目次
1.はじめに
皆さんこんにちは。
今回は、DatabricksでローコーティングでETL/ELTを実現するためのbamboolibを利用する方法について説明していきます。
bamboolibは、データの読み込み、クリーニング、変換、可視化などの一連のデータ分析タスクを容易に実行するためのインタラクティブなインターフェースを提供します。非常に直感的で使いやすいGUIを備えています。
Pythonに関する知識は若干必要ですが、ローコード開発を行うことができます。
2.前提要件
実施する際の前提条件は
・操作ユーザーは Azure Databricks ワークスペースにアクセス権限があること。
・操作ユーザーは、ノートブックの作成・実行権限があること。権限が付与されていない場合、管理者に権限を付与してもらう様に依頼してください。
このライブラリは Pythonバージョン 3.10.12で動作します。
そのため、ノートブックを実行するクラスターには Databricks Runtime 14.3 LTSまたはDatabricks Runtime 13.3 LTS(推奨)を使用する必要があります。
3.bamboolibでノートブック作成
3-1.CSVファイルをDBFSにアップロード
まず、Databricksワークスペース上でCSVファイルを DBFS にアップロードします。
① Databricksワークスペースにログインします。
② Databricks画面のサイドバーメニューから「カタログ」をクリックします。
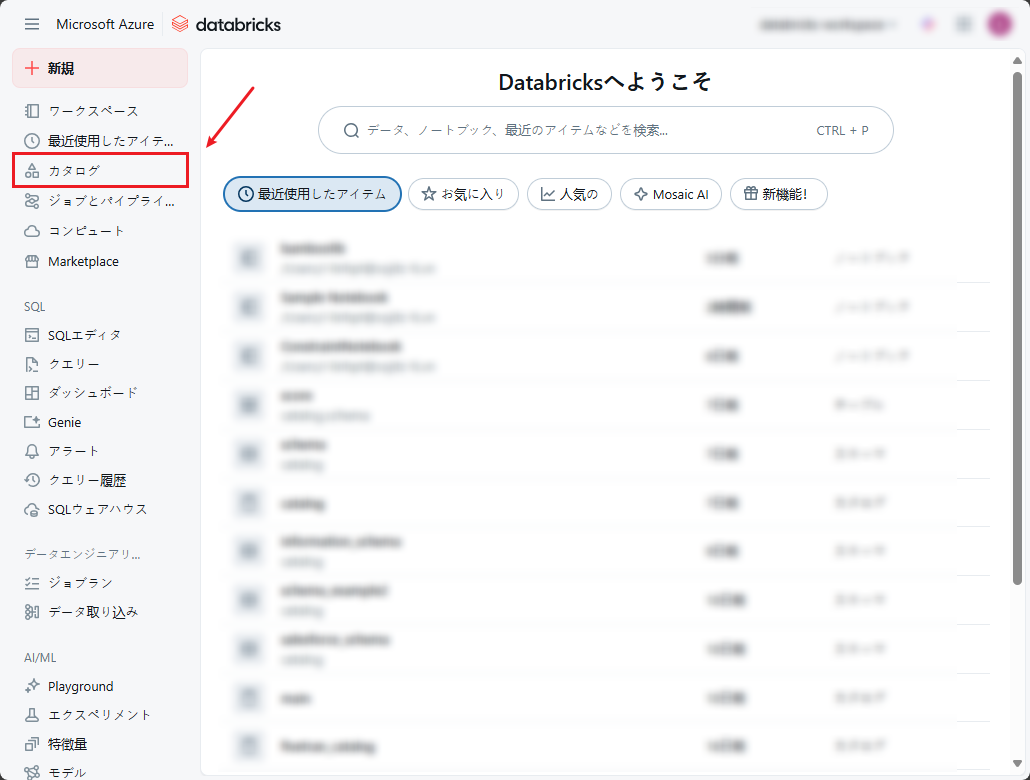
③ データエクスプローラーから「DBFSを閲覧」を選択します。
※このボタンが表示されない場合は、Admin SettingsのWorkspace settingsタブで有効にするよう管理者にご相談ください。
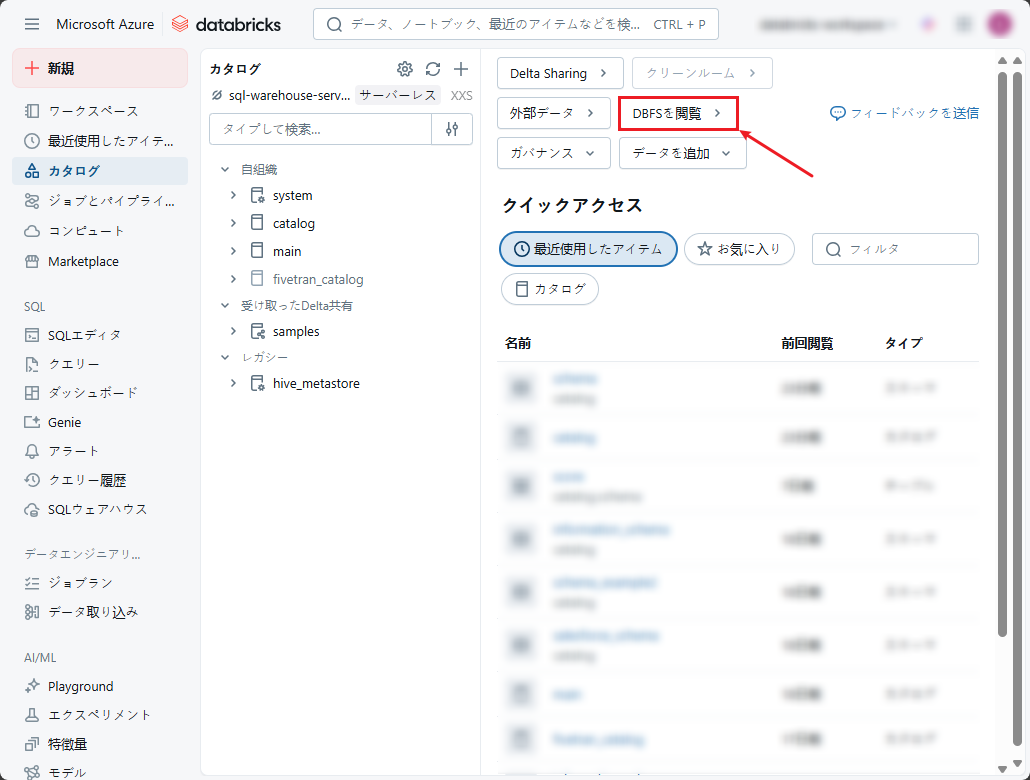
④ DBFSから「FileStore」フォルダを選択し、「アップロード」をクリックします。
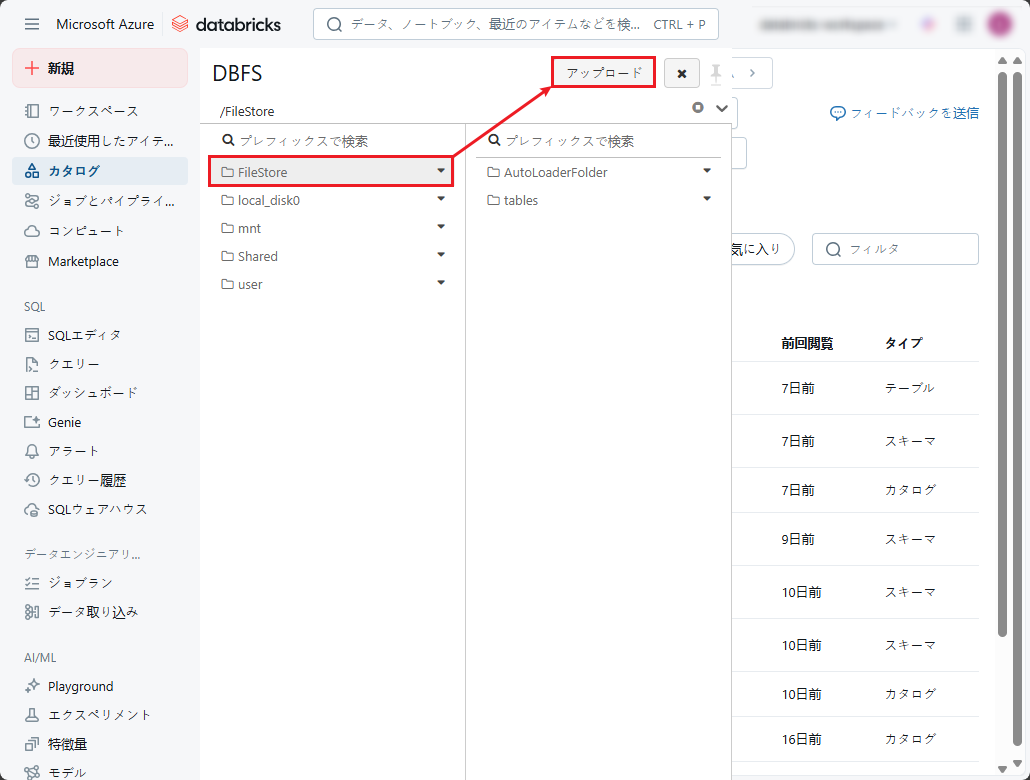
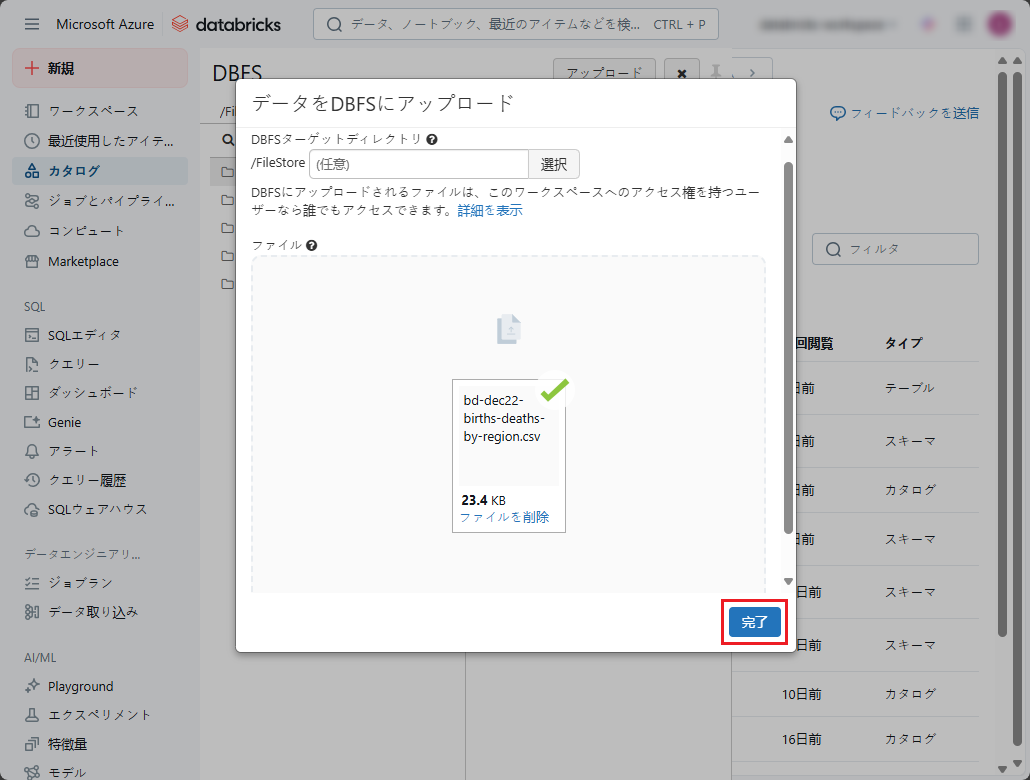
⑤ 「データをDBFSにアップロード」ダイアログでローカルコンピューターからのファイルをアップロードできます。
こちら をクリックすると、テスト用ファイルをダウンロードできます。
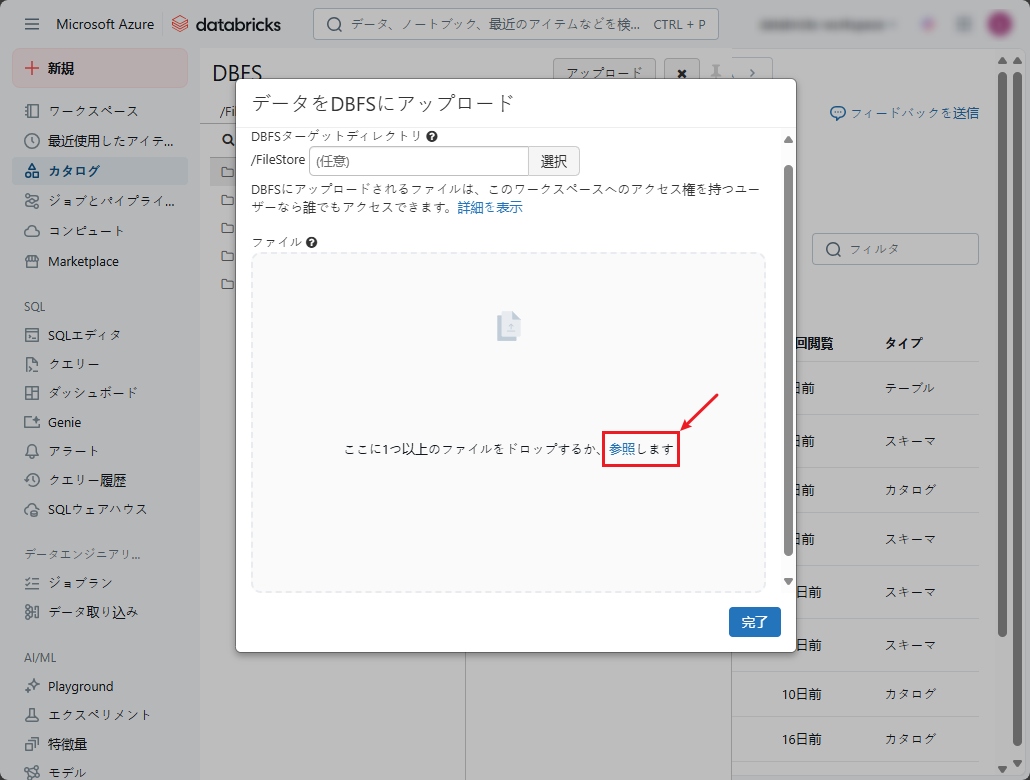
⑥ ファイルを選択し、「完了」ボタンをクリックします。
3-2.bamboolibのインストール
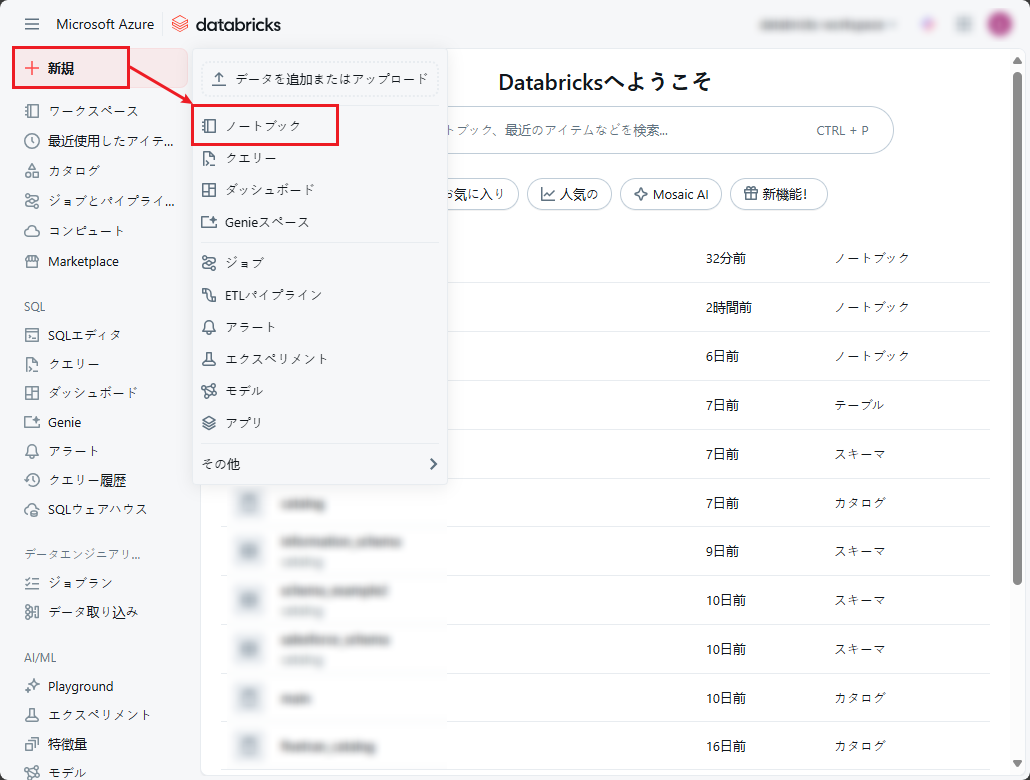
① 左側のサイドバーメニューから「新規」をクリックし、「ノートブック」を選択します。
② 新規作成したノートブック画面が表示されたら、ノートブックの名前を付け、デフォルトの言語としてPythonを選択します。
③ 以下のコードをノートブックの1行目と2行目にコピーし、bamboolibライブラリをインストールします。
※例としてご参照ください。
|
1 |
%pip install bamboolib |
|
1 2 |
import bamboolib as bam bam |
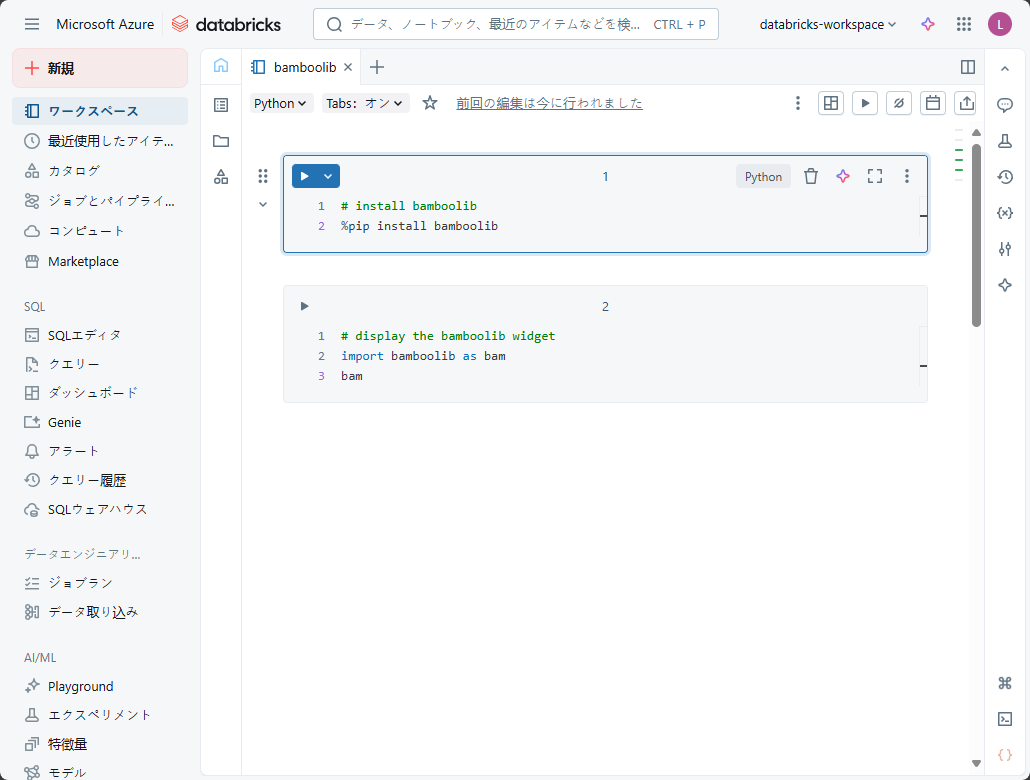
④「Shift」+「Enter」キーを押してコマンドを実行します。
⑤ 実行後、bamboolibライブラリがインストールされ、bamboolibウィジェットが表示されます。
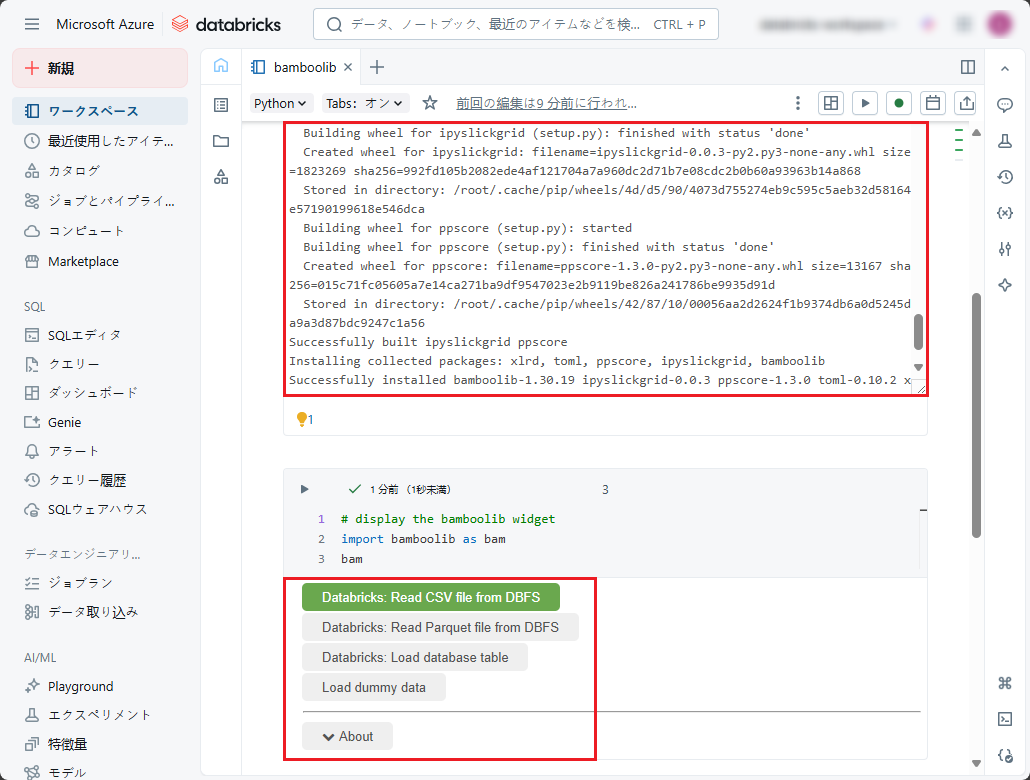
4.Databricks ワークスペースでETL/ELT実行
4-1.DBFSからデータ読み込み
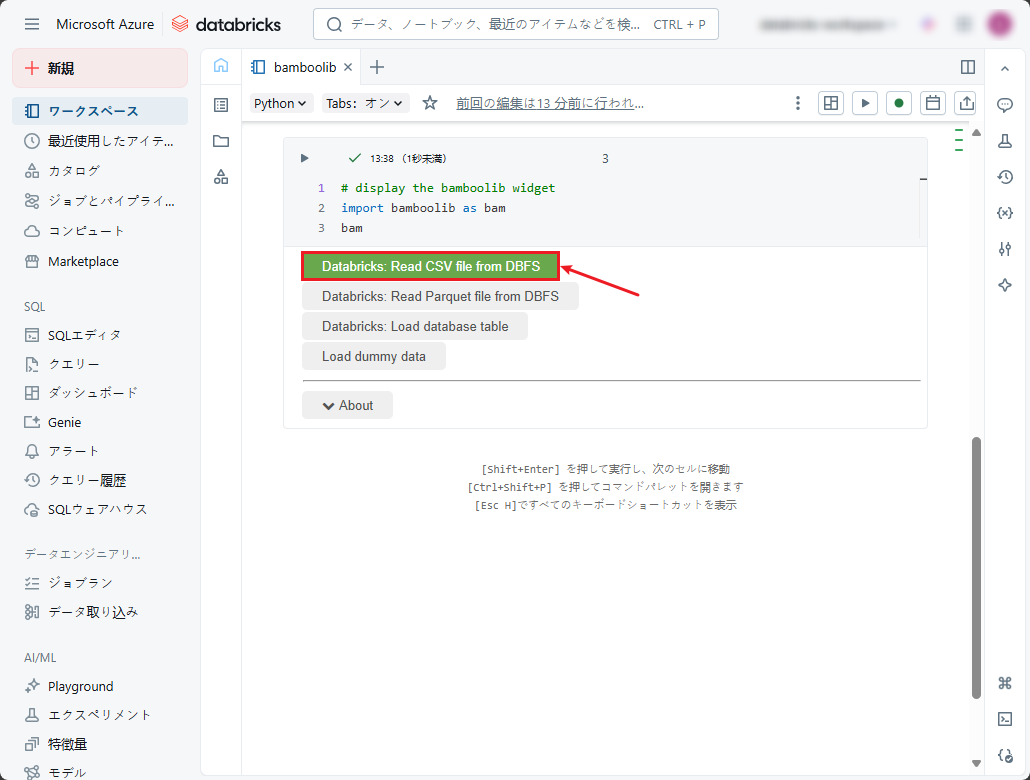
①「Databricks: Read CSV file from DBFS」をクリックします。
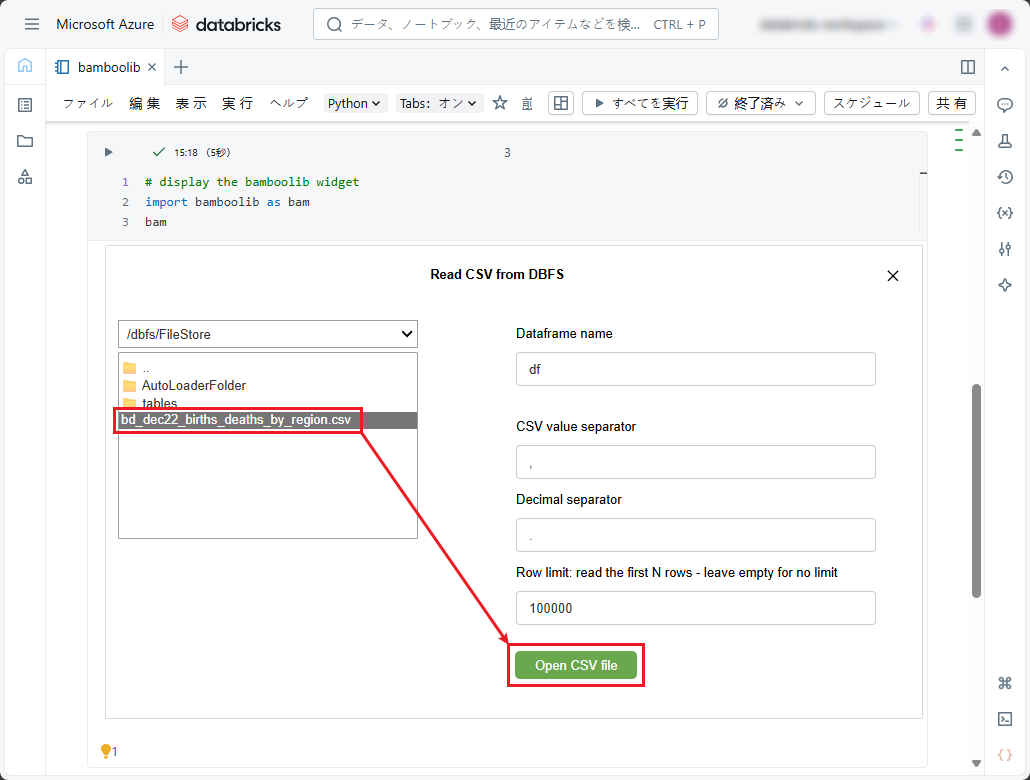
②「Read CSV from DBFS」ダイアログボックスで、前の手順でDBFSにアップロードしたCSVファイルを選択し、「Open CSV file」ボタンをクリックします。
③ CSVファイルのデータとウィジェットが表示されます。
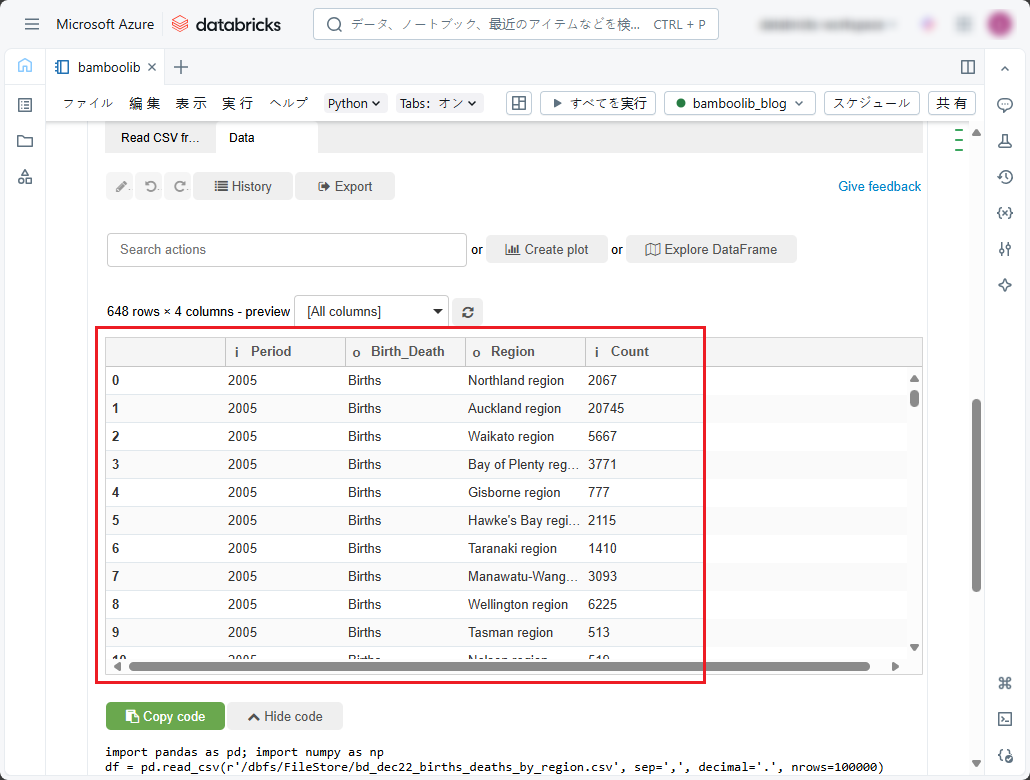
4-2.データ変換
このデータセットは、2010年から2022年までの地域別の出生数と死亡数です。2022年のみの地域別の死亡数を降順で表示したい場合、「Data」タブの「Search actions」ドロップダウンリストで以下の手順に従ってください。
①「filter」と入力します。
②「Filter rows」を選択します。
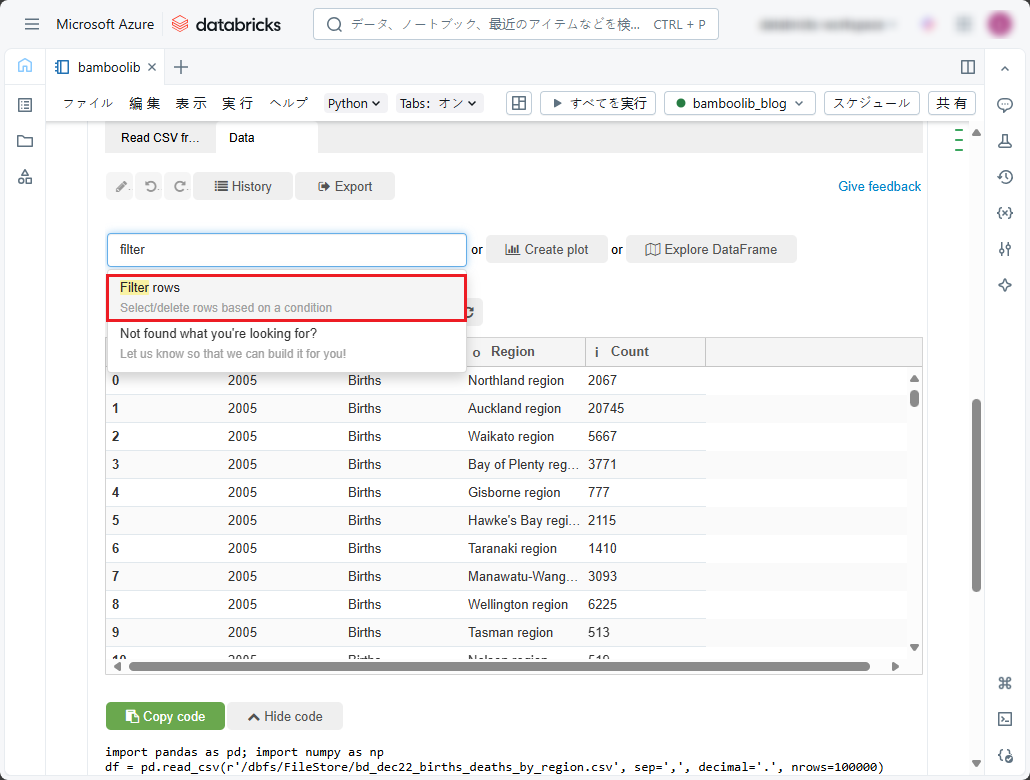
③ 最初のフィルタリング条件を指定します。
④ 別のフィルタリング条件を追加するには、「add condition」をクリックし、次のフィルタリング条件を指定します。
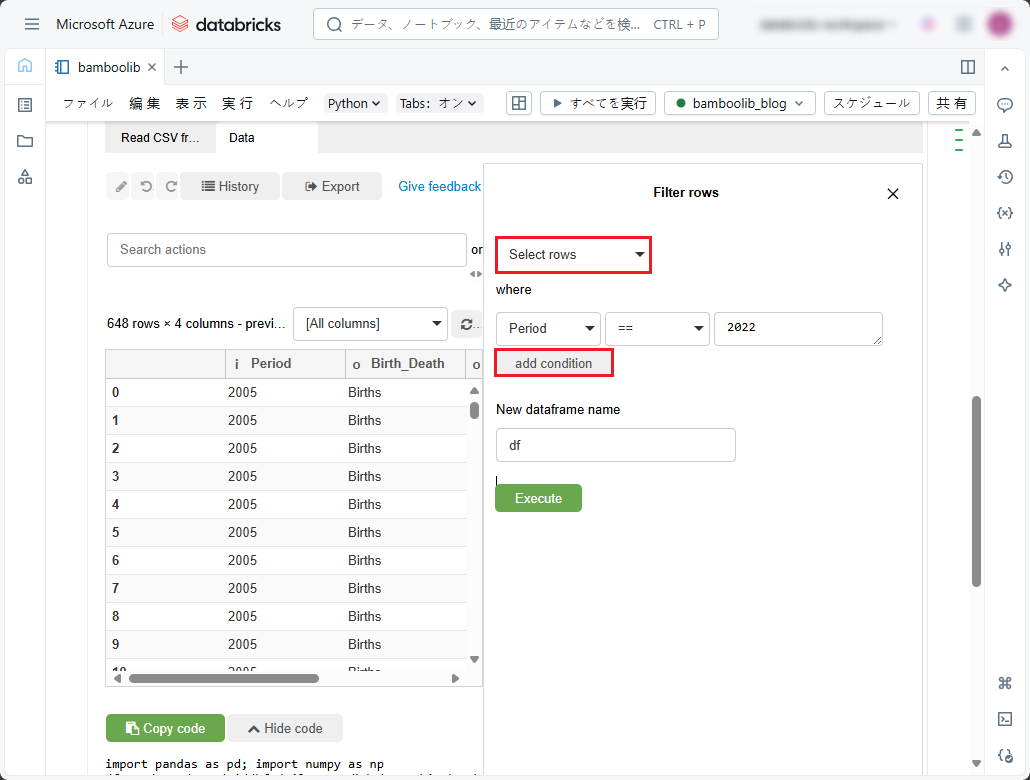
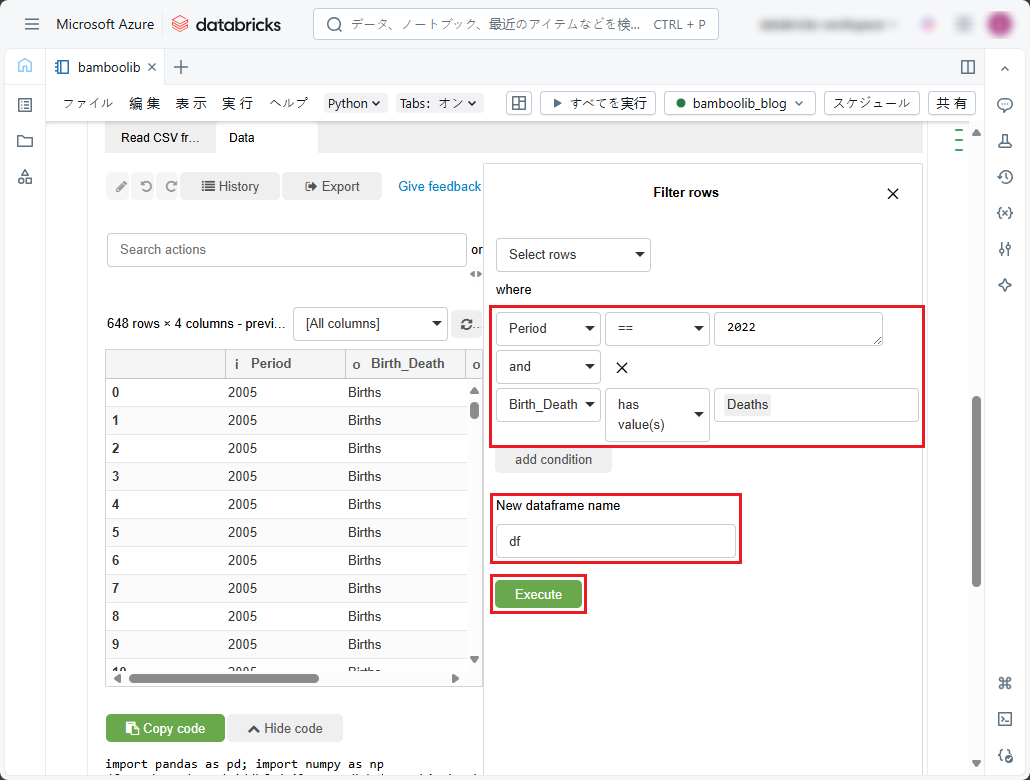
⑤「Dataframe name」では、テーブルの内容のプログラム識別子をデータフレームとして指定します。または、デフォルトの「df」のままにします。
⑥「Execute」をクリックします。
実行後の結果を確認できます。
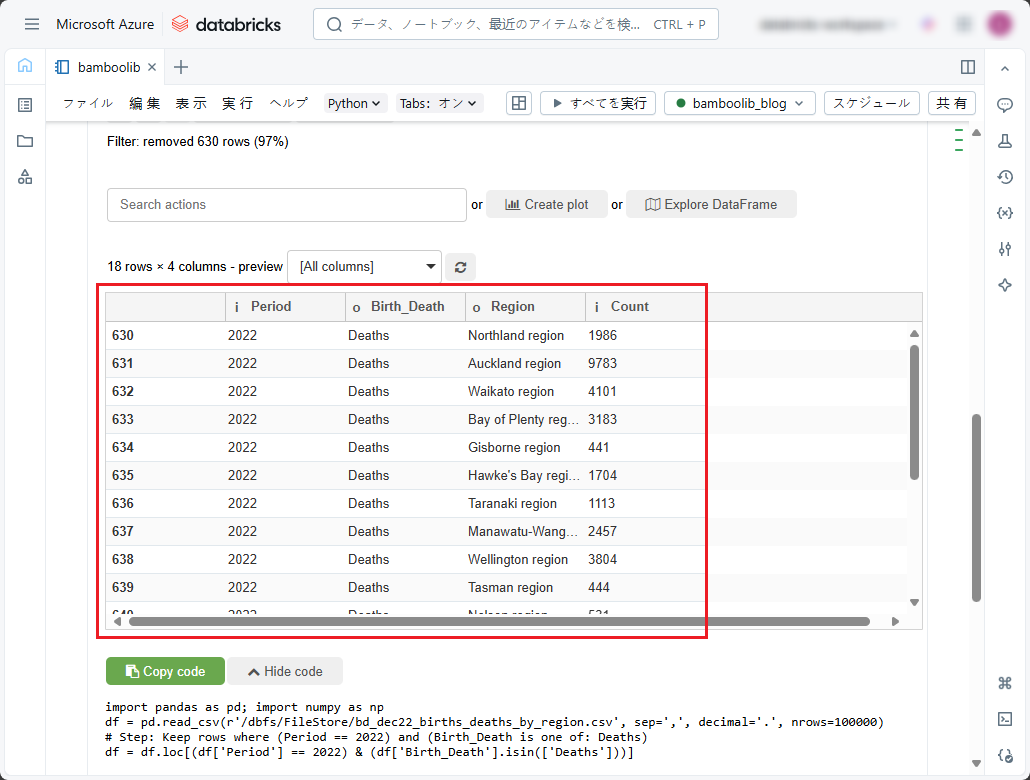
特定のカラムに欠損値がある行を削除したい場合(例えば、このデータセットでは「Region」カラムに欠損値の行を削除したい)、「Data」タブの「Search actions」ドロップダウンリストで以下の手順に従ってください。
①「drop」あるいは「remove」と入力します。
②「Drop missing values」を選択します。
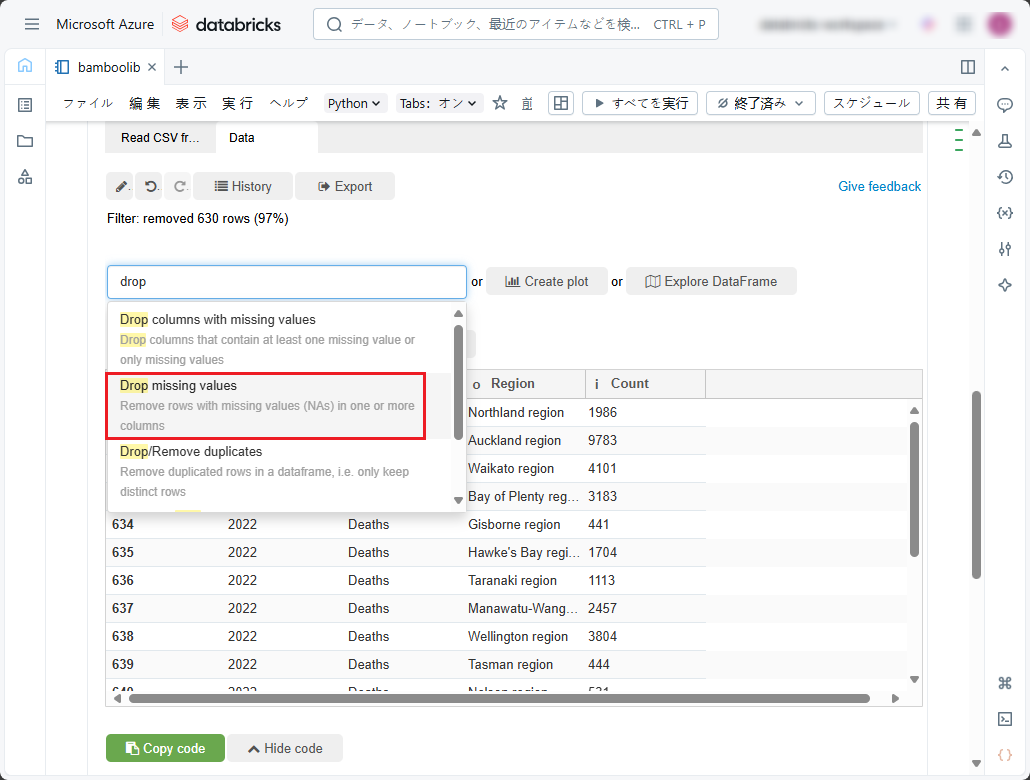 ③「Drop missing values」ペインで欠損値をチェックするカラムを指定します。
③「Drop missing values」ペインで欠損値をチェックするカラムを指定します。
④「Dataframe name」では、テーブルの内容のプログラム識別子をデータフレームとして指定します。或いは、デフォルトの「df」のままにします。
⑤「Execute」をクリックします。
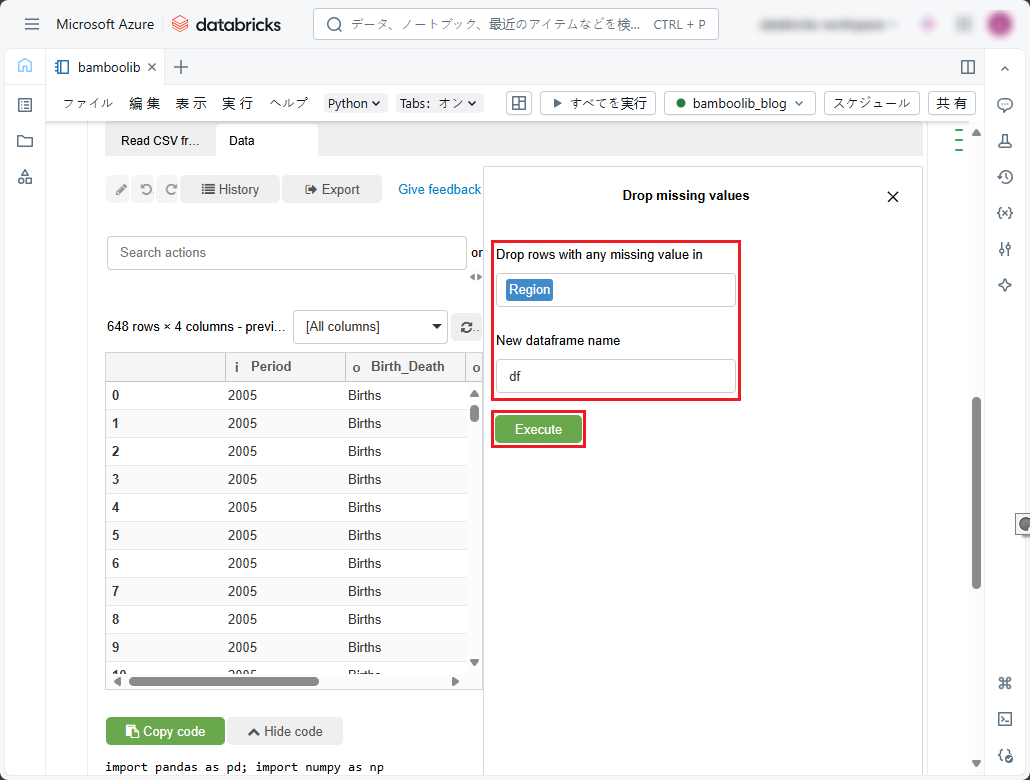
実行後の結果を確認できます。
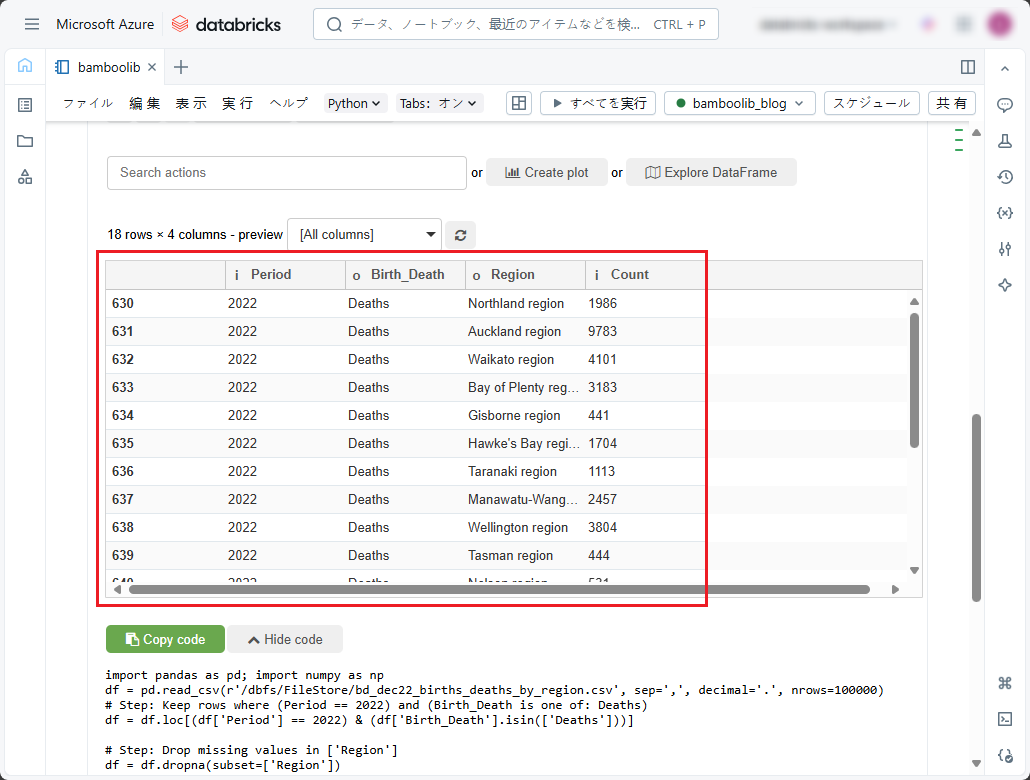
フィルタリング後のデータセットの行をカラム別に降順(Z-A)にソートするには、「Data」タブの「Search actions」ドロップダウンリストで以下の手順に従ってください。
①「sort」と入力します。
②「Sort rows」を選択します。
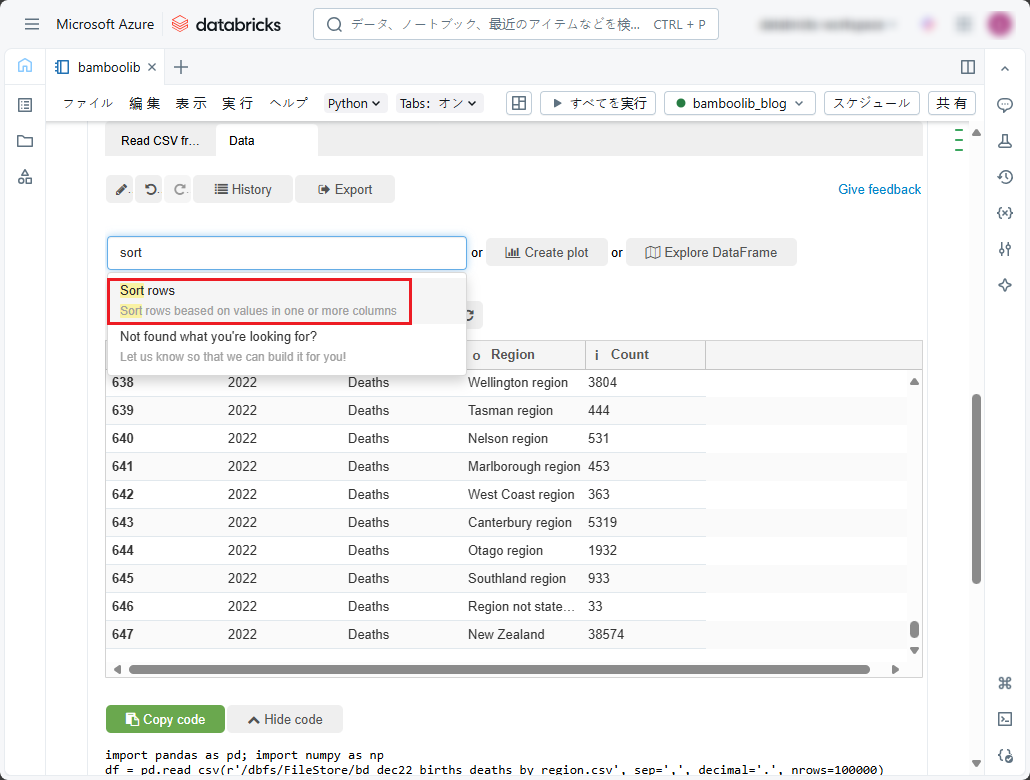
③「Sort column(s)」ペインでソートする最初のカラムとソート順を選択します。
④ 別のソート条件を追加するには、「add column」をクリックし、次のソート条件を指定します。
⑤「Dataframe name」では、テーブルの内容のプログラム識別子をデータフレームとして指定します。或いは、デフォルトの「df」のままにします。
⑥「Execute」をクリックします。
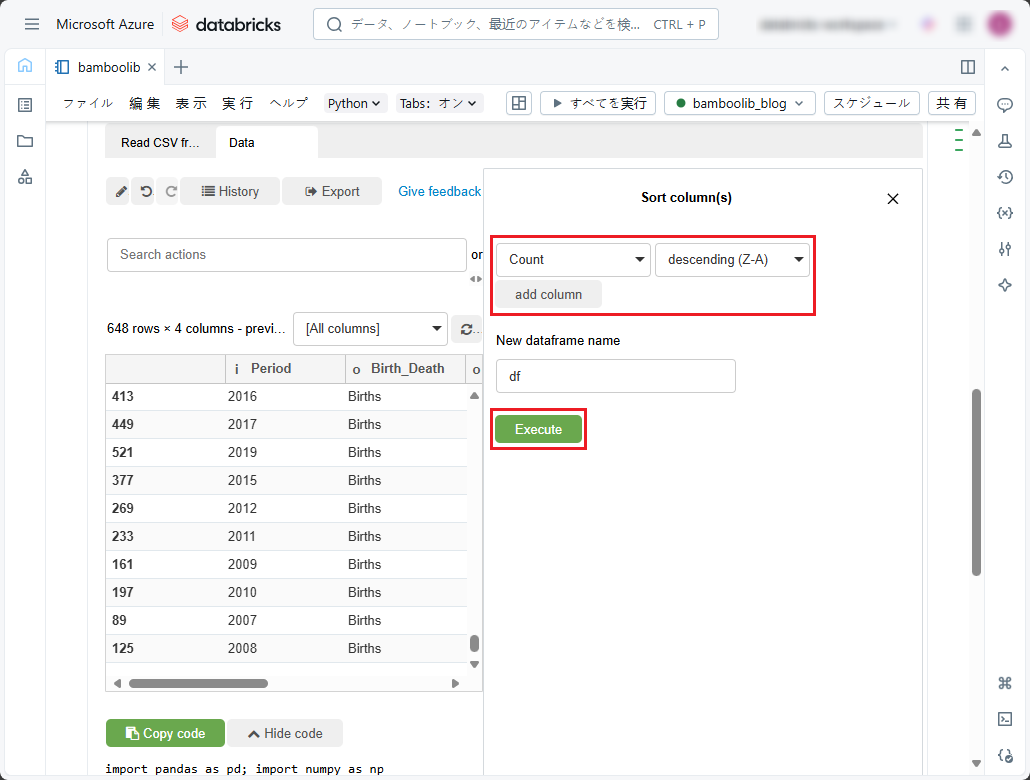
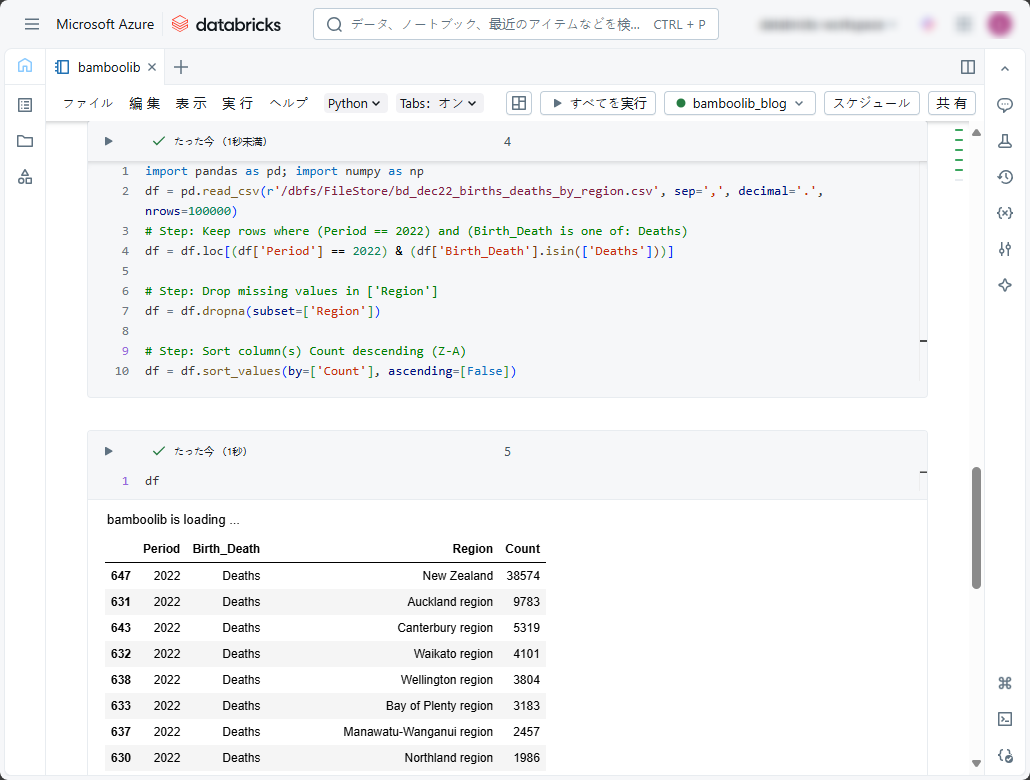
その後、実行後の結果を見ると、2022年のみの地域別の死亡数を降順で表示しました。
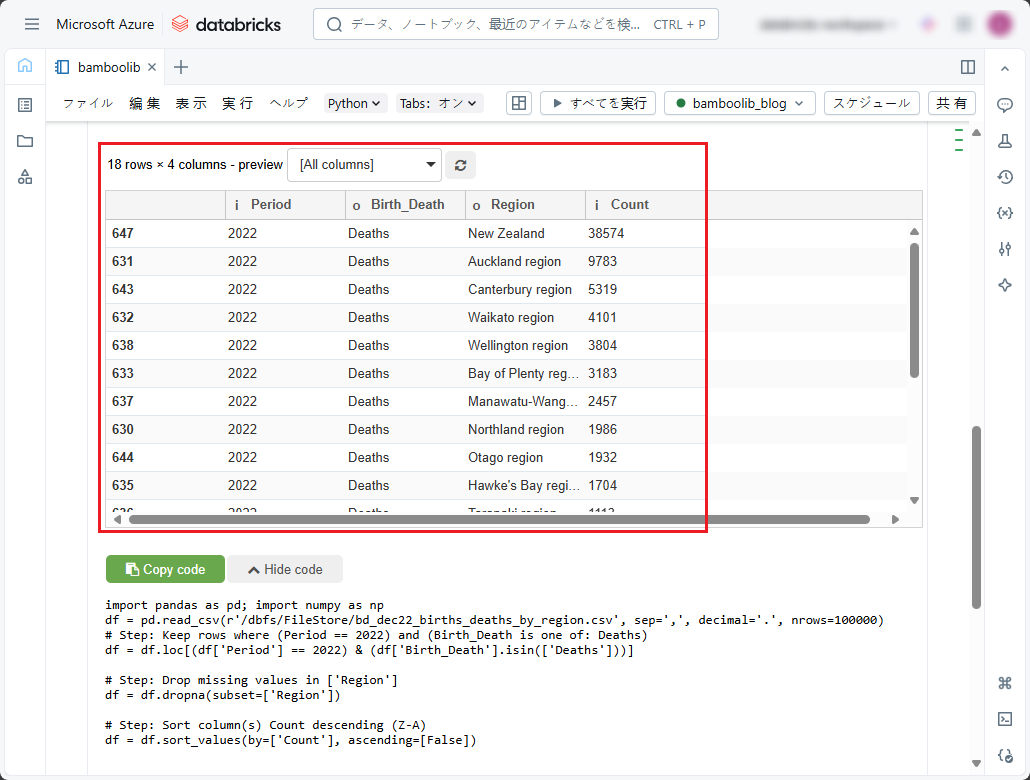
4-3.データ抽出
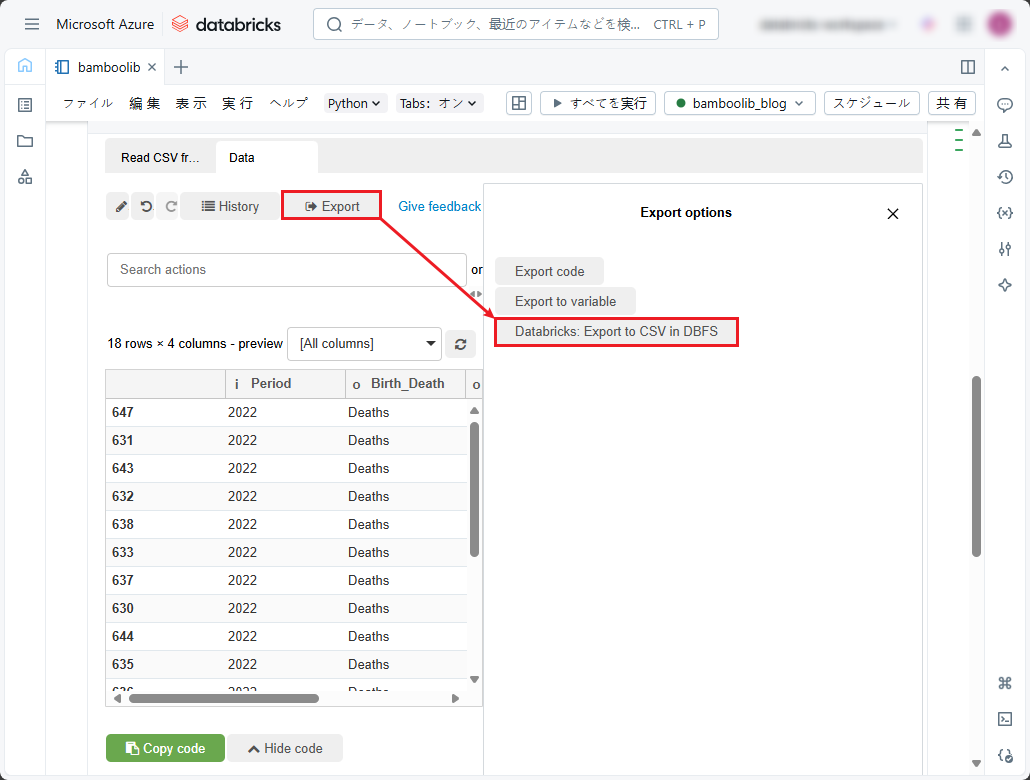
データを変換した後、抽出してDBFSストレージに保存できます。
①「Export」をクリックし、「Databricks: Export to CSV in DBFS」を選択します。
②DBFSに保存するファイル名を入力します。
③「Execute」ボタンをクリックします。
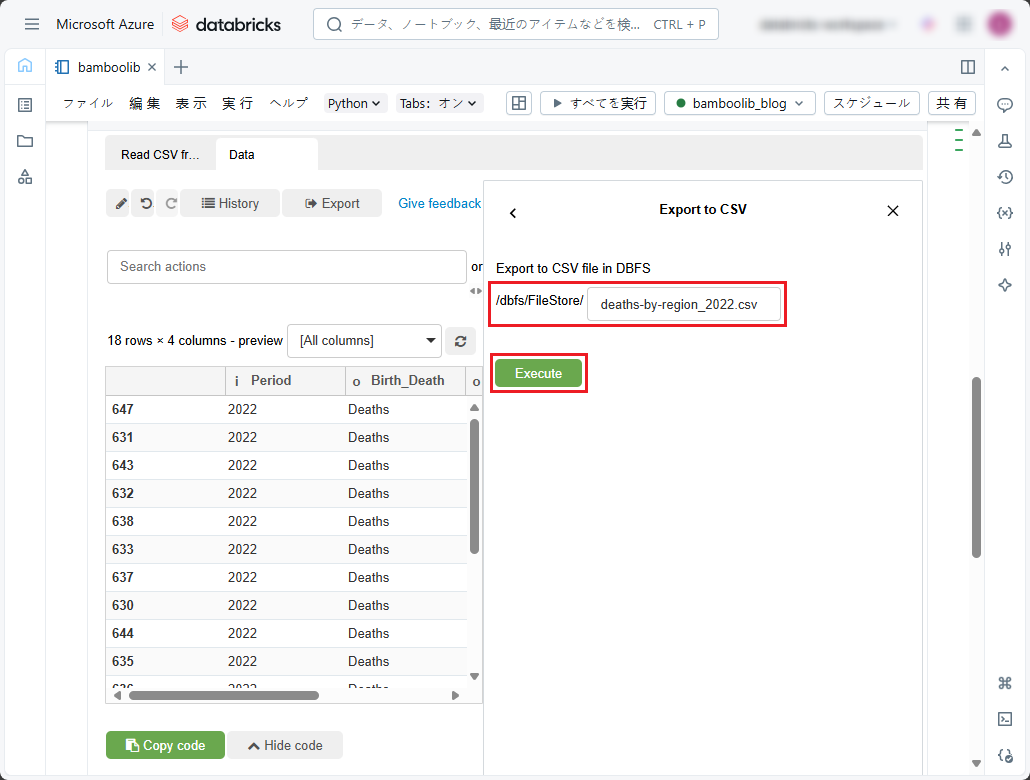
DBFSに保存されたファイルを確認できます。
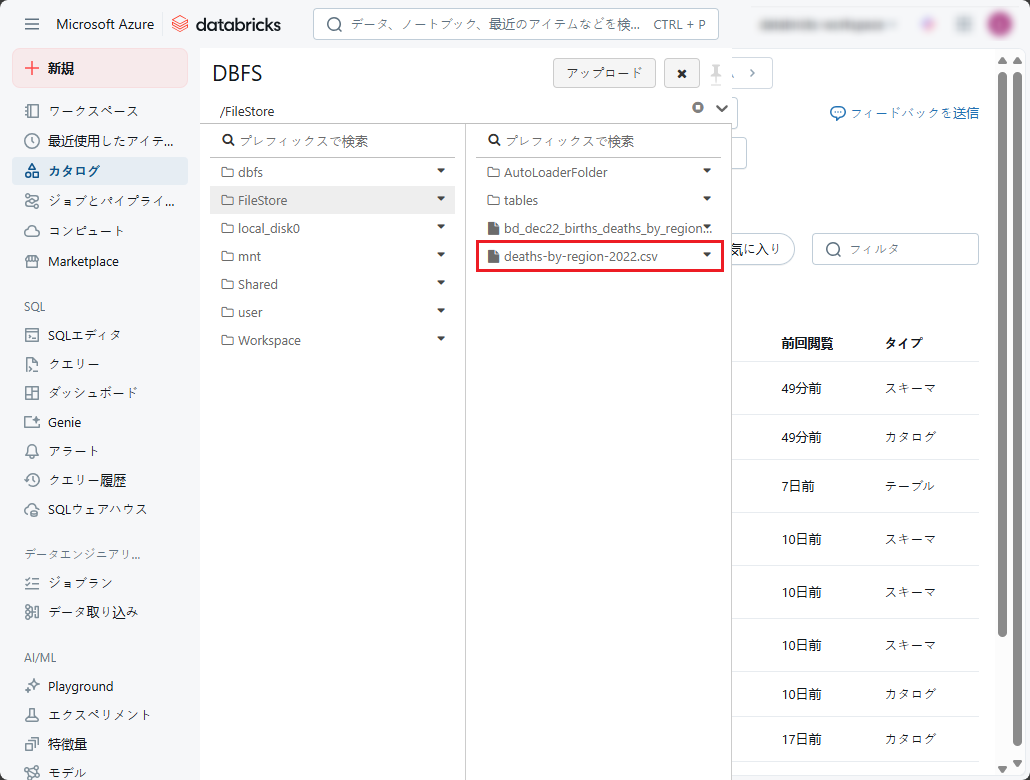
現在のウィジェットの状態をpandas DataFrameとしてプログラム上で再作成するためのPythonコードを取得したい場合、それをコードにエクスポートすることができます。
①「Export」をクリックし、「Export code」を選択します。
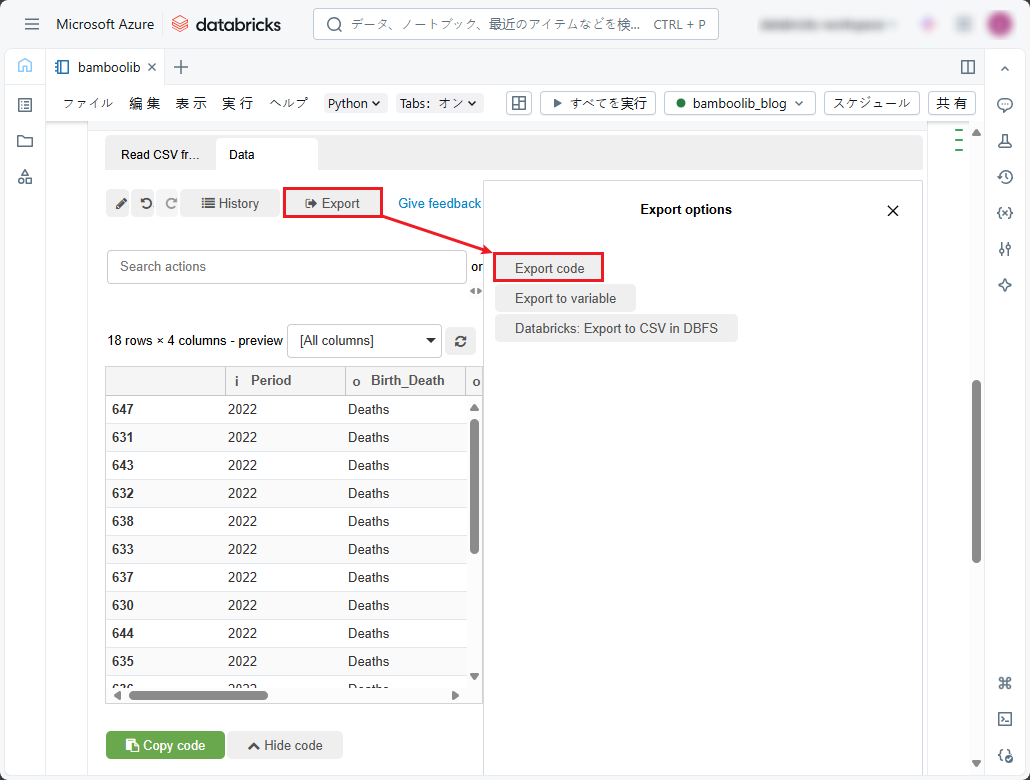
②「Copy code」をクリックします。
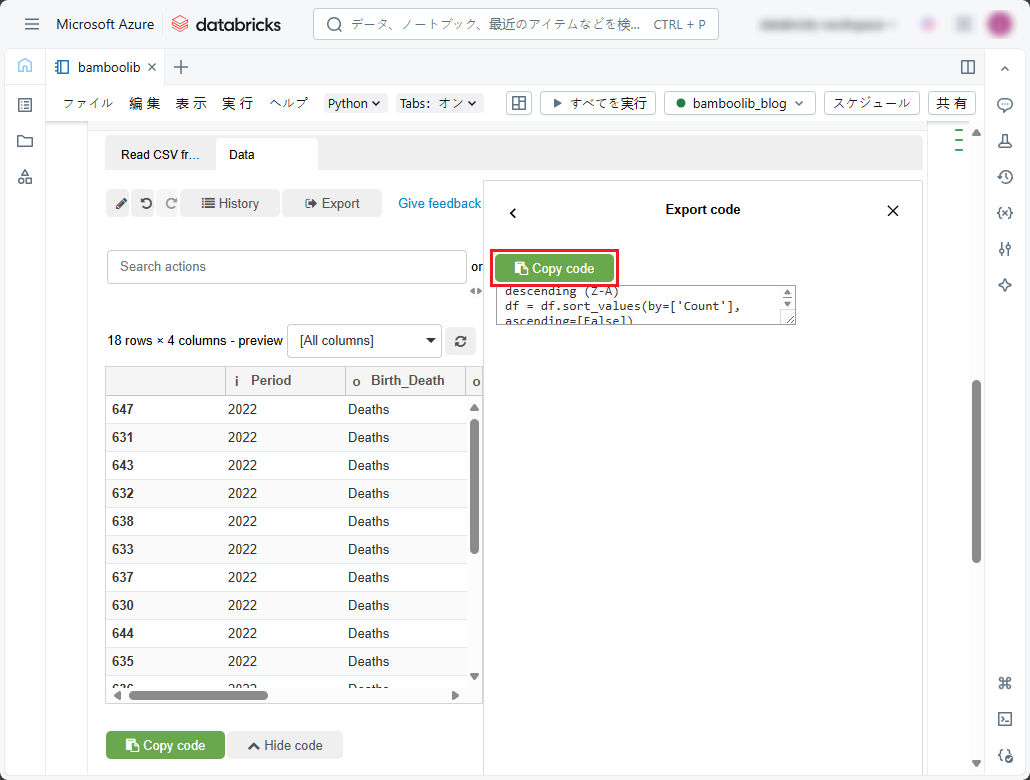
③ このブック内の別のセル、又は別のブックにコードを貼り付けます。
④ このpandas DataFrameとプログラム上で連携するための追加のコードを記載し、そのセルを実行します。 たとえば、DataFrameの内容を表示するには、DataFrameがプログラム上でdfとして表現されていると想定します。
また、データを変数に抽出きます。
①「Export」をクリックし、「Export to variable」を選択します。
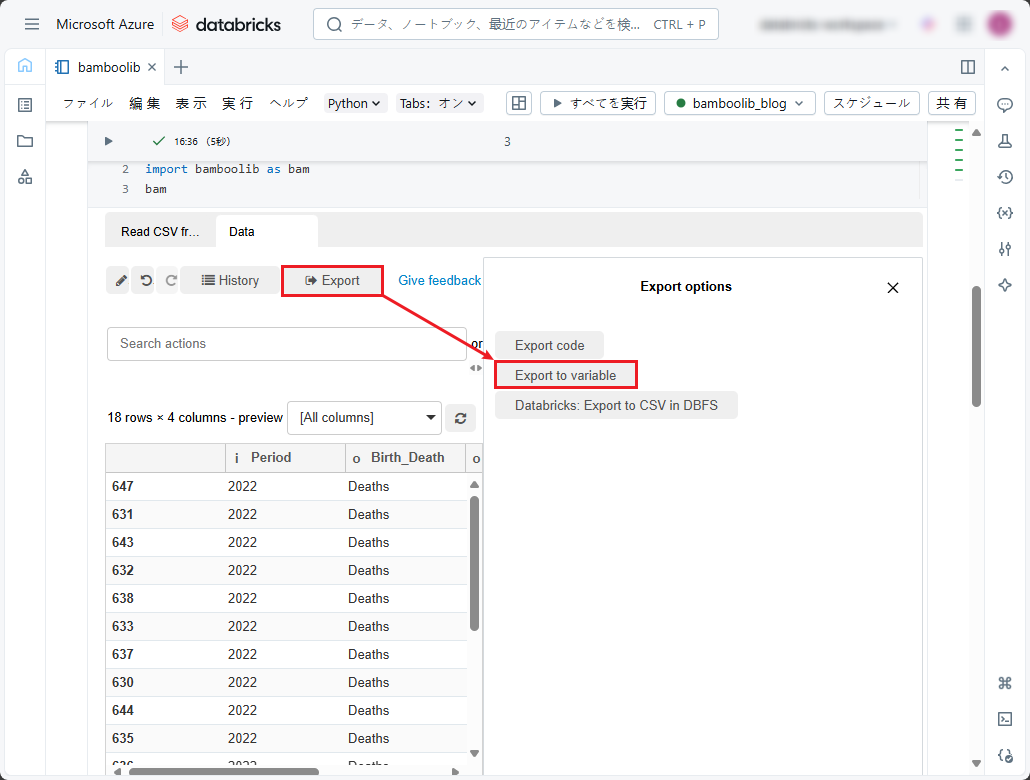
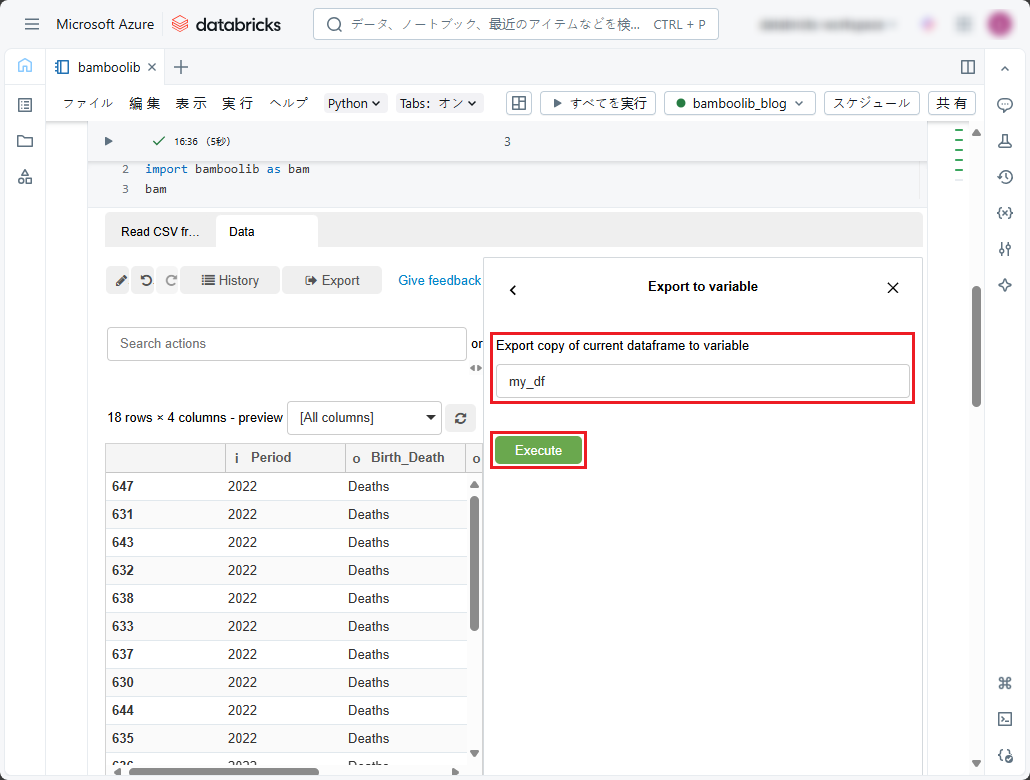
② 変数の名前を入力します。
③「Execute」ボタンをクリックします。
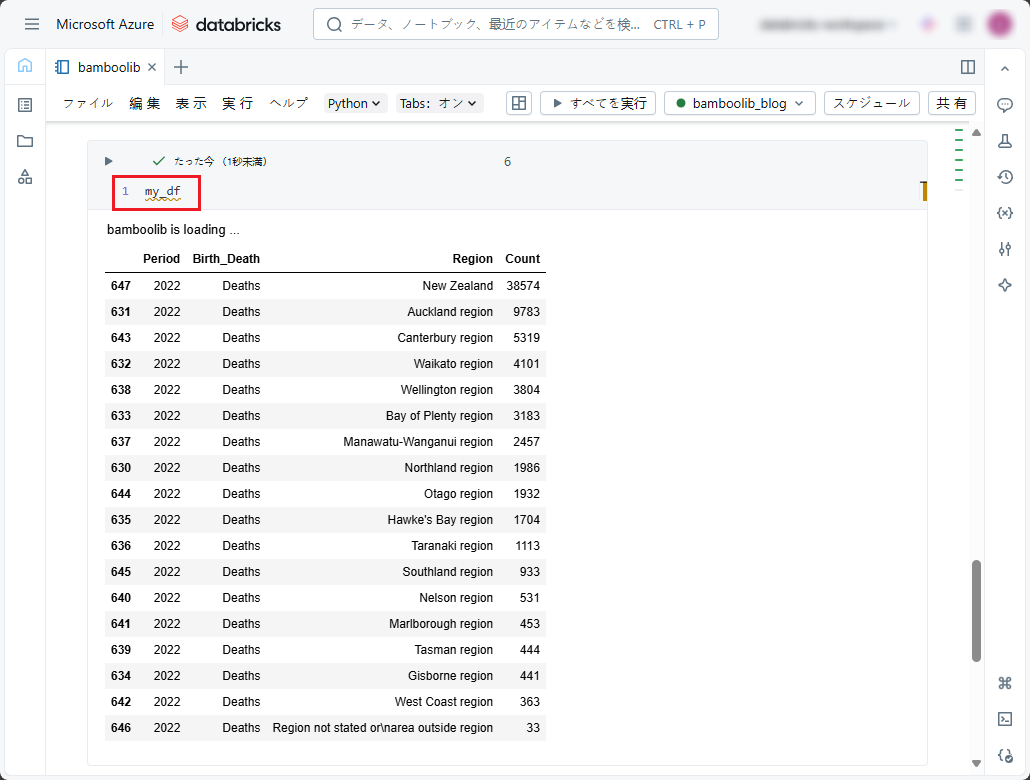
④ この変数を使用して、現在のウィジェットの状態をpandas DataFrameとしてプログラム上で再作成できます。
4-4.データ保存
この変数を使用して、データを保存します。
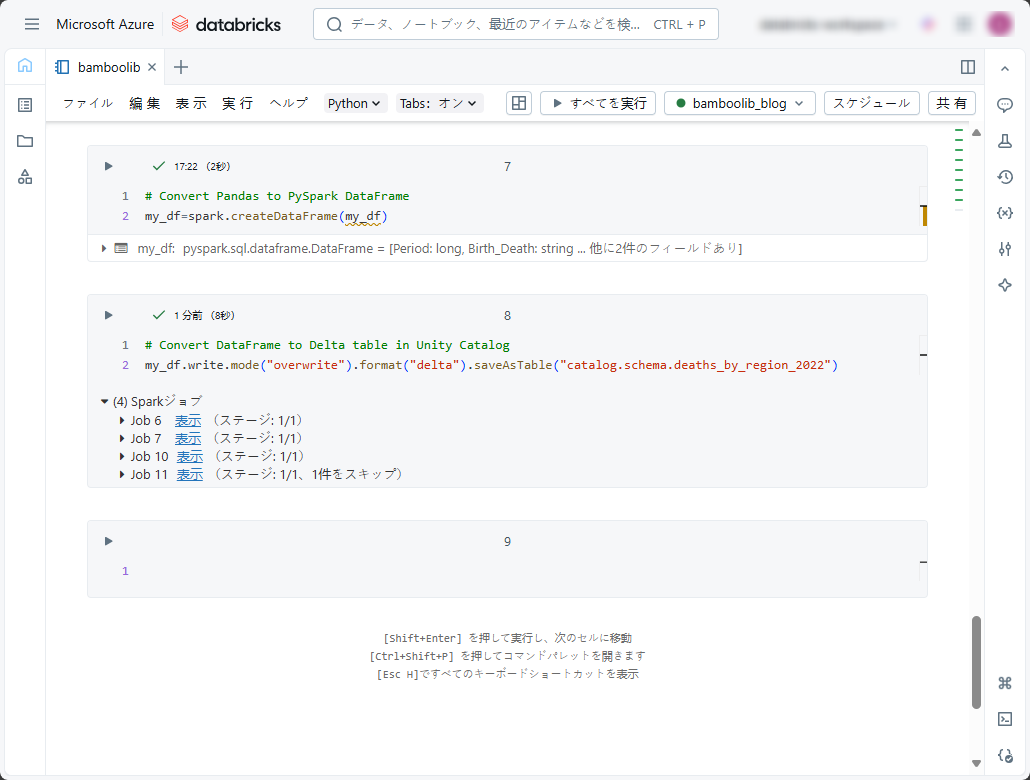
① 以下のコードをコピーしてデータを表示し、ノートブックで実行します。
※例としてご参照ください。
|
1 |
my_df=spark.createDataFrame(my_df) |
|
1 |
my_df.write.mode("overwrite").format("delta").saveAsTable("catalog.schema.deaths-by-region_2022") |
上記のコマンドを実行すると、データがUnityカタログのデルタ テーブルに保存されました。
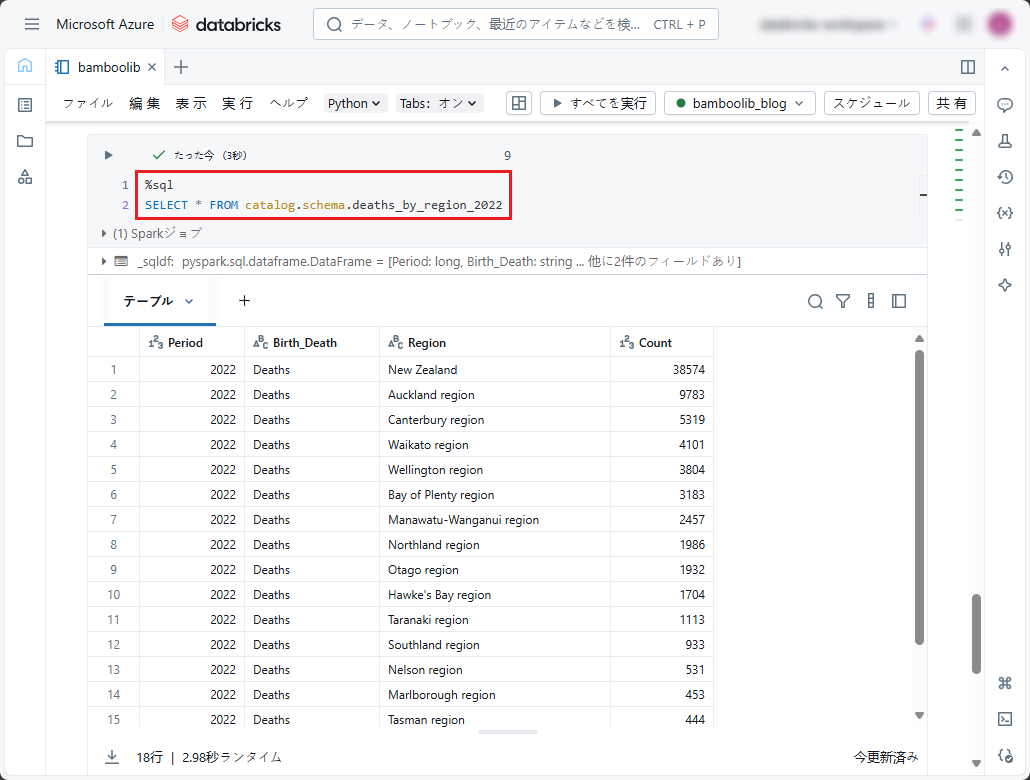
下記の SQLコマンドを実行して、DataFrameから保存したデルタ テーブルを表示します。
※例としてご参照ください。
|
1 |
SELECT * FROM catalog.schema.deaths_by_region_2022 |
5.まとめ
DatabricksでローコーティングでETL/ELTを実現するためのbamboolibを利用する方法について説明しました。
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
・Azure Databricks連載シリーズはこちら