1. はじめに
皆さんこんにちは。
今回は、Azure DatabricksでAuto Loaderの利用方法について説明していきます。
第1回: Auto Loaderの概要、自動取込方法を使用してみる (今回)
第2回:【Azure Databricks】Auto Loader と Lakeflow 宣言パイプラインを組み合わせて使用してみる
第3回: Auto LoaderのSchema inferenceとEvolutionの機能について説明する
※ 背景
DatabricksでADLS Gen2 または DBFSからデータをロードした後、データを処理し、読み取られたデータをUnity Catalog または Hive Metastoreに保存します。
ただし、新規のファイルが ADLS Gen2 に追加されるタイミングで処理を動かす必要があります。
※ 目的
Auto loader は、新規ファイルが追加された際に自動でデータを検知し処理を行います。
2. 前提条件
・Databricksワークスペースが必要です。
・Unity Catalogに読み込みと書き込みの権限が必要です。
3. Auto Loaderの概要
Auto LoaderはAWS S3、ADLS Gen2、GCS、Azure Blob Storage ADLS Gen1、DBFSからデータをロードできるDatabricksの機能です。
Auto Loader は、定義されたフォルダーに新規ファイルが追加されたときに、構造化ストリーミングとチェックポイントを使用してファイルを検出し、処理します。
Auto LoaderはJSON, CSV、 XML、PARQUET、 AVRO、 ORC、 TEXT、BINARYFILEのファイル形式をロードできます。
4. Auto Loader 自動取込方法
以下の手順はAuto Loaderが新規のファイルを自動検出して、処理することについて説明していきます。
新規のファイルがDBFSにアップロードされるとき、データを処理してUnity Catalogに処理済みのデータを保存します。
① Azure Databricks ワークスペース画面から >「新規」 > 「ノートブック」をクリックします。
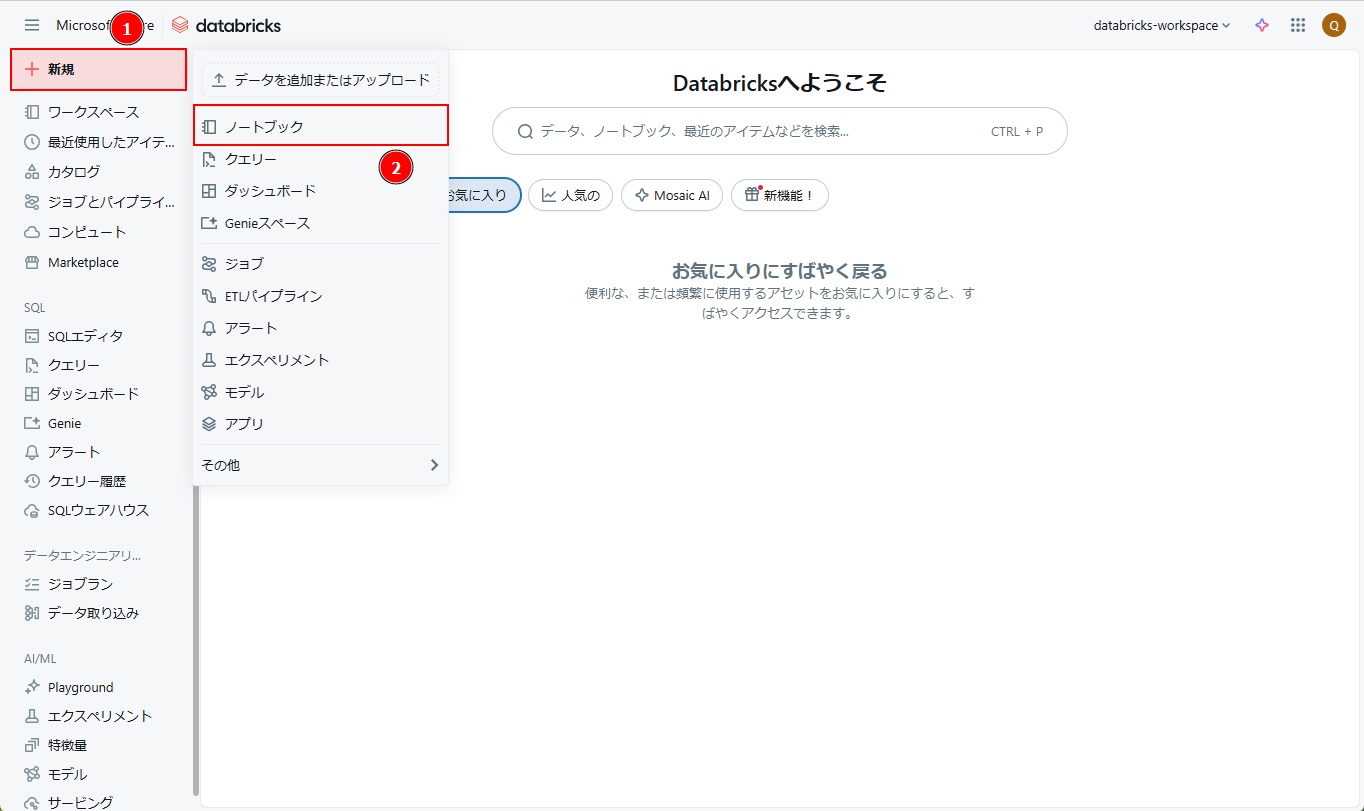
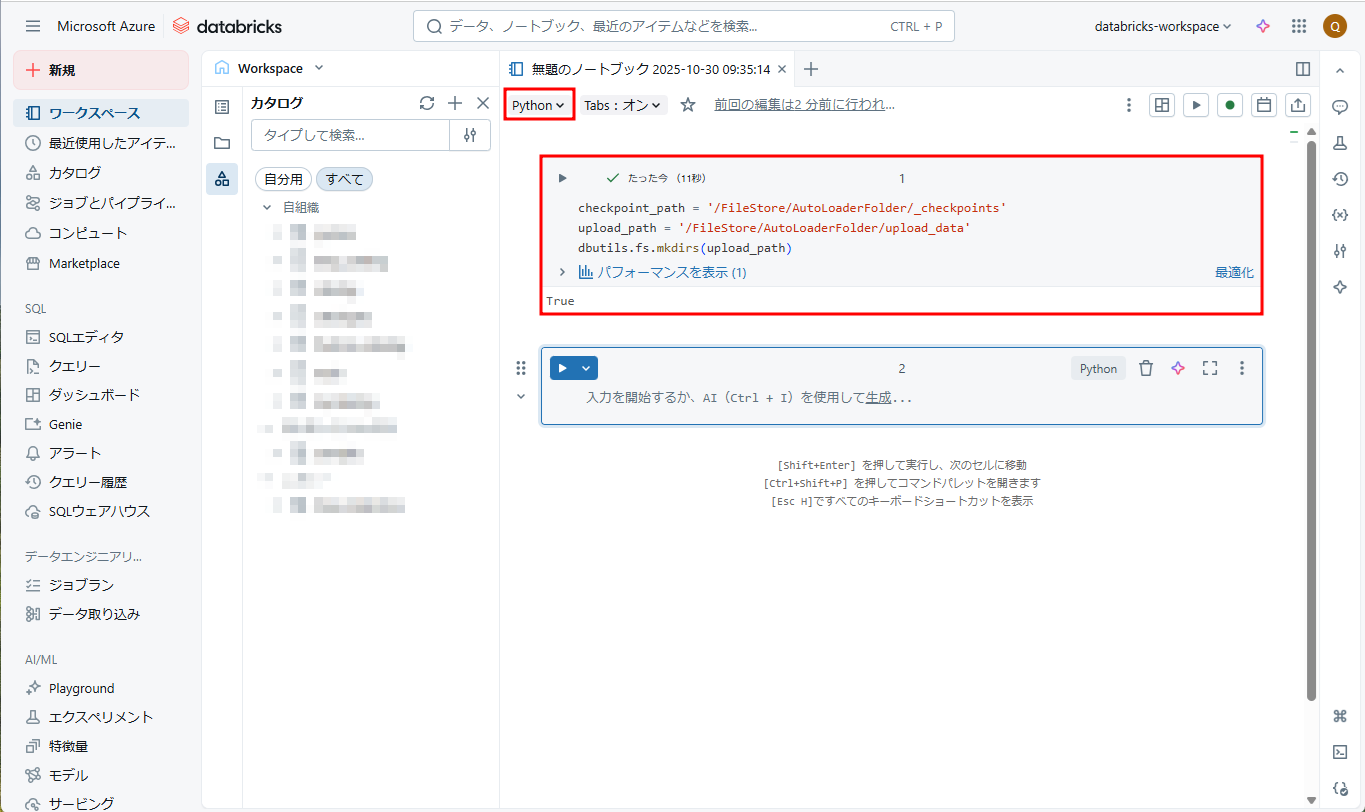
② ノートブック名を「AutoLoader-Notebook」に変更します。以下のコマンドを入力して、 「Shift + Enter」を押して、DBFSに「AutoLoaderFolder/upload_data」フォルダーを作成します。
|
1 2 3 |
checkpoint_path = '/FileStore/AutoLoaderFolder/_checkpoints' upload_path = '/FileStore/AutoLoaderFolder/upload_data' dbutils.fs.mkdirs(upload_path) |
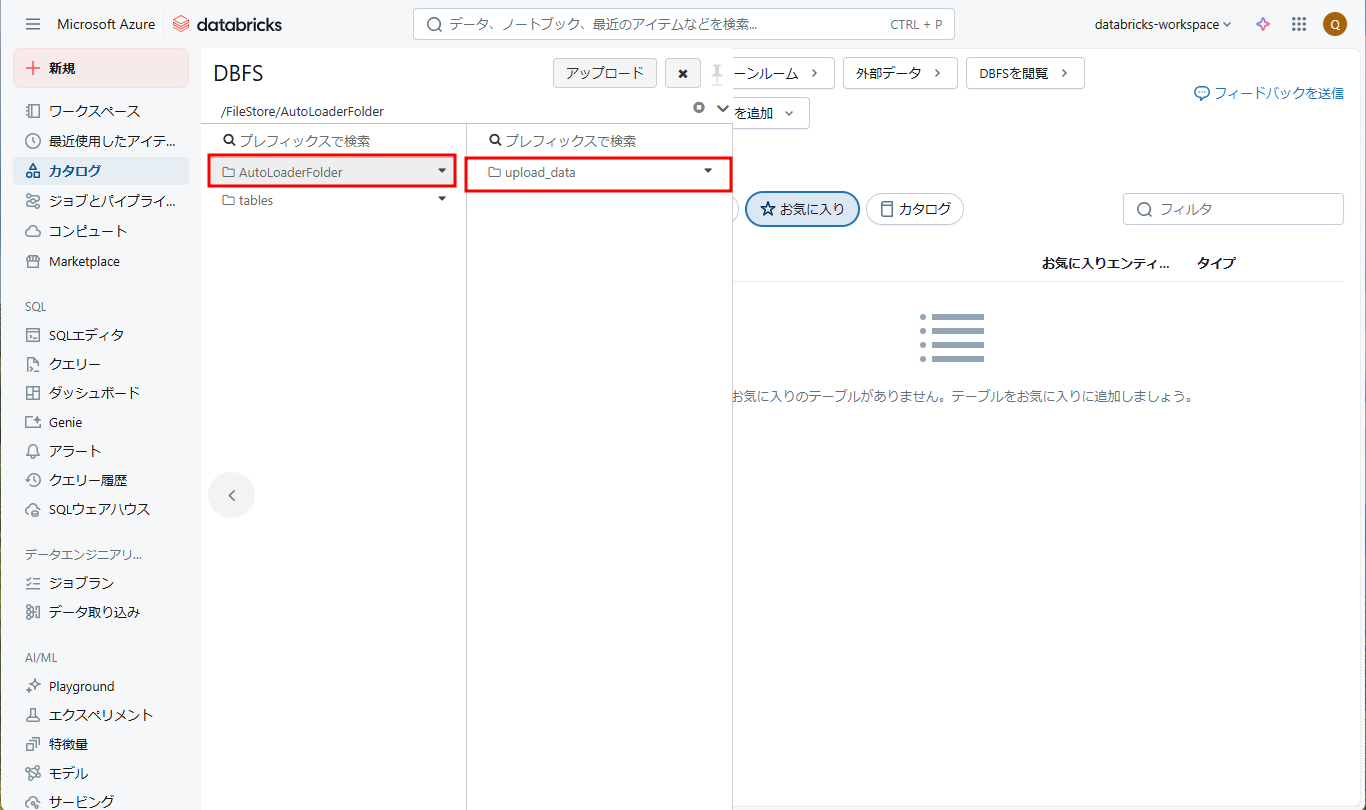
③ DBFSで「/FileStore/AutoLoaderFolder/upload_data」フォルダが「/FileStore/AutoLoaderFolder/upload_data」パスの下に作成されました。
④ 以下のCSVファイルを作成して、「upload_data」フォルダーにアップロードします。
|
1 2 3 |
StudentID,StudentName,StudentClass 1,Johnny,ClassA 2,Sara,ClassB |
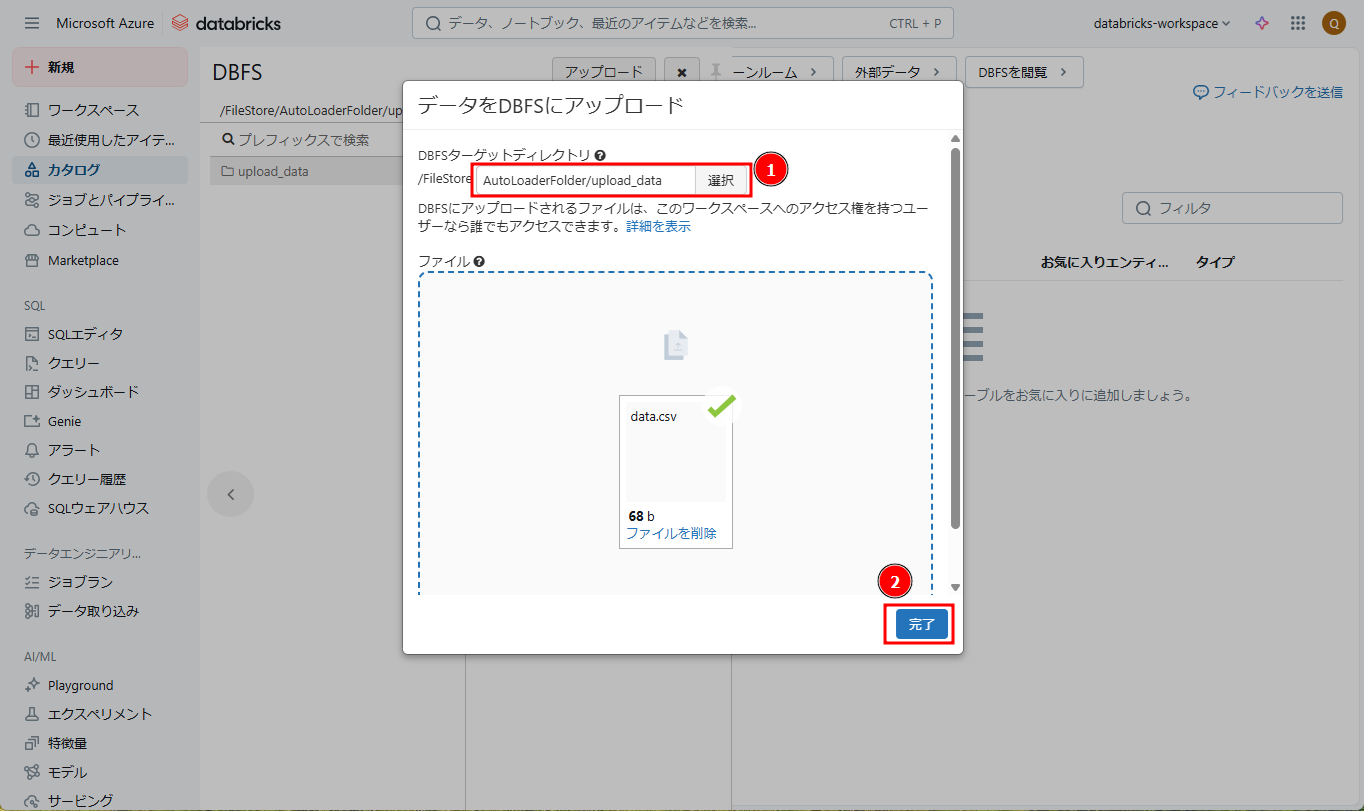
⑤「アップロード」をクリックします。
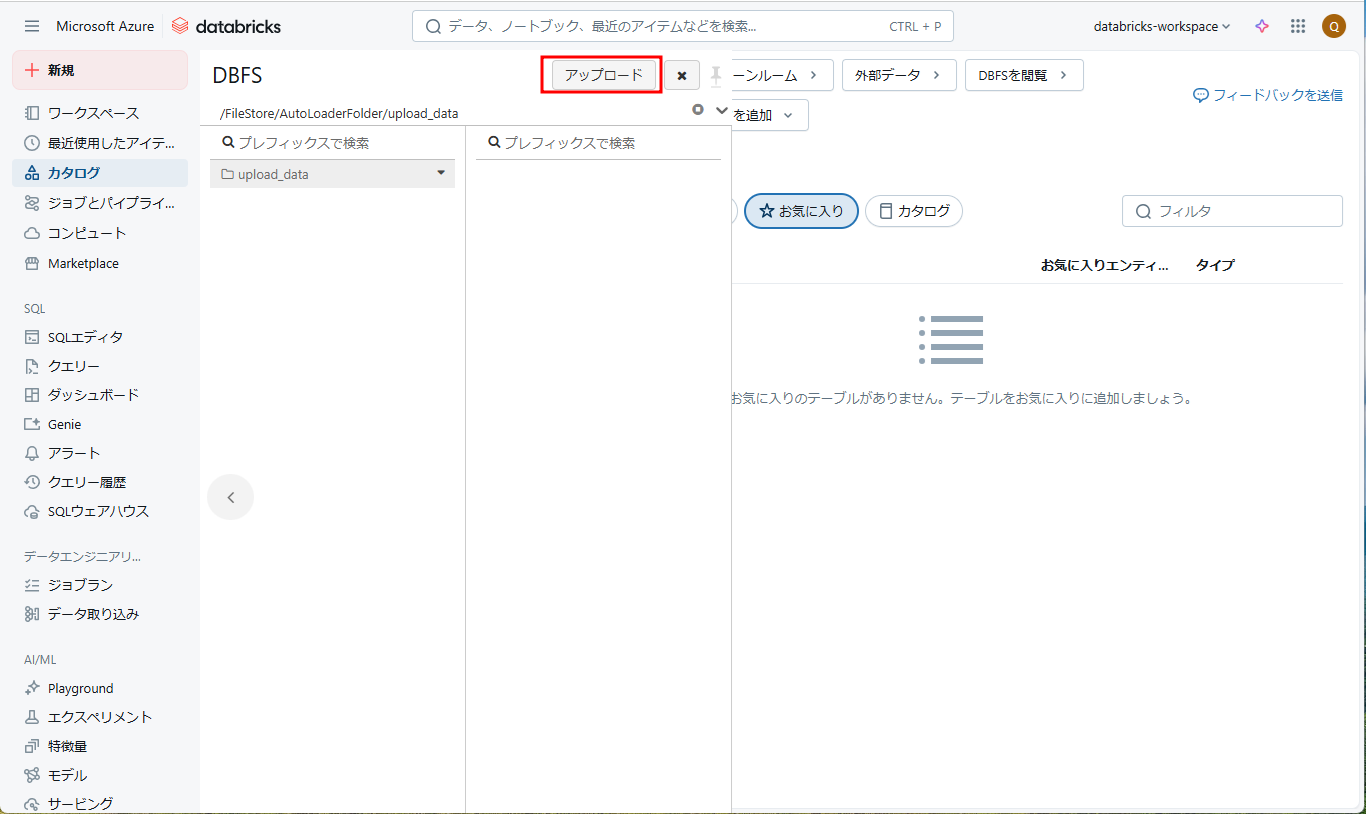
⑥「 DBFSターゲットディレクトリ 」に「 /FileStore/AutoLoaderFolder/upload_data 」を選択します。「ファイル」で 作成したCSVファイルをアップロードします。
⑦「完了」をクリックします。
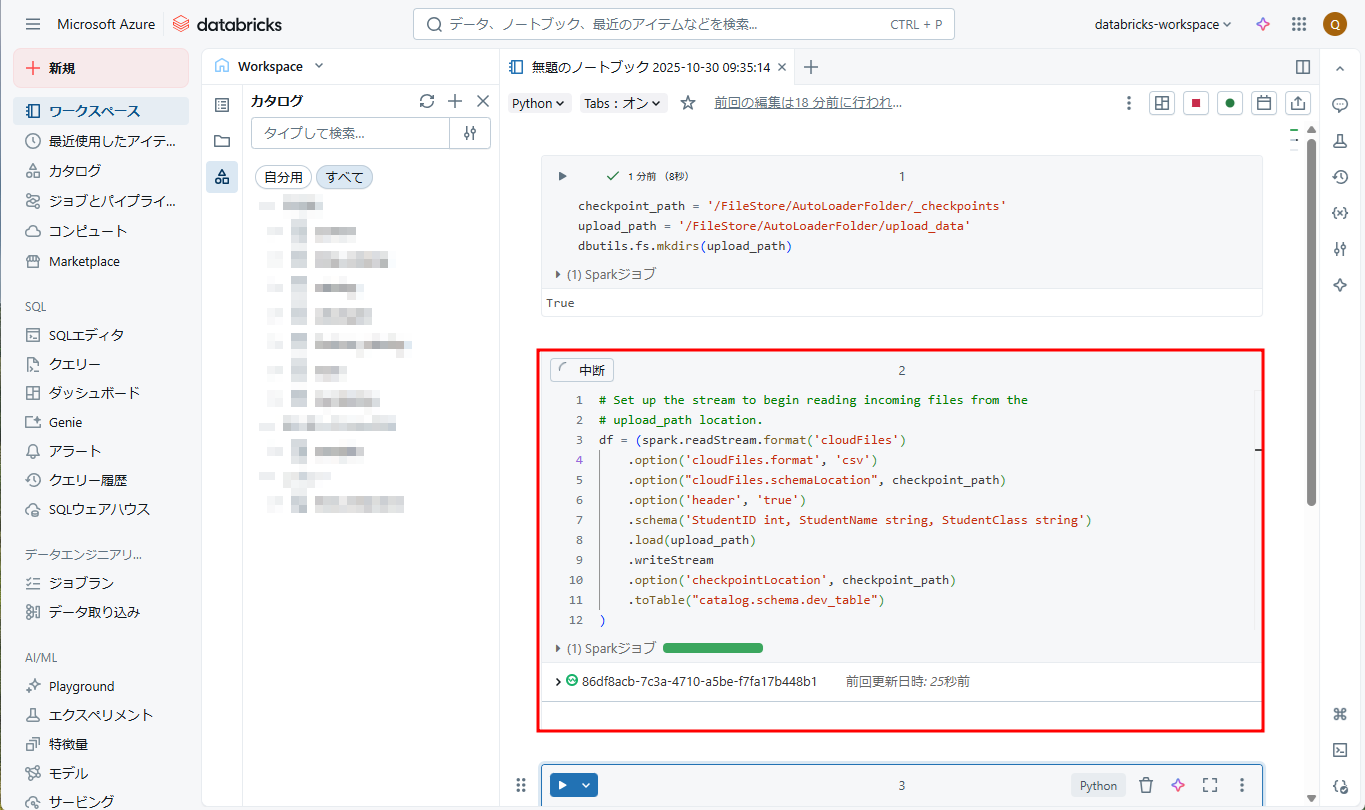
⑧ 次に、AutoLoader-Notebookノートブックに戻り、以下のコマンドを実行することでAuto Loaderを起動します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# Set up the stream to begin reading incoming files from the # upload_path location. df = (spark.readStream.format('cloudFiles') .option('cloudFiles.format', 'csv') .option("cloudFiles.schemaLocation", checkpoint_path) .option('header', 'true') .schema('StudentID int, StudentName string, StudentClass string') .load(upload_path) .writeStream .option('checkpointLocation', checkpoint_path) .toTable("catalog.schema.dev_table") ) |
・ “.format(‘cloudFiles’)”: クラウドストレージからファイルを読み取るために、Auto Loaderによって提供される構造化ストリーミング ソースを利用します。
・ “cloudFiles.format”: 読み取るファイルの形式を指定します。 例: JSONファイルを[.json]に、[.csv]はCSVファイルを[.csv]に指定します。
・ “cloudFiles.schemaLocation”: スキーマの変更履歴を追跡するために、スキーマ情報の格納場所を指定します。
・ “header”: CSVファイルにヘッダーが含まれるかことを指定します。
・ “.schema” : 読み取るデータのスキーマを指定します。
・ “.load(upload_path)”: 読み取るデータの格納場所を指定します。
・ “checkpointLocation”: ストリームのチェックポイントの場所を指定します。
・ “.toTable(“”)”: データの格納場所を指定します。
「自動ローダーのオプション」はこのリンクをご参照してください。
※ 注意:上記のコマンドはUnity Catalogの[catalog.schema.dev_table]テーブルに保存されているので、コマンド実行前にカタログとスキーマを設定しておくことが必要です。
⑨ 以下のコマンドを実行して、データが[catalog.schema.dev_table]に保存されたかを確認します。
|
1 |
spark.sql("select * from catalog.schema.dev_table").display() |
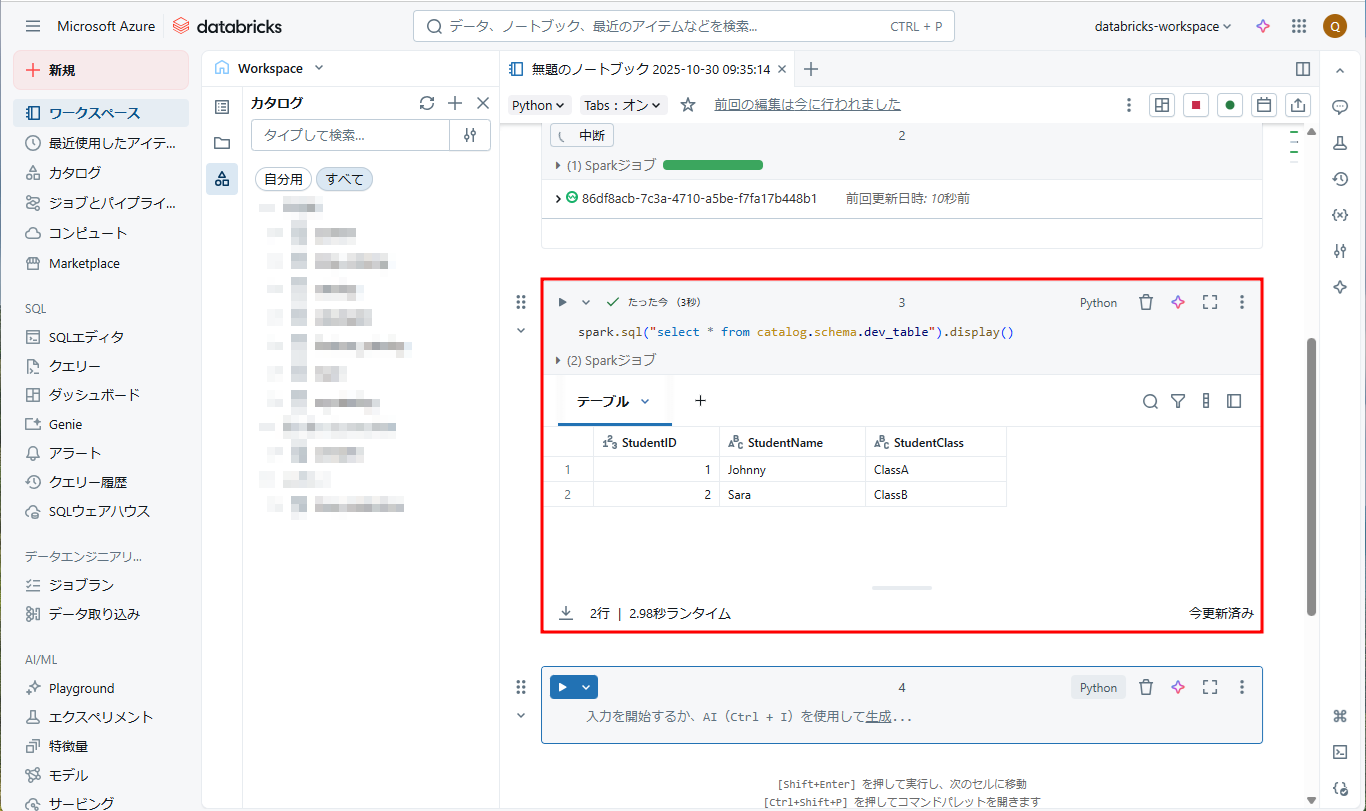
画像の通り、CSVファイルのデータが読み込まれ、「Johnny」と「Sara」という2つのレコードが[catalog.schema.dev_table]に保存されました。
⑩ 次に、別のCSVファイルを「upload_data」フォルダーにアップロードしてみます。
|
1 2 3 |
StudentID,StudentName,StudentClass 3,Henry,ClassA 4,Lucas,ClassA |
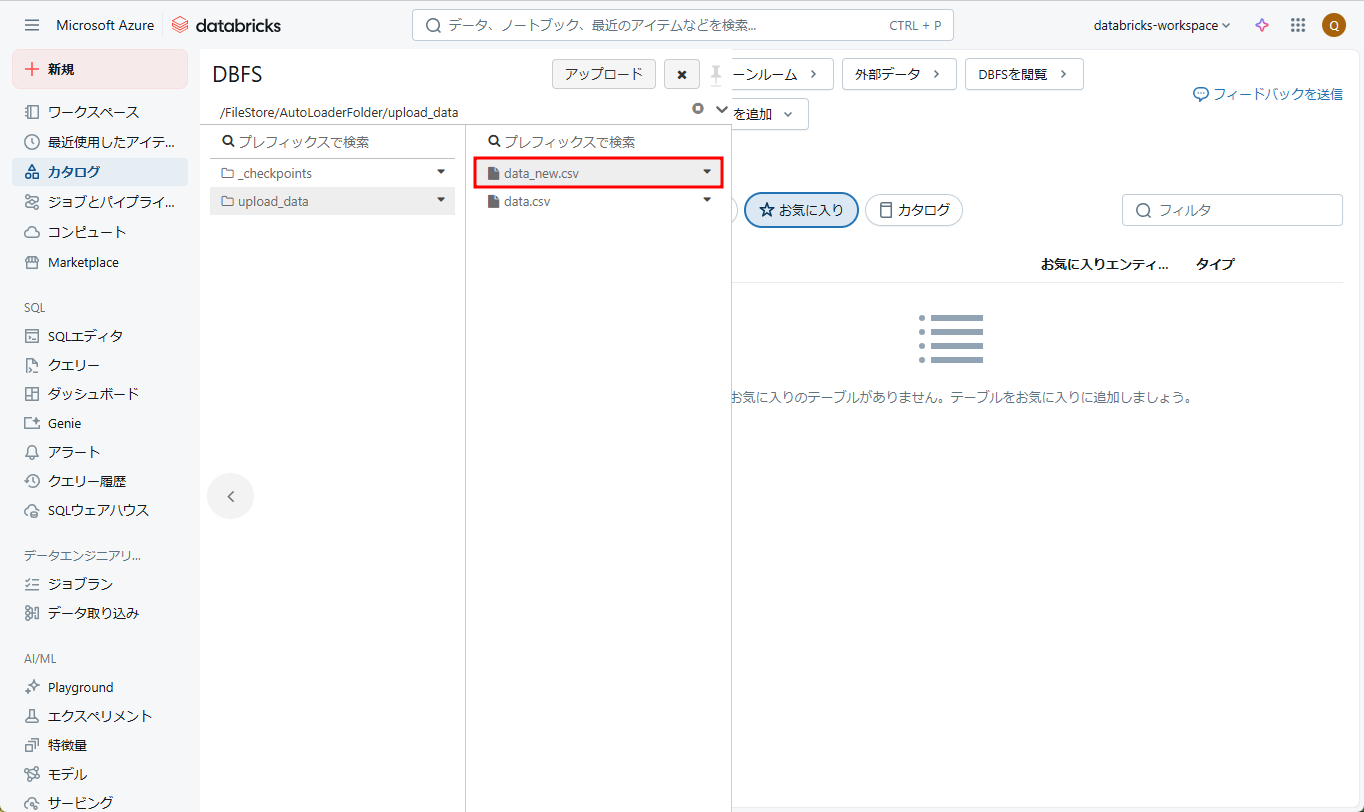 ⑪ ⑨のコマンドを再実行すると、新規のCSVファイルのデータが自動処理され、[catalog.schema.dev_table]に保存されました。
⑪ ⑨のコマンドを再実行すると、新規のCSVファイルのデータが自動処理され、[catalog.schema.dev_table]に保存されました。
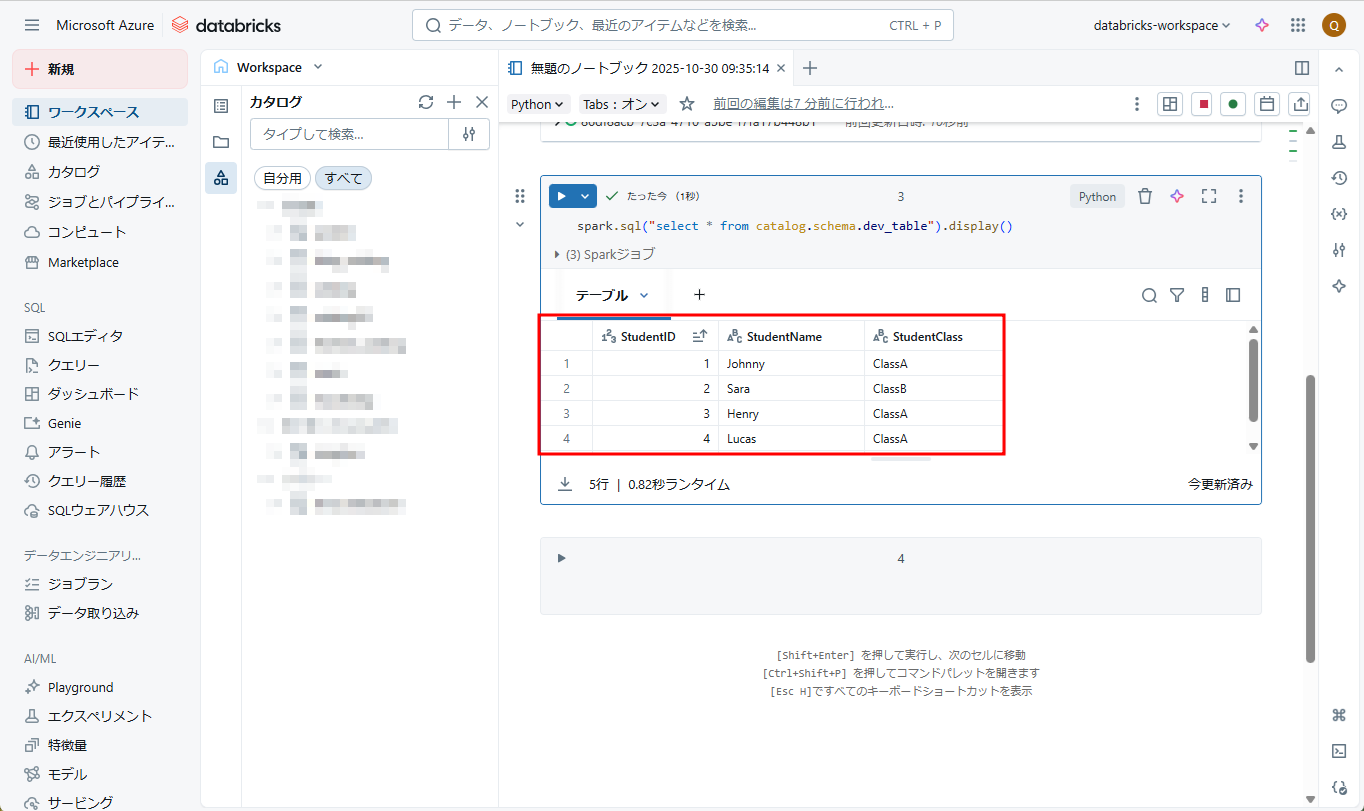 Auto Loaderを設定・起動した後、CSVファイルが新規追加されることを自動検出して処理します。
Auto Loaderを設定・起動した後、CSVファイルが新規追加されることを自動検出して処理します。
次の記事は、Delta Live Tableを使用することでAuto Loaderを設定して、ADLS Gen2でファイルを自動的に読み取り、処理済みのデータをUnity Catalogに保存する方法について説明します。
5. まとめ
今回は、Azure DatabricksでAuto Loaderの利用方法について説明しました。
第1回: Auto Loaderの概要、自動取込方法をしてみる (今回)
第2回:【Azure Databricks】Auto Loader と Lakeflow 宣言パイプラインを組み合わせて使用してみる
第3回: Auto LoaderのSchema inferenceとEvolutionの機能について説明する
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
Azure Databricks連載記事のまとめはこちら
![]() お問い合わせはこちら
お問い合わせはこちら