Cognitive Search のベクトル検索のメリットとは?
ChatGPTシステムと連携したデモで解説!

現代において、情報の検索や管理は日常業務の大部分を占めています。
特に、大量のデータから必要な情報を迅速かつ正確に見つけ出すことは業務の効率化に直結します。
多くの業務は、情報を収集し、集めたデータをもとに資料を作ったり、なにかしらの成果物を作ることが多いと思います。

そのため、「いかに素早く欲しい情報にたどり着けるか」が作業を効率化させます。
このブログでは、Microsoftの提供するAzure Open AI Serviceと、検索サービスAzure Cognitive Searchを使った「ベクトル検索」が従来の「全文検索」と比べてどのようなメリットがあるかについて、デモンストレーションと共に解説します。
Cognitive Search とは?
Azure Cognitive Searchは、Microsoft Azureが提供するクラウドベースの検索サービスです。このサービスは、大規模なデータに対して、高度な検索機能、AIによる分析、および機械学習モデルを組み込むことができます。ユーザーは、ウェブサイト、モバイルアプリケーション、企業内システムなど、さまざまなアプリケーションでこのサービスを利用して、効率的な検索機能を組み込むことができます。
ベクトル検索とは?
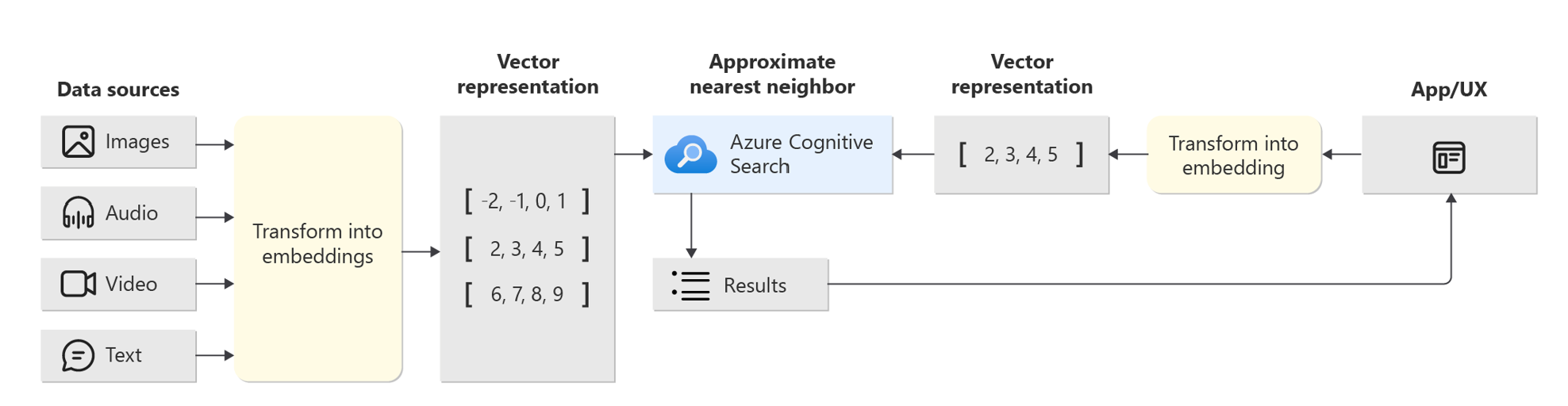
ベクトル検索は、テキストや画像などのデータを数値のベクトルに変換し、このベクトル間の距離や類似性を計算することで検索を行う技術です。この方法は、特に意味的な類似性や文脈を重視する検索において、従来のキーワードベースの検索よりも高い精度となります。
全文検索との違いは?
従来の全文検索は、文書内のキーワードの出現を基に検索を行います。これに対して、ベクトル検索は、データの意味的な内容を理解し、より文脈に即した結果を提供します。例えば、同じキーワードを含まない文書でも、その内容が類似していれば検索結果として表示される可能性があります。
これにより、ユーザーが求める回答を高精度で検索することができます。
デモンストレーション
このCognitive SearchとChatGPTを使ってPDFファイルに書かれた情報から、ユーザーの求める回答を生成します。
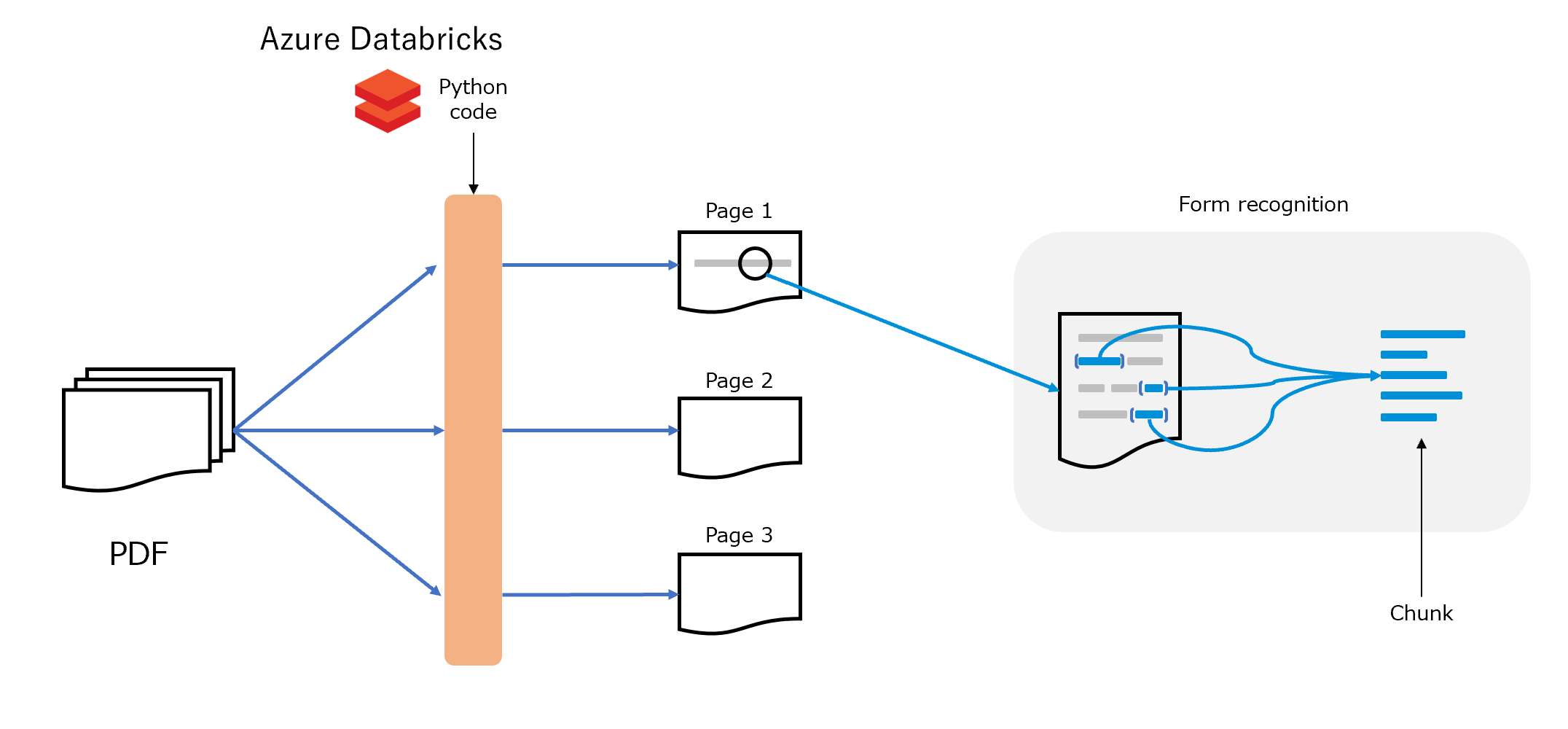
今回のデモンストレーションでは、Blobストレージに保存されたPDFファイルをAzure Databrick を使ってページ単位に分割します。その後Azure Open AI の Form Recognizer を使ってチャンク分割します。
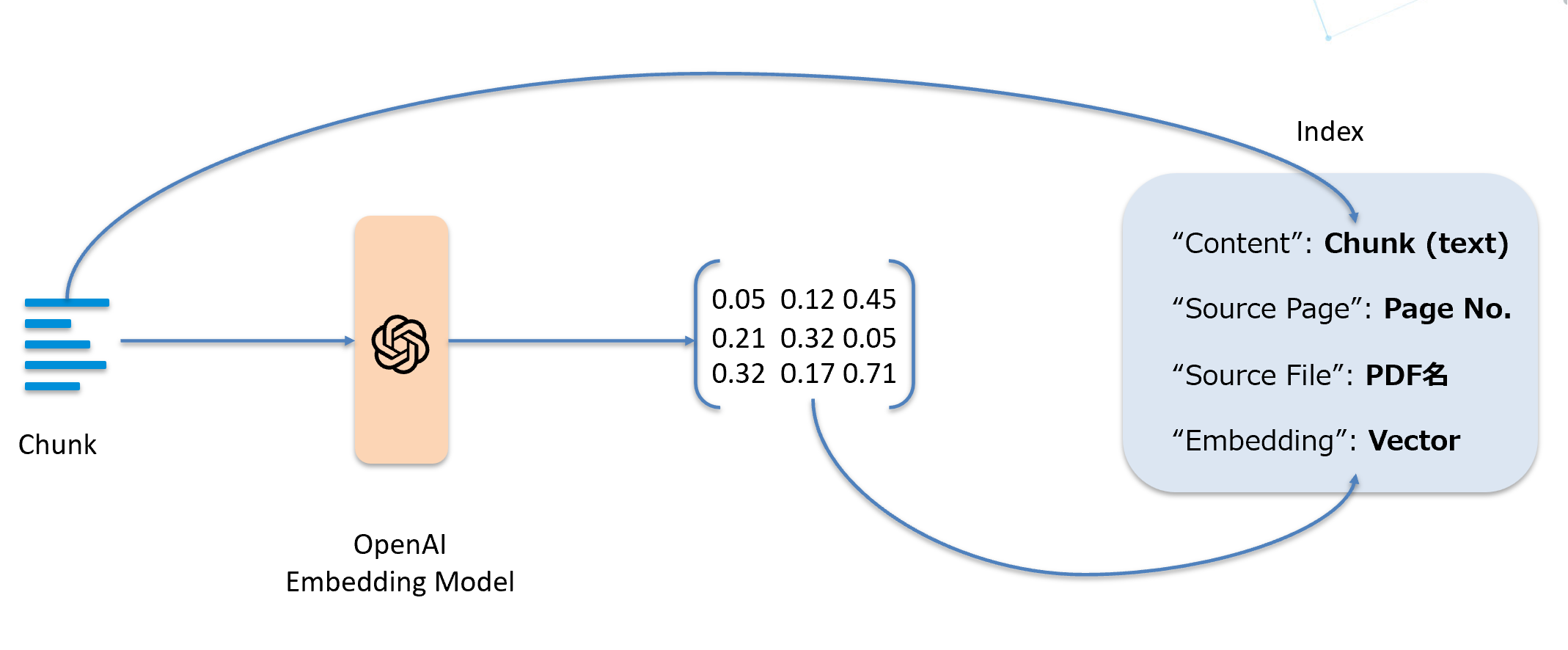
チャンクをOpen AI の Embedding Model でベクトル化し、Cognitive Search でインデックス化することで、社内ChatGPTシステムから検索できるよう構成します。
では早速設定してみましょう。
①Blob StorageにPDFファイルを格納。各ファイルには歴史の人物に関する情報が記載されています。
②Azure Databricks のユニティカタログで、Blobストレージを接続します。
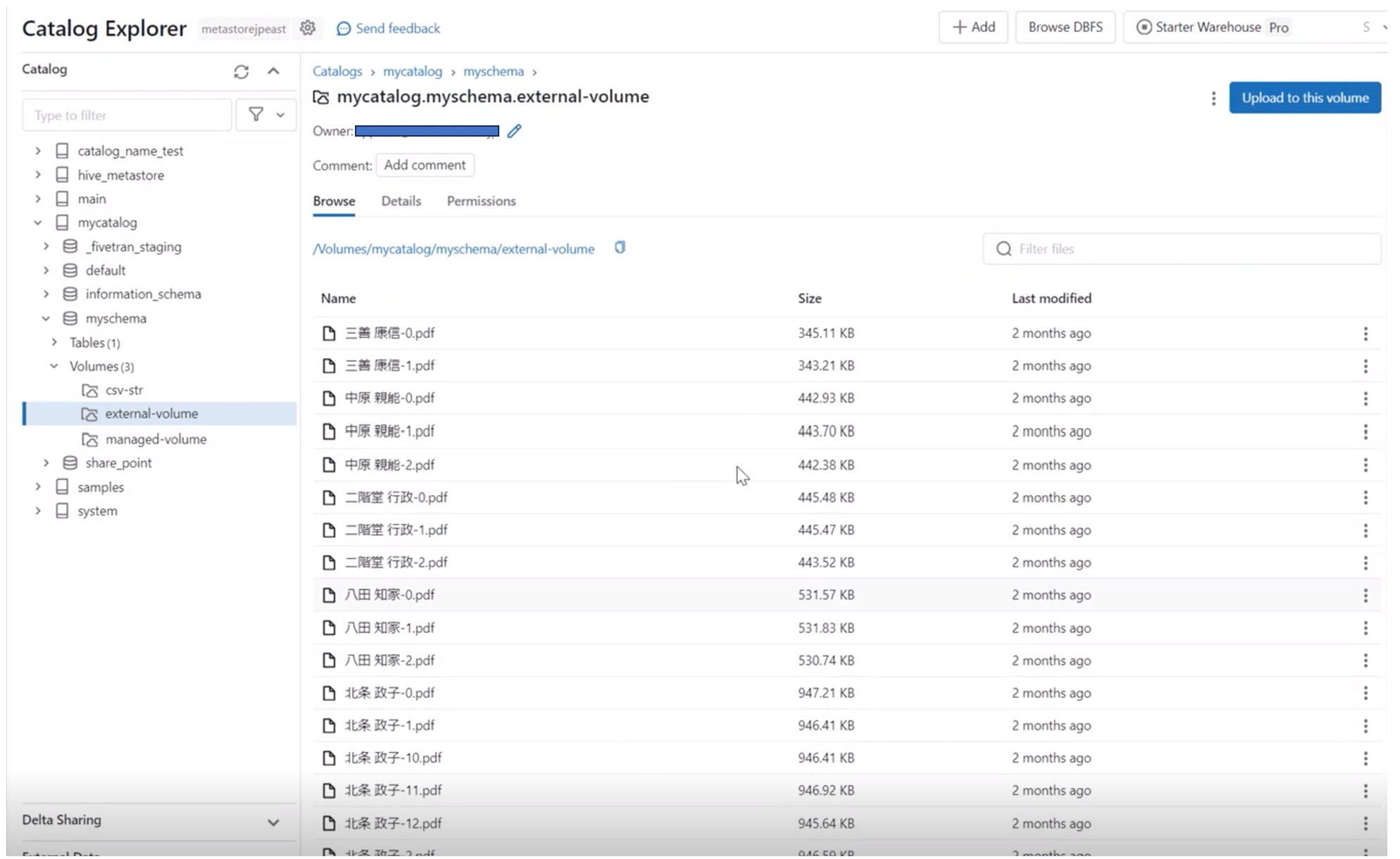
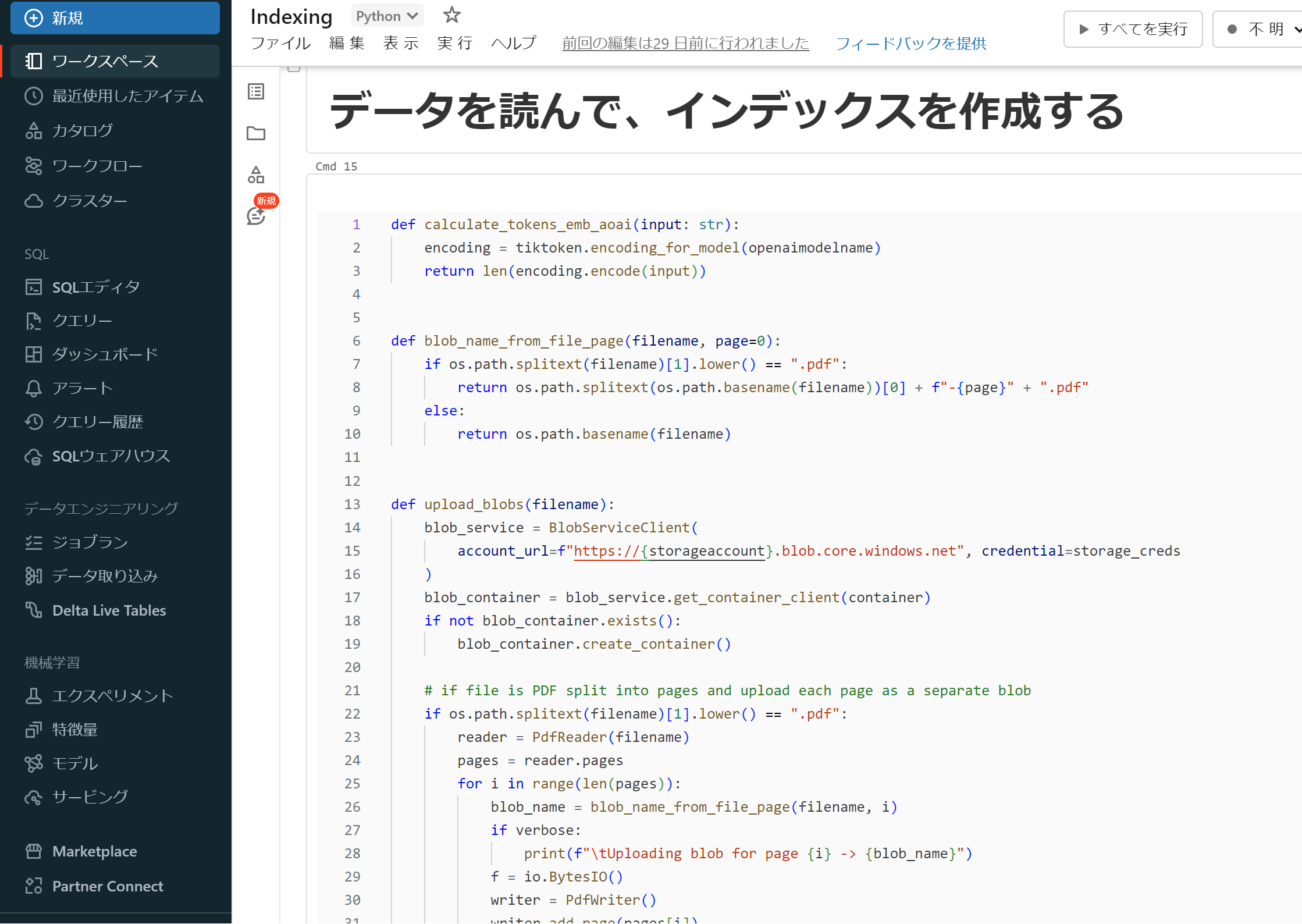
③Azure Databricks のノートブックでPythonを使ってPDFファイルを1ページ毎に分割し、Form Recognizer を使って1ページの文章からチャンクを生成します。その後、生成したチャンクをAzure Open AI の Embedding Modelを使ってベクトル化します。
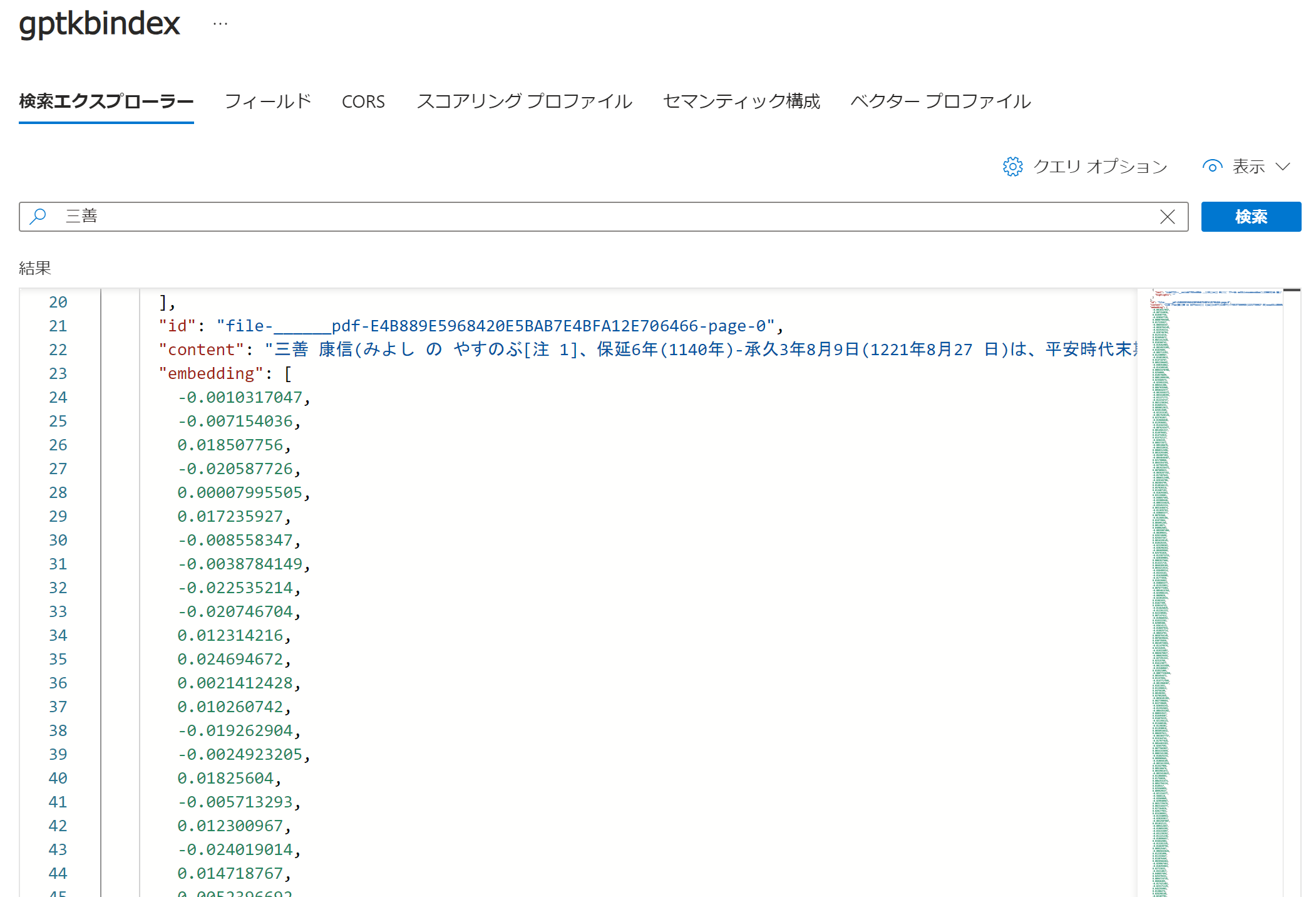
④Cognitive Search でベクトルをインデックス化します。
⑤では社内ChatGPTシステムで検索してみましょう。
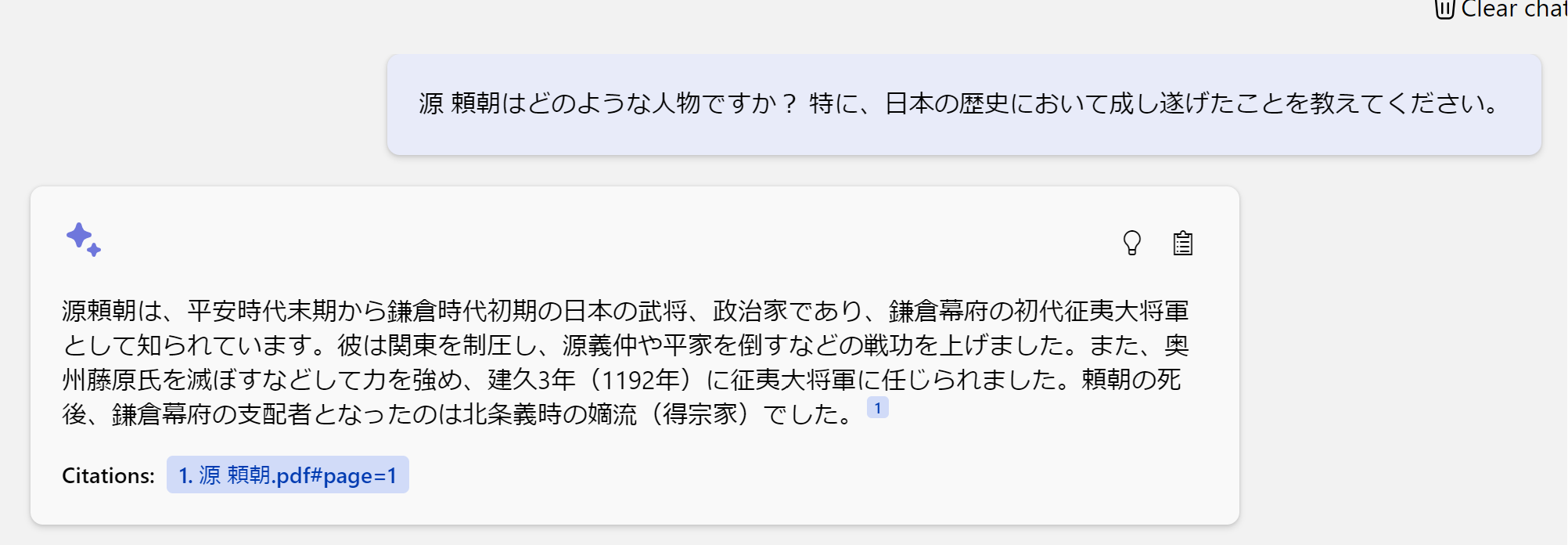
しっかりとプロンプトに入力された文脈を理解し回答されていますね。
さらに詳しく質問してみましょう。
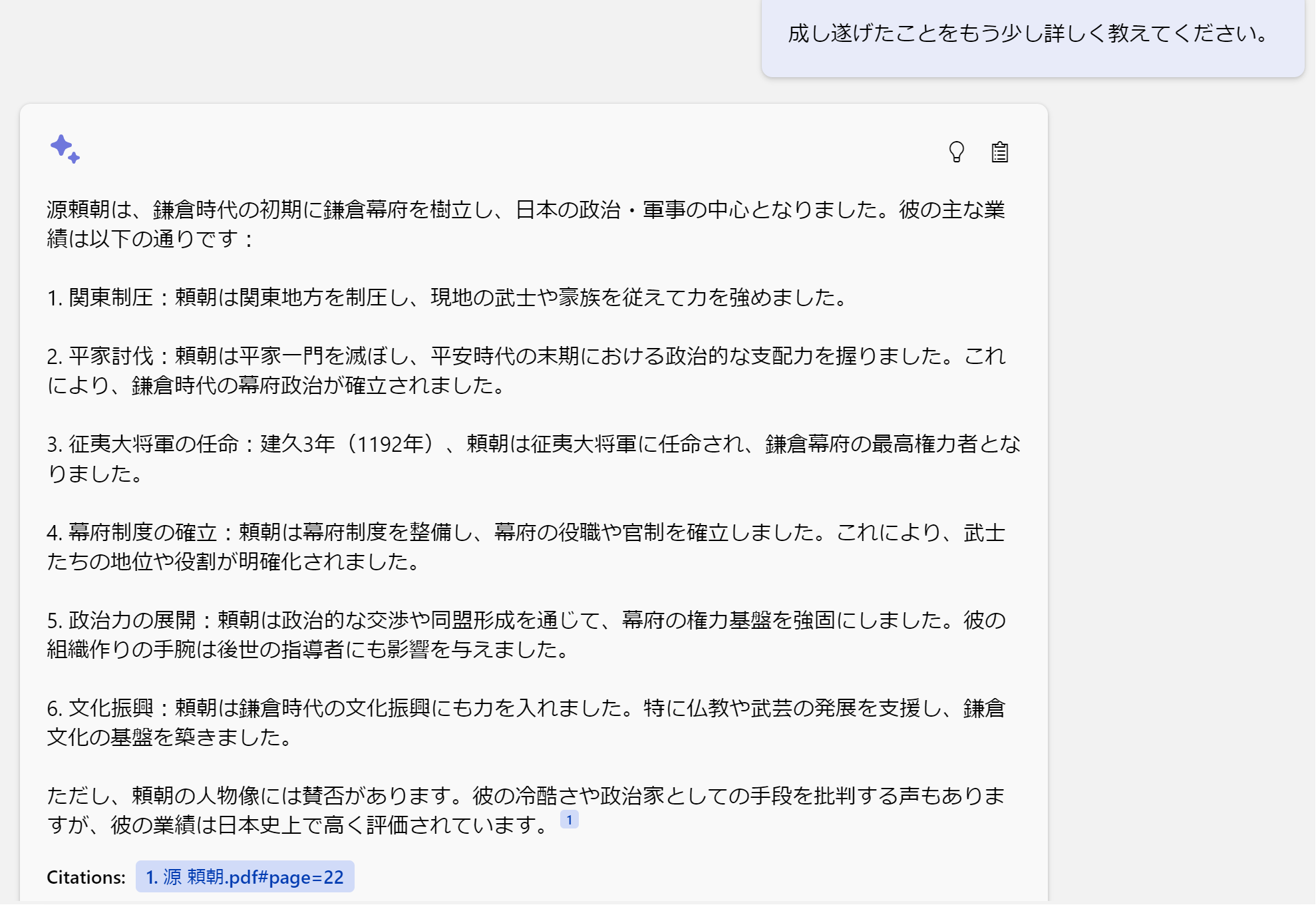
「源 頼朝が成し遂げたこと」という文章の意味を理解して、数十ページにおよぶPDFから正確に回答されています。
この記事を書いた人

-
テクニカルマーケターとして、新技術の検証、ブログ執筆、セミナー講師を行っております!
学生時代はアプリ開発に興味がありましたが、インフラ、セキュリティ事業を経て、現在はクラウド屋さんになっております。
コロナ禍前は、月1で海外旅行にいくなどアクティブに活動していましたが、最近は家に引きこもってゲームが趣味になっています。
宜しくお願い致します!
この投稿者の最新の記事
- 2024年3月25日ブログOracle Database@Azureが東日本リージョンに展開されることが発表されました!
- 2024年3月22日ブログAzure SQL DatabaseでCopilotがプレビュー公開!
- 2024年3月18日ブログAzureリソースの誤削除を防ぐ「ロック」機能とは
- 2024年3月14日ブログCopilot for Security の一般公開日が発表