1. はじめに
背景
現代のデータ分析基盤において、Azure Data Lake Storage Gen2(ADLS Gen2)は、高いスケーラビリティを備えた標準的なストレージとして広く利用されています。しかし、Azure Databricksと連携する際には、「柔軟性」と「セキュリティ」をどのように両立するかが大きな課題となります。従来のMount PointやAccess Keyを利用した接続方法は、設定が容易である一方、セキュリティリスクや権限管理の複雑化といった課題を抱えています。その中で、Unity Catalogにおける外部ロケーションは、これらの課題を解決する有力な選択肢として注目されています。
外部ロケーションは単なるデータパスではなく、一元的なガバナンスレイヤーとして機能し、統一されたセキュリティポリシーに基づいてアクセス権限を管理することが可能です。
目的
本記事では、Unity Catalogにおける外部ロケーションの構成方法および利用方法について紹介します。
これにより、ADLS Gen2上のデータへ、安全かつ標準化された形でアクセスし、効率的に権限管理を行う方法を理解することを目的としています。
目標
本記事を読み終えることで、以下を実現できるようになります。
- Unity Catalogにおける外部ロケーションの仕組みを理解し、自身で設定できるようになる。
- セキュアなデータアクセス手法に関する理解を深め、システム全体の安全性向上につなげられるようになる。
デモシナリオの概要
詳細な設定手順に入る前に、本セクションでは記事全体を通して利用するデモシナリオの概要について紹介します。具体的には、デモの目的、実施フロー、および最終的に得られる結果について説明します。
本デモでは、Unity Catalogアーキテクチャに基づき、Azure DatabricksからAzure Data Lake Storage Gen2(ADLS Gen2)へ接続する標準的な構成を実装します。主な目的は、外部ロケーションを利用して、マネージドIDによる安全なデータアクセスを実現することです。これにより、従来のAccess Keyベースの接続方式を廃止し、よりセキュアで管理しやすい構成を構築します。
概要レベルでは、以下の流れでデモを実施します。
- Azure DatabricksアクセスコネクタおよびマネージドIDを構成し、AzureとDatabricks 間のシステムレベルアクセス権限を設定す。
- データガバナンス領域を定義する。
Unity Catalog上でストレージ資格情報および外部ロケーションを登録し、データの所有範囲とアクセススコープを管理す。 - SQLおよびPythonを利用した実際のデータ操作を通じて、接続およびアクセス動作を検証する。
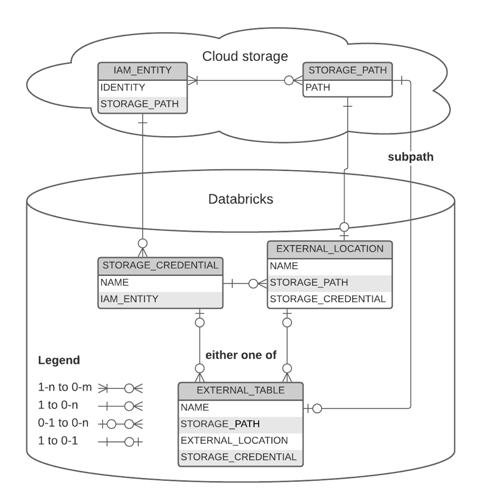
2. Unity Catalogにおける外部ロケーションの概要
Data Lakehouseアーキテクチャにおいて、外部ロケーションはDatabricksとAzure Data Lake Storage Gen2(ADLS Gen2)を安全に接続するための「セキュアな橋渡し」の役割を担います。
従来利用されていたAccess Key(セキュリティリスクが高い)やMount Point(管理が煩雑)といった接続方式とは異なり、外部ロケーションはUnity Catalogを通じて一元的なガバナンスを提供します。
外部ロケーションは、主に以下2つの要素で構成されます。
- ストレージ資格情報:Azureへアクセスするための認証情報です。一般的にはマネージドIDが利用されます
- パス:Azure上のデータ保存先を示す物理パスです。「abfss://」形式で定義されます。
なぜ外部ロケーションを利用するのか?
- 高いセキュリティ:Access Keyやパスワードを手動で管理する必要がなく、マネージドIDを利用した安全な認証を実現できます。
- 一元的な権限管理:Databricks上からSQLを利用して、データの参照・読み取り・書き込み権限を統一的に管理できます。
- データの安全性確保:データ自体はユーザー管理下のストレージアカウントに保存されます。そのため、Databricks上でテーブルを削除した場合でも、元データファイルは保持されます。
簡単に言えば、外部ロケーションを利用することで、Azure上に分散して存在するストレージ領域を、「安全かつ統制されたデータ基盤」として管理できるようになります。
3. 前提条件
本手順を実施する前に、以下の前提条件を満たしていることを確認してください。
- Azureポータル上でアクセスコネクタの作成およびマネージドIDへのロール割り当てを実施可能な管理者権限を保有していること
- Unity Catalogが有効化されたDatabricks Workspaceを利用していること
4. 外部ロケーションへのデータ接続設定手順
4.1 Azure Data Lake Storage Gen2の準備
Azure Datalake Storage Gen2の準備手順についてご説明いたします。
① Azureのホーム画面へアクセスする。
②「ストレージ アカウント」を検索し、該当するサービスを選択する。
③「ストレージ アカウント」の管理画面から「+作成」タブをクリックして作成を開始する。
④「基本情報」タブにて、以下の情報を入力する。
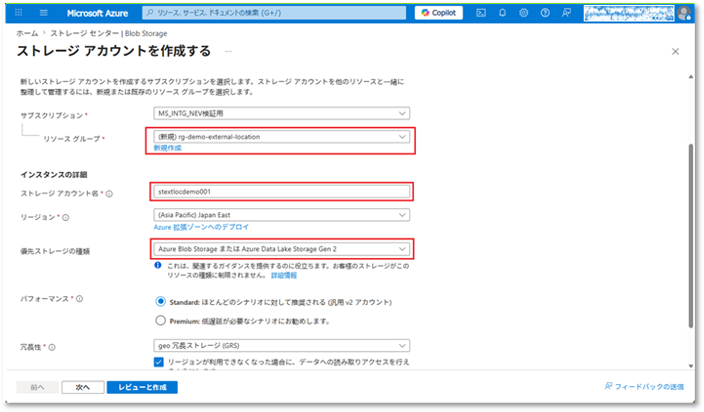
- サブスクリプションのリソースグループ:ドロップダウンリストから既存リソースグループを選択する
または、「新規作成」をクリックして新規のリソースを作成する。(例:rg-external-location-demo) - 「インスタンスの詳細」項目のストレージ アカウント名: ストレージアカウント名を一意の名称で入力する。
- 優先ストレージの種類:「Azure Blob Storage または Azure Data Lake Storage Gen 2」を選択する。
⑤「詳細」タブにて、「階層型名前交間」項目で「階層型名前交間を有効にする」のチェックボックスを有効にする。
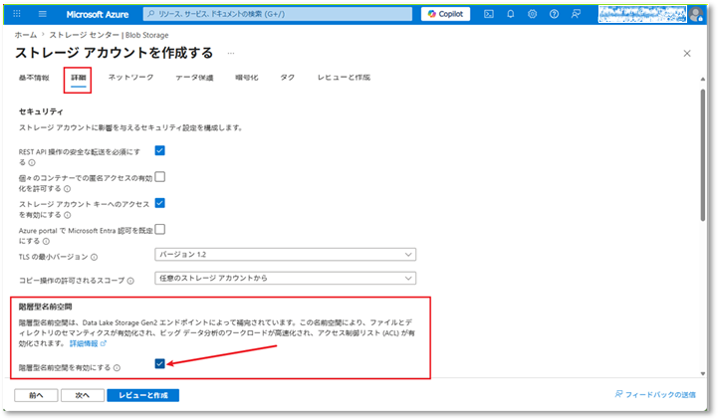
※この設定は、ストレージアカウントをData Lake Storage Gen2として利用するための重要なオプションである。
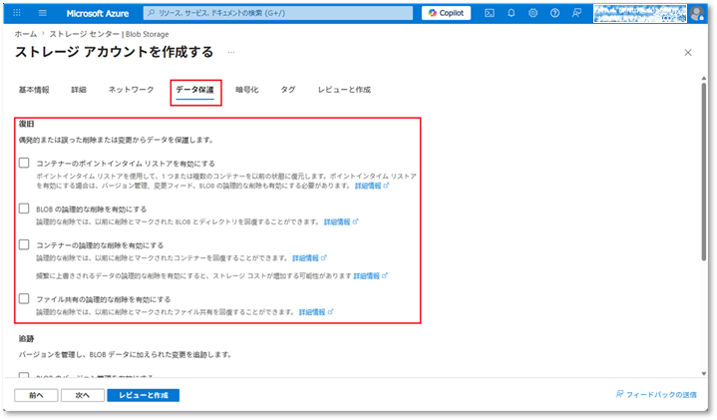
⑥「データ保護」タブにて、Blobおよびコンテナーの論理的な削除機能のチェックボックスを外して無効化にする。
本デモでは、リソース削除後に一時的なバックアップデータが保持されないようにするため、論理的な削除を有効化している。
これにより、検証後のリソースクリーンアップを簡単に実施できる。
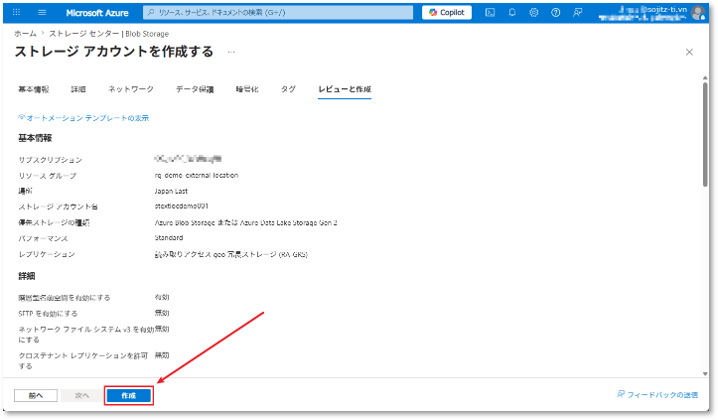
⑦ 設定内容を確認し、「作成」ボタンをクリックしてデプロイを実施する。
⑧「デプロイが完了しました」と表示されたら、「リソースに移動」をクリックしてストレージアカウントへアクセスする。
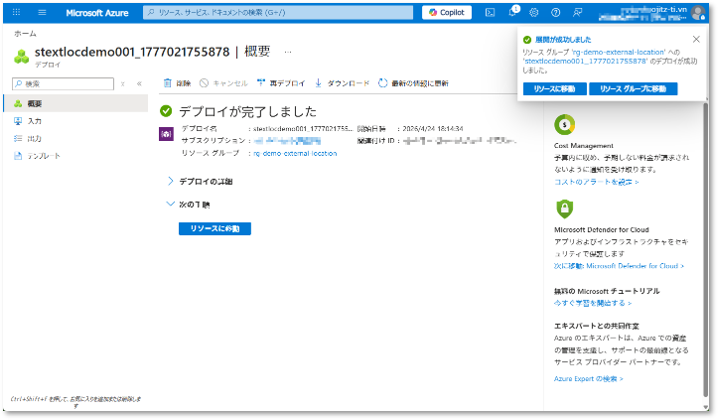
⑨ サイドバーメニューから「コンテナー」を選択し、「+ コンテナーの追加 」タブをクリックしてファイル保存先を作成する。
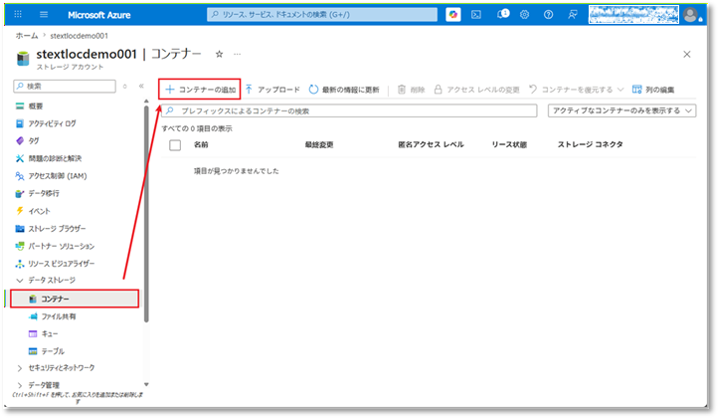
⑩「新しいコンテナー」ポップアップの「名前」項目でコンテナー名を入力する。(例:cnt-raw-data)
そのあと、「作成」ボタンをクリックする。
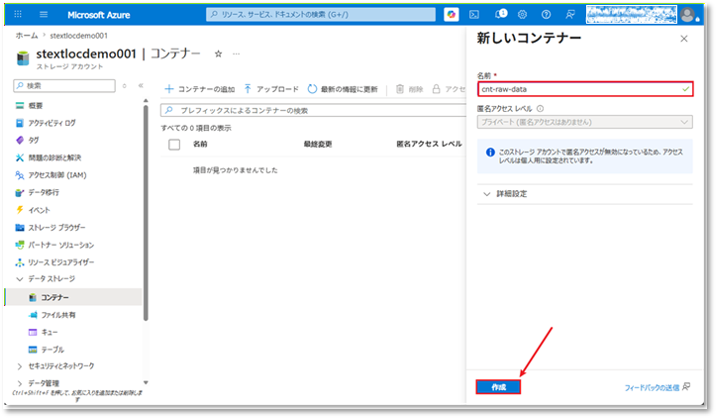
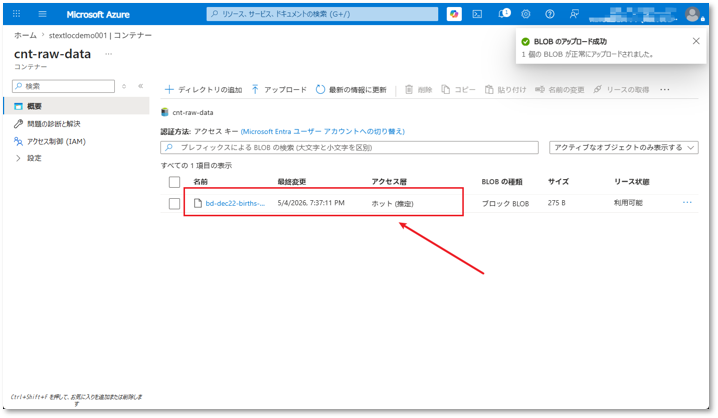
⑪ 先ほど作成したコンテナーにアクセスし、「アップロード」をクリックした後、アップロード領域へCSVファイルをドラッグアンドドロップする。
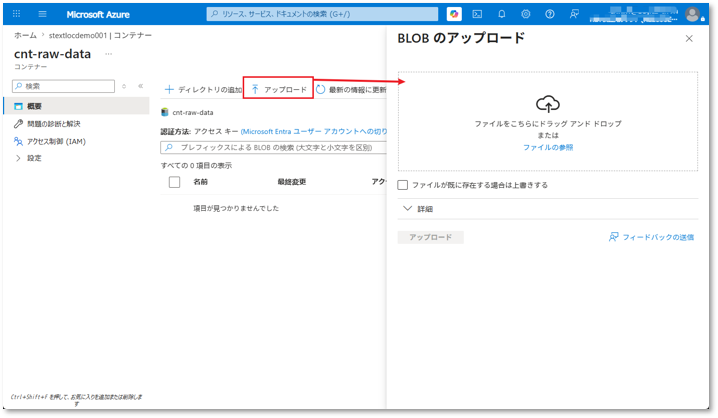
本デモで使用するサンプルCSVファイルは、以下よりダウンロードできる。
bd-dec22-births-deaths-by-region.csv
⑫「アップロード」ボタンをクリックしてアップロードを完了する。
※アップロード後、コンテナーの一覧に対象ファイルが表示されていることを確認してください。
4.2 アクセスコネクタの設定および必要な権限の付与
この手順では、Access Keyを使用せずにDatabricksから Azure Storageへアクセスするための「認証 ID」を作成します。
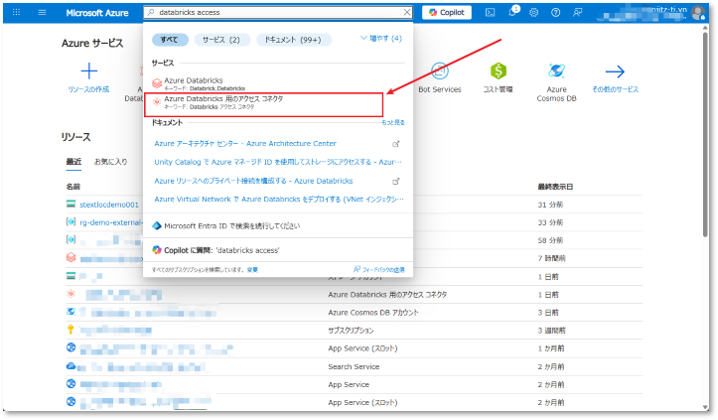
① Azure のホーム画面にて、「Azure Databricks用のアクセス コネクタ」を検索して選択する。
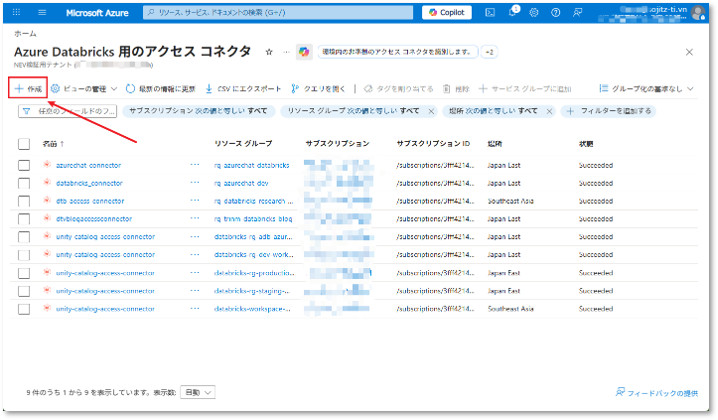
②「+作成」タブを選択して新規のコネクタを作成する。
③ 必要情報を入力する。
- 「サブスクリプション」項目のリソース グループ:前手順で作成したストレージアカウントと同じリソースグループを選択する。
- 「インスタンスの詳細」項目の名前:アクセスコネクタの識別名を入力する。
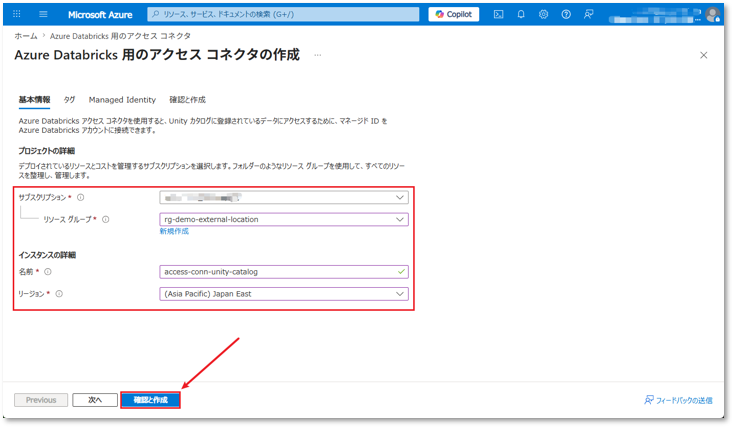
入力完了後、「確認と作成」ボタンをクリックする。
④ 入力した情報を確認し、「作成」ボタンをクリックする。
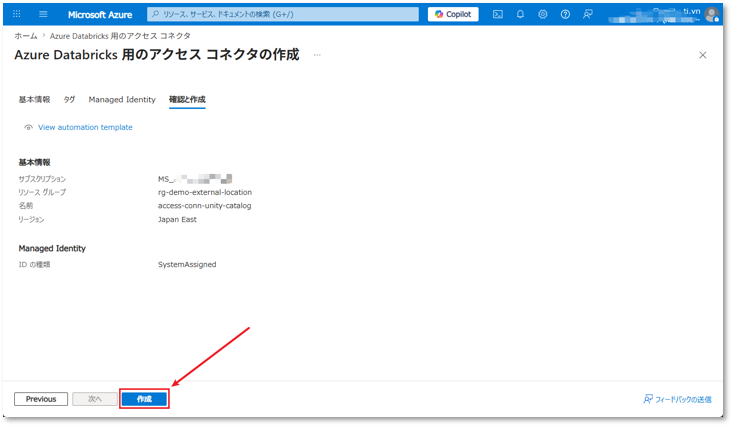
⑤ リソースのデプロイ完了後、「リソースに移動」をクリックする。
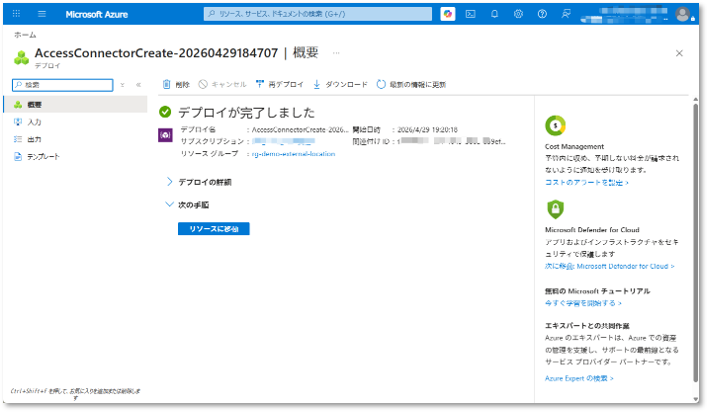
⑥ この手順では、アクセスコネクタに対してRBAC権限を付与します。
アクセスコネクタが配置されているリソースグルーへアクセスする。
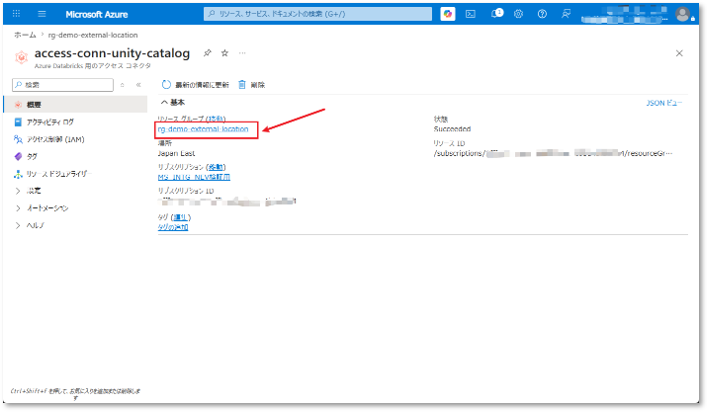
⑦ 前手順で作成したストレージアカウントを選択する。
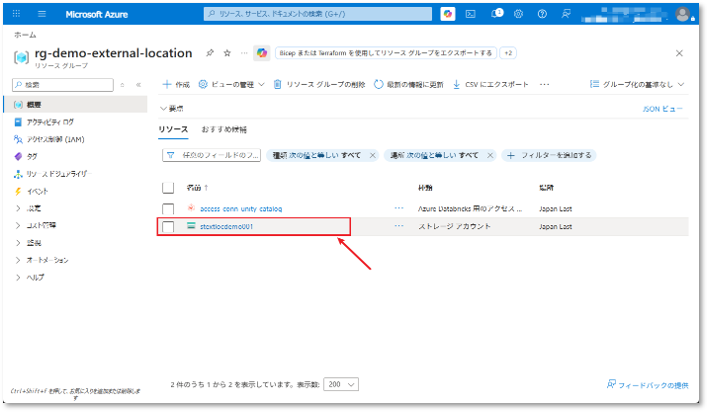
⑧ サイドバーメニューから「アクセス制御 (IAM)」を選択し、
「+追加」タブで「ロールの割り当ての追加」をクリックする。
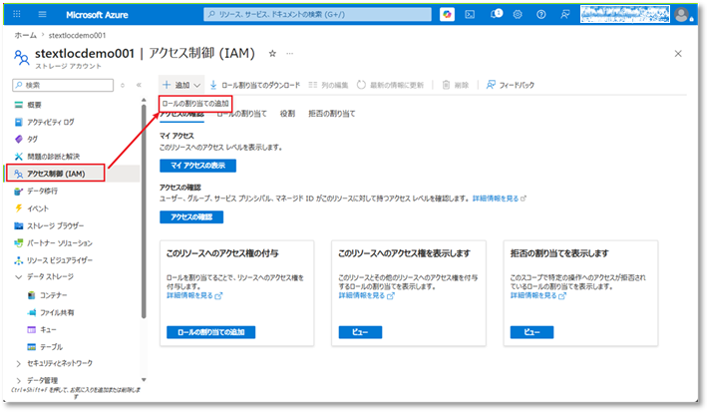
⑨ ロール一覧から「ストレージ BLOB データ共同作成者」ロールを選択する。
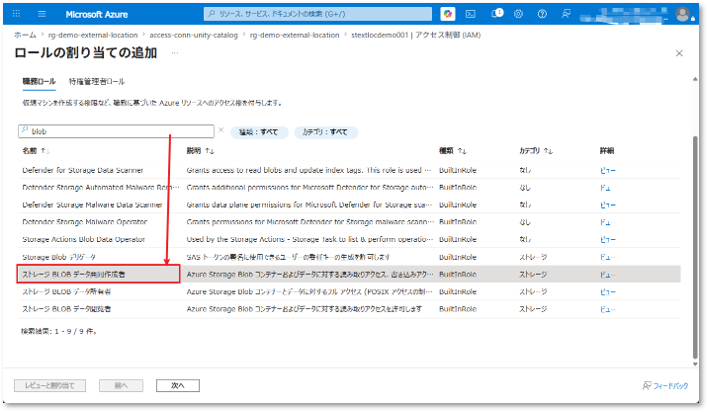
⑩「メンバー」タブにて、「アクセスの割り当て先」項目で「マネージド ID」を選択し、
「メンバー」項目で「+ メンバーを選択する」をクリックする。
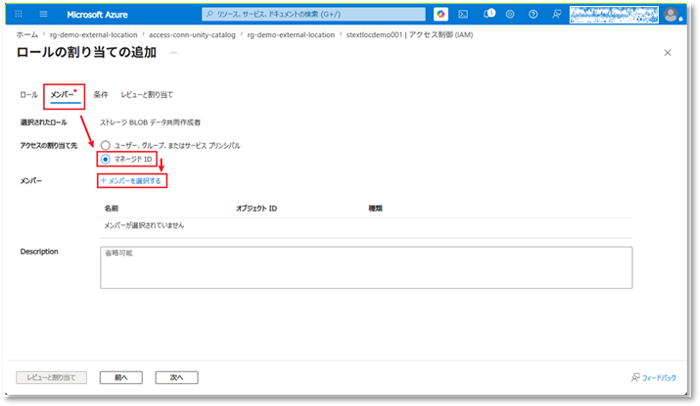
⑪「マネージドIDの選択」ポップアップで、以下の内容を設定する。
- サブスクリプション: 現在利用しているサブスクリプションを選択する。
- マネージドID:「Azure Databricks 用のアクセス コネクタ」を選択する。
- 「選択したメンバー」で手順3で作成したアクセスコネクタ名を選択し、「選択」ボタンをクリックする。
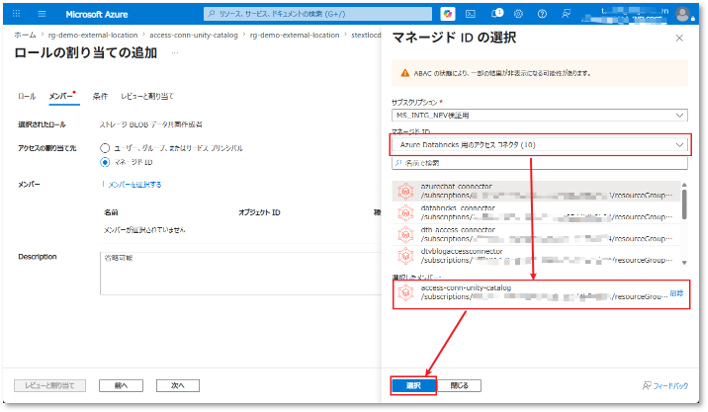
⑫ 入力した情報を確認し、「レビューと割り当て」ボタンをクリックする。
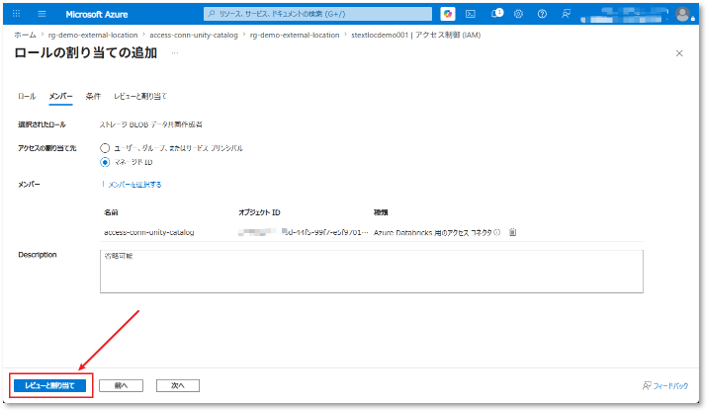
⑬ 権限付与完了のメッセージが表示されれば、アクセスコネクタに対するデータの読み取り/書き込み権限の設定は完了です。
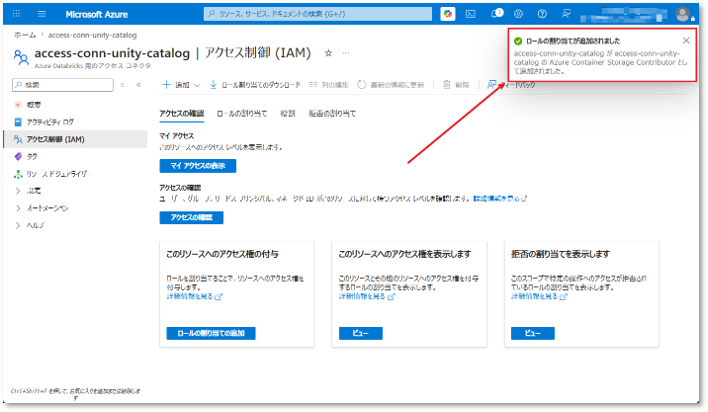
4.3 Databricksで外部ロケーションの作成
ここからは、Azure上のデータ領域をDatabricksのガバナンス管理対象として登録していきます。
① Databricks Workspaceにアクセスし、サイドバーメニューから「カタログ」を選択する。
②「接続」メニューを開き、「外部ロケーション」を選択する。
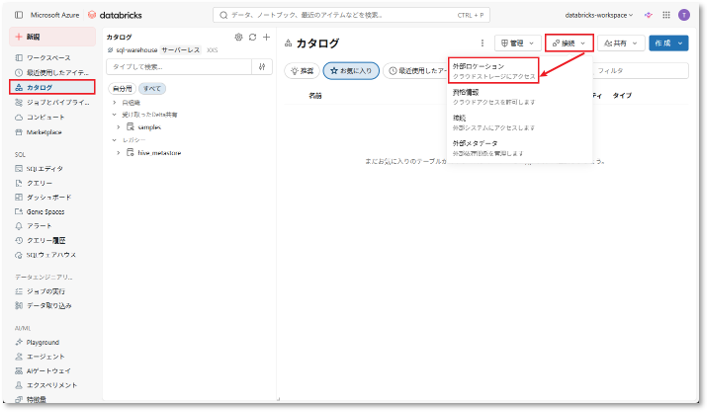
③「外部ロケーションを作成」ボタンをクリックして新規の外部ロケーションを作成する。
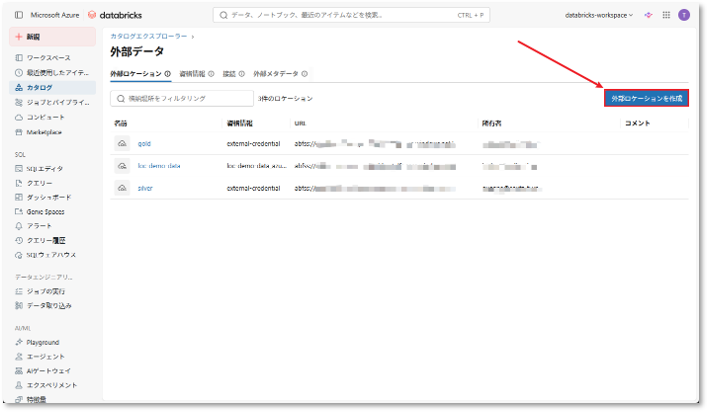
④ 基本情報を設定する。
- 外部ロケーション名:識別しやすい名前を設定する。
- ストレージタイプ:「Azure Data Lake Storage」を選択する。
- URL:以下の形式で入力する。
abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/
※注意:
・<container-name>:CSVファイルを格納しているコンテナー名
・<storage-account-name>:対象ストレージアカウント名
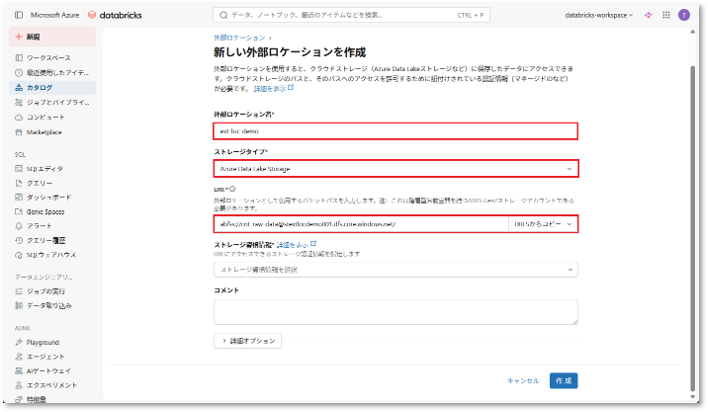
⑤「ストレージ資格情報」項目にて、「新規のストレージ認証情報を作成」を選択する。
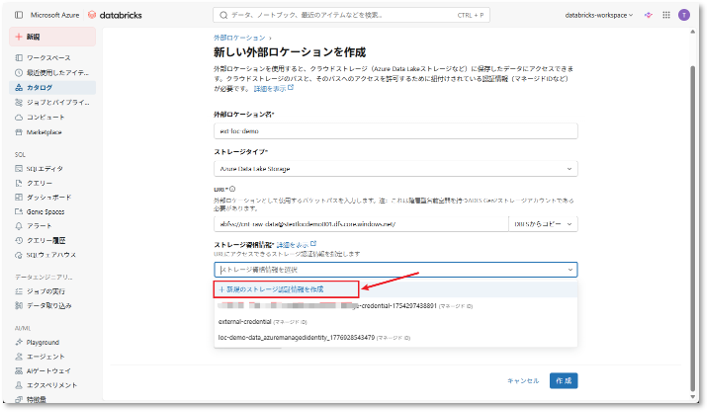
※資格情報とは?
資格情報は、Databricks上でAzureのアクセスコネクタを表現するためのオブジェクトです。実際の資格情報やセキュリティキーを直接扱うことなく、データアクセス権限を抽象化して管理できる仕組みとなっています。これにより、エンドユーザーはセキュリティ情報を意識せず、安全にデータへアクセスできるようになります。
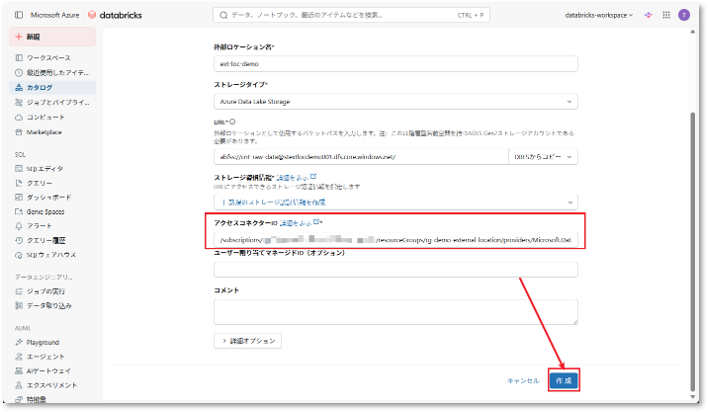
⑥「アクセスコネクターID」項目に、アクセスコネクタのリソースIDを入力する。
※このIDは、Azure Portal上のアクセスコネクタの「プロパティ」タブから確認できる。
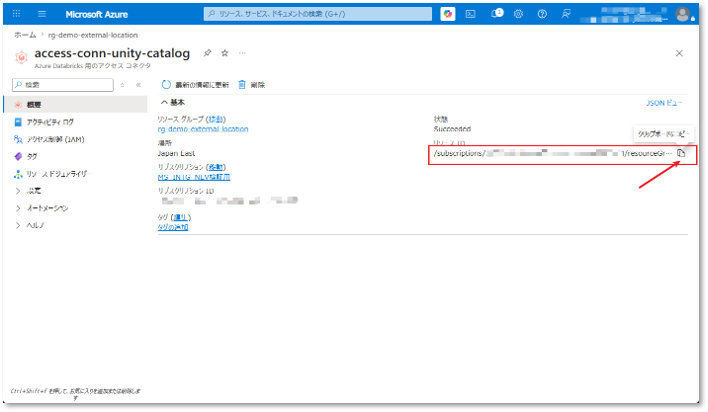
※ Azure Portalにて対象のアクセスコネクタへアクセスし、画像の「リソース ID」欄からIDをコピーできる。
⑦ 必要情報の入力完了後、「作成」をクリックする。
作成時に、システム側で自動的に接続テストが実行される。
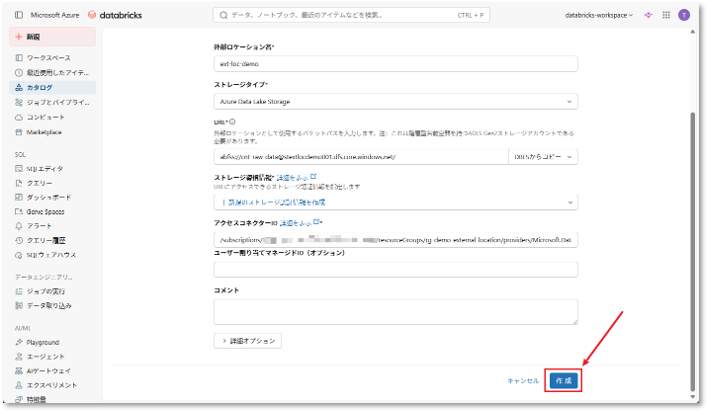
⑧ 接続状態を確認する。
基本権限であ「読み取り」、「書き込み」、「リスト」が緑色(成功)で表示されていれば問題ありません。
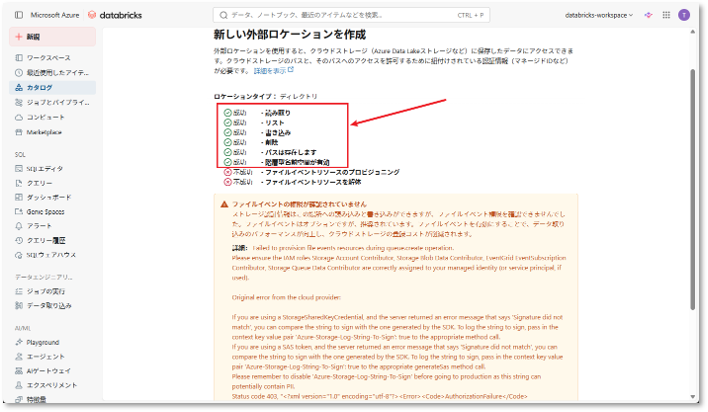
※注意: 本デモの範囲では、ファイルイベント関連の接続エラーについては一時的に無視して問題ありません。
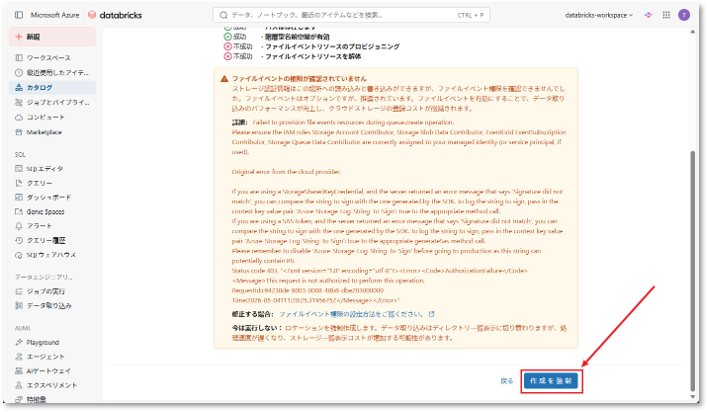
⑨ 必要な接続状態が正常(成功)となっていることを確認後、「作成を強制」をクリックして登録を完了する。
4.4 動作確認
ここからは、実際にデータへアクセスし、動作確認を行います。
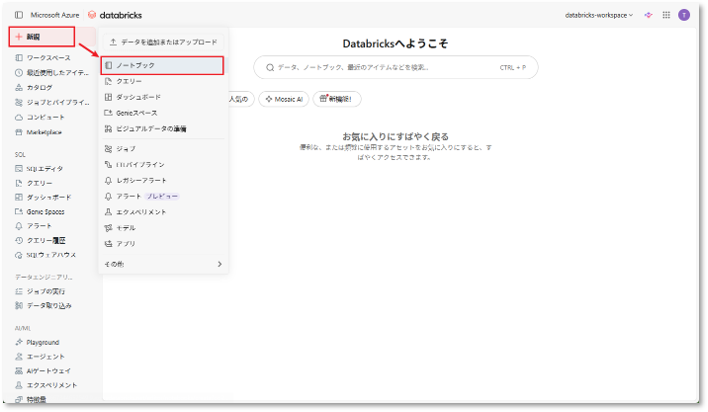
① Databricksのホーム画面にて、「+新規」を選択し、「ノートブック」をクリックする。
② 以下のSQLを実行し、外部テーブルを作成する。
※<>内の値は環境に合わせて書き換えてください。
|
1 2 3 4 5 6 |
%sql create table if not exists <catalog-name>.<schema-name>.<table-name> USING CSV OPTIONS (header = 'true', inferSchema = 'true') LOCATION ‘abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/' |
※注意:
- <catalog-name>:カタログ名
- <schema-name>:スキーマ名
- <container-name>:CSVファイルを格納しているコンテナー名
- <storage-account-name>:ストレージアカウント名
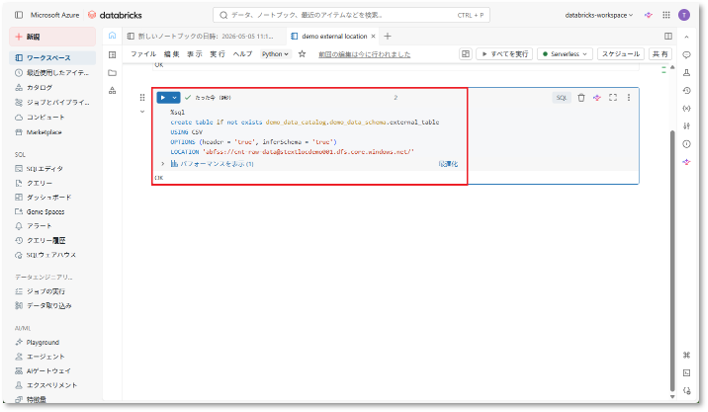
③ テーブル作成後、以下のクエリを実行してデータを確認する。
|
1 |
select * from <catalog-name>.<schema-name>.<table-name> |
※注意:
・<catalog-name>:カタログ名
・<schema-name>:スキーマ名
・<table-name>:テーブル名
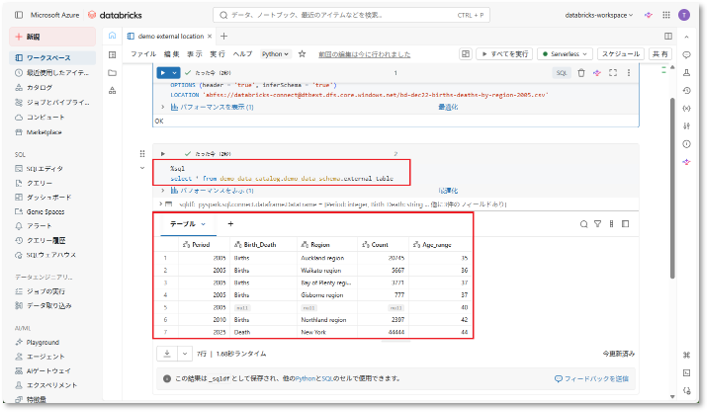
→ データが正常に表示されれば、Unity Catalogに準拠したセキュアかつ標準的なデータ接続構成のセットアップは完了です。
5. まとめ
マネージドIDを利用した外部ロケーションの構成は、単なるデータ接続設定ではありません。Azure上でモダンかつセキュア、さらに高い拡張性を備えたData Lakehouseアーキテクチャを構築するための重要な基盤となります。本記事では、一連の構成手順を通じて、以下3つの重要なポイントを実現しました。
- Zero-Trustを前提としたセキュリティ標準化:Azure Databricksアクセスコネクタを利用することで、従来必要だったAccess Keyの手動管理を完全に排除しました。これにより、DatabricksとADLS Gen2間のアクセスはすべてアイデンティティベースで認証される構成となり、機密情報漏洩リスクを大幅に低減できます。
- データガバナンスの最適化:Unity Catalogを利用することで、アクセス権限管理をAzure Portal側の複雑なIAM設定に依存させることなく、一元的に管理できるようになります。管理者はDatabricks上から、データアクセス制御、権限管理、監査(Audit)を統合的かつ可視化された形で実施できます。
- コンピュートとストレージの分離:外部ロケーションを利用した外部テーブル構成により、物理データは Azureストレージ上で管理したまま、Databricksの強力なデータ処理能力およびメタデータ管理機能を活用できます。これにより、ストレージ管理とデータ処理基盤を疎結合に保ちながら、柔軟で拡張性の高いデータ基盤を構築できます。
今回の記事が少しでもDatabricksを知るきっかけや、業務のご参考になれば幸いです。
双日テックイノベーションでは、Azure Databricksの環境構築パッケージを用意しています。
Azure DatabricksやAzure活用、マイクロソフト製品の活用についてご相談事がありましたらぜひお問い合わせください!
Azure Databricks連載記事のまとめはこちら
![]() お問い合わせはこちら
お問い合わせはこちら