |
※ <acr-name>をAzureコンテナーレジストリ名に変更します。
※ <custome_image_name> を任意の名前に変更します。
例:
|
1 |
docker build -t dtbrickscontainerrgt.azurecr.io/python_custome_image:16.4 . |
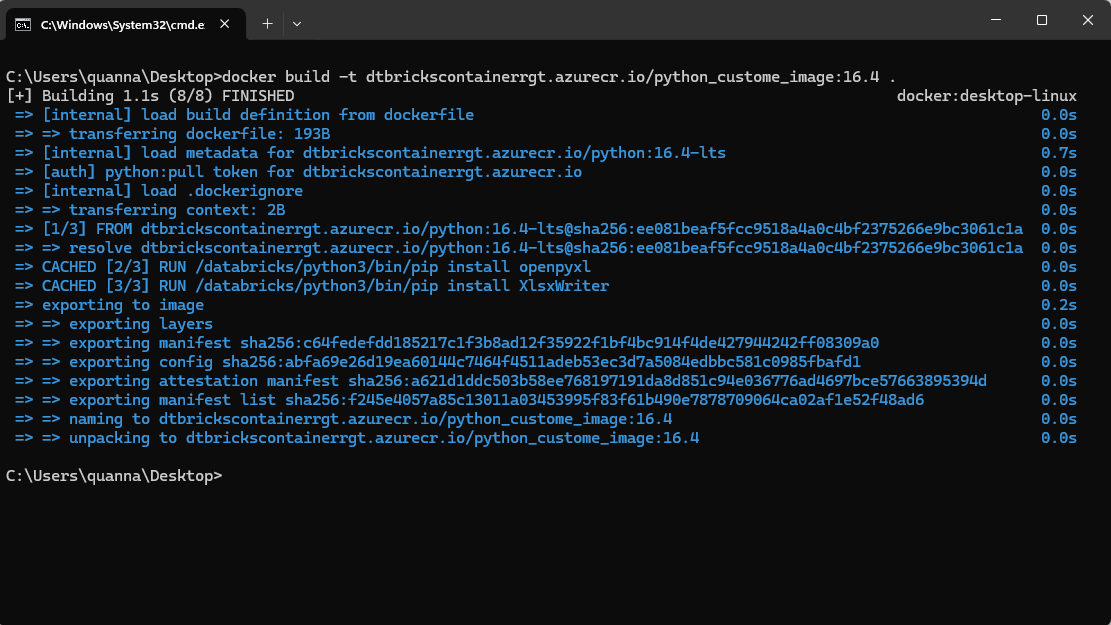
④ 構築完了後、Azureコンテナーレジストリにイメージをプッシュします。
文法:
|
1 |
docker push <acr-name>.azurecr.io/<custome_image_name> |
※ <acr-name>をAzureコンテナーレジストリ名に変更します。
※ <custome_image_name> を構築したイメージ名に変更します。
例:
|
1 |
docker push dtbrickscontainerrgt.azurecr.io/python_custome_image:16.4 |
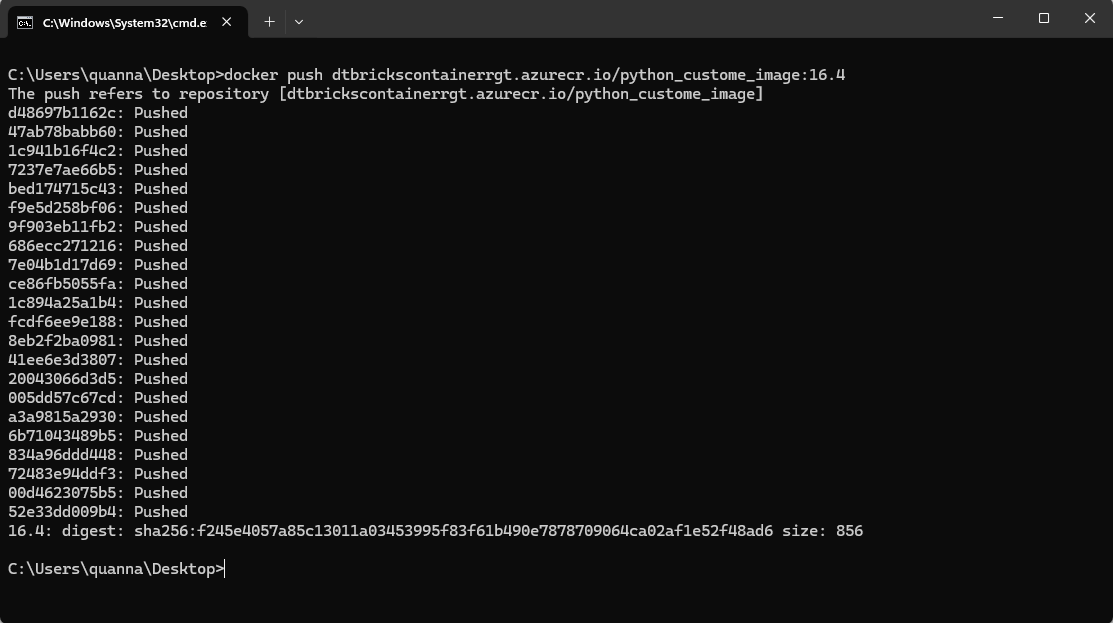
6. 汎用クラスターを起動する
① Databricks画面から、「コンピュート」 →「コンピュートを作成」をクリックします。
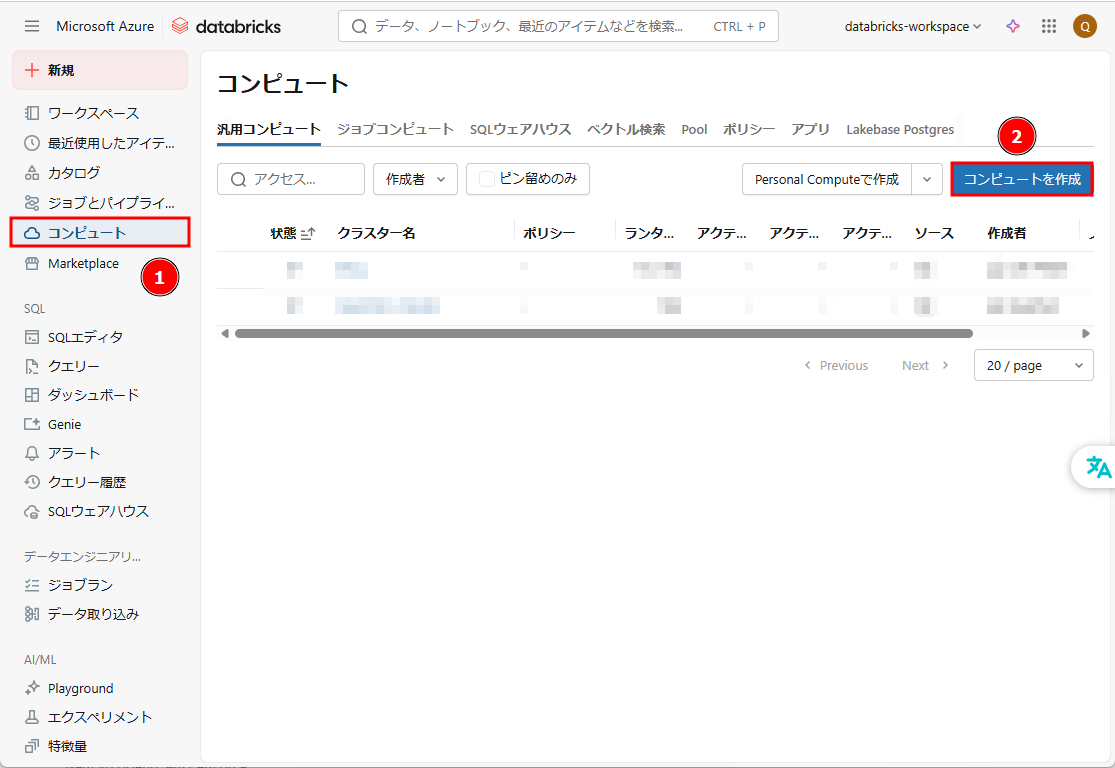
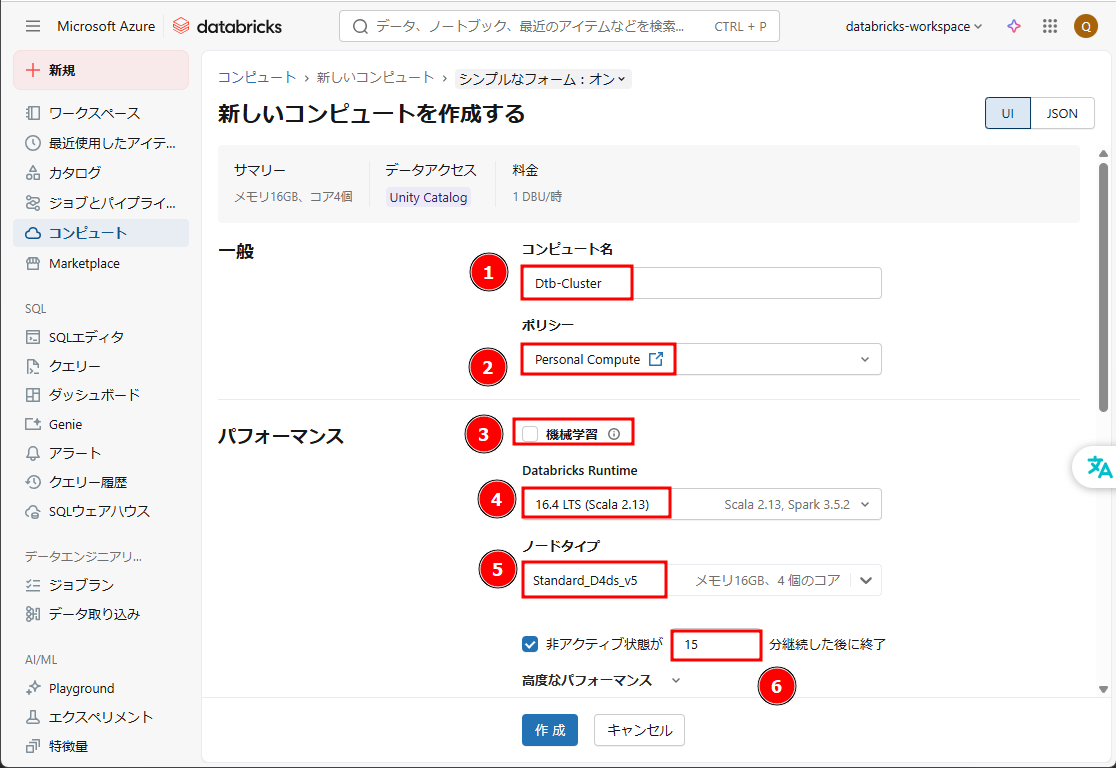
② クラスター構成を設定します。
- 「コンピュート名」: コンピュート名を入力します。例:「Dtb-Cluster」
- 「ポリシー」:Personal Compute
- 「機械学習」:無効
- 「Databricks Runtime」:16.4 LTS (Scala 2.13)
- 「ワーカータイプ」:Standard_D4ds_v5
- 「非アクティブ状態が」:15
③ 「Docker」タブで「自分のDockerコンテナを使用する」を有効にします。
④ 「DockerイメージURL」にDockerイメージのURLを入力します。
文法:
|
1 |
<acr-name>.azurecr.io/<image-name> |
※ <acr-name>をAzureコンテナーレジストリ名に変更します。
※ <custome_image_name> を構築したイメージ名に変更します。
例:
|
1 |
dtbrickscontainerrgt.azurecr.io/python_custome_image:16.4 |
⑤ 「認証」 : 「ユーザー名とパスワード」
⑥ ユーザー名とパスワードを入力します。Azureコンテナーレジストリの「アクセス キー」からユーザー名とパスワードを取得できます。
⑦ 「作成」をクリックします。
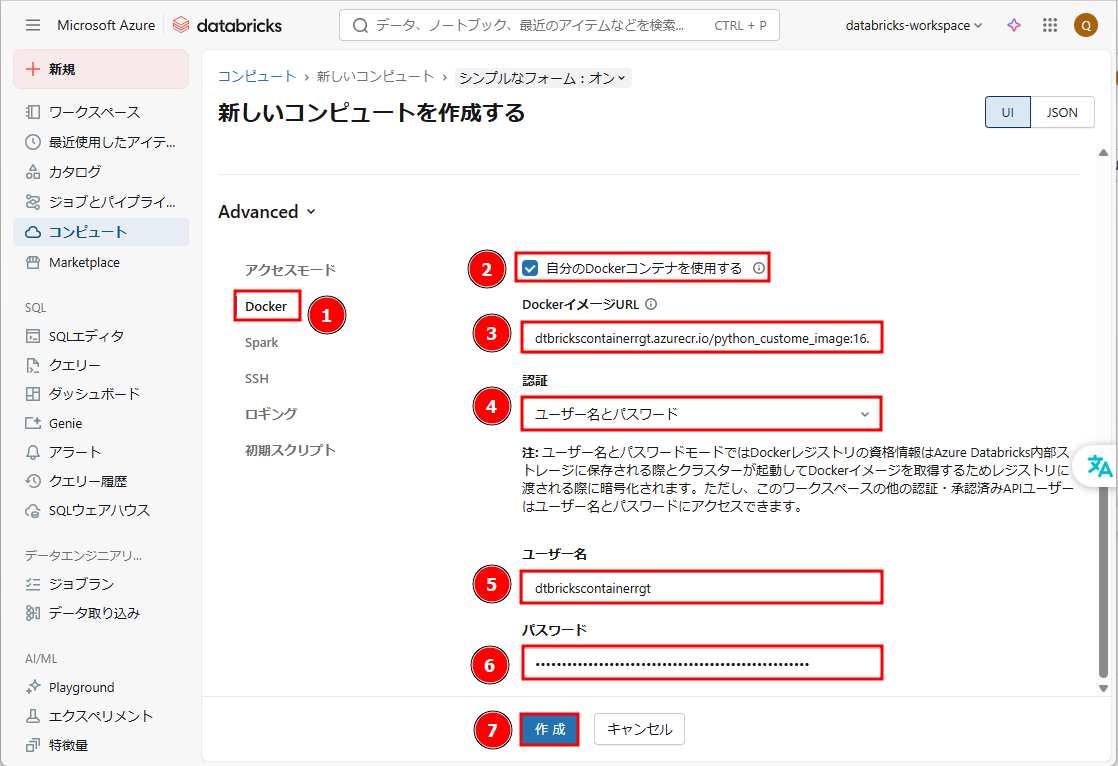
Databricks Container Service を使用したクラスターの作成が完了しました。
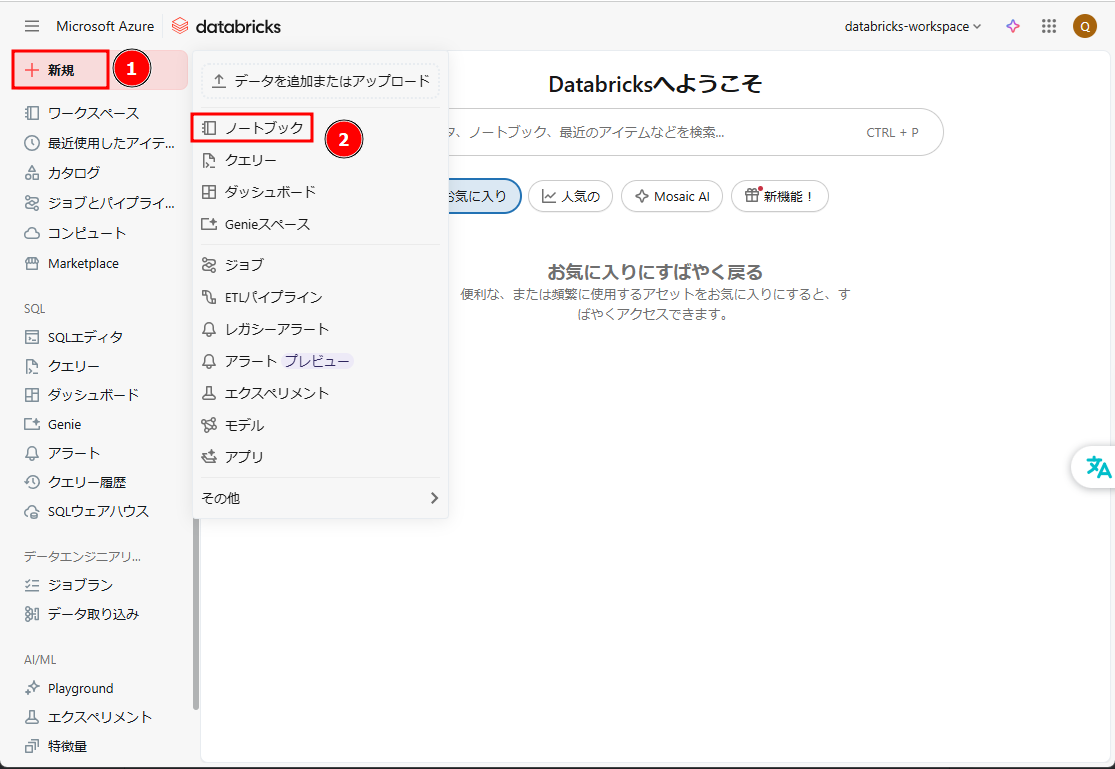
「XlsxWriter」と「openpyxl」ライブラリを利用したノートブックを作成し、汎用クラスターを確認します。
⑧ Databricksワークスペース画面から → 「新規」 → 「ノートブック」
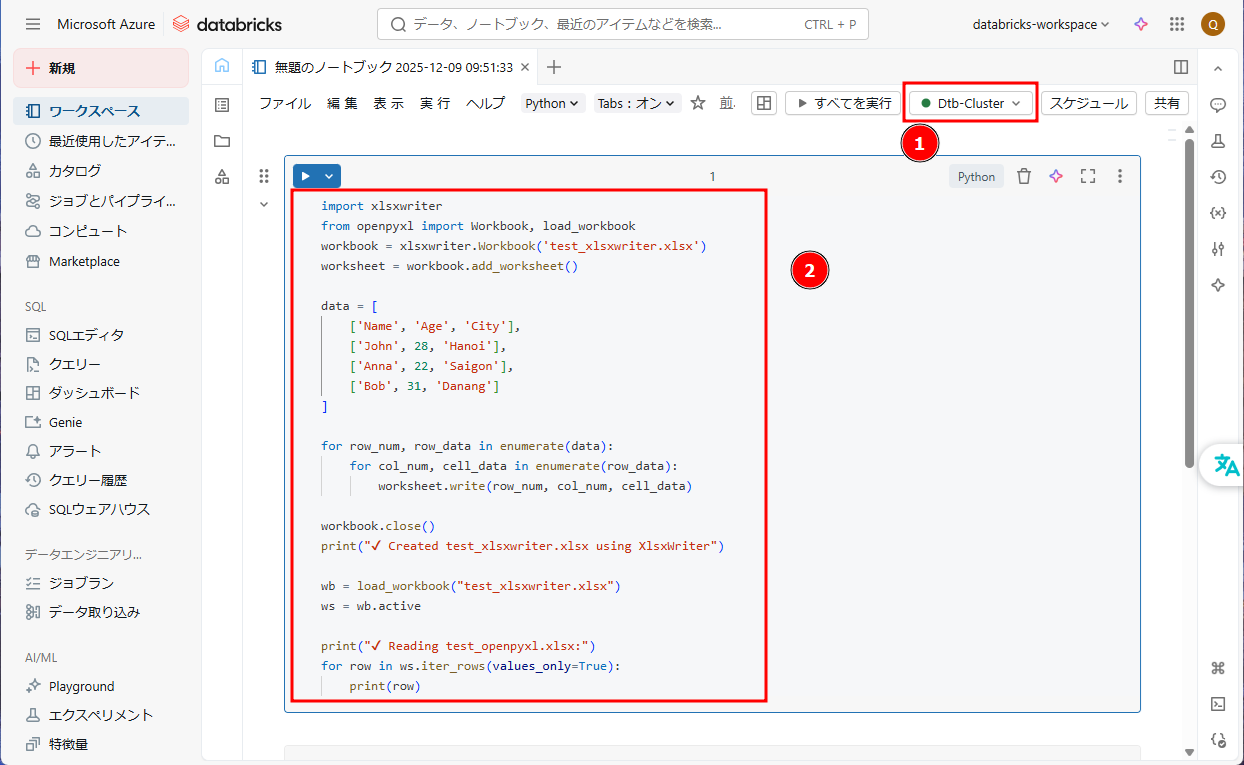
⑨ 作成したクラスタを選択し、ノートブックを実行します。以下のコマンドを入力して、「Shift + Enter」を押します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import xlsxwriter from openpyxl import Workbook, load_workbook workbook = xlsxwriter.Workbook('test_xlsxwriter.xlsx') worksheet = workbook.add_worksheet() data = [ ['Name', 'Age', 'City'], ['John', 28, 'Hanoi'], ['Anna', 22, 'Saigon'], ['Bob', 31, 'Danang'] ] for row_num, row_data in enumerate(data): for col_num, cell_data in enumerate(row_data): worksheet.write(row_num, col_num, cell_data) workbook.close() print("✔ Created test_xlsxwriter.xlsx using XlsxWriter") wb = load_workbook("test_xlsxwriter.xlsx") ws = wb.active print("✔ Reading test_openpyxl.xlsx:") for row in ws.iter_rows(values_only=True): print(row) |
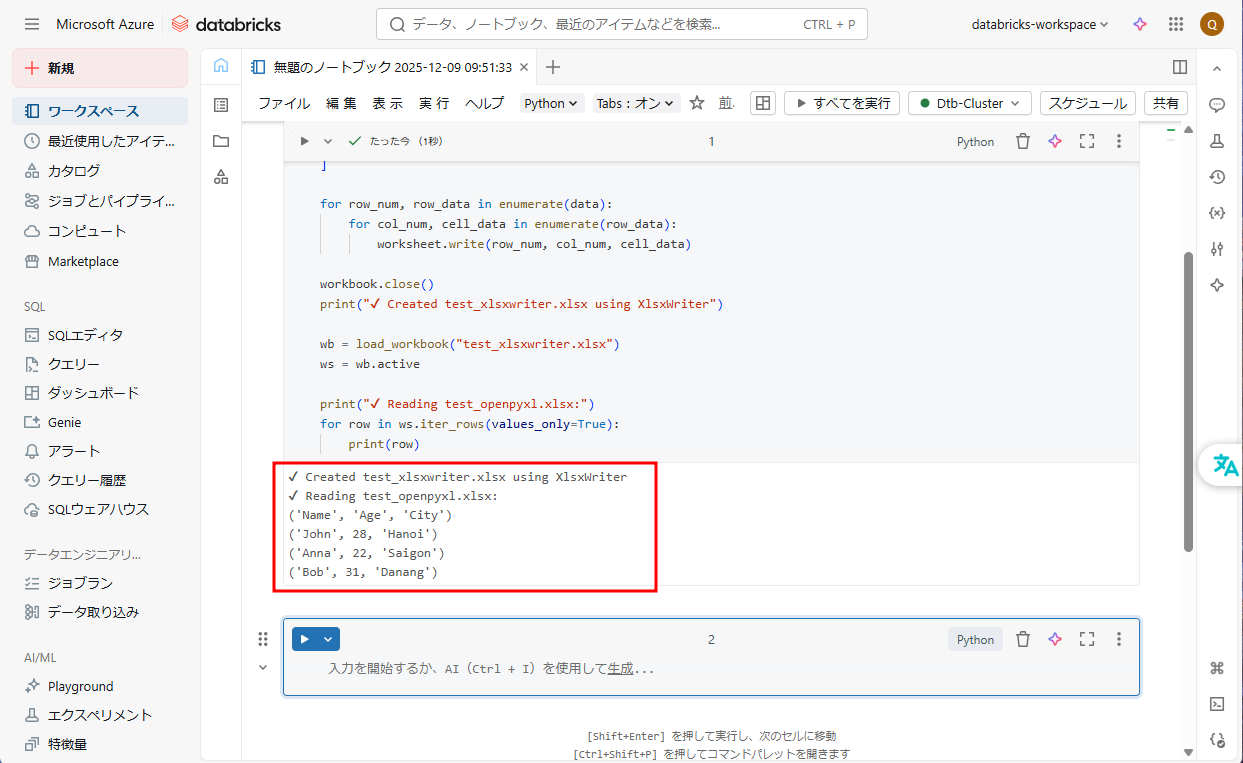
⑩ 結果が以下の画像通りです。
7. ジョブクラスターを起動する
① Databricksワークスペース画面から、「ジョブとパイプライン」 → 「作成」→「ジョブ」をクリックします。
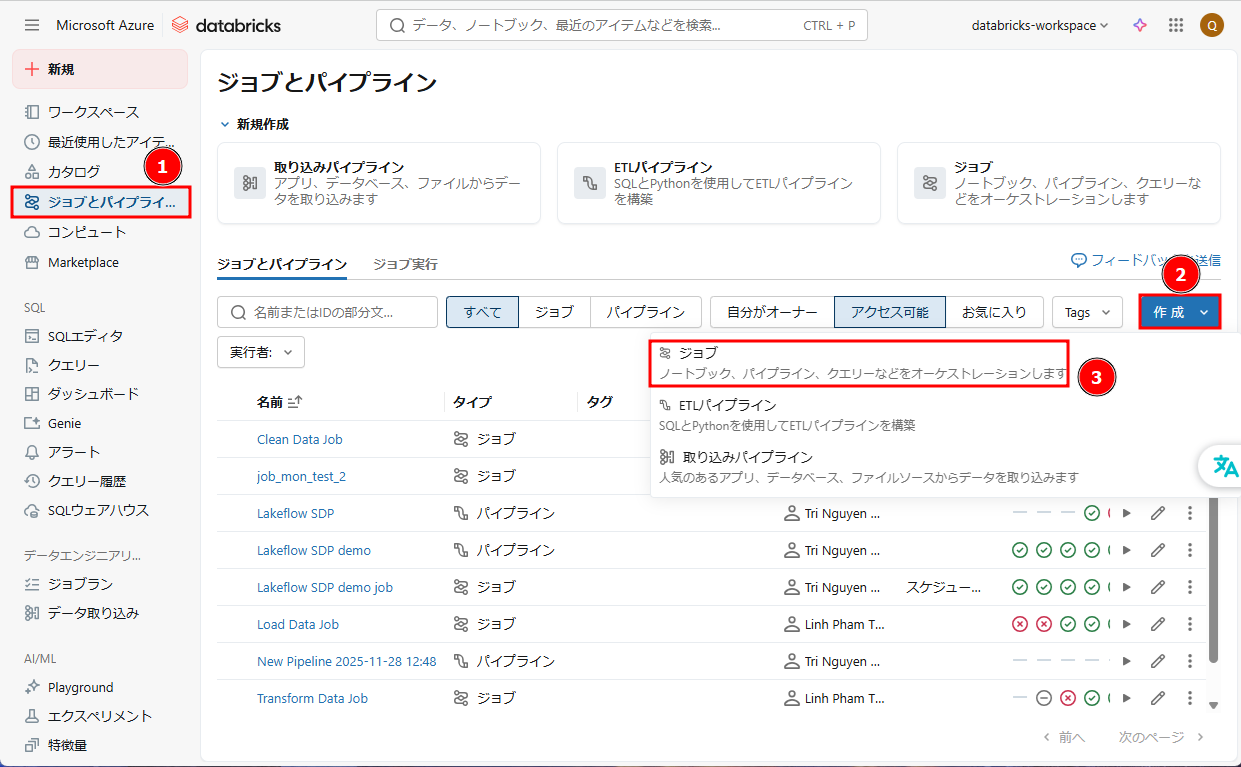
②「ノートブック」をクリックします。
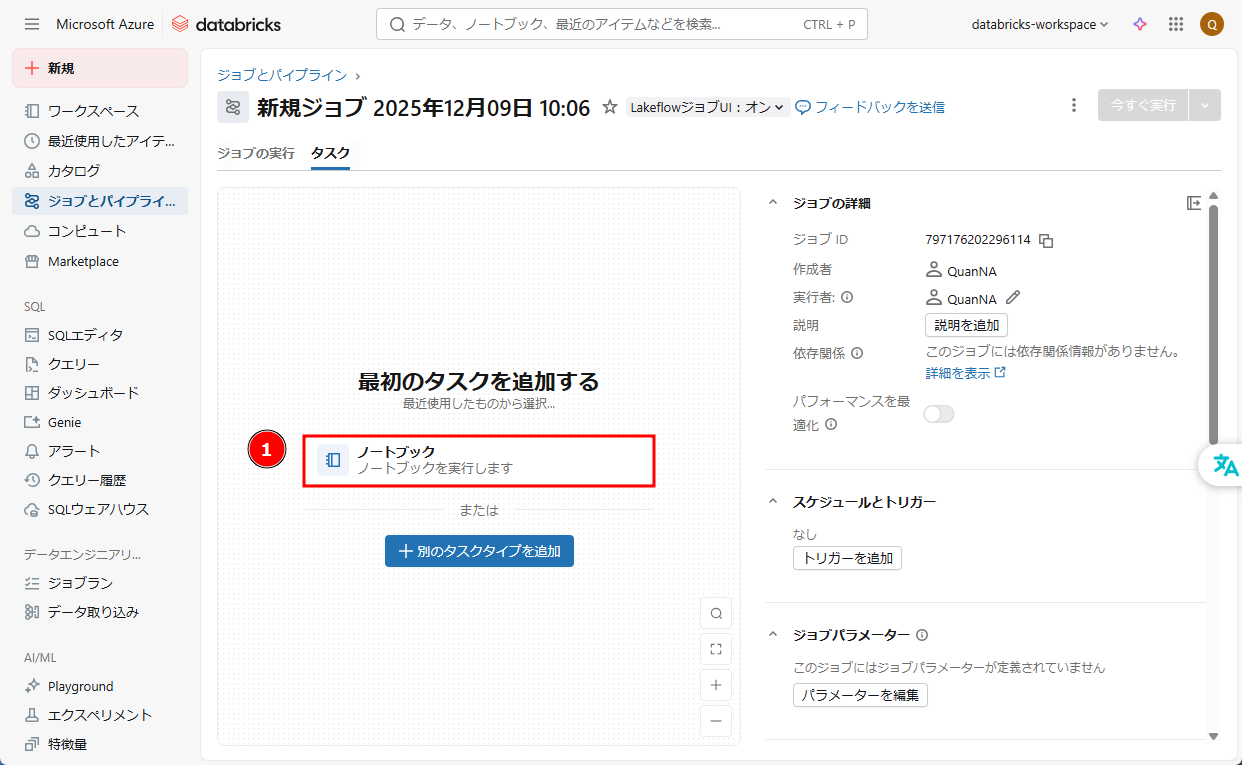
③ ジョブ構成を設定します。
- 「タスク名」 →「My-Task-001」
- 「種類」 →「ノートブック」
- 「ソース」→「ワークスペース」
- 「パス」: 作成したノートブックのパス
- 「コンピュート」項目で「Job_cluster」を選択して、
 アイコンをクリックします。
アイコンをクリックします。
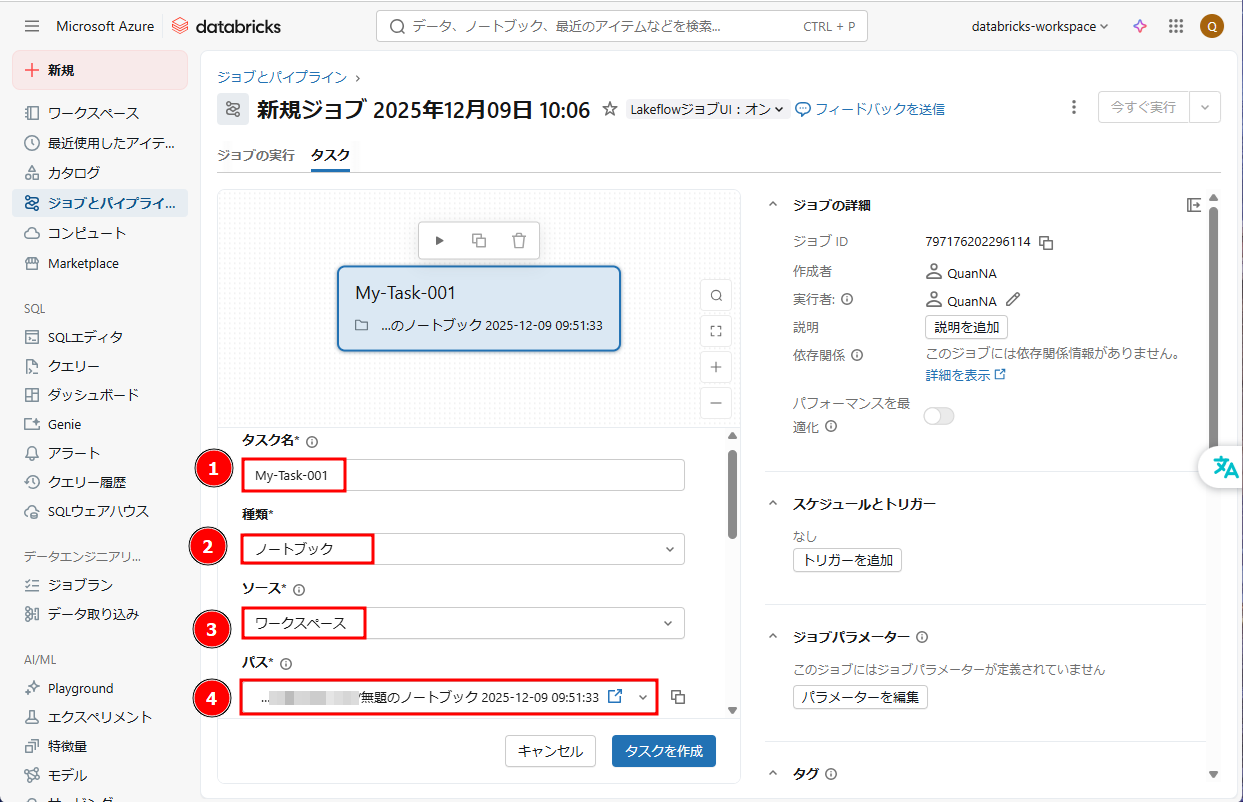
④ ジョブクラスター構成を設定します。
- 「コンピュート名」: Job_cluster
- 「ポリシー」:権限なし
- 「機械学習」:無効
- 「Databricks Runtime」:16.4 LTS (Scala 2.12)
- 「Photonのアクセラレーション」:有効
- 「ワーカータイプ」:Standard_D4ds_v5
- 「ワーカー」:8
- 「シングルノード」:無効
- 「オートバックス」:無効
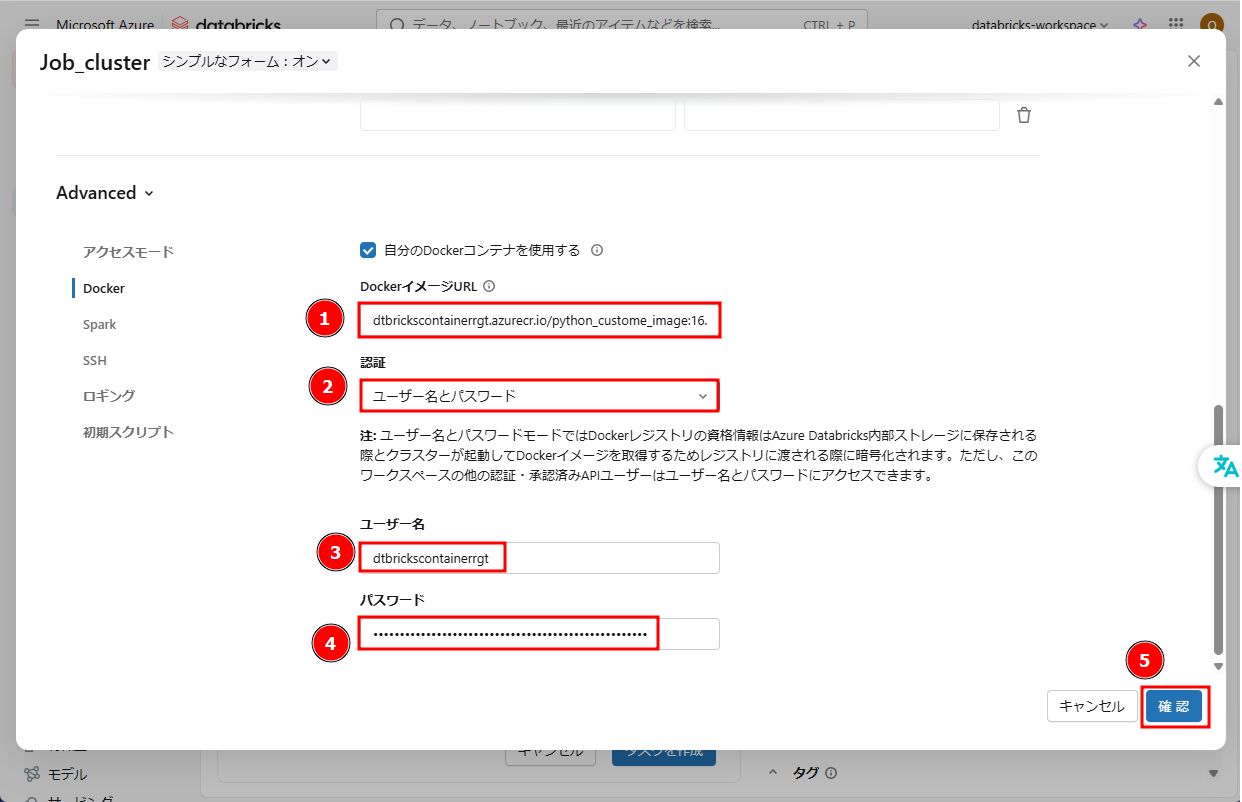
⑤ 「Docker」タブで「自分のDockerコンテナを使用する」を有効にします。
⑥ 「DockerイメージURL」にDockerイメージのURLを入力します。
文法:
|
1 |
<acr-name>.azurecr.io/<image-name> |
※ <acr-name>をAzureコンテナーレジストリ名に変更します。
※ <custome_image_name> を構築したイメージ名に変更します。
例:
|
1 |
dtbrickscontainerrgt.azurecr.io/python_custome_image:16.4 |
⑦ 「認証」 : 「ユーザー名とパスワード」
⑧ ユーザー名とパスワードを入力します。Azureコンテナーレジストリの「アクセス キー」からユーザー名とパスワードを取得できます。
⑨ 「確認」をクリックします。
⑩ 「タスクを作成」をクリックします。

⑪ 「今すぐ実行」をクリックします。

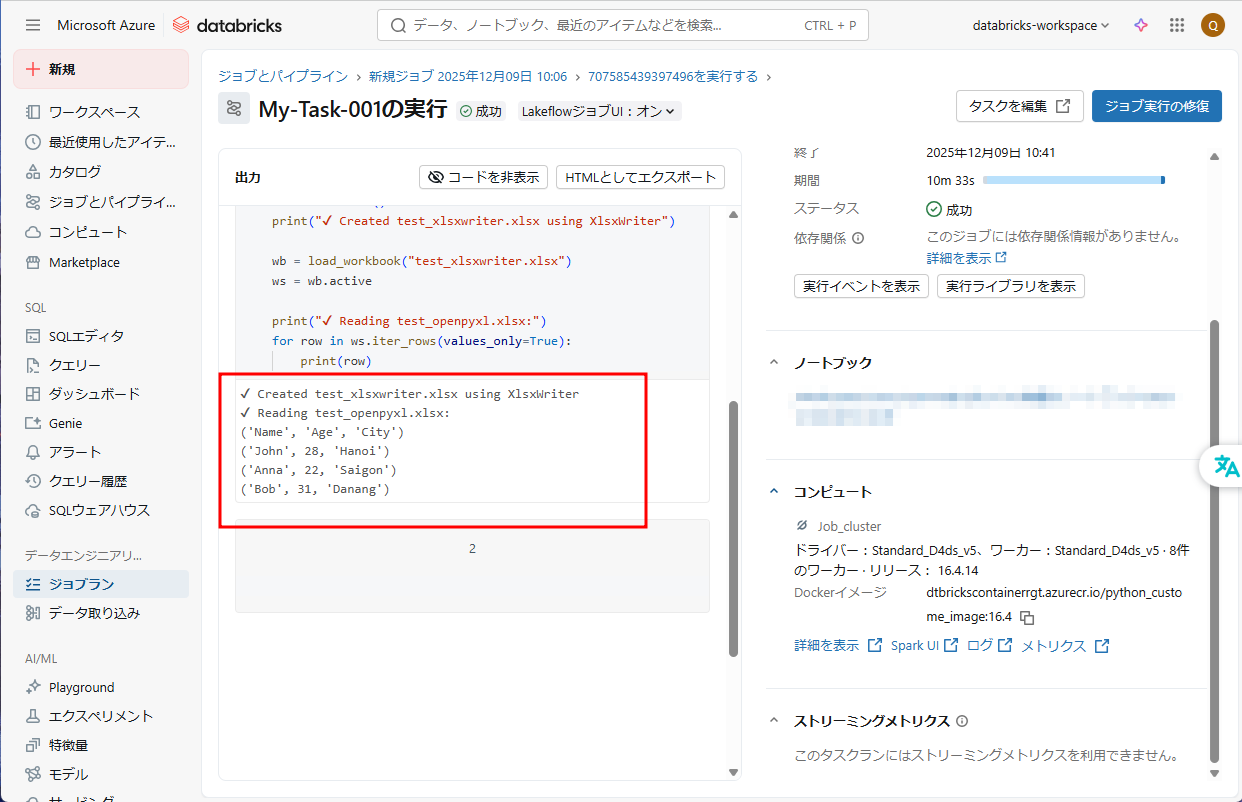
⑫ 結果が以下の画像通りです。
8. まとめ
本記事ではDatabricks container servicesの利用方法について説明しました。
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
Azure Databricks連載記事のまとめはこちら
![]() お問い合わせはこちら
お問い合わせはこちら
この記事を書いた人
この投稿者の最新の記事
- 2026年5月28日ブログ【Azure Databricks】外部ロケーションに新しいファイルが追加された際に、Databricks ジョブを自動的に起動する
- 2026年4月8日ブログ【Azure Databricks】Databricks環境におけるDatabricks Appsの設定および利用方法
- 2024年3月7日ブログ【Azure Databricks】Apache Airflow を使用して Azure Databricks ジョブを調整する
- 2024年2月27日ブログ【Azure Databricks】Auto Loader と Lakeflow 宣言パイプラインを組み合わせて使用してみる