目次
1. はじめに
皆さん、こんにちは。
近年、LLM(大規模言語モデル)の普及が進み、多くの企業や組織がその活用を検討しています。LLMを理解し、適切に活用することで、業務の効率化やイノベーションの推進が可能になります。そのため、組織内でLLMを効果的に導入し、運用できるスキルがますます重要になっています。
このブログでは、LLMの基礎から応用、そして最先端の活用方法までを体系的に解説します。初心者の方でも理解しやすいように、基本的な概念から始め、徐々に高度な活用例へとステップアップしていきます。
LLMの活用に興味がある方は、ぜひ最後までご覧ください!
2. 大規模言語モデル(LLM)とはなんですか?
大規模言語モデル(Large Language Model, LLM)は、膨大な量の自然言語データを処理・分析し、その情報を基にユーザーの入力に対する応答を生成するように設計されたAIシステムです。これらのシステムは、膨大なデータセットを使って高度な機械学習アルゴリズムでトレーニングされ、人間の言語のパターンや構造を学習し、さまざまな入力に対して自然な言語での応答を生成することができます。
ChatGPT-4の登場により、LLMは企業や世界中の人々から大きな注目を集めました。
では、企業は大規模言語モデルをどのように活用しているのでしょうか?以下は、LLMの一般的な使用例です:
- チャットボットとバーチャルアシスタント
- コード生成とデバッグ
- 言語翻訳
- 要約と言い換え
- コンテンツ生成
- センチメント分析
- テキスト分類とクラスタリング
LLMは強力なツールですが、それをビジネスに適用するのは簡単な作業ではありません。その為、データに強いバックグラウンドを持つDatabricksは、企業が自社のデータをLLMと統合しやすい方法を提供しています。これにより、基本的な活用から最先端の利用法まで、スムーズに導入できるようになっています。
3. Databricksで企業のデータをLLMに適用する方法
Databricksは、すべてのデータとガバナンスのためにオープンで統一された基盤を提供するLakehouse上に構築されたデータインテリジェンスプラットフォームです。多くの企業がデータウェアハウジングとしてDatabricksを活用しています。現在、データ層の上にデータインテリジェンスエンジン層を導入し、Databricksは自企業のデータをLLMと統合するための強力で簡単なツールを提供しています。
Databricksが提供する機能をより深く理解するために、基本的なレベルから最先端のレベルまで、4つのタスクを通じてDatabricksでのLLM統合方法をご紹介します。これらのタスクは、プロンプトエンジニアリング、検索強化型生成(RAG)、ファインチューニング、ゼロから学習です。
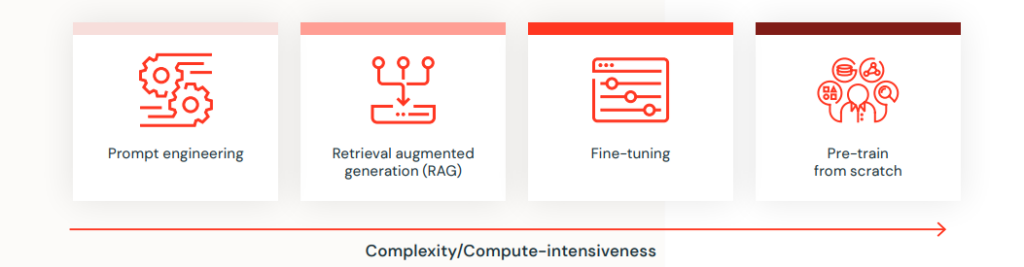
4. プロンプトエンジニアリング
多くの企業は、生成AI技術の導入においてまだ基礎段階にあります。彼らは包括的なAI戦略を持っておらず、追求すべき明確なユースケースもなく、会社のAI導入の旅を導くことができるデータサイエンティストや他の専門家のチームにもアクセスできません。
この基本レベルでは、市販のLLM(大規模言語モデル)を出発点とするのが良いでしょう。これらのLLMはカスタムAIモデルのようなドメイン固有の専門知識を欠いていますが、実験を通じて次のステップを計画するのに役立ちます。従業員は、使用方法を導くための専門的なプロンプトやワークフローを作成できます。リーダーは、これらのツールの強みと弱みをよりよく理解し、AIの初期成功がどのようなものかをより明確に把握できます。組織は、Databricks AI Playgroundのようなものを使用して、より強力なAIツールやシステムに投資する場所を見つけ、運用上の大きな利益をもたらすことができ、さらにはLLMを審査員として使用して応答を評価することもできます。

5. 検索強化生成(RAG)
ビジネスがAI Playgroundを通じてLLMがもたらす可能性のあるすべての利益をテストしている場合、次のステップとして、データセットを安全なプライベート環境でLLMと迅速に統合することを検討してください。RAG (Retrieval-augmented generation)は、企業に適用したい次のレベルです。RAGは、高価な大規模モデル全体を再訓練することなく、データセットをLLMと迅速に統合するプロセスです。RAGには、データセットに適用された検索エンジンが必要で、関連するデータのみを取得し、LLMモデルに入力する前に必要なプライベート情報を提供して、ビジネス専用のカスタマイズされたソリューションを生成します。
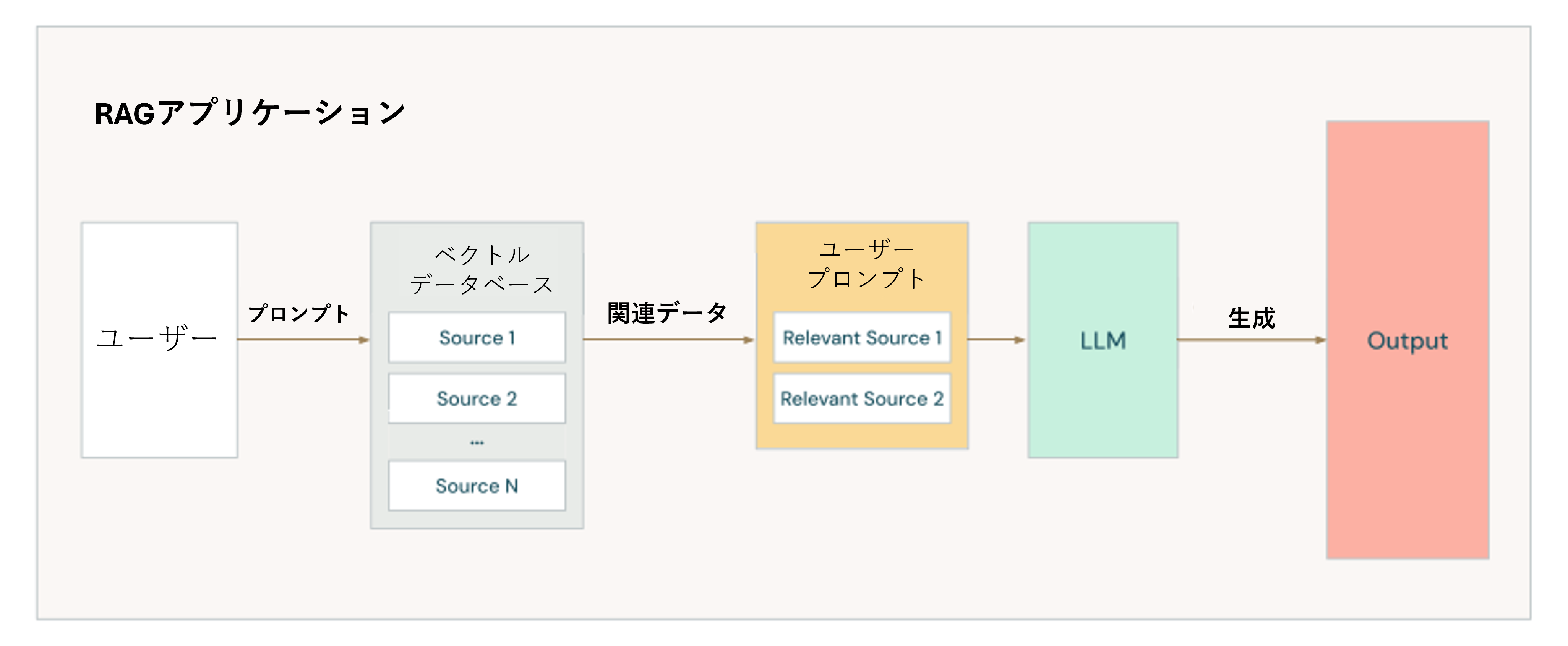
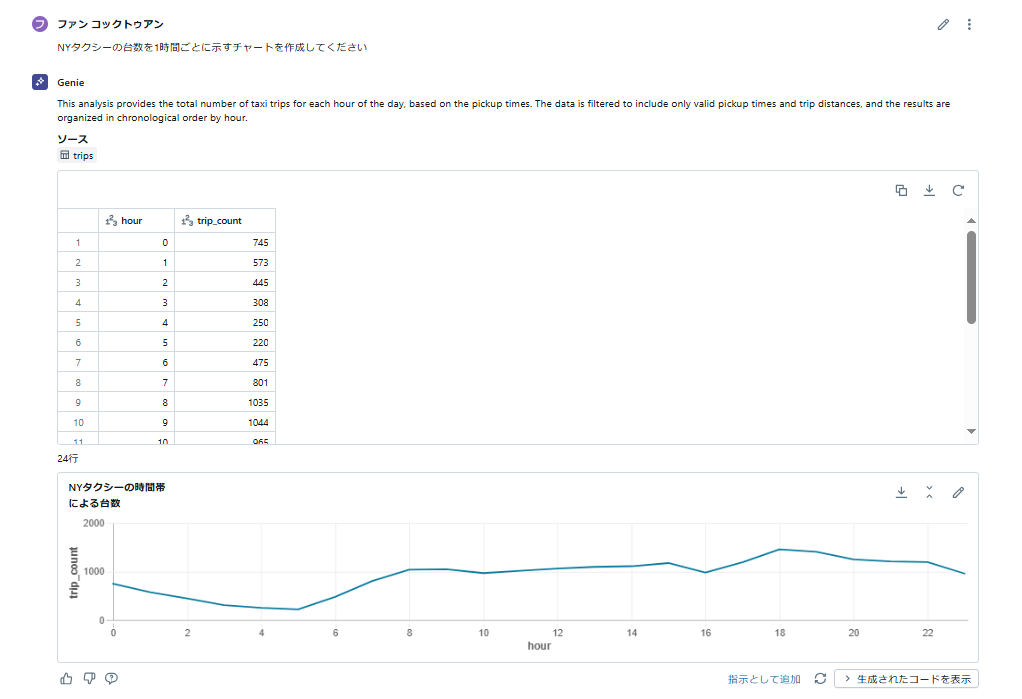
RAGを構造化データに最も簡単かつ迅速に適用する方法として、DatabricksはGenieを提供しています。Genieは、ビジネスチームが自然言語を使用してデータと対話できる機能です。Genieを使用すると、希望するデータセットを選択してチャットを開始するだけで、Databricksが背後のすべての難しい作業を処理します。
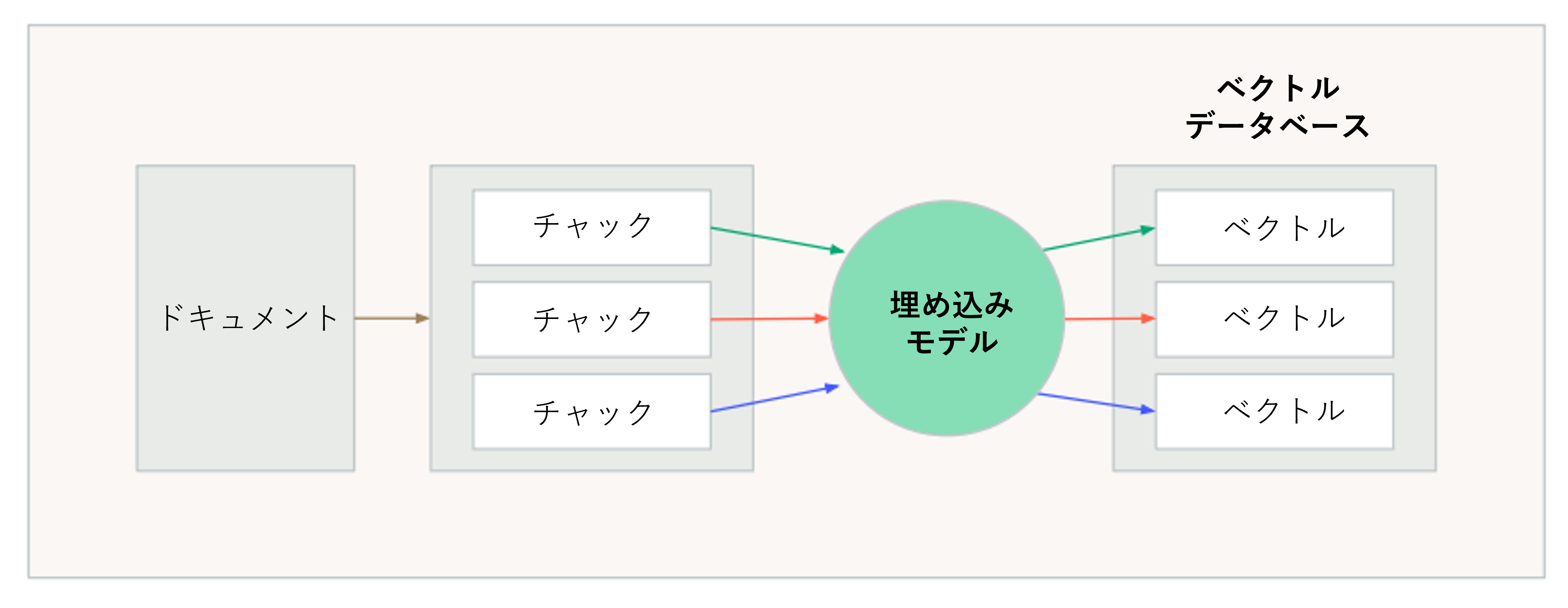
非構造化データ(例えばPDFファイル)に対して、DatabricksはVector Searchというネイティブツールを提供しています。これにより、基本的なユーザーでも非構造化データを数値ベクトルに変換し、Vector Databaseに保存することができます。ベクトルデータベースは、ベクトルデータを効率的に保存および取得するために最適化されています。従来のデータベースと同様に、ベクトルデータベースは権限管理、メタデータ管理、データの整合性を管理するために使用でき、情報への安全で整理されたアクセスを確保します。RAGを実行する前に、データ(この場合は非構造化テキストデータ)をベクトルデータベースに取り込み、その後、通常のRAGチェーンを適用してドキュメントデータをLLMに入力することができます。
6. ファインチューニング
RAGを超えてモデルのファインチューニングに進むことで、ビジネスにより深くパーソナライズされたモデルを構築し始めることができます。すでに商用モデルを運用全体で試している場合、この段階に進む準備ができている可能性があります。
ファインチューニングを行うことで、Llama 3.3のような汎用のオープンソースモデルを自社の特定のデータでトレーニングすることができます。ただし、AIシステムのファインチューニングには膨大な量の専有情報が必要であり、ビジネスがAI成熟度曲線を進むにつれて、実行されるモデルの数は増加し、データアクセスの需要も増加します。そのため、データが生成された瞬間から最終的に使用されるまでの追跡メカニズムを適切に整備する必要があり、Unity CatalogがDatabricksの顧客の間で人気のある機能となっている理由です。Unity Catalogのデータリネージ機能により、企業はデータがどこに移動し、誰がアクセスしているかを常に把握できます。
LLMの高度な使用をサポートするために、Databricksはすべての機械学習ライブラリが統合されたノートブックを備えたLLM開発環境を提供しており、さまざまなチーム間で簡単に管理、共有、コラボレーションができます。さらに、DatabricksはHugging Face Transformersをネイティブにサポートしています。
Hugging Face Transformersは、Hugging Faceによって作成されたディープラーニングのオープンソースフレームワークです。最先端の事前トレーニング済みモデルをダウンロードし、さらにチューニングしてパフォーマンスを最大化するためのAPIとツールを提供します。Databricks Runtime 10.4 LTS ML以降でサポートされているHugging Face Transformersを使用すると、DatabricksはLLMモデルのチューニングに最適なツールとなります。

7. ゼロから学習
ゼロからモデルをトレーニングすることは、既存のモデルの事前知識や重みを使用せずに、大規模なデータコーパス(例:テキスト、コード)でゼロから言語モデルをトレーニングするプロセスを指します。これは、すでに事前トレーニングされたモデルを特定のタスクやデータセットにさらに適応させるファインチューニングとは対照的です。
ゼロからLLMをトレーニングすることを選択することは、データと計算リソースの両方の観点から重要なコミットメントです。以下のようなシナリオで意味があります:
- ユニークなデータソース:利用可能な事前トレーニング済みLLMが見たことのない、独自で広範なデータコーパスを持っている場合、そのユニークさを捉えるためにモデルを事前トレーニングする価値があるかもしれません。
- ドメイン固有性:組織は、モデルの基礎知識がドメイン固有であることを確保するために、特定のドメイン(例:医療、法務、コード)に合わせたベースモデルを望むかもしれません。
- トレーニングデータの完全な管理:ゼロからの事前トレーニングは、モデルがトレーニングされるデータに対する透明性と管理を提供します。これは、データのセキュリティ、プライバシー、およびモデルの基礎知識のカスタム調整を確保するために不可欠です。
- サードパーティのバイアスを回避:事前トレーニングにより、LLMアプリケーションがサードパーティの事前トレーニング済みモデルからバイアスや制限を引き継がないようにすることができます。
必要なすべての機能が組み込まれた簡単な環境に加えて、強力で高速かつ大規模なデータ前処理をサポートすることが、ゼロからLLMモデルをトレーニングする際に重要です。Databricks Mosaic AI Trainingは、数十億パラメータのモデルを高度に最適化された自動化された方法でトレーニングするためのプラットフォームを提供します。GPUの故障を自動的に処理し、人間の介入なしにトレーニングを再開し、Mosaic AI Streamingを活用してデータを効率的にトレーニングプロセスにストリーミングするなどの機能が標準で提供されています。必要なサポートとインフラストラクチャを提供することで、Databricksは顧客がゼロから独自のモデルをトレーニングし、AI資産を完全に所有できるようにするためのユニークな能力を持っています。
8. まとめ
Databricksは、LLMを企業に適用するための統合された、最もシンプルで強力なツールです。
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
Azure Databricks連載記事のまとめはこちら
![]() お問い合わせはこちら
お問い合わせはこちら
この記事を読んだ方へのオススメコンテンツはこちら
この記事を書いた人
この投稿者の最新の記事
- 2025年6月13日ブログ【Azure Databricks】Databricks Data + AI Summit Day 3:基調講演ハイライトまとめ
- 2025年6月12日ブログ【Azure Databricks】Databricks Data + AI Summit Day 2:基調講演ハイライトまとめ
- 2025年6月11日ブログ【Azure Databricks】Databricks Data + AI Summit Day 1:Databricksとパートナー企業からの最新アップデート
- 2025年3月7日ブログ【Azure Databricks】LLMとDatabricksで企業のデータ活用を加速する方法