目次
1.はじめに
皆さんこんにちは。
Azure Databricksでデータを処理する際、必ずしもすべてのデータが完全であるとは限りません。Delta Live Tableを用いて外部ロケーションからCSVデータを読み込み、ストリーミングテーブルを作成する際に、以下のような一般的な問題に遭うことがあります。
- 列が欠落している、またはフォーマットが正しくないデータ
- 特殊文字や不正な形式が含まれているデータ
- データに不備があるが、ジョブを中断させたくない
これらの問題を適切に対処しないと、パイプラインが停止し、ETL 処理全体に影響を与える可能性があります。したがって、正常なデータの処理を継続しながらエラーレコードを保存して、どのCSVファイルがエラーを引き起こしたかを特定できますか?
「badRecordsPath」を利用してデータ読み込み時に不良レコードを絞り込み、エラーレコードを制御・保存することで、後続の処理や調査に活用できます。
今回は、Azure Databricksにおける【badRecordsPath】を活用し、エラーデータを効率的に処理する方法について説明していきます。
2.前提条件
この例を実施するため、以下が必要です。
- Databricksワークスペース: Unity Catalogが有効になっていること
- ストレージアカウント: 既存のものであり、コンテナを作成する権限があること
- Demo-Data.csv: 下記4-1のCSVファイルをダウンロードしてください
3.「badRecordsPath」とは
「badRecordsPath」はSparkのオプションの一つであり、パイプライン全体を失敗させるのではなく、エラーとなったレコードを絞り込み、指定したフォルダーに保存することができます。レコードが正しいフォーマットで読み取れない場合、そのレコードはJSON形式でこのパスに保存されます。
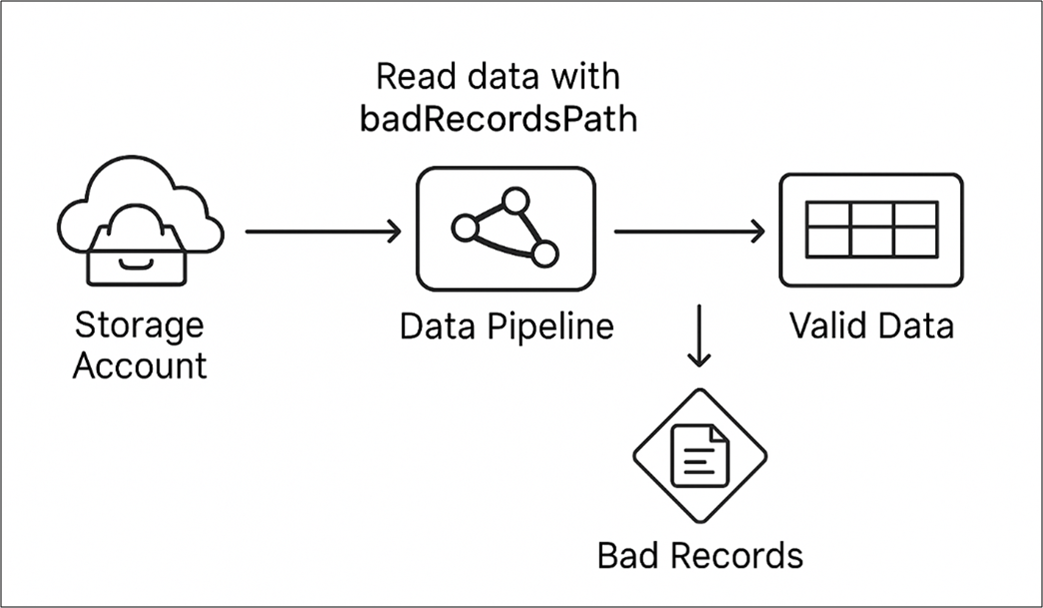
不良レコードの処理方法をより深く理解するために、以下のステップに沿って実施していきます。
① CSVデータの読み込み: Delta Live Table(Python)を使用し、外部ロケーションからCSVデータを読み込みます。
② 不正なレコーの処理: badRecordsPathを設定して、不良レコードを自動的に絞り込み、、外部ロケーションにJSONファイルとして保存します。
③ 不良レコードの読み取り及び分析: Python Notebook又はSQL Alertを使って保存された不良レコードを読み取り、どのCSVファイルにエラーが含まれていたのかを特定します。
4.Delta Live Table(Python)による外部ロケーションからのCSV読み込み
4-1.デモ用のデータ準備
今回の例を実施するためには、CSVデータを準備し、外部ロケーションに保存する必要があります。まず、以下のCSVデータをダウンロードしてください。このCSVファイルには3つのレコードが含まれています。そのうち、2つは有効で、1つは無効です。
Demo-Data.csvファイルをダウンロードするにはここをクリックしてください
| id | student_name | student_code |
| 1 | Grace | 5613 |
| 2 | Hank | invalid_int |
| 3 | Ivy | 4566 |
- 2番目のレコードは不良レコードであり、「student_code」フィールドに文字列型の値「invalid_int」が含まれています。
- 「student_code」フィールドには、整数型「Int」の値が必要です。
ストレージアカウント画面から、CSVデータおよび不良レコードを保存するためのコンテナ「ext01」を作成します。
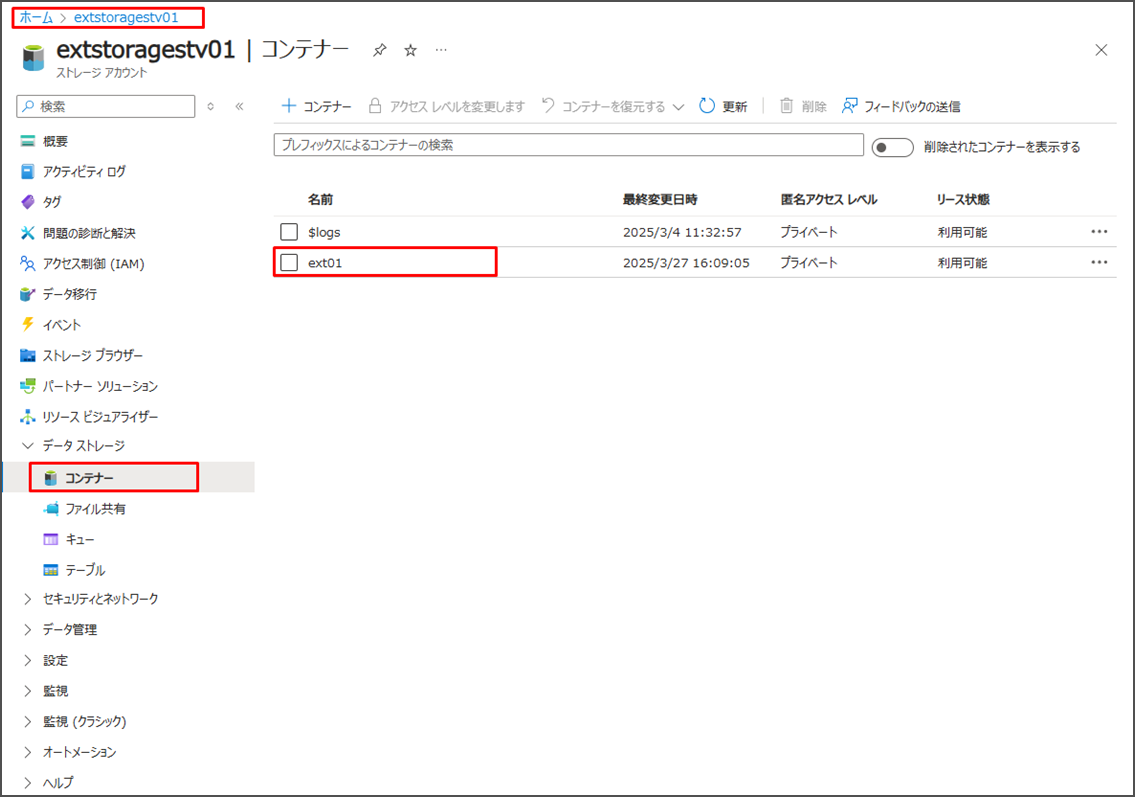
コンテナ「ext01」を開きます。
「アップデート」をクリックします。
「Demo Data.csv」ファイルを選択し、アップロードします。
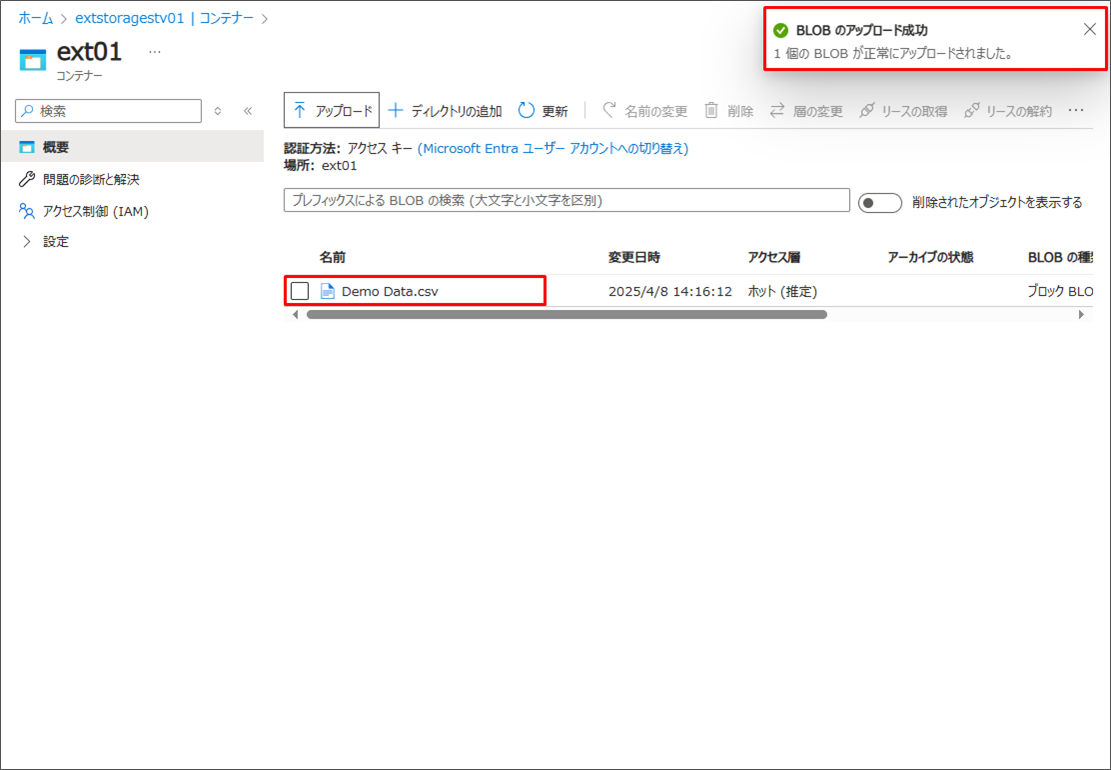
正常にアップロードされたか確認します。
コンテナ「ext01」に「Demo Data.csv」が表示されたか確認します。
4-2.Delta Live Tableの準備
「Databricksワークスペース」にアクセスします。
「カタログ」→「外部データ」にクリックします。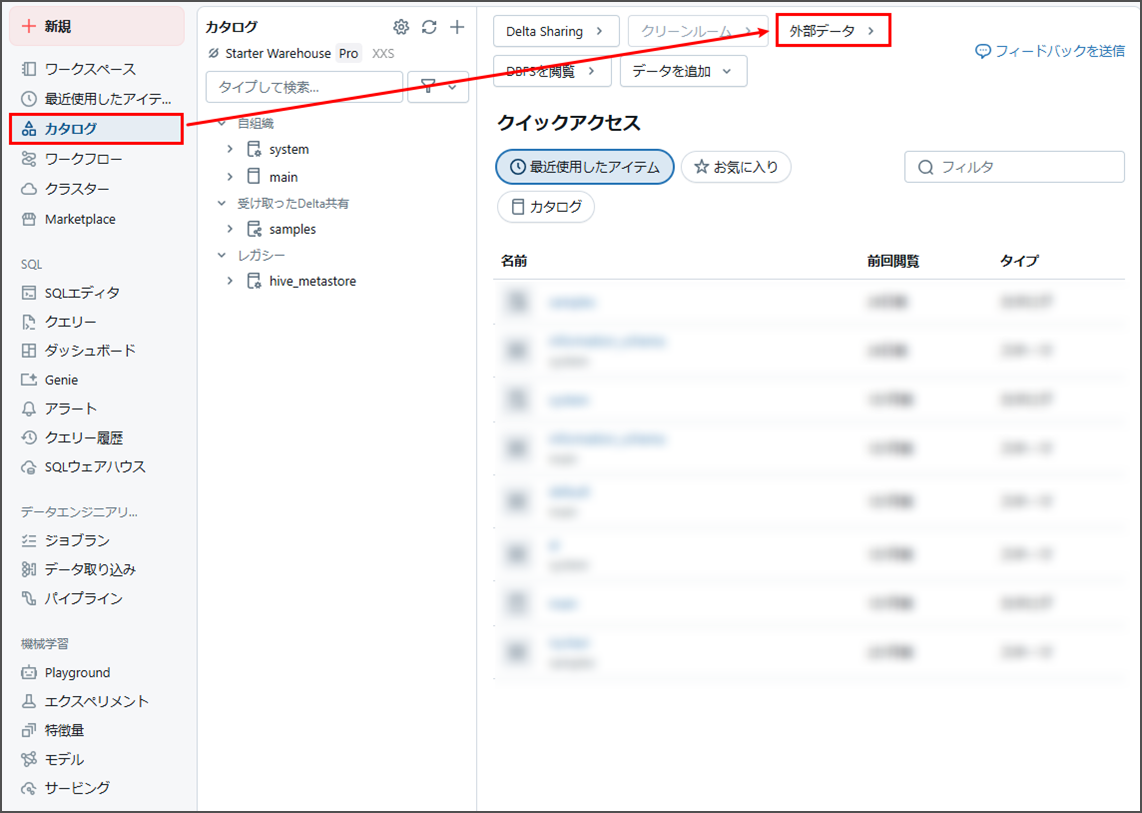
「外部ロケーションを作成」をクリックします。
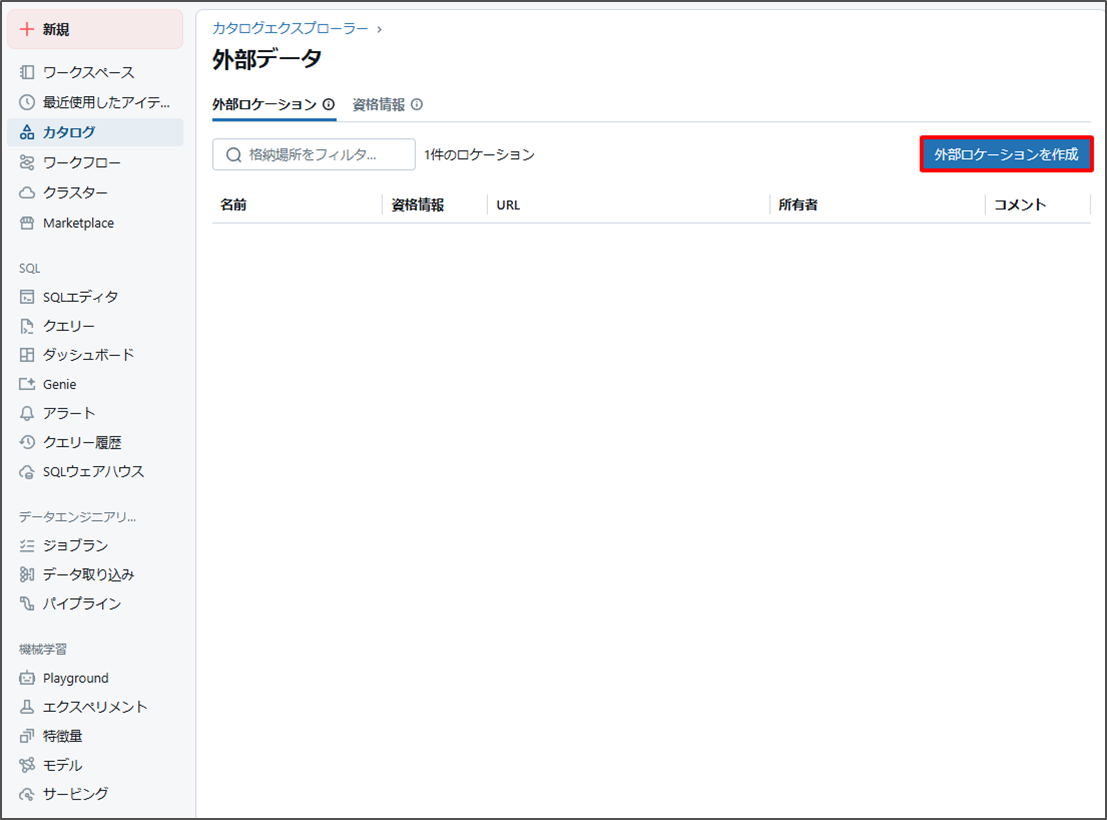
以下の情報で外部ロケーションを作成します。
- 外部ロケーション名: ext01
- URL: abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/
- <container_name>: Azureストレージ内のコンテナ名
- <storage_account_name>: Azureストレージアカウント名
- ストレージ資格情報: 事前に作成した認証情報を使用して、ストレージにアクセスします。
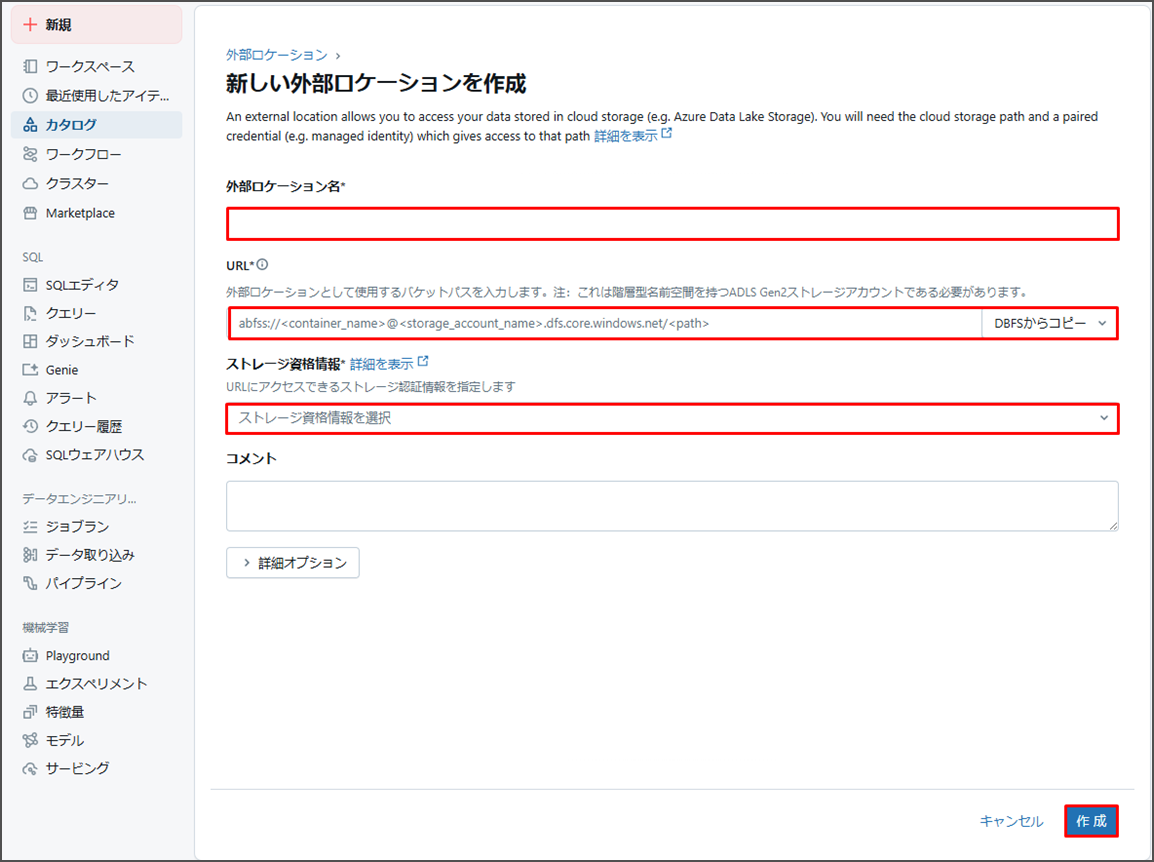
外部ロケーションが正常に作成されました。
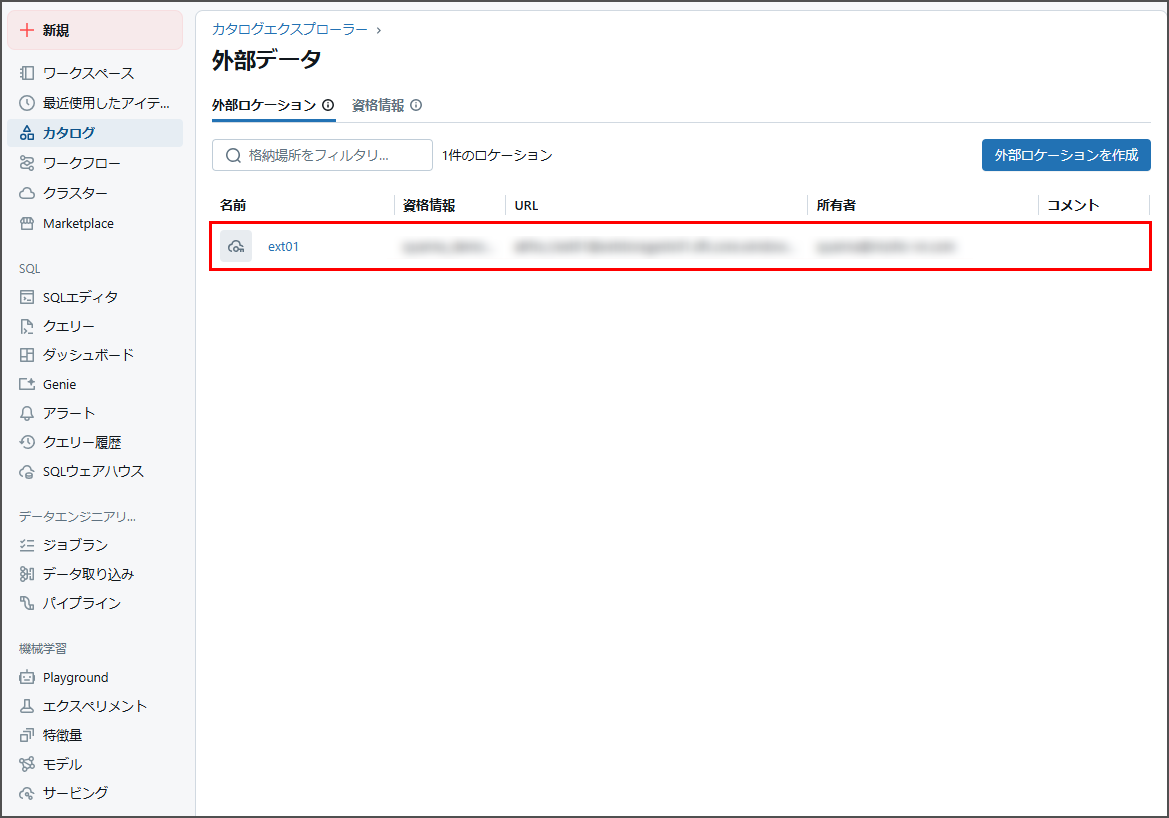
「ext01」にアクセスし、「ブラウザ」を選択します。
「Demo Data.csv」ファイルが読み取られたことを確認します。
外部ロケーションのURLをコピーします。
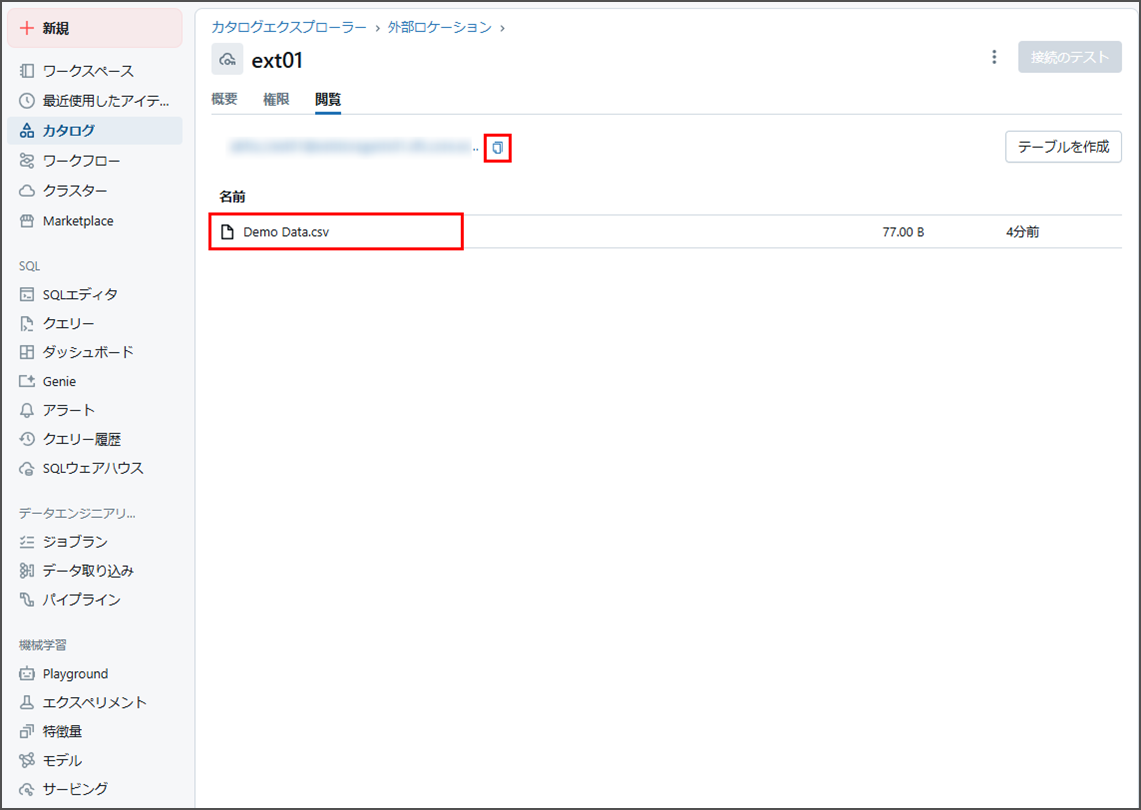
「パイプライン」→「パイプラインを作成」→「ETLパイプライン」をクリックします。
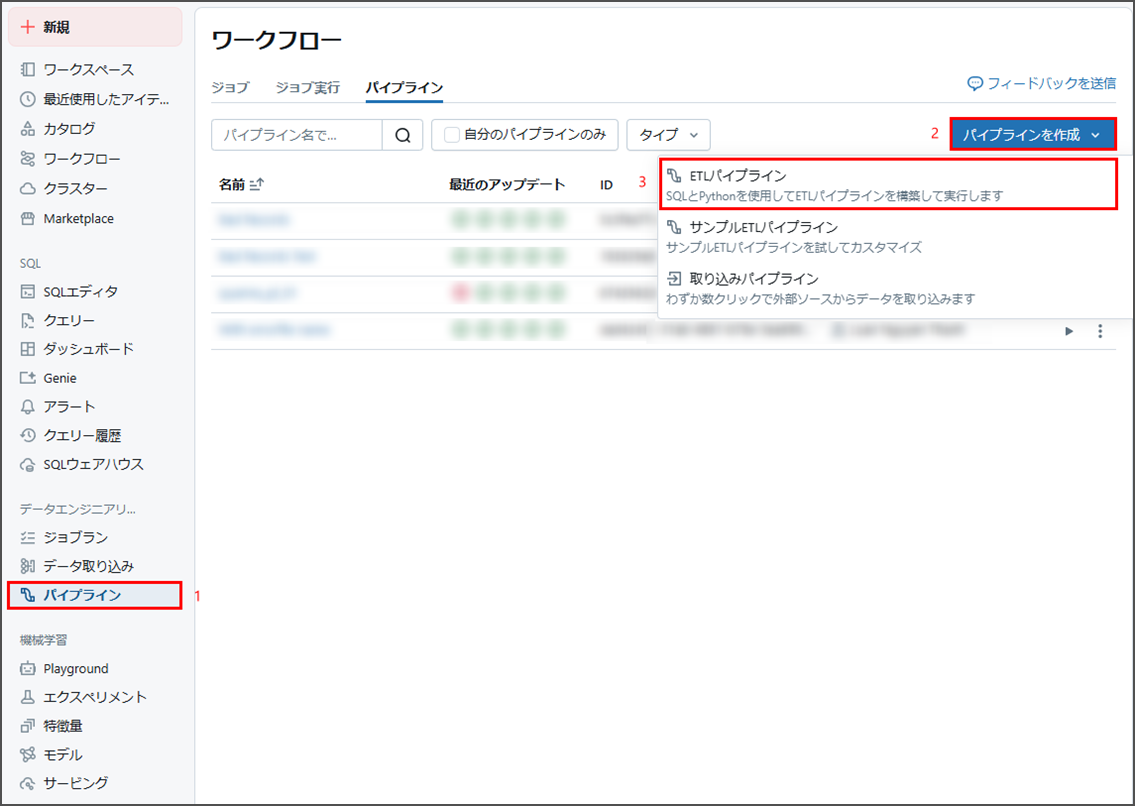
基本設定:
- パイプライン名: Bad Records
- ソースコード: (空白)
- パイプラインモード: トリガー
- ストレージオプション: Unity Catalog
- デフォルトカタログ: main
- デフォルトスキーマ: default
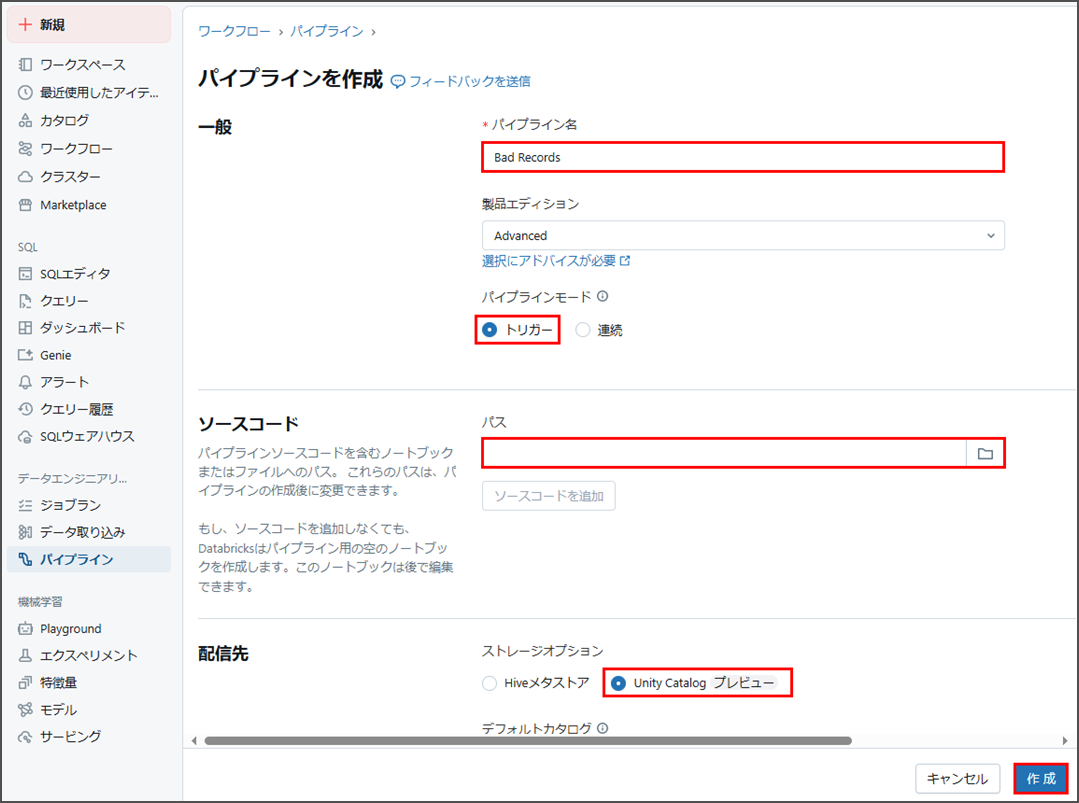
「パイプラインを作成」をクリックします。
Databricksが空のノートブックを作成し、そのあと編集できます。
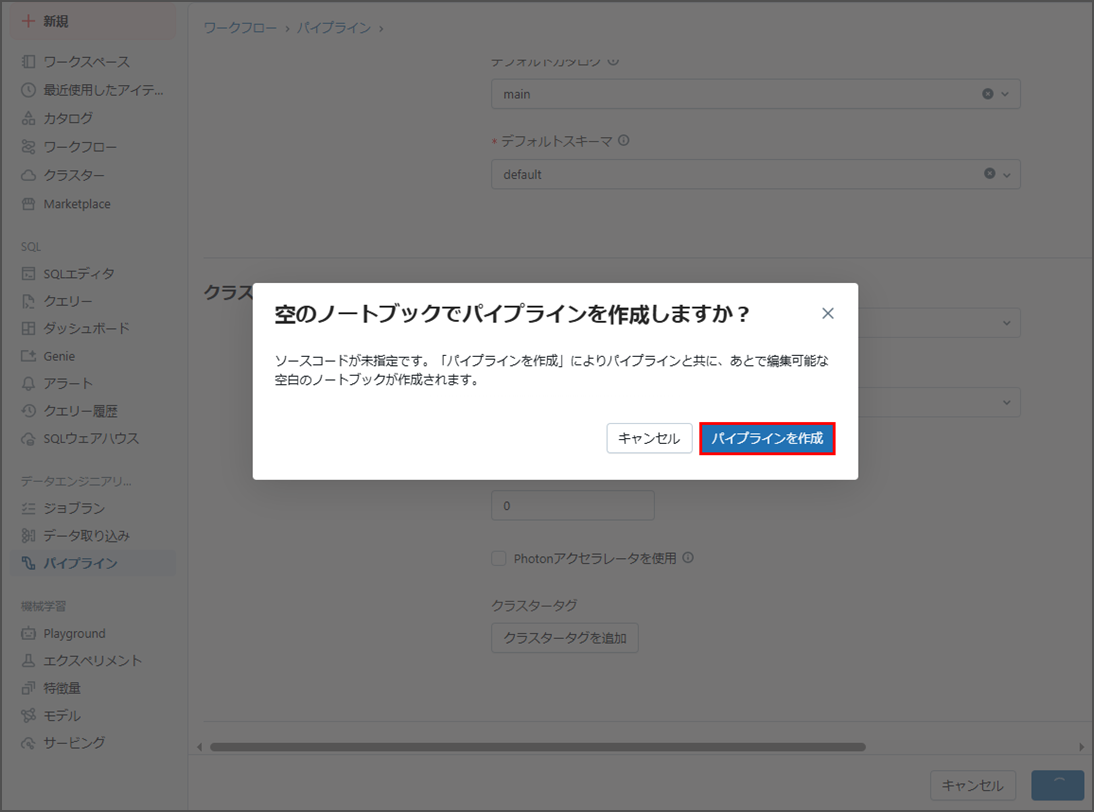
パイプラインが正常に作成されました。
対応するNotebookは自動的に作成されました。
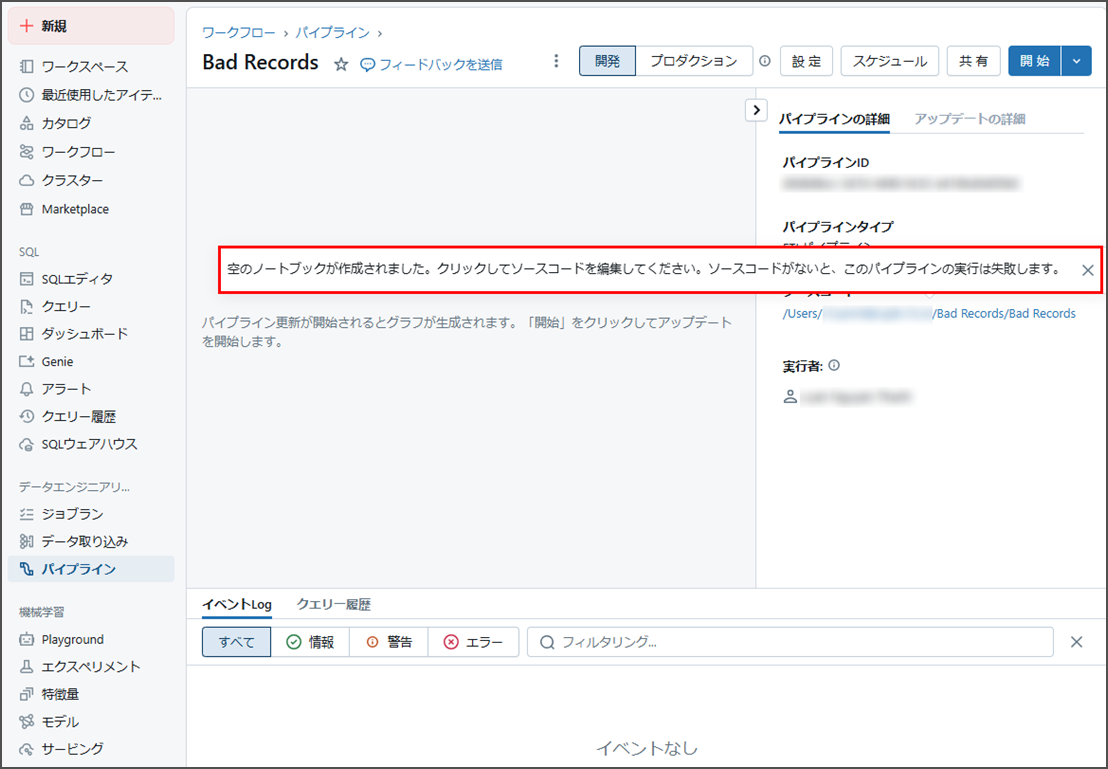
4-3.「badRecordsPath」を設定し、不良レコードを絞り込み、外部ロケーションに保存
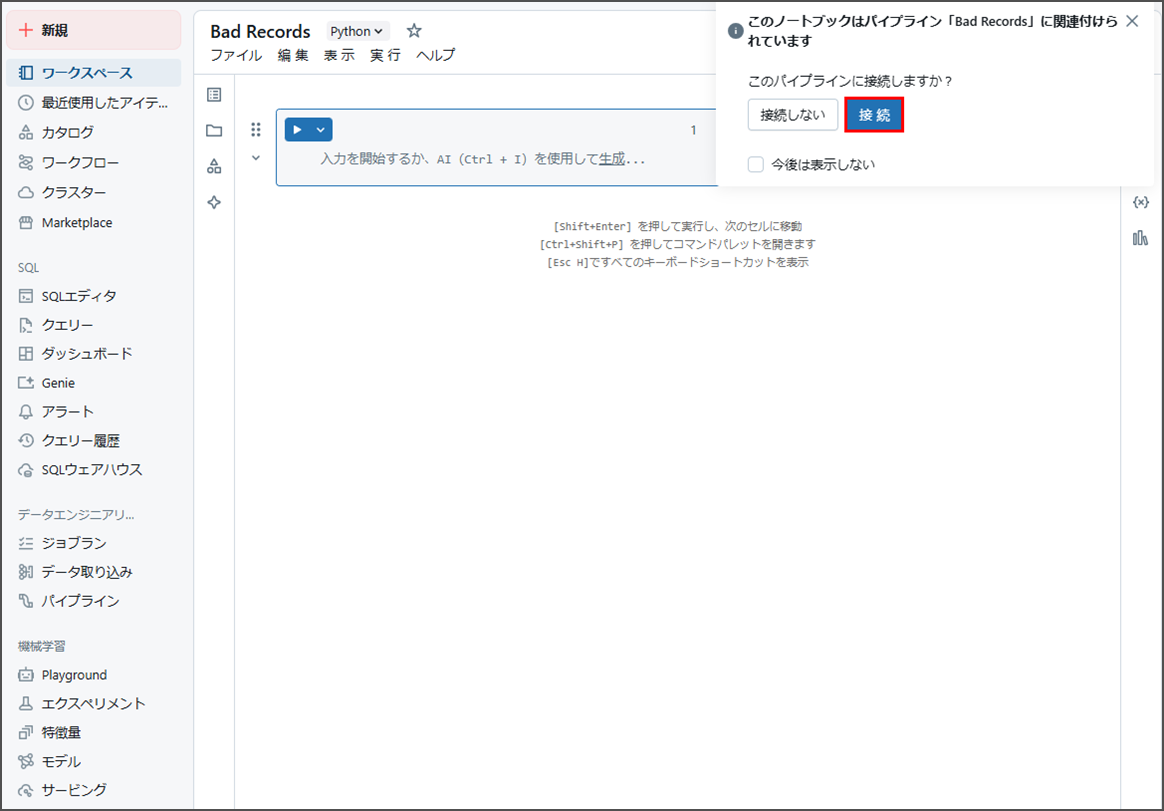
作成したノートブックをクリックし、編集します。
「接続」をクリックし、そのノートブックがパイプラインに関連付けます。
ノートブックに以下のコードを使用します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import dlt from pyspark.sql.functions import col, input_file_name from pyspark.sql.types import StructType, StructField, IntegerType, StringType @dlt.table( name="validated_csv_data", comment="CSV data with schema validation and bad records handling" ) def validated_csv_data(): # Define schema that expects integers strict_schema = StructType([ StructField("id", IntegerType(), True), StructField("student_name", StringType(), True), StructField("student_code", IntegerType(), True) ]) return ( spark.read .format("csv") .option("header", "true") .schema(strict_schema) .option("badRecordsPath", "<external-location-url>") .load("<external-location-url>") ) |
<external-location-url>: その前にコピーした外部ロケーションのURLに書き換えてください。
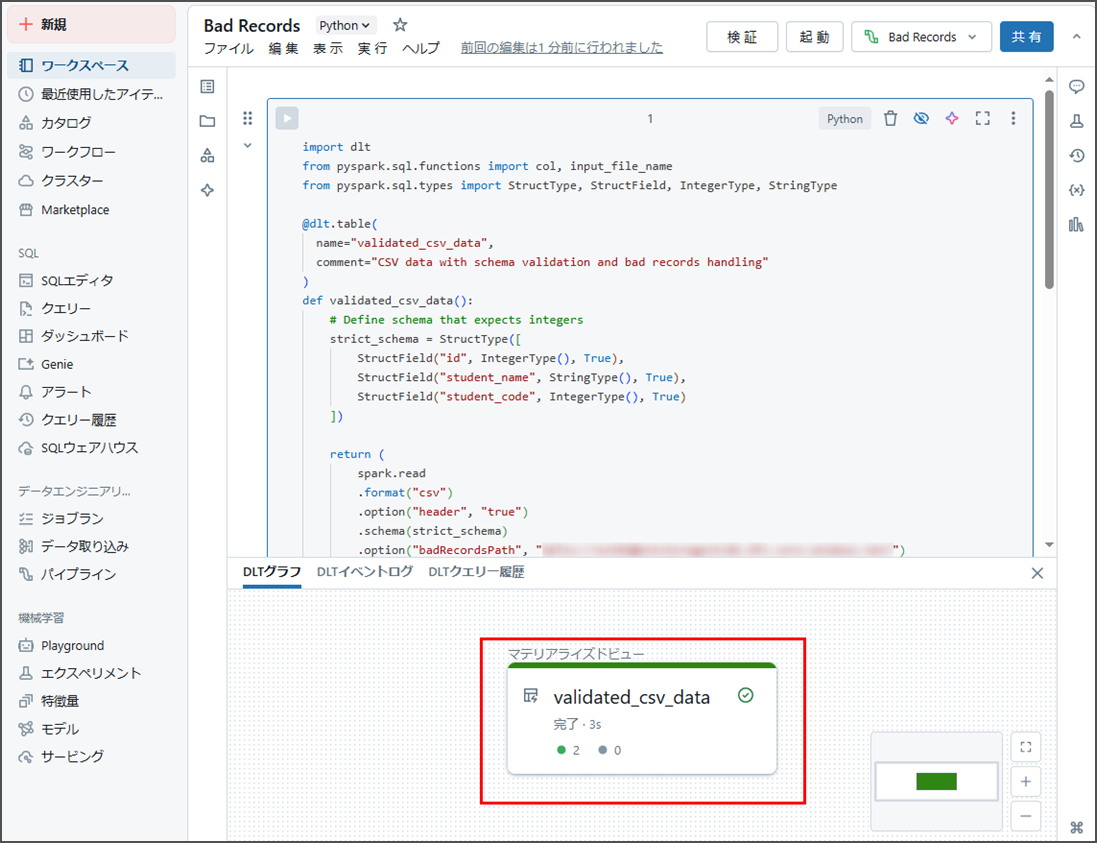
「起動」をクリックし、パイプラインを実行します。
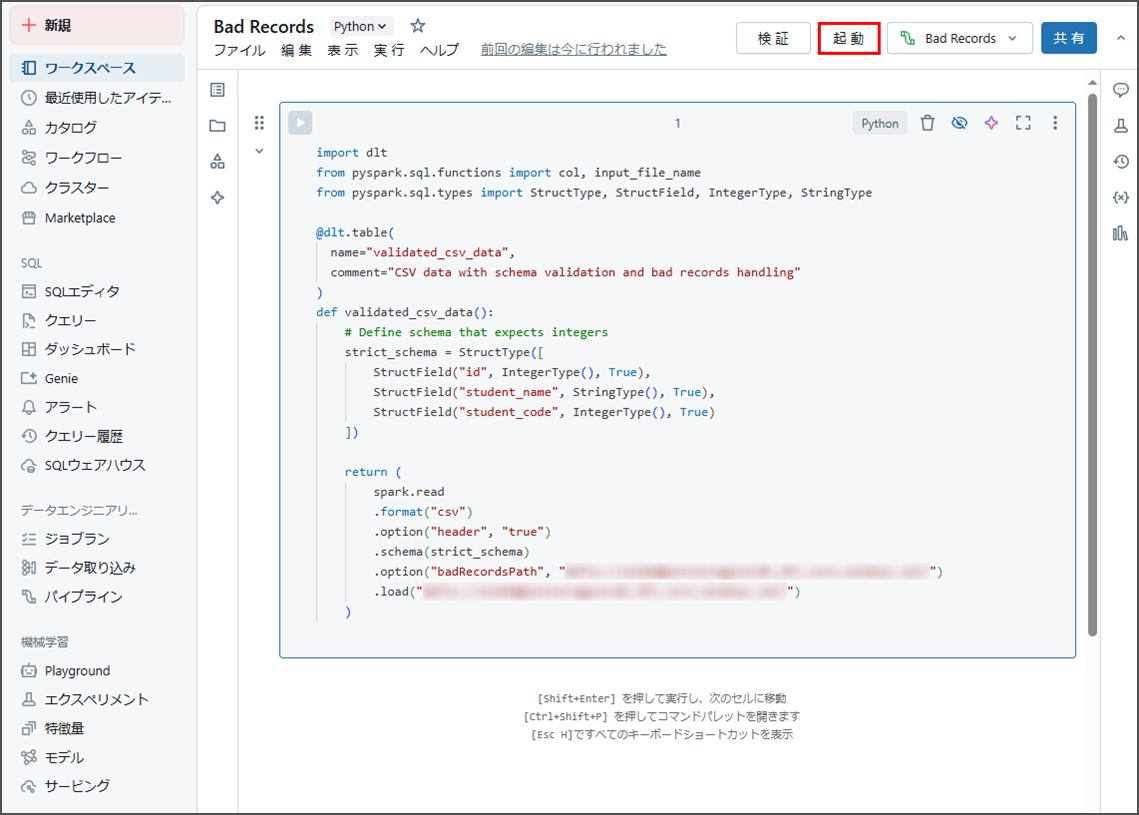
パイプラインの実行はCSVファイルに1つの不良レコードが含まれているにもかかわらず、エラーなく完了しました。
CSVデータ内の2つの有効なレコードは正常に処理され、1つの不良レコードは外部外部ロケーションに保存されました。
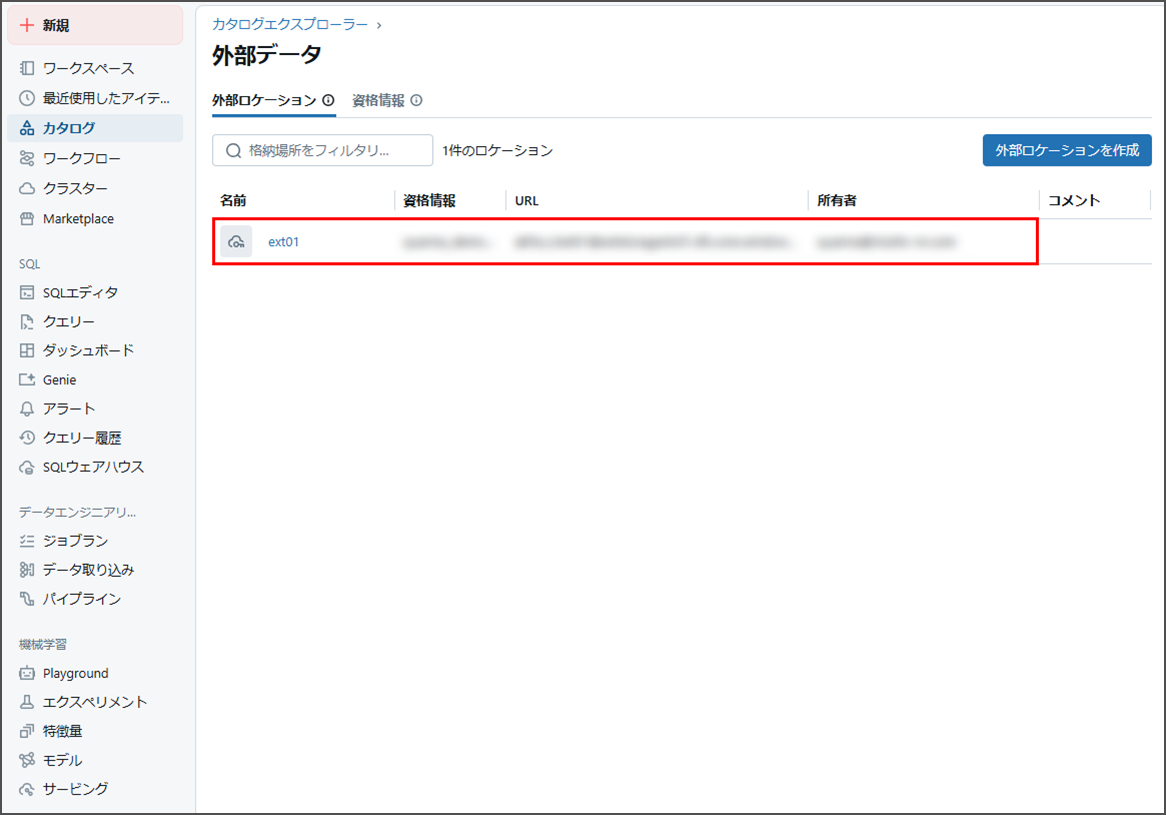
不良レコードを確認するには、次の手順に従ってください。
「カタログ」 → 「外部データ」 → 「ext01」 にアクセスし、データを確認します。
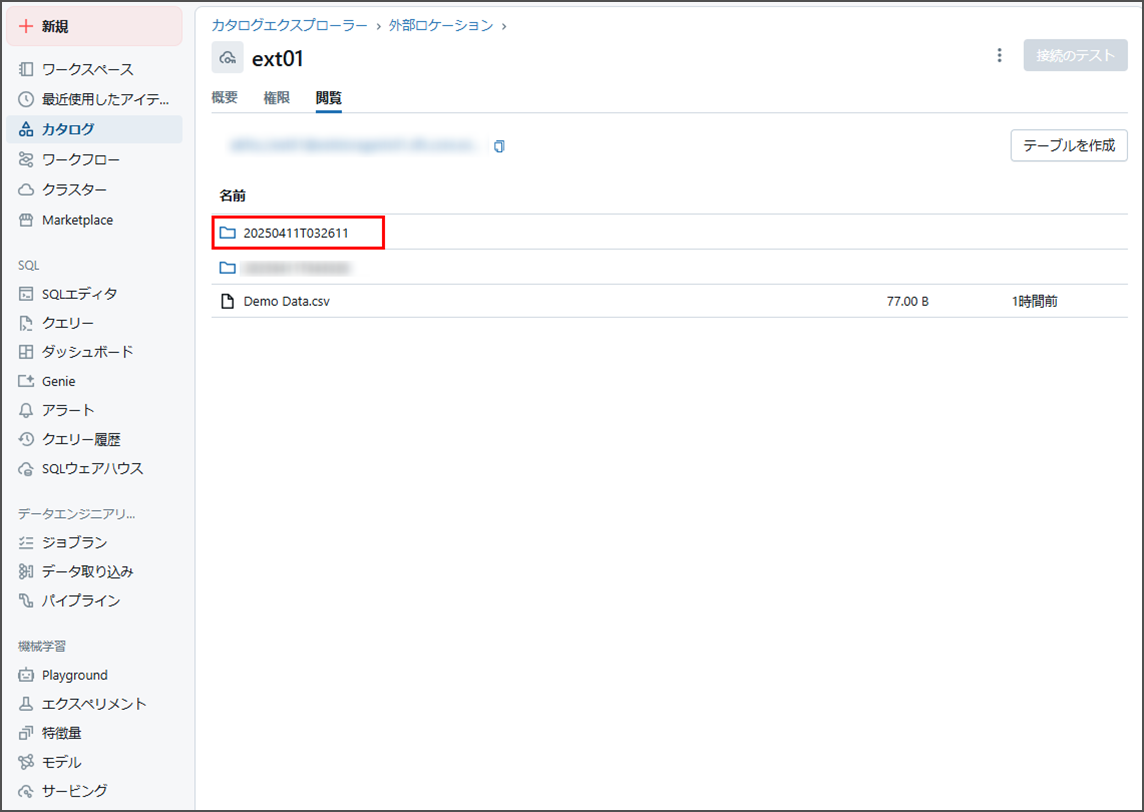
ブラウズでは、日付形式のフォルダ名でフォルダが自動的に作成されました。
作成されたフォルダをクリックし、確認します。
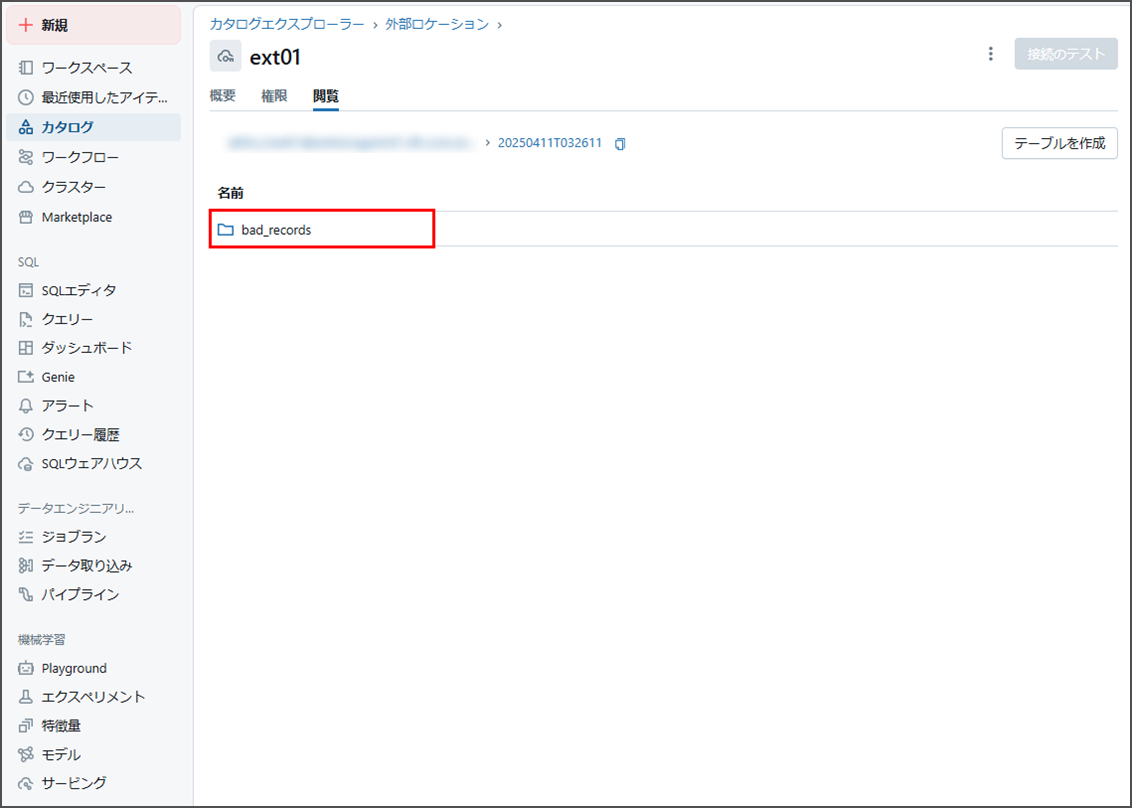
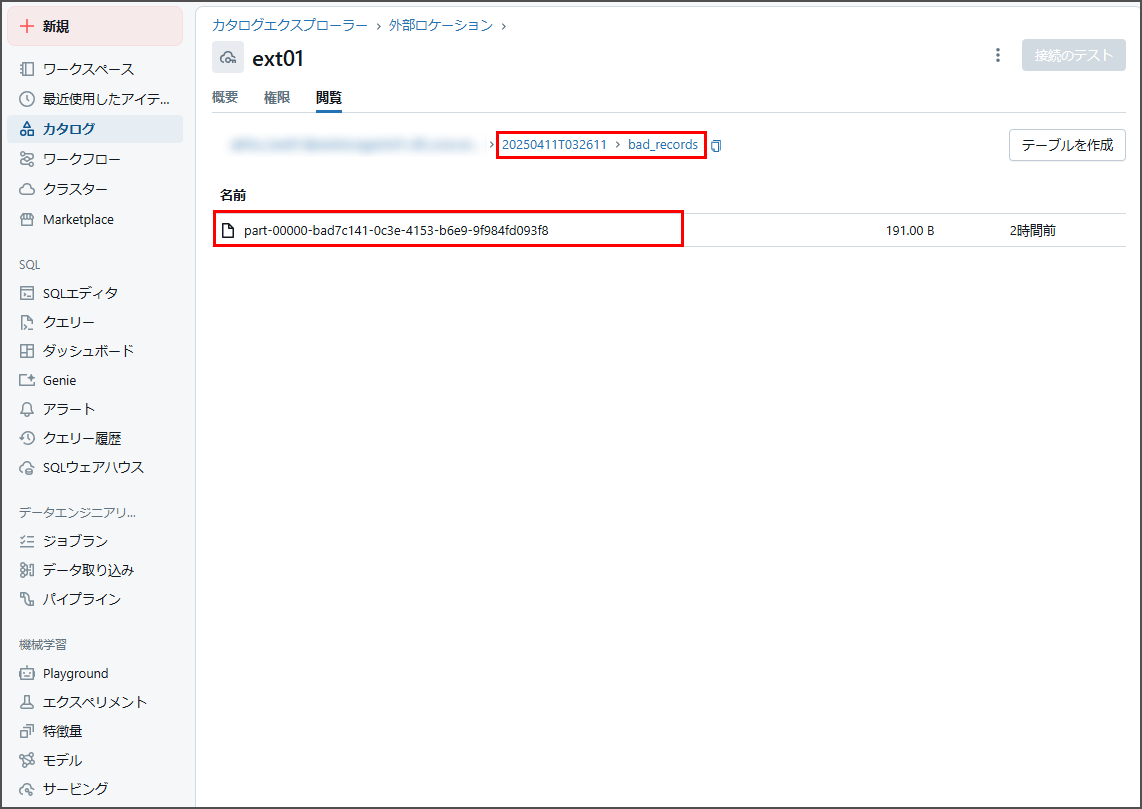
そのの中に、「bad_records」フォルダが含まれています。
「bad_records」フォルダをクリックし、確認します。
その中に、JSON ファイルに不良レコードが含まれています。
以下は、保存された不良レコードをノートブックで再読み込みするためのPythonコードです。このコードを使用して、不良レコードを含むCSVファイルを特定できます。
|
1 2 3 |
file_path = "<external-location-url>/*/bad_records" raw_content = spark.read.json(file_path) raw_content.display() |
<external-location-url>:その前にコピーした外部ロケーションのURLに書き換えてください。
実行後の結果は以下の通りです。

5.発生した「badRecordsPath」を検知する方法
不良レコードが処理中に発生した場合でも、パイプラインはエラーを発生させることなく処理を続行します。そのため、不良レコードが発生したことが分かりません。ユーザーに通知する方法はありますか?
Databricksの機能であるSQLアラートを使用して通知を送信することができます。
【目的】
- 不良レコードを発生する際、自動的に検知し、通知します。
- エラーデータを検出する手間を最小限に抑えます。
- データの品質に関する問題を迅速に対応できるようにします。
【実施方法】
- ストレージ内で不良レコードを確認するため、SQLクエリを作成します。
- アラート条件を設定します。 (例: 不良レコードの件数 > 0)
- メールや他の連絡手段による通知を設定します。
- 定期的に実行するためのスケジュールを構成します。 (※時間/日/週単位)
5-1.SQLアラートを使って、不良レコードの監視
「クエリー」 → 「クエリ文を作成」をクリックし、新規クエリーを作成します。
クエリーを「Bad Records Monitor」と名前付けます。
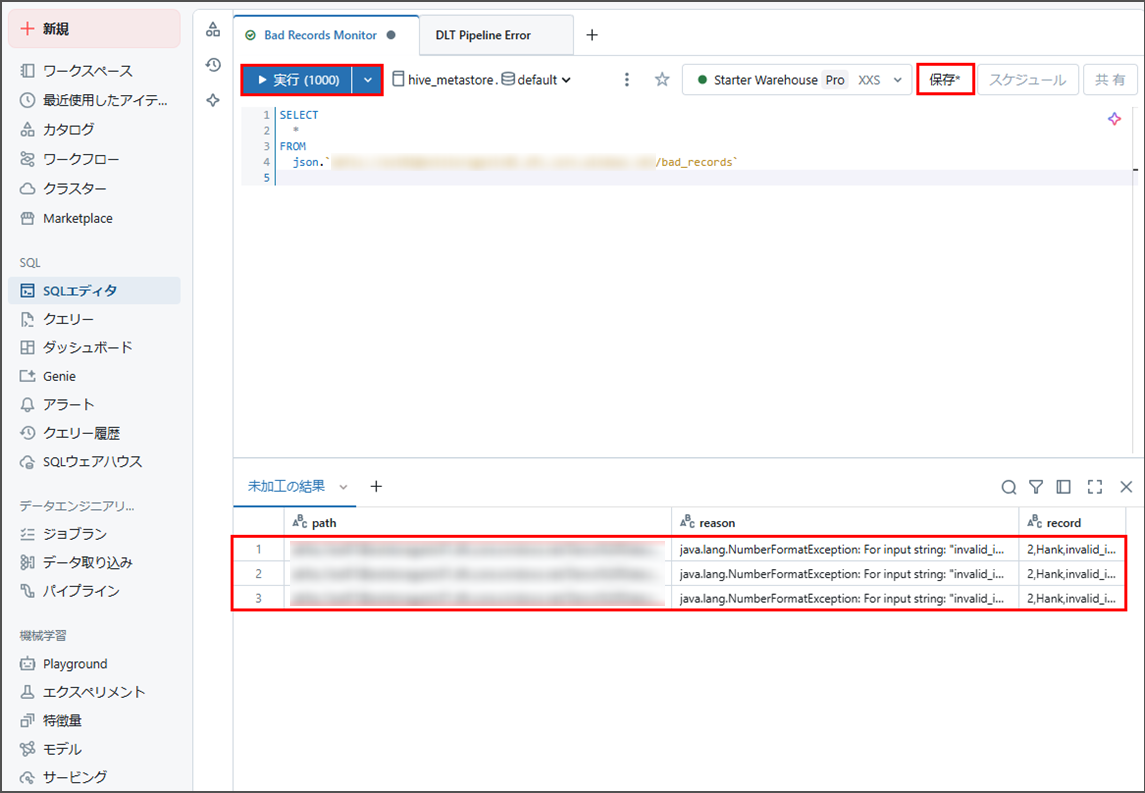
以下のSQLクエリーを入力します。
|
1 2 3 4 |
SELECT * FROM JSON.`<external-location-url>/*/bad_records` |
<external-location-url>:その前にコピーした外部ロケーションのURLに書き換えてください。
「実行」をクリックすると、クエリーを実行でき、不良レコードを確認できます。
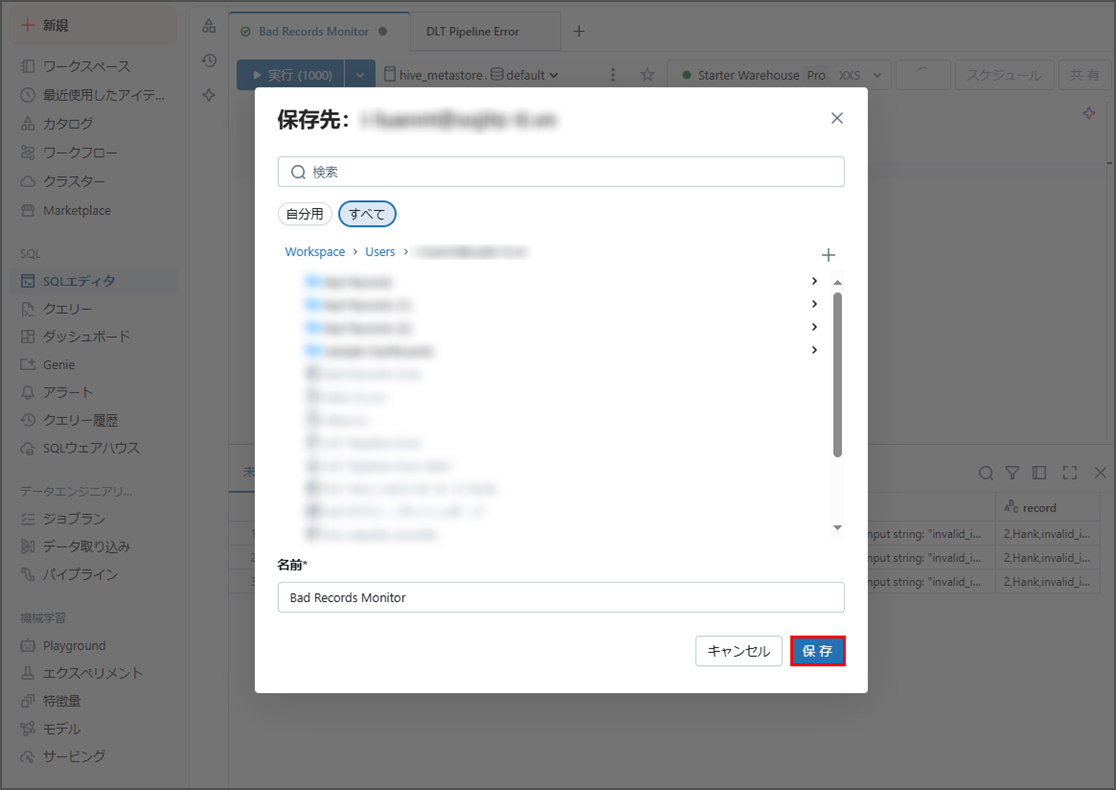
「保存」をクリックします。
「保存」をクリックすると、クエリーが保存されます。
「アラート」 → 「アラートを作成」をクリックし、新規アラートを作成します。
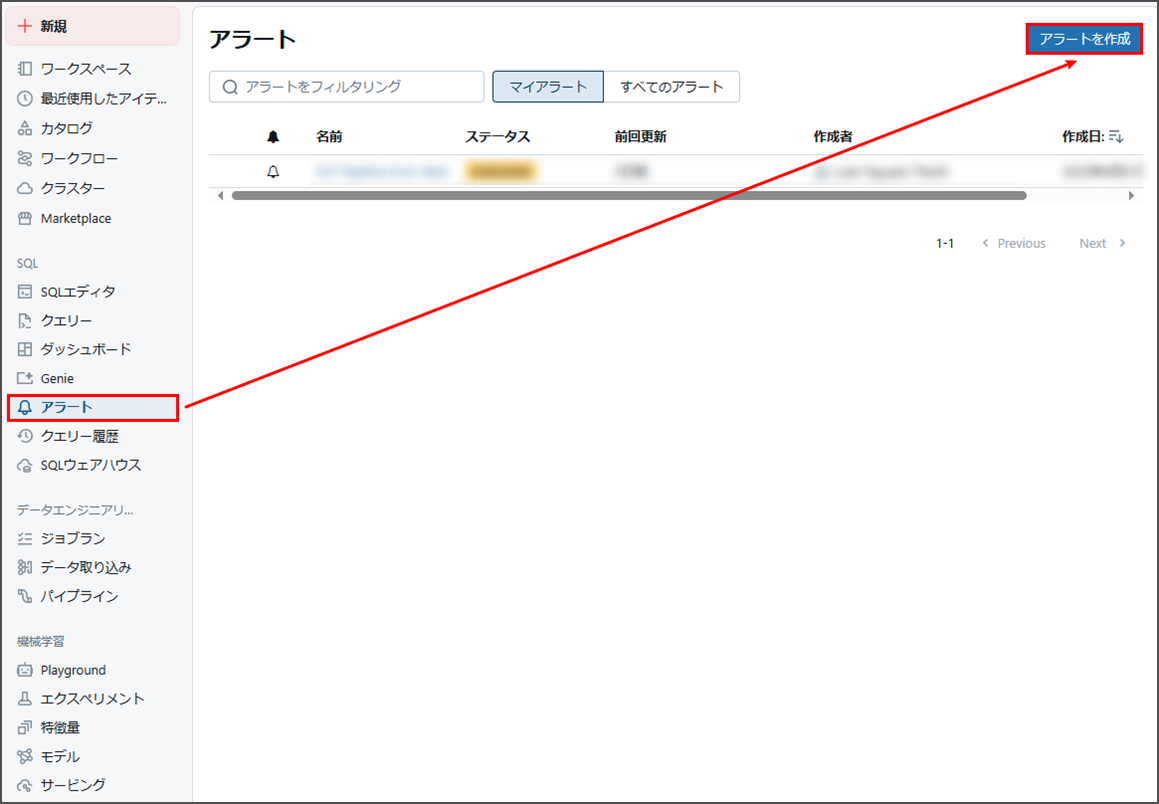
アラート名: Bad Records Alert
Qクエリー: Bad Records Monitor
トリガー条件: しいき値 > 0
テンプレート: default templateを使用(または必要に応じてカスタマイズ)
「アラートを作成」をクリックします。
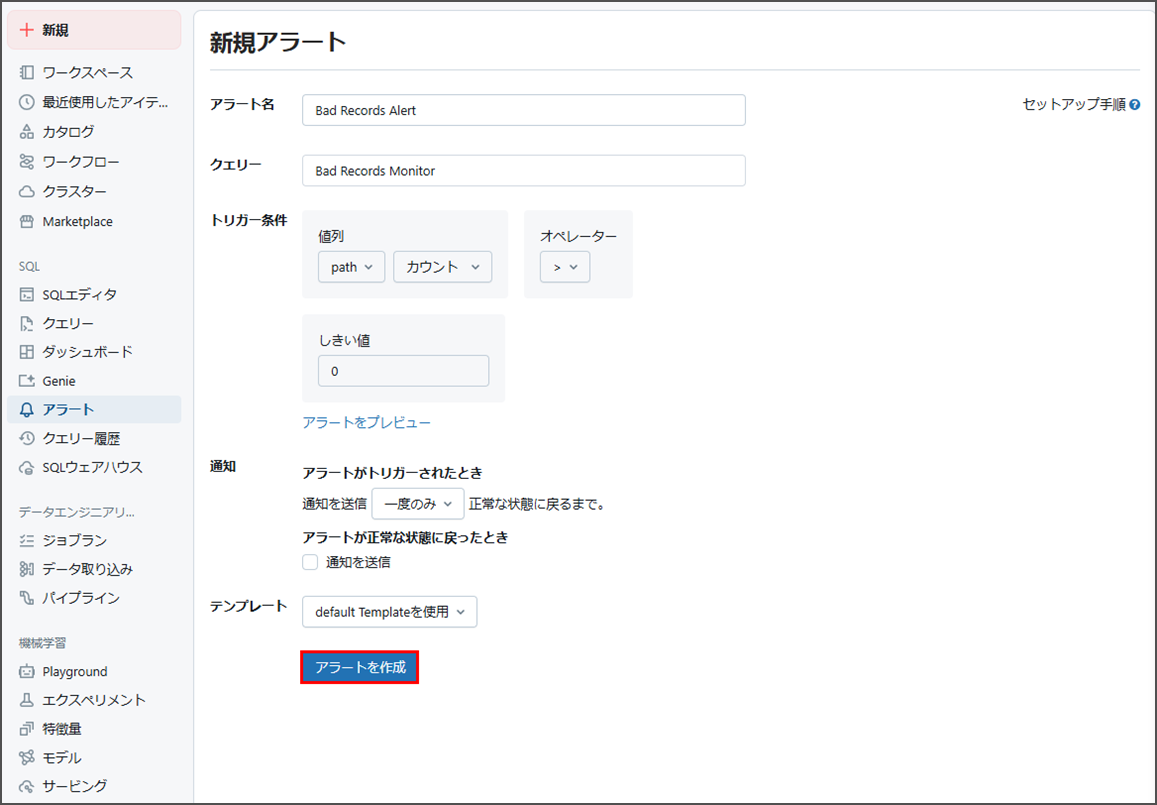
「スケジュールを追加」をクリックすると、アラートのスケジュールを追加できます。
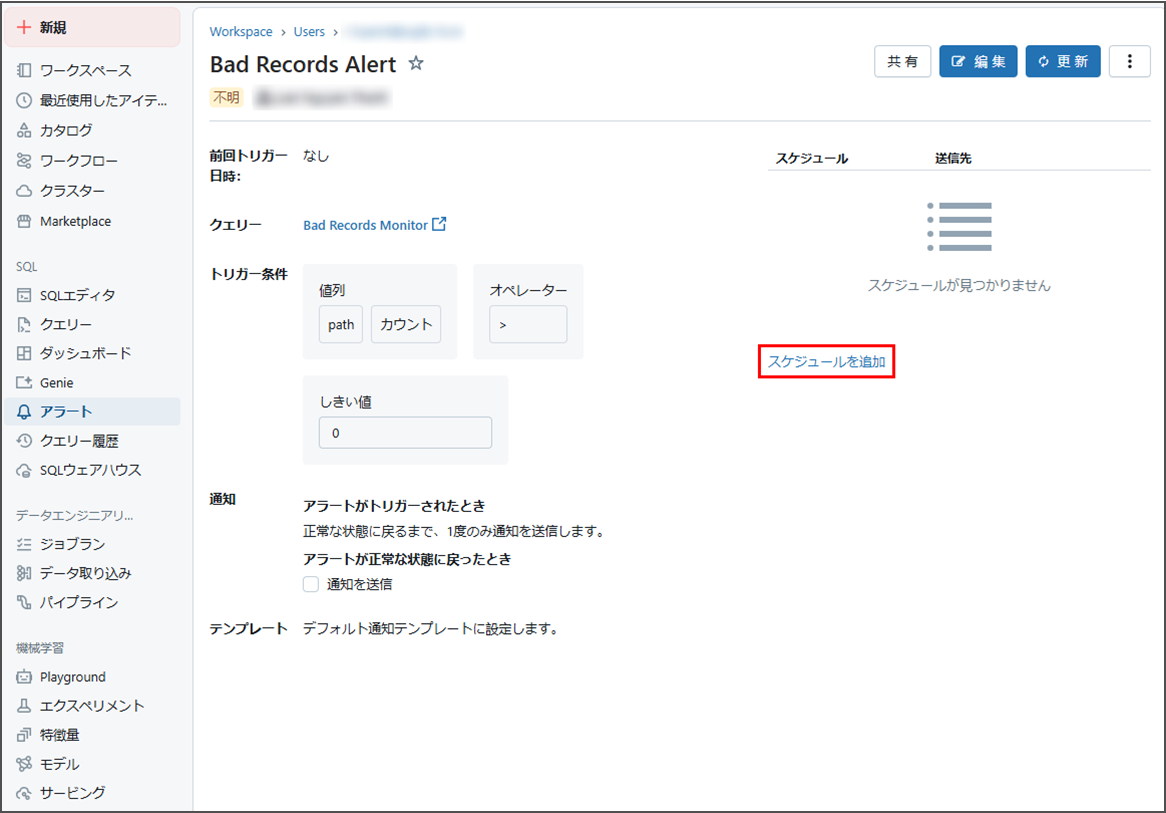
適切なスケジュール、及びタイムゾーンを選択します。
「送信先」をクリックします。
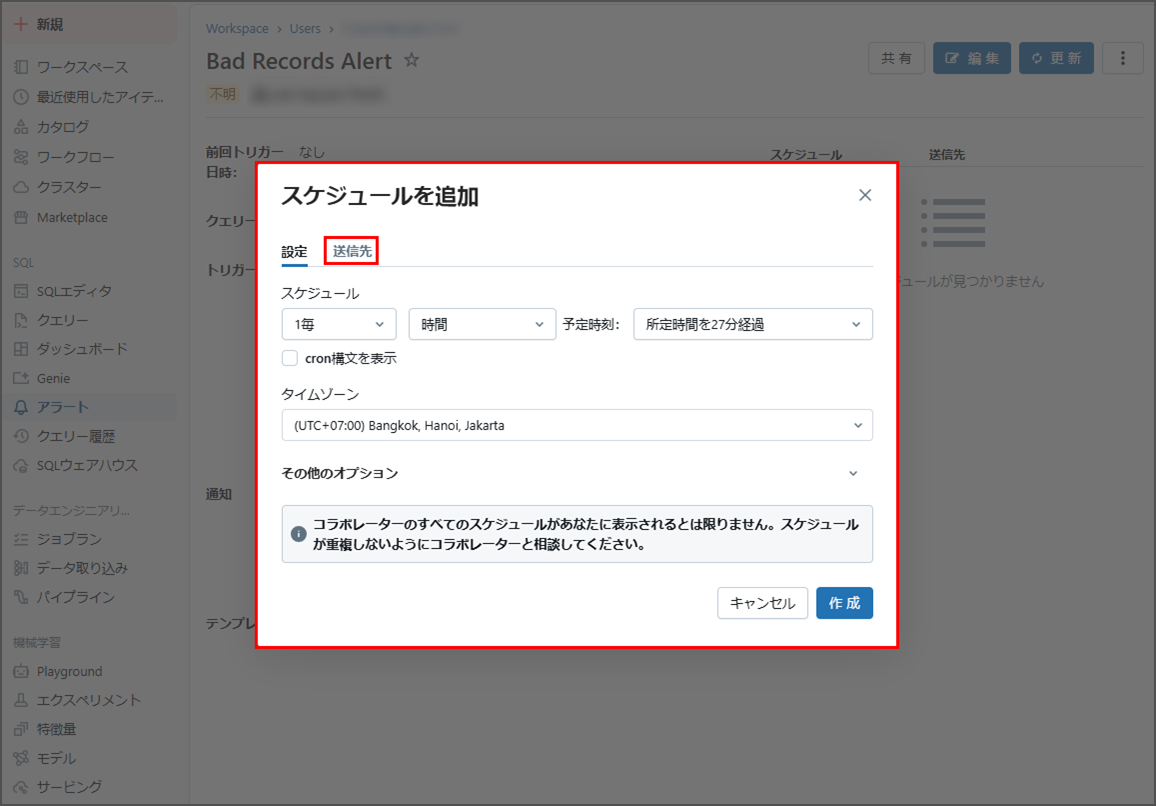
「配信先」を選択します。
「作成」をクリックします。
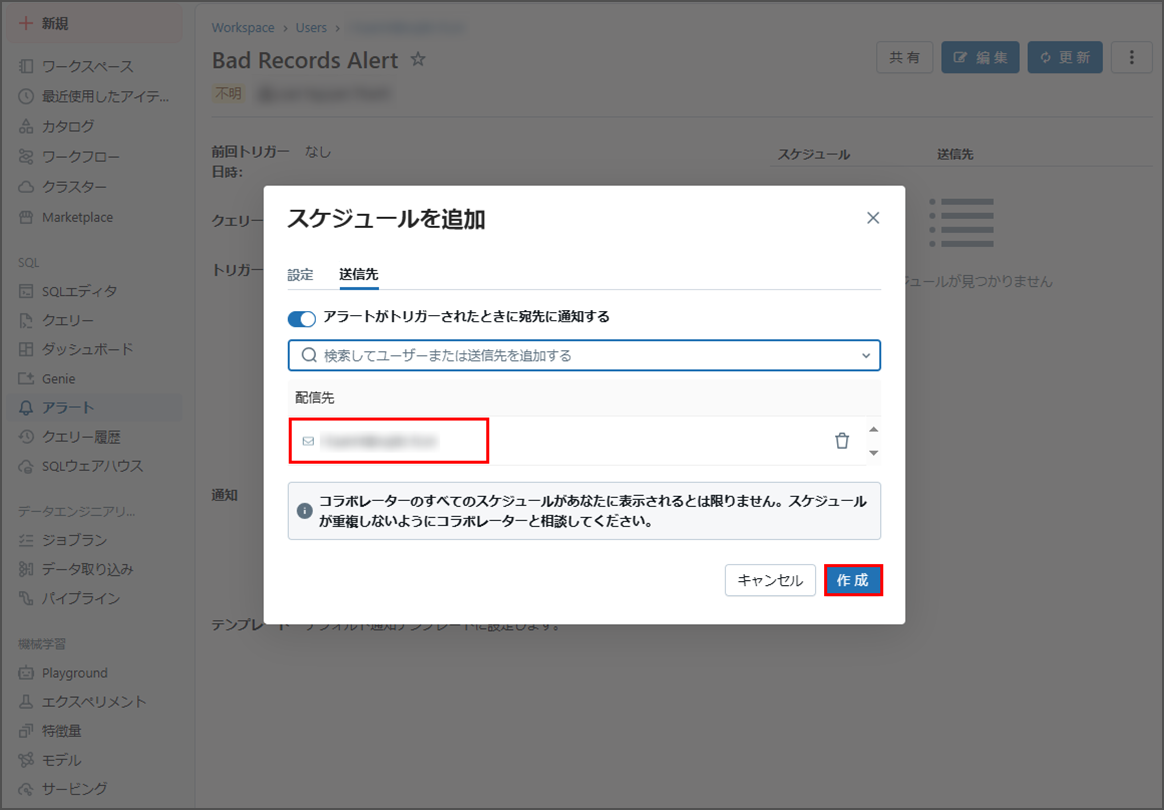
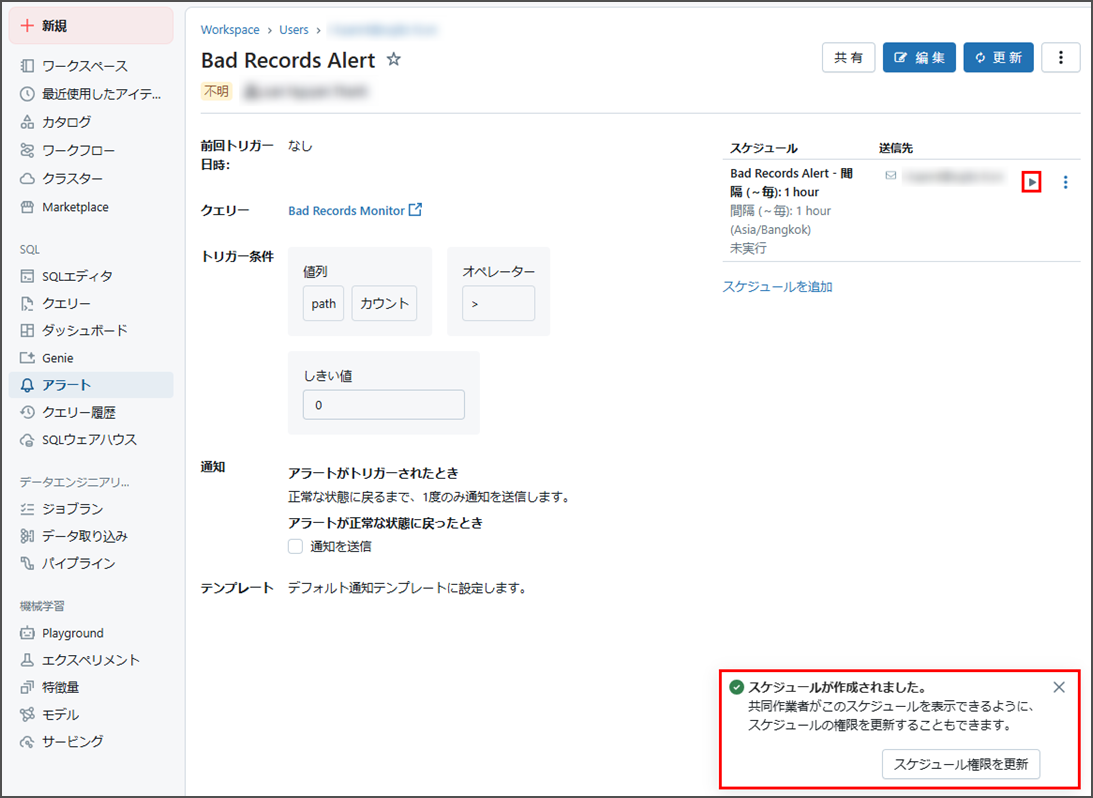
アラートが正常に作成されました。
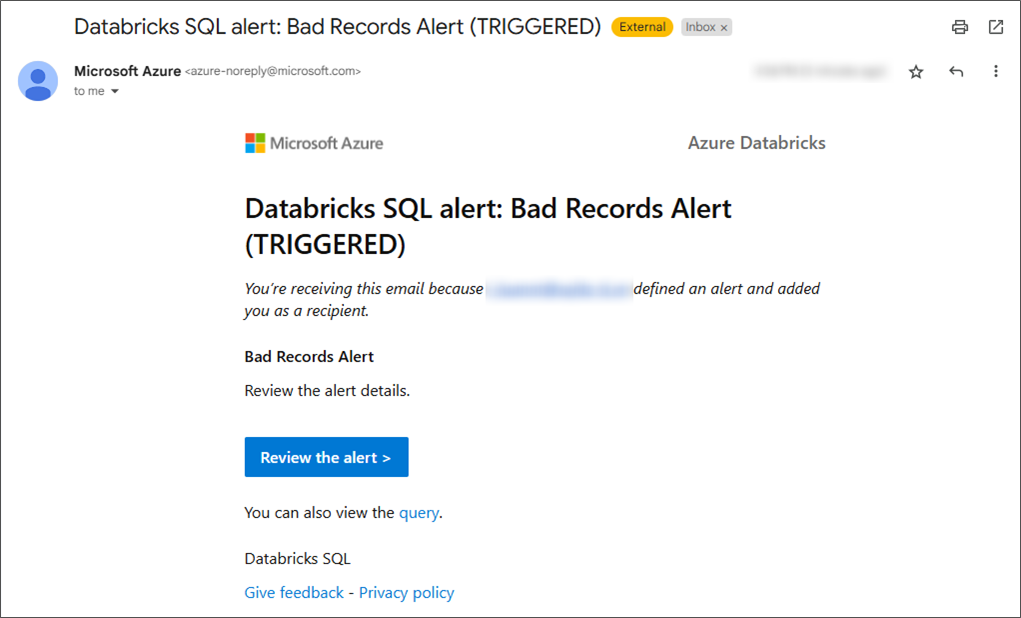
「実行」アイコンをクリックすると、実行でき、動作を確認できます。
メールが正常に送信されました。
6.まとめ
Azure Databricksにおける【badRecordsPath】を活用し、エラーデータを効率的に処理する方法について説明しました。
今回の記事が少しでも皆さんの新しい知識や業務のご参考になれば幸いです。双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたら是非お問い合わせください!
・Azure Databricks連載記事のまとめはこちら