目次
皆さんこんにちは。
今回は、Microsoft PurviewとDatabricksの連携をする方法について説明します。
1.Microsoft PurviewとDatabricksの連携の概要
- Microsoft Purviewとは
Microsoft Purviewは、データカタログとデータガバナンスのためのクラウドサービスです。 データの一元管理、可視性向上、セキュリティ確保、コンプライアンス遵守を支援します。 クラウドとオンプレミスのデータ環境に対応しており、データの管理と活用を効果的に支援します。
- Databricksとは
Databricksは、クラウドベースのデータプラットフォームで、データエンジニアリング、データサイエンス、機械学習のための統合環境を提供します。
スケーラブルなデータ処理、コラボレーション、高度な分析、機械学習モデルの開発を支援し、データ駆動型の洞察と意思決定を可能にします。

- Microsoft PurviewとDatabricksを連携させる利点

2.Microsoft PurviewでAzure Databricksを登録する
前提条件
・アクティブなサブスクリプションを持つ Azure アカウントが必要です。無料でアカウントを作成します。
・アクティブな Microsoft Purview アカウントが必要です。
・Azure Key Vaultのシークレットにアクセスするためのアクセス許可を Microsoft Purview に付与します。
・最新の セルフホステッド統合ランタイムを設定します。サポートされている最小限のセルフホステッド Integration Runtime バージョンは 5.20.8227.2 です。
・セルフホステッド統合ランタイムがインストールされているマシンに JDK 11 がインストールされていることを確認します。
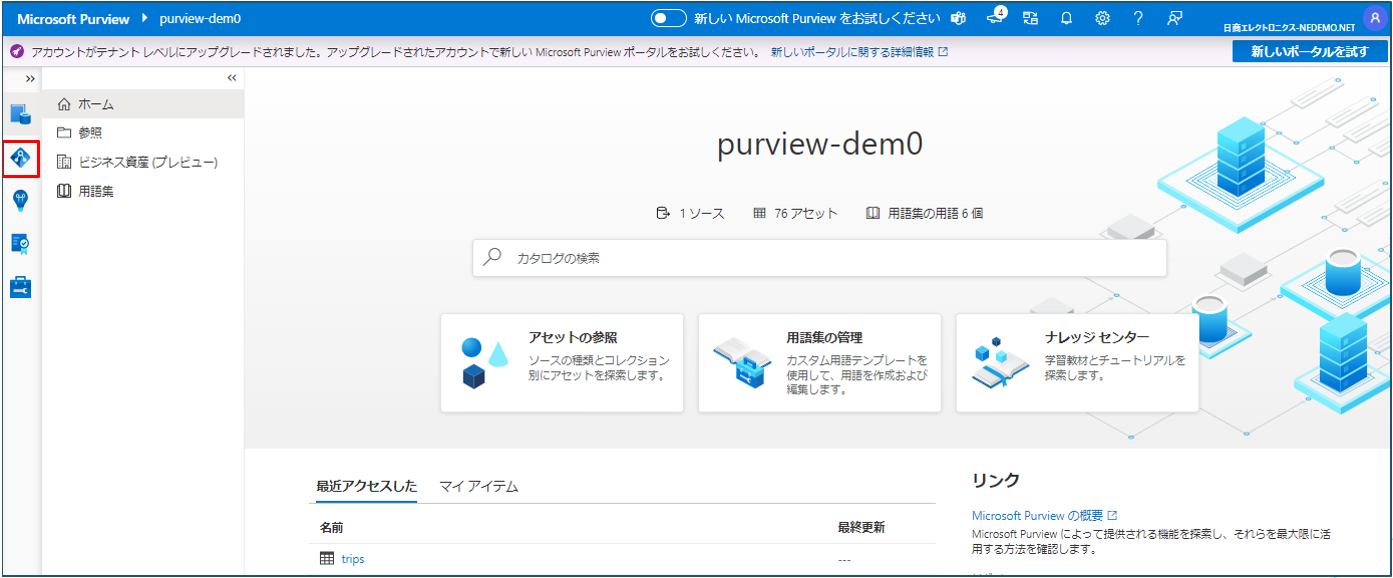
① Microsoft Purviewポータルを開きます。
② 左側のウィンドウから データマップ ![]() クリックします。
クリックします。
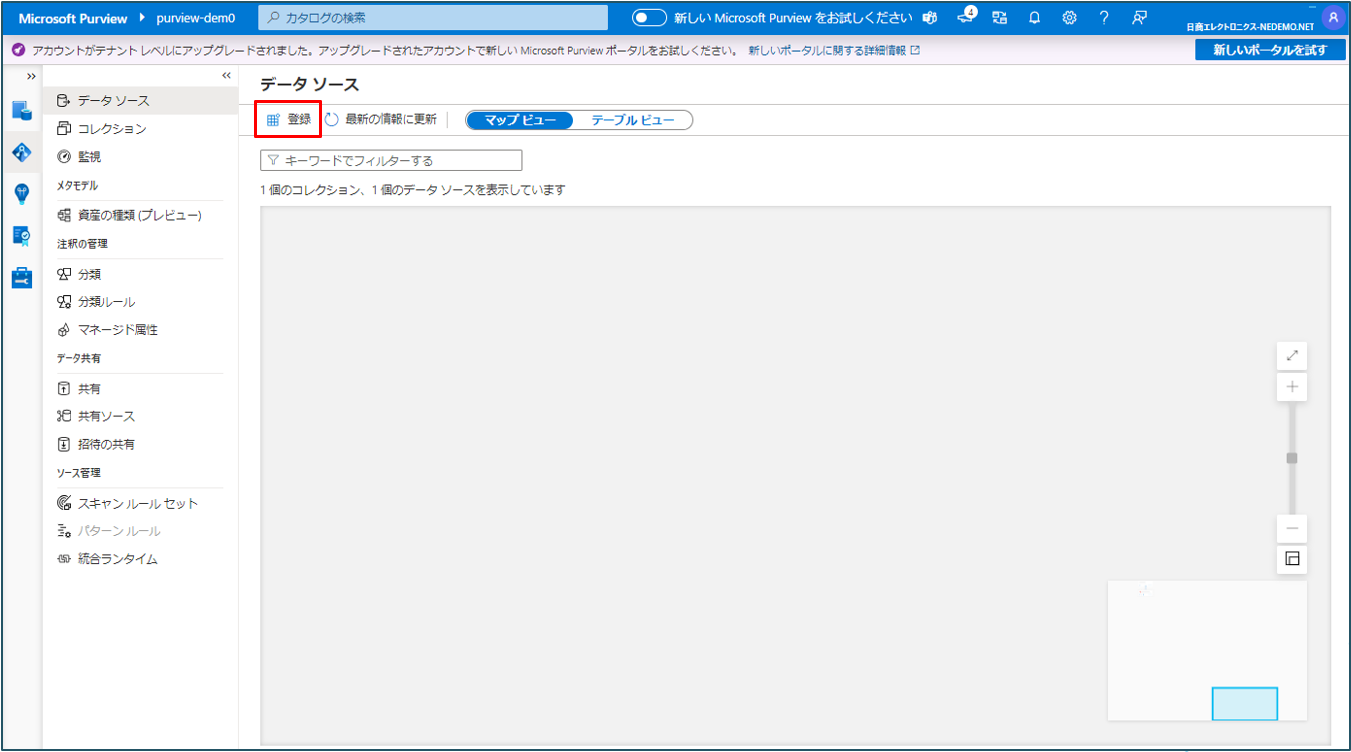
③ 登録をクリックします。
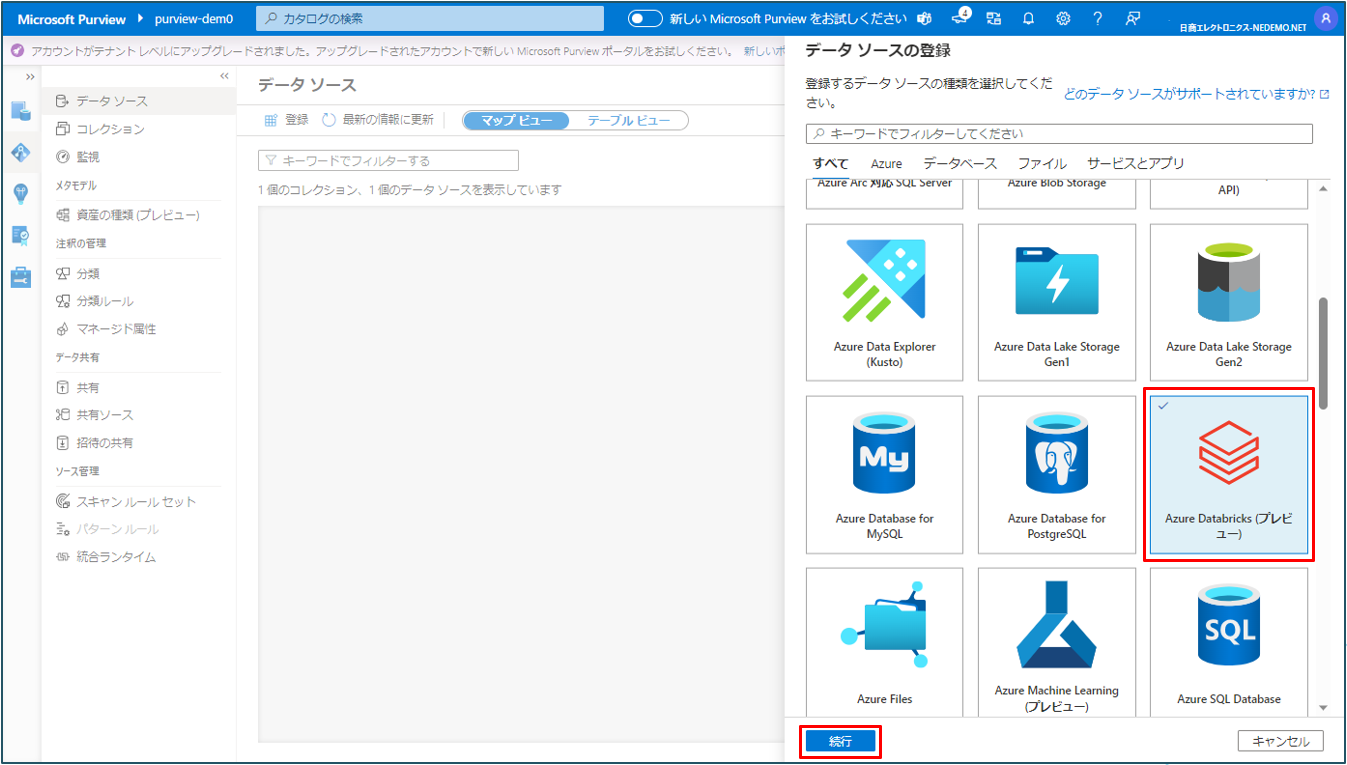
④ データ ソースの登録 で Azure Databricks を選択し、続行 をクリックします。
⑤ 登録するDatabricksワークスペースの詳細を入力します(次ページ参照)
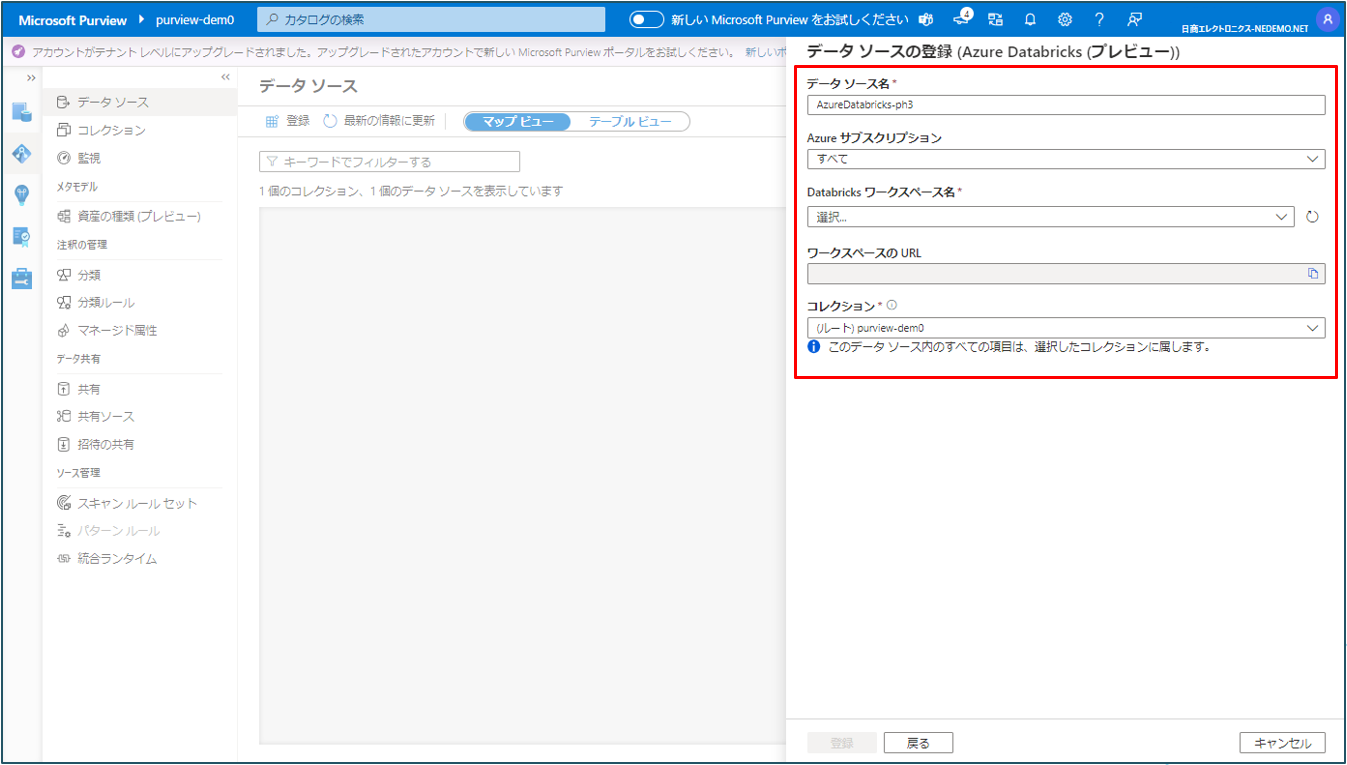
データソース名:Microsoft Purviewがデータソースとして一覧表示する名前を入力します。
Azure サブスクリプション:登録するワークスペースのサブスクリプション名を選択します。
Databricksワークスペース名:登録するワークスペースを選択します。
DatabricksワークスペースURLは自動的に設定されます。
コレクション:格納するコレクションを選択します。

⑥ 入力が出来たら 登録 をクリックします。
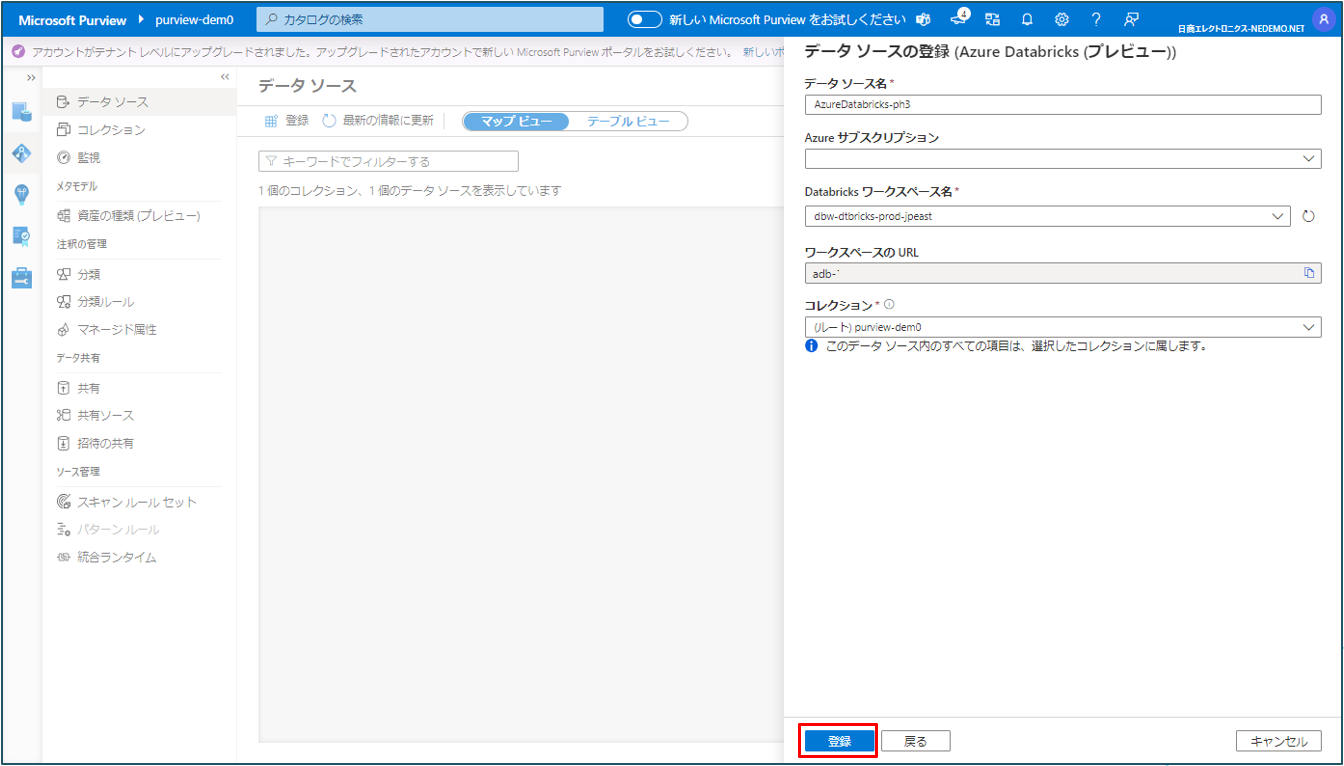
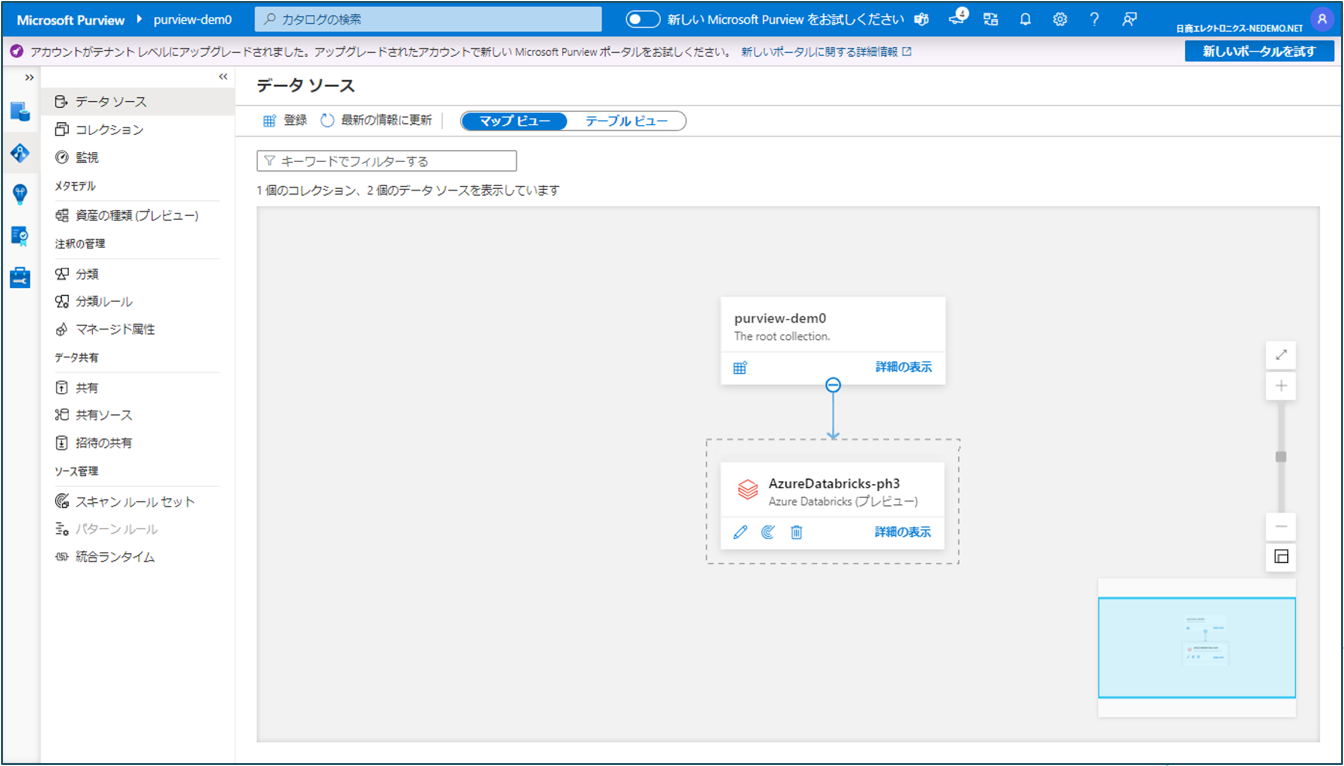
データマップにデータソース名が表示されれば登録完了です。
3.Microsoft Purviewを使用してAzure Databricksソースをスキャンする
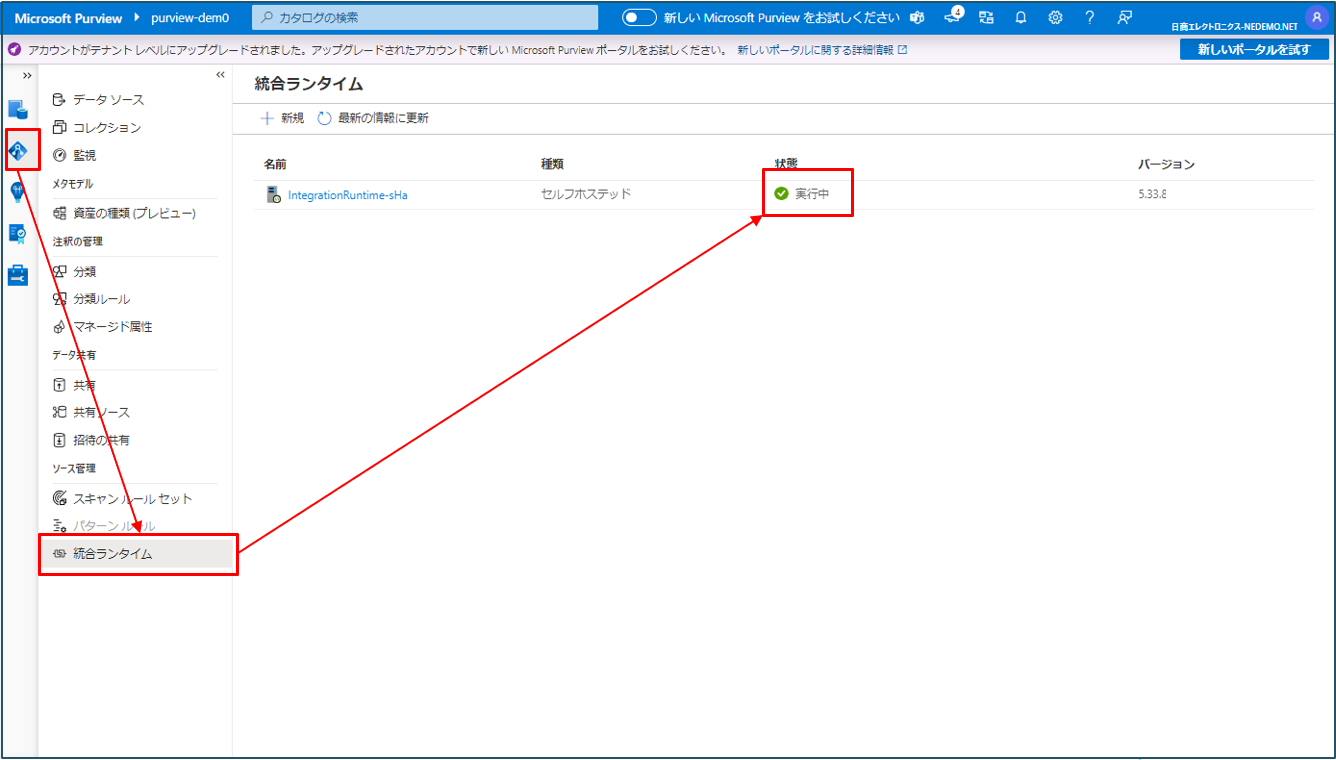
① データマップ > 統合ランタイム をクリックし、セルフホステッド統合ランタイムが実行中であることを確認します。実行中でなければ実行状態にします。
② データソース をクリックし、登録した Azure Databricks の詳細の表示 をクリックします。
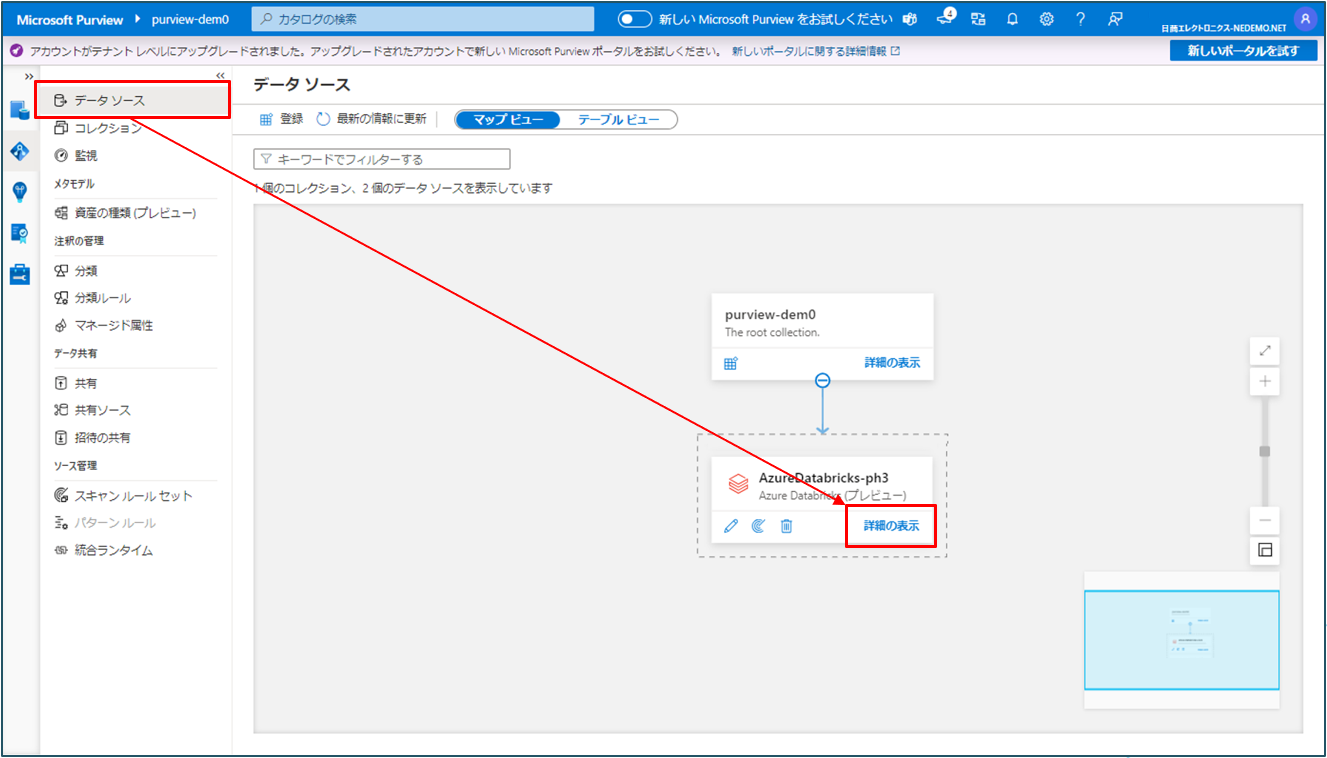
③ 新しいスキャンをクリックします。
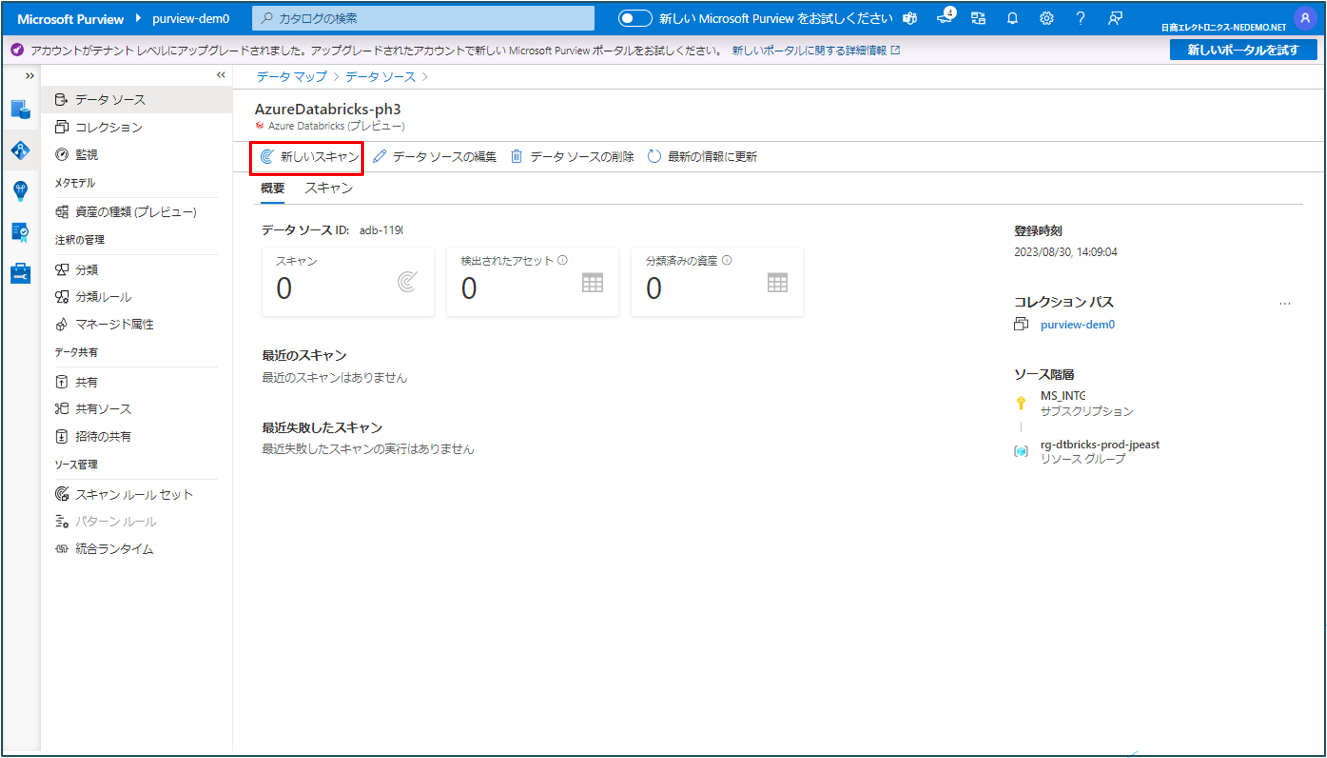
④ データソースに関する情報を入力します。(詳細は後述参照)
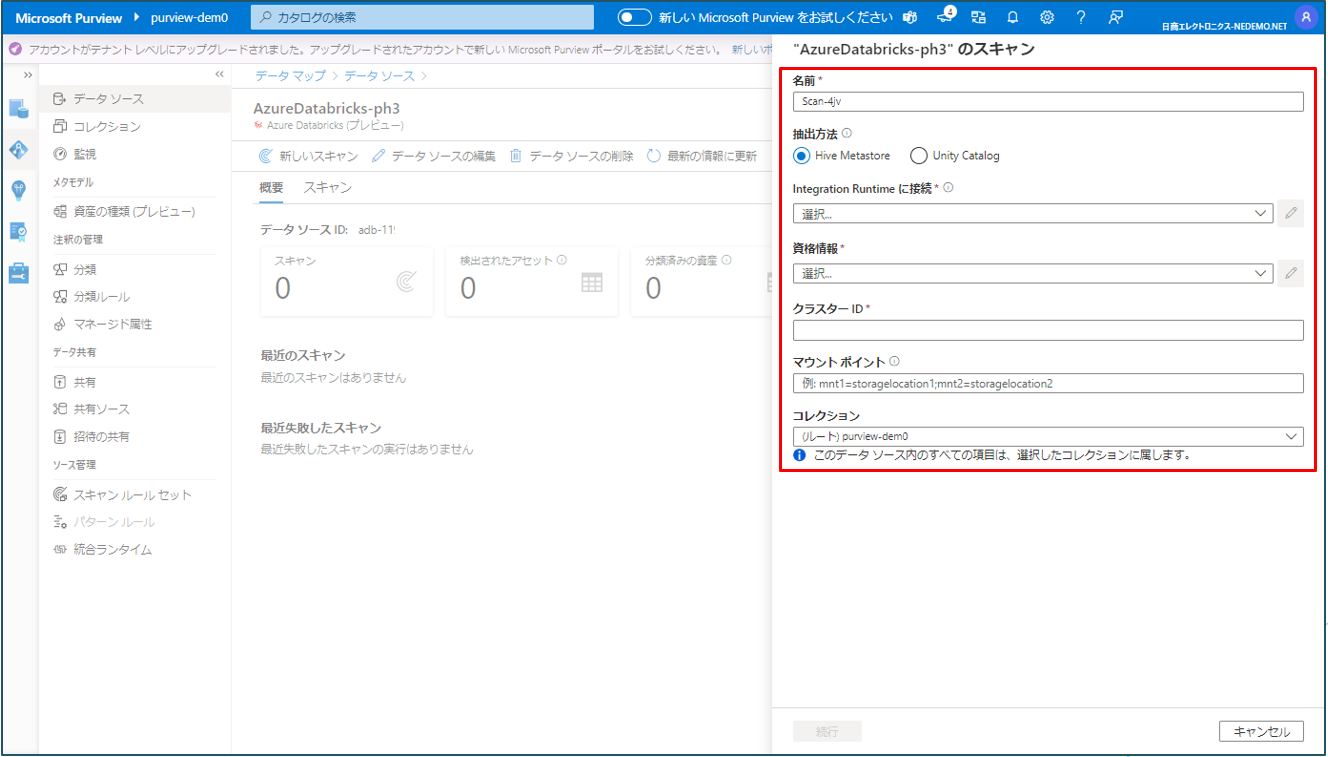
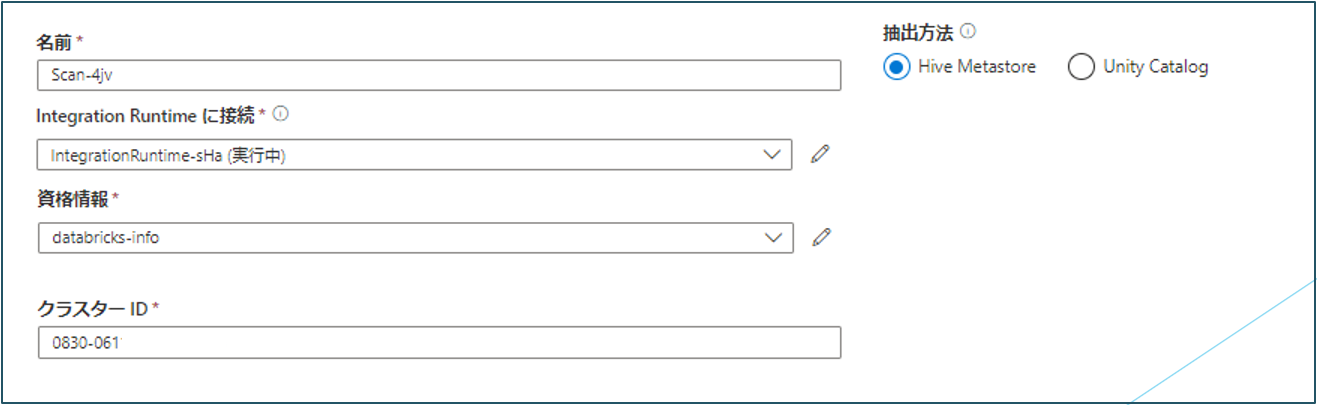
Hive metastoreからスキャンする場合(必須入力)
・名前:スキャンの名前を入力します。
・抽出:Hive metastoreを選択します。
・Integration Runtimeに接続:構成済みのセルフホステッド統合ランタイムを選択します。
・資格情報:データソースに接続する資格情報を選択します。資格情報の作成時にアクセストークン認証を選択した場合、ドロップダウンでアクセストークンが表示されます。
・クラスターID:Microsoft Purviewがスキャンに接続して電源を共有するクラスターIDを指定します。クラスターIDはDatabricksワークスペースでクラスターをクリックし、タグから自動で追加されたタグをクリックすると確認できます。
Unity Catalogからスキャンする場合(必須入力)
・名前:スキャンの名前を入力します。
・抽出:Unity Catalogを選択します。
・Integration Runtimeに接続:構成済みのセルフホステッド統合ランタイムを選択します。
・資格情報:データソースに接続する資格情報を選択します。資格情報の作成時にアクセストークン認証を選択した場合、ドロップダウンでアクセストークンが表示されます。
・HTTPパス:Databricks SQL WarehouseリソースURLを指定します。HTTPパスはDatabricksワークスペースでSQL Warehouseをクリックし、接続の詳細をクリックすると確認できます。
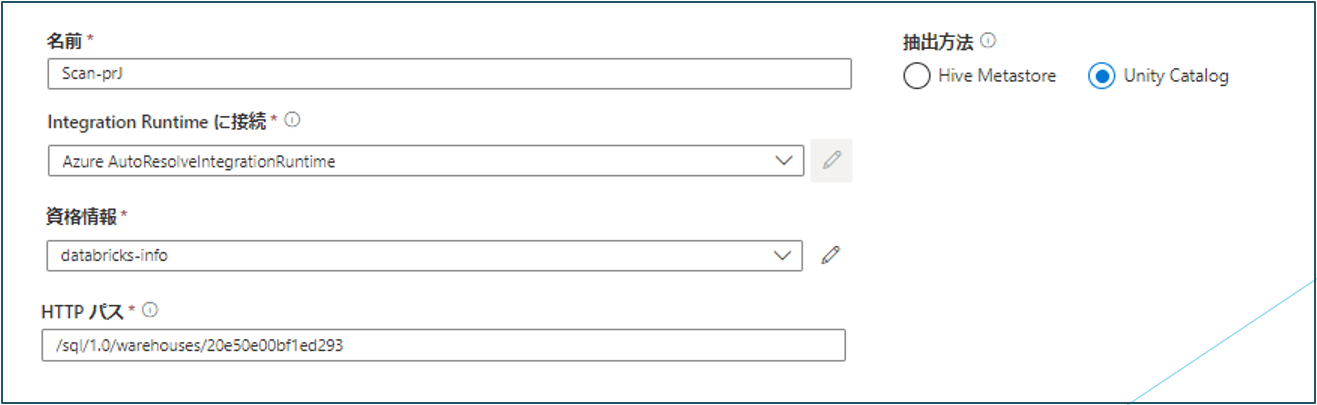
⑤ データソースに関する情報を入力したら 続行 をクリックします。
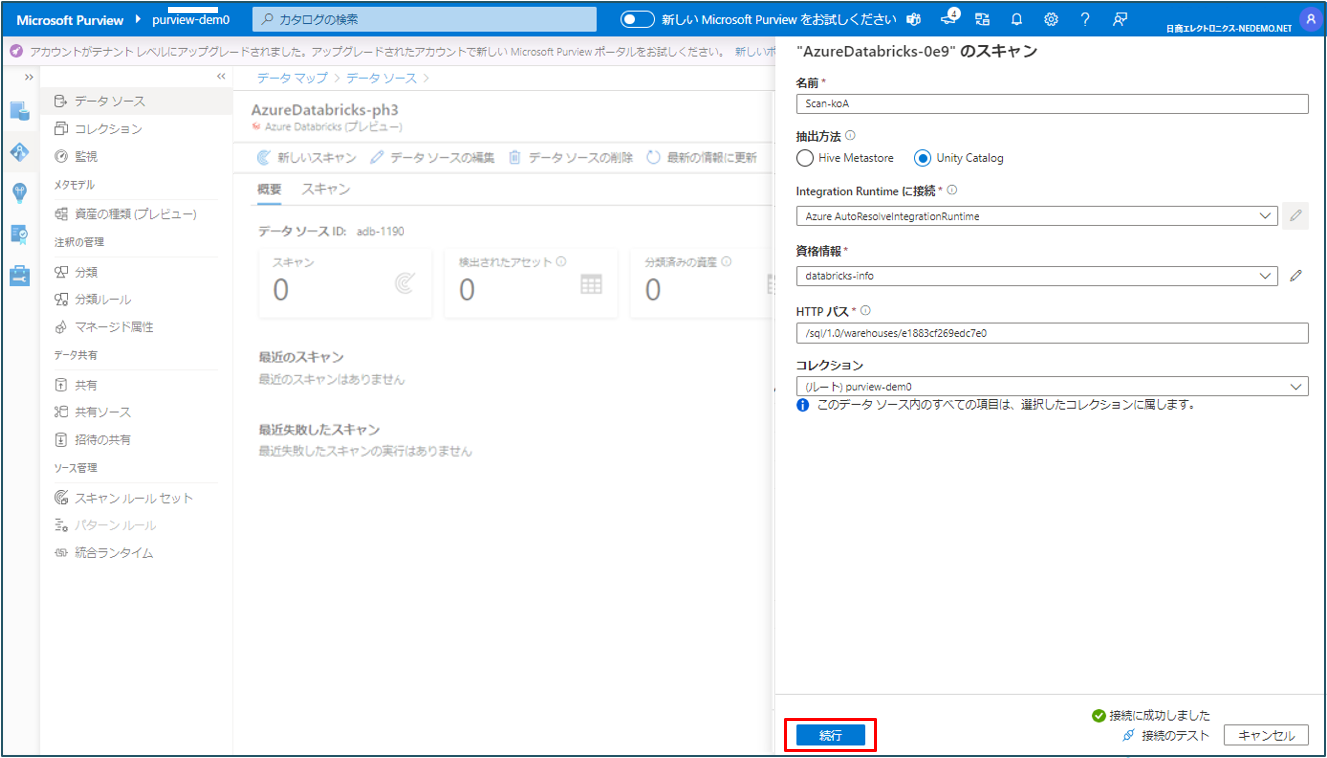
⑥ 取り込みたいカタログを選択し、続行 をクリックします。
(Hive metastoreからスキャンする場合はこの工程はありません)
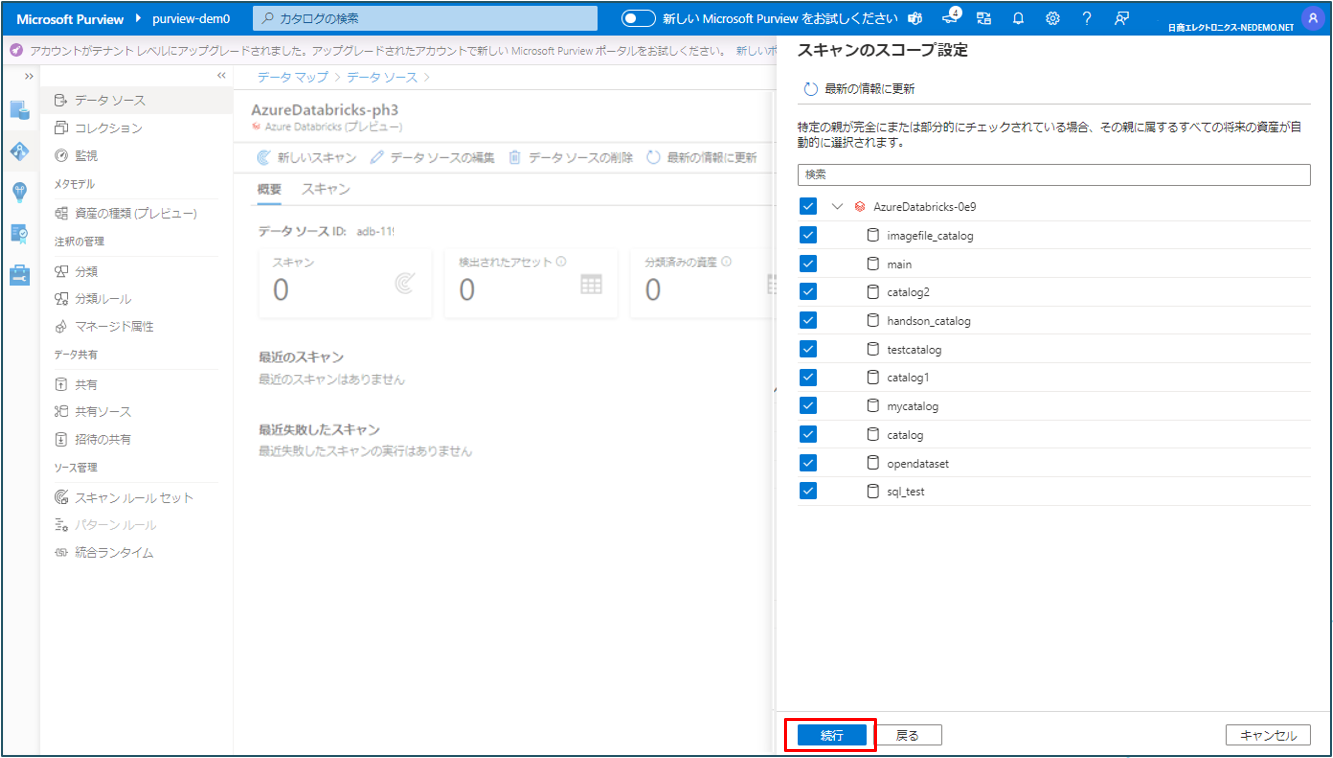
⑦ スキャンのトリガーを設定します。定期的の場合は日時を選択します。どちらか選択出来たら 続行 をクリックします。
⑧ スキャンのレビューを確認し、 続行 をクリックします。
⑨ 実行したスキャン名をクリックします。
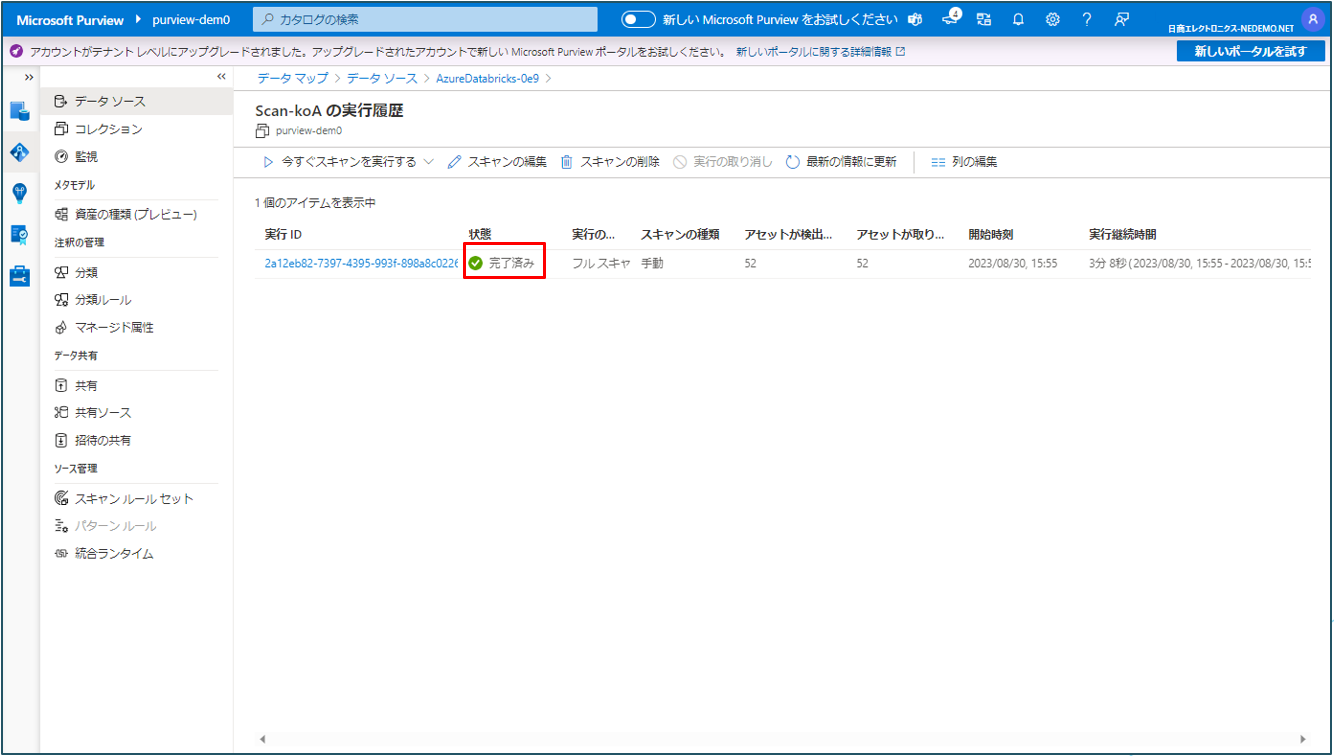
⑩ 状態が 完了済み になればスキャンの実行は完了です。
4.スキャンの管理
① 左側のウィンドウから データマップ をクリックします。
② データセットの 詳細を表示 をクリックします。
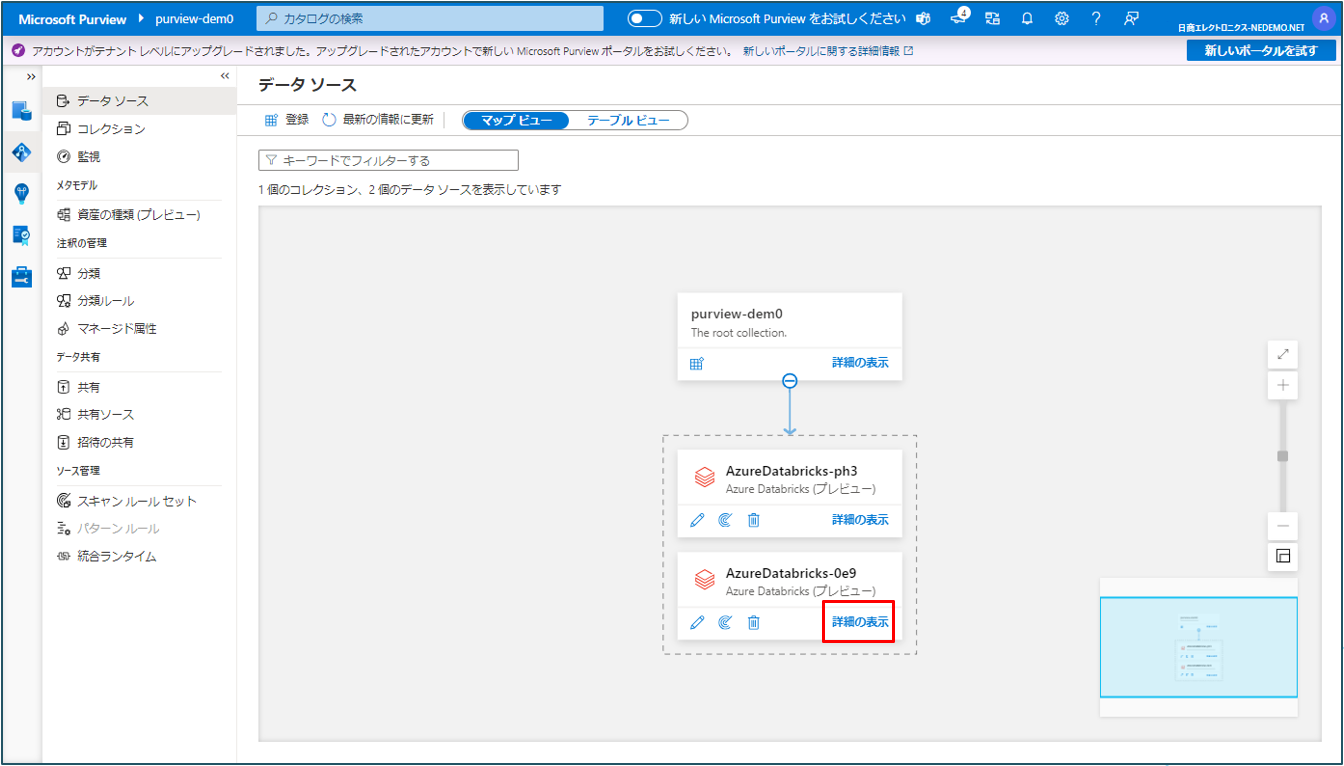
③ スキャン をクリックするとスキャンの一覧が表示されます。
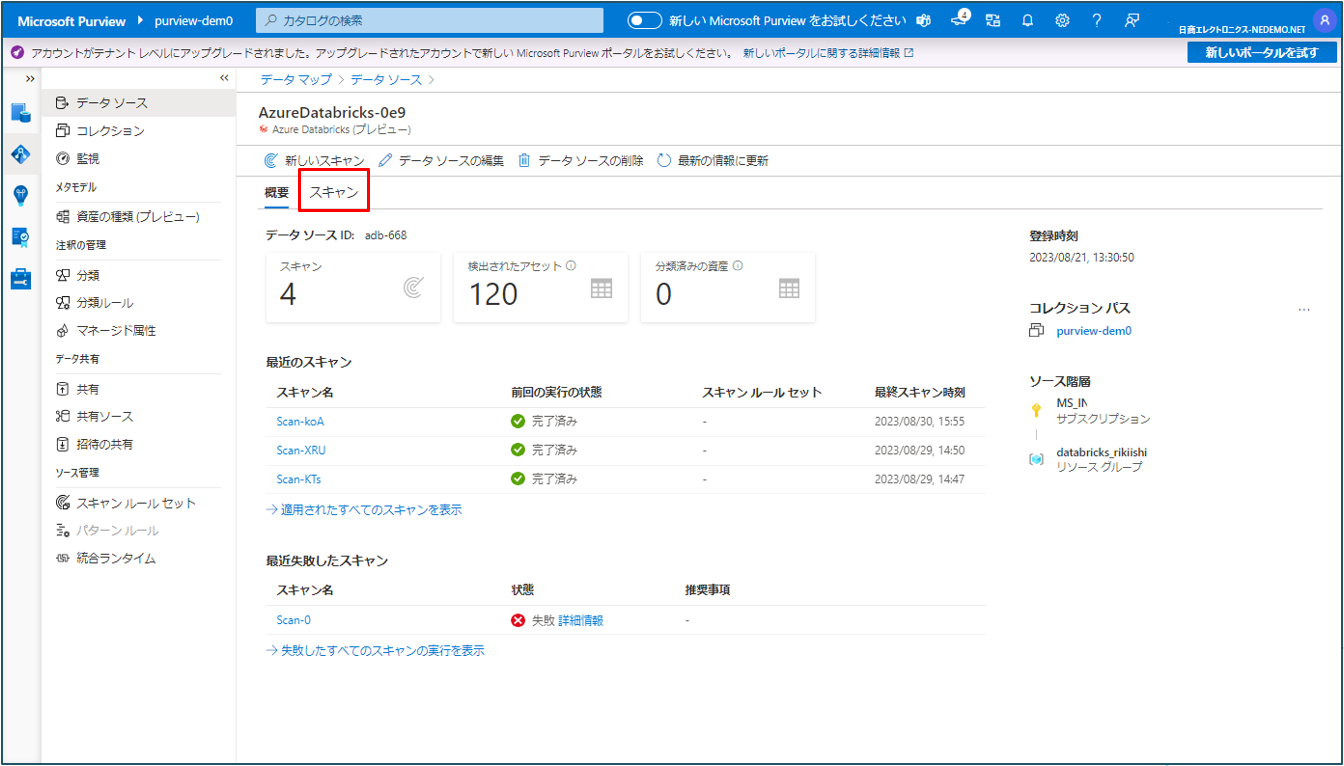
④ 確認したいスキャン名をクリックします。
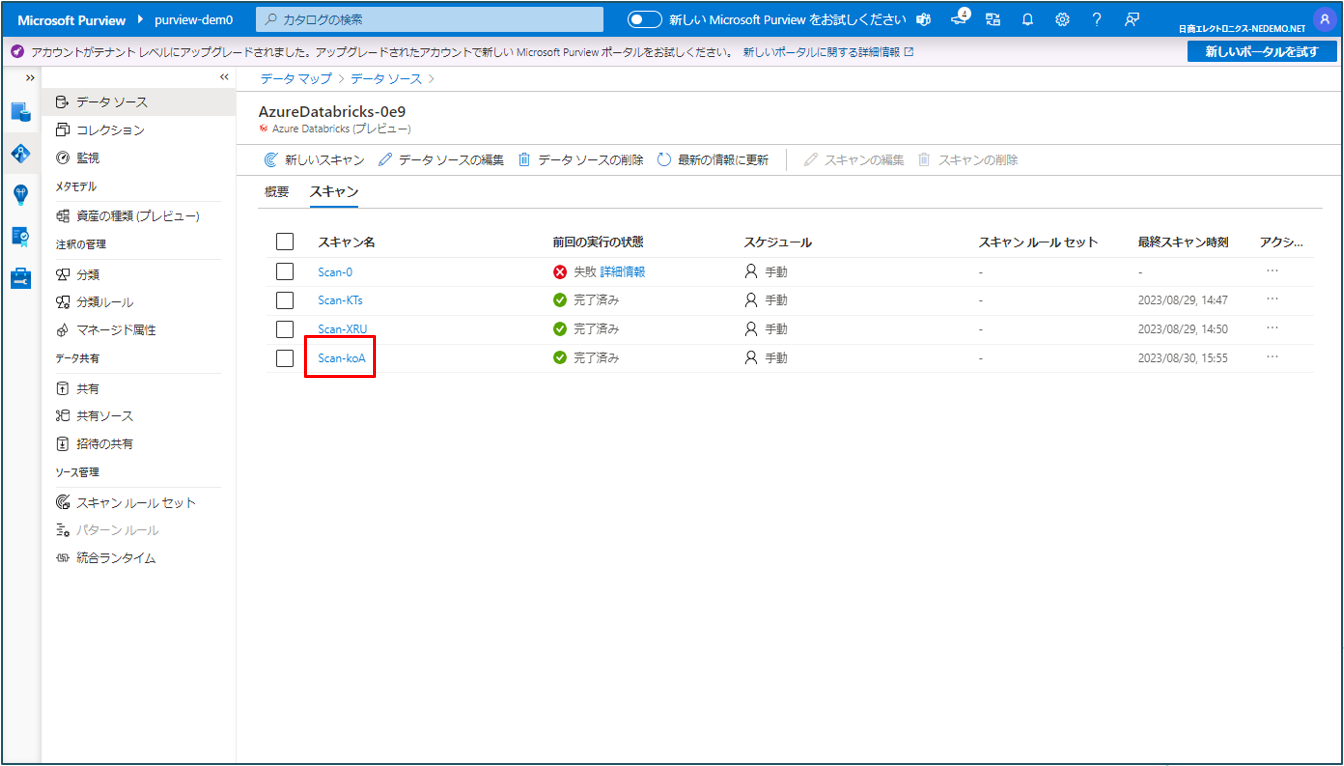
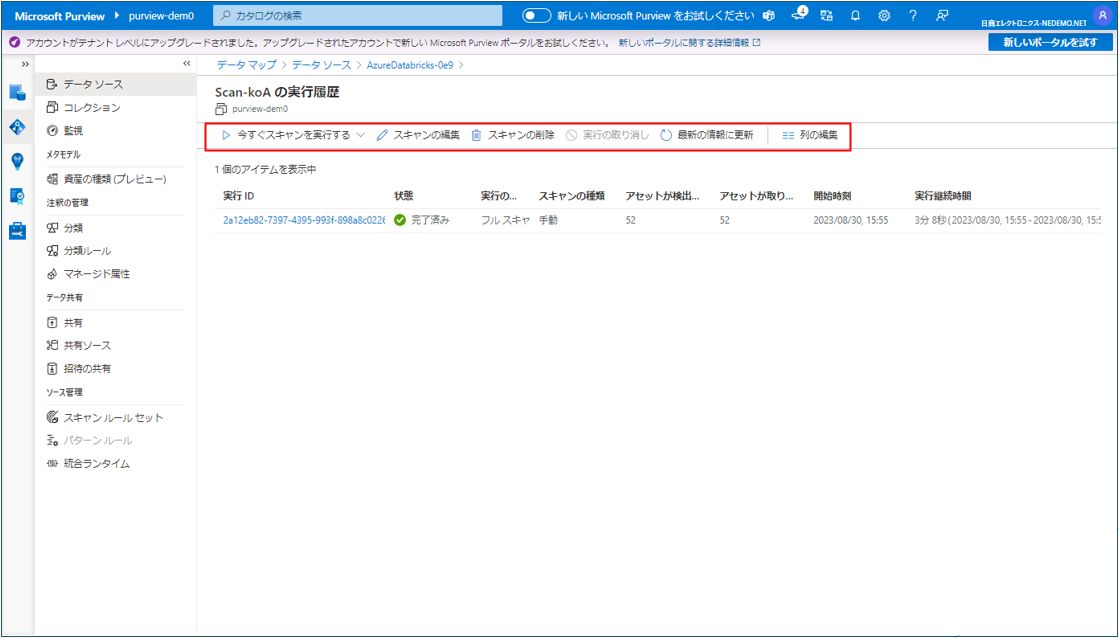
⑤ スキャンの実行履歴が確認できます。
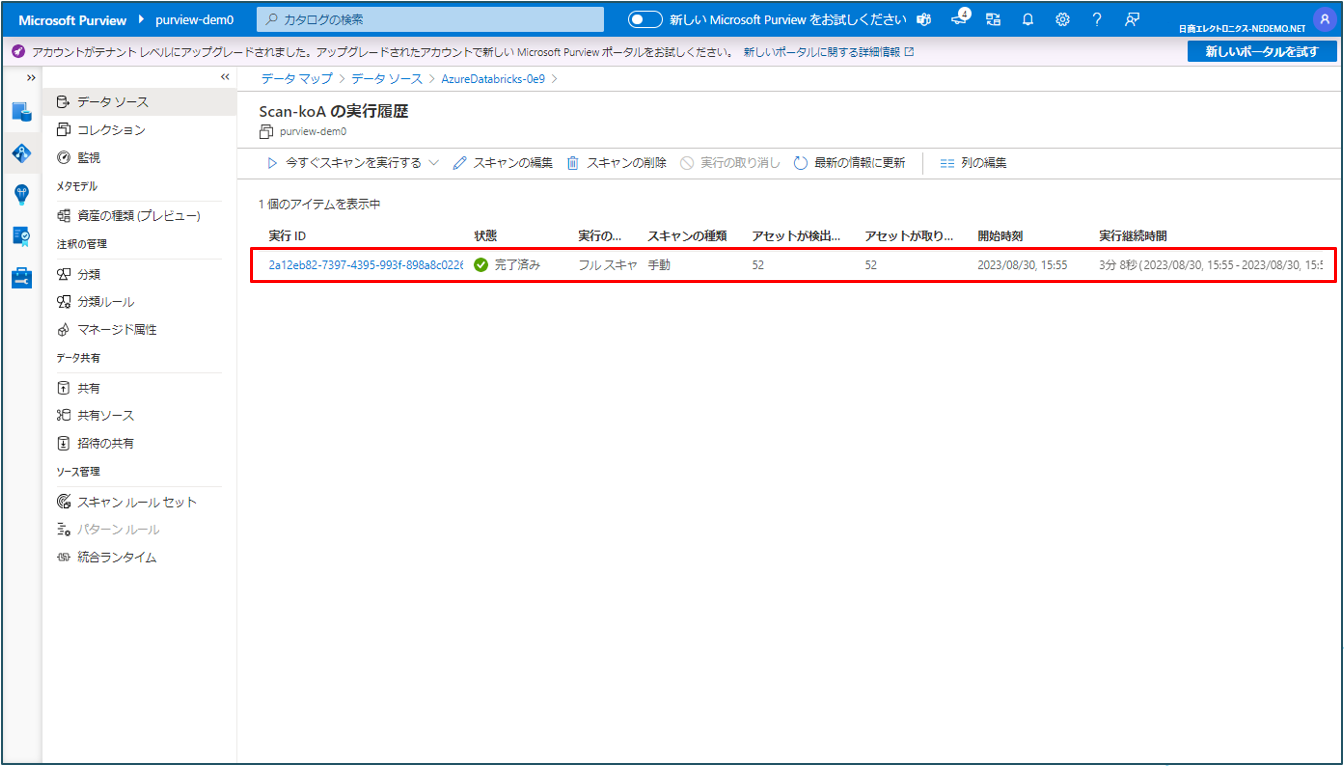
⑥ スキャンの実行、スキャンの編集、スキャンの削除、実行中であれば実行の取り消しができます。
スキャンを削除しても、以前のスキャンから作成されたカタログ資産は削除されません。
5.スキャンしたカタログを参照する
① Microsoft Purview ポータル画面から 参照 をクリックし、ソースの種類別 をクリックします。
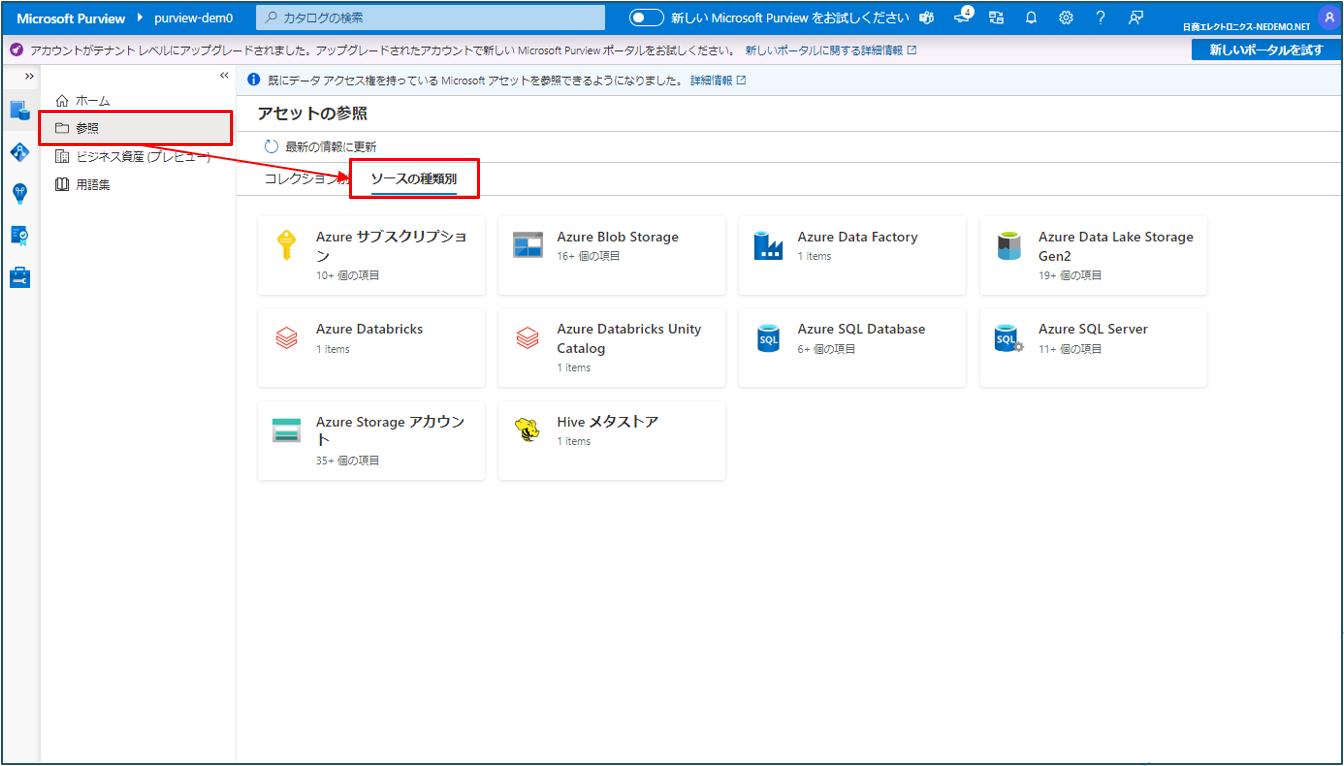
② Unity Catalogからスキャンしたカタログを参照する際は Azure Databricks Unity Catalog を、Hive metastore からスキャンしたカタログを参照する際は Hive メタストア をクリックします。
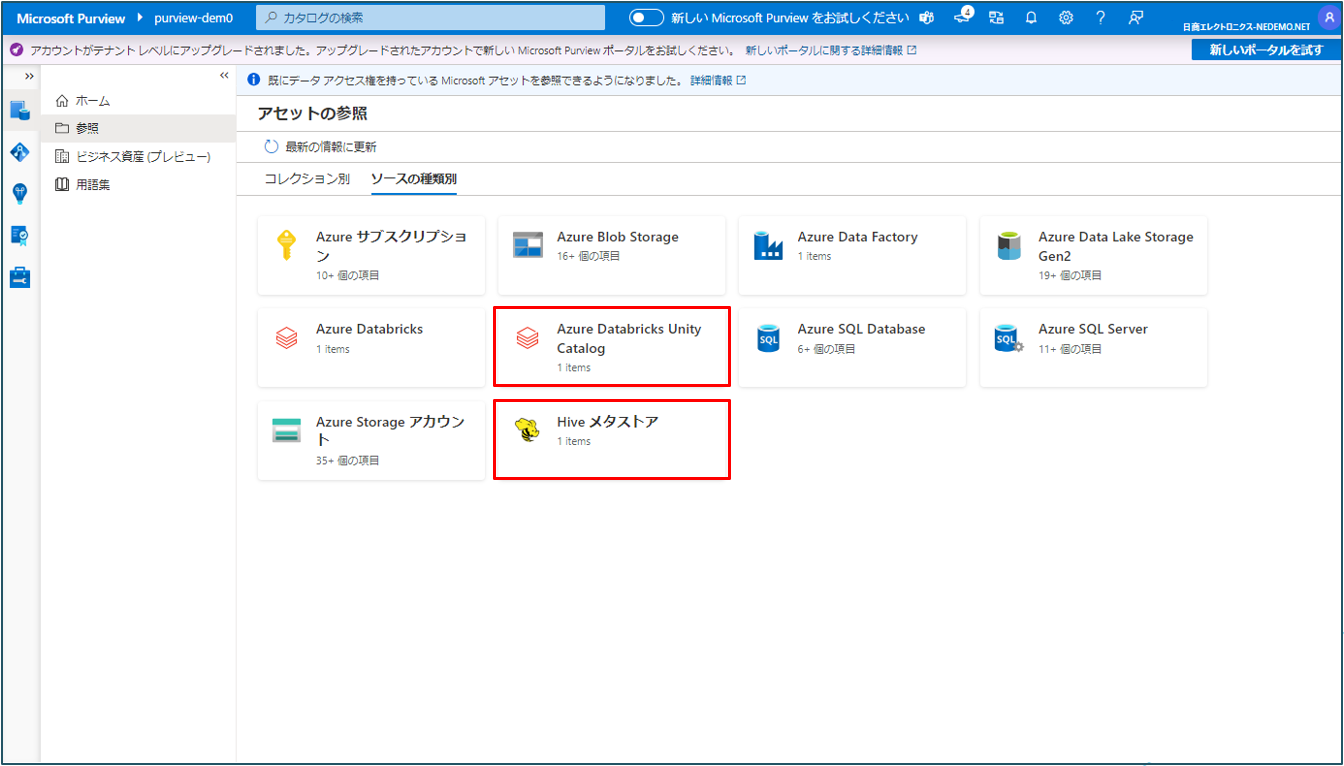
Hive metastoreの参照の場合
③ 参照したい項目をクリックします。
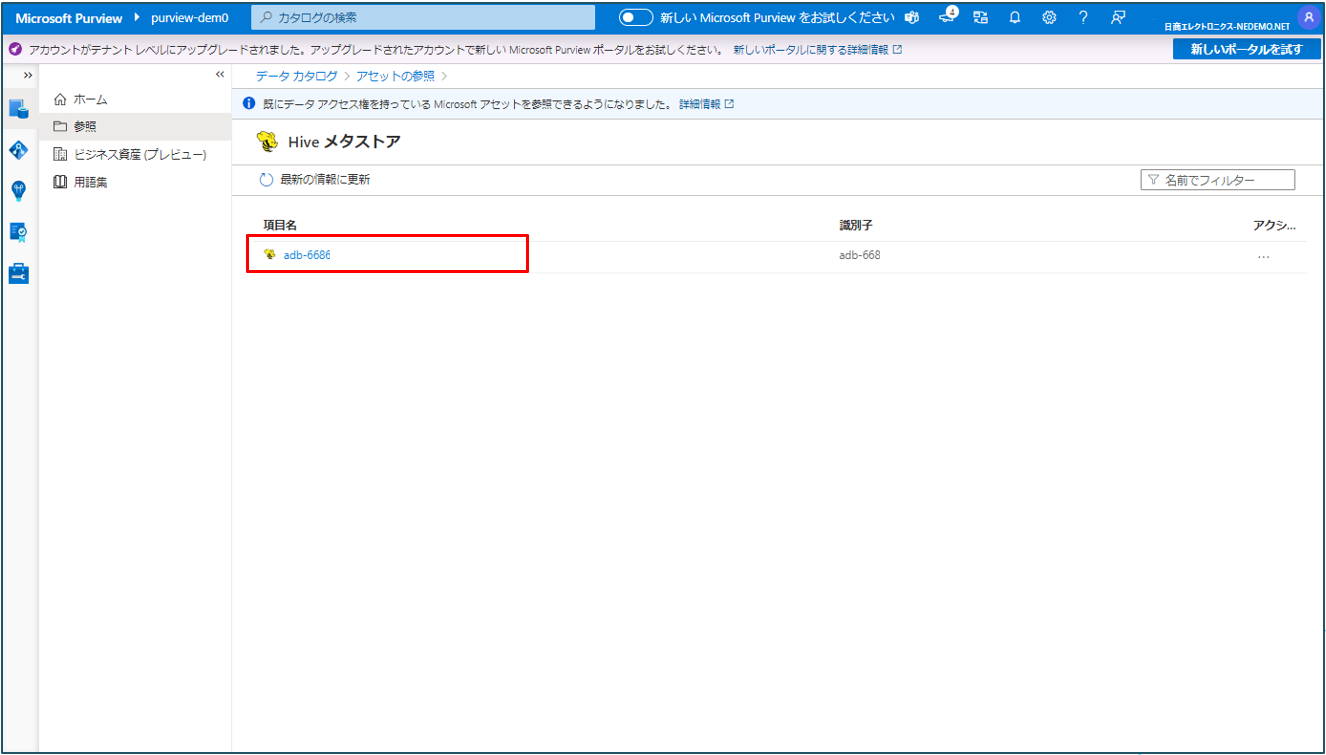
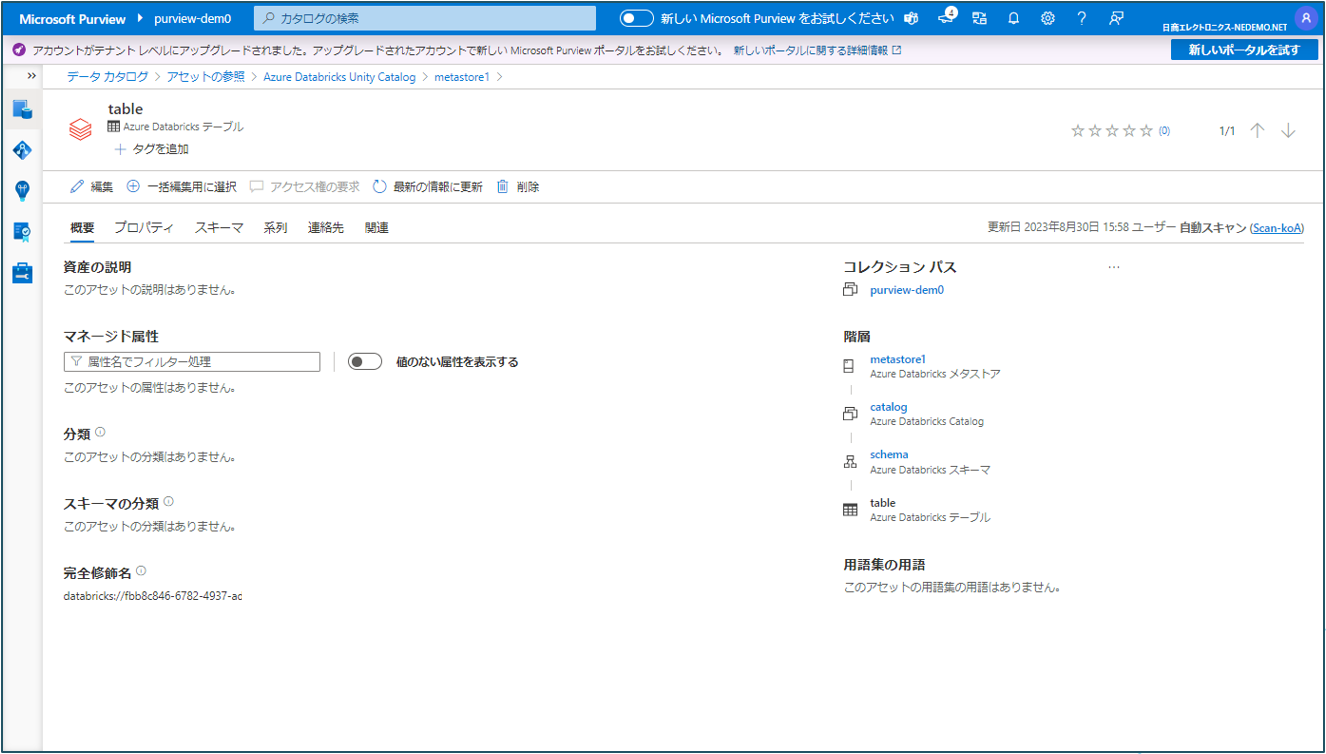
④ カタログごとに表示されます。テーブルをクリックするとテーブルの情報が確認できます。
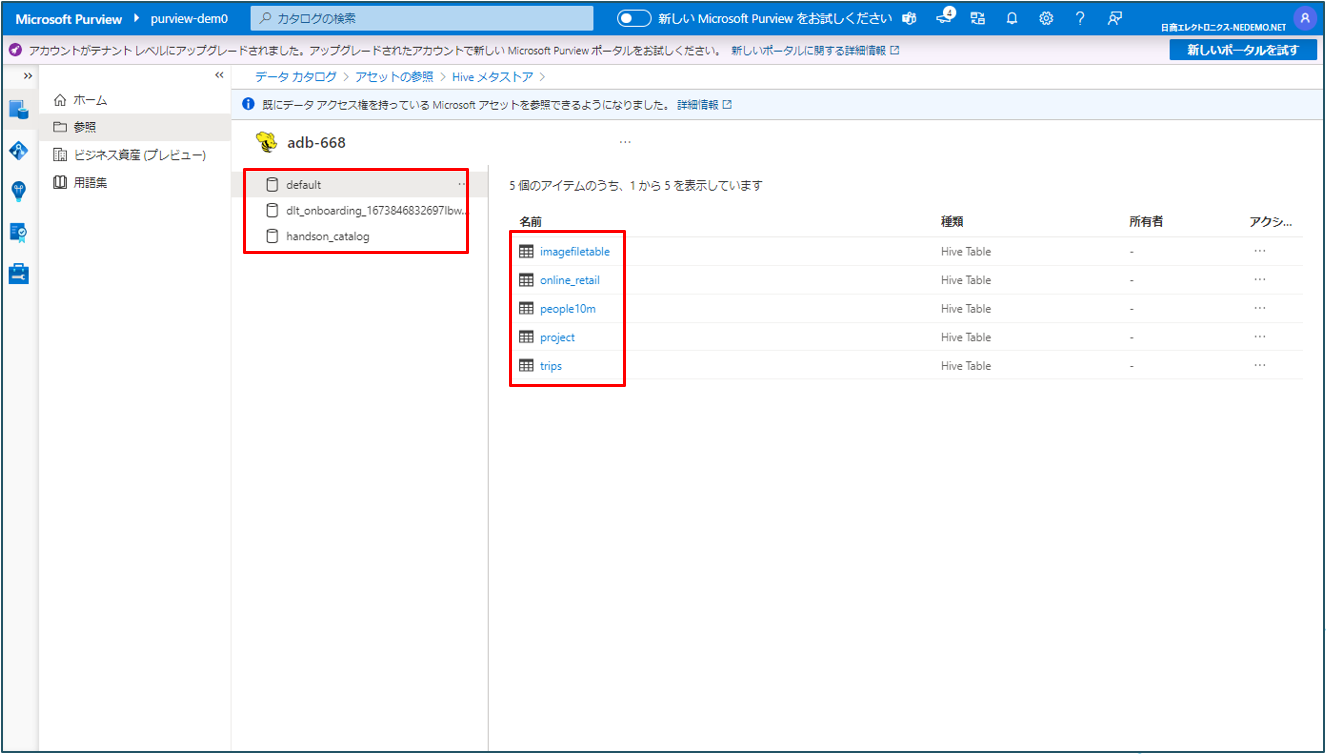
テーブルの情報が確認できます。
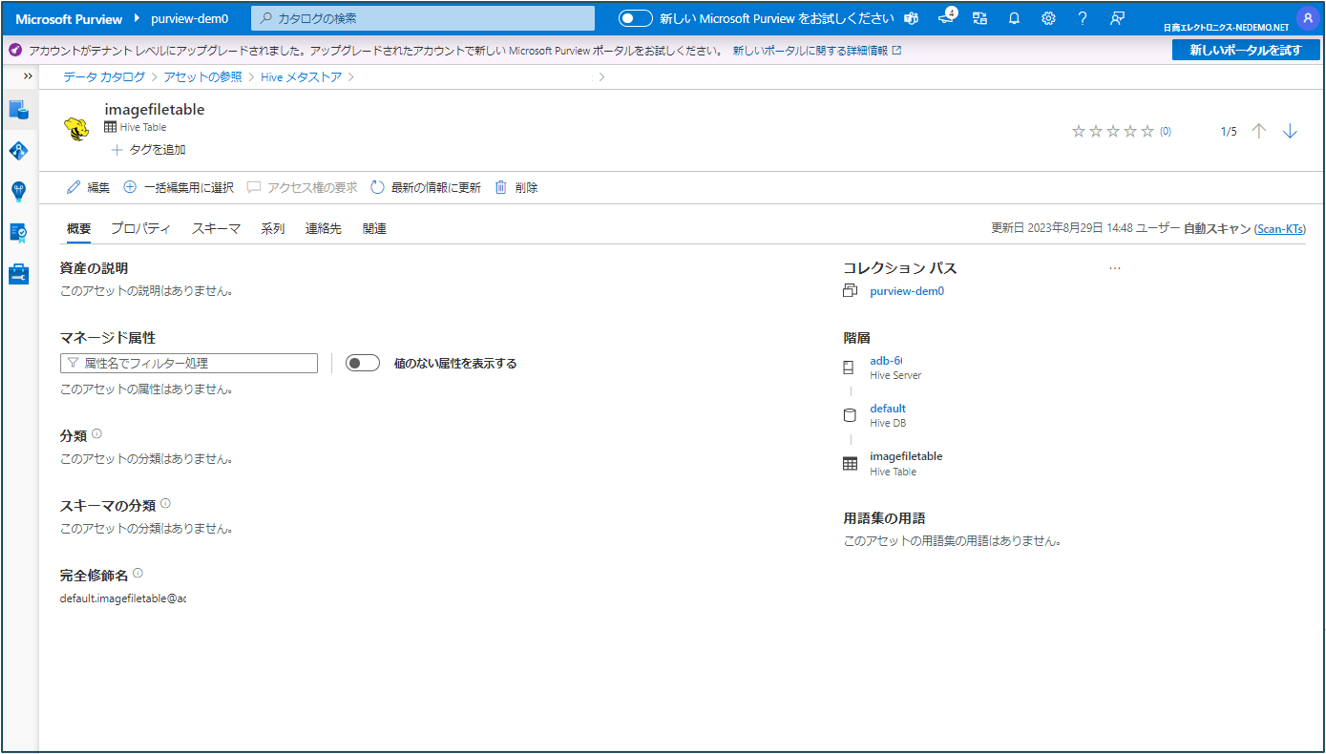
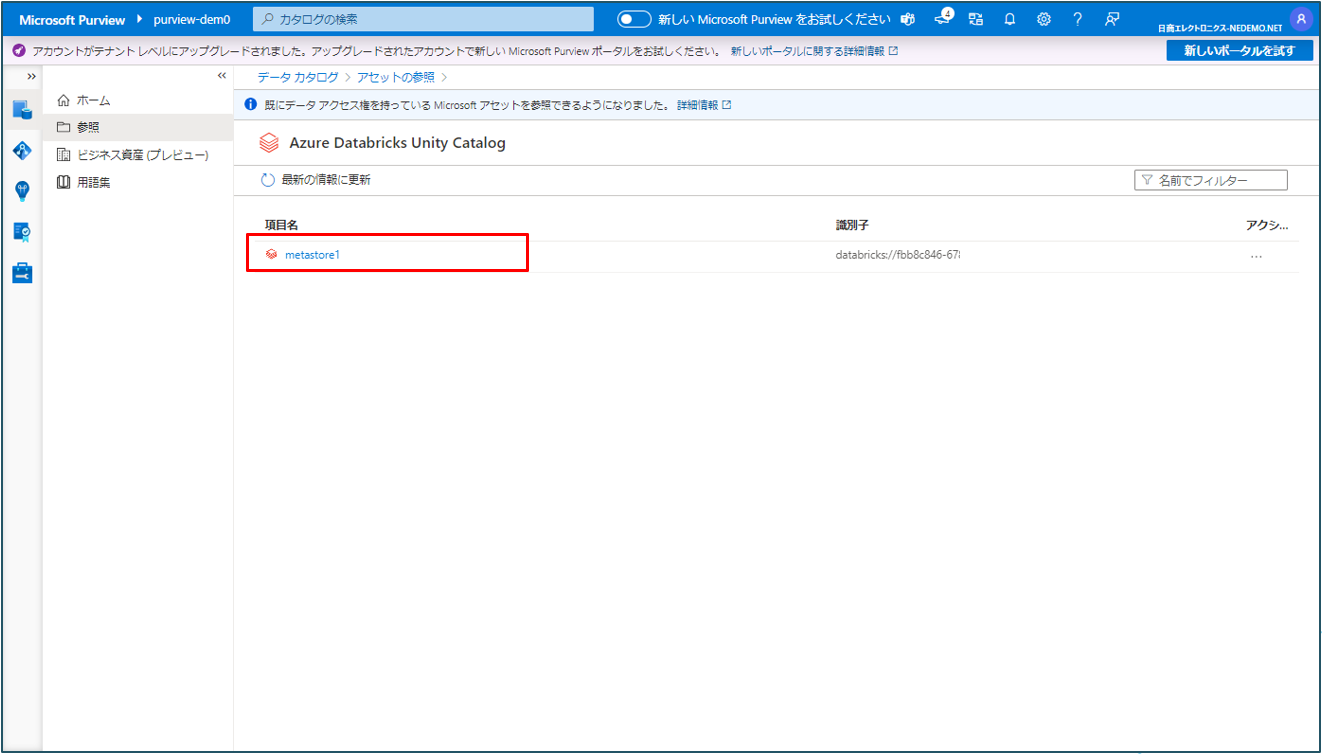
Unity Catalogの参照の場合
③ メタストア名が表示されるので参照したい項目をクリックします。
④ カタログごとに表示されます。テーブルをクリックするとテーブルの情報が確認できます。
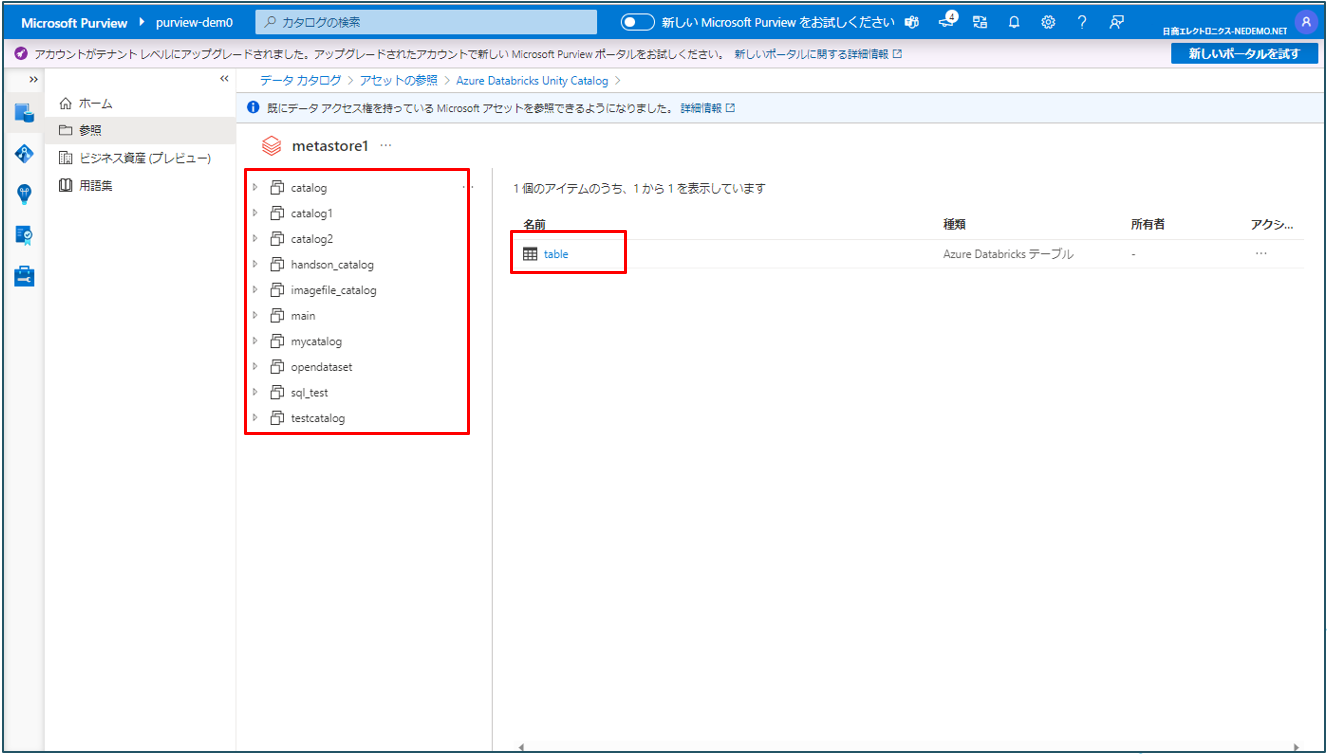
テーブルの情報が確認できます。
6.まとめ
Microsoft PurviewとDatabricksの連携についてについて説明しました。
今回の記事が少しでもMicrosoft Purview、Databricks を知るきっかけや、 業務のご参考になれば幸いです。
Azure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問 い合わせください!
・Azure Databricks連載シリーズはこちら