目次
1.はじめに
皆さんこんにちは。
この連載では、SQLエンジニア向けにAzure Data Factoryの利用方法について説明していきます。
SQLエンジニアがSQLを使ってデータを操作していることを、Azure Data Factoryでどう実現できるかを解説していきたいと思います。
今回は、SQLコマンドをAzure Data Factoryでどう実装したらよいのか、Data Flowを中心に説明していきます。
第1回:SQLコマンドをAzure Data Factoryで実現する(今回)
第2回:Azure Data Factoryでインラインビュー、サブクエリーを実現する
第3回:Azure Data Factory上でinsert、delete、update、mergeの処理を実行する
2.前提要件
実施する際の前提条件は以下の通りです。
・操作ユーザーは、ストレージ アカウントとAzure Data Factoryの作成権限があること。権限が付与されていない場合、管理者に権限を付与してもらう様に依頼してください。
3.Azure Data Factory へ CSV ファイルをインポートする
ストレージアカウントを作成します。
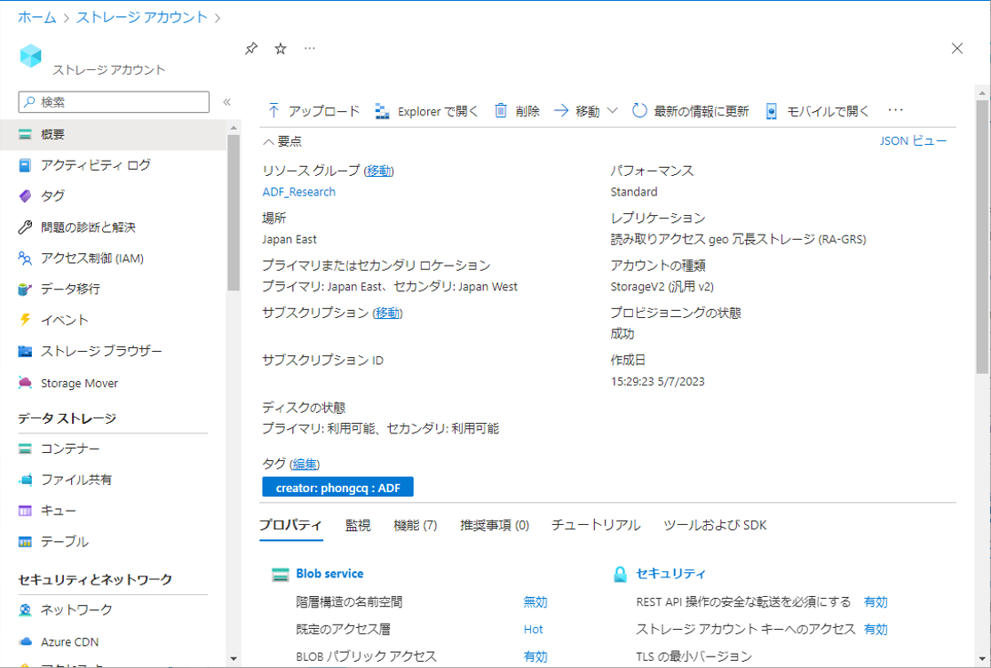
① ストレージア カウントの画面でコンテナーを作成し、CSVファイルを格納します。
② サイドバーで「コンテナー」を選択し、「コンテナー」をクリックします。
③ コンテナーに「container-name」等の名前を付けます。
④「作成」ボタンをクリックします。
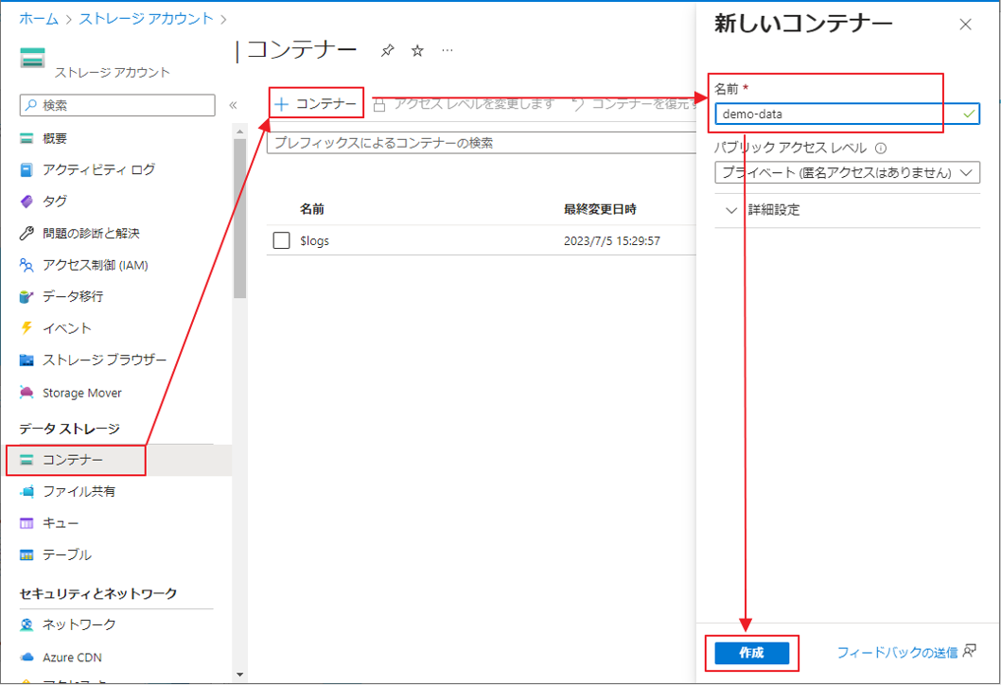
コンテナーの一覧が表示されます。
⑤ 作成したコンテナーをクリックします。
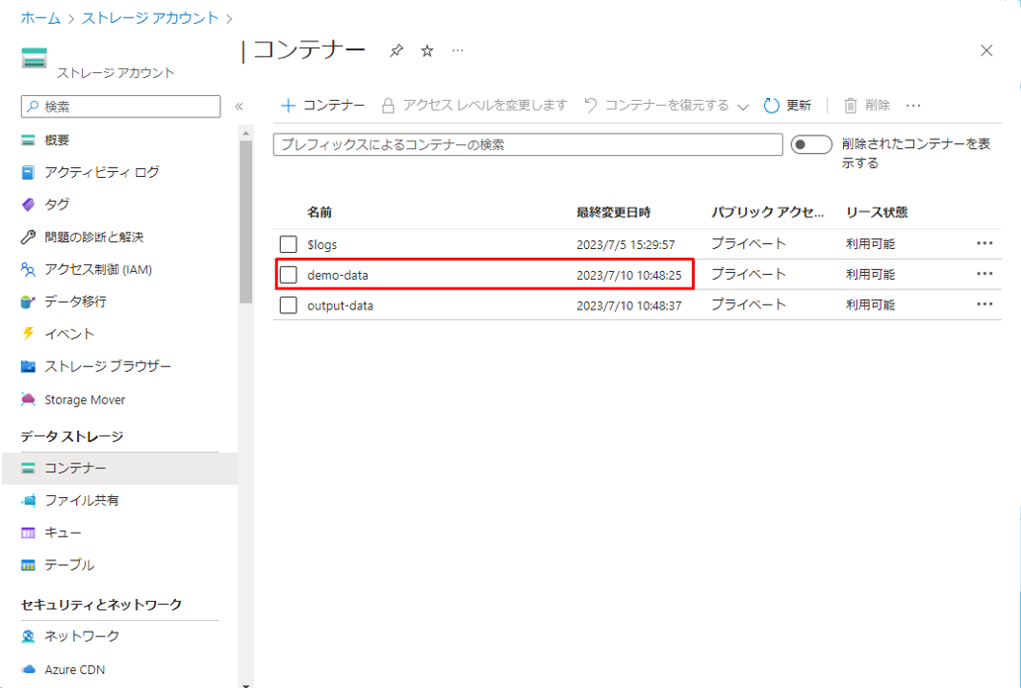
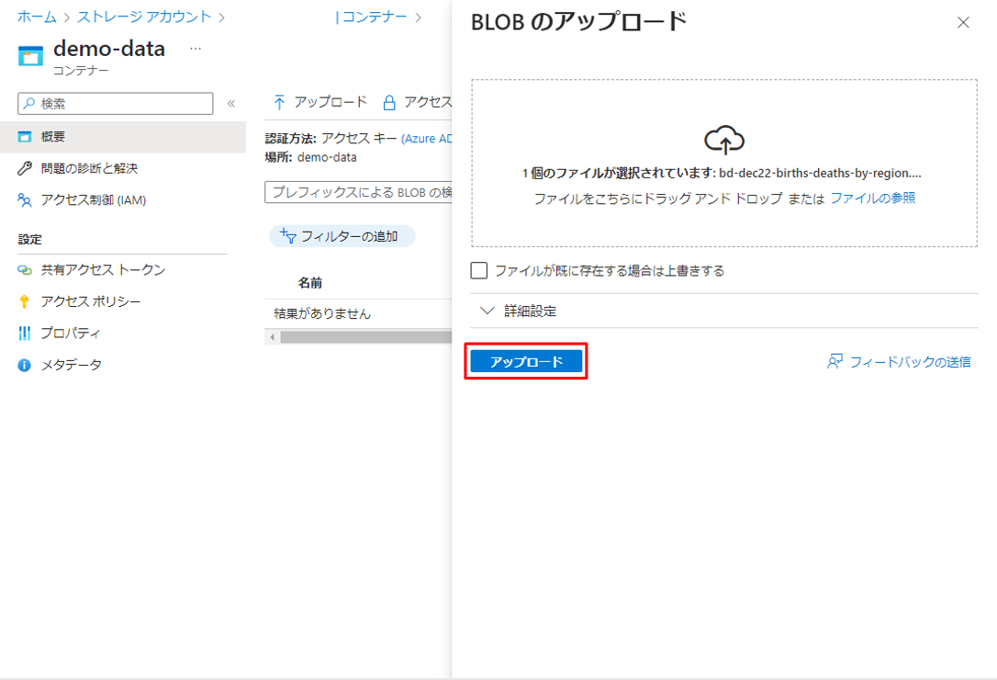
⑥「アップロード」をクリックし、「ファイルを参照」をクリックします。
ダイアログでローカル コンピューターのファイルをアップロードできます。
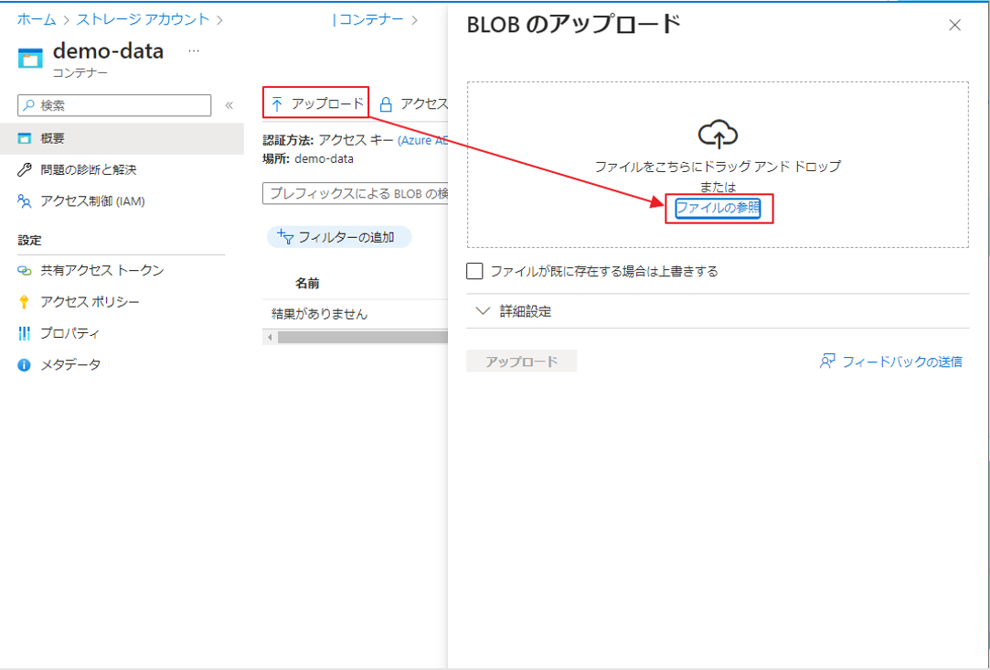
⑦ ファイルを選択して、「アップロード」ボタンをクリックします。
bd-dec22-births-deaths-by-region.csvファイルをダウンロードする。
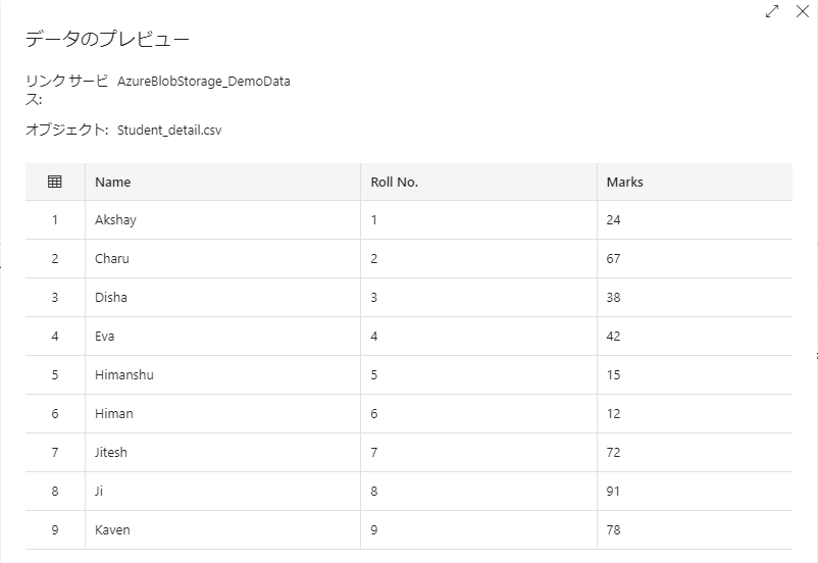
Student_detail.csvファイルをダウンロードする。
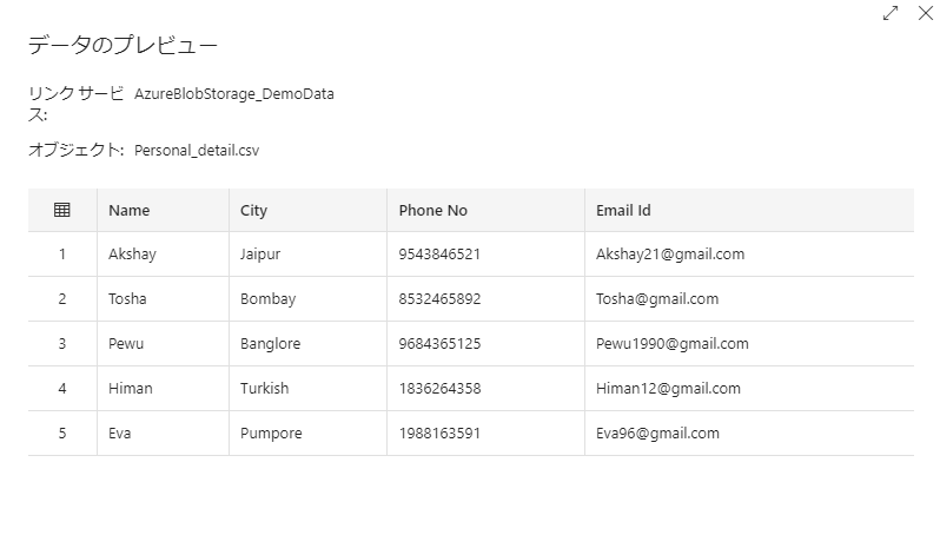
Personal_detail.csvファイルをダウンロードする。
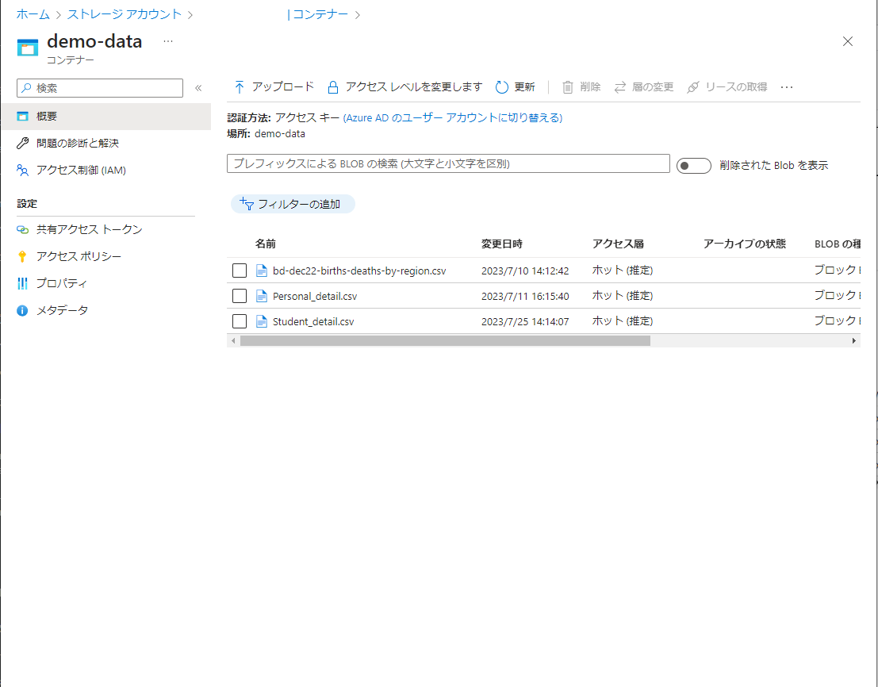
同様に、他のファイルをストレージ アカウントにアップロードします。
Azure Data Factory を作成します。
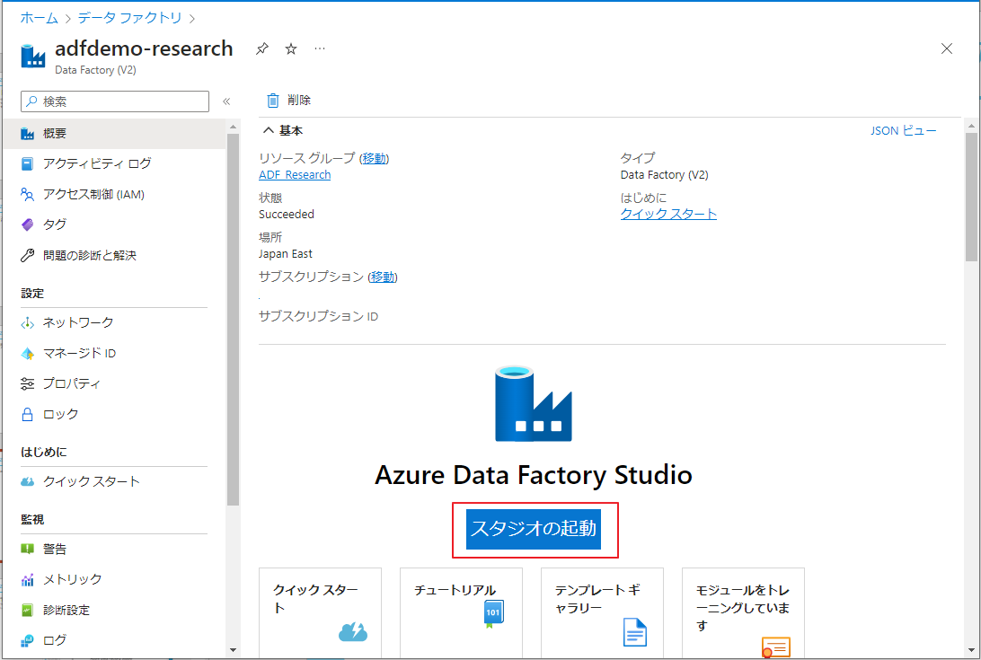
① Azure Data Factory 画面で「スタジオの起動」をクリックしてワークスペースを起動します。
② サイドバーで「Author」をクリックして、次に「Datasets」をクリックして、「新しいデータセット」を選択します。
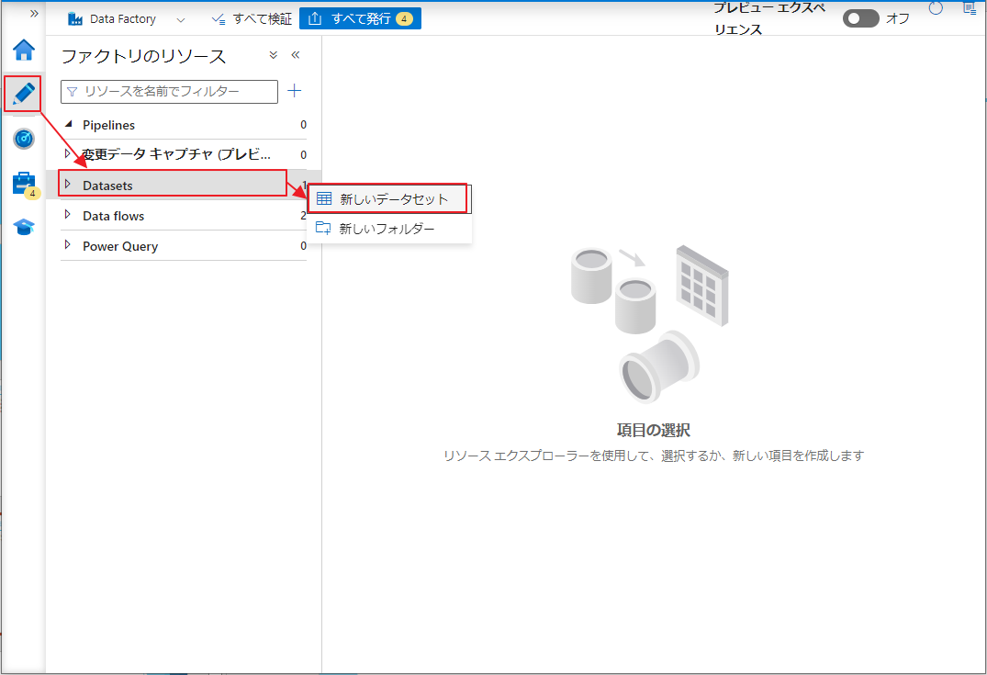
③「新しいデータセット」ダイアログボックスで「Azure BLOBストレージ」を選択し、「実行」ボタンをクリックします。
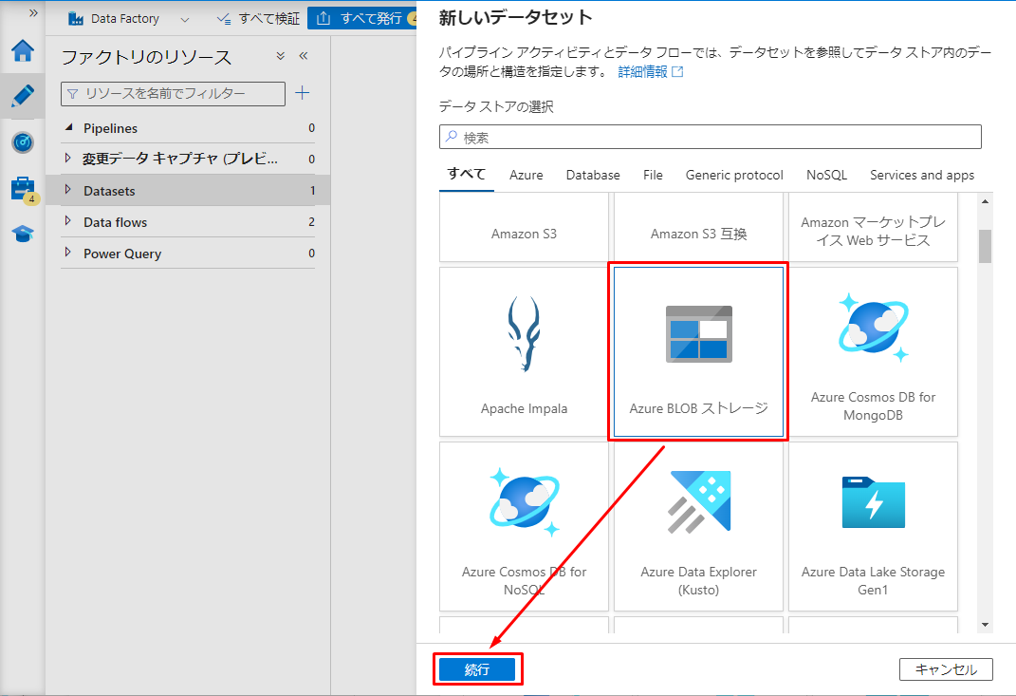
④「DelimitedText」を選択して「実行」ボタンをクリックします。

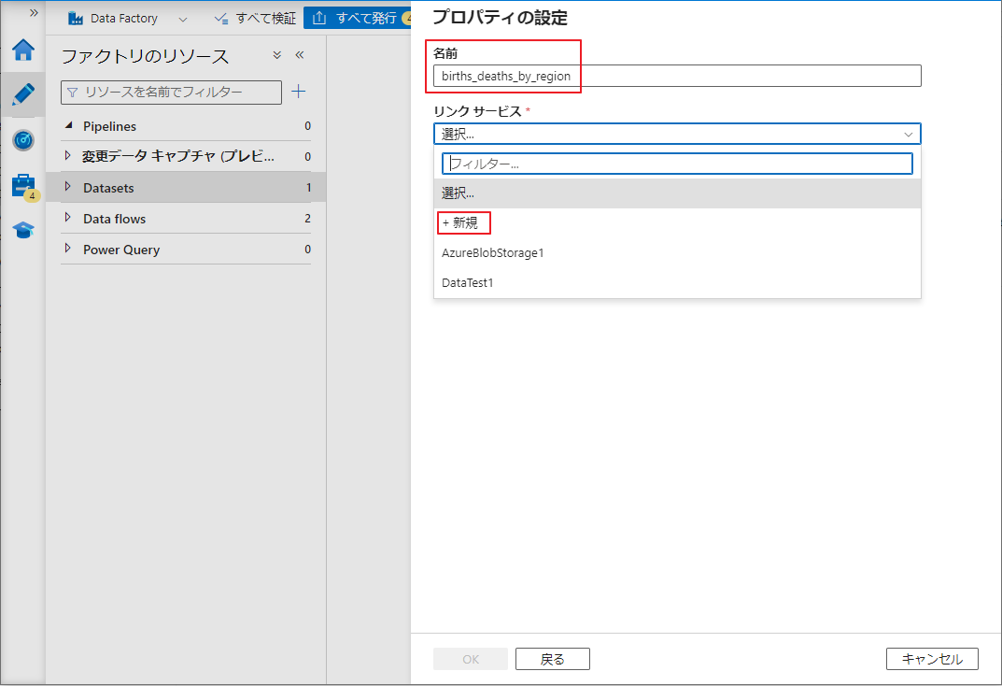
⑤ データセットの名前を入力します。
⑥ リンクサービスで、「+ 新規」 を選択します。
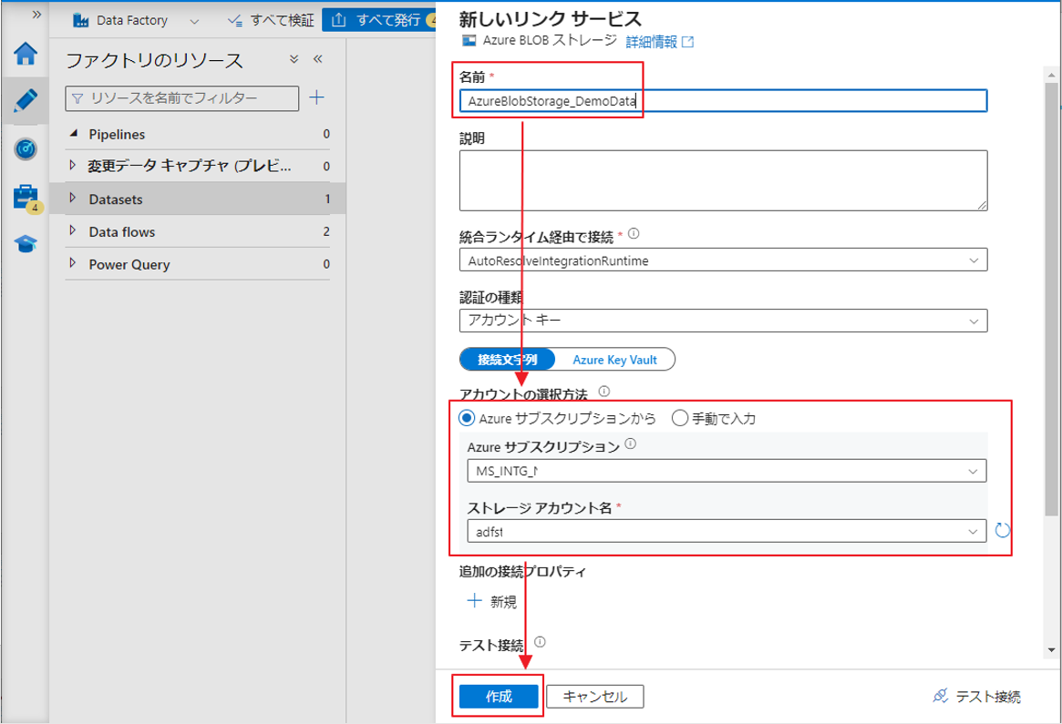
⑦ 新しいリソース サービスの名前を入力します 。
⑧ 次に、前の手順でデータをアップロードしたサブスクリプションとストレージ アカウントを選択します 。
⑨「作成」ボタンをクリックします。
⑩ ファイルパスで「参照」アイコンをクリックします。
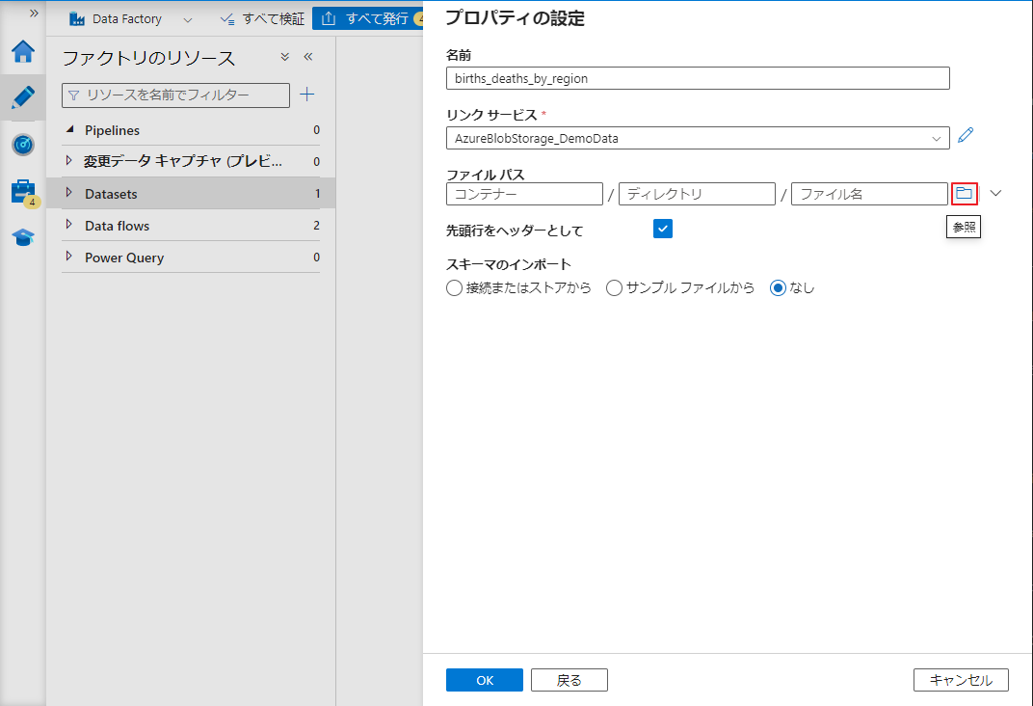
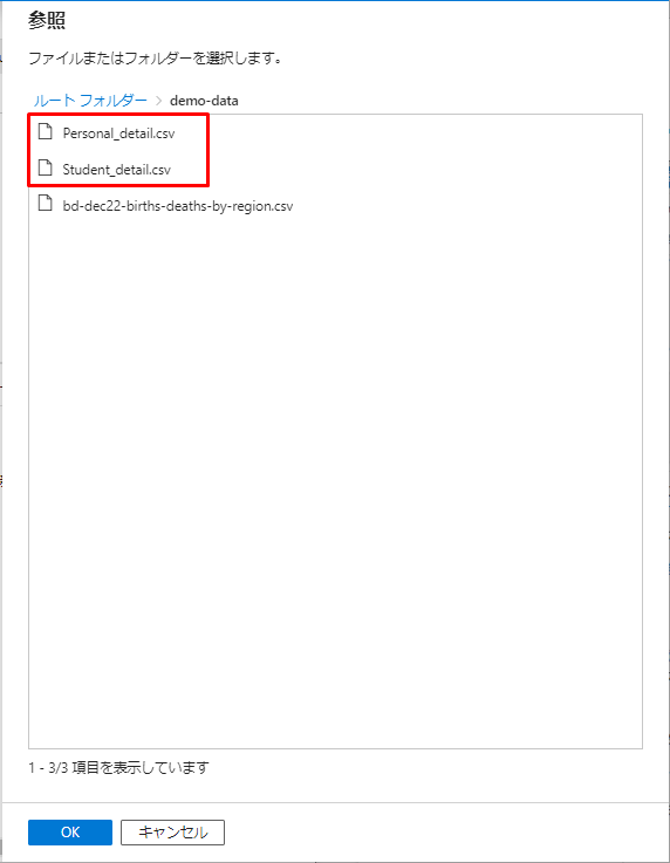
⑪ フォルダ「demo-data」をクリックします。
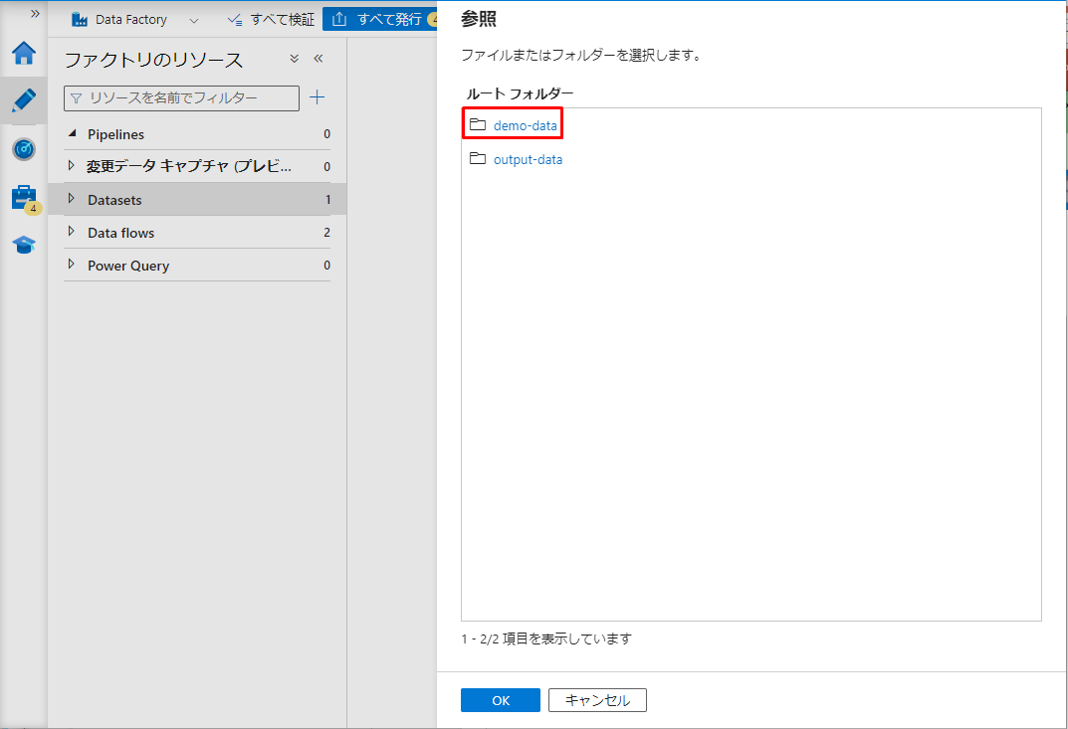
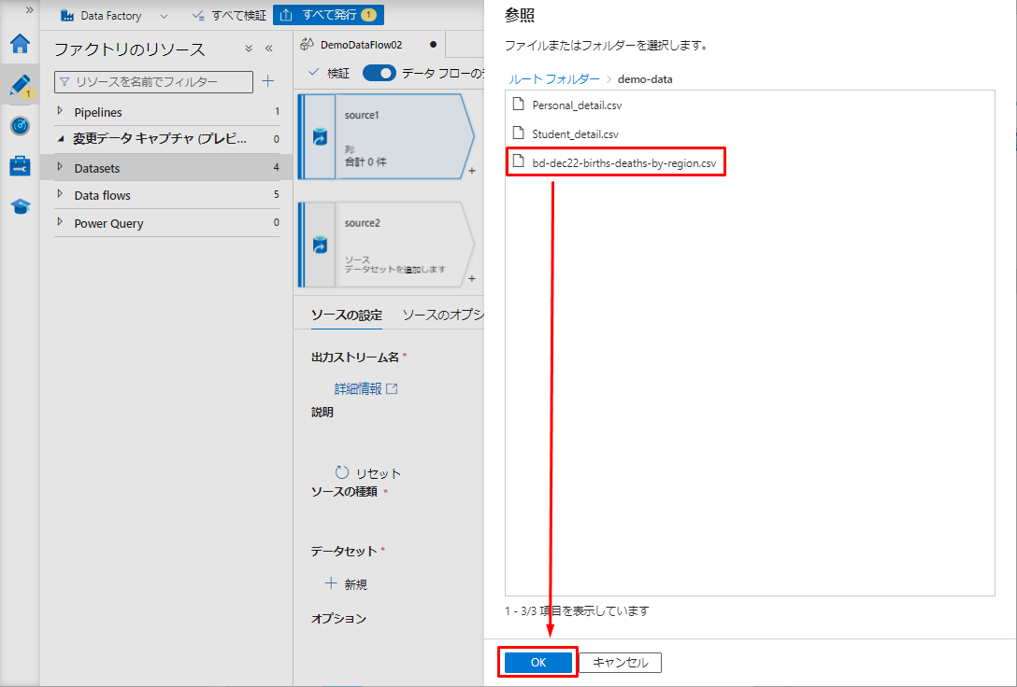
⑫ アップロードされたCSVファイルを選択します。
⑬「OK」をクリックします。
⑭「OK」をクリックします。
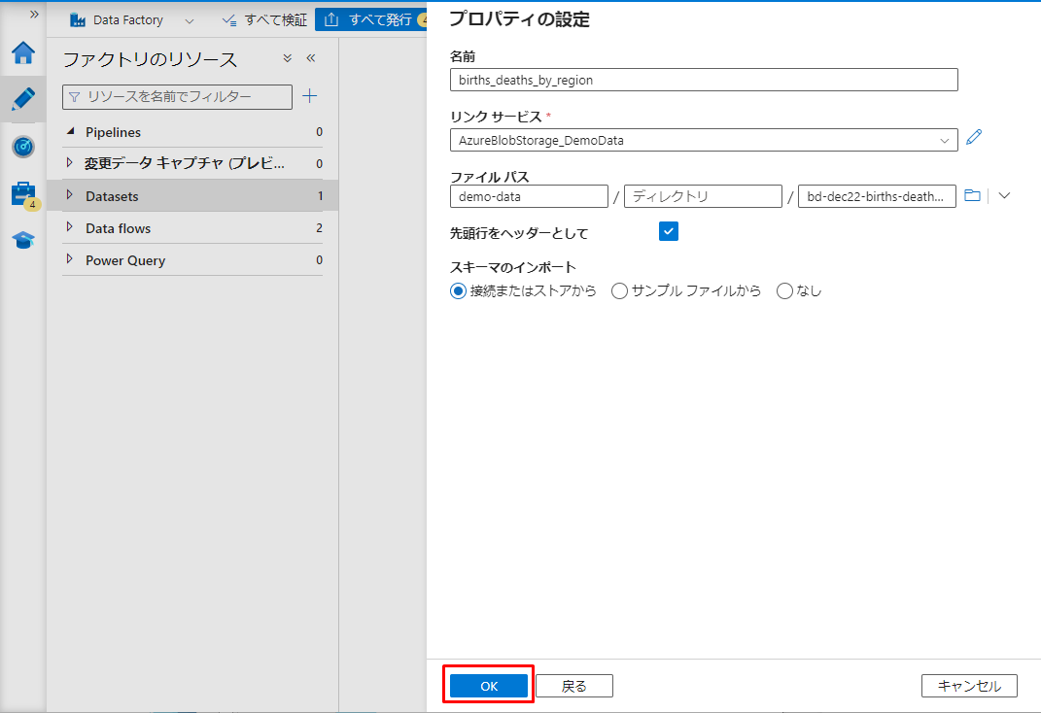
同様の手順に従って、次のデータセットを作成します。
「Student_detail」、「Personal_detail」
4.SQLコマンドを実現する
4-1.FROM テーブル指定
SQLのFROM文のように特定のテーブルからSELECTするには、ADFでソース変換を使用します。
テーブルの選択は、「ソースの変換」タブの「データセット」項目でデータセットを選択することと同じです。
実行の手順は次の通りです。
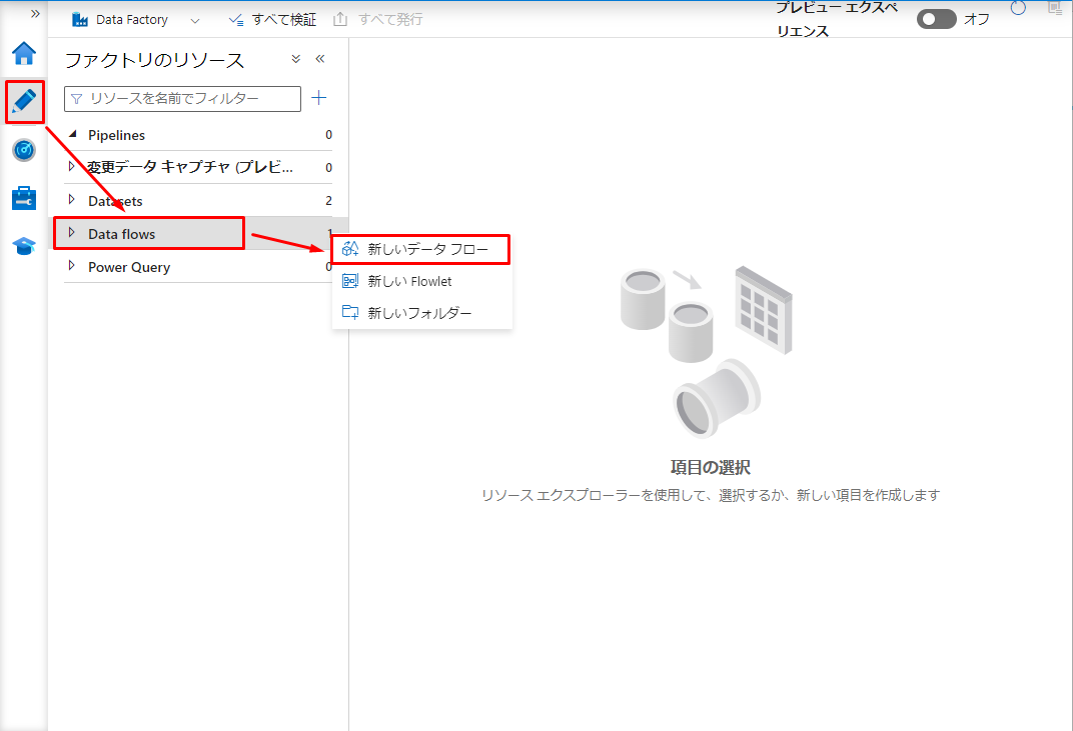
① ADFのサイドバーで「Author」をクリックして、次に「Data flows」をクリックして、「新しいデータフロー」を選択します。
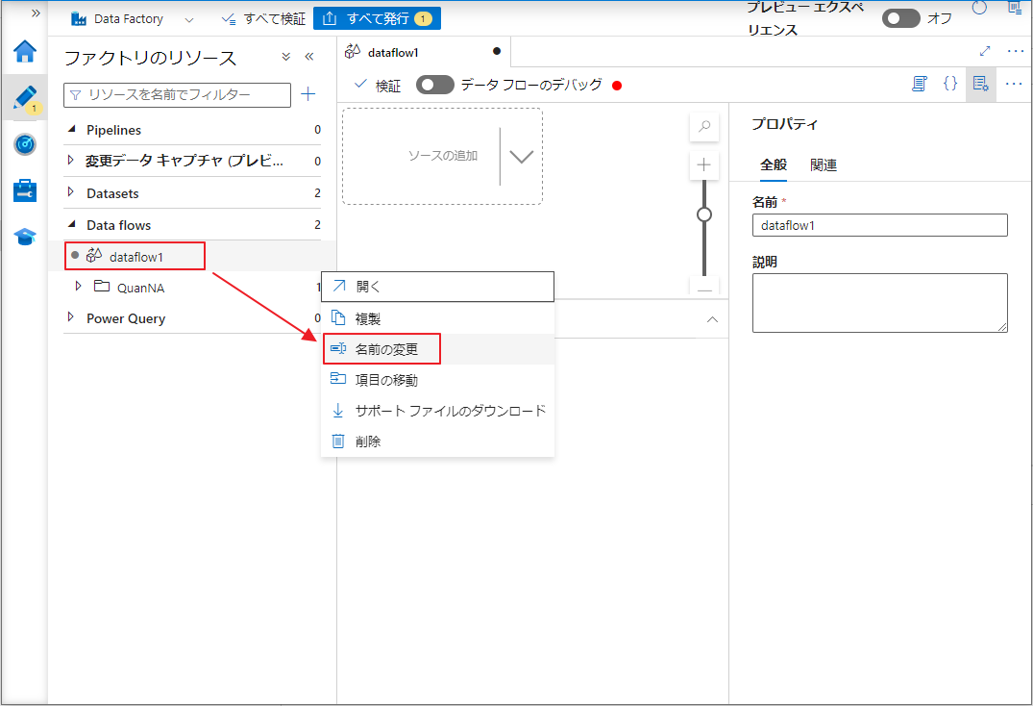
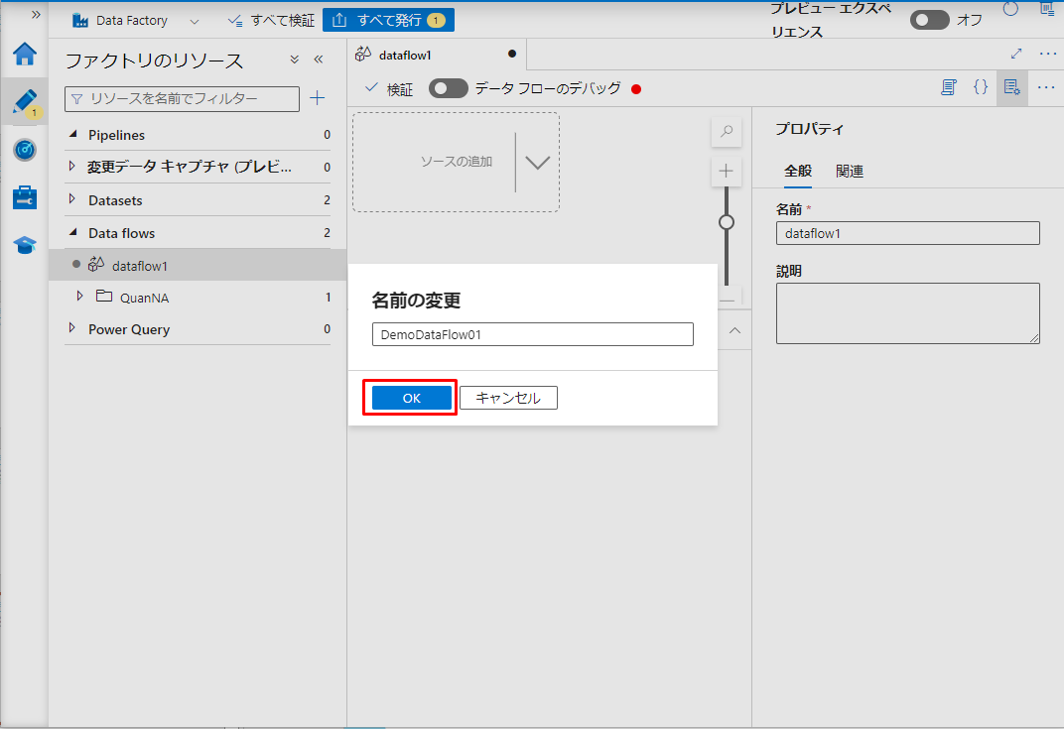
②「名前の変更」をクリックしてデータフローの名前を変更します。
③ データ フローの名前を入力し、「OK」ボタンをクリックします。
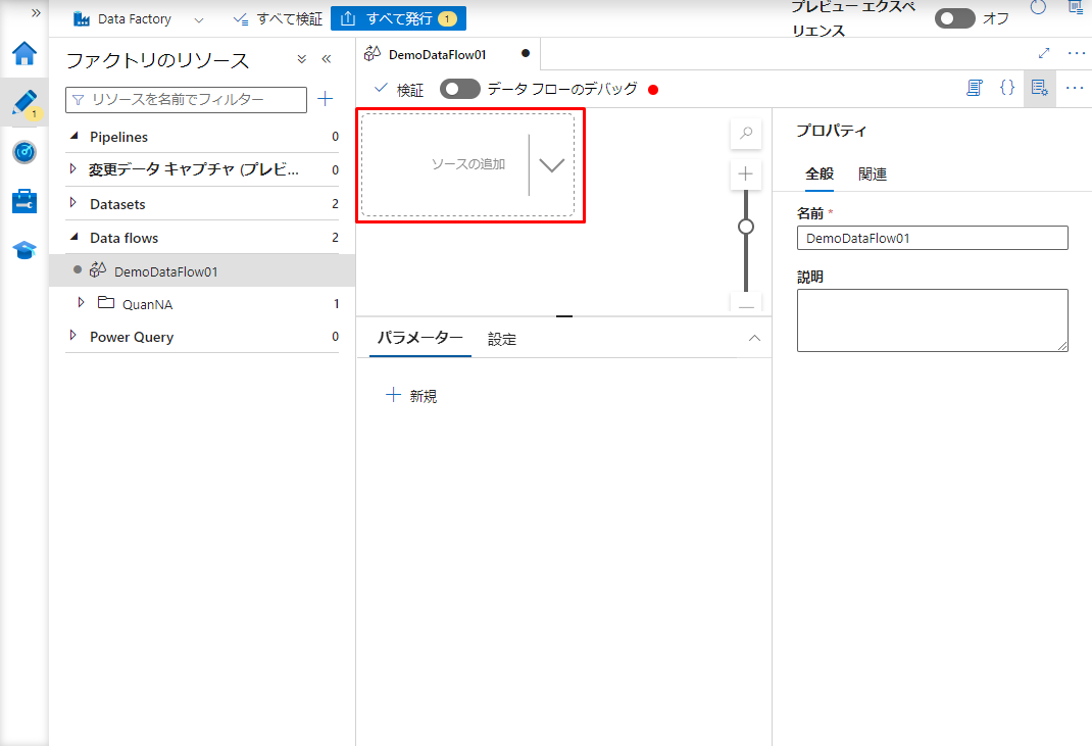
④ データフローの画面で「ソースの追加」をクリックします。
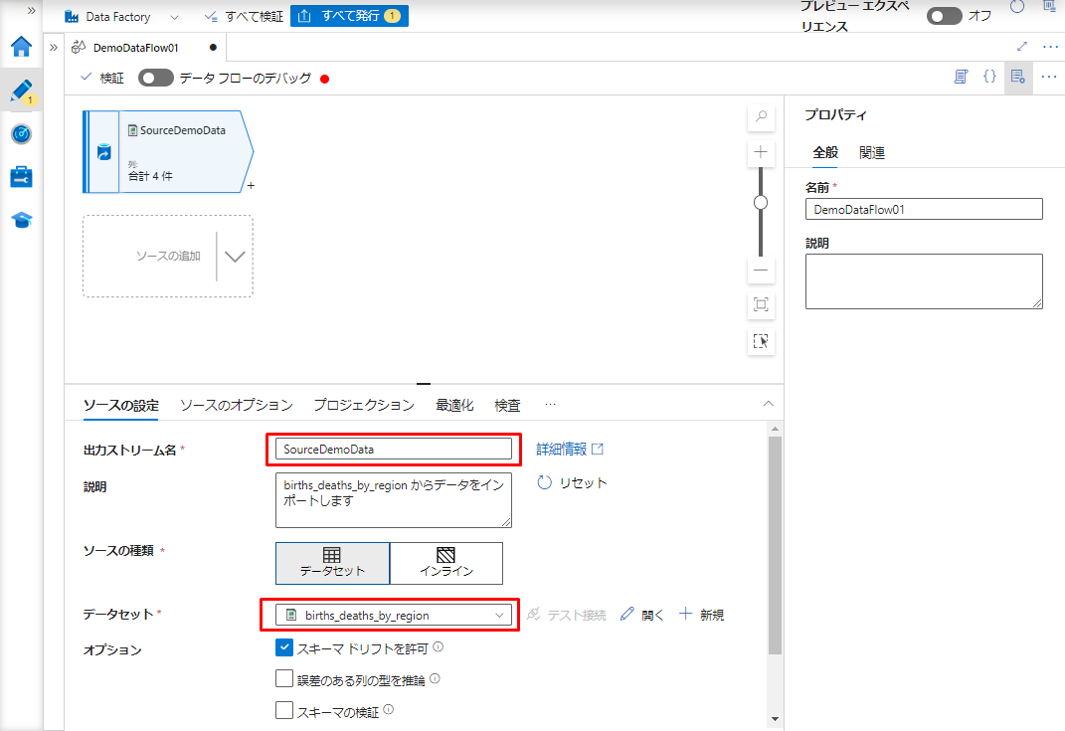
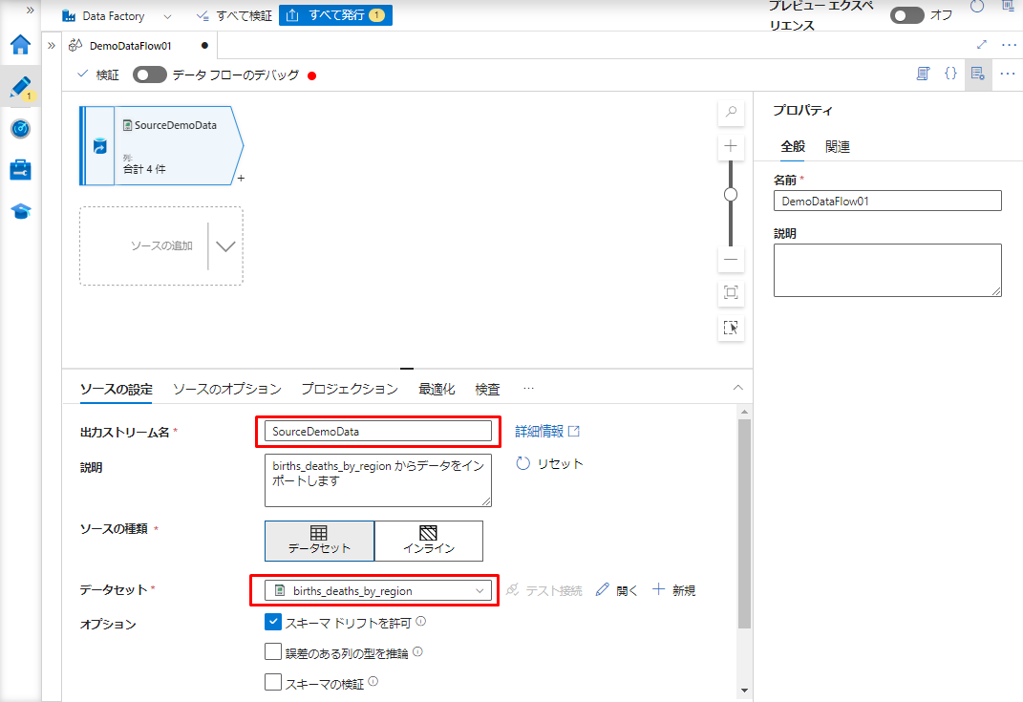
⑤「ソースの設定」タブで、データフロー名を変更して、ストレージアカウントでアップロードしたデータセットを選択します。
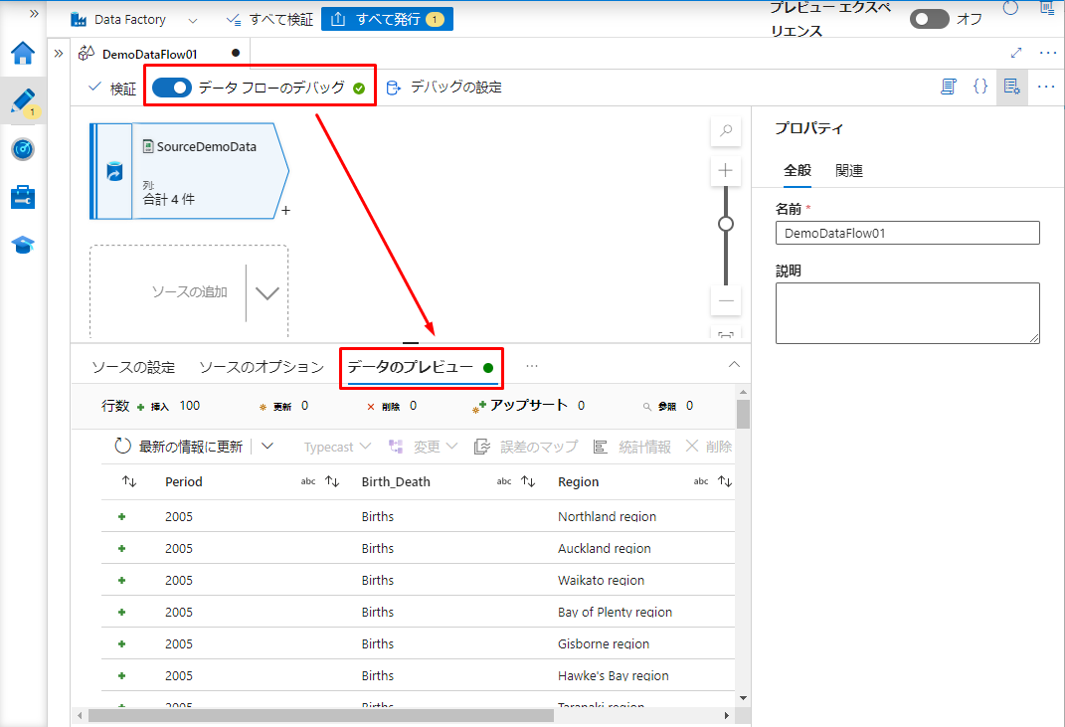
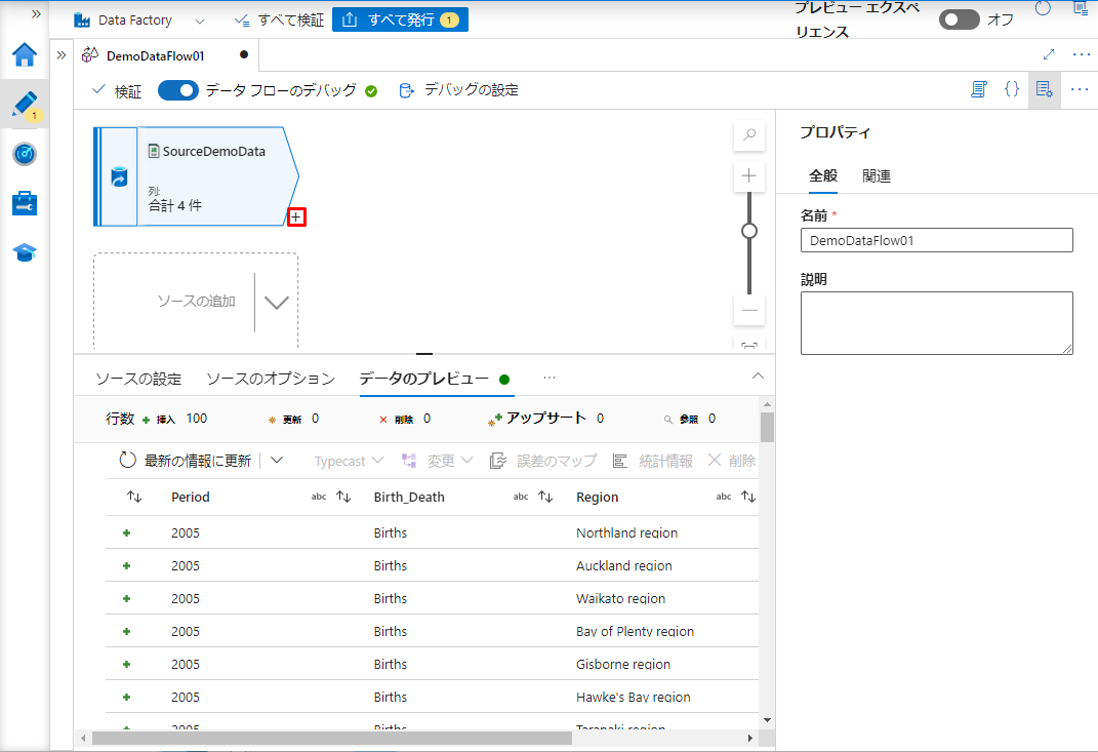
次に、データ フローのデバッグを有効にして、「データのプレビュー」タブをクリックして、CSV ファイルからインポートされたデータを確認します。
例えば、このデータセットは、 2005年から2022年までの地域別の出生数と死亡数です。
4-2.SELECT
SQLのSELECT文のようにテーブルからデータをSELECTするには、ADFで選択変換を使用します。
「設定の選択」タブの「入力列」項目でテーブルからの列を選択します。
実行の手順は次の通りです。
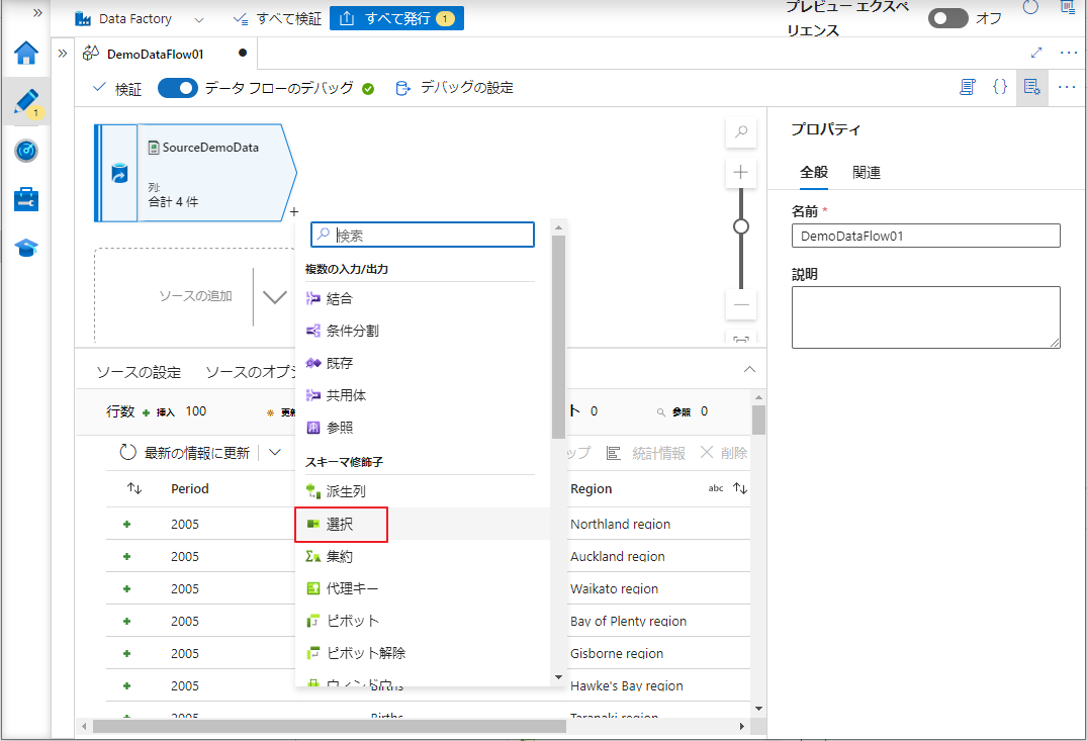
① プラスアイコンをクリックして、作成されたソース変換から新しい変換を追加します。
②「選択」をクリックします。
列の名前変更、削除、または並べ替えを行うには、選択変換を使用します。
この変換は、行データを変更することなく、処理希望の列を選択します。
この例では、データセット内のすべての列を選択します。
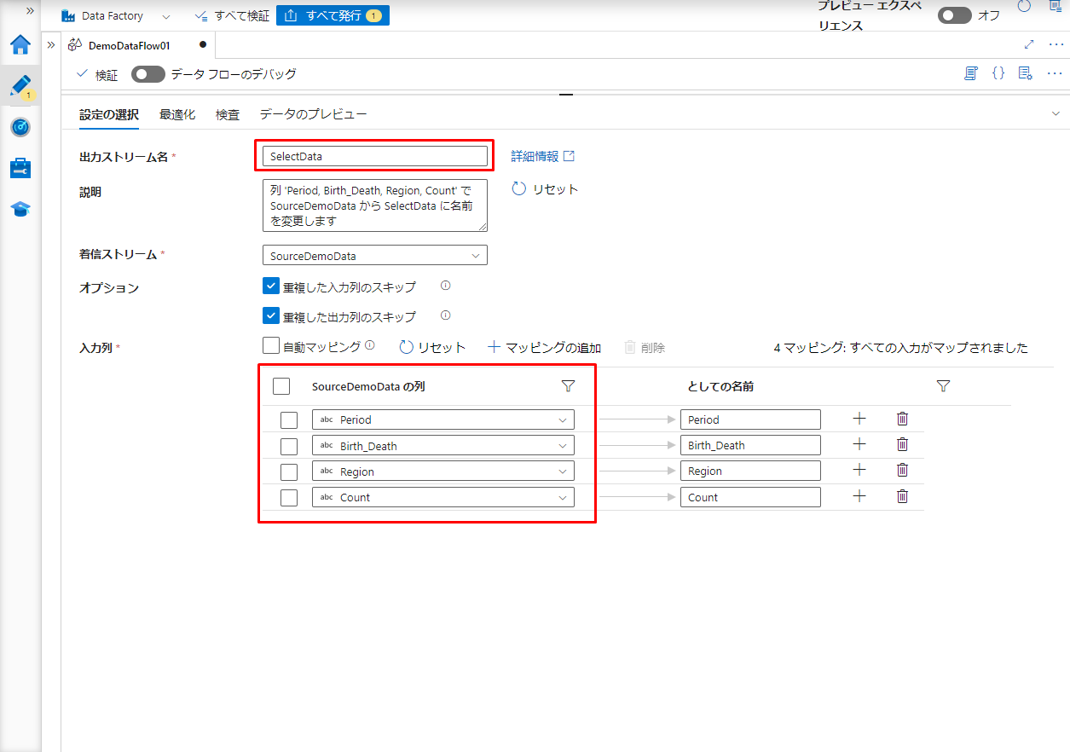
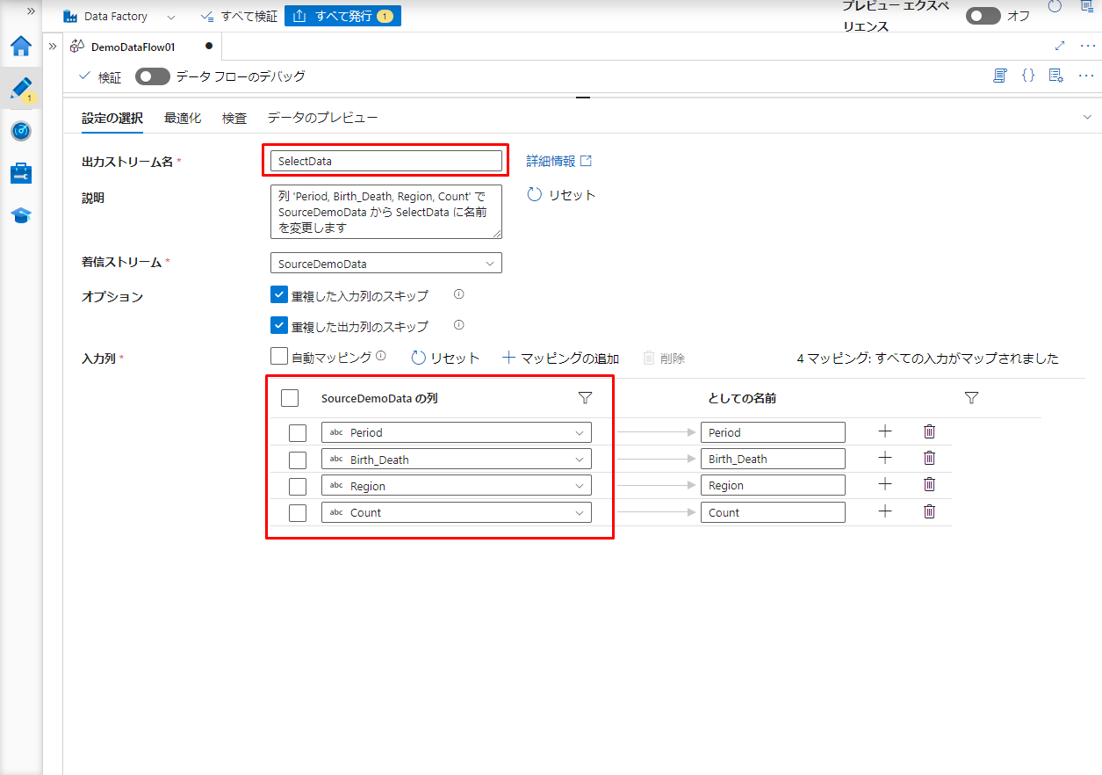
③ 選択変換に「SelectData」という名前を付けます。
「入力列」項目のデフォルトでは、変換ソースで指定のテーブルから全ての列を選択します。該当チェックボックスをクリックして、希望の列を選択できます。
4-3.AS(エイリアス指定)
「入力列」項目に対して、「としての名前」列を設定することで列名を変更できます。
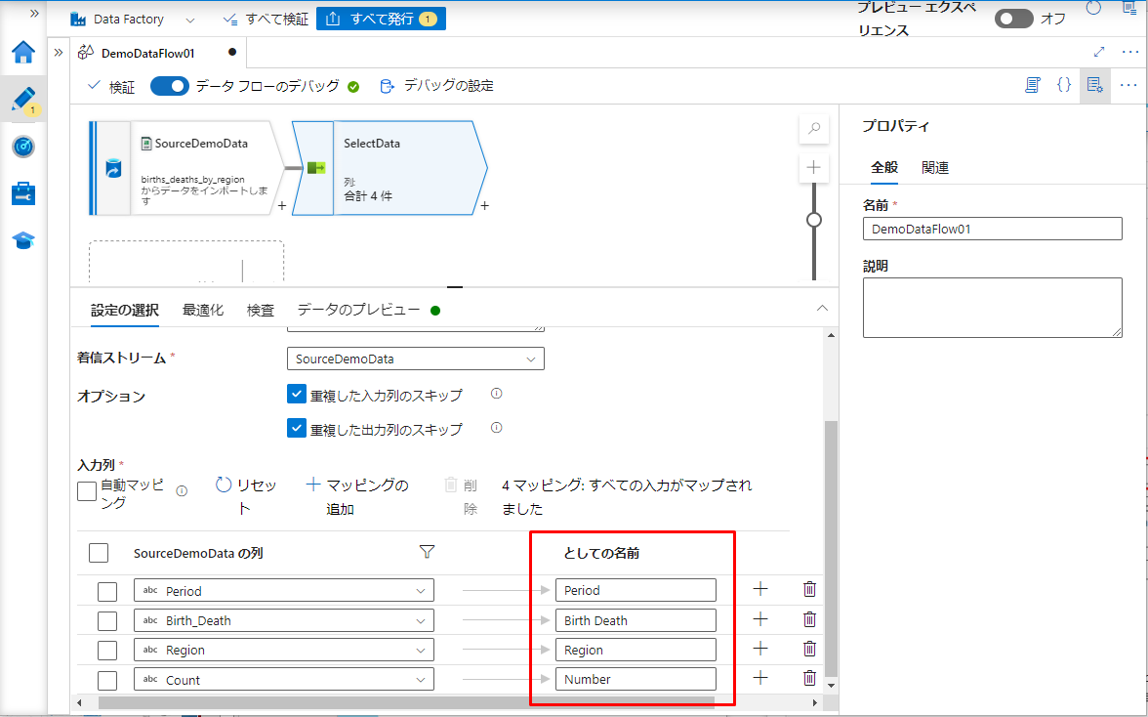
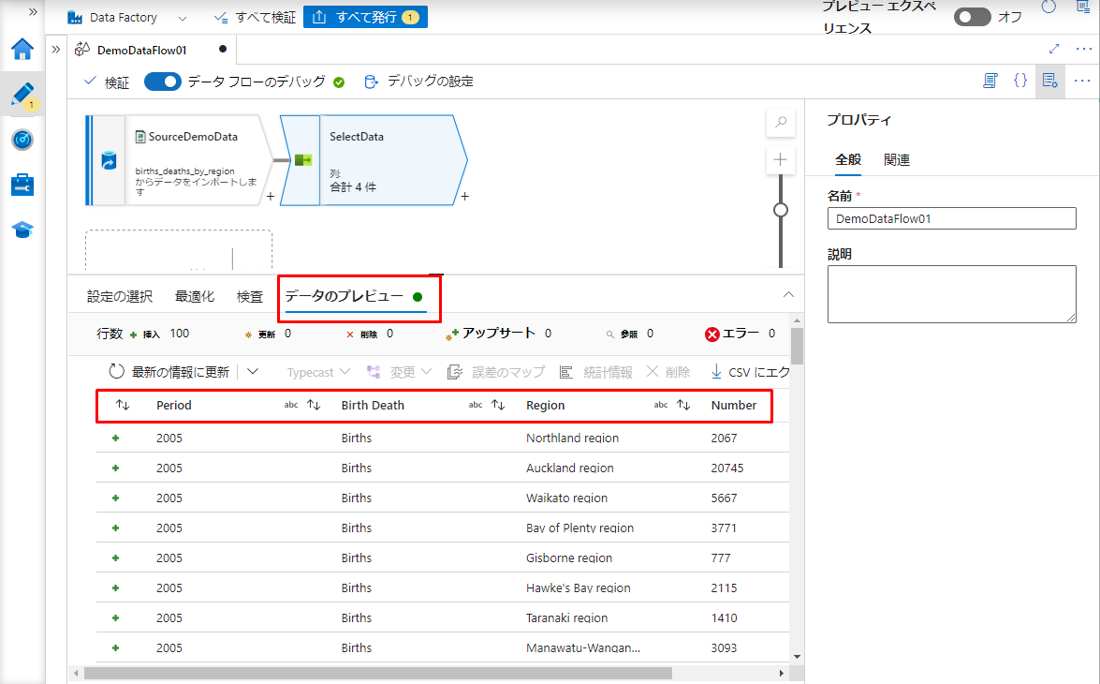
その後、「データのプレビュー」タブでデータが表示されます。
テーブルの全ての列及び、前の手順で名前変更された「Birth Death」と「Number」列が表示されます。
4-4.CAST(型・桁数指定)
SQL の CAST のように各列のデータ型を変更するには、ADF でキャスト変換を使用します。
「キャスト設定」タブの「列」項目でキャストする列のデータ型を選択します。
実行の手順は次の通りです。
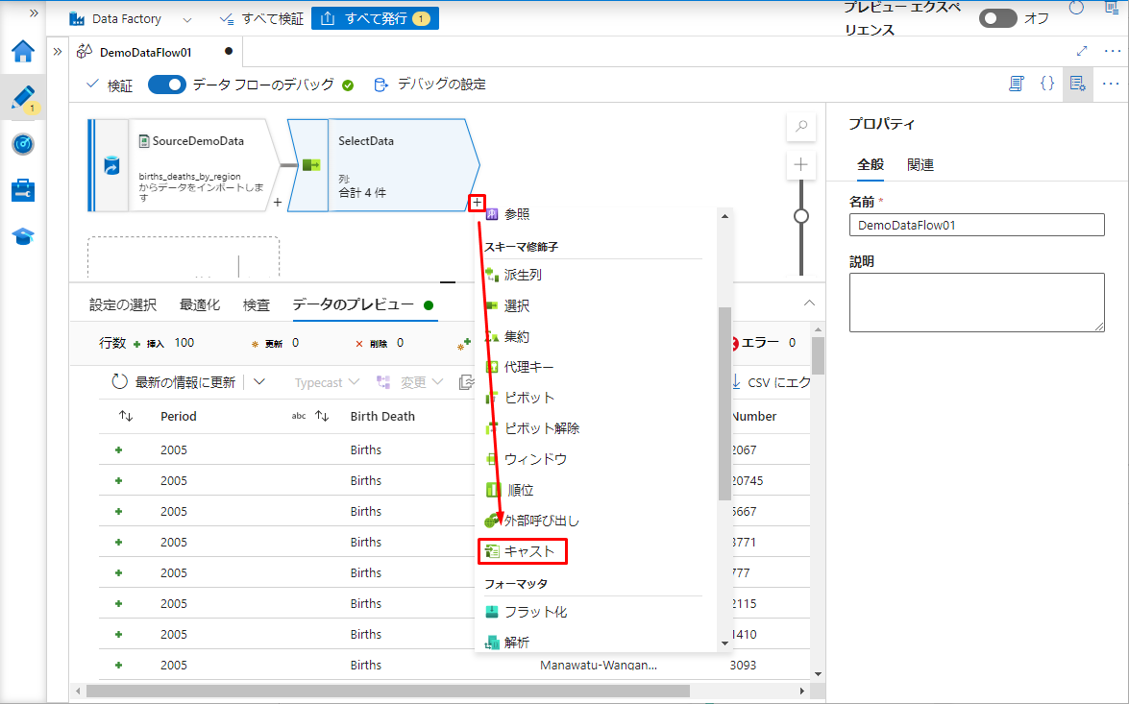
① プラスアイコンをクリックして選択変換からキャスト変換を追加し、選択した後に列のデータ型を変更します。
②「キャスト」をクリックします。
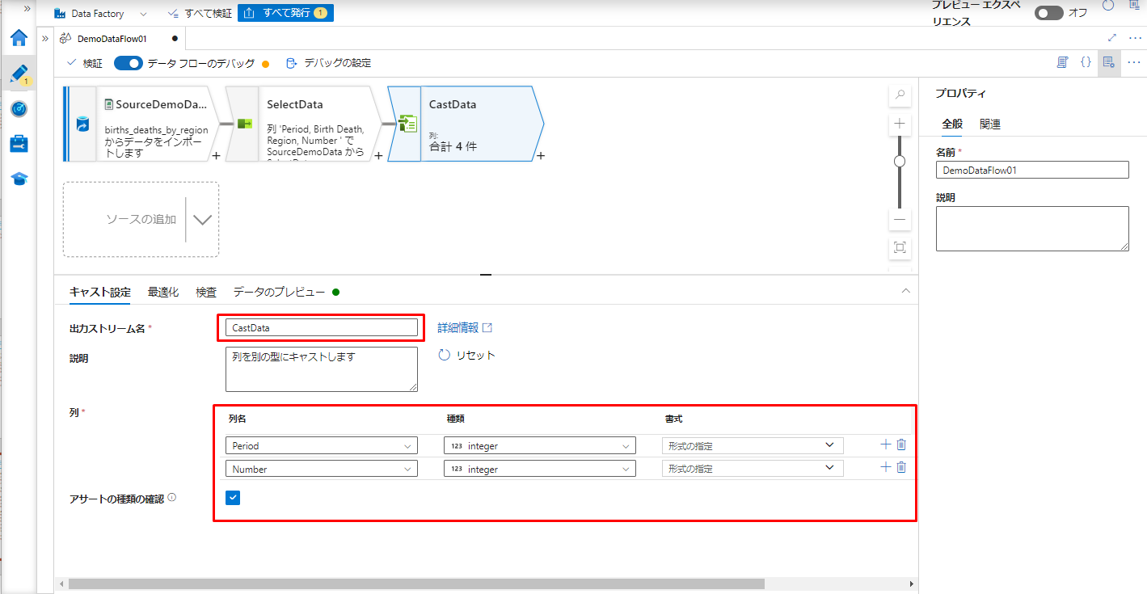
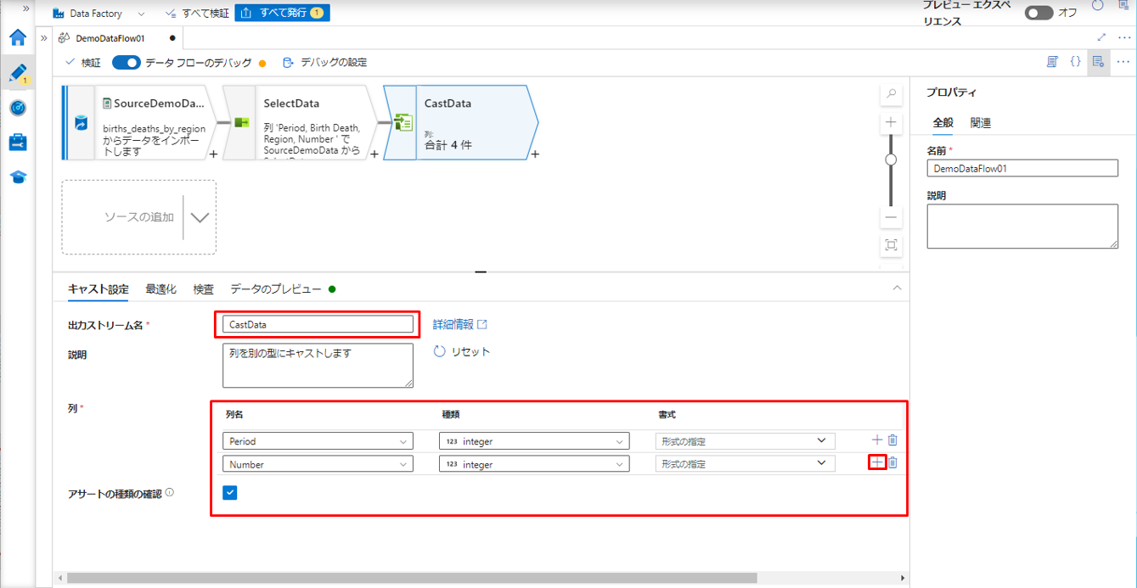
③ キャスト変換に「CastData」という名前を付けます。
列名: メタデータ列の一覧からキャスト変換する列を選択します。
型: 列をキャスト変換するデータ型を選択します。
形式: 10 進数や日付などの一部のデータ型では、追加の書式設定オプションを使用できます。
アサートの種類の確認: キャスト変換を使用すると、型チェックを実行できます。
この例では、Period 列と Number 列のデータ型を String から Integer に変更しました。
必要に応じて、プラスアイコンをクリックして列を追加できます。
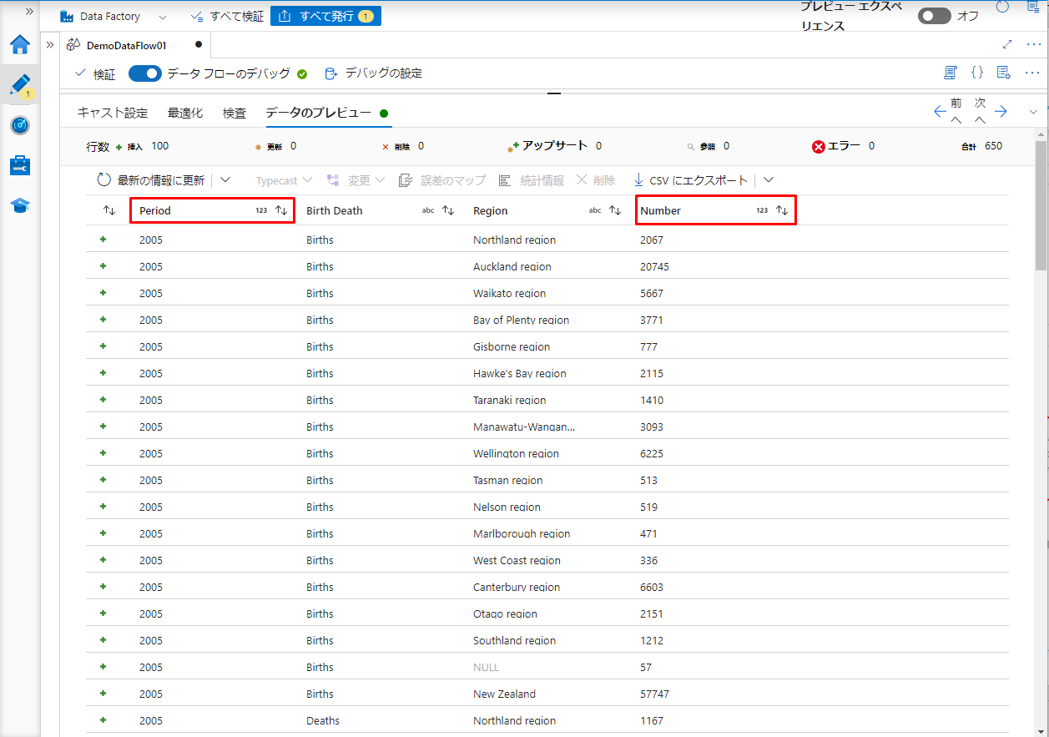
その後、「データのプレビュー」タブでデータが表示されます。
Period 列と Number 列のデータ型を Integer に変更しました。
4-5.WHERE
SQL の WHERE句のように条件でデータをフィルターするには、ADF でフィルター変換を使用します。
データのフィルターを実行するための WHERE 条件は、「フィルター設定」タブの「フィルターオン」項目にあります。
実行の手順は次の通りです。
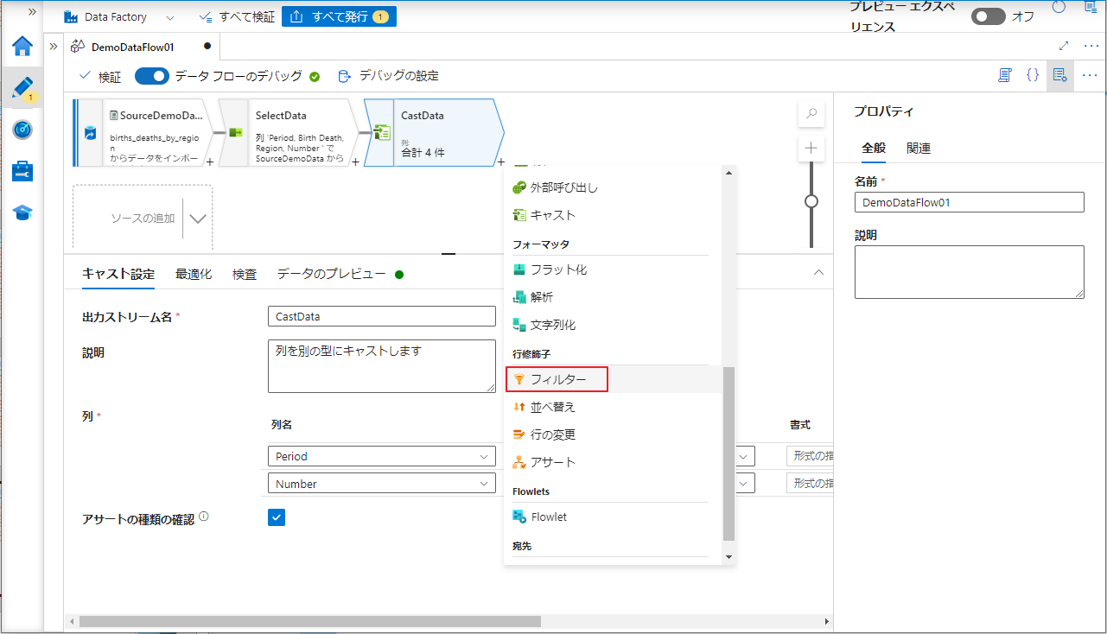
① プラスアイコンをクリックして、キャスト変換からフィルター変換を追加して、条件でデータをフィルターします。
②「フィルター」をクリックします。
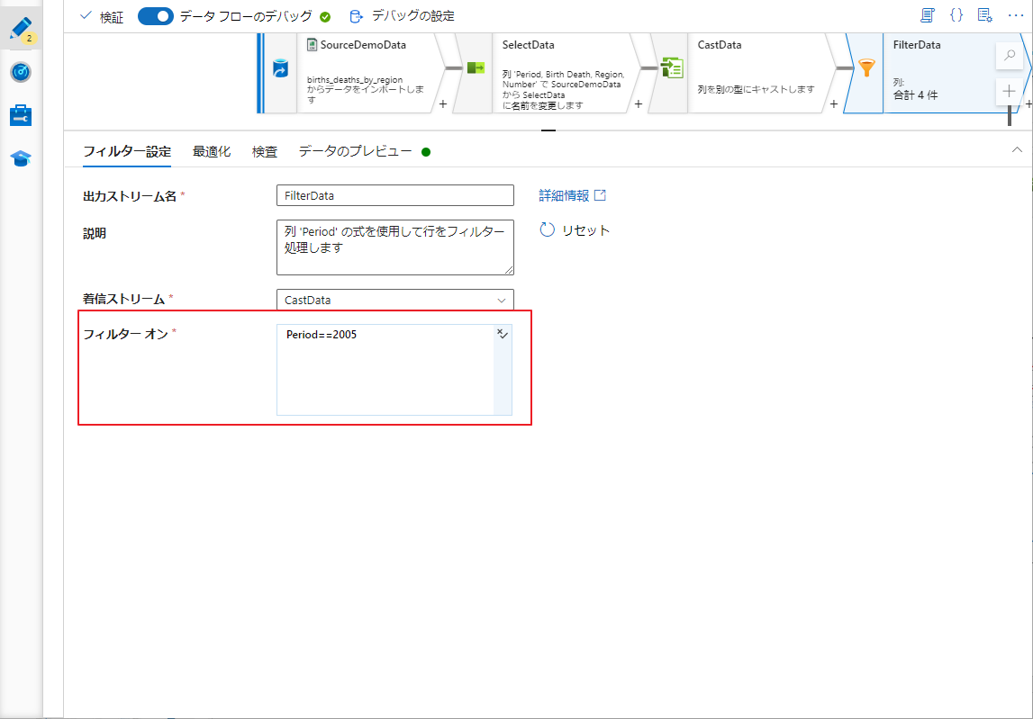
③ フィルター変換に「FilterData」という名前を付けます。
④「式ビルダーを開く」をクリックして、式ビルダーを開きます。( フィルター条件はブール型にする必要があります。)
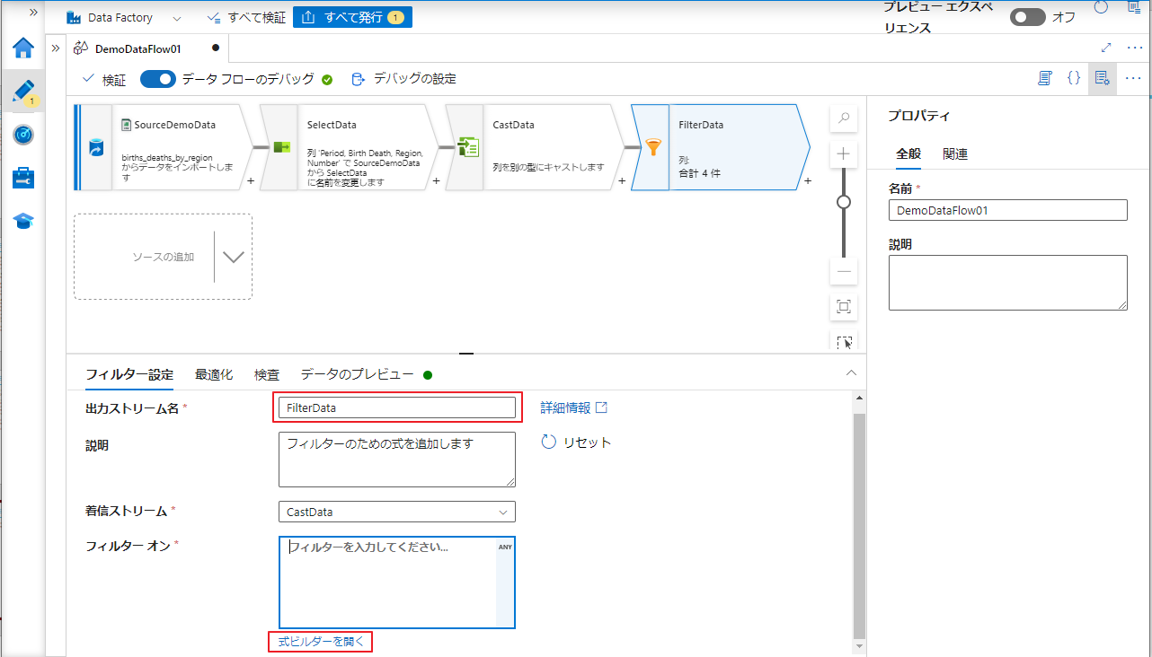
列の値、パラメーター、関数、ローカル変数、演算子、リテラルで式を構成できます。
フィルター条件に基づいて選択できます。
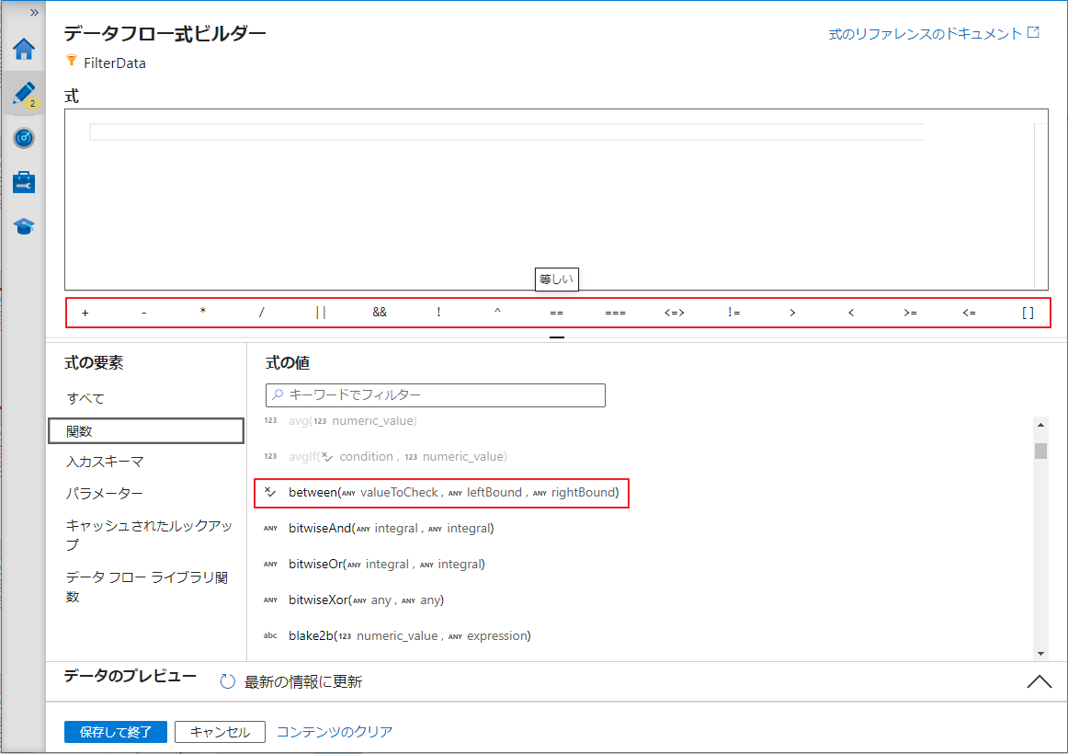
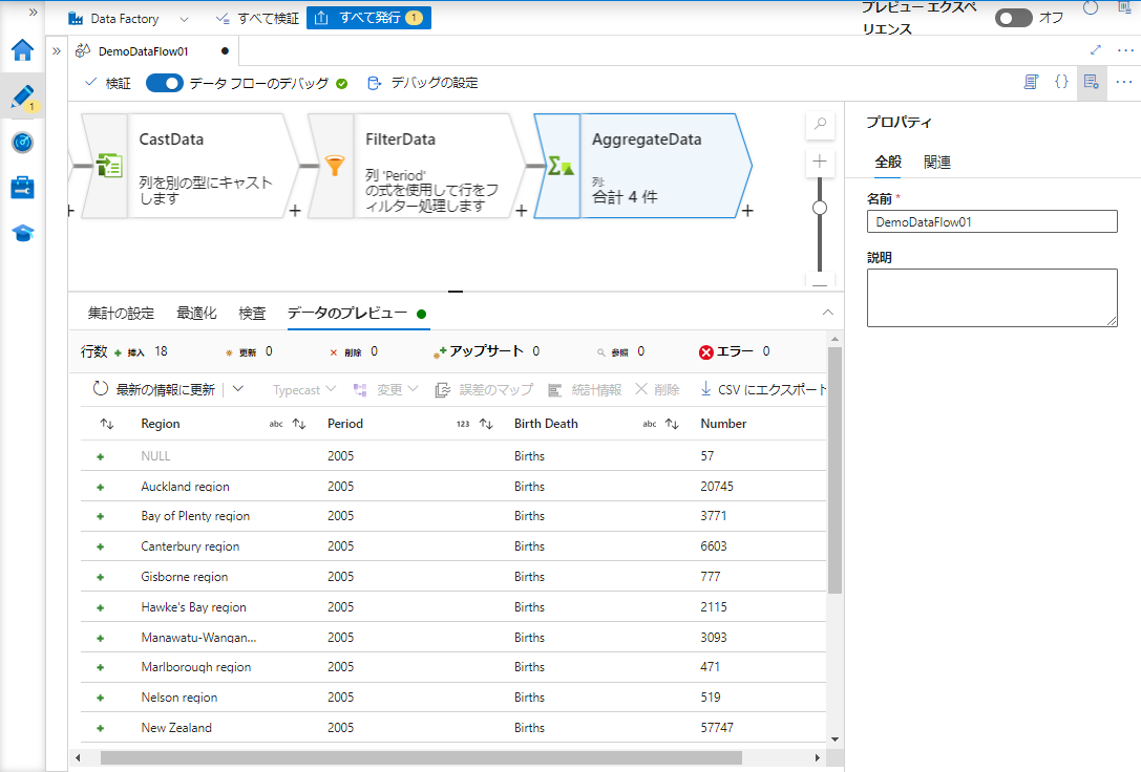
この例では、2005 年のみの地域別出生数と死亡数を表示します。
UI で、フィルター変換は次の画像のようになります。
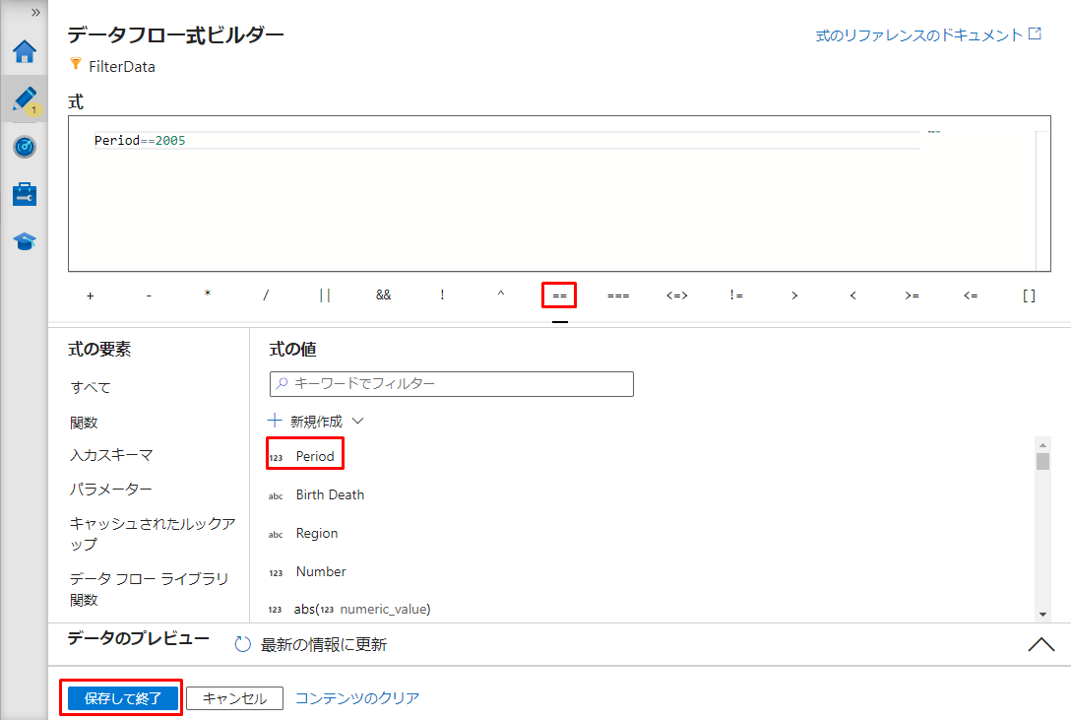
⑤「保存して終了」ボタンをクリックして式を保存します。
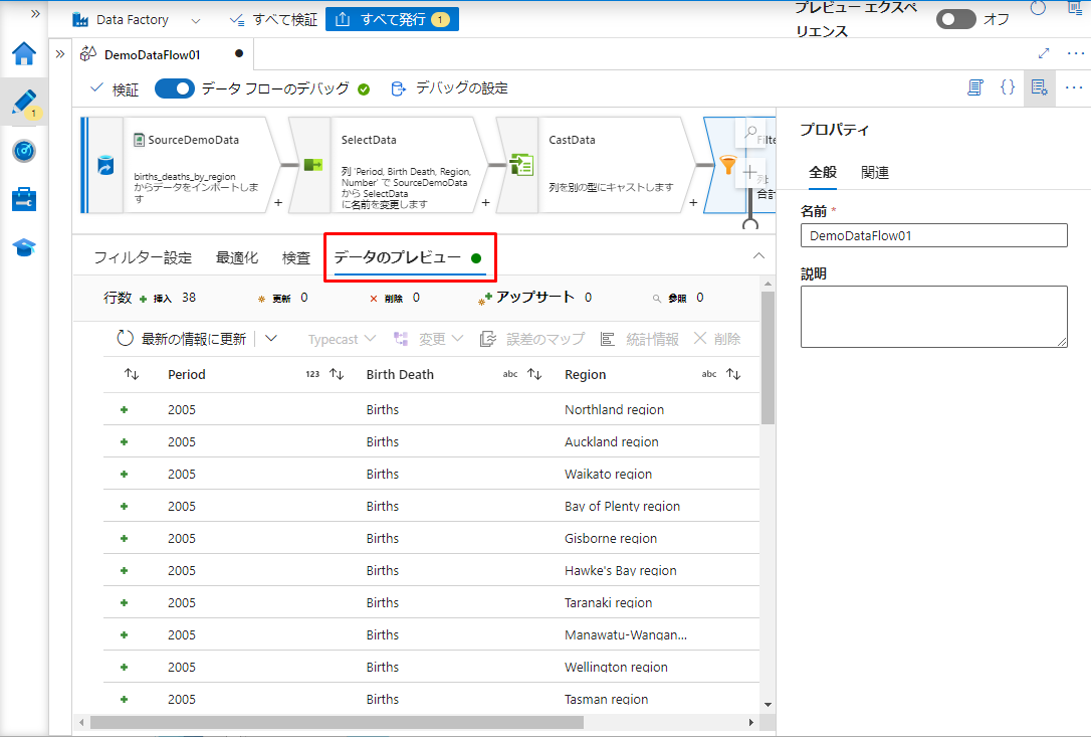
デバッグ モードを有効にする場合は、「データのプレビュー」タブで更新されたデータをプレビューできます。
表示されているデータは、 「Period」列の値が 2005となります。
4-6.COUNT & GROUP BY
SQL の COUNT と GROUP BY のように、集計行の同じ値を持つ行数及びグループ行数をカウントするには、ADFで集計変換を使用します。
式ビルダーの count() 関数を使用して行数をカウントします。
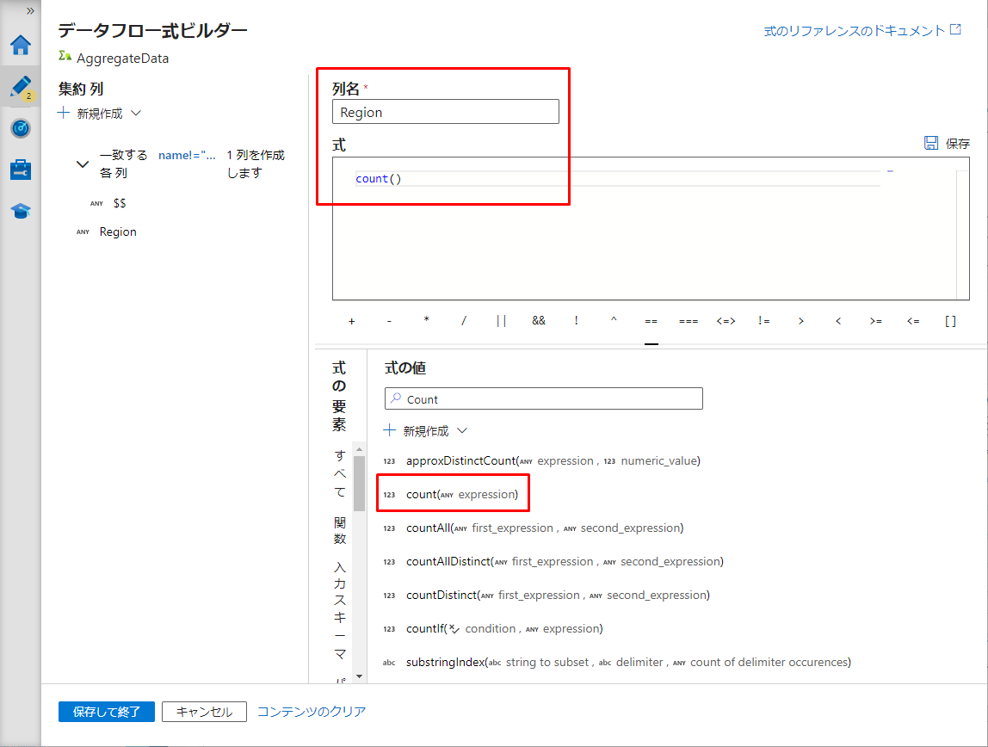
グループ化は「グループ化」タブで実行されます。
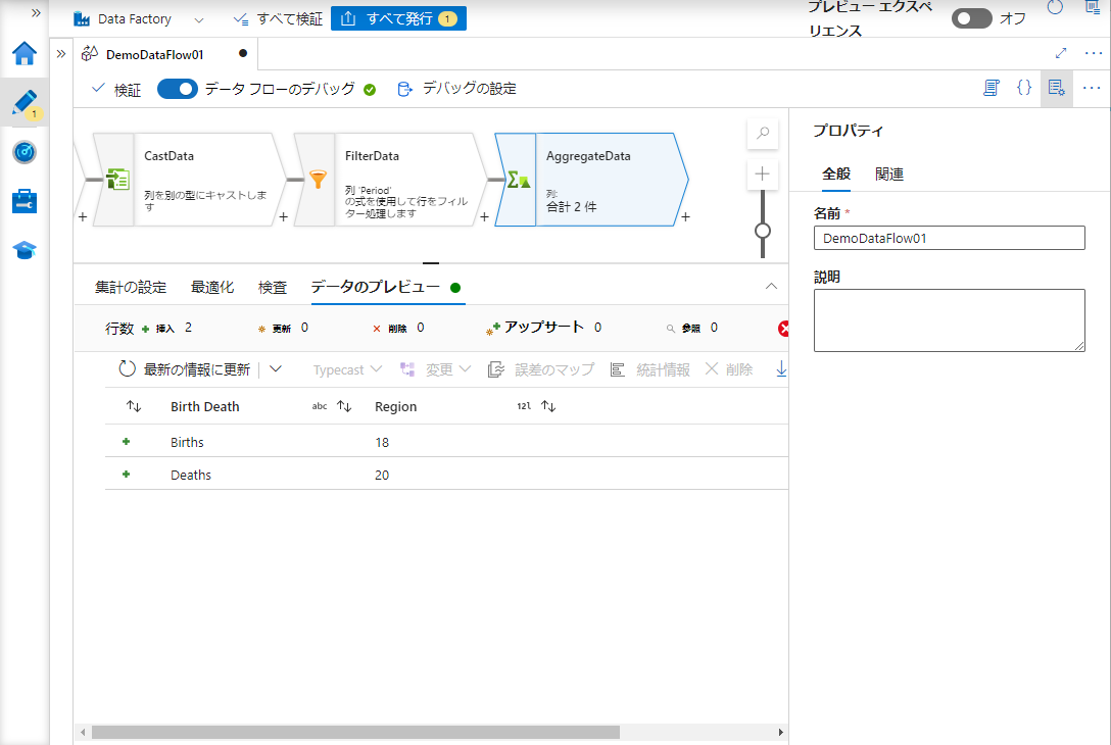
この例では、Birth と Death 別のRegion 列のレコード数をカウントします。
実行の手順は次の通りです。
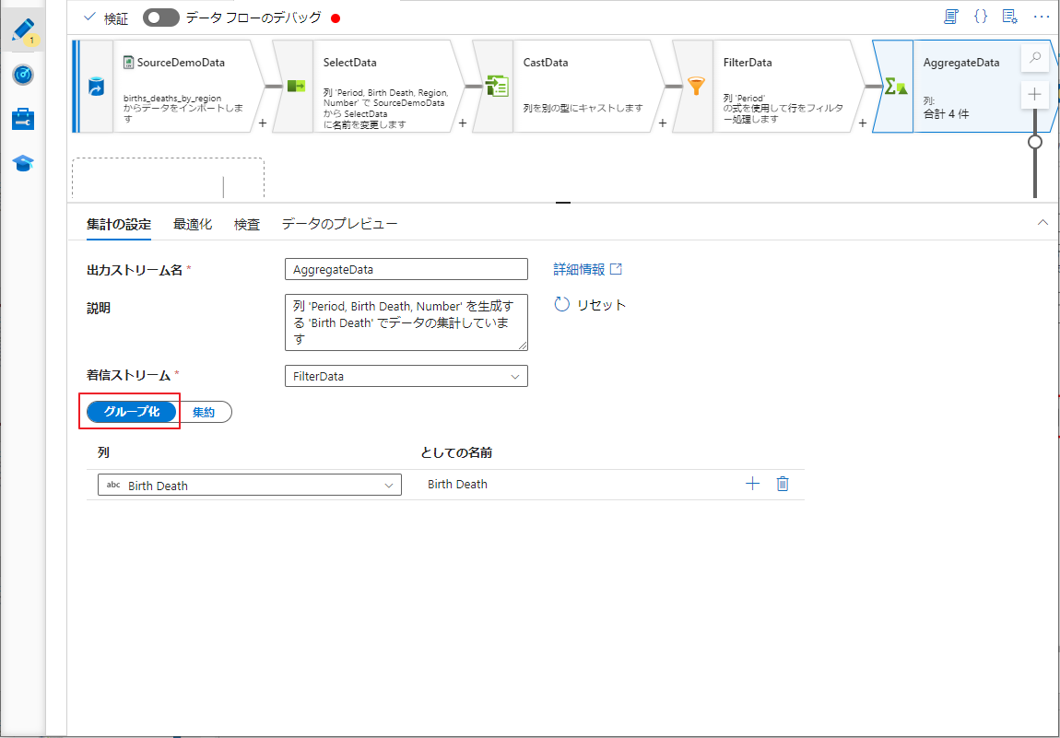
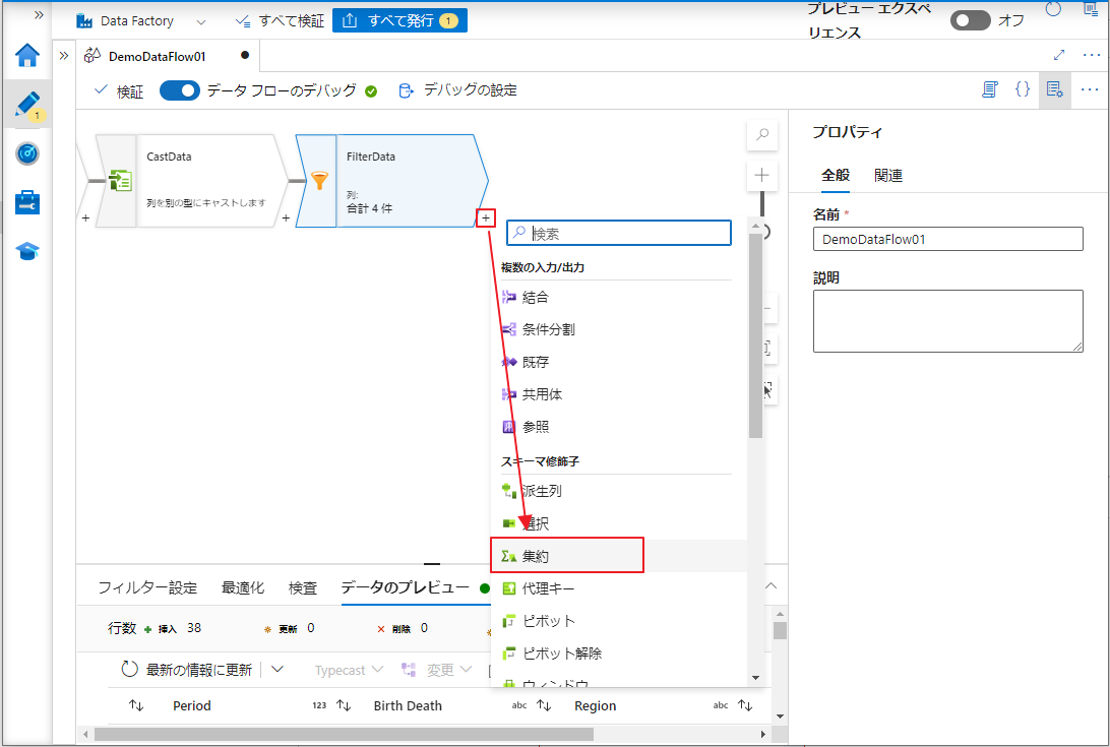
① プラスアイコンをクリックして、フィルター変換からの変換集約変換を追加します。
②「集約」をクリックします。
③ 集計変換に「AggregateData」という名前を付けます。
集計で句ごとのグループ化として使用するために、既存の列を選択するか、新しい計算列を作成します。既存の列を使用するには、ドロップダウンから列を選択します。
④「Birth Death」列を選択します。
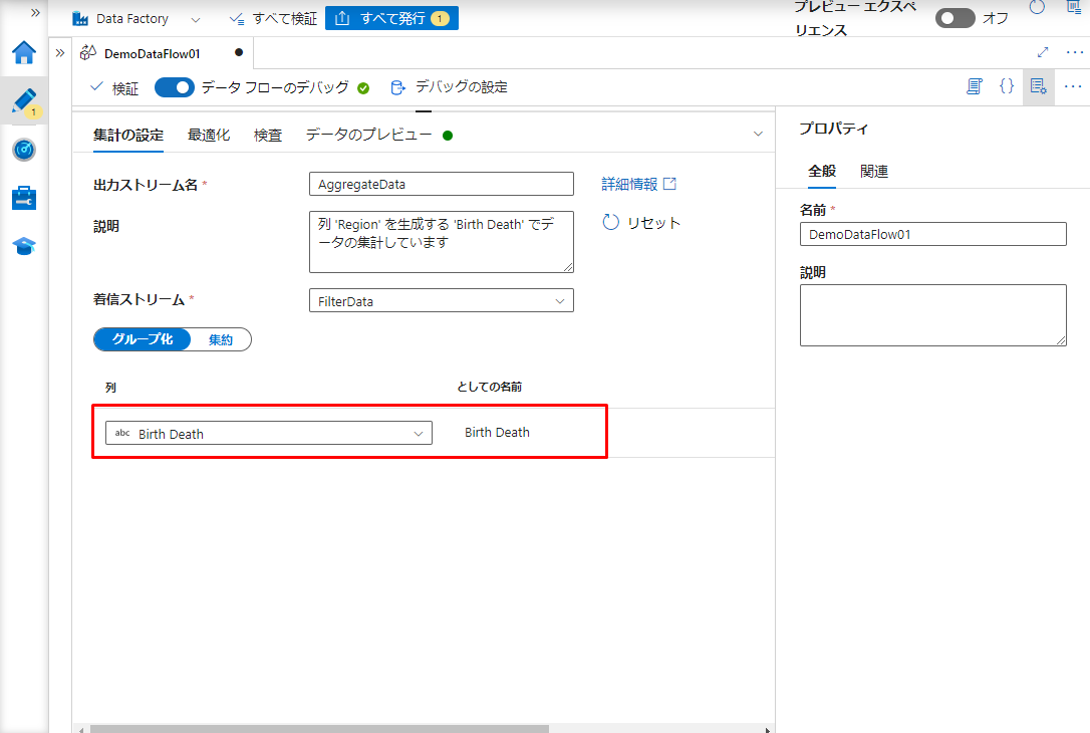
⑤「集約」タブに移動して、集計式を作成します。
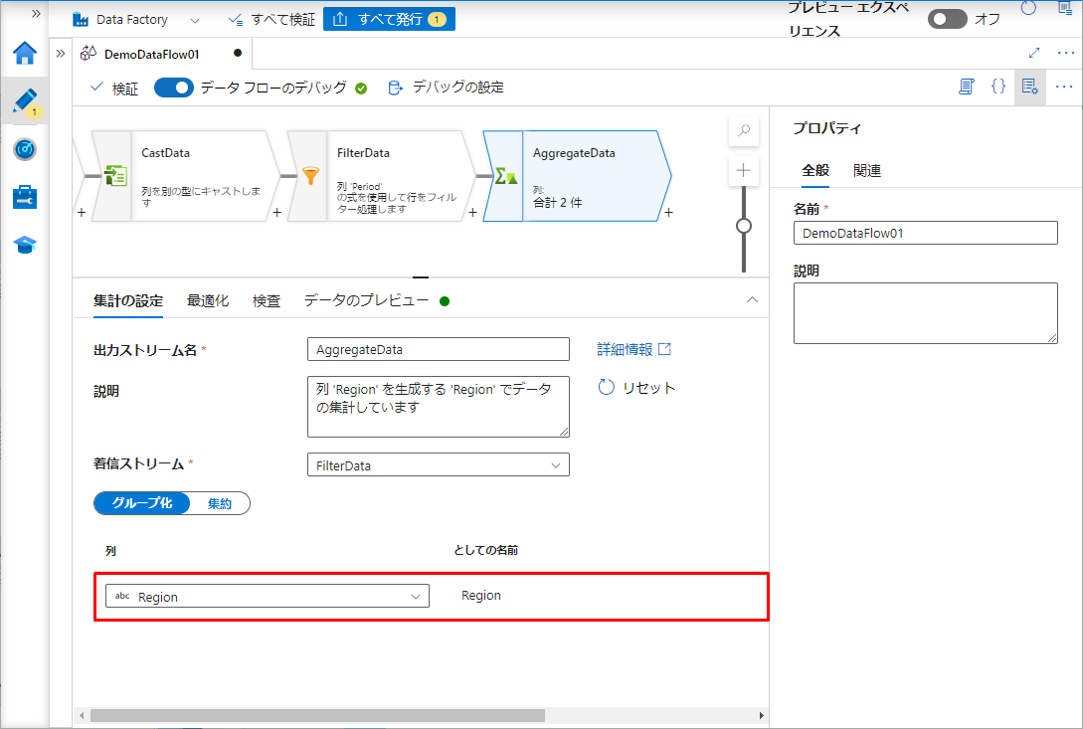
⑥「Region」列を選択します。
⑦「式ビルダーを開く」をクリックして式ビルダーを開きます。
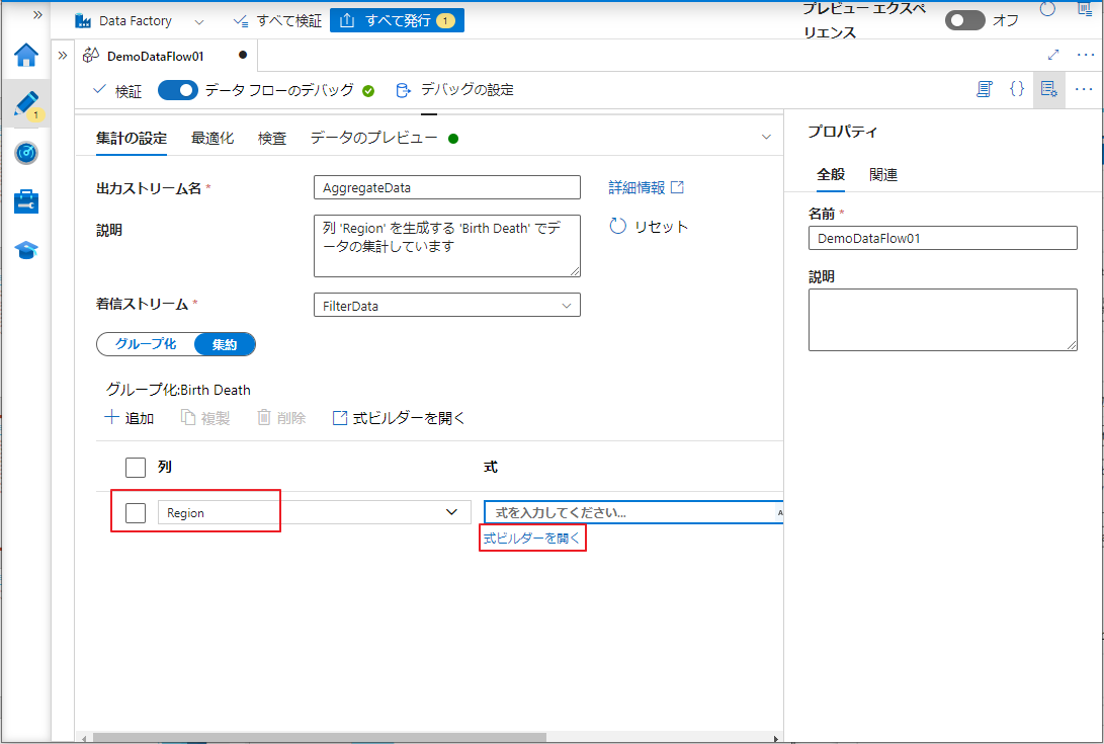
⑧ 式の値で「Count」を入力します。
⑨ 関数 count() を選択します。
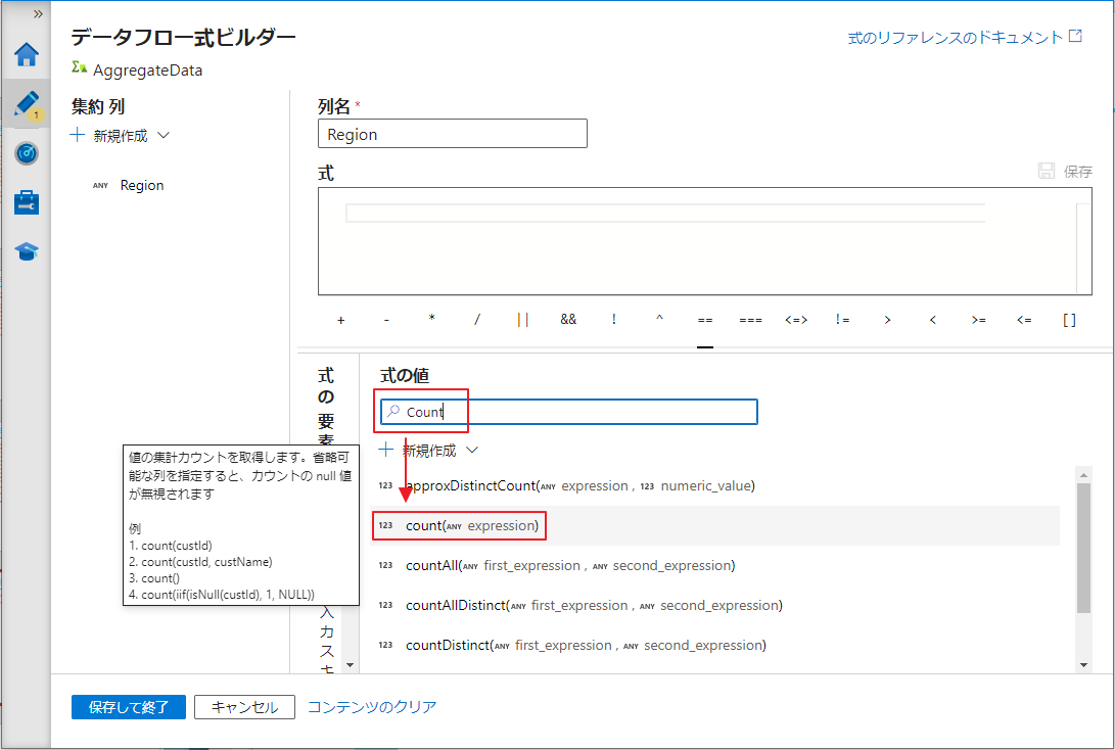
⑩「保存して終了」ボタンをクリックして式を保存します。
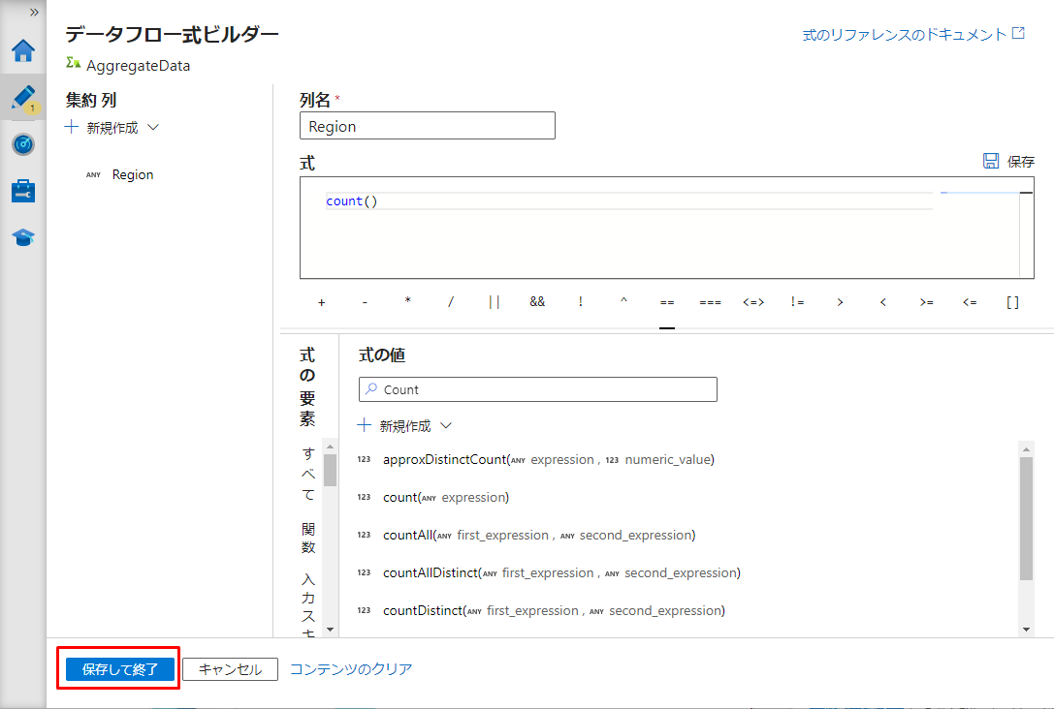
デバッグ モードを有効にするる場合は、「データのプレビュー」タブで集計変換のデータをプレビューできます。
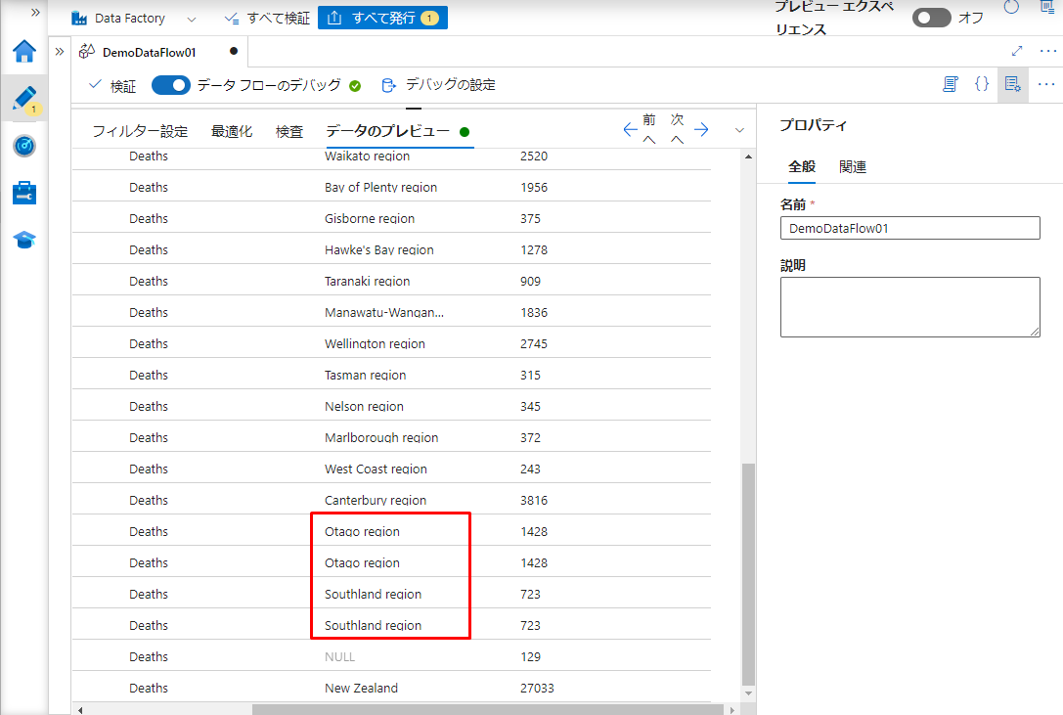
4-7.DISTINCT 重複レコードの除去
SQLのDISTINCT文のように列内の重複値を削除または特定するには、ADFで集計変換を使用します。
式ビルダーで列パターンと関数 first() を使用して、実行します。
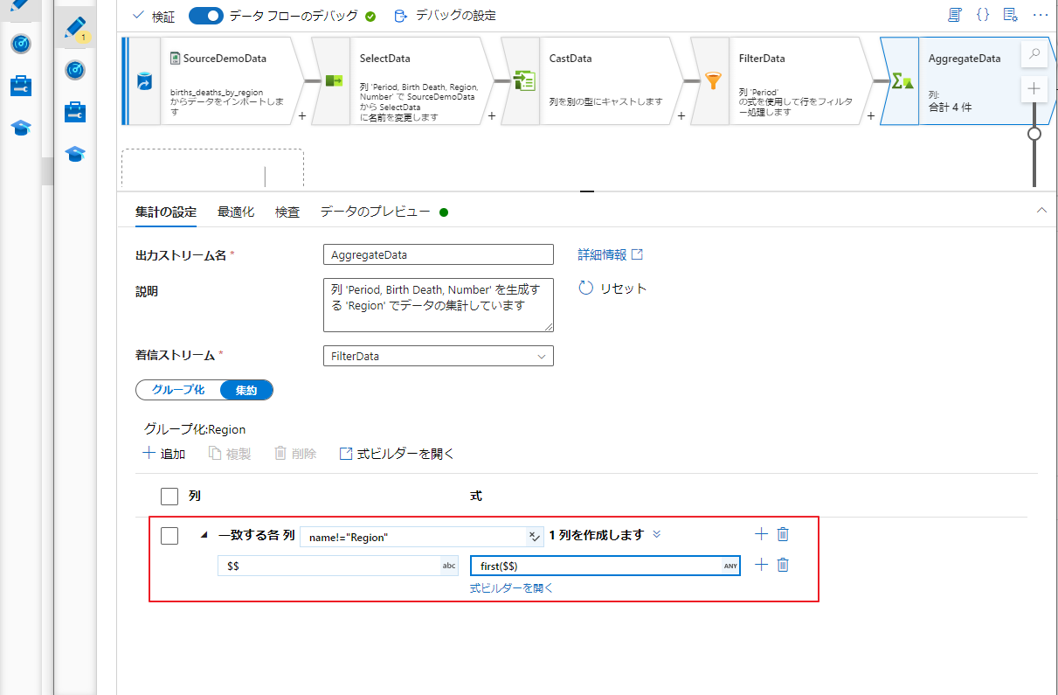
この例では、「Region」列にある重複データを削除します。
実行の手順は次の通りです。
①「グループ化」タブで「Region」列を選択します。
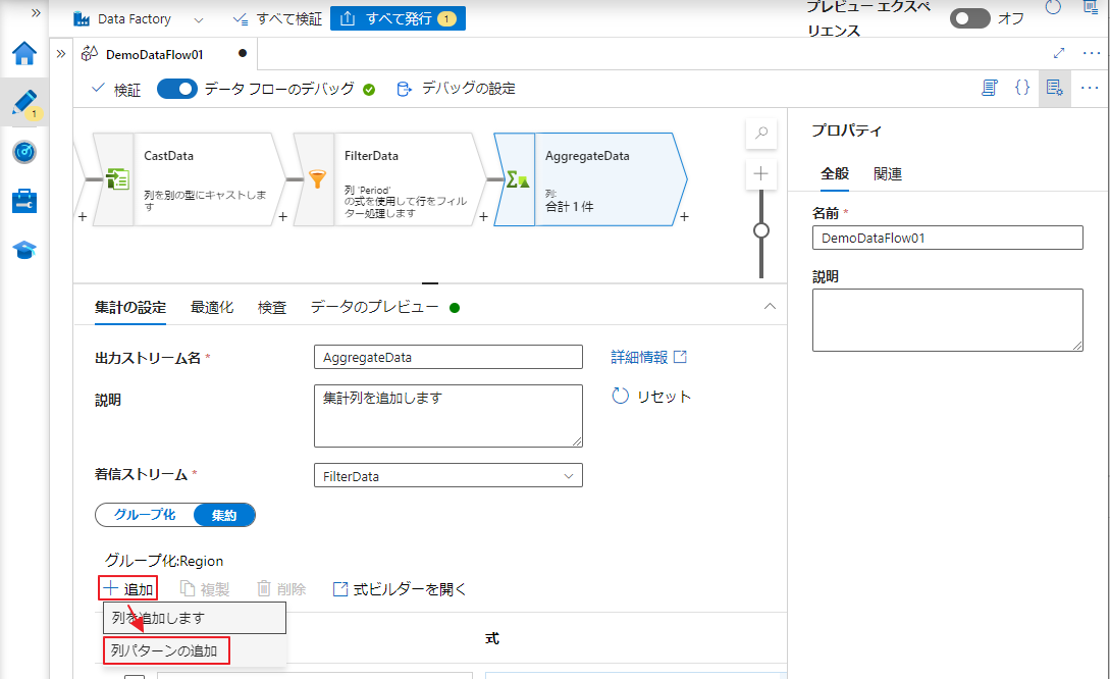
②「集約」タブで「追加」をクリックし、「列パターンの追加」を選択します。
③「式ビルダーを開く」をクリックして式ビルダーを開きます。
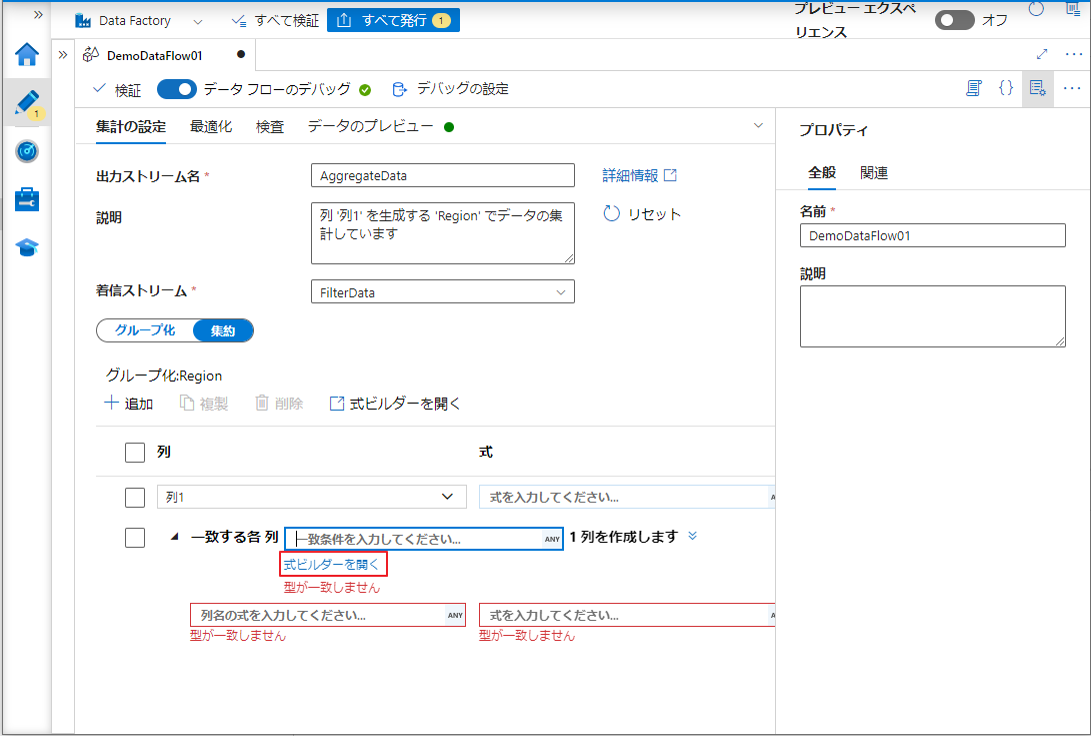
「Region」列を除くすべての列を保持するために、この変換は画像のようになります。
「name」: すべての列を示します。
④「保存して終了」 ボタンをクリックして式を保存します。
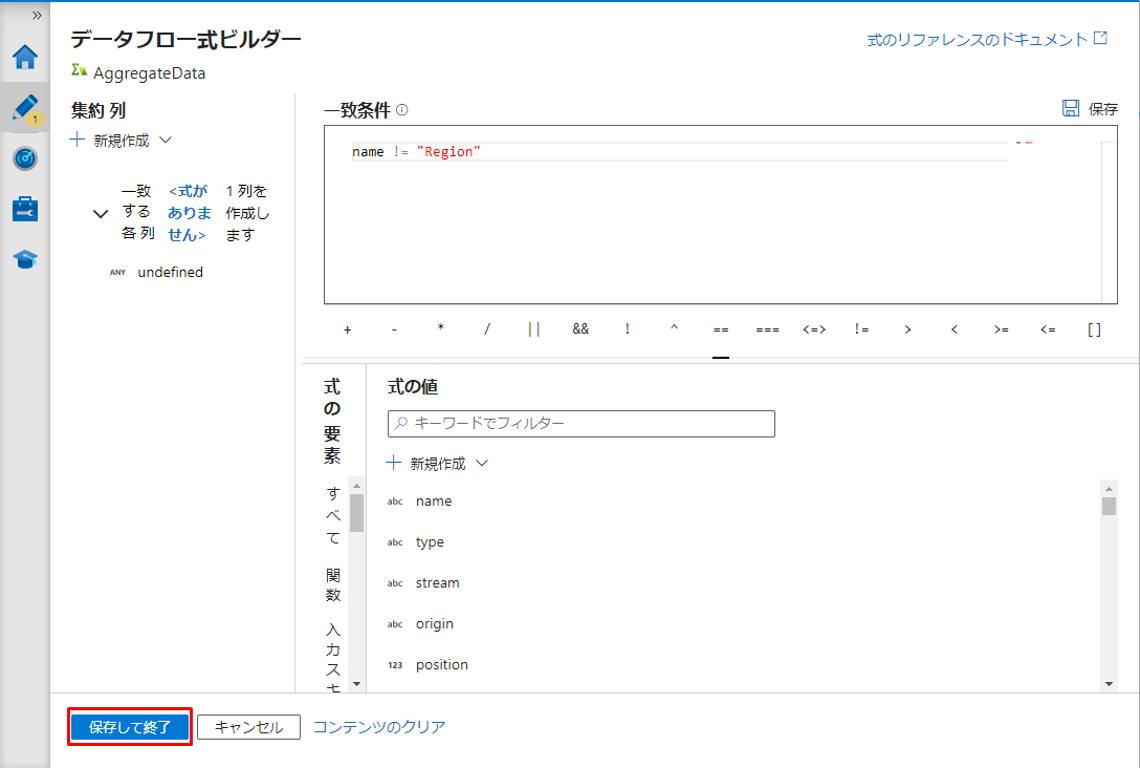
⑤「式ビルダーを開く」をクリックして式ビルダーを開きます。
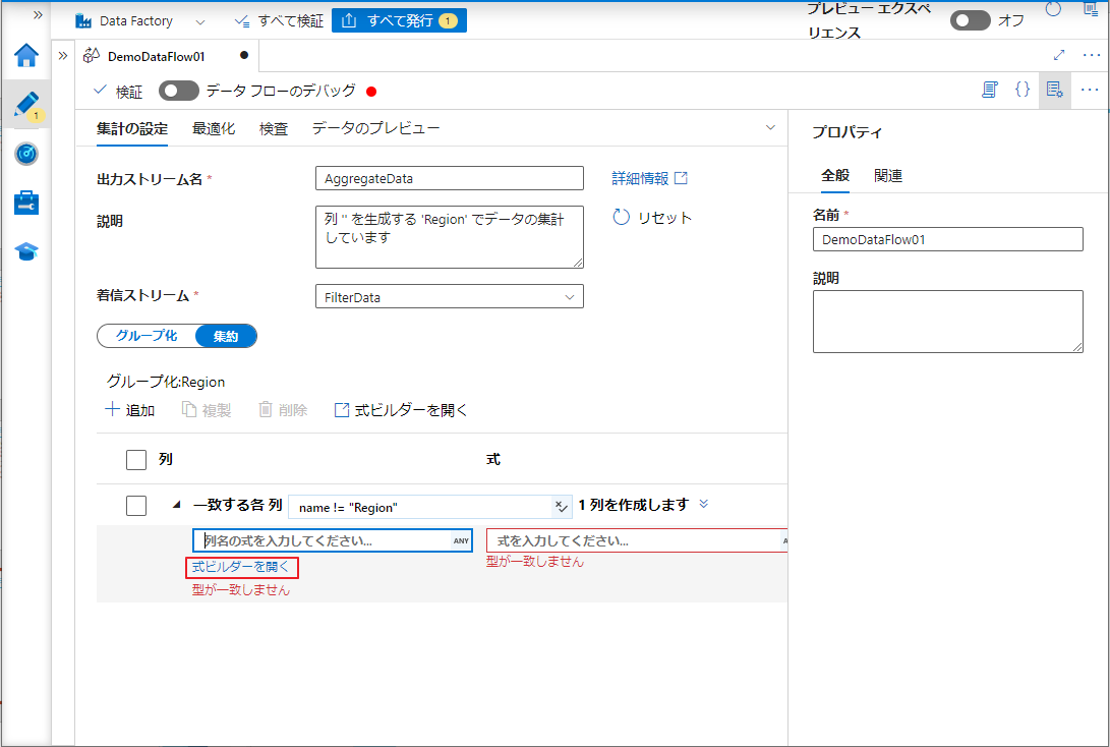
列名の式で $$ を選択します。
値式では、重複データがある場合に最初の行を返す first() 関数を使用します。
⑥「保存して終了」 ボタンをクリックして式を保存します。
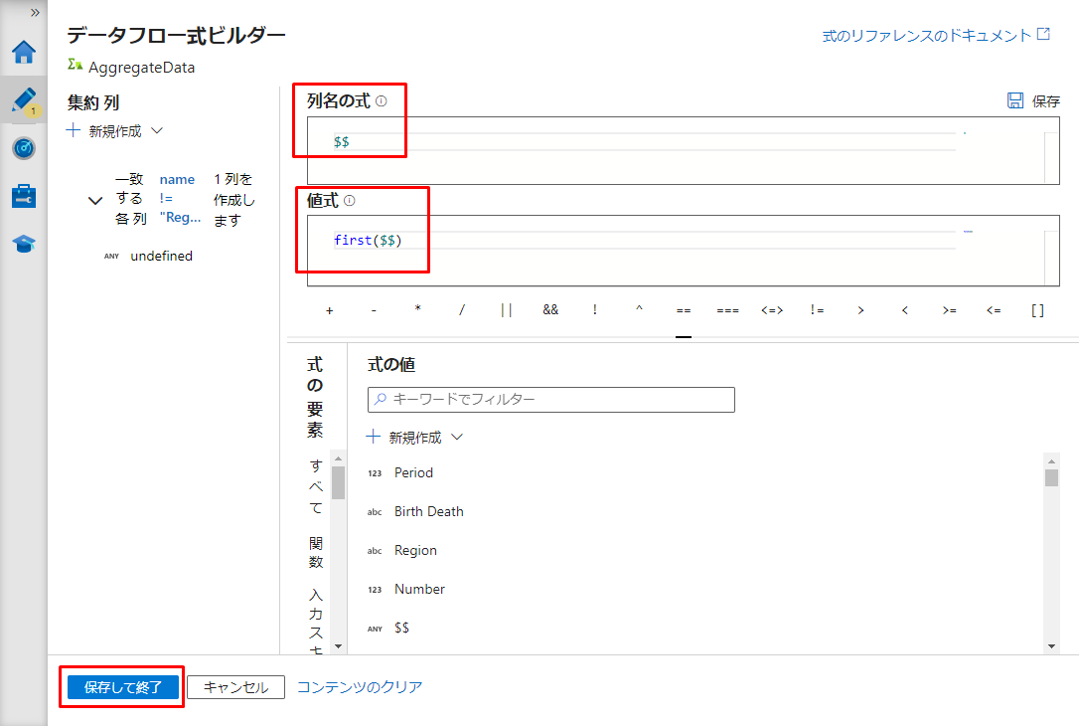
デバッグ モードを有効にする場合は、「データのプレビュー」タブで集計変換のデータをプレビューできます。
「Region」列に重複データがあるの行を削除しました。
4-8.JOIN(複数テーブル指定)
4-8-1.INNER JOIN(内部結合)
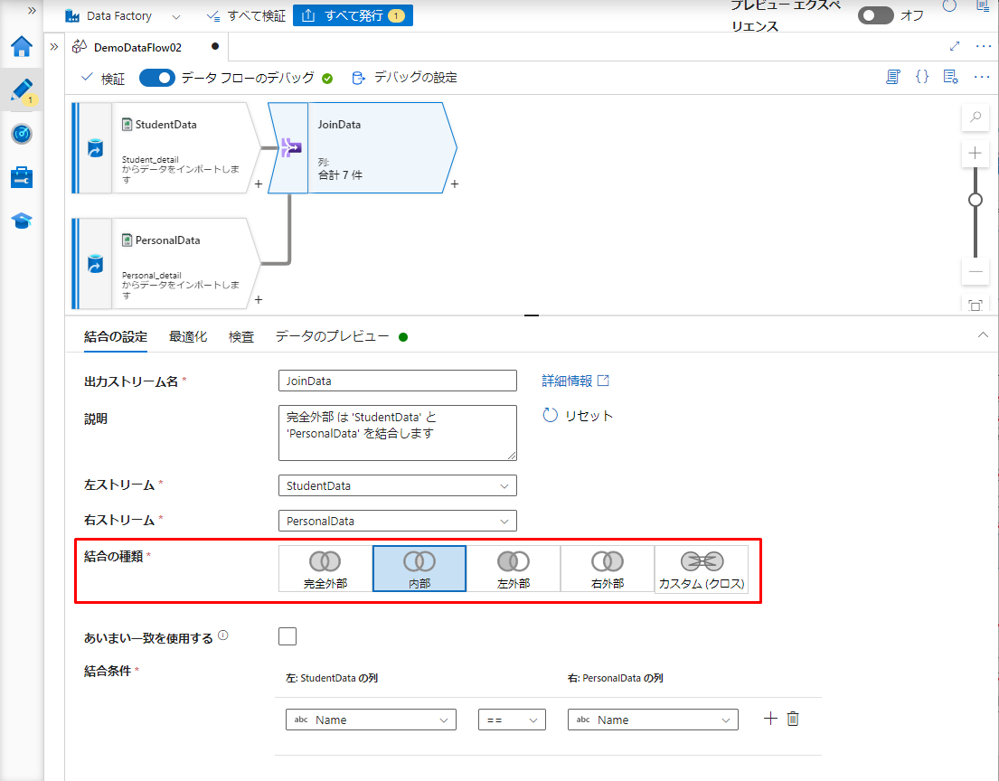
SQL の JOIN結合のように、結合の列を元に2つ以上のテーブルを結合するには、ADF で結合変換を使用します。
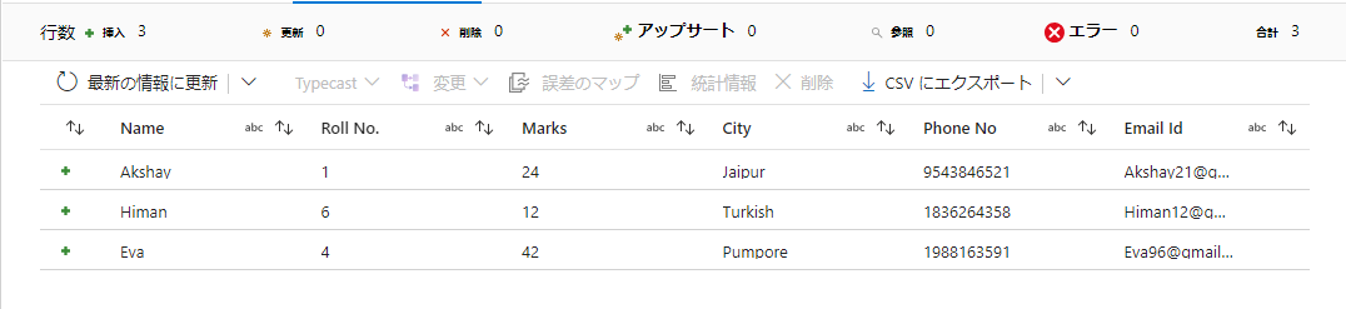
この例では、以下の2つのテーブルを内部結合します。
「Name」列は、以下の2つテーブルを結合する際の基準となることです。
「結合の設定」タブの「結合の種類」項目で結合タイプを選択できます。
希望の出力データは次のようになります。
実行の手順は次の通りです。
データフローを新規作成します。
① サイドバーで「Author」をクリックして、次に「Data flows」をクリックして、「新しいデータセット」を選択します。
②「名前の変更」をクリックしてデータフローの名前を変更します。
③ データフローの名前を入力し、 「OK」ボタンをクリックします。
④ データ フローの画面で「ソースの追加」をクリックし、2つのテーブルに対応する 2 セットのソース データを作成して、結合します。
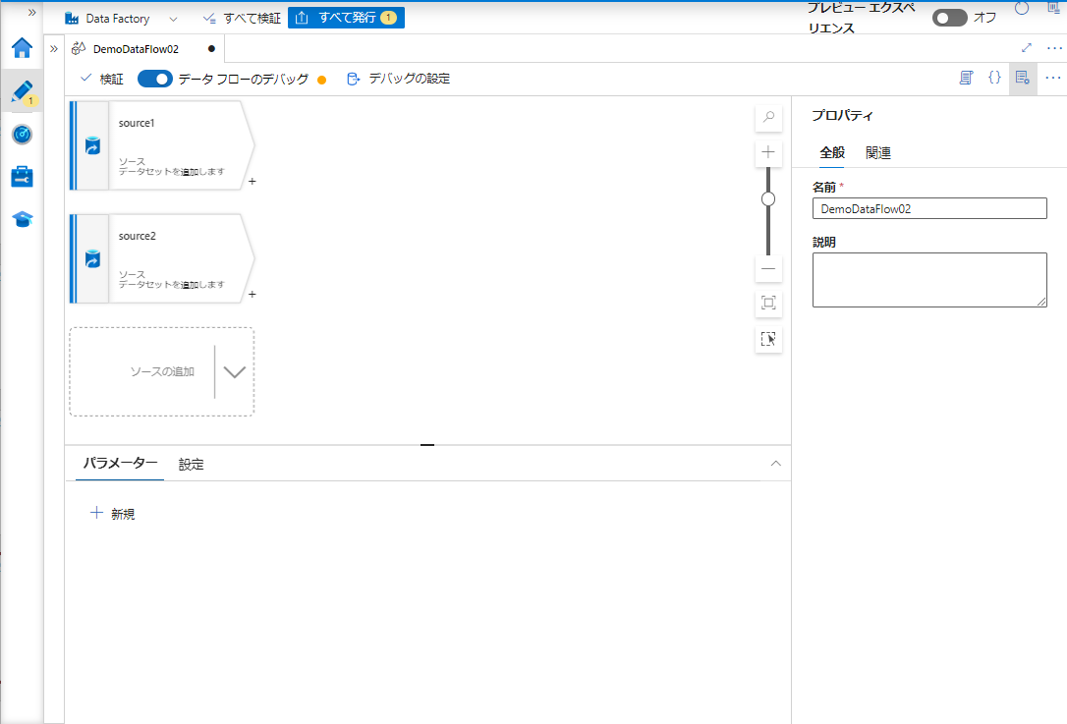
⑤「ソースの設定」タブで、名前を変更して、データ セットを選択します。(画像に表しているのはStudent_detail テーブルです。)
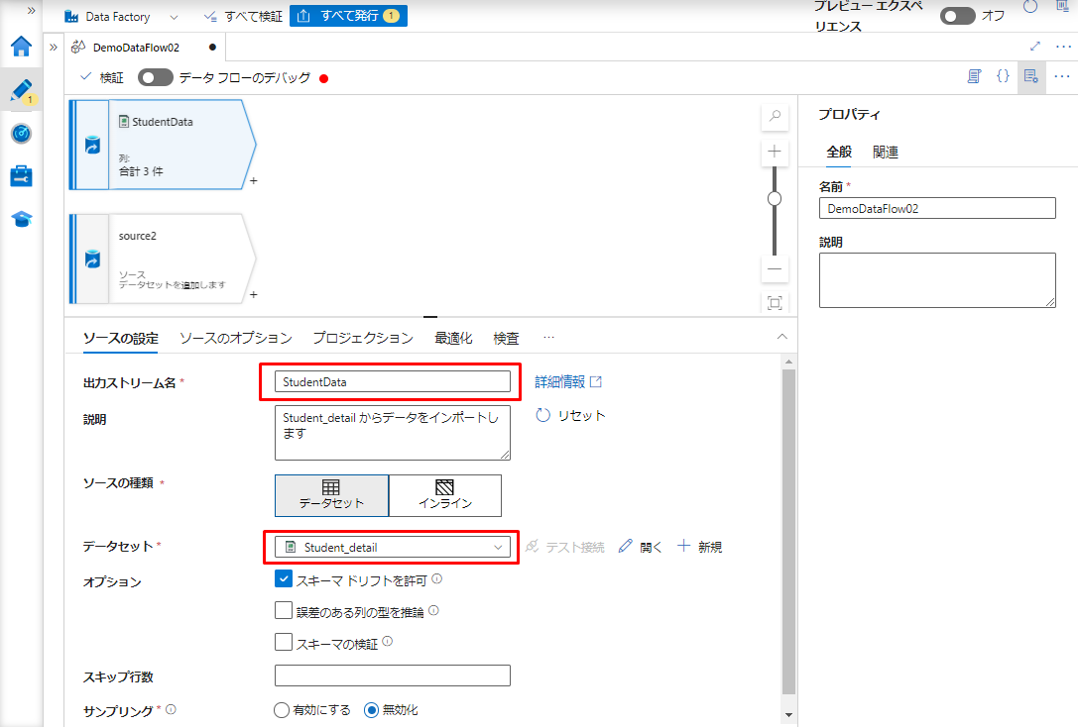
⑥「ソースの設定」タブで、名前を変更して、データ セットを選択します。((画像に表しているのはPersonal_detail テーブルです。)
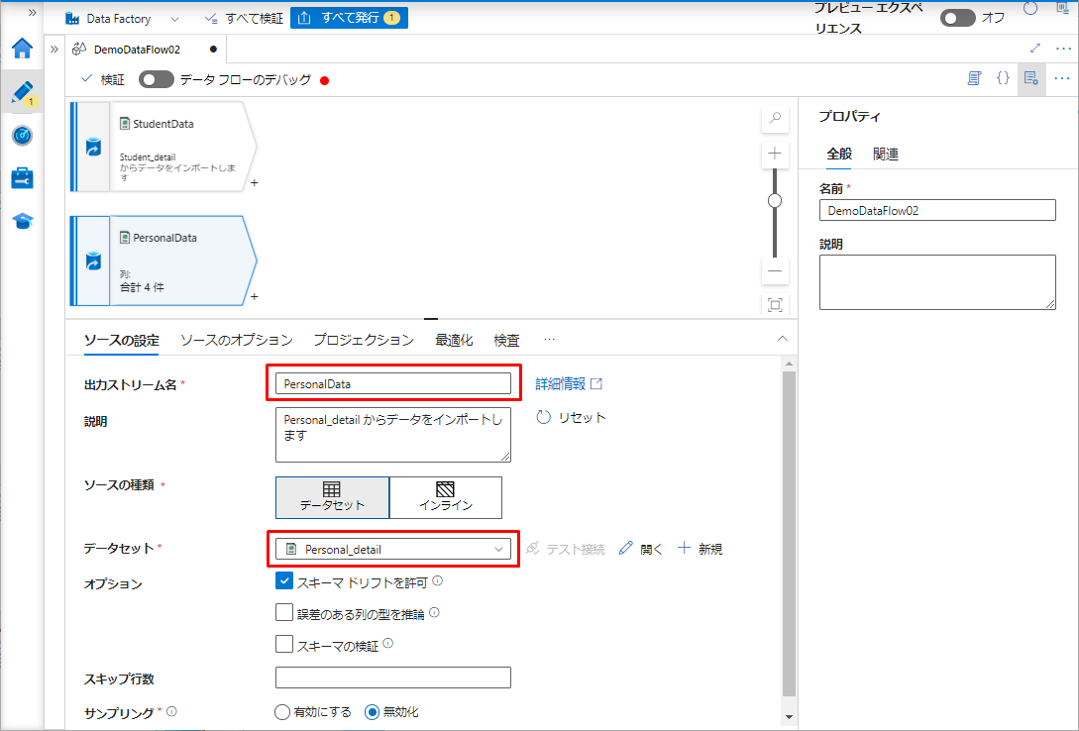
⑦ プラスのアイコンをクリックして結合変換を追加します。
⑧「結合」をクリックします。
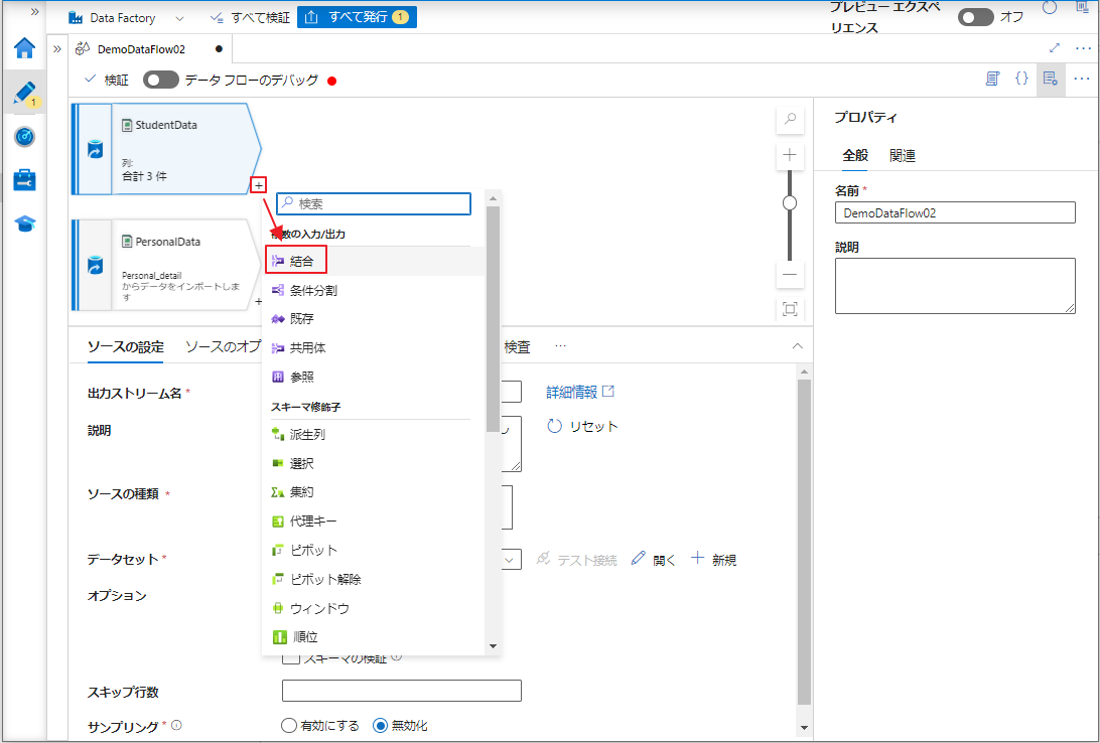
⑨ 結合変換に「JoinData」という名前を付けます。
⑩「左ストリーム」項目で「StudentData」を選択します。
⑪「右ストリーム」項目で「PersonalData」を選択します。
⑫「結合の種類」項目で対象のテーブルに内部結合を選択します。
⑬「結合条件」項目で両方のテーブルの「Name」列をキー列として選択します。
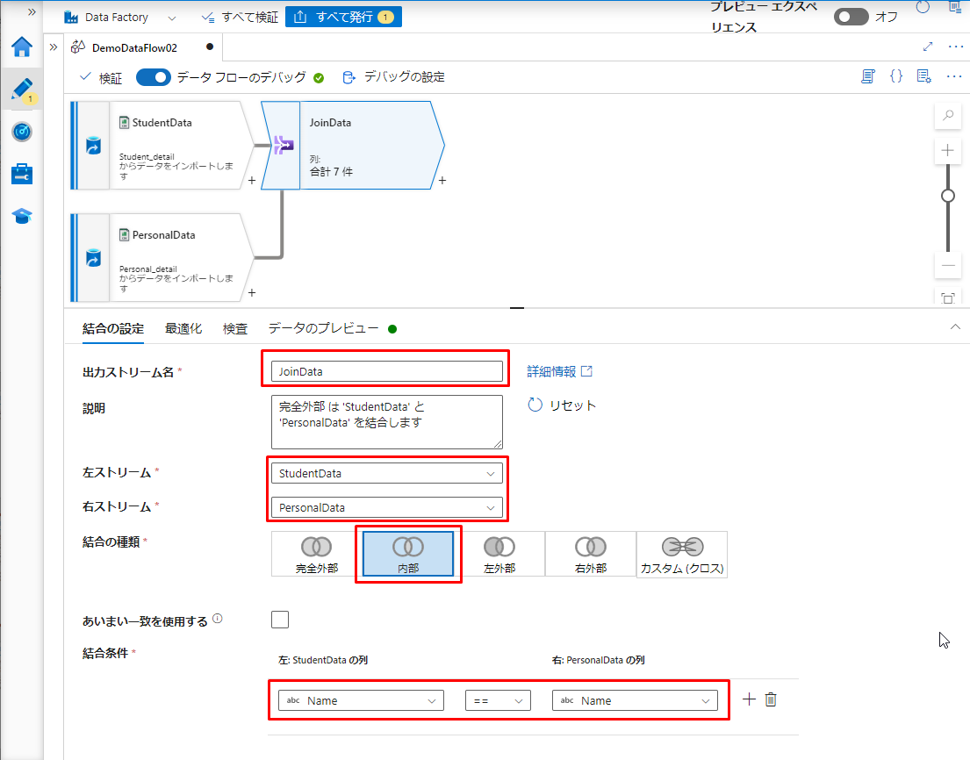
結合変換を実行した後、2 つのテーブルから必要な列を選択するための選択変換を追加します。
⑭ プラスアイコンをクリックして結合変換から選択変換を追加します。
⑮「選択」をクリックします。
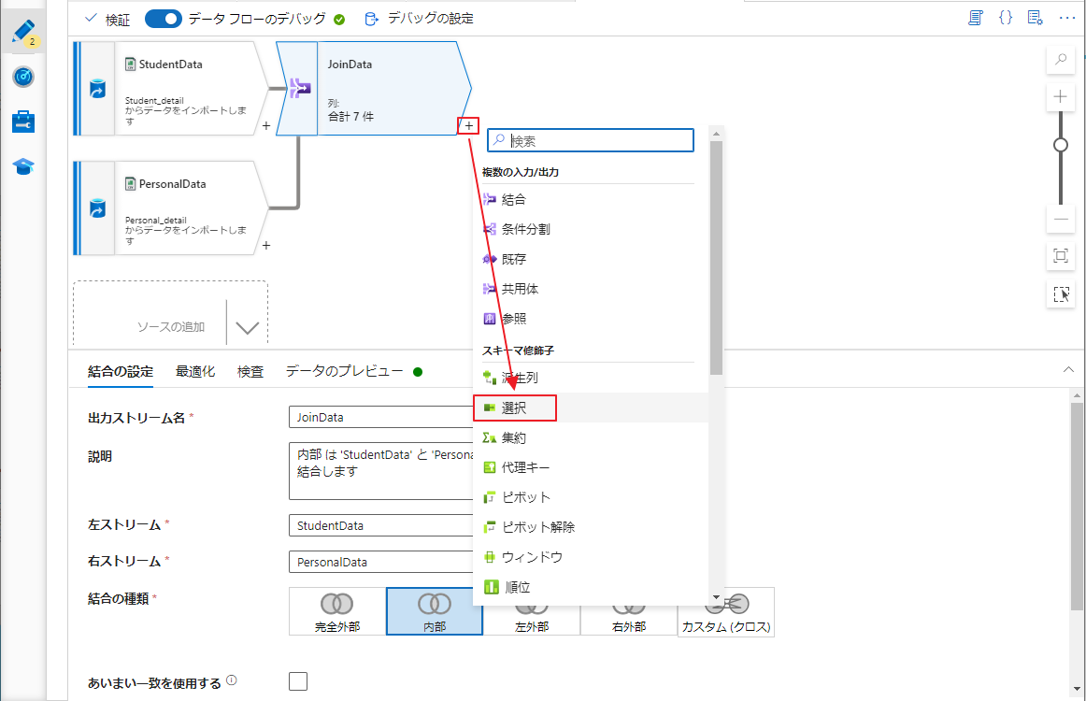
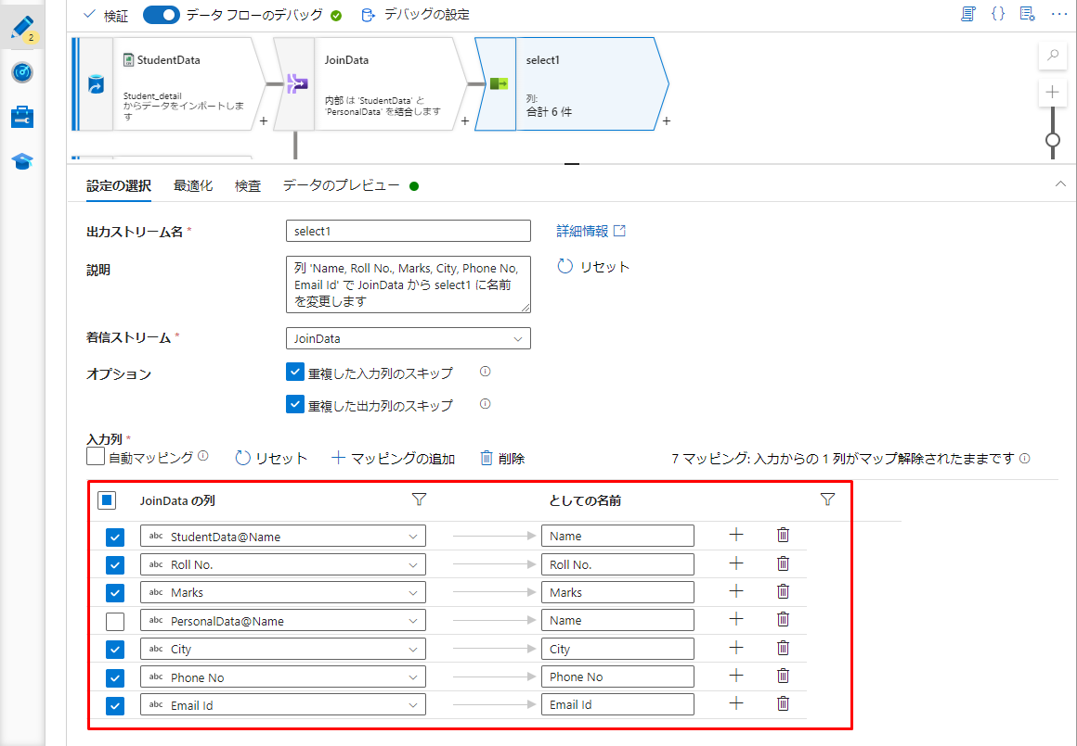
⑯「入力列」で、2 つのテーブルの結合実行後に表示用の列を選択します。
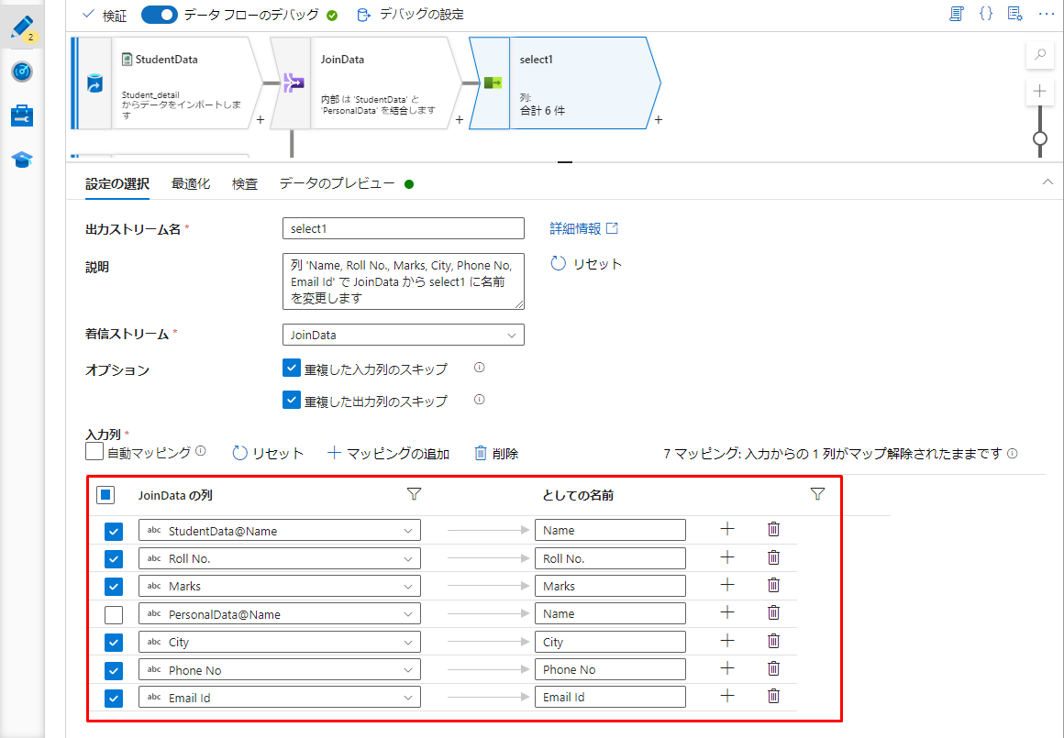
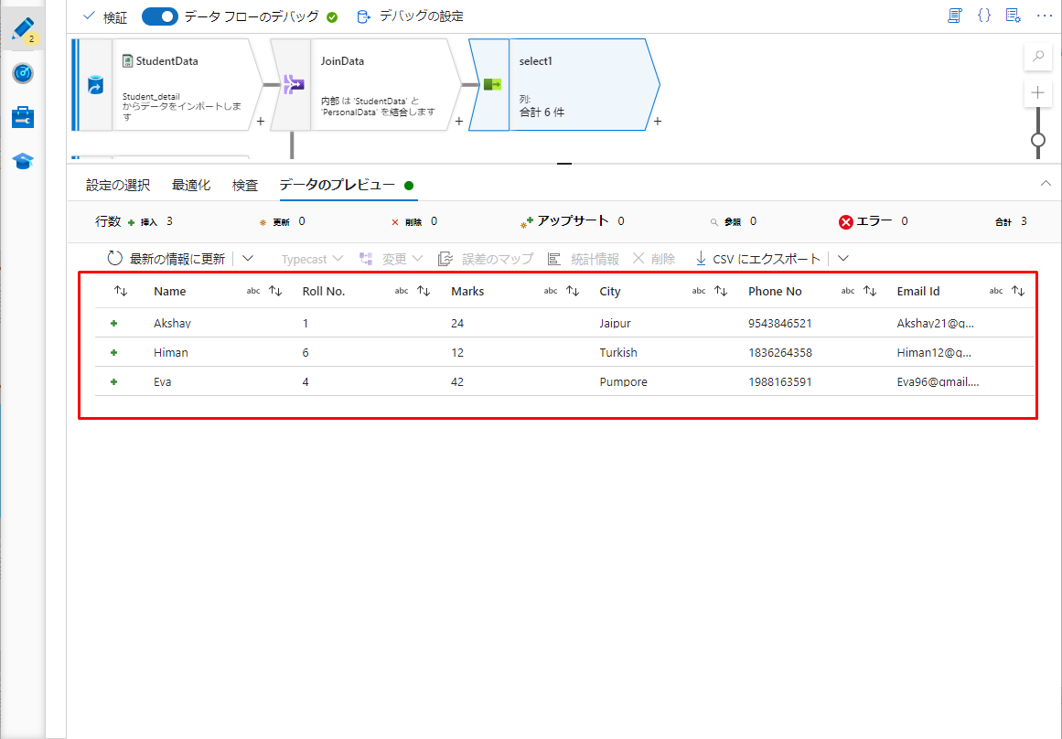
デバッグ モードを有効にする場合は、「データのプレビュー」タブで結合変換のデータをプレビューできます。
この結合タイプは内部結合であるため、条件が満たされる限り、出力では両方のテーブルのすべての行が選択されます。
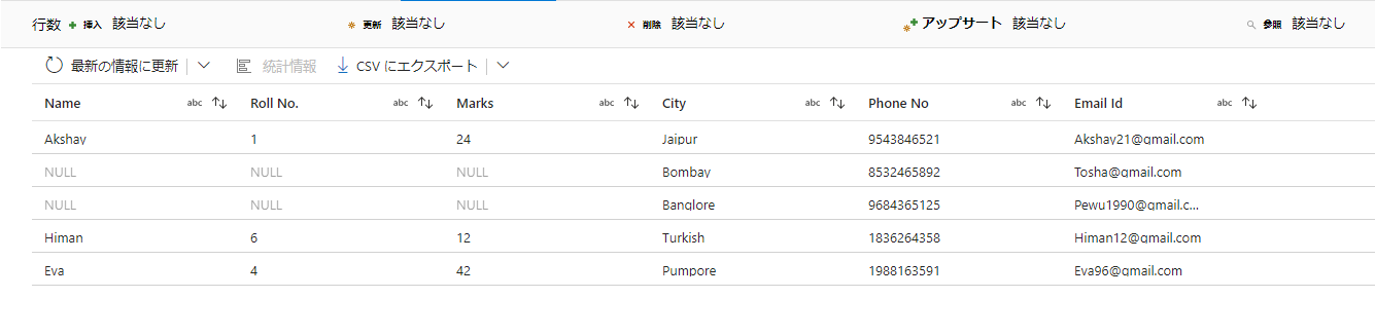
4-8-2.RIGHT OUTER JOIN(右外部結合)
この例では、以下の 2 つのテーブルに対して、右外部結合を実行します。
「Name」列は、以下の2つテーブルを結合する際の基準となることです。
希望の出力データは次のようになります。
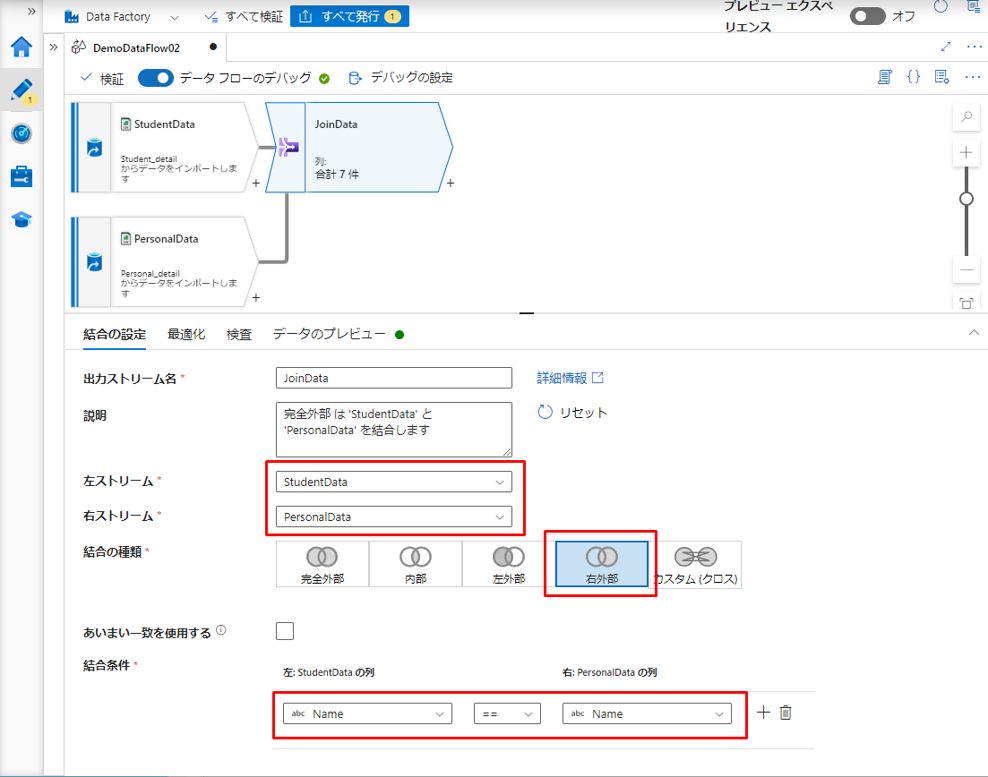
実行の手順は次の通りです。
①「左ストリーム」で「StudentData」を選択します。
②「右ストリーム」で「PersonalData」を選択します。
③「結合の種類」で対象のテーブルに右外部結合を適用します。
④「結合条件」項目で両方のテーブルの「Name」列をキー列として選択します。
⑤「入力列」で、2 つのテーブルの結合実行後に表示用の列を選択します。
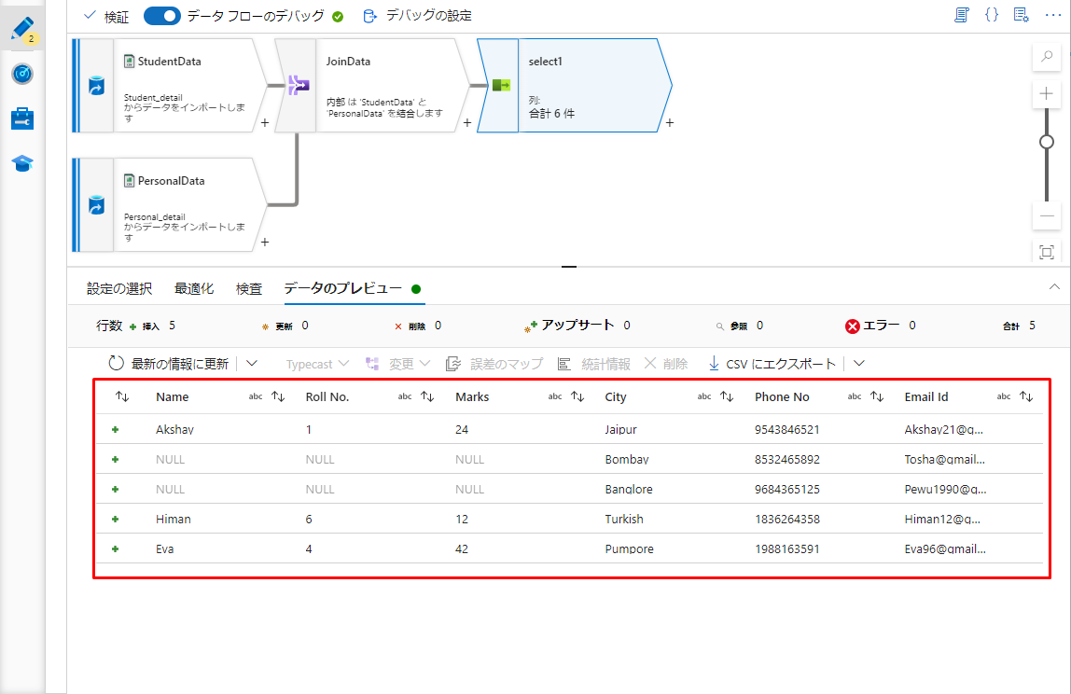
デバッグ モードを有効にする場合は、「データのプレビュー」タブで結合変換のデータをプレビューできます。
この結合タイプは右外部結合であるため、出力は結合の右側のストリームにあるテーブルの全ての行及び、結合の左側のストリームにあるテーブルの一致する行が返却されます。左側のストリームの一致する行がない場合、結果セットには null 値が含まれます。
4-8-3.LEFT OUTER JOIN(左外部結合)
この例では、以下の 2 つのテーブルに対して左外部結合を実行します。
「Name」列は、以下の2つテーブルを結合する際の基準となることです。
希望の出力データは次のようになります。
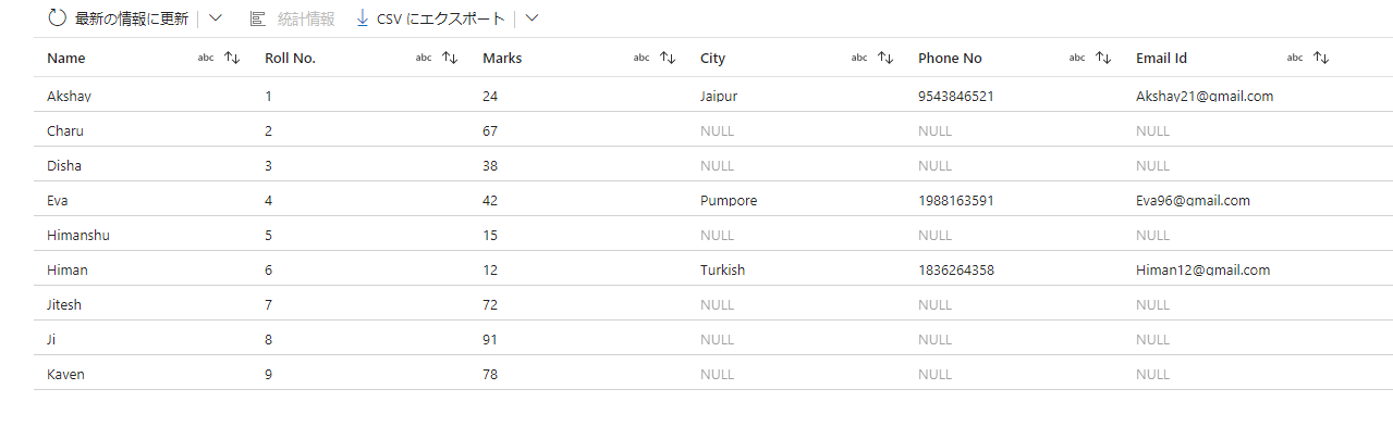 実行の手順は次の通りです。
実行の手順は次の通りです。
①「左ストリーム」で「StudentData」を選択します。
②「右ストリーム」で「PersonalData」を選択します。
③「結合の種類」で対象のテーブルに左外部結合を適用します。
④「結合条件」項目で両方のテーブルの「Name」列をキー列として選択します。
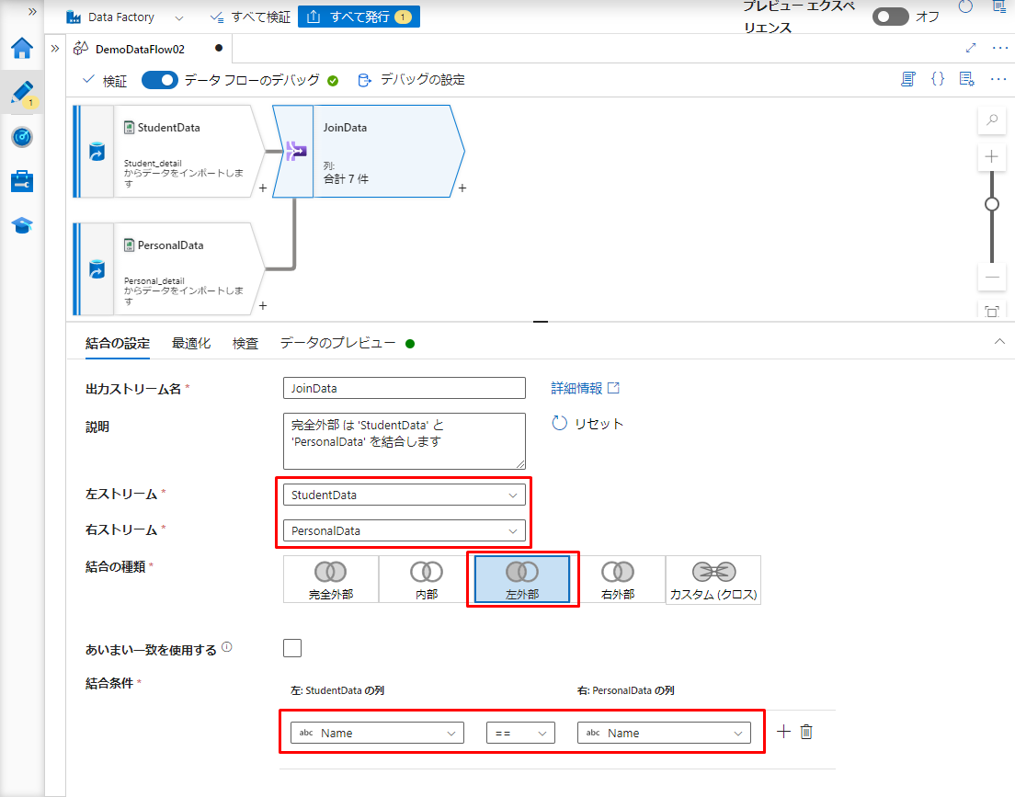
⑤「入力列」で、2 つのテーブルの結合実行後に表示用の列を選択します。
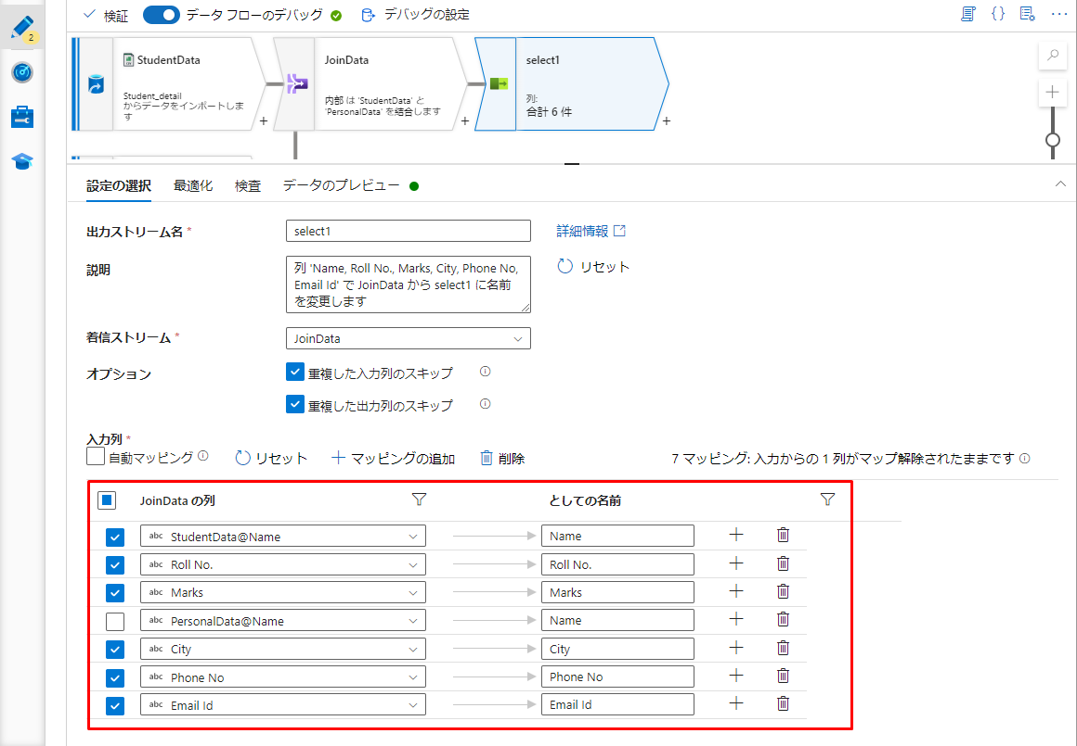
デバッグ モードを有効にする場合は、「データのプレビュー」タブで結合変換のデータをプレビューできます。
この結合タイプは左外部結合であるため、出力は結合の左側のストリームにあるテーブルの全ての行及び、結合の右側のストリームにあるテーブルの一致する行が返却されます。右側のストリームの一致する行がない場合、結果セットには null 値が含まれます。
4-8-4.FULL OUTER JOIN(完全外部結合)
この例では、以下の 2 つのテーブルを完全外部結合形式で結合します。
「Name」列は、以下の2つテーブルを結合する際の基準となることです。
希望の出力データは次のようになります。
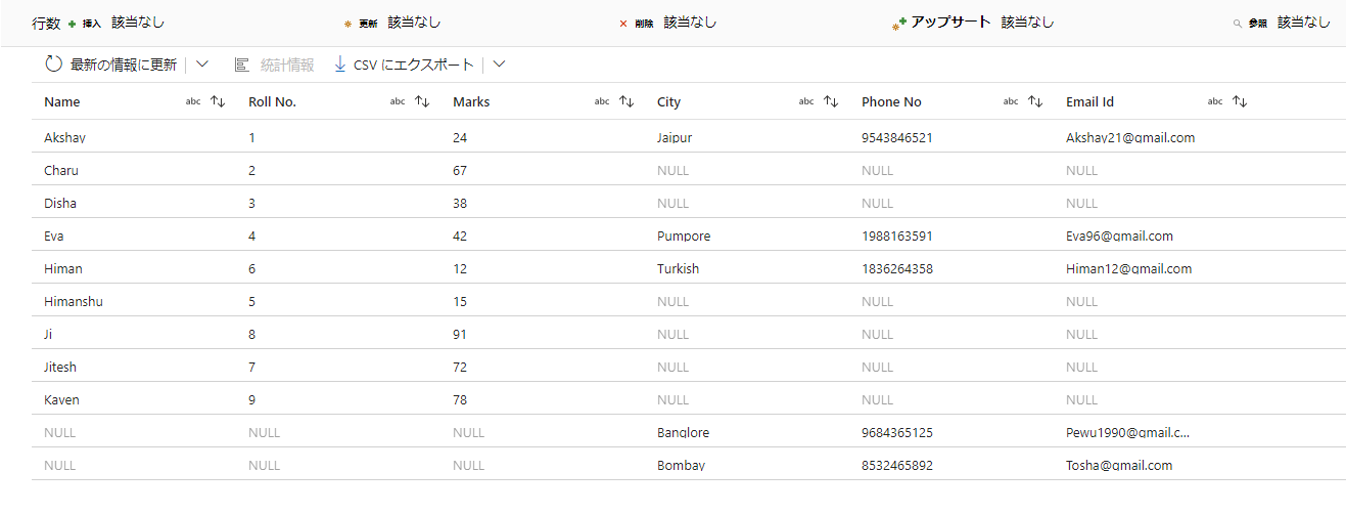
手順は次のようになります。
①「左ストリーム」で「StudentData」を選択します。
②「右ストリーム」で「PersonalData」を選択します。
③「結合の種類」で対象のテーブルに完全外部結合を適用します。
④「結合条件」項目で両方のテーブルの「Name」列をキー列として選択します。
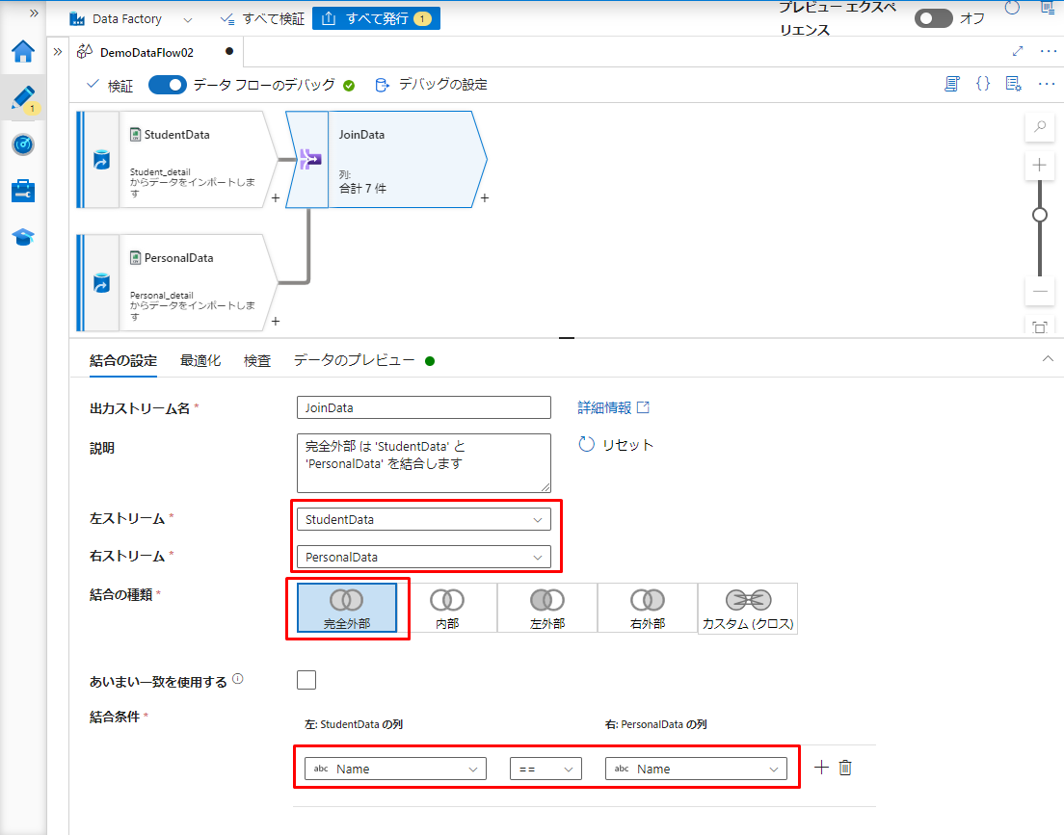
⑤「入力列」で、2 つのテーブルの結合実行後に表示用の列を選択します。
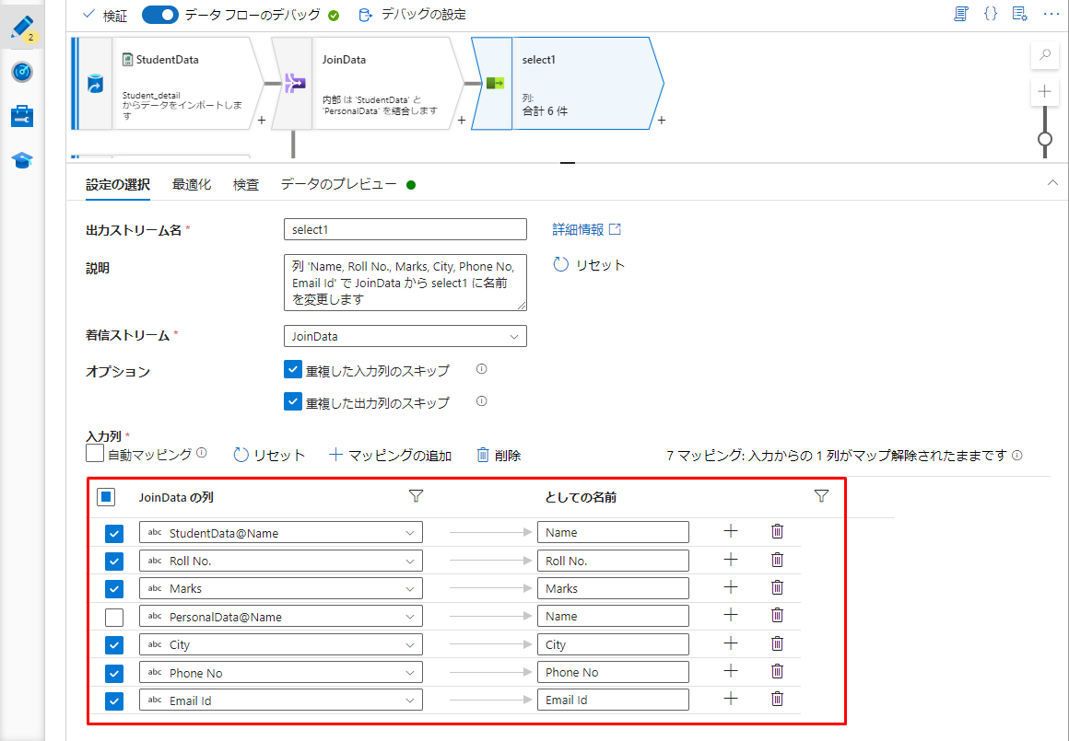
デバッグ モードを有効にする場合は、「データのプレビュー」タブで結合変換のデータをプレビューできます。
この結合タイプは完全外部結合であるため、出力には両方のテーブルのすべての行が含まれます。 一致する行がない場合、結果セットには null 値が含まれます。
5.まとめ
本連載では、
SQLコマンドをAzure Data Factoryで実現する方法について詳細に説明していきます。
第1回:SQLコマンドをAzure Data Factoryで実現する(今回)
第2回:Azure Data Factoryでインラインビュー、サブクエリーを実現する
第3回:Azure Data Factory上でinsert、delete、update、mergeの処理を実行する
今回の記事が少しでもAzure Data Factoryを知るきっかけや、業務のご参考になれば幸いです。
Azure Data FactoryやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
・Azure Data Factory連載シリーズはこちら