Databricksが実現できること
データサイロの解消

データレイクハウスは、データレイクの非構造データであっても、DWHの構造データと同様に管理し、ひとつのプラットフォームで両方の処理を実現します。
データの管理にはDelta Lakeと呼ばれる技術を利用し、あらゆるデータの一貫性やガバナンスを確保することができます。
BI &SQLアナリティクス

DatabricksはPython、SQL、Scala、Rをサポートしており、SQLなどのスクリプトはApache Sparkで実行可能な形に変えられて結果を得ることができます。
全ての処理はApache Sparkを基盤として行われるため、大量のデータを効率的に分散処理することが可能です。
AI、機械学習

DatabricksではML Flowと呼ばれる機械学習のプロセスを効率的に管理するオープンソースのプラットフォームを提供します。
ML FLowでは機械学習の実験の追跡、モデルの一元管理、モデルの簡単なデプロイ、そしてプロジェクトの再利用・再現性を高めるためのパッケージ化の機能が提供されます。
将来にわたって使い続けられる基盤

Databricksのアーキテクチャはクラウドネイティブかつスケーラブルですので、将来のデータ規模の増大や技術の変化にも柔軟に対応することが可能です。また、オープンソースベースであるため、テクノロジーの進化と共に成長し続けることが可能なため、現時点の選択が将来の利用を制限することがありません。
Databricksが優れている理由、独自のテクノロジー
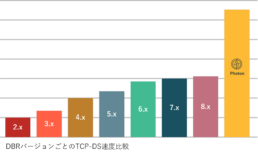
Apache SparkとPhoton
Apache Sparkの開発者が独立してDatabricksを設立。独自の技術でApache Sparkを高度化し、データ分析をより早く・低コストで実現します。
Delta Lake
構造データ・非構造データに関わらず、すべてのデータ更新処理をトランザクションログに記録。自社のあらゆるデータにACIDトランザクションを保証します。

Unity Catalog
すべてのワークスペースおユーザーやデータへのアクセスを集中管理。ガバナンス・セキュリティの確保、データリネージュ機能で、データ活用が進みます。
双日テックイノベーション導入事例

双日テックイノベーションは、分散していた顧客情報を統合し、データに基づく意思決定を促進するためにAzure Databricksを導入しました。このことでデータ活用の文化の醸成と、集計にかかっていた作業を大幅に軽減させました。
”見える化”で終わらせない、データ活用のススメ

Databricksを導入を進めるため、導入前のデータ活用の構想支援、データ基盤の構築、そしてデータの活用フェーズまで、一貫して全体支援をします。