目次
1. はじめに
皆さんこんにちは。
今回は、Azure DatabricksでAuto Loaderの利用方法について説明していきます。
第1回: Auto Loaderの概要、自動取込方法を使用してみる
第2回: Auto Loader と Lakeflow 宣言パイプライン を組み合わせて使用してみる (今回)
第3回: Auto LoaderのSchema inferenceとEvolutionの機能を使用してみる
2. 前提条件
- Databricksワークスペースが必要です。
- Azure ストレージアカウントが必要です。
- ワークスペースのUnity Catalogが有効です。
- Unity Catalogの更新権限が必要です。
- ストレージ資格情報が必要です。
3. Auto Loader を Lakeflow 宣言パイプラインと組み合わせて使用方法
自動ローダーとLakeflow 宣言パイプラインは、増加し続けるデータがクラウドストレージに到着するとすぐに読み込むように設計されています。そのため、Databricksでは、クラウドオブジェクトストレージからのほとんどのデータインジェストタスクについて、Lakeflow 宣言パイプラインで自動ローダーを使用することを推奨します。
- コスト削減のためのコンピューティング インフラストラクチャの自動スケーリング
- 期待(エクスペクテーション)を伴うデータ品質チェック
- 自動スキーマ推論の処理
- メトリクスによるイベントログの監視
Lakeflow 宣言パイプラインで自動ローダーを使用する場合、スキーマやチェックポイントの場所は Lakeflow 宣言パイプラインによって自動的に管理されるため、指定する必要はありません。
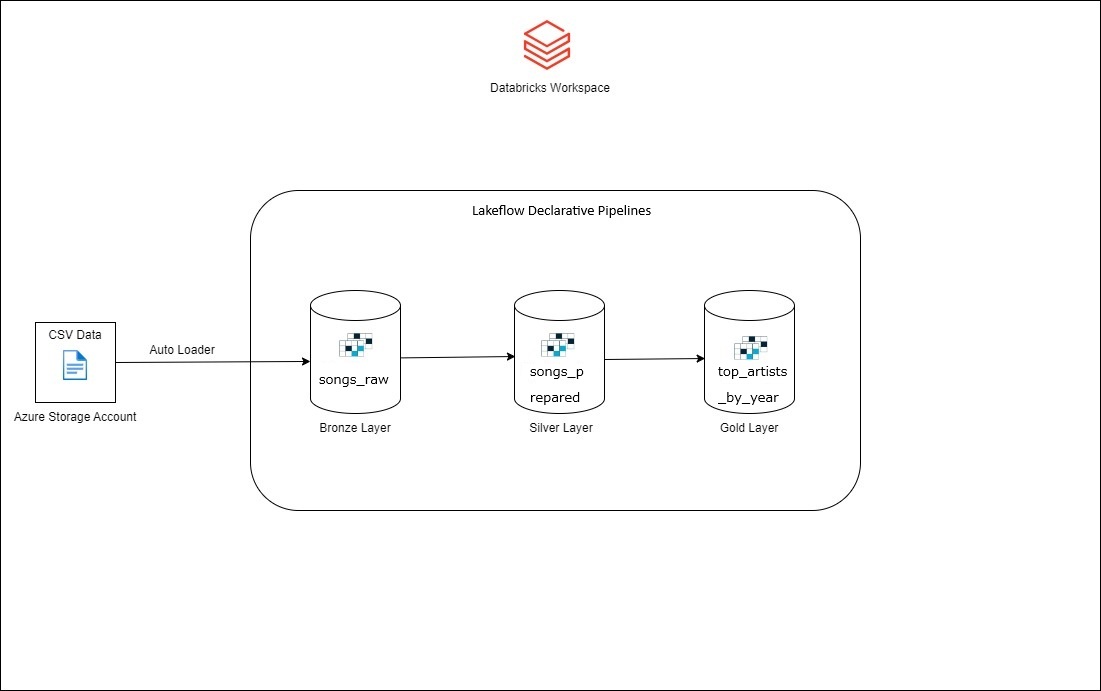
今回の例では、ADLS(Azure Data Lake Storage)からCSVデータをロードし、読み込んだデータをUnity Catalogのテーブルに保存する方法について説明します。このプロセスは、Lakeflow 宣言パイプラインと組み合わせて自動ローダーを使用します。この方法により、データのロードと保存が効率的に行えます。
この例で使用するデータセット「2025_million_songs_sample_dataset」は、現代音楽トラックの特徴とメタデータのコレクションである Million Song Dataset のサブセットです。 このデータセットは、Azure Databricks ワークスペースに含まれているサンプル データセット内にあります。
このデータセットから、ブロンズ、シルバー、ゴールドの3つ層を通して変換とクリーンデータを実行します。
【シナリオ】
1. ストレージアカウントからの「2025_million_songs_sample_dataset.csv」データセットを取り込み 、「songs_raw」テーブルを作成します。
2. 「songs_raw」テーブルをクレンジングし、「songs_prepared」テーブルを作成します。
3. 「top_artists_by_year」テーブルを作成し、「songs_prepared」テーブルから年間トップアーティストを計算します。
4. データ準備
まず、サンプルデータをAzure ストレージアカウントにアップロードして、次の手順を実施します。
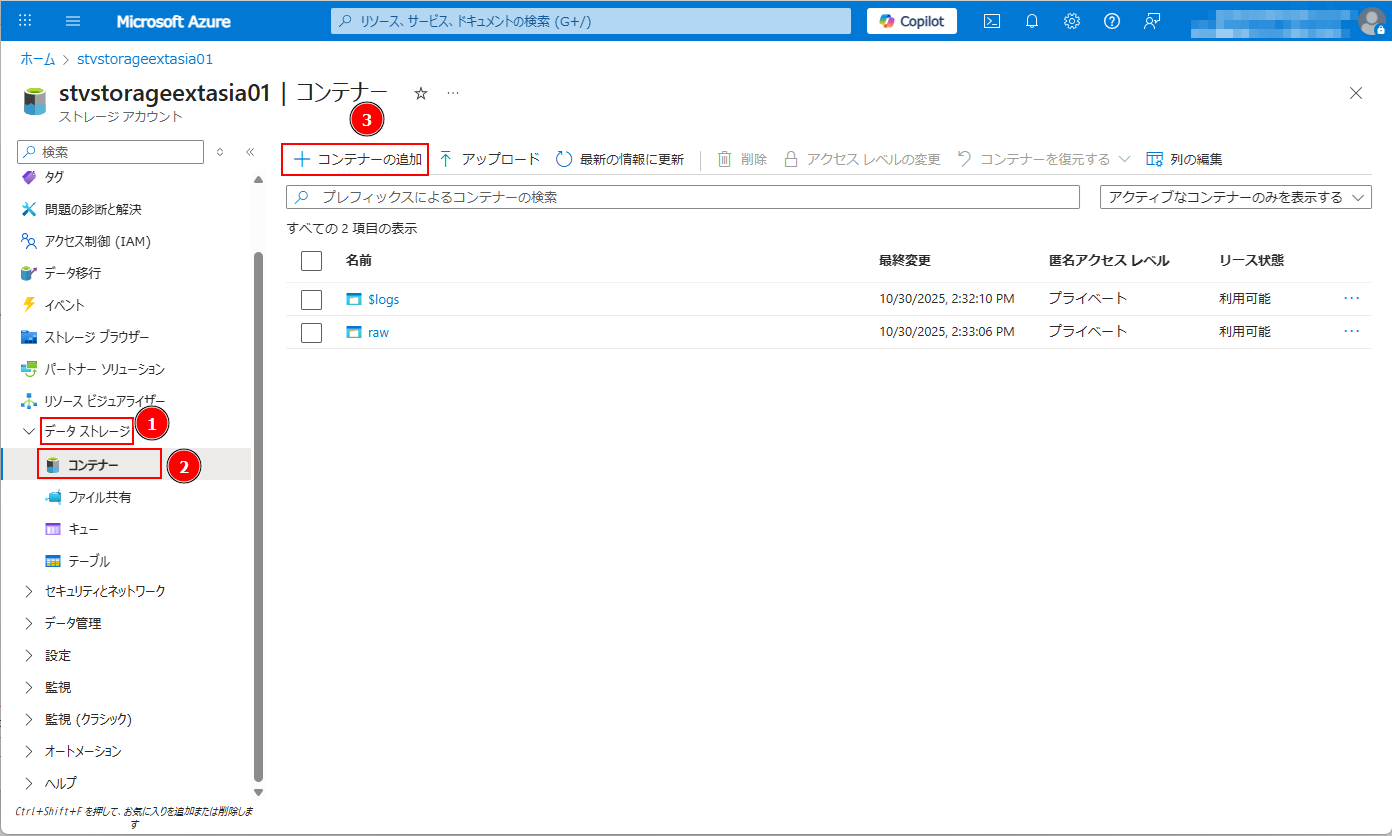
① ストレージアカウントの画面から >「データ ストレージ」→ 「コンテナー」→ 「コンテナーの追加」をクリックします。
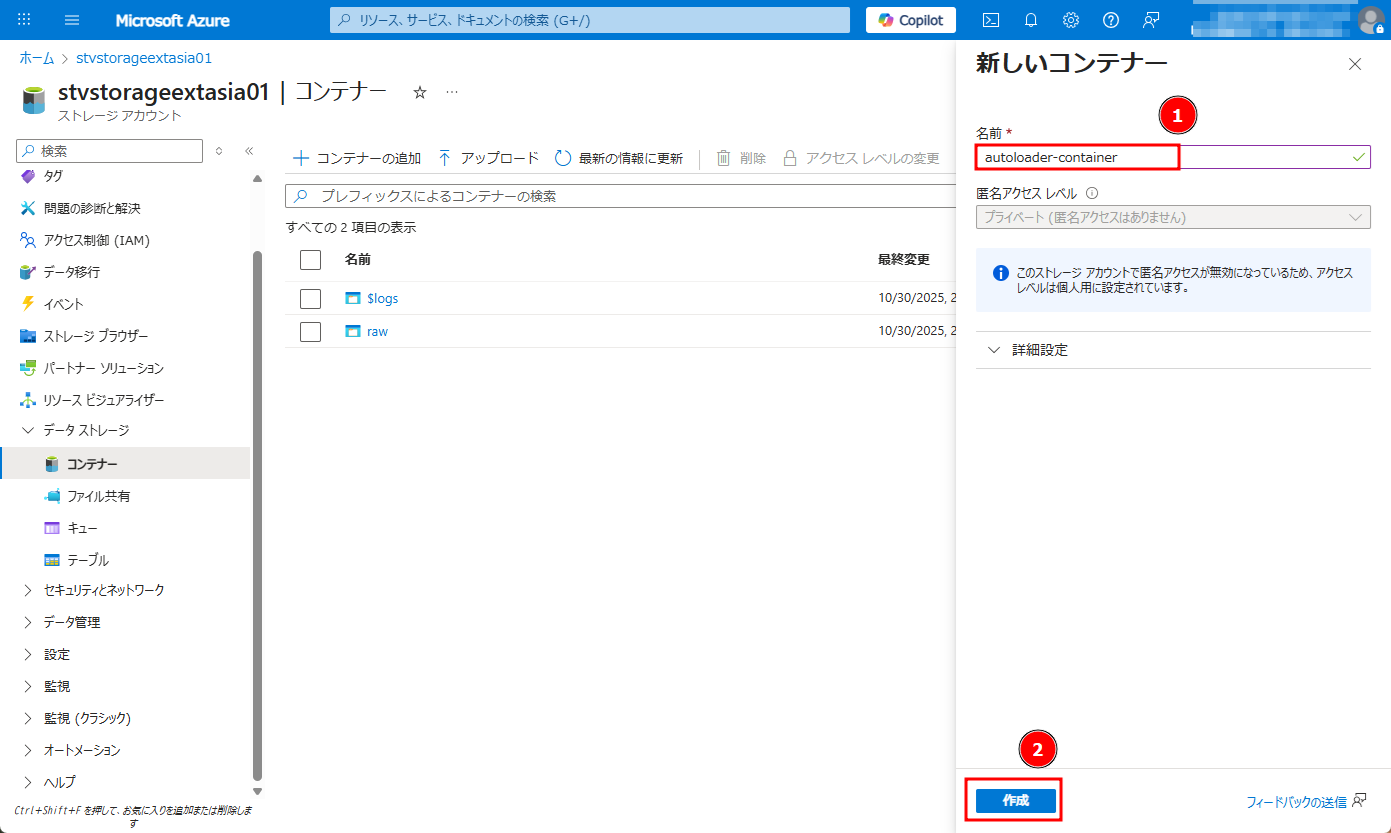
②「autoloader-container」というコンテナー名を付けます。「作成」をクリックします。
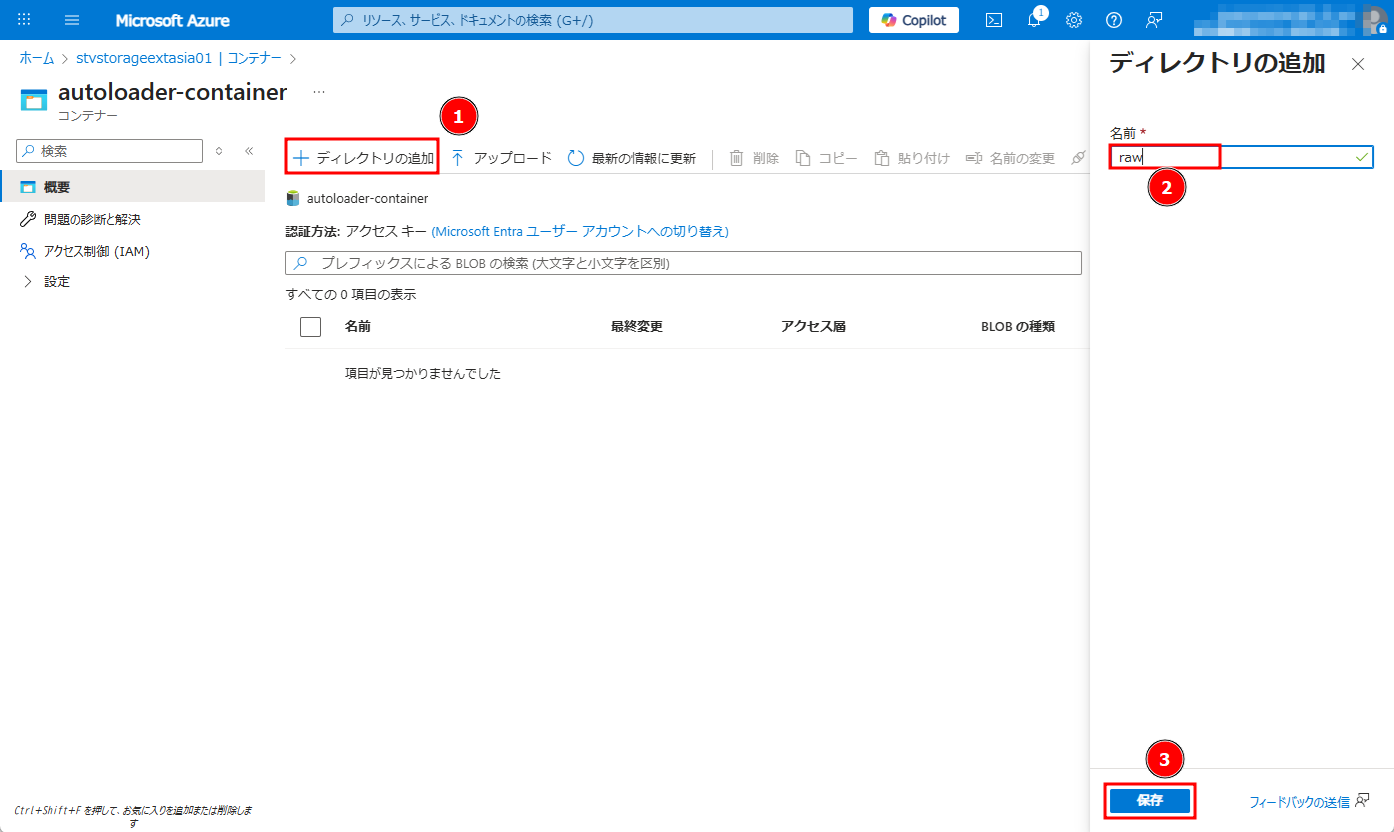
③ コンテナーでフォルダーを作成するには、「ディレクトリの追加」をクリックします。
④「 raw 」というフォルダー名を付けます。「保存」をクリックします。
⑤「raw」フォルダに移動して、以下のCSVファイルをアップロードします。
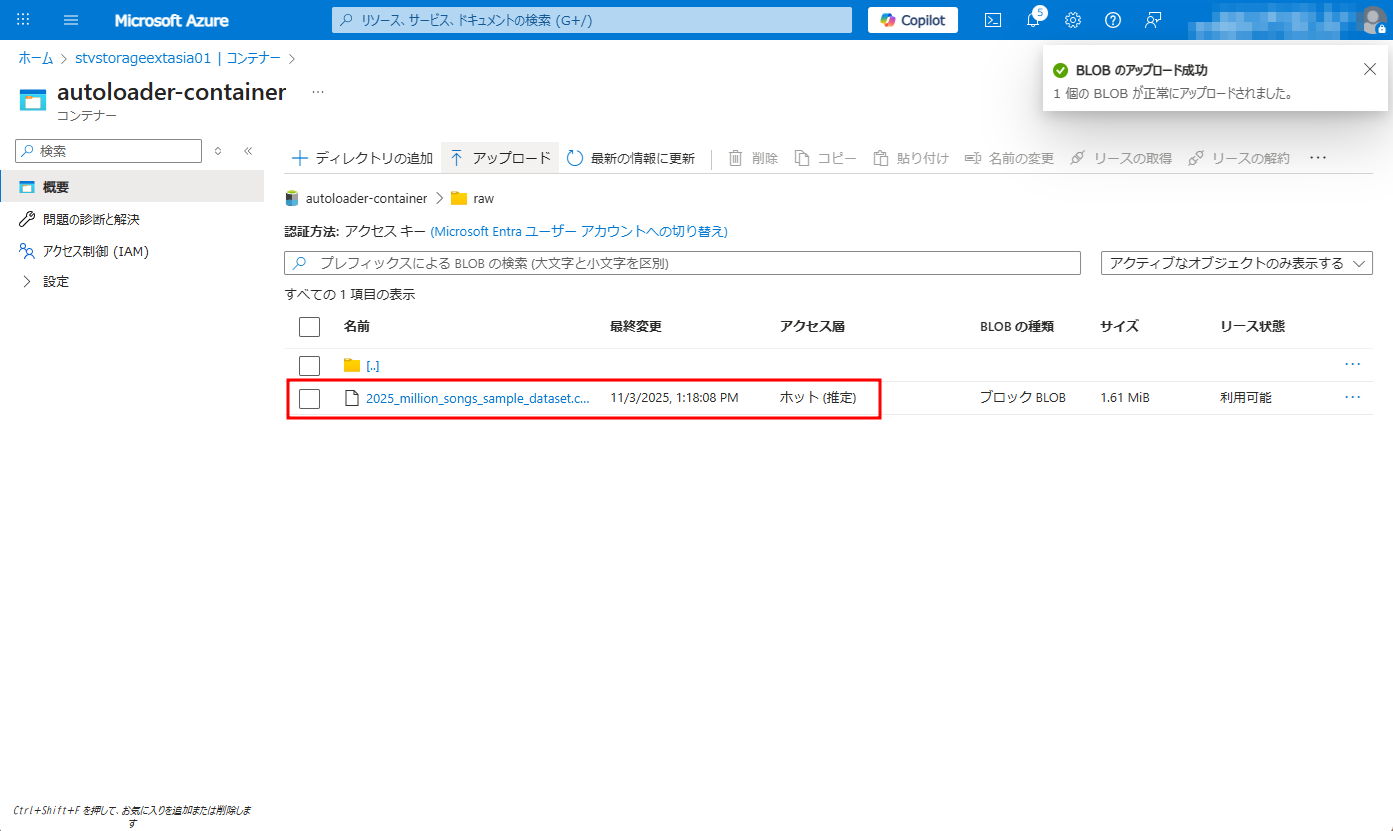 次に、外部ロケーションをDatabricksで作成します。
次に、外部ロケーションをDatabricksで作成します。
5. 外部ロケーション作成
① Azure Databricksの画面から →「カタログ」→「外部データ」→「外部ロケーションを作成」をクリックします。
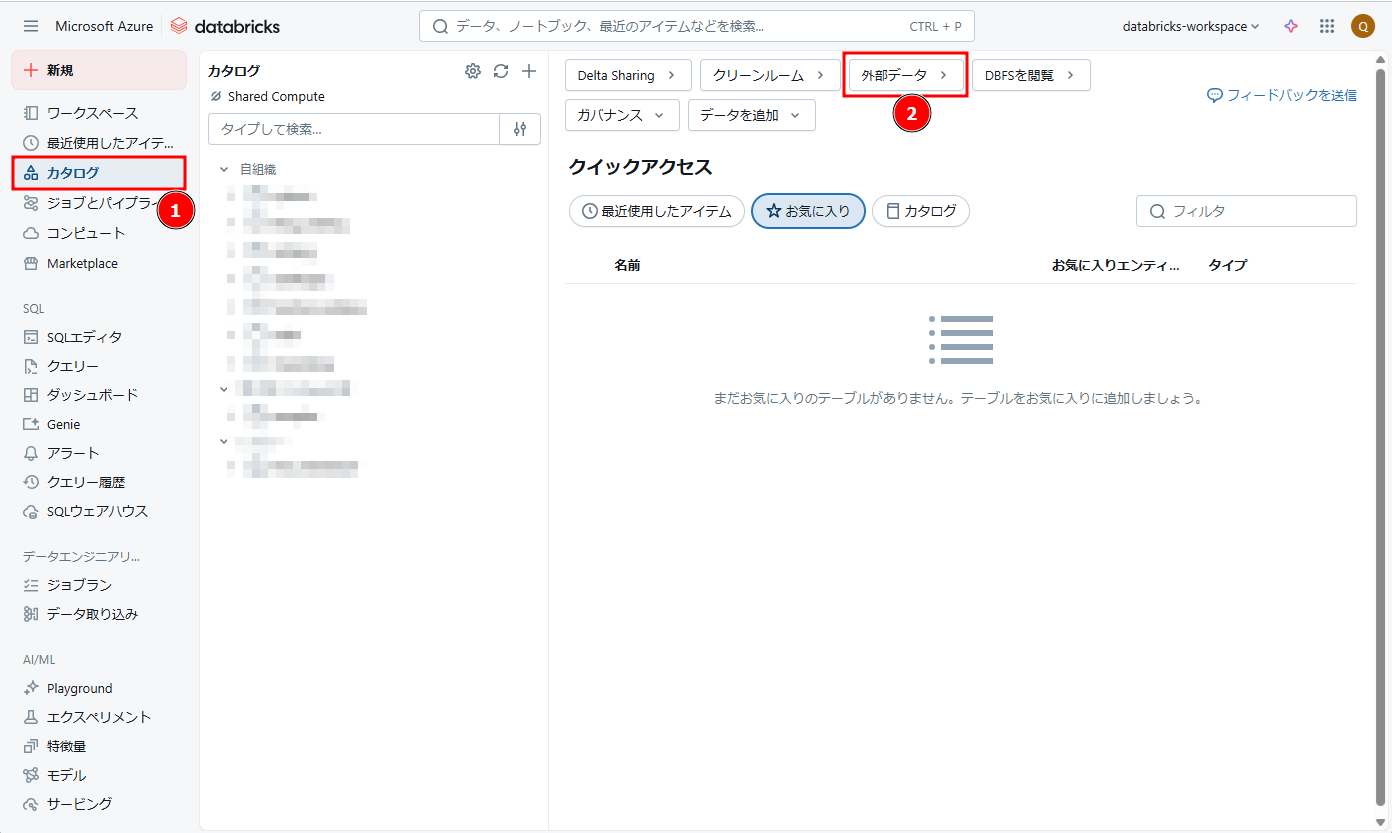
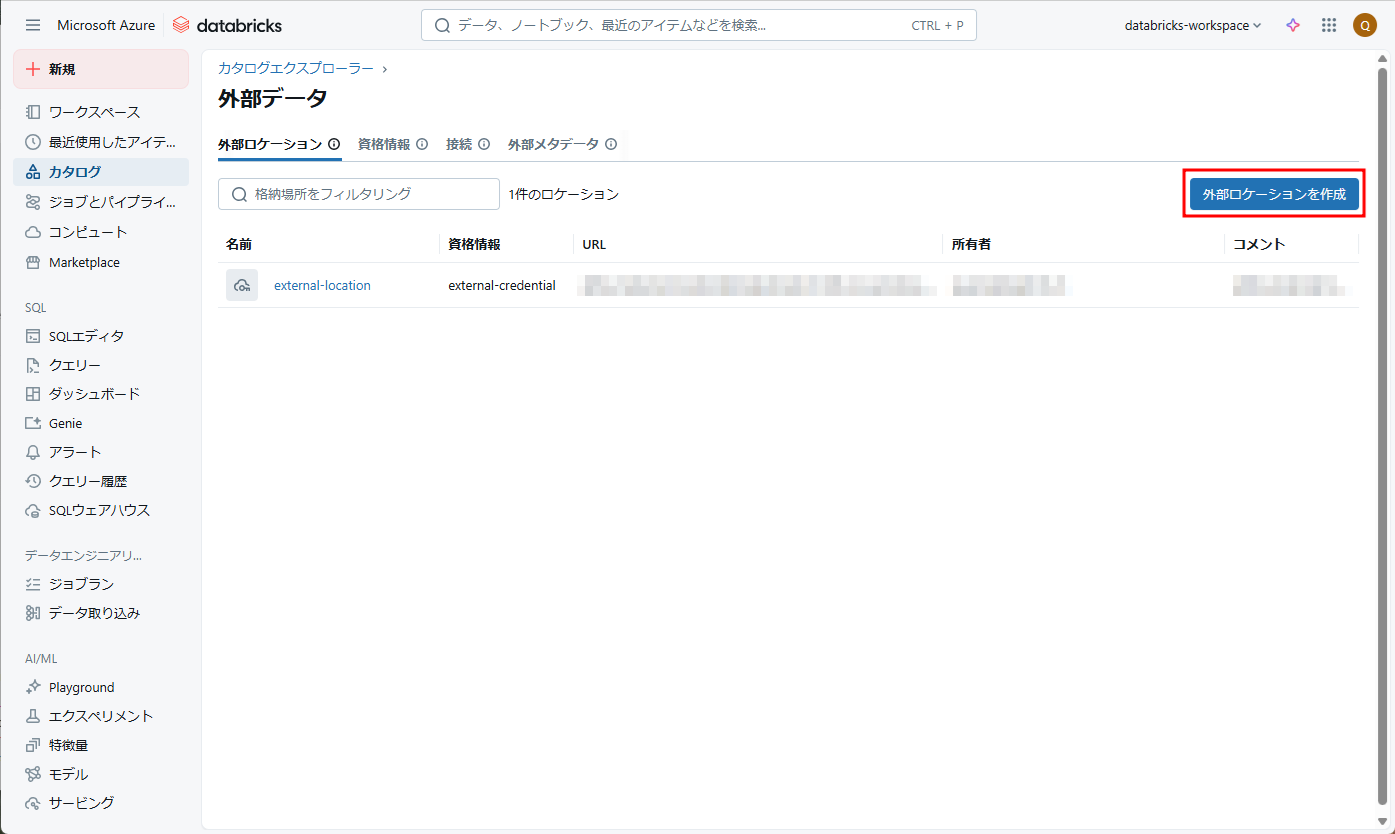 ② 必要な情報を入力します。
② 必要な情報を入力します。
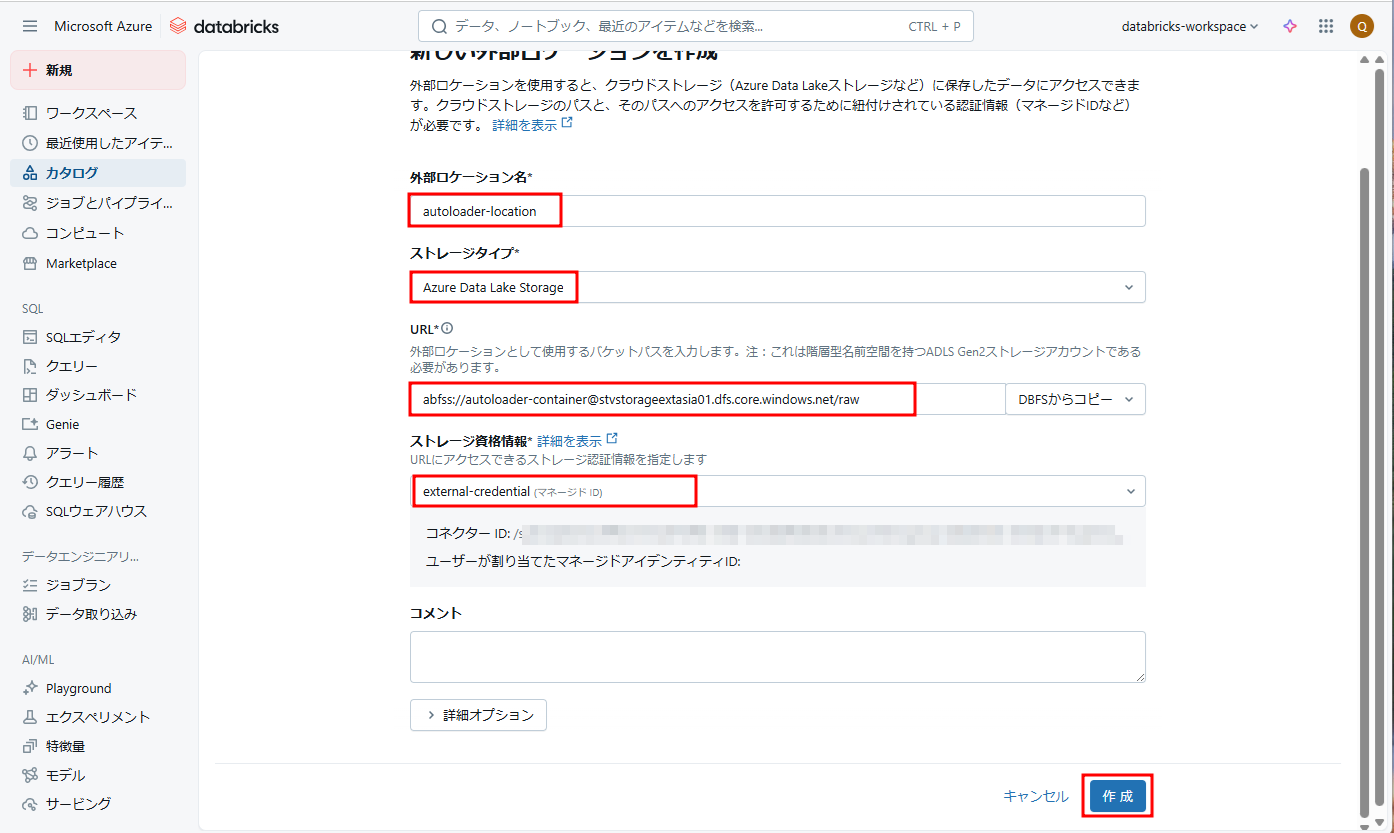
- 「外部ロケーション名」→ 「autoloader-location」という外部ロケーション名を付けます。
- 「ストレージタイプ」→ Azure Data Lake Storage
- 「ストレージ資格情報」→ ストレージ資格情報を選択します。
③「URL」→ 以下の内容を入力します。
文法:
|
1 |
abfss://<container>@<storage-account>.dfs.core.windows.net/<folder> |
例:
|
1 |
abfss://autoloader-container@stvstorageextasia01.dfs.core.windows.net/raw |
④「作成」をクリックします。
6. Lakeflow 宣言パイプラインパイプライン作成
Lakeflow 宣言パイプラインのパイプラインを作成して、ETLを実施します。
① Databricksワークスペース画面から → 「ジョブとパイプライン」→「作成」→「ETLパイプライン」をクリックします。
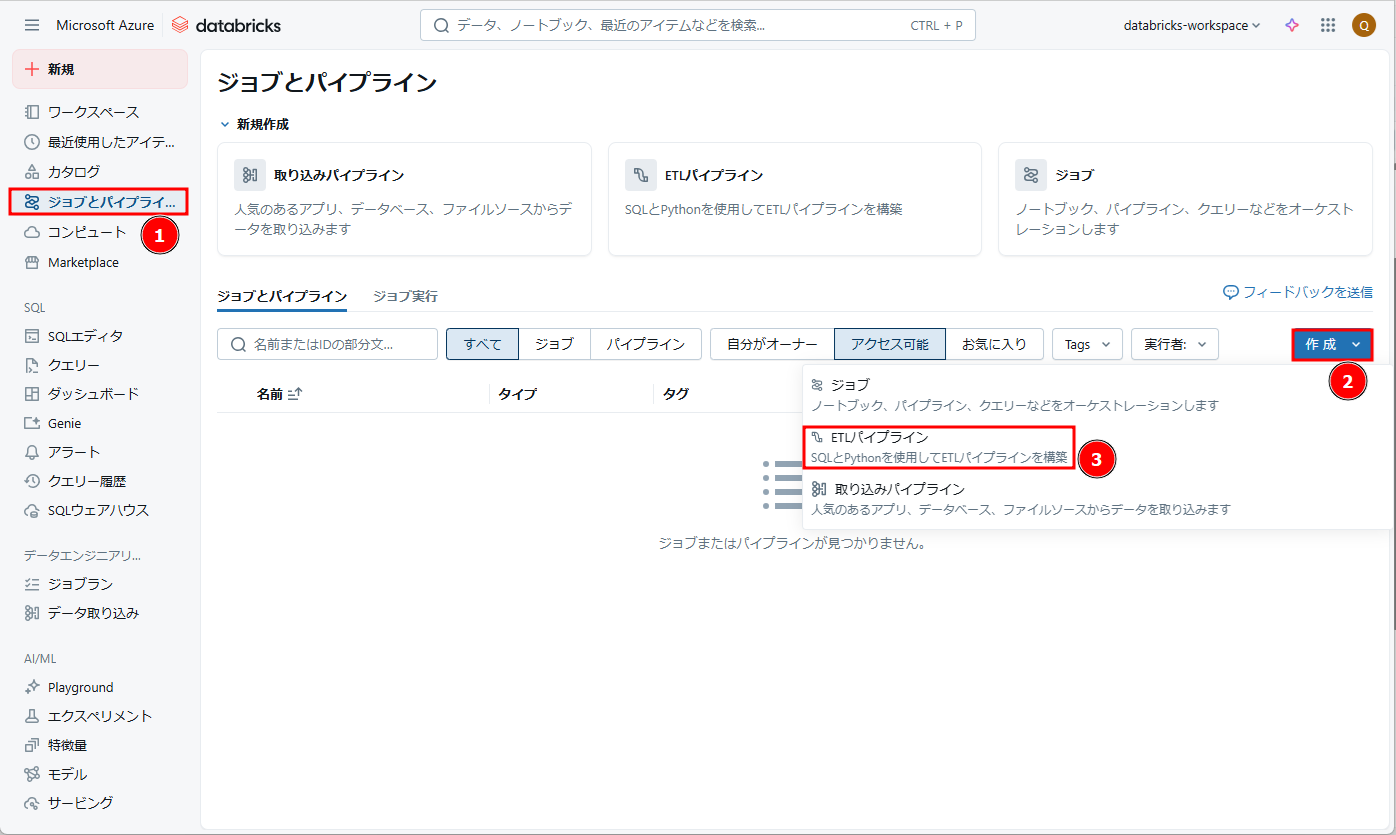
②「パイプライン名」>「demo-pipeline」というパイプライン名を付けます。
「カタログ」:カタログ名を選択します。
「スキーマ」:スキーマ名を選択します。
③「空のファイルで開始」をクリックします。
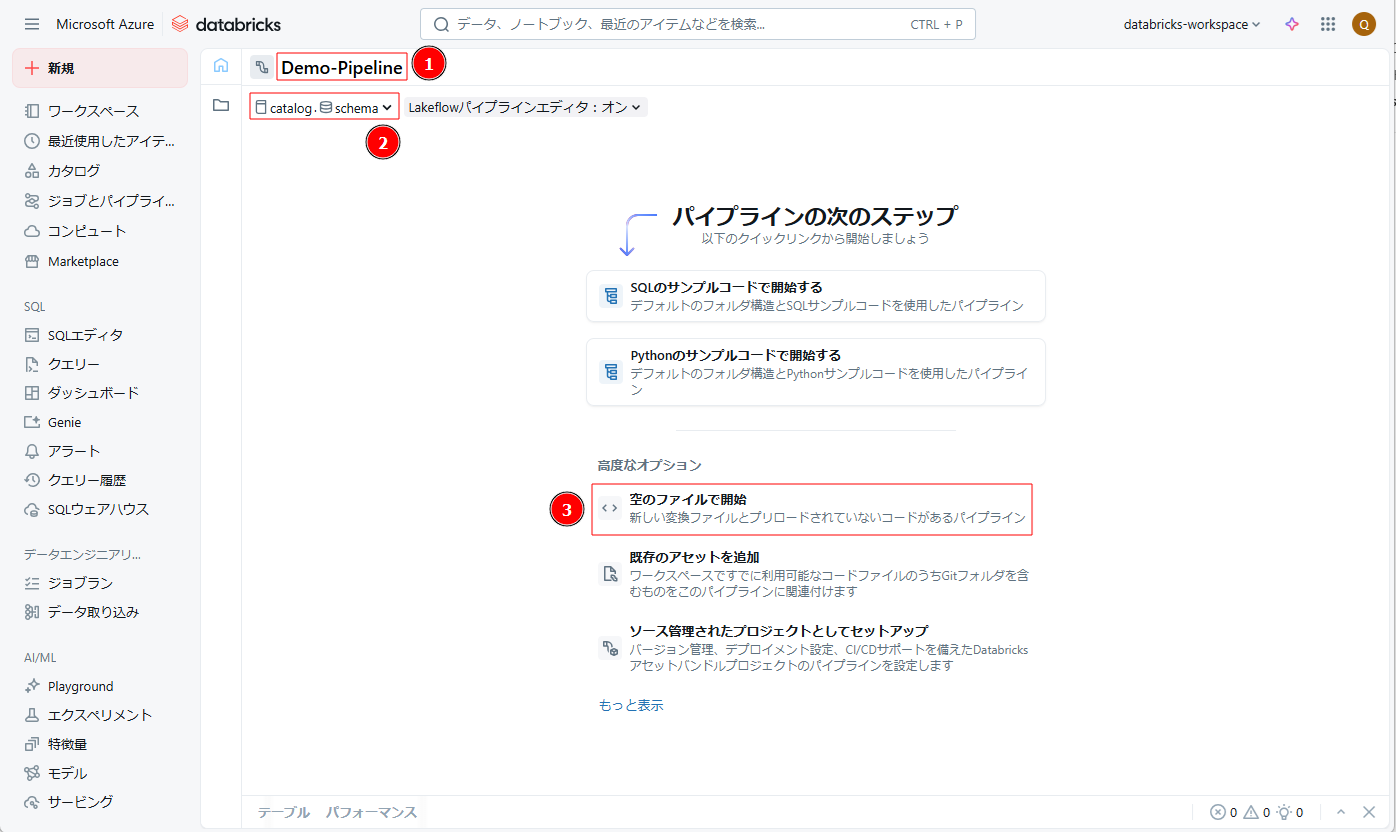
③ 「 フォルダー パス」 で、ソース ファイルの場所を指定するか、既定値 (ユーザー フォルダー) をそのまま使用します。
最初のソース ファイルの言語として 「Python」 を選択します
「選択」をクリックします
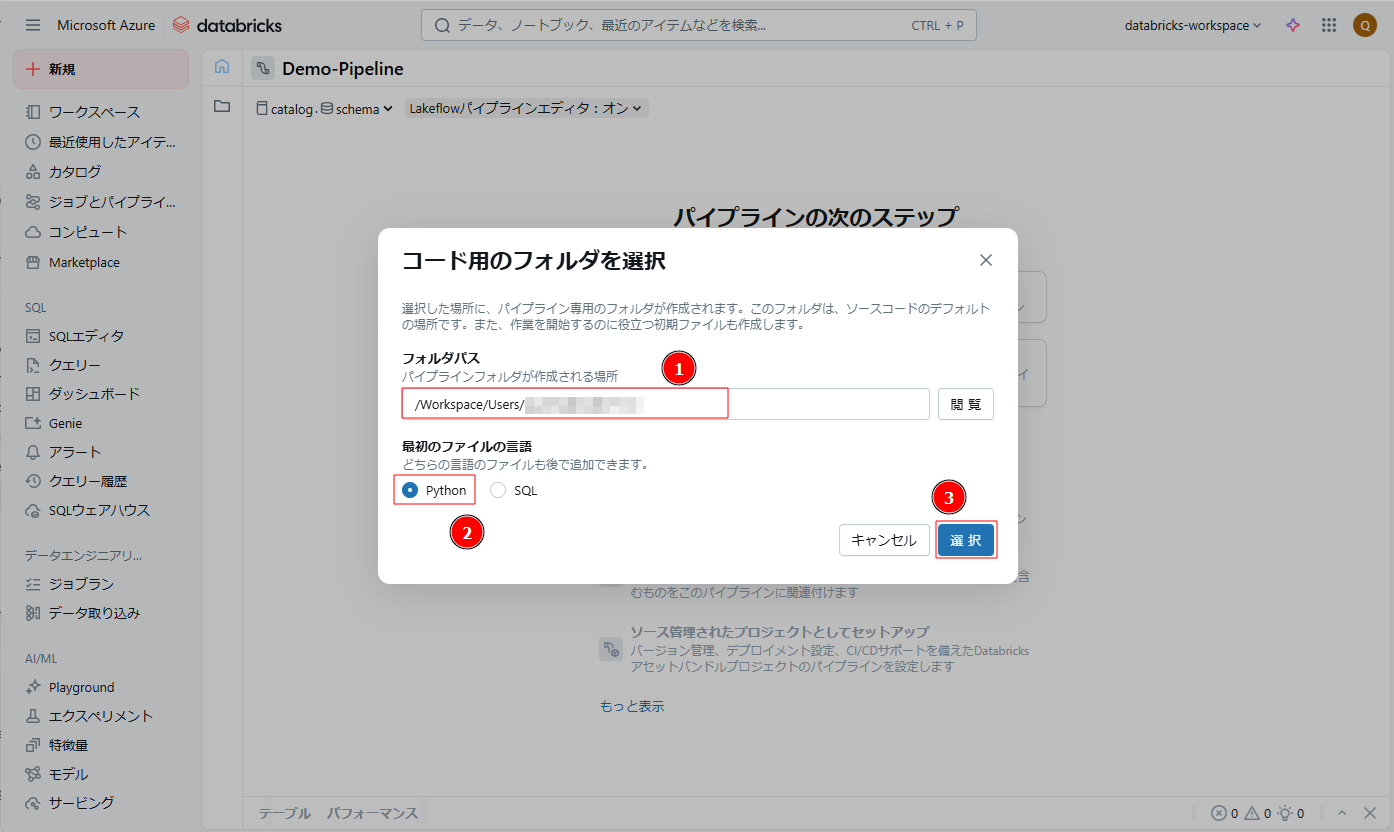
④ 次のコードをコピーしてソース ファイルに貼り付けます。「パイプラインを実行」をクリックします
「file_path」という変数に外部ロケーションURLをご変更ください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
# Import modules from pyspark import pipelines as dp from pyspark.sql.functions import * from pyspark.sql.types import DoubleType, IntegerType, StringType, StructType, StructField # Define the path to the source data file_path = f"abfss://autoloader-container@stvstorageextasia01.dfs.core.windows.net/raw" # Define a streaming table to ingest data from a volume schema = StructType( [ StructField("artist_id", StringType(), True), StructField("artist_lat", DoubleType(), True), StructField("artist_long", DoubleType(), True), StructField("artist_location", StringType(), True), StructField("artist_name", StringType(), True), StructField("duration", DoubleType(), True), StructField("end_of_fade_in", DoubleType(), True), StructField("key", IntegerType(), True), StructField("key_confidence", DoubleType(), True), StructField("loudness", DoubleType(), True), StructField("release", StringType(), True), StructField("song_hotnes", DoubleType(), True), StructField("song_id", StringType(), True), StructField("start_of_fade_out", DoubleType(), True), StructField("tempo", DoubleType(), True), StructField("time_signature", DoubleType(), True), StructField("time_signature_confidence", DoubleType(), True), StructField("title", StringType(), True), StructField("year", IntegerType(), True), StructField("partial_sequence", IntegerType(), True) ] ) @dp.table( comment="Raw data from a subset of the Million Song Dataset; a collection of features and metadata for contemporary music tracks." ) def songs_raw(): return (spark.readStream .format("cloudFiles") .option('cloudFiles.format', 'csv') .option('header', 'true') .option("sep",",") .schema(schema) .load(file_path)) # Define a materialized view that validates data and renames a column @dp.materialized_view( comment="Million Song Dataset with data cleaned and prepared for analysis." ) @dp.expect("valid_artist_name", "artist_name IS NOT NULL") @dp.expect("valid_title", "song_title IS NOT NULL") @dp.expect("valid_duration", "duration > 0") def songs_prepared(): return ( spark.read.table("songs_raw") .withColumnRenamed("title", "song_title") .select("artist_id", "artist_name", "duration", "release", "tempo", "time_signature", "song_title", "year") ) # Define a materialized view that has a filtered, aggregated, and sorted view of the data @dp.materialized_view( comment="A table summarizing counts of songs released by the artists who released the most songs each year." ) def top_artists_by_year(): return ( spark.read.table("songs_prepared") .filter(expr("year > 0")) .groupBy("artist_name", "year") .count().withColumnRenamed("count", "total_number_of_songs") .sort(desc("total_number_of_songs"), desc("year")) ) |
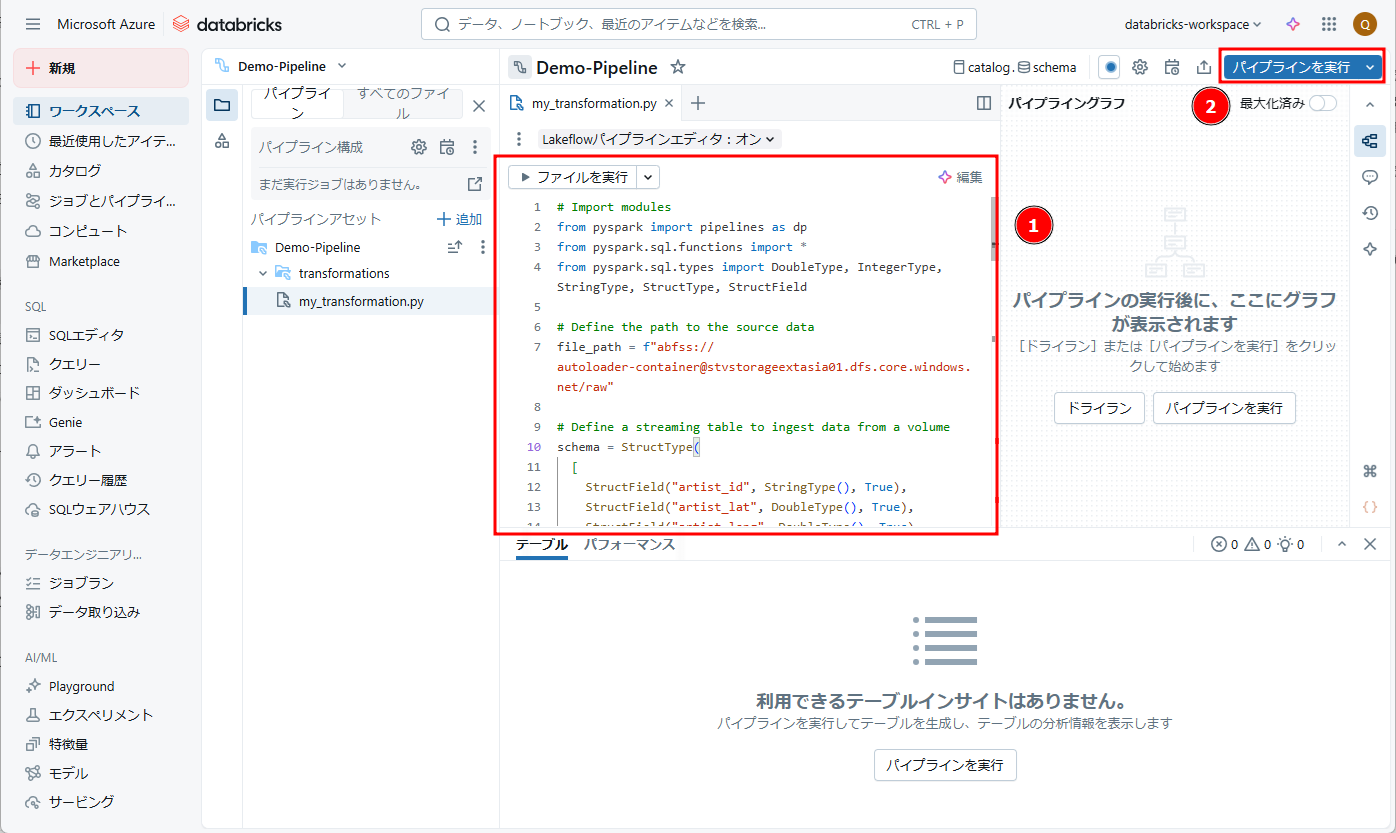
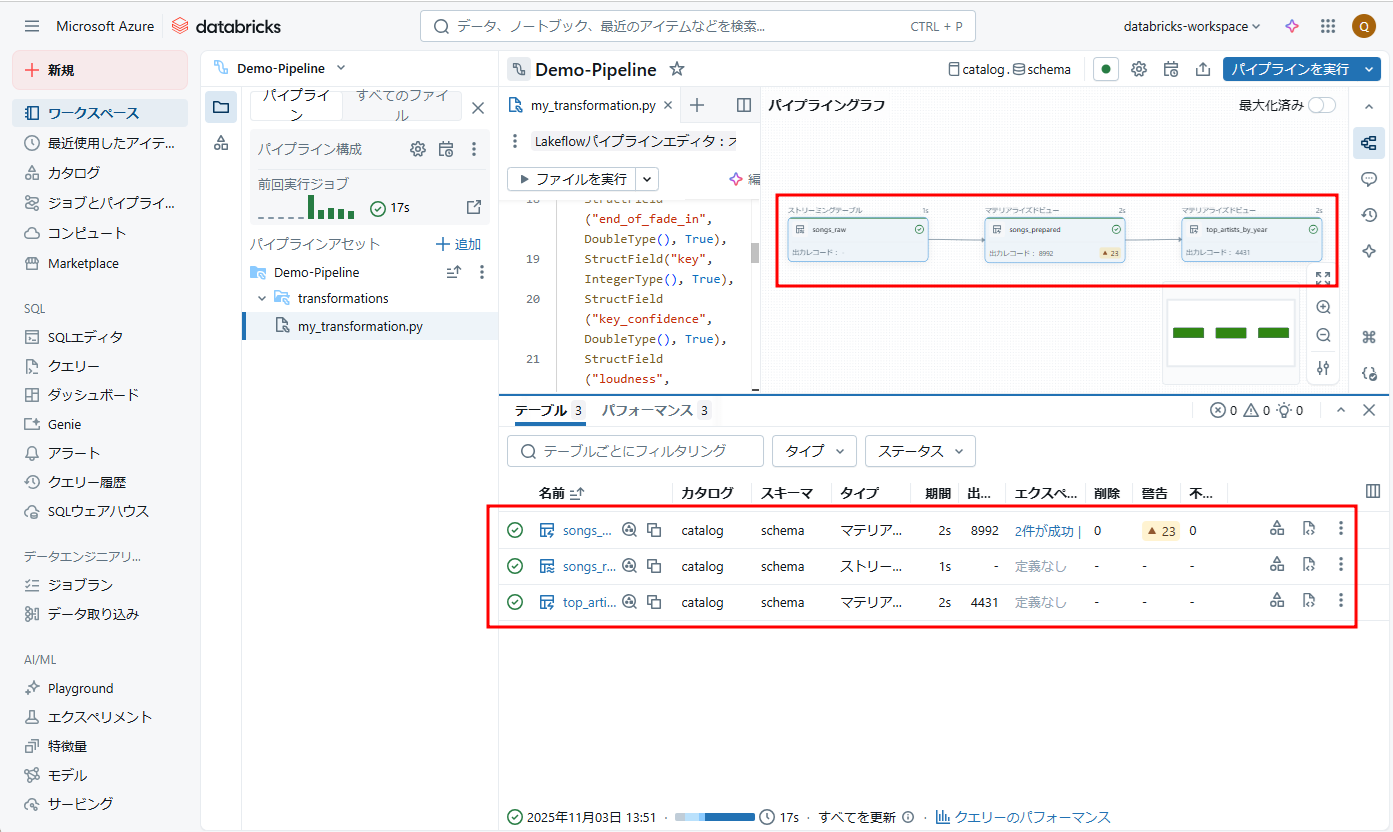
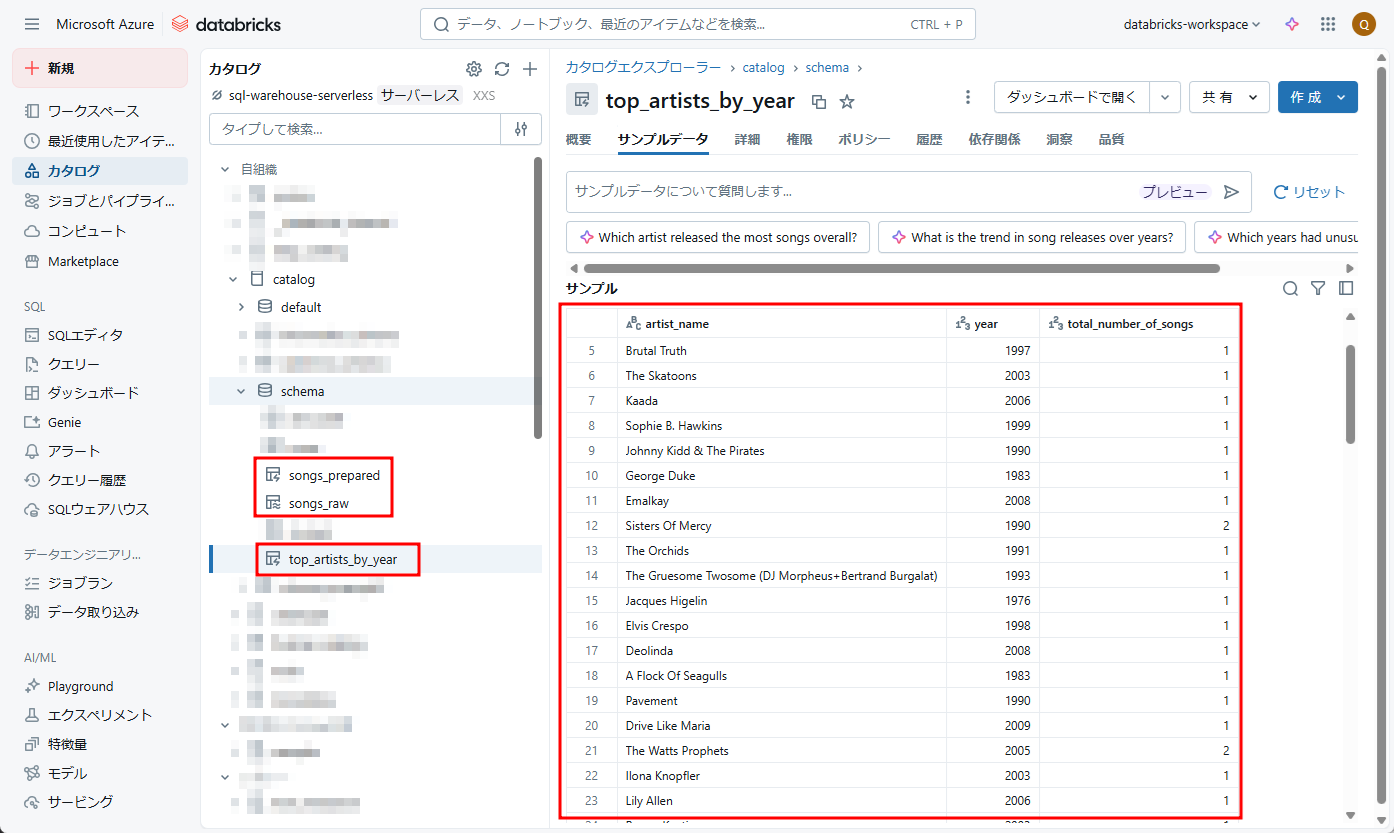
⑥ パイプラインの実行が正常に完了しました。
CSVデータがストレージアカウントから読み込まれ、Unity Catalogに保存されました。
 8. まとめ
8. まとめ
今回は、Auto Loader を Lakeflow 宣言パイプライン と組み合わせて使用方法について説明しました。
第1回: Auto Loaderの概要、自動取込方法を使用してみる
第2回: Auto Loader を Lakeflow 宣言パイプラインと組み合わせて使用してみる (今回)
第3回: Auto LoaderのSchema inferenceとEvolutionの機能について説明する
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
Azure Databricks連載記事のまとめはこちら
![]() お問い合わせはこちら
お問い合わせはこちら