
データ分析からAI活用まで必要なプロセスを簡素化Azure Databricks1つで
データウェアハウスとデータレイク機能を実現
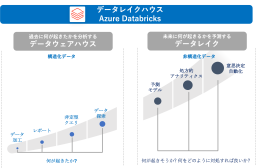
従来、BI分析を目的としたデータウェアハウス(構造化データ)と
AI活用や機械学習を目的としたデータレイク(非構造化データ)を利用するにはそれぞれ互換性の無い2つの基盤が必要でした。
しかし、レイクハウスというそれぞれの機能を持ち合わせた
Azure Databricksは1つの基盤でBI分析もAI活用も実現できます。
多くの企業で利用されているAzure ADやMicrosoft 365などの
サービス間連携も容易で、拡張性に優れています。
レイクハウスとは?
レイクハウスとは、データベースなどで作成されたデータ(構造データ)など膨大な量のデータを利用者の目的に応じて整理・格納し
BI分析できるよう管理する仕組みのデータウェアハウスと、画像・音声・メールログ(非構造データ)などを生のまま格納して
AI分析や予測検知などに活かすデータレイクの両方を実現できる新しい技術です。
Azure Databricksの特長
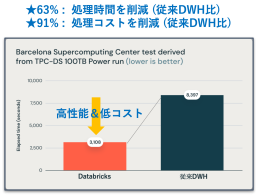
01.圧倒的な処理性能とスケーリングで
生産性を向上
Azure DatabricksはApache Sparkの上に構築されており、分散処理をサポートしています。これにより大量のデータを効率的に処理でき、データの読み込みや書き込みが高速化されます。また、クラウド上で動作するため必要なリソースを柔軟かつ迅速にスケーリングすることができます。
実際に従来のデータウェアハウスと比較して、処理時間を最大63%削減することが証明されています。
02.Azure サービスとの連携が容易で
セキュリティの制御、
環境管理が簡単
Azure のサービスとシームレスに統合することができ、
データアクセスの高速化や管理の簡素化を実現します。
Azure Active Directoryを利用したシングルサインオン、
新規ユーザーの作成、適切なアクセス権限の付与、
ユーザーの削除に伴うアクセスのプロビジョニング解除が可能です。

03.ユーザーにあったインターフェースの用意と
ワークフローの自動化で使いやすい
ローコードにてダッシュボード検索やPython、Scala、Javaなどお好みの言語で簡単にデータ処理を実行できます。ジョブのスケジューリングや自動フェールオーバーなど、ワークフローの自動化機能も提供しており、ユーザーを選ばずどのような分析にも対応できます。
Azure Databricksの機能
Azure Databricksの役割としてすべての構造化・非構造化データを蓄積するAzure のストレージ部分と
それらデータを処理するDatabricksの機能の大きく2つに分けられます。
ストレージにはAzure Blob Storage、Azure Data Lake Storageを利用することができます。
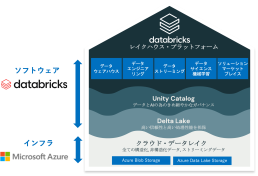
Delta Lake
Delta Lakeはデータレイクの信頼性、一貫性、スケーラビリティを向上させることを目的としている機能です。

主な機能
- トランザクションを使用して、データの原子性、一貫性、分離性、耐久性を保証
- データの変更履歴を保持するためにバージョニングをサポート。異なる時点でのデータを比較することができ、データ品質の改善が可能。
- データのスキーマ変更時に旧バージョンのデータも保持され、新しいスキーマに適合するようにデータが変換。
- データを論理的に分割し、検索やクエリのパフォーマンスを向上させる。
- データの圧縮によりストレージの使用量が削減され、クエリのパフォーマンスが向上。
- データの一貫性を保ちながら、ストリーミングデータのバッチ処理と統合を行う。
- Delta Lakeに保存されたデータを機械学習モデルに統合。
Unity Catalog
Unity Catalogとは、データカタログにデータを統合し一元管理・検索できることを目的とした機能です。

主な機能
- データセットはファイル、テーブル、ノートブック、ワークフローなどの形式で保存可能
- データセットの名前、タグ、説明などを検索条件として使用できる検索機能
- タグ付けにより、データセットを簡単に分類
- データに変更があった場合、過去のバージョンと比較できるバージョン管理
- ユーザーごとのアクセス制御機能
- データの重複や欠落などの問題を検出し解決
活用例
さまざまなデータを
一元的に取り扱ってDXを促進
お客様の課題
- データ量が膨大で適切に分析するためのデータ分析基盤を持っていない。
- 分析の作業などをパートナーに任せていて欲しい情報がすぐに手に入らない。スピード感がない。
- 分析作業を業務委託しているのでコストがかかる。投資対効果が薄い。
Azure Databricks導入後
- 社内外の様々なデータがAzureDataFactoryを経由して Azure Databricks に蓄積。また、基盤に蓄積されたデータは必要に応じて SQL Database に出力、格納され、Power BI を使って可視化することで社内ユーザーへの共有が簡単に。
- 自分たちでAzureサービスを組み合わせて、使いやすい基盤を構築できた。
- リソースの拡張が簡単なので、使いたいときに使いたい分だけ利用できるようになってコストを最適化できた。
Azure Databricks 導入価格
Azure databricksは月額従量課金制です。
※インスタンスの1年予約・3年予約で割引を受けることは可能です。
データ量により価格は変動しますが、以下ご参考ください。
費用の変動要素
費用の変動要素として、大きく2つあります。
①Azureリソース分(インフラレイヤー)- VMの種類と稼働時間
②Databricks利用時間分(ソフトウェアレイヤー)-Data Bricksの稼働時間
SQLサーバーを使うか、サーバレスにするかで費用も変わります。
詳しくは、当社にご相談ください。ご相談はこちら>
| Azure(月額) | ¥159,590~ |
|---|---|
| 構築作業 | ¥300,000~ |
| 保守(月額) | ¥200,000 |
| メンテナンス(月額)*オプション | ¥200,000~ |
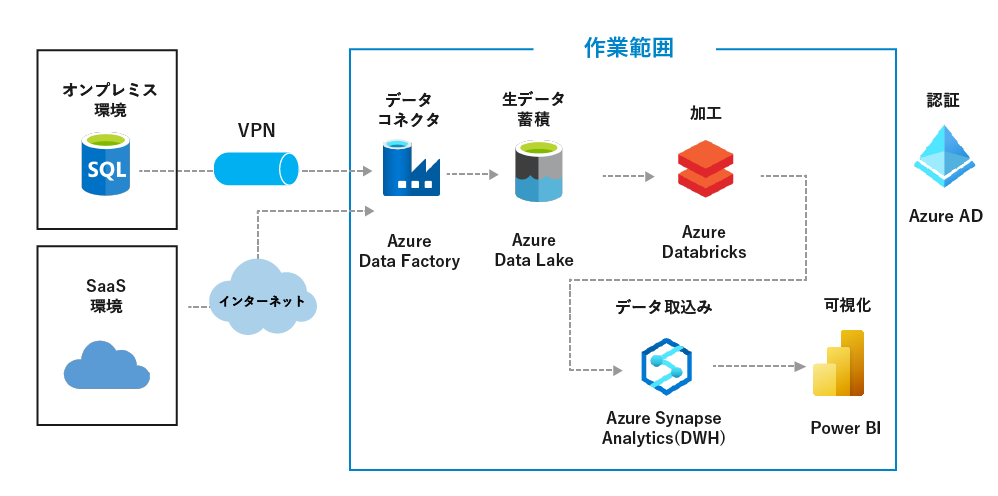
- オンプレミス/SaaSアプリに散乱する企業データをAzure Data Factoryを活用し、
Azure Data Lakeの大容量ストレージに収集・蓄積します。 - 収集・加工したデータはPower BIで可視化します。
- Azure Data Factoryを補完するために、CDateを活用すれば、
収集できるデータはさらに広がります。