Azureの画像認識サービス「Azure AI Custom Vision」を触ってみた

今回は、Azure上の画像認識サービスである、Azure AI Custom Visionを実際に触ってみましたので、
機能や具体的な使い方などをご紹介していこうと思います。
Azure AI Custom Vision とは?
視覚的な特性に基づいて画像にラベルを適用する画像識別サービスです。
Custom Vision ではユーザーが独自のラベルを指定し、それらを検出するためのカスタムモデルをトレーニングして、特定のタスクや業種に適した画像認識モデルを作成できるサービスです。
Custom Vision には「物体検出」と「画像分類」の機能があります。
画像分類とは?
画像分類は、対象のオブジェクトまたは画像全体を分析し、クラス分類する機能です。
事前に、学習させる画像をアップロードして分類(タグ付)を行う必要があります。
この機能の使い方としては、製品の型番判定や、料理の出来上がり判定や、製品が完成品か否かといった判断などのタスクで利用できます。
物体検出とは?
物体検出は、対象のオブジェクトが、画像内の「どこに」、「いくつ」あるのか検出する機能です。
事前に、学習させる画像内のオブジェクトに正解データとしてタグをつけるラベリング(アノテーション)作業が必要になります。
この機能の使い方としては、製品の不備、部品の不足、個数のチェックといったタスクで利用できます。
デモにて機能をご紹介!
物体検出デモ
この物体検出についてデモにて性能をご紹介します。
1.事前準備
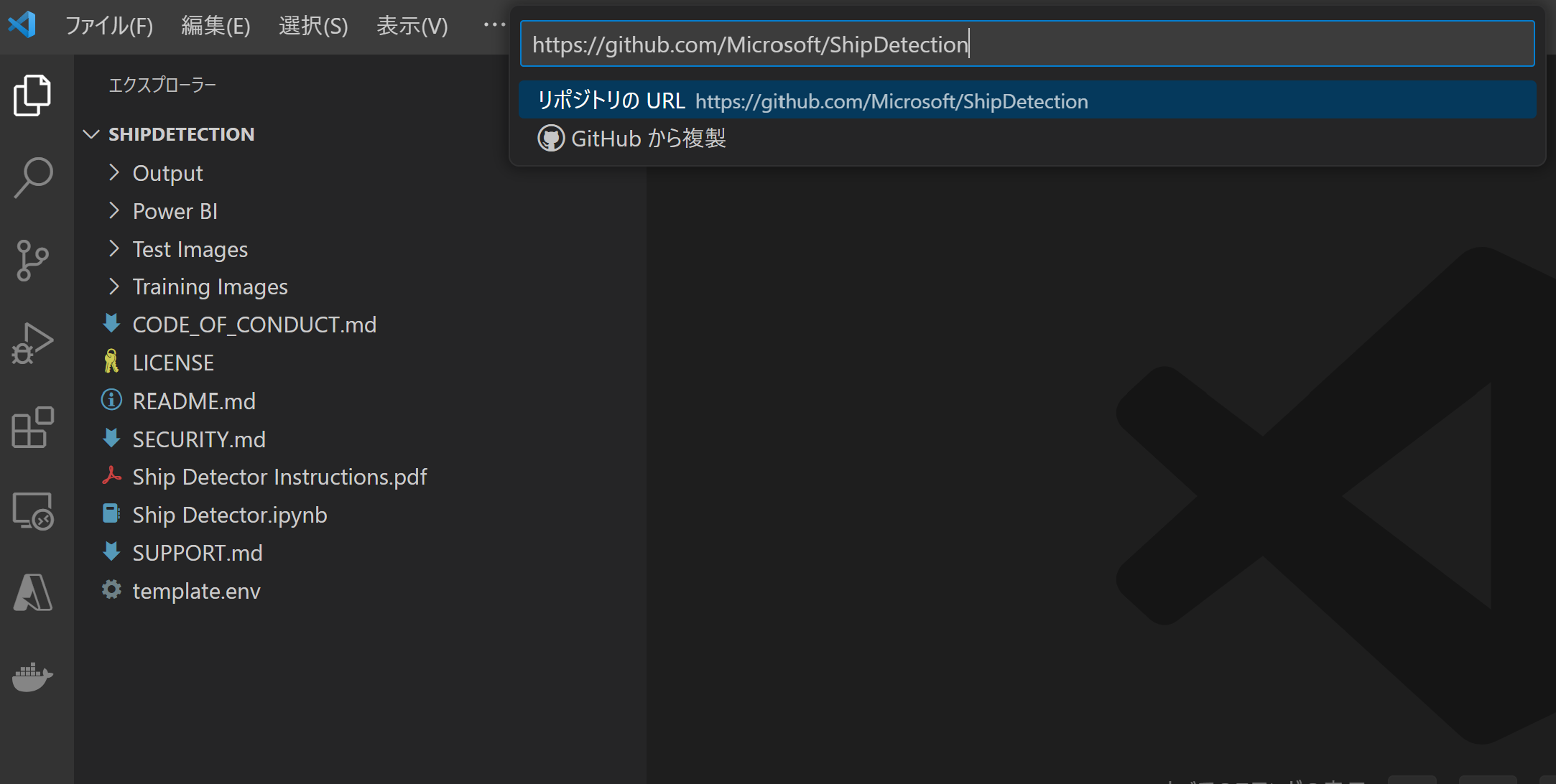
Visual Code Studio でGit Cloneコマンドで下記URLのリポジトリをローカルにクローンします。
https://github.com/Microsoft/ShipDetection
2.Custom Vision リソースの作成
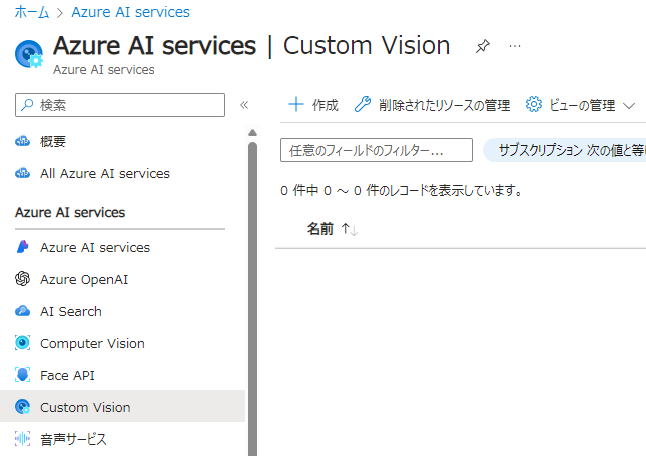
Azure Portal > Azure AI services > Custom Visionを開き、作成をクリックします。
以下の設定でCustom Visionを作成します。
■基本タブ
作成オプション:両方
サブスクリプション:お使いのサブスクリプション
リソースグループ:任意のリソースグループ or 新規作成
リージョン:Japan East
名前:一意な名前
トレーニング価格レベル:F0
予測価格レベル:F0
■ネットワークタブ
「インターネットを含むすべてのネットワークがこのリソースにアクセスできます。」を選択
3.Custom Vision プロジェクトの作成
新しいタブで、以下のURLを開き、「New Project」をクリックします。
https://customvision.ai
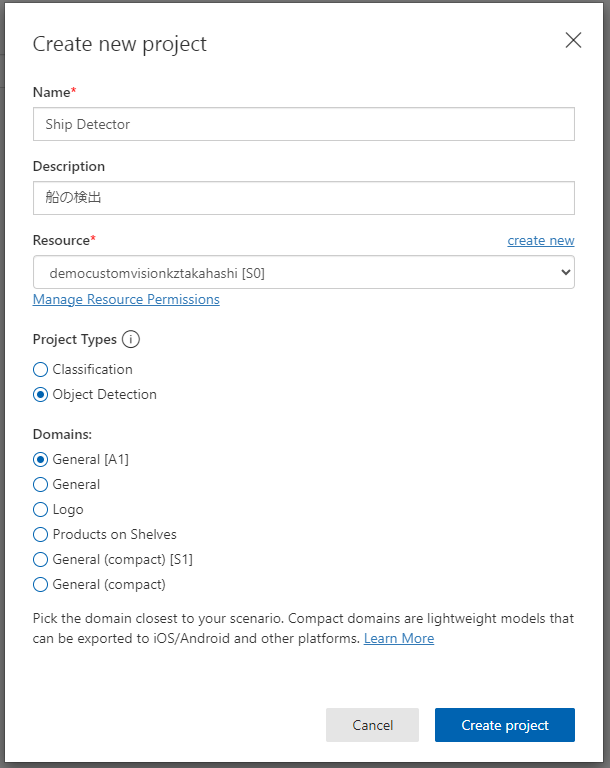
以下の設定でプロジェクトを作成します。
Name:Ship Detector
Description:船の検出
Resource:作成したCustom Visionリソースを選択
Project Types:Object Detection
Domains:General
4.画像とタグの追加
Visual Studio Codeを開き、クローンしたリポジトリの「Training Images」フォルダにトレーニングに利用する画像が入っています。
Custom Vision プロジェクトの「Add images」をクリックし、これらの画像をアップロードします。
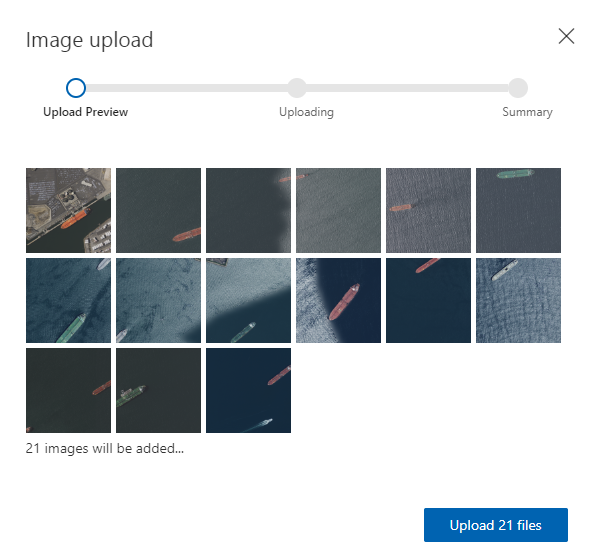
アップロード完了後、一枚目の画像を選択し、マウスを船の上に持っていくと自動的に検出されます。
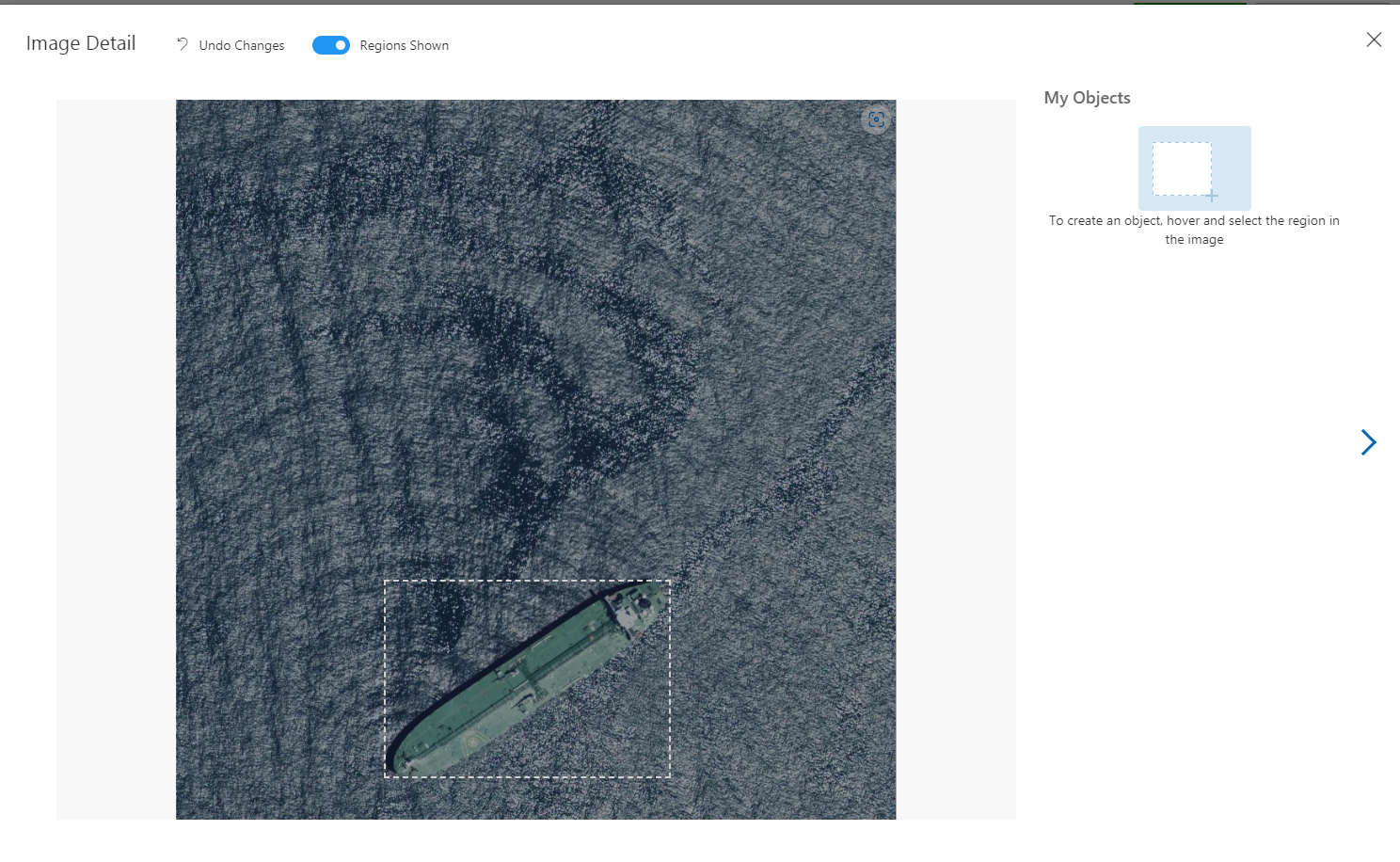
検出された領域をクリックして、タグを追加します。今回は「船」というタグをつけます。

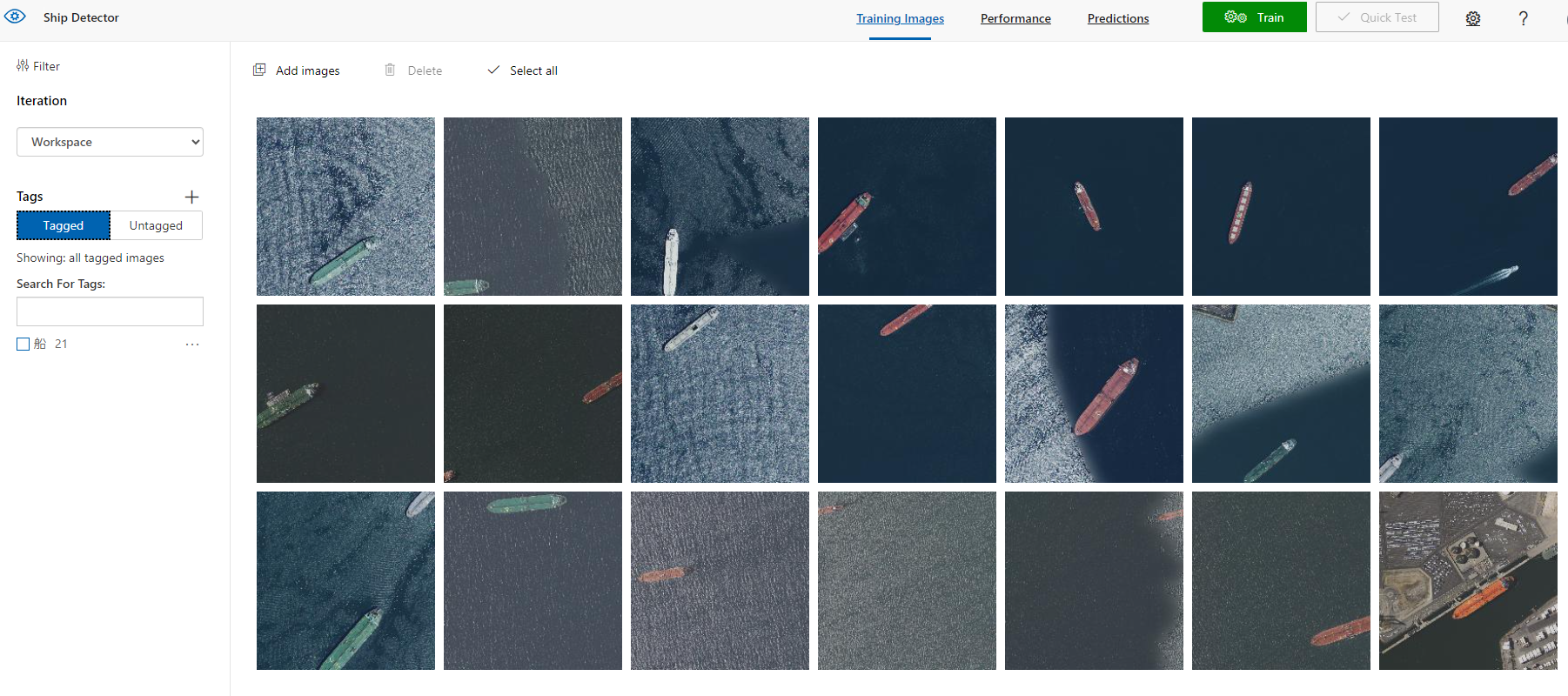
他の画像にも同様にタグをつけていきます。
完了後、すべての画像がTaggedに表示されていることを確認します。
このタグ付の作業は、GUIでも出来ますが、APIを使って行うこともできます。
5.モデルのトレーニングとテスト
タグ付された画像をつかってモデルをトレーニングします。
右上の「Train」をクリックして、Quick Trainingを選択し、トレーニングを行います。

トレーニングは数分で完了し、以下の画面が表示されます。
表示されている内容は、分類モデルの予測精度を測定するものですべて高くなっているはずです。
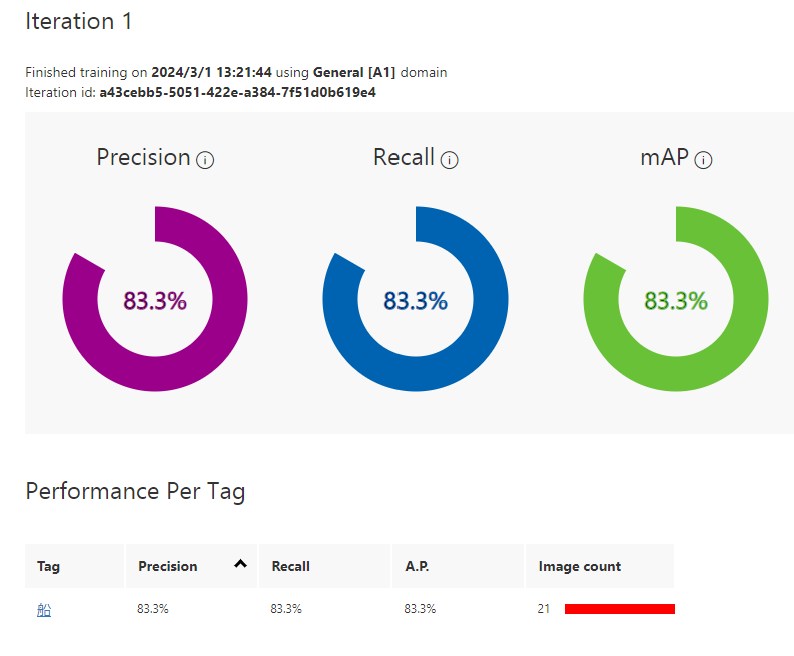
右上の「Quick Test」でGUI上で簡単なテストが可能です。
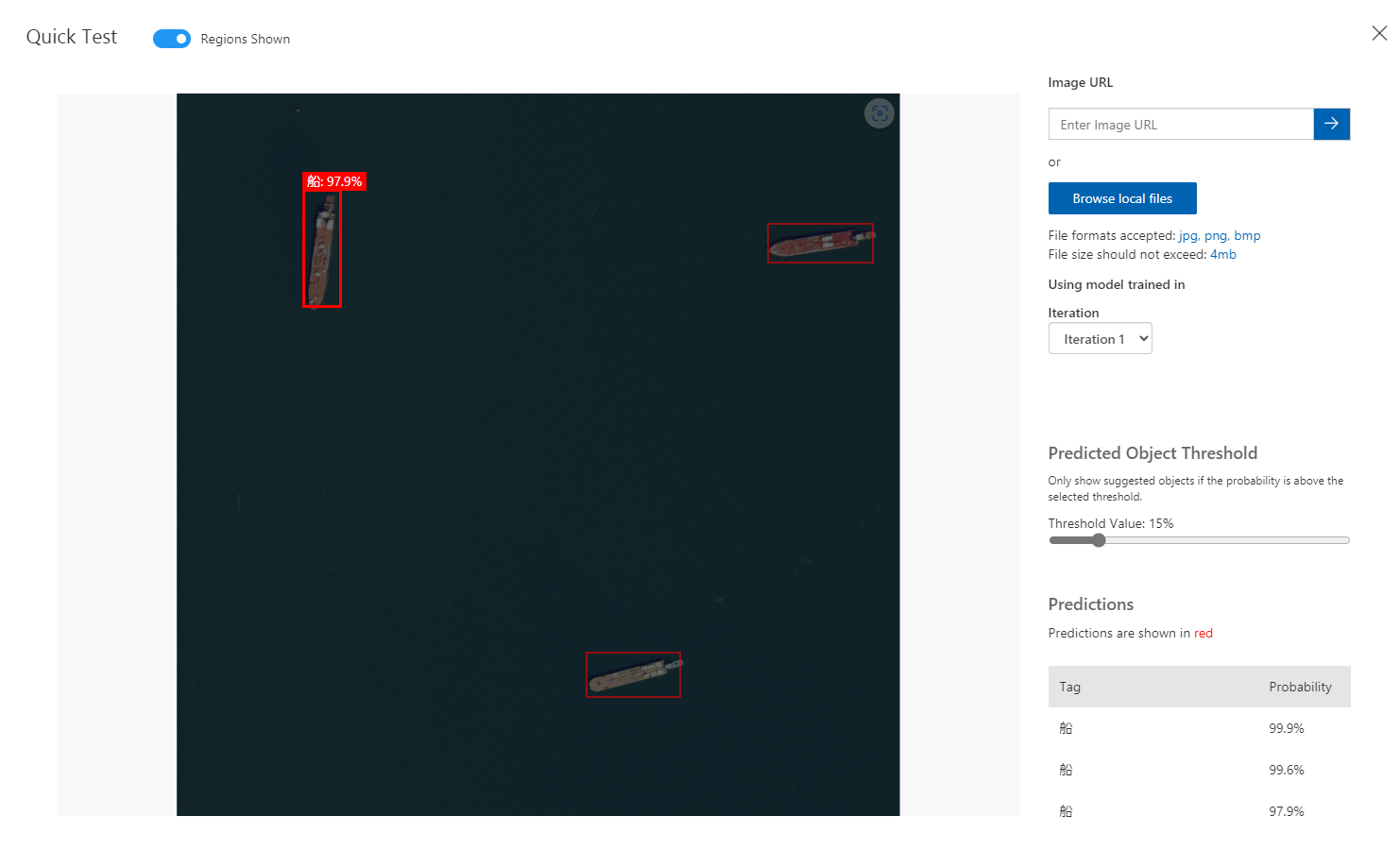
「Browse local files」をクリックして、クローンしたリポジトリ内のTest Imagesの画像のいずれかをアップロードします。
正常に船が検出されていますね!
画像分類デモ
この画像分類についてデモにて性能をご紹介します。
1.プロジェクトの作成
新しいプロジェクトを以下の設定で作成します。
Name:犬猫分類
Description:犬と猫の分類
Resource:作成したCustom Visionリソースを選択
Project Types:Classification
Domains:General
2.画像の追加とタグ付け
物体検出と同様に「Add images」から猫の画像を追加します。
その際に「猫」のタグを指定します。
犬の画像も同様にアップロードします。
3.モデルのトレーニングとテスト
Quick Trainingでトレーニングを行います。
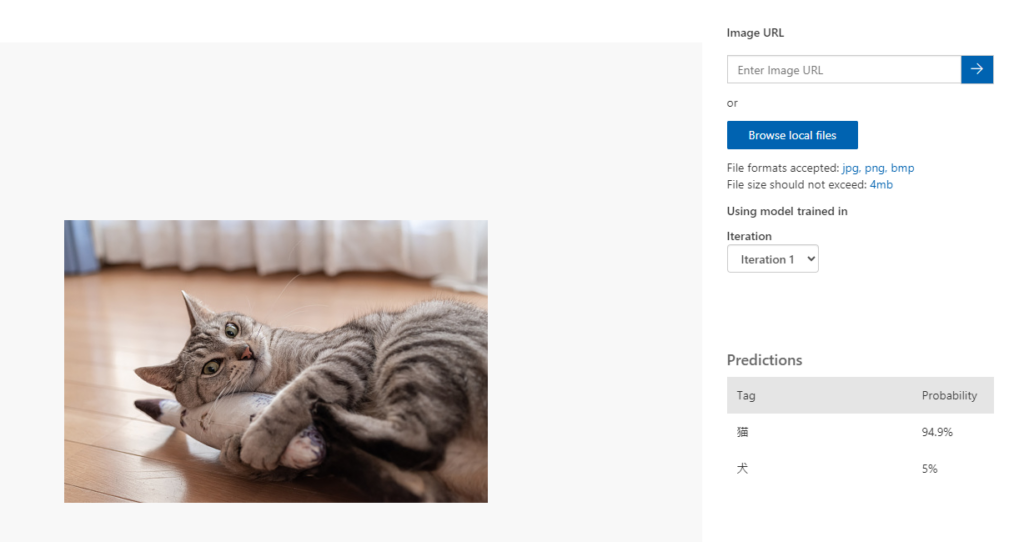
猫の画像でモデルのテストをしてみます。
猫の画像でテストしてみると、Probabilitiyが94.6%で猫に分類していますね。さらに画像の枚数やトレーニングの時間を増やすことで精度も向上して行くと思います。
まとめ
いかがでしたでしょうか。
物体検出と画像分類それぞれの機能や使い方の違いは以下のようになります。
画像分類:対象のオブジェクトまたは画像全体を分析し、クラス分類する機能
使い方:製品の型番判定や、料理の出来上がり判定や、製品が完成品か否かといったタスク
物体検出:対象のオブジェクトが、画像内の「どこに」、「いくつ」あるのか検出する機能
使い方:製品の不備、部品の不足、個数のチェックといったタスク
無償でテストが可能なので、気になる方は是非お試しください。
この記事を書いた人

-
テクニカルマーケターとして、新技術の検証、ブログ執筆、セミナー講師を行っております!
学生時代はアプリ開発に興味がありましたが、インフラ、セキュリティ事業を経て、現在はクラウド屋さんになっております。
コロナ禍前は、月1で海外旅行にいくなどアクティブに活動していましたが、最近は家に引きこもってゲームが趣味になっています。
宜しくお願い致します!
この投稿者の最新の記事
- 2024年3月25日ブログOracle Database@Azureが東日本リージョンに展開されることが発表されました!
- 2024年3月22日ブログAzure SQL DatabaseでCopilotがプレビュー公開!
- 2024年3月18日ブログAzureリソースの誤削除を防ぐ「ロック」機能とは
- 2024年3月14日ブログCopilot for Security の一般公開日が発表