1. はじめに
AI技術の急速な発展に伴い、多くの企業では大規模言語モデル(LLMs)をデータパイプラインや業務アプリケーションへ統合するニーズが高まっています。
Azure Databricksでは、AI Functionsを利用することで、複雑なインフラ構築を行うことなく、LLMを簡単かつ安全に利用できます。AI FunctionsはDatabricksに統合された関数群であり、NotebookやSQLから直接LLMを呼び出せる点が大きな特徴です。本記事は、以下のようなデータエンジニア、データサイエンティスト、開発者を対象としています。
- OpenAIやAzure OpenAIなどのLLMをNotebookやSQLから直接利用したい。
- LLMをデータ処理フローへ組み込みたい。
- 既存のAI Functionsを活用し、AIアプリケーション開発を迅速化したい。
本記事では、Azure DatabricksのAI Functionsを利用して、データ処理環境へ直接LLMを統合する方法について紹介します。NotebookやSQL上でAI Functionsを呼び出す方法に加え、Azure OpenAIとの接続設定についても、実運用を意識したシンプルかつ実践的な構成例をベースに解説します。
2. AI Functionsの概要
AI Functionsは、Azure Databricks上に保存されたデータに対して、大規模言語モデル(LLM)や高度なAI技術を利用し、データ変換やデータ拡張を実現するための組み込み関数群です。
これらの関数は、Databricks SQL、Notebook、Lakeflow Spark Declarative Pipelines、Workflowsなど、Databricks上のさまざまな実行環境で利用できます。
AI Functionsは、シンプルな利用方法、高速な処理性能、そして高いスケーラビリティを考慮して設計されています。データアナリストは、企業固有のデータに対して AI を活用した分析を容易に実施できるほか、データエンジニア、データサイエンティスト、機械学習エンジニアは、本番レベルの大規模データ処理パイプラインへAI機能を統合することが可能です。
AI Functionsは、大きく以下 2 種類に分類されます。
- タスク固有のAI Functions
- ai_query
タスク固有のAI Functionsは、特定のユースケース向けに最適化されたAI Functions群です。例えば、以下のような処理に対応しています。
- ドキュメント解析(Document Parsing)
- エンティティ抽出(Entity Extraction)
- 分類(Classification)
- 感情分析(Sentiment Analysis)
これらの関数は、Azure Databricksが管理する高度なAIシステム上で実行されており、先進的な研究成果をベースに提供されています。また、一部の機能では専用 UI も提供されています。対応している関数やモデル一覧については、タスク固有のAI Functionsの公式ドキュメントをご参照ください。
ai_queryは、タスクおよび利用モデルの両方に対して高い柔軟性を持つ汎用AI Functionsです。ユーザーはプロンプトを指定し、利用したい基盤モデルAPI を選択するだけで、任意のLLMを呼び出すことができます。 詳細については、ai_query使用の公式ドキュメントをご参照ください。
本番ワークフローにおけるAI Functionsの活用
大規模なバッチ推論(Batch Inference)処理においては、タスク固有のAI Functionsや「ai_query」を、Lakeflow Spark Declarative Pipelines、Databricks Workflows、Structured Streamingなどの本番ワークフローに統合できます。これにより、大量データに対するAI処理を、本番レベルの安定性およびスケーラビリティを維持したまま実行可能になります。
AI Functionsの実行状況監視
AI Functionsでは、完了した推論数や失敗した推論数を確認できるほか、パフォーマンス分析や問題調査を行うために、クエリプロファイルを利用して実行状況を監視できます。
AI Functions利用時のコスト確認
AI Functionsを利用したワークロードのコストは、「MODEL_SERVING」プロダクト内の「BATCH_INFERENCE」サービス種別として記録されます。バッチ推論ワークロードのコスト確認方法については、バッチ推論ワークロードのコスト確認のドキュメントをご参照ください。
3. 前提条件
本手順を実施する前に、以下の前提条件を満たしていることをご確認ください。
- Databricks Workspaceがプレミアムプランであり、サーバーレスに対応したリージョン上に配置されていること
- Databricks WorkspaceにてUnity Catalogが有効化されていること
- Unity Catalog上でSQL Warehouseおよびテーブルを作成可能な権限を保有していること
- ユーザーがAzure OpenAI Serviceを利用可能であること
サンプルデータを事前にダウンロードしていること。
4. AI Functionsを使用したデモンストレーション実施
4.1 デモの概要および実施手順
本実践編では、Amazon Reviews Datasetのサンプルデータを用い、Azure DatabricksのAI関数による顧客フィードバック分析のユースケースを模擬します。
本データセットには、商品品質、配送体験、カスタマーサポート、ユーザー満足度などに関する実際のレビュー内容を含む、Amazon利用者の商品レビューが格納されています。このデータセットを用いて、レビュー内容の自動要約、顧客感情の分類、レビューからの重要情報抽出を行うAIベースのデータ処理フローを構築します。
これらのタスクは、個別の機械学習モデルを構築または学習することなく、AI関数を用いて直接実行します。
実施手順
デモは以下の手順で実施します。
① Azure OpenAI/OpenAIへの接続を構成する。基盤モデルエンドポイントの設定、またはAPIキーの構成を行い、DatabricksからAI関数で利用するAIモデルを使用可能にする。
② サンプルデータを準備し、Amazon ReviewsデータセットをDatabricksへインポートして、分析用テーブルを作成する。
③ AI関数を用いて、各顧客レビューの簡潔な要約を生成する。
④ レビューをPositive、Neutral、Negativeに分類し、顧客満足度を評価する。
⑤ 商品名、発生した問題、関連サービス、特徴的なフィードバックキーワードなど、レビューから重要情報を抽出する。
4.2 Azure OpenAI/OpenAI接続設定
本セクションでは、DatabricksとAzure OpenAI/OpenAIを接続するための設定を行い、AI関数がデータ処理タスク向けの基盤モデルを利用できるようにします。
DatabricksはMosaic AI Model Servingの「External Models」機能を通じて、Azure OpenAI Service/OpenAI APIとの直接統合をサポートしています。
以下の手順を実施します。
① Azure PortalでAzure OpenAIにアクセスする。
② 「Foundry ポータルの詳細」ボタンを押下して、「Microsoft Foundry|Azure Open AI」ページにアクセスする。
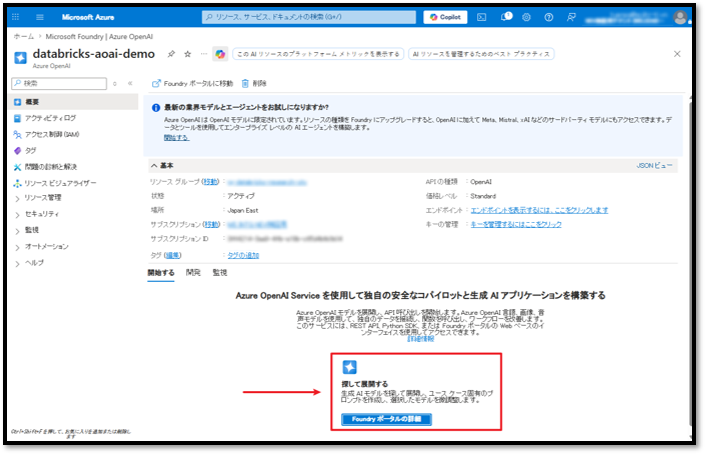
③ サイドバーの「デプロイ」セクションに移動する。
④ 以下の情報をコピーして保存する。
- ターゲット URI
- キー
- 名前
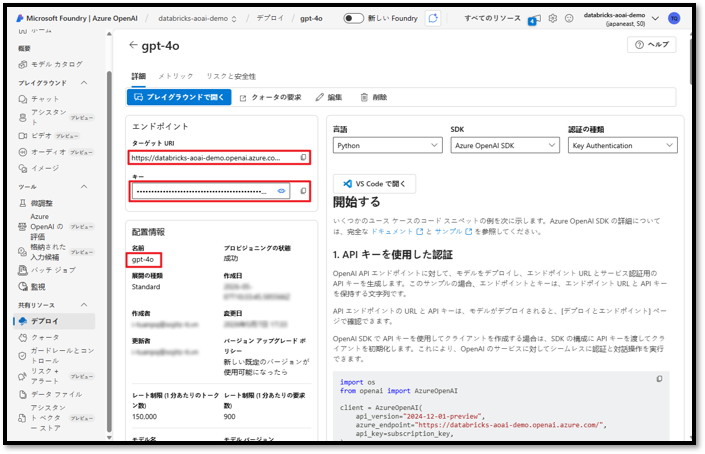
次に、Databricks Workspaceにアクセスします。
⑤ サイドバーの「ワークスペース」セクションを選択する。
⑥ Workspaceに移動し、「作成」を選択した後、「ノートブック」を選択してノートブックを作成する。
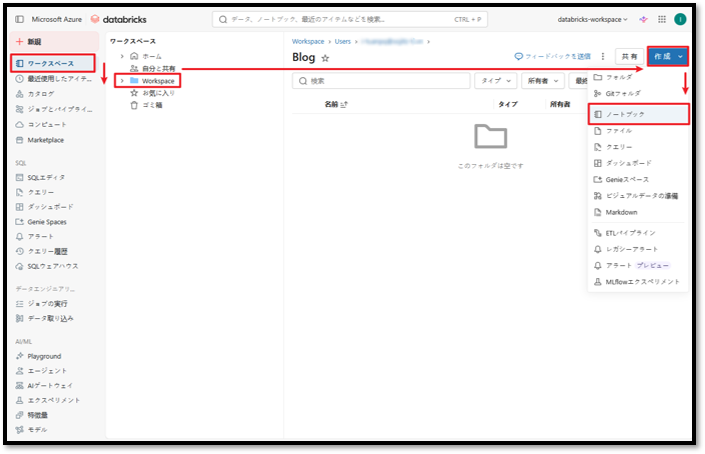
⑦ 次のコマンドをノートブックにコピーする。
|
1 |
%pip install mlflow[genai]>=2.9.0 |
⑧ その後、「実行」アイコンを選択してノートブックを実行し、MLflowをインストールする。
インストールが正常に完了すると、画面表示が以下の図のように変わります。
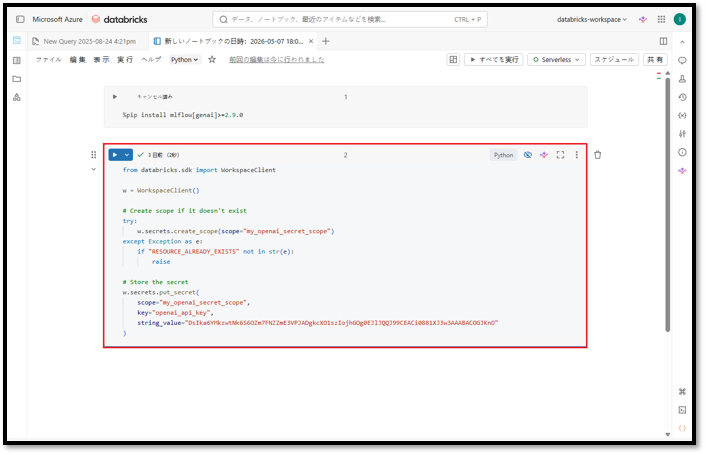
次に、新しいセルを作成して、Azure OpenAI内のモデルのAPIキー用のシークレット変数を作成します。以下の手順を続行します。
⑨ 次のコマンドを新しく作成したセルにコピーする。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from databricks.sdk import WorkspaceClient w = WorkspaceClient() # Create scope if it doesn't exist try: w.secrets.create_scope(scope="my_openai_secret_scope") except Exception as e: if "RESOURCE_ALREADY_EXISTS" not in str(e): raise # Store the secret w.secrets.put_secret( scope="my_openai_secret_scope", key="openai_api_key", string_value="<api-key>" ) |
パラメータ説明:
<api-key>:Azure Open AI内のモデルのAPIキー
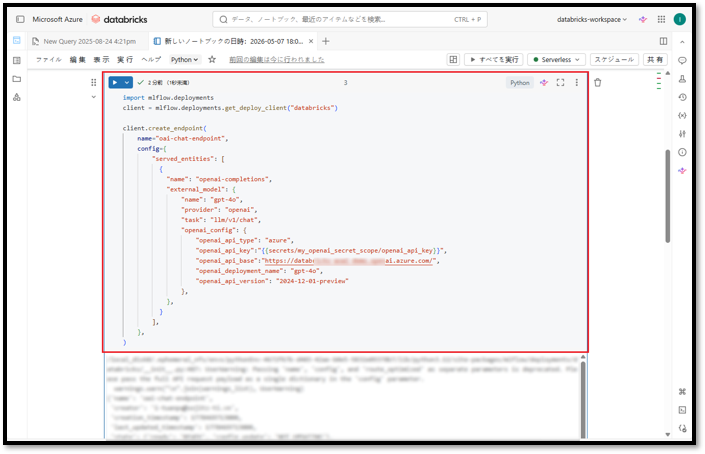
最後に、新しいセルを作成してAzure Open AIのモデルとの接続を確立し、外部モデルエンドポイントを作成します。
大規模言語モデル(LLM)用の外部モデルエンドポイントを作成するには、MLflow Deployments SDKのcreate_endpoint()メソッドを使用します。
⑩ 次のコマンドを新しく作成したセルにコピーする。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import mlflow.deployments client = mlflow.deployments.get_deploy_client("databricks") client.create_endpoint( name="oai-chat-endpoint", config={ "served_entities": [ { "name": "openai-completions", "external_model": { "name": "<deployment-name>", "provider": "openai", "task": "llm/v1/chat", "openai_config": { "openai_api_type": "azure", "openai_api_key": "{{secrets/my_openai_secret_scope/openai_api_key}}", "openai_api_base":"<endpoint-url>", "openai_deployment_name": "<deployment-name>", "openai_api_version": "<api-version>" }, }, } ], }, ) |
パラメータ説明
- <endpoint-url>:Azure Open AI内のモデルのエンドポイント
- <api-version>:Azure Open AI内のモデルのAPIバージョン
- <deployment-name>:Azure Open AI内のモデルの名前
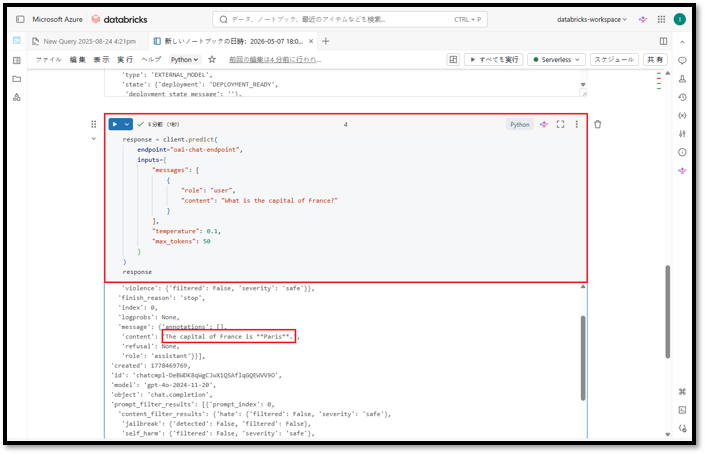
以下のコマンドを実行して、GPT-4oモデルで接続を検証します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
response = client.predict( endpoint="oai-chat-endpoint", inputs={ "messages": [ { "role": "user", "content": "What is the capital of France?" } ], "temperature": 0.1, "max_tokens": 50 } ) response |
「Paris」という回答が返されれば、接続が正常に確立されたことが確認できます。
4.3 データ準備
本セクションでは、Amazon Reviews Datasetのサンプルデータセットをインポートして分析を実施します。
以下の手順を順番に実施します。
① サイドバーの「データ取り込み」メニューを選択し、「テーブルを作成または変更」を選択する。
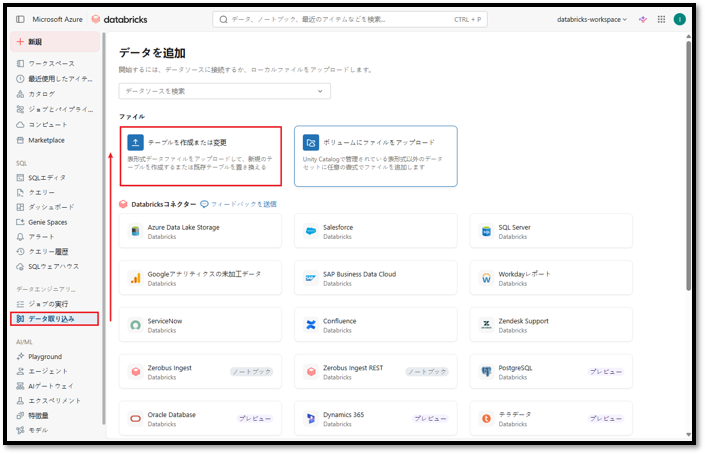
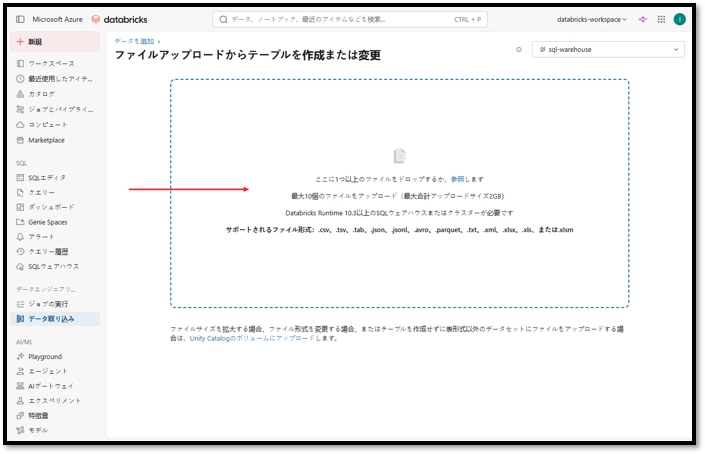
② 次に「ここに1つ以上のファイルをドロップするか、参照します」をクリックしてDatabricksにデータをインポートする。
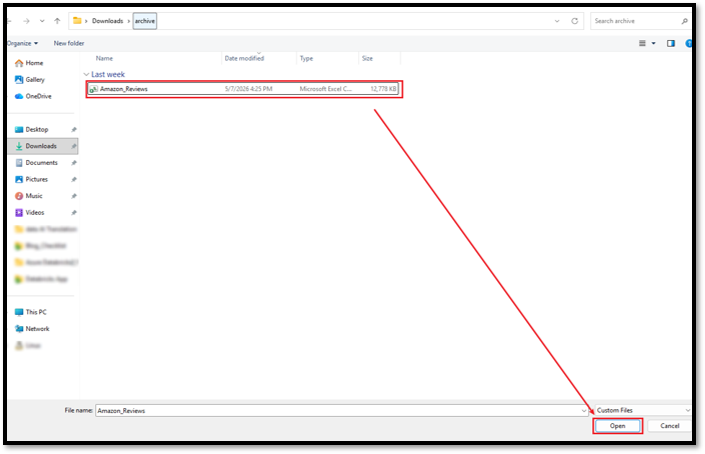
③ インポート対象のデータセットを選択し、「Open」ボタンを押下する。
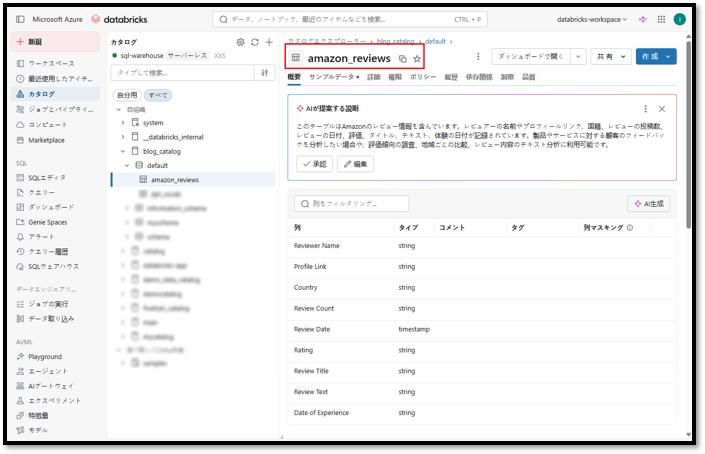
正常に作成されると、テーブル「amazon_reviews」がカタログ「blog_catalog」のスキーマ「default」に作成されます。
4.4 AI関数を使用したテキスト要約
次に、ai_queryを用いたAI関数を使用してAmazonの顧客レビューを要約します。
次のコマンドをノートブックの新しいセルにコピーして実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
%sql SELECT `Reviewer Name`, Rating, ai_query( 'oai-chat-endpoint', CONCAT( 'You are analyzing customer reviews for business insights. ', 'Summarize the review in one neutral sentence. ', 'Do not repeat offensive, hateful, abusive, or discriminatory language. ', 'Focus only on product quality, delivery, price, support, or user experience. ', 'Review: ', `Review Text` ) ) AS summary FROM blog_catalog.default.amazon_reviews WHERE `Review Text` IS NOT NULL LIMIT 20; |
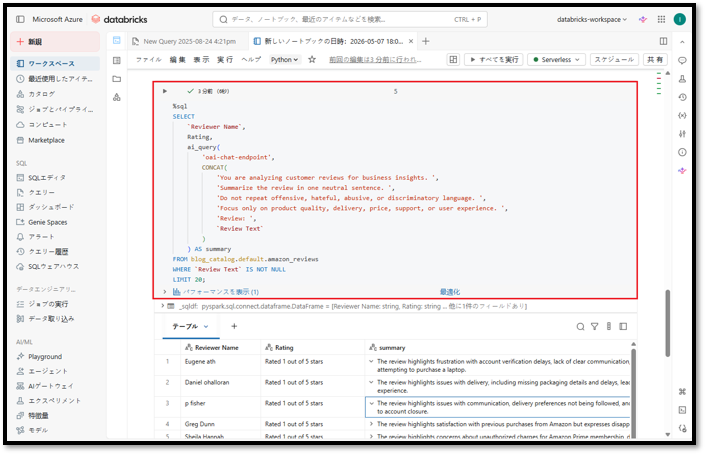
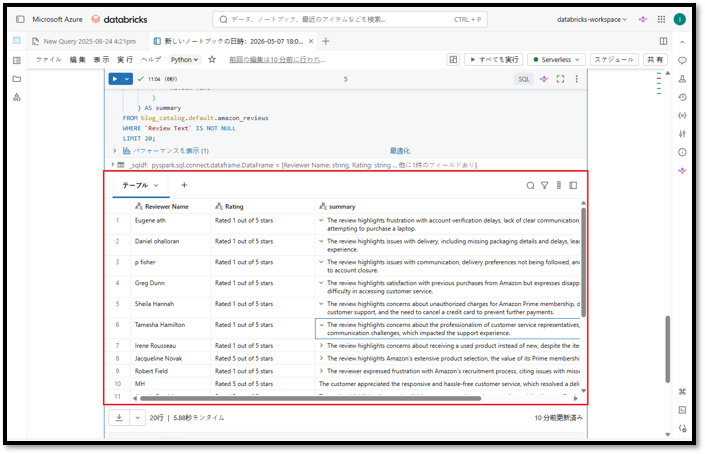
上記コマンドを実行すると、このクエリは最大20件のレビューを3列で返します。
- Reviewer Name:レビュー投稿者名
- Rating:星評価/評価点
- Summary:AI関数が生成したレビュー要約
4.5 顧客感情分類
レビュー内容の要約後、次のステップとして感情分類(Sentiment Classification)を実施し、顧客の反応傾向を判定します。
- Positive
- Neutral
- Negative
AI関数により、機械学習モデルを個別に学習させることなく、この処理をSQLで直接実行できます。
実施するには、次のコマンドをコピーして実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
%sql SELECT `Reviewer Name`, Rating, ai_query( 'oai-chat-endpoint', CONCAT( 'Classify the sentiment of the following customer review as Positive, Neutral, or Negative. ', 'Return only one label. ', 'Review: ', `Review Text` ) ) AS Sentiment FROM blog_catalog.default.amazon_reviews WHERE `Review Text` IS NOT NULL LIMIT 20; |
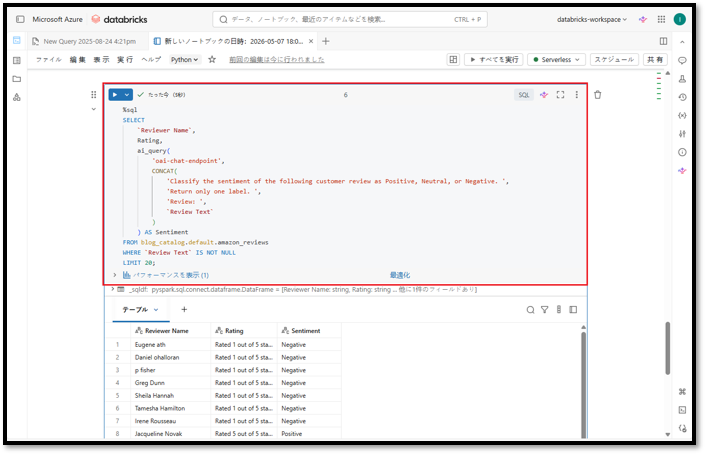
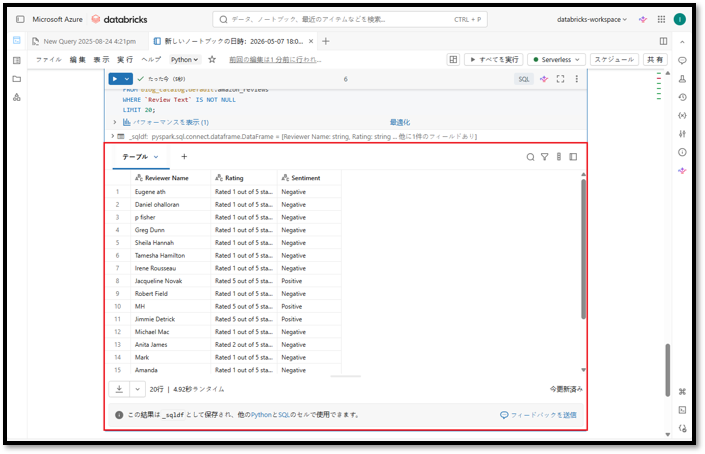
上記コマンドを実行すると、このクエリは最大20件のレビューを3列で返します。
- Reviewer Name:レビュー投稿者名
- Rating:星評価/評価点
- Sentiment:AI関数が生成した顧客レビューの感情分類結果
4.6 重要情報抽出
要約および感情分類に加えて、AI関数はレビュー内容から重要情報を抽出する用途にも使用できます。
例を以下に示します。
- 顧客が直面した問題
- 顧客が満足したポイント
- 商品、配送、価格、サポートに関連する観点
- フィードバック内の主要キーワード
実施するには、次のコマンドをコピーして実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
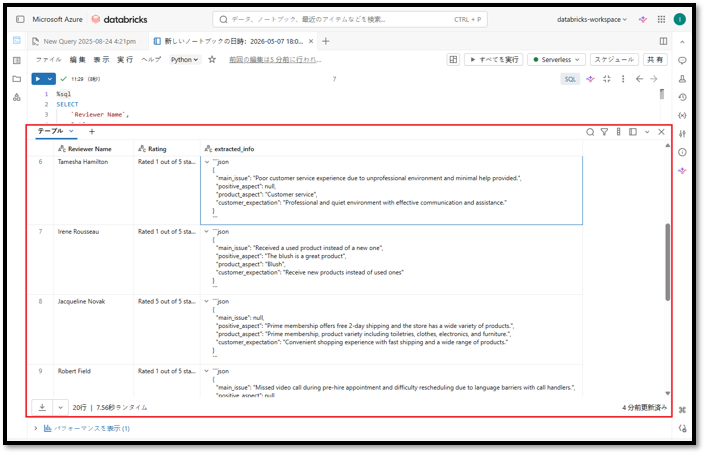
SELECT `Reviewer Name`, Rating, ai_query( 'oai-chat-endpoint', CONCAT( 'Extract important information from the following customer review. ', 'Return the result in JSON format with the fields: ', 'main_issue, positive_aspect, product_aspect, customer_expectation. ', 'Use null if a field is not mentioned. ', 'Do not repeat offensive, hateful, abusive, or discriminatory language. ', 'Review: ', `Review Text` ) ) AS extracted_info FROM blog_catalog.default.amazon_reviews WHERE `Review Text` IS NOT NULL LIMIT 20; |
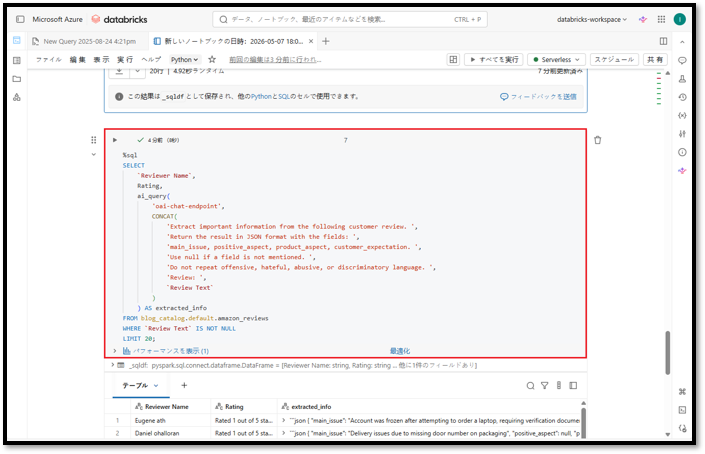
上記コマンドを実行すると、このクエリは最大20件のレビューを3列で返します。
- Reviewer Name:レビュー投稿者名
- Rating:星評価/評価点
- extracted_info:AIがJSON形式で抽出した重要情報
この結果により、企業は頻出課題の集約、顧客体験の分析、フィードバック分析ダッシュボードの構築、ならびに後続のAI/分析パイプラインへの活用を容易に実施できます。
5. まとめ
Azure DatabricksのAI関数は、SQLまたはNotebookによるデータ処理フローに生成AIを直接統合できる、シンプルかつ効果的な手段です。
Amazon Reviews Datasetを用いた本デモでは、レビュー要約、顧客感情分類、レビューからの重要情報抽出といった代表的なタスクを実施しました。
AI関数は高い拡張性を有し、Azure OpenAIや基盤モデルとも容易に統合できるため、実運用におけるテキストデータ分析およびデータ処理自動化のユースケースに適したソリューションです。
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
Azure Databricks連載記事のまとめはこちら
![]() お問い合わせはこちら
お問い合わせはこちら
この記事を読んだ方へのオススメコンテンツはこちら
この記事を書いた人

- 双日テックイノベーション(旧:日商エレクトロニクス)特設サイト「Azure導入支援デスク」サイトマスターです。