目次
1. はじめに
皆さんこんにちは。
前回の連載の続きとして、Azure Databricksの「汎用クラスタ作成」について説明していきます。
今回は実際に汎用クラスタの作成したあと、汎用クラスタ変更/権限付与/起動・停止までを実施したいと思います。
第1回:「汎用クラスタ作成」をしてみる (今回)
第2回:「SQL Warehouse作成」をしてみる
第3回:「ジョブクラスタ作成」をしてみる
2.汎用クラスタ作成
2-1.汎用クラスタ作成
こちらの手順でワークスペースにアクセスします。
「コンピュート」を選択し、それから表示された画面で「コンピュートを作成」をクリックします。
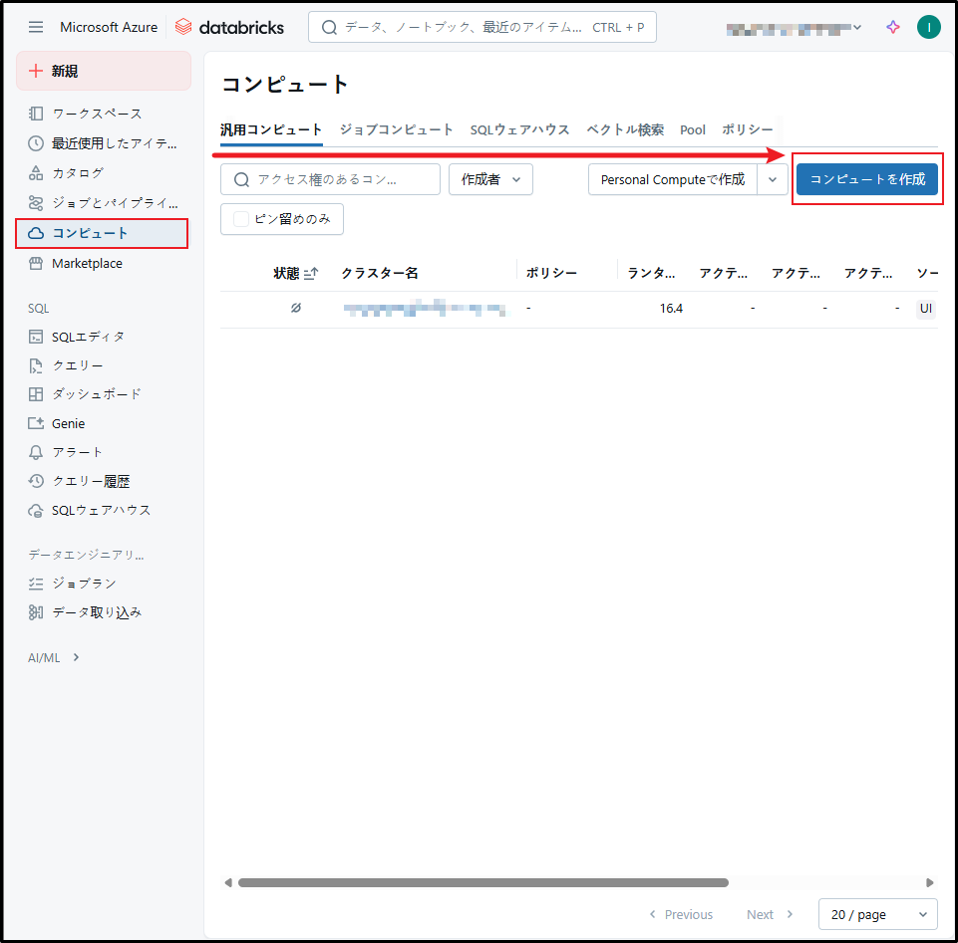
UIを使用して共通クラスタの作成
必要な設定を行います。
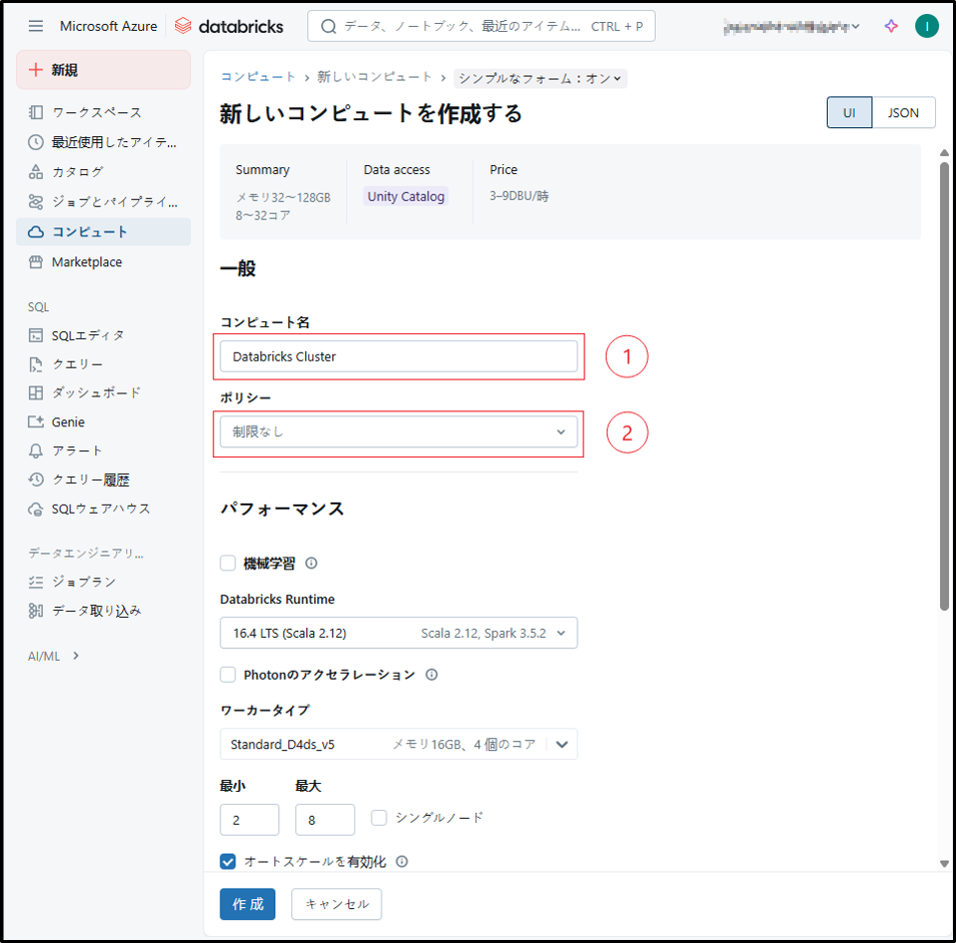
① 「コンピュート名」を入力します。
②プルダウンリストからポリシーを選択します。
利用ユーザーを制限しない→制限なし
小〜中規模のデータや、pandasやscikit-learnなどのライブラリを使用する場合に適しています。Sparkはローカルモードで実行されます。→Personal Compute
高度で複雑なデータサイエンスプロジェクトを専用リソースで実行する場合に適しています。→Power User Compute
チームで共有して、対話的なデータ探索、データ分析、機械学習を行う場合に適しています。→Shared Compute
チームで共有して、対話的なデータ探索、データ分析、機械学習を行う場合に適していますが、Unity Catalog にはアクセスできません。→Legacy Shared Compute
(続き)必要な設定を行います。
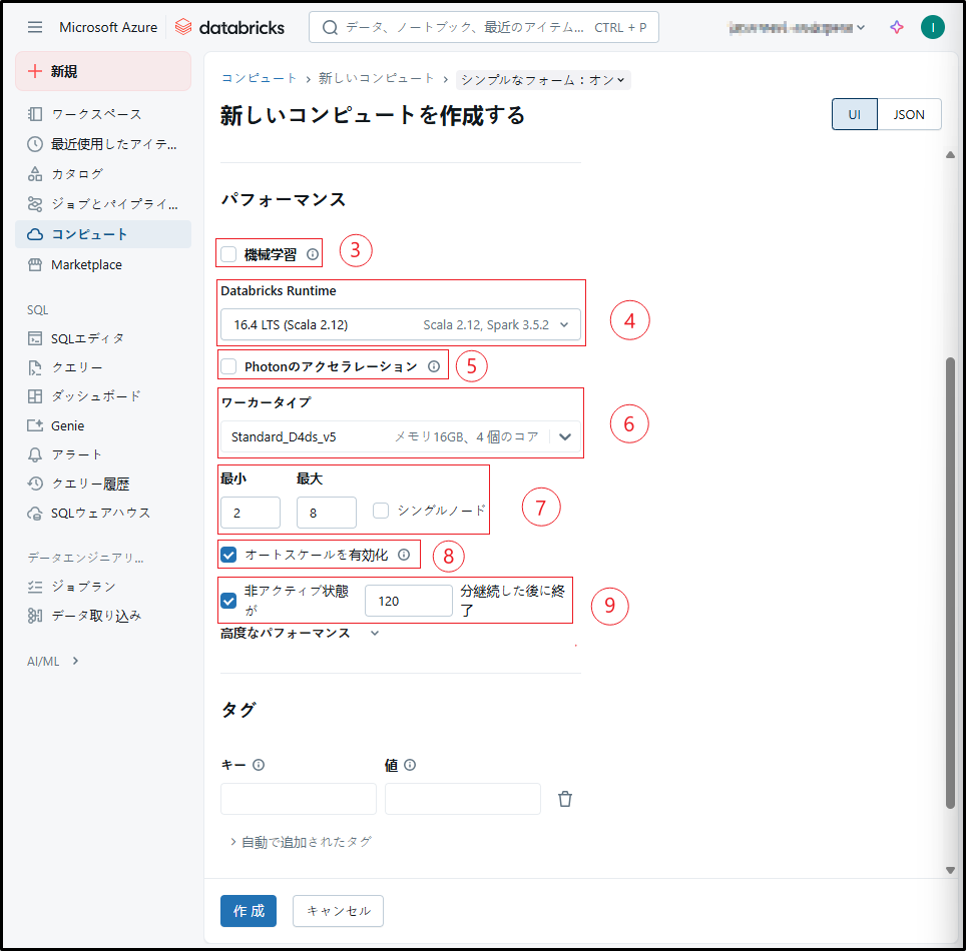
③ 既存のライブラリを使用して機械学習用のDatabrick runtimeを選択する場合、「機械学習」のチェックボックスをオンにします。
④ Databricks runtime
最新版を指定します。
または状況に応じて適切なバージョンを選択します。
参考URL:Databricks ランタイム – Azure Databricks | Microsoft Learn
⑤ Photonのアクセラレーション
Photonは最新のApache Sparkワークロードを加速し、
ワークロード当たりの総コストを削減します。
参考URL: Photon ランタイム – Azure Databricks | Microsoft Learn
⑥ ワーカータイプ
クラスタのスペックまたはプールを選択します。
⑦ 最小 最大
「シングルノード」のチェックボックスをオンにしません。
オートスケーリングを有効にした場合にホストの最小数、最大数を入力します。
⑧ オートスケールを有効化
ホストのオートスケーリングの有無を選択します。
チェックを付けた場合、「⑨」で最小数、最大数を設定します。
参考URL:クラスターを構成する – Azure Databricks | Microsoft Learn
⑨ 非アクティブ状態が「120」分継続した後に終了
ホストの自動停止の有無を選択します。
非アクティブ状態が続いた場合、自動で停止させるまでの時間(分)の設定をします。
参考URL:クラスターの管理 – Azure Databricks | Microsoft Learn
(続き)必要な設定を行います。
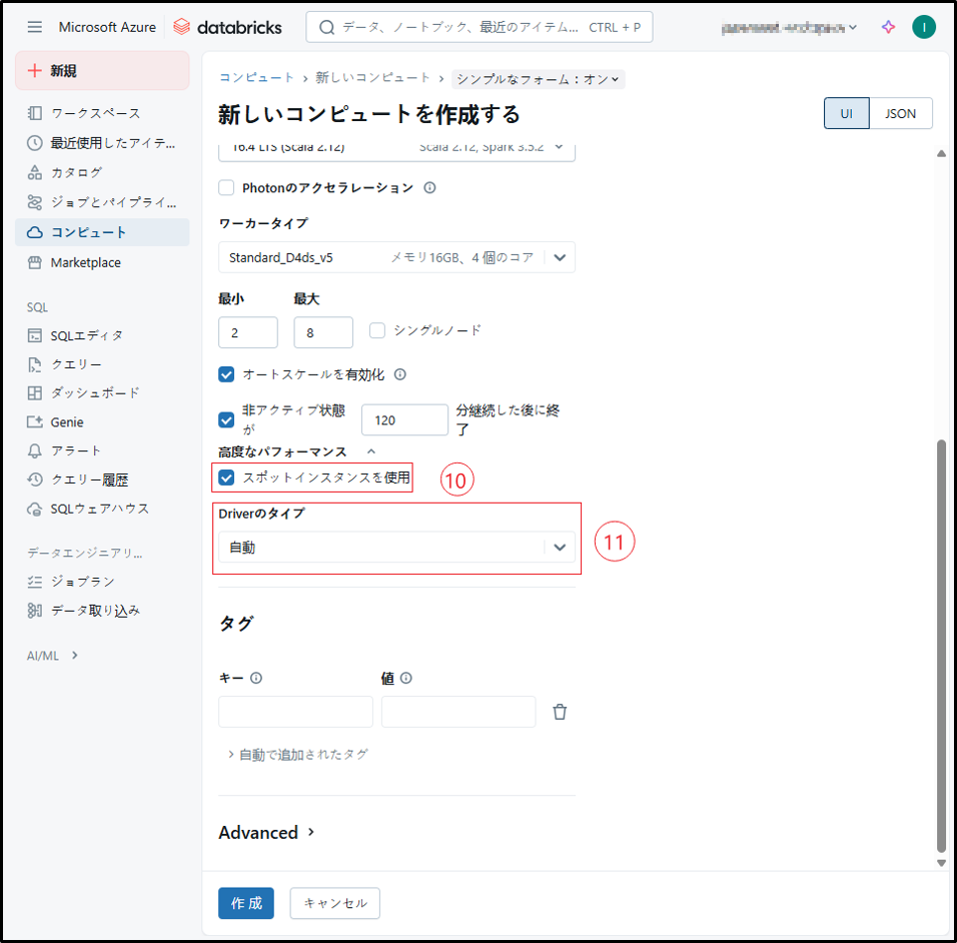
⑩ スポットインスタンスを使用
チェックを入れた場合、
ホストにAzureの余剰リソースを使用します。
80%のコスト削減が見込まれますが、
混雑している場合はクラスタが再起動し、
チェックを入れない場合と同様の専用のインスタンスに
切り替わります。本番環境ではおすすめしません。
参考URL:クラスターを構成する – Azure Databricks | Microsoft Learn
⑪ Driverのタイプ
「自動」に設定するか、要求に応じて別のオプションを選択することも可能です。
(続き)必要な設定を行います。
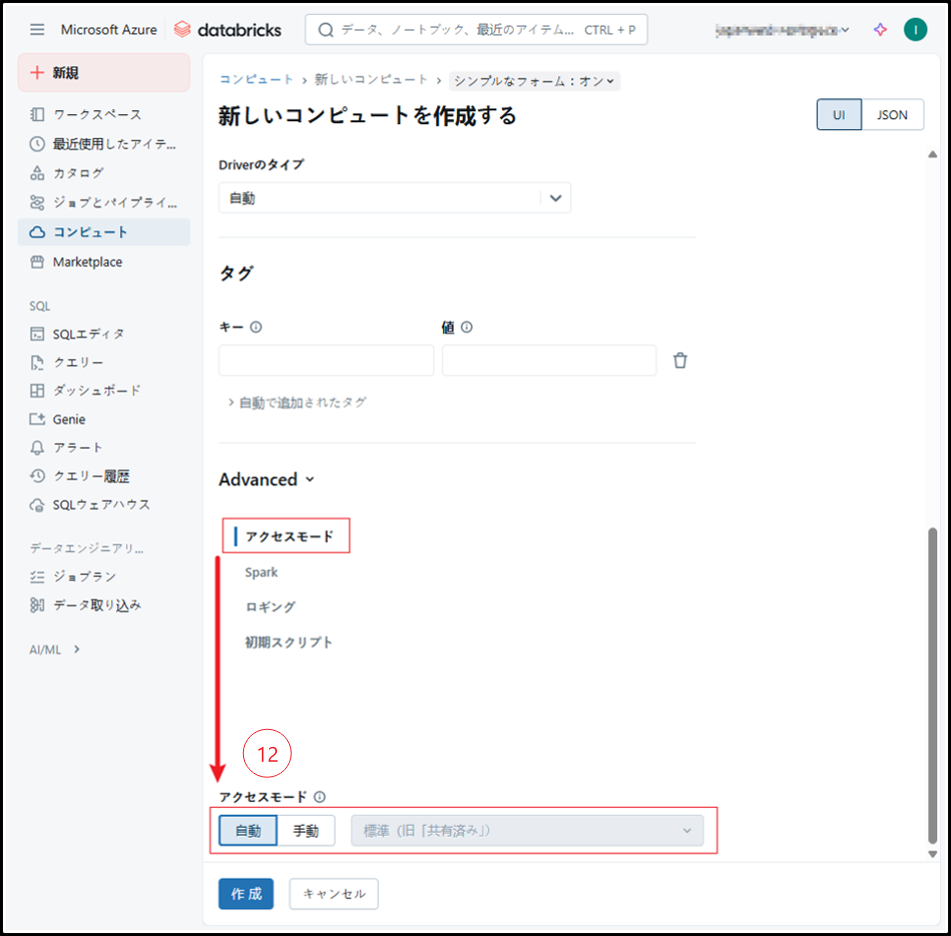
⑫ アクセスモード
Databricksは、コンピュート構成に基づいて最適なアクセスモードを自動的に選択します。
特別なモードを使用する場合は、「手動」を選択します。
(続き)必要な設定を行います。
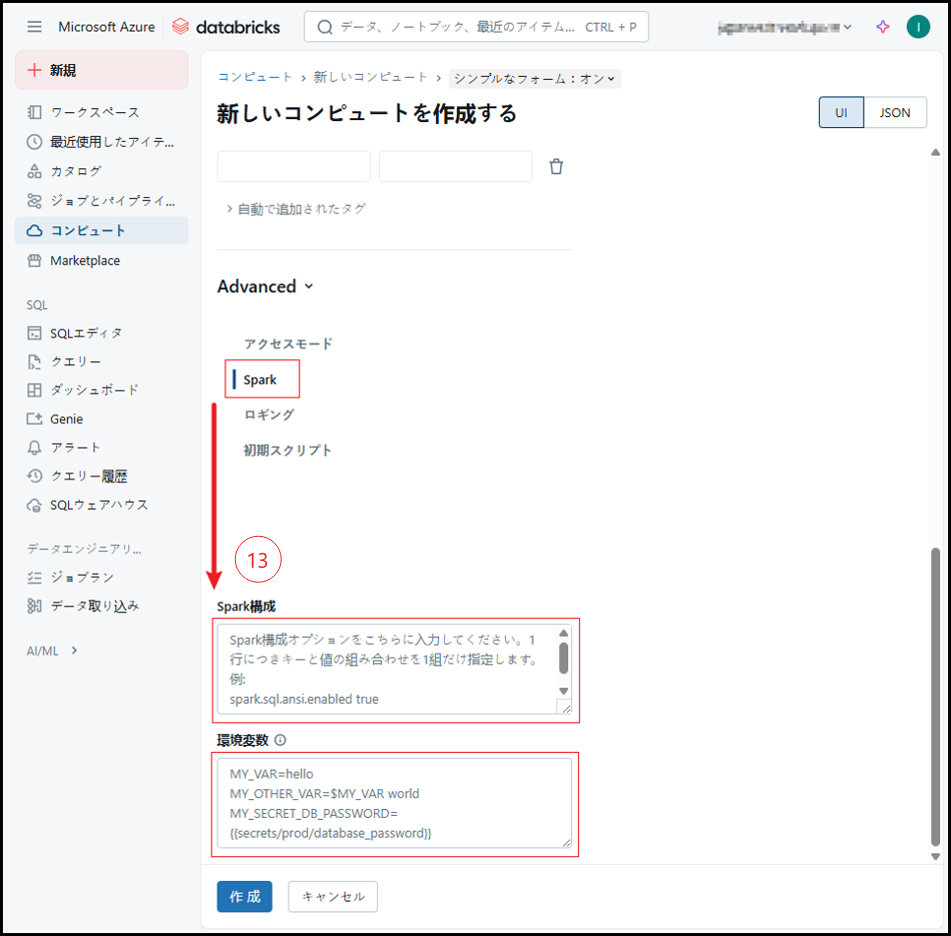
⑬ Spark
Sparkの構成は環境変数を通じて設定されます。
ここで設定された変数は、該当の環境変数のデフォルト値を上書きします。
(続き)必要な各設定を行います。
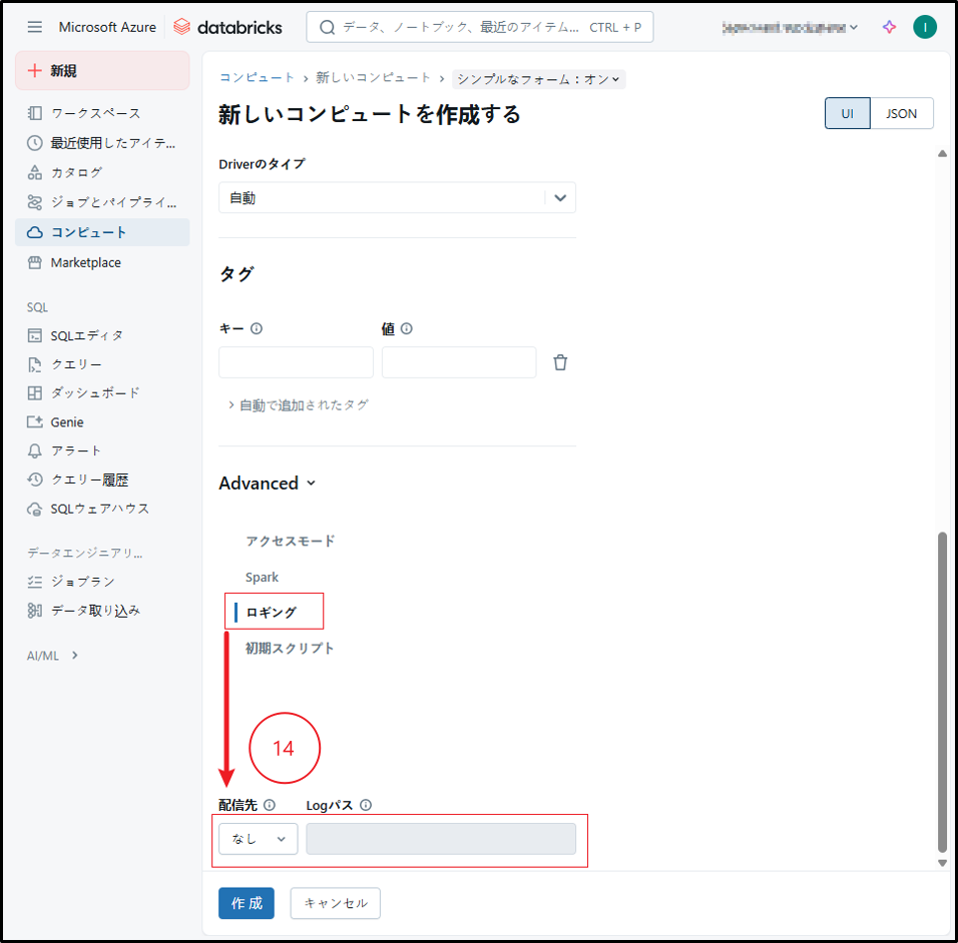
⑭ ロギング
「ロギング」を選択してクラスタログの配信先アドレスを設定します。
すべてのクラスタのログは、ベストエフォートベースで5分ごとにクラウドストレージへ送信されます。
各設定をします(続き)
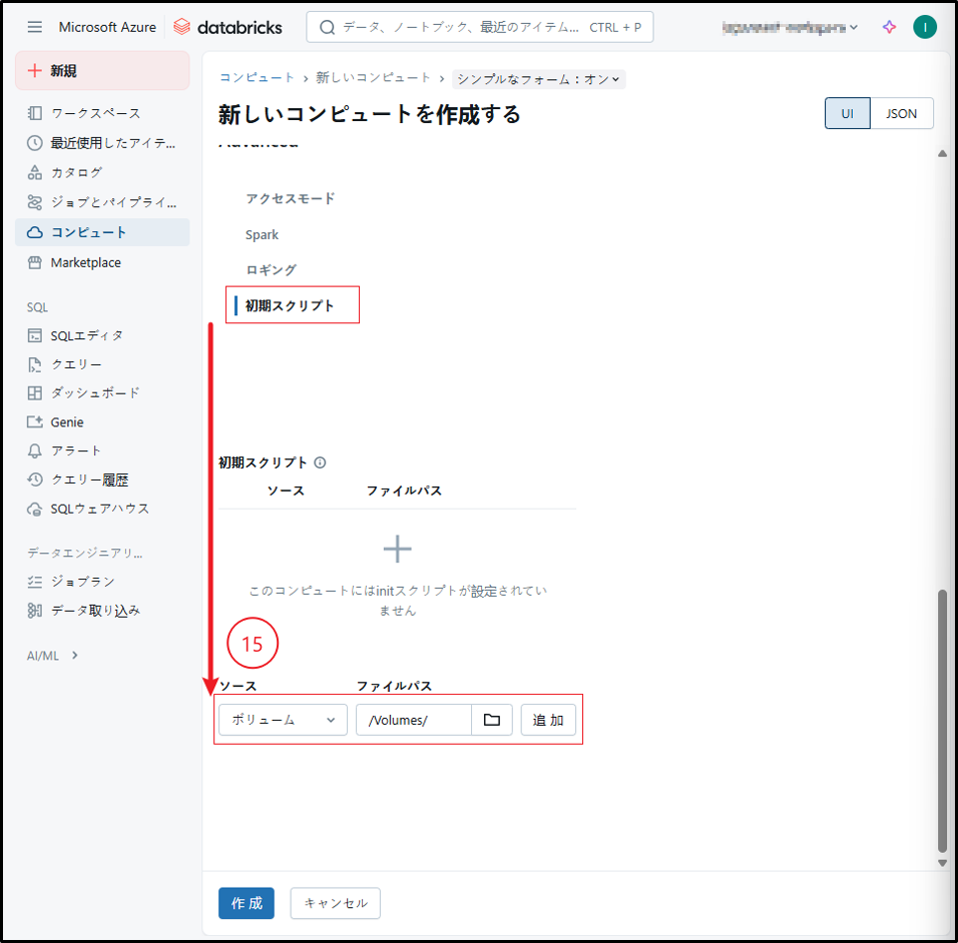
⑮ ロギング
このコンピュートに対して定義された初期スクリプトを追加します。
「作成」ボタンをクリックします。
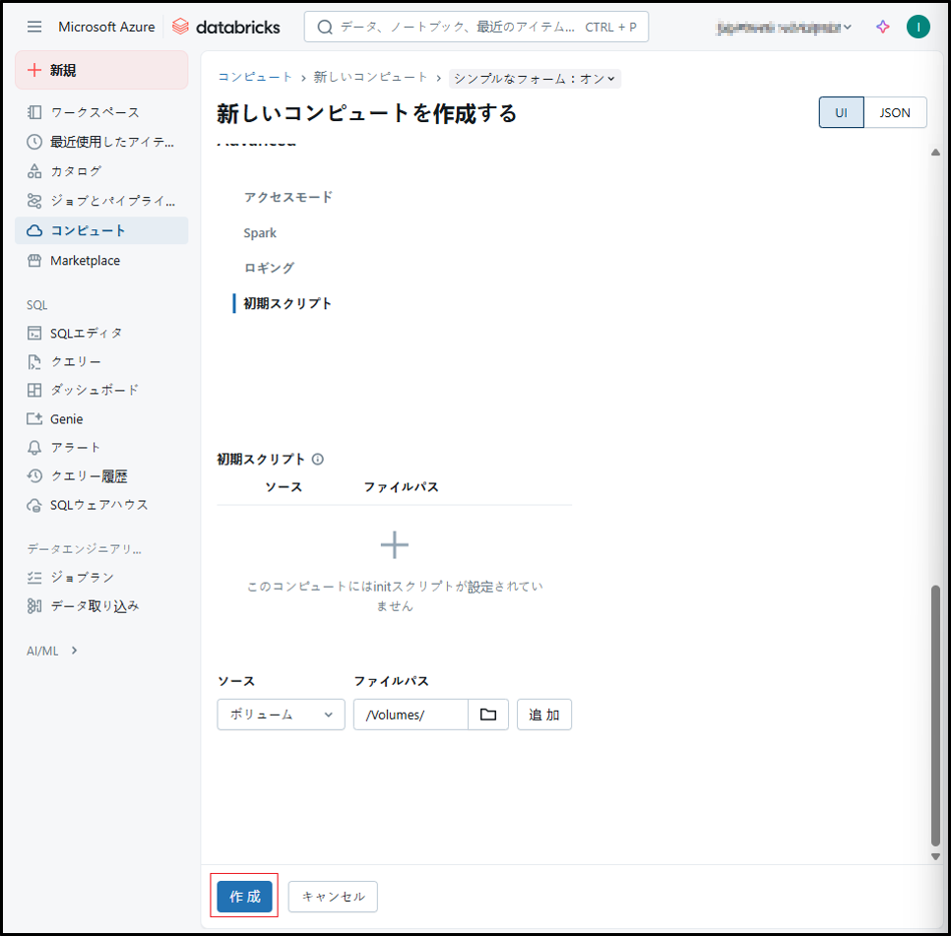
以上で汎用クラスタ作成が完了です。
JSONを使って共通クラスタの作成
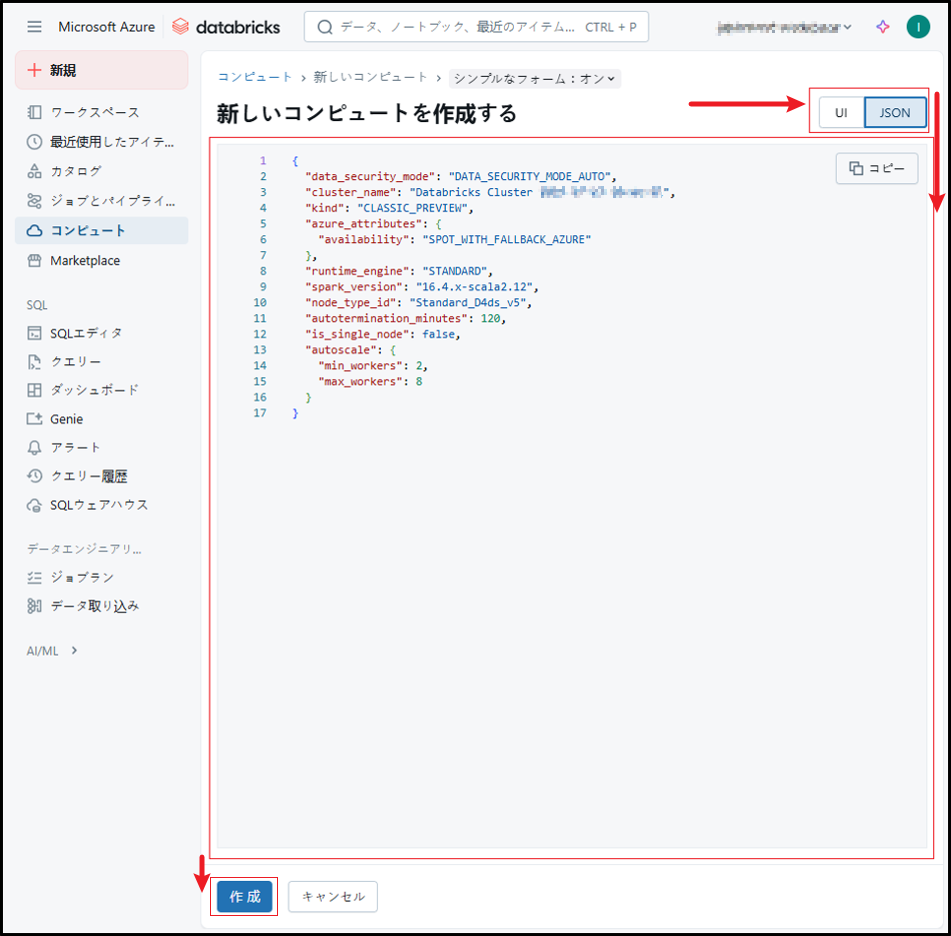
「JSON」をクリックします。
JSONコマンドで構成を設定します。
「作成」ボタンをクリックします。
以上で汎用クラスタ作成が完了です。
2-2.汎用クラスタ変更
作成した汎用クラスタは変更する事が出来ます。
当手順を実施する際の前提条件は以下の通りです。
- 作業用Azure AD(Databricks)アカウントに下記の権限が付与されていること
- Databricks構築パッケージの「Admin Group」
または「Can Manage」権限が付与されたユーザ・グループ
- Databricks構築パッケージの「Admin Group」
こちらの手順でワークスペースにアクセスします。
左メニューから「コンピュート」を選択し、それから表示された画面で編集するクラスタをクリックします。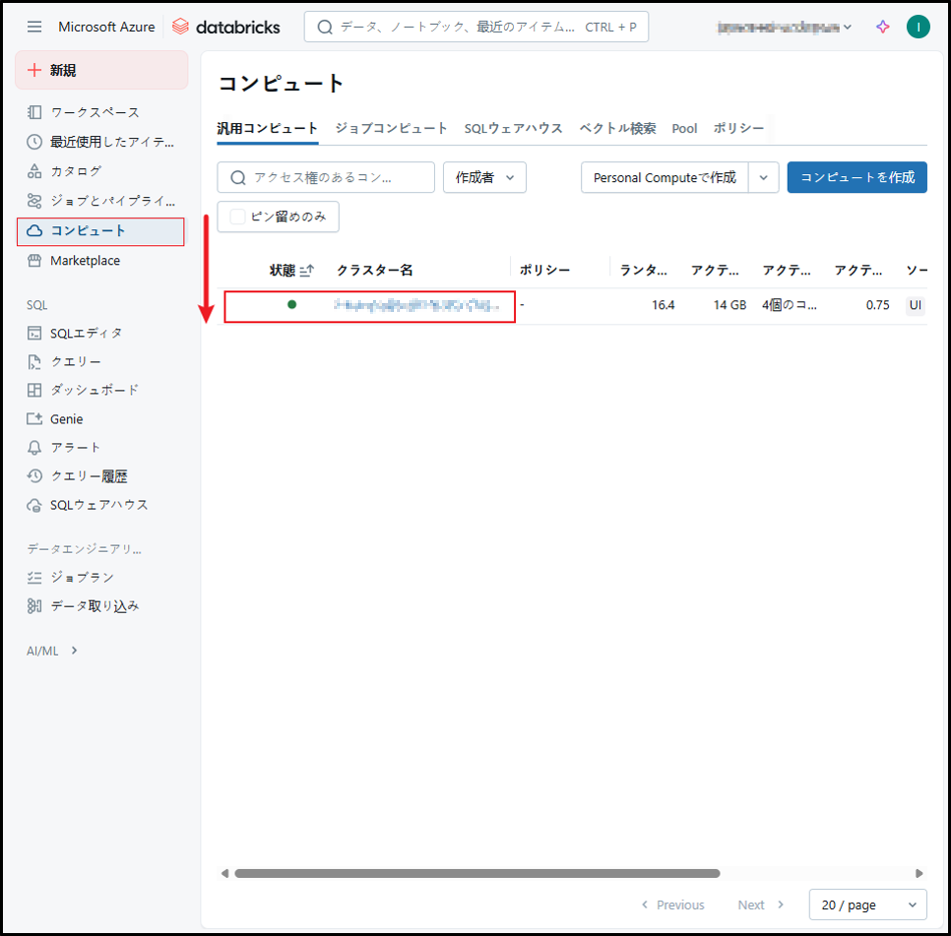
「編集」ボタンをクリックします。
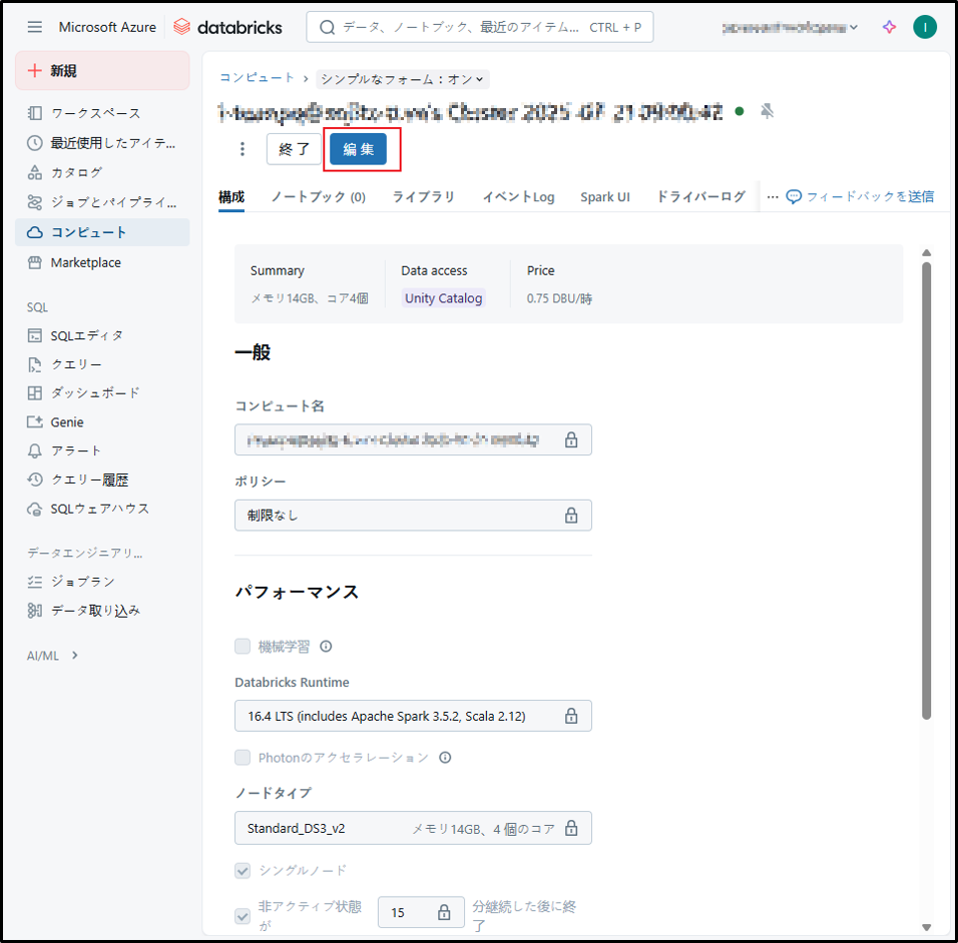
必要な内容を編集し、「確認して再起動」ボタンをクリックします。
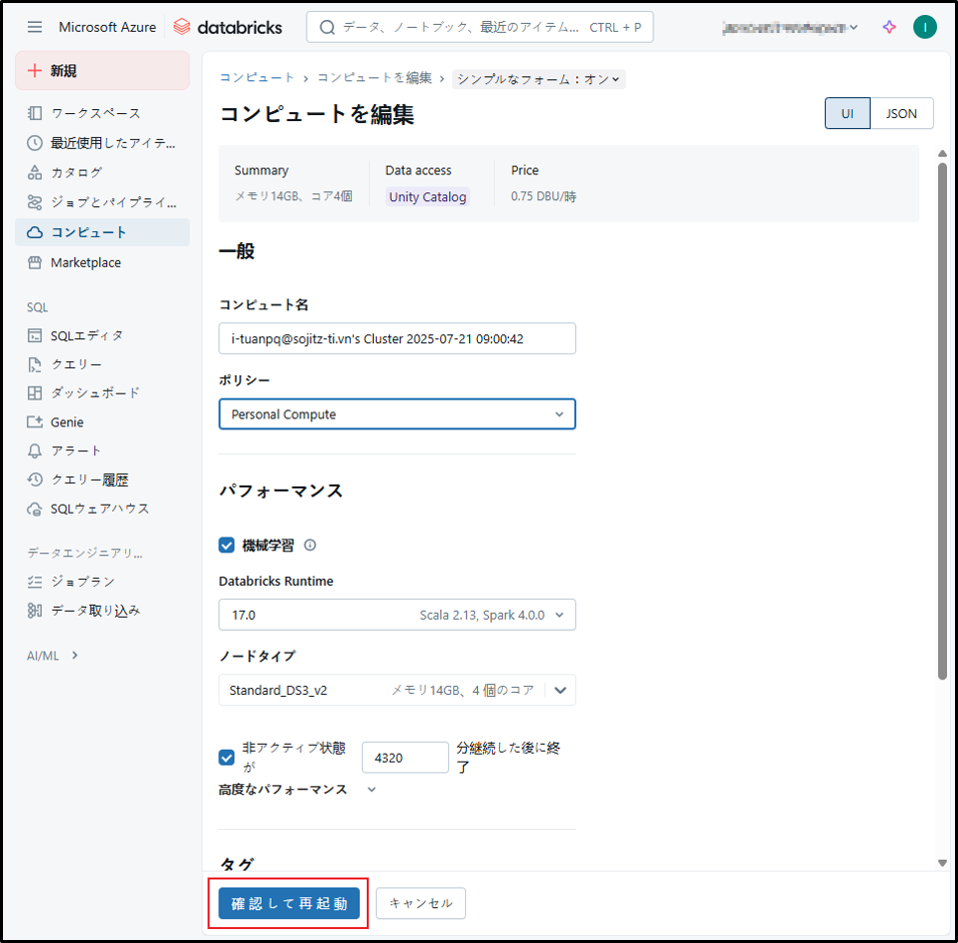
以上で汎用クラスタの変更が完了です。
2-3.汎用クラスタの権限変更
汎用クラスタの権限変更については、別連載のこちらの手順をご確認ください。
※「■汎用クラスターへの権限割り当て」の箇所です
2-4.汎用クラスタの起動
こちらの手順でワークスペースにアクセスします。
左メニューから「コンピュート」をクリックし、それから表示された画面で起動する共通クラスタをクリックします。
「起動」ボタンをクリックします。
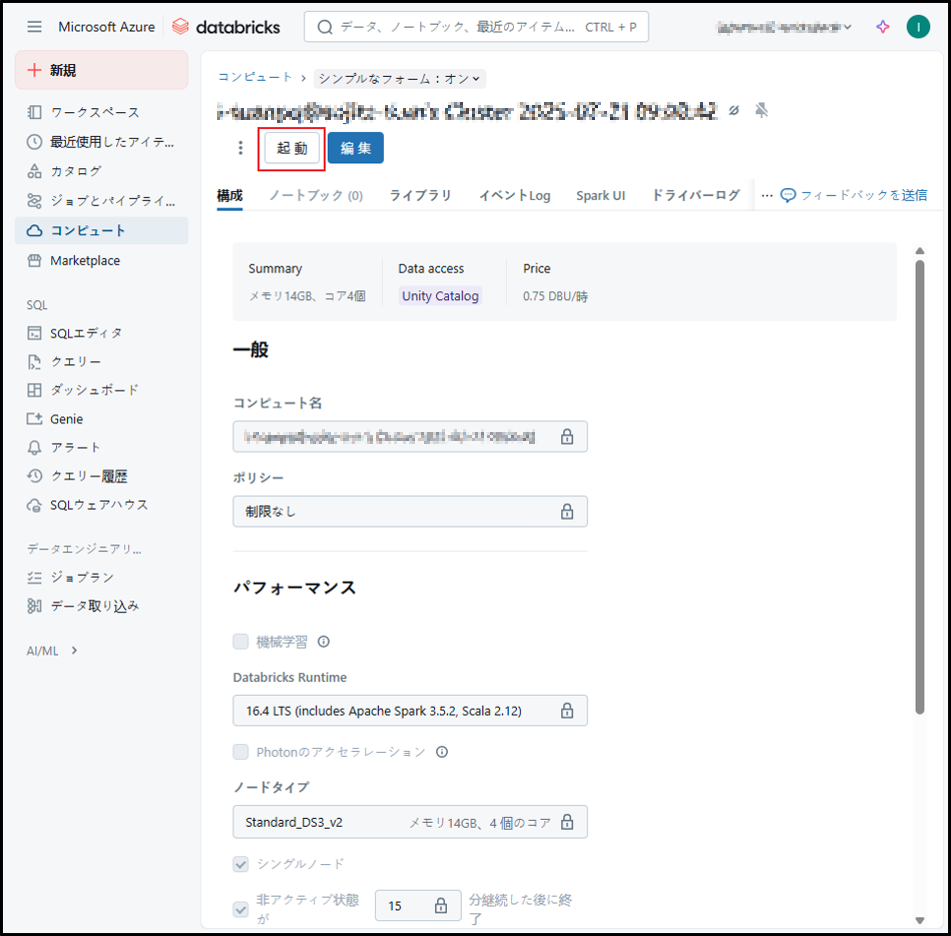
汎用クラスタが起動します(ステータスが緑色になれば起動完了という状態になる)。
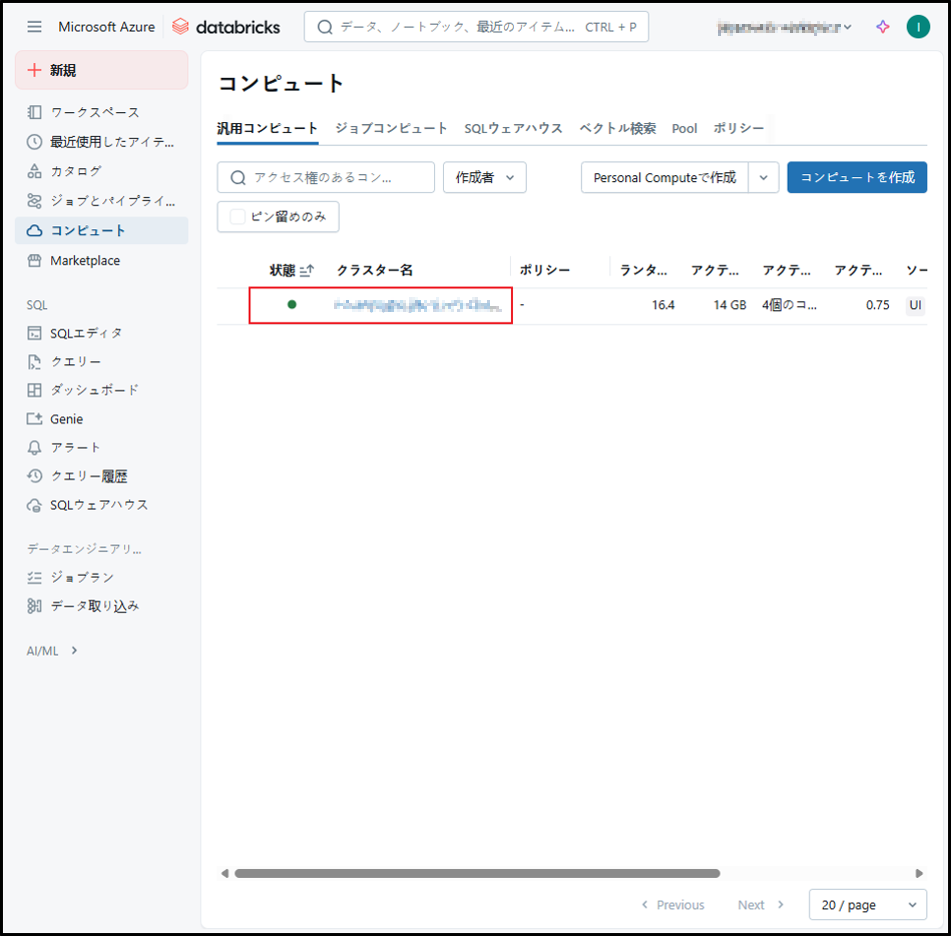
2-5.汎用クラスタの停止
こちらの手順でワークスペースにアクセスします。
左メニューから「コンピュート」を選択し、それから表示された画面で停止するクラスタをクリックします。
「終了」ボタンをクリックします。
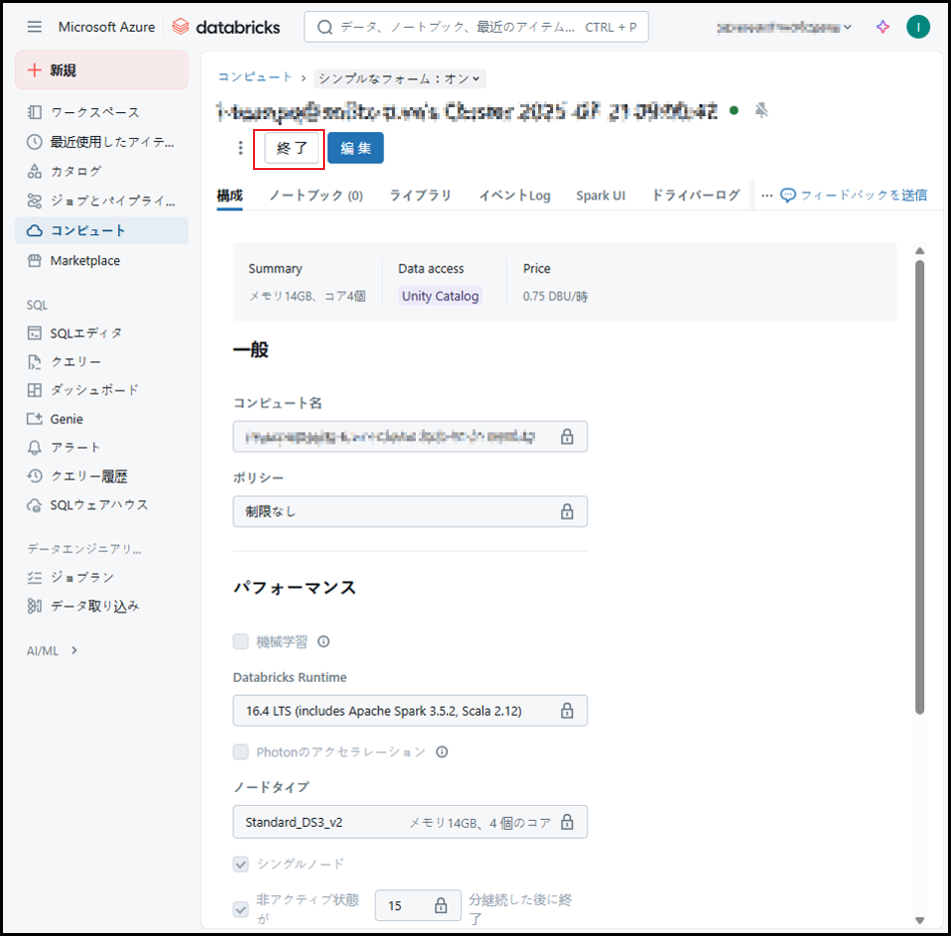
汎用クラスタが停止します(ステータスが灰色になれば停止完了という状態になる)。
3. まとめ
本記事ではAzure Databricksにおける「汎用クラスタ作成/変更/起動/停止」「権限付与」について説明しました。
本連載では、
第1回:「汎用クラスタ作成」をしてみる (今回)
第2回:「SQL Warehouse作成」をしてみる
についてご説明しています。
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
Azure Databricks連載記事のまとめはこちら
![]() お問い合わせはこちら
お問い合わせはこちら
この記事を読んだ方へのオススメコンテンツはこちら
この記事を書いた人
この投稿者の最新の記事
- 2023年4月18日ブログ【Azure Databricks】ジョブ監視をしてみる(番外編)
- 2023年4月17日ブログ【Azure Databricks】ジョブ監視をしてみる(後編)
- 2023年4月13日ブログ【Azure Databricks】ジョブ監視をしてみる(前編)
- 2023年3月30日ブログ【Azure Databricks クラスタ管理】「SQL Warehouse作成」をしてみる