目次
1. はじめに
多くの企業では、従来型のデータパイプラインの構築・運用が依然としてデータエンジニアに大きく依存しています。列の追加、変換ロジックの修正、新しいデータセットの作成などの小さな変更であっても、開発・テスト・デプロイといった技術的なプロセスを経る必要があります。その結果、データアナリストは対応を待つことになり、一方でデータエンジニアは増え続けるデータ処理要求への対応に追われるという状況が発生しがちです。
Lakeflow Designerは、このような課題を解決するために提供された機能です。直感的なユーザーインターフェースとローコード/ノーコードによるパイプライン設計機能を備えており、ビジネス部門と技術部門の間にあるギャップを縮めます。これにより、データチームは手作業によるコーディングに過度に依存することなく、データパイプラインを迅速に構築、管理、拡張できるようになります。
本記事は、以下のような方を対象としています。
・なぜ従来のデータパイプラインが組織のボトルネックになりやすいのかを理解したい方
・データ処理プロセスにおけるアナリストとエンジニア間の依存関係を軽減したい方
・Lakeflow Designerによる直感的で拡張性の高いパイプライン開発手法を知りたい方
・データ基盤の構築・運用にかかる時間を削減し、より多くのリソースを分析業務やビジネス価値の創出へ振り向けたい方
本記事を通じて、読者は Lakeflow DesignerをDatabricksエコシステムにおける最新のデータパイプライン構築・管理ソリューションとして理解できるようになります。
また、従来のETLプロセスへの依存を軽減し、より柔軟かつ効率的なデータ基盤運用を実現する手段として、Lakeflow Designerを紹介できるようになることを目指します。
2. 前提条件
本手順を実施する前に、以下の条件を満たしていることを確認してください。
- Databricks Workspaceがプレミアムプランであり、 サーバーレスに対応したリジョンで稼働していること
- Databricks WorkspaceでUnity Catalogが有効化されていること
- ユーザーがUnity Catalog上でテーブルを作成する権限を保有していること
- Databricksにアクセスするための安定したWebブラウザ環境が利用可能であること
3. Lakeflow Designerの概要
Lakeflow Designerは、Databricksプラットフォームに完全統合されたノーコード/ローコード型のビジュアルデータ準備・分析ツールです。直感的なドラッグ&ドロップのビジュアルキャンバスを提供しており、filter・join・transformなどの演算子をつなぎ合わせてDAG(有向非巡回グラフ)型の処理フローを組み立て、目的のデータを生成することができます。さらに、AI搭載の自然言語アシスタントであるGenie Codeが内蔵されており、シンプルな指示文だけでデータ変換ステップを作成・調整できます。
Lakeflow Designerの最大の目的は、データアナリストがコードを書かずに、データの準備・分析・基本的な自動化を自ら実施できるようにすることです。一方で、技術的な整合性も完全に担保されています。すべてのビジュアル操作はプラットフォームによってサポートされており、データエンジニアチームがGitによるバージョン管理やジョブスケジューリングを通じて、データパイプラインを本番環境へシームレスに展開・運用できるようになっています。
詳細はこちらをご参照ください。
4. 利用時の制約事項
Lakeflow DesignerはETLプロセスを簡素化するための最新ソリューションとして提供されています。実際の運用で効果を最大化し、適切なアーキテクチャを選択するために、各組織は以下の制約事項を把握しておく必要があります。
- 利用クォータを超過した場合、ワークスペースのコンピューティングリソースはその日の残り時間(場合によっては月末まで)一時停止されます。
- 非常に複雑な変換ロジックに対しては、ビジュアルインターフェースが再帰アルゴリズムや高度なループ処理に未対応なため、Notebook / dbt による手動コーディングの方が最適な選択肢となります。
【重要な注意事項】
- Lakeflow Designerは、データプレビューおよびパイプライン実行のタスクを処理するために、サーバーレスコンピューティング アーキテクチャ上で稼働することが必須です。
- 高い柔軟性を要件とする組織の場合、Lakeflow DesignerはDatabricksとUnity Catalogのエコシステムに完全依存しており、他のプラットフォームへのパイプラインエクスポートはできない点にご注意ください。
- スムーズなドラッグ&ドロップ操作を提供するものの、データのインポートと処理を正常に実行するためには、Unity Catalog上の特定のスキーマに対してCreate / Write権限が付与されている必要があります。
5. 実践デモンストレーション実施:Lakeflow Designerを用いたデータパイプライン構築
デモで使用するデータソースは、Kaggleの「Japan Cherry Blossoms Forecasts 2024」データセットで、日本全国の桜の開花予測データが含まれています。
全体の流れとして、デモは以下の主要ステップで実施します:
- データセットをUnity Catalogにインポート
- Lakeflow Designerでパイプラインの作成
- AI/Genie Codeを使って変換処理の作成
- パイプラインのプレビューおよびテスト実施
- データを出力先テーブルに書き込み
5-1. データセットをUnity Catalogにインポート
まず、デモデータ「Japan Cherry Blossoms Forecasts 2024」をDatabricksに読み込みます。
以下の手順を実施してください。
① サイドバーから「データ取り込み」を選択する。
②「テーブルを作成または変更」を選択してデータをインポートする。
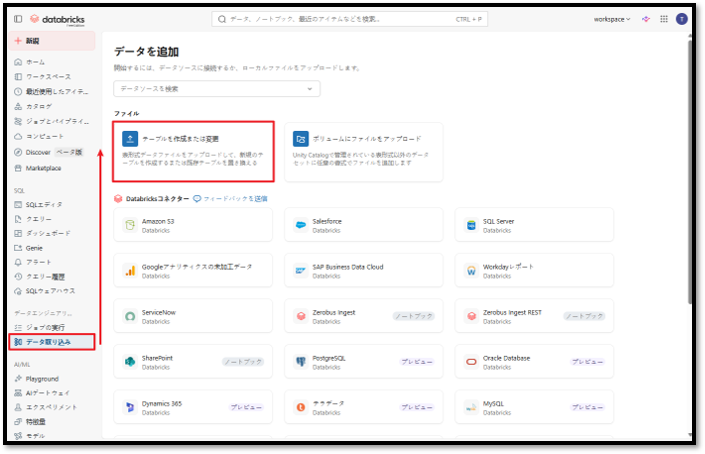
③「ファイルアップロード からテーブルを作成または変更」でcherry_blossom_forecasts.csvファイルを追加する。
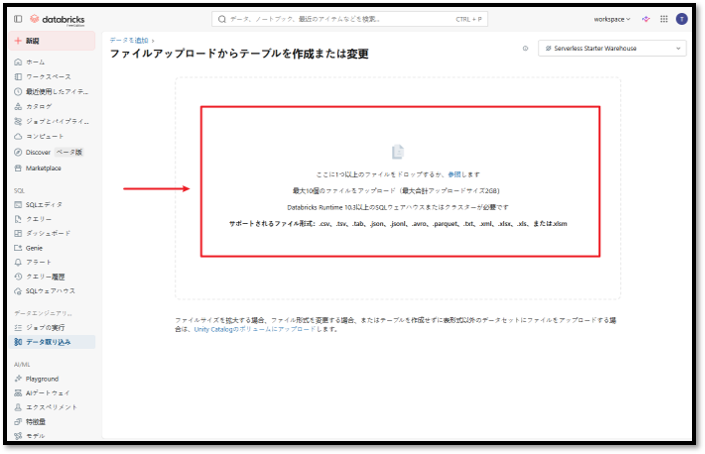
④「テーブルを作成」ボタンをクリックして、デフォルトカタログにテーブルを作成する。
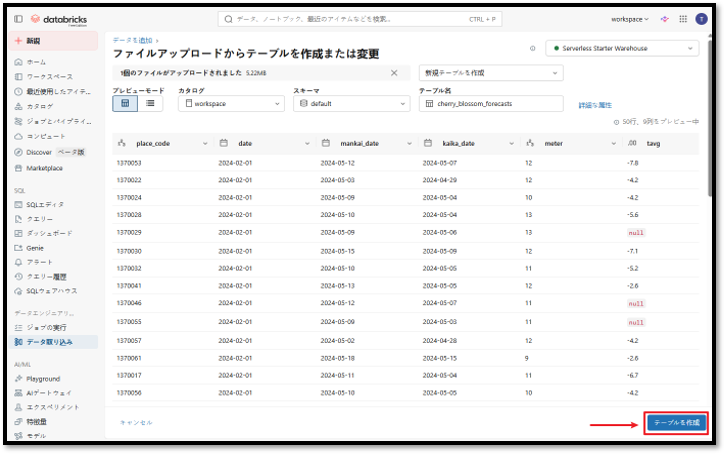
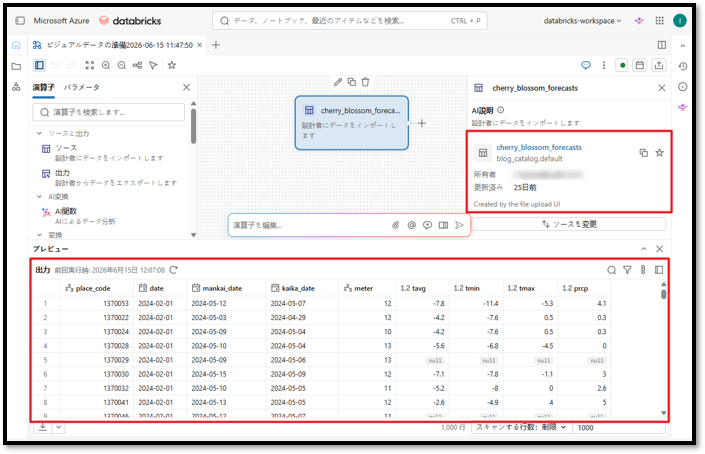
データの追加が完了すると、デフォルトカタログのdefaultスキーマ内にcherry_blossom_forecastsテーブルのデータが表示されます。
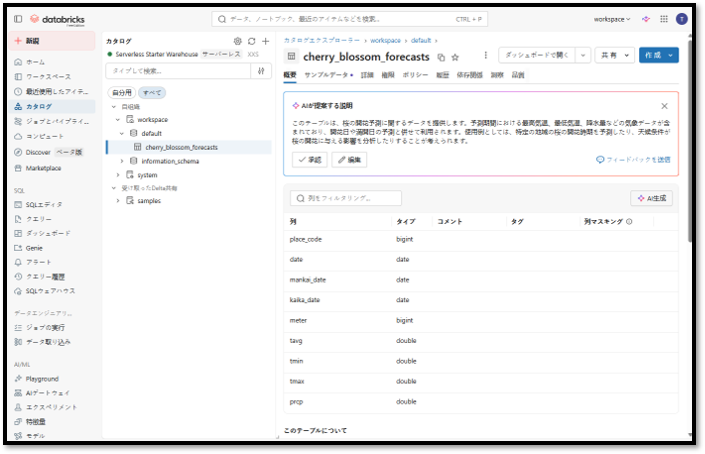
5-2. Lakeflow Designerでパイプラインの作成
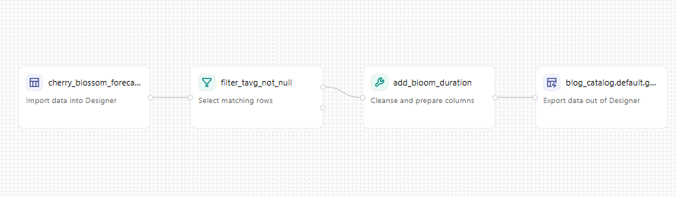
以下は、桜の生データを分析に活用できるゴールドレイヤーテーブルに変換する、非常にシンプルな 4 ステップのデータ処理フロー(Transformation Pipeline)です:
① 生データを読み込む
② 有効なデータをフィルタリングする
③満開日から開花日を引いて「開花期間(日数)」の新しい指標を計算する
④ 整形されたデータを出力する
以下の手順でLakeflow Designer内にパイプラインを作成します:
以下の手順を実施してください。
① サイドバーから「ワークスペース」を選択する。
② 次に「作成」ボタン横のドロップダウンを開き、「ビジュアルデータの準備」を選択する。
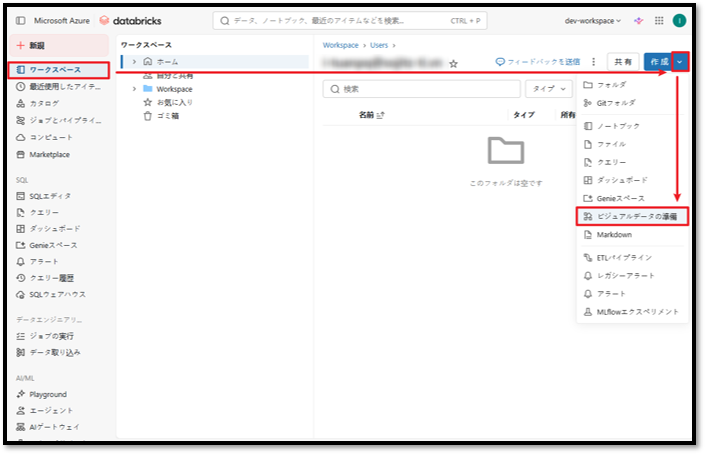
Lakeflow Designerの作業画面が表示されます。パイプラインの作成操作はこの画面上で行います。
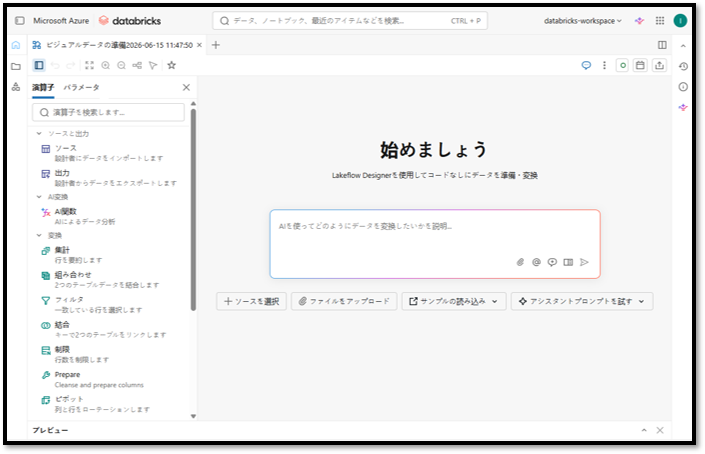
③「ソース」を選択してドラッグし、「始めましょう」エリアにドロップする。
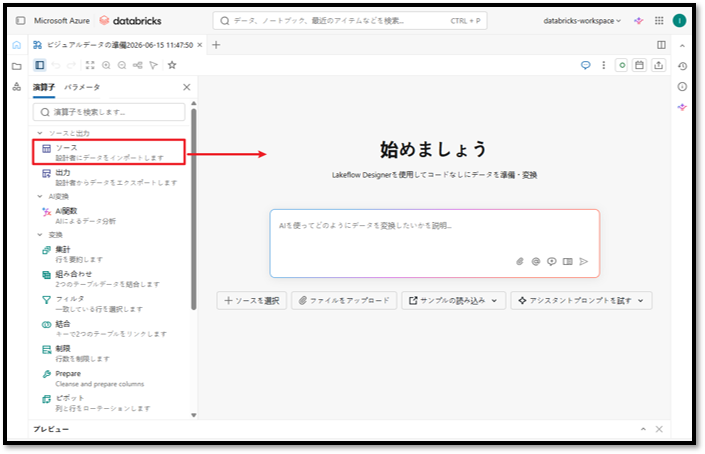
④ 作成したノードを選択すると、パイプラインノードをカスタマイズするためのプロパティ画面が表示されます。ここでノードを設定してください。
⑤「既存を参照」を選択して、「4.1 データセットをUnity Catalogにインポートする」でインポートしたデータが入っているテーブルを検索する。
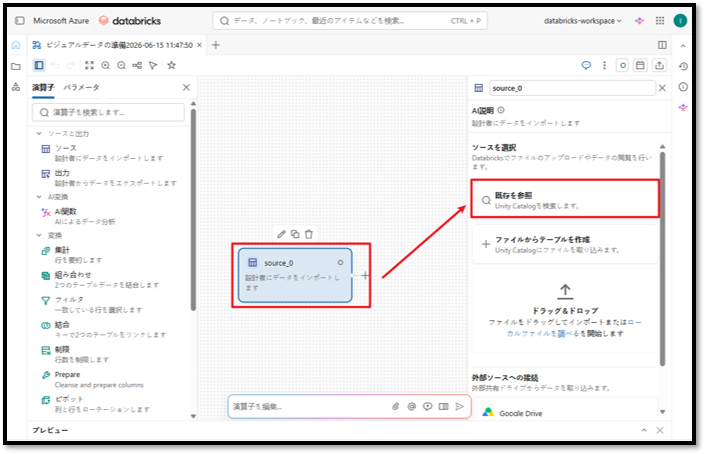
⑥「4.1 データセットをUnity Catalogにインポートする」でインポートした「Japan Cherry Blossoms Forecasts 2024」のデータセットの「catalog → schema → table」を検索する。
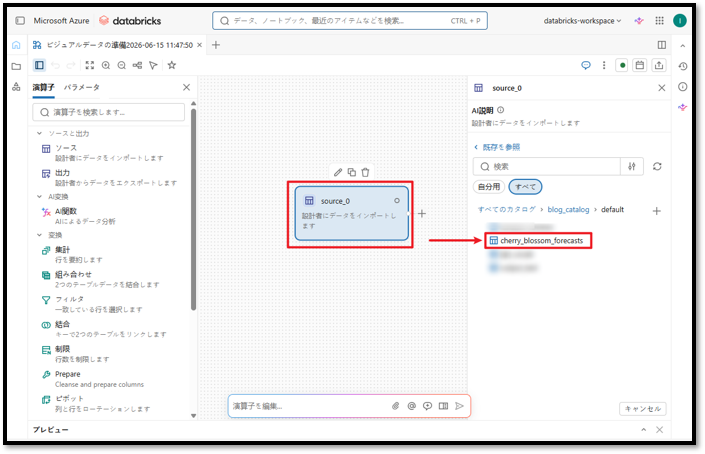
インポートが完了すると、インポートした「Japan Cherry Blossoms Forecasts 2024」のデータがインターフェース上に表示されます。
5-3. AI/Genie Codeを使って変換処理の作成
次はデータの変換とクリーニング(Transformation)です。このステップでは通常、データエンジニアがSQLやPySparkのコードの記述とデバッグに多くの時間を費やします。しかし、DatabricksのAIサポートにより、作業が大幅に簡素化されます。
AIを使って変換処理を作成するには、以下の手順を実施してください:
実施手順:
① 作成した「cherry_blossom_forecasts」ノードを選択する。
② 以下のプロンプトを入力し、アイコンをクリックしてAIに変換処理の作成をリクエストする。
|
1 |
Filter out rows where tavg is null. Add a new column named bloom_duration calculated as the difference in days between mankai_date and kaika_date. |
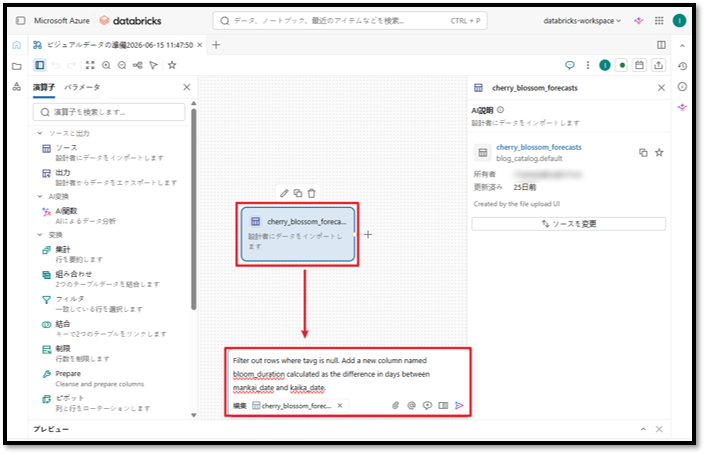
AIがプロンプトの要求に応じて2つのノードを生成します。生成完了後、システムが「Added filter removing null tavg rows and computed bloom_duration (days between mankai_date and kaika_date).」と通知します。
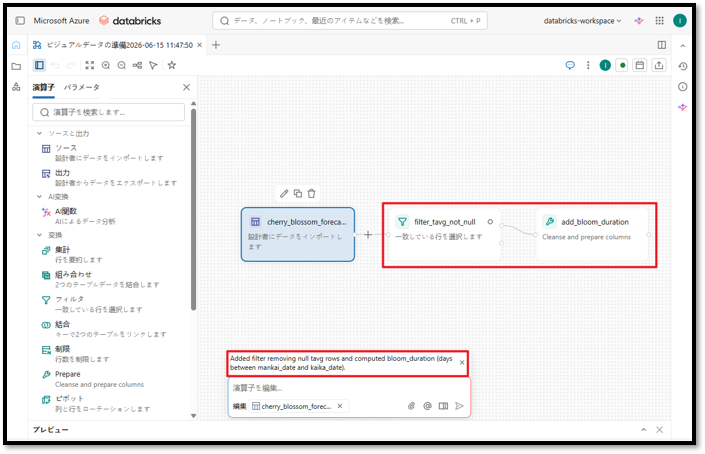
5-4. パイプラインのプレビューおよびテスト実施
このパイプラインを実際に稼働させる前に、AIの変換ロジックが正確であることを確認する必要があります。
Lakeflow Designerは処理後のデータを事前確認できる非常に便利なプレビュー機能を提供しています。以下の手順を実施してください:
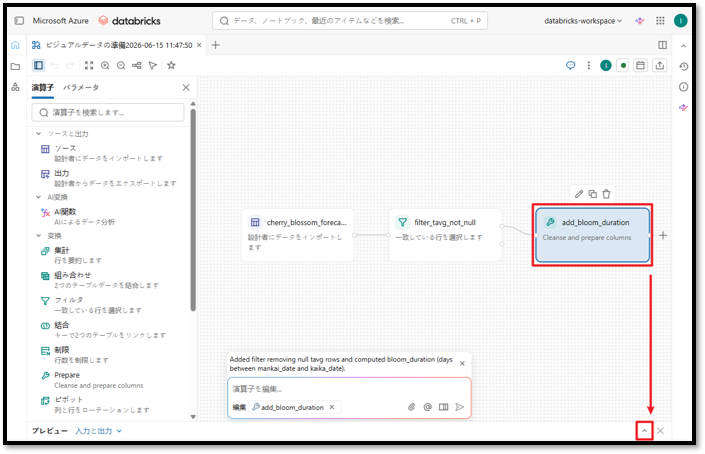
① AIがコードを生成したadd_bloom_durationノードを選択する。
② 次にアイコン を選択する。
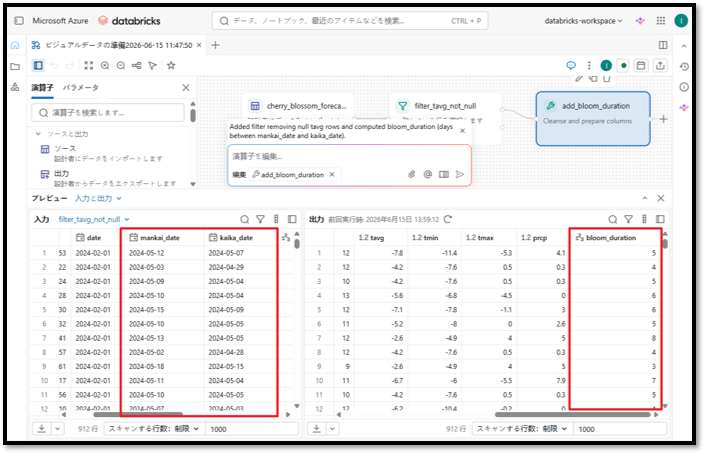
「mankai_date」と「kaika_date」の2列を基に新規作成された「bloom_duration」列が確認できます。
5-5. データを出力先テーブルに書き込み
処理ロジックに問題がないことを確認したら、最後のステップとしてクリーニング済みデータを出力先テーブルに書き出します。
以下の手順を順番に実施してください:
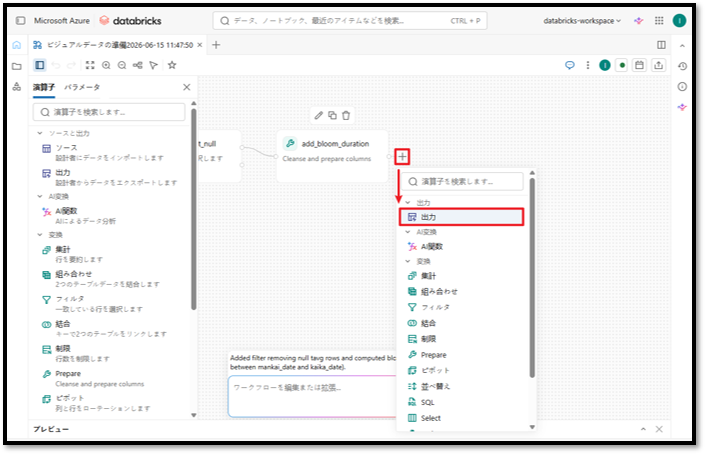
①「add_bloom_duration」ノードの隣にある アイコンを選択する。
②「出力」オプションを選択する。
③ 画面右側に表示される設定パネル(プロパティ)で、新規作成したノードの出力情報を以下のとおり入力・選択してください:
- テーブル名:gold_cherry_blossomと入力する。
- 出力場所:2つのドロップダウンでCatalogとSchemaをそれぞれ選択する。
例:catalog: blog_catalog、schema: default
④ 「実行」ボタンを選択する。
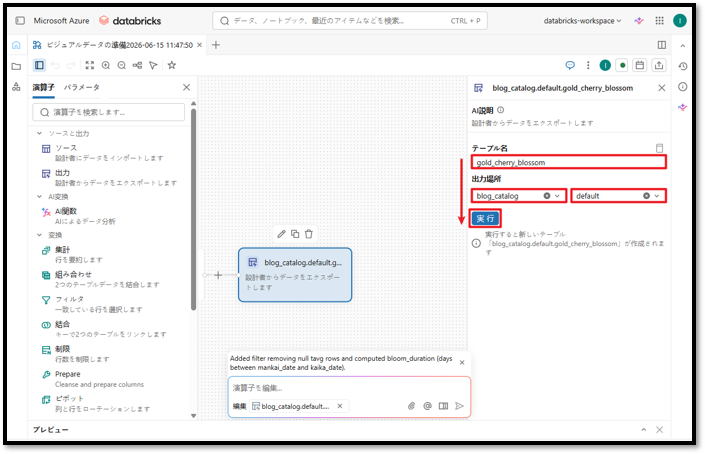
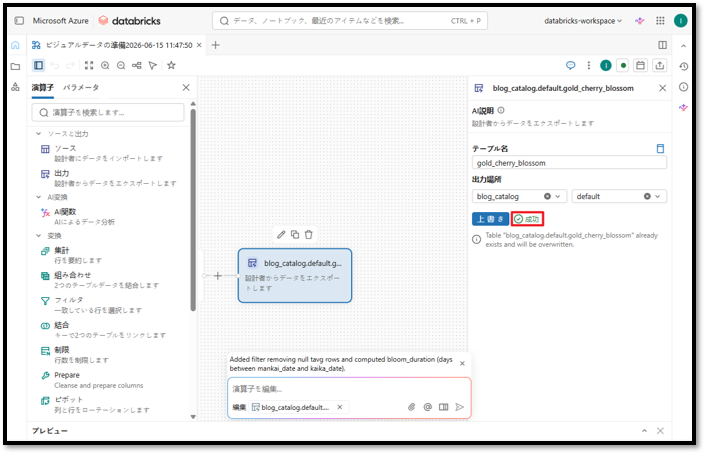
作成が完了すると、システムが「成功」と通知し、「実行」ボタンが「上書き」ボタンに変わります。
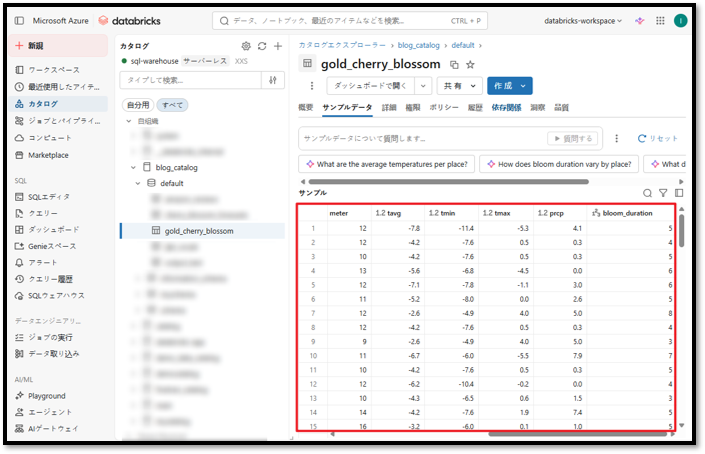
「カタログ」から新規作成されたデータテーブルを確認できます。
6. Lakeflow Designerと従来のノーコードETLツールとの比較
| 比較基準 | 従来のETLツール | Databricks Lakeflow Designer |
| データアーキテクチャ | 中間サーバー経由で処理し、データサイロが生まれやすい。 | Data Lake上で直接処理し、不要なデータ移動が発生しない。 |
| ガバナンスとセキュリティ | ツールごとに分散した権限管理。 | Unity Catalogとエンドツーエンドで緊密に統合。 |
| コンピューティングインフラ | 手動管理のため柔軟なスケールが難しく、ボトルネックが生じやすい。 | サーバーレス:データフローを自動で把握し、リソースを自動割り当て・最適化。 |
| AIの能力 | 通常は搭載されていないか、非常に基本的な補助機能のみ。 | アシスタントが深く統合されており、自然言語から複雑なコードを自動生成。 |
| 柔軟性 | 複雑な課題に対して深いカスタマイズが困難。 | 統合されたエクスペリエンス:柔軟なドラッグ&ドロップ操作が可能で、必要に応じて高度なコード操作も実施できる。 |
Lakeflow Designerは単なるデータフロー作図ツールではありません。ノーコードの使いやすさを提供しながら、その裏側では膨大なビッグデータ処理能力を備えており、データエンジニアがインフラの管理に追われることなく、ビジネスロジックに集中できるようになります。
7. メリット・制約事項・適用ユースケース
Lakeflow Designerはデータパイプラインの構築方法に多くの革新をもたらしていますが、長所と注意点を正確に把握することで、各組織が最も効果的な導入判断を下せるようになります。
メリット:
- データデモクラタイゼーション:直感的なドラッグ&ドロップインターフェースにより、Lakeflow Designerは技術的な参入障壁を下げます。データエンジニアだけでなく、データアナリストやデータサイエンティストもITチームのサポートを待つことなく、自分自身でデータクリーニングパイプラインを構築できます。
- AIの能力:各処理ノードにDatabricks Assistant / Genieが深く統合されており、自然言語を複雑なSQL / Pythonコードへ変換します。定型的なコードの記述や構文エラーのデバッグに費やす時間を大幅に削減できます。
- 自動化されたインフラ(サーバーレス): Lakeflow Spark Declarative Pipelines (SDP) 基盤上に構築されており、データの依存関係を自動で把握し、クラスターを自動割り当て・パフォーマンスを最適化するため、手動設定が不要です。
- Unity Catalogによる一元管理:ソースから宛先(Raw層からGold層)まですべてのデータテーブルの権限制御とデータリネージュ追跡が自動的に実施され、企業のセキュリティコンプライアンスを確保します。
注意が必要な制約事項(Limitations)
- Databricksエコシステムへの依存:Lakeflow DesignerはDatabricksの専用ツールです。利用するには、データアーキテクチャ全体をDatabricksのData Intelligence Platform上で運用する必要があります。
- Lakehouseの基礎知識が必要:ドラッグ&ドロップ操作は非常に簡単ですが、効果的なパイプラインを設計するためには、Medallionアーキテクチャ(Bronze – Silver – Gold)やUnity Catalogのデータ階層管理など、Databricksの基本概念を理解している必要があります。
- コスト管理:インフラの自動化(サーバーレス)は絶大な利便性をもたらしますが、頻度やデータ量を十分に計算せずに継続実行(Continuous)パイプラインを作成した場合、監視設定がなければクラウドのコンピューティングコストが高騰する可能性があります。
Lakeflow Designerに最も適したユースケース
- 迅速な試験と構築
- 従来のETL / ELTプロセスの移行
- ビジネスアナリティクスチームのデータ連携自動化に最適
8. まとめ
Lakeflow Designerは、コードの学習や複雑なインフラ設定に多大な時間を投資することなく、Databricksプラットフォーム上でデータパイプライン構築を始めたい方に理想的な選択肢です。データのインポート、処理ノードのドラッグ&ドロップ操作、AI(Databricks Assistant)を使ったデータ標準化まで、基本的な実践手順を通じて、最新のData Intelligenceプラットフォーム環境におけるエンドツーエンドのデータ処理フロー全体を把握することができます。
ローコード/ノーコードツールは完全手動プログラミングと比較して深いカスタマイズに一定の制約があることもありますが、Lakeflow Designerは学習・迅速なPoC(概念実証)・中小規模データプロジェクトの構築に必要な十分な能力を備えています。これはデータアナリストとデータエンジニアがデータクリーニングを容易に行い、高度な分析・機械学習・AIアプリケーションといった上位課題へスムーズに移行するための非常に重要なステップとなります。
このビジュアル基盤から、より複雑な実際のユースケースへと自信を持って拡張し続けることができます。プロジェクトや企業の要件が高度化した場合でも、Databricksの柔軟なアーキテクチャ基盤により、容易なアップグレード・コードによる詳細介入・大規模本番環境へのパイプライン展開が可能になります。
今回の記事が少しでも皆さんの新しい知識や業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたら
是非お問い合わせください!
Azure Databricks連載記事のまとめはこちら
この記事を読んだ方へのオススメコンテンツはこちら
この記事を書いた人

- 双日テックイノベーション(旧:日商エレクトロニクス)特設サイト「Azure導入支援デスク」サイトマスターです。