目次
1. はじめに
皆さんこんにちは。
今回からMicrosoft Fabricについての連載ブログを始めていきます。
全 5 回を予定しています。第3回ではData Factory ユーザー向け Fabric チュートリアルについて説明いたします。
第1回:Microsoft Fabric 概要と試用版の作成方法
第2回:Power BI ユーザー向け Fabric チュートリアル
第3回:Data Factory ユーザー向け Fabric チュートリアル (今回)
第4回:Synapse Data Engineering ユーザー向け Fabric チュートリアル_第1回
第5回:Synapse Data Engineering ユーザー向け Fabric チュートリアル_第2回
前回のブログで、 Microsoft Fabric のPower BI の使用方法について説明しました。今回は、Microsoft Fabric の Data Factory の使用方法を簡単に説明していきます。
MS Fabric の Data Factory を利用することで、一般的なエンドツーエンドのデータ統合シナリオを完了する方法を理解できます。
これには、ソースストからレイアハウスの Bronze テーブルへの生データの取り込み、すべてのデータの処理、データレイクハウスの Gold テーブルの移動、すべてのジョブの完了時に通知する電子メールの送信、最後にスケジュールに基づいて実行するフロー全体の設定が含まれます。
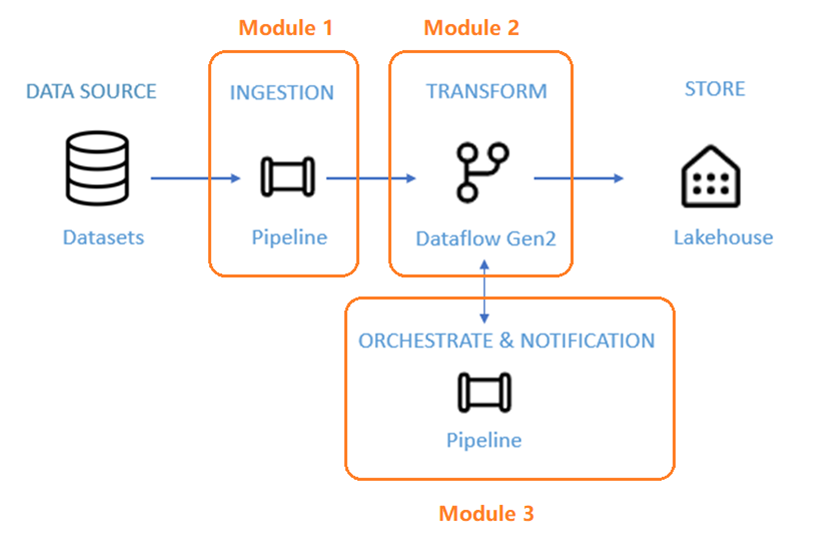
2. 前提要件
実施する際の前提条件は以下の通りです。
・開始する前に、組織に対して Fabric を有効にする必要があります。
・まだサインアップしていない場合は、無料試用版にサインアップしてください。
・「green_tripdata_2015-01.parquet」ファイルをダウンロードする必要があります。
3. Data Factory とは?
Data Factory は、さまざまなデータ ソースからデータを取り込み、準備し、変換するために、サーバーレスで最新のデータ統合機能を備えたデータ統合ソリューションです。
Microsoft Fabric の Data Factory は、データピイプライとデータフローの両方に高速コピー (データ移動) 機能を備えています。高速コピーを使用すると、希望のデータストア間でデータを高速で移動できます。それに、分析のために Microsoft Fabric のレイクハウスとデータウェアハウスにアクセスできます。
4. Microsoft Fabric に Data Factory の役割
Fabric の Data Factory は、Power Query の使いやすさと、Azure Data Factory のスケールとパワーを兼ね備えています。
その結果、両方の製品の長所が統合され、統一されたエクスペリエンスが提供されます。目標は、Factory の Data Integration が市民およびプロフェッショナルのどちらのデータ開発者にも適切に機能するようにすることです。
これは、ハイブリッドのマルチクラウド接続、ペタバイト規模の変換、ローコードで AI 対応のデータ準備と変換の能力を備えた数百のコネクタを提供します。
5. パイプラインを作成する
5-1. パイプラインを作成する
① Microsoft Fabric にサインインします。
② 作成されたワークスペースにアクセスする
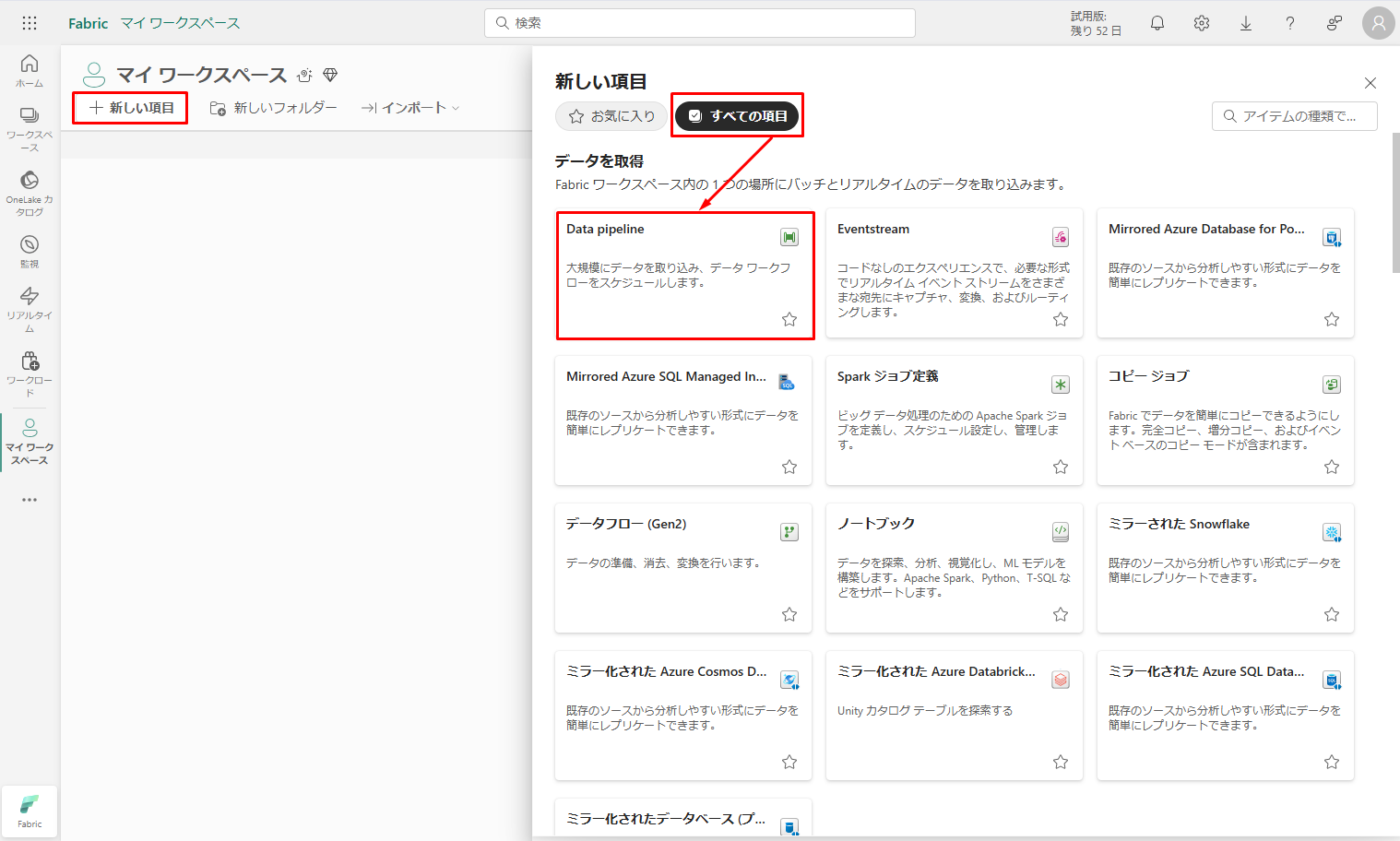
③「新しい項目」をクリックして「すべての項目」を選択し、「データを取得」するタブを見つけて「データ パイプライン (Data Pipeline)」を選択します
5-2. パイプラインで「データのコピー」を使用して、サンプルデータをデータ Lakehouse に読み込みます。
Copy アシスタントを使用してコピーアクティビティを構成します。
①「データ コピーのアシスタント」を選択して
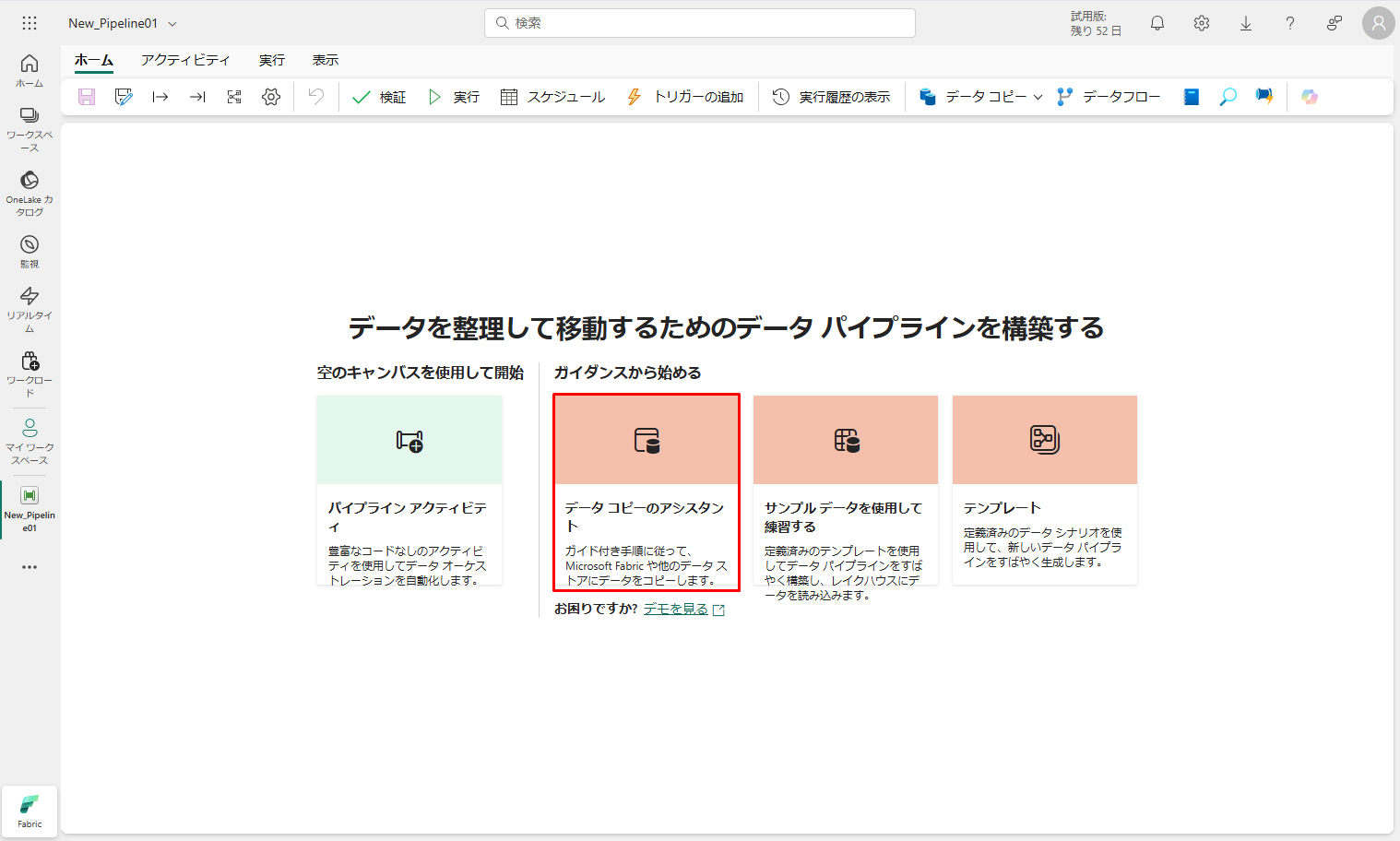
コピーアシスタントで設定を構成します。
②「データのコピー」ダイアログが表示され、最初の手順である 「データ ソースの選択」が強調表示されています。
③ 「新規」タブを選択し、「すべて」を選択します、Azure Data Lake Storage Gen2 データ ソースの種類を選択します。
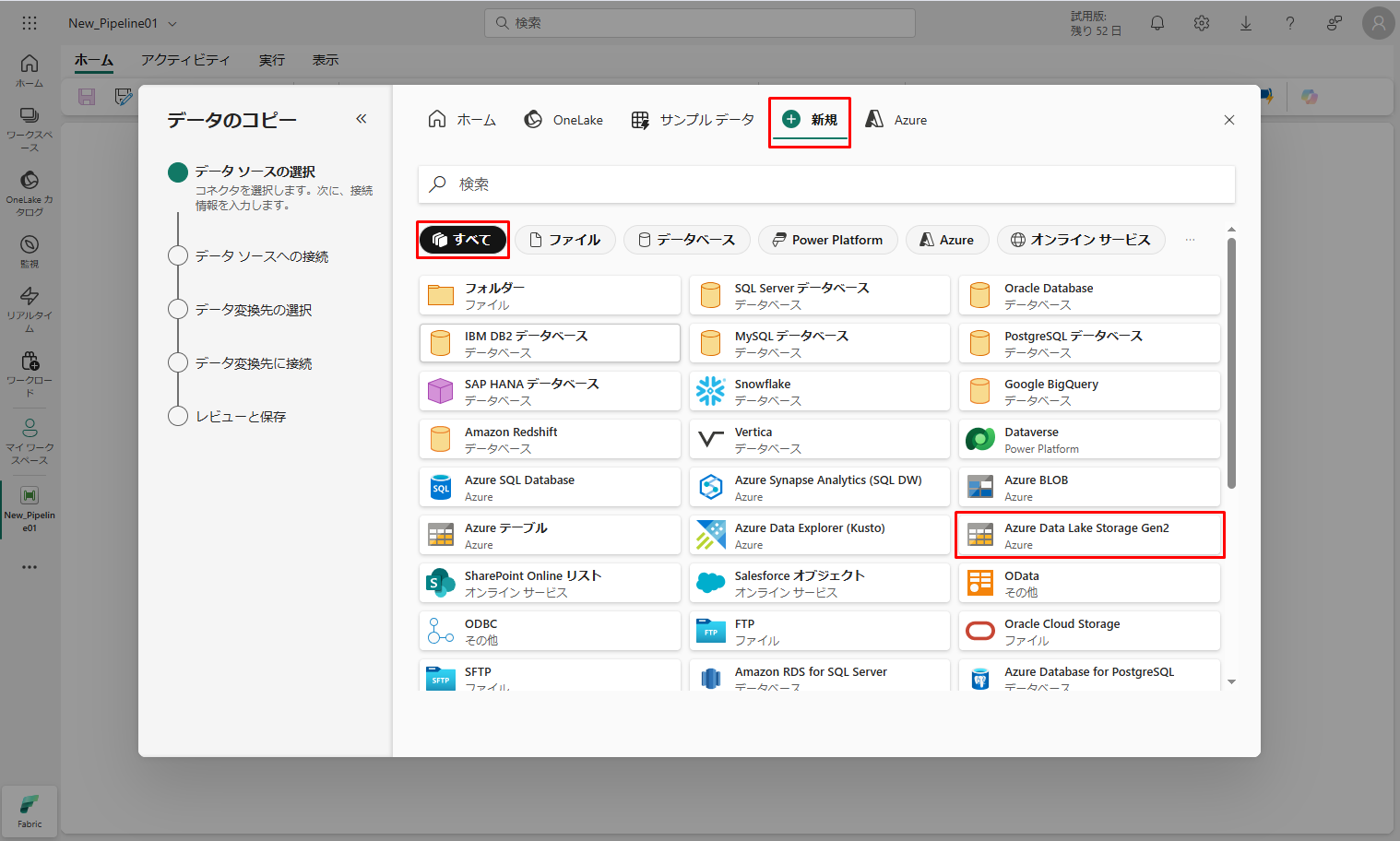
④ 次は、「新規接続の作成」を選択し、サンプル データが配置されているストレージ gen2 の URL を指定します。
文法:
|
1 |
https://<storage-account-name>.dfs.core.windows.net/<container-name> |
<container-name>:作成したコンテナー名
<storage-account-name>:ストレージアカウント名
※ 例
|
1 |
https://dtbacc.dfs.core.windows.net/raw |
⑤ 認証の種類はサービス プリンシパルです。URL および、サービス プリンシパルの構成用の情報を入力し、「次へ」をクリックします。
Azure Portal でサービス プリンシパルとそのクライアント シークレットを作成する必要があります。
接続対象のストレージ アカウントの作成されたサービス プリンシパルにストレージ BLOB データ共同作成者権限を付与する必要があります。
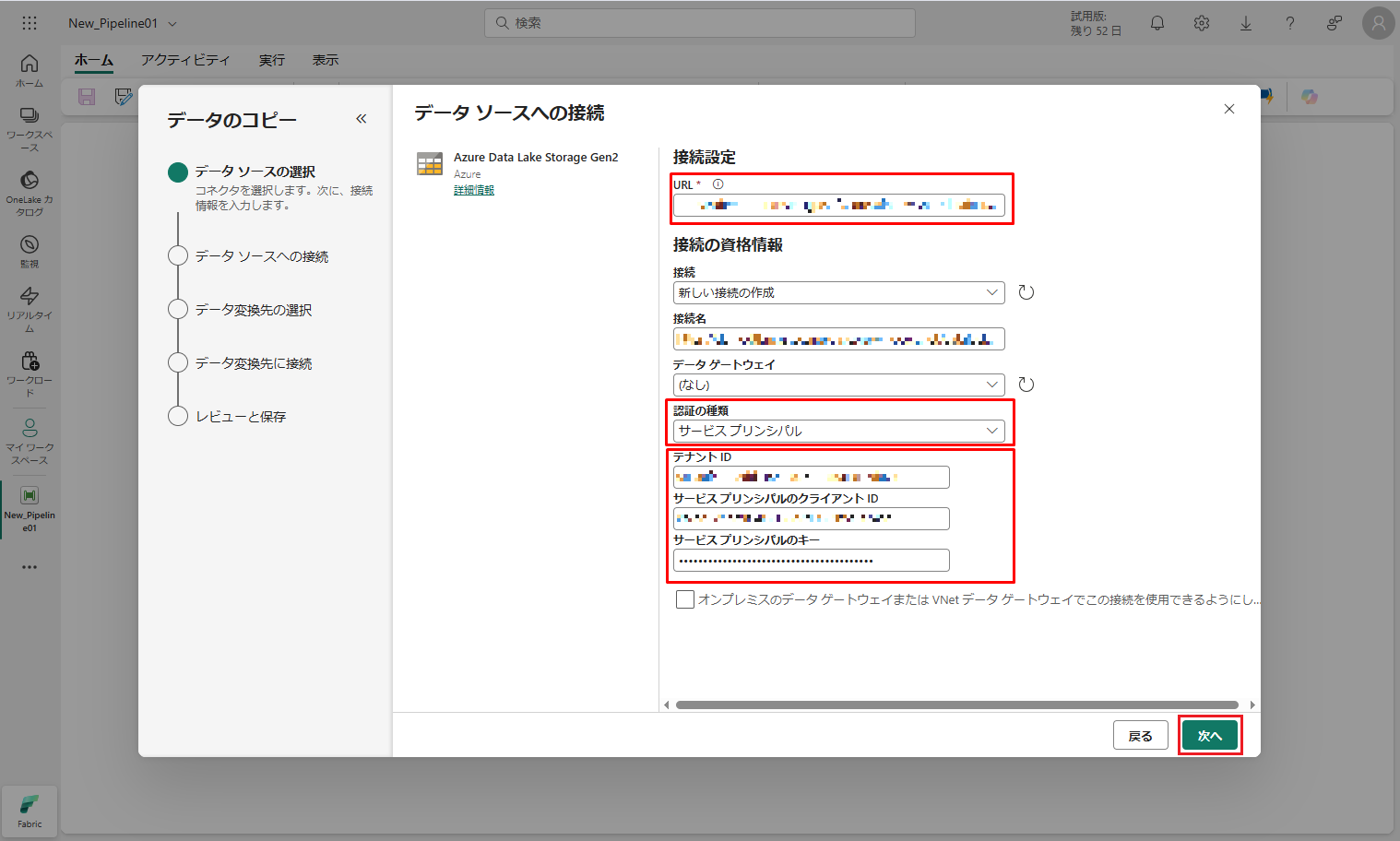
⑥「ファイル システムまたはファイルの選択」で、接続済みのストレージ アカウントのコンテナーにアップロードしたデータを選択します。
選択対象のファイルの形式はアップロードされたファイルの形式と一致する必要があります。
⑦ green_tripdata_2015-01.parquetファイルを選択して、データ プレビューが表示されるまで待機します。「次へ」をクリックします。
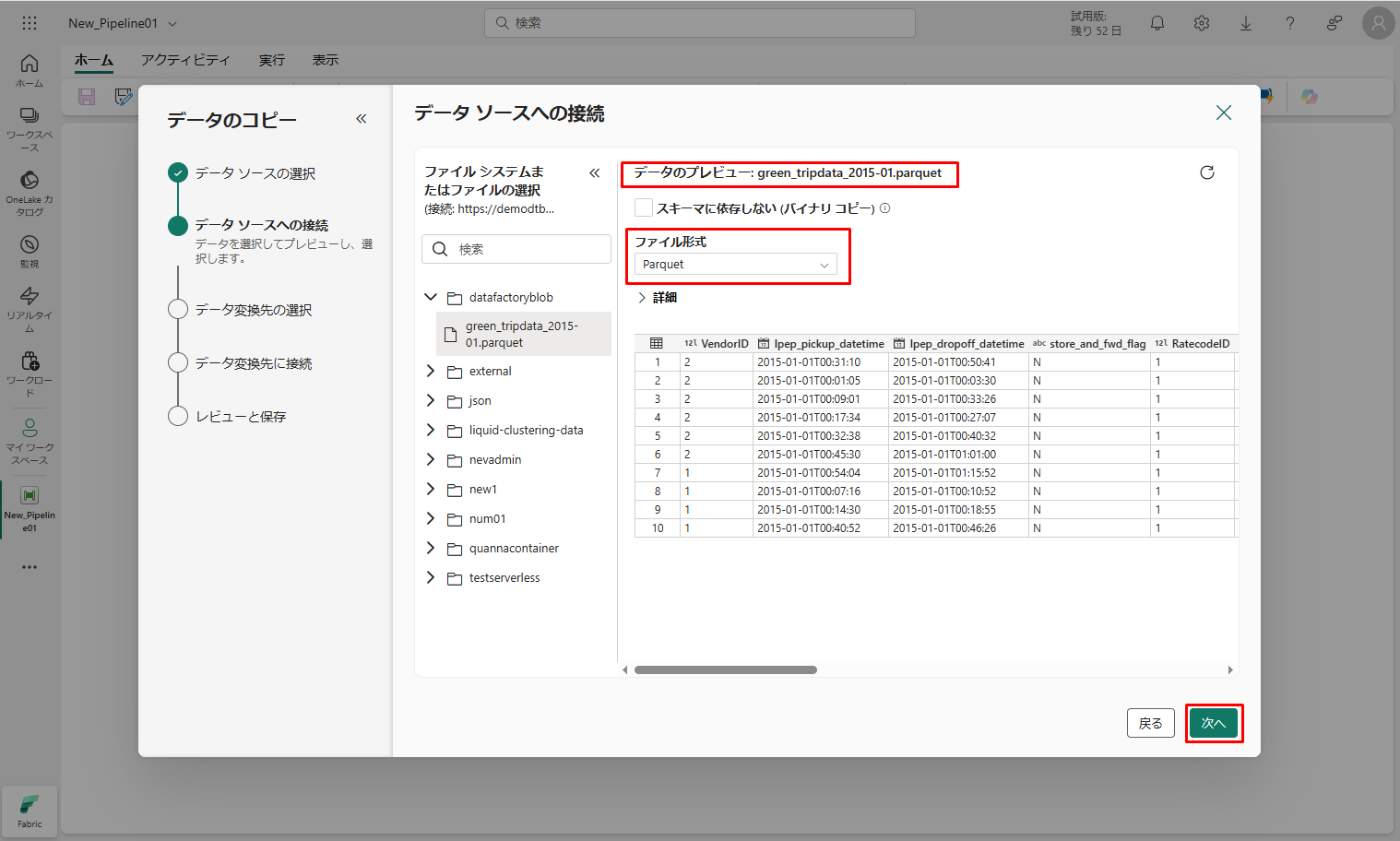
⑧「データ変換先の選択」ステップで、「レイクハウス」を選択します。
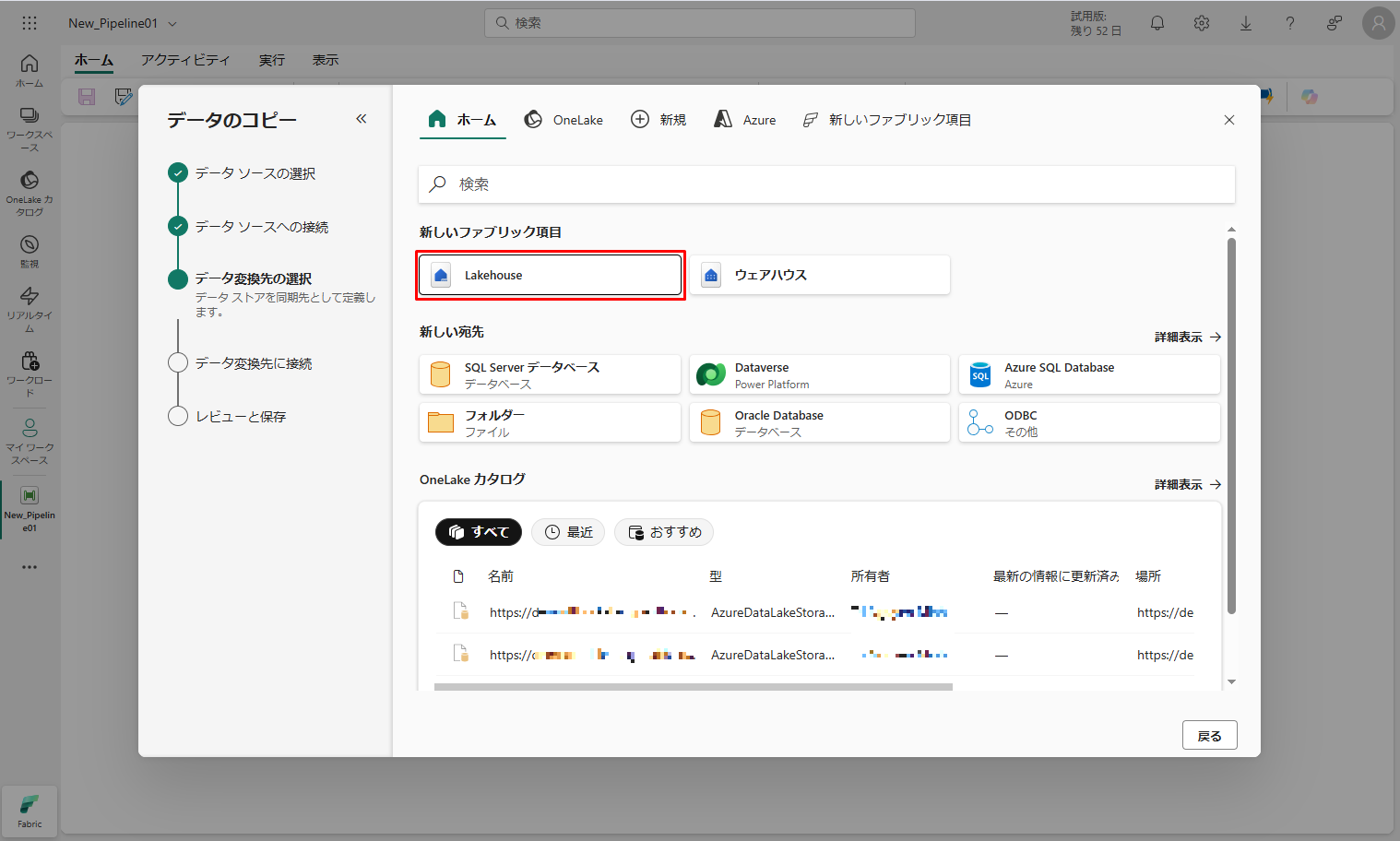
⑨「データ変換先の選択」ダイアログで「新しいレイクハウス」をチェックし、Lakehouse 名を入力します。「作成して接続」をクリックします。
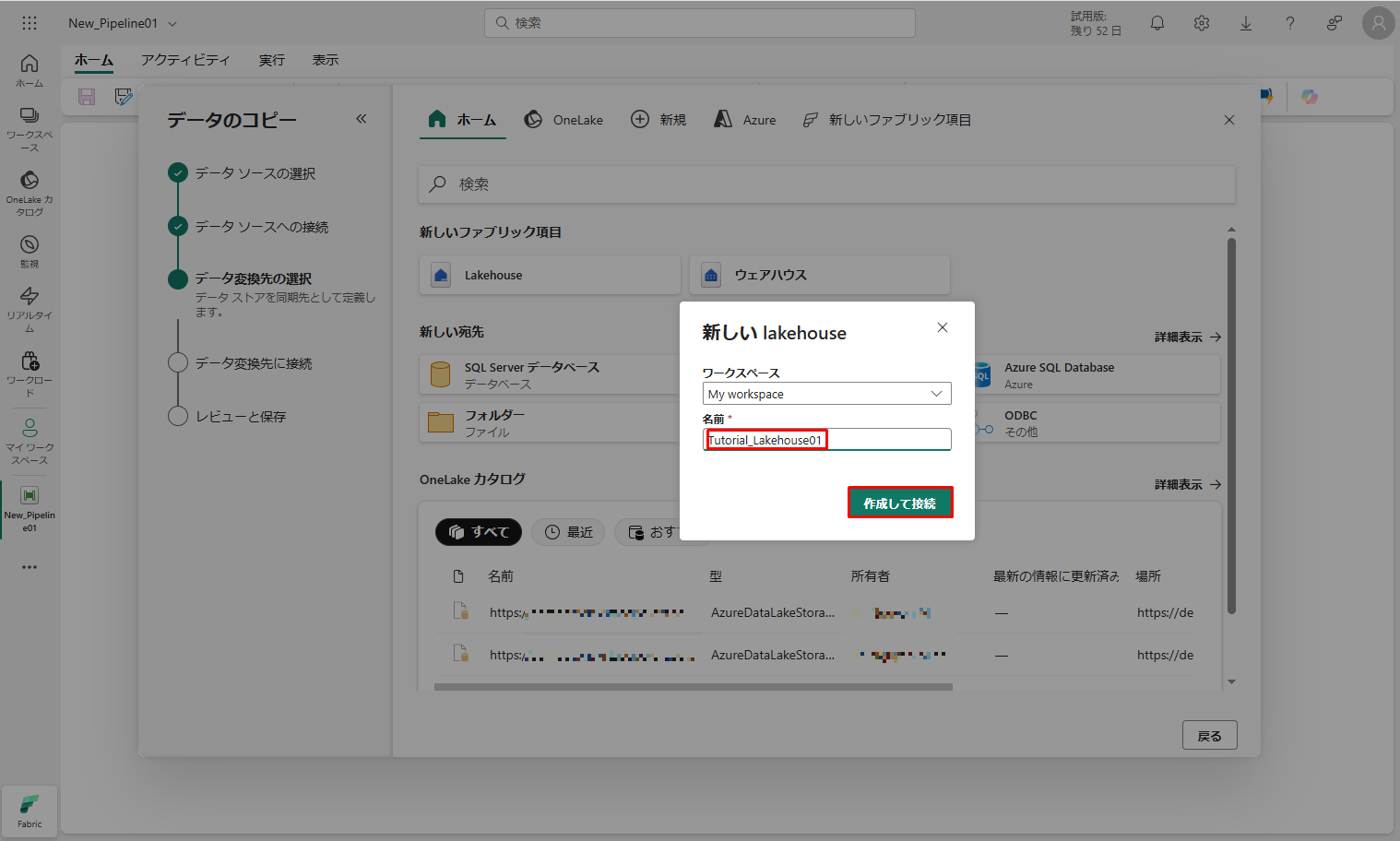
次に、「データ変換先に接続」で、Lakehouse の宛先の詳細を構成します。
⑩ ルート フォルダーの「テーブル」と「新しいテーブルに読み込む」をチェックし、テーブル名を指定します。
⑪「パーティションを有効にする」 チェックボックスをオンにしないでください。「次へ」をクリックします。
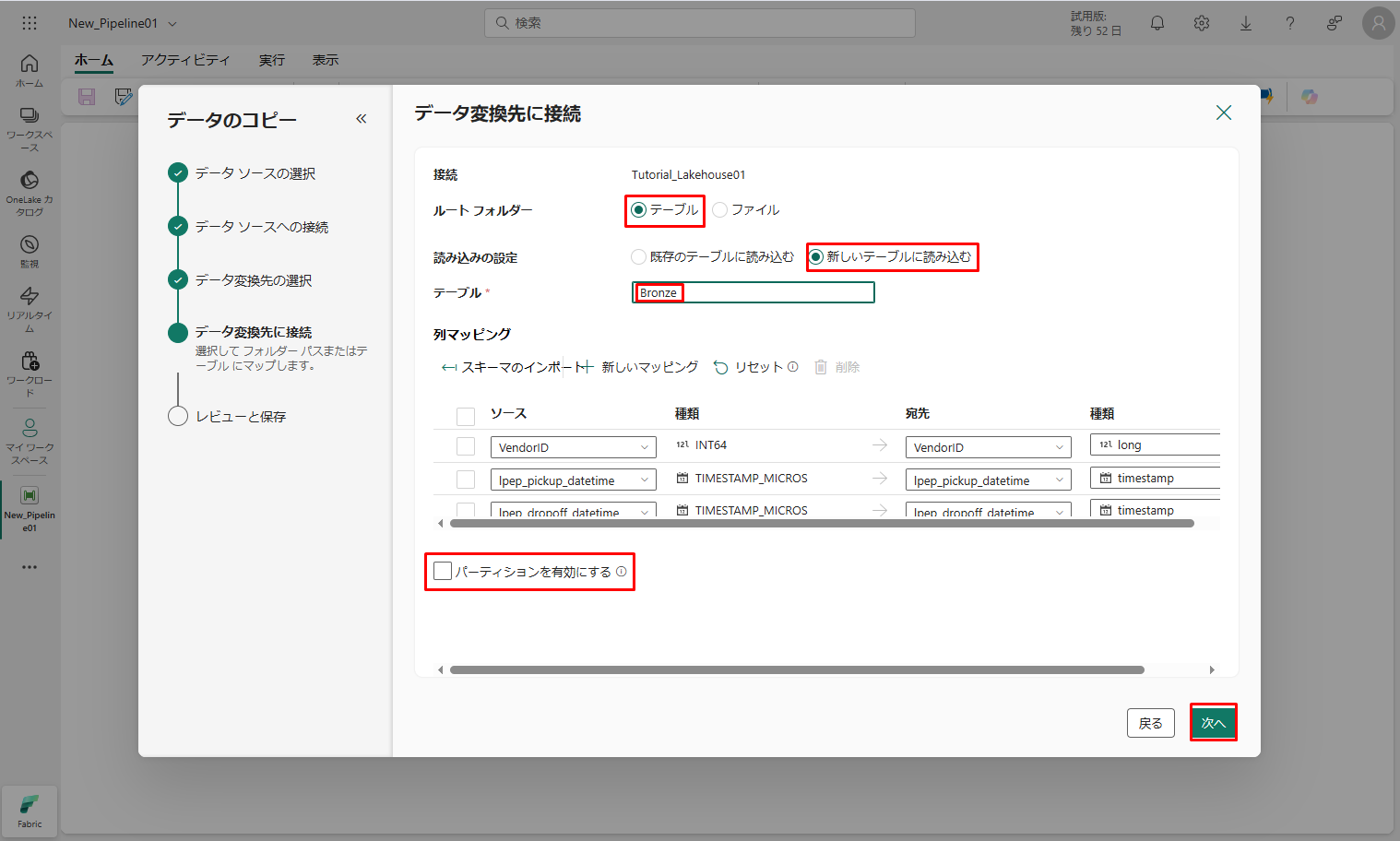
最後に、「レビューと保存」で、構成を確認します。
⑫ 今回は、次のステップでアクティビティを手動で実行するため、「データ転送をすぐに開始する」チェックボックスをオフにします。
⑬「OK」をクリックします。
5-3. Copy アクティビティを実行し、結果を表示します。
①「実行」ボタンをクリックし、プロンプトで「保存および実行」をクリックして、Copy アクティビティを実行します。
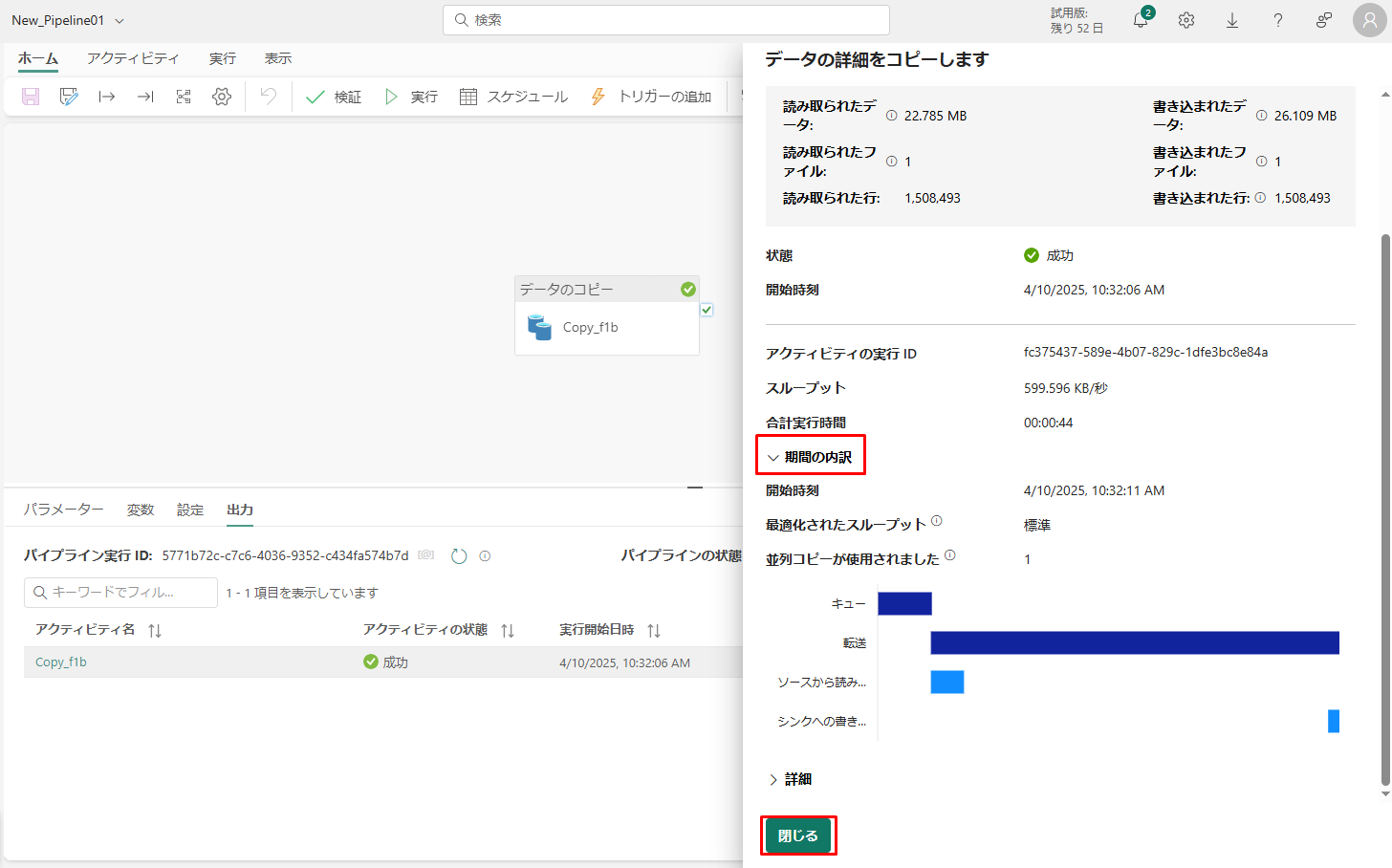
実行の進捗状況を監視し、パイプライン キャンバスの下にある 「出力」タブで実行結果を確認できます。
② パイプライン名をクリックして、実行の詳細を表示します。
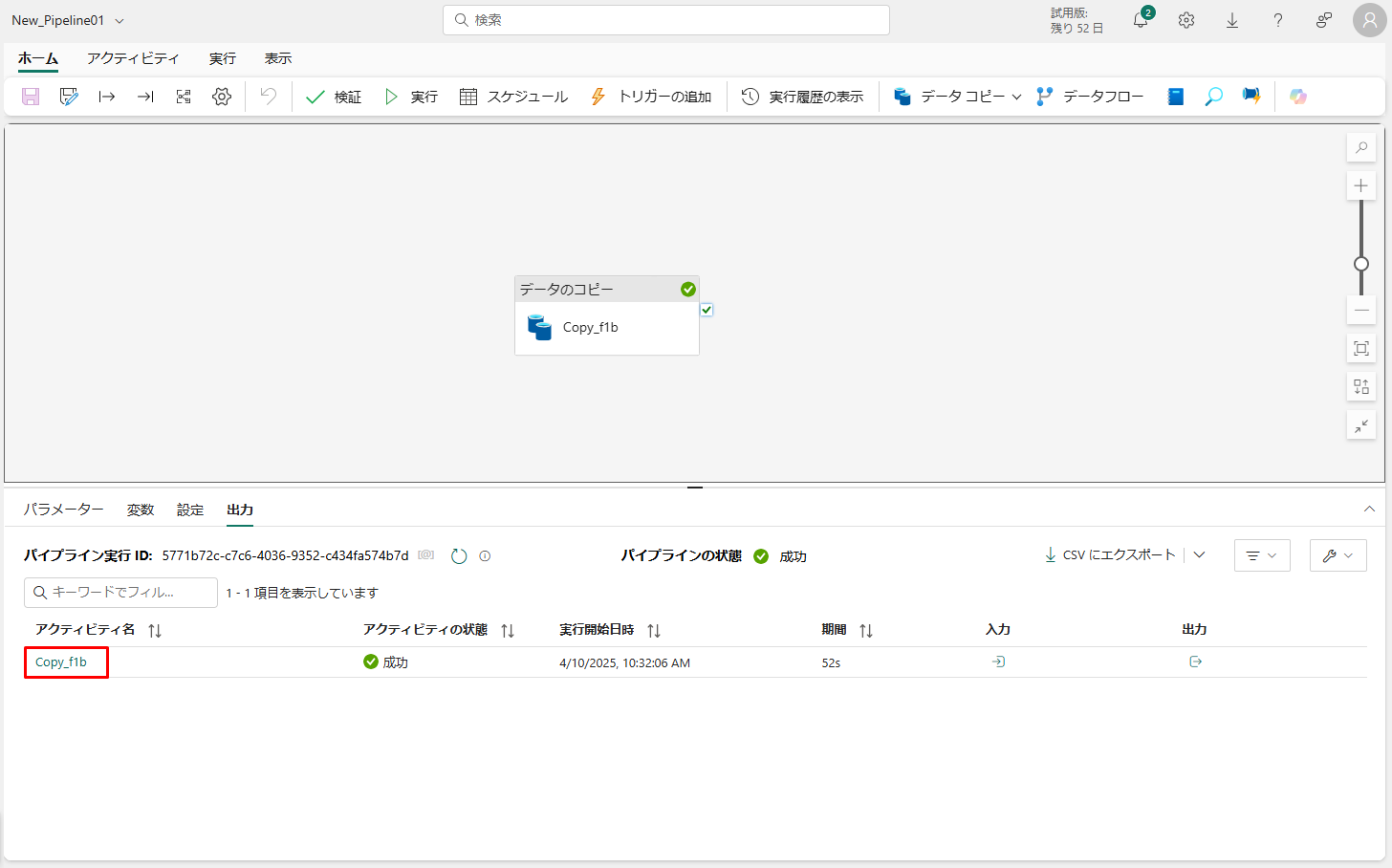
実行の詳細が表示されます。
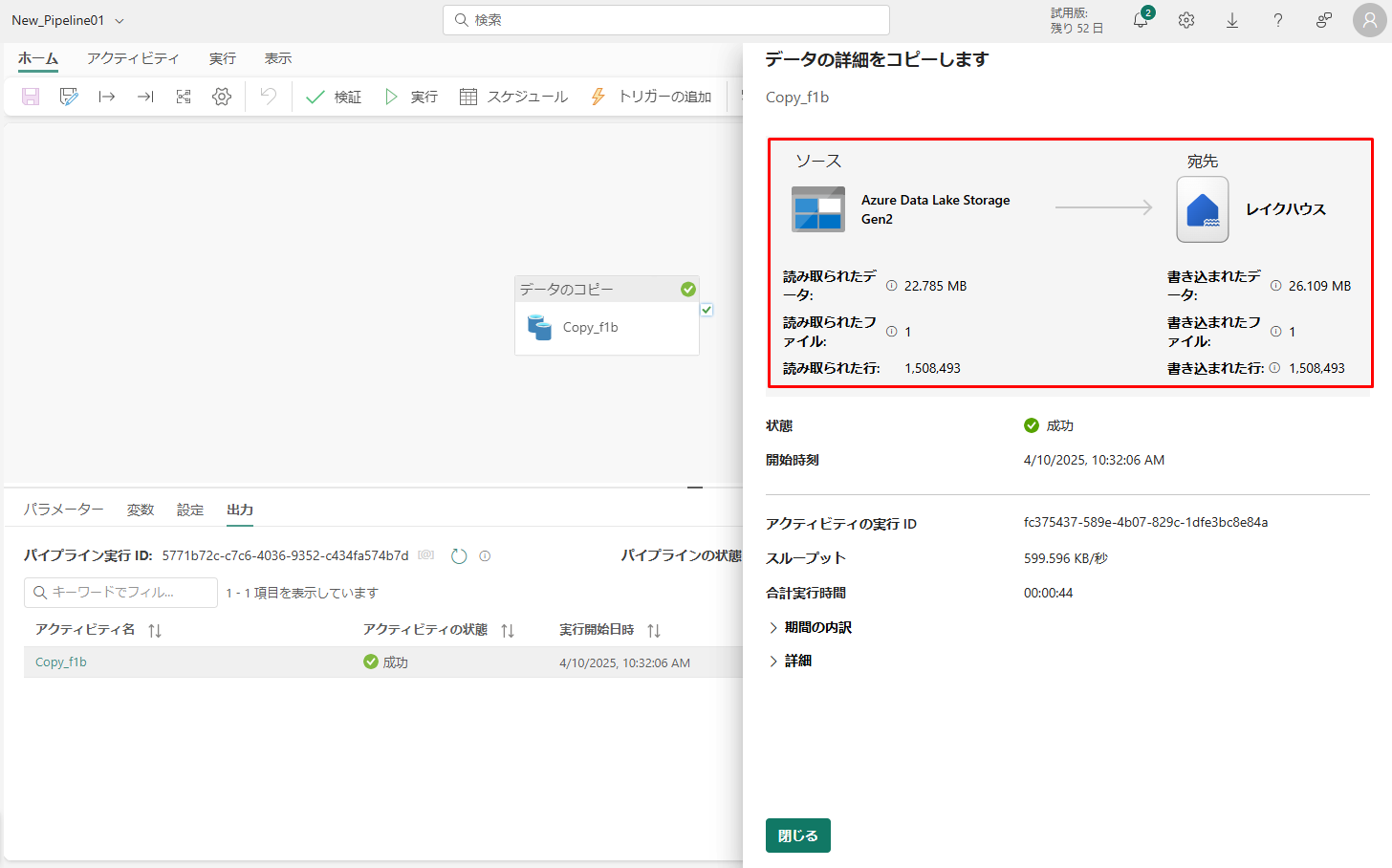
③「期間の内訳」セクションを展開すると、Copy アクティビティの段階の期間が表示されます。
④ コピーの詳細を確認した後、「閉じる」をクリックします。
6. データフローを使用してデータを変換する
6-1. レイクハウステーブルからデータを取得する
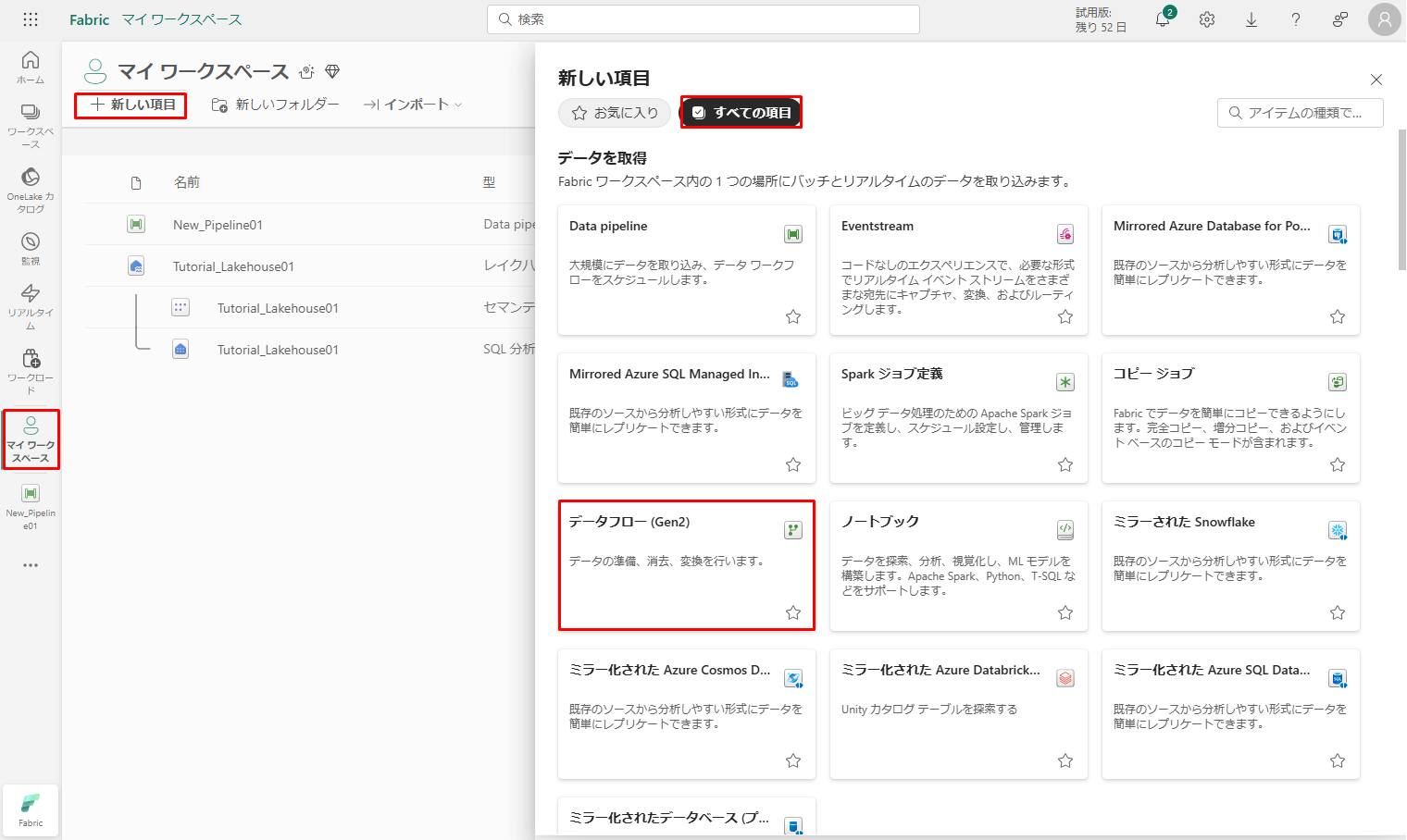
① 「マイ ワークスペース」にアクセスします。「新しい項目」をクリックし、「データフロー (Gen2)」を選択して新しい データフロー Gen2 を作成します。
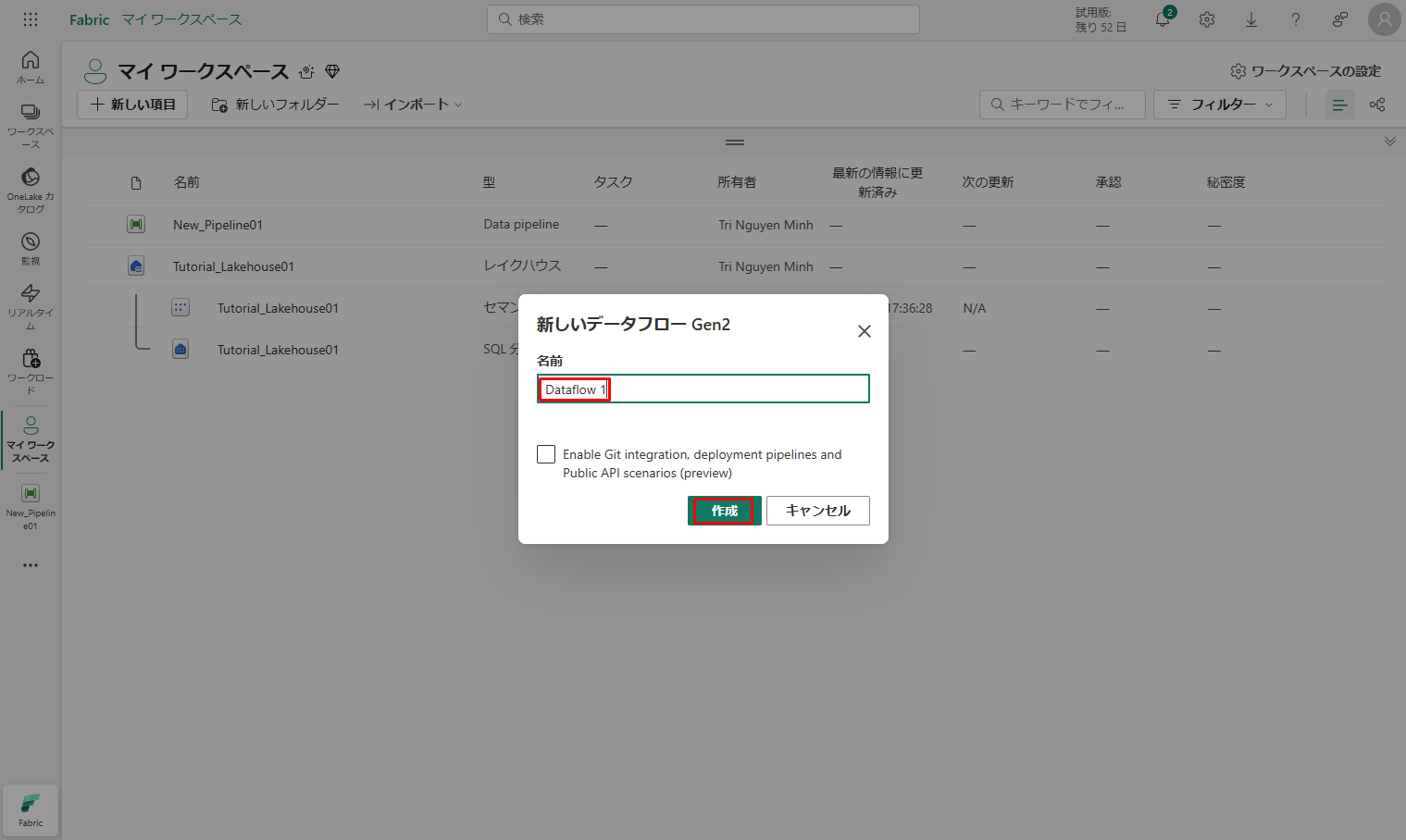
データフローに名前を付けて「作成」をクリックします
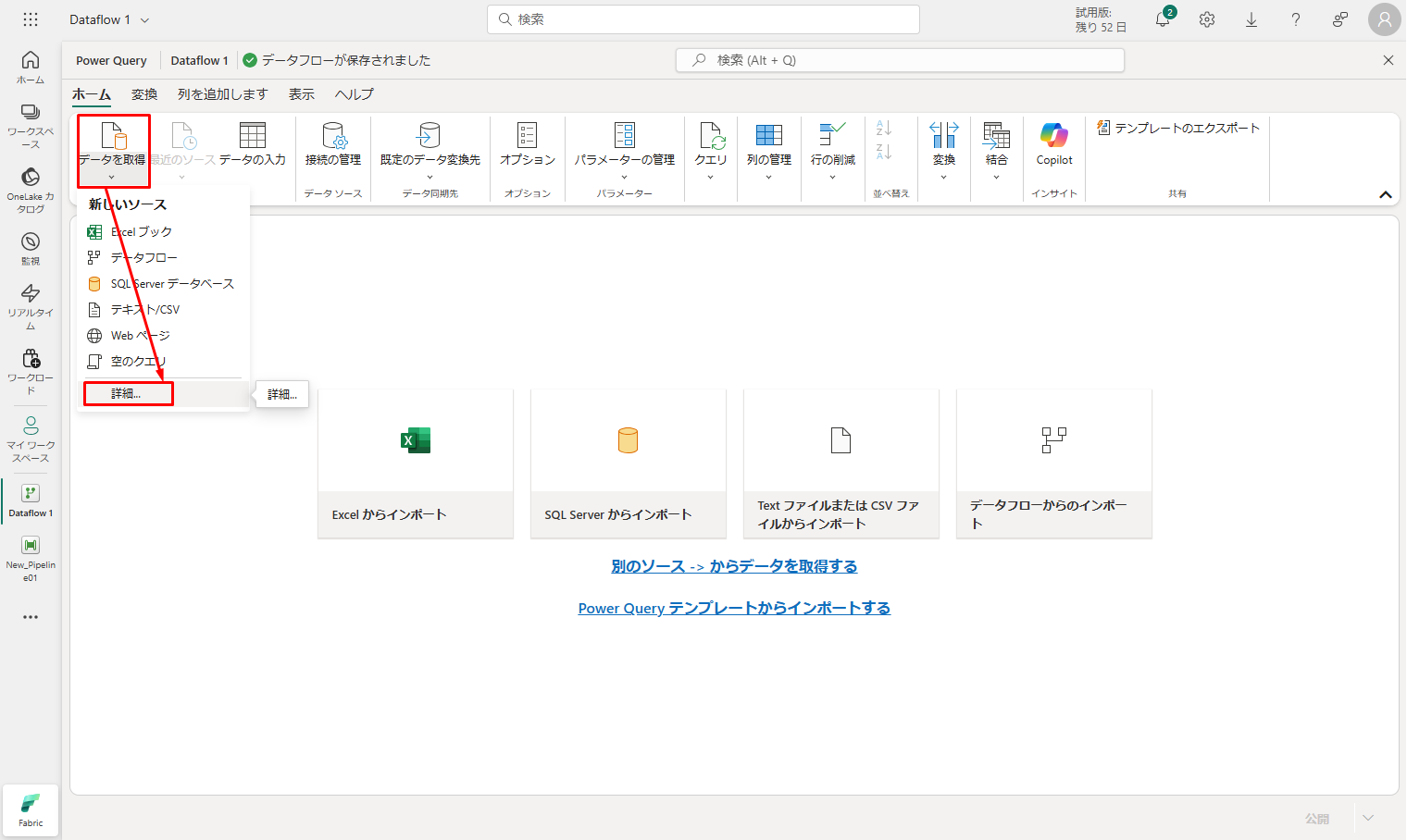
 ② 新しいデータフロー メニューで、「データを取得」をクリックし、「詳細…」をクリックします。
② 新しいデータフロー メニューで、「データを取得」をクリックし、「詳細…」をクリックします。
③「Lakehouse」(レイクハウス) コネクタを検索して選択します。
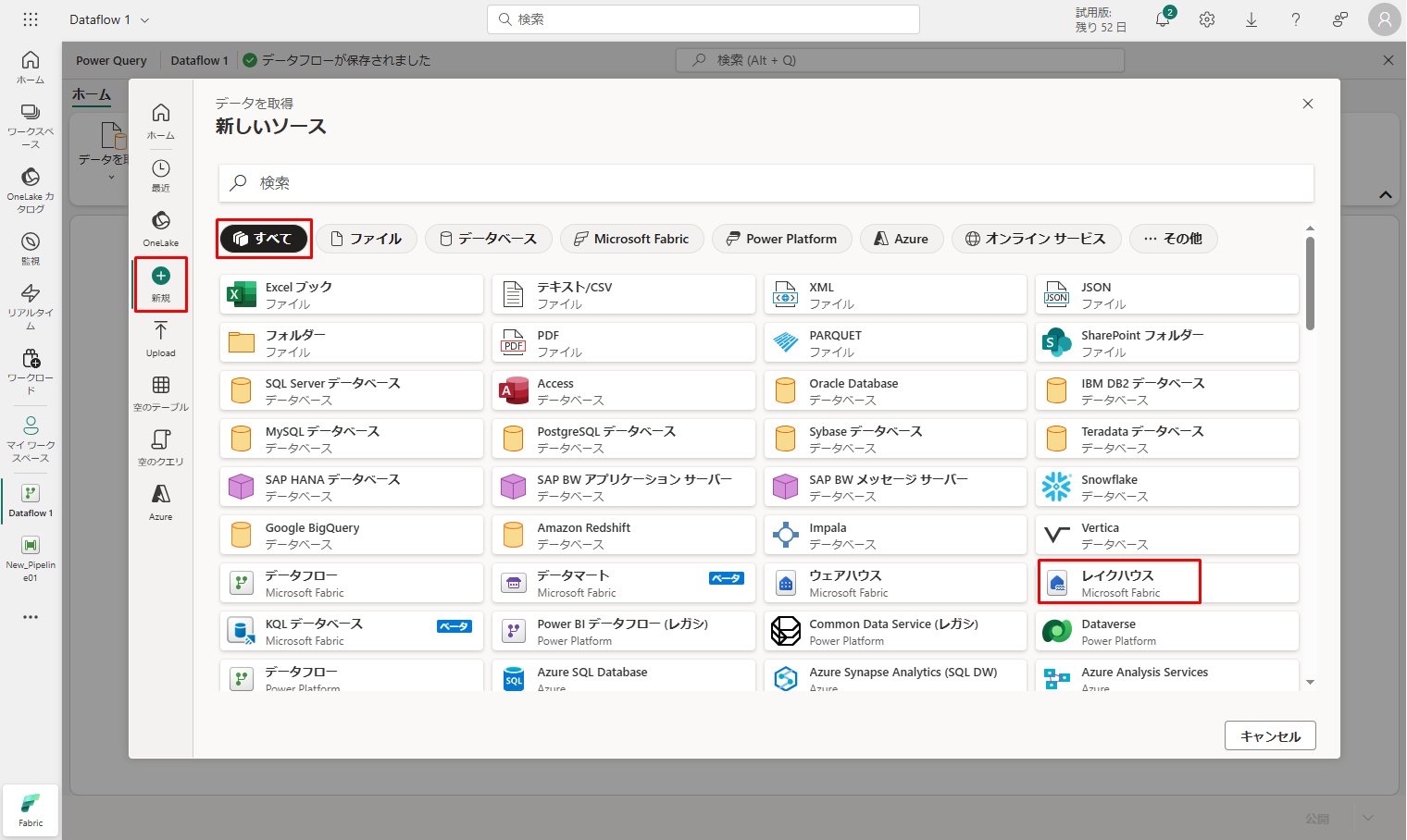
④「Connect to data source」(データ ソースへの接続) ダイアログが表示され、現在サインインしているユーザーに基づいて接続が自動的に作成されます。「次へ」をクリックします。
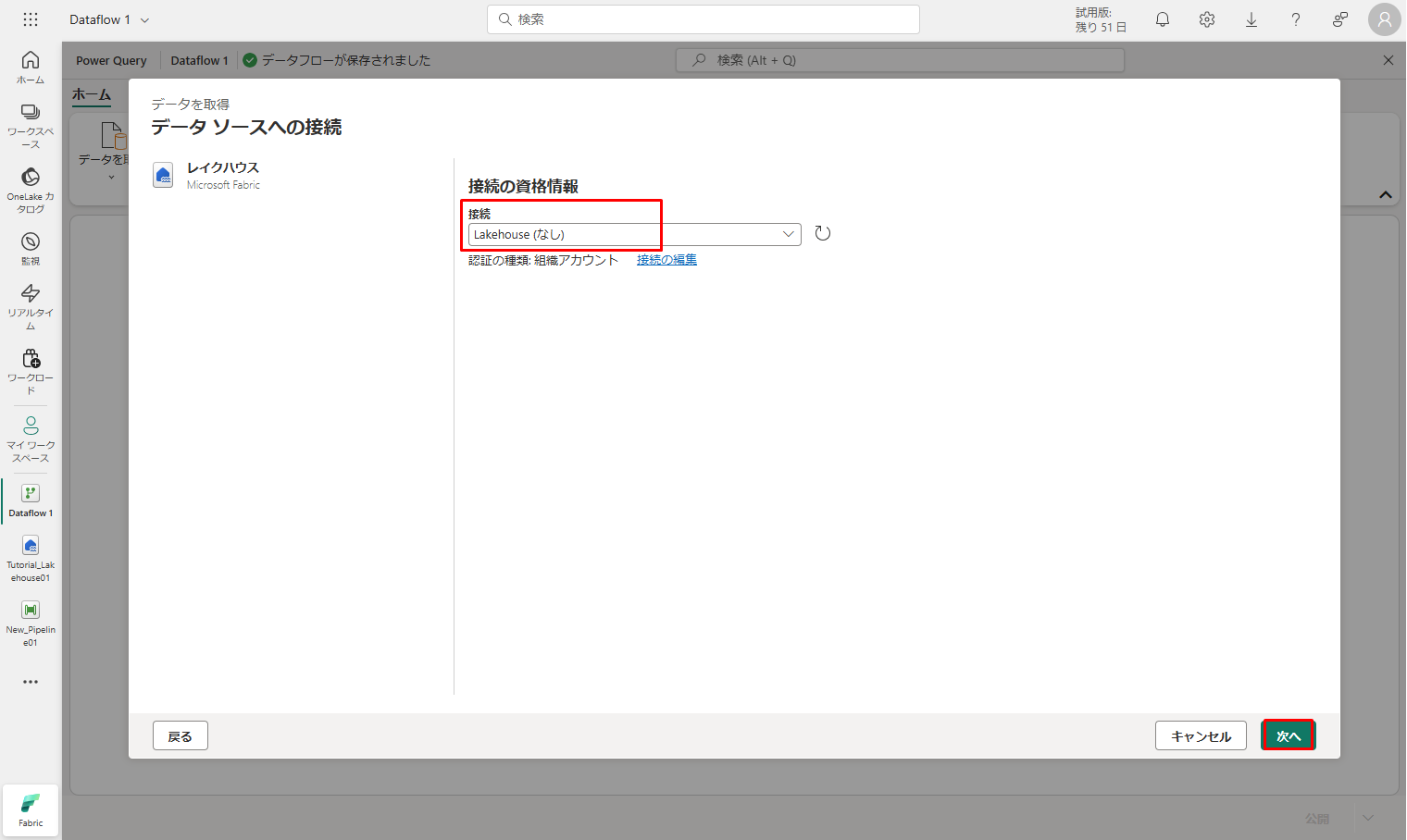 「データの選択」ダイアログが表示されます。
「データの選択」ダイアログが表示されます。
⑤ ナビゲーションウィンドウを使用すると、前のモジュールで変換先として作成したレイクハウスを見つけ、 Tutorial_Lakehouse01 データ テーブルを選択します。
⑥「Bronze」テーブルを選択し、「作成」をクリックします。
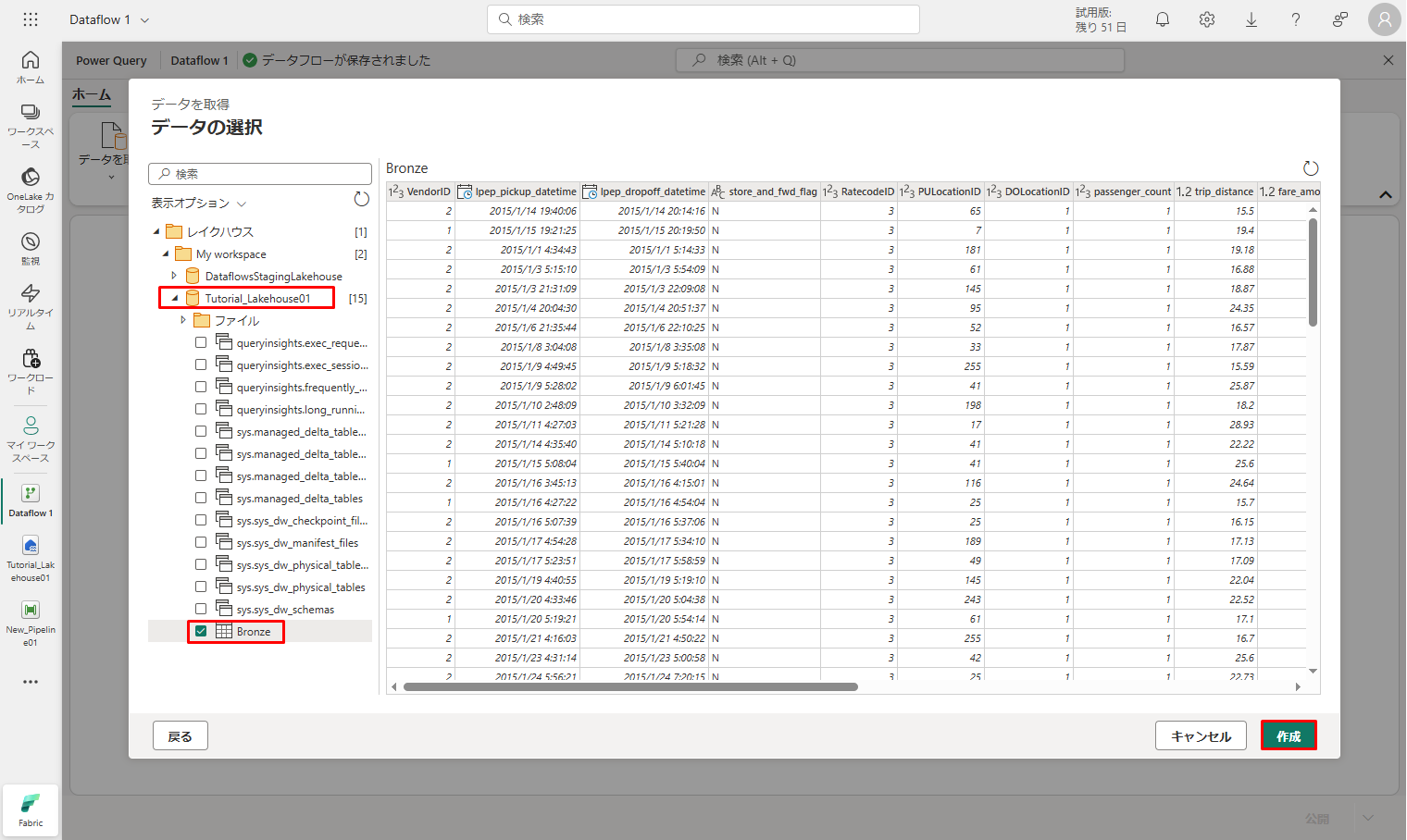
キャンバスにデータを設定した後、列プロファイル情報を設定できます。これにより、データ プロファイルの設定が容易になります。適切な変換を適用することで、適切なデータ値をターゲットにすることができます。
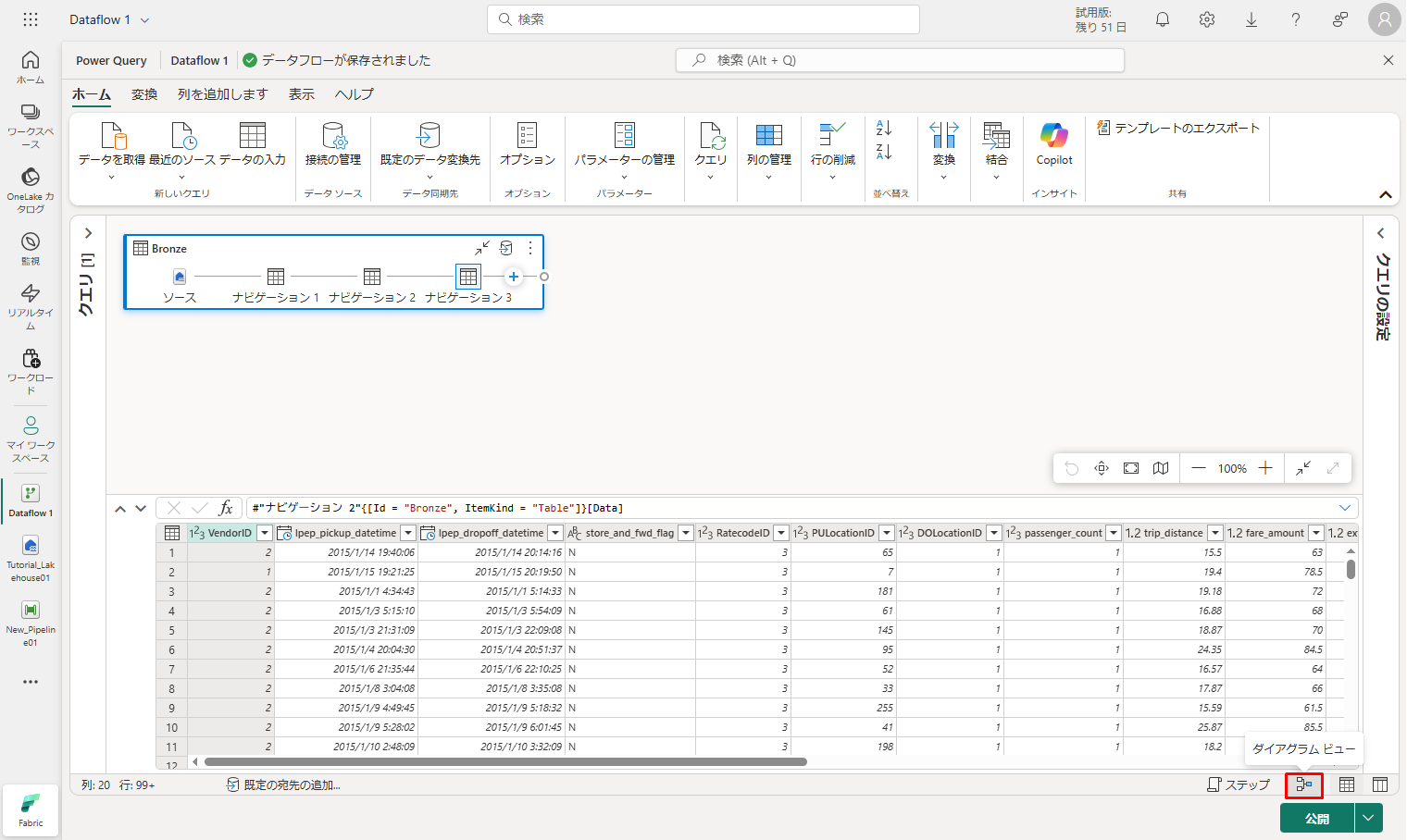
6-2. レイクハウスからインポートされたデータを変換する。
① 2 番目の列 Ipep_pickup_datetime の列ヘッダーにあるデータ型アイコンを選択してドロップダウン メニューを表示し、メニューからデータ型を選択して、列の型を 「日付と時刻」から「日付」に変換します。
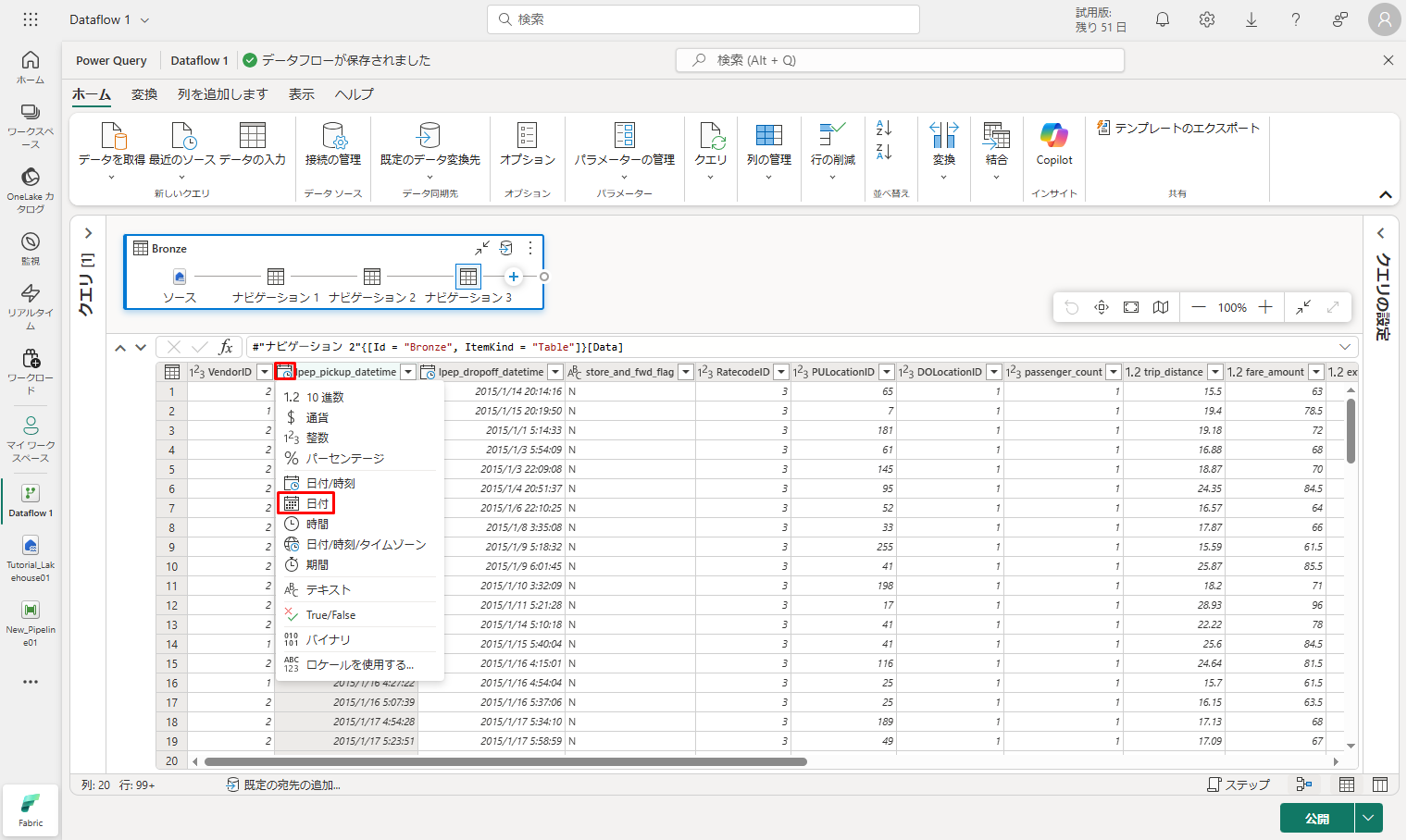
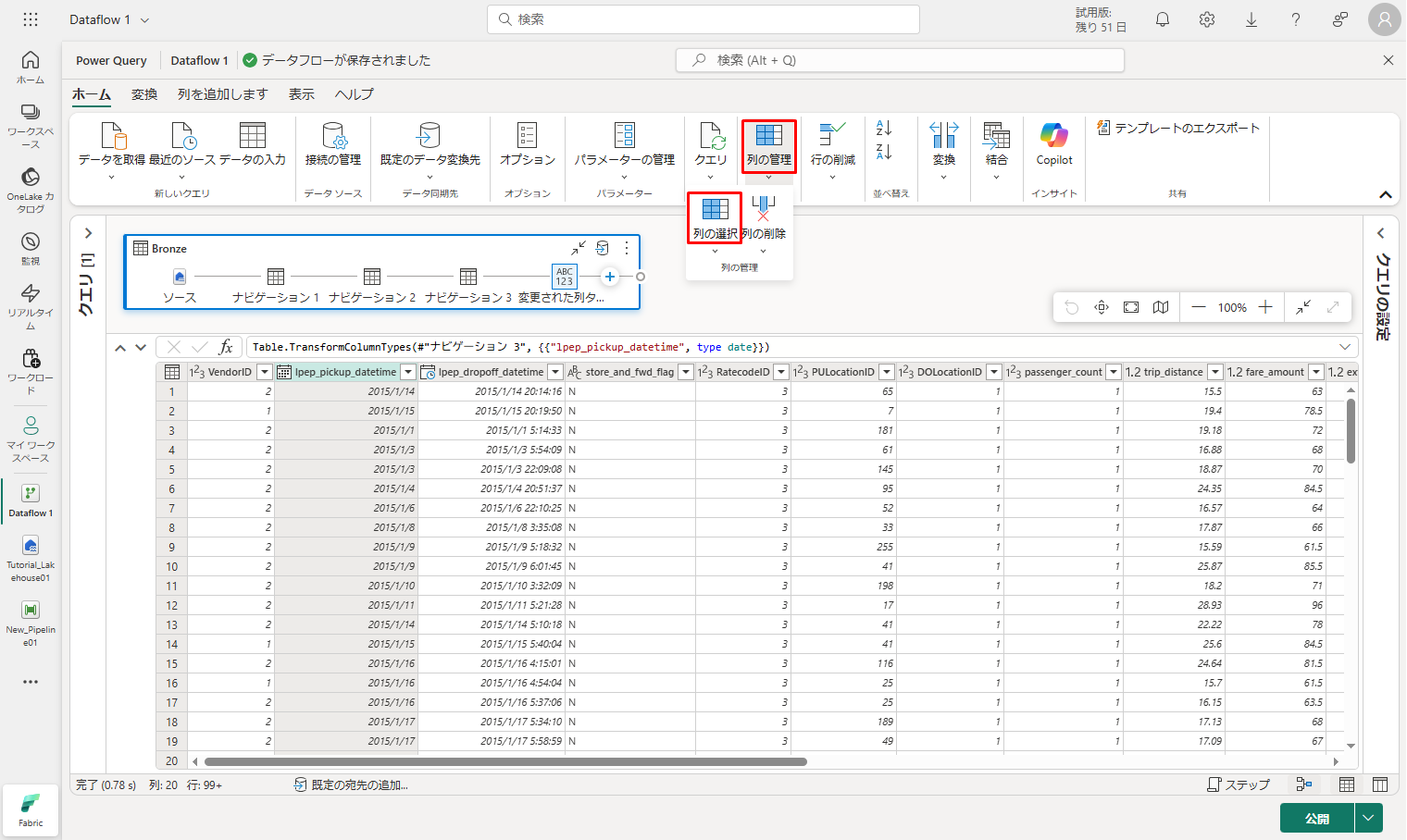
② リボンの「ホーム」タブで、「列の管理」グループから「列の選択」オプションを選択します。
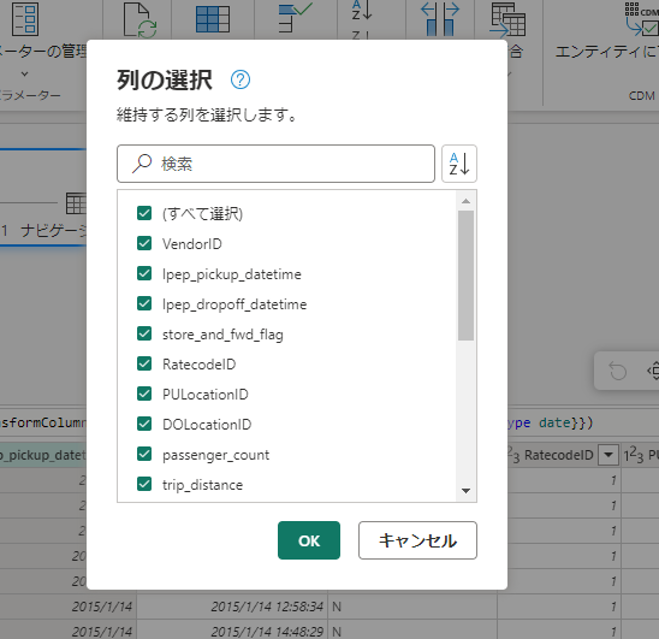
ここにリストされている一部の列の選択を解除できます。
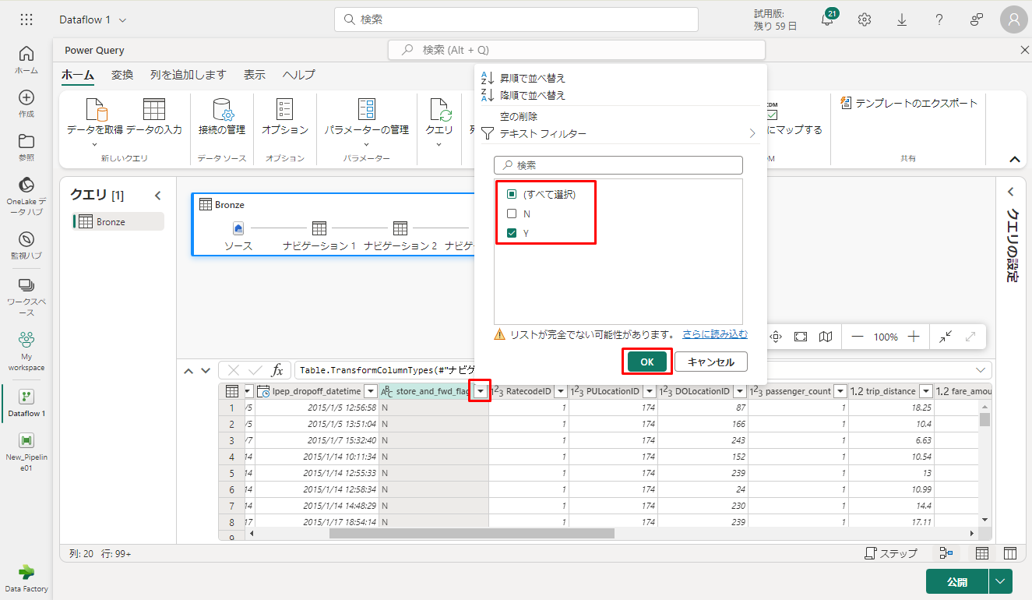
③ store_and_fwd_flag 列のフィルターを選択し、ドロップダウンメニューを並べ替え。(警告 “リストが不完全である可能性があります” が表示される場合は、「さらに読み込む」を選択してすべてのデータを表示します)。
④「Y」を選択して、割引が適用された行のみを表示し、「OK」をクリックします。
⑤ lpep_pickup_datetime 列の並べ替えを選択してドロップダウン メニューをフィルター処理し、「日付フィルター」を選択し、「日付」および 「日付と時刻」 型に対して提供されている「期間…」フィルターを選択します。
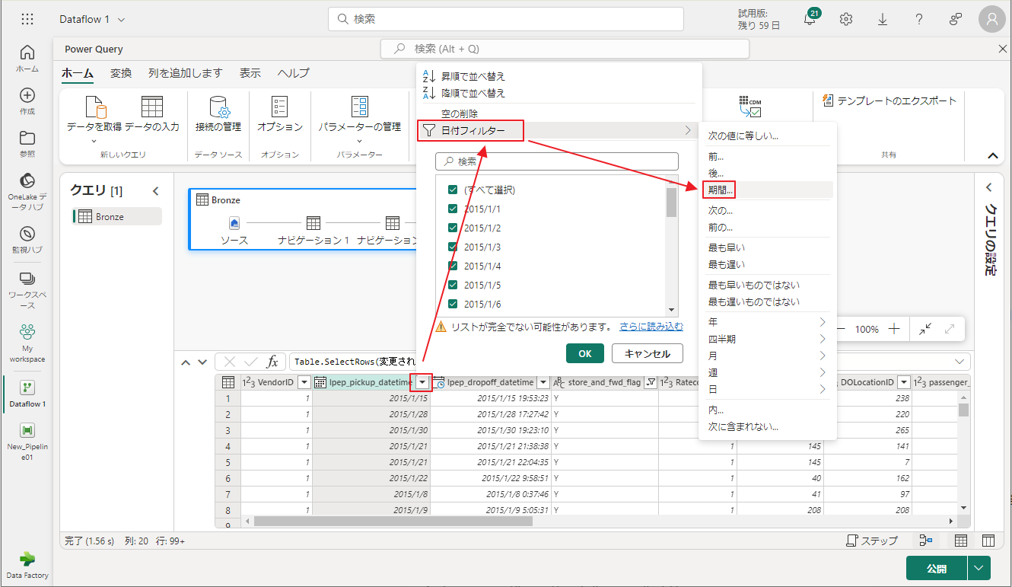
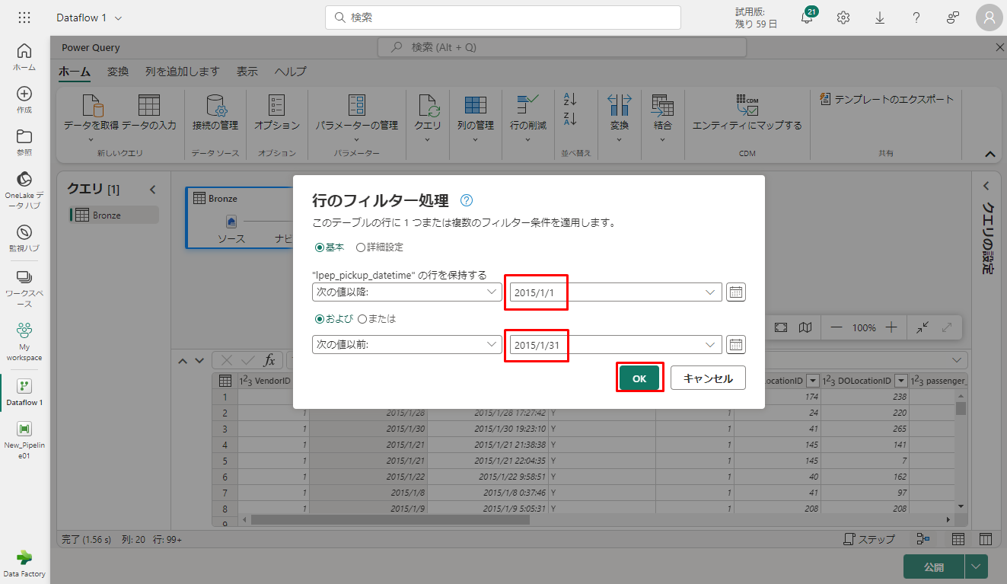
⑥「行のフィルター処理」 ダイアログで、2015年1月1日から2015年1月31日までの日付を選択し、「OK」をクリックします。
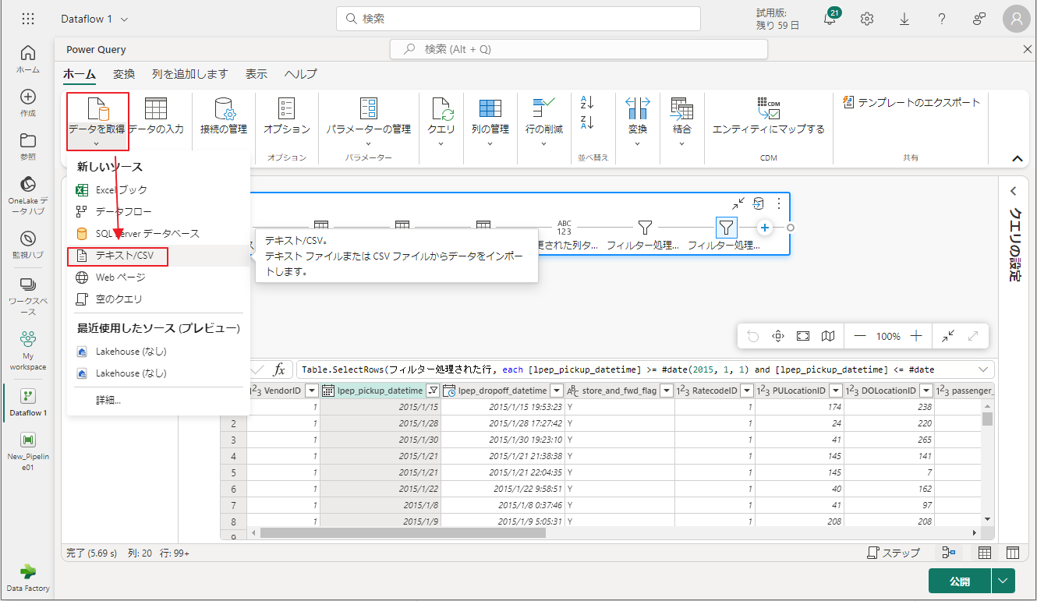
6-3. 割引データを含む CSV ファイルに接続する
次に、乗車データを適切な場所に配置します。各日と VendorID の割引に関するデータを読み込み、準備した後、乗車データと組み合わせます。
①「ホーム」タブで「データを取得」→「テクスト/CSV」をクリックします。
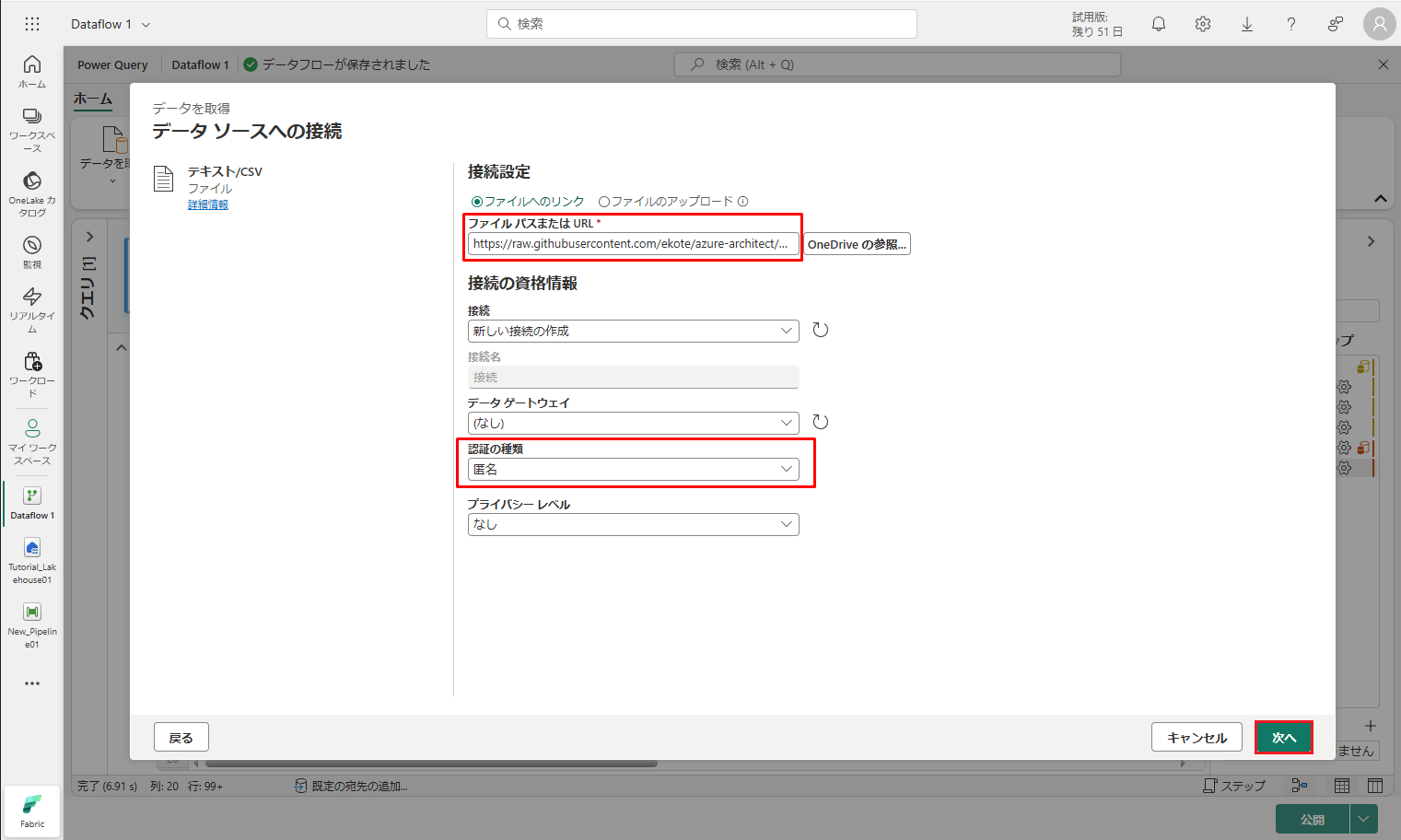
②「データ ソースへの接続」ダイアログで、次の詳細を指定します。
ファイル パスまたは URL :
|
1 |
https://raw.githubusercontent.com/ekote/azure-architect/master/Generated-NYC-Taxi-Green-Discounts.csv |
認証の種類 – 匿名
③「次へ」をクリックします。
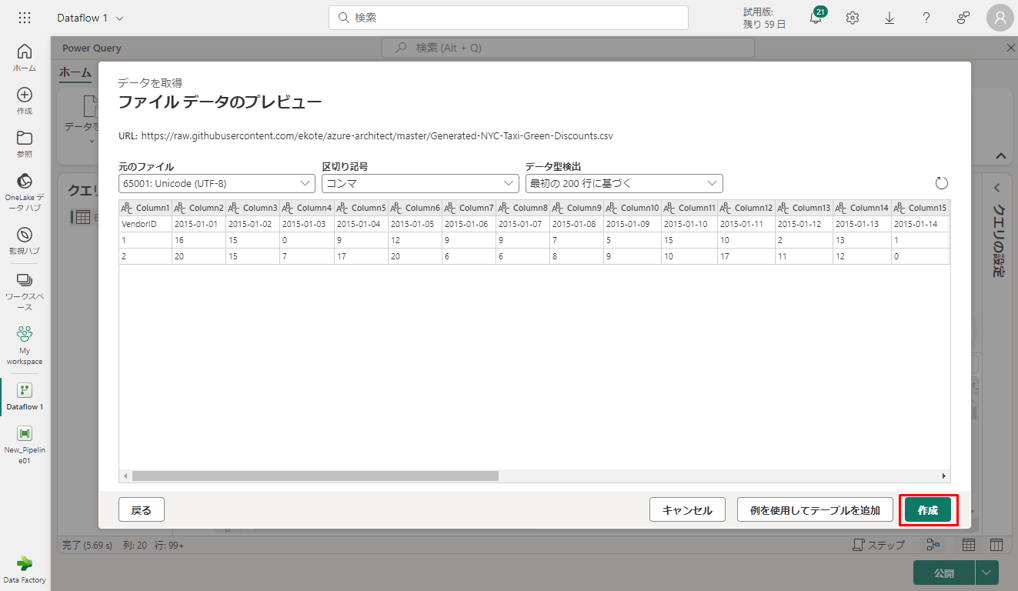
 ④「ファイル データのプレビュー」ダイアログで、「作成」をクリックします。
④「ファイル データのプレビュー」ダイアログで、「作成」をクリックします。
6-4. 割引データを変換する
① データを確認すると、ヘッダーが最初に行に表示されます。プレビューグリッド領域の左上にあるテーブルのコンテキストメニューから、「1行目をヘッダーとして使用」を選択して、ヘッダーに昇格させます。
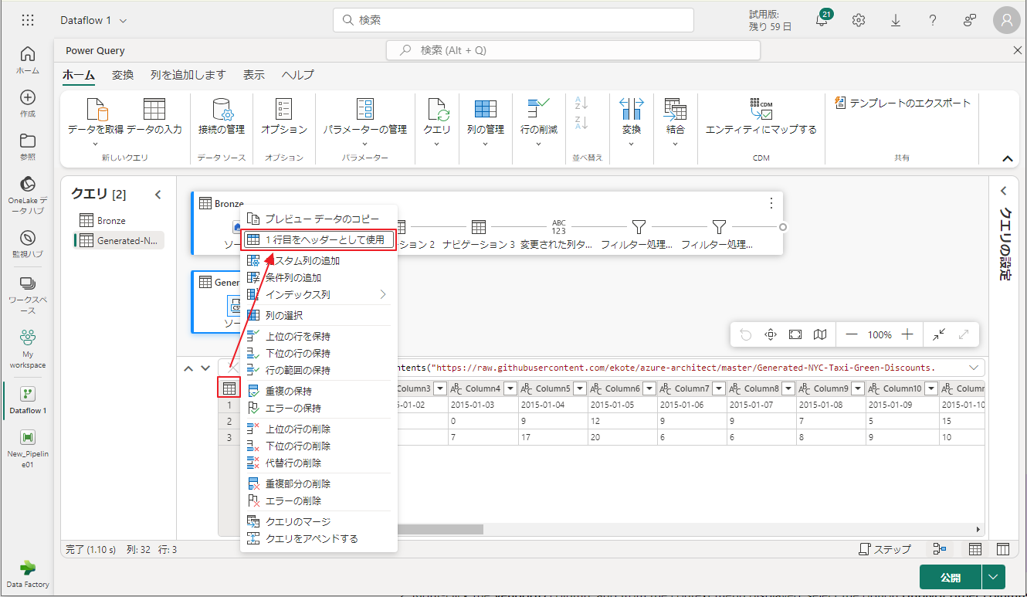
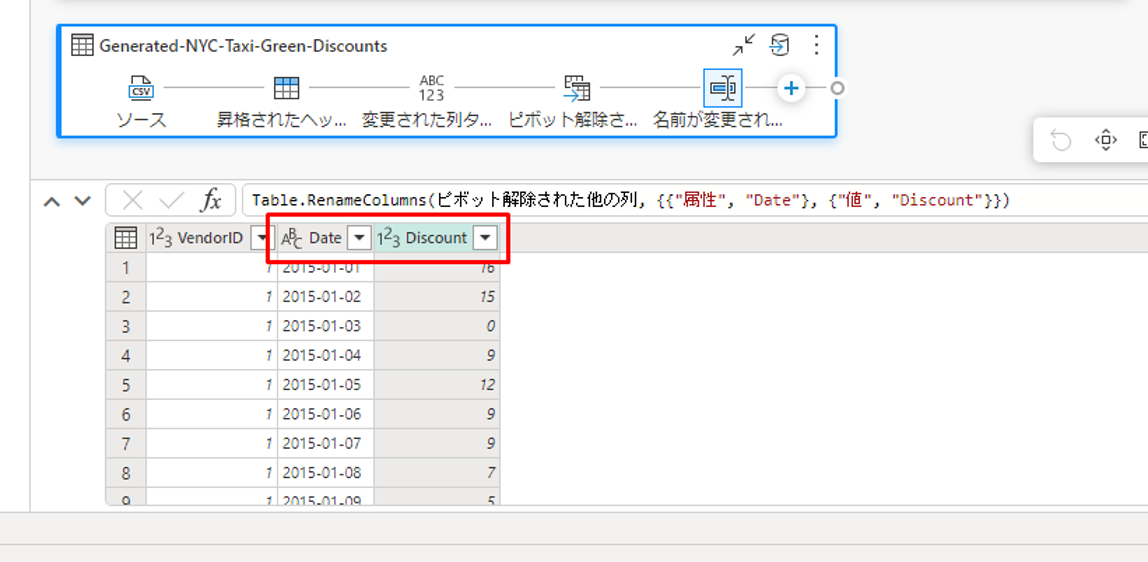
② VendorID 列を右クリックして、コンテキストメニューから「その他の列のピボット解除」を選択します。これにより、例を行に変換し、属性と値のペアに変換することができます。
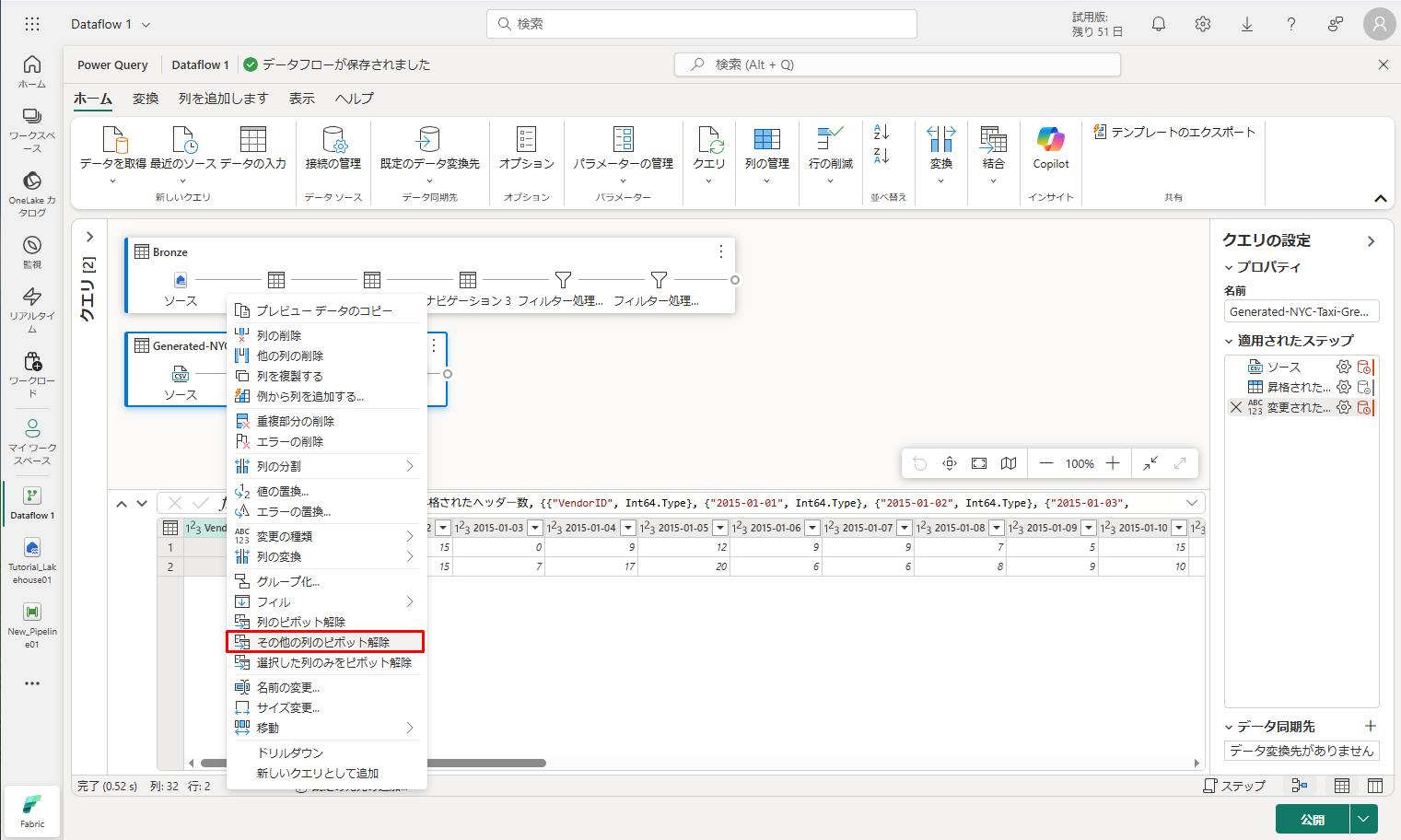
③ テーブルのピボットを取り除き、Attribute および Value 列の名前を変更します。これを行うには、それぞれをダブルクリックし、Attribute を Date に、Value を Discount に変更します。
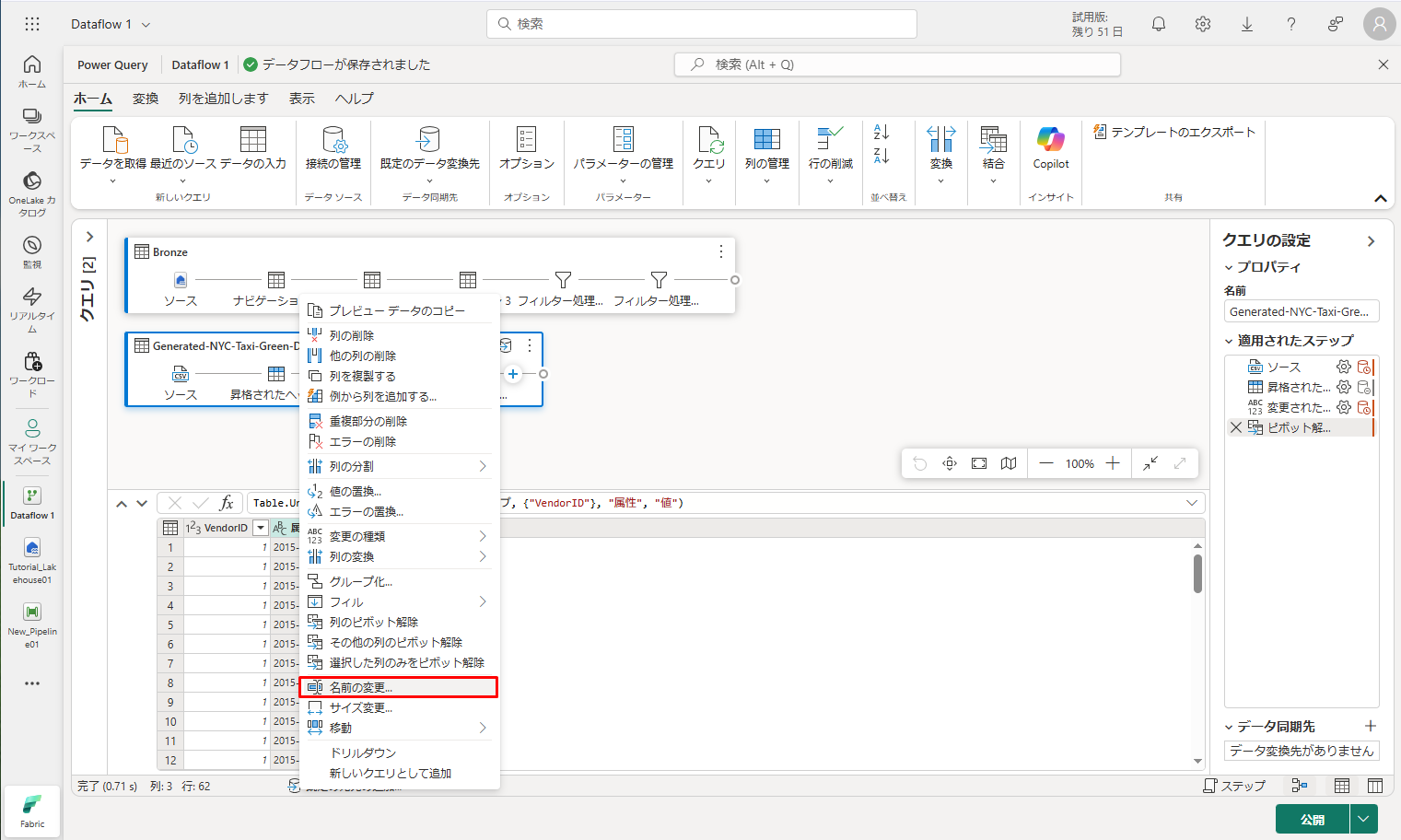
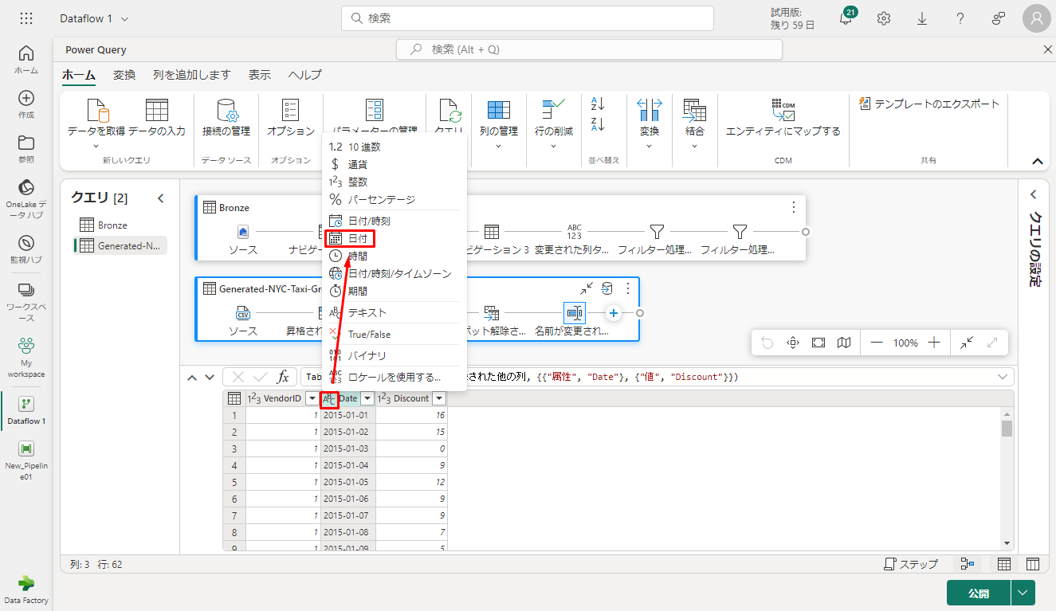
④ 日付列のデータ型を変更するには、列名の左側にあるデータ型メニューから「日付」を選択します。
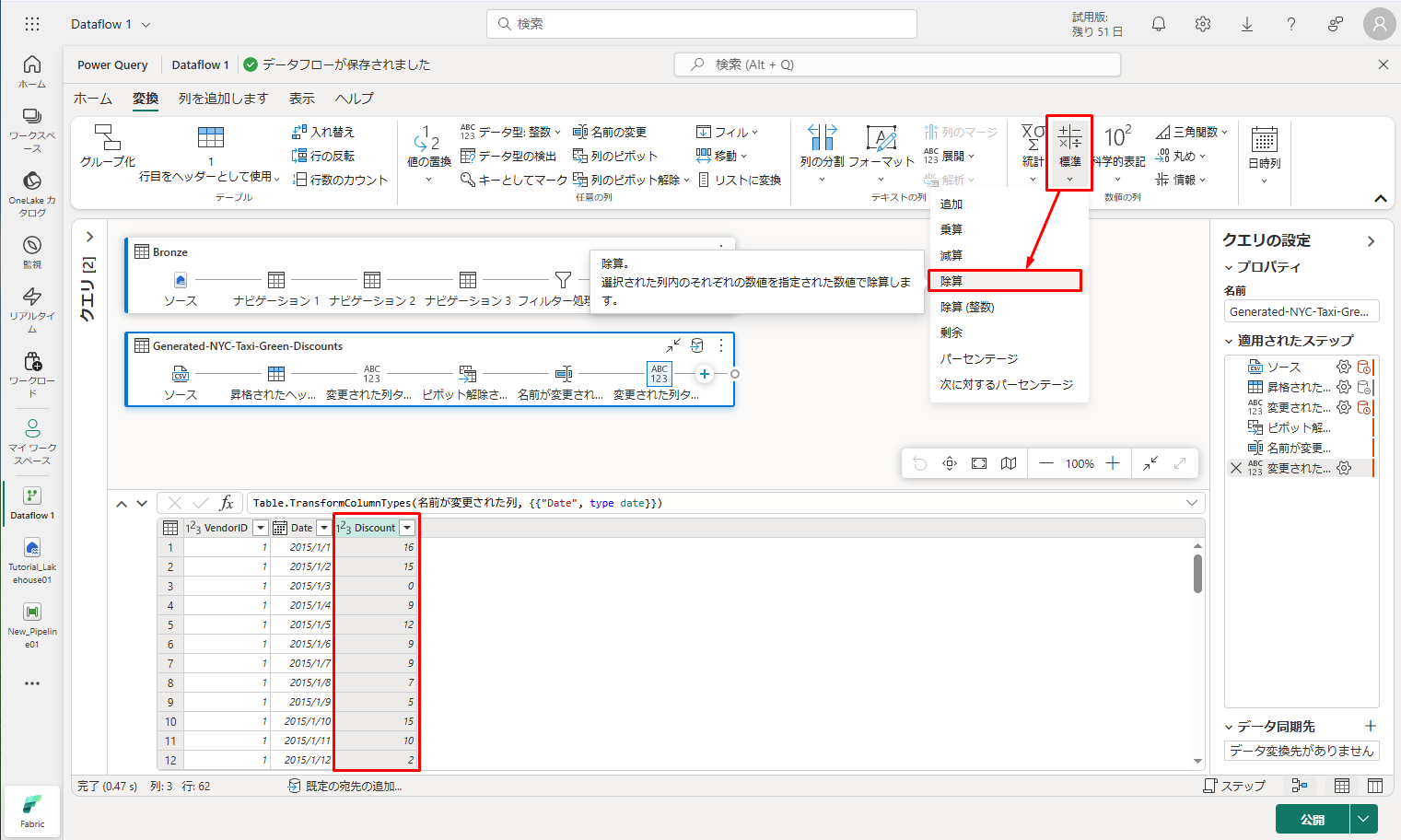
⑤ Discount 列を選択し、メニューの 「標準」タブを選択し、「除算」を選択します。
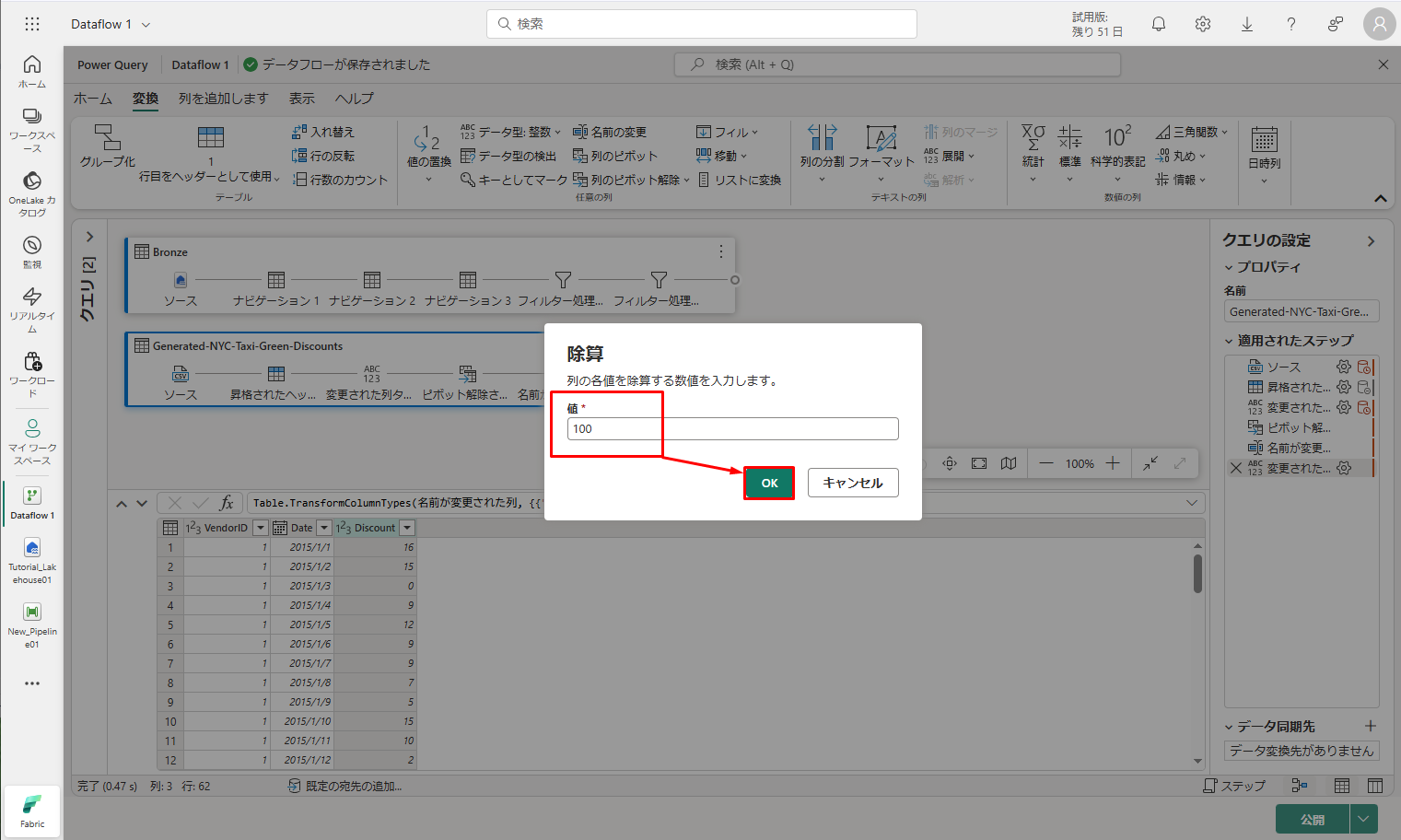
⑥「除算」 ダイアログで、値 100 を入力します。
 6-5. 乗車と割引データを組み合わせる
6-5. 乗車と割引データを組み合わせる
次に、両方のテーブルを統合して、乗車に適用される割引と調整された会計を備えた新しいテーブルを作成します。
① 最初に、「Diagram view」(ダイアグラム ビュー) ボタンをクリックし、両方のクエリを表示できるようにします。
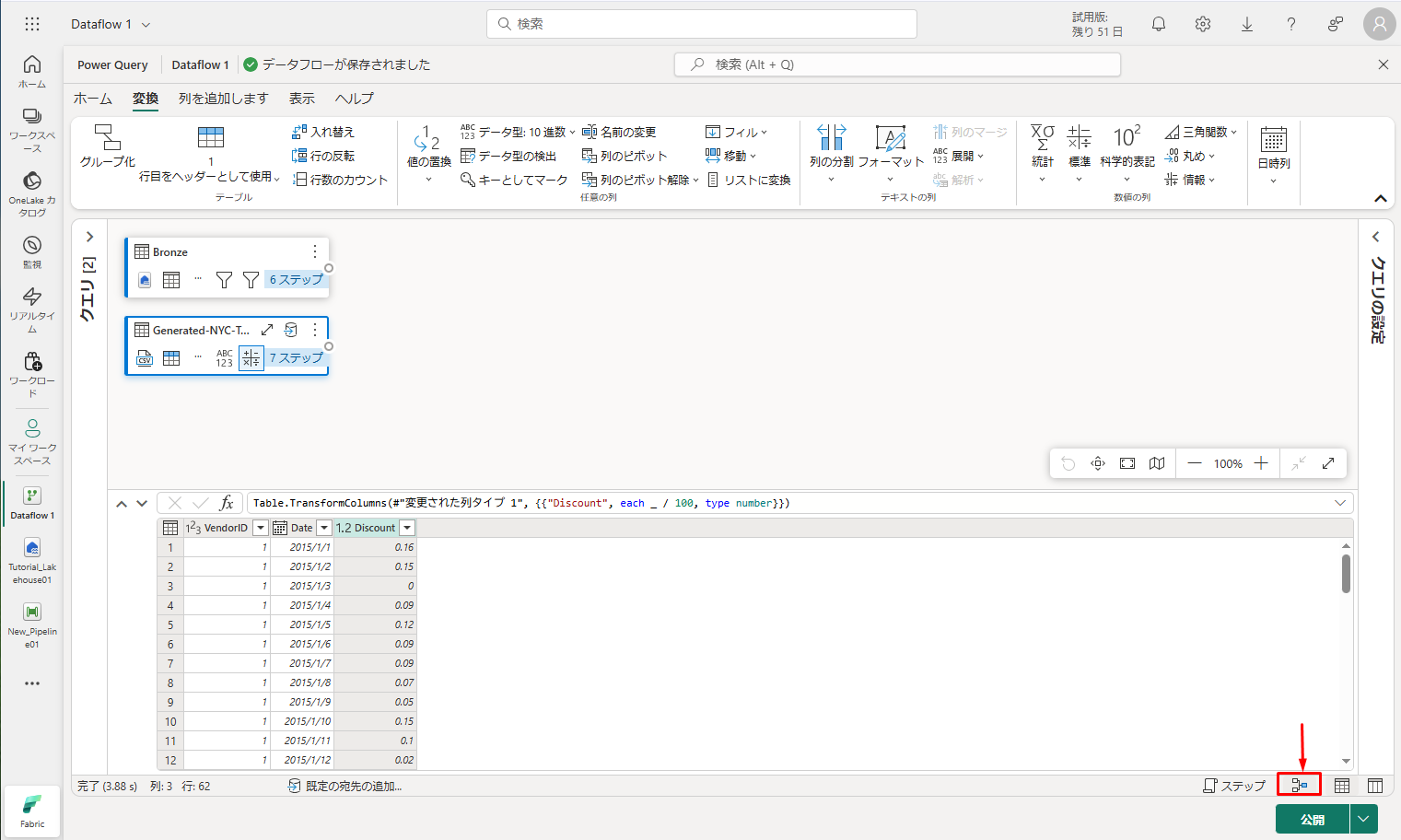 ② Bronze クエリを選択し、「ホーム」 タブで 「Combine」(結合) →「Merge queries」(クエリのマージ) →「Merge queries as new」(新規としてクエリをマージ) をクリックします。
② Bronze クエリを選択し、「ホーム」 タブで 「Combine」(結合) →「Merge queries」(クエリのマージ) →「Merge queries as new」(新規としてクエリをマージ) をクリックします。
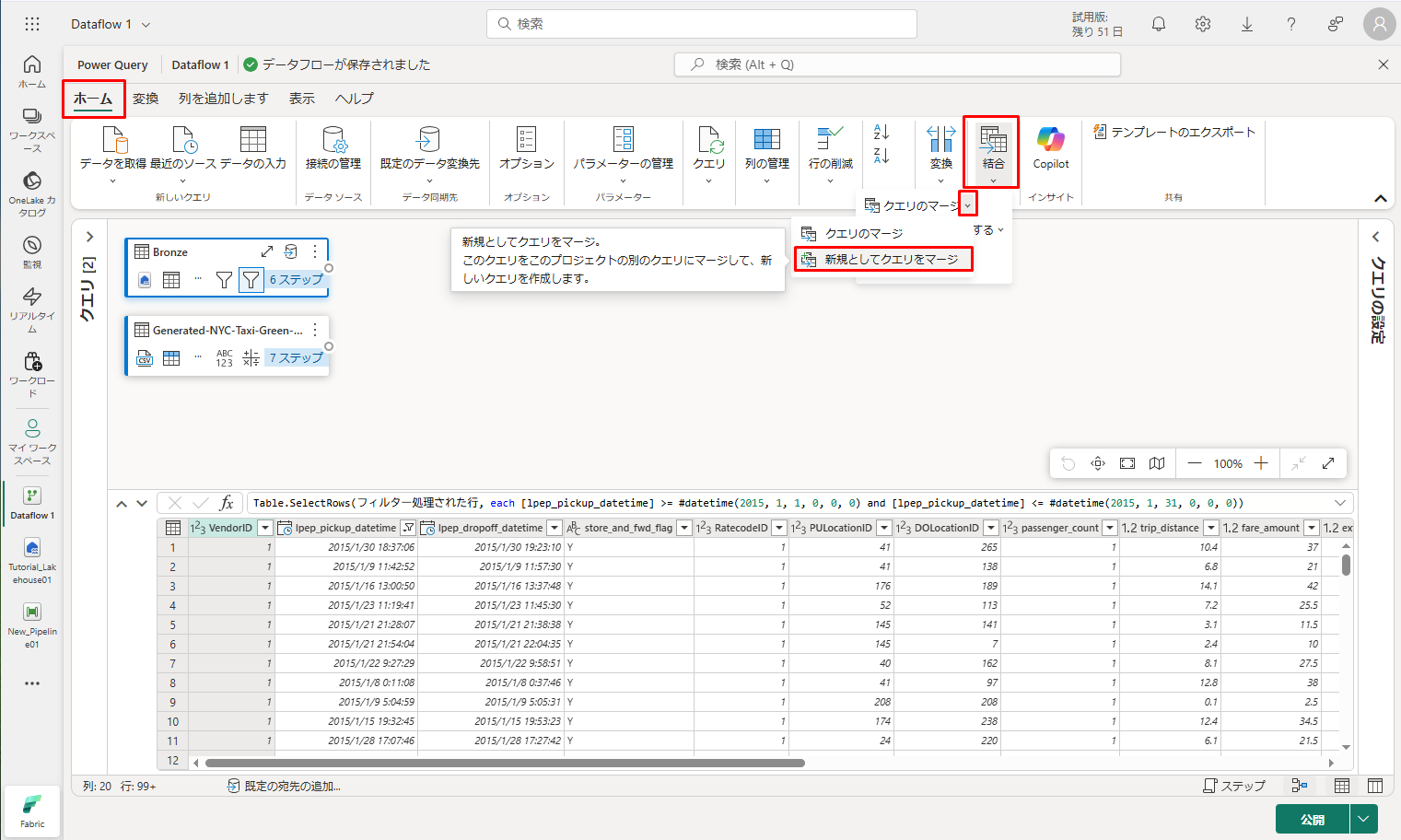 ③「マージ」ダイアログで、「マージ用の右テーブル」ドロップダウンから Generated-NYC-Taxi-Green-Discounts を選択します。ダイアログの右上にある「電球」アイコンを選択して、2 つのテーブル間の推奨される列マッピングを表示します。
③「マージ」ダイアログで、「マージ用の右テーブル」ドロップダウンから Generated-NYC-Taxi-Green-Discounts を選択します。ダイアログの右上にある「電球」アイコンを選択して、2 つのテーブル間の推奨される列マッピングを表示します。
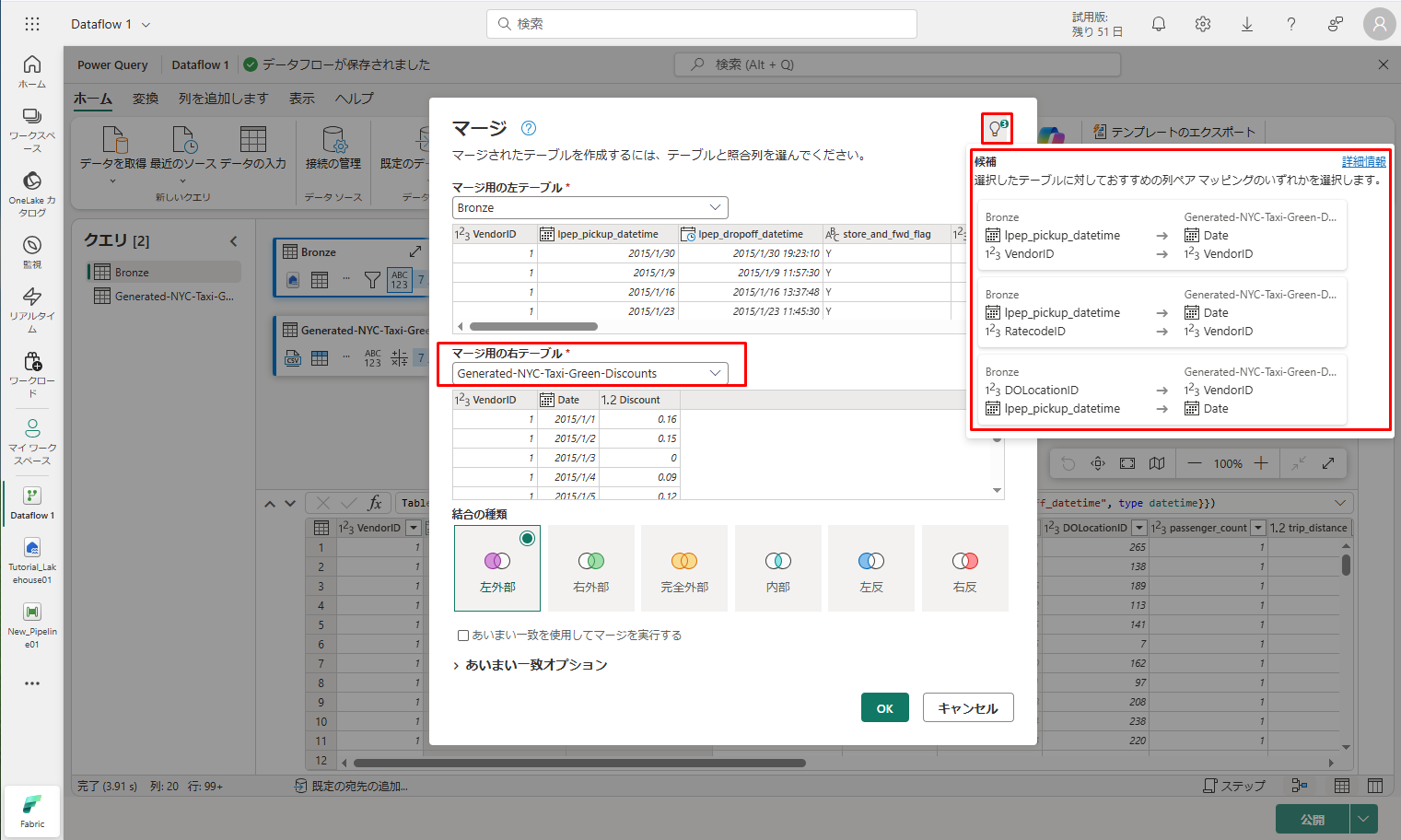 ④ 推奨された 2 つの列マッピング (両方のテーブルの VendorID 列と Date 列のマッピング) を一度に 1 つずつ選択します。 両方のマッピングが追加されると、一致する列ヘッダーが各テーブルで強調表示されます。
④ 推奨された 2 つの列マッピング (両方のテーブルの VendorID 列と Date 列のマッピング) を一度に 1 つずつ選択します。 両方のマッピングが追加されると、一致する列ヘッダーが各テーブルで強調表示されます。
⑤ 次ご画像のようなメッセージが表示されます。「OK」をクリックします。
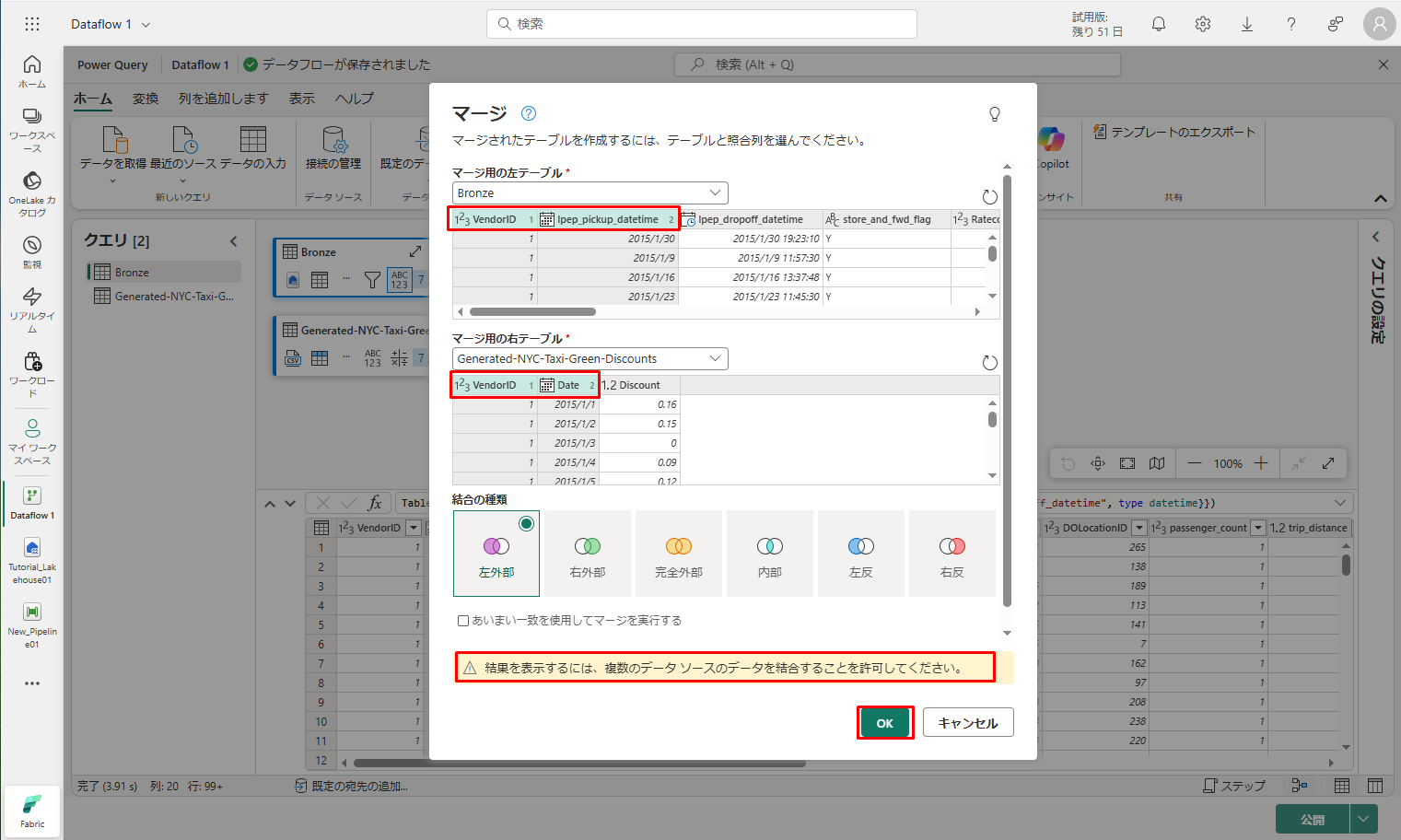
⑥ テーブル領域には、「データのプライバシーに関する情報が必要です。」メッセージが表されます。「続行」をクリックします。
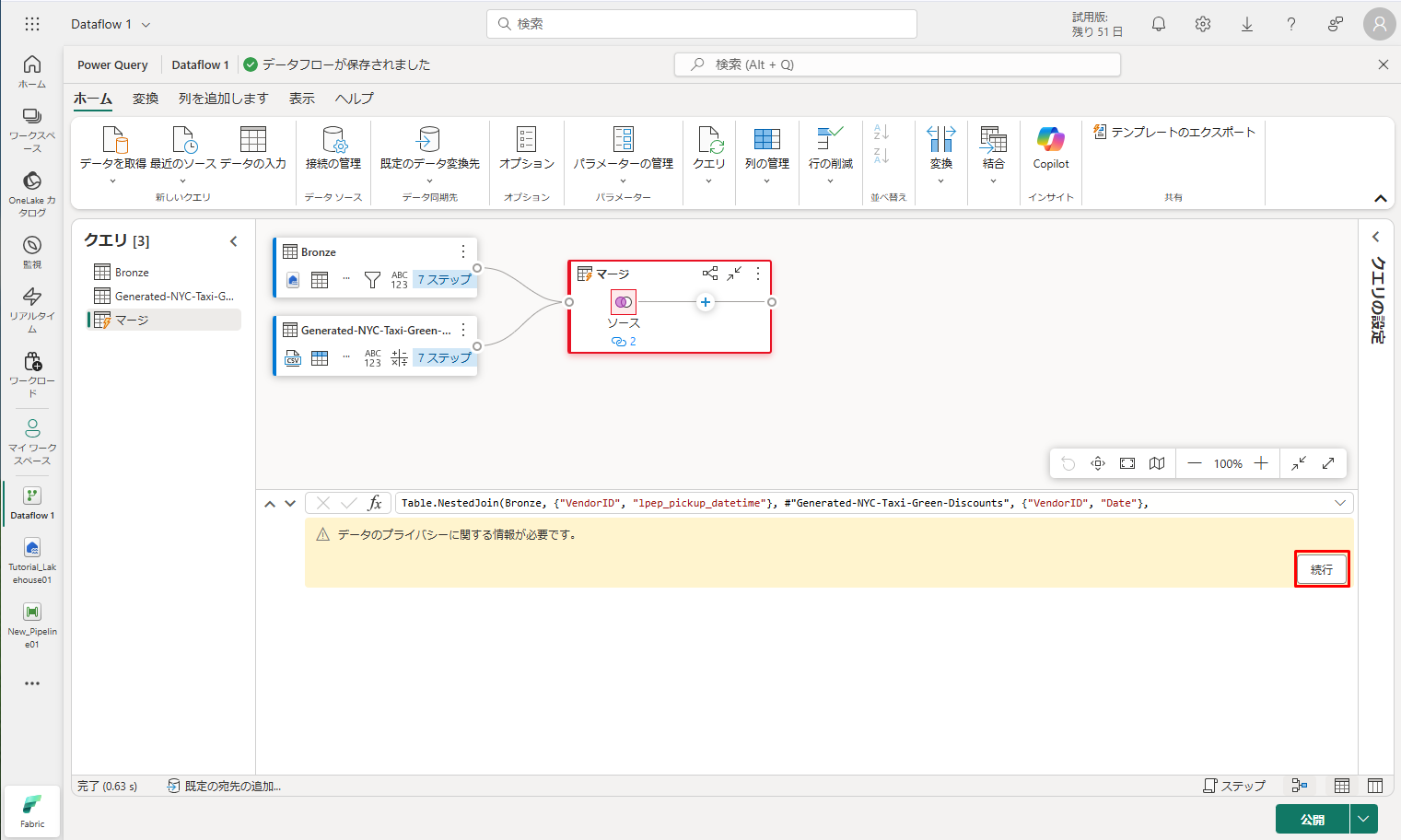 ⑦「保存」をクリックして、結合されたデータを表示します。
⑦「保存」をクリックして、結合されたデータを表示します。
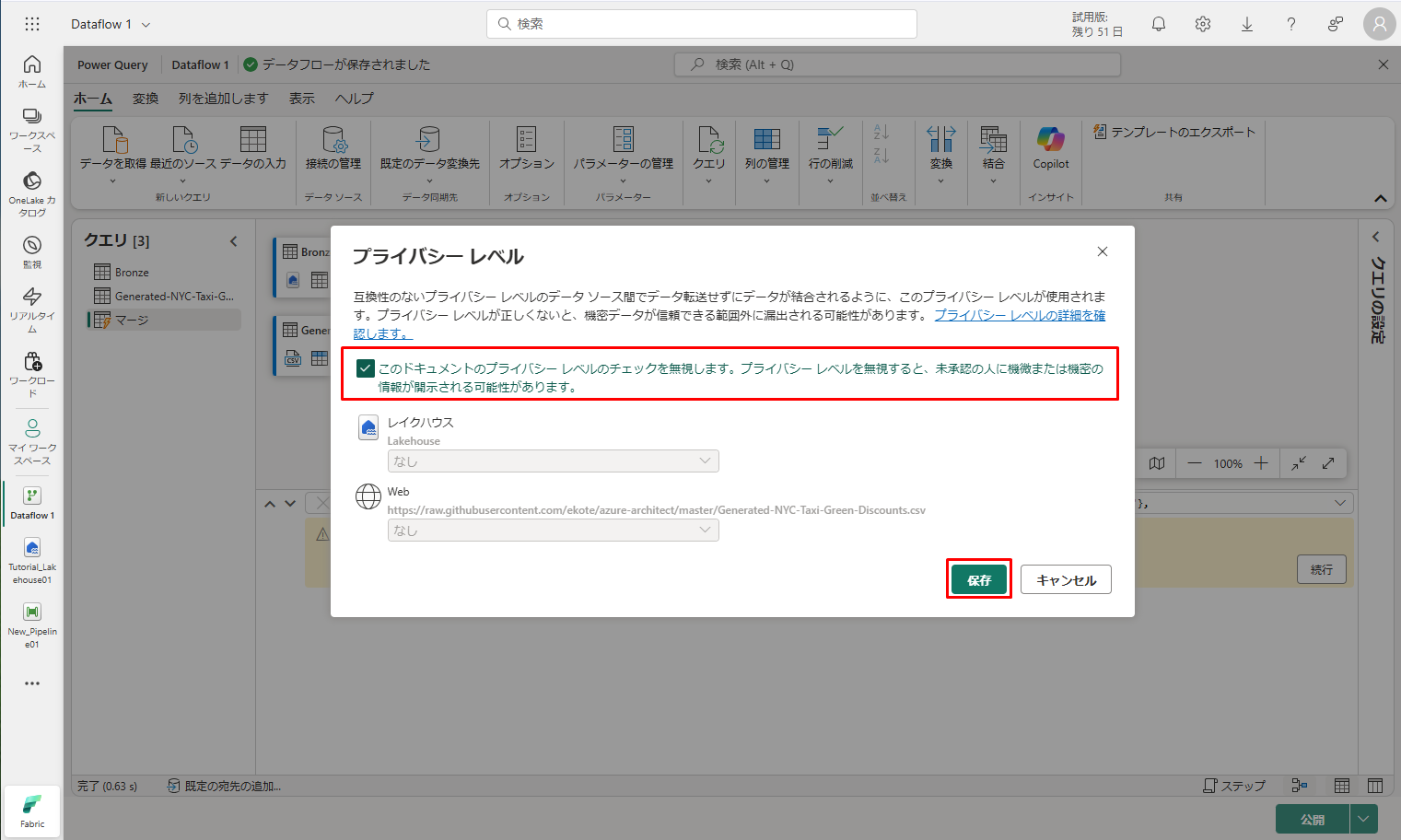 マージクエリ例リストの右側にあるエディターのテーブルウィンドウズを見て、テーブル値を持つ新しい例が存在することを確認します。「Generated-NYC-Taxi-Green-Discounts」という列は、テーブル形式です。
マージクエリ例リストの右側にあるエディターのテーブルウィンドウズを見て、テーブル値を持つ新しい例が存在することを確認します。「Generated-NYC-Taxi-Green-Discounts」という列は、テーブル形式です。
⑧ 列ヘッダーには、反対方向を向いた 2 つの矢印が付いたアイコンがあります。これにより、テーブルから列を選択できます。 Discountを除くすべての例を選択した後、「OK」をクリックします。
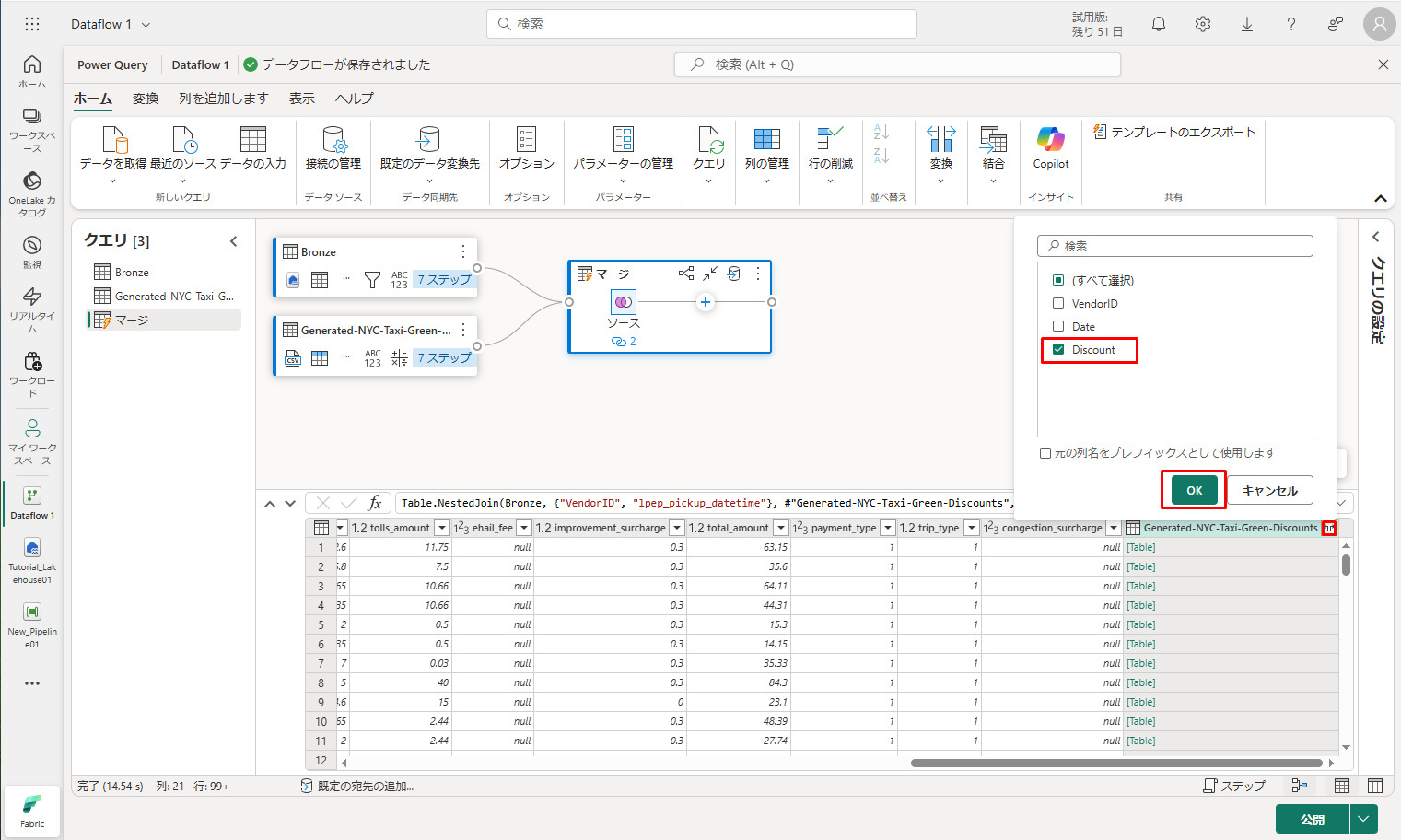 割引の値が行レベルになったので、新しい列を作成して割引後の合計金額を計算できます。
割引の値が行レベルになったので、新しい列を作成して割引後の合計金額を計算できます。
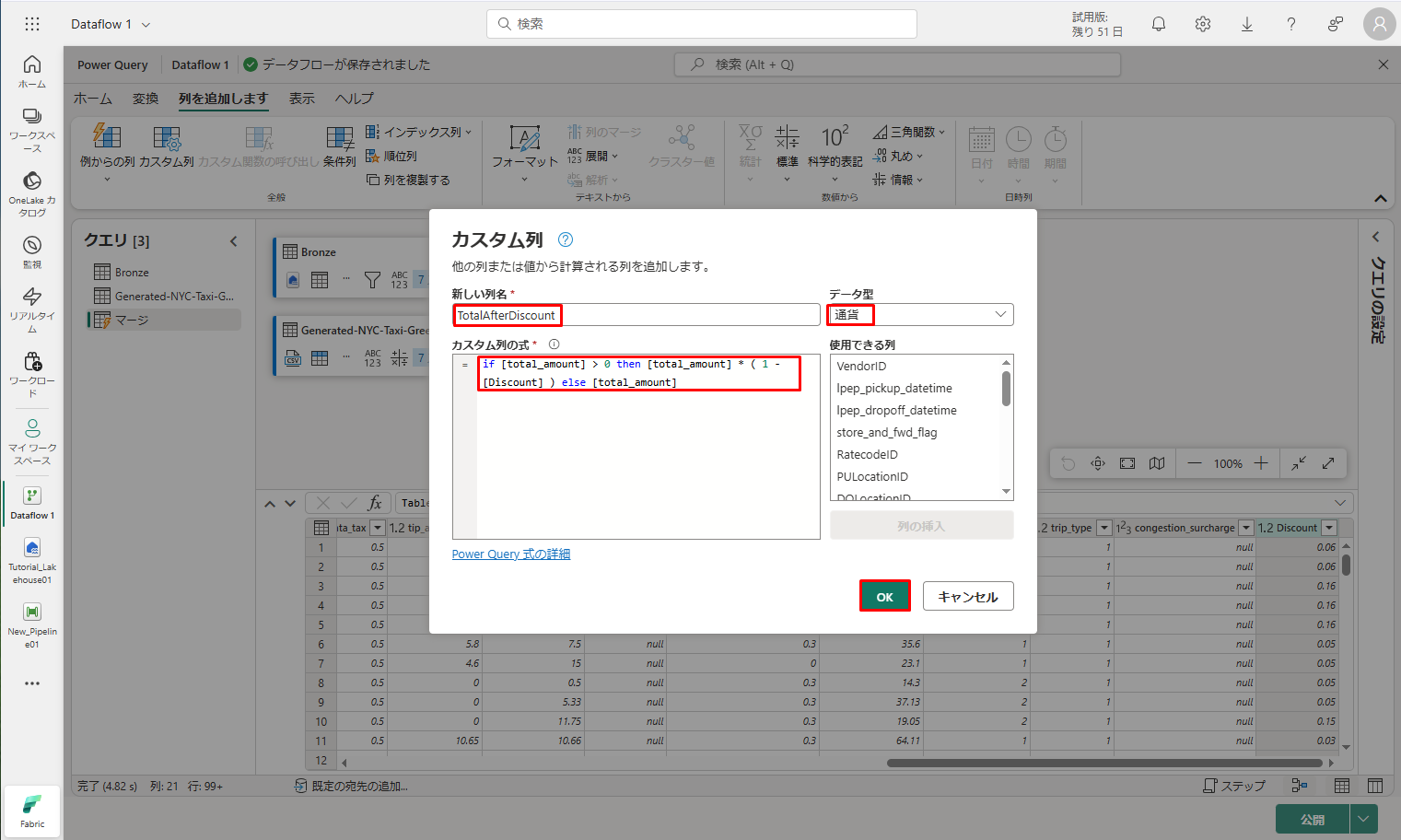
⑨ これを行うには、エディターの上部にある「列を追加します」タブをクリックします。次に、「標準」グループから「カスタム列」を選択します。
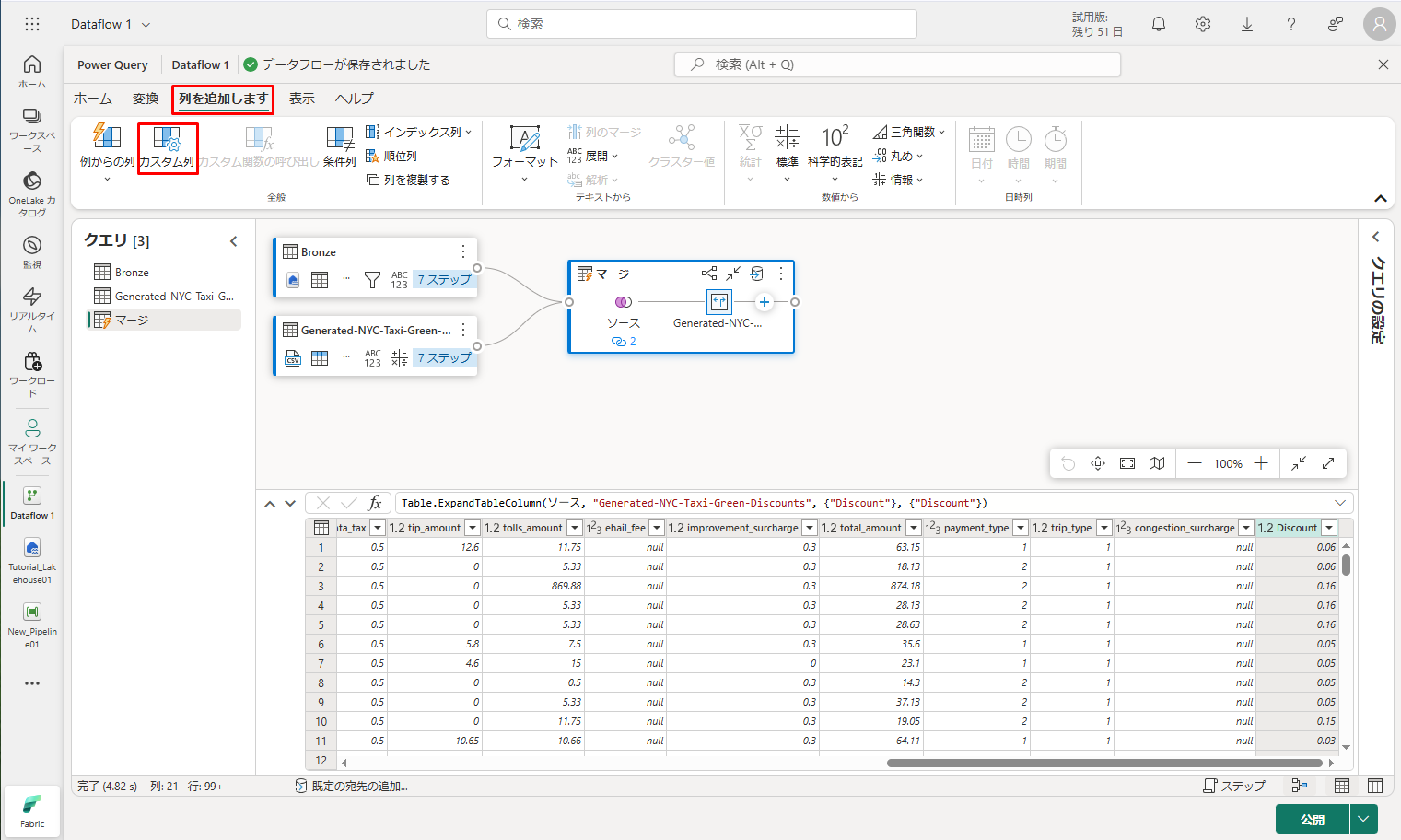 「カスタム列」ダイアログでは、Power Query 数式言語 (M) を使用して新しい列の計算方法を決定できます。
「カスタム列」ダイアログでは、Power Query 数式言語 (M) を使用して新しい列の計算方法を決定できます。
⑩「TotalAfterDiscount」という新しい列名を入力し、「通貨」というデータ型を選択し、「カスタム列の式」に次の M 式を指定します。
|
1 |
if [total_amount] > 0 then [total_amount] * ( 1 -[Discount] ) else [total_amount] |
⑪「OK」をクリックします。
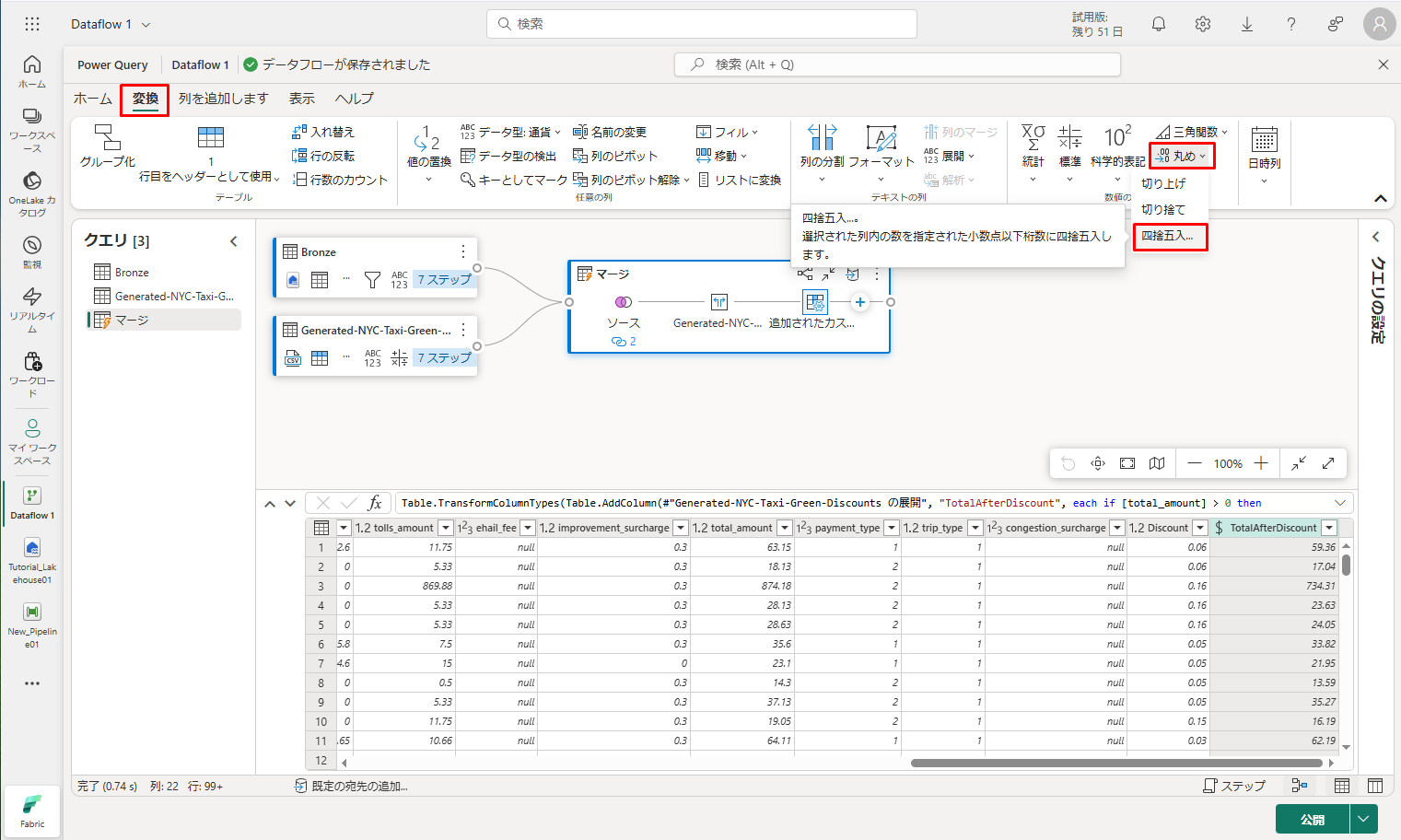
 ⑫ エディター ウィンドウの上部にある「変換」タブを選択し、新たに作成した TotalAfterDiscount 列を選択します。
⑫ エディター ウィンドウの上部にある「変換」タブを選択し、新たに作成した TotalAfterDiscount 列を選択します。
⑬「数値列」グループで、「丸め」ドロップダウンを選択し、「四捨五入…」を選択します。
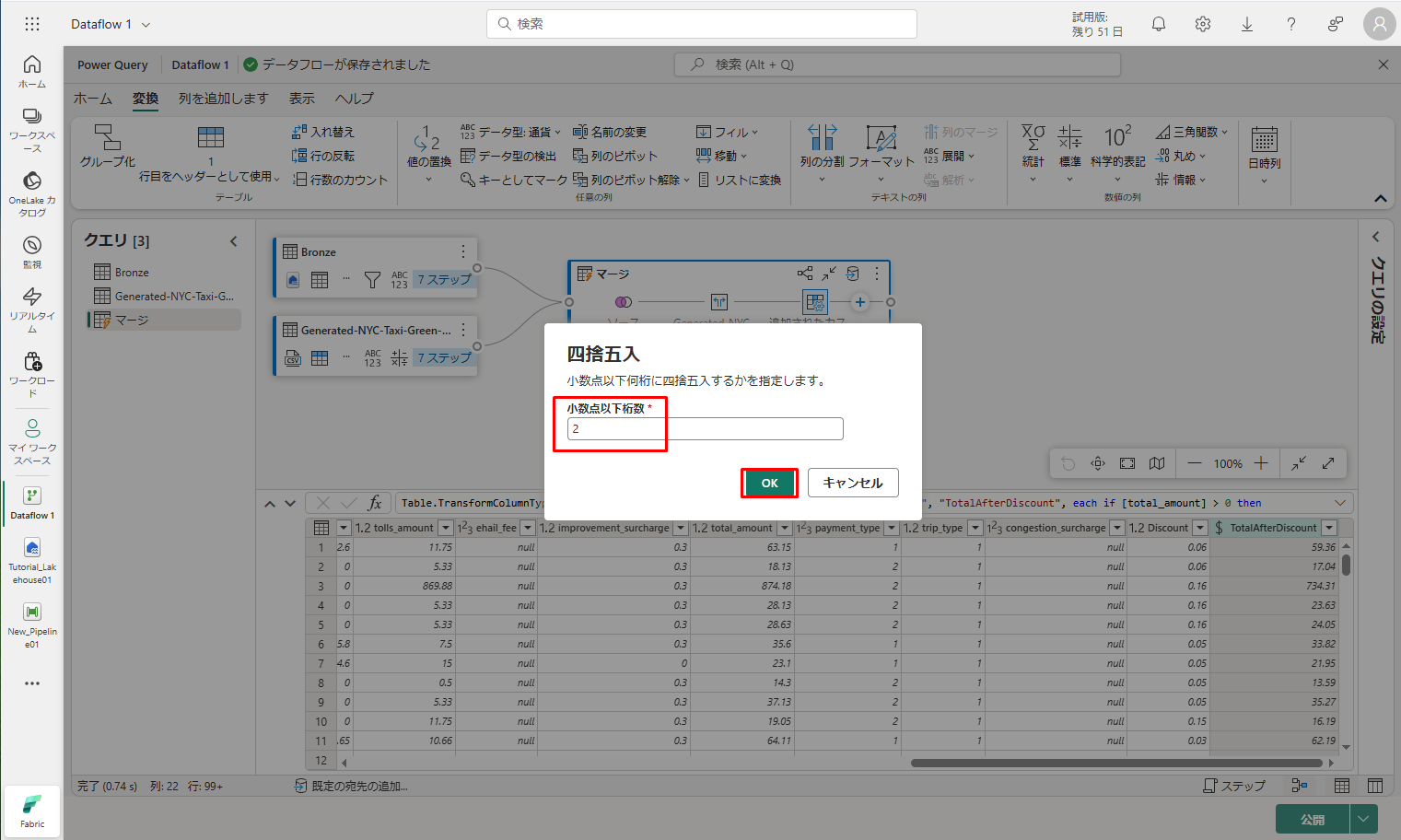
 ⑭「四捨五入」ダイアログで、「小数点以下桁数」として「2」を入力し、「OK」をクリックします。
⑭「四捨五入」ダイアログで、「小数点以下桁数」として「2」を入力し、「OK」をクリックします。
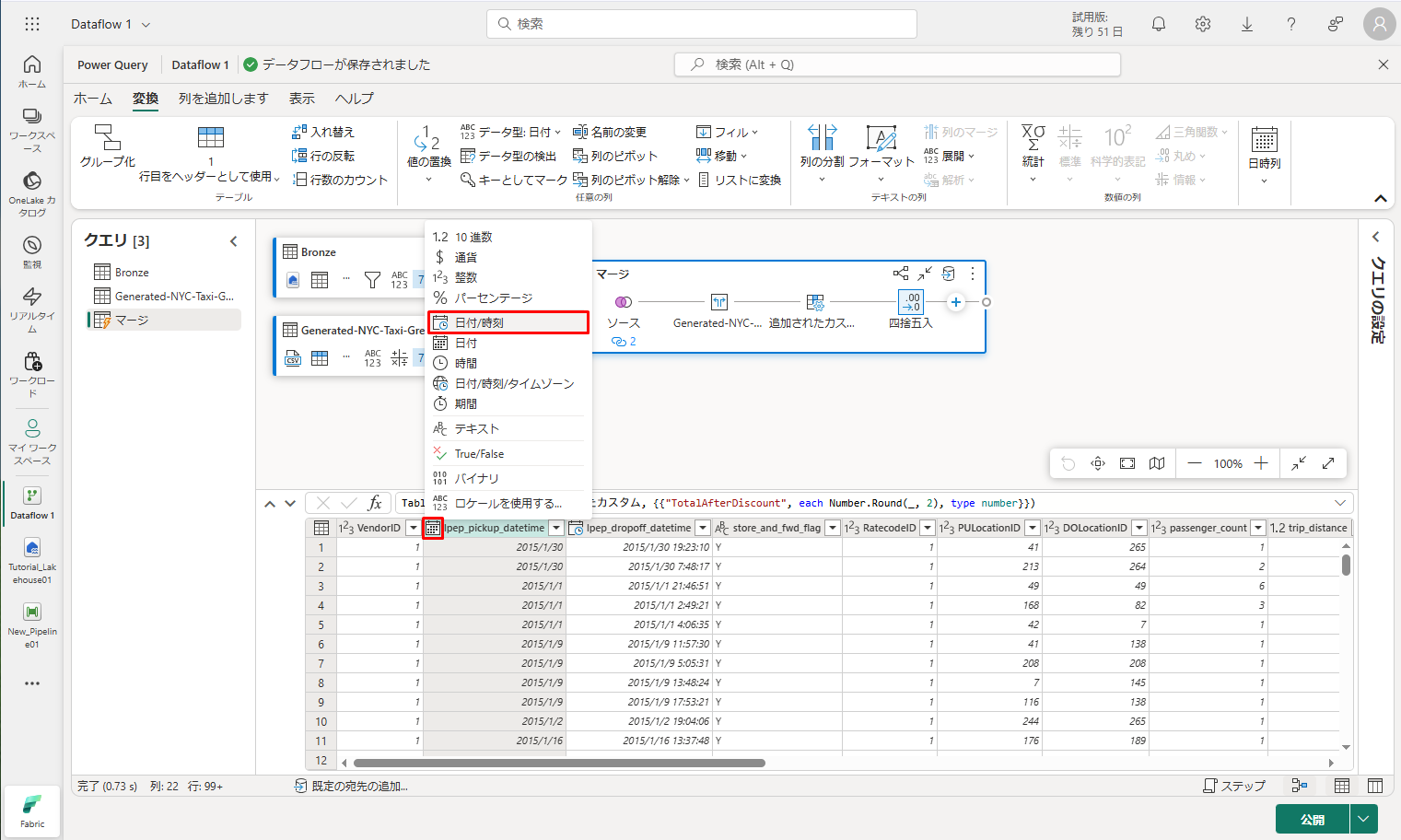
 ⑮ lpep_pickup_datetime のデータ型を 「日付」から「日付/時刻」に変更します。
⑮ lpep_pickup_datetime のデータ型を 「日付」から「日付/時刻」に変更します。
 ⑯ 最後に、エディターの右側から「クエリ設定」ウィンドウを展開し (まだ展開されていない場合)、クエリの名前を Merge から Output に変更します。
⑯ 最後に、エディターの右側から「クエリ設定」ウィンドウを展開し (まだ展開されていない場合)、クエリの名前を Merge から Output に変更します。
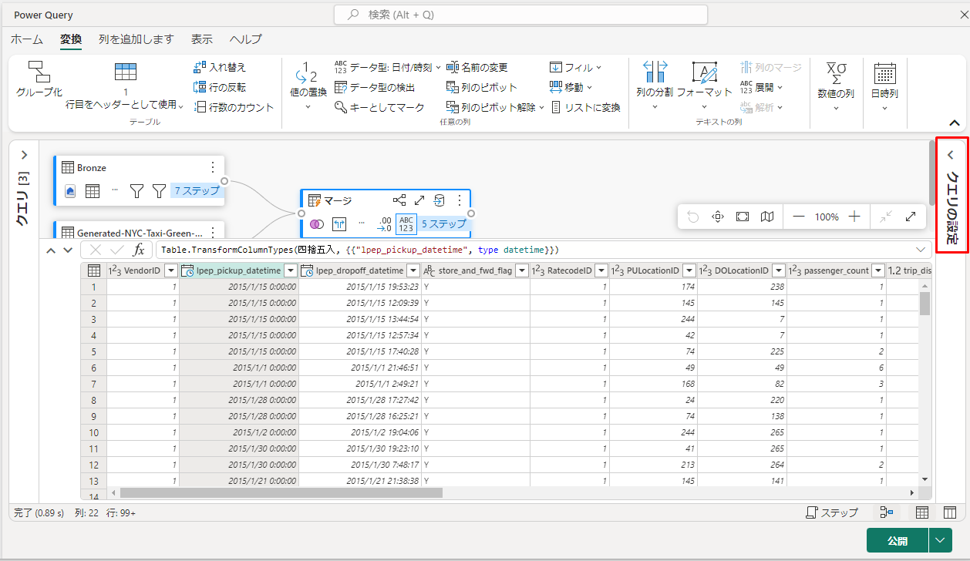
 6-6. レイクハウスのテーブルに出力クエリを読み込む
6-6. レイクハウスのテーブルに出力クエリを読み込む
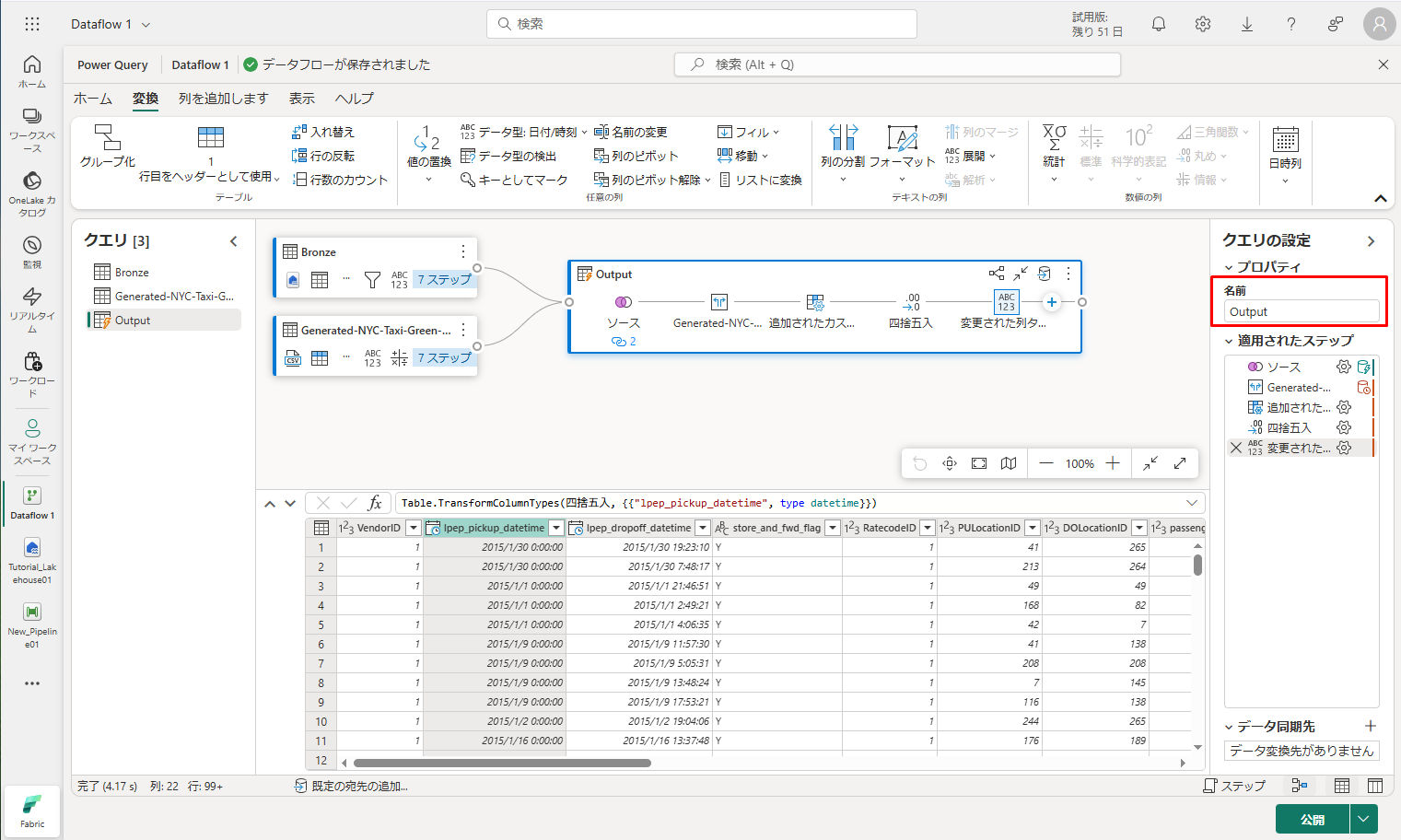
出力クエリが完全に準備され、データを出力する準備ができたので、クエリの出力先を定義できます。
① 以前に作成した Output マージ クエリを選択します。
② 次に、リボンを最小化し、「既定の宛先」をクリックして「クエリの宛先」タブでレイクハウスを選択します。
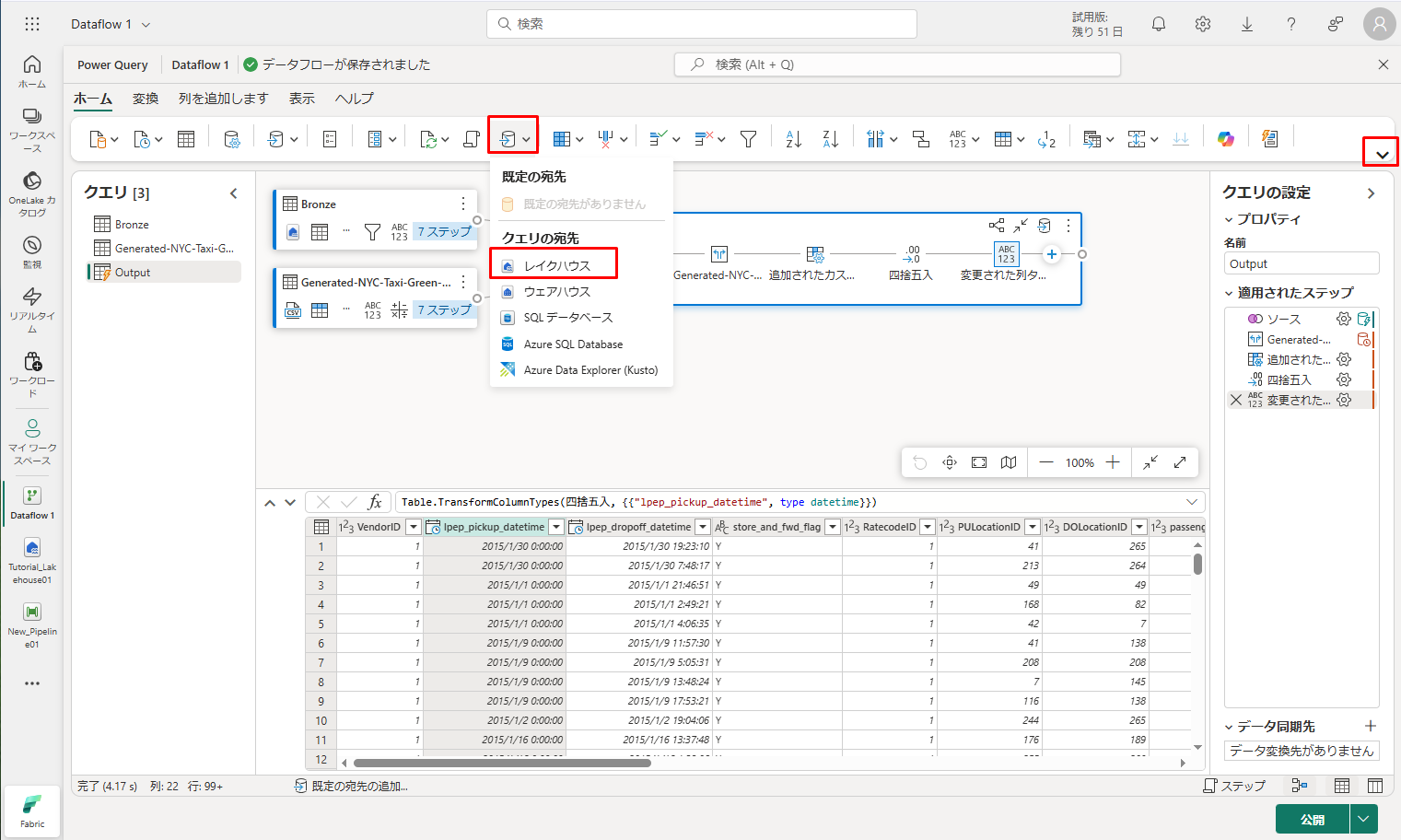 ③「データ変換先に接続」ダイアログで、接続が既に選択されました。
③「データ変換先に接続」ダイアログで、接続が既に選択されました。
④「次へ」をクリックして続行します。
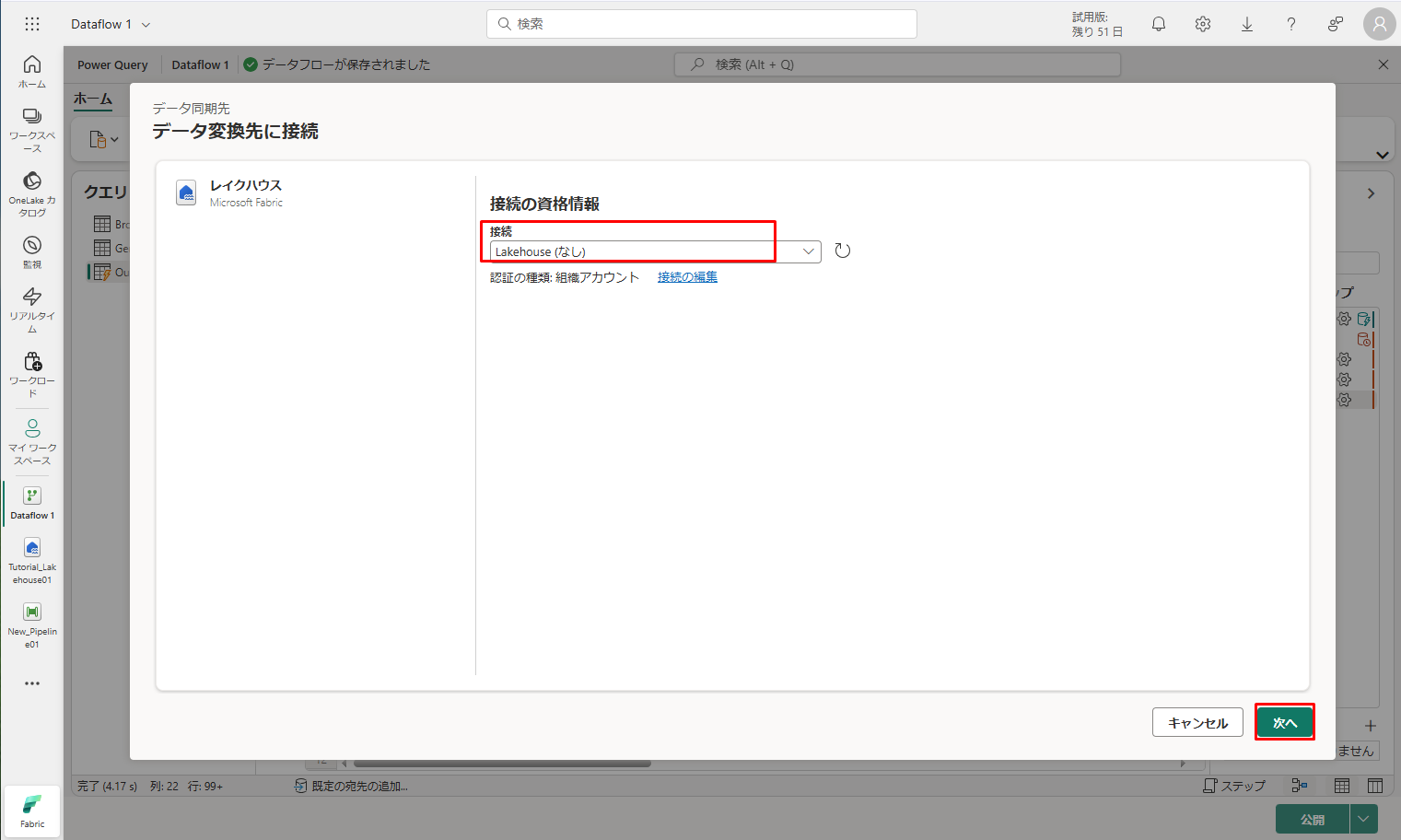 ⑤「既定宛先ターゲットの選択する」ダイアログで、データを読み込むレイクハウスを参照し、新しいテーブルに nyc_taxi_with_discounts という名前を付けてから、「次へ」をクリックします。
⑤「既定宛先ターゲットの選択する」ダイアログで、データを読み込むレイクハウスを参照し、新しいテーブルに nyc_taxi_with_discounts という名前を付けてから、「次へ」をクリックします。
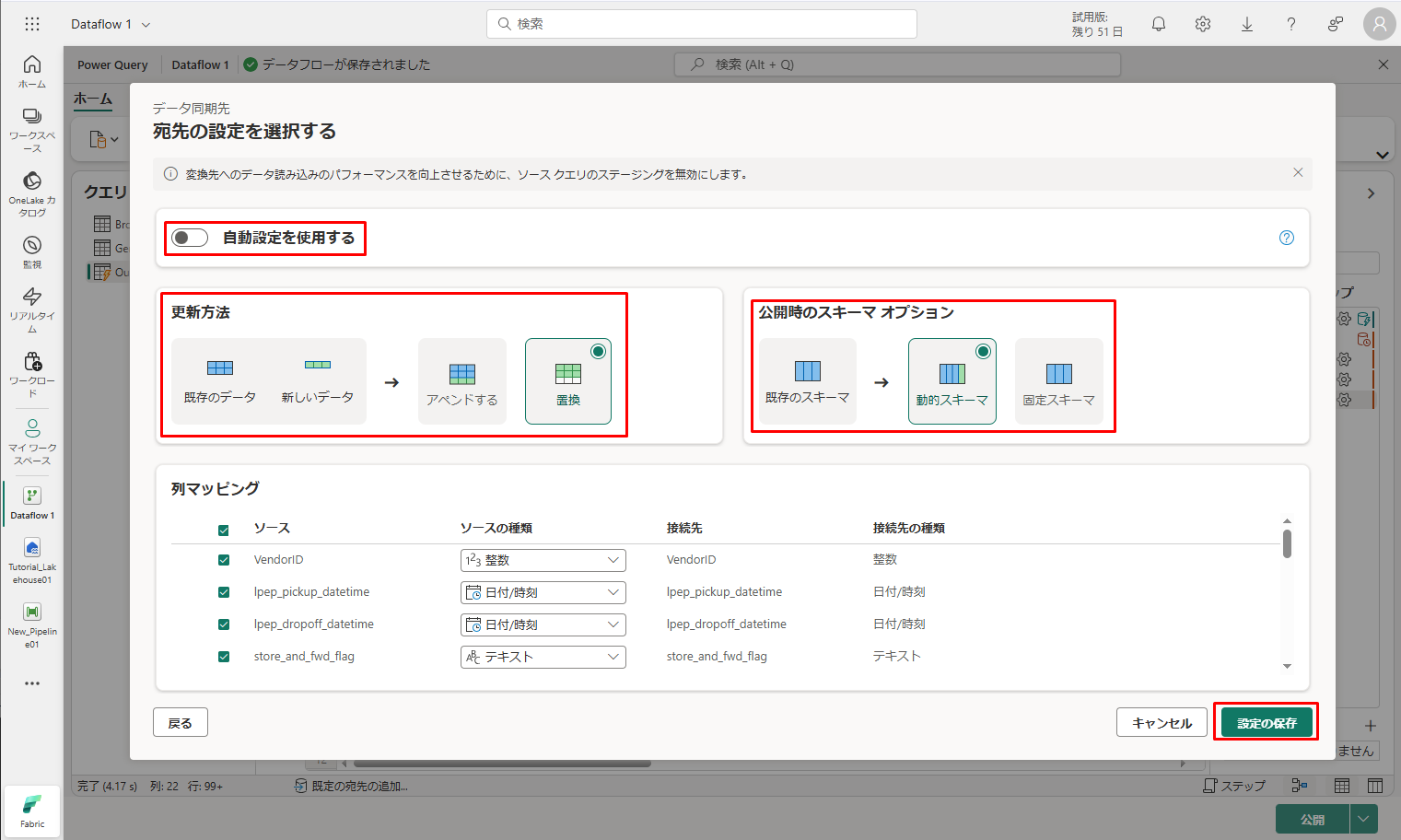
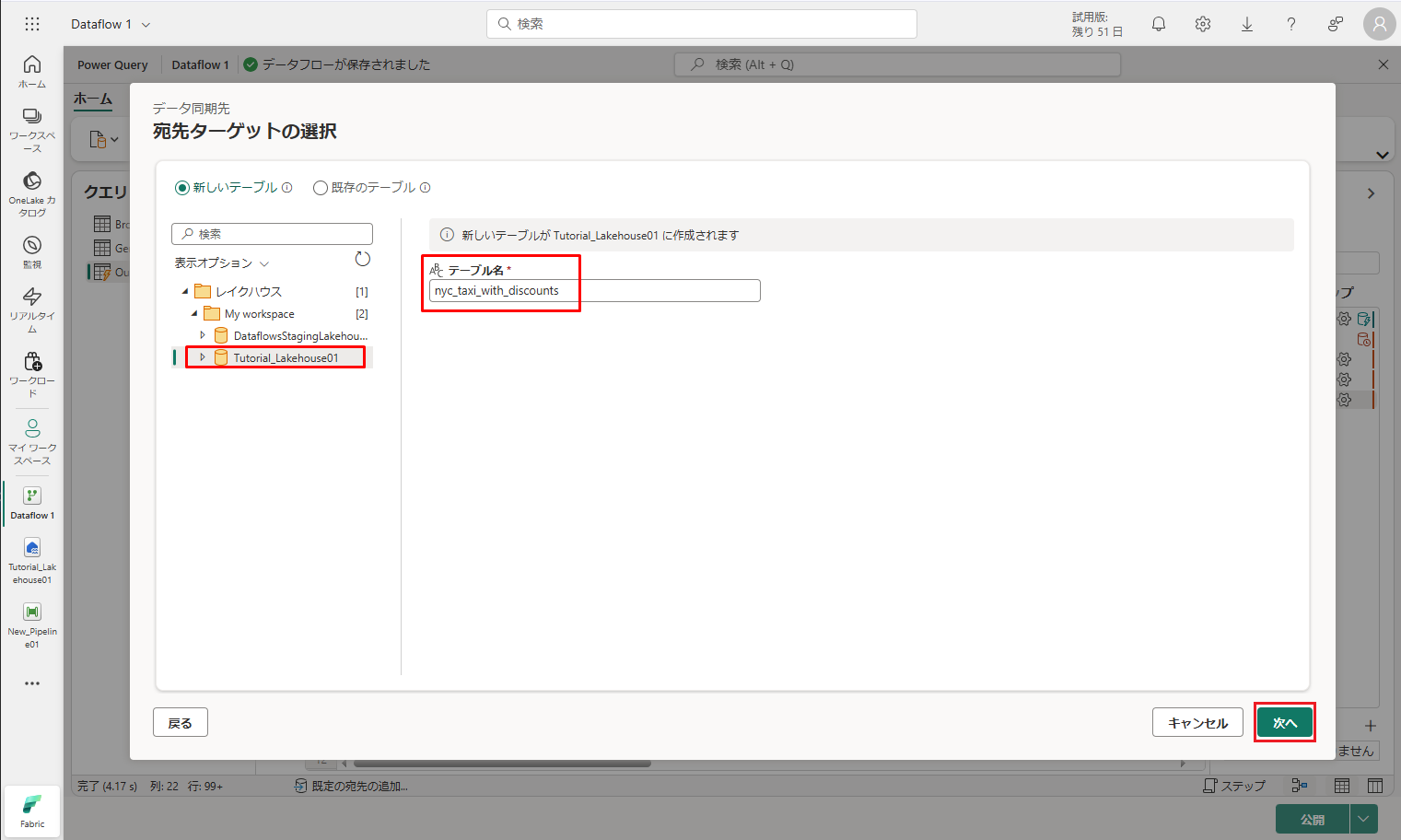 ⑥「宛先の設定を選択する」ダイアログで、更新方法を既定の「置換」のままにし、列が正しくマップされていることを再確認して、「設定の保存」をクリックします。
⑥「宛先の設定を選択する」ダイアログで、更新方法を既定の「置換」のままにし、列が正しくマップされていることを再確認して、「設定の保存」をクリックします。
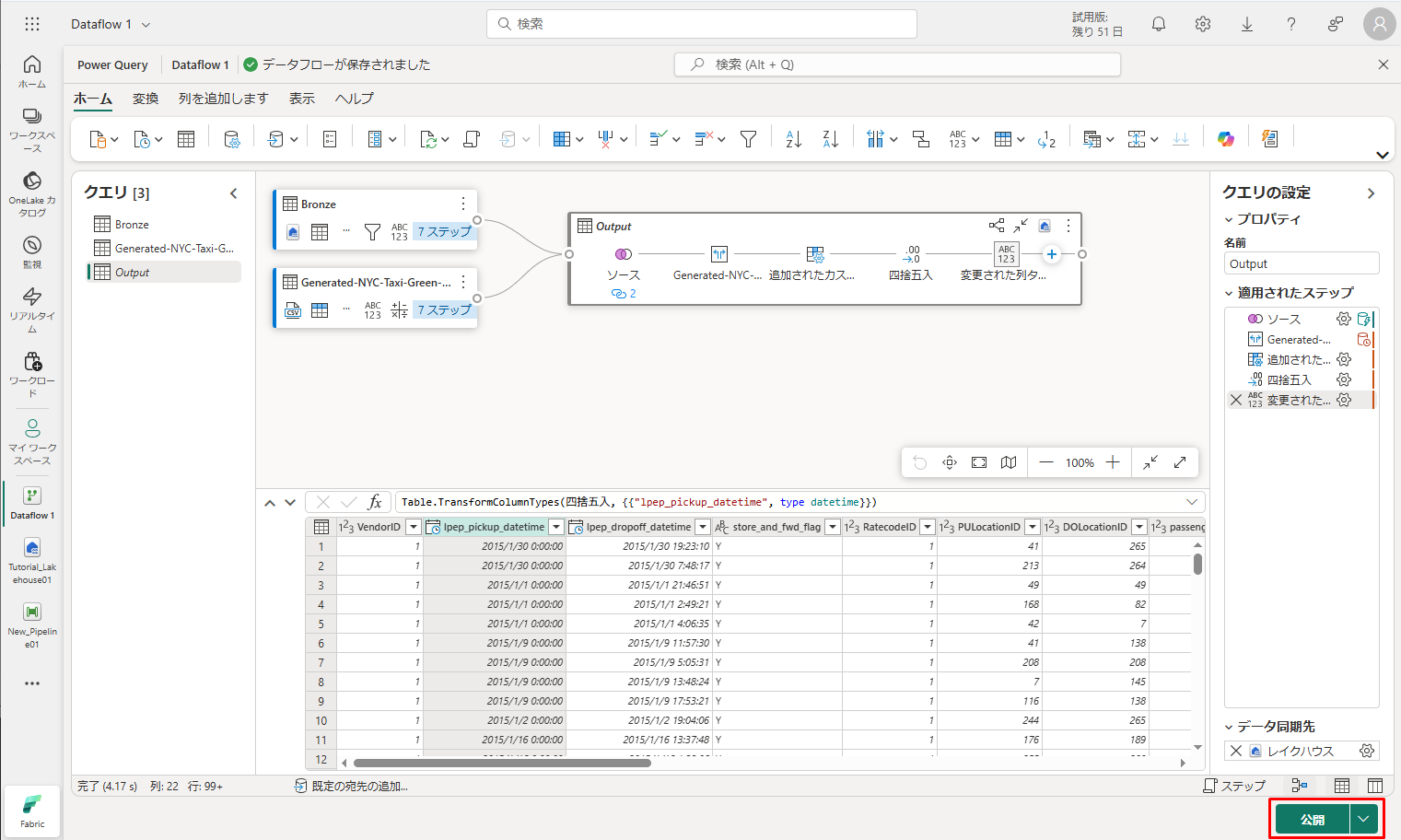
 ⑦ エディターのメイン ウィンドウに戻り、「クエリ設定」ウィンドウで Output テーブルの出力先を確認して、「公開」を選択します。
⑦ エディターのメイン ウィンドウに戻り、「クエリ設定」ウィンドウで Output テーブルの出力先を確認して、「公開」を選択します。
 7. Data Factory を使用して通知を自動化して送信する
7. Data Factory を使用して通知を自動化して送信する
7-1.「Data Factory でパイプラインを作成する」で作成したパイプラインを使用します。
① パイプライン エディターで 「アクティビティ」タブを選択し、Office Outlook アクティビティを見つけます。
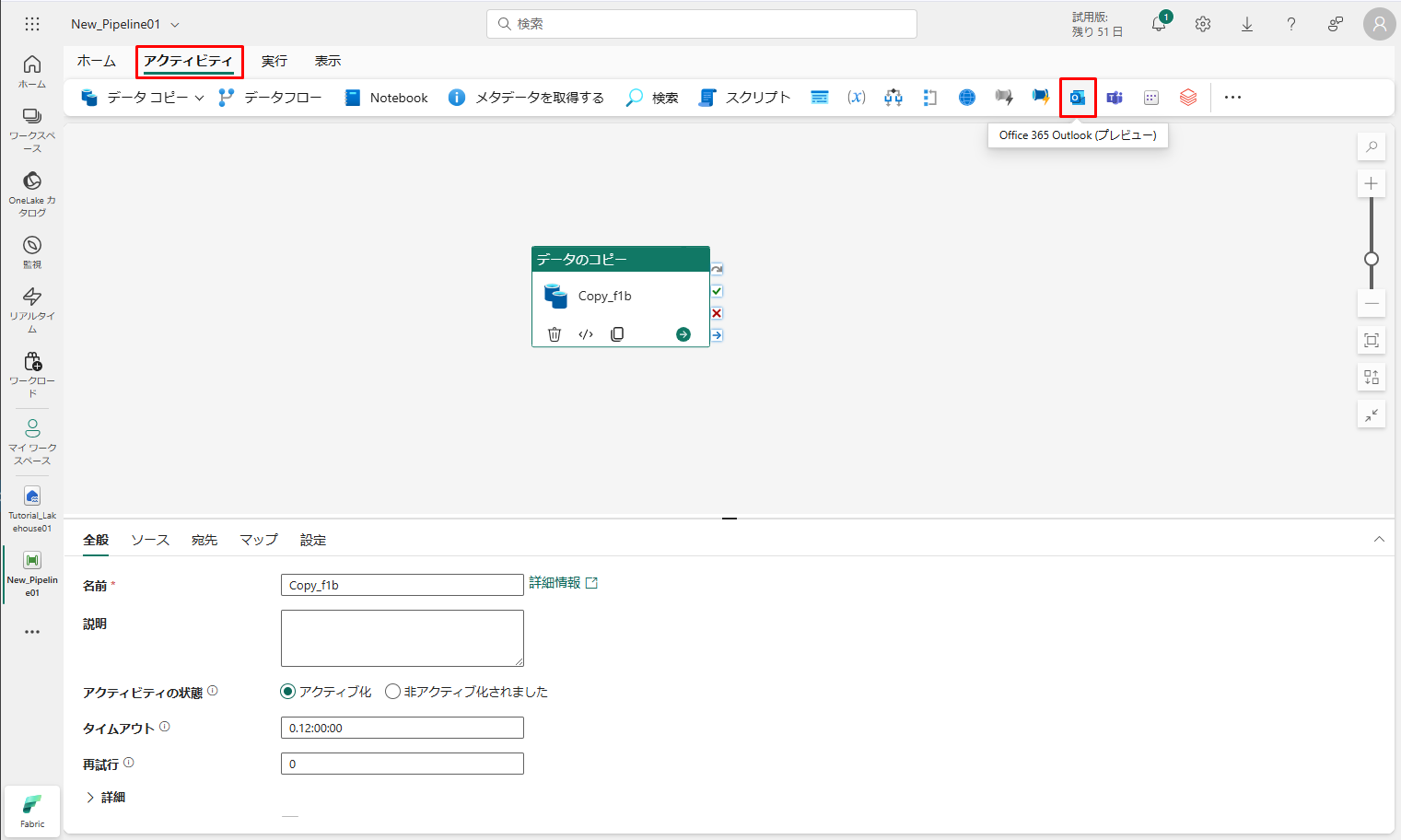 ②「サイイン」をクリックして、メール アドレスの使用に同意します。
②「サイイン」をクリックして、メール アドレスの使用に同意します。
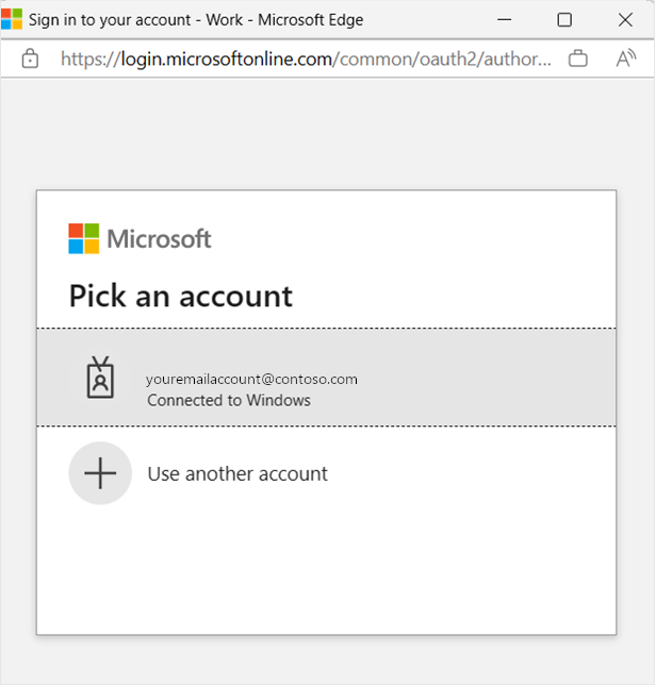
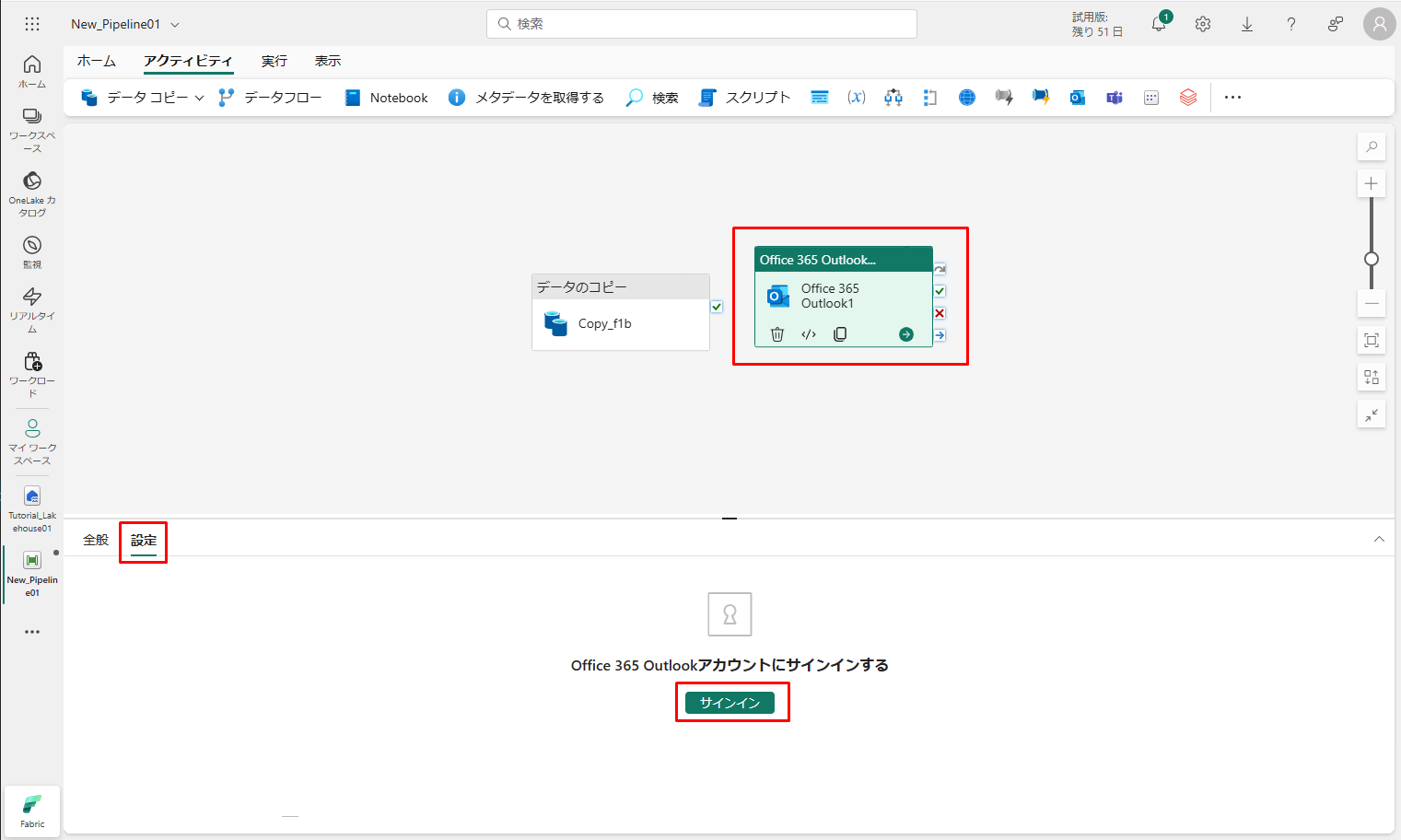 ③ 使用するメール アドレスを選択します。
③ 使用するメール アドレスを選択します。
現在、このサービスは個人用のメール アドレスをサポートしていません。 ビジネスのメール アドレスを使用することが不可欠です。
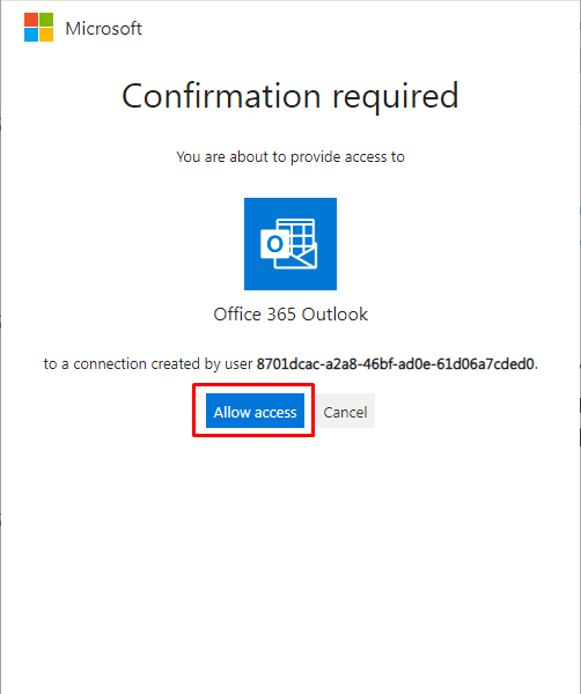
④「Allow access」をクリックして確認します。
⑤「成功時」パス (パイプライン キャンバスのアクティビティの右上にある緑色のチェックボックス) を選択して、Copy アクティビティから新しいOffice 365 Outlook アクティビティにドラッグします。
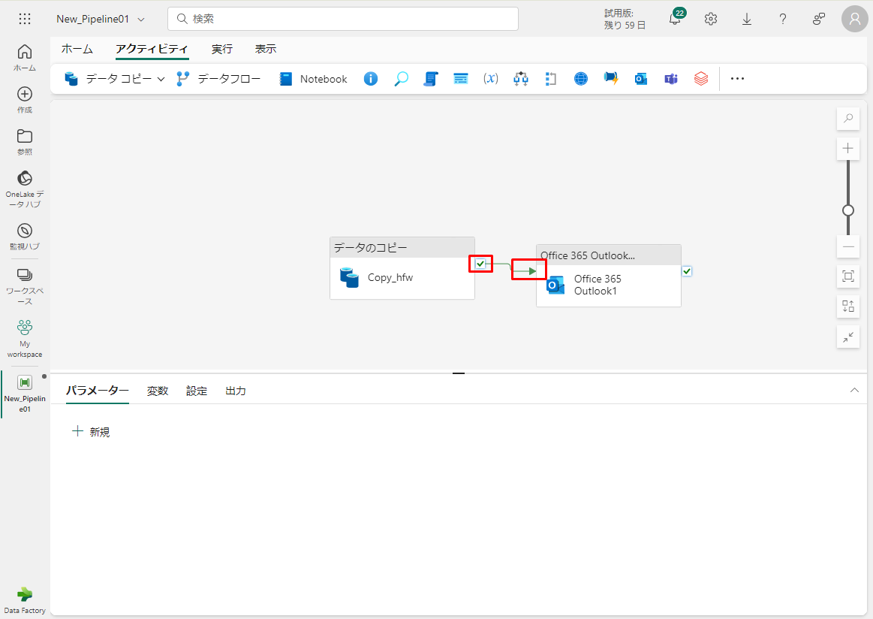
⑥ Office 365 Outlook アクティビティをパイプライン キャンバスから選択します。キャンバスの下にあるプロパティ領域で「設定」タブを選択して、メール アドレスを設定します。
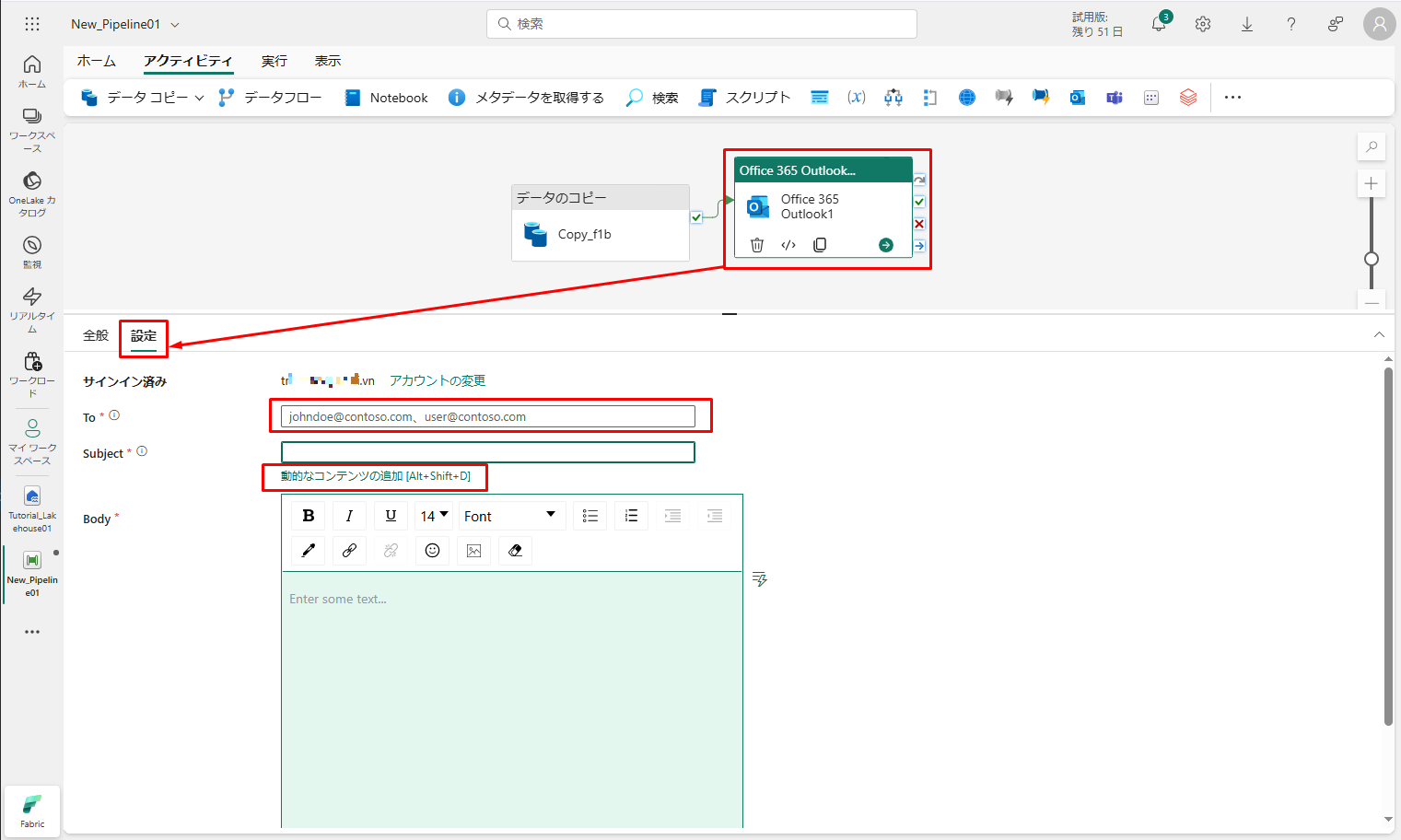
⑦「To」セクションに電子メールアドレスを入力します。 複数のアドレスを使用する場合は、区切りを使用します。
⑧「Subject」で、フィールドを選択して「動的なコンテンツの追加」オプションが表示されるようにし、それを選択してパイプライン式ビルダー キャンバスを表示します。
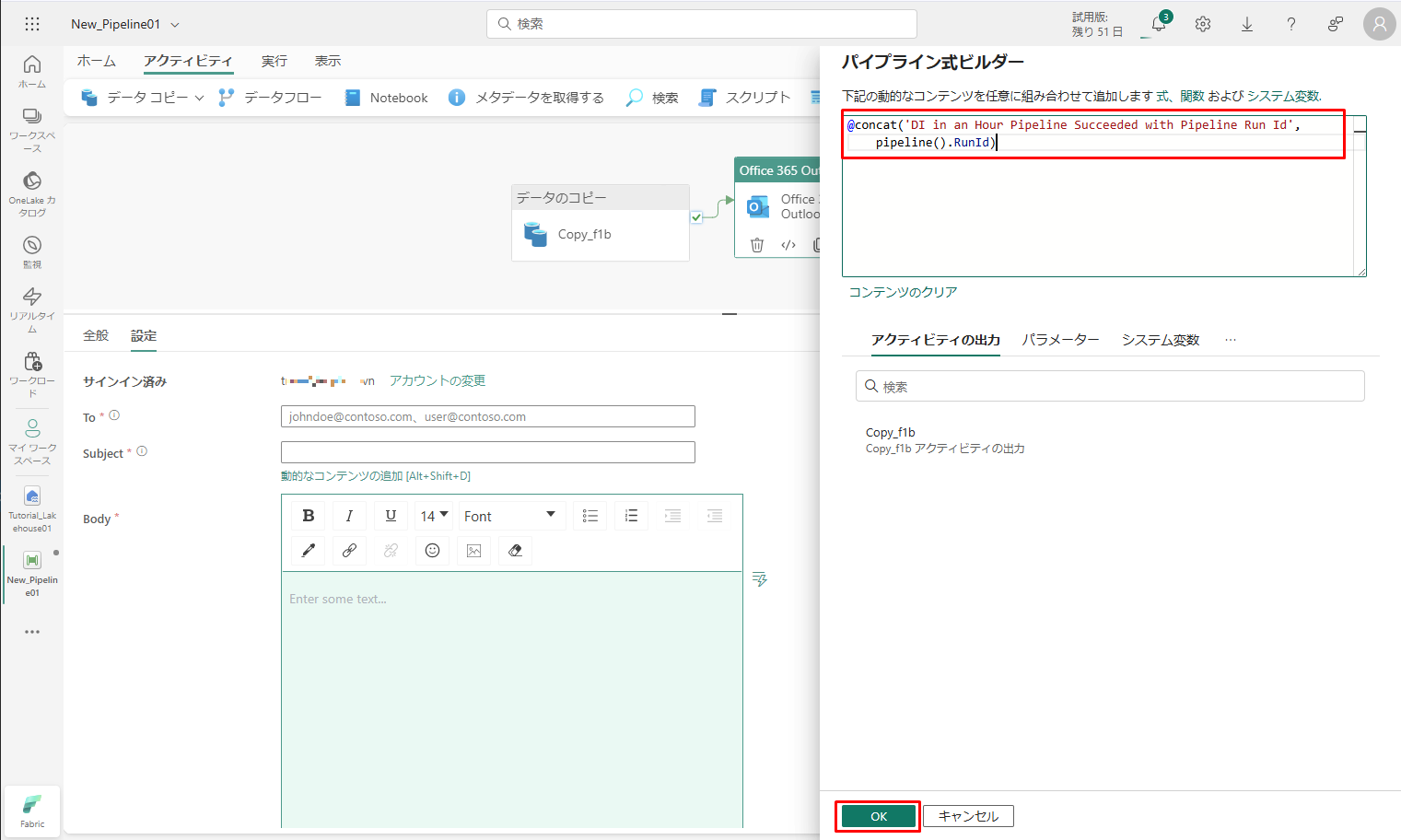
 ⑨「パイプライン式ビルダー」ダイアログが表示されます。 次の式を入力し、「OK」をクリックします。
⑨「パイプライン式ビルダー」ダイアログが表示されます。 次の式を入力し、「OK」をクリックします。
|
1 |
@concat('DI in an Hour Pipeline Succeeded with Pipeline Run Id', pipeline().RunId) |
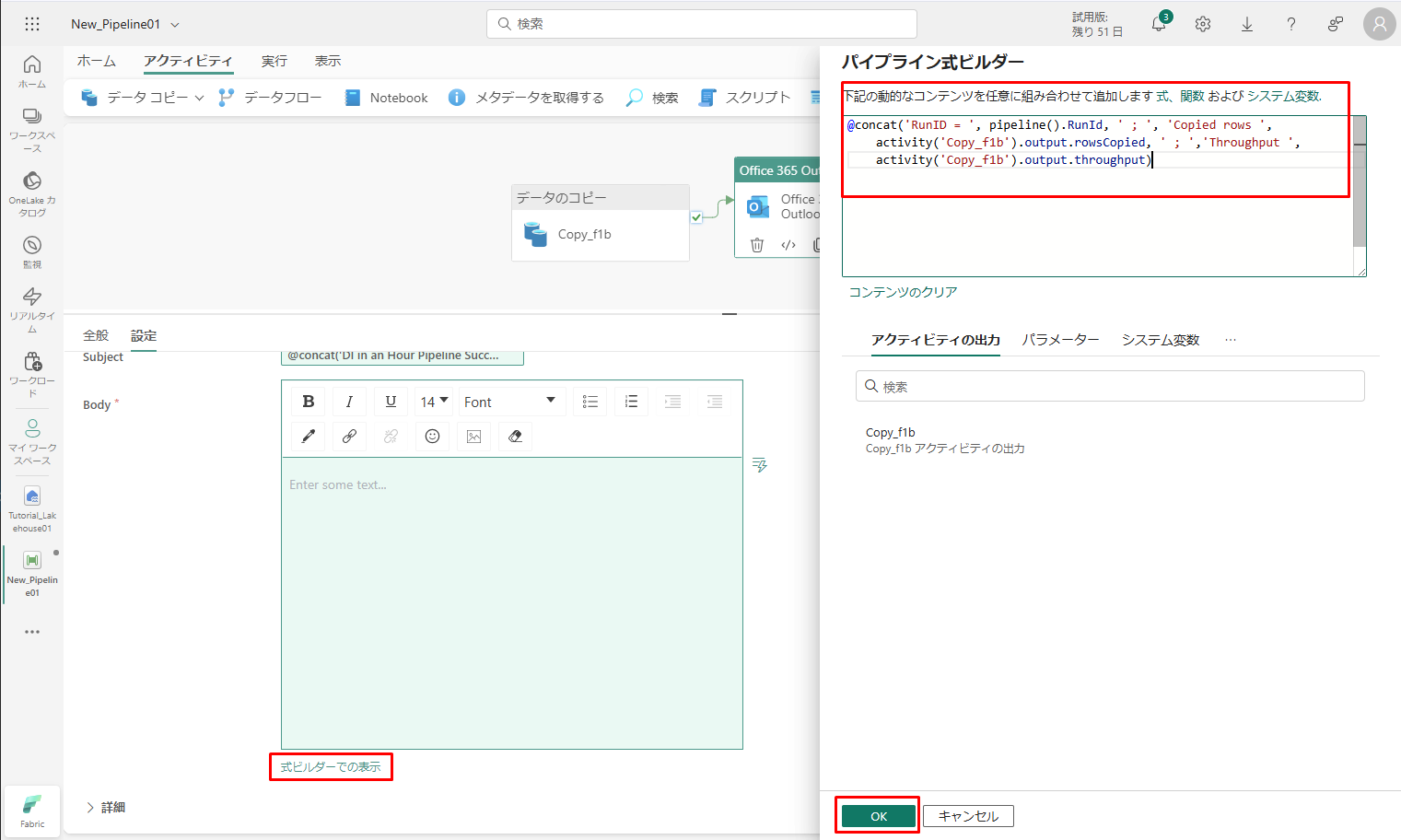
 ⑩「本文」のフィールドをもう一度選択します。次に、テキスト領域の下に表示されるオプション「動的なコンテンツの追加」を選択します。 パイプライン式ビルダーのダイアログで、次の式を追加し、「OK」をクリックします。
⑩「本文」のフィールドをもう一度選択します。次に、テキスト領域の下に表示されるオプション「動的なコンテンツの追加」を選択します。 パイプライン式ビルダーのダイアログで、次の式を追加し、「OK」をクリックします。
⑪ Copy data1 は、自分のパイプライン コピー アクティビティの名前に置き換えます。
|
1 |
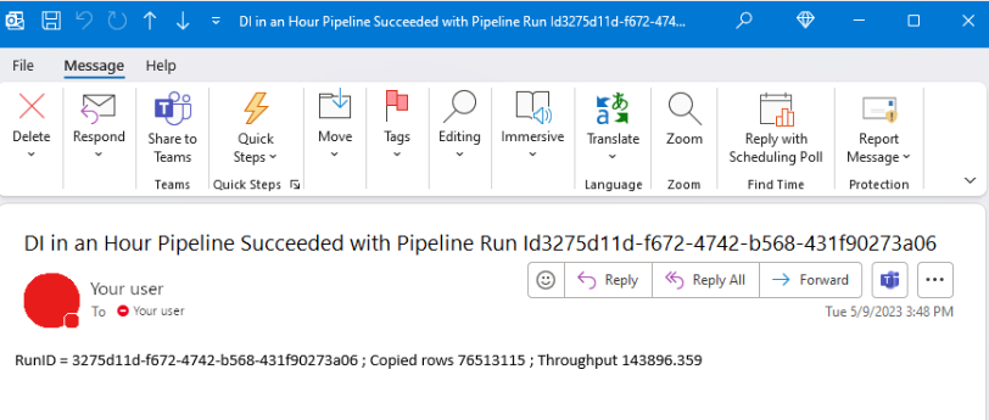
@concat('RunID = ', pipeline().RunId, ' ; ', 'Copied rows ', activity('Copy data1').output.rowsCopied, ' ; ','Throughput ', activity('Copy data1').output.throughput) |
 ⑫ 最後に、「ホーム」タブで 「実行」を選択します。 次に、確認ダイアログで「保存および実行」をクリックして、これらのアクティビティを実行します。
⑫ 最後に、「ホーム」タブで 「実行」を選択します。 次に、確認ダイアログで「保存および実行」をクリックして、これらのアクティビティを実行します。
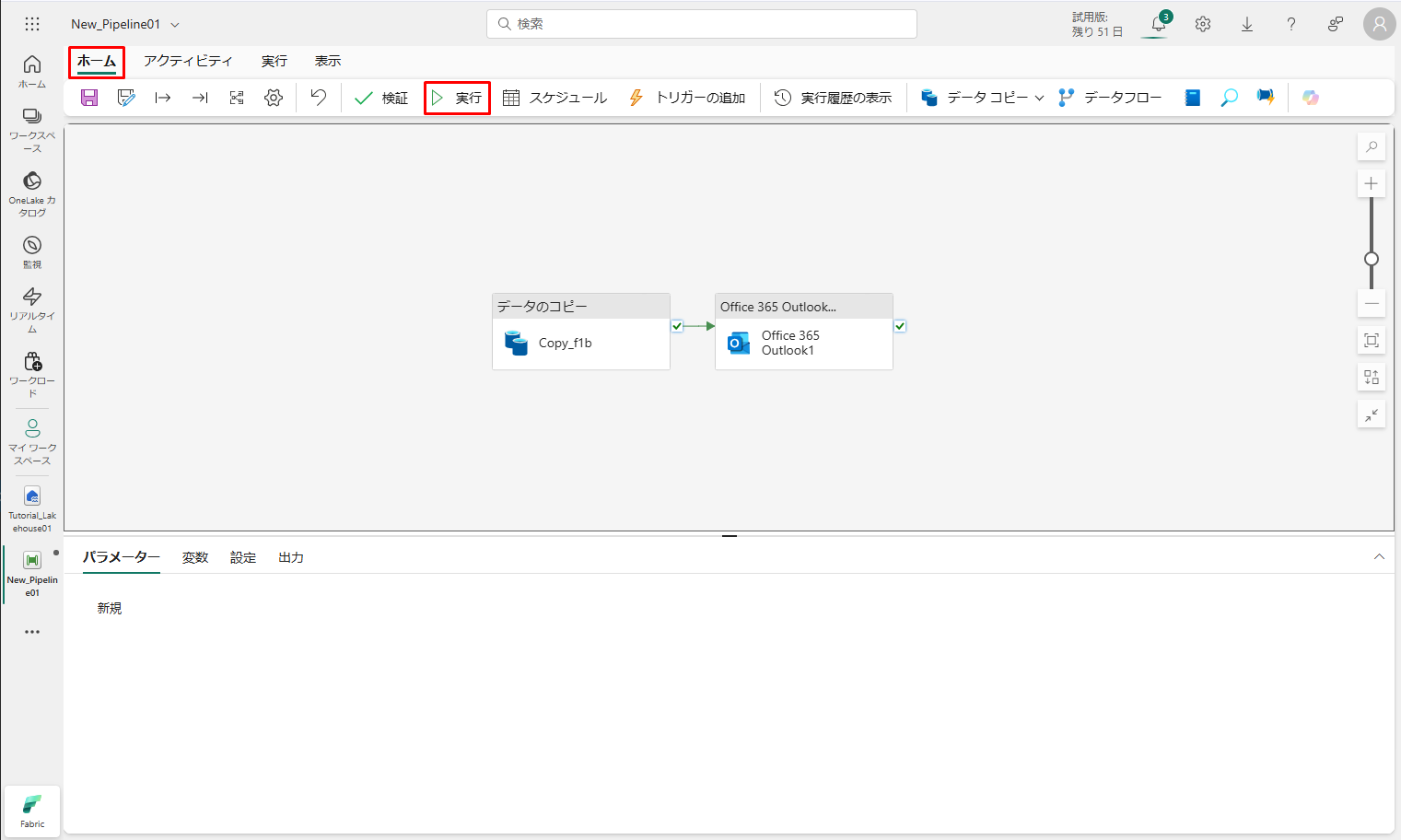
パイプラインが正常に実行されたら、メールを調べて、パイプラインから送信された確認メールを見つけます。
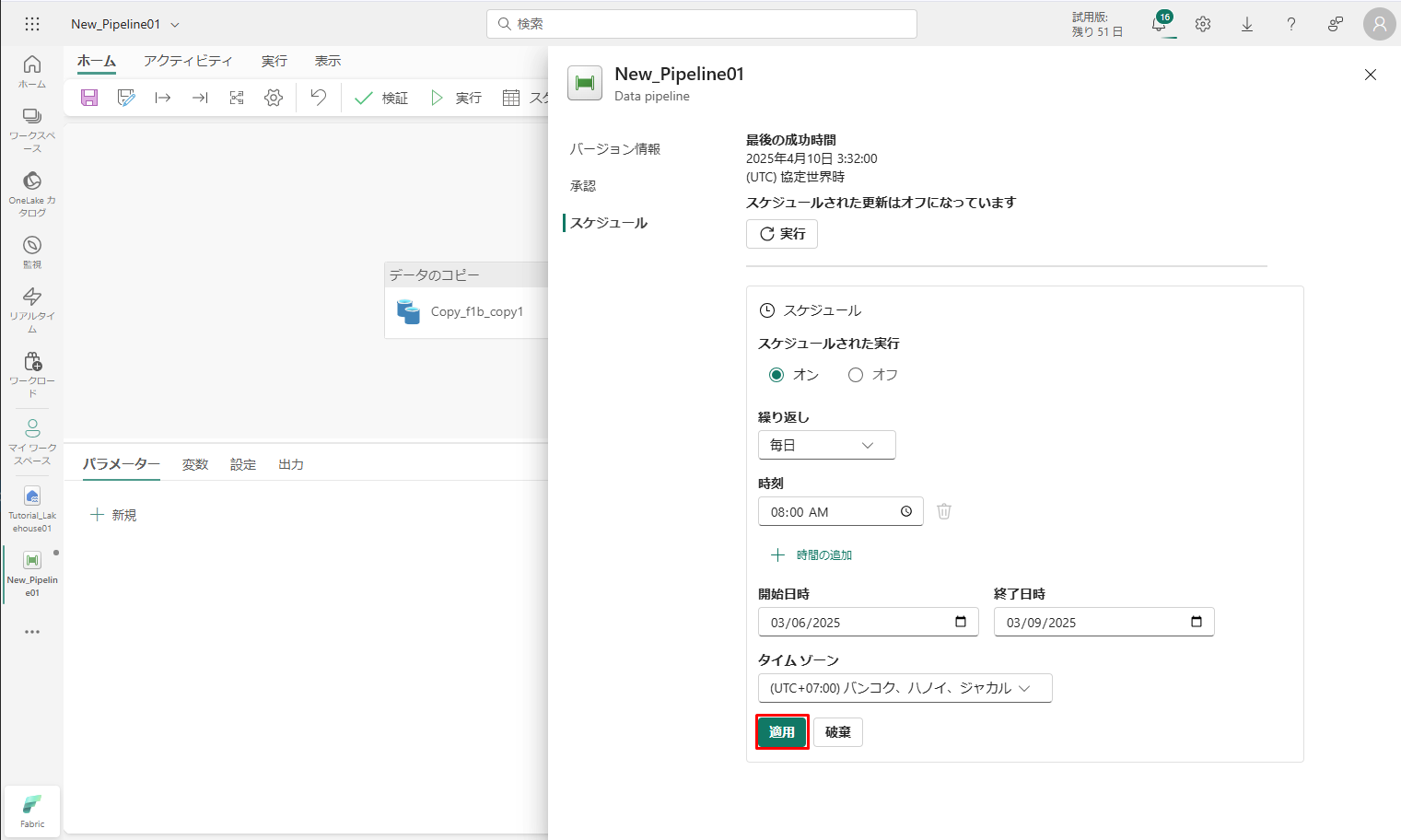
7-2. パイプラインの実行をスケジュールする
パイプラインの作成とテストが完了すると、実行を自動的にスケジュールできます。
① パイプライン エディター ウィンドウの「ホーム」タブで、「スケジュール」を選択します。
 必要に応じてスケジュールを設定します。
必要に応じてスケジュールを設定します。
② その後「通用」をクリックします。
 8. まとめ
8. まとめ
Microsoft Fabric の Data Factory の使用方法をについて実施してみました。 今回の記事が少しでも Microsoft Fabric を知るきっかけや、業務のご参考になれば幸いです。
第1回:Microsoft Fabric 概要と試用版の作成方法
第2回:Power BI ユーザー向け Fabric チュートリアル
第3回:Data Factory ユーザー向け Fabric チュートリアル (今回)
第4回:Synapse Data Engineering ユーザー向け Fabric チュートリアル_第1回
第5回:Synapse Data Engineering ユーザー向け Fabric チュートリアル_第2回