目次
1.はじめに
皆さんこんにちは。
この連載では、SQLエンジニア向けにAzure Data Factoryの利用方法について説明していきます。
SQLエンジニアがSQLを使ってデータを操作していることを、Azure Data Factoryでどう実現できるかを解説していきたいと思います。
今回は、Azure Data Factory上でinsert、delete、update、mergeの処理を実行する方法について説明していきます。
第1回:SQLコマンドをAzure Data Factoryで実現する
第2回:Azure Data Factoryでインラインビュー、サブクエリーを実現する
第3回:Azure Data Factory上でinsert、delete、update、mergeの処理を実行する(今回)
2.前提要件
実施する際の前提条件は以下の通りです。
・操作ユーザーは、ストレージ アカウントとAzure Data Factoryの作成権限があること。権限が付与されていない場合、管理者に権限を付与してもらう様に依頼してください。
・ユーザーは、insert、delete、update、mergeの処理を実行する前に、Azure SQL Database でテーブルの作成と Azure Data Factory でAzure SQL Server への接続を実行する必要があります。 (実行完了した場合、これらの処理の実行手順に進みます。)
3.Azure SQL Databaseでテーブルを作成する
Azure SQL Serverを作成する。
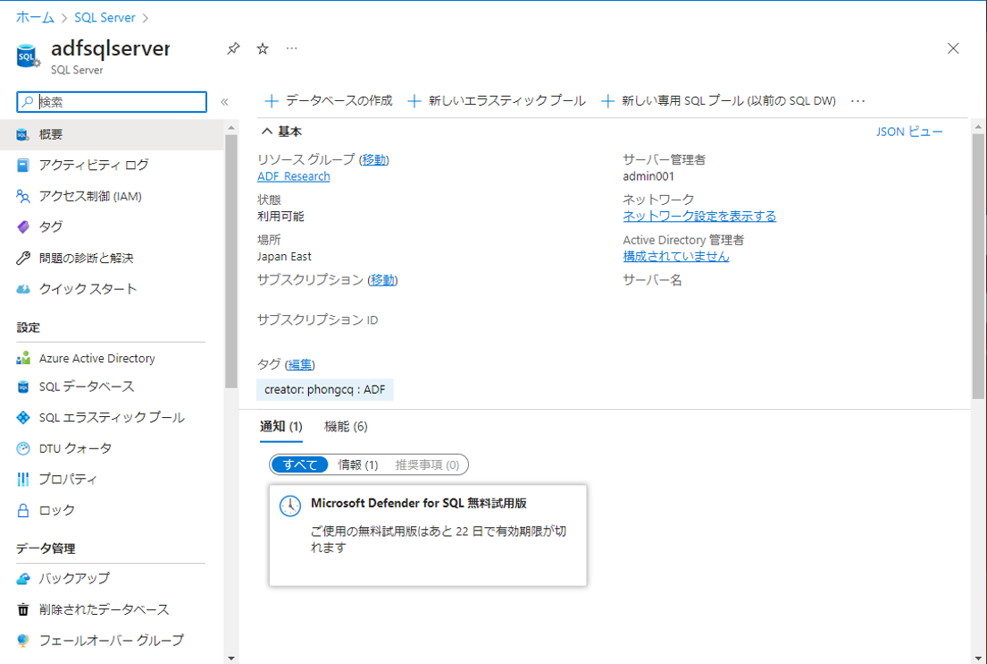
① Azure SQL Server で、「SQL データベース」をクリックし、作成したデータベースをクリックします。
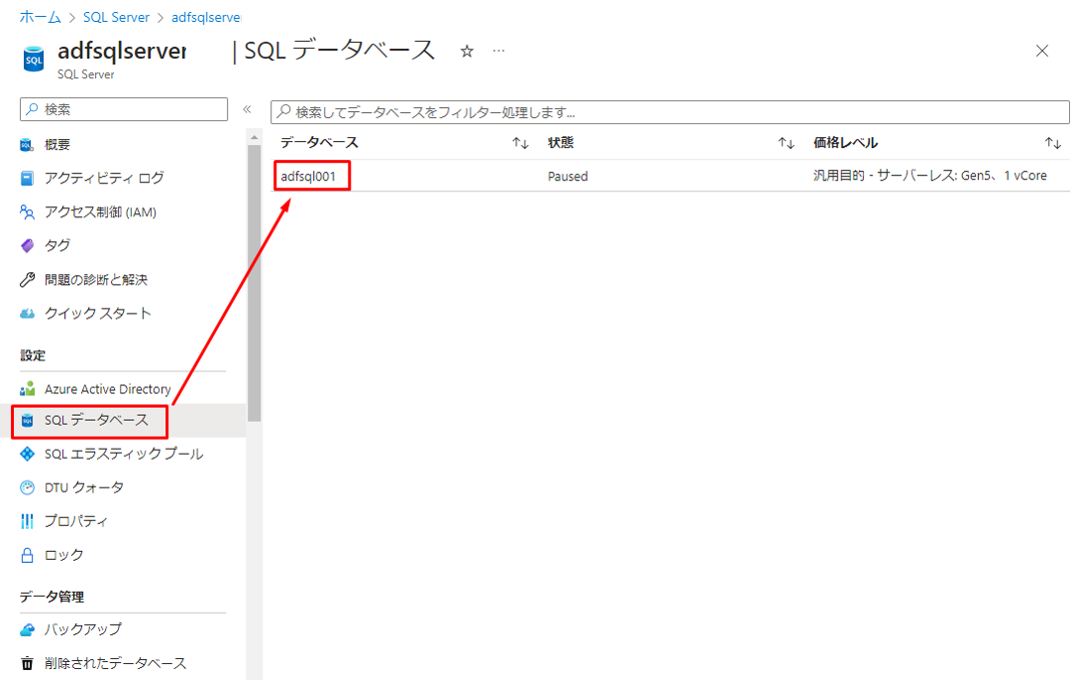
② SQLデータベース画面で、「クエリエディター」をクリックします。
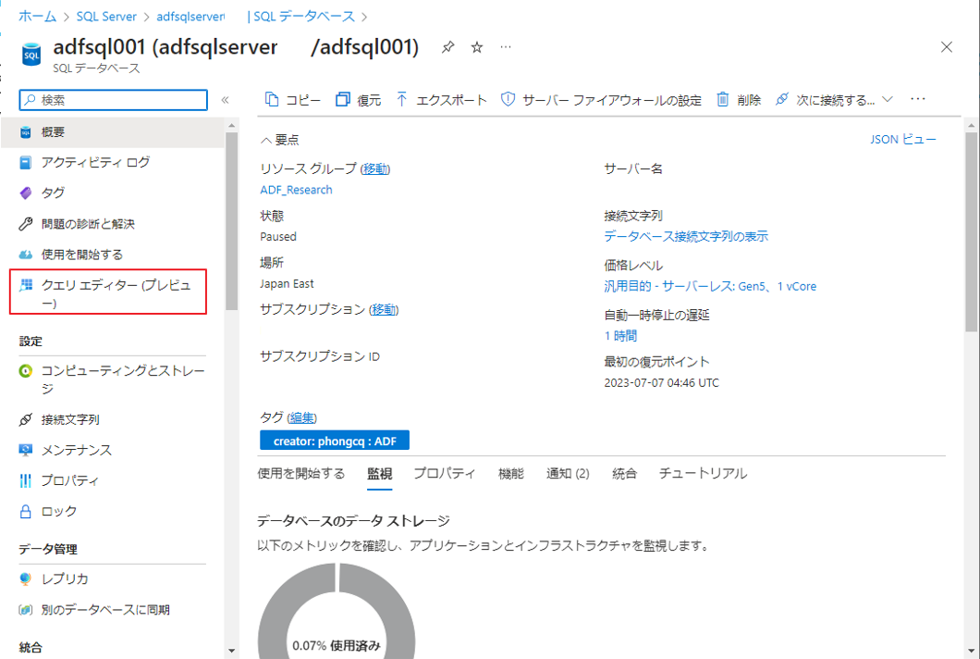
③ ログイン名とパスワードを入力して、SQL 認証を使用してサーバーにアクセスします。
④「OK」をクリックします。
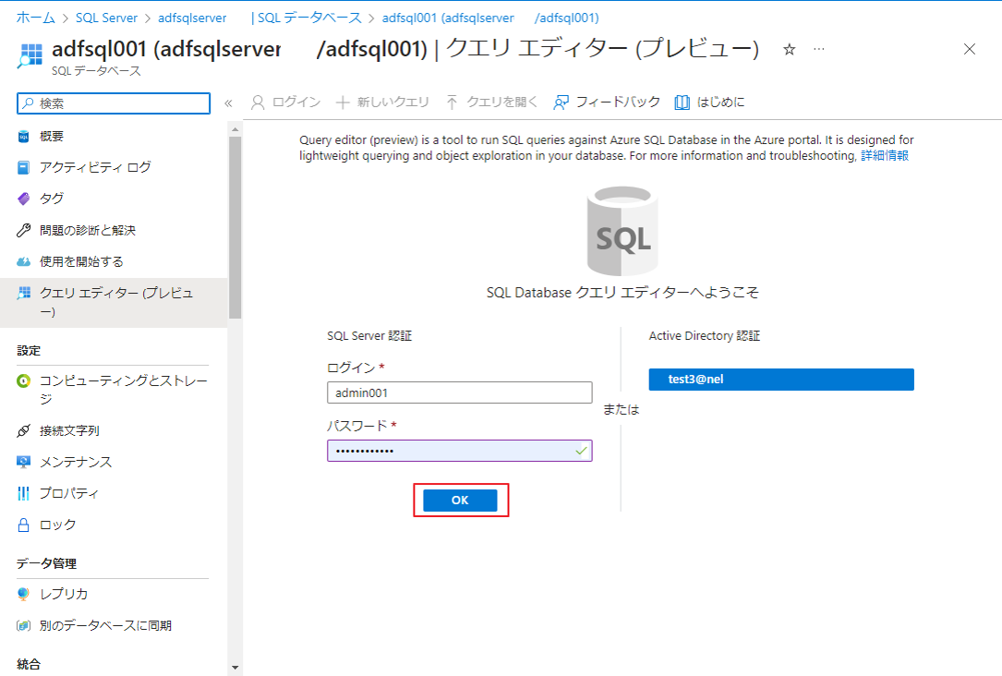
⑤ 次の SQL コマンドをクエリ エディターにコピペします。
※例
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE [dbo].[Student]( [Name] [nvarchar](20) NOT NULL, [Roll No.] [nvarchar](20) NOT NULL, [Mark] [nvarchar](30) NOT NULL, CONSTRAINT PK_Student PRIMARY KEY ([Roll No.]) ) ON [PRIMARY]; |
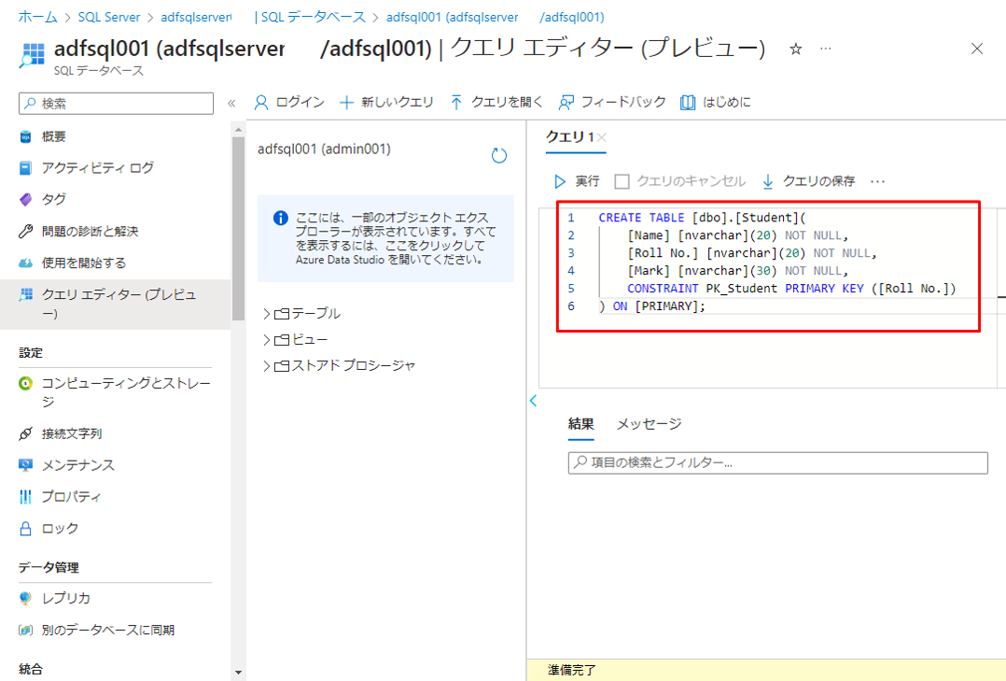
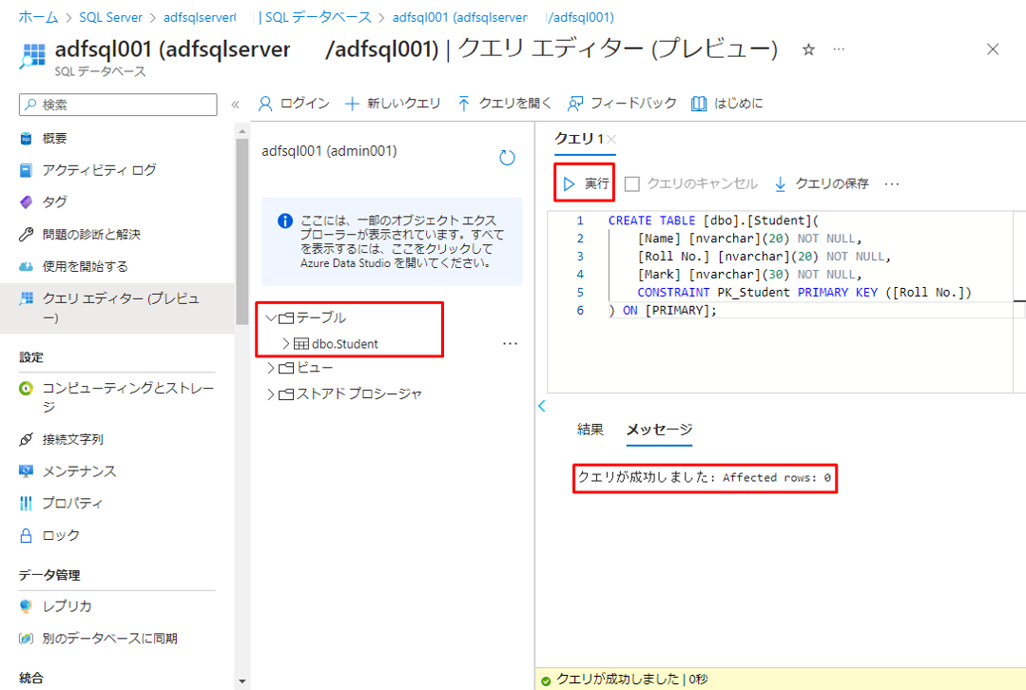
⑥「実行」をクリックして SQL スクリプトを実行します。
実行が成功すると、以下のメッセージが表示され、テーブル フォルダーに [dbo].[Student] テーブルが表示されることがわかります。
4.Azure Data FactoryでAzure SQL Serverに接続する
① Azure Data Factory 画面で「スタジオの起動」をクリックしてワークスペースを起動します。

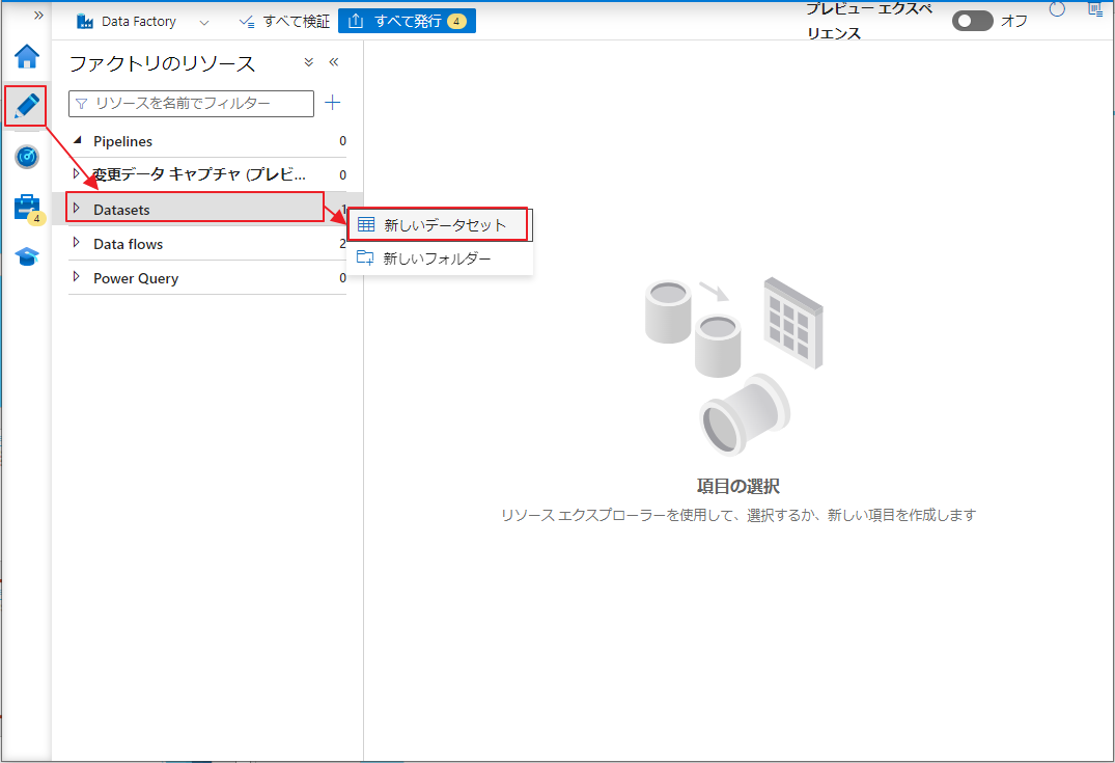
② サイドバーで「Author」をクリックして、次に「Datasets」をクリックして、「新しいデータセット」を選択します。
③「新しいデータセット」ダイアログボックスで「Azure SQL Database」を選択し、「実行」ボタンをクリックします。
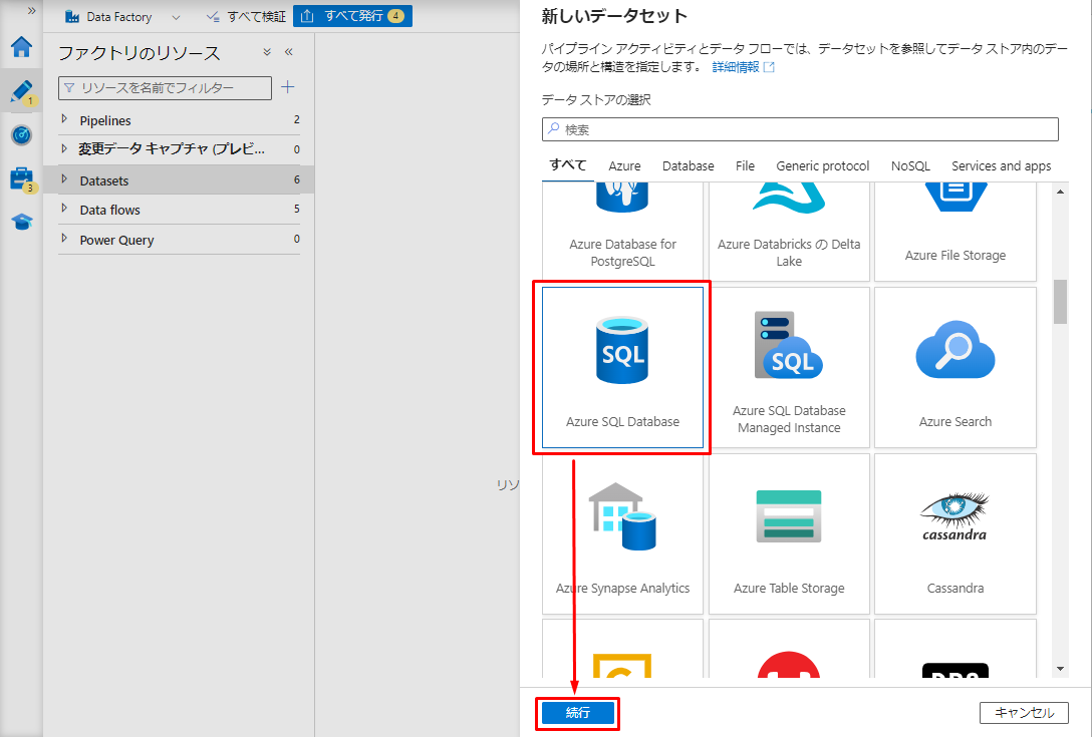
リンクされたサービスは、接続文字列として、またはパイプラインがデータセットへの接続に使用する承認として使用できます。
データセットはパイプラインのソースおよびターゲットとして考えることができます。
④ データセットの名前を入力します。
⑤ リンクサービスで、「+ 新規」 を選択します。
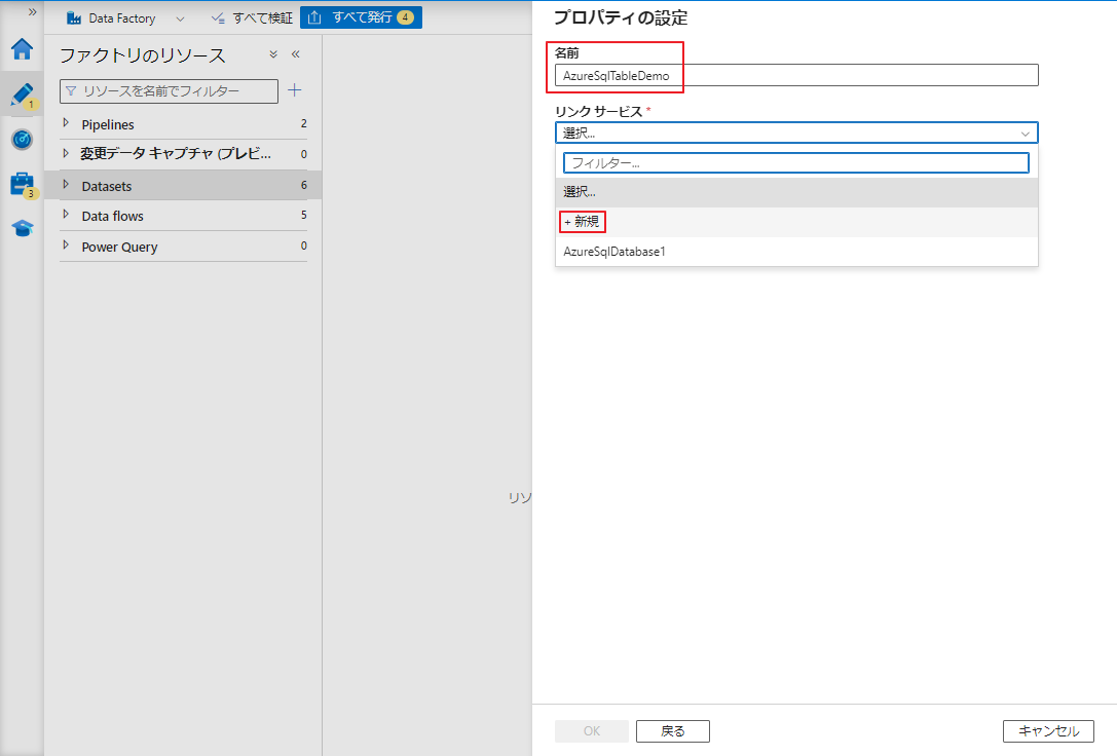
⑥ 新しいリソース サービスの名前を入力します 。
⑦ 次に、前の手順で作成したサブスクリプション、SQL Server、および SQL Database を選択します。
⑧ ログイン名とパスワードを入力して、SQL 認証を使用してサーバーにアクセスします。
⑨「作成」ボタンをクリックします。
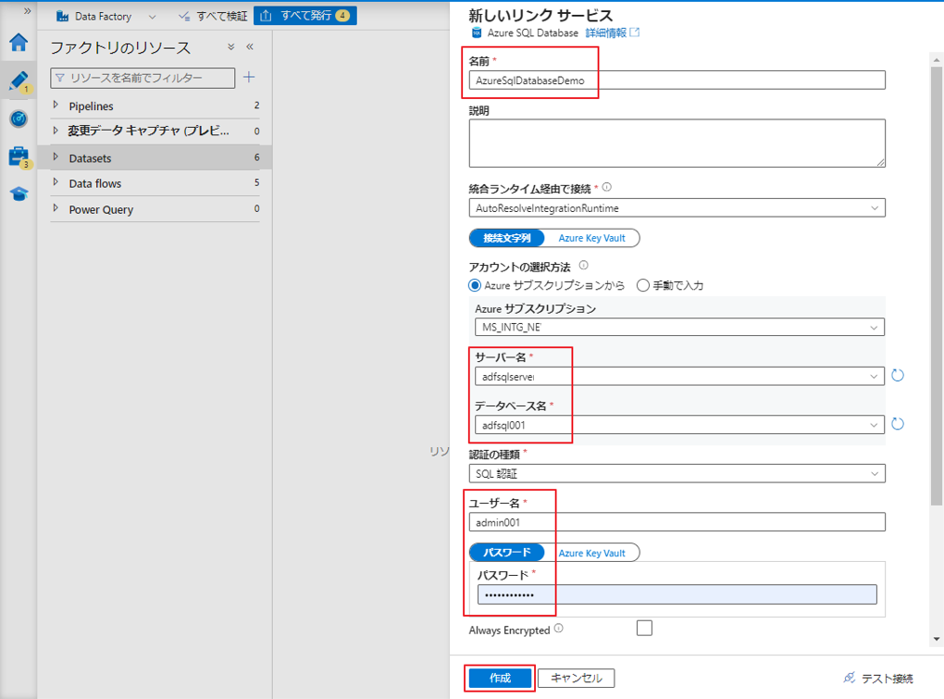
⑩「前の手順」でSQL Databaseに作成したテーブルを選択します。
⑪「OK」をクリックします。
5.Insert、delete、update、mergeの処理を実行する
5-1.Insert
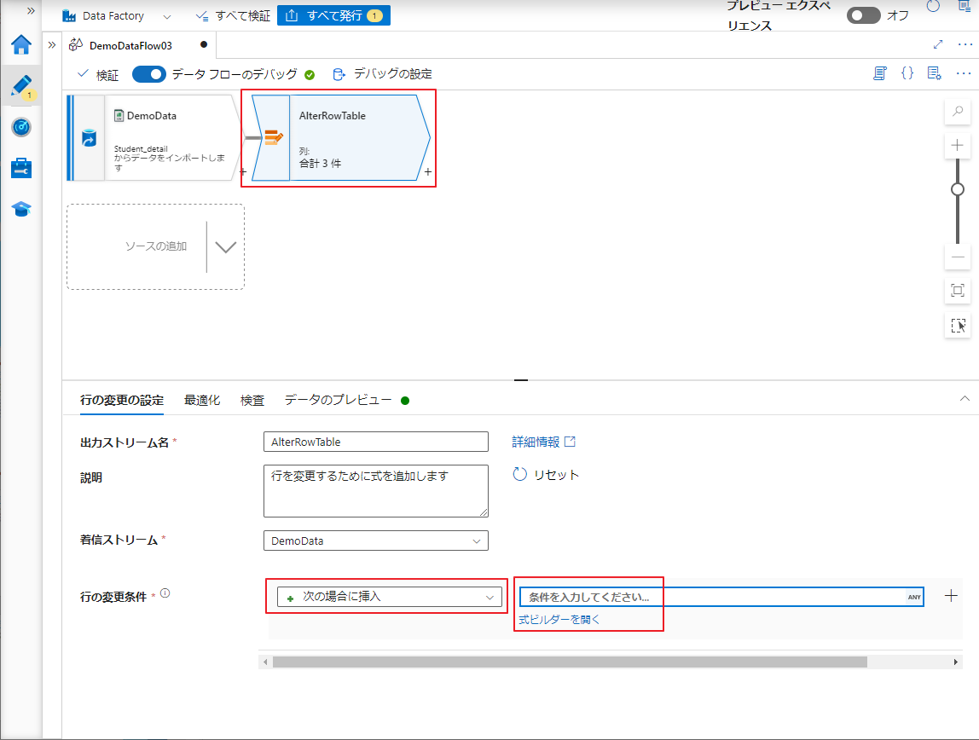
SQL の INSERT文のようにテーブルにデータを挿入するには、ADF で行の変更変換を使用します。
insertの処理実行は、「行の変更の設定」タブの「行の変更条件」で「次の場合に挿入」を選択することに対応します。挿入の条件が式ビルダーに追加されます。
ソース変換を作成します。
① ADFのサイドバーで「Author」をクリックして、次に「Data flows」をクリックして、「新しいデータフロー」を選択します。
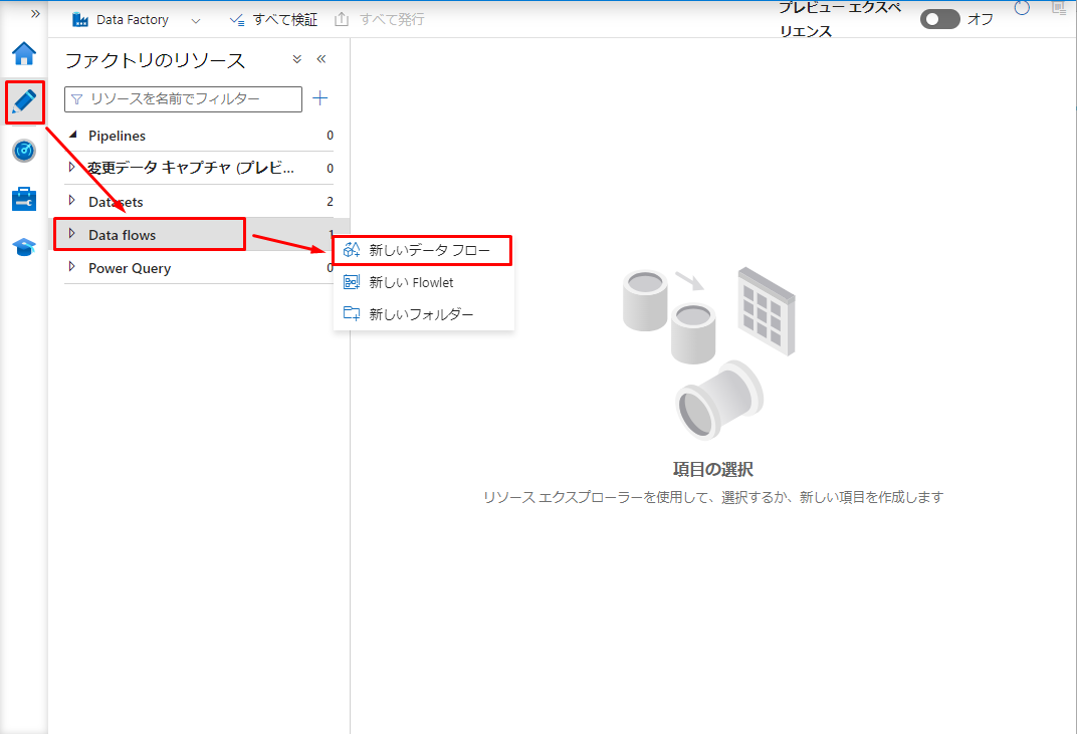
②「名前の変更」をクリックしてデータフローの名前を変更します。
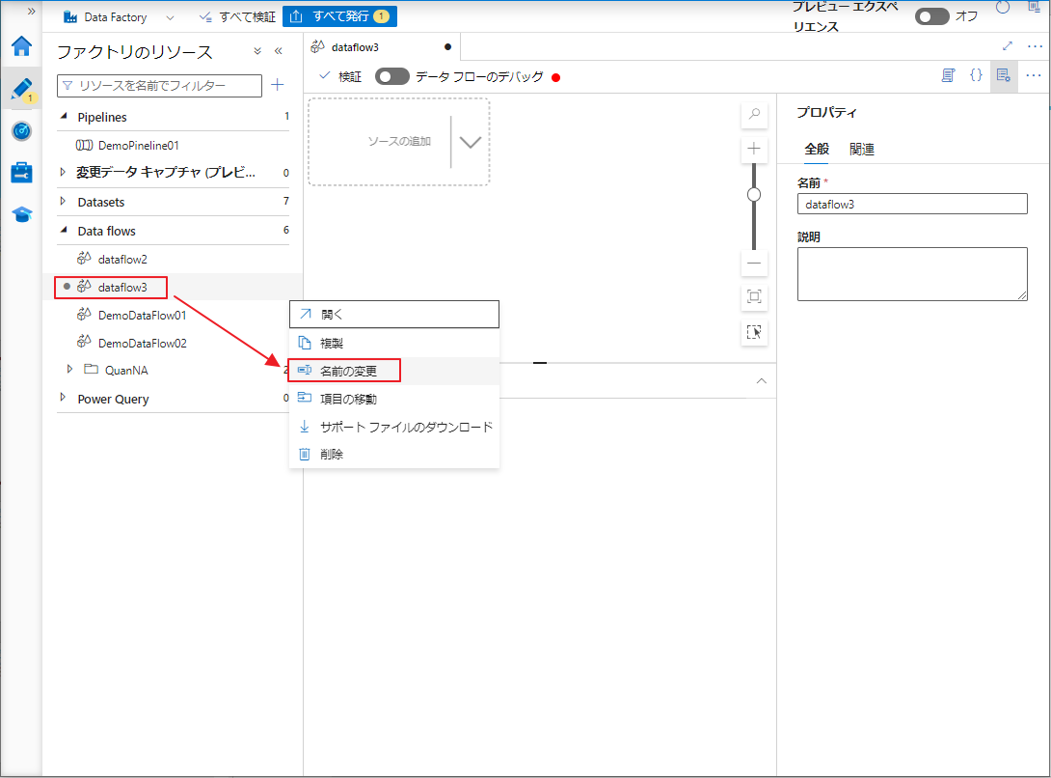
③ データ フローの名前を入力し、「OK」ボタンをクリックします。
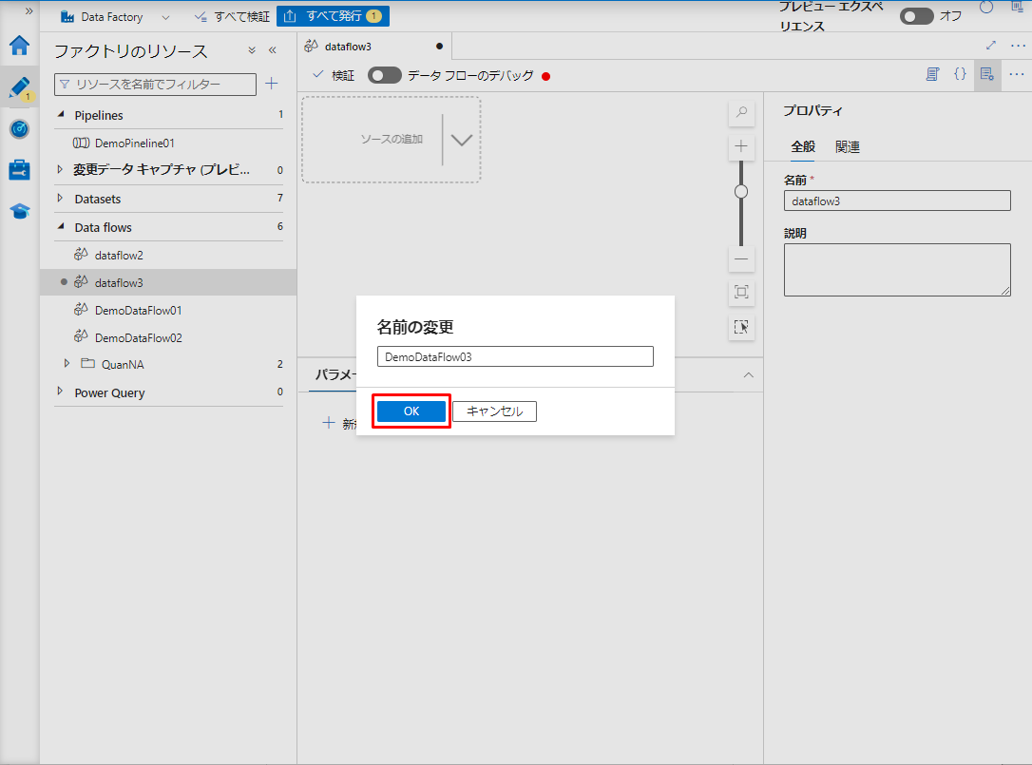
④ データフローの画面で「ソースの追加」をクリックします。
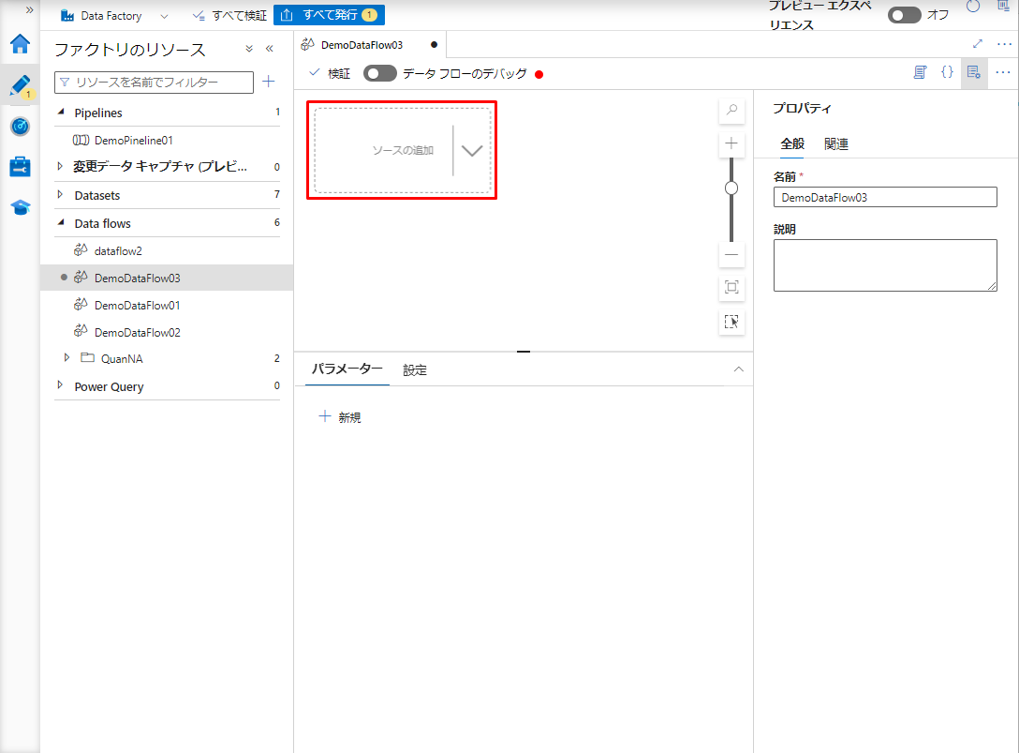
⑤「ソースの設定」タブで、ソース変換の名前を変更して、ストレージアカウントでアップロードしたデータセットを選択します。
行の変更変換は、データ フローのデータベース、REST、または Azure Cosmos DB シンクでのみ動作します。
ソース列が頻繁に変更される場合は、スキーマ ドリフトを許可チェック ボックスをオンにします。 この設定により、すべての受信ソース フィールドが変換を通してシンクに流れることができます。
スキップ行数 : このスキップ行数フィールドでは、データセットの先頭で無視する行数を指定します。
サンプリング:ソースからの行数を制限するには、サンプリングを有効にします。
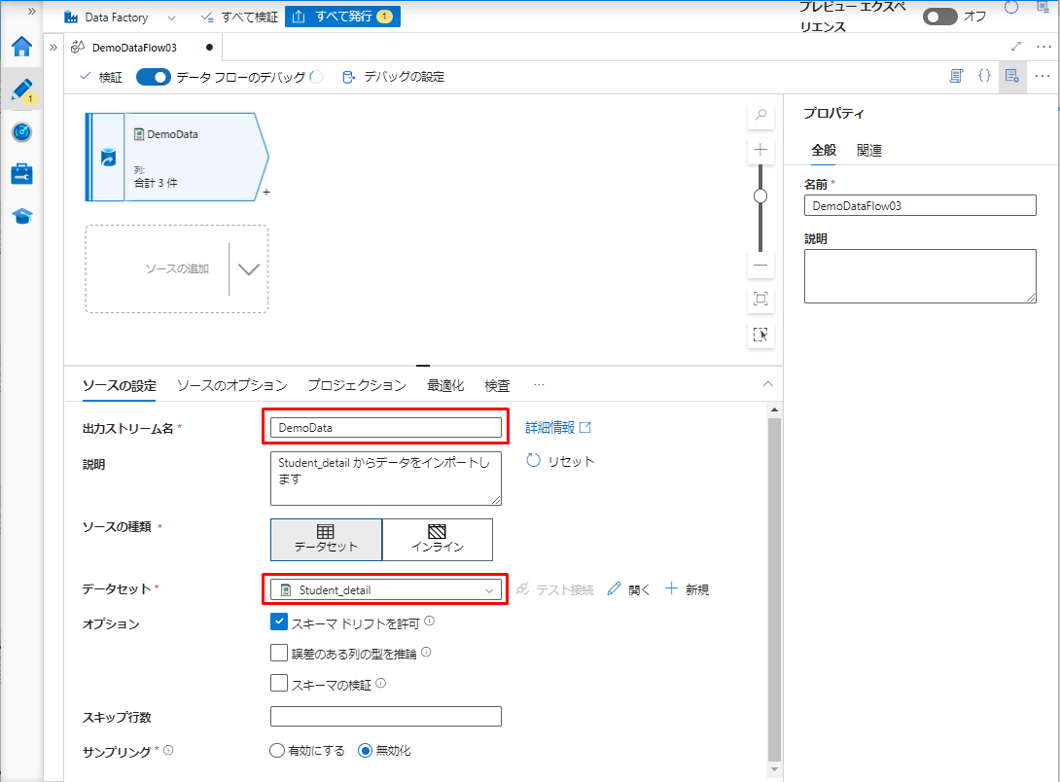
デバッグ モードを有効にする場合は、「データのプレビュー」タブをクリックして、CSV ファイルからインポートされたデータを確認します。
このデータを SQL Database のテーブルにインポートします。
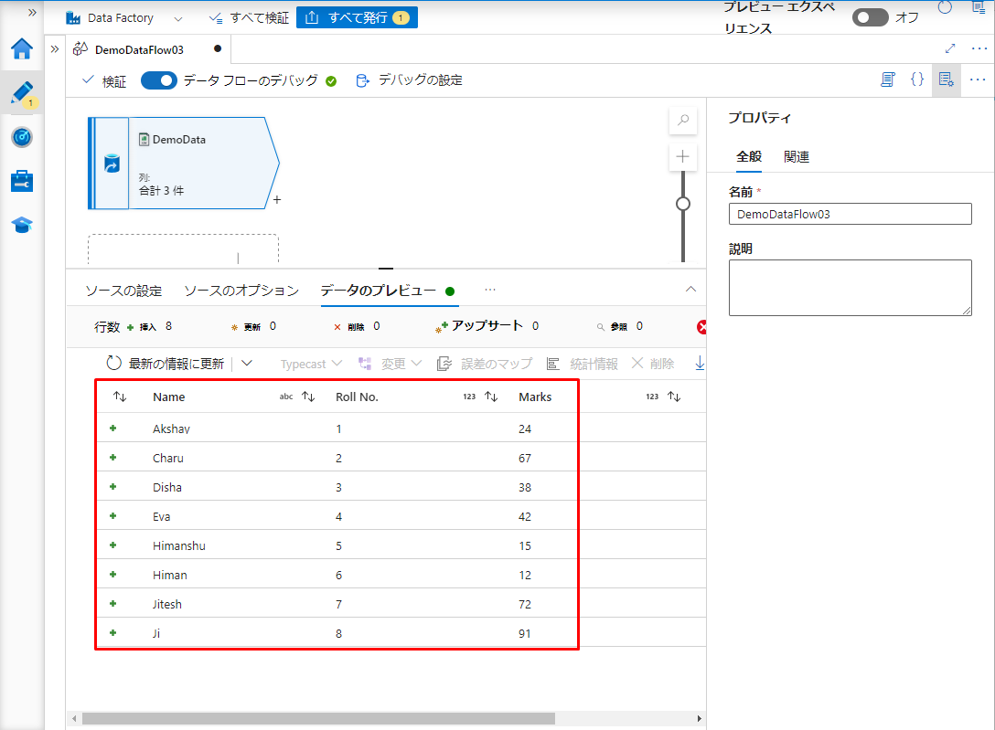
① プラスのアイコンをクリックして、作成されたソース変換から新しい変換を追加します。
②「行の変更」を選択します。
行の変更変換を使用して、行の挿入、削除、更新、アップサート ポリシーを設定します。 一対多の条件を式として追加できます。
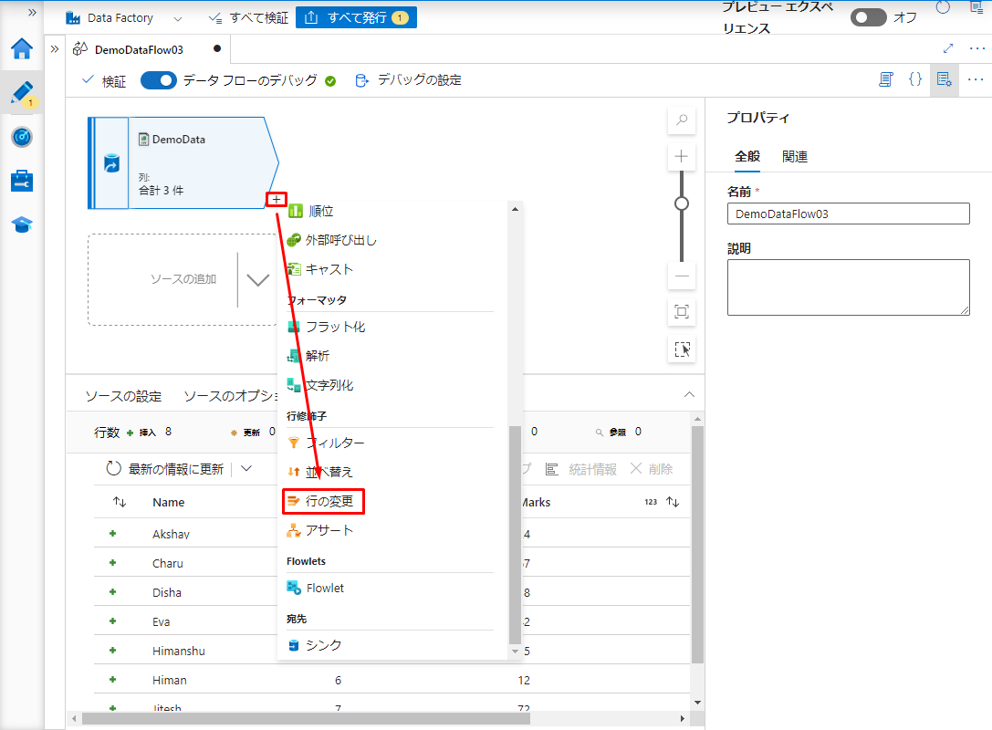
③ 行の変更変換に「AlterRowTable」という名前を付けます。
④「行の変更条件」で「次の場合に挿入」を選択します。
⑤「式ビルダーを開く」をクリックして、式ビルダーを開きます。
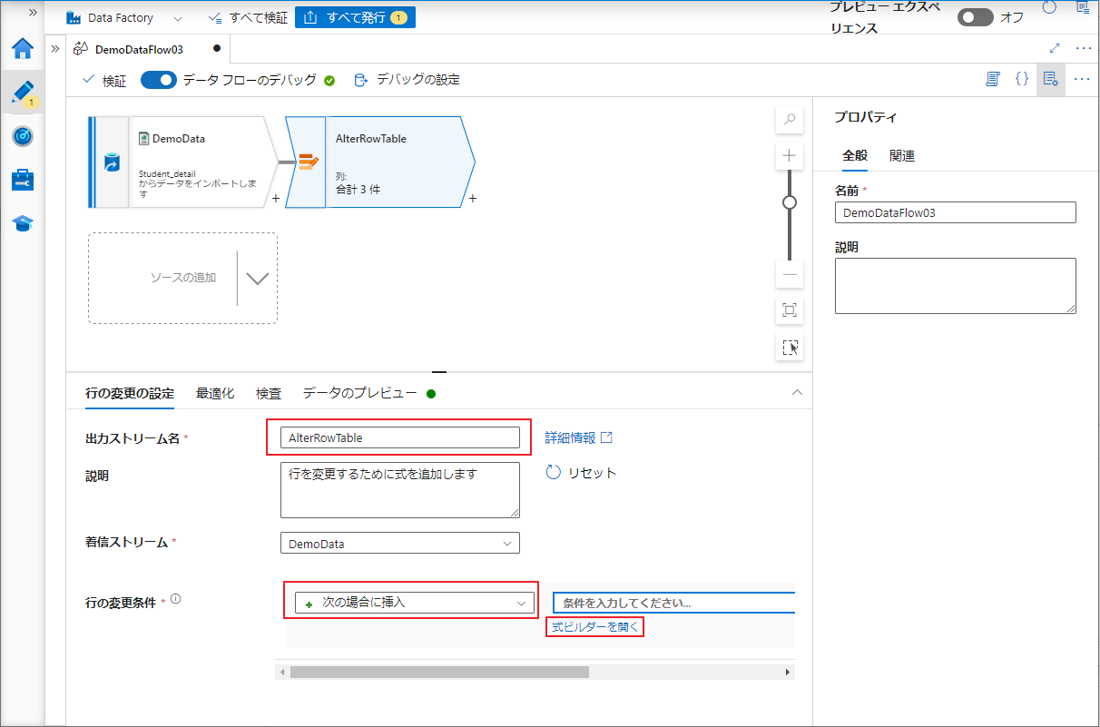
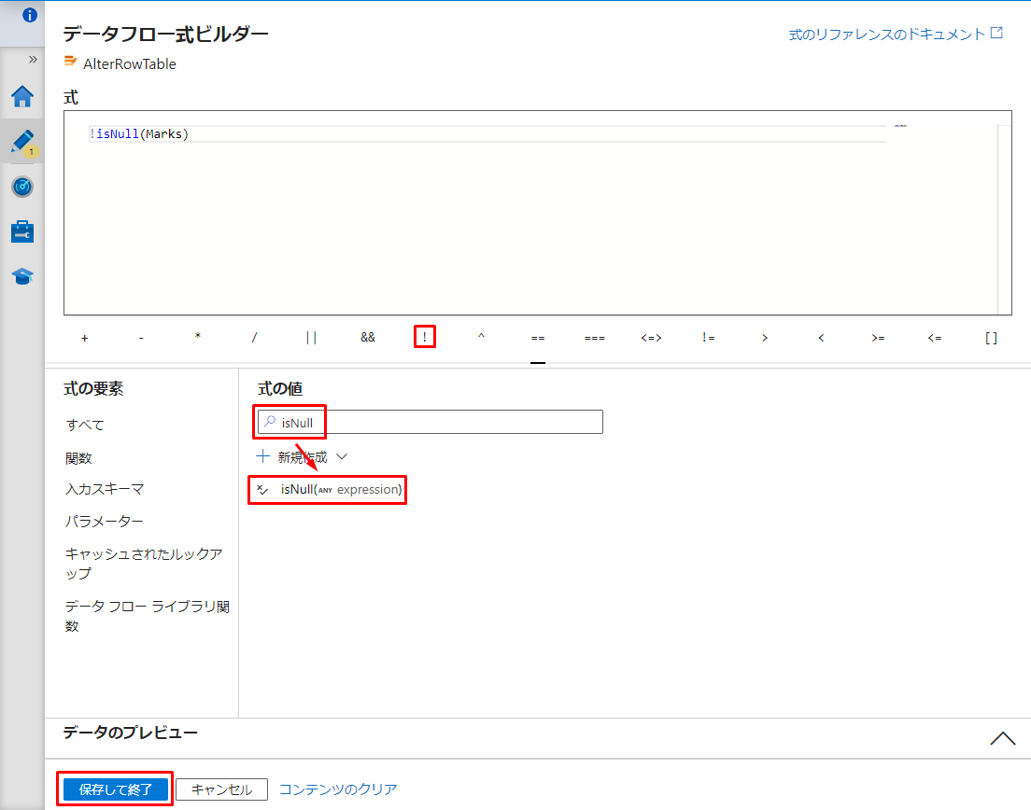
この例では、Marks 列の値が NULL以外の行を挿入したいと思います。
①「!」演算子を選択する。
② 式の値で「isNull」と入力し、isNull()関数を選択します。
UI では、この変換は次の図のようになります。
③「保存して終了」ボタンをクリックして式を保存します。
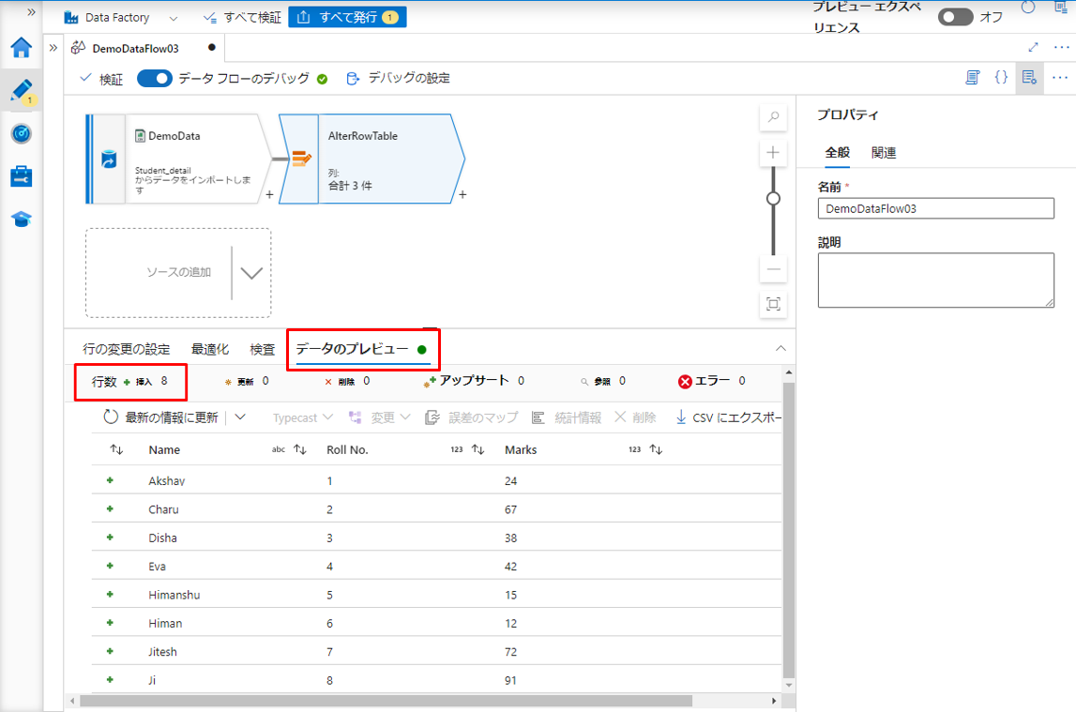
「データのプレビュー」タブをクリックして、挿入条件を満たすソース データの行かを確認します。
ここでは、挿入条件を満たす8 件のレコードが表示されます。
行の変更ポリシーを機能させるには、データ ストリームがデータベースまたは Azure Cosmos DB シンクに書き込む必要があります。
① プラスのアイコンをクリックして、作成された行の変更変換から新しい変換を追加します。
②「シンク」を選択します。
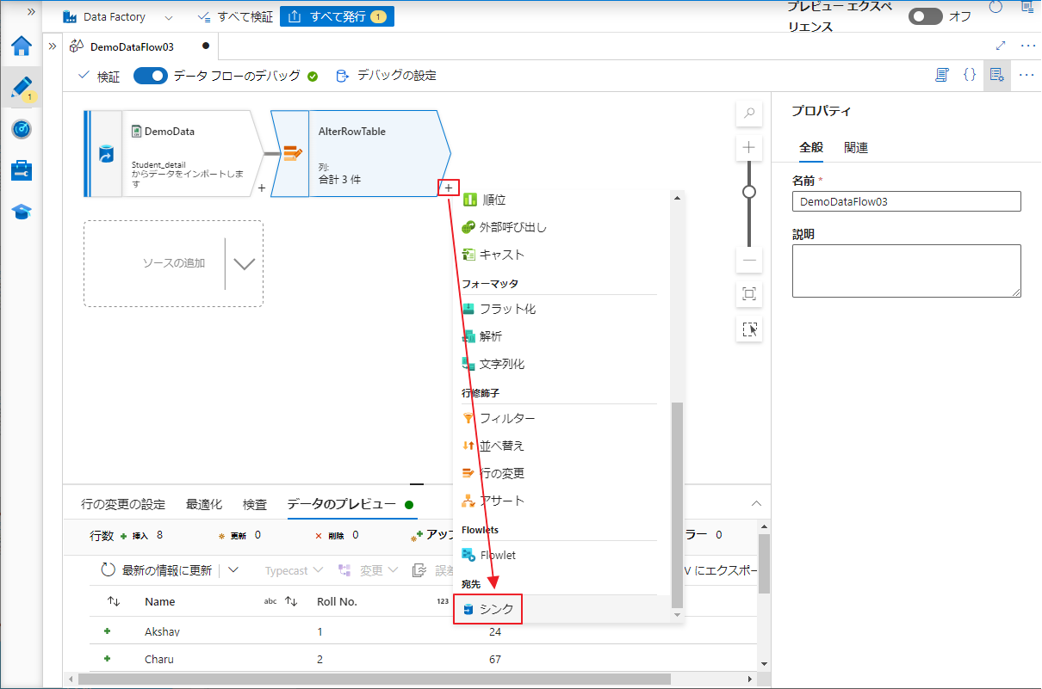
③ シンク変換に「SinkData」という名前を付けます。
④「データセット」で、前の手順で Azure SQL Server に関連付けられたデータセットを選択します。
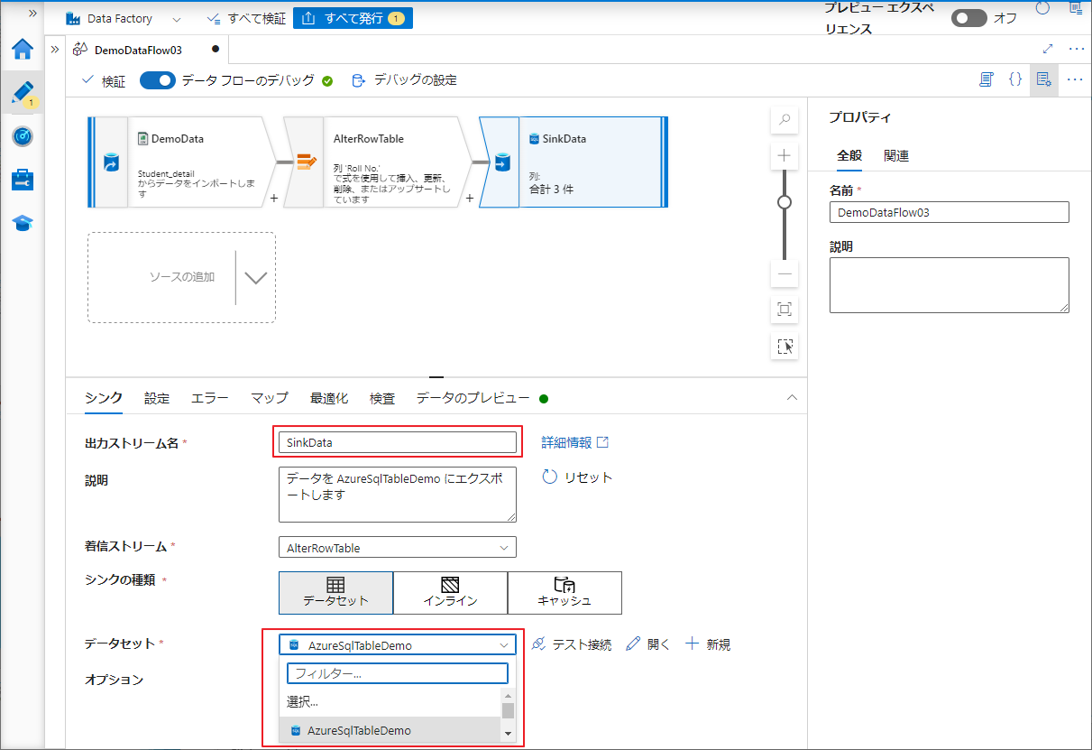
⑤ シンクの設定タブで、そのシンクで許可する行の変更ポリシーを有効にします。
既定の動作では、挿入のみが許可されます。
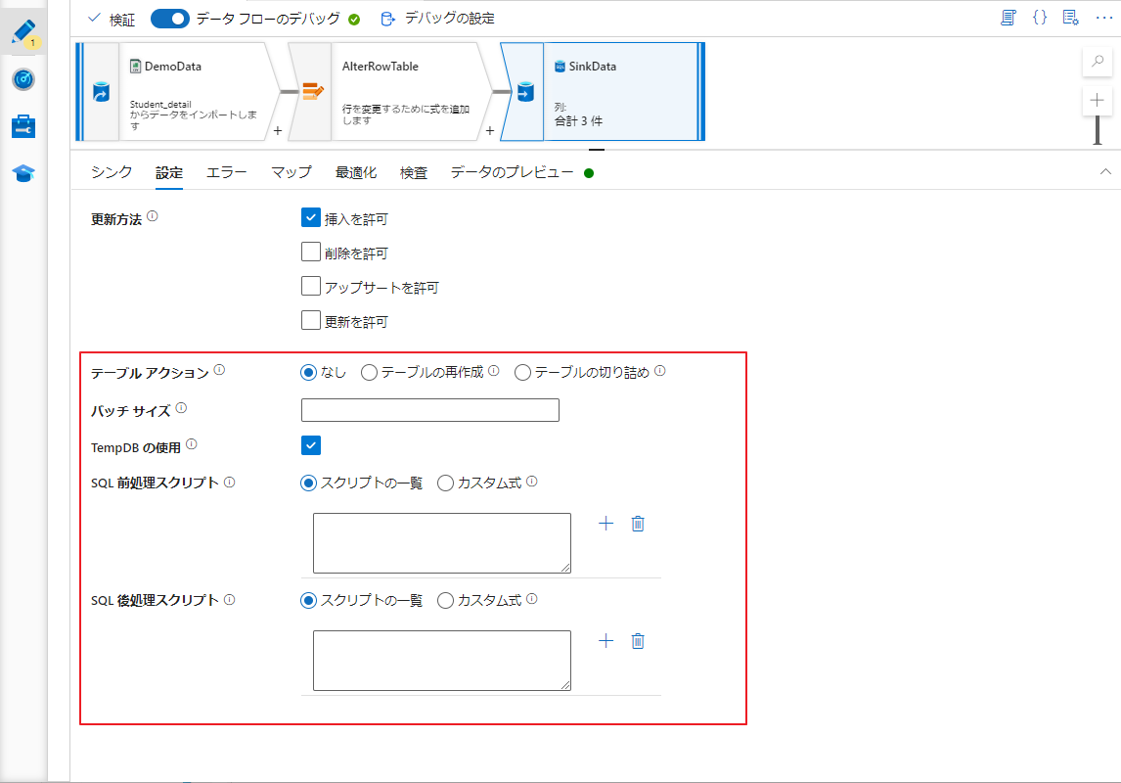
注意:挿入、更新、または upsert によりシンクのターゲット テーブルのスキーマが変更される場合、データ フローは失敗します。 データベース内のターゲット スキーマを変更するには、テーブル アクションとしてテーブルの再作成を選択します。 これにより、新しいスキーマ定義でご利用のテーブルがドロップされ、再作成されます。
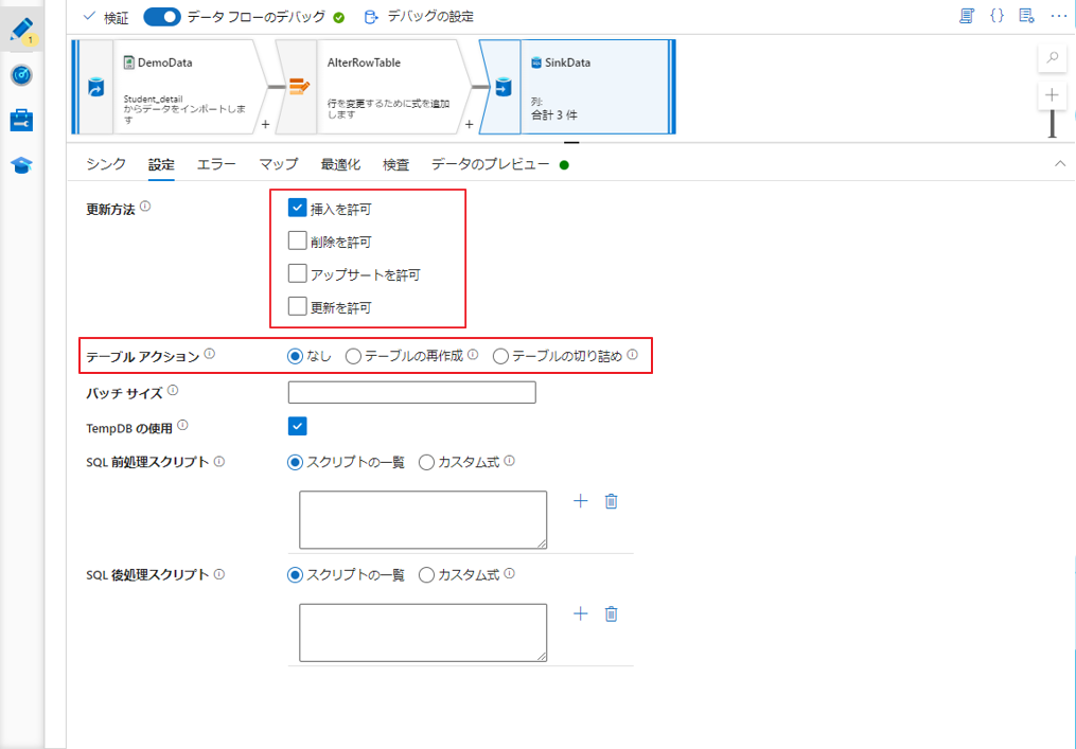
バッチ サイズ: 列のキャッシュのバッチのサイズを制御します。
TempDB の使用: SQL データベースに大量のデータを書き込む場合は、これをオフにして、Data Factory がアップストリーム データを読み込んで完了時に自動クリーンアップするためのステージング テーブルを作成するスキーマ名を指定します。
SQL 前処理スクリプト: お客様のシンク データベースにデータが書き込まれる前に実行される複数行の SQL スクリプトを入力します。
SQL 後処理スクリプト: お客様のシンク データベースにデータが書き込まれた後に実行される複数行の SQL スクリプトを入力します。
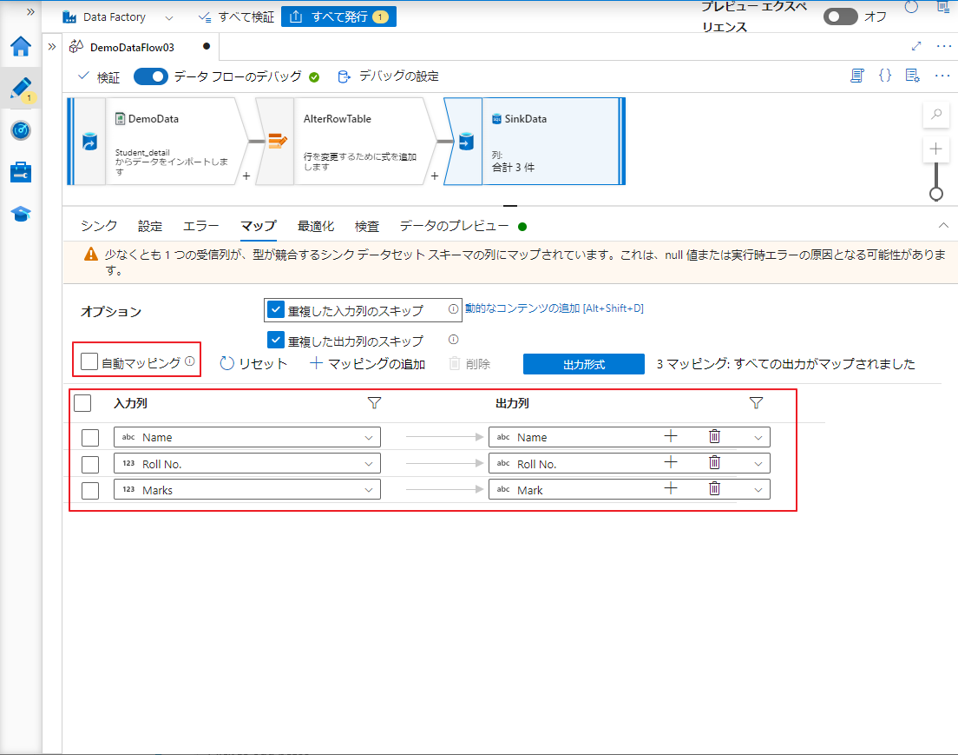
シンクの [マッピング] タブ上では、Select 変換と同様に、受信列が書き込まれるかどうかを決定できます。 既定では、誤差のある列を含め、すべての入力列がマップされます。 この動作は “自動マッピング” として知られています。
自動マッピングを無効にすると、固定列ベースのマッピングまたはルールベースのマッピングのいずれかを追加することができます。
⑥ マッピングタブで、自動マッピングのチェックを外します。
⑦ 次に、該当の入力列と出力列を選択します。
パイン ラインを作成し、実行して、データ フロー のアクティビティを実行します。
①「Pipelines」をクリックして、「新しいパイプライン」を選択します。
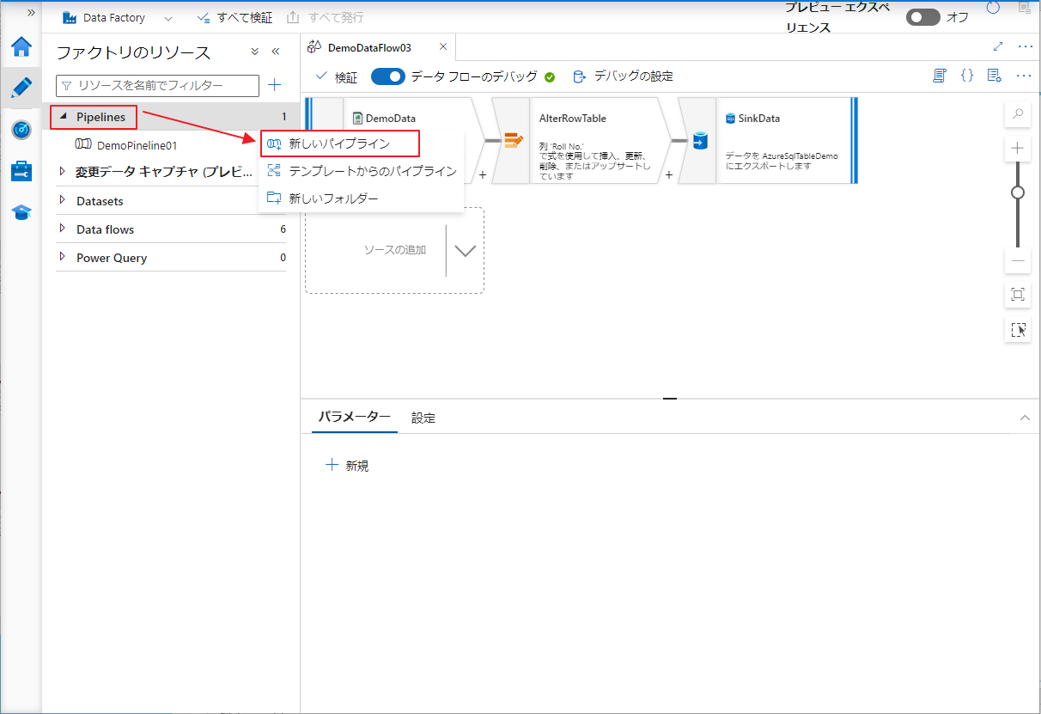
②「名前の変更」をクリックしてパイン ラインの名前を変更します。
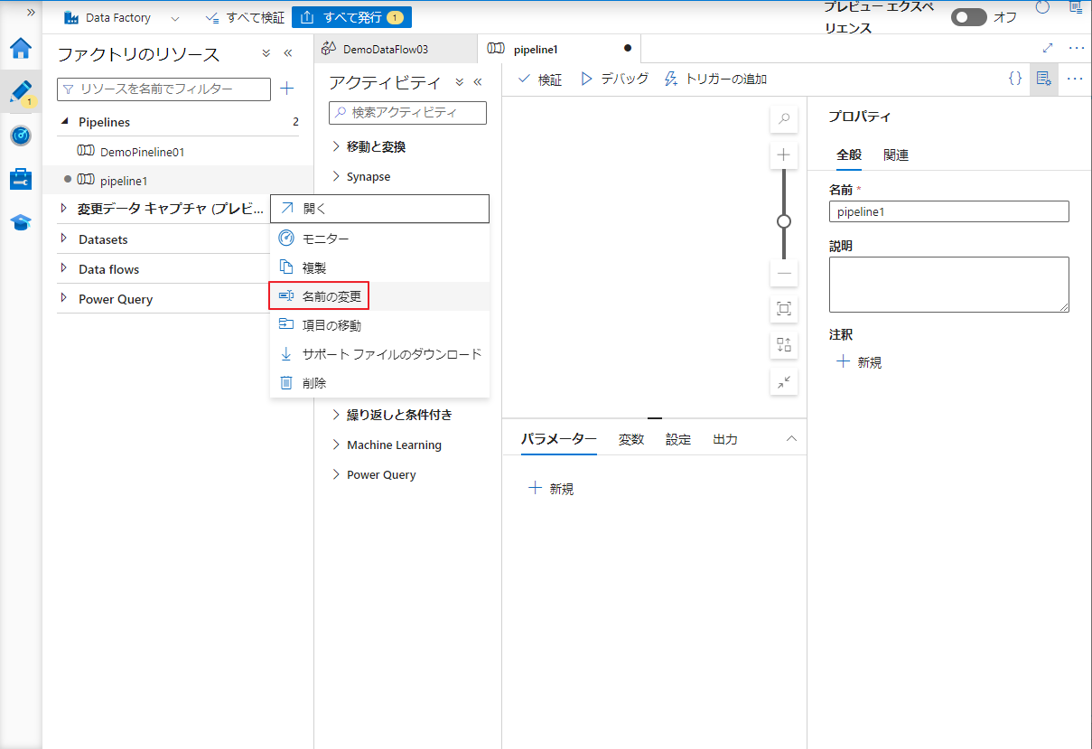
③ パイン ラインの名前を入力し、「OK」ボタンをクリックします。
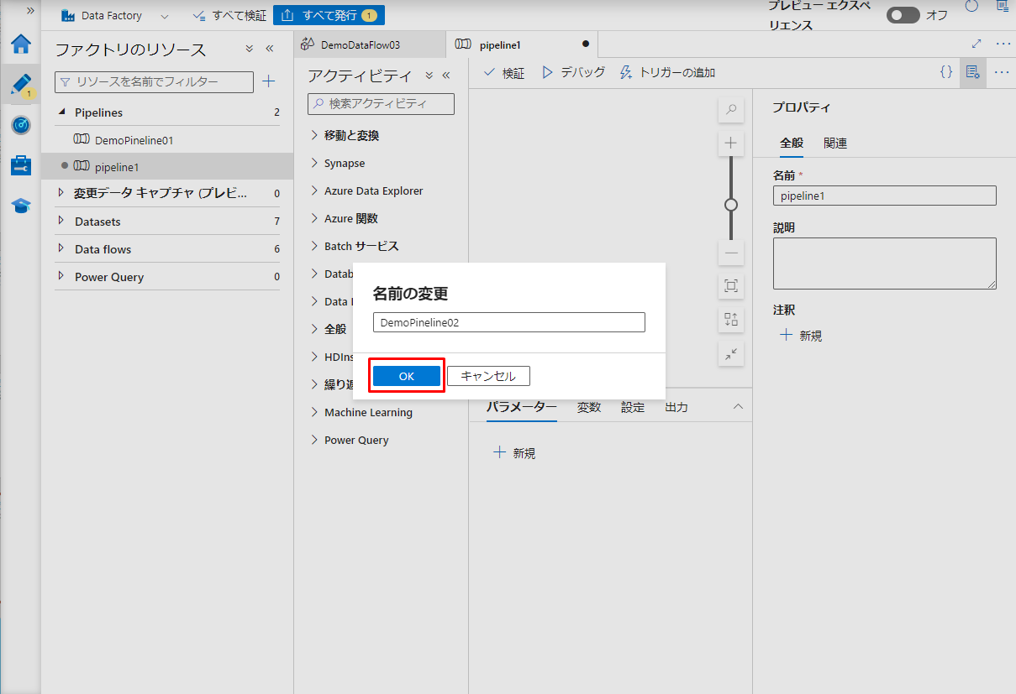
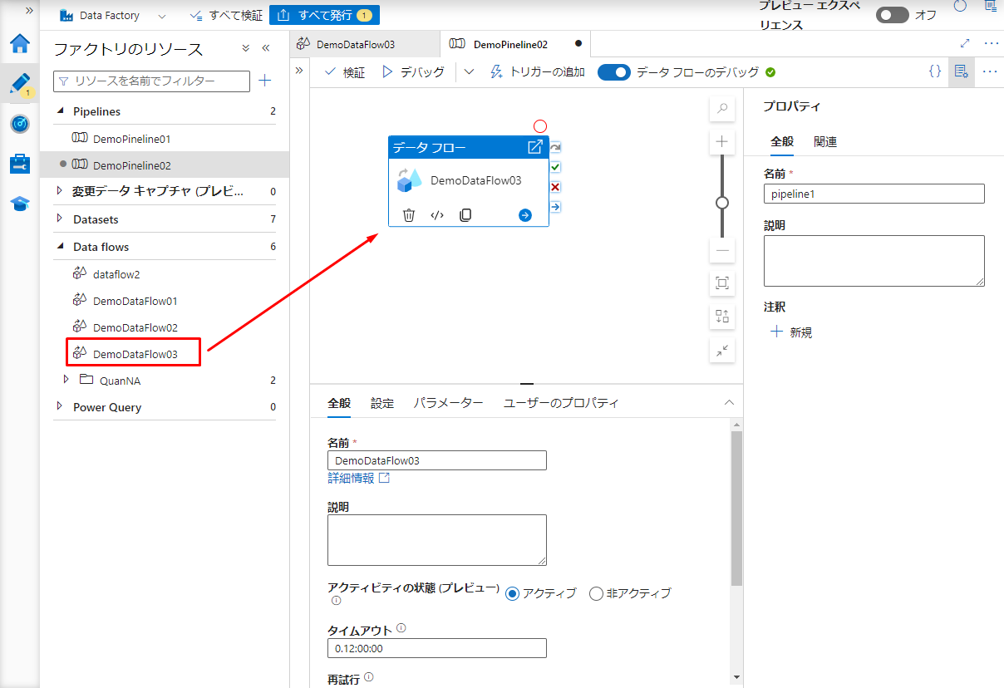
④ データ フローをパインライン スペースにドラッグ アンド ドロップして、データ フロー のアクティビティを実行します。
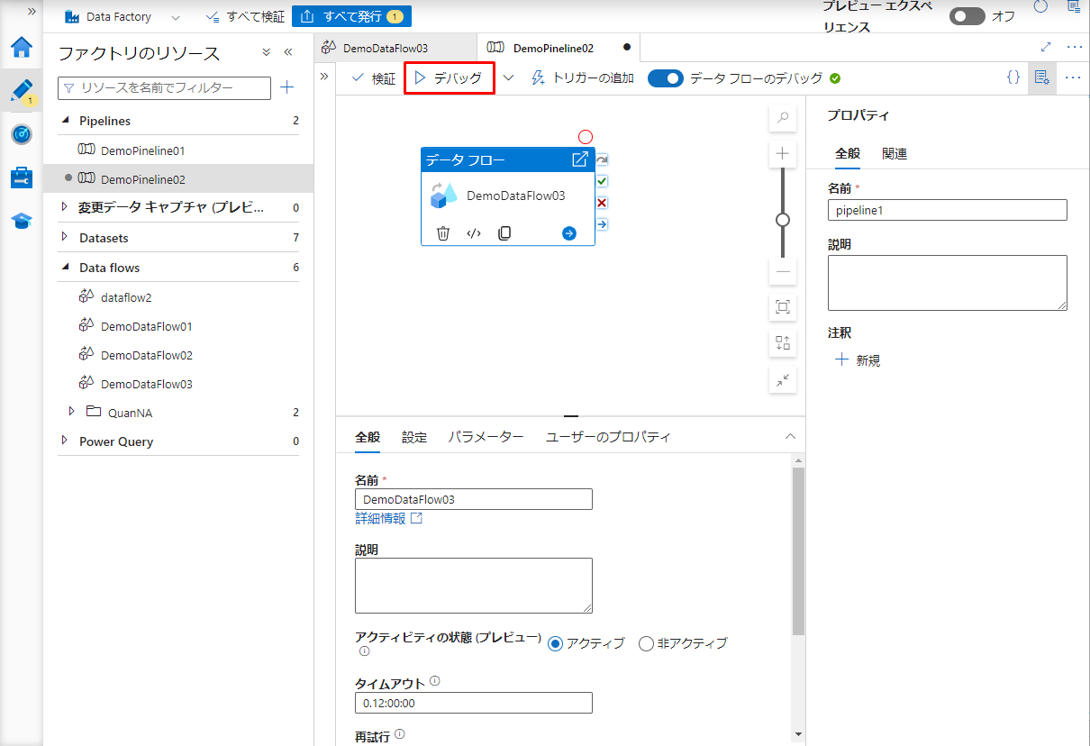
⑤「デバッグ」ボタンをクリックしてパイプラインを実行します。
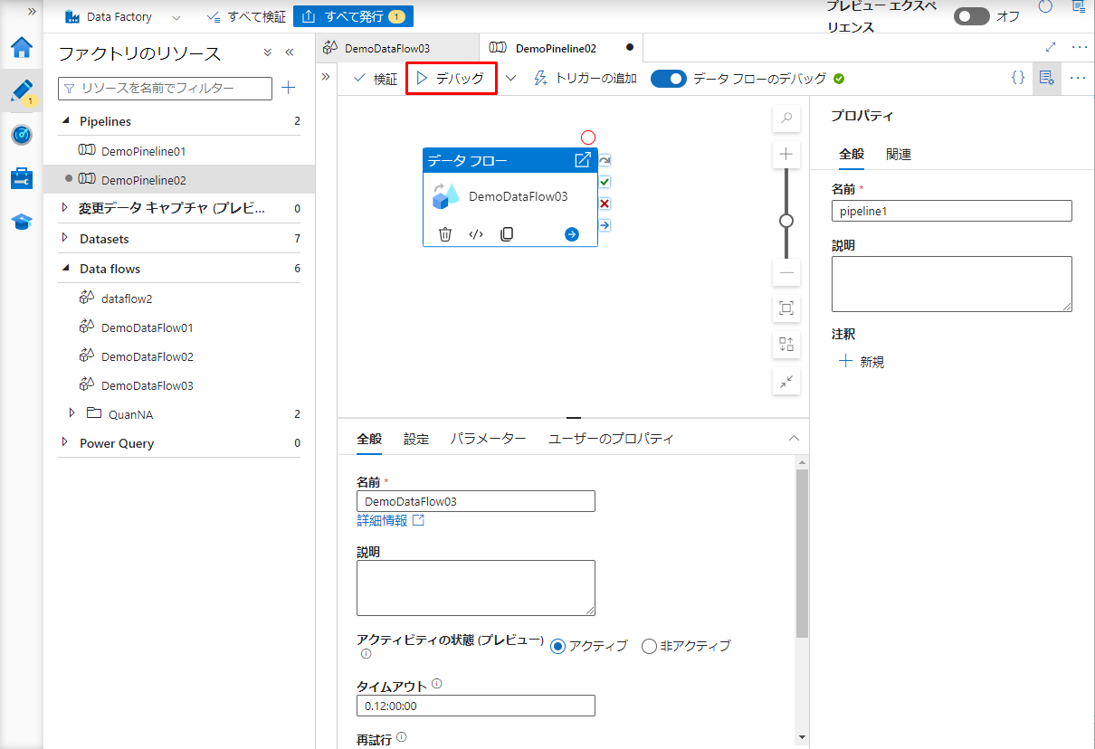
パイプラインが正常に実行された時、時間とステータスが以下に表示されます。
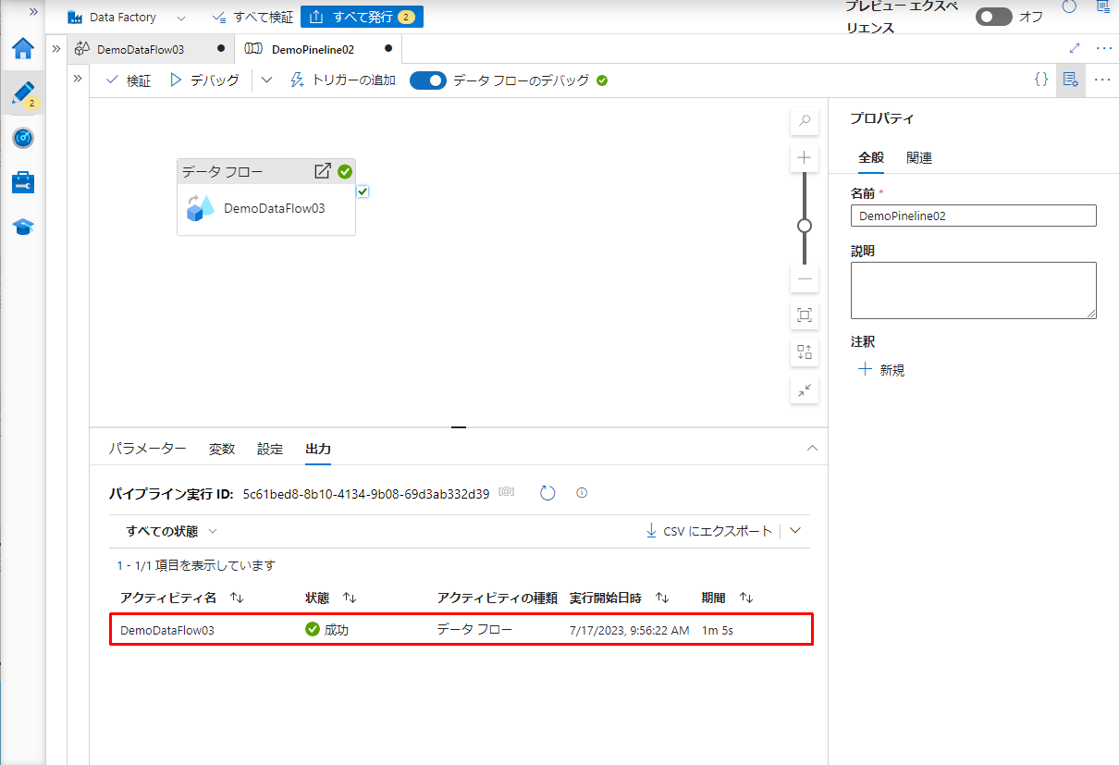
次の SQL コマンドをコクエリ エディターにコピペします
※例
|
1 |
SELECT * FROM [dbo].[Student] |
ソース データから SQL Database のテーブルに挿入されたデータを確認できます。
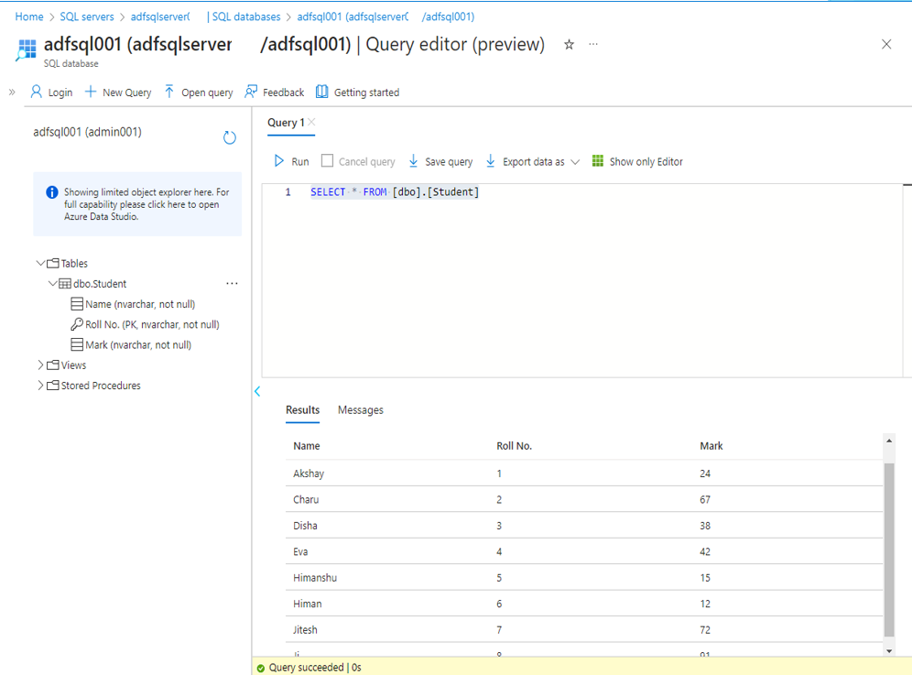
5-2.Update
SQL の UPDATE文のようにテーブルにデータを更新するには、ADF で行の変更変換を使用します。
updateの処理実行は、「行の変更の設定」タブの「行の変更条件」で「次の場合に更新」を選択することに対応します。更新の条件が式ビルダーに追加されます。
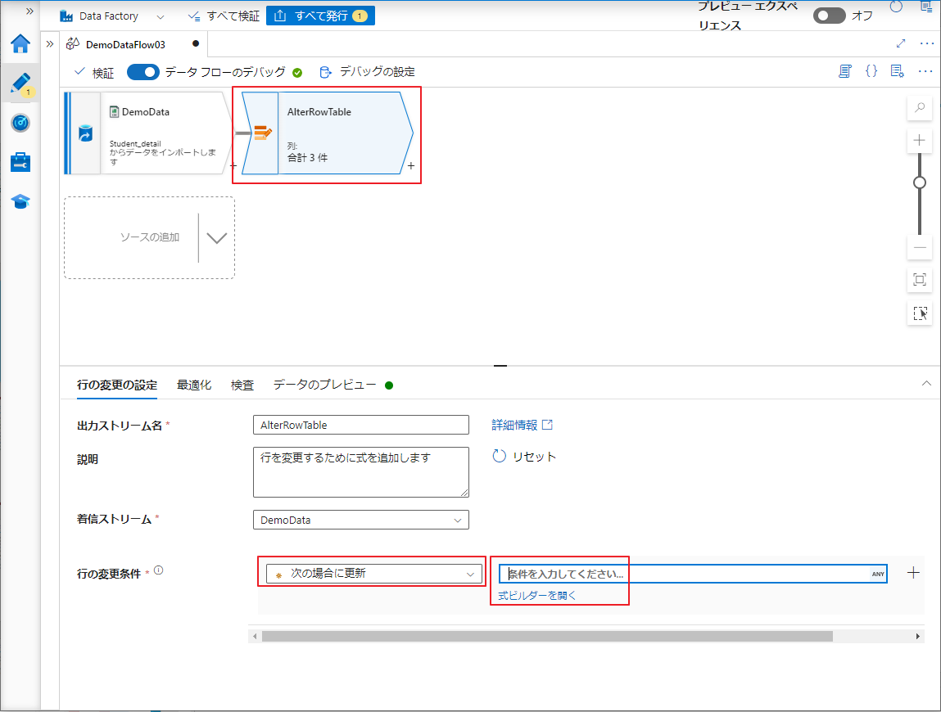
次の例では、行の変更変換の更新条件を使用して、テーブル内の列の値を更新します。
① プラスのアイコンをクリックして、作成された行の変更変換から新しい変換を追加します。
②「派生列」を選択します。
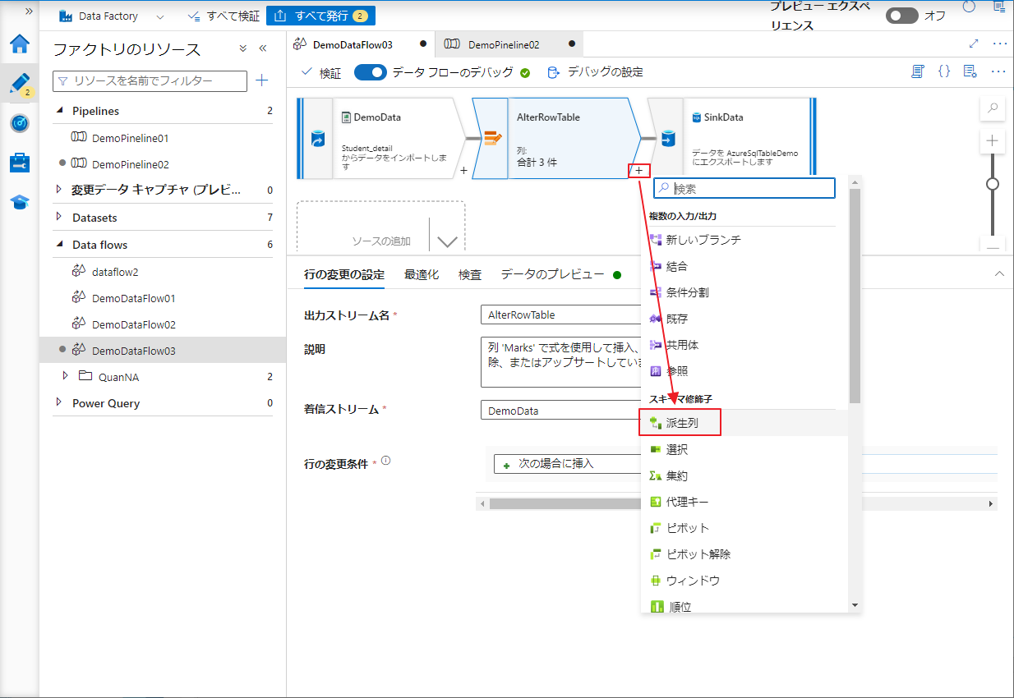
スキーマ内の既存の列を上書きするには、列ドロップダウンを使用できます。
③ Marks 列を選択します。
④ 式で「100」を入力します。
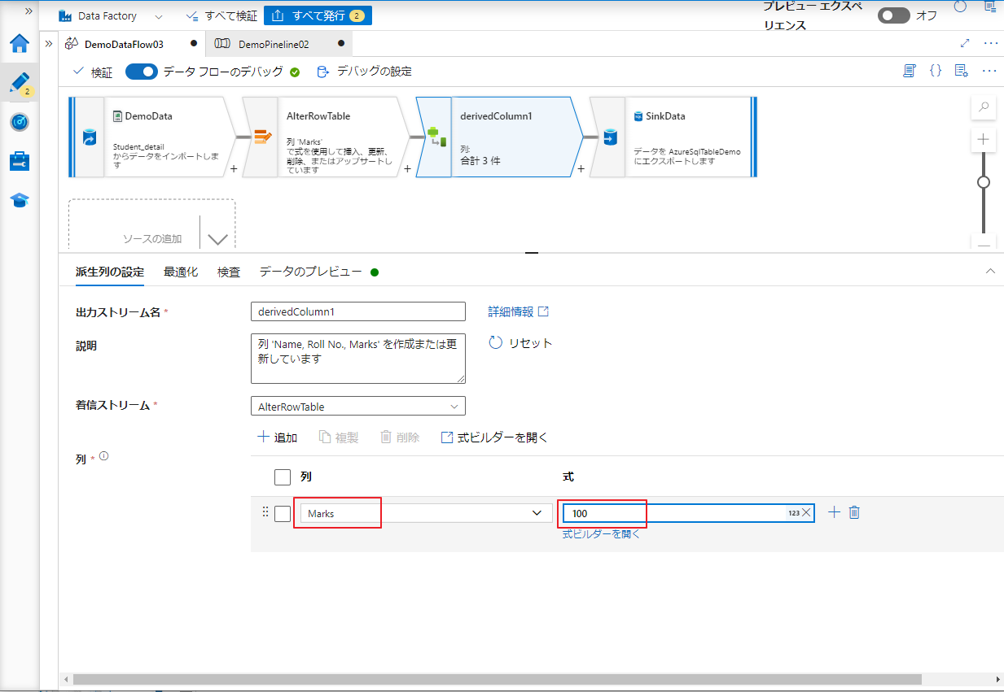
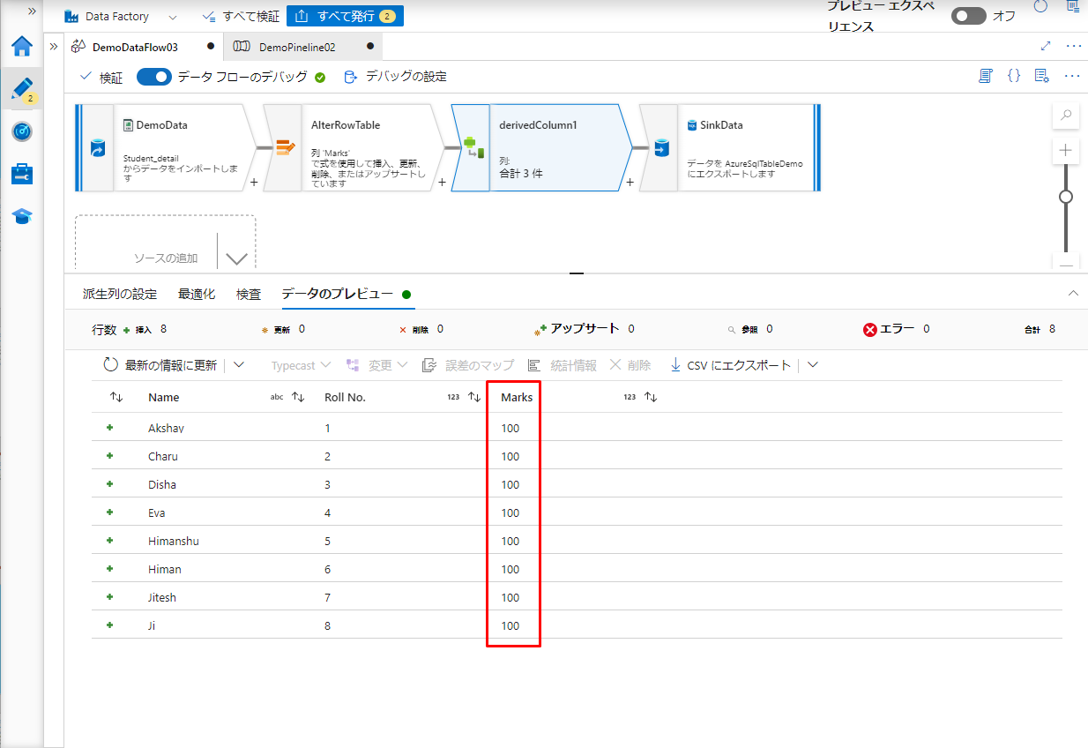
「データのプレビュー」タブをクリックして、更新されたデータを表示します。
Marks 列の全ての値が「100」となります。
⑤「行の変更条件」で「次の場合に更新」を選択します。
⑥「式ビルダーを開く」をクリックして、式ビルダーを開きます。
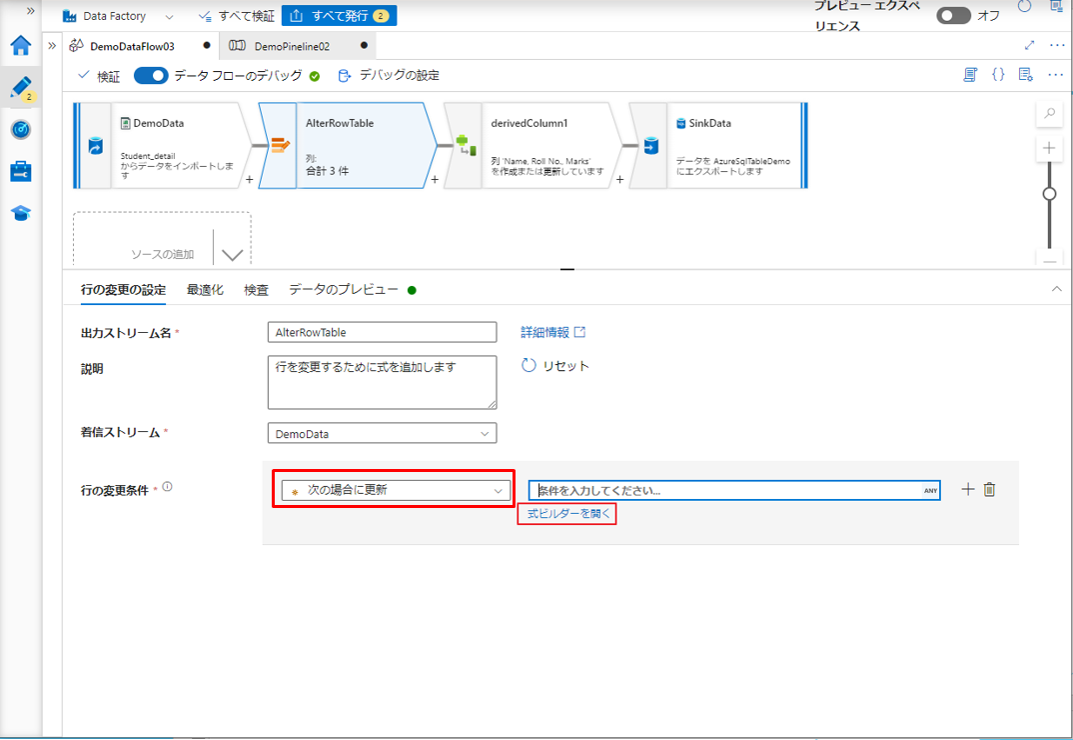
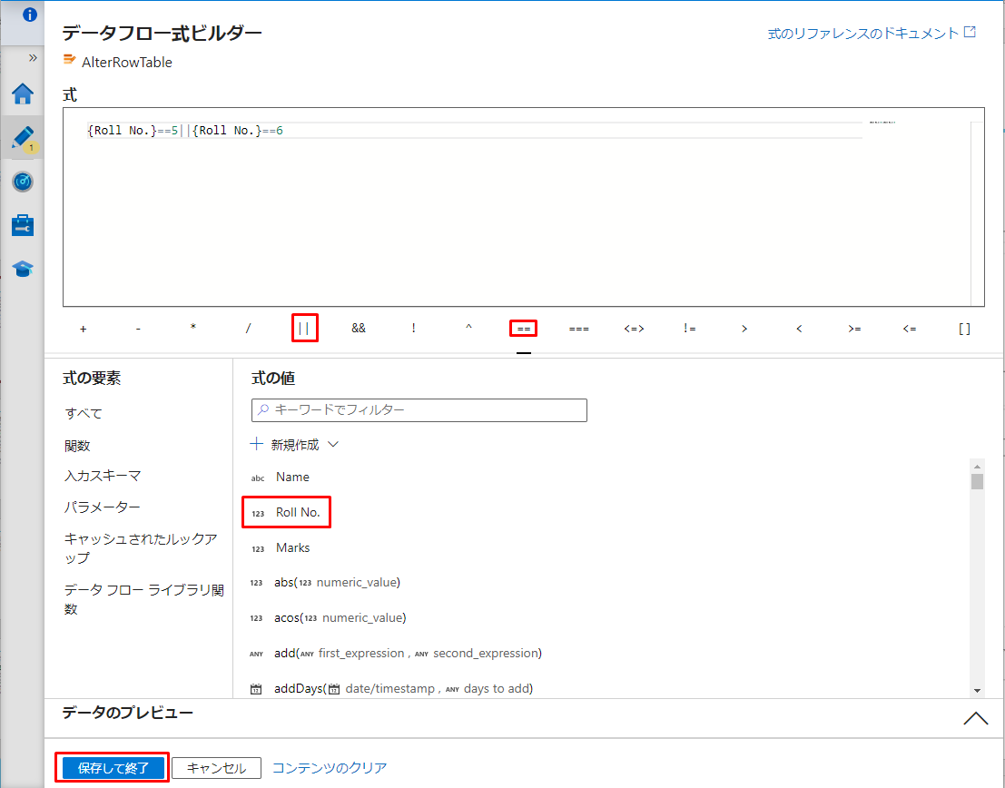
Roll No. が 5 または 6 のレコードに対して、Marks 列の新規値を更新します。
UI では、この変換は次の図のようになります。
⑦「保存して終了」ボタンをクリックして式を保存します。
⑧ シンクの設定タブで、更新方法の「更新を許可」を有効にし、「挿入を許可」を無効にして、テーブルにデータを追加せず、テーブルの更新のみを行うようにします。
更新、upsert、または削除が有効になっている場合は、シンク内のどのキー列を照合するかを指定する必要があります。
⑨ キー列で、Roll No. 列を選択します。

作成したパイプラインで「デバッグ」ボタンをクリックするとパイプラインが実行され、更新後にデータフローアクティビティが実行されます。
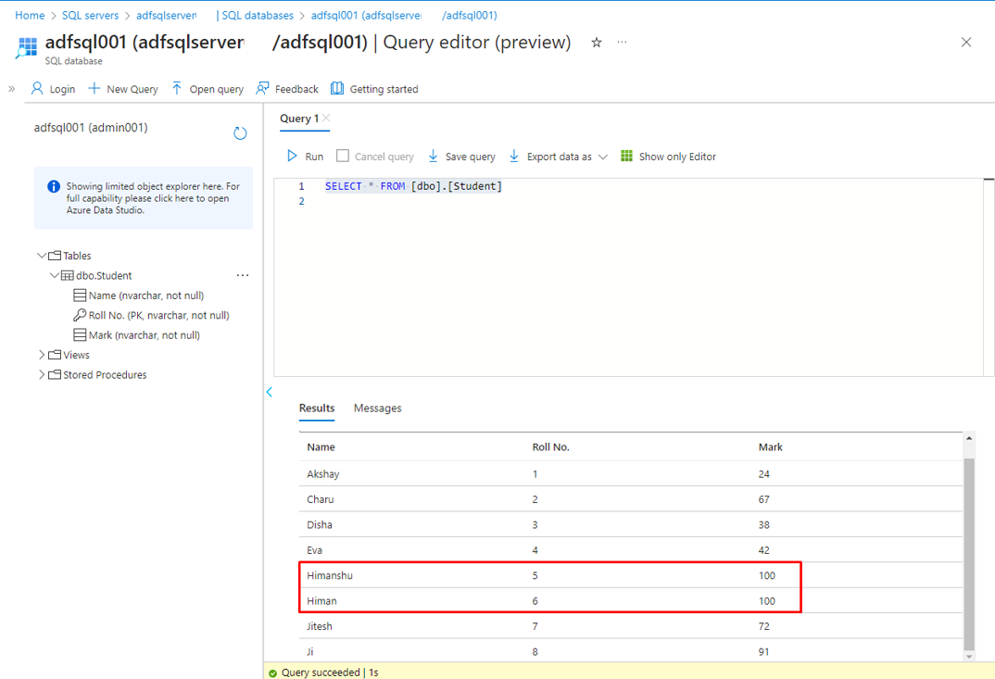
次の SQL コマンドをコクエリ エディターにコピペします。
※例
|
1 |
SELECT * FROM [dbo].[Student] |
前の手順でSQL DBのテーブルにソース データから挿入されたデータ中で、Roll No. が 5 または 6 のレコードのMark 列値が更新されました。
5-3.Merge
SQL の MERGE 文のようにデータをテーブルにマージするには、ADF で行の変更変換を使用します。
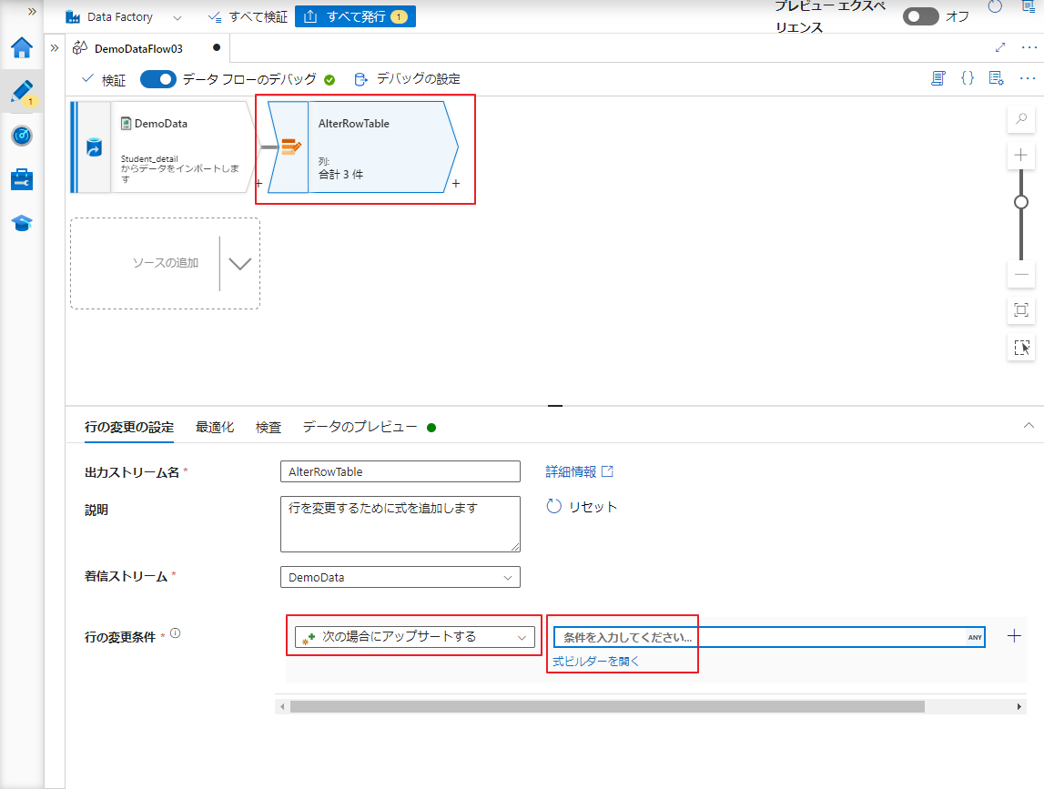
mergeの処理実行は、「行の変更の設定」タブの「行の変更条件」で「次の場合にアップサートする」を選択することに対応します。更新の条件が式ビルダーに追加されます。
次の例では、行変更変換の Upsert 条件を使用して、テーブル内のレコードの値を更新します。そのレコードが存在しない場合は、テーブルに挿入します。
① ソース変換で、新規のデータをデータセットに追加します。
② 派生列変換でも Marks 列を選択し、式で値「100」を入力します。
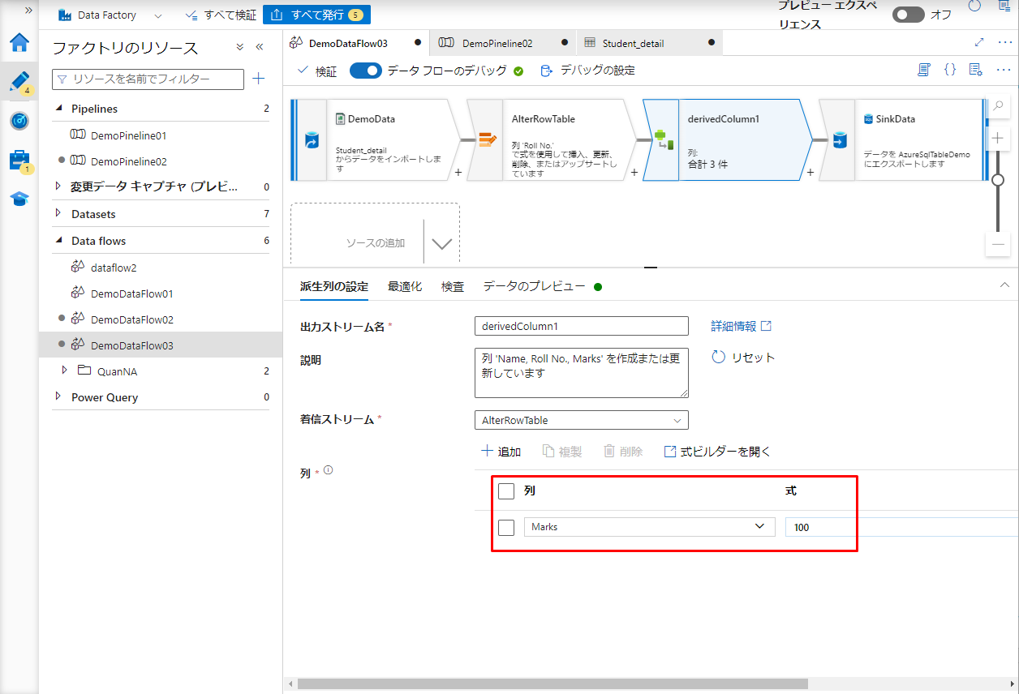
③ 行の変更条件で「次の場合にアップサートする」を選択します。
④「式ビルダーを開く」をクリックして、式ビルダーを開きます。
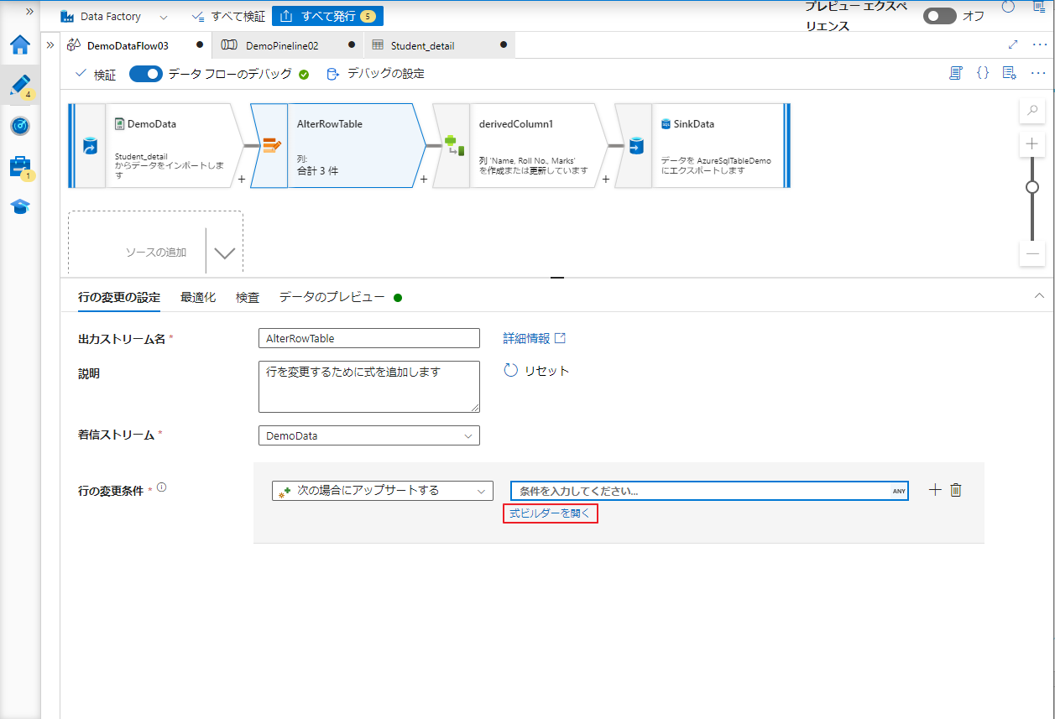
Roll No. の値が 7 以外であるのレコードに対して Marks 列の新規値を更新・挿入します。そのレコードが SQL Database のテーブルに存在しない場合、テーブルに挿入します。
UI では、この変換は次の図のようになります。
⑤「保存して終了」ボタンをクリックして式を保存します。
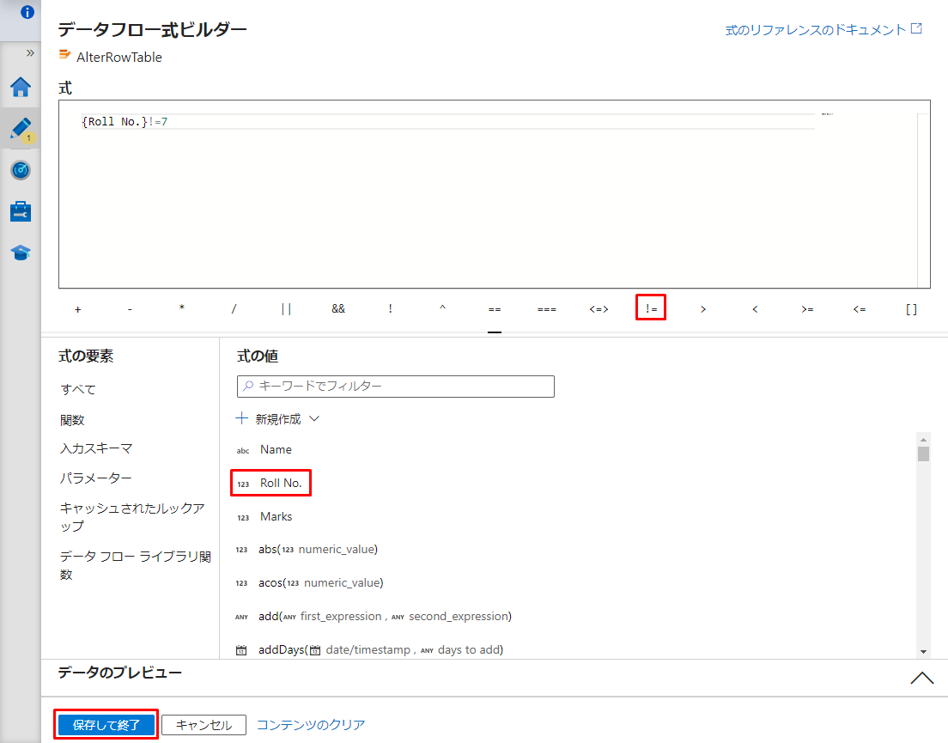
⑥ シンクの設定タブで、更新方法の「アップサートを許可」を有効にします。
更新、upsert、または削除が有効になっている場合は、シンク内のどのキー列を照合するかを指定する必要があります。
⑦ キー列で、Roll No. 列を選択します。
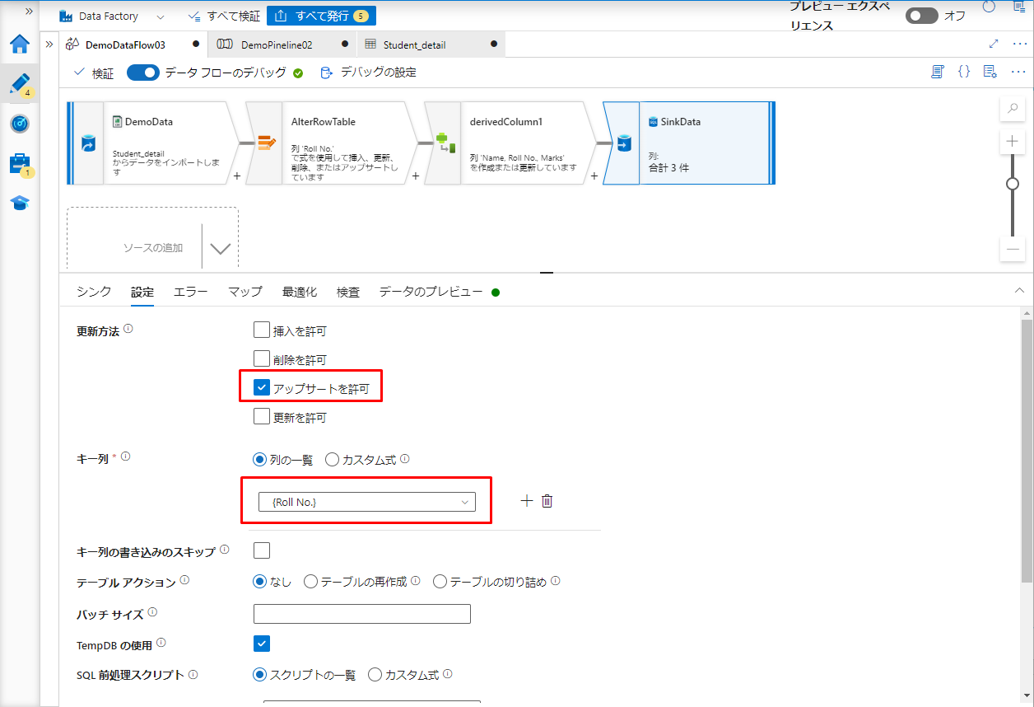
作成したパイプラインで「デバッグ」ボタンをクリックするとパイプラインが実行され、更新後にデータフローのアクティビティが実行されます。
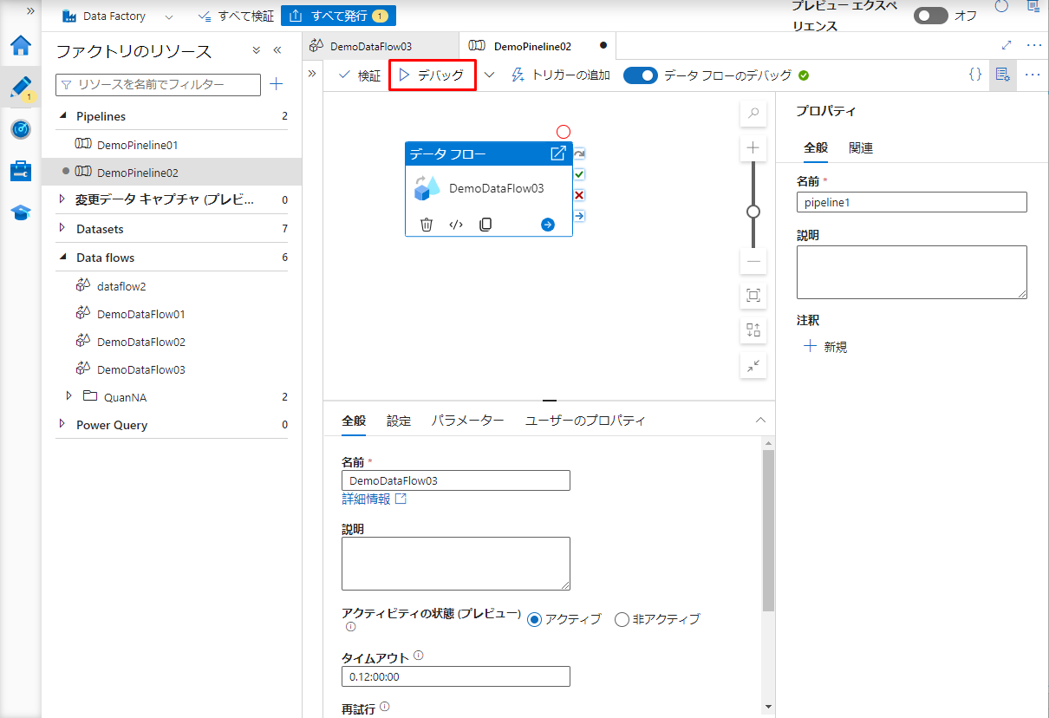
次の SQL コマンドをクエリ エディターにコピペします。
※例
|
1 |
SELECT * FROM [dbo].[Student] |
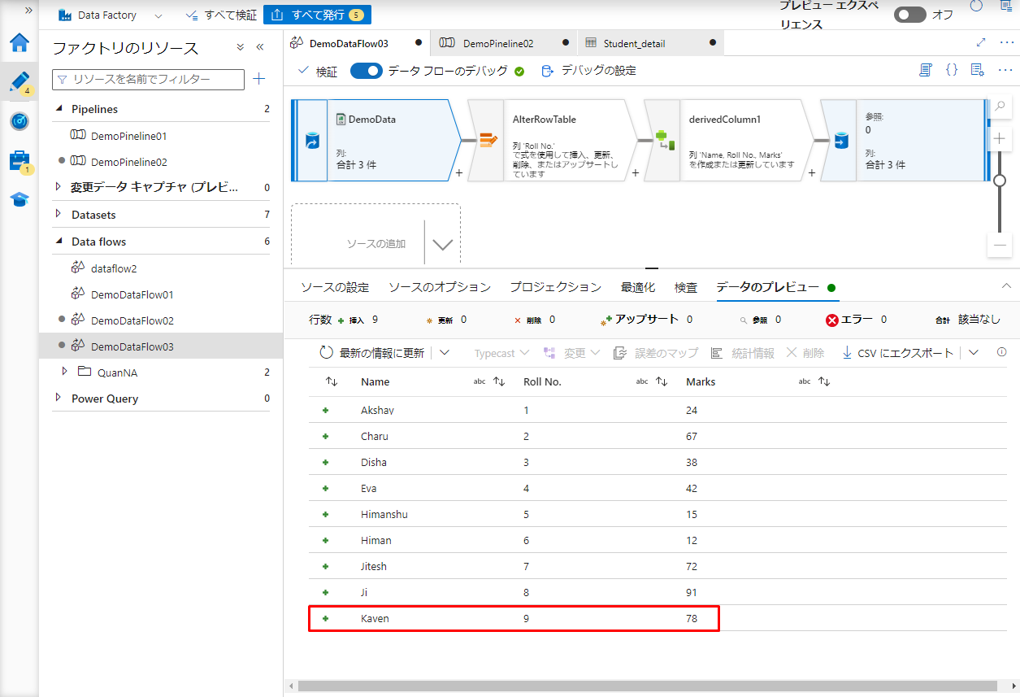
Roll No. の値が 7 以外であるのレコードに対して、Mark列の値が更新されます。それに、Roll No. が 9 であるのレコードを挿入されます。
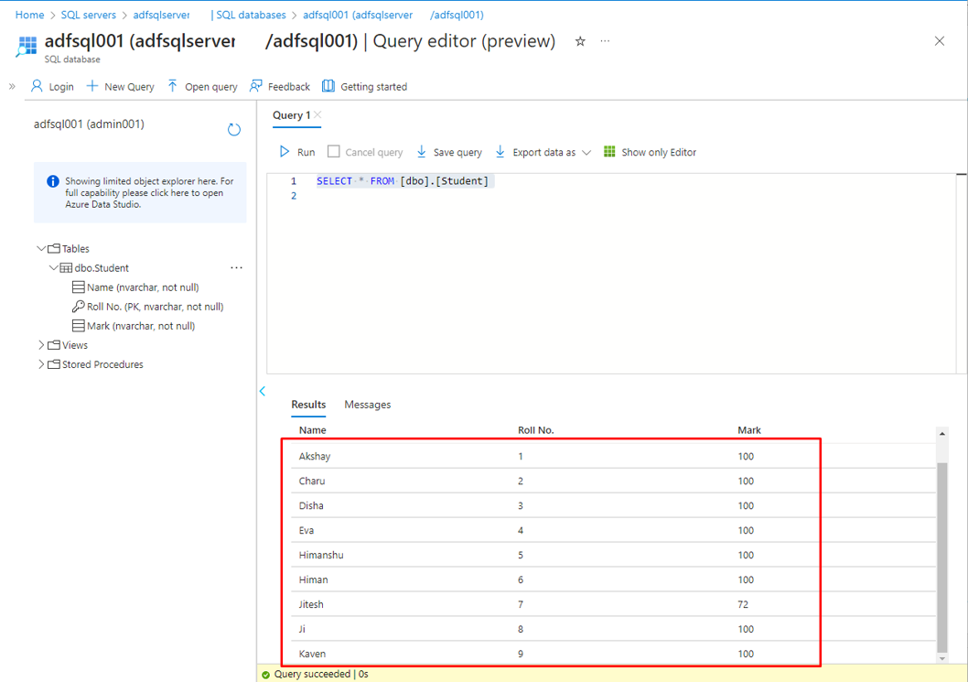
5-4.Delete
SQL の DELETE文のようにテーブルにデータを削除するには、ADF で行の変更変換を使用します。
DELETEの処理実行は、「行の変更の設定」タブの「行の変更条件」で「次の場合に削除」を選択することに対応します。更新の条件が式ビルダーに追加されます。
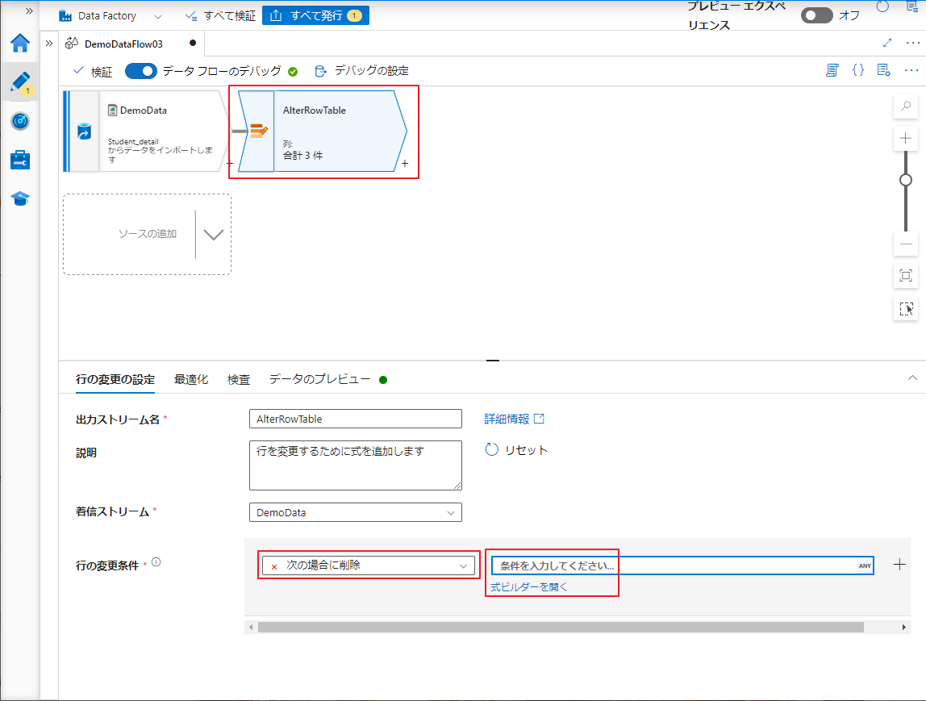
上記の挿入例と似ていますが、行の変更変換で削除条件を使用します。
① 行の変更条件で「次の場合に削除」を選択します。
②「式ビルダーを開く」をクリックして、式ビルダーを開きます。
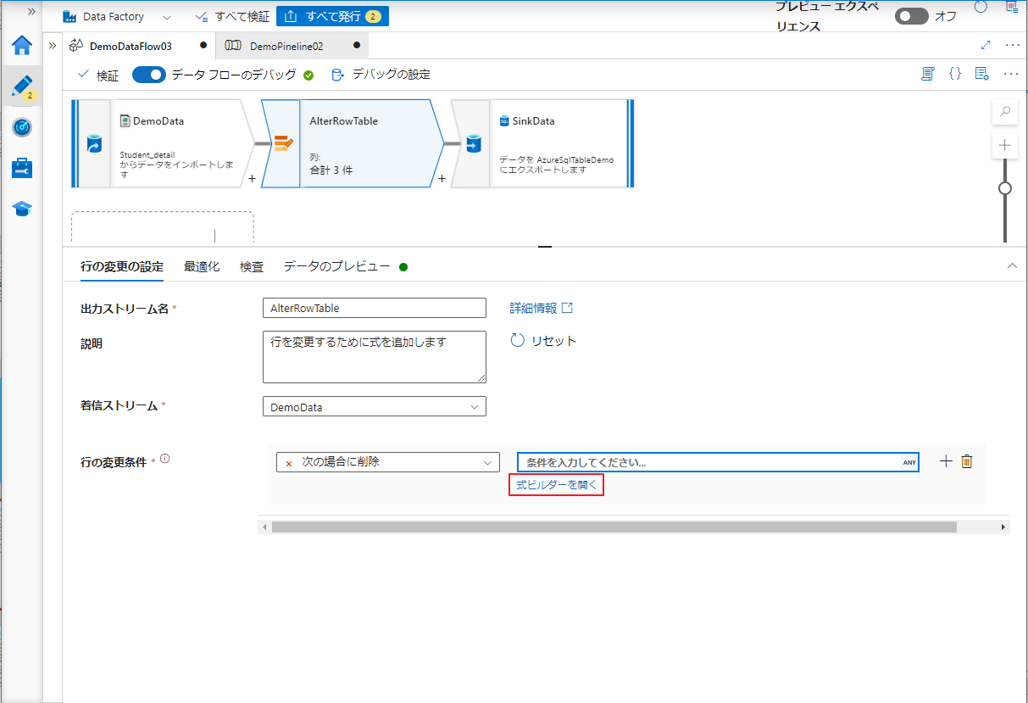
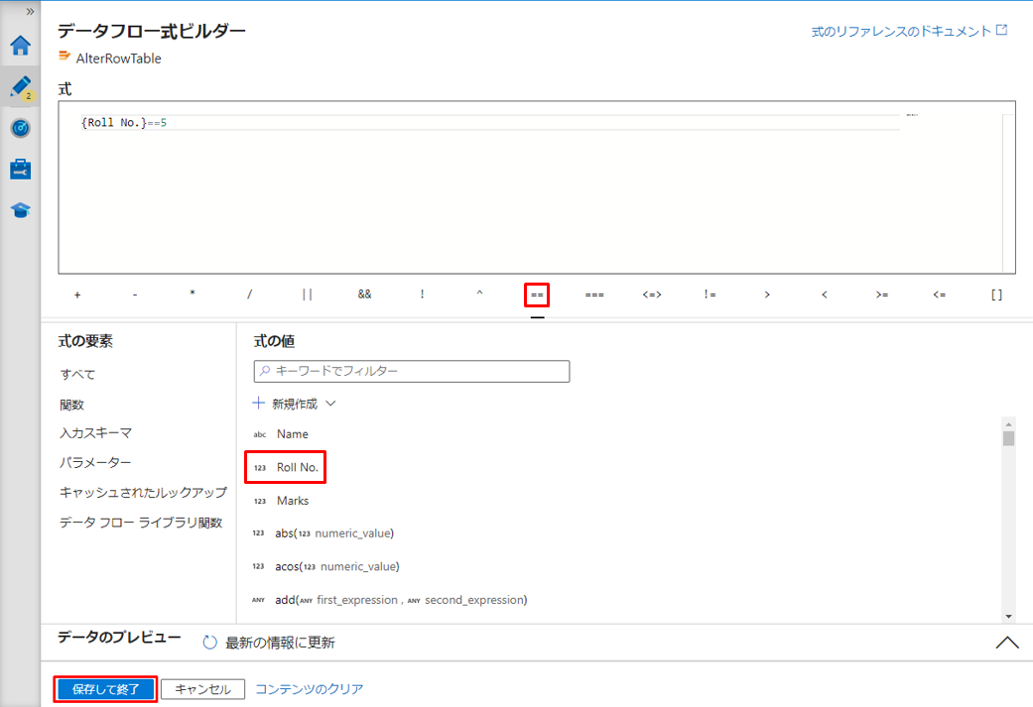
この例では、Roll No. が 5 であるのレコードを削除したいと思います。
UI では、この変換は次の図のようになります。
③「保存して終了」ボタンをクリックして式を保存します
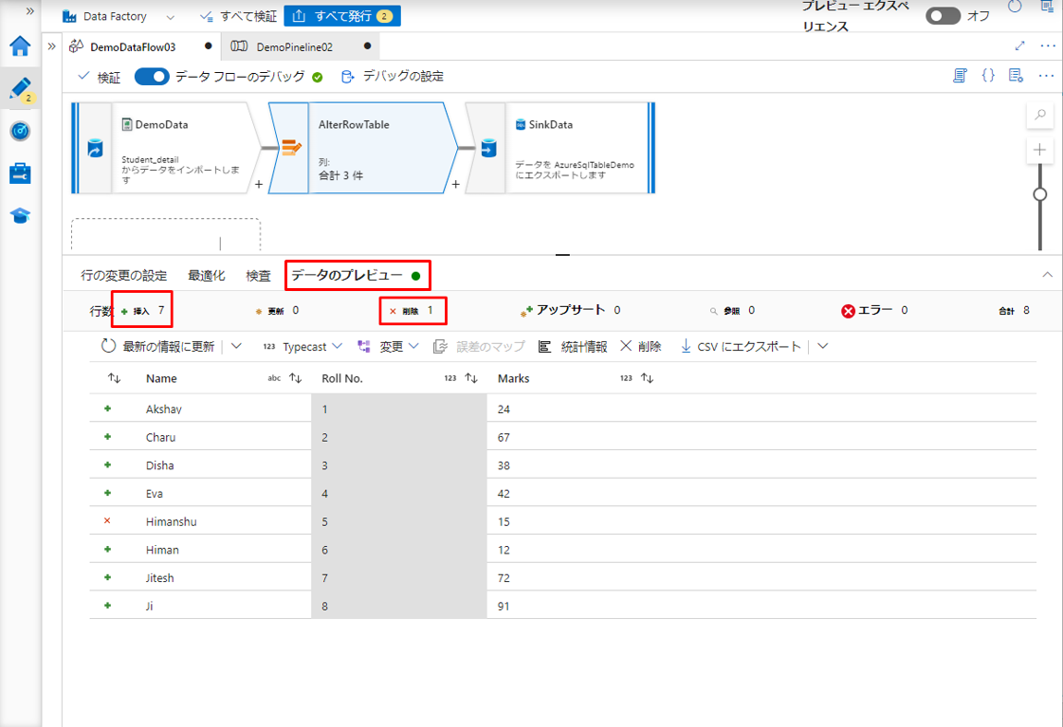
「データのプレビュー」タブをクリックして、ソース データから挿入条件を満たす行を確認します。
挿入条件を満たす 7件のレコードを確認できます。削除条件を満たす 1 件のレコードが削除されました。
④ シンクの設定タブで、更新方法の「削除を許可」を有効にします。
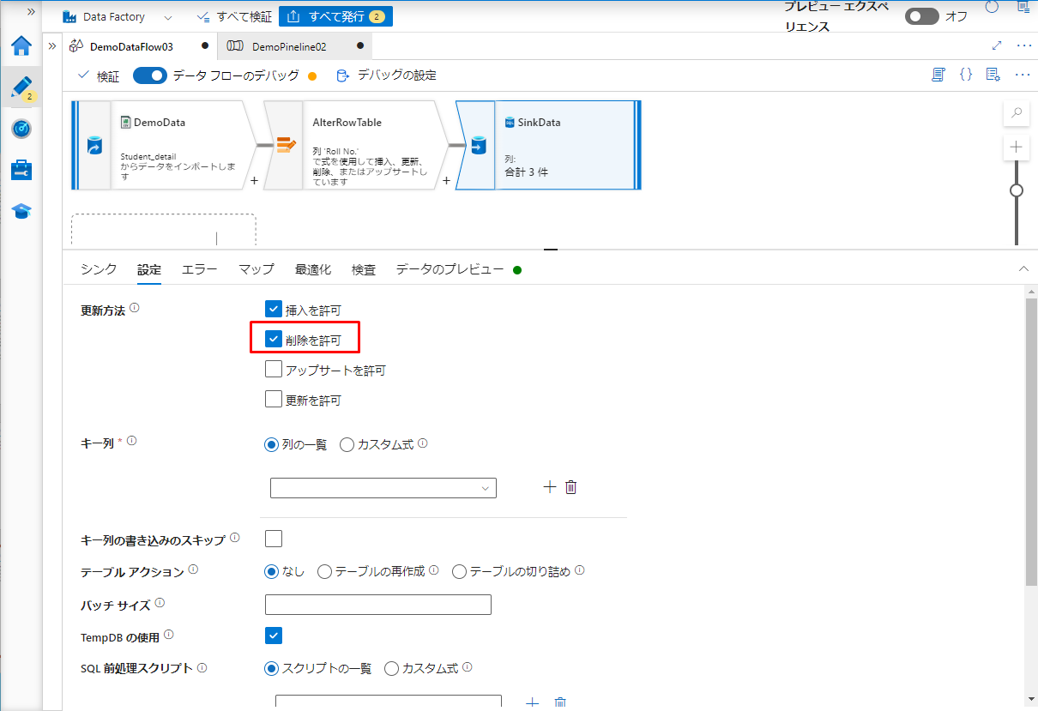
更新、upsert、または削除が有効になっている場合は、シンク内のどのキー列を照合するかを指定する必要があります。
⑤ キー列で、Roll No. 列を選択します。
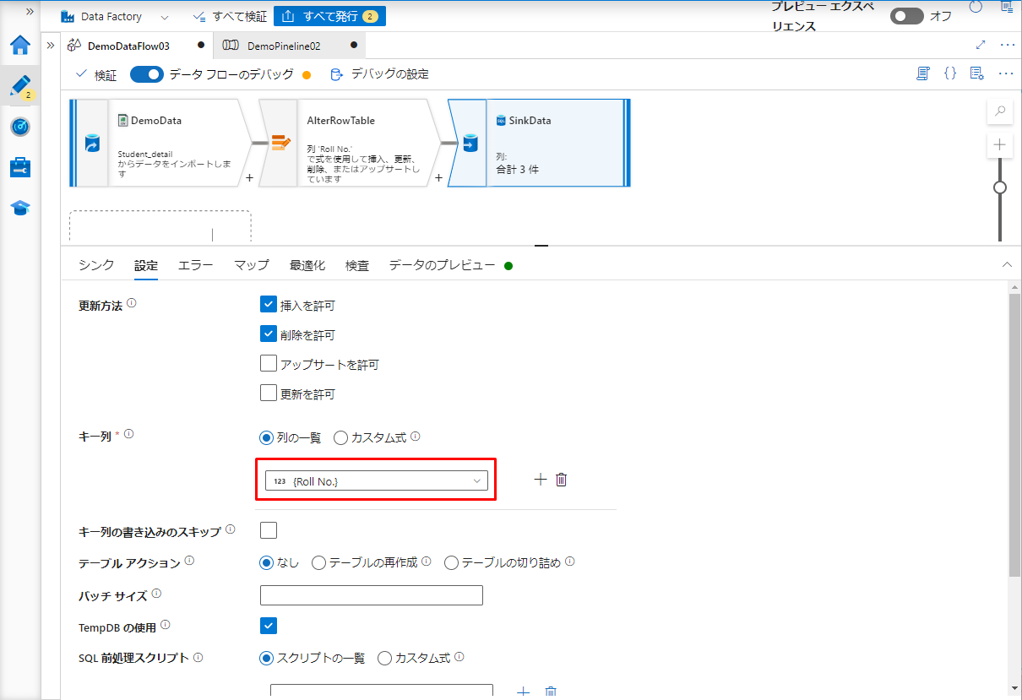
作成したパイプラインで「デバッグ」ボタンをクリックするとパイプラインが実行され、更新後にデータフローアのクティビティが実行されます。
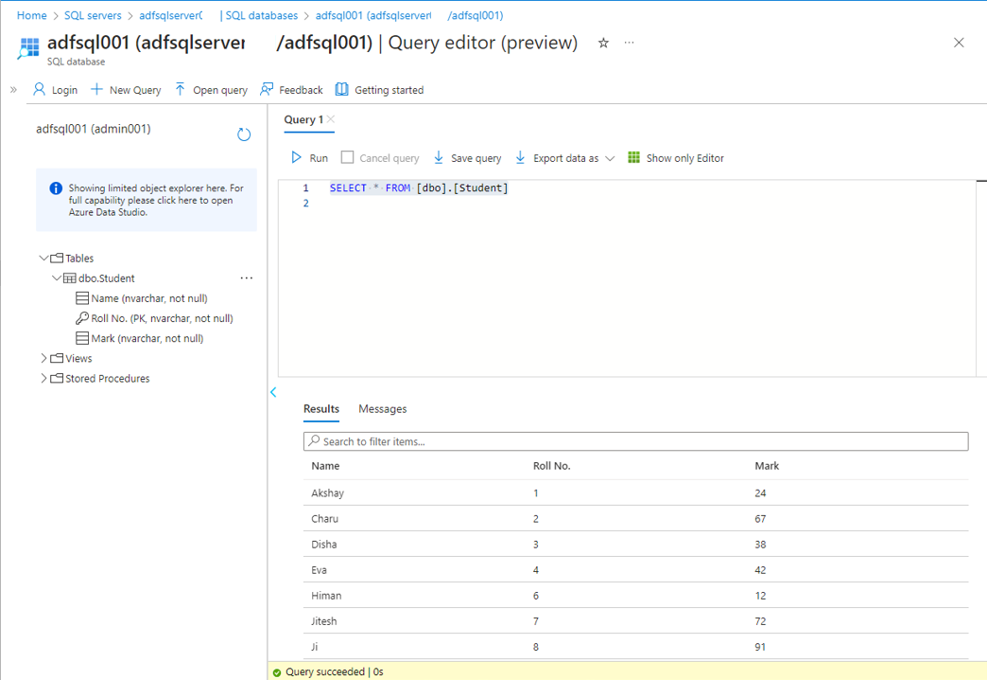
次の SQL コードをクエリ エディターにコピペします。
※例
|
1 |
SELECT * FROM [dbo].[Student] |
Roll No. が 5であるのレコードを除き、他のデータはソース データからSQL データベースのテーブルに挿入されました。(このテーブルは、この手順を実行する前にクリアされました。)
6.まとめ
本連載では、
Azure Data Factory上でinsert、delete、update、mergeの処理を実行する方法について詳細に説明していきます。
第1回:SQLコマンドをAzure Data Factoryで実現する
第2回:Azure Data Factoryでインラインビュー、サブクエリーを実現する
第3回:Azure Data Factory上でinsert、delete、update、mergeの処理を実行する(今回)
今回の記事が少しでもAzure Data Factoryを知るきっかけや、業務のご参考になれば幸いです。
Azure Data FactoryやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
・Azure Data Factory連載シリーズはこちら
![]() お問い合わせはこちら
お問い合わせはこちら