目次
1. はじめに
最近、Databricksは新しいプラットフォーム「Agent Bricks(エージェント・ブリックス)」を発表しました。
このプラットフォームを利用することで、Azure Databricks環境内でAIエージェントの構築や管理が可能になります。
これにより、特定のタスクに強いエージェントを作成し、複数のエージェントを一つの画面上で連携させ動かすことができます。
また、Lakehouseのデータに直接アクセスし、安全に知識を活用することも可能です。
本記事では、Agent Bricksの「情報抽出」「カスタムLLM」「ナレッジアシスタント」「マルチエージェントAIシステム」の活用方法について
わかりやすく紹介します。
2. Agent Bricksの紹介
2.1. Agent Bricksの概要と主なユースケース
① Agent Bricksの概要
Azure DatabricksのAgent Bricksとは、柔軟なアプローチでAIエージェントシステムを構築・最適化できる新しいプラットフォームです。ユーザーは、実務上の課題やデータ、効果の評価方法に集中するだけで済みます。
Agent BricksはAzureエコシステムと深く統合されており、データはAzure Geographiesを通じて管理・処理されるため、データ保存およびセキュリティに関する各種規定に準拠しています。これにより、Agent Bricksはアイデアと実際のAIプロダクトとの間のギャップを縮め、AIエージェントをAzure Databricksのデータおよびクラウドコンピューティングエコシステムの中で、よりアクセスしやすい存在にしています。
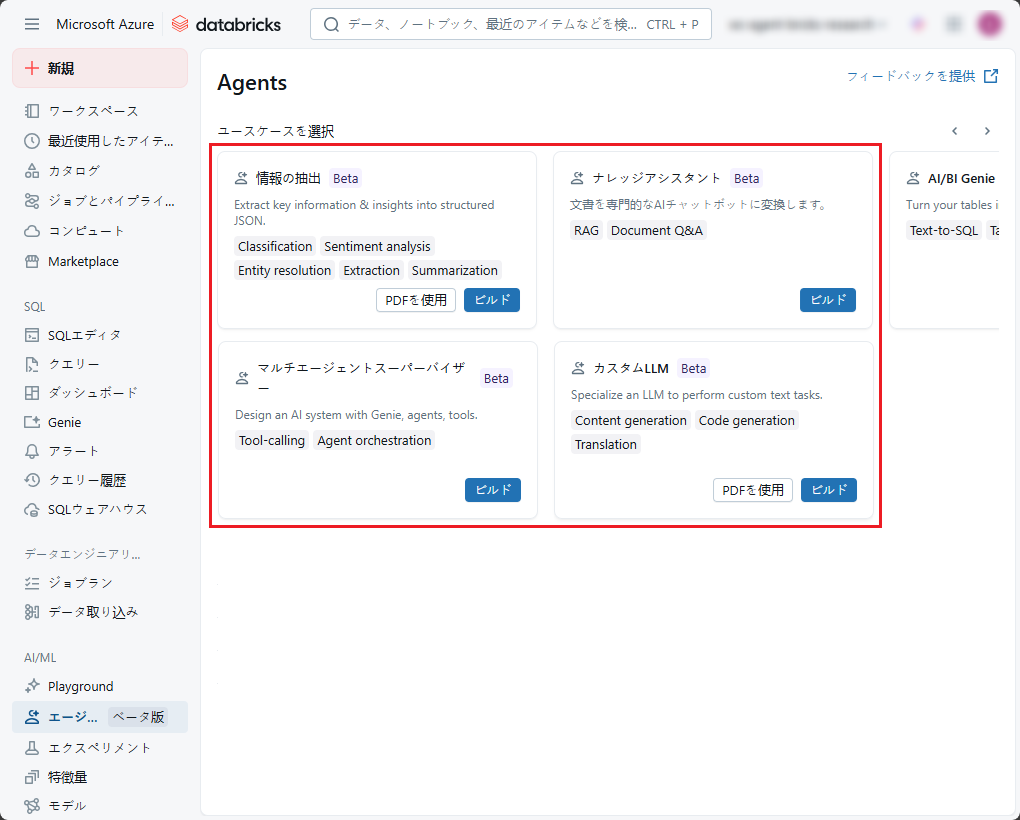
② Agent Bricksの主なユースケース
情Agent Bricksは、AI分野における多様な利用シーンに対応できます。主なユースケースは以下のとおりです。
- 報抽出(Information Extraction):大量のテキストドキュメントを処理し、構造化データに変換できます。
- カスタムLLM(Custom LLM):ユーザーのニーズに適したテキスト生成タスクを作成できます。目的やデータを明確に定義・調整することで、AIエージェントはコンテキストに合わせてより正確な回答が生成できます。
- ナレッジアシスタント(Knowledge Assistant):ナレッジ化した企業の文書を参照し、質問応答が可能なチャットボットを構築できます。生成された回答には参照元が含まれるため、ユーザーは情報の正確性や信頼性を検証することが可能です。
- マルチエージェントスーパーバイザー(Multi-Agent Supervisor):相互に補完し合う複数のAIエージェントを組み合わせて、複雑なAIシステムを作成し、多層的な課題にも対応でき、包括的な解決策を提供できます。
Agent Bricksは単なるAI開発ツールではなく、AI活用のアイデアを迅速かつ体系的に、そしてスケーラブルに実現するためのプラットフォームです。
2.2. Agent Bricksの利用方法
ユーザーは自動化プロセスにより特定のニーズやデータに合わせてAIエージェントを構築・カスタマイズできます。
運用中に、システムはバックグラウンドで追加のテストやハイパーパラメータのチューニングを自動的に実行し、モデルのパフォーマンスを継続的に改善します。Agent Bricksがより良いモデルを検出した場合、ユーザーに通知し、追加コストなしで切り替えオプションを提案します。
Agent BricksはDatabricks Data Intelligence Platformと緊密に統合され、AIエージェントの構築から運用まで実行できる包括的な環境を提供します。
2.3. Azure AI FoundryとDatabricks Agent Bricksの比較
| 比較基準 | Azure AI Foundry | Databricks Agent Bricks |
| 1. 利用対象 | Azure上の既存AIモデルを構築・展開したい企業ユーザー | 自社データに基づいてAIエージェントシステムを構築・最適化したい企業ユーザー |
| 2. データアクセス | Azureデータソース(Blob、SQL Database、Cognitive Searchなど)を統合し、データの調整やパイプライン設定は手動で行います。 | Databricks Lakehouse Platformを統合し、データのエンリッチメント・処理を行い、AIを統一することでAIの学習やデータの更新をシームレスに実行できます。 |
| 3. 展開構造 | モジュール方式で、各コンポーネント(モデルエンドポイント、オーケストレーション、ベクトルストアなど)は手動で設定します。 | モデル選定から自社データによるチューニング、ハイパーパラメータの最適化、エンドポイント展開まで、プロセスの大部分が自動化されます。 |
| 4. ワークフロー統合 | Azure Logic Apps、Power Automate、AzureのMLOpsサービスと統合され、Microsoftエコシステムを使用する企業に適しています。 | Databricks Workflows、Unityカタログ、MLflowと統合され、データパイプラインの同期、モデル管理、パフォーマンス監視をDatabricks環境内で一元的に実行できます。 |
| 5. 利用料金 | Azureリソースの使用量によって異なります。予期しない費用を避けるために、ユーザー自身がリソースを管理する必要があります。 | サーバーレス方式を採用し、3日間非稼働の場合は自動的にスケールダウン(scale-to-zero)されます。
さらに、Databricksが自動的に最適化を行い、より良いモデルの提案を無料で提供することで、管理負担とコストを軽減できます。 |
| 6. リリース状況 | すでに商用化され、多くの統合機能が利用可能で安定稼働しています。 | Beta版のみ提供されています。
一部機能に制限はあるものの、AIエージェント開発プロセスの自動化・最適化に大きな潜在能力を秘めています。 |
2.4. Agent Bricks利用の前提条件
Azure DatabricksでAgent Bricksを利用するには、ユーザーの作業環境が以下の基本条件を満たす必要があります。
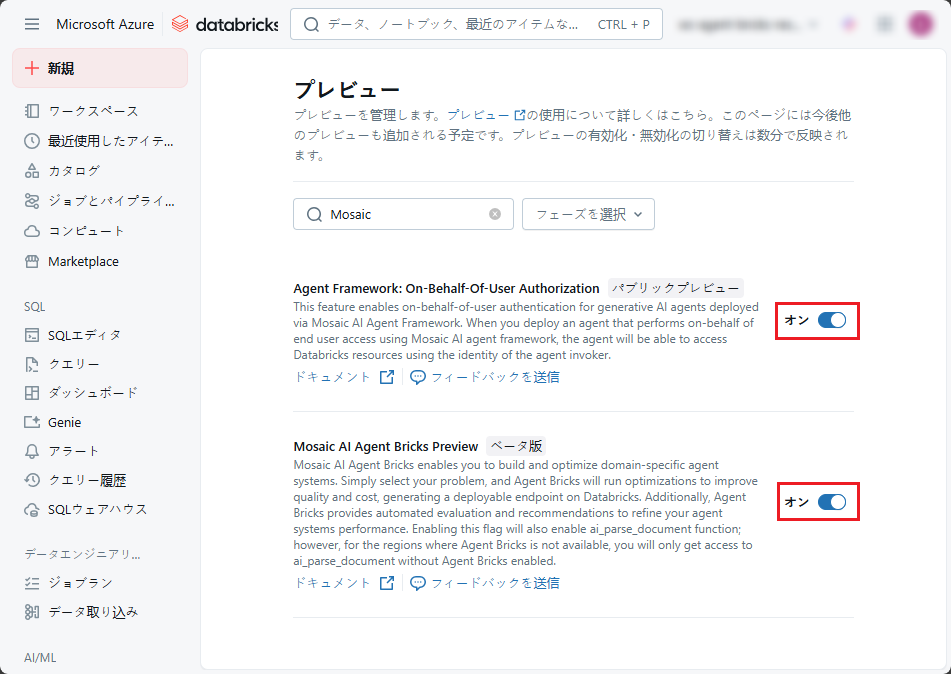
- ワークスペースでMosaic AI Agent Bricks Preview(ベータ版)機能が有効になっていること。
- サーバーレス コンピューティング(サーバーインフラを自己管理せずにAIプロセスを実行できるモード)が有効になっていること。
- Unityカタログが有効になっていること。
データおよびモデルへのアクセス権限を一元管理するためにUnityカタログを有効化し、ユーザーはsystem.aiスキーマを通じてUnity カタログの基礎モデル(Foundation Models)にアクセスできる権限を持つ必要があります。 - サーバーレス予算ポリシー(Serverless Budget Policy)へのアクセス権が付与されていること。
AIプロセスに必要なリソースを確保するために、ワークスペースが0以外の予算を持つサーバーレス予算ポリシー にアクセスできることが求められます。
尚、Agent Bricksは現在 (2025年10月まで、以下のAzureリージョンでのみ利用可能です。
centralus、eastus、eastus2、northcentralus、southcentralus、westus、westus2
最新の対応リージョンについては、こちらをご参照ください。
3. Azure DatabricksでのAgent Bricksの利用方法
3.1. 情報抽出エージェントの作成
① 情報抽出(Information Extraction)の概要
Agent Bricksの情報抽出(Information Extraction)は、ラベル付けされていない大量のテキスト ドキュメントを、
ドキュメントごとに抽出された情報を含む構造化テーブルに変換するプロセスを簡略化するツールです。
情報抽出の例を次に示します。
- 契約書から価格やリース情報を抽出します。
- 顧客のメモからデータを整理します。
- 記事から重要な情報を抽出します。
Agent Bricksの情報抽出は、 MLflow及びエージェント評価(Agent Evaluation)を含む自動評価機能を活用して、
特定の抽出タスクにおけるコストと品質の兼ね合いを迅速に評価することができます。
この評価により、精度とリソース投資のバランスに関する情報に基づいた意思決定を行うことができます。
② 情報抽出を利用する際の前提条件
Agent Bricksの条件を満たすこと。(「2.4. Agent Bricks利用の前提条件」をご参照ください。)
情報抽出用のai_query SQL 関数を使用可能であること。
データを抽出するファイルは、Unityカタログのボリュームまたはテーブル内にある必要があります。
情報抽出したいドキュメントは、Unityカタログのテーブルまたはボリュームに含まれている必要があります。
PDFを使用する場合は、最初にUnityカタログ テーブルに変換する必要があります。
エージェントをビルドするには、Unity カタログ ボリュームに少なくとも 1 つのラベル付けされていないドキュメント、
またはテーブル内の1行が必要です。
エージェントを最適化するには、Unityカタログ ボリュームにラベル付けされていないドキュメントが少なくとも75個、
またはテーブル内に少なくとも 75 行ある必要があります。
技術要件やガイドラインの詳細は以下を参照:
③ 使用データ:
novelテーブルには、以下の2冊の書籍から抽出したコンテンツを格納するtext列が含まれています。
- 「Pride and Prejudice」(著者: Jane Austen)
- 「The Little Girl at the Window」(著者: Tetsuko Kuroyanagi)
④ エージェント作成の手順
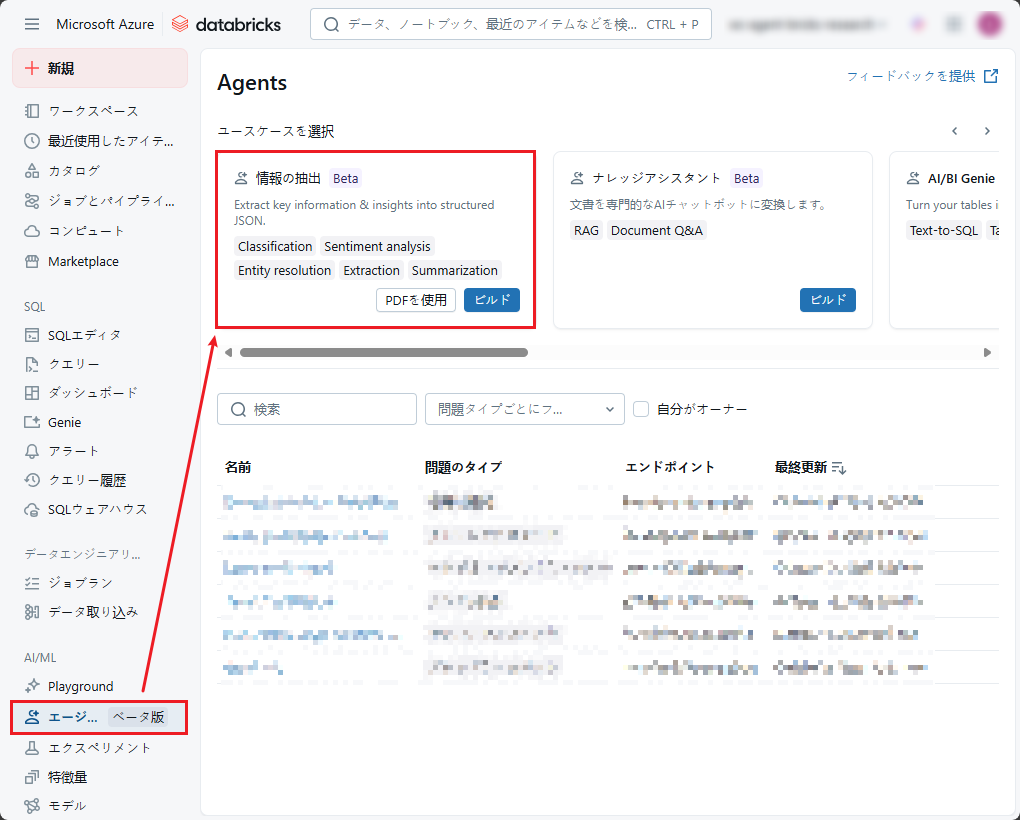
ステップ1: 情報抽出エージェントを作成します。
Databricks画面で、
ナビゲーション ウィンドウにある「エージェント」をクリックします。
「情報の抽出」を選択します。
基本情報を入力します。
「名前」フィールドにエージェント名を入力します。
「ソースデータ」のタイプを選択します。
- 「ラベル付きデータセット」: ラベル付きデータで、入力データに対して正確な出力/ラベルが付いています。
- 「ラベルなしのデータセット」:ラベルが付いていないデータで、生の入力データのみが含まれます。※注:PDF形式のラベルなしデータを使用する場合、最初にカタログテーブルに変換する必要があります。詳細はこちらをご参照ください。
本デモの範囲では、「ラベルなしのデータセット」を選択します。
- 「データセットの場所」フィールドでソースデータへのパスを入力します。
- 「テキストデータを含む列を選択」で、入力データを含む列を選択します。
入力データを指定すると、「JSON出力の例」フィールドに抽出されたデータを含むサンプルJSONが自動生成されます。内容を確認し、問題なければ、「エージェントを作成」をクリックします。
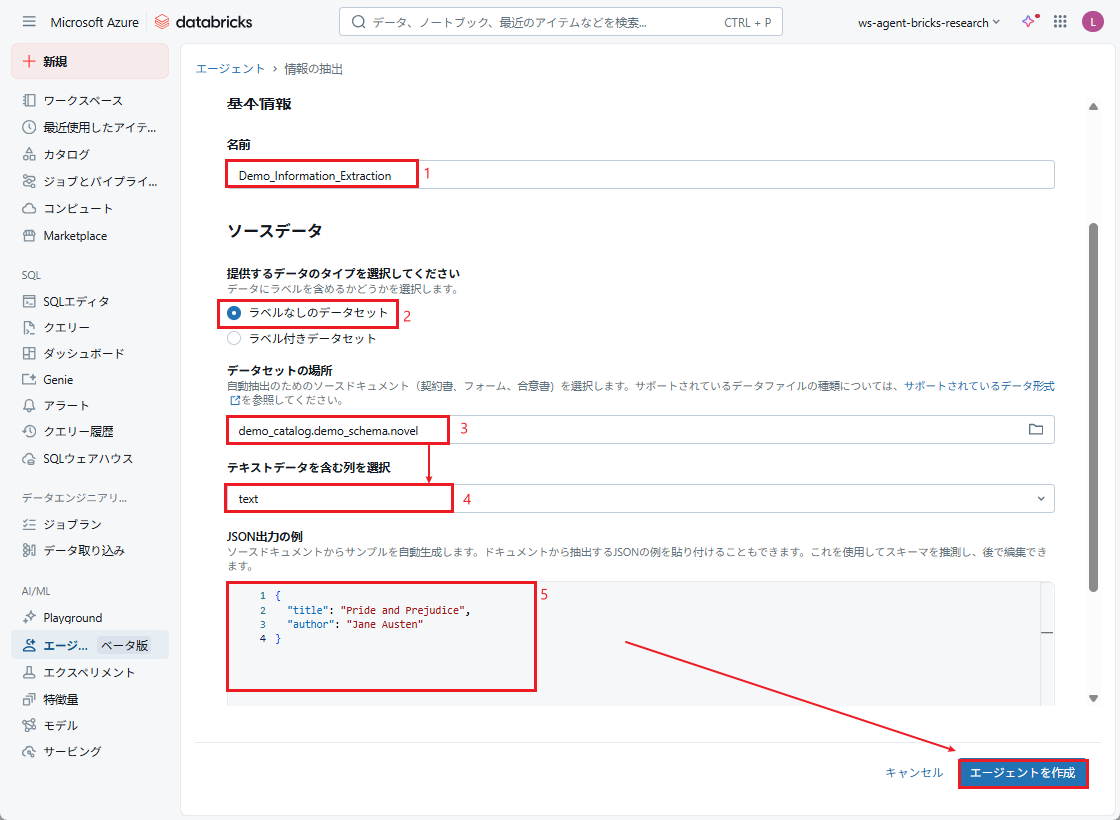
エージェントが正常に作成されると、以下のようなインターフェースが表示されます。
出力プレビュー:次の列が表示されます。
- 「入力」列:入力データを表示します。
- 「エージェントの応答」列:エージェントによって抽出された情報を表示します。
- 「エージェント構成」:応答内で抽出する情報フィールドを定義します。
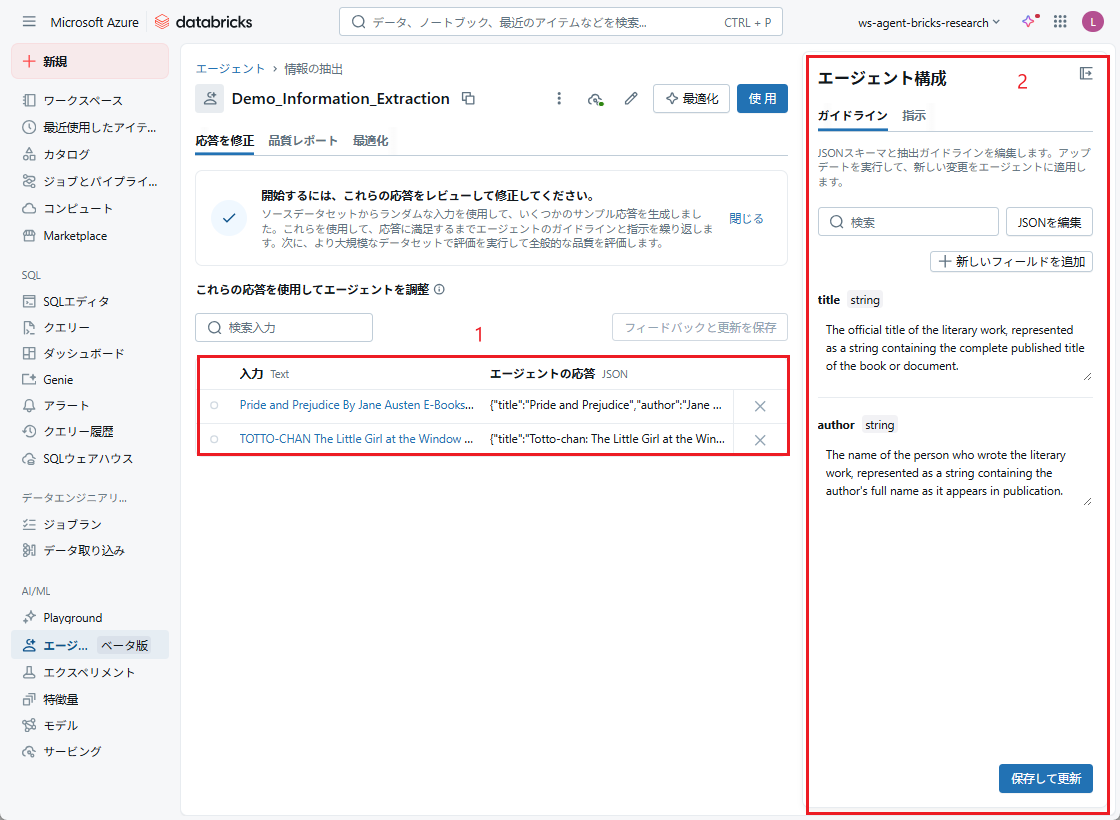
ステップ2: エージェントを改善する
「新しいフィールドを追加」、または「JSONを編集」をクリックして、抽出フィールドの追加・編集・削除できます。
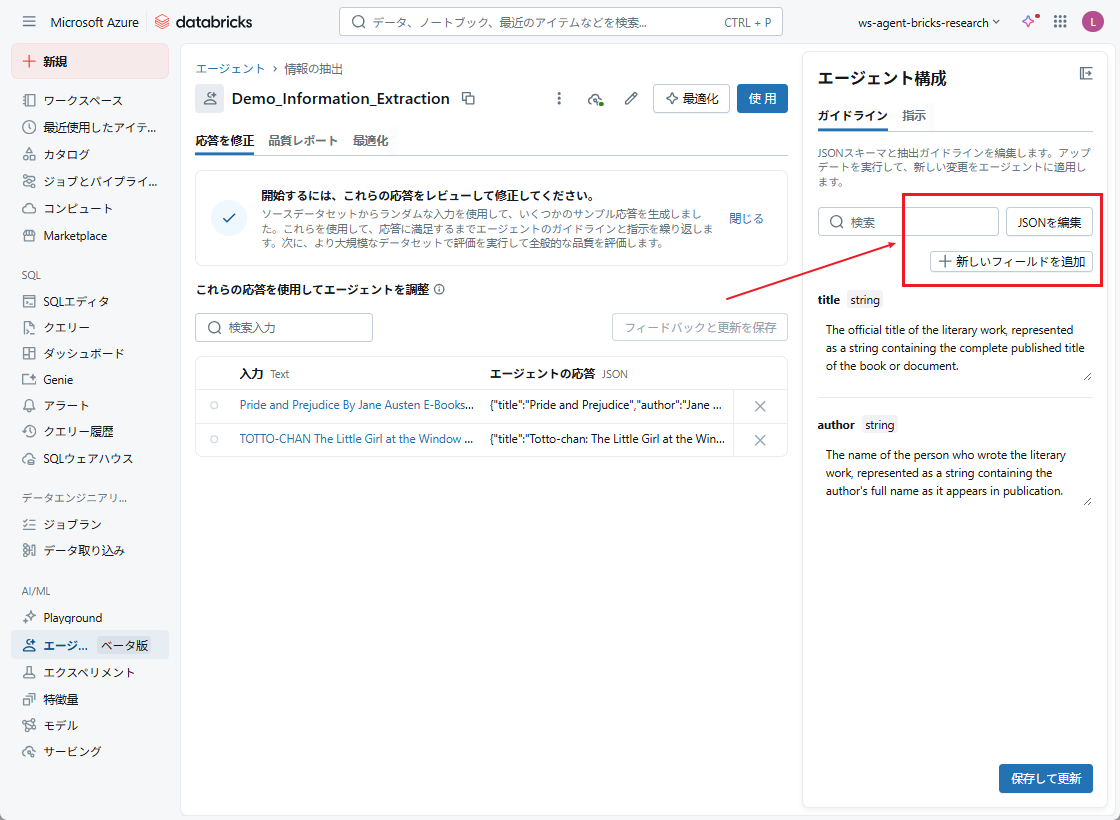
エージェントの情報抽出機能を明確にするために、ここでキャラクターやイベントの詳細情報を含むフィールドを追加します。
本デモで使用するJSONファイルはこちらをご参照ください。
必要なフィールドを追加した後、「保存して更新」をクリックしてエージェントを更新します。
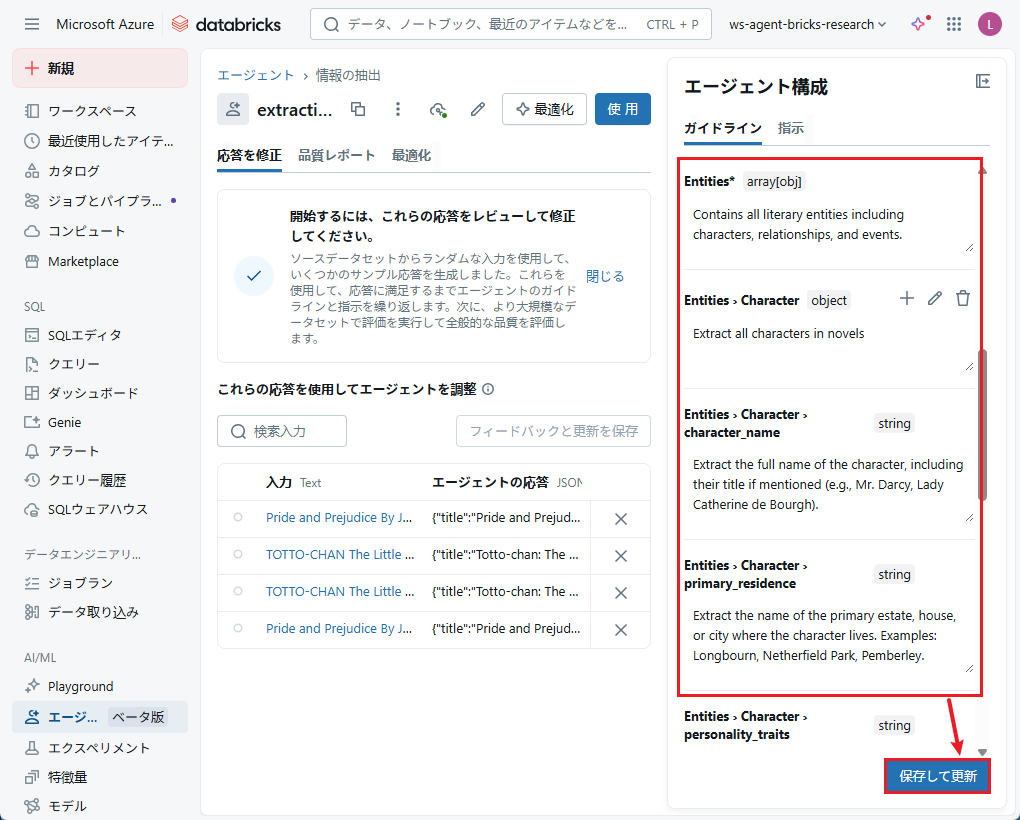
ステップ3: エージェントを使用する
エージェントの使用を開始するには、[ 使用] をクリックします。
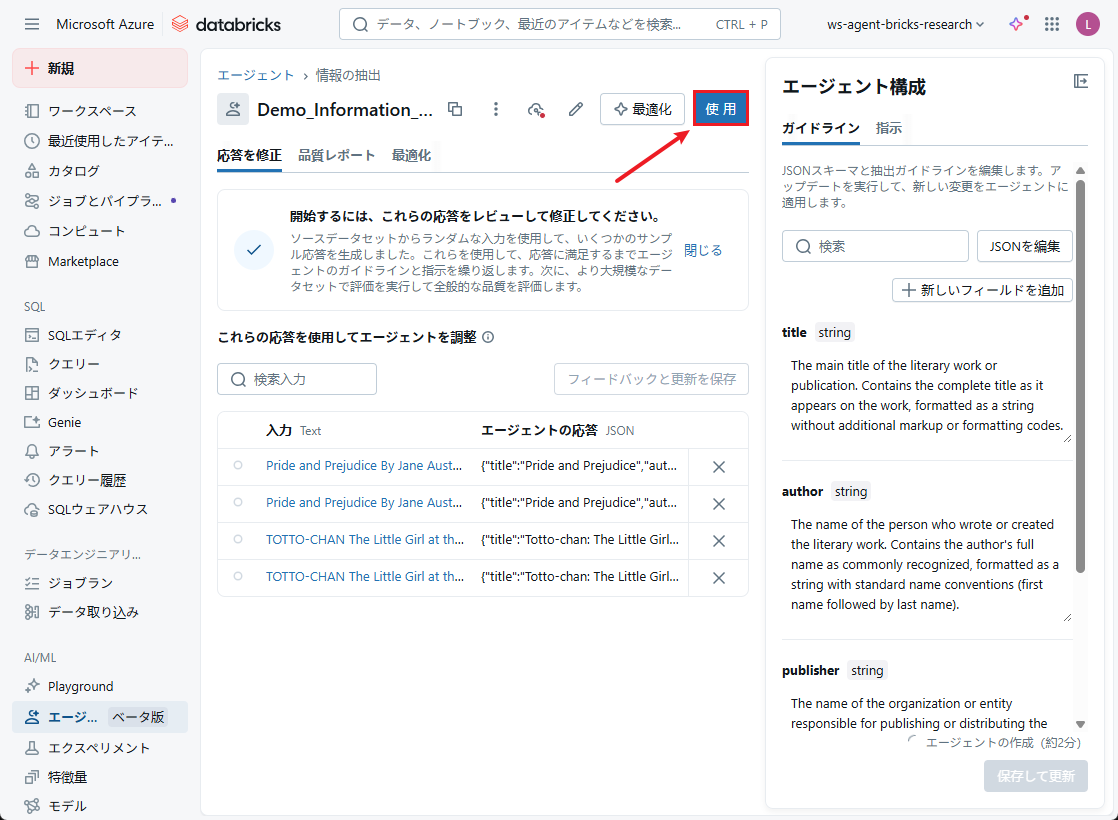
エージェントの使用方法は、次の3つから選択できます。
- 「すべてのドキュメントのデータを抽出」:SQLエディタでai_queryを実行して情報を抽出します。
- 「ETLパイプラインを作成」:新しいデータに対してパイプラインを作成し、スケジューリングします。
- 「エージェントをテスト」:Playgroundで直接プロンプトを使用してエージェントの動作を確認します。
本デモでは、「すべてのドキュメントのデータを抽出」機能でテストを行います。
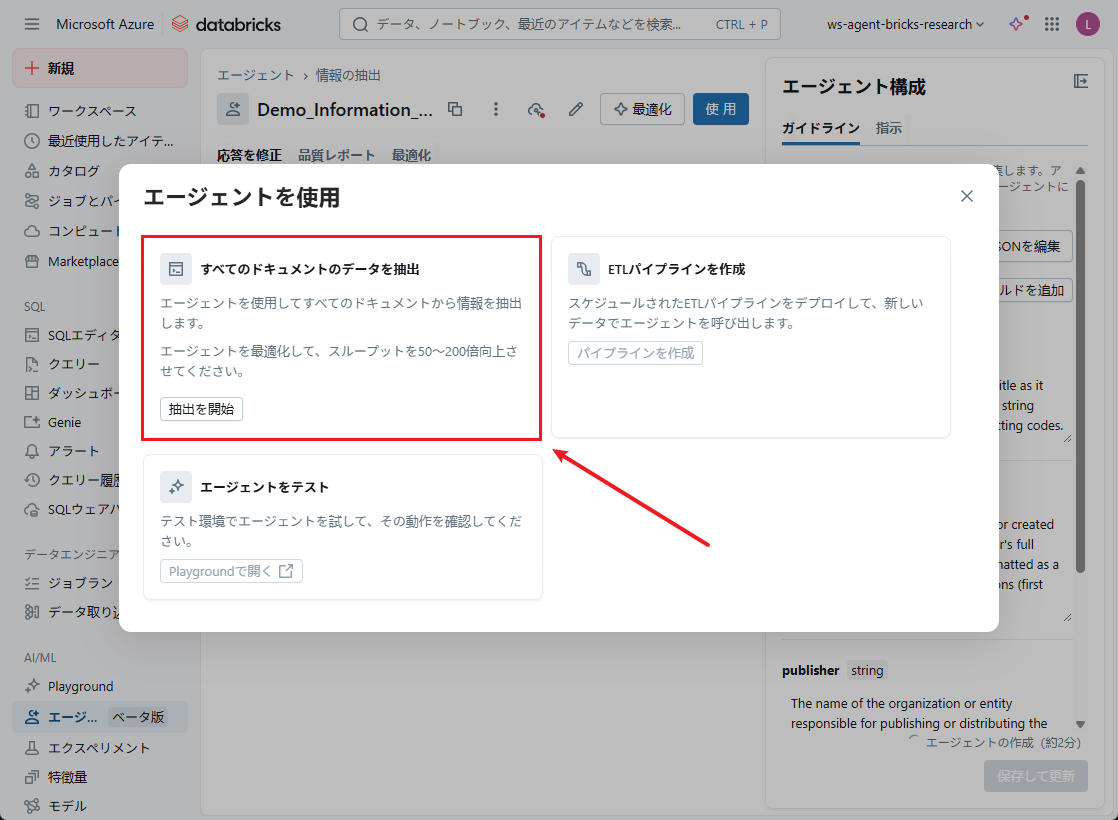
SQLエディタ画面で
- クエリの情報(パス、列名など)を再確認します。
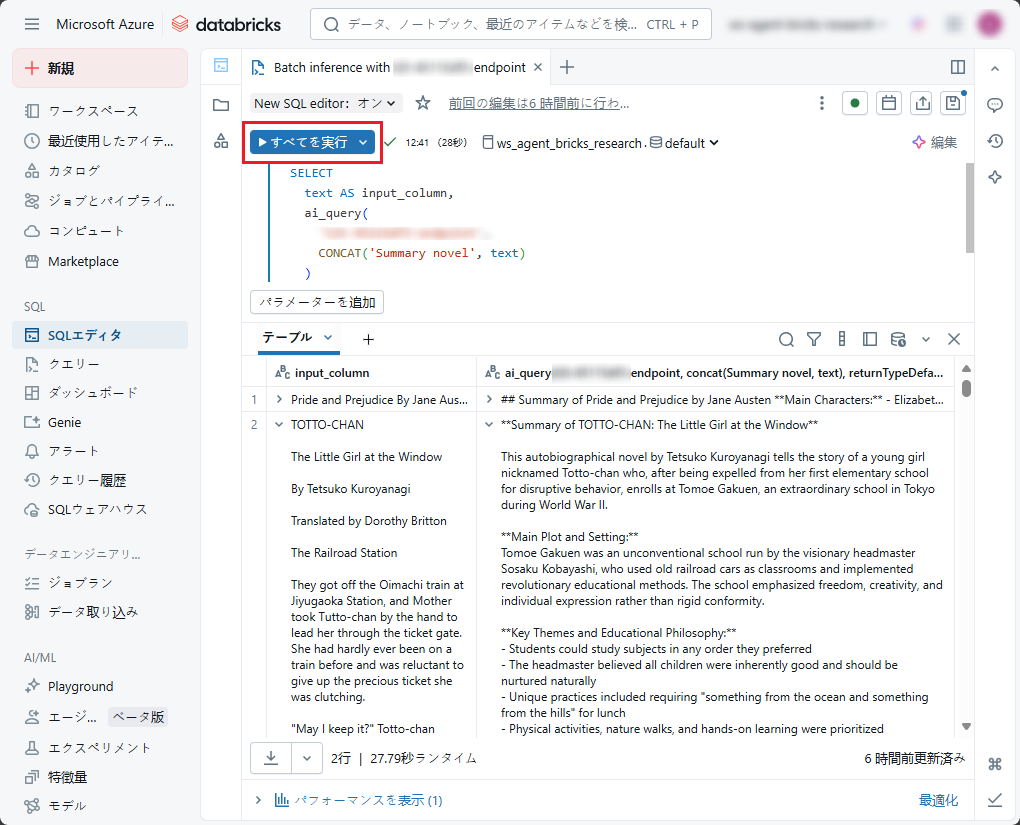
- 問題なければ、「すべてを実行」をクリックします。
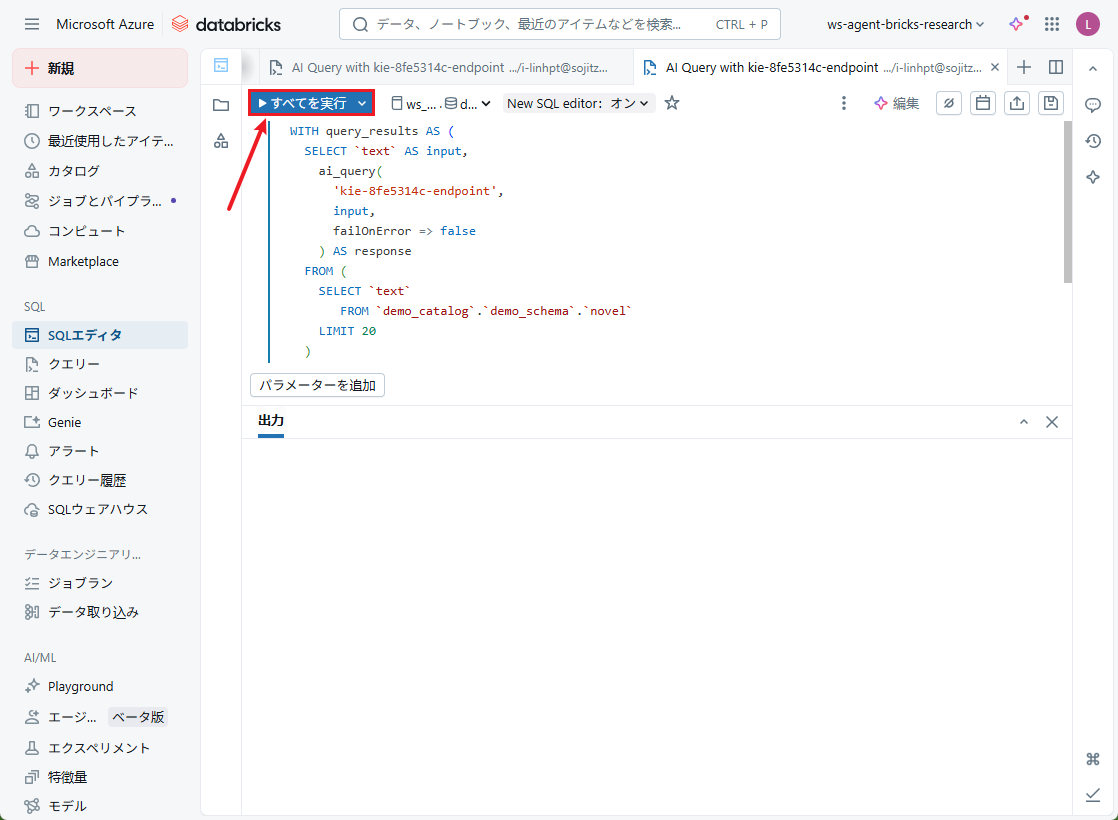
結果:
クエリ実行後、入力データから抽出された情報を含むレスポンスが返却されます。レスポンスには事前に定義されたフィールドがすべて含まれます。
⑤ メリット
- Agent Bricks情報抽出(IE)は、最適化プロセス全体を自動化できるため、Azure AI Foundryと比べてモデルのトレーニング及び最適化が優れています。
- Foundaryのように既存のモデルを使用するだけでなく、DatabricksではUnityカタログ内の実データに基づいてプロンプトやモデルを自動的にチューニングし、評価基準を自動設定したうえで最適なエンドポイントを生成できます。
- これにより、情報抽出タスクにおける技術的な作業量や運用コストが大幅に削減できます。
⑥ デメリット(制限)
- Databricksでは、エージェントの最適化には少なくとも1,000個のドキュメントが推奨されています。
ドキュメントを追加すると、エージェントが学習できるナレッジ ベースが増え、エージェントの品質と抽出精度が向上します。 - 情報抽出エージェントには、128kトークンの最大コンテキスト長があります。
- セキュリティ強化とコンプライアンス(Enhanced Security and Compliance)が有効化されたワークスペースはサポートされていません。
- 制限されたサーバレスのエグレス制御ネットワークポリシーがあるワークスペース、またはワークスペースストレージアカウントのファイアウォールサポートが有効になっているワークスペースでは、最適化が失敗する可能性があります。
- ユニオンスキーマ型はサポートされていません。
3.2. カスタムLLMエージェントの作成
① カスタムLLM(CustomLLM)の概要
Agent BricksのカスタムLLM(Custom LLM)は、既存の大規模言語モデル(LLM)の挙動を特定の分野や目的に合わせて柔軟にカスタマイズできるツールです。これにより集計、分類、テキスト変換、コンテンツ生成などのタスクにおいて、出力結果の精度と品質を向上させることができます。
カスタム LLM は、次の使用例に最適です。
- 顧客との通話内容の要約
- 顧客レビューのセンチメントの分析
- 研究論文のトピック別の分類
- 新機能のプレスリリースの生成
また、MLflow およびエージェント評価(Agent Evaluation)の統合により、モデルの性能・コスト・品質を迅速に評価し、自身のニーズに最適な構成を選択することが可能です。
② カスタムLLMを利用する際の前提条件
ワークスペースは次の条件を満たす必要があります。
- Agent Bricksの条件を満たすこと。(「2.4. Agent Bricks利用の前提条件」をご参照ください。)
- パートナーを利用したAI機能が有効になっていること。
- モザイクAIモデルサービスにアクセスできること。
- ai_query SQL 関数を使用可能であること。
以下の入力データ形式のいずれかを指定する必要があります。 。
- Unityカタログテーブル。(サポートされるデータ型: string、int、double)
- データテーブルが存在しない場合は、少なくとも3つの入力と出力の例を提供し、 エージェントのスキーマの宛先パスを指定する必要があります。(CREATE REGISTERED MODELおよびCREATE TABLE 権限が必要)
③ カスタムLLMの作成
左側のナビゲーション ウィンドウで 「エージェント」をクリックします。
「カスタム LLM」で「ビルド」をクリックします。
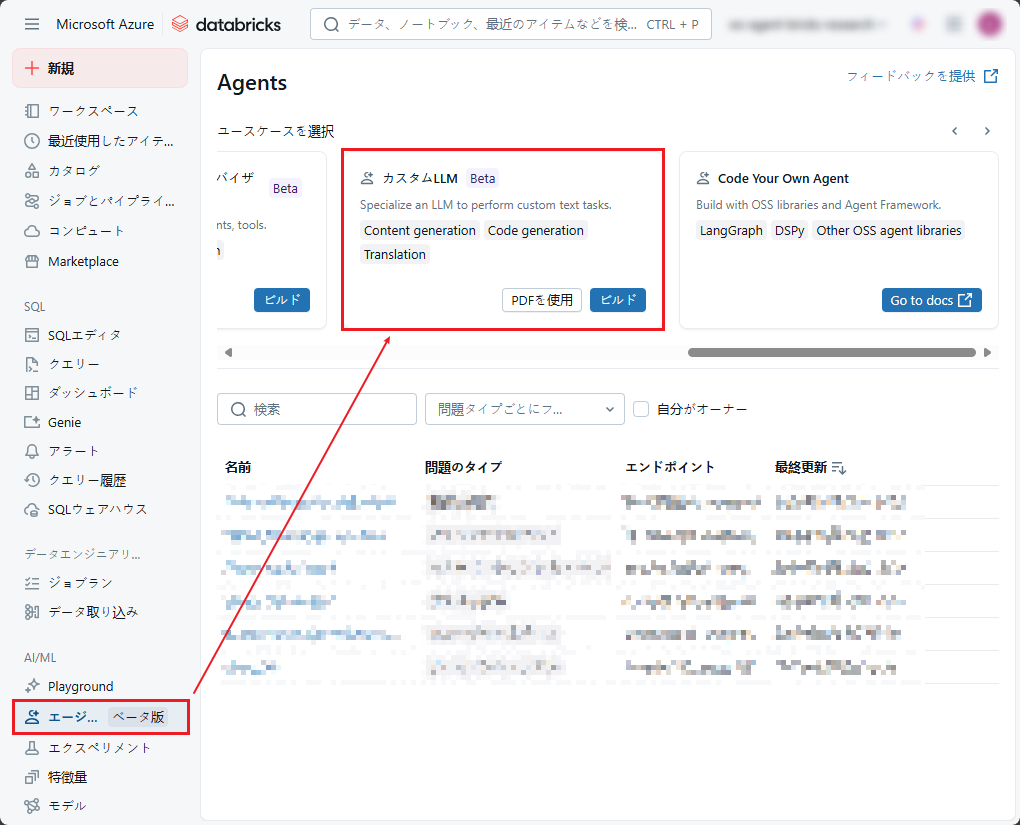
ステップ1:CustomLLMエージェントを構成します。
以下の情報を入力します。
- 「名前」 フィールドにエージェント名を入力します。
- 「タスクを説明してください」 フィールドにエージェントに実行させたい内容を入力します。
例:Summarize, categorize, transform writing styles, generate, etc., based on the book Pride and Prejudice
- 「エージェントの作成に使用したデータを入力してください」 フィールドで 「ラベルなしのデータセット」を選択します。
- 「データセットをUCテーブルとして選択」 フィールドにデータを含むスペース名を入力します。
- 「入力列」 フィールドに入力データを含む列名を入力します。
- 「エージェントを作成」をクリックしてCustomLLMエージェントを作成します。
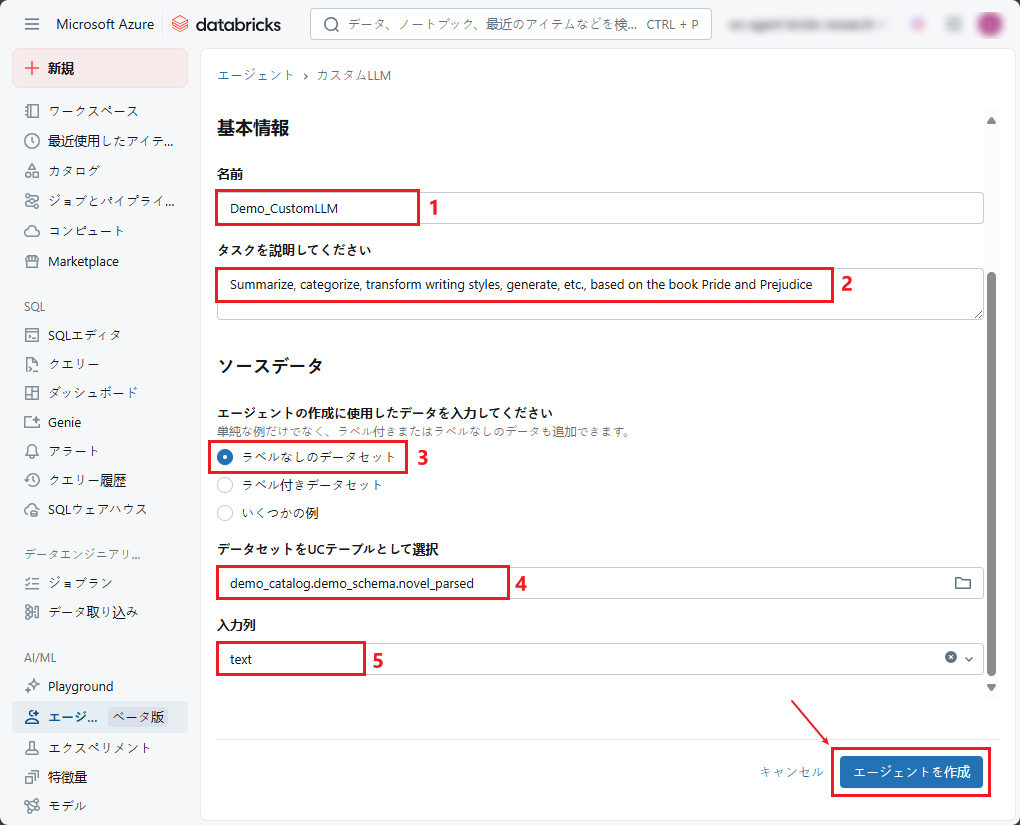
ステップ2:CustomLLMエージェントをビルドして改善します。
「応答を改善するためにフィードバックを提供」の「入力」及び「エージェントの応答」フィールドを確認します。
結果に満足していない場合は、「いいえ」をクリックしモデルの応答を改善するためのフィードバックを提供します。
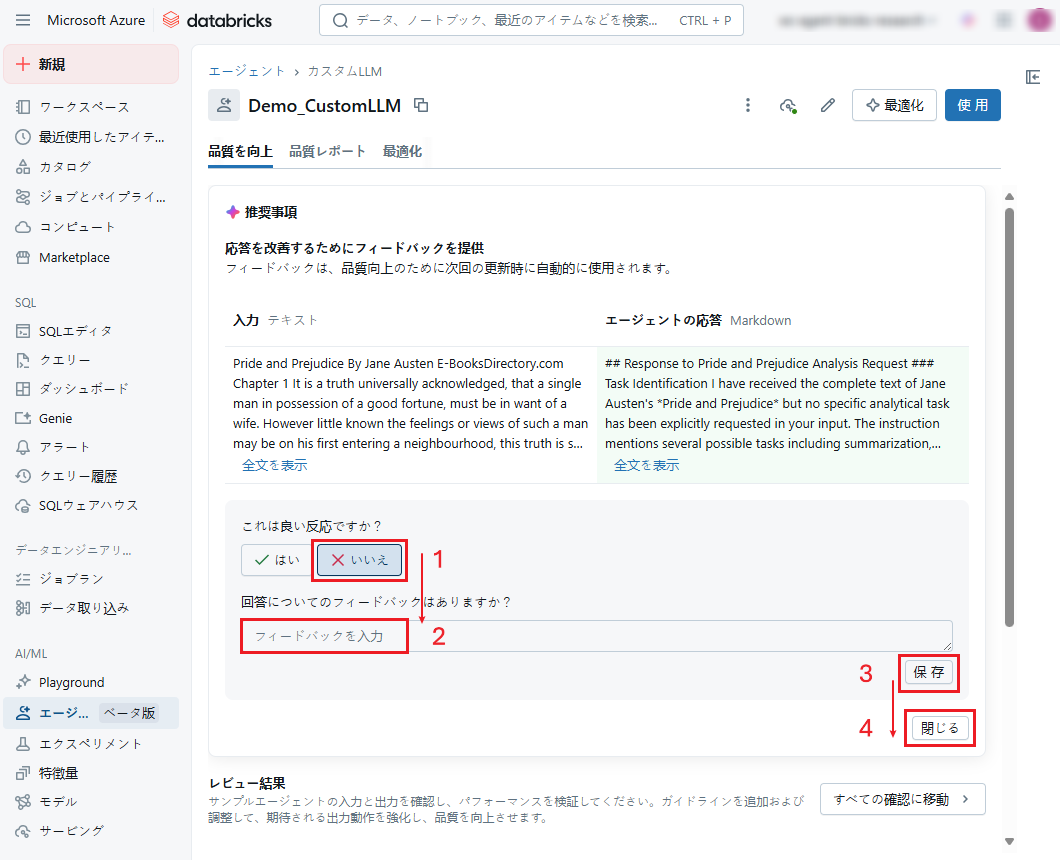
「エージェント構成」タブで、Databricksはエージェントの応答を評価する指標を提案します。
これら指標は、Databricksによってい自動的に推定されます。必要に応じて見直し、エージェントを最適化します。
提案された指標を無視する場合は「X」をクリックします。
エージェントに独自の評価基準を追加する場合は、「+ 追加」をクリックします。
最後に、「保存して更新」をクリックして保存します。
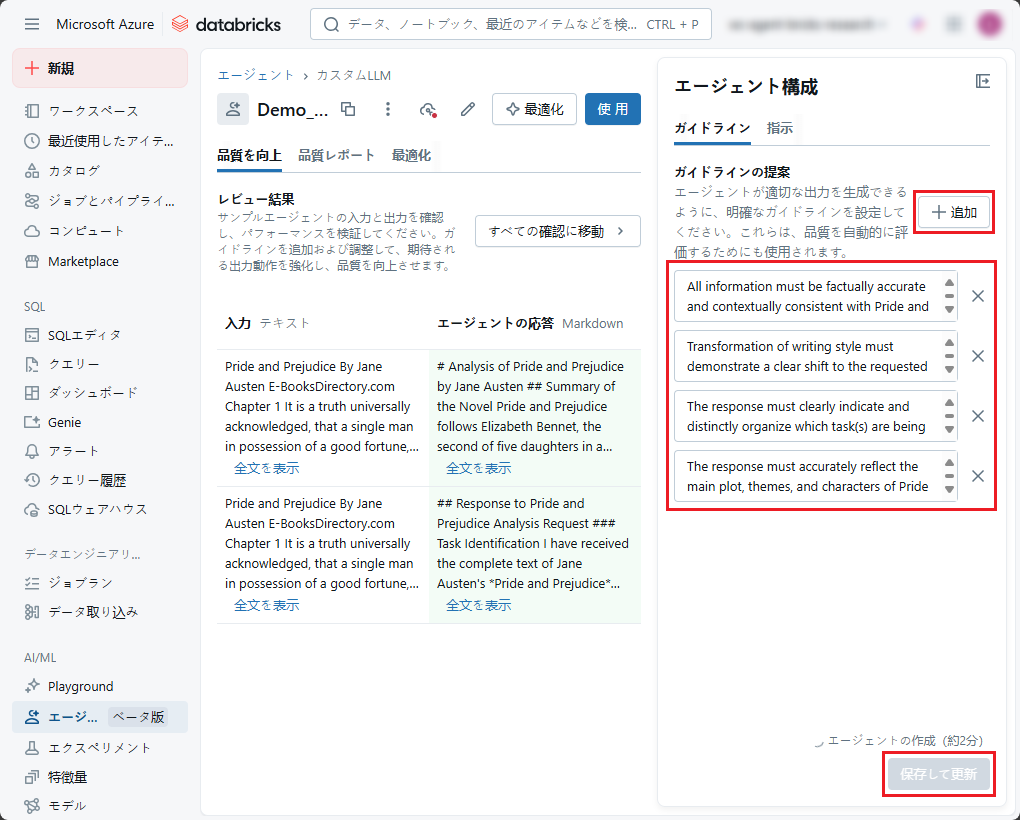
ステップ3: エージェントを試して最適化します。
「エージェントを使用」タブで (1)「使用」をクリックします。
- 「自分のデータで試してみる」で(2)「SQLで試す」をクリックしてSQL エディターを開き、 ai_query を使用してCustomLLM エージェントに要求を送信します。
- また、「エージェントをテスト」で(3) 「Playgroundで開く」 をクリックして Playgroundでテストすることもできます。
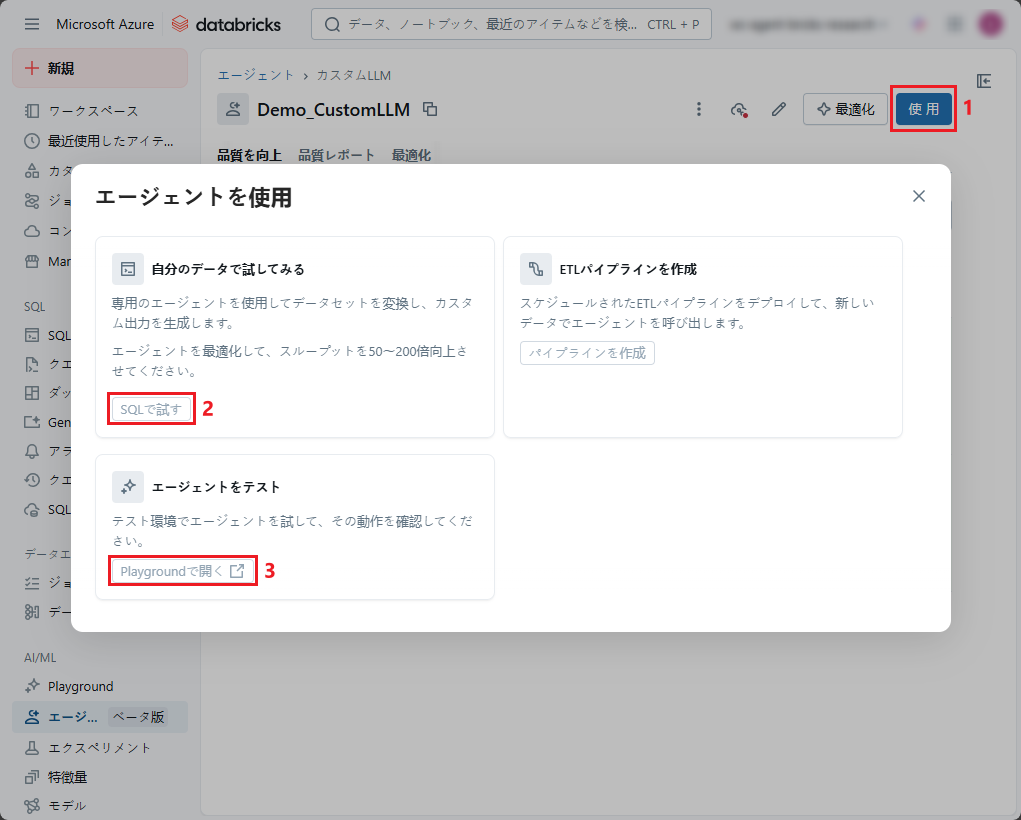
「Playgroundで「データに適用する」を選択します。 自分のデータを使ってテストすることができます。
例:エージェントに小説の要約を依頼します。
④ メリット
- DatabricksのCustomLLMを使用することで、ユーザーがDatabricks環境で独自の学習データを使用して言語モデルを直接微調整できます。
一方、Azure AI FoundryはAPI レベルでのファインチューニングのみをサポートしており、学習パイプラインのカスタマイズ性が制限されています。
⑤ デメリット(制限)
- エージェントを最適化するために、少なくとも100個の入力サンプルが必要です。
- 現在、使用容量は 1 分あたり 100,000 個の入力トークンと出力トークンに制限されています。
- セキュリティ強化とコンプライアンス(Enhanced Security and Compliance)が有効化されたワークスペースはサポートされていません。
- エグレス制御ネットワーク ポリシーがあるワークスペースや、ストレージ アカウントのファイアウォール サポートを有効にしているワークスペースでは、最適化が失敗する可能性があります。
3.3. ナレッジアシスタントエージェントの作成
① ナレッジアシスタント(Knowledge Assistant)の概要
Agent Bricksのナレッジアシスタント(Knowledge Assistant)は、ドキュメントに基づいて明確な引用付きで質問に答えるチャットボットを作成するツールです。
RAG(retrieval-augmented generation)技術を用いて、提供された専門的なコンテンツ(知識)に基づいて正確で信頼性の高い回答を生成します。
ナレッジ アシスタントは、次のユース ケースをサポートするのに最適です。
- 製品ドキュメントに基づいたユーザーの質問回答
- 社内ポリシーに関する社員サポート
- 技術サポートのナレッジベースを活用したカスタマーサポート
Review Appのラベル付きセッションを通じて専門家からの自然言語フィードバックを収集することで、チャットボットの品質を向上させ、エージェントのパフォーマンスを最適化することができます。
Knowledge Assistant は完全なエンドポイントを生成し、AI Playgroundでのチャットなど、さまざまなアプリケーションに統合することが可能です。
② ナレッジアシスタントを利用する際の前提条件
Agent Bricksの条件を満たすこと。(「2.4. Agent Bricks利用の前提条件」をご参照ください。)
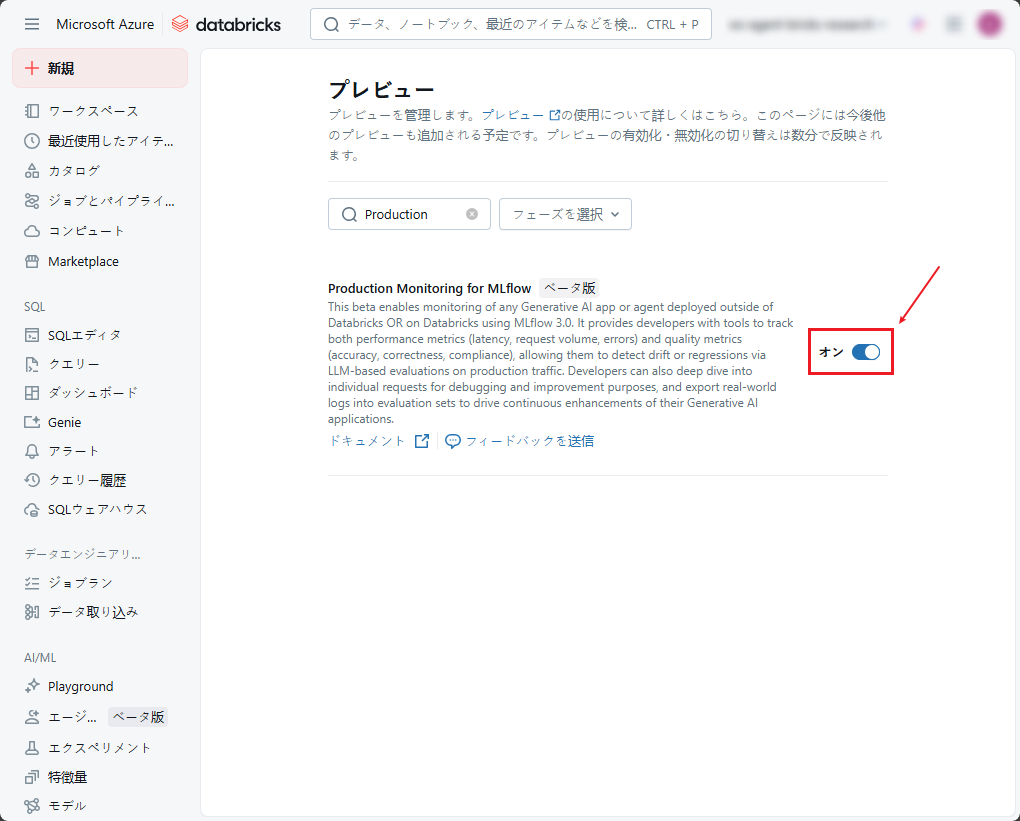
MLflow (ベータ) の運用監視(Production Monitoring) が有効になっていること。
パートナーを利用したAI機能が有効になっていること。
入力データは以下のいずれかを指定する必要があります 。
- Unity Catalog ボリュームまたはボリューム ディレクトリ内のファイル。 (サポートされているファイルの種類:txt、pdf、md、ppt/pptx、doc/docx)
- 埋め込みモデルとして databricks-gte-large-en を使用するベクター検索インデックス。
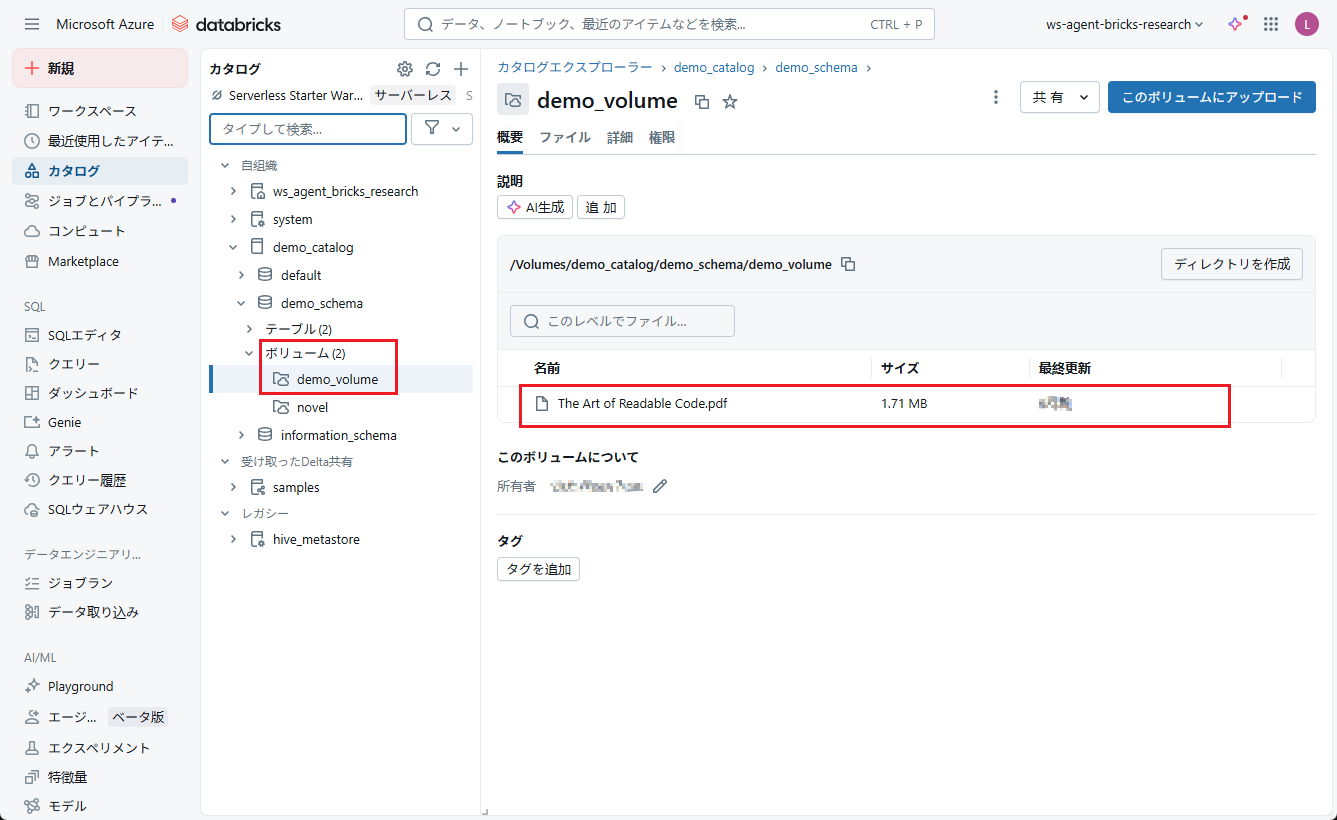
③ 使用データ
本デモでは、エージェントのナレッジデータとしてプログラミングに関する書籍を使用します。
PDF形式のデータはカタログボリュームにアップロードします。
④ Knowledge Assistantエージェントをの作成
ステップ1:Knowledge Assistantエージェントを作成します。
Databricksの「Agent」タブで、
「ナレッジアシスタント」をクリックします。
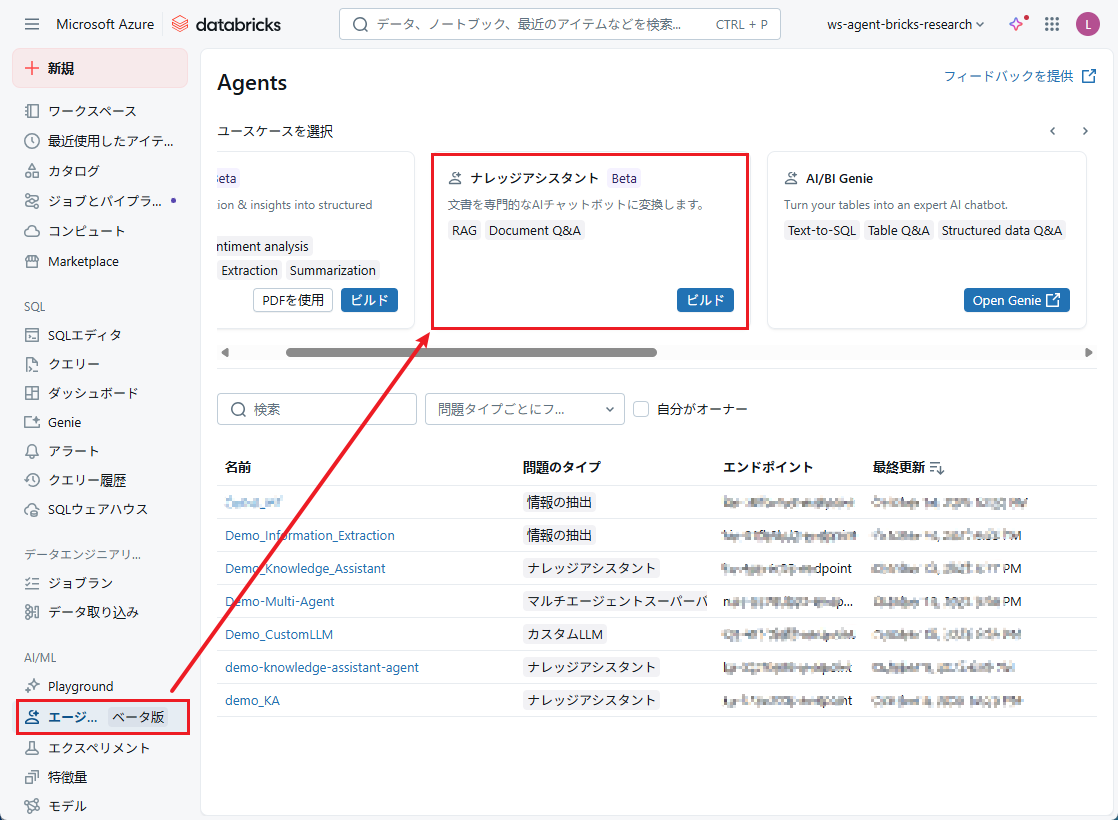
- 「名前」フィールドに、エージェントの名前を入力します。
- 「説明」フィールドで、エージェントでできることを記載します。
例:Answer question about the given books - 「ナレッジソースを設定」でデータ保存場所のパスを入力します。エージェントの入力データとして最大10個までのデータソースを選択できます。
- 「コンテンツを説明」で、データの概要を入力します。
内容が包括的であればあるほど、エージェントのパフォーマンスが向上します。
すべての必須項目を入力後、「エージェントを作成」 をクリックしてエージェントを作成します。
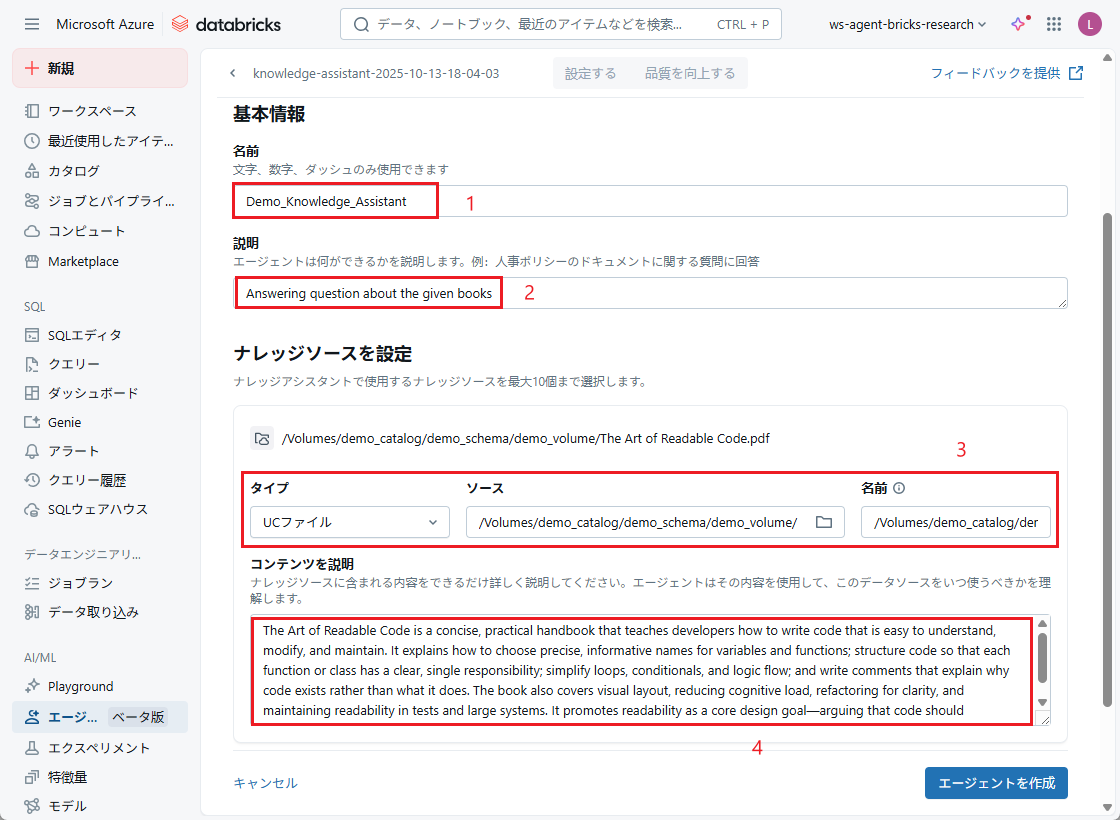
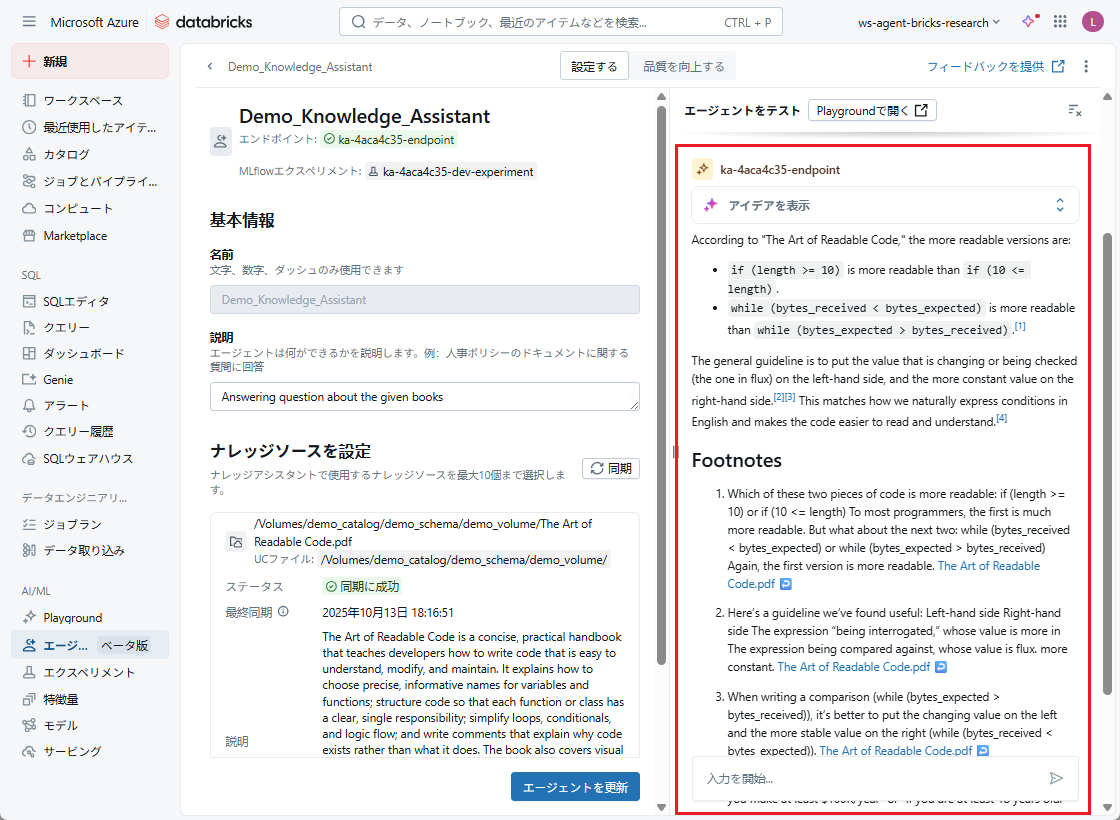
ステップ2: エージェントをテストします。
エージェントの作成が完了したら、ステータスが「同期に成功」であることを確認します。
その後、データに関連する質問を入力することで、エージェントの動作を確認することができます。
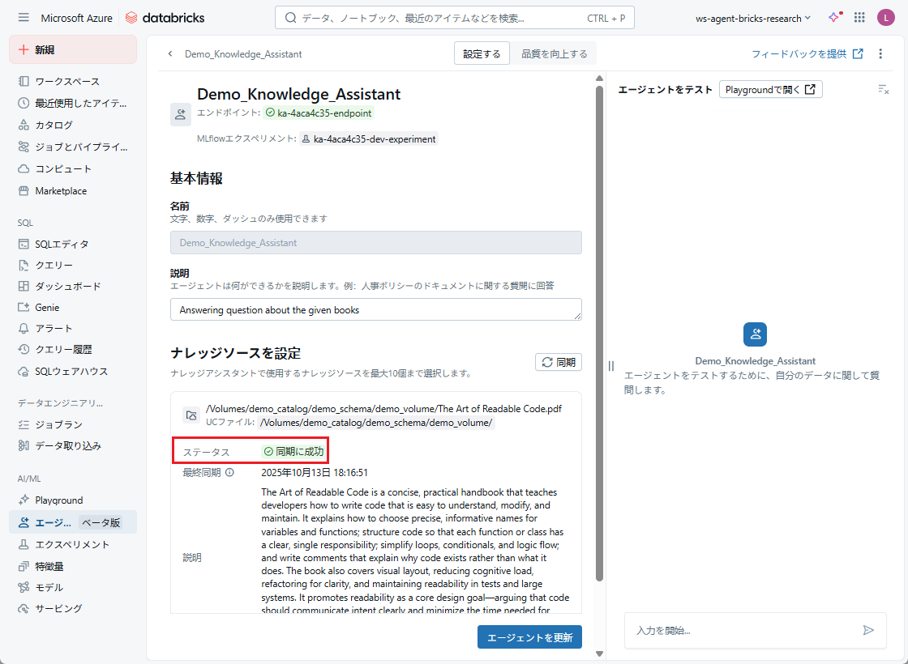
例:以下を「入力を開始」に入力します。
|
1 2 3 4 5 6 7 8 |
<i>Which of these two pieces of code is more readable:</i> if (length >= 10) or if (10 <= length) <i>To most programmers, the first is much more readable. But what about the next two:</i> while (bytes_received < bytes_expected) <i>or</i> while (bytes_expected > bytes_received) |
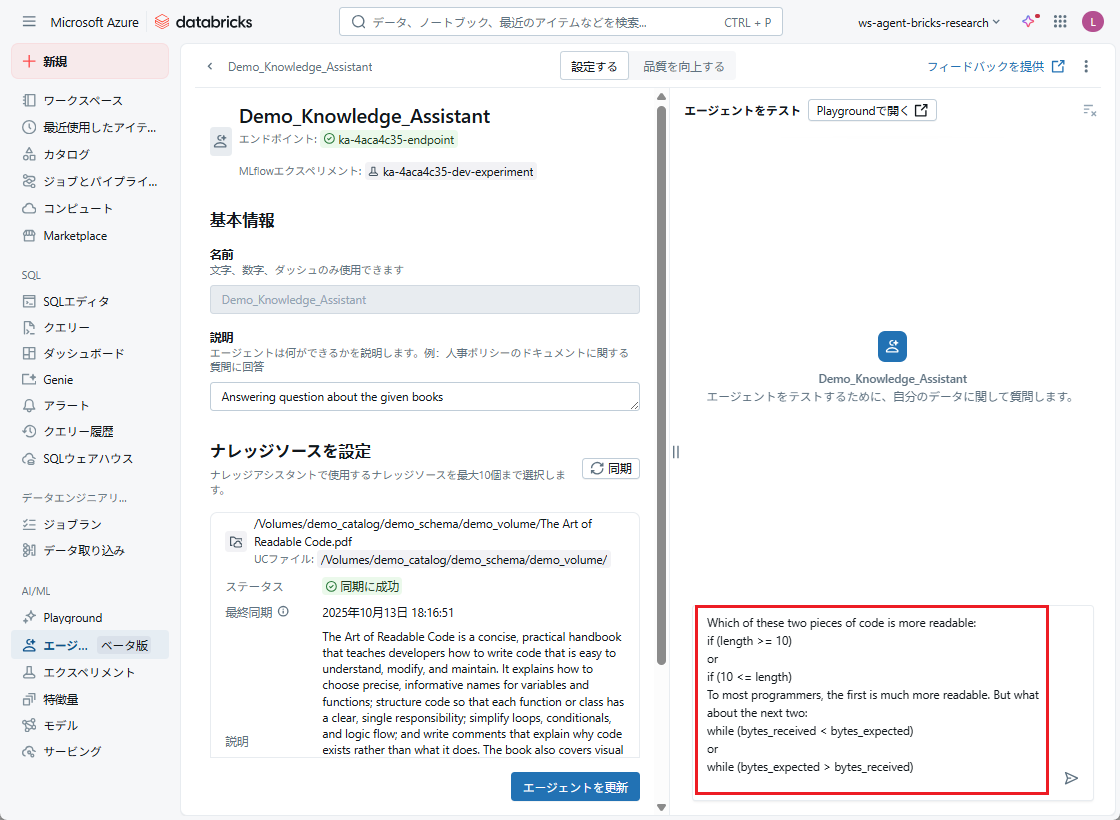
結果:
ナレッジアシスタントエージェントは、使用した書籍内のナレッジに基づいて回答を生成し、関連情報が記載されている箇所への参照も添付します。
⑤ メリット
DatabricksのKnowledge Assistantは、Unity Catalog内のデータに直接アクセスすることができます。
Unity Catalogには、権限設定、リネージ、およびメタデータの一元管理の仕組みが既に備わっているため、チャットボットはシステム外部にデータをコピーすることなく、常に更新され、完全に安全な実データソースに基づいて応答できます。
⑥ デメリット(制限)
50 MB を超えるファイルはインジェスト中に自動的にスキップされ、ナレッジ ベースには含まれません。
セキュリティ強化とコンプライアンス(Enhanced Security and Compliance)が有効化されたワークスペースはサポートされていません。
Unity カタログ テーブルはサポートされていません。
埋め込みモデルとして databricks-gte-large-en を使用するベクター検索インデックスのみがサポートされます。
トレースを機能させるには、 MLflow (ベータ) の運用監視を有効にする必要があります。 Azure Databricks プレビューの管理を参照してください。
3.4. マルチエージェント スーパーバイザーシステムの作成
① マルチエージェント スーパーバイザーシステム(マルチエージェント スーパーバイザー System)の概要
Agent Bricksのマルチエージェント スーパーバイザー(マルチエージェント スーパーバイザー)は、複数のエージェント エンドポイント、Genieスペースおよびツールを連携・調整させ、複雑なタスクを処理するための監視システムを構築するツールです。
マルチエージェント スーパーバイザーは、AIオーケストレーションモデルを使用して、エージェント間の対話管理、タスクの割り当て、結果を集約し、包括的なソリューションを提供します。
システムは自動的に構築され、時間の経過と共に人間のフィードバックを取り入れて継続的に改善されます。
次のようなユース ケースをサポートするのに最適です。
- 調査レポート及び利用状況データから市場分析やインサイト情報を提供します。
- 内部プロセスに関する質問に回答し、そのバックログを自動処理します。
- ポリシー、アカウント、 FAQなどの問い合わせに迅速に回答し、顧客サービスを高速化します。
② マルチエージェント スーパーバイザーを利用する際の前提条件
ワークスペースは次の条件を満たす必要があります。
- Agent Bricksの条件を満たすこと。(「2.4. Agent Bricks利用の前提条件」をご参照ください。)
- MLflow(ベータ)の運用監視が有効になっていること。
- エージェント フレームワーク:On-Behalf-Of-User 承認が有効になっていること。
- ワークスペースでパートナーを利用した AI(Partner-powered AI)機能が有効になっていること。
- モザイク AI モデル サービス(Mosaic AI Model Service)にアクセスできること。
使用可能なエージェントまたはツールが存在し、少なくとも以下のいずれかを指定する必要があります。
- 既存のAgent Bricks:Knowledge Assistantのエンドポイント
- 既存のGenieスペース
スーパーバイザ エージェントのエンド ユーザーは、次のアクセス権限を持っている必要があります。
- CAN QUERYアクセス権限(エージェント エンドポイントの場合)
- Genie space及びUnityカタログ内のデータへのアクセス権限(Genieスペースの場合)
③ マルチエージェント スーパーバイザーシステムの作成
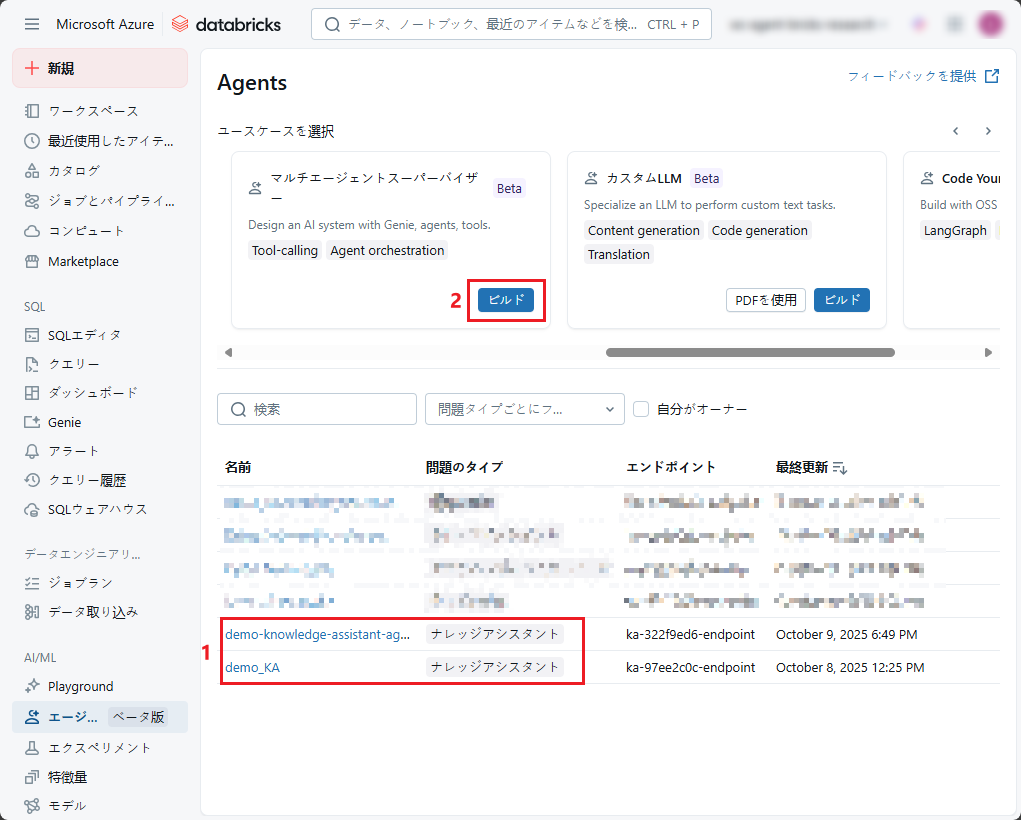
ステップ1:サブエージェントを作成し、アクセス許可を付与します。
マルチエージェント スーパーバイザーシステムを作成するため、最初にGenieスペースまたは Knowledge Assistantエージェントを事前に作成する必要があります。
本記事では、前のセクションで作成した Knowledge Assistantエージェントを使用します。
エンド ユーザーに、Knowledge Assistant エージェントエンドポイントの CAN QUERY 権限を付与します。
(1)でKnowledge Assistantエージェントが利用可能な状態であることを確認したら 、 (2) 「マルチエージェントスーパーバイザー」で 「ビルド」をクリックして、マルチエージェント スーパーバイザーを構築します。
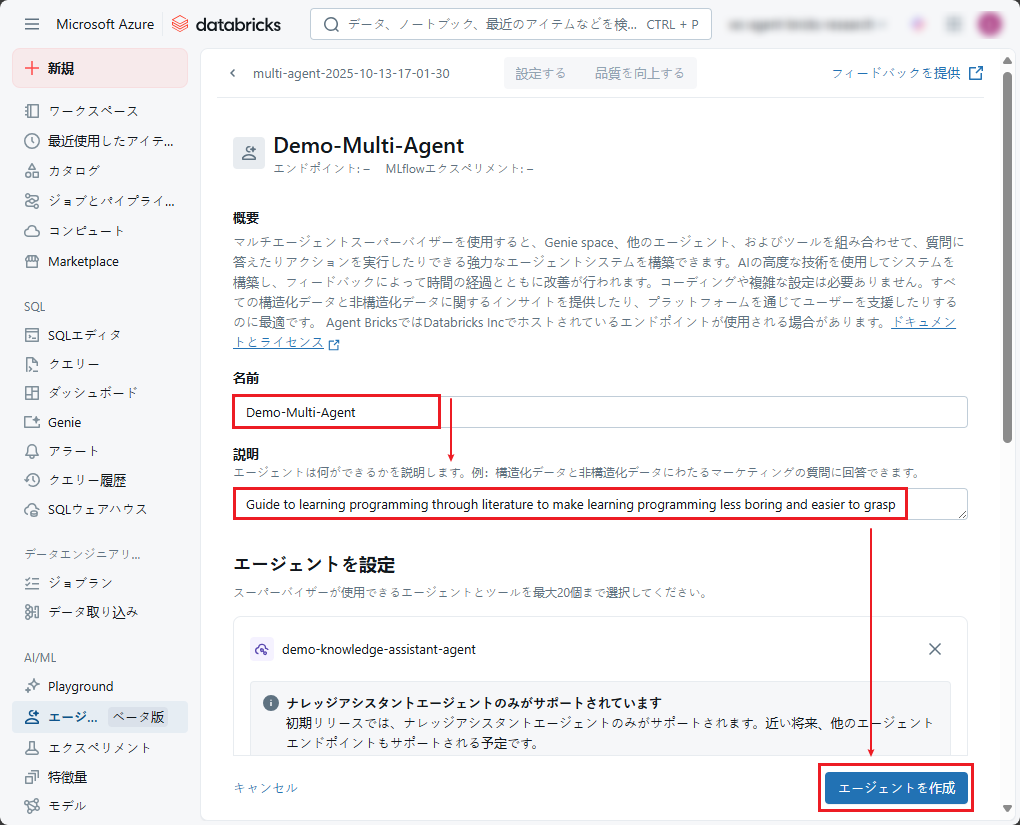
ステップ2:スーパーバイザーを構成します。
- 「名前」フィールドに、スーパーバイザ エージェントの名前を入力します。
- 「説明」フィールドで、スーパーバイザ システムに実行させたいことを記載します。
- 「エージェントを設定」フィールドで、最大 10 個のエージェント エンドポイントまたは Genieスペースを選択します。
本記事のデモで、文学的な表現を通じてプログラミング学習をより楽しく、わかりやすくすることを目的に、2つのKnowledge Assistant(1つは文学用、もう1つはコーディング用のエージェント)を使用してマルチエージェント スーパーバイザーを作成します。
「エージェントを作成」をクリックします。
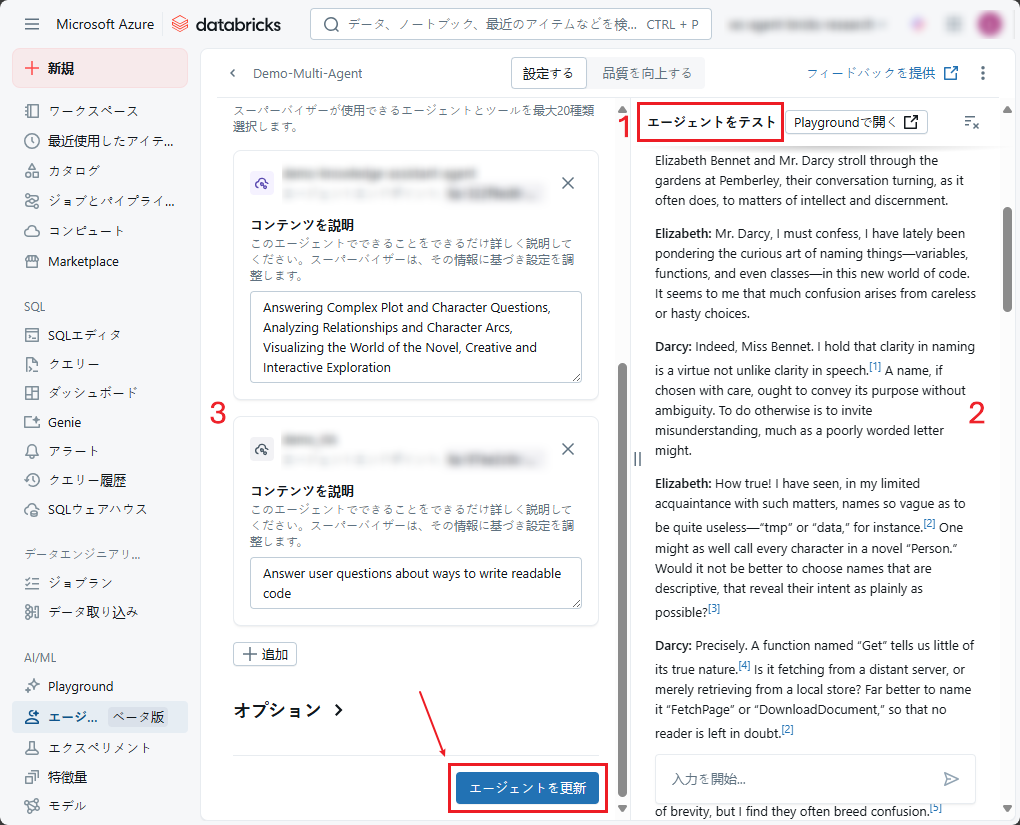
ステップ3: スーパーバイザ エージェントをテストします。
スーパーバイザーのビルドが完了したら、 AI Playground または右側の 「エージェントをテスト」ウィンドウでテストできます。
本記事では、(1) 「エージェントをテスト」のウィンドウでテストを実施します。
例:Elizabeth BennetとDarcyの会話スタイルで、ソースコード内の変数・関数・クラスの命名方法を説明します。
(2)でスーパーバイザーの実行結果を監視し、各エージェントに適切なタスクが割り当てられていることを確認します。その後、スーパーバイザーの応答を評価します。
左側のパネル(3)の説明と命令の内容を調整して構成を改善します。
「エージェントを更新」をクリックして変更内容を保存します。
④ メリット
- スーパーバイザーを使用すると、ユーザーは自然言語のフィードバックをプロセスに取り入れ、エージェント間の連携動作を微調整できます。
- この仕組みにより、コードやプロンプトを書き直すことなく、徐々により効果的な協調戦略を学習することができます。
- 一方、AI Foundryは主にモデルやエンドポイントの管理に注力し、 ユーザーのフィードバックから直接学習しエージェントを調整する仕組みは整えていません。
- マルチエージェント スーパーバイザーシステム は、タスク間の関係を理解し、作業を細分化して特化したエージェントに分担し、最終的な結果を統合して包括的な回答を生成できます。
- これに対し、Azure AI Foundryは依然としてモデルまたはエージェントを個別に動作させる仕組みであり、エージェント同士が「チームとして」連携するような自動オーケストレーションレイヤーが備わっていません。
⑤ デメリット(制限)
- Agent BricksのKnowledge Assistantを使用して作成されたエージェント エンドポイントのみがサポートされています。
- セキュリティ強化とコンプライアンス(Enhanced Security and Compliance)が有効化されたワークスペースはサポートされていません。
- 1つのスーパーバイザ システムで10を超えるエージェントを使用することはできません。
4. まとめ
本記事では、Azure DatabricksのAgent Bricksについて、概要から使用方法や各種エージェントの作成手順まで紹介しました。
情報抽出エージェント、カスタムLLMエージェント、ナレッジアシ。スタントエージェント、マルチエージェント スーパーバイザーなどの生成AIエージェントを導入・展開することで、Databricksの力を活用し、柔軟で安全かつ高拡張性なデータ分析とモデル管理プロセスを自動化することができます
本記事は、 DatabricksにおけるAIの統合の仕組みを理解し、実際のの導入・活用に参考資料となれば幸いです。
Azure Databricks、Agent Bricks、または企業環境におけるAIの応用に関する質問がございましたら、お気軽にお問い合わせください。
Azure Databricks連載記事のまとめはこちら
![]() お問い合わせはこちら
お問い合わせはこちら
この記事を書いた人

- 双日テックイノベーション(旧:日商エレクトロニクス)特設サイト「Azure導入支援デスク」サイトマスターです。