目次
1. はじめに
皆さんこんにちは。
今回はAzure Databricks Lakeflow Spark 宣言型パイプラインについて説明していきます。
この連載では、Azure DatabricksのLakeflow Spark 宣言型パイプラインの基本から実行手順について説明していきます。
第1回:Lakeflow Spark 宣言型パイプライン
第2回:Lakeflow Spark 宣言型のパイプラインを実装してみよう(今回)
第3回:Lakeflow Spark 宣言型パイプラインのデータの品質管理とは?
2.Lakeflow Spark 宣言型パイプラインとは?
Lakeflow Spark 宣言型パイプライン (SDP) は、Azure DatabricksにおけるDelta Live Tables Foundationの後継として進化した機能です。
SDPは、バッチ処理とストリーミング処理を単一のフレームワークに統合することで、データパイプラインの構築・管理・実行を容易にします。
データセット(テーブルやビュー)は、SQLまたはPythonを用いた宣言的な方法で定義することができ、システムがそれらの依存関係を自動的に解決します。
さらに、SDPはUnity CatalogおよびLakeflowと密に連携しており、データの一元管理およびセキュアな運用を実現します。
【メリット】
・処理ステップを自動的にオーケストレーションし、正しい順序と最適なパフォーマンスの保証
・宣言型のシンプルな構文により、SQLまたはPythonで容易に定義可能(複雑なロジック不要)
・SCD Type 1/Type 2をサポートし、Change Data Capture(CDC)の実装を簡素化
・差分処理に対応し、新規または変更されたデータのみを処理可能
⇒ 例えば、データ品質ルールを定義してデータの正確性や完全性を検証したり、
ダッシュボードでデータ品質の状況を監視したり、
問題が発生した場合にアラートを受け取ったりできます。
3.パイプラインを作成する
【準備】ETLパイプラインの作成
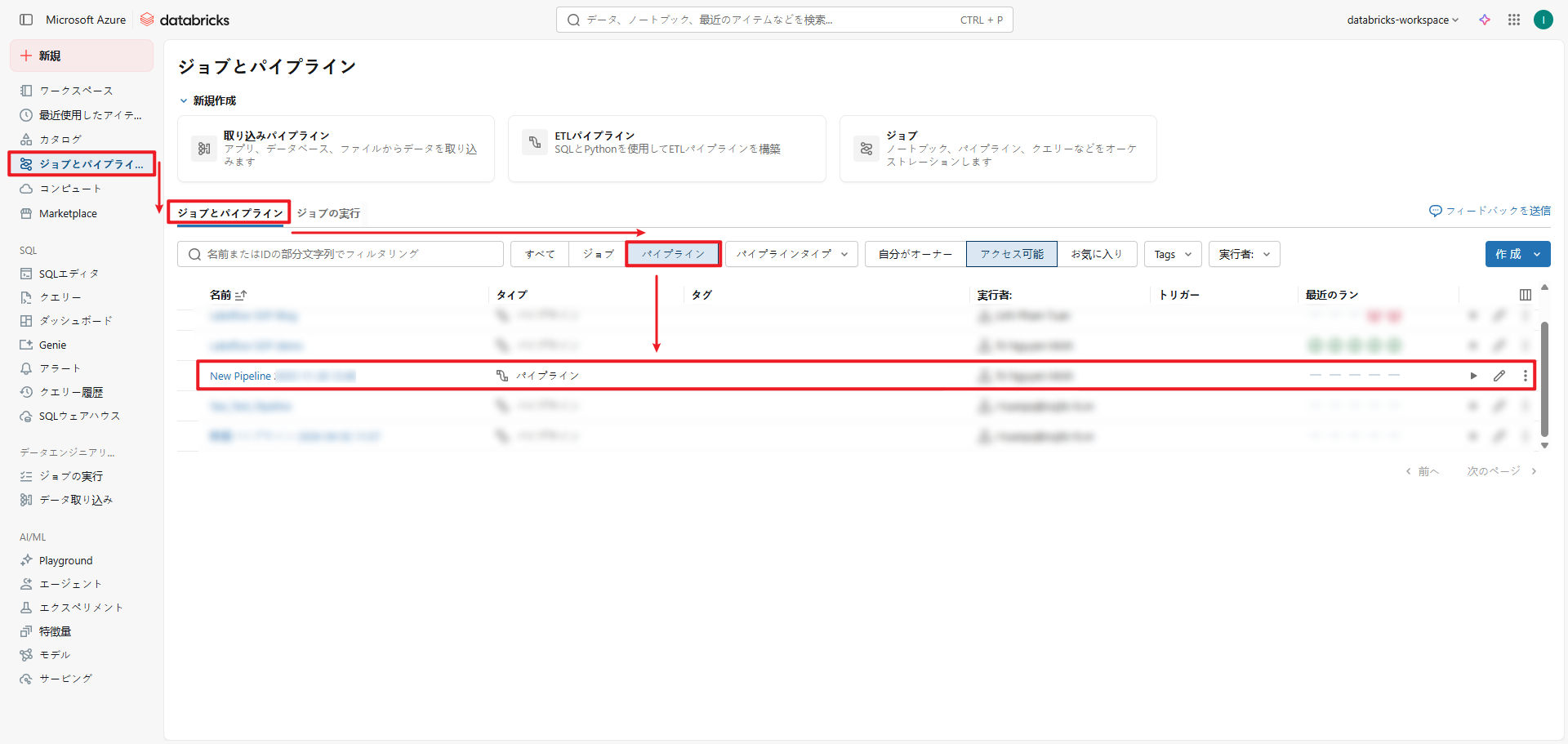
◇既存のパイプラインを開きます。
①こちらの手順でワークスペースにアクセスします。
②Azure Databricksポータル画面で、サイドバーを展開します。
③ ジョブとパイプライン > ジョブとパイプライン > パイプライン>自分のユーザー名 > 使用するノートブック を選択します。
 ◇新規のノートブックの作成
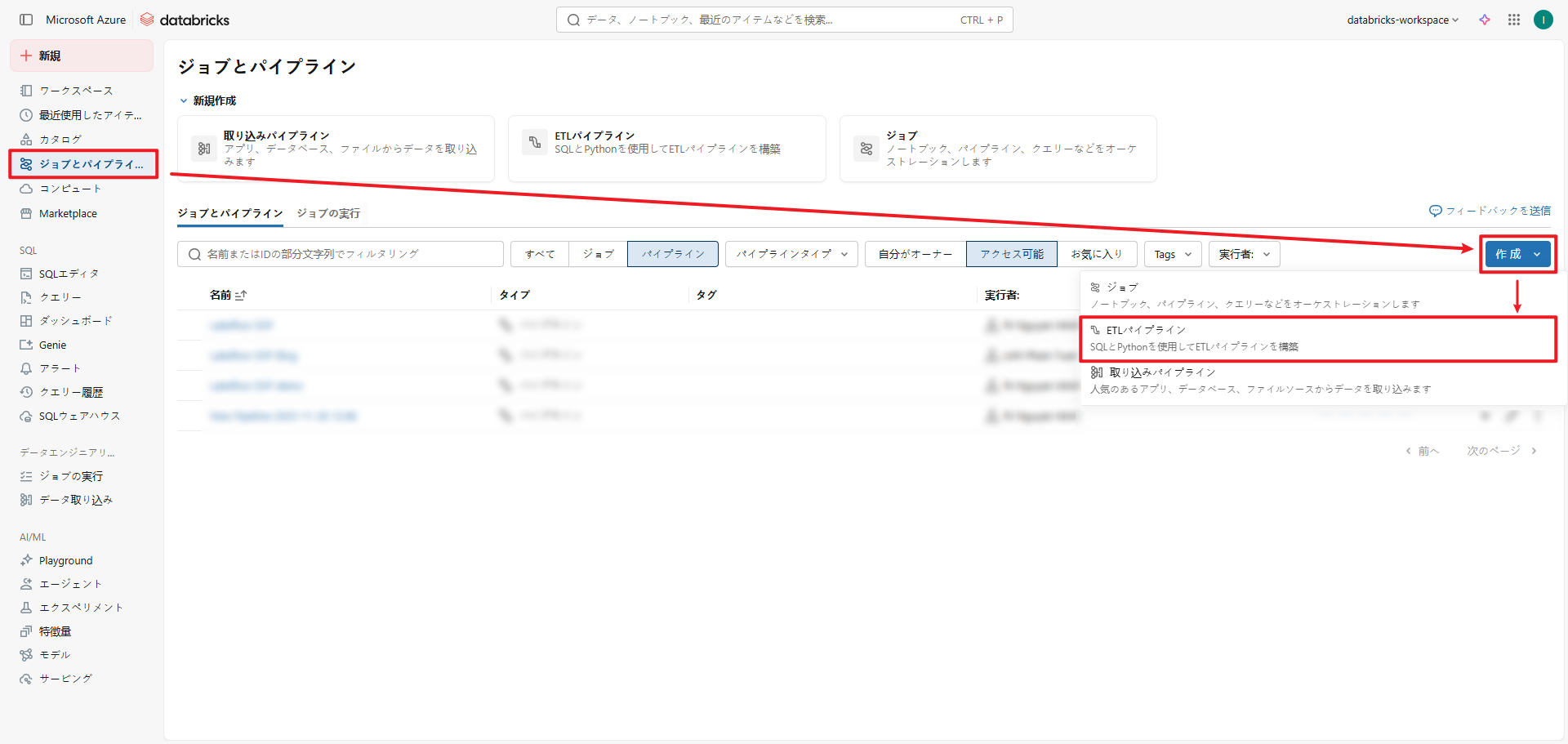
◇新規のノートブックの作成
①こちらの手順でワークスペースにアクセスします。
②左のサイドメニューから「ジョブとパイプライン」を選択します。
③「作成」を選択し、「ETLパイプライン」を選択します。
 ④ Lakeflowパイプラインエディタが開かれていることを確認し、タイトルバーにパイプライン名を入力します。
④ Lakeflowパイプラインエディタが開かれていることを確認し、タイトルバーにパイプライン名を入力します。
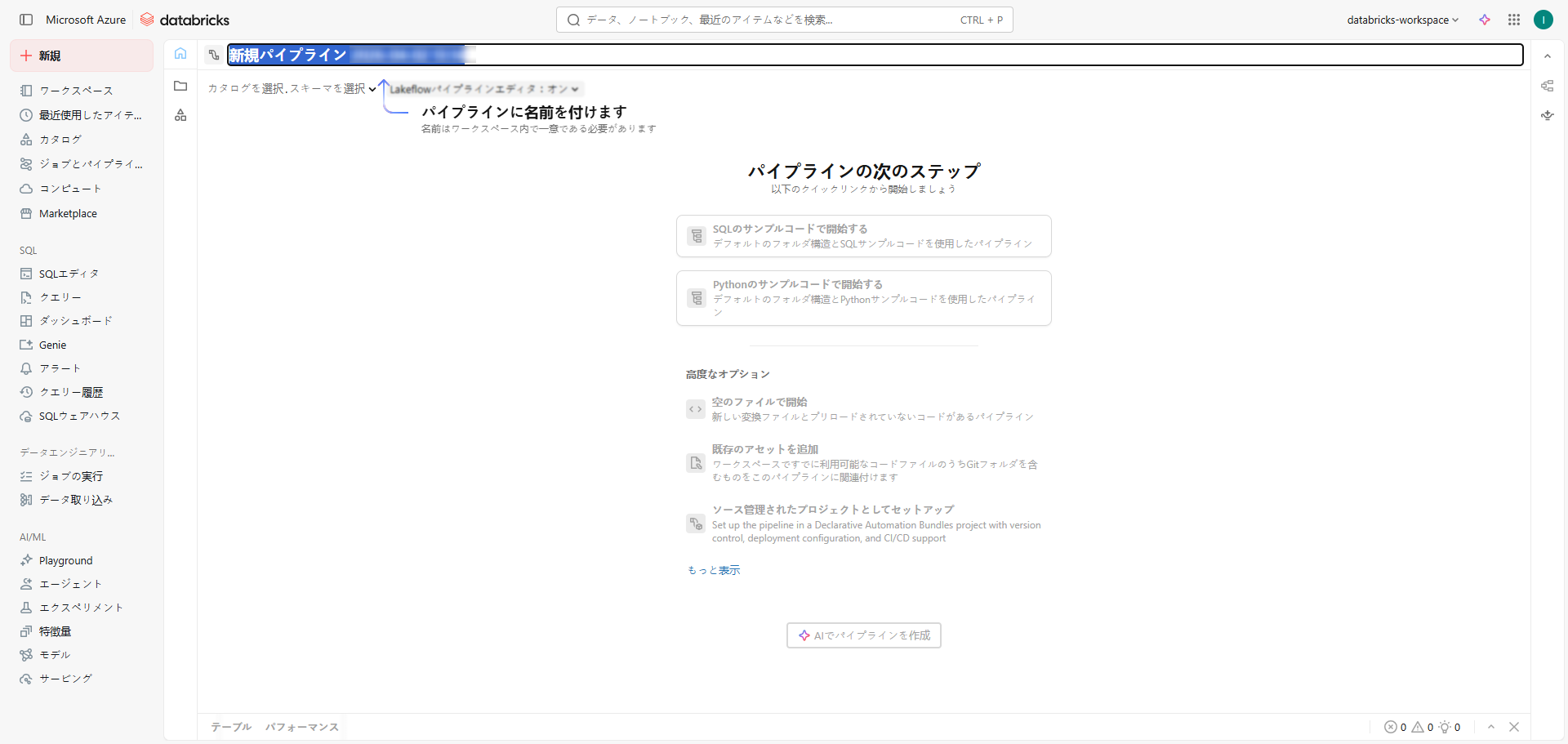
⑤ パイプライン名の直下に、デフォルトのカタログおよびスキーマが選択されていることを確認できます。これらを変更することで、パイプラインのデフォルト値を設定します。
デフォルトのカタログおよびスキーマは、コード内でカタログまたはスキーマを明示的に指定しない場合に、データの読み書き先として使用されます。
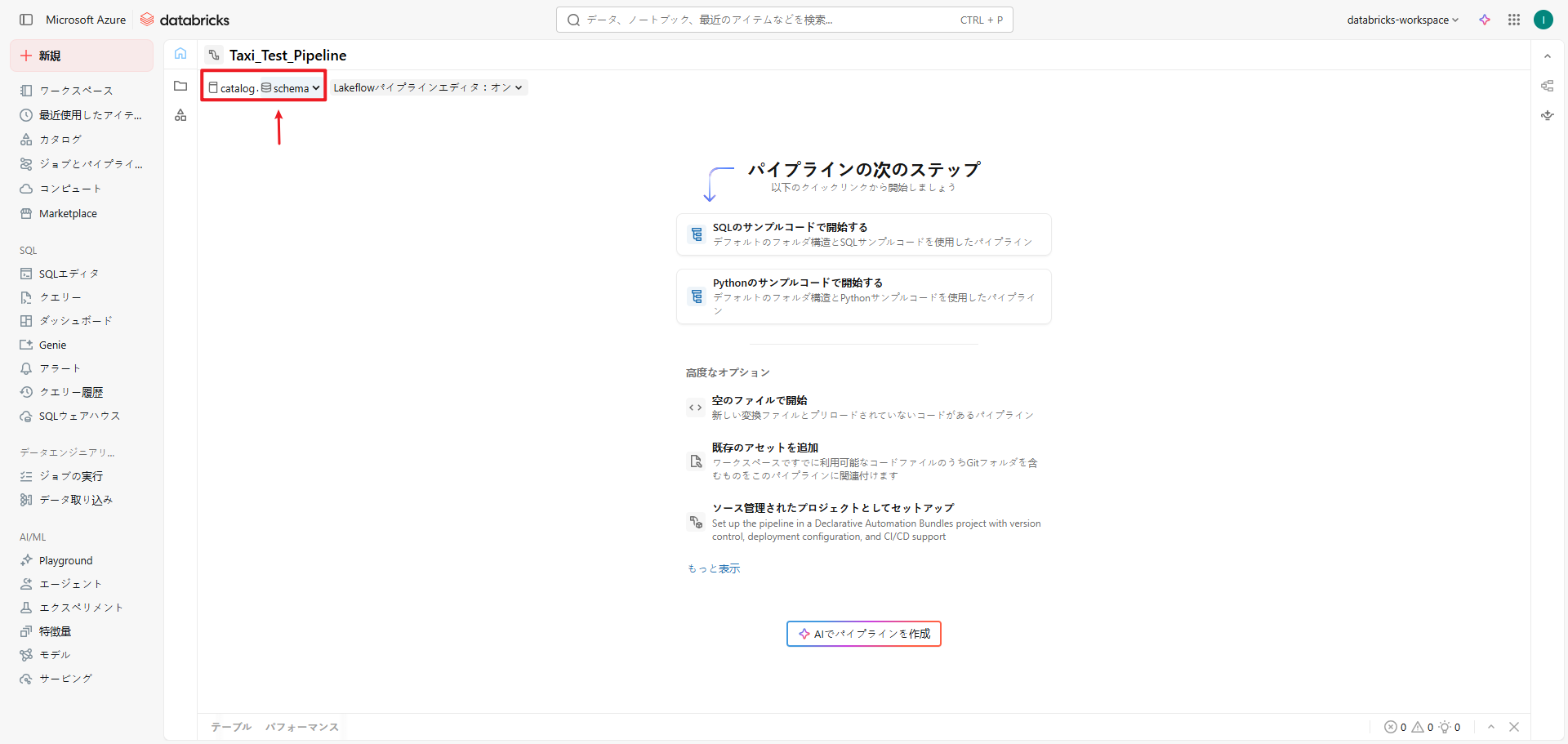
⑥ 「SQLのサンプルコードで開始する」を選択し、SQLのサンプルコードを含む新しいフォルダ構成およびパイプラインを作成します。
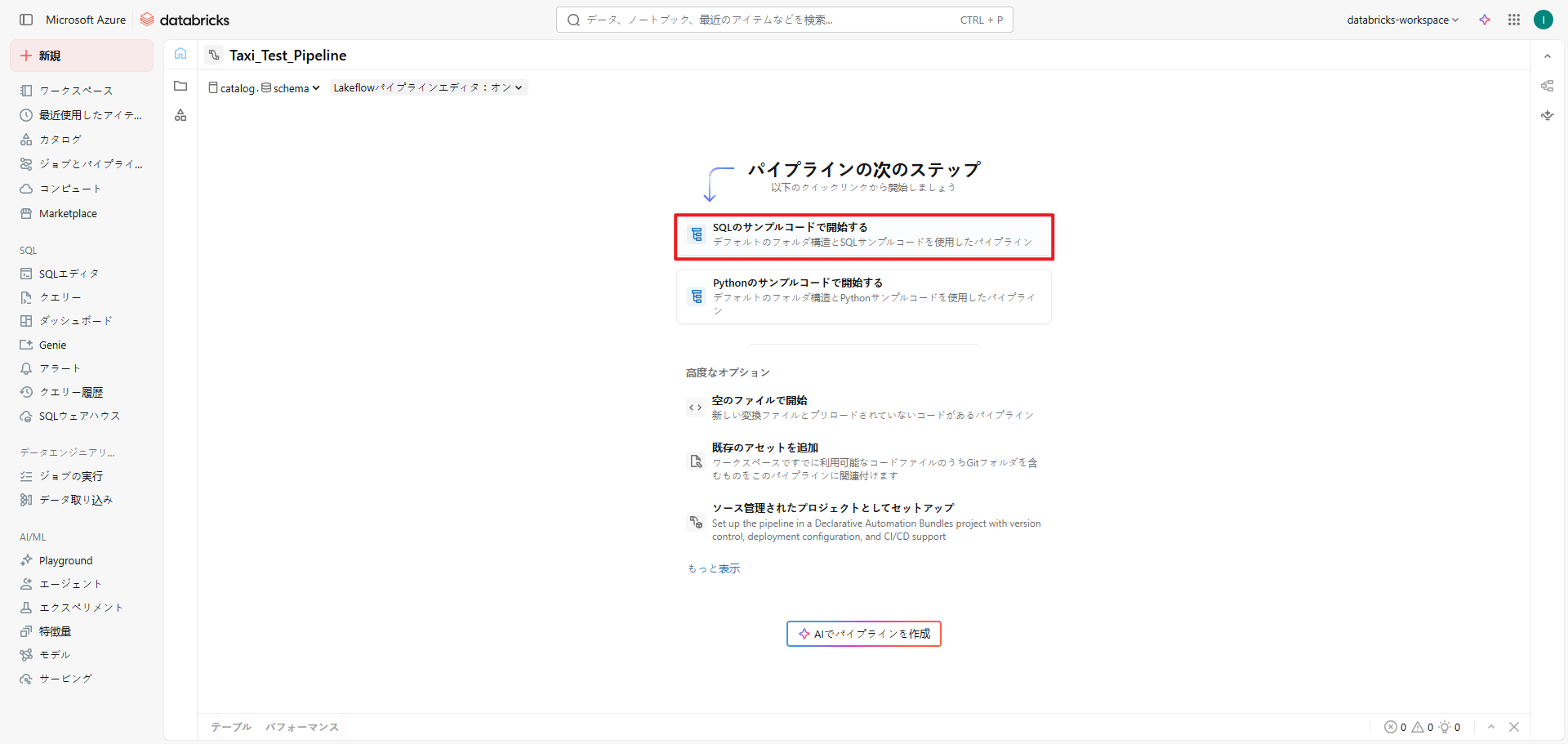
新しいパイプラインを作成すると、システムはデフォルトのフォルダ構成を自動的に生成します。
これはパイプライン内のファイルを整理するための推奨構成であり、以下を含みます:
- transformations: パイプライン内でテーブル定義やデータ処理を行うための主要なコード(Python、SQL)を格納する
- explorations: Notebookやクエリなど、データの探索・分析に使用する補助的なファイルを格納する
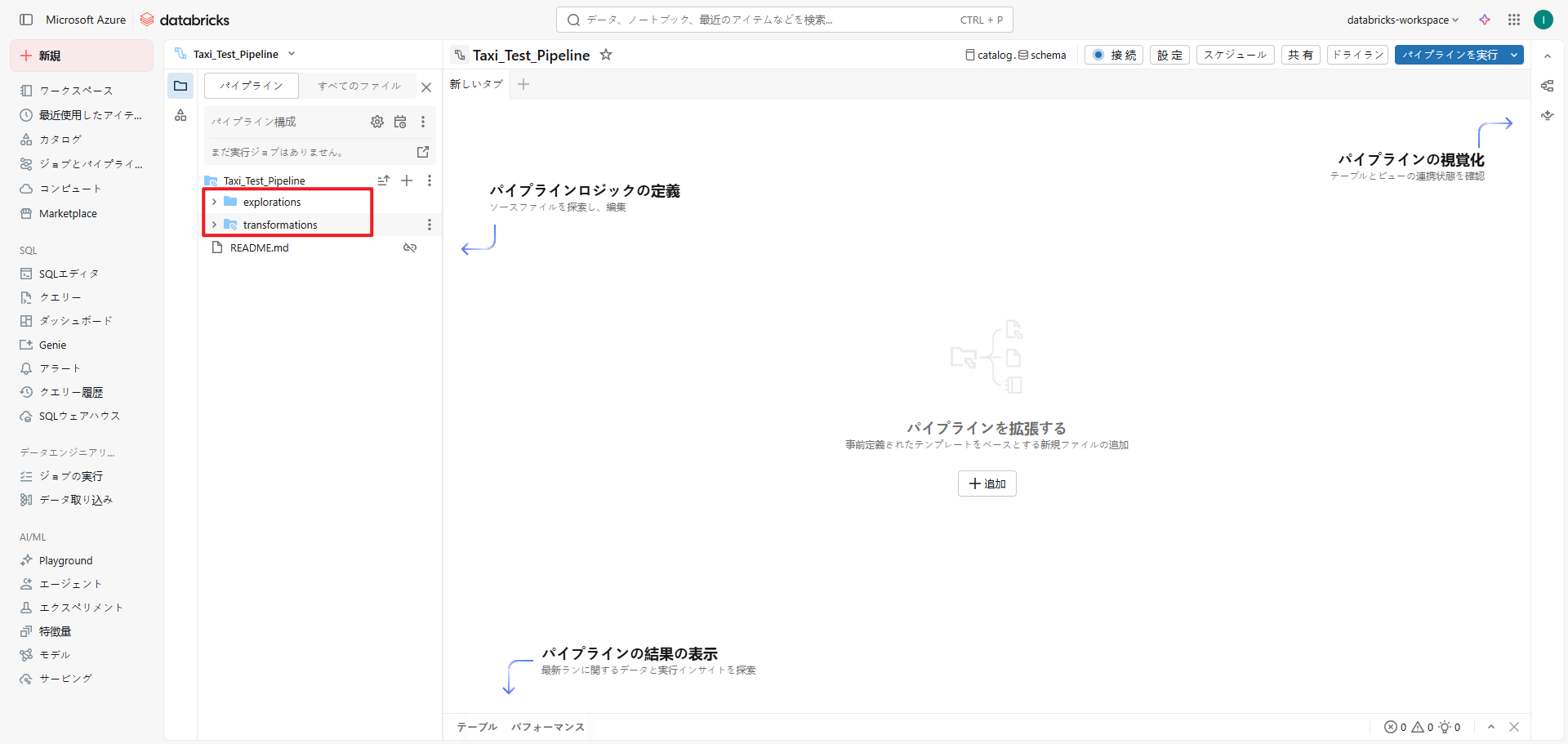
パイプラインの主要定義に該当するソースコードファイルを作成します。ソースコードファイルは、パイプライン実行時に処理されるファイルであり、パイプライン定義の中核となります。
これらのファイル/フォルダには、パイプラインアイコンが付与されます。新しいソースコードファイルの追加手順は以下のとおりです:
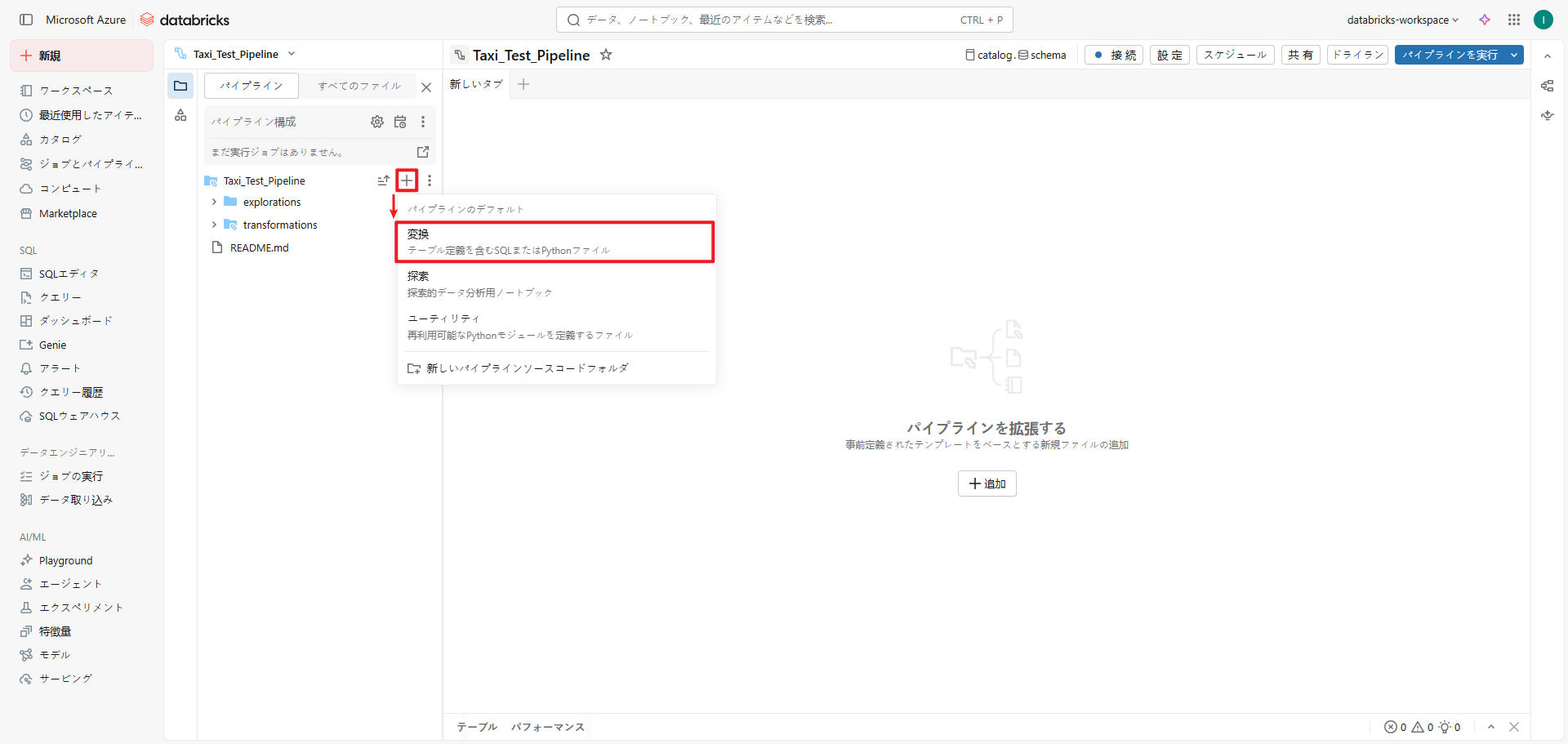
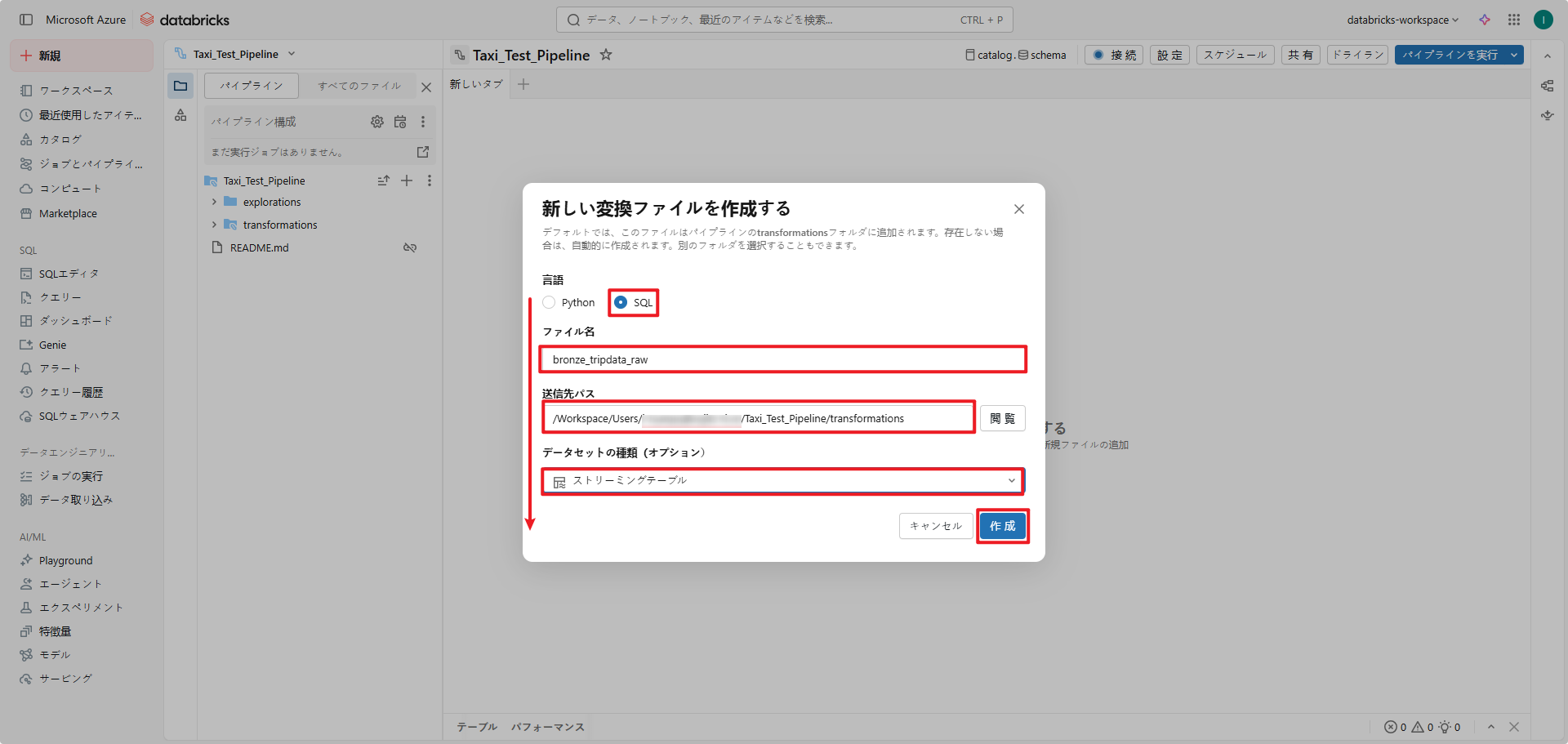
⑦ 「パイプライン」タブで「+」をクリックし、「変換”」を選択します。
⑧ ファイル名を入力し、言語(PythonまたはSQL)を選択します。それから、「作成」をクリックします。
 3-1.パイプラインエディタ内のソースコードファイルにコード入力
3-1.パイプラインエディタ内のソースコードファイルにコード入力
【シナリオ】
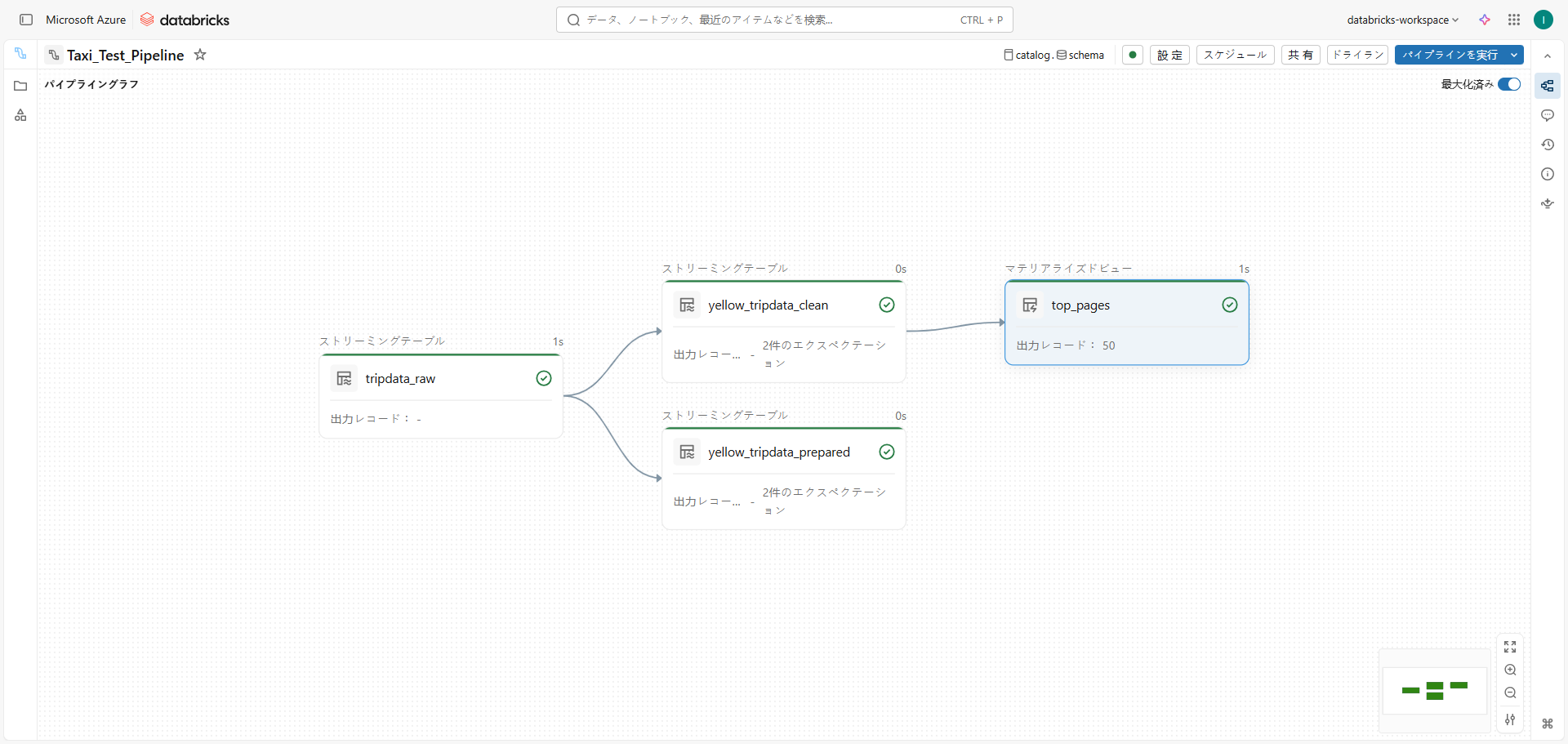
①ストレージからのyellow trip datasetという生データを取り込み 、tripdata_rawというテーブルを作成する
②tripdata_rawテーブルをクレンジングし、 tripdata_preparedテーブルを作成する
③tripdata_rawテーブルをクレンジングした、tripdata_cleanテーブルを作成し、データ型/列名と品質の期待値を持つデータに加工する
④ピックアップした場所ごとにグループ化し、通行料金の合計額を計算する
さらに計算結果を降順に並び替え上位50件に絞り込んだtop_pagesテーブルを作成する
【SQLの詳細】
① 【準備】ETLパイプラインの作成における手順⑦、⑧に従い、ファイル名を「bronze_tripdata_raw」、言語をSQL、データセットの種類をストリーミングテーブルとして作成します。
その後、「bronze_tripdata_raw.sql」ファイル内で、ストレージからのyellow trip datasetという生データを取り込み、「tripdata_raw」というテーブルを作成します。
|
1 2 3 4 5 6 7 8 |
CREATE OR REFRESH STREAMING TABLE tripdata_raw COMMENT 'The raw yellow tripdata dataset, ingested from files.' AS SELECT * EXCEPT (tpep_pickup_datetime, tpep_dropoff_datetime) FROM STREAM read_files( 'dbfs:/FileStore/yellow_tripdata/', format => 'parquet' ); |
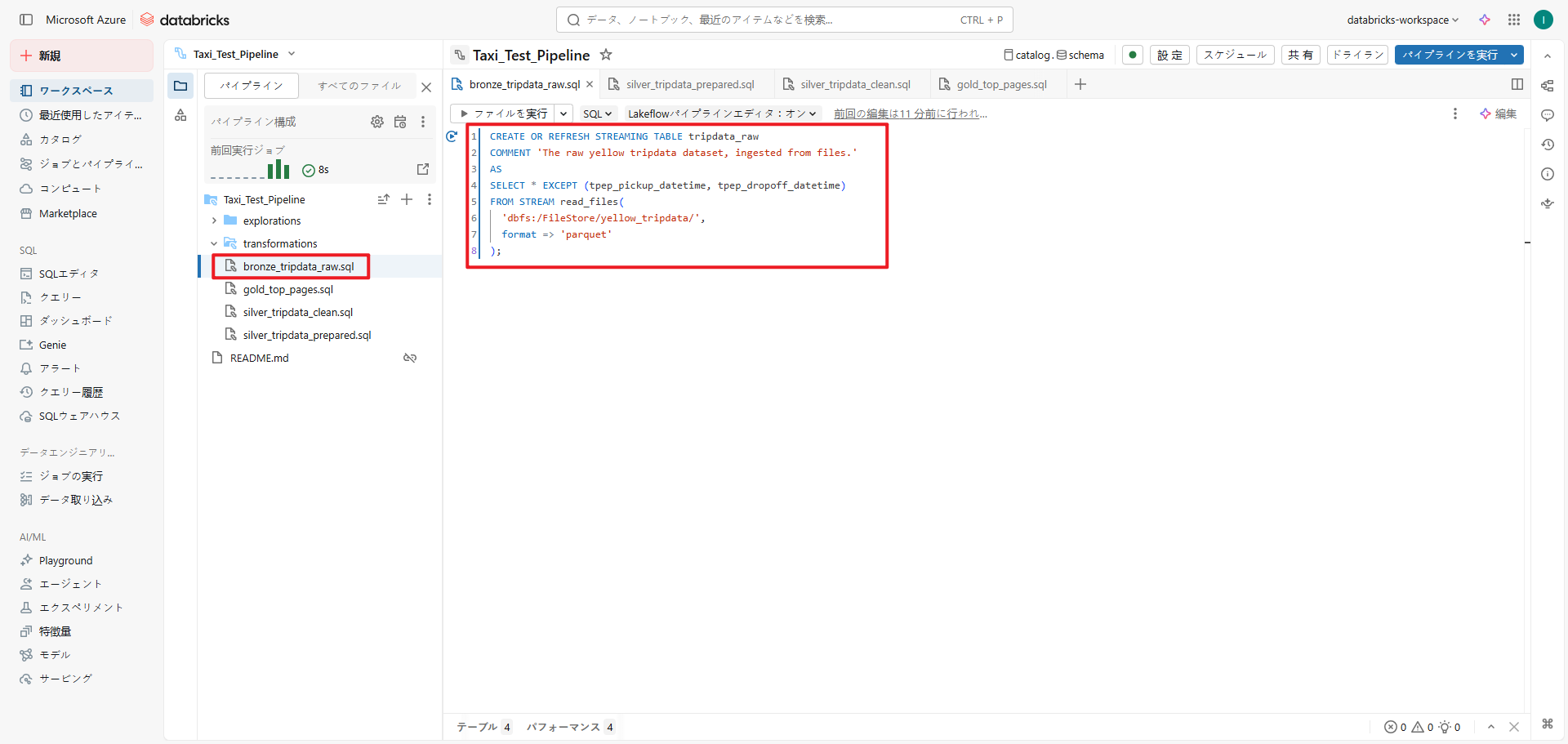 ② 【準備】ETLパイプラインの作成における手順⑦、⑧に従い、ファイル名を「silver_tripdata_prepared」、言語をSQL、データセットの種類をストリーミングテーブルとして作成します。
② 【準備】ETLパイプラインの作成における手順⑦、⑧に従い、ファイル名を「silver_tripdata_prepared」、言語をSQL、データセットの種類をストリーミングテーブルとして作成します。
その後、「silver_tripdata_prepared.sql」ファイル内で、tripdata_rawテーブルをクレンジングし、「tripdata_prepared」テーブルを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE OR REFRESH STREAMING TABLE tripdata_prepared ( CONSTRAINT valid_tollsAmount EXPECT(Tolls_Amount IS NOT NULL), CONSTRAINT valid_passengerCount EXPECT(Passenger_Count > 0) ) COMMENT 'yellow tripdata cleaned and prepared for analysis.' AS SELECT passenger_count AS Passenger_Count, tip_amount AS Creditcard_Amount, trip_distance AS Trip_Distance, tolls_amount AS Tolls_Amount From STREAM(tripdata_raw) |
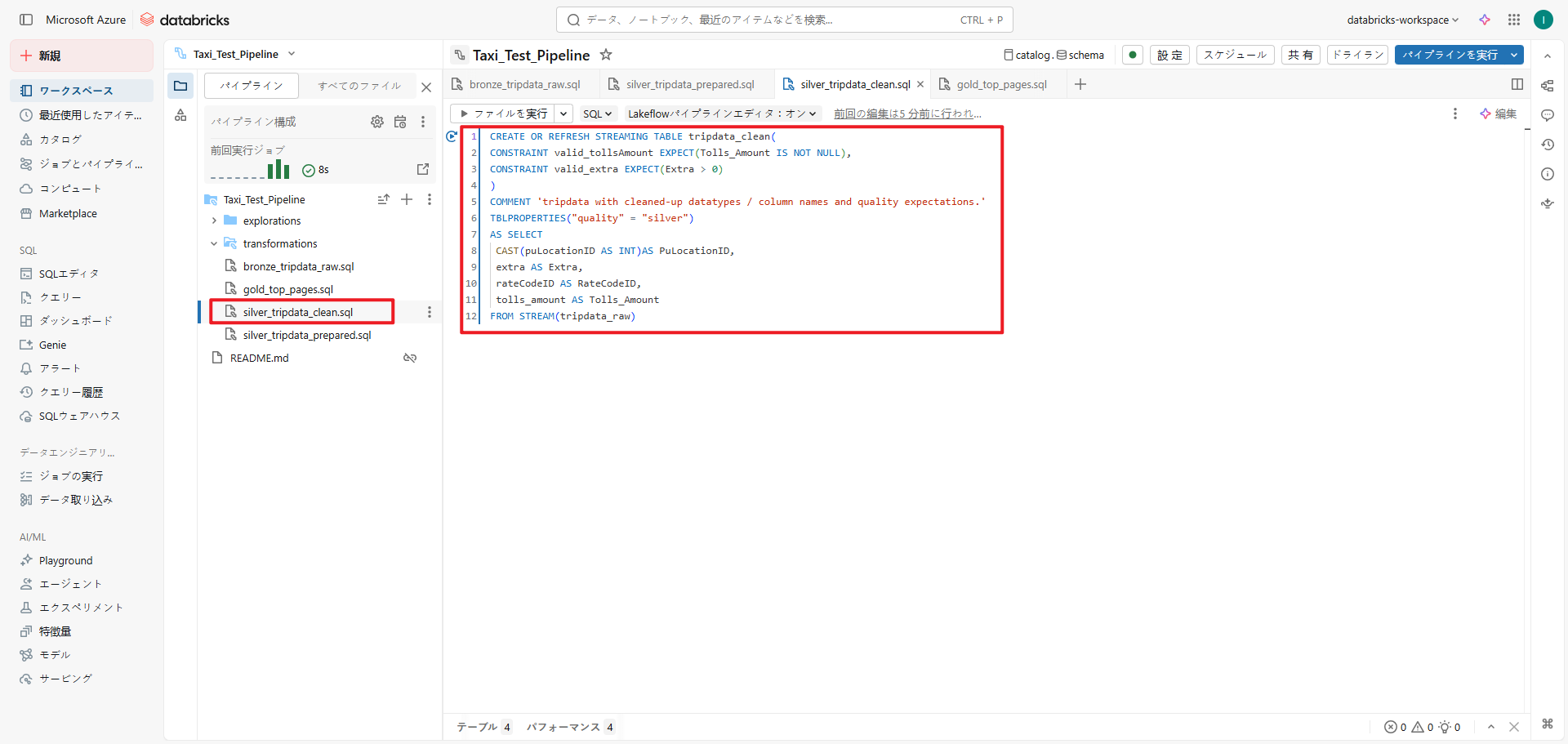
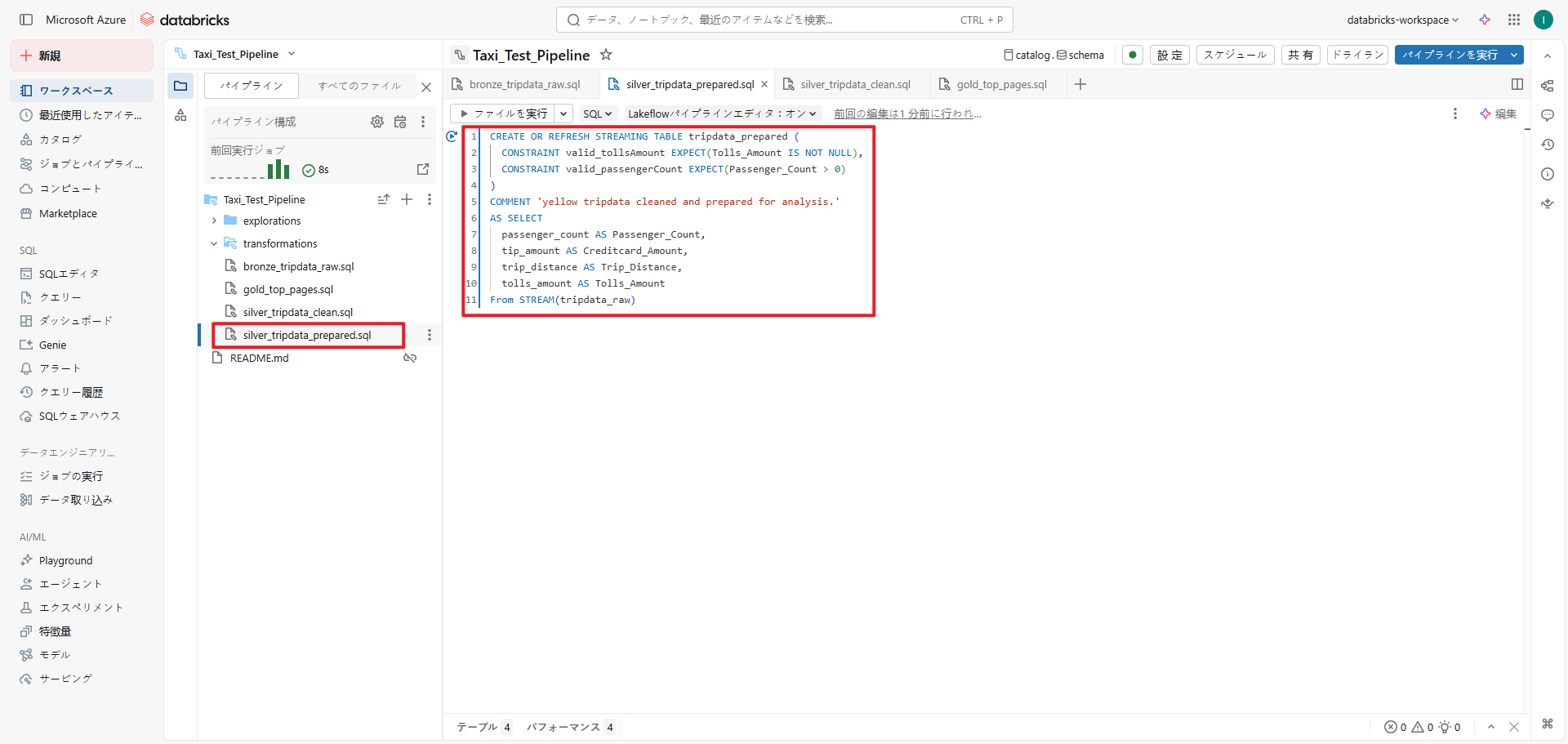 ③ 【準備】ETLパイプラインの作成における手順⑦、⑧に従い、ファイル名を「silver_tripdata_clean」、言語をSQL、データセットの種類をストリーミングテーブルとして作成します。
③ 【準備】ETLパイプラインの作成における手順⑦、⑧に従い、ファイル名を「silver_tripdata_clean」、言語をSQL、データセットの種類をストリーミングテーブルとして作成します。
その後、「silver_tripdata_clean.sql」ファイル内で、tripdata_rawテーブルをクレンジングし、「tripdata_clean」テーブルを作成します。また、データ型/列名の整形および品質の期待値を満たすデータへ加工します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE OR REFRESH STREAMING TABLE tripdata_clean( CONSTRAINT valid_tollsAmount EXPECT(Tolls_Amount IS NOT NULL), CONSTRAINT valid_extra EXPECT(Extra > 0) ) COMMENT 'tripdata with cleaned-up datatypes / column names and quality expectations.' TBLPROPERTIES("quality" = "silver") AS SELECT CAST(puLocationID AS INT)AS PuLocationID, extra AS Extra, rateCodeID AS RateCodeID, tolls_amount AS Tolls_Amount FROM STREAM(tripdata_raw) |
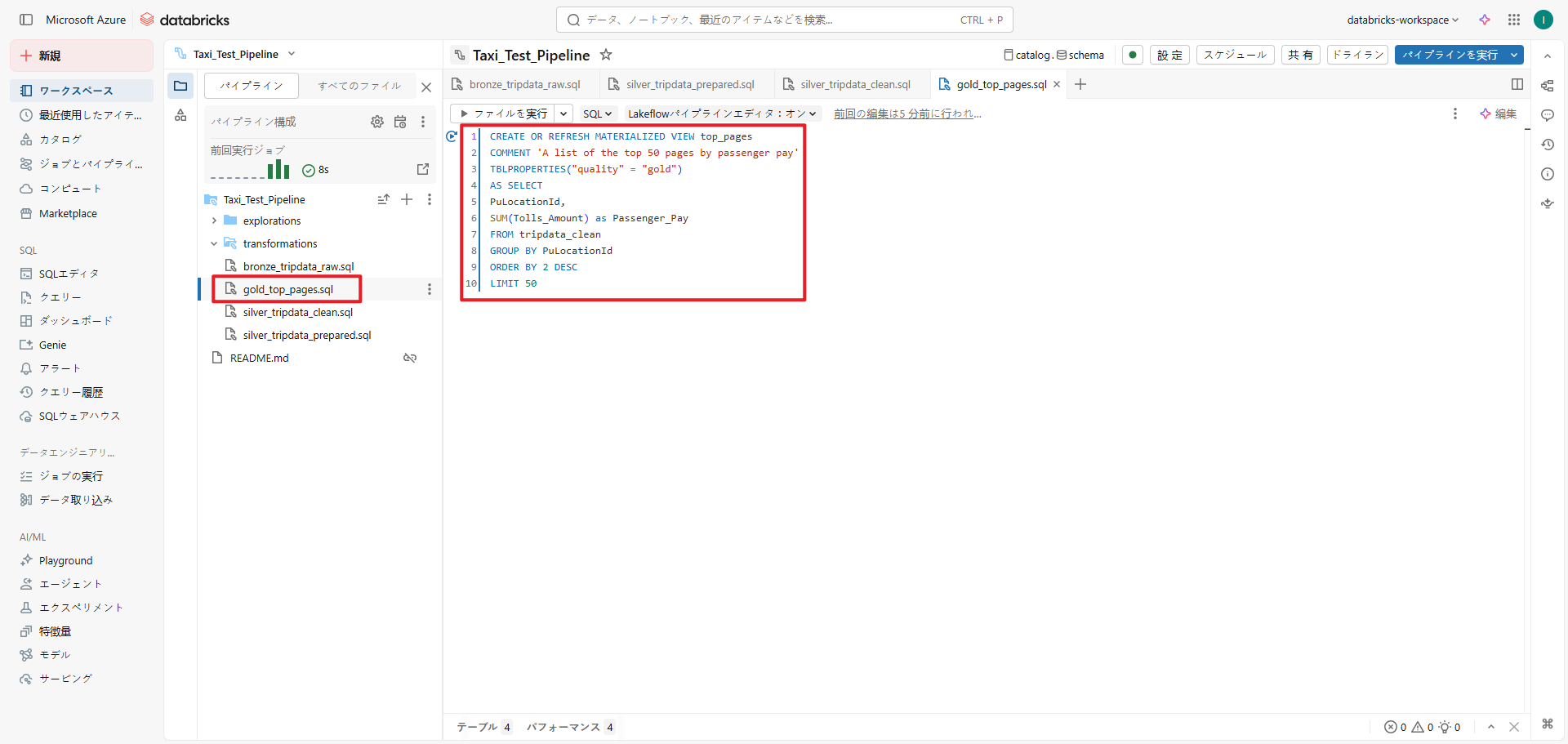
 ④ 【準備】ETLパイプラインの作成における手順⑦、⑧に従い、ファイル名を「gold_top_pages」、言語をSQL、データセットの種類をマテリアライズドビューとして作成します。
④ 【準備】ETLパイプラインの作成における手順⑦、⑧に従い、ファイル名を「gold_top_pages」、言語をSQL、データセットの種類をマテリアライズドビューとして作成します。
その後、「gold_top_pages.sql」ファイル内で、ピックアップした場所ごとにグループ化し、通行料金の合計額を計算します。
さらに、計算結果を降順に並び替え、上位50件に絞り込んだ「top_pages」テーブルを作成します。
|
1 2 3 4 5 6 7 8 9 10 |
CREATE OR REFRESH MATERIALIZED VIEW top_pages COMMENT 'A list of the top 50 pages by passenger pay' TBLPROPERTIES("quality" = "gold") AS SELECT PuLocationId, SUM(Tolls_Amount) as Passenger_Pay FROM tripdata_clean GROUP BY PuLocationId ORDER BY 2 DESC LIMIT 50 |
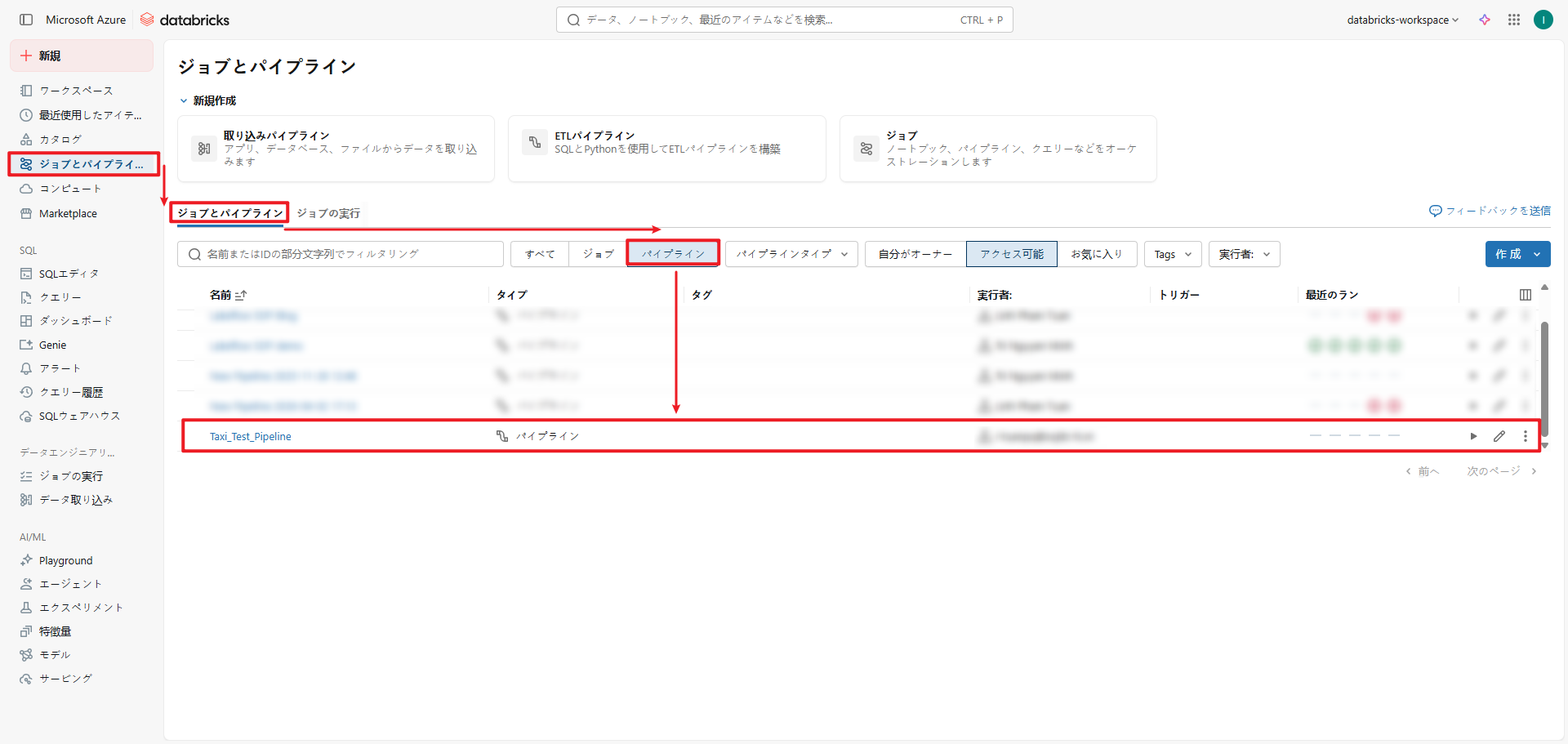
4.パイプラインの実行
① ジョブとパイプライン > ジョブとパイプライン > パイプライン>自分のユーザー名 > 使用するノートブック を選択します。
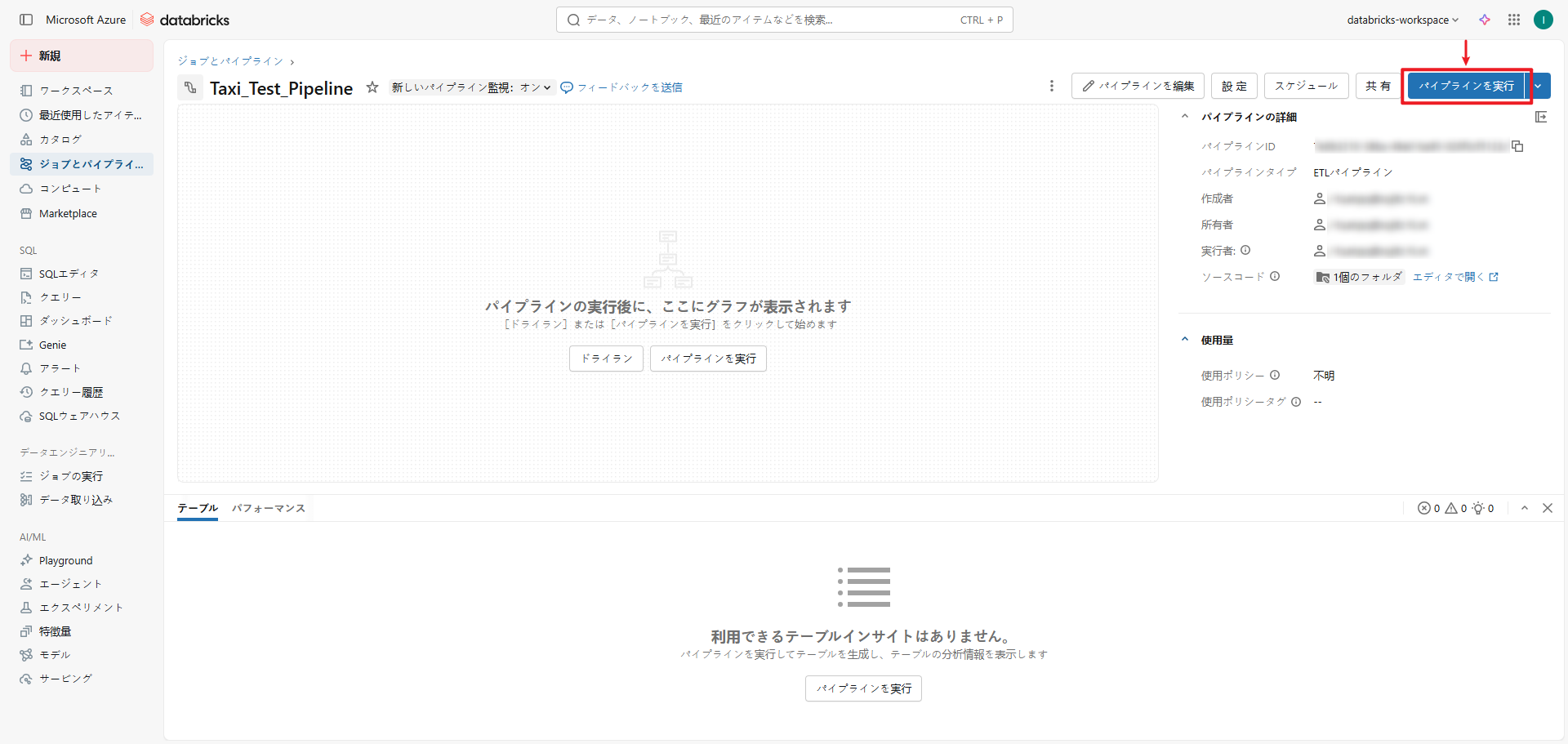
②「パイプラインを実行」をクリックするとパイプラインが開始されます。
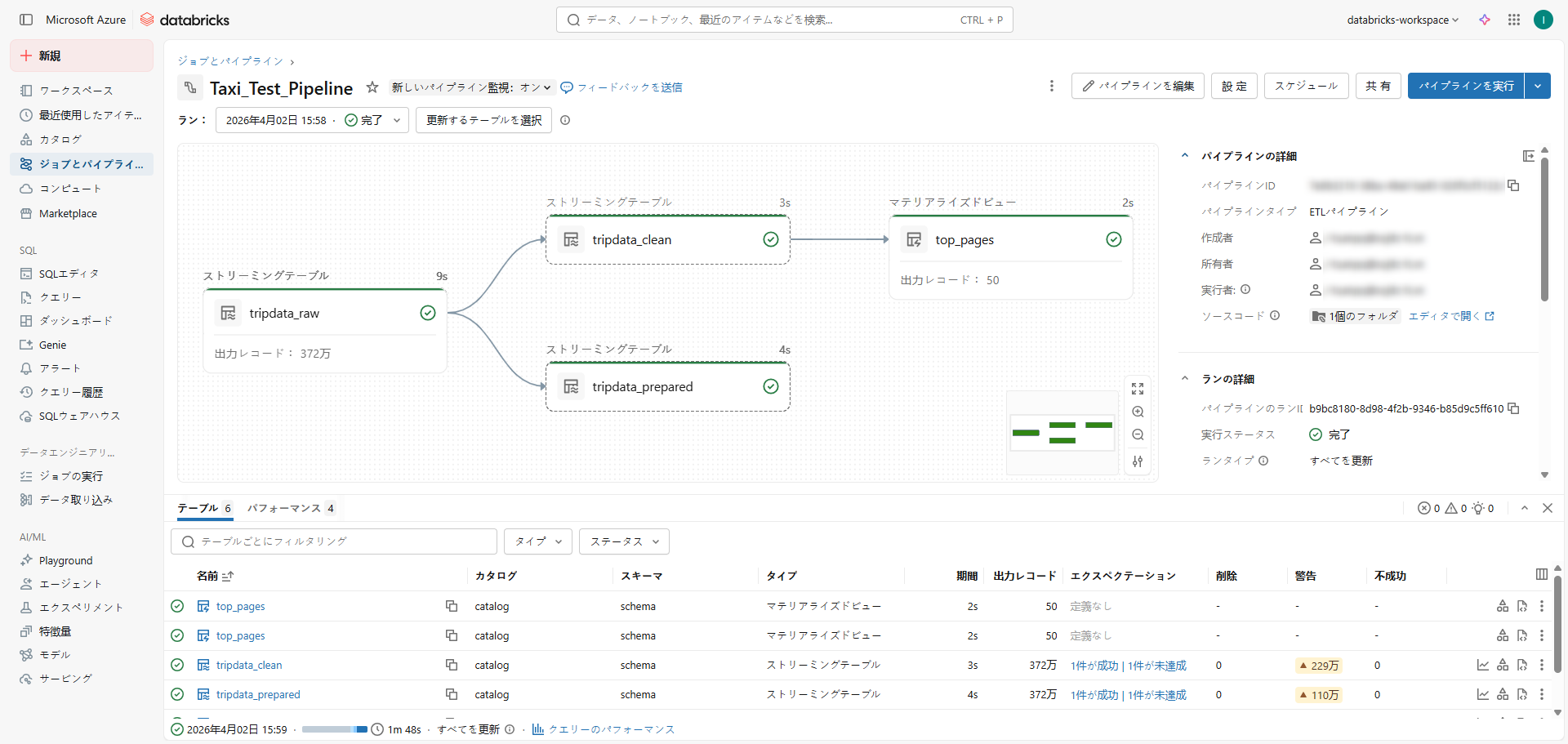
 ③実行結果が表示されます。
③実行結果が表示されます。
 5. まとめ
5. まとめ
本記事では、Azure Databricks上でのLakeflow Declarative Pipelineの構築手順について説明しました。
本シリーズでは、Lakeflow Declarative Pipelineの基礎知識から実際の実装手順まで順を追って解説していきます。
ぜひ、関連する他の記事もあわせてご参照ください。
第1回:Lakeflow Spark 宣言型パイプラインの基本を知ろう
第2回:Lakeflow Spark 宣言型のパイプラインを実装してみよう(今回)
第3回:Lakeflow Spark 宣言型パイプラインのデータの品質管理とは?
今回の記事が少しでも皆さんの新しい知識や業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたら
是非お問い合わせください!
Azure Databricks連載記事のまとめはこちら
この記事を読んだ方へのオススメコンテンツはこちら
この記事を書いた人

- 双日テックイノベーション(旧:日商エレクトロニクス)特設サイト「Azure導入支援デスク」サイトマスターです。
この投稿者の最新の記事
- 2026年5月22日ブログAzure DatabricksとAzure Key Vaultの連携による セキュリティ強化
- 2026年5月15日ブログAzure Databricks連載記事のまとめページ
- 2026年5月15日ブログ【Azure Databricks】Azure Databricksと大規模言語モデル(LLMs)を活用したAI Functionsの利用方法
- 2026年4月24日ブログDatabricks無料版