1.概要
Databricksを使用していると、DeltaテーブルやParquetファイルなどのストレージ上のデータを更新したはずなのに、クエリ結果に反映されないケースがあります。「なぜこうなるのか?」と疑問に思ったことはありませんか?
実は、こうした状況ではREFRESH TABLEコマンドが大きな役割を果たします。本記事では、このREFRESH TABLEの動作について、具体的な例を交えて解説します。
2.背景
REFRESH TABLEが必要になるのはどんなとき?
- Databricks上でPARQUETやCSVファイル等の外部テーブルを使用する際、ストレージ上のファイルデータを更新しても、Databricks側のメタデータキャッシュは自動で更新されない。
- 複数のノートブック間で同じテーブルを操作する際、セッション間でキャッシュが残ってしまう。
その結果、ノートブック上でSELECTクエリを実行しても、実際のファイル内容がすでに変更されているにもかかわらず、古いデータが返ってくることがあります。
こういった状況を防ぐために、データ更新後やノートブック間でのデータ連携時には、REFRESH TABLEの実行を推奨します。
次の内容は詳細に説明します。
3.具体的な例
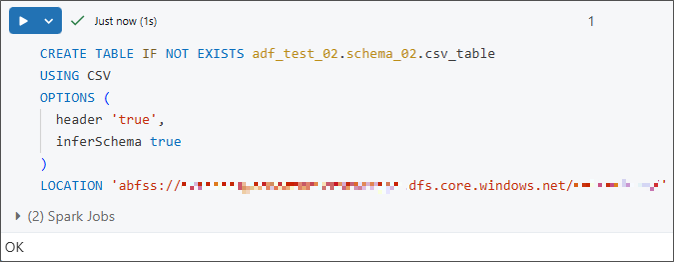
①ストレージアカウント上のCSVファイルに接続する外部テーブルを作成します。
文法:
|
1 2 3 4 5 6 7 |
CREATE TABLE IF NOT EXISTS <catalog_name>.<schema_name>.<table_name> USING CSV OPTIONS ( header 'true', inferSchema true ) LOCATION 'abfss://<container_name>@<storageaccount_name>.dfs.core.windows.net/<path_to_data>' |
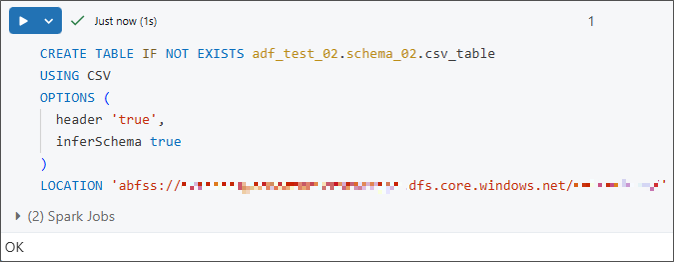
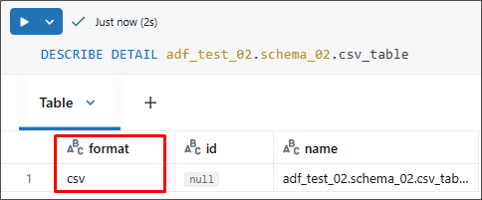
その後、以下のコマンドを使って、テーブルの情報がCSV形式として正しく反映されているかを確認します。
|
1 |
DESCRIBE DETAIL <catalog_name>.<schema_name>.<table_name>; |
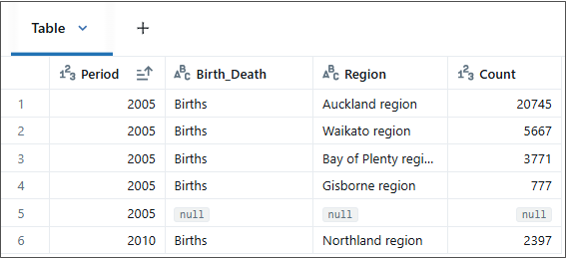
② セッションキャッシュの仕組みをより明確に説明するために、別のノートブックを作成し、それを独立したセッションとして扱います。
そして、両方のノートブックで同時に「csv_table」に対して「SELECT」を実行すると、ストレージアカウントからのデータがテーブルに反映されている結果が確認できます。
|
1 |
SELECT * FROM adf_test_02.schema_02.csv_table; |
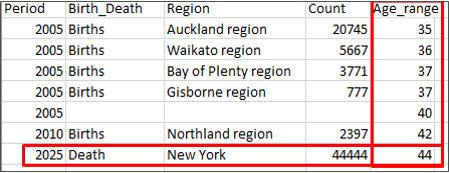
③ 外部テーブルを読み込んだ後、CSVファイルで直接編集し、以下の操作を実施します。
- 「Age_range」列を追加する
- 新規の行を1つ追加する
④元データを変更した後、ステップ①のコマンドを再実行し、テーブルの内容を再読み込みします。
メインセッションのNotebookで、SELECTを実行してテーブルのデータを確認します。
|
1 |
SELECT * FROM adf_test_02.schema_02.csv_table; |
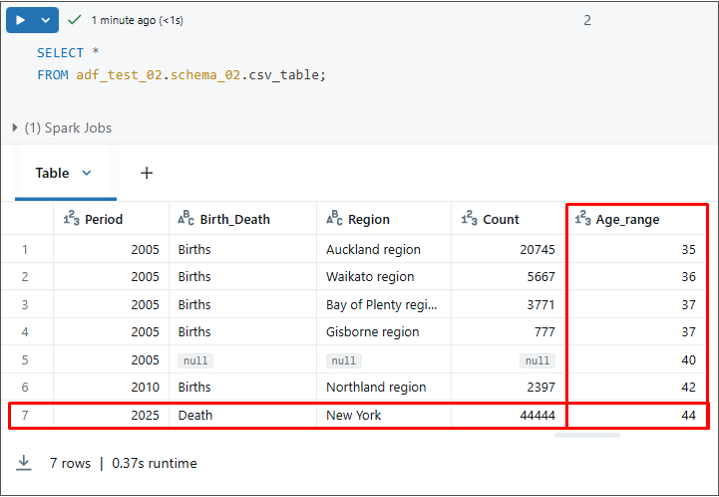
「Age_range」列および新規の行が無事に追加されました。
⑤ ステップ②で作成した別のノートブックで、再び「SELECT」文を実行して確認します。
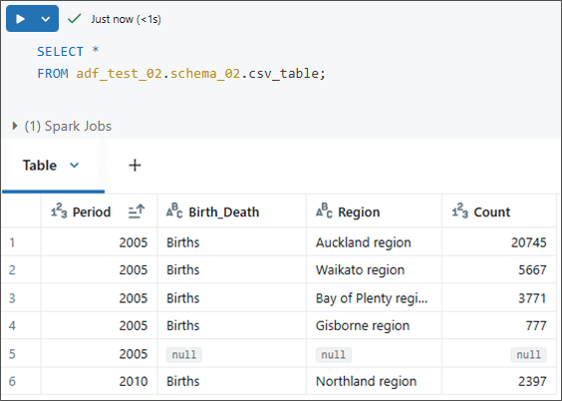
ただし、「Age_range」列や新しいデータがまだ反映されていないのが分かりますよね?では、説明します。
※留意:
Databricksでは、ノートブックやQuery Editor、Jobタスクなどの各セッションごとに以下の情報を個別に保持しています。
- データファイルの一覧(ファイルインデックス)
- テーブル構造(スキーマ)
これは、繰り返しクエリを実行する際のパフォーマンス向上につながる一方で、外部ストレージ上のデータが変更されても、セッション側の情報が更新されない限り、古いデータがそのまま返ってきてしまうというリスクもあります。
👉 このようなケースでは、REFRESH TABLEを使ってメタデータキャッシュを明示的に更新することで、常に最新の状態でデータを参照することができます。
⑥ 他のセッションでキャッシュされたデータの問題を解消するために、以下のようにREFRESH TABLEコマンドを実行します。
文法:
|
1 |
REFRESH TABLE <catalog_name>.<schema_name>.<table_name>; |
結果として最新情報が更新されました。
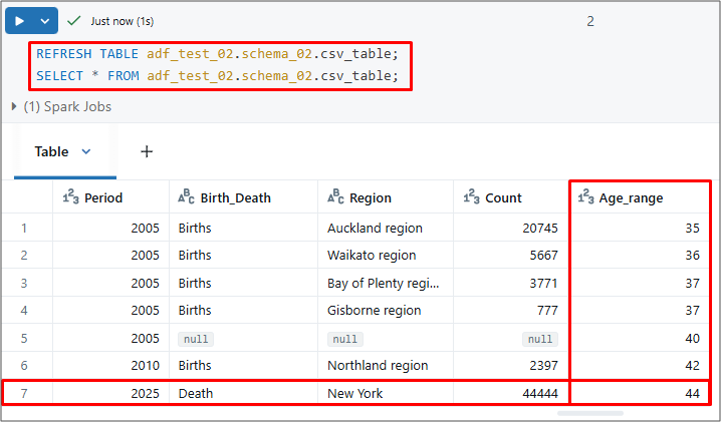
そのため、複数のノートブック(セッション)で同じテーブルのデータを扱う場合は、REFRESH TABLEを実行して、常に最新のデータが反映・統一されるようにしてください。
4.注意事項
REFRESH TABLEを使えばキャッシュの問題を回避できますが、すべてのケースで必ずしも使用が必要というわけではありません。
たとえば、DatabricksのDelta Tableに対して「INSERT」や「ALTER TABLE」を直接実行する場合は、REFRESH TABLEを使わなくても常に最新のデータが反映されるようになっています。これは、Delta Lakeの仕組みにより、すべての更新操作が「_delta_log」と呼ばれるトランザクションログに記録され、その内容に基づいてメタデータも自動的に同期されるためです。したがって、こういった内部更新においては、Databricksが自動的に情報を反映してくれるため、手動で REFRESH TABLEを実行する必要はありません。
※詳細は公式ドキュメントでも確認できます。Delta Lake – Databricks SQL | Microsoft Learn
REFRESH TABLEは、Databricksにおいてクエリ結果が実際のデータを正しく反映するために重要な手段です。特に、複数のセッションが存在する場合や、外部データストレージ上でデータが更新された場合に、その効果を発揮します。
Databricksのキャッシュの仕組みを理解した上で、REFRESH TABLE を必要な場面に限定して使うことが、無駄なリソース消費を避け、システムのパフォーマンスを最適化し、より安定したパイプライン構築につながります。
5.まとめ
Databricksにおける外部テーブル使用時のキャッシュの仕組みと、それに伴うREFRESH TABLEコマンドの重要性について、具体例を交えて解説しました。
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
・Azure Databricks連載シリーズはこちら
この記事を読んだ方へのオススメコンテンツはこちら
この記事を書いた人

- 双日テックイノベーション(旧:日商エレクトロニクス)特設サイト「Azure導入支援デスク」サイトマスターです。