データとAIの活用を加速させるには、
その前提となるデータ基盤の整備が欠かせません
データとAIの活用が競争優位性を左右する時代、旧来のデータ環境ではその価値を十分に引き出すことは困難です
多くの企業が、旧来のシステムが引き起こすデータのサイロ化、専門人材の不足、肥大化する運用コストという共通課題を抱えています
企業の持続的な成長のためには、これらの課題を解決する戦略的なデータ基盤の再設計が必要です
-
PROBLEM 01
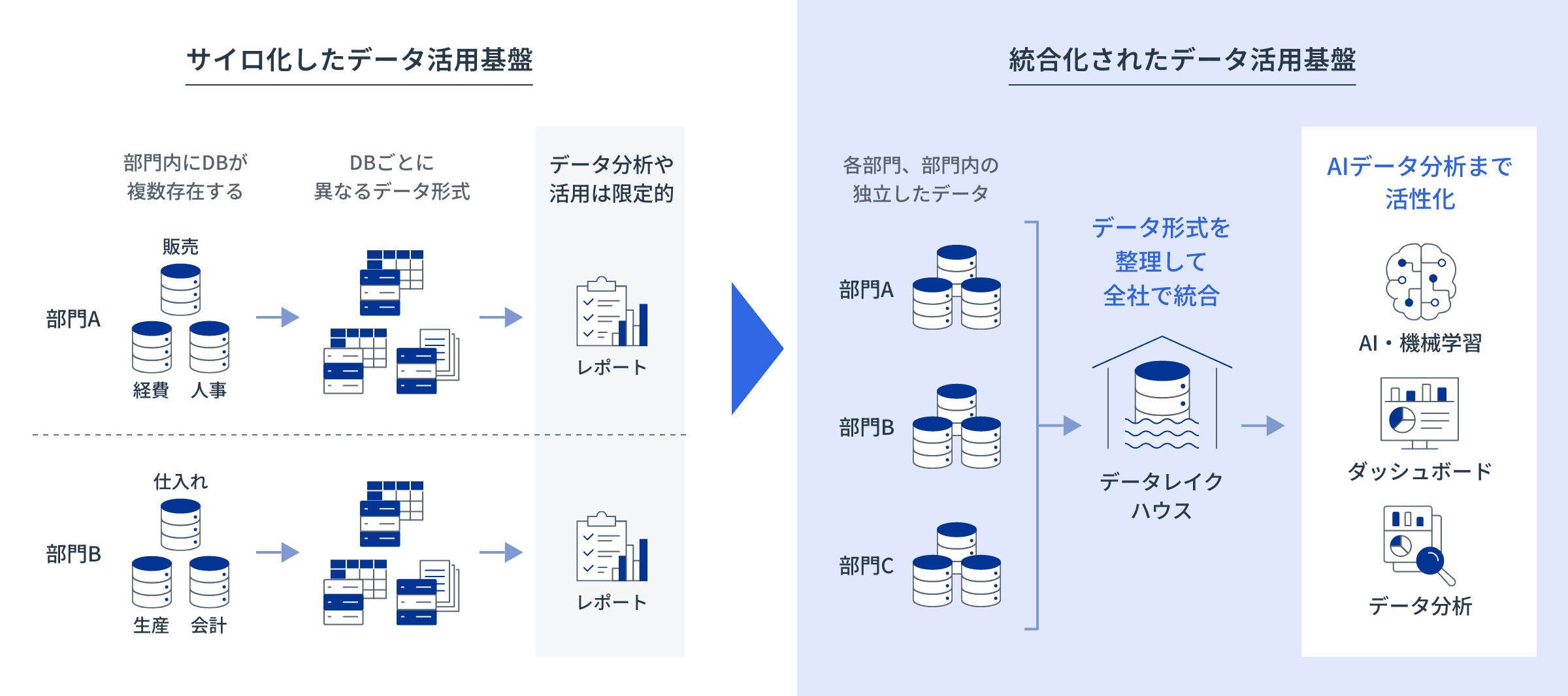
部門ごとにデータが
サイロ化され、分析が困難部門間で情報資産がサイロ化し、統合的な分析が困難な状況は、全社横断での迅速な意思決定や経営判断を阻害します
-
PROBLEM 02
人材が不足しており、
AI活用が進んでいない高度な情報資産の分析やAI導入に不可欠な専門人材が不足し、データからの価値創出やAI活用が計画通りに進まない状況を招きます
-
PROBLEM 03
データは増加し続け、
運用管理の負荷が肥大化既存データ基盤の運用・管理の複雑化は、運用負荷の増大とTCO(総保有コスト)の肥大化を招き、企業の長期的な成長を圧迫します
-
Databricks
Databricksの「レイクハウス」「Unity Catalog」で、
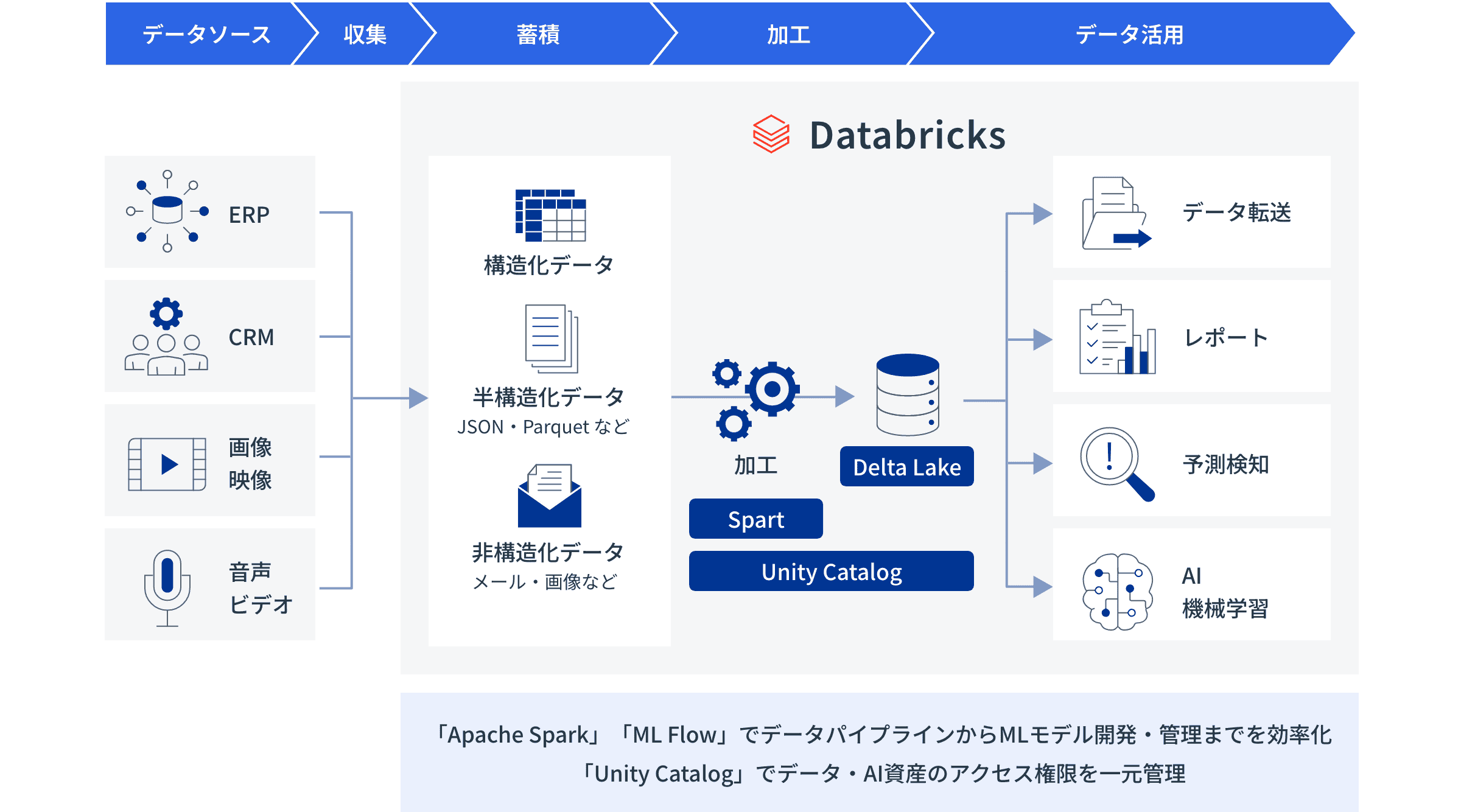
全社横断のデータ統合とAIによる価値創出を推進しますDatabricksはDelta Lakeに基づくレイクハウスアーキテクチャを採用することで、構造化・非構造化データを統一的に管理し、データレイクの柔軟性とDWHの信頼性を統合します
ETLからBI、AI/ML活用までを単一基盤で実現し、Unity Catalogでアクセス権限を一元管理します
全社的な情報資産を基盤とした、データドリブンな意思決定を加速させます-
特長①構造化から非構造化まで
多様なデータを統合管理レイクハウスアーキテクチャが、構造化から非構造化まで多様なデータを単一基盤で統合管理します
データ分析、BI、AI/ML開発といった幅広いニーズに、一つのプラットフォームで柔軟に応えます -
特長②データエンジニアリングから
MLモデル開発・管理までを効率化Apache Spark基盤上で、データエンジニアリングからMLモデル開発・管理までを効率化します
MLflowで実験追跡やデプロイも容易にすることで、分析業務の全工程を統合運用し、迅速な意思決定を支援します -
特長③データとアクセス権限を
安全に一元管理Unity Catalog機能がデータとAI資産のアクセス権限を一元管理し、全社レベルでのセキュアな運用体制構築を支援します
データリネージュ機能で、資産のトレーサビリティも向上させます
-
Microsoft Fabricの「OneLake」「Power BI」「Copilot」で、
部門横断のデータ統合と現場での情報資産活用を加速します
Microsoft Fabricは、データ統合、エンジニアリング、BIなどの多様な機能をSaaSで提供する統合分析プラットフォームです
OneLakeを中核に各機能がシームレスに連携することで、部門を越えたデータ共有を促進し、複雑な運用管理の解消と迅速な意思決定の仕組みを後押しします
-
特徴①
Copilotで自然言語による
データへのアクセスが可能Copilot機能が、自然言語でのデータ操作を可能にします
専門家以外もデータにアクセスしやすい環境を提供し、現場でのデータ活用定着を促進します -
特徴②
OneLakeで安全に
データの共有と連携が可能OneLakeは、組織内の全データを「データのためのOneDrive」として一元管理します
データコピーを不要とし、整合性を保ちながら部門横断での安全なデータ共有と連携を促します -
特徴③
データの仮想化により
場所を意識せずに分析が可能データの仮想化機能が、既存のAzure/AWSデータ資産をコピーせず直接参照します
データ移行の負担を軽減し、マルチクラウド環境でも場所を意識しない迅速な分析開始を支援します


