目次
1.はじめに
皆さんこんにちは。
今回は、CSVファイルを取込む方法について説明していきます。
2.前提要件
本書を実施する際の前提条件は
- ストレージアカウントが作成済みであること
- Access connectorが作成済みであること
- ストレージアカウントのBLOB データ共同作成者ロールをAccess connectorに付与していること
- Metastoreが作成済みであること
- Unity CatalogのDatabricks ワークスペースを有効にしていること
- ストレージの認証情報を作成済みであること
- Unity Catalog 外部ロケーションを作成済みであること
- 操作ユーザはUnity Catalogのテーブル更新権限があること
- CSVファイルをこちらからダウンロードしてください
以上が作成済み、指定済みであることを前提としています。
3.CSVファイルをテーブルに格納する
3-1.ストレージアカウントへcustomer.csv ファイルをインポートする
ストレージア カウントの画面でコンテナーを作成し、CSVファイルを格納します。
サイドバーで「コンテナー」を選択し、「コンテナー」をクリックします。
コンテナーに「container-name」等の名前を付けます。
④「作成」ボタンをクリックします。
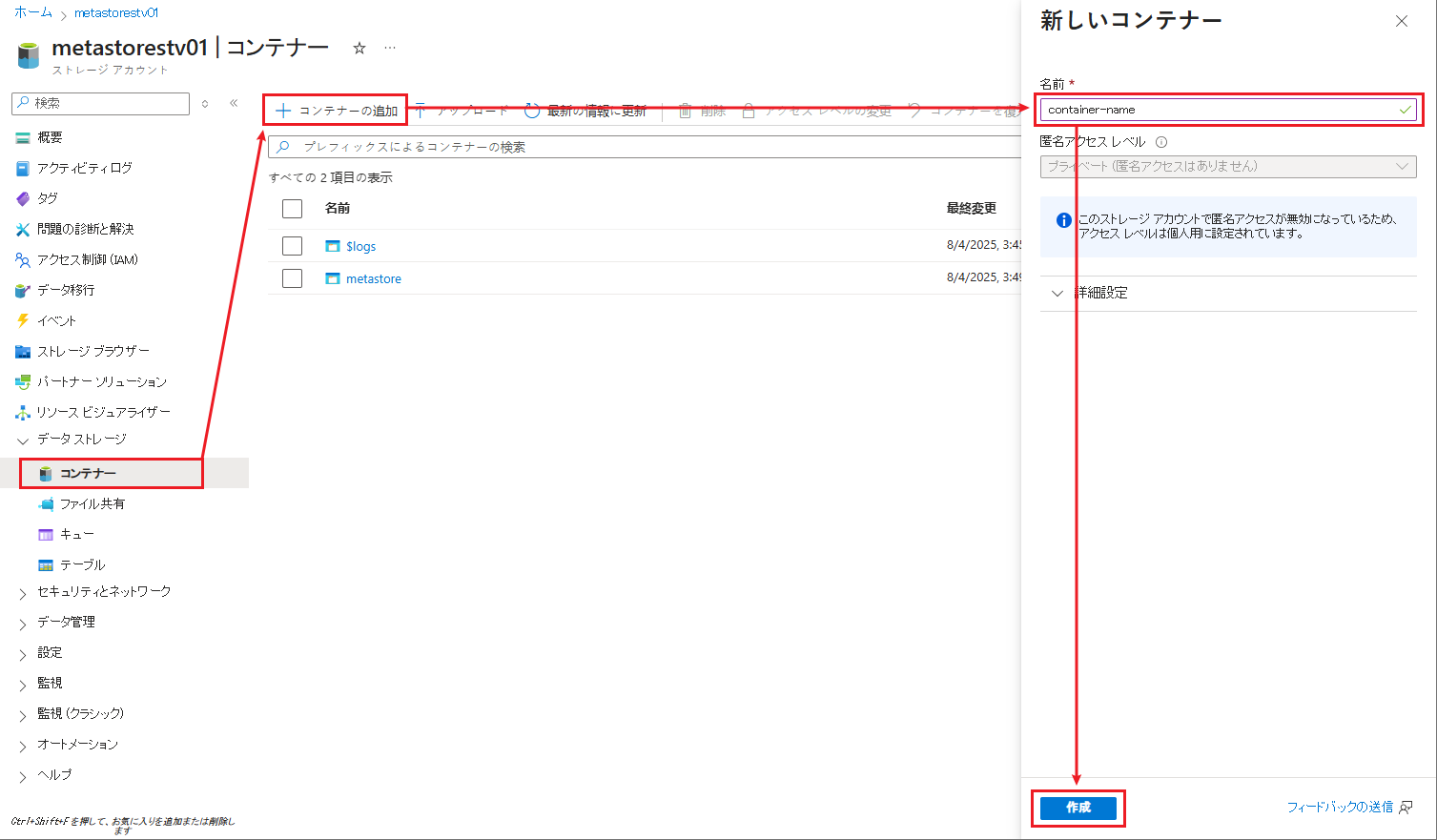 ⑤ コンテナーの一覧が表示されます。
⑤ コンテナーの一覧が表示されます。
作成したコンテナーをクリックします。
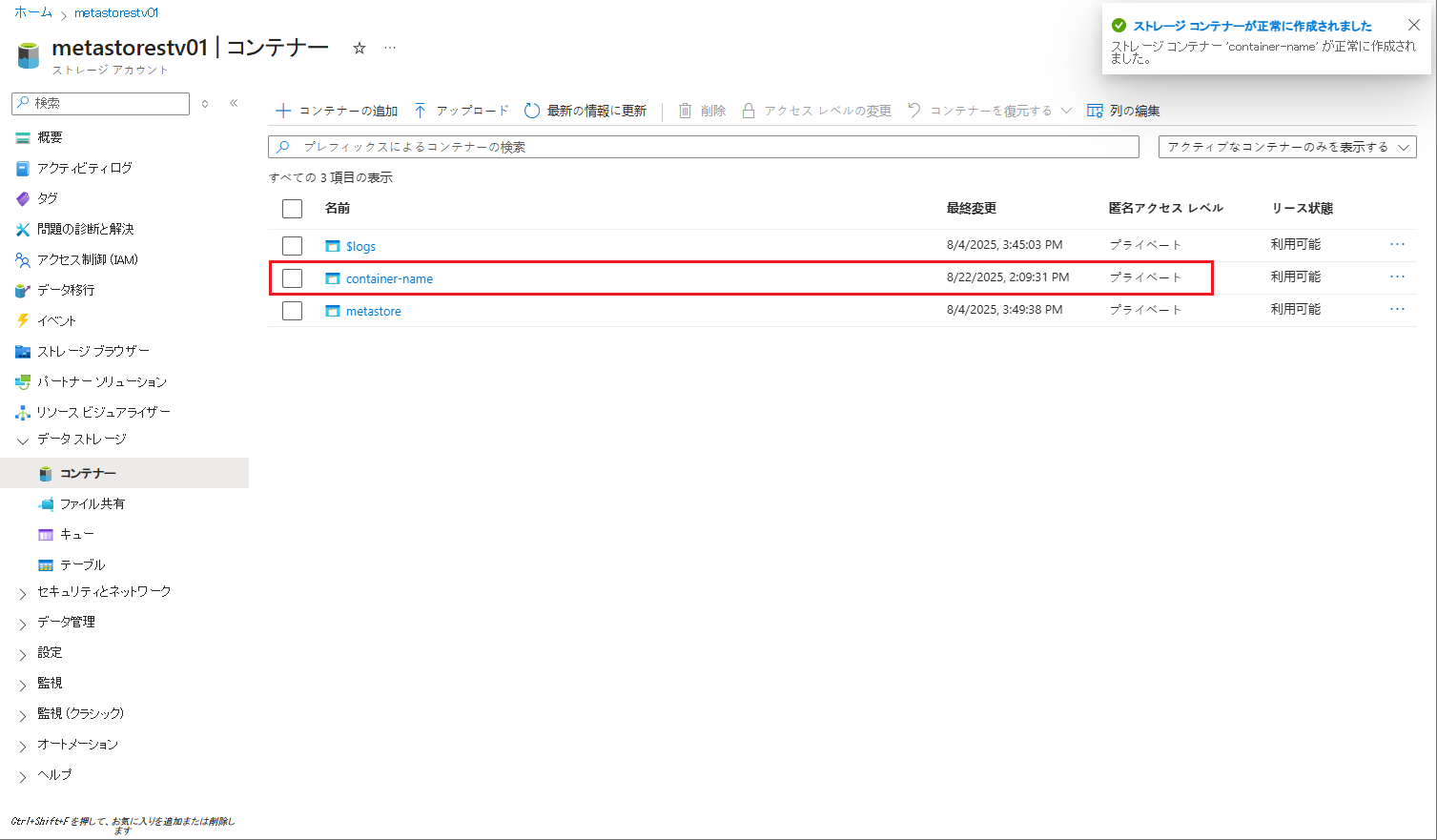 ⑥ 次に、フォルダーを作成し、CSVファイルを格納します。
⑥ 次に、フォルダーを作成し、CSVファイルを格納します。
⑦「ディレクトリーの追加」をクリックします。
⑧ フォルダーに「raw」等の名前を付けます。
⑨「保存」ボタンをクリックします。
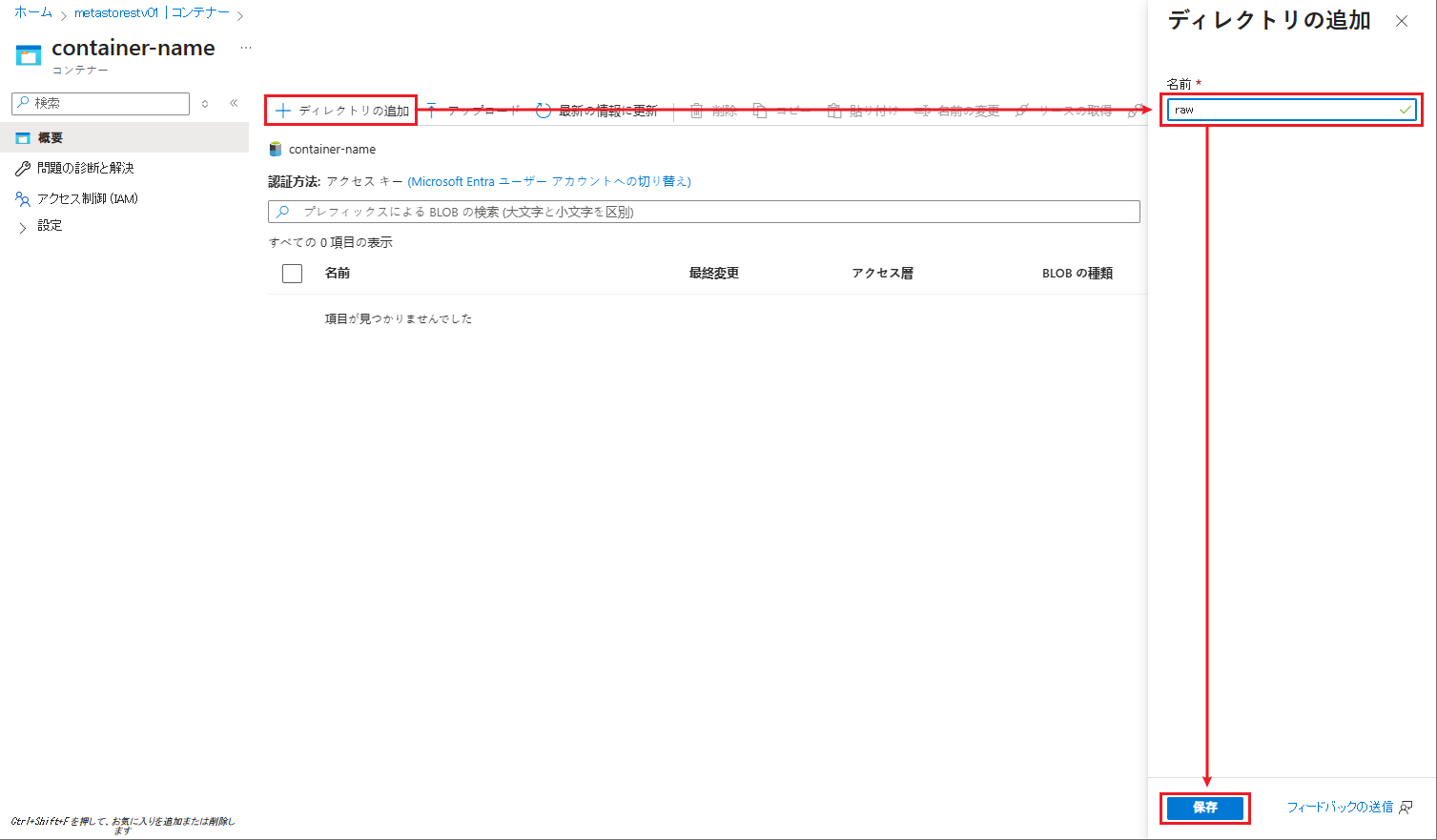 ⑩ フォルダーの一覧が表示されます。
⑩ フォルダーの一覧が表示されます。
作成したフォルダーをクリックします。
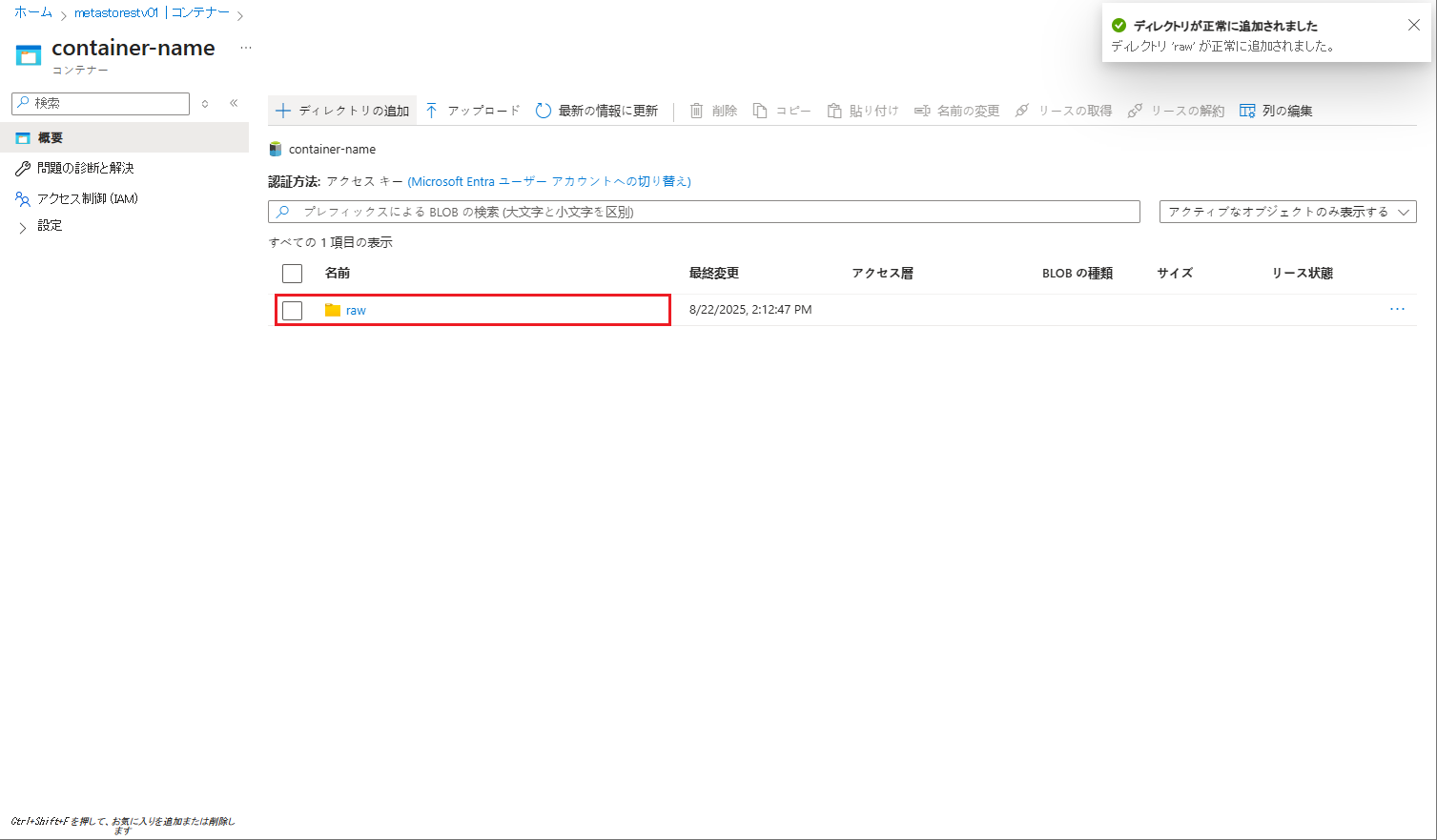 ⑪ 作成したフォルダーにて 「アップロード」をクリックし、「ファイルを参照」をクリックします。
⑪ 作成したフォルダーにて 「アップロード」をクリックし、「ファイルを参照」をクリックします。
⑫ ダイアログでローカル コンピューターのファイルをアップロードできます。customer.csv ファイルを選択してください。
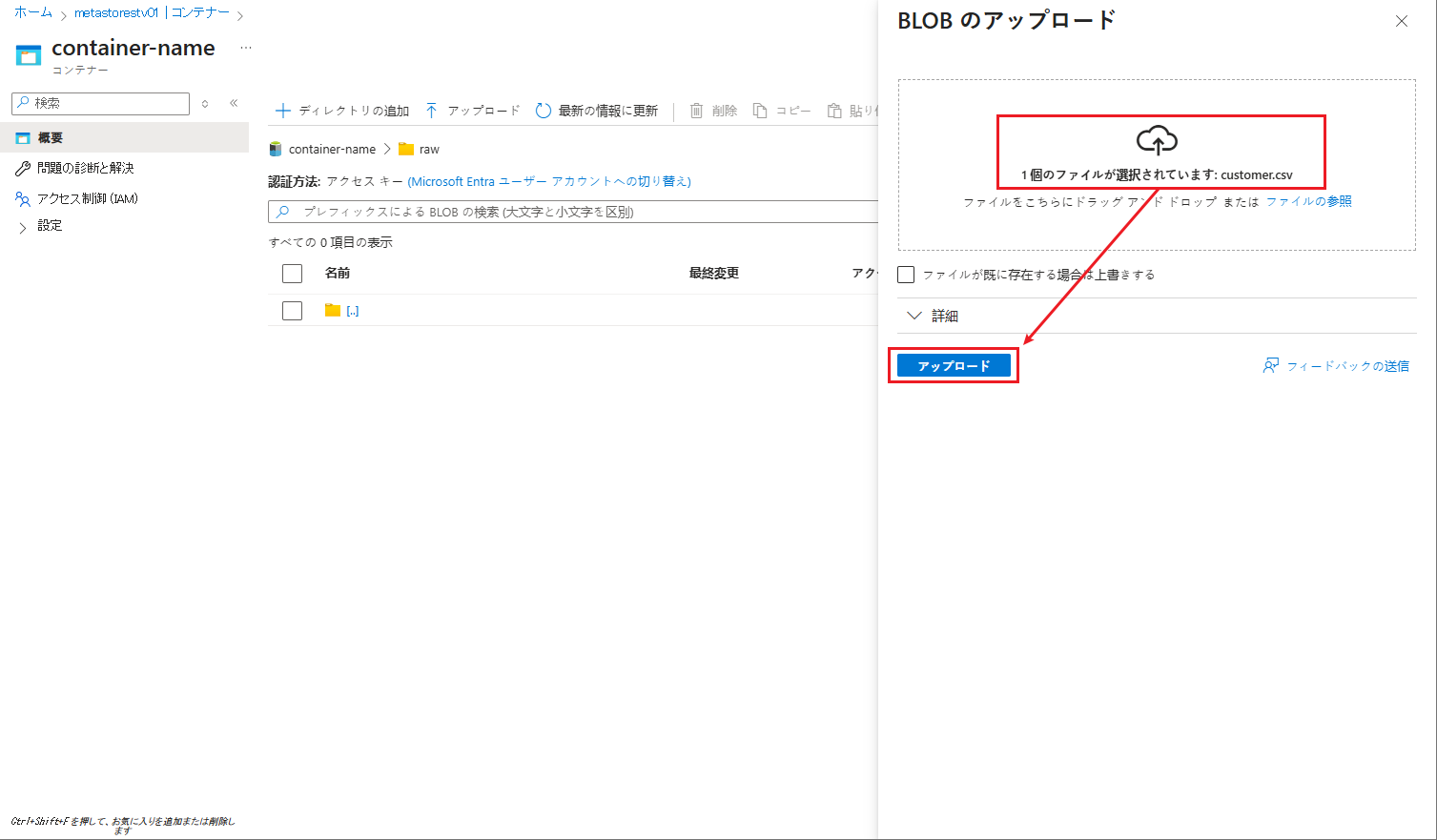
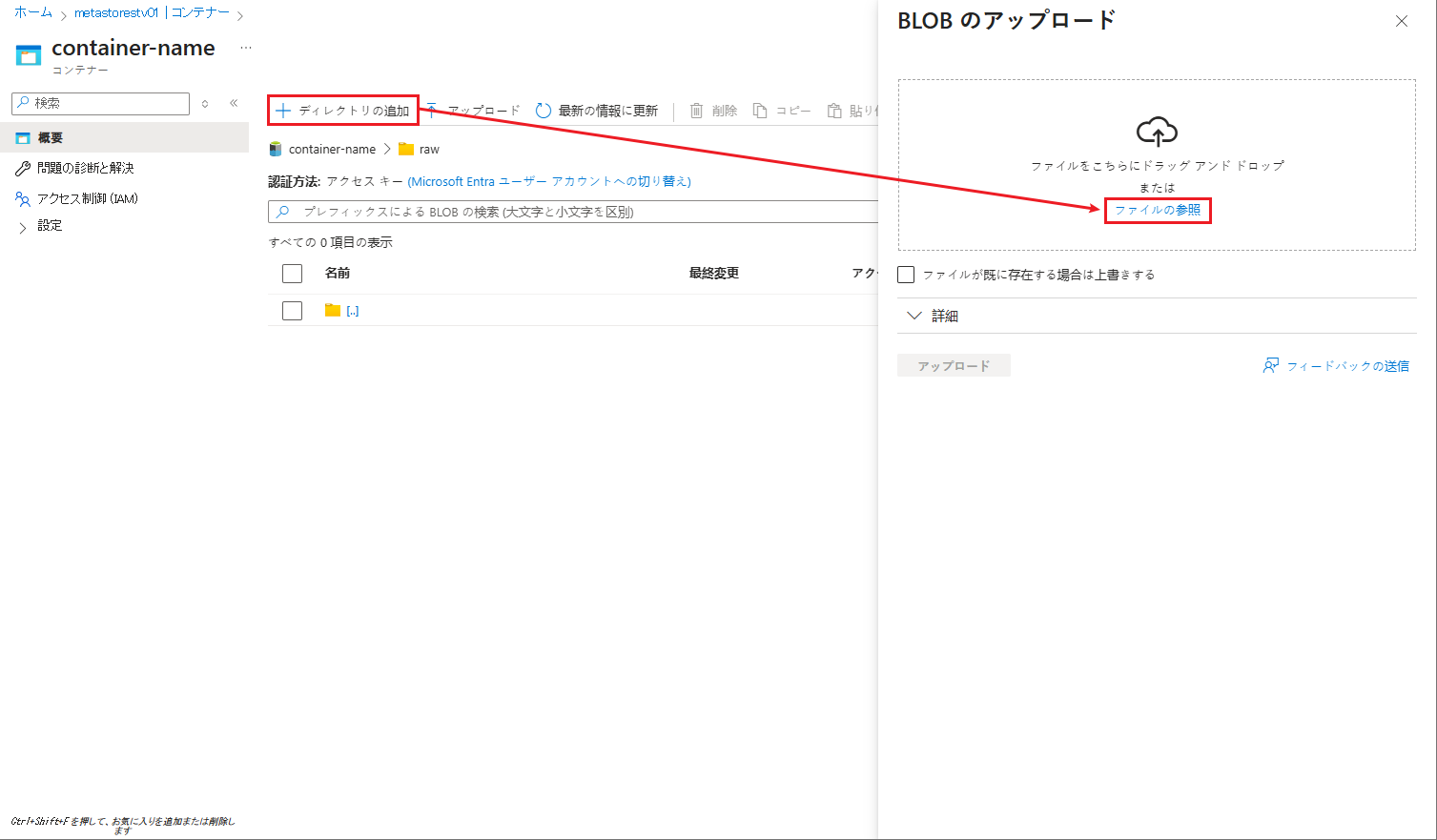 ⑬ ファイルを選択して、「アップロード」ボタンをクリックします。
⑬ ファイルを選択して、「アップロード」ボタンをクリックします。
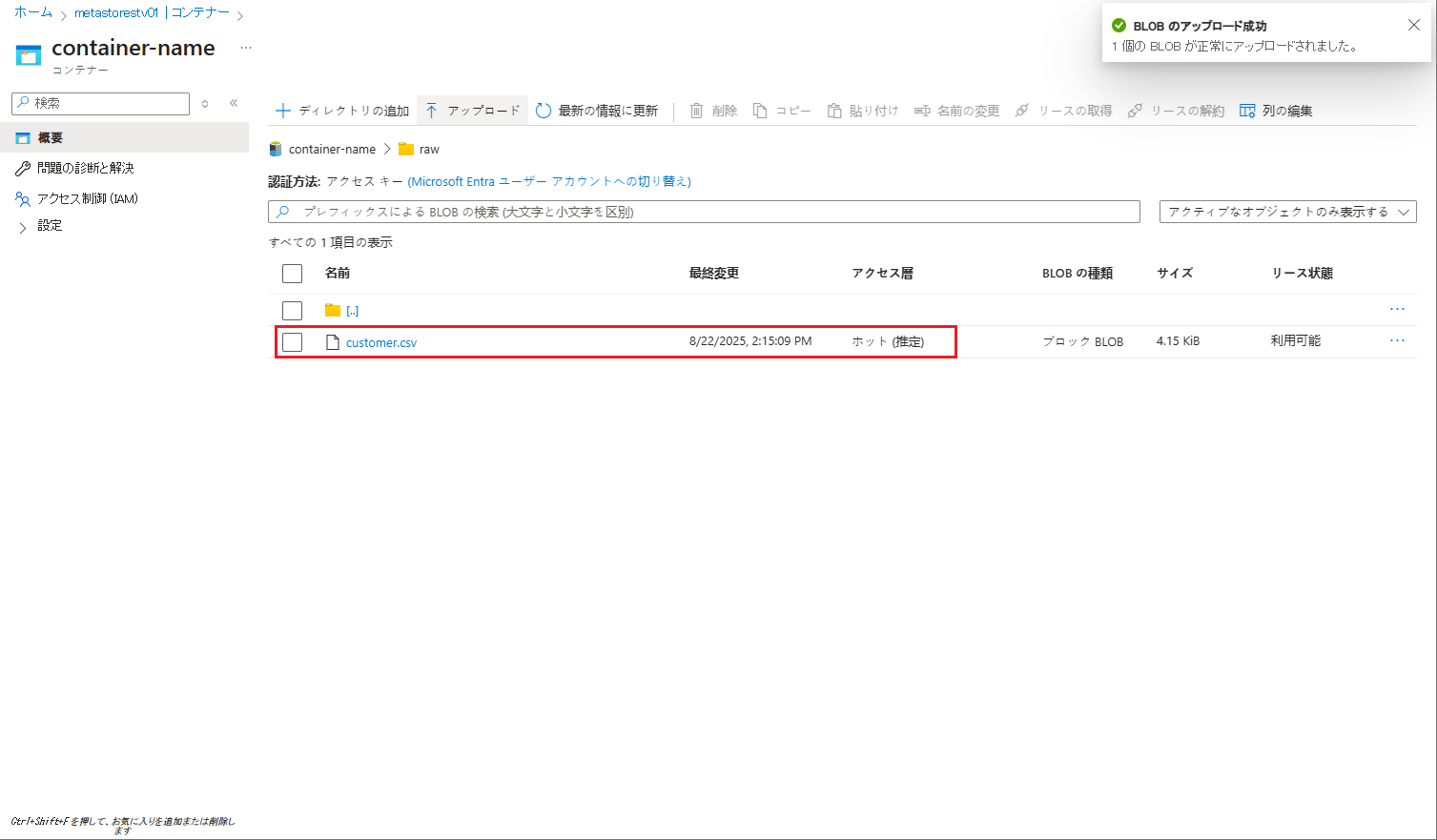
 ストレージ アカウントの「raw」フォルダーにcustomer.csv ファイルがアップロードされました。
ストレージ アカウントの「raw」フォルダーにcustomer.csv ファイルがアップロードされました。
3-2.ノートブックを使用して、CSVファイルをテーブルに格納する
ワークスペースでノートブックを作成してCSVファイルを読み込みます。次に、 Unity Catalog でテーブルを作成して、CSVファイルをマージします。
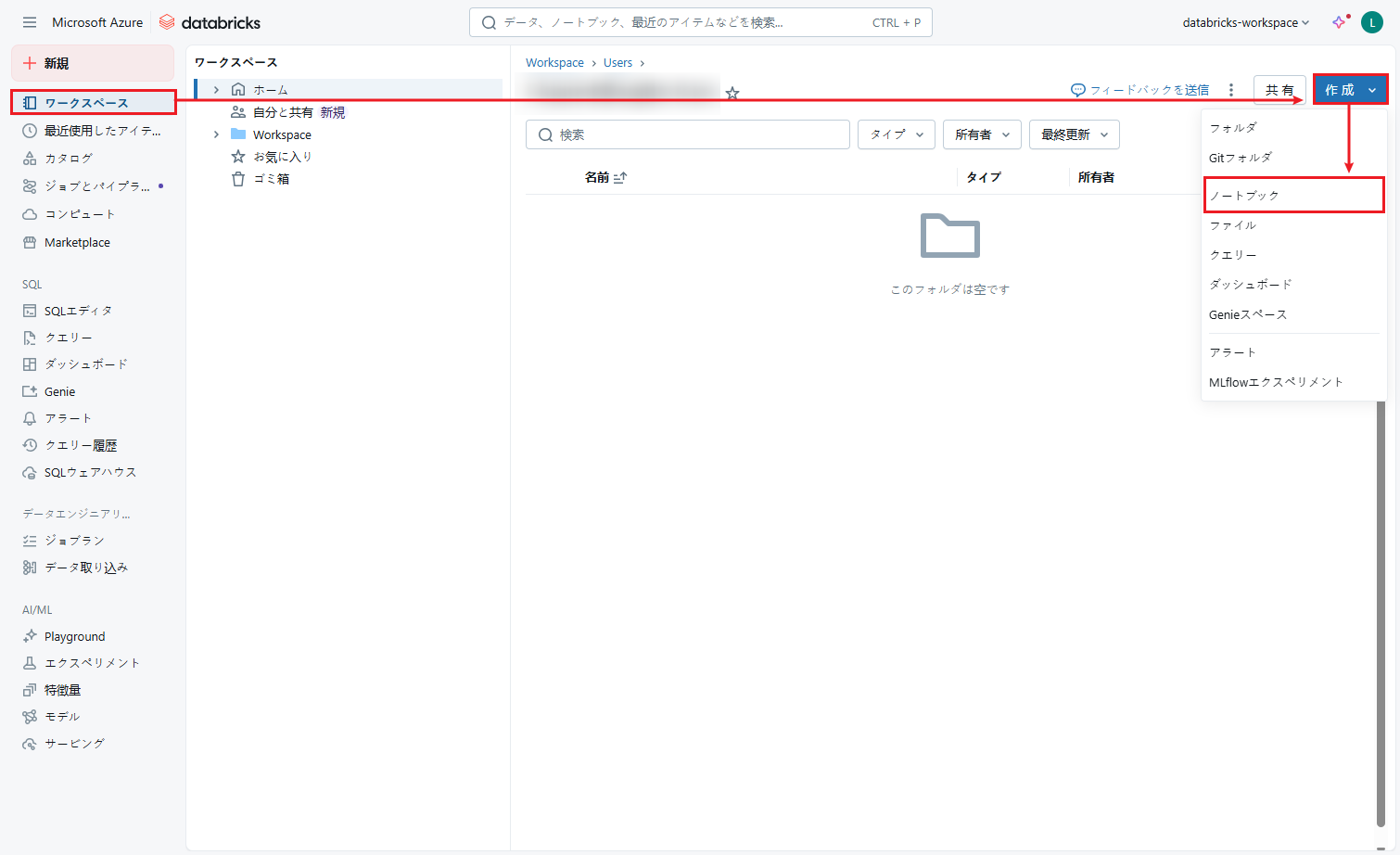
① Databricksワークスペースをログインします。
② 左のメニューから「ワークスペース」をクリックします。
③ 画面右上の「作成」ボタンをクリックし、ドロップダウンリストから「ノートブック」を選択して新規のノートブックを作成します。
 ④ ノートブックの名前を設定します。例:convert-notebook
④ ノートブックの名前を設定します。例:convert-notebook
⑤ デフォルト言語としてPythonを選択します。
⑥ 既存クラスターを選択して使用します。
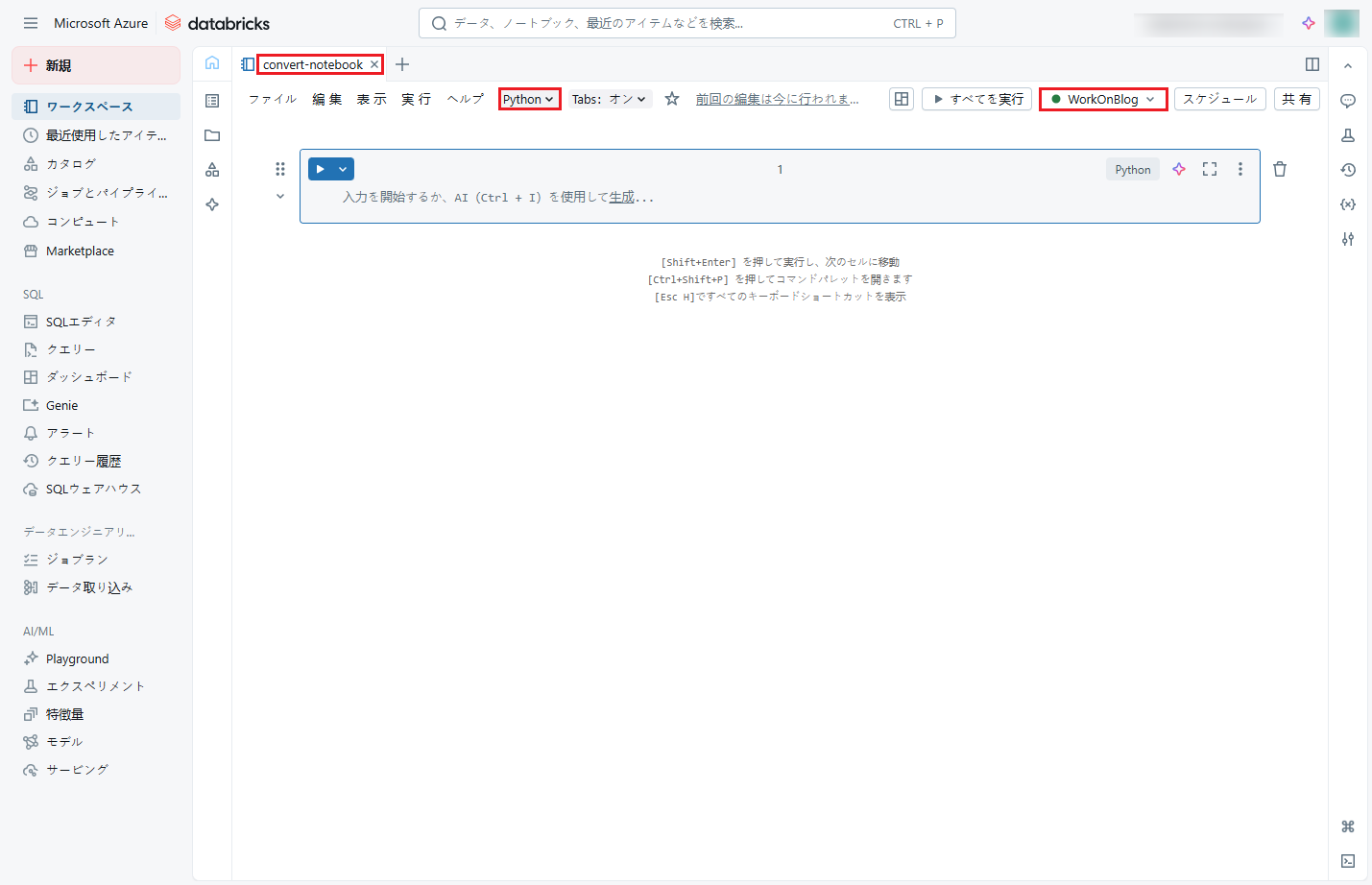 ⑦ 次に、CSVファイルを読み込み、そのデータから「customer_view」という一時ビューを作成します。
⑦ 次に、CSVファイルを読み込み、そのデータから「customer_view」という一時ビューを作成します。
以下のコードをノートブックにコピーし、「Shift + Enter」を押して実行します。
|
1 2 3 4 |
spark.conf.set("fs.azure.account.key.<your_storage_account_name>.dfs.core.windows.net", <your_storage_access_key>) input_file_path = "abfss://<your_storage_container-name>@<your_storage_account_name>.dfs.core.windows.net/raw/<path_to_your_csv_file>" df = spark.read.format("csv").option("header", True).load(input_file_path) df.createOrReplaceTempView("customer_view") |
※ 注意:
- 「
<your_storage_account_name>」を実際のAzureストレージアカウント名に置き換えること。例:myaccount - 「
<your_storage_access_key>」を実際のAzureストレージアカウントのアクセスキーに置き換えること。 - 「
<your_storage_container-name>」を実際のAzureストレージ内のコンテナー名に置き換えること。例:mycontainer - 「
<path_to_your_csv_file>」をコンテナー内のCSVファイルの実際のパスに置き換えること。例:data/customer.csv
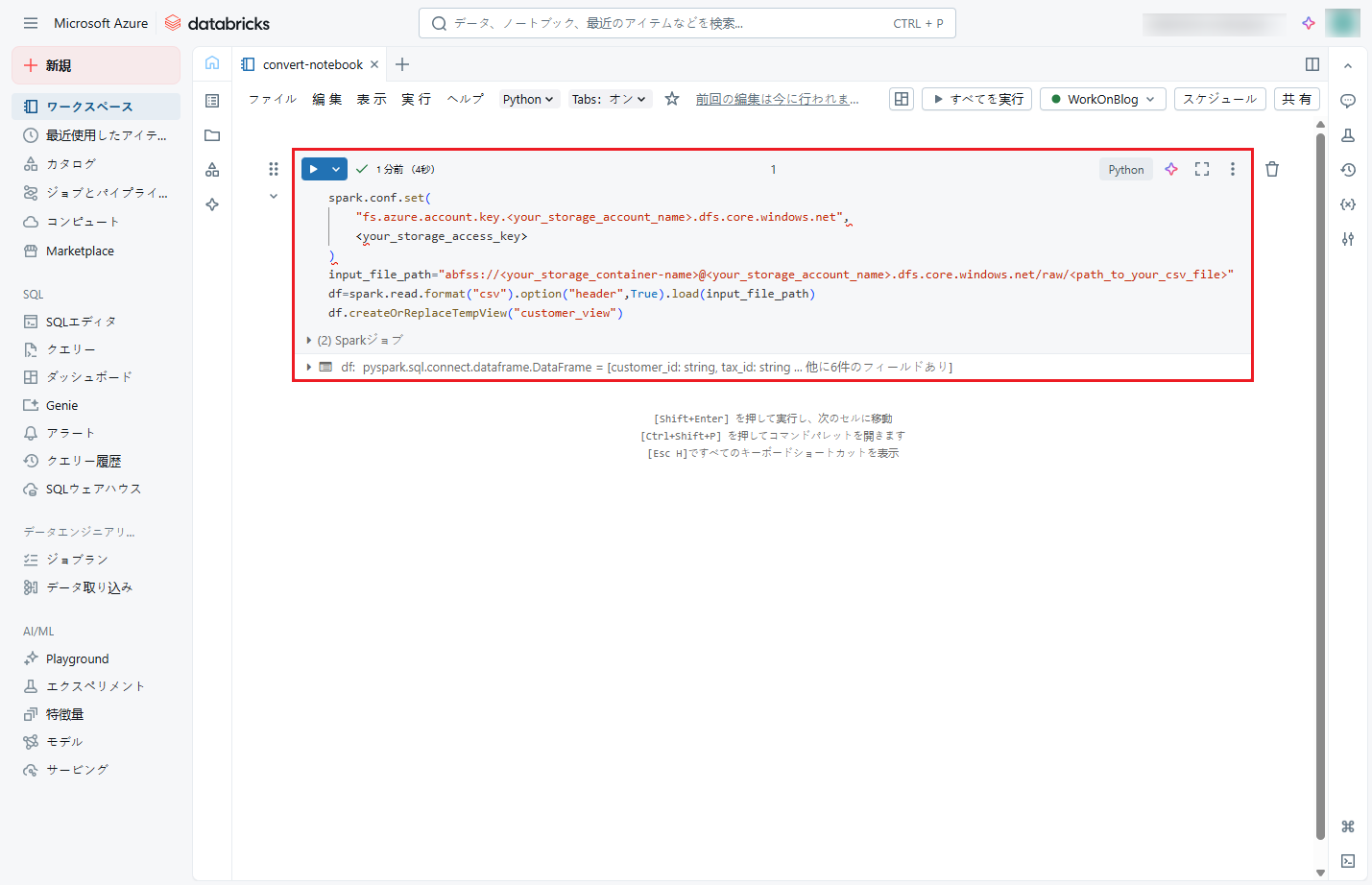 ⑧ データがビューに保存されたかどうかを確認するために、以下のコマンドをノートブックにコピーし、「Shift + Enter」を押して実行します。
⑧ データがビューに保存されたかどうかを確認するために、以下のコマンドをノートブックにコピーし、「Shift + Enter」を押して実行します。
実行後、結果は下図のように表示されます。
|
1 |
SELECT * FROM customer_view |
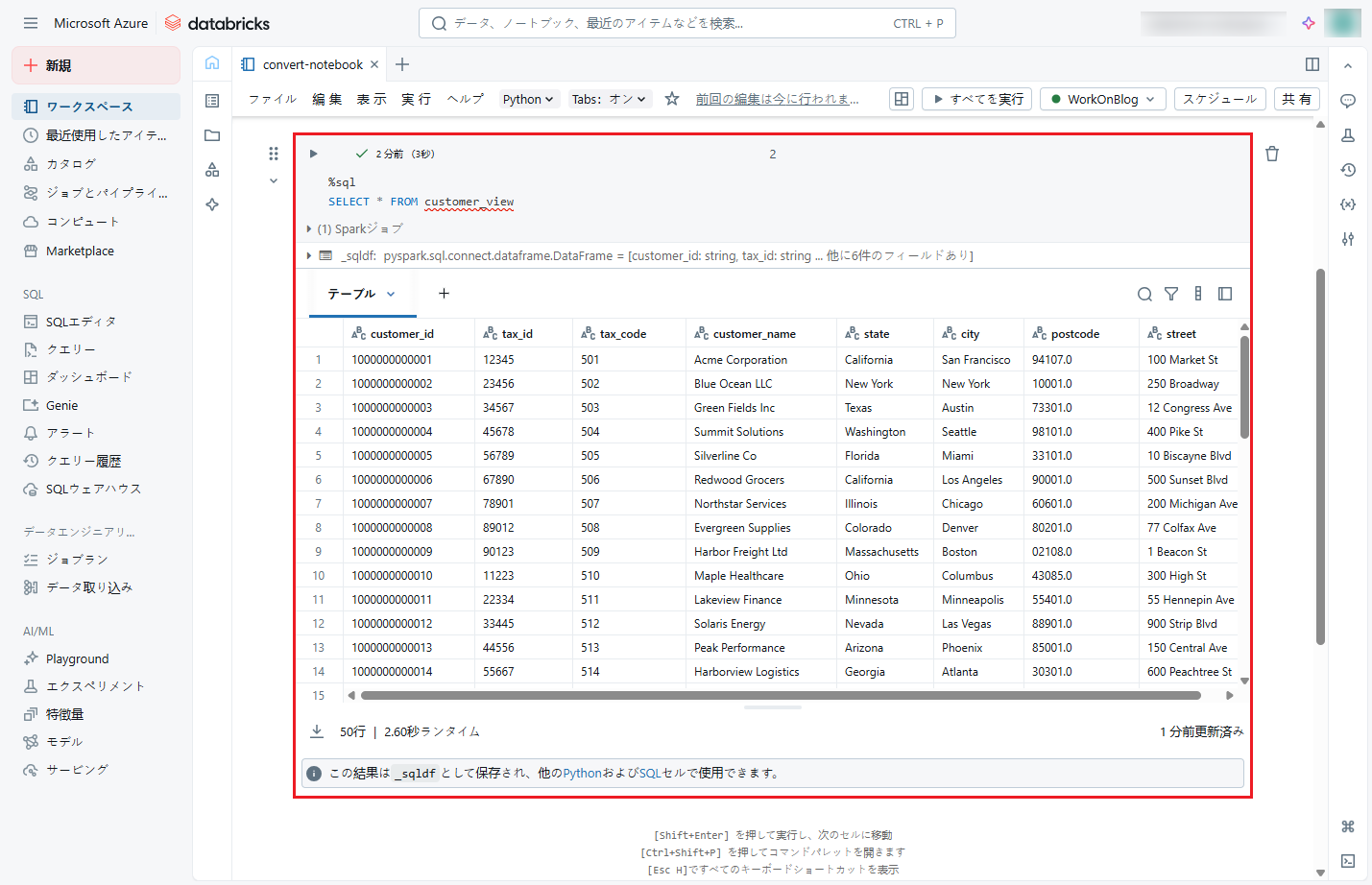 ⑨ 次に、Unity Catalogにカタログ、スキーマ、テーブルを作成し、ビューからデータを保存する準備を行います。
⑨ 次に、Unity Catalogにカタログ、スキーマ、テーブルを作成し、ビューからデータを保存する準備を行います。
以下のコマンドをノートブックにコピーし、「Shift + Enter」を押して実行します。
実行後、「MyCatalog」のカタログ、「MySchema」のスキーマ、「MyTable」のテーブル が作成されします。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE CATALOG IF NOT EXISTS MyCatalog; CREATE SCHEMA IF NOT EXISTS MyCatalog.MySchema; CREATE TABLE IF NOT EXISTS MyCatalog.MySchema.MyTable( customer_id bigint, tax_id int, tax_code int, customer_name string, state string, city string, postcode float, street string ) |
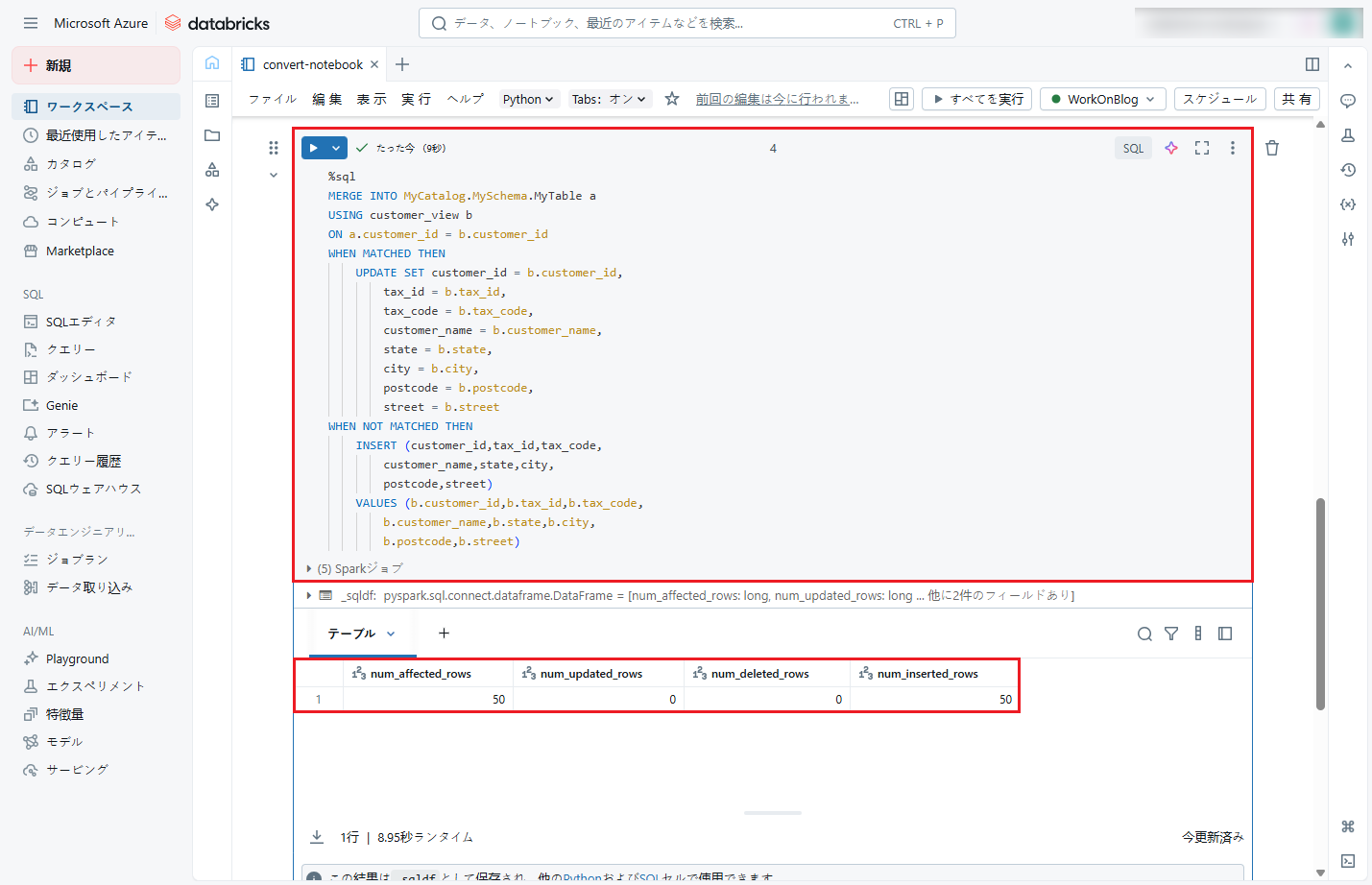
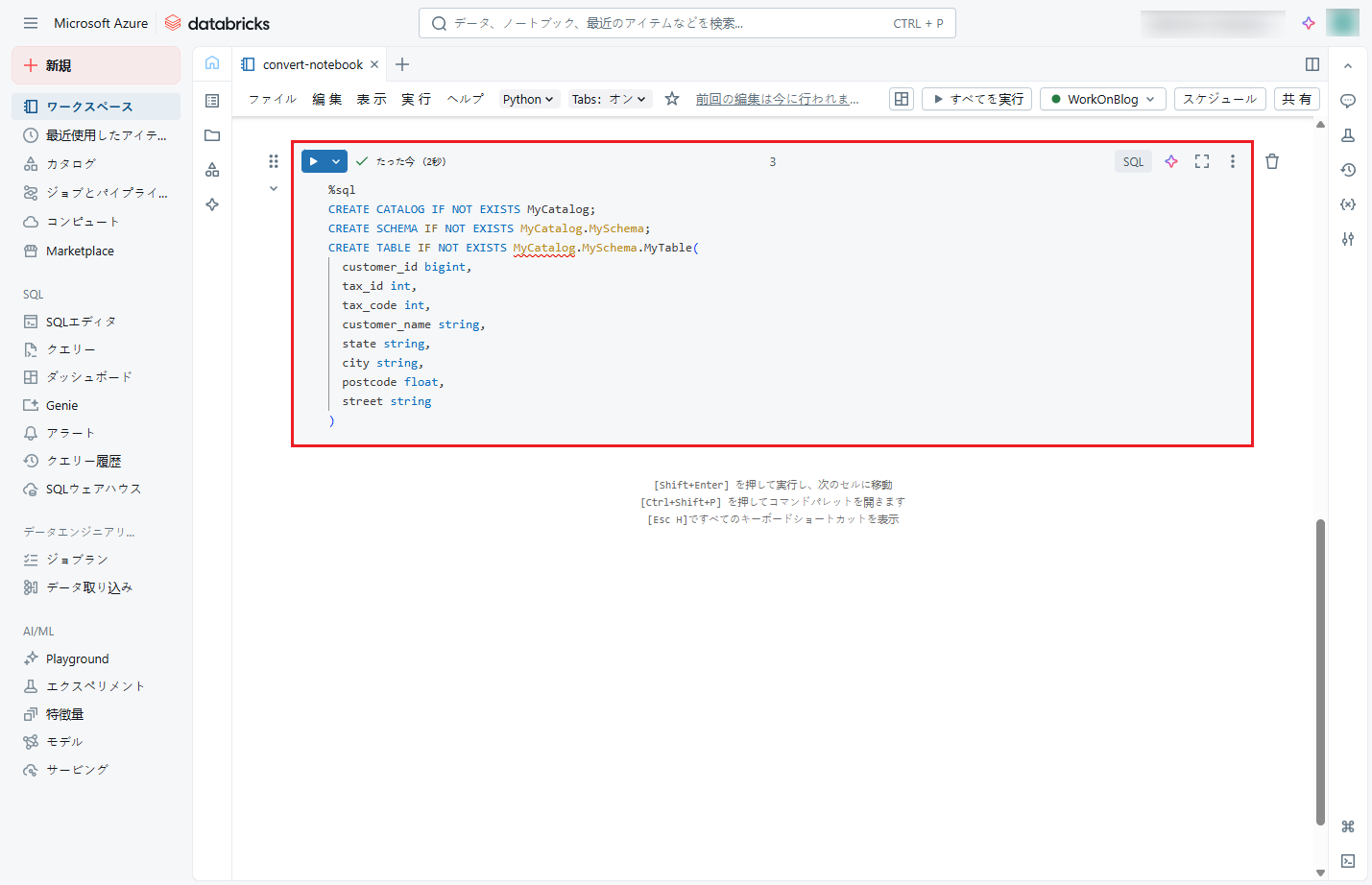 ⑩ テーブル作成後、以下のコマンドを実行して、「customer_view」からデータをテーブルにマージします。
⑩ テーブル作成後、以下のコマンドを実行して、「customer_view」からデータをテーブルにマージします。
以下のコマンドをノートブックにコピーし、「Shift + Enter」を押して実行します。
実行後、更新または挿入された行数が下図のように表示されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
MERGE INTO MyCatalog.MySchema.MyTable a USING customer_view b ON a.customer_id = b.customer_id WHEN MATCHED THEN UPDATE SET customer_id = b.customer_id, tax_id = b.tax_id, tax_code = b.tax_code, customer_name = b.customer_name, state = b.state, city = b.city, postcode = b.postcode, street = b.street WHEN NOT MATCHED THEN INSERT (customer_id,tax_id,tax_code, customer_name,state,city, postcode,street) VALUES (b.customer_id,b.tax_id,b.tax_code, b.customer_name,b.state,b.city, b.postcode,b.street) |
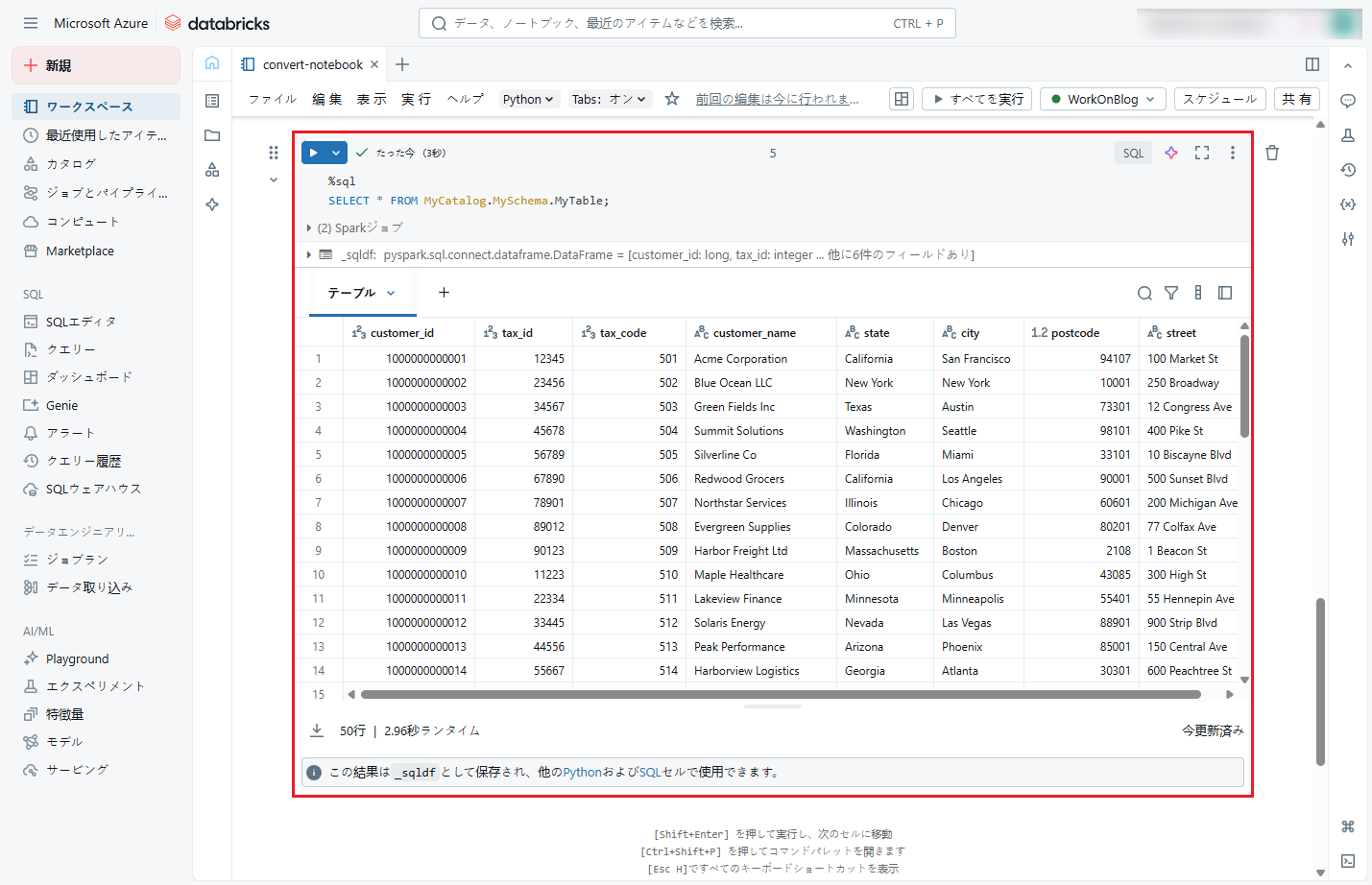
 ⑪ データがテーブルにマージされたかどうかを確認するために、以下のコマンドをノートブックにコピーし、「Shift + Enter」を押して実行します。
⑪ データがテーブルにマージされたかどうかを確認するために、以下のコマンドをノートブックにコピーし、「Shift + Enter」を押して実行します。
実行後、テーブル内のデータが下図のように表示されます。
|
1 |
SELECT * FROM MyCatalog.MySchema.MyTable; |
 4.まとめ
4.まとめ
これでCSVファイルを取込む方法について説明しました。
今回の記事が少しでも皆さんの新しい知識や業務のご参考になれば幸いです。双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたら是非お問い合わせください!
・Azure Databricks連載シリーズはこちら
この記事を読んだ方へのオススメコンテンツはこちら