目次
1. はじめに
皆さんこんにちは。
近年、データ基盤はますます高度化しており、運用プロセスの自動化と最適化は非常に重要な要素となっています。特にAzure Databricksのようなデータ分析プラットフォームにおいては、ユーザーインターフェース(UI)上での操作だけでは柔軟性に欠け、CI/CDパイプラインへの統合が難しい場合があります。
こうした課題を解決する手段として登場したのがDatabricks CLI(Command Line Interface)です。このツールを利用することで、コマンドライン経由でDatabricksワークスペースと連携し、Notebook、クラスター、ジョブ、ワークフローなどを効率的に管理することが可能になります。また、スクリプトとの連携も容易であるため、自動化を進めるうえで非常に有効です。これにより、作業効率の向上だけでなく、手動による繰り返し作業の削減にもつながります。
一方で、CLIに初めて触れる方にとっては、インストールやAzure Databricksとの接続設定など、いくつかのハードルがあるのも事実です。
そこで本記事では、Databricks CLIの概要や導入するメリットに加え、インストール手順、設定方法、そしてよく使うコマンドの実践例について順を追って解説していきます。これにより、全体像を把握し、実務にすぐ活用できるレベルまで理解を深めることを目指します。
1.1.Databricks CLIとは
Databricks CLI(Command Line Interface)とは、ターミナル(ローカル環境)や自動化スクリプトを通じて、Azure Databricksと直接やり取りできるコマンドラインツールです。
Web UI上で手動操作を行う代わりに、CLIコマンドを利用することで、さまざまなタスクを迅速かつ効率的に実行することが可能になります。
1.2.Databricks CLIを使うべき場面
Databricks CLIの大きな強みの一つは、自動化プロセスとの高い親和性です。CLIをCI/CDパイプライン(例:Azure DevOpsやGitHub Actions)に組み込むことで、Notebookのデプロイ、ジョブの実行、環境構成の設定などを手動操作なしで実現できます。
2.Databricks CLIのインストール方法
Databricks CLIは、macOS・Linux・Windowsといった主要なOSで簡単にインストールすることができます。
macOSやLinuxではHomebrewやCurl、WindowsではWinGet・WSL・Chocolateyなどのパッケージマネージャーを利用可能です。
また、必要に応じてDatabricksが提供するソースコードやバイナリファイルから手動でインストールすることもでき、この方法はすべてのOSで利用可能です。
本記事では、Windows環境におけるDatabricks CLIのインストール手順について解説します。
2.1 前提条件
Windowsでは、Databricks CLIは以下の方法でインストール可能です。
・WinGet (推奨)
・Chocolatey
・WSL
詳細については、Azure Databricksの公式ドキュメントをご参照ください。
https://learn.microsoft.com/ja-jp/azure/databricks/dev-tools/cli/
2.2. WindowsでのDatabricks CLIインストール手順
Databricks CLIは、WinGet、WSL、Chocolatey、またはソースコードからインストールすることができますが、本記事ではChocolateyを利用した方法を紹介します。
以下に、Chocolateyを使用したインストール手順を示します。
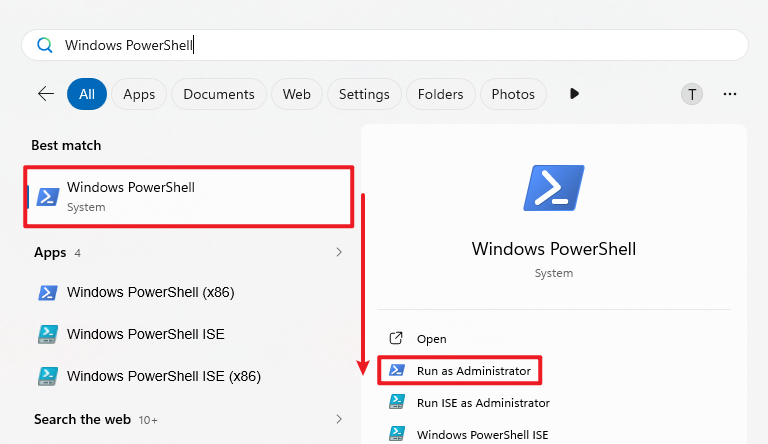
① PowerShellを管理者権限で起動
Windowsの検索で「Windows PowerShell」を検索し、右クリックして「Run as Administrator」を選択します。

② Chocolateyを使用してDatabricks CLIのダウンロード
Chocolateyを利用してDatabricks CLIをダウンロードするには、以下のコマンドを実行します。
|
1 |
choco install databricks-cli |
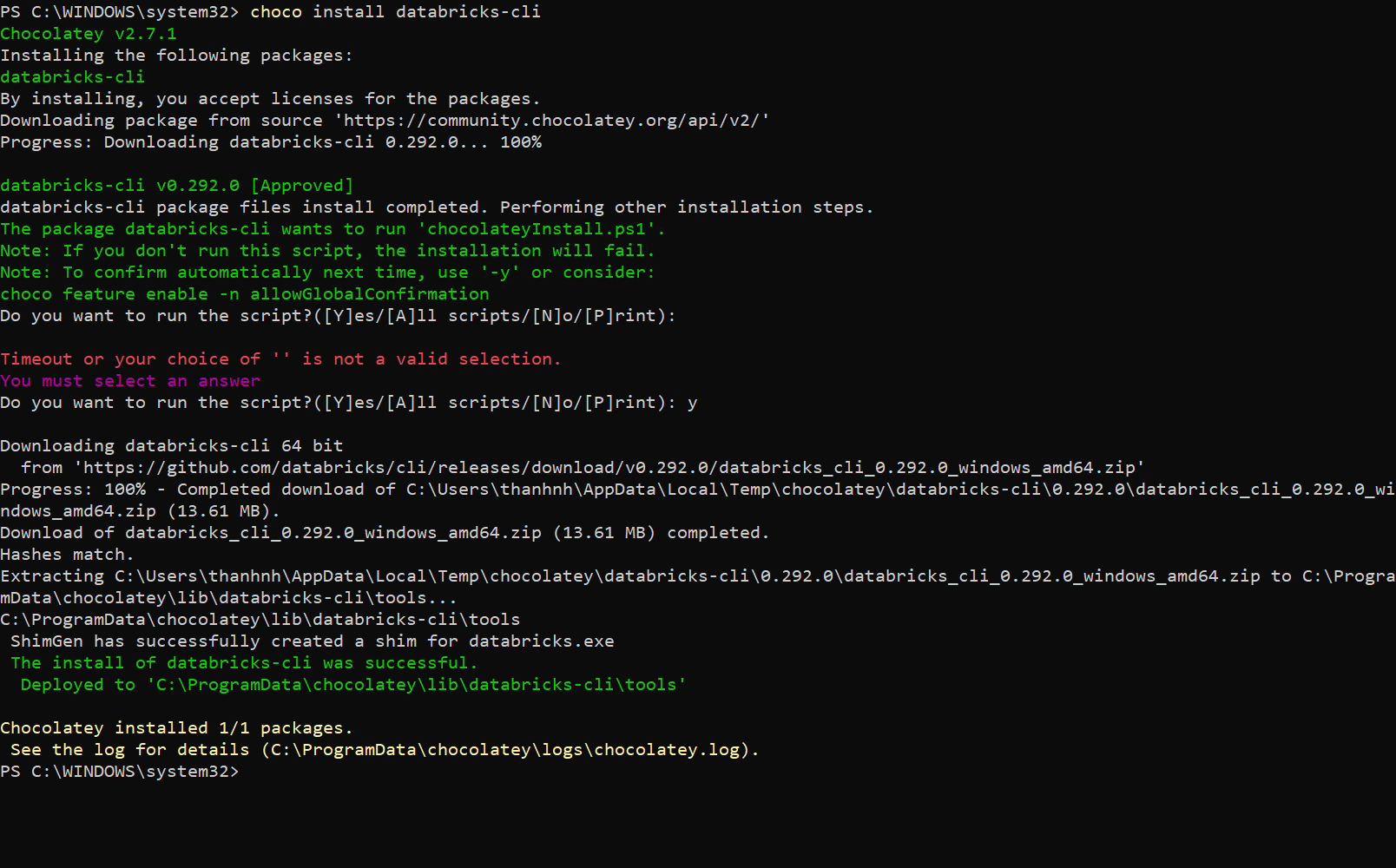 その後、Databricks CLIを利用できるようになります。
その後、Databricks CLIを利用できるようになります。
③ インストールバージョンの確認
Databricks CLIのインストール後、正しくインストールされていることを確認する必要があります。
実行ファイルが正常にインストールされているかを確認するために、新しいターミナル(または新しいタブ)を開き、以下のコマンドを実行してください。
|
1 |
databricks --version |
 ご覧のとおり、Databricks CLIが正しくインストールされていれば、上記のコマンドを実行することでCLIのバージョンが表示されます。
ご覧のとおり、Databricks CLIが正しくインストールされていれば、上記のコマンドを実行することでCLIのバージョンが表示されます。
※注意:「command not found」エラーや、Databricksコマンドが認識されない場合は、CLIが正しくインストールされていない、または環境変数PATHに登録されていない可能性があります。
Chocolateyを利用している場合、通常はPATH(C:\ProgramData\chocolatey\bin)が自動的に設定されます。それでもエラーが発生する場合は、以下の方法で確認してください。
|
1 |
echo $env:Path |
3. Databricks CLIの認証設定方法
Databricks CLIのインストールが完了したら、次のステップとして、CLIがAzure Databricksワークスペースと接続し、認証できるように設定を行います。
この設定により、CLIコマンドを実行し、Databricks上のリソースを直接操作できるようになります。
Databricks CLIは複数の認証方式に対応しており、代表的なものは以下の通りです。
- OAuth (推奨:現在のデフォルト方式)
- Personal Access Token (PAT)
Databricks CLIのチュートリアルにおいても、現在はMicrosoftよりOAuth user-to-machine(U2M) を利用したログイン方法が、安全かつ利便性の高い方法として推奨されています。
3.1. OAuthによる接続設定
CLIをAzure Databricksに接続するために、以下の手順をご実施ください。
① ログインコマンドの実行
|
1 |
databricks auth login --host <workspace-url> |
- ここで、 <workspace-url> はワークスペースのURLを指します。
 ② ブラウザで認証を行う
② ブラウザで認証を行う
- コマンドを実行すると、CLIが自動的にブラウザを起動します。
- Azureアカウントでログインしてください。
- 認証が完了すると、認証情報はローカル環境に保存されます。
 ※注意:CLIはトークンを自動的に管理し、必要に応じてリフレッシュを行うため、何度もログインし直す必要はありません。
※注意:CLIはトークンを自動的に管理し、必要に応じてリフレッシュを行うため、何度もログインし直す必要はありません。
3.2. Personal Access Token (PAT)による接続設定
OAuth以外にも、Personal Access Token(PAT)を利用することができます。これは従来からある認証方式であり、シンプルなスクリプトでの利用に適しています。
PATを使用して接続設定を行うには、以下の手順をご実施ください。
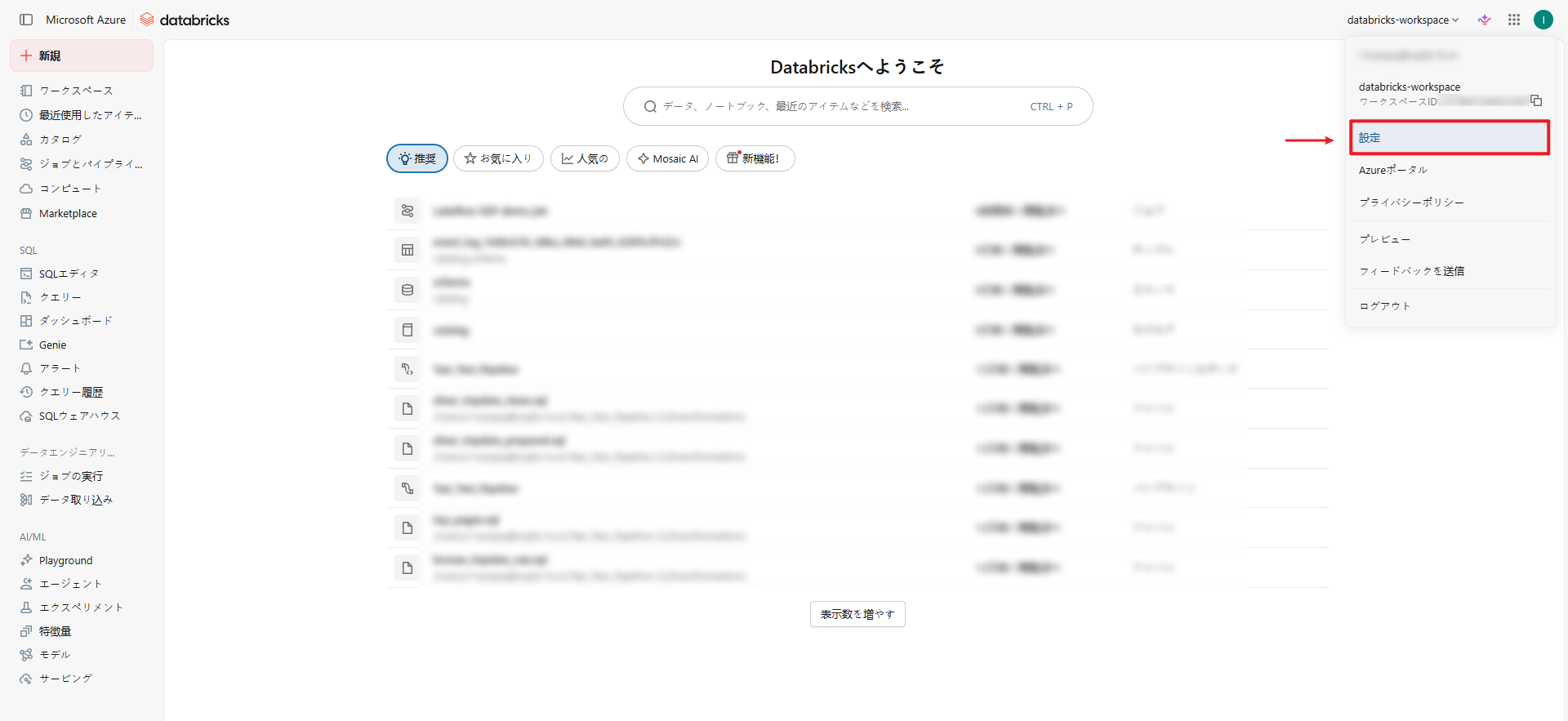
① Personal Access Tokenの作成
- Databricksワークスペースにアクセスし、 「設定」をクリックします。
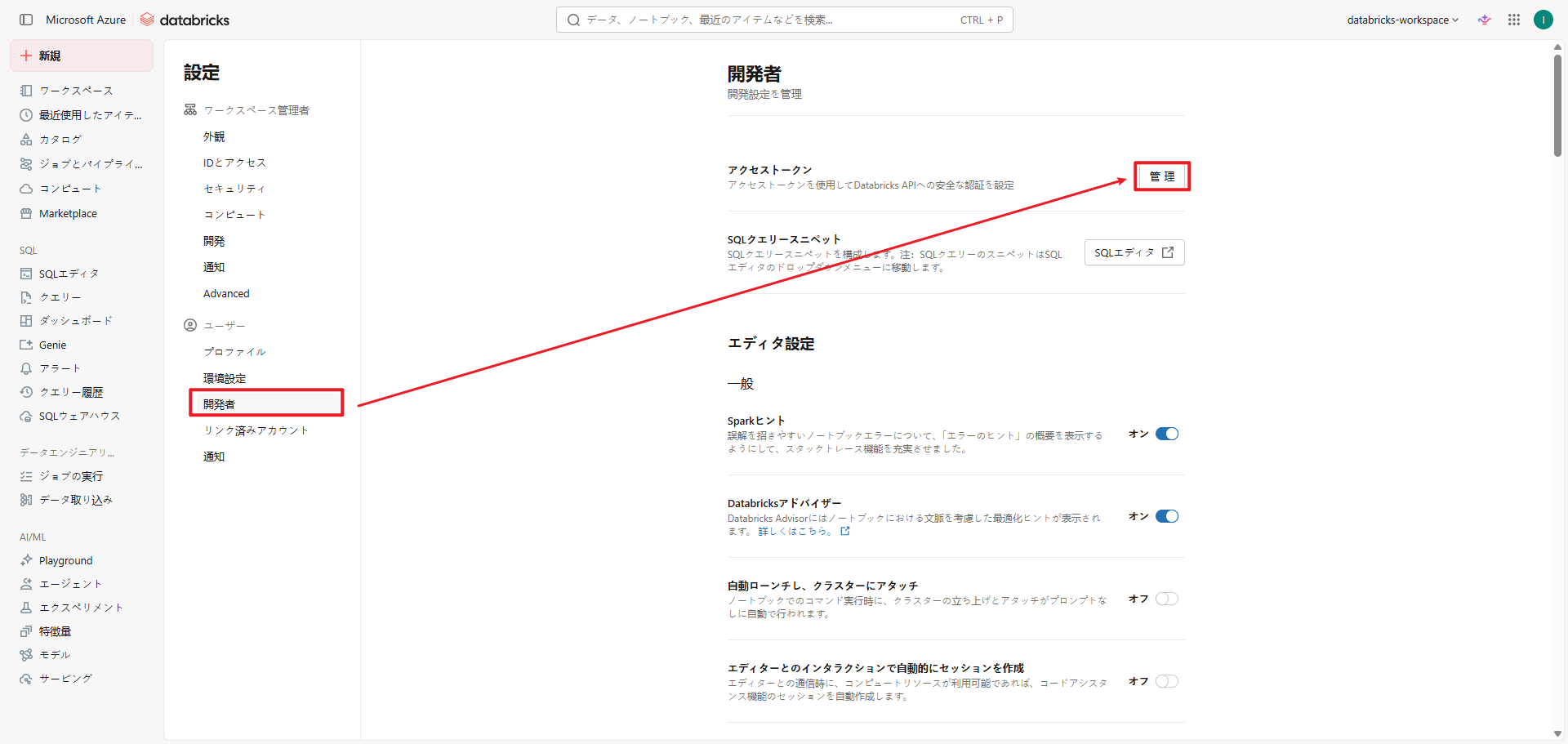
- 「開発者」を選択し、「アクセストークン」項目の「管理」をクリックします。
- 「新規トークンを生成」ボタンをクリックして新しいトークンを作成します。
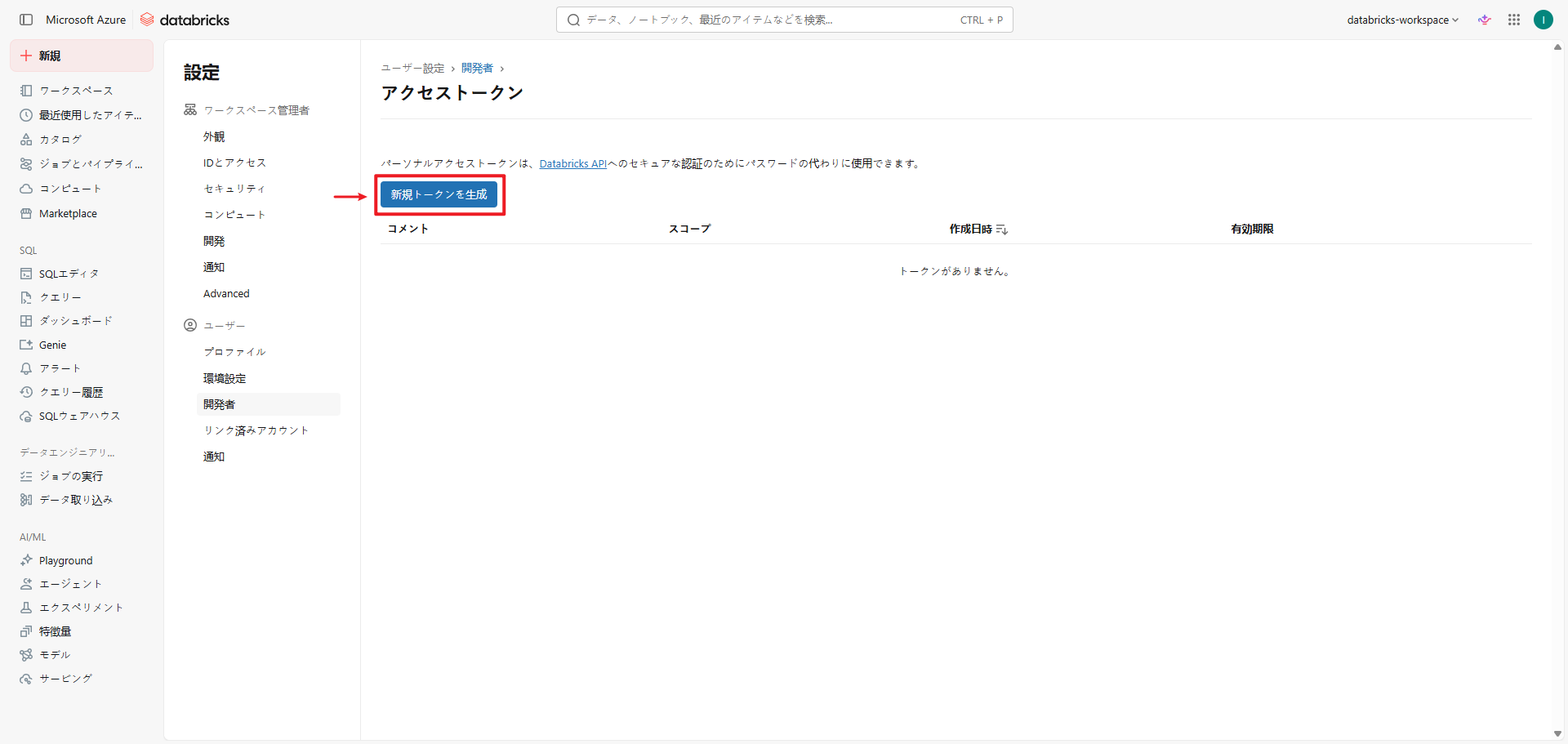
- 「新規トークンを生成」ポップアップで新しいトークンの設定を行います。
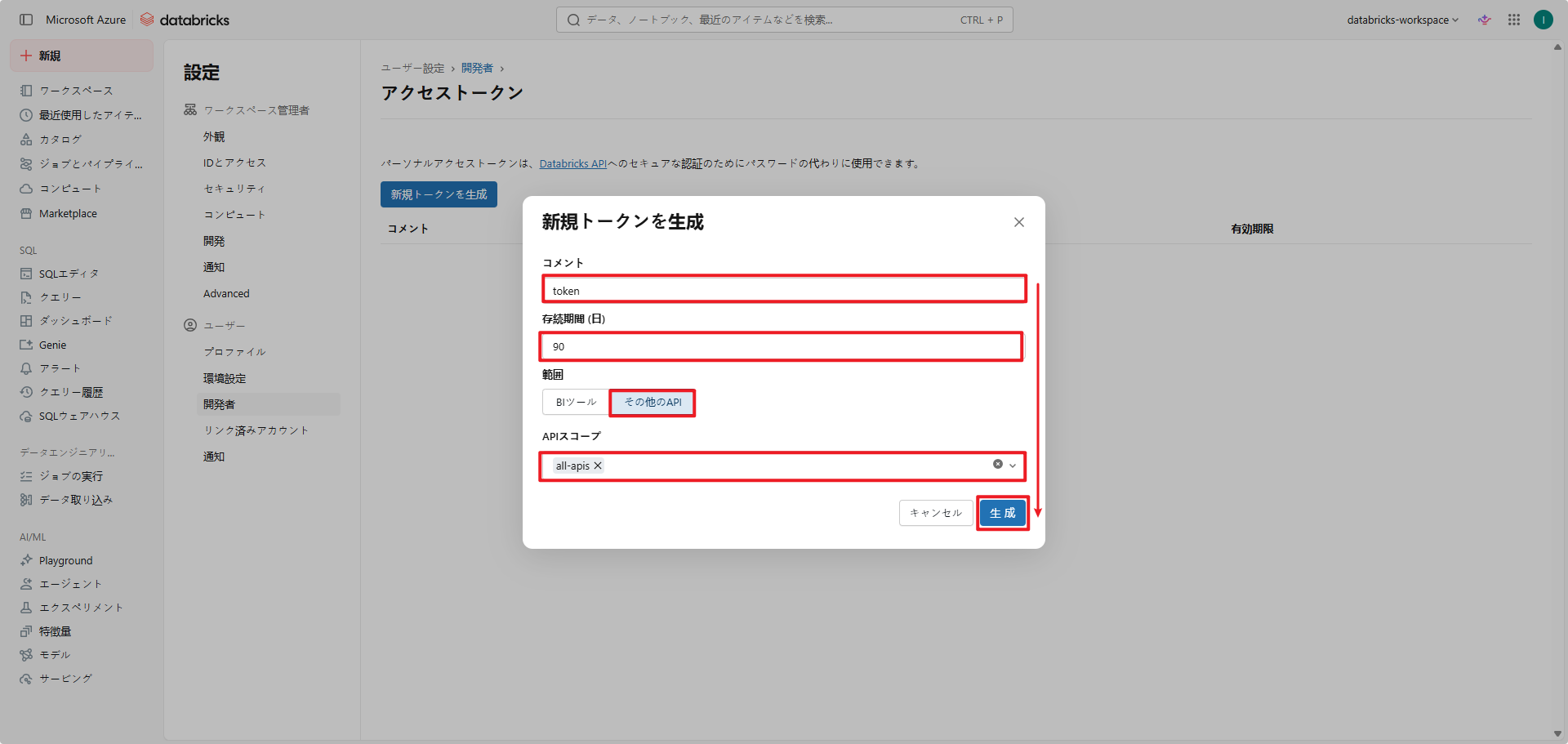
- 作成したトークンの情報をコピーしておきます。
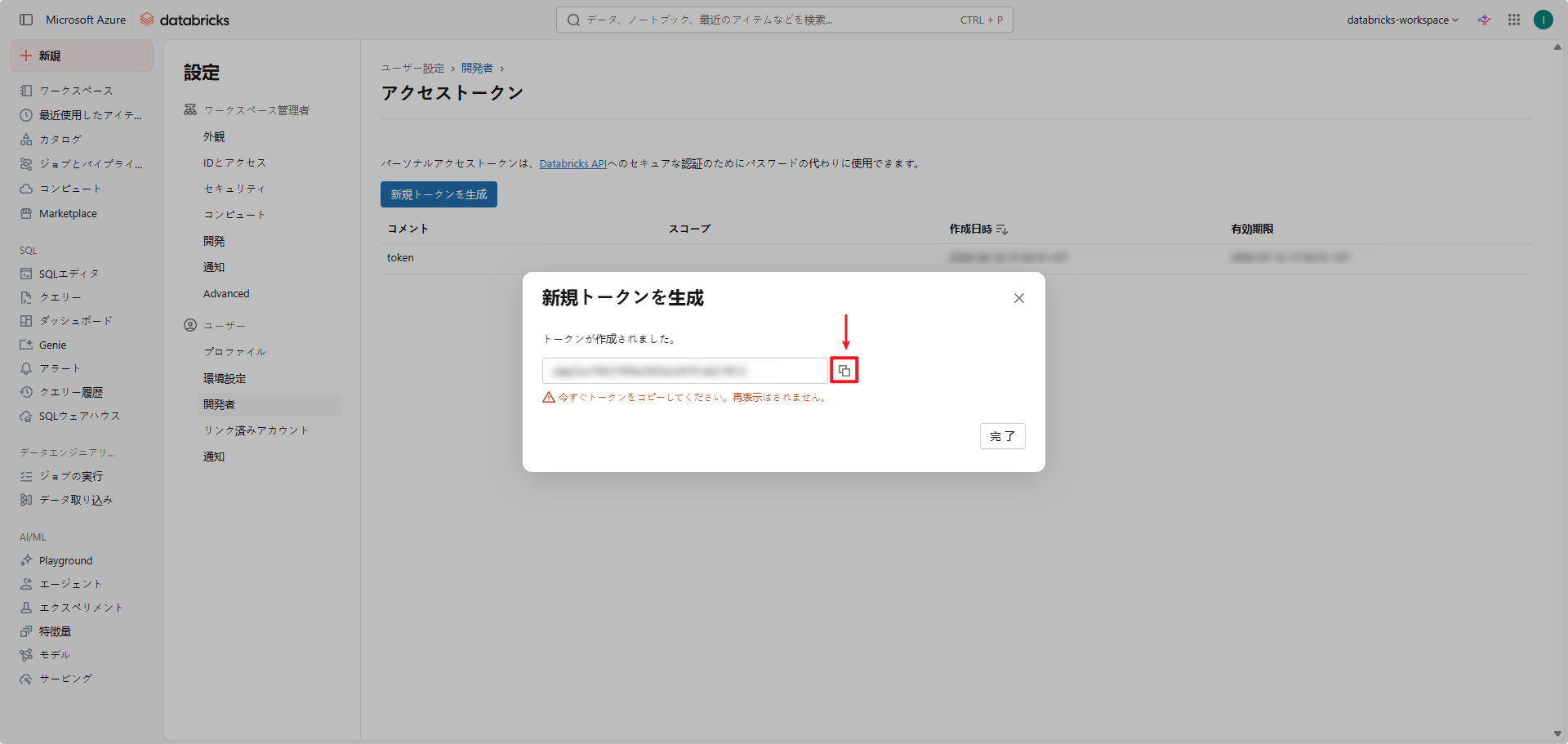
DatabricksでPAT認証方式を設定・利用するためには、設定プロフィールを作成する必要があります。
これを行うには、以下の手順に従ってください。
② ローカル環境でTerminal / Command Prompt / PowerShellの起動
ご利用の端末で、Terminalまたは任意のコマンドラインツールを起動し、設定ファイルを作成したいディレクトリへ移動してください。
 ③ Databricksの設定コマンド実行
③ Databricksの設定コマンド実行
以下のコマンドを入力し、「Enter」キーを押して実行してください。
このコマンドにより、設定プロセスが開始されます。
|
1 |
databricks configure |
④ DatabricksワークスペースのURL入力
「Databricks Host」の入力が求められますので、ご利用のDatabricksワークスペースのURLを正確にご入力ください。
例:https://dbc-123456789.cloud.databricks.com

⑤ Personal Access Tokenの入力
次に、「Personal Access Token」の入力が求められます。
事前の手順でコピーしたトークンの情報を貼り付け、または入力してください。
この操作により、.databrickscfg ファイルに設定プロフィールが作成されます。
Personal access token – Databricks CLIの入力
設定が完了すると、.databrickscfg ファイル(Databricks CLI)が自動的に作成されます。
 ⑥ 承認の確認
⑥ 承認の確認
設定済みのすべてのプロフィール情報を確認するには、auth profiles コマンドをご実行ください。
|
1 |
databricks auth profiles |

以下のコマンドを実行して認証が正しく設定されているかを確認することができます。
|
1 |
databricks clusters spark-versions |
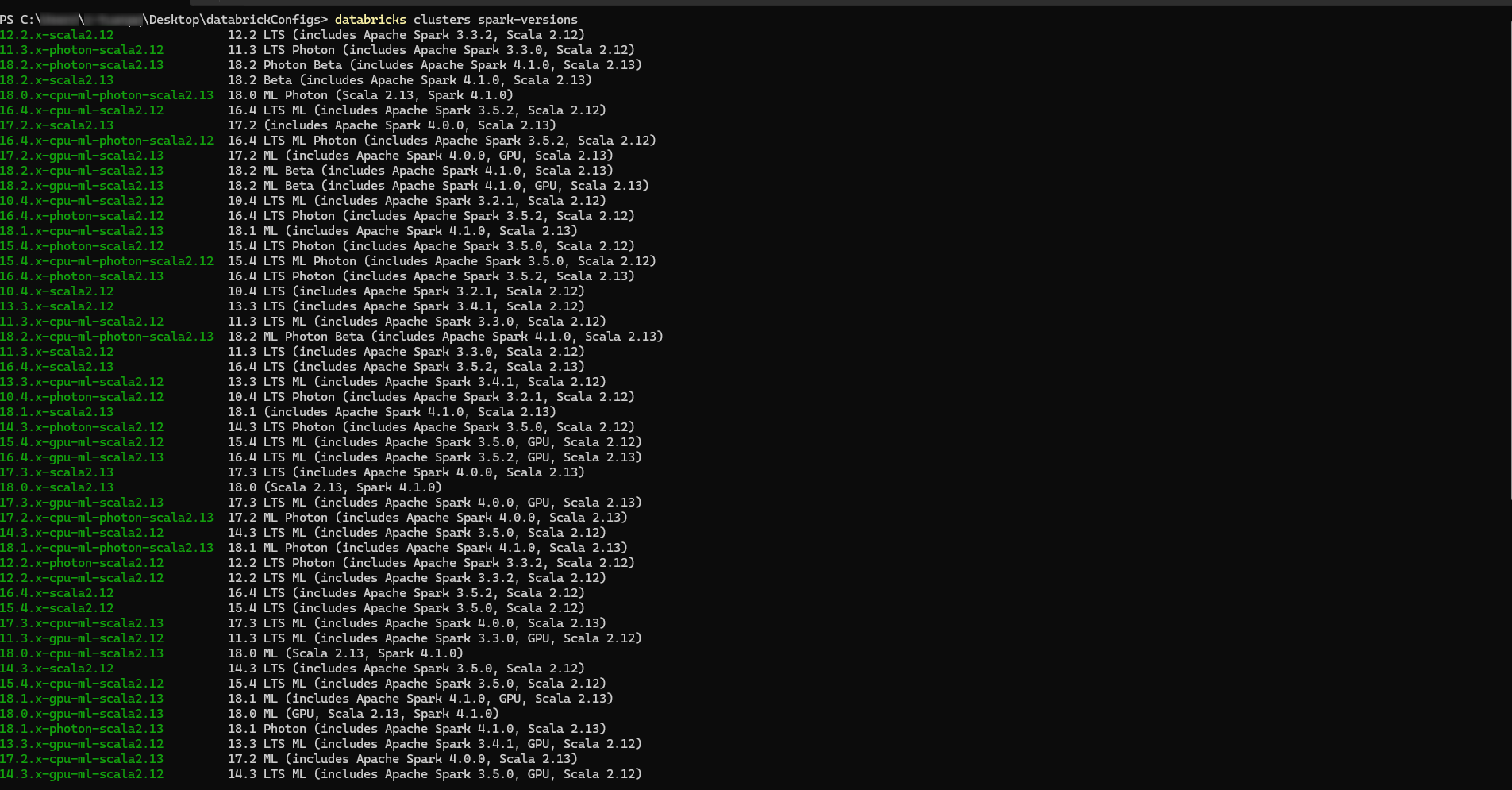
表示されたとおり、このコマンドを実行すると、デフォルトプロファイルに紐づけられたDatabricksワークスペースで利用可能なDatabricks Runtimeの一覧が表示されます。
設定プロフィールを作成することで、そのプロフィールを利用して、コード内からDatabricksへの認証を行うことが可能になります。
4. Databricks CLIコマンドの使い方 — 実践ユースケース
本項では、実際のユースケースを通して、Databricks CLIの使い方を解説します。
- Notebookの管理
- クラスターの管理
- ジョブおよびワークフローの管理
4.1. Notebookの管理
Databricks CLIを利用することで、コマンドラインから柔軟にNotebookの操作・管理を行うことができます。
- Notebookをワークスペースへインポート
|
1 |
databricks workspace import <workspace_path> --file <local_path> --language PYTHON --overwrite |
パラメータ:
<workspace_path>: Databricksワークスペース上のディレクトリーパス (例:/Users/your_name/example)
<local_path>: インポート対象となるローカル環境のファイルパス (例:./notebooks/example.py)

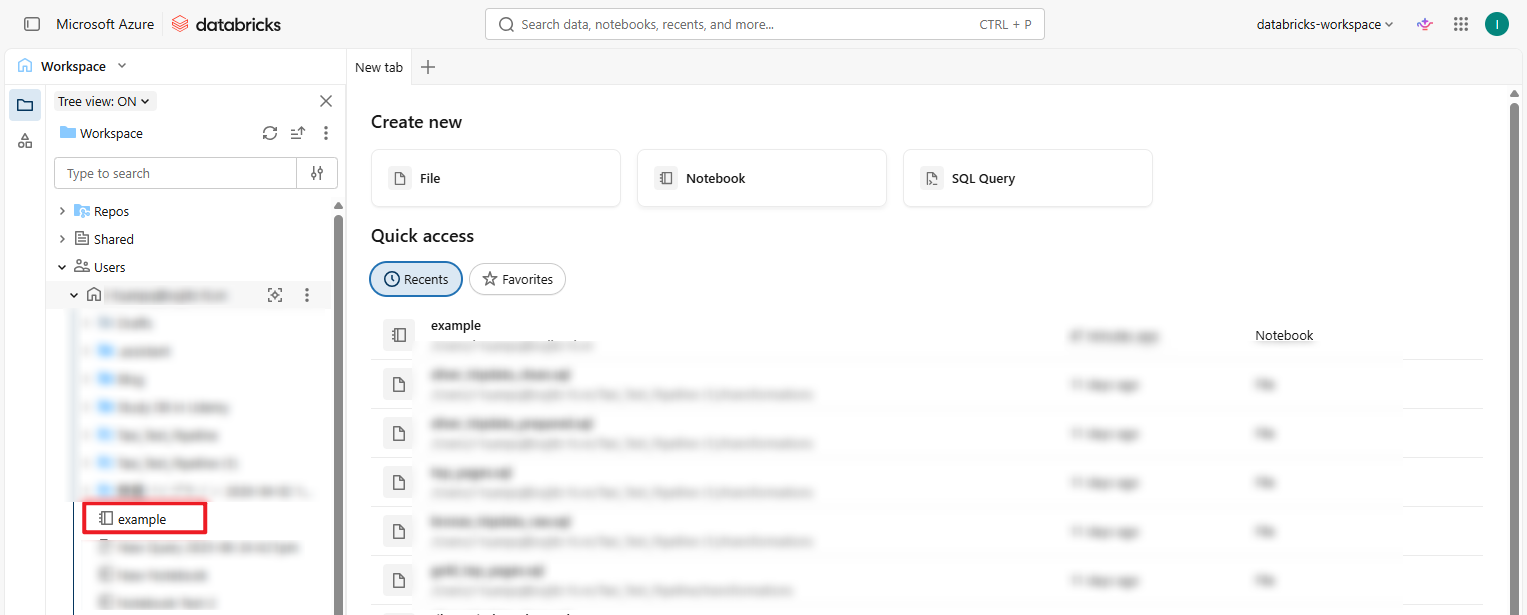
- Notebookをワークスペースからエクスポート
|
1 |
databricks workspace export <workspace_file_path> <local_file_path> --format SOURCE |
パラメータ:
<workspace_file_path>: Databricksワークスペース上のNotebookまたはファイルのパス (例:/Users/your_name/example)
<local_file_path>: ローカル環境のファイルパス (例:./example.py)

その後、ローカルのフォルダを確認すると、「example.py」ファイルが .py 形式でダウンロードされていることを確認できます。
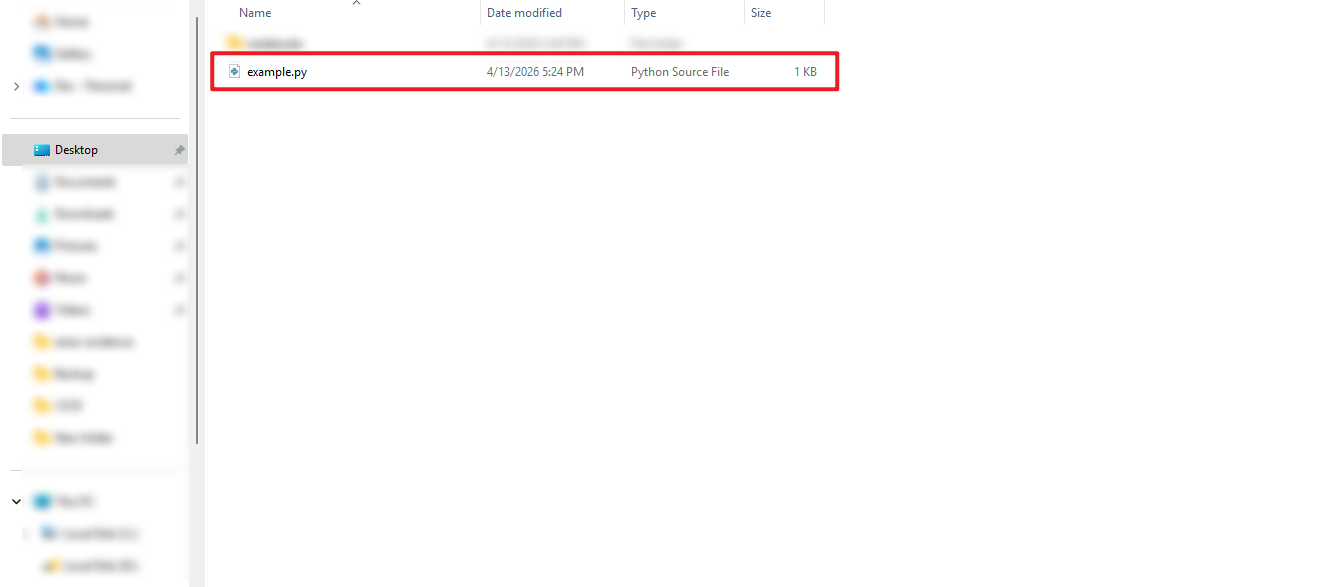
- フォルダ一覧表示
ワークスペースの指定パス配下にあるすべてのファイルおよびフォルダを表示するには、以下のコマンドをご実行ください。
|
1 |
databricks workspace list <workspace_folder_path> |
パラメータ:
<workspace_folder_path>: Databricksワークスペース上のフォルダパス Workspace (例:/Users/your-email@example.com/)
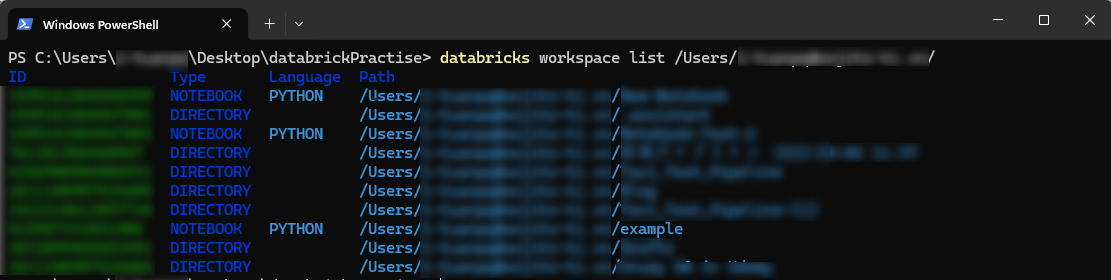
指定したパス配下のフォルダおよびファイルの一覧が表示されます。
- ワークスペース内のNotebook /ファイルの削除
このコマンドは、DatabricksワークスペースからNotebookまたはファイルを削除するために使用します。
|
1 |
databricks workspace delete <workspace_file_path> |
パラメータ:
<workspace_file_path>: Databricksワークスペース上のNotebookまたはファイルのパス (例:/Users/your-email@example.com/example)

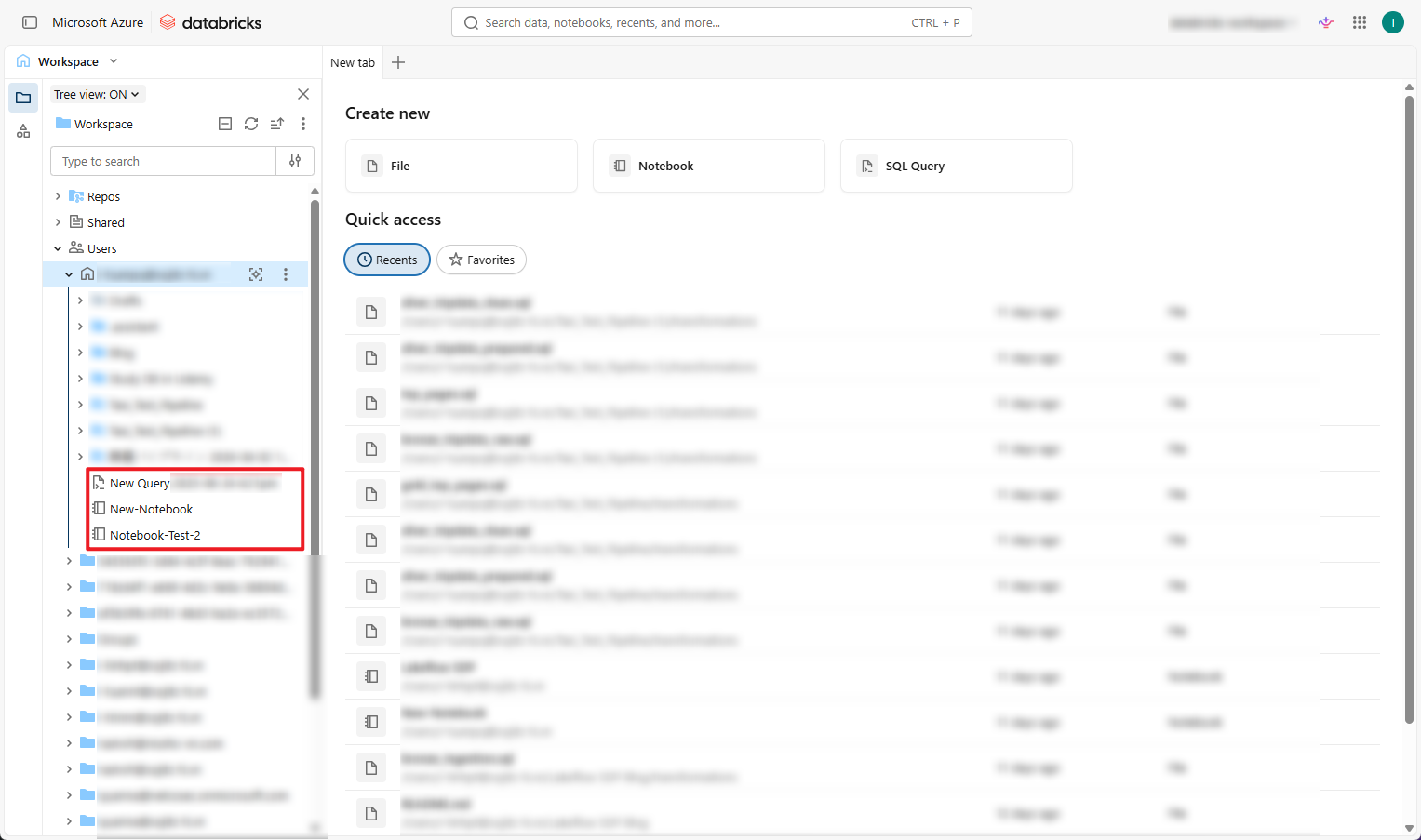
4.2. クラスターの管理
クラスターはDatabricksにおいて主要なコスト発生要因の一つであるため、 CLIで管理することでコスト最適化(FinOps)に大きく貢献します。
※注意:クラスターは起動中にコストが発生します。
- クラスター一覧の表示
|
1 |
databricks clusters list |

- クラスターの開始
|
1 |
databricks clusters start <cluster_id> |
パラメータ
<cluster_id>: ユーザーがアクセスおよび管理権限を持つ、Databricksワークスペース内のクラスターを一意に識別するID
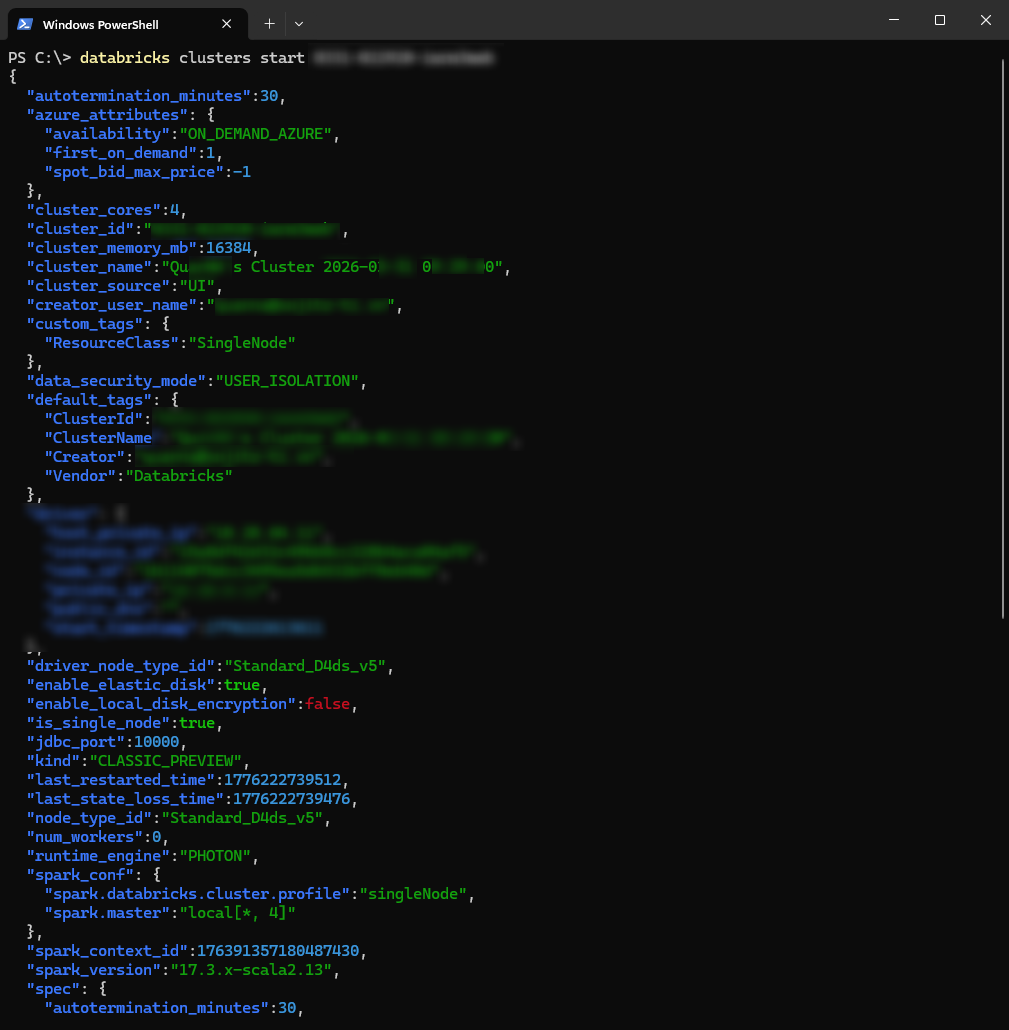
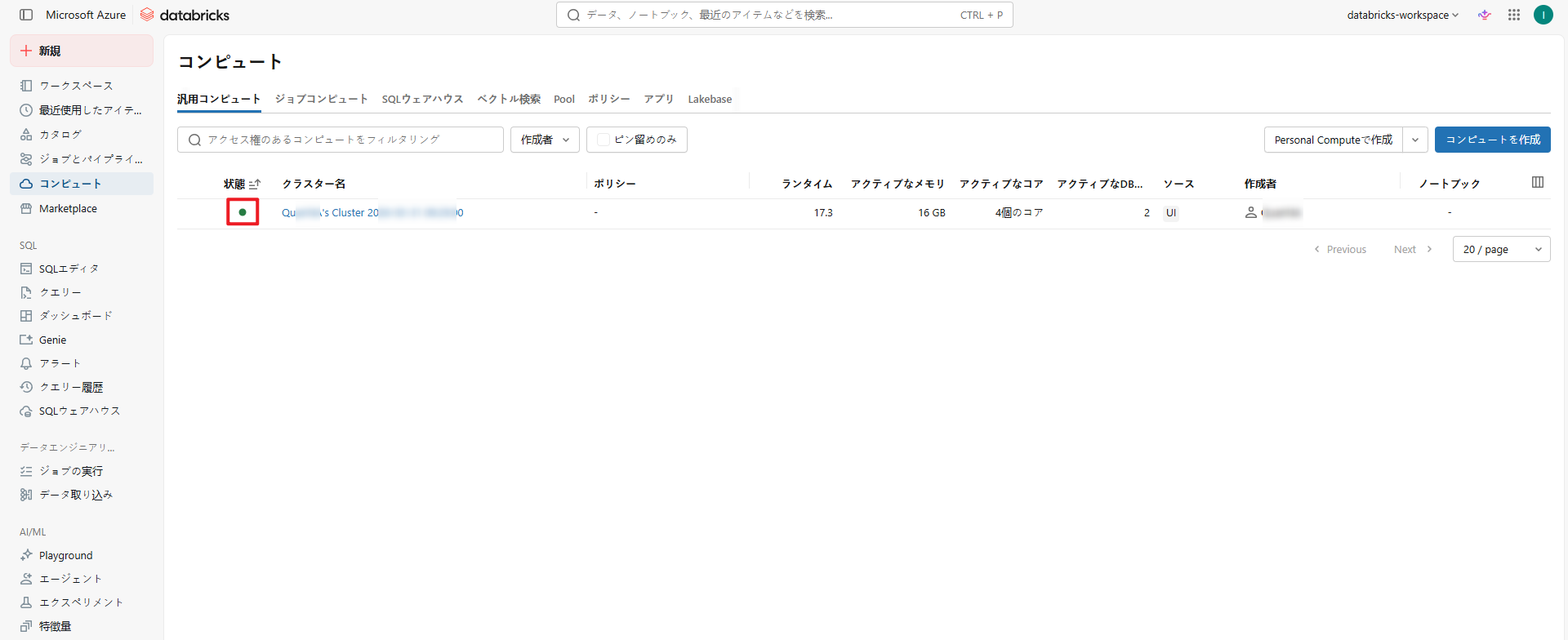
ワークスペース上で、クラスターが正常に起動していることを確認できます。
- クラスター(terminate)の削除
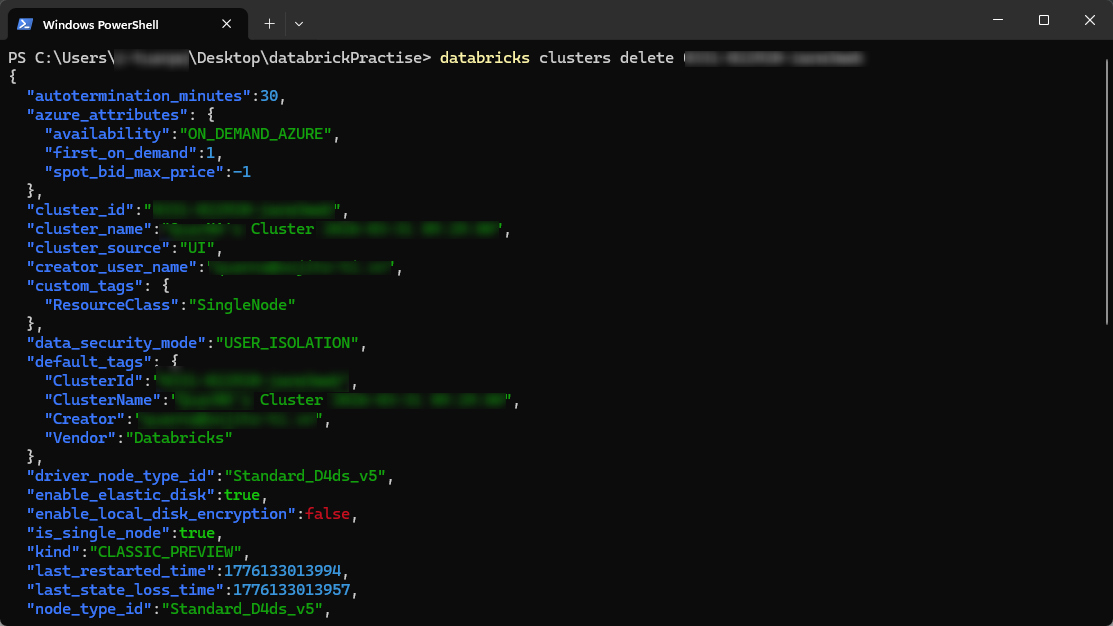
このコマンドはクラスターをterminate(停止)するために使用します。
処理が完了すると、クラスターは「TERMINATED」状態になります。
この処理は非同期で実行されます。
すでにクラスターが「TERMINATING」または「TERMINATED」状態の場合、本コマンドは実行されません。
|
1 |
databricks clusters delete <cluster_id> |
パラメータ:
<cluster_id>: Databricksワークスペース内のクラスターを一意に識別するID
databricks clusters list コマンド、またはDatabricksワークスペースのUIから取得できます。
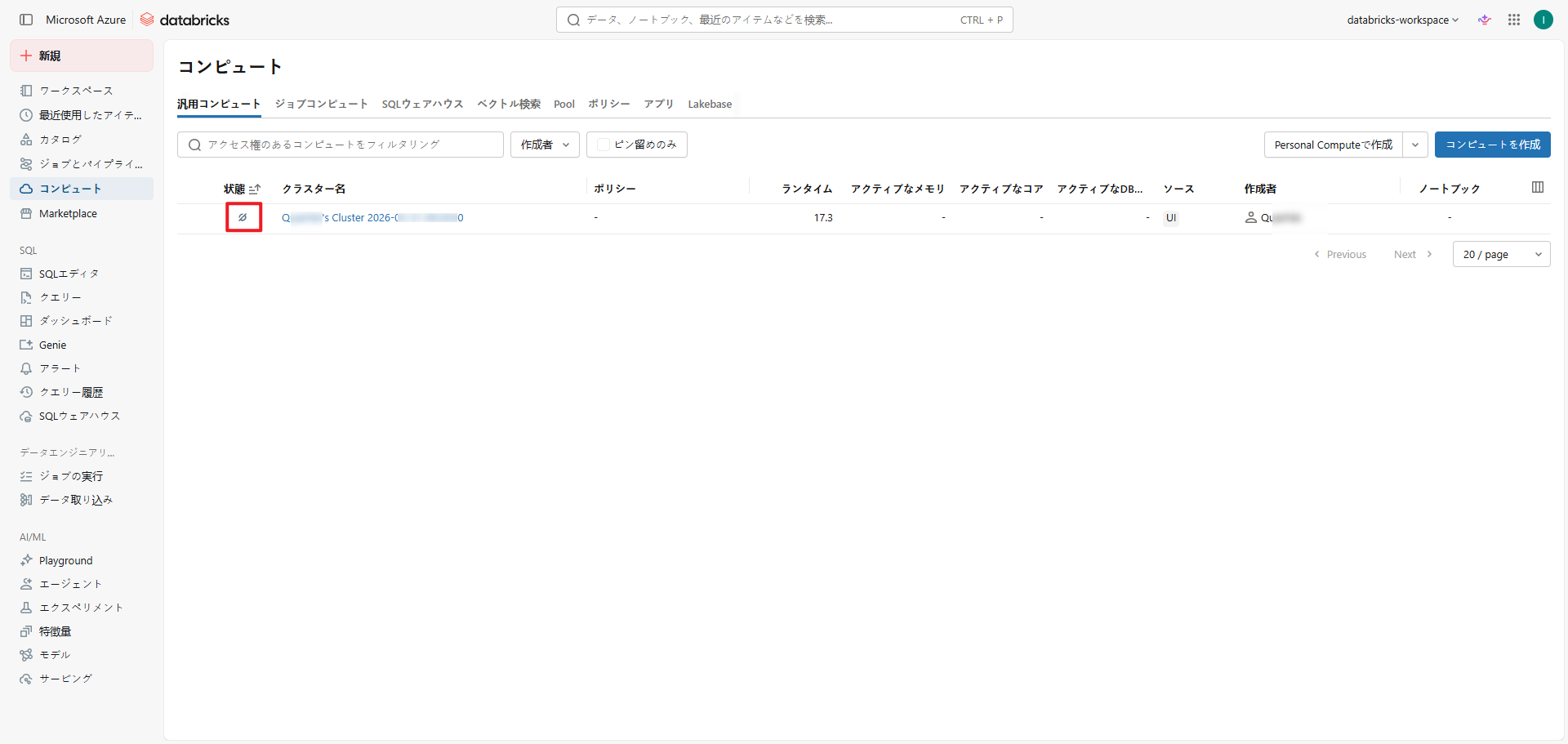
Databricksワークスペース上で確認すると、クラスターはterminateされ、「TERMINATED」状態に遷移していることが確認できます。
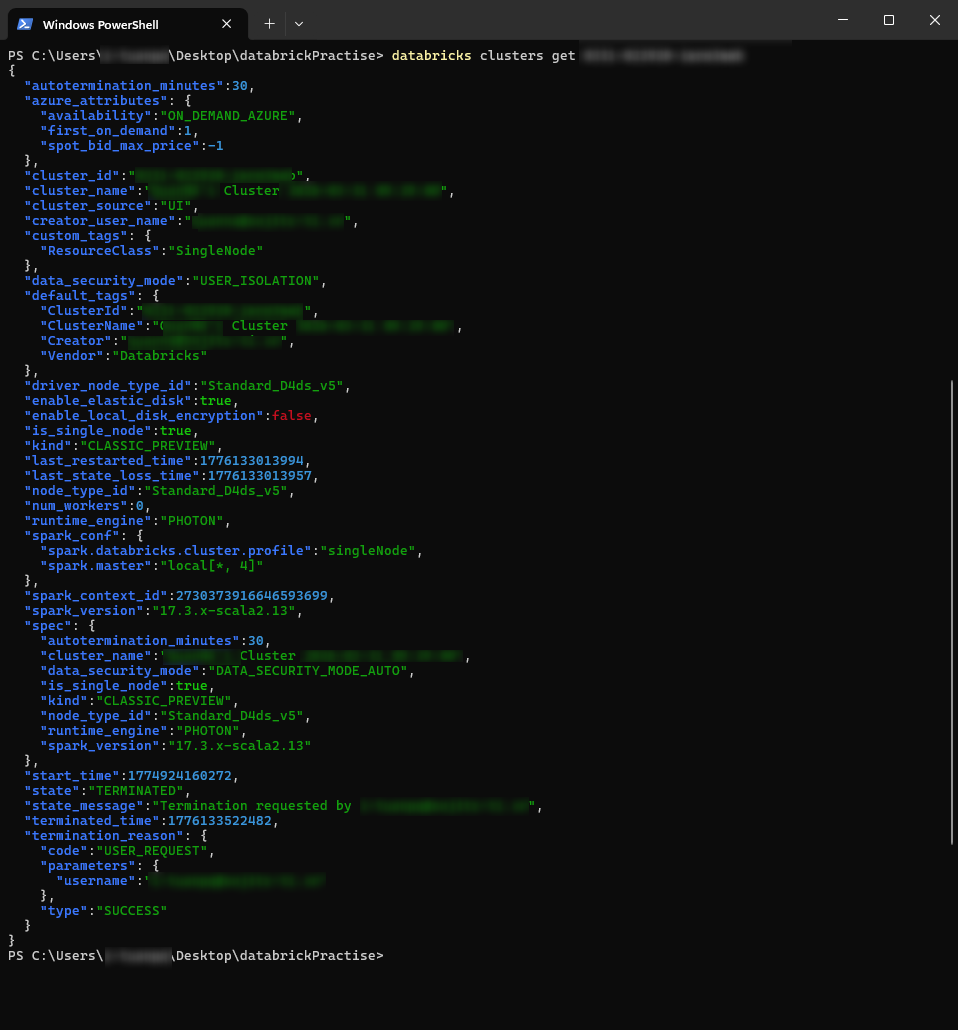
- クラスターの詳細確認
|
1 |
databricks clusters get <cluster_id> |
パラメータ:
<cluster_id>: ユーザーがアクセスおよび管理権限を持つ、Databricksワークスペース内のクラスターを一意に識別するID
4.3. ジョブおよびワークフローの管理
- ジョブ一覧の表示
|
1 |
databricks jobs list |

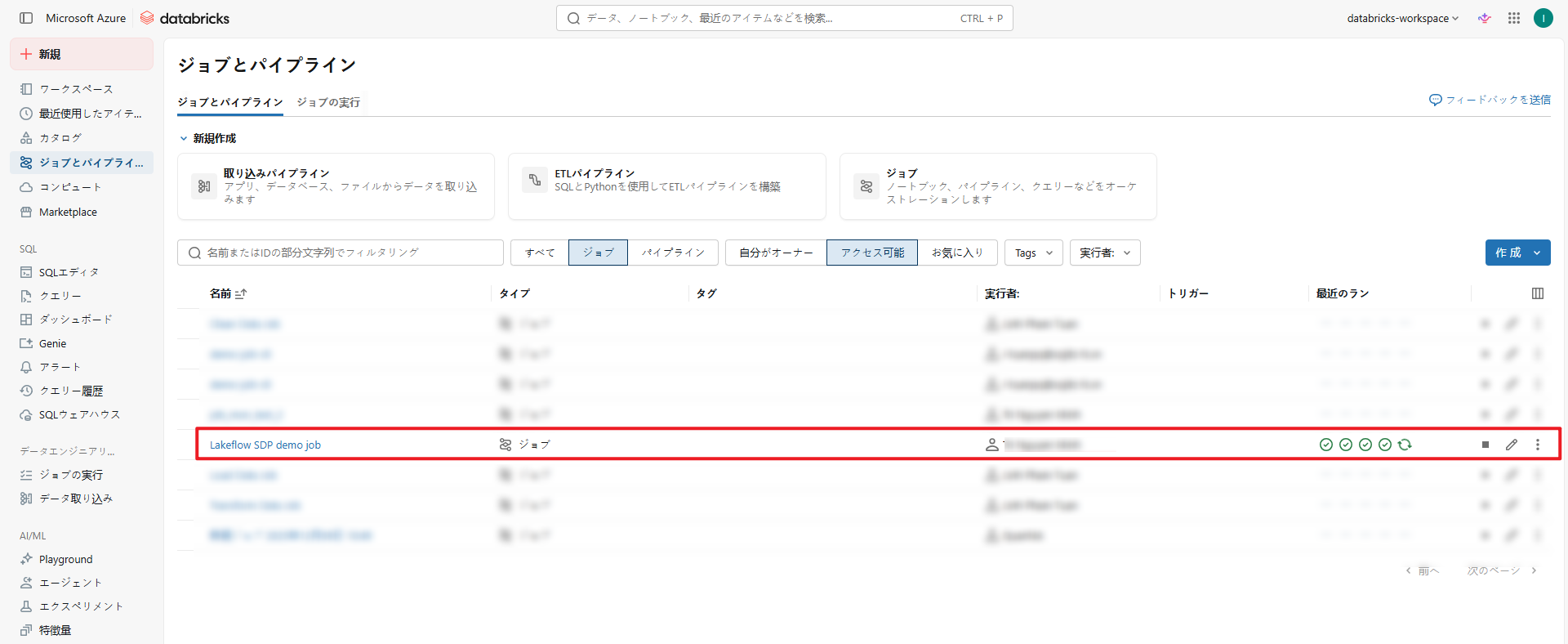
- ジョブ実行のトリガー
|
1 |
databricks jobs run-now <job_id> |
パラメータ:
<job_id>: Databricksワークスペース内のジョブを一意に識別するID
DatabricksのUI(ジョブおよびパイプライン)でジョブの詳細を確認するか、databricks jobs list コマンドで取得できます。

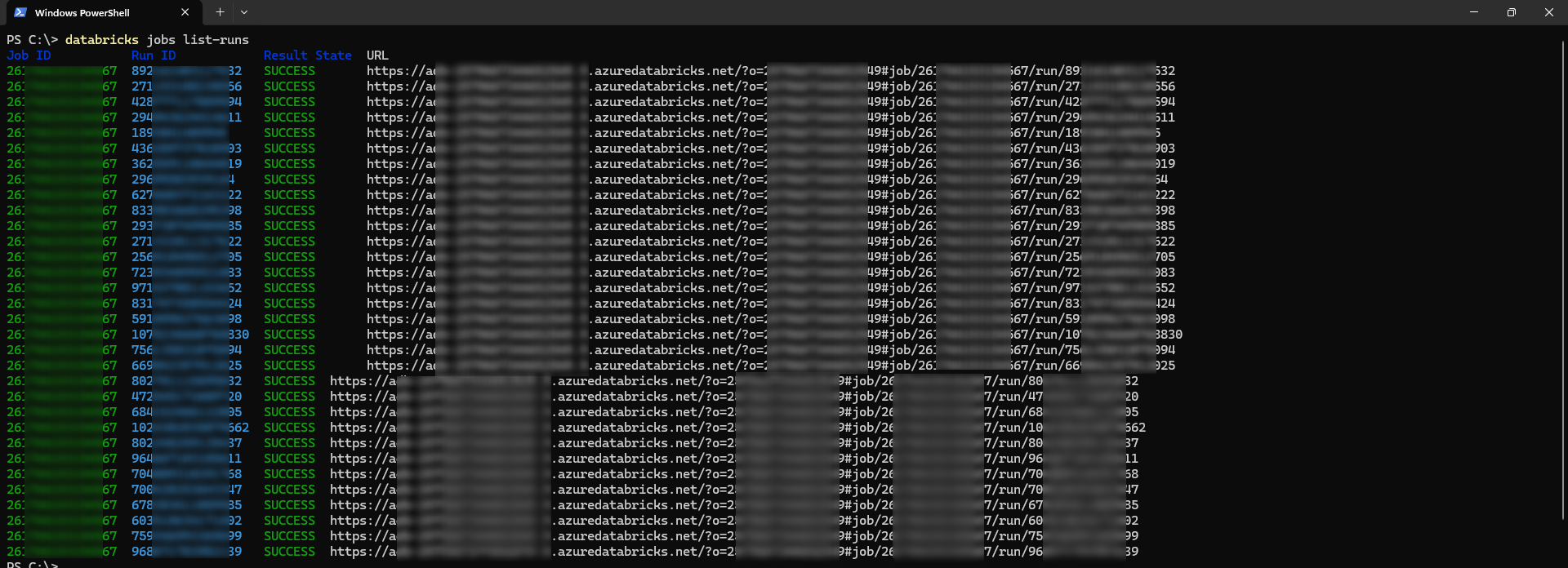
- ジョブ実行の状況確認
|
1 |
databricks jobs list-runs |
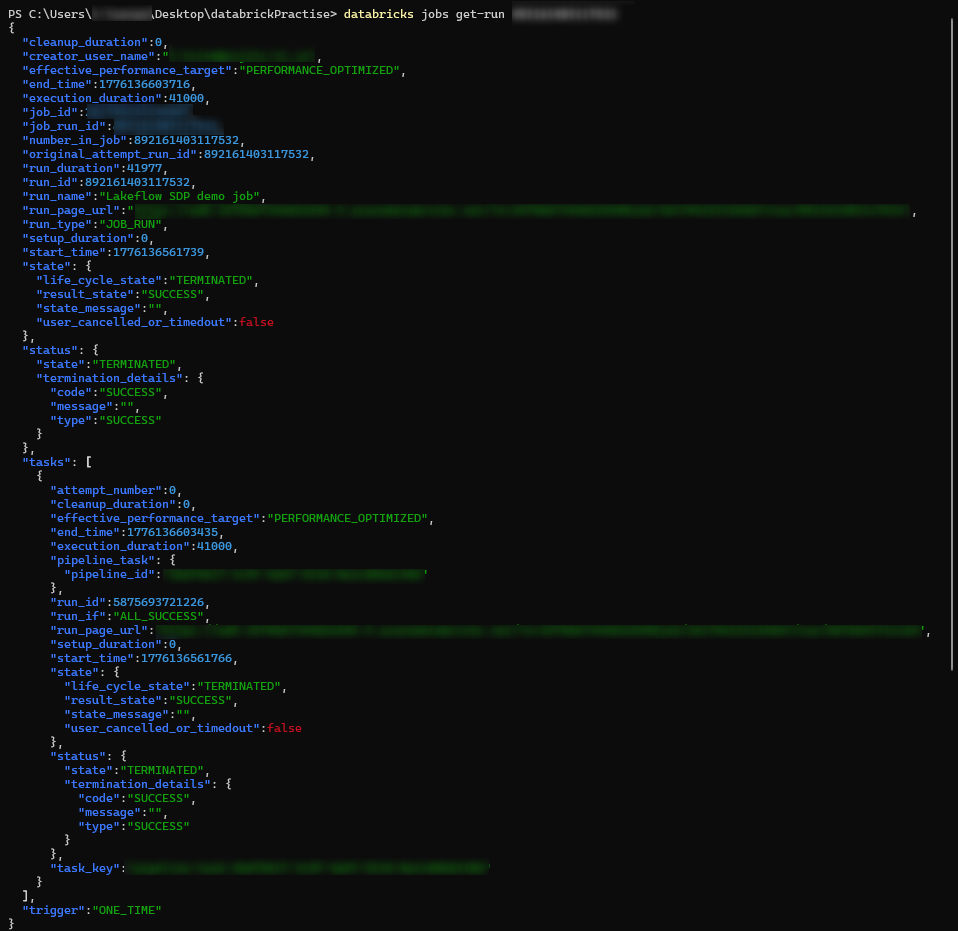
- 実行の詳細確認
|
1 |
databricks jobs get-run <run_id> |
パラメータ:
<run_id>: 各ジョブ実行(job run)を一意に識別するIDであり、実行の詳細情報やメタデータを取得する際に使用されます(必須項目)。
DatabricksのUI(ジョブおよびパイプライン→ジョブ実行)または databricks jobs list-runs コマンドから取得できます。
- ローカル環境にあるJSONファイルからジョブ作成
|
1 |
databricks jobs create --json "@<local_json_file_path>" |
パラメータ:
<local_json_file_path>: ジョブの設定情報を含むローカル環境のJSONファイルのパス (例:job.json)

Databricksワークスペース上で確認すると、job.json の設定に基づいた新しいジョブが作成されていることが確認できます。
 5. まとめ
5. まとめ
以上で、本記事の内容はすべてとなります。
Databricks CLIは、コマンドラインから直接Databricksのワークフローを管理できる、強力かつ柔軟なツールです。
管理タスクの自動化や、繰り返し作業のスクリプト化を通じて、作業効率を大幅に向上させることができます。
これにより、従来のようにWeb UIへログインしてワークフローを実行したり、リソースを設定したりする必要はなくなります。
シンプルなスクリプトを作成し、ターミナルから実行するだけで対応可能です。
本記事では、以下の内容について解説しました。
- Databricks CLIの概要と用途
- Databricks CLIのインストール方法
- HWindows環境におけるインストール手順
- Databricks CLI (主にOAuth)の認証設定
- 実践例を通じたDatabricks CLIコマンドの使い方
今回の記事が少しでも皆さんの新しい知識や業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたら
是非お問い合わせください!
Azure Databricks連載記事のまとめはこちら
この記事を読んだ方へのオススメコンテンツはこちら
この記事を書いた人

- 双日テックイノベーション(旧:日商エレクトロニクス)特設サイト「Azure導入支援デスク」サイトマスターです。