目次
1.はじめに
皆さんこんにちは。
この連載では、Azure Databricks サンプルダッシュボードを使ったデータの可視化と基本的な操作方法と
ダッシュボードの作成方法について説明します。
今回は、「NYCタクシーデータセット」を使用して総走行数の可視化の作成方法についての詳細を説明していきます。
第1回:【Azure Databricks SQL ダッシュボード】サンプルダッシュボードのインポートと基本操作
第2回:【Azure Databricks SQL ダッシュボード】総走行数の可視化の作成(今回)
第3回:【Azure Databricks SQL ダッシュボード】曜日ごとの運賃と距離の可視化の作成
第4回:【Azure Databricks SQL ダッシュボード】乗車時間分布の可視化の作成
第5回:【Azure Databricks SQL ダッシュボード】ルート別運賃の分析の可視化の作成
第6回:【Azure Databricks SQL ダッシュボード】降車時間別の乗車回数の可視化の作成
2.データの準備
2-1.Unity カタログにデータの保存
本書では、Databricks で NYC タクシーのデータセットを使用します。 次は、ノートブックを使用してこのデータセットをUnity Catalogにコピーします。
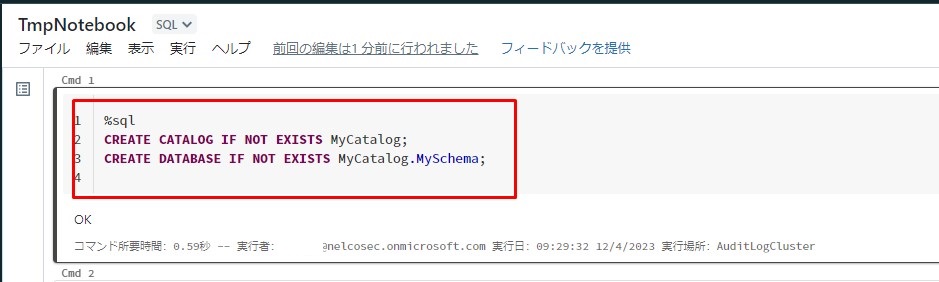
①「MyCatalog」カタログ及び「MySchema」スキーマを作成するにノートブックを開き、以下のコードをコピーして実行します。
文法
%sql
CREATE CATALOG IF NOT EXISTS 「カタログ名」;
CREATE DATABASE IF NOT EXISTS 「カタログ名」.「スキーマ名」;
例
|
1 2 3 4 |
%sql CREATE CATALOG IF NOT EXISTS MyCatalog; CREATE DATABASE IF NOT EXISTS MyCatalog.MySchema; |
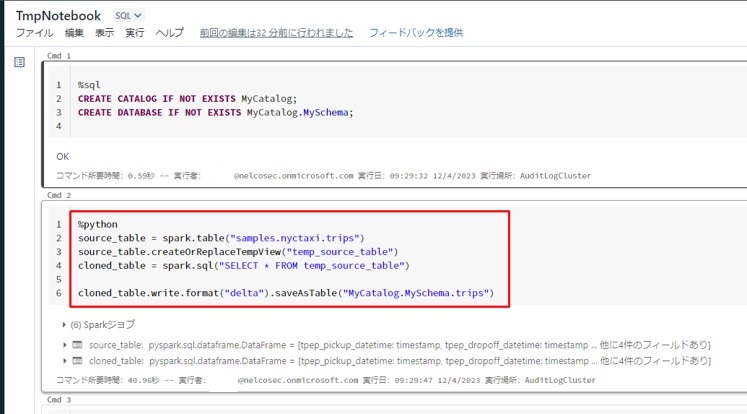
②以下のコードを実行し、Hiveメタストアでの「NYC タクシー」データセットをコピーして、作成したスキーマに保存します。
文法
%python
source_table = spark.table(“samples.nyctaxi.trips”)
source_table.createOrReplaceTempView(“「一時的テーブル名」”)
cloned_table = spark.sql(“SELECT * FROM 「一時的テーブル名」”)
cloned_table.write.format(“delta”).saveAsTable(“「カタログ名」.「カタログ名」.「テーブル名」”)
例
|
1 2 3 4 5 6 |
%python source_table = spark.table("samples.nyctaxi.trips") source_table.createOrReplaceTempView("temp_source_table") cloned_table = spark.sql("SELECT * FROM temp_source_table") cloned_table.write.format("delta").saveAsTable("MyCatalog.MySchema.trips") |
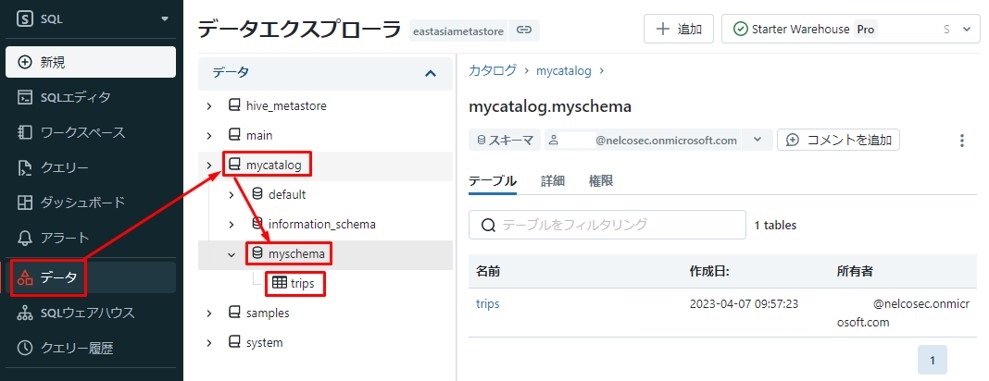
③以下の通りで実行し、Unity Catalogに保存されたデータを確認します。
※サイドバーで「データ」をクリックし、作成したカタログを確認します。
※「mycatalog」をクリックし、作成したスキーマを確認します。
※「myschema」をクリックし、作成したテーブル「trips」を確認します。
3.ダッシュボードの作成
3-1.クエリを作成
総走行数を可視化するには、クエリを作成し、総走行数を取得します。
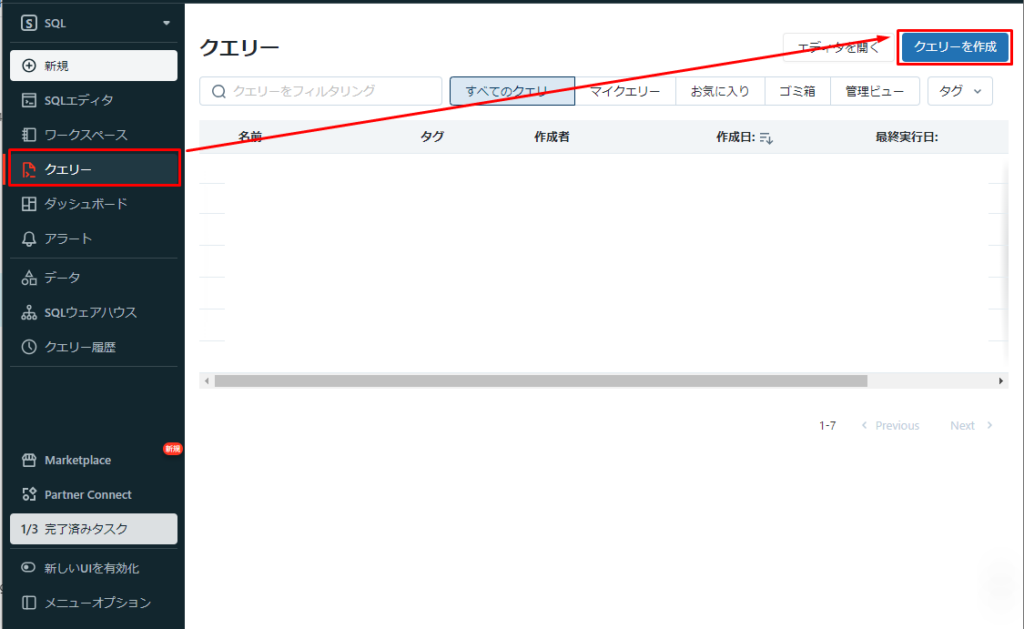
①サイドバーで「クエリー」をクリックし、「クエリーを作成」ボタンをクリックします。「SQLエディタ」画面が表示されます。SQLエディタは、SQLクエリを実行するためのツールです。
②以下のコードをエディタにコピーし、指定時間内の総走行数を取得します。以下の2つテキストボックスでパラメーターを入力し、コマンドを実行します。
※動的に値を指定したい場合は列名を {{ パラメータ名 }} で囲います。
※日付の範囲指定を行う場合 {{ パラメータ名.start }}と{{ パラメータ名.end }} で指定します。
文法
USE CATALOG 「カタログ名」;
SELECT
count(*) as 「別名」
FROM
「カタログ名」.「スキーマ名」.「テーブル名」
WHERE
「列名」 BETWEEN TIMESTAMP ‘{{ 「パラメータ名」.start }}’
AND TIMESTAMP ‘{{ 「パラメータ名」.end }}’
AND 「列名」 IN ({{ 「パラメータ名」 }})
例
|
1 2 3 4 5 6 7 8 9 |
USE CATALOG MyCatalog; SELECT count(*) as total_trips FROM `MyCatalog`.`MySchema`.`trips` WHERE tpep_pickup_datetime BETWEEN TIMESTAMP '{{ pickup_date.start }}' AND TIMESTAMP'{{ pickup_date.end }}' AND pickup_zip IN ({{ pickupzip }}) |
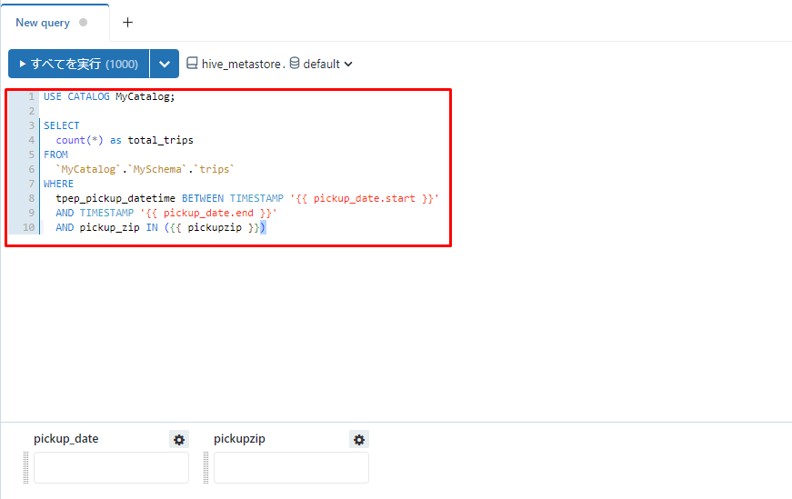
③「pickup_date」の隣の![]() をクリックすると、ダイアログが表示されます。「Title」項目でタイトルを入力します。(例:「利用期間」)
をクリックすると、ダイアログが表示されます。「Title」項目でタイトルを入力します。(例:「利用期間」)
④「Type」項目で「日時範囲」を選択して、「OK」をクリックします。
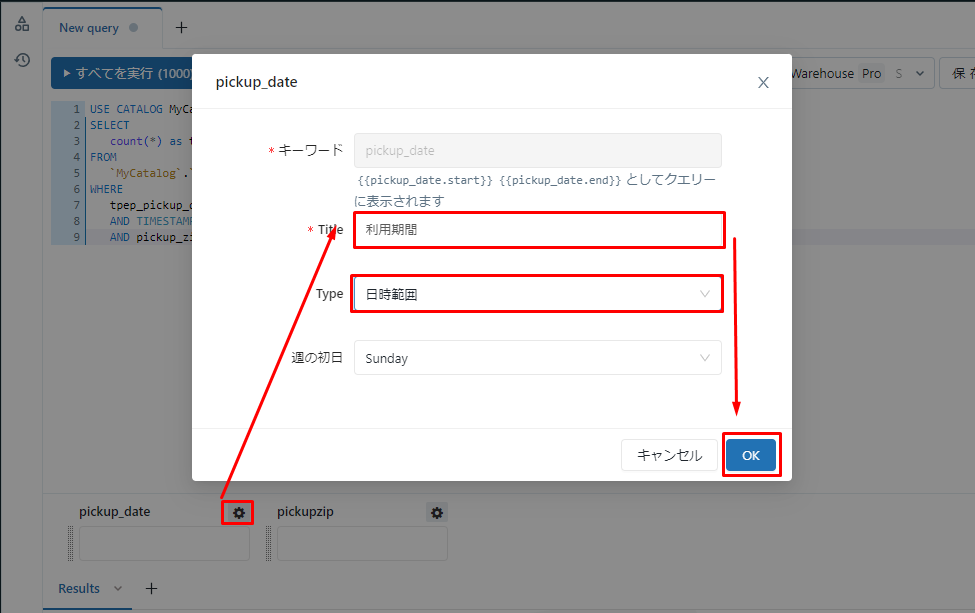
開始日と終了日を選択できるように以下のテキストボックスが変更されました。
⑤「pickupzip」の隣の![]() をクリックするとダイアログが表示されます。
をクリックするとダイアログが表示されます。
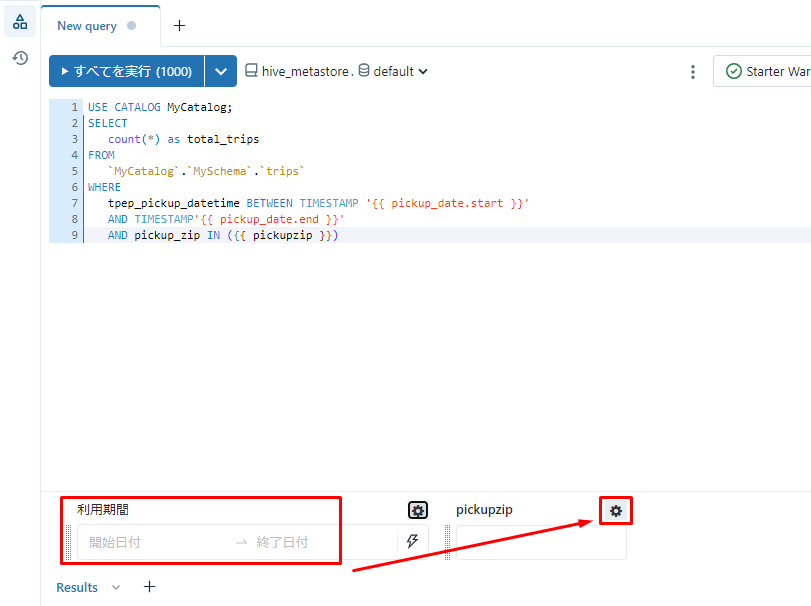
⑥「Title」項目で「ピックアップジップ」を入力します。「Type」項目で「ドロップダウンリスト」を選択します。
⑦「値」項目で以下の値を入力します。
|
1 2 3 4 5 6 |
10154 10065 10001 11369 11223 7087 |
⑧「複数の値を許容」にチェックをいれて、「OK」をクリックします。
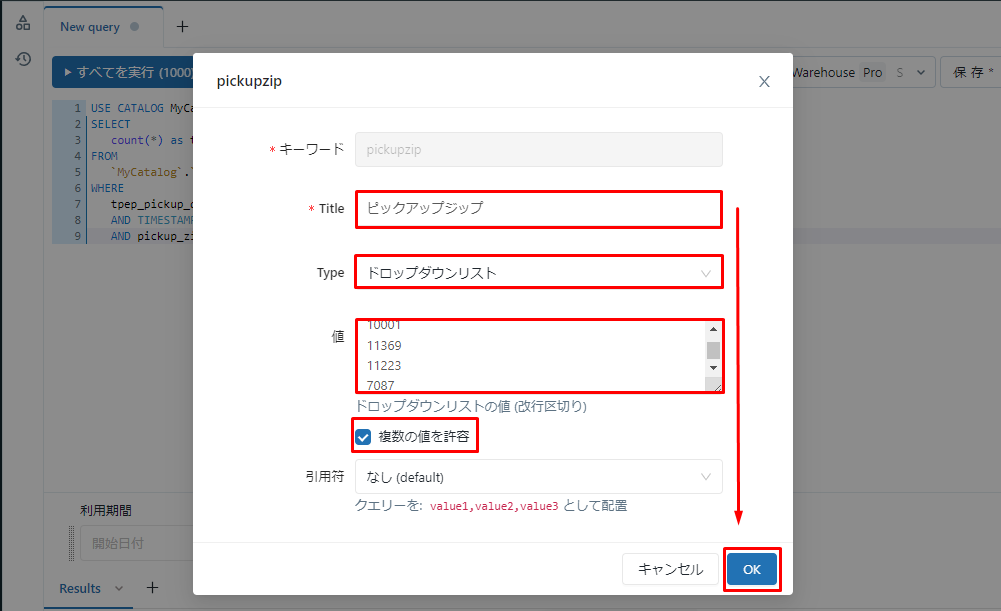
⑨テキストボックスで値を選択し、「変更を適用」をクリックします。
例: 「利用期間」:「2016-01-01」~「2016-01-31」
「 ピックアップジップ 」:「10001」
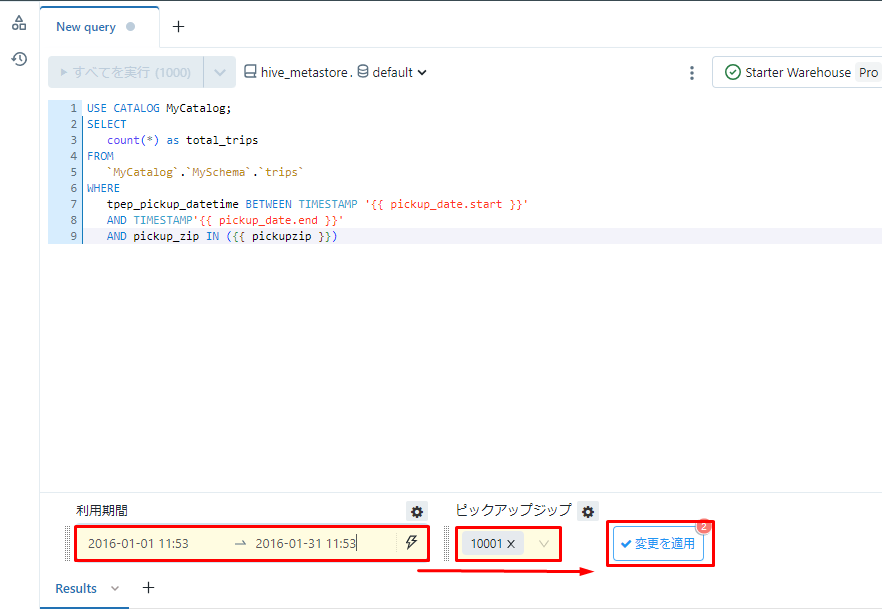
⑩pickup_zip が 10001 となる場合、2016年1月の総走行数が以下の画像の通りに出力されます。 「保存」をクリックしてクエリを保存します。
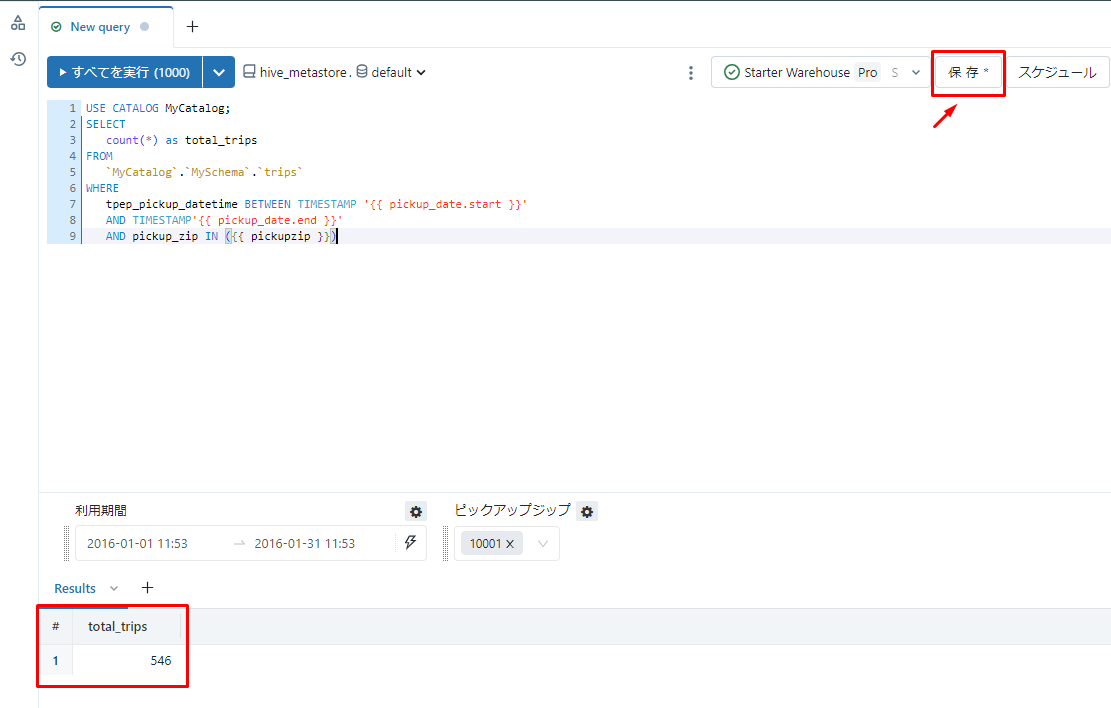
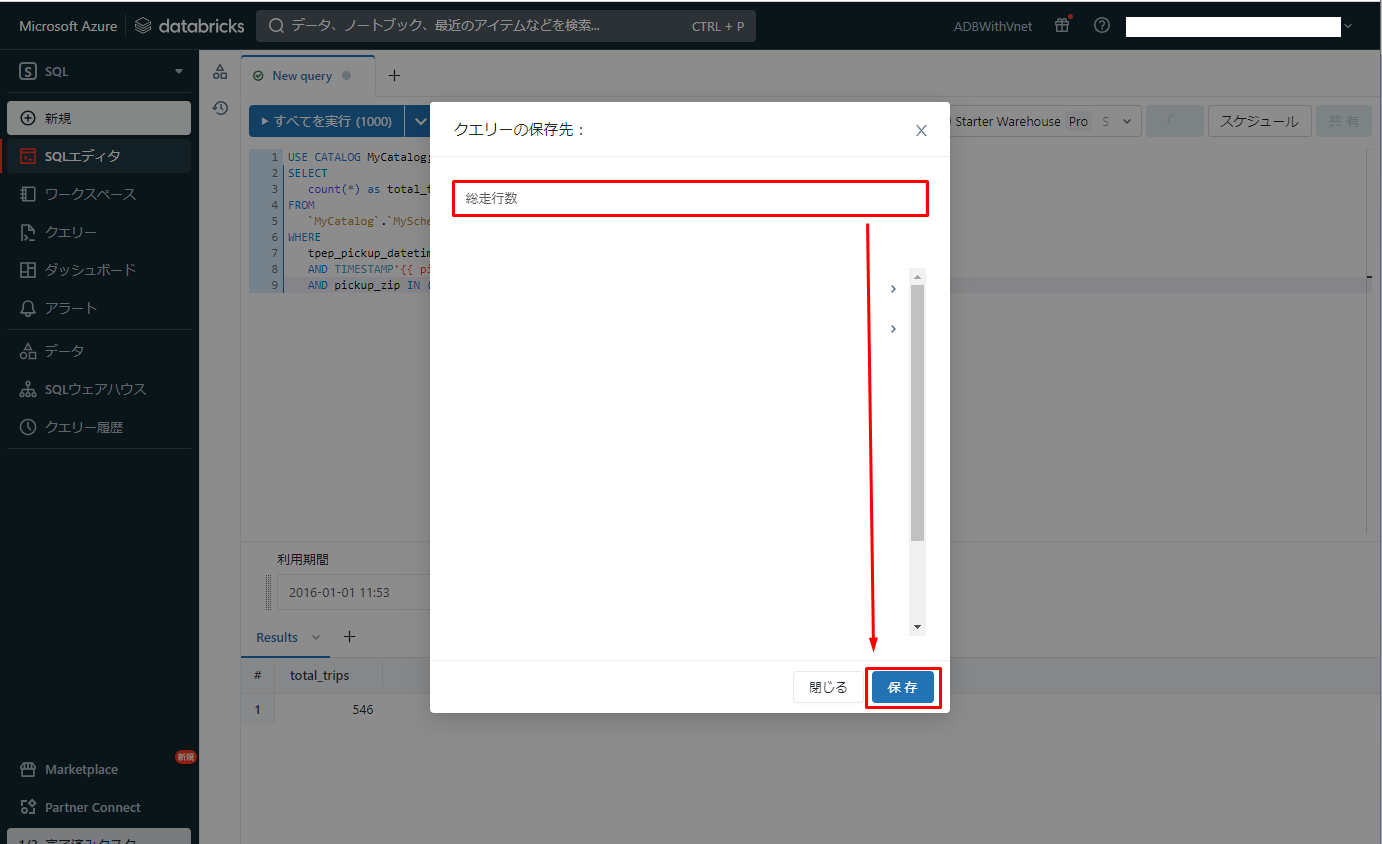
⑪「保存」をクリックすると、ダイアログが表示されます。クエリに「総走行数」等の名前を付けて、「保存」をクリックします。
3-2.総走行数の可視化の作成
クエリを作成した後、ダッシュボードを作成し、可視化します。
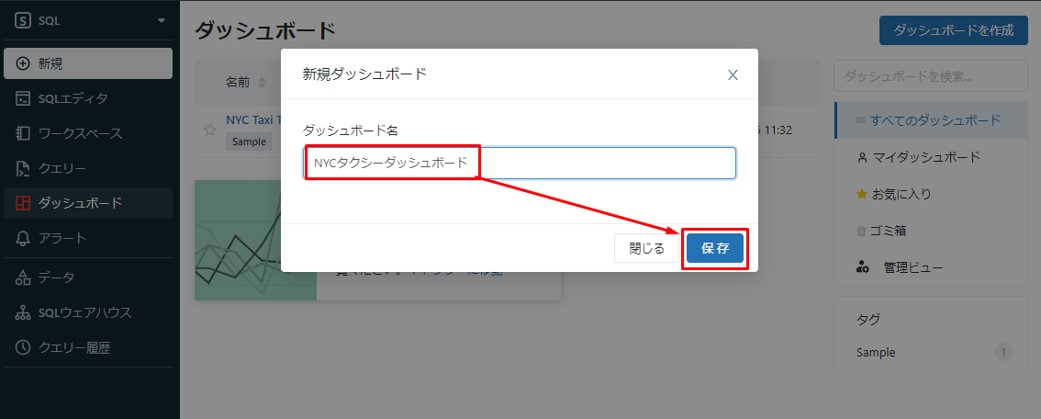
①ダッシュボードを作成するには、サイドバーで「ダッシュボード」をクリックして「ダッシュボードを作成」をクリックします。
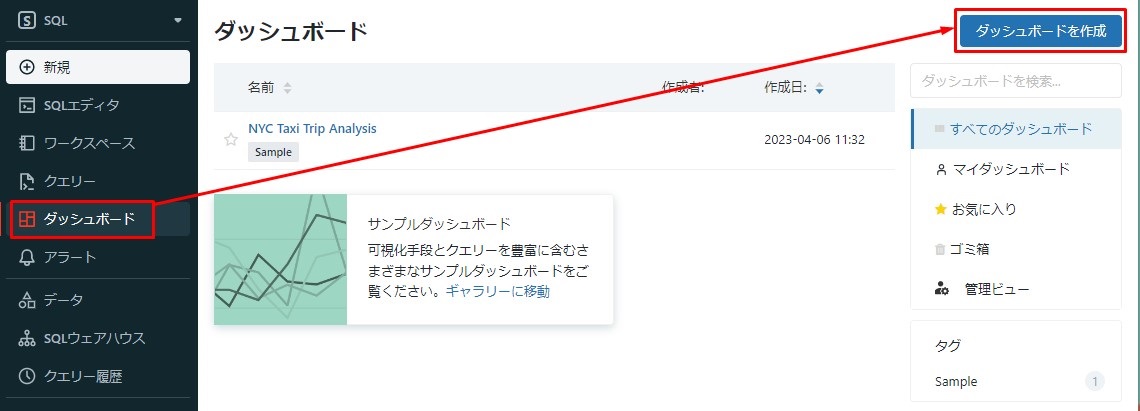
②表示されるダイアログでダッシュボードの名前を入力できます。例えば、「NYCタクシーダッシュボード」と入力し、「保存」をクリックします。
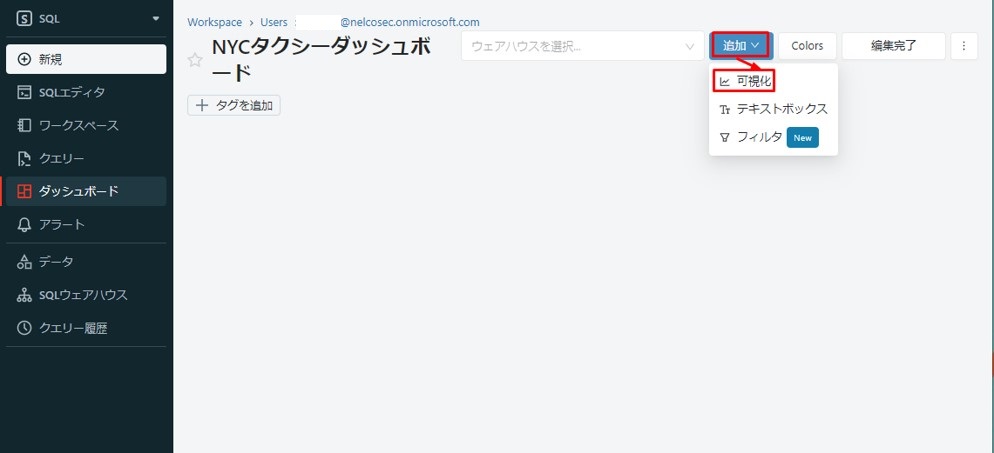
③「追加」をクリックして、「可視化」を選択します。
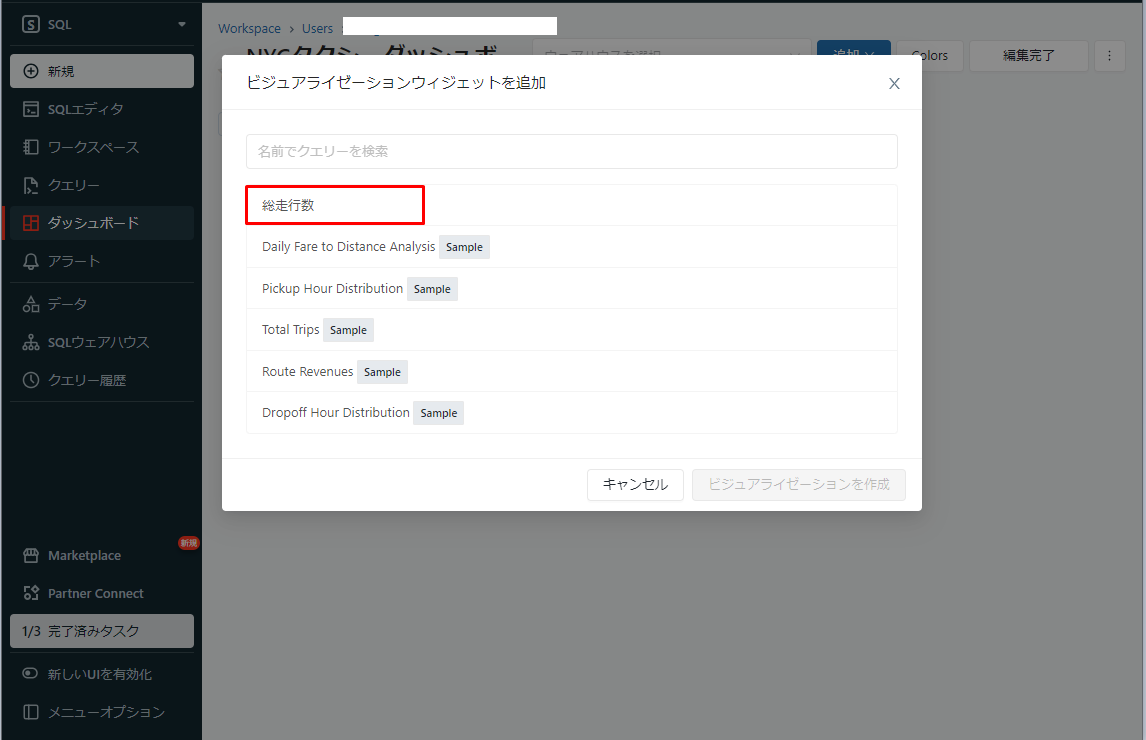
④作成したクエリを表示しているダイアログで選択します。
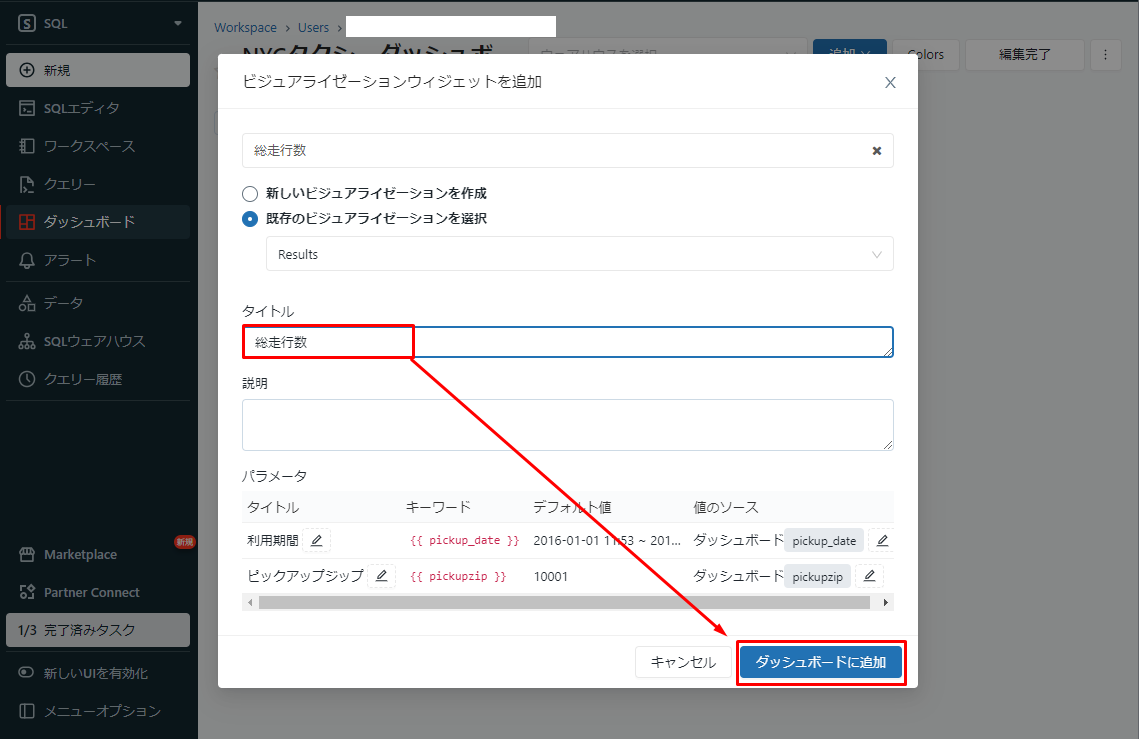
⑤「タイトル」項目で「総走行数」等のタイトルを入力して、「ダッシュボードに追加」をクリックします。
⑥ビジュアライゼーションを改善させるため、マウスを移動して、![]() をクリックして、 「ビジュアライゼーションを編集」を選択します。
をクリックして、 「ビジュアライゼーションを編集」を選択します。
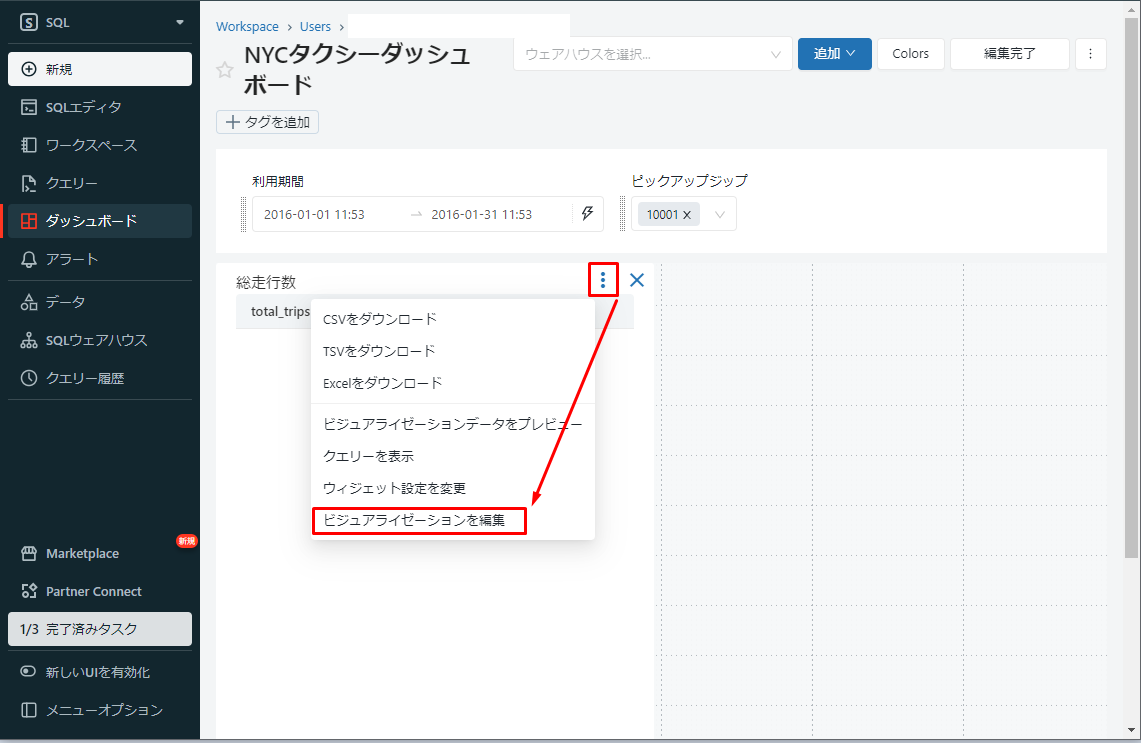
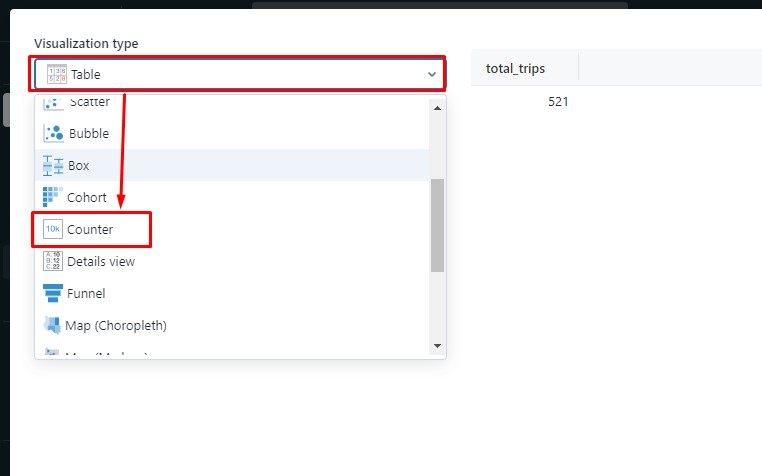
⑦ダイアログの「Visualization type」項目で「Counter」を選択します。
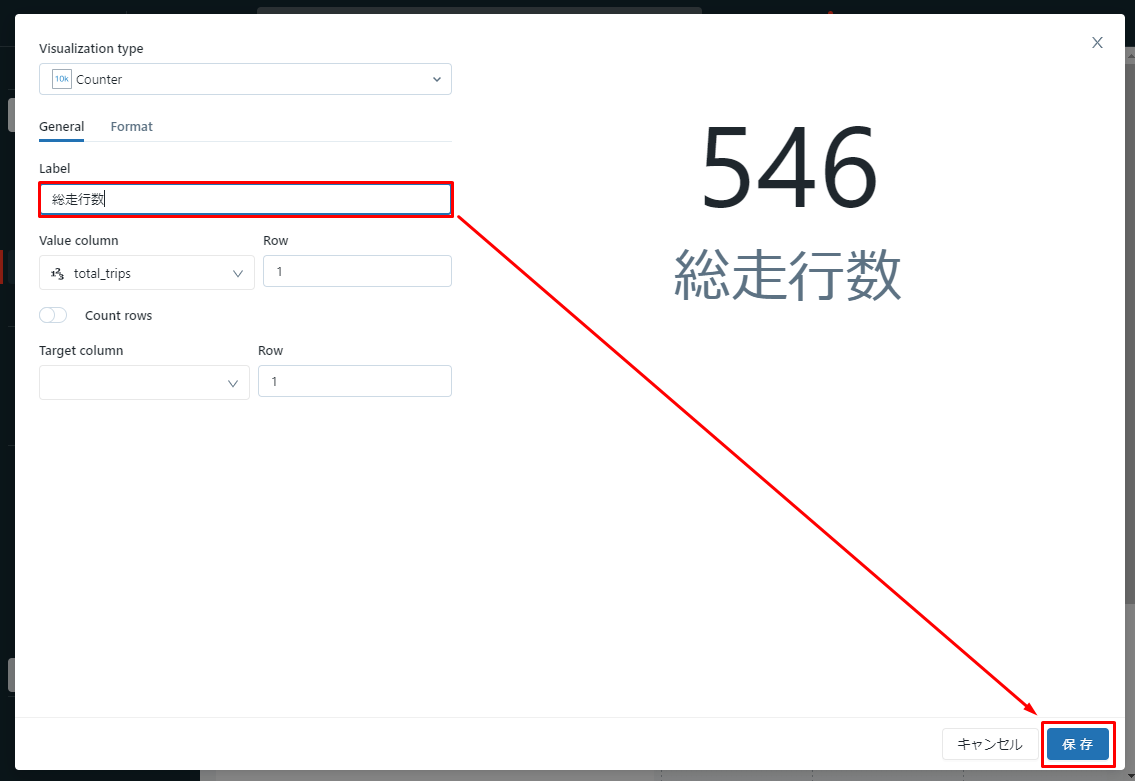
⑧「Counter」を選択した後、「Label」項目で「総走行数」を入力して、「保存」をクリックします。
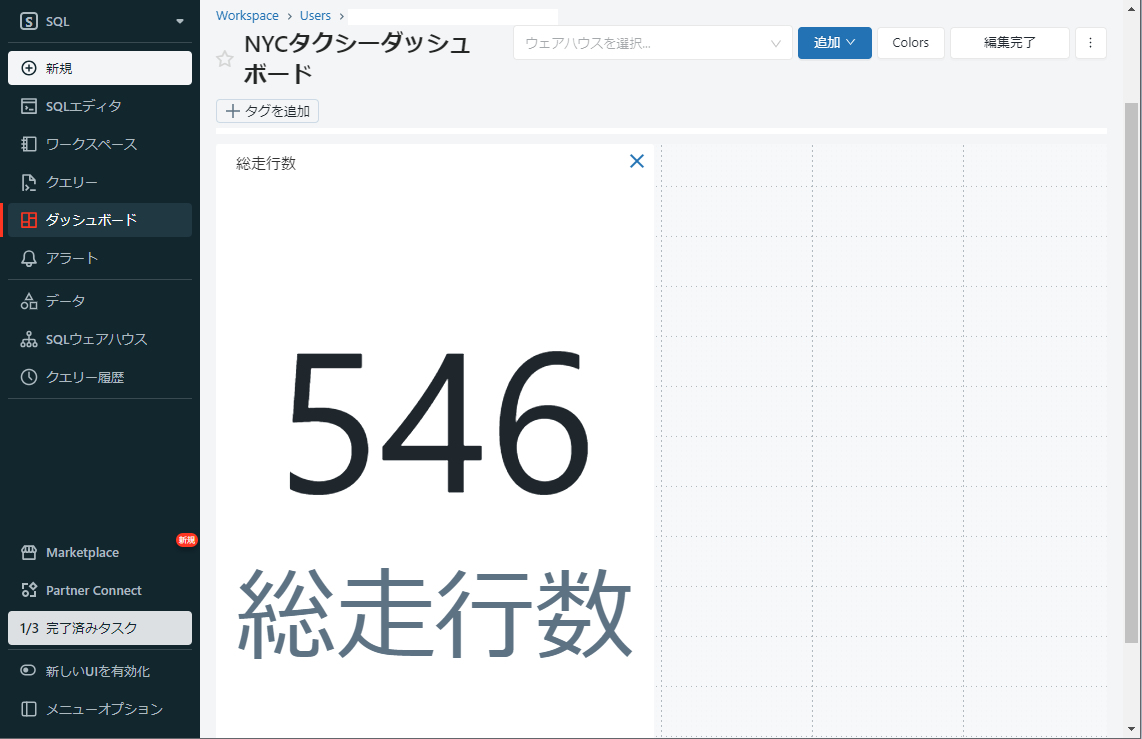
⑨ビジュアライゼーションがダッシュボードに表示されます。
4.まとめ
本連載では、
「NYCタクシーデータセット」を使用して総走行数の可視化の作成方法について詳細に説明していきます。
第1回:【Azure Databricks SQL ダッシュボード】サンプルダッシュボードのインポートと基本操作
第2回:【Azure Databricks SQL ダッシュボード】総走行数の可視化の作成(今回)
第3回:【Azure Databricks SQL ダッシュボード】曜日ごとの運賃と距離の可視化の作成
第4回:【Azure Databricks SQL ダッシュボード】乗車時間分布の可視化の作成
第5回:【Azure Databricks SQL ダッシュボード】ルート別運賃の分析の可視化の作成
第6回:【Azure Databricks SQL ダッシュボード】降車時間別の乗車回数の可視化の作成
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
日商エレクトロニクスでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
・Azure Databricks連載シリーズはこちら