目次
1.はじめに
皆さんこんにちは。
今回は、「COPY INTO」SQLを使用してDatabricksのボリュームに保存されたCSVファイルから、カタログのテーブルにデータを取り込む手順について説明していきます。
COPY INTOを使用してテーブルにデータを取り込む仕組みはINSERT文と同じです。
- COPY INTO: クラウドストレージ(ADLS、S3、GCS)のファイルからテーブルにデータを取込みます。
- INSERT INTO: SELECT文、または特定の値からデータをテーブルに挿入します。
ただし、COPY INTOを使用した場合Deltaテーブルへのデータ取込はINSERT INTOコマンドとは異なる処理が行われます。
- COPY INTOは、インクリメンタルロード(テーブルにまだロードされていないファイルのみをロード)をサポートします。
- 一方、INSERT INTOは各行を一つずつ挿入する方法でデータをロードし、インクリメンタルロードはサポートしていません。
2.準備
2-1.データの準備及びクラスター構成
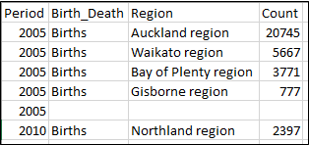
テストデータとして、次のCSV ファイルを使用します。この CSV ファイルは Databricksのボリュームに保存します。
「bd-dec22-births-deaths-by-region-2005.csv」ファイルをダウンロードしてください。
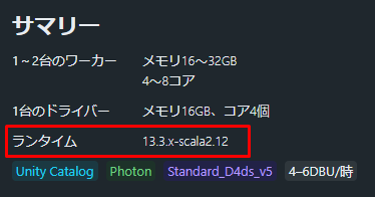
ボリュームからCSVファイルを読み込む為、Databricks Runtimeバージョン 13.3 LTS 以降のクラスターを構成する必要があります。
2-2.カタログ、スキーマ、テーブルの作成
カタログ、スキーマ、テーブルを作成するには、ノートブックを使用して下記のSQLコマンドを実行します。
文法:
|
1 2 3 |
CREATE CATALOG IF NOT EXISTS <catalog_name>; CREATE SCHEMA IF NOT EXISTS <catalog_name>.<schema_name>; CREATE TABLE IF NOT EXISTS <catalog_name>.<schema_name>.<table_name>; |
<catalog_name>: カタログ名
<schema_name>: スキーマ名
<table_name>: テーブル名
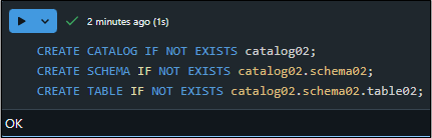
例:
|
1 2 3 |
CREATE CATALOG IF NOT EXISTS catalog02; CREATE SCHEMA IF NOT EXISTS catalog02.schema02; CREATE TABLE IF NOT EXISTS catalog02.schema02.table02; |
2-3.ボリューム作成及びファイルアップロード
ボリュームを作成するには、ノートブックを作成してSQLコマンドを実行します。
文法:
|
1 |
CREATE VOLUME IF NOT EXISTS <catalog_name>.<schema_name>.<volume_name>; |
<catalog_name>: カタログ名
<schema_name>: スキーマ名
<volume_name>: ボリューム名
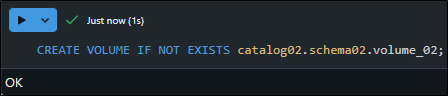
例:
|
1 |
CREATE VOLUME IF NOT EXISTS catalog02.schema02.volume_02; |
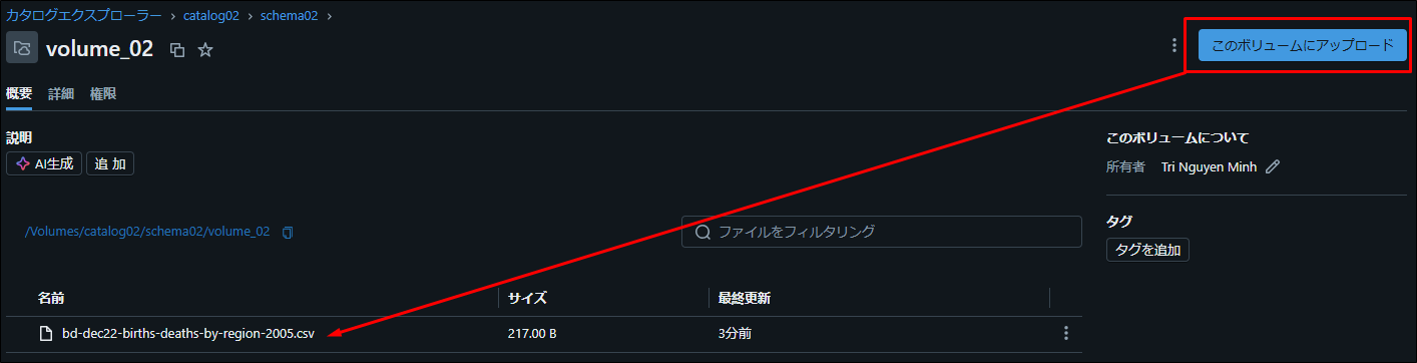
次に、作成したボリュームにアクセスしてCSVファイルをアップロードします。
「このボリュームにアップロード」をクリックしてCSVファイルをアップロードします。
3.データの取り込み
3-1.Databricksのボリュームに保存されたCSVファイルから、カタログのテーブルにデータの取り込み
ボリュームにアクセスしてファイルのパスをコピーします。
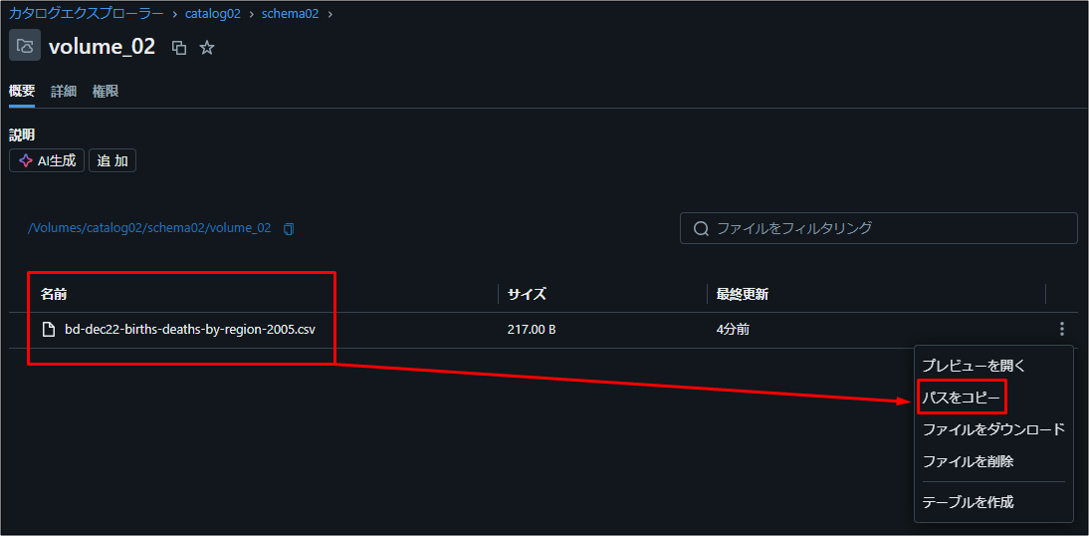
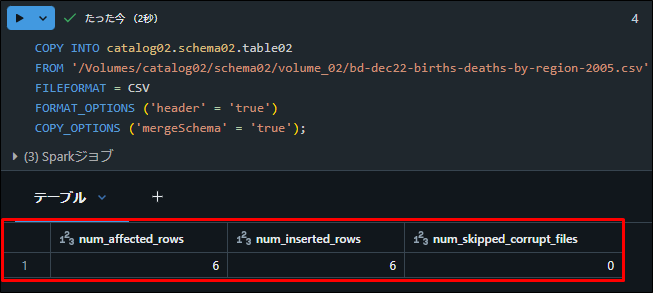
COPY INTOコマンドを使用してデータを読み込みます。
文法:
|
1 2 3 4 5 |
COPY INTO <catalog_name>.<schema_name>.<table_name> FROM '<volume_url>' FILEFORMAT = CSV FORMAT_OPTIONS ('header' = 'true') COPY_OPTIONS ('mergeSchema' = 'true'); |
<catalog_name>: カタログ名
<schema_name>: スキーマ名
<table_name>: テーブル名
<volume_url>: コピーしたデータファイルのパス
例:
|
1 2 3 4 5 |
COPY INTO catalog02.schema02.table02 FROM '/Volumes/catalog02/schema02/volume_02/bd-dec22-births-deaths-by-region-2005.csv' FILEFORMAT = CSV FORMAT_OPTIONS ('header' = 'true') COPY_OPTIONS ('mergeSchema' = 'true'); |
SELECT文を実行して、データがボリュームからカタログテーブルに取り込まれたことを確認します。
文法:
|
1 |
SELECT * FROM <catalog_name>.<schema_name>.<table_name>; |
<catalog_name>: カタログ名
<schema_name>: スキーマ名
<table_name>: テーブル名
例:
|
1 |
SELECT * FROM catalog02.schema02.table02; |
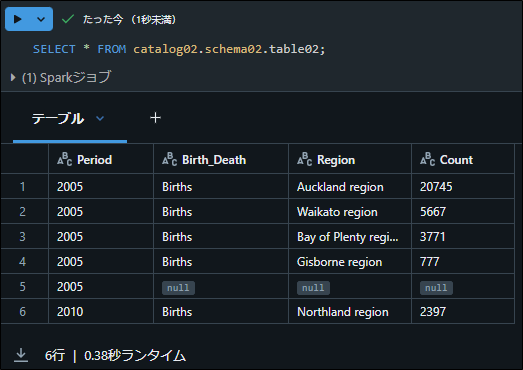
データがボリュームからカタログテーブルに正常に取り込まれました。
4.まとめ
Databricksのボリュームに保存されたCSVファイルから、カタログのテーブルにデータを取り込む手順書について説明しました。
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
・Azure Databricks連載シリーズはこちら